1. Introduction
Autonomous driving [
1] is a common example of an AI application in real life. However, the driving safety problems that are caused by autonomous driving should be given more attention and solved urgently. There are many factors that affect the driving behavior of autonomous vehicles, one of which is the dataset. Including enough autonomous driving scenarios under different environmental conditions in a dataset is a key aspect to ensure more accurate and safer driving behaviors; in contrast, an insufficient amount of data on autonomous driving scenarios, especially in bad weather, makes it easy for the autonomous driving system to produce a wrong judgment, resulting in traffic accidents. Currently, most of the published autonomous driving datasets are collected in sunny or cloudy conditions, and few datasets are collected in foggy, rainy, and snowy conditions. Moreover, it is difficult and costly to collect and annotate autonomous driving data under these harsh conditions.
Recently, image fogging technology has attracted significant attention in computer vision, automated driving, and remote sensing, mainly for data enhancement, algorithm robustness testing, and haze scene simulation. The current techniques fall into three main categories: image fogging based on atmospheric scattering models, image fogging based on deep learning, and image fogging based on depth maps. The method based on atmospheric scattering models simulates the optical property using physical formula and synthesizes fog effects from transmittance and atmospheric light parameters, which is computationally efficient but relies on manual adjustments. Among them, the FoHIS model proposed by Zhang N et al. is based on the atmospheric scattering model to add fog against pixel points on a clear image [
2]. The image fogging method based on deep learning often applies generative adversarial networks and variational autoencoders to achieve end-to-end synthetic fog images. It learns the distribution features of many genuine fog photos to produce more realistic fog maps, but it has high requirements for both the volume and quality of the training data. Sun H et al. proposed a fog map generation method based on a domain adaptation mechanism and employed a variational autoencoder to reduce the difference between synthetic and real domains [
3]. The method based on the depth map model incorporates the scene depth information and generates a non-uniform fog effect to enhance the spatial realism, making it suitable for scenes requiring geometric consistency like stereo vision or autonomous driving. Sakaridis C et al. further synthesized fog images by using the depth information of the image, integrated with the image’s object and distance information [
4]. Li Liang et al. used depth estimation to obtain the distance information of the scene and simulated the fog effect based on the physical scattering model to achieve realistic foggy image generation [
5]. However, this method is more dependent on the acquisition effect of the depth information of the image. If the acquisition effect is not good, it will lead to a worse synthesis effect of the foggy image.
At present, CycleGAN-based image generation for data enhancement is a commonly used method due to its great advantage in generating the desired image without a paired dataset. When the neural network is being trained, the converter part of the generator can only extract features from a limited window, which results in the network being unable to fully capture the overall semantic information of the original image, leading to lost information in the generated image. Tommaso Dreossi et al. proposed an automatic driving scene image generator based on a CNN model [
6]. This method seeks new loopholes in the automatic driving system by changing the brightness, the saturation of the image, the position of the object in the image, etc. However, the effect of generating images needs to be strengthened. Zhang et al. designed the DeepRoad framework [
7], whose core function is to enhance the scene generalization ability of autonomous driving technology by synthesizing road images under complex meteorological conditions such as snowy days and rainy days. The haze image generation algorithm based on CycleGAN published by Xiao et al. can capture relationships between synthetic and hazy pixels in the training process, enabling mutual conversion of fog-free and foggy visual scenes [
8]. Nevertheless, the current existing image fogging methods remain unable to solve the image domain adaptation problem well, and there is still a certain gap between the generated image and the real foggy day scene. Therefore, the current research mainly focuses on enhancement of the realism of the fog effect, the improvement of the computational efficiency, and the combination of multiple methods to optimize the fogging effect.
