


AI-Powered Trade Forecasting: A Data-Driven Approach to Saudi Arabia’s Non-Oil Exports



Abstract
1. Introduction
- (1)
- It develops an Advanced Transformer model achieving unparalleled accuracy (MAPE: 0.73%), demonstrating AI’s potential for economic diversification.
- (2)
- It introduces Blending and Stacking models, combining diverse algorithms with Explainable AI to improve prediction robustness and transparency.
- (3)
- It explores GDP integration in the Transformer and Temporal Fusion Transformer (MAPEs of 2.67% and 5.48%, respectively), offering new macroeconomic insights despite noise challenges, advancing contextual forecasting.
- (4)
- It provides AI-driven trade forecasting insights, supporting economic diversification and enable real-time policymaking aligned with Vision 2030 objectives.
- (5)
- It establishes a new benchmark for AI-based economic forecasting, addressing gaps in prior studies through comprehensive model evaluation and enhancement.
2. Literature Review
3. Materials and Methods
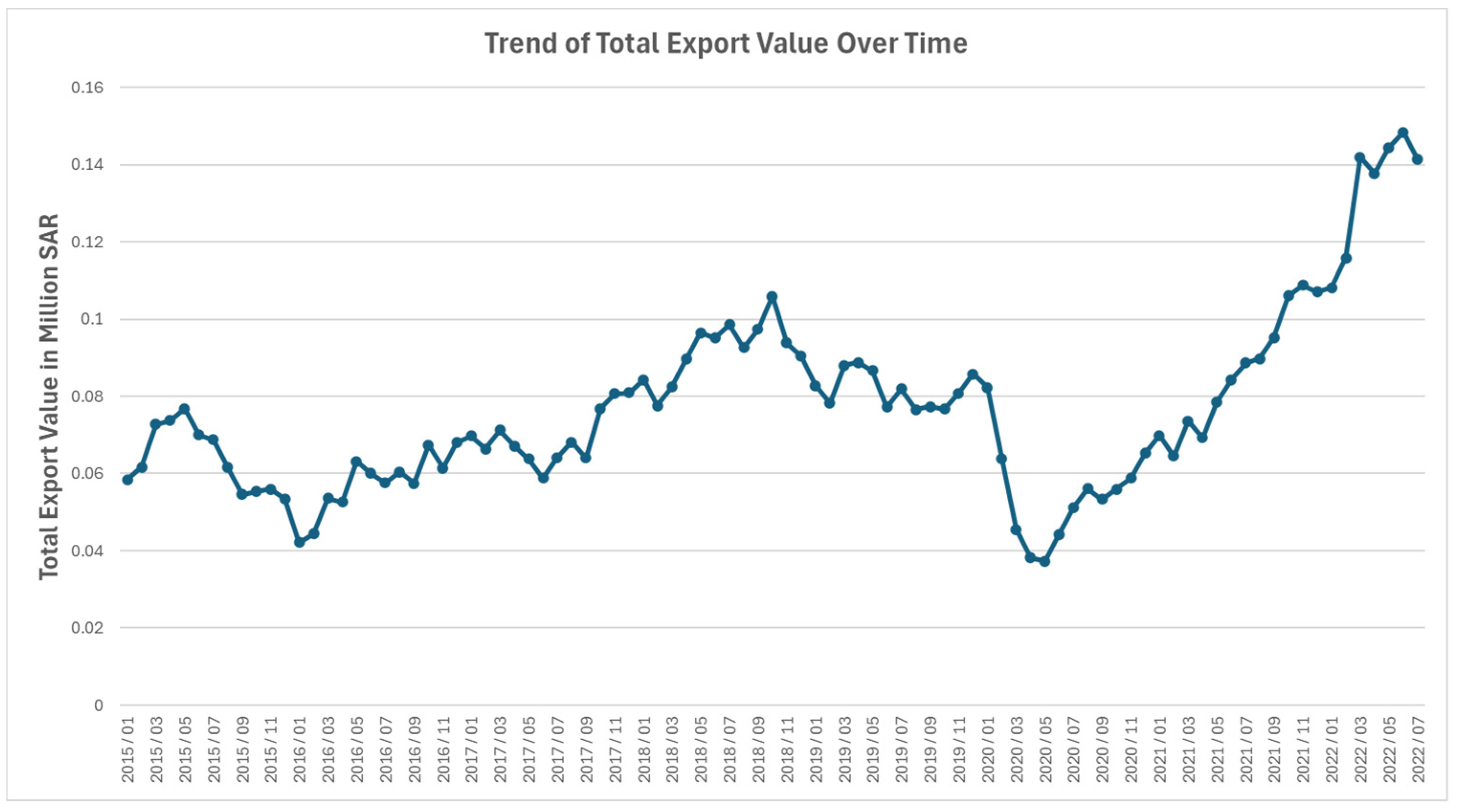
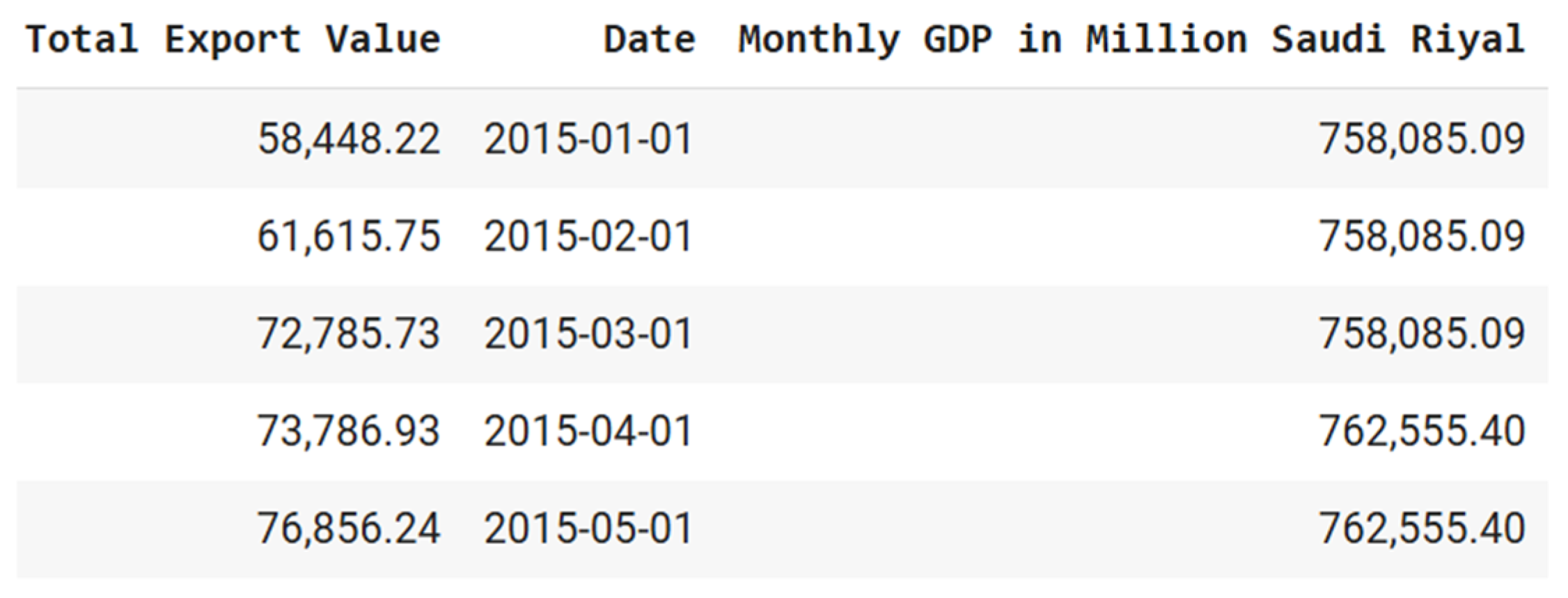
3.1. Data Description
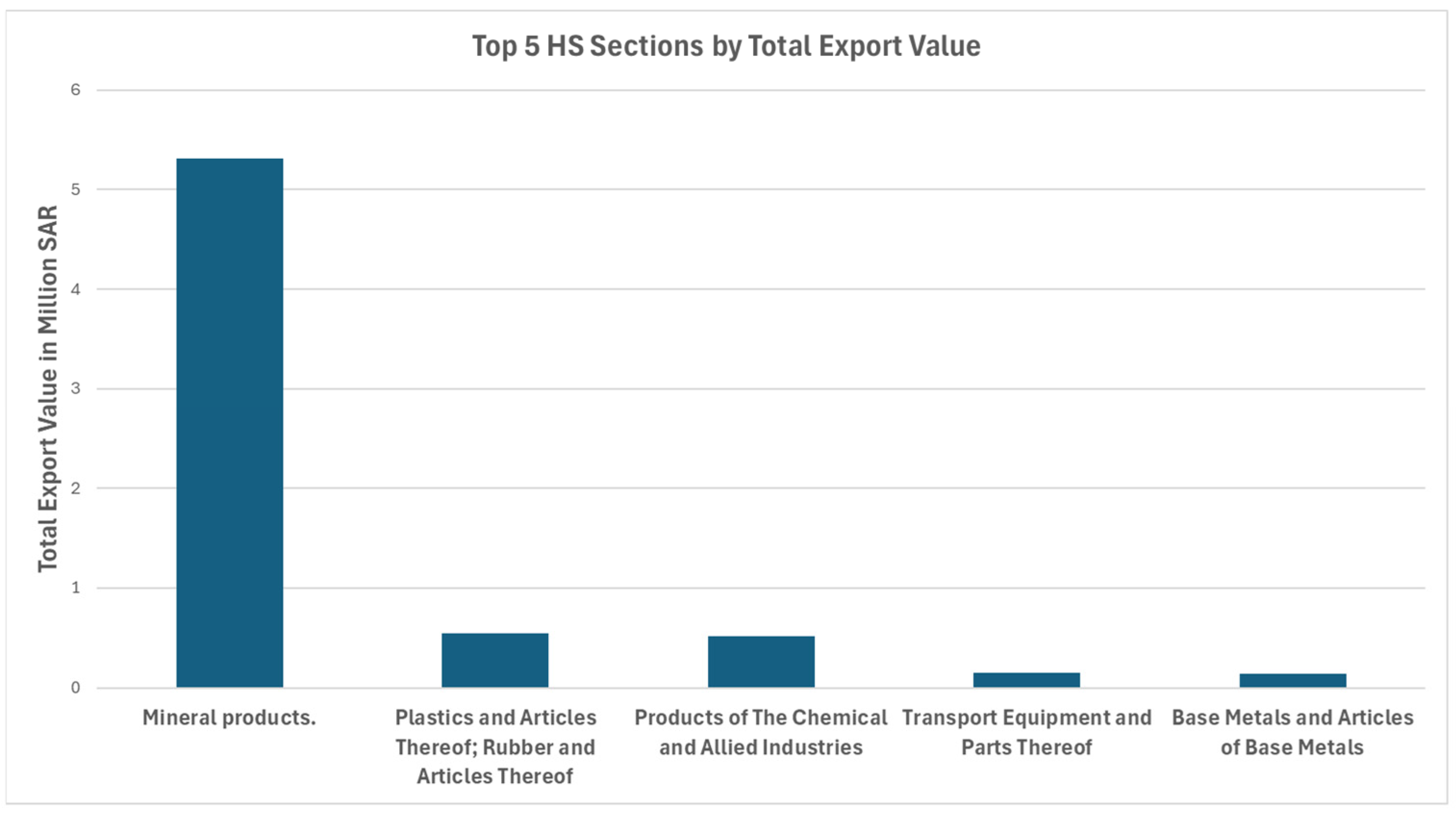
3.1.1. Export Values by Harmonized System (HS)
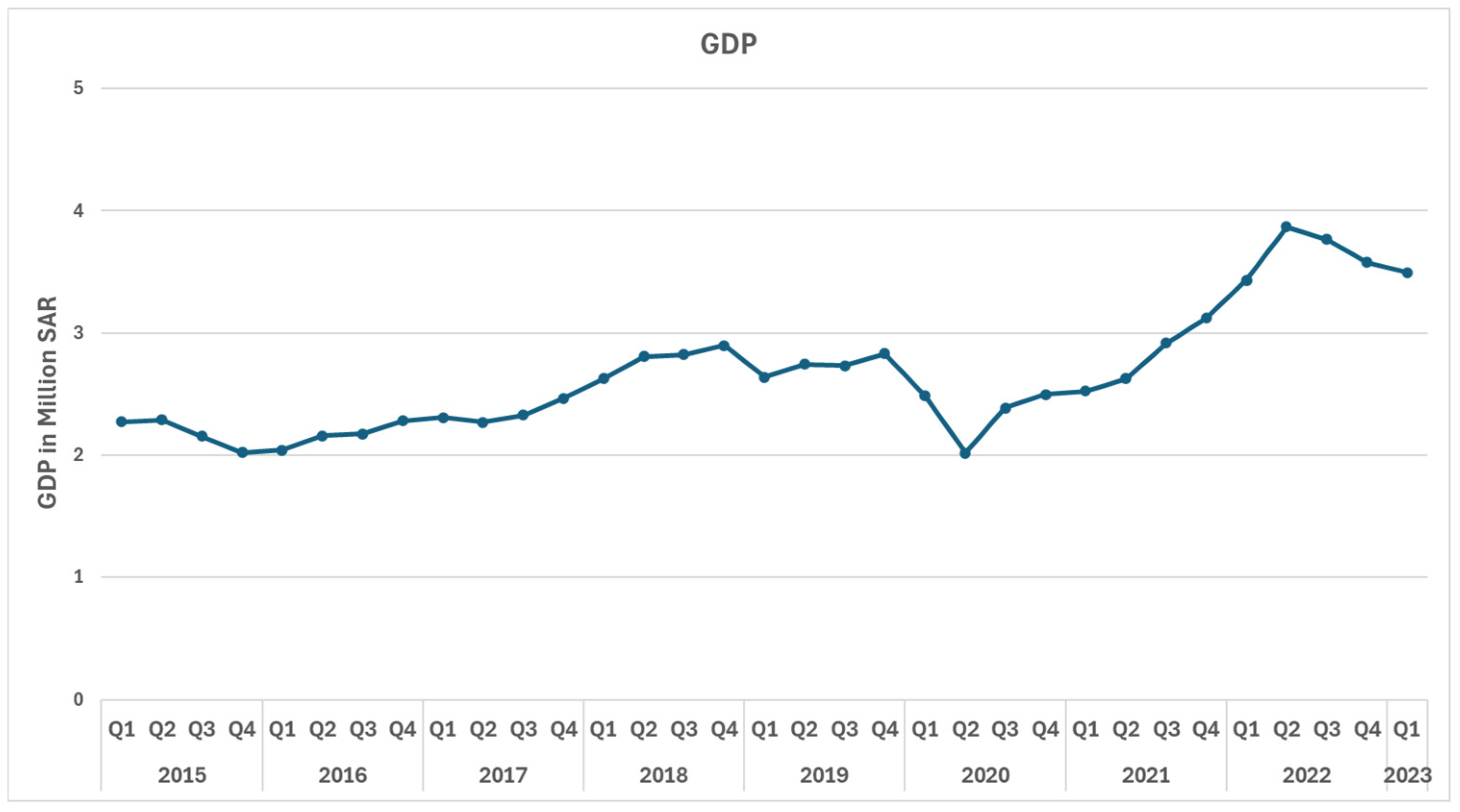