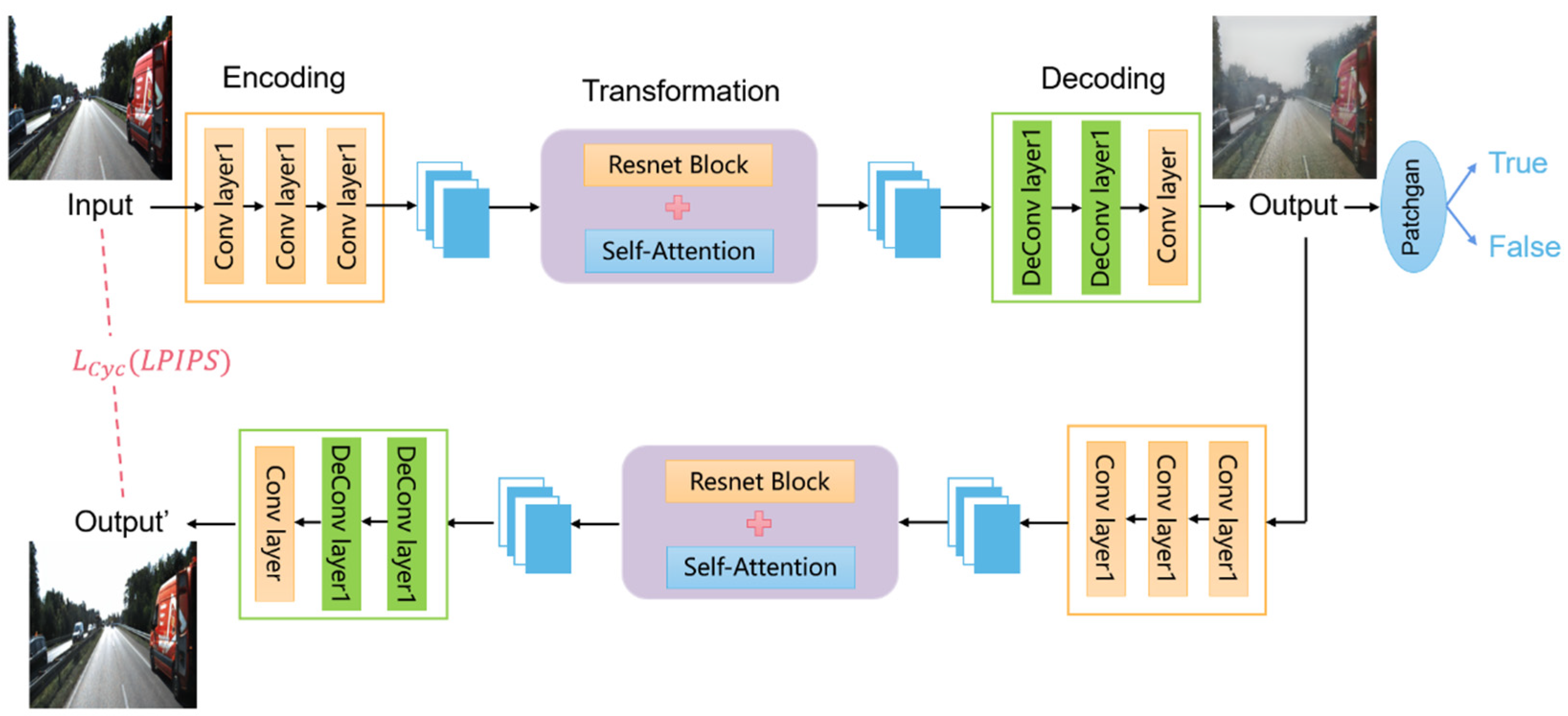
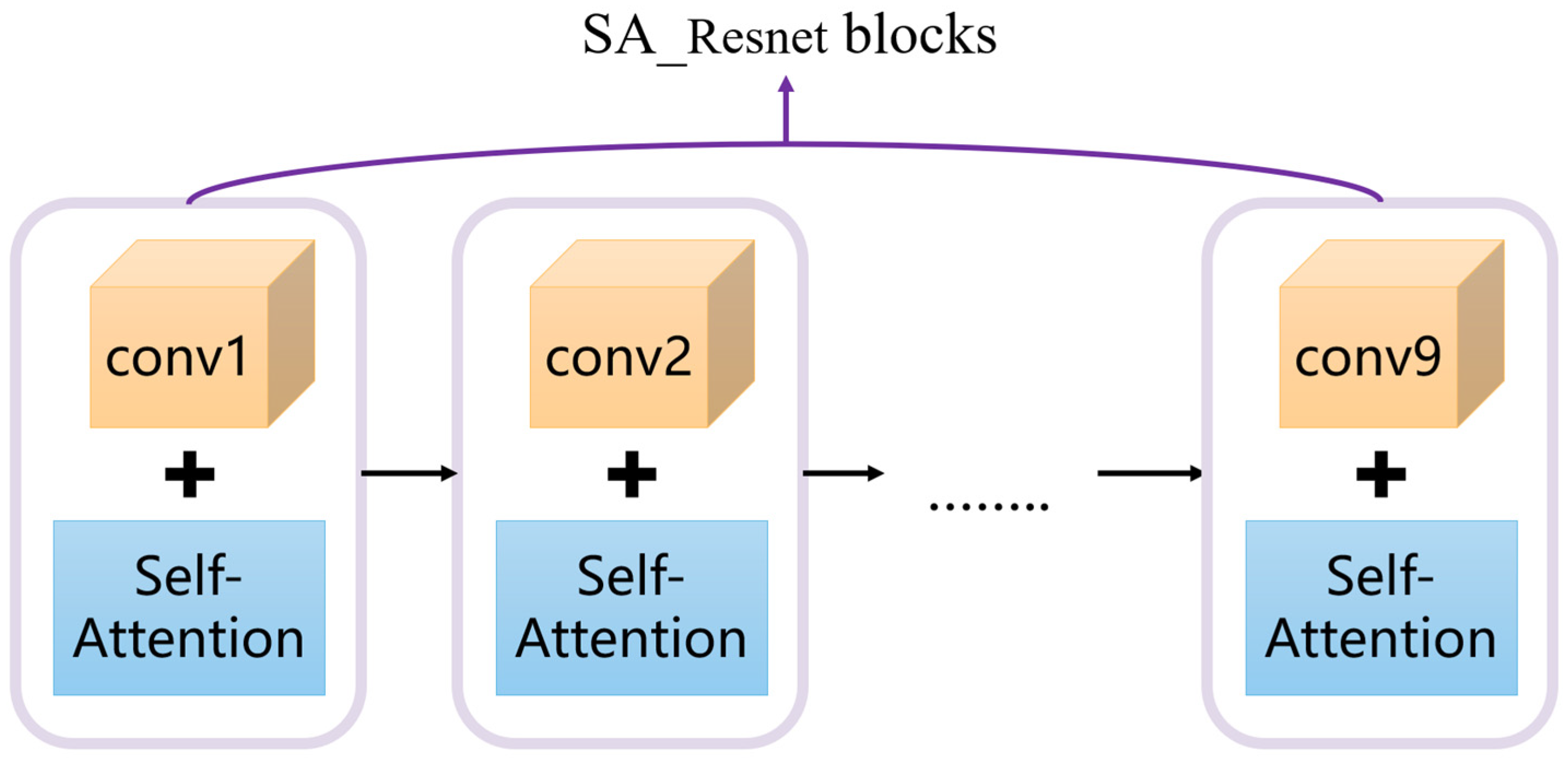
As a classic framework for unsupervised image-to-image transformation, CycleGAN has demonstrated good performance in many tasks like image defogging, style migration, etc. However, the direct application of CycleGAN models for image fogging still encounters many challenges, such as the global consistency of the generated images, the detail preservation capability, and insufficient perceptual quality. We suggest a CycleGAN-based data augmentation technique to improve foggy scene datasets for autonomous driving systems in order to more effectively handle the aforementioned problems. Initially, global feature extraction from the initial pictures was made possible by integrating the self-attention mechanism into the residual network. Then, the L1 loss in cycle consistency computation was replaced by LPIPS to improve the perceptual similarity between the generated and real images. The experimental results demonstrated that the proposed method can achieve better quantitative performance and improved image quality.
3. Results
3.1. Experimental Environment
All experiments applied the same configuration to prevent the experimental environment from affecting the creation of foggy images. The operating system for this experiment was Windows11, the development environment was python3.7 and PyCharm Community Edition 2022, the deep learning framework was pytorch1.12.1, the number of iterations was 200, the learning rate was 0.0002, the graphics card model was NVIDIA GeForce RTX 3050 Ti Laptop GPU (manufactured by NVIDIA Corporation, Santa Clara, CA, USA), and the optimizer was Adam.
3.2. Experimental Dataset
The KITTI dataset [
26], O-HAZE dataset [
27], Dense-HAZE dataset [
28], I-HAZE dataset [
29], and NH-HAZE dataset [
30] were employed in this paper. The experimental dataset was divided into four parts: trainA, testA, trainB, and testB. The training dataset that generated the model included trainA and trainB, and the test dataset that generated the model included testA and testB. Among them, 400 real street view images were selected during vehicle driving to form datasets trainA and testA from the image pool in the KITTI dataset. Since there was no corresponding fog scene image in the KITTI dataset, and a smaller dataset of foggy images, we chose the 185 foggy images in the O-HASE dataset, Dense-HASE dataset, I-HASE dataset, and NH-HASE dataset to compose datasets trainB and testB.
3.3. Fog Image Generation Experiment
The difficulty of the acquisition environment of foggy images are the reason for the low number of publicly available foggy datasets for autonomous driving scenarios. In order to alleviate the lack of foggy datasets, this paper generated a large number of foggy images that were more similar to a realistic environment through the improved CycleGAN network, which is conducive to training a stable automatic driving system. The network consists of two GAN networks. One of them can convert sunny images into foggy images in an autonomous driving environment. In contrast, the other one converts a foggy image in the autonomous driving environment into a fog-free image. The images created by the network during training are displayed in
Figure 4.
Among them, the input real fog-free image is shown in
Figure 4a, and the fake foggy one generated from the real fog-free image is shown in
Figure 4b and can be sent to the discriminator to judge whether it is true or false. If it is false, the discriminator continues to train the generator to generate a more realistic foggy image.
Figure 4c is a fake foggy picture that was re-entered into the generator to generate a fog-free picture, and
Figure 4d is a real fog-free picture that was used to generate a fog-free picture. Similarly,
Figure 4e is the input real foggy picture, while
Figure 4f is the fake fog-free picture that was generated from the real foggy picture, which can be sent to the discriminator for discrimination.
Figure 4g is the fake fog-free picture that was generated back to the foggy picture, while
Figure 4h is the real foggy picture that was generated from the foggy picture. At the same time,
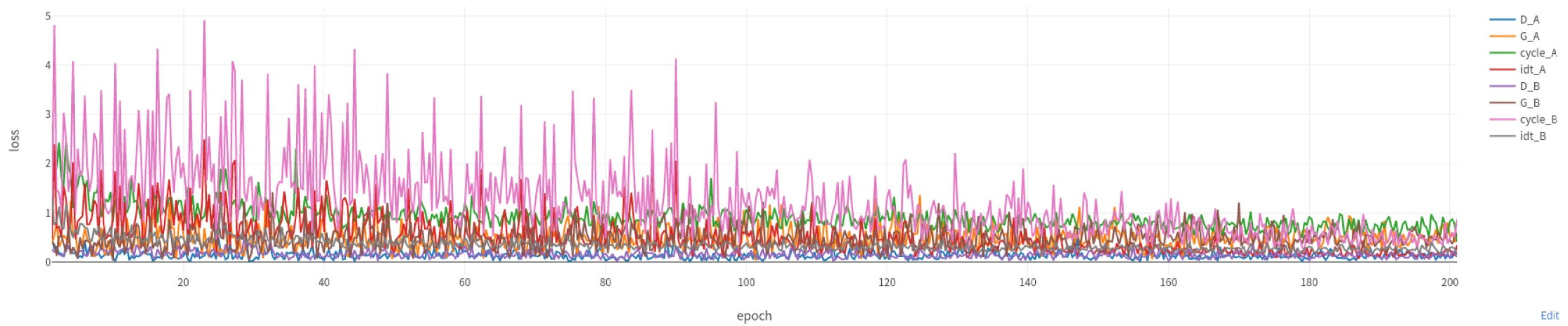
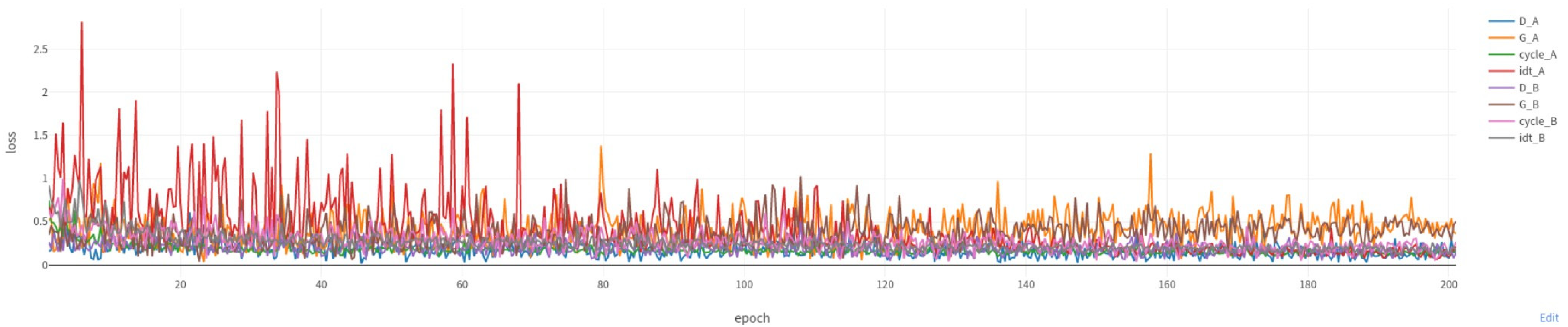
Figure 5 and
Figure 6 display the differences in the loss functions of the original model and the enhanced network model.
By comparing
Figure 5 and