3.1.2. Gross Domestic Product (GDP)
3.1.3. Data Sources and Preprocessing Procedure
3.2. Methodology
3.2.1. Implementation Environment
3.2.2. Transformer
3.2.3. Advanced Transformer
3.2.4. Long Short-Term Memory (LSTM)
3.2.5. Deep LSTM
3.2.6. XGBRegressor
3.2.7. Random Forest
3.2.8. AdaBoostRegressor
3.2.9. Temporal Fusion Transformer (TFT)
- LSTM Encoder: Extracts sequential information and retains long-term dependencies.
- Transformer Blocks: Utilize multi-head attention mechanisms to enhance the model’s focus on relevant temporal features, capturing long-range dependencies.
- Dense layers: Serve as the final prediction layers, incorporating GDP data as contextual input to forecast export values.
3.2.10. Ensemble Stacking
- Base models: Random Forest captures non-linear patterns, XGBoost focuses on gradient boosting optimization, and AdaBoost reduces variance and bias in predictions.
- Meta-learner: Ridge Regression aggregates the outputs of the base models while applying regularization to prevent overfitting.
3.2.11. Ensemble Blending
- Base models: Each model independently predicts export values, with Random Forest reducing variance, XGBoost optimizing through gradient boosting, and AdaBoost balancing bias.