Figure 6, we can observe that the enhanced model’s loss values decrease at a faster rate. In particular, the losses of cycle_A, cycle_B, idt_A, and idt_B become more stable after 100 epochs, indicating that the improved model has better training convergence. This allows the model to reach a stable state within fewer training epochs, improving the training efficiency while reducing the risk of overfitting. Additionally, the original model exhibits higher overall values and greater fluctuations in cycle_A and cycle_B, suggesting significant errors when converting images back to the original domain. In contrast, the improved model shows clear reductions in the cycle_A and cycle_B values, with less fluctuation, indicating that the generated transformed images have higher quality and stronger content consistency than the original images. Since the identity loss reflects the model’s capacity to maintain the initial features of the unconverted images, the lower and more stable values of idt_A and idt_B in the improved model imply that it recognizes and retains the style of input images better, enhancing the reliability of the style transfer. Finally, the values of G_A and G_B in the improved model gradually stabilize and remain within a lower range, indicating that the model has learned a more stable mapping relationship, effectively avoiding the mode collapse problem. As a result, the generated images appear more realistic and diverse.
However, the improved model also has certain limitations. Since the incorporation of a self-attention mechanism into the generator architecture inevitably expands the model’s parameter count and elevates its computational demands, it requires more computing resources and time for training. At the same time, the LPIPS loss function needs to calculate the feature difference between the generated image and the real image in the pre-training network in each training iteration, thereby increasing the overall training time. According to the experimental training, the original model training dataset takes 200 rounds and 60,823 s, and the improved model training dataset takes 200 rounds and 75,046 s.
3.3.1. Subjective Evaluation
To confirm that the enhanced network structure in this paper is effective,
Figure 7 compares the foggy image generation experiments of eight groups of the FoHIS model, RadialFog model, Lightroom Classic software version 2024, CycleGAN model, and improved model in an autonomous driving environment.
As shown above, the experimental results of the FoHIS model, RadialFog model, Lightroom Classic software, traditional CycleGAN model, and improved CycleGAN model are compared. Among them, the FoHIS model is based on the atmospheric scattering model [
31] and adds fog features to a fog-free image through pixels. The Lightroom Classic software has a dehazing function, which can achieve the effect of image fogging by adjusting the value to a negative value. The RadialFog model performs fog synthesis and diffusion through a center point in the picture. The longer the distance from the center point of the fog is, the weaker the effect of the fog synthesis is.
Figure 7a is the input content image, that is, the fog-free image in good weather.
Figure 7b is the input style image, that is, the original image that will be converted into an image in a foggy state.
Figure 7c–g are the result comparisons of the five models under eight groups of fog image generation experiments. It can be observed by the naked eye that the FoHIS model retains the most complete features of the input image, but the added fog features are too average, and the tone is gray, resulting in the generated fog image not being realistic. The image after fogging with the Lightroom Classic software has a hazy fog feeling, but the whole image is white, and the third picture is a failed attempt at fogging. The effect of the RadialFog model is similar to that of the FoHIS model, and the generated images are all grayish, but the effect of the RadialFog model is heavier, and any detailed information is more lost. Both the original and improved CycleGAN models generate fog features that are not overly uniform, making them more realistic. However, the enhanced model retains more information from the input image than the original CycleGAN and generates fog features that seem more realistic and natural. Overall, the improved model outperforms the traditional CycleGAN, demonstrating its effectiveness.
3.3.2. Objective Evaluation
Because a subjective evaluation is mainly judged by the direct observation of the human eye, it is easily affected by subjective factors. To further validate the efficacy of the enhanced model, this experiment took 40 pictures generated by the RadialFog model, Lightroom Classic fogging software, FoHIS model, improved model, and original model, respectively, and evaluated the fogging effect of these five models through the objective measurement indicators of Frechet Inception Distance (FID), Inception Score (IS), and structural similarity (SSIM).
Table 2 displays the experimental results.
The FID is used to comprehensively evaluate models’ performances by measuring the distribution difference between the generated samples and the real samples, and the lower its value is, the closer the generating ability of the model is to the real data. The IS index is based on the classification model to quantitatively analyze the diversity and clarity of the generated results. The higher the IS value is, the better the quality and richness of the generated content are. The SSIM is used to judge the quality of the generation by comparing by comparing the structural similarity; the higher its value is, the higher the matching of details between the generated result and the original input is, and the more natural the visual effect is.
Table 2 demonstrates that the FID values of the three control experiments, the RadialFog model, Lightroom Classic fogging software, and FoHIS model, are higher, indicating that the quality of the foggy images generated by these three methods is quite different from that of real foggy images, which means that they are not suitable for amplifying foggy image datasets. At the same time, the IS value of the original CycleGAN model is low, indicating that the use of this network architecture will reduce the clarity of the generated image, and we need to optimize the network structure. In the evaluation and comparison of the five models, the three indicators of the improved model are superior and the most suitable for foggy image dataset amplification in a real-life autonomous driving scenario.
Then, based on the eight sets of experiments that were compared in the subjective evaluation above, we compared the structural similarity of the existing model and the improved model one by one, as shown in
Table 3.
It can be seen from
Table 3 that except for the fourth set of experiments, the improved models of other experiments are higher than the SSIM values of the existing CycleGAN model, indicating that the improved model can better retain the information of the input image as a whole after integrating the fog features. It can be seen that the improved model does not weaken the connection between the generated image and the input image, while generating a more realistic foggy image.
Lastly, we assessed both the updated model and the current model overall.
Table 4 displays the findings of this.
Table 4 shows that compared to the previous model, the FID of the improved model was 3.34 lower, indicating that the difference between the foggy image generated by the improved model and the real foggy image was smaller, and that it was closer to the real foggy image. The IS increased by 15.8%, and the SSIM increased by 0.1%, indicating that the improved model not only generates foggy images, but also enhances the quality of the produced hazy photos while preserving the original image’s features. The method of this paper is better than the traditional CycleGAN model based on three objective measures, which proves the effectiveness of the improved model.
3.4. Ablation Experiment
In order to further test whether each module in the improved network in this paper can produce a performance gain, CycleGAN was used as the baseline model, and we compared the models with only the self-attention module being added, only the LPIPS-based cycle consistency loss function being added, and the self-attention module and LPIPS-based cycle consistency loss function experiments being added. All of the experiment’s parameters were set to the same values to guarantee its fairness, and the comparison results of the ablation experiment are shown in
Figure 8.