- Meta-learner: The XGBoost Regressor integrates the predictions of the base models to capture both linear and non-linear dependencies in the data.
3.2.12. Performance Metrics Formulas
- The Mean Squared Error (MSE), which is calculated as
- The Root Mean Squared Error (RMSE), which is the square root of MSE:
- The Mean Absolute Deviation (MAD) reflects the average absolute differences:
- The Mean Absolute Percentage Error (MAPE) expresses accuracy as a percentage using the following form:
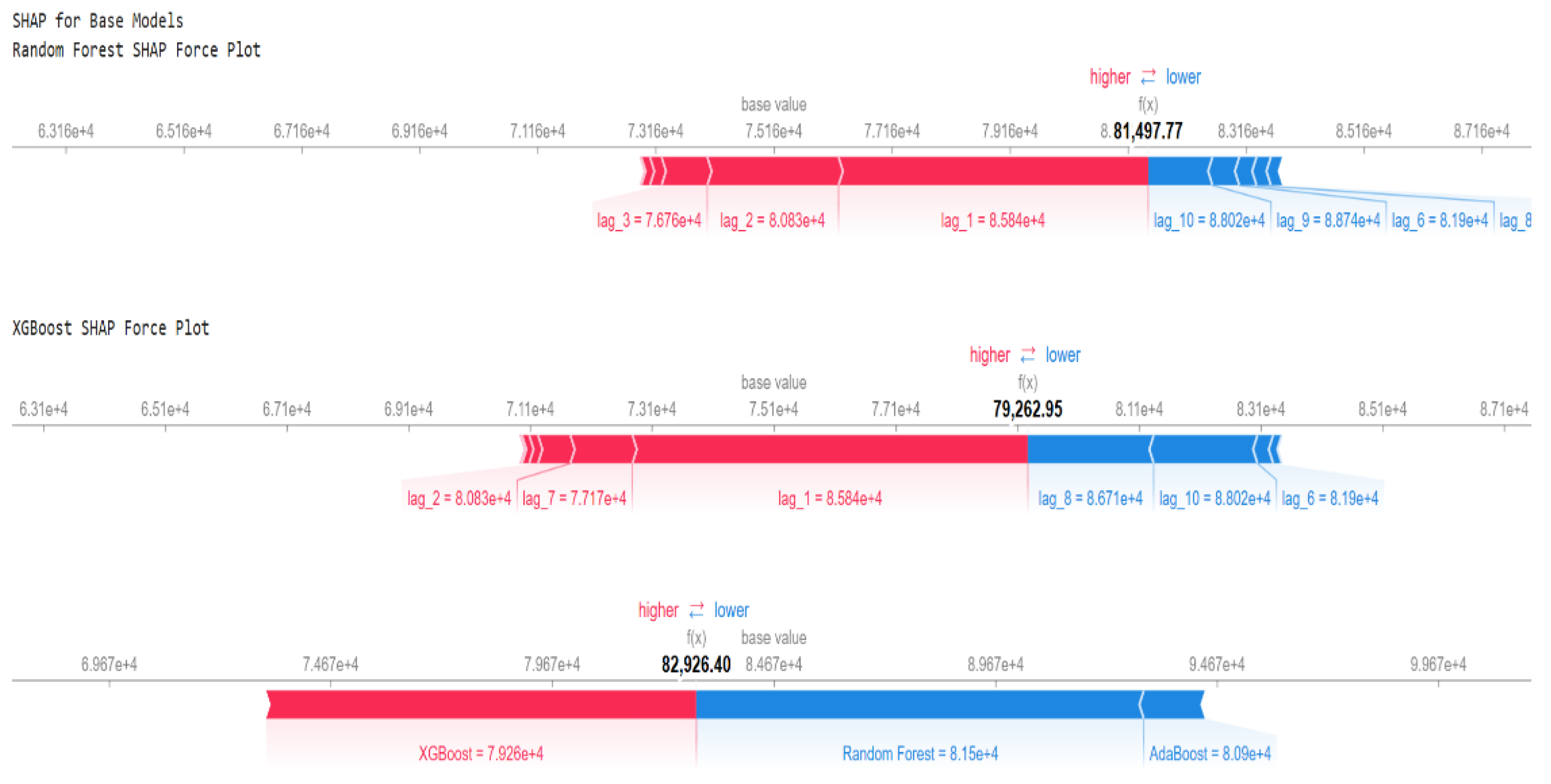
3.3. Explainable AI Tools: SHAP and Partial Dependence Plots (PDPs)
4. Experimental Results and Analysis
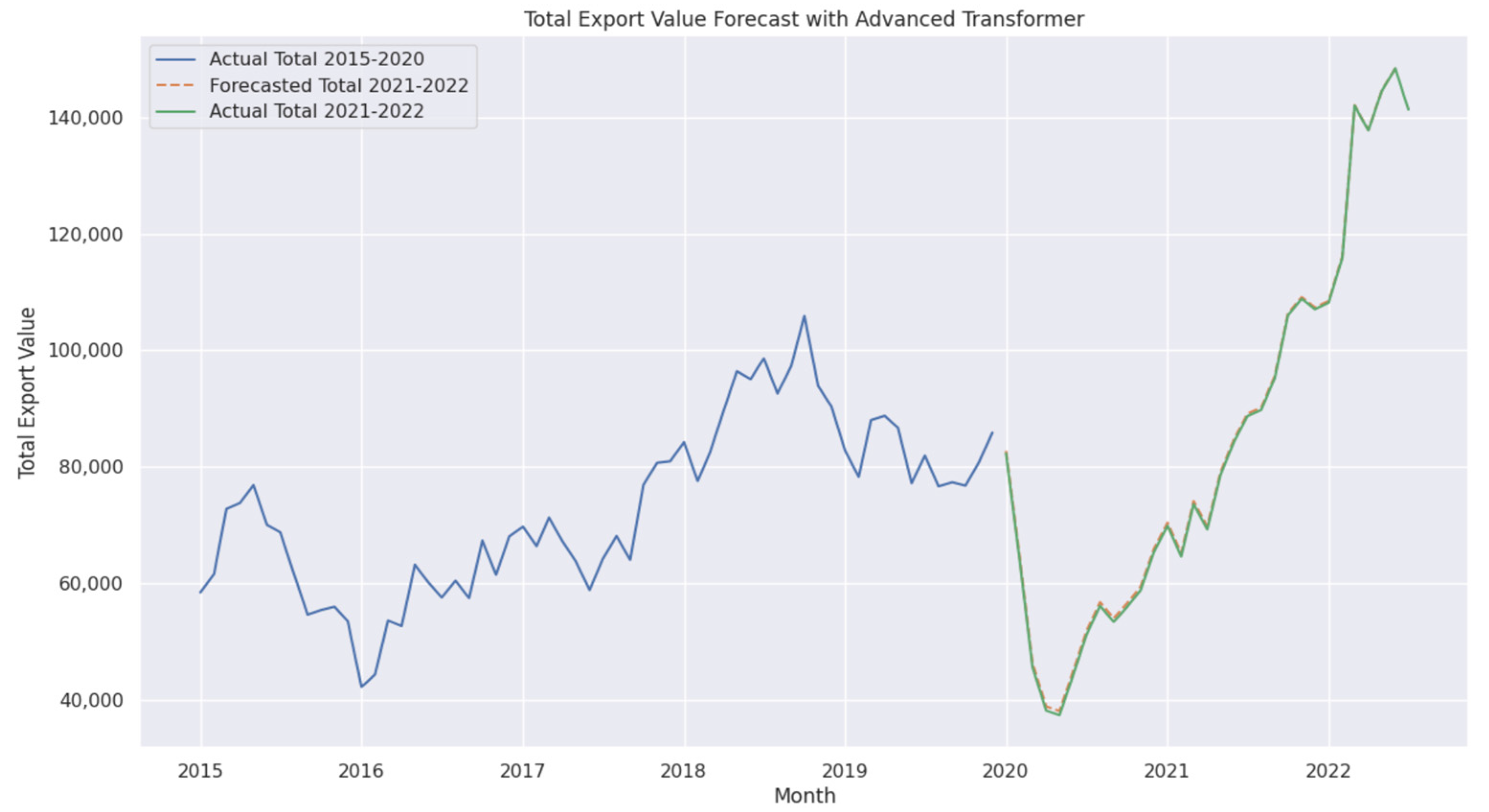
4.1. Performance of Advanced Transformer