As can be seen from
Figure 8b, the foggy image generated by the original CycleGAN is too foggy, with the fog covering most of the useful information of the image and retaining too little input image information, and the authenticity is not high. Therefore, the foggy image generated by the original CycleGAN is not ideal. It can be seen from
Figure 8c that after adding the self-attention mechanism, the fog generated by the image is more natural and more realistic, which improves the information retention of the input image. It can be seen from
Figure 8d that the fog generated by the loss function after adding LPIPS is also natural, but the generated picture is blurred. In
Figure 8e, the foggy images generated by our method are better than those of the above methods. While not losing too much of the input image information, the natural fog is also well generated. Then, we used objective evaluation indicators to evaluate the above experiments.
Table 5 displays the outcomes of the experiment.
It can be seen from
Table 5 that the self-attention module makes different degrees of contribution to the three indicators of model performance, among which the contribution to the SSIM is the largest, and the value of the SSIM increases by 0.8%. Because the feature extraction after adding the self-attention module has global linkability, it can retain the detailed information of the source image better and has less distortion. The LPIPS-based cycle consistency loss function makes a significant contribution to the IS and FID indexes, but it affects the effect of the SSIM index and blurs some details. The value of the IS increases by 13.1%, and the value of the FID decreases by 2.53, mainly due to the fact that LPIPS can improve the perceptual similarity between images, so that the generated foggy image is closer to the real foggy image, and the quality of the generated foggy image is also improved. The experimental results show that the integration of the self-attention module within the LPIPS-based cycle consistency loss function demonstrably enhances the network performance, confirming the reliability and effectiveness of the proposed improvements.
4. Discussion
Currently, there are many generative adversarial network methods performing well in image conversion tasks, among which CycleGAN is still a powerful benchmark model for unsupervised image fogging tasks. Its unsupervised training mechanism makes it particularly suitable for tasks that lack paired training data, such as image fogging. However, the CycleGAN model encounters some limitations, such as the excessive uniformity of the fog in the generated images, the inadequate ability to retain details, and the lack of perceptual quality. Therefore, it is necessary to improve the adaptability of CycleGAN, which was the focus of this study. The modified method proposed in this paper is more suitable for training automatic driving system models. It can not only extract foggy features comprehensively but also generate foggy images that are closer to real life, which is dependent on the powerful self-attention mechanism, which captures image details more accurately and enhances the authenticity of fog features. At the same time, the LPIPS perceptual loss further optimizes the realistic effect of foggy images by reducing the visual difference between the generated results and the real scene. The method described in this paper can effectively augment the autopilot dataset in foggy environments to adequately train the autopilot system, improve the safety and robustness of the autopilot system, and reduce the risk of traffic accidents.
However, the method in this paper also needs to be perfected in the future. Even if the LPIPS loss and the self-attention mechanism can successfully raise the overall quality of the generated foggy images, the cost is a significant increase in computational complexity, memory overhead and optimization difficult.
Bayraktar, E, and Yigit, C B, proposed a novel pooling method called conditional pooling [
32], which integrates the advantages of average pooling and maximum pooling to dynamically select the optimum pooling strategy based on the characteristics of the input data, thus reducing information loss and improving the transmission efficiency. As an adaptive feature extraction method, conditional pooling can significantly improve the model’s capacity to retain local features, improve the adaptability of the model to different foggy scenes, and reduce the computational overhead to a certain extent. Therefore, in future research, we plan to further explore its application in image fogging tasks and continuously optimize the image generation model or design a new backbone network to generate more realistic foggy images, as well as to conduct more in-depth research on how to balance the efficiency and quality of the model.
5. Conclusions
In this paper, an optimized CycleGAN model is proposed for unsupervised image fogging tasks. The self-attention mechanism and LPIPS perceptual loss were introduced to improve the quality of foggy images. The self-attention mechanism and residual network were first employed to improve the feature extraction of foggy images by the adversarial generative network, while retaining the ability of the residual network to prevent network degradation. Secondly, LPIPS was added to the cycle consistency loss due to its potent ability to detect the perceptual similarity between images, in order to preserve the full details of the original image as well as possible in the generated image. The experimental findings demonstrated that, compared to the conventional CycleGAN network, the enhanced CycleGAN network suggested in this paper performs better in producing images that are more akin to the actual foggy driving scene, while also retaining the detailed information of the input driving scene image better.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}