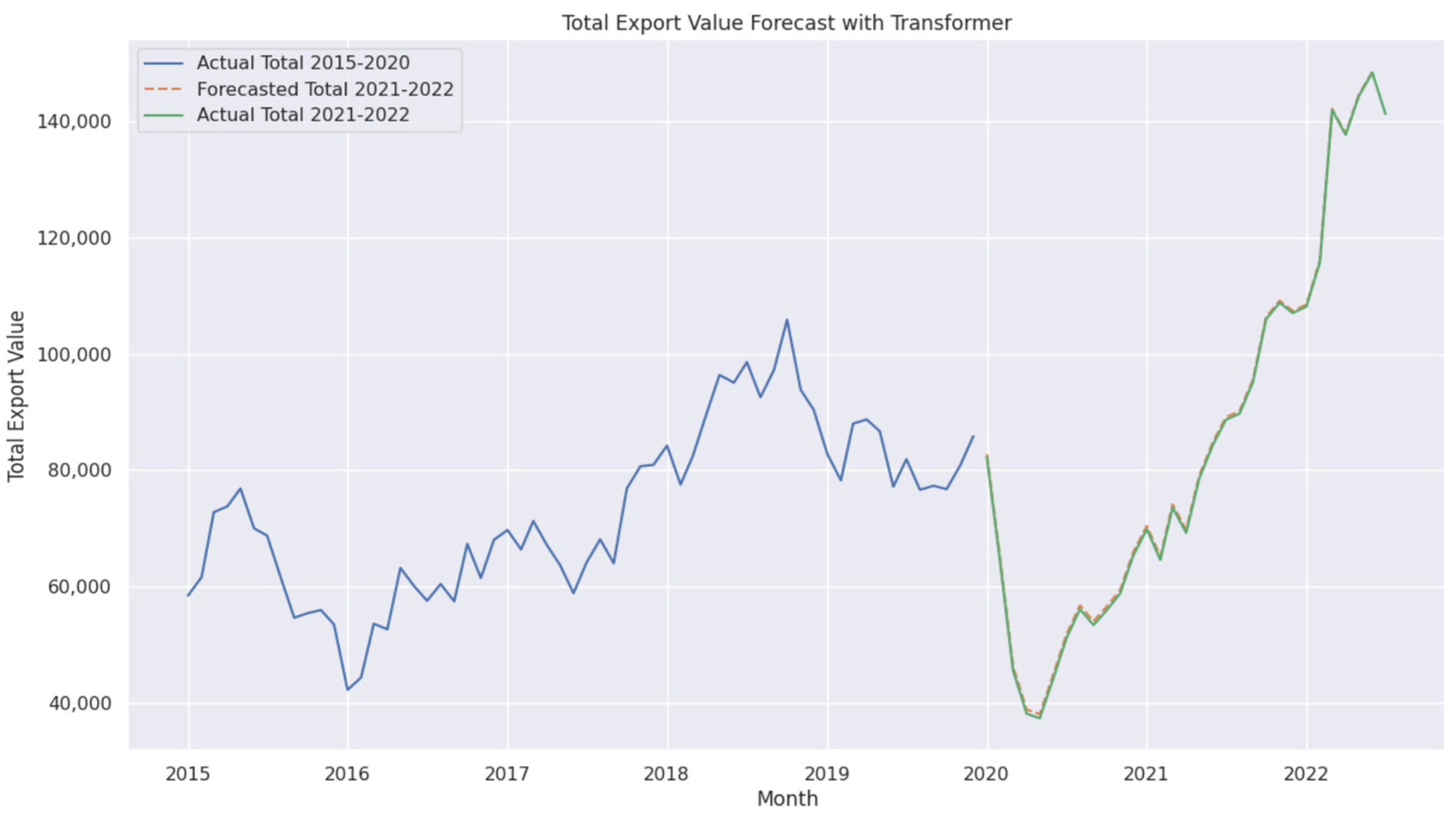
4.2. Performance of Standard Transformer
4.3. Performance of Ensemble Blending
- is the final prediction of the Blending model.
- are the predictions from Random Forest, XGBoost, and AdaBoost, respectively.
- Meta(.) represents the XGBoost Regressor, which combines the predictions of base models.
4.3.1. Analysis of Ensemble Blending Performance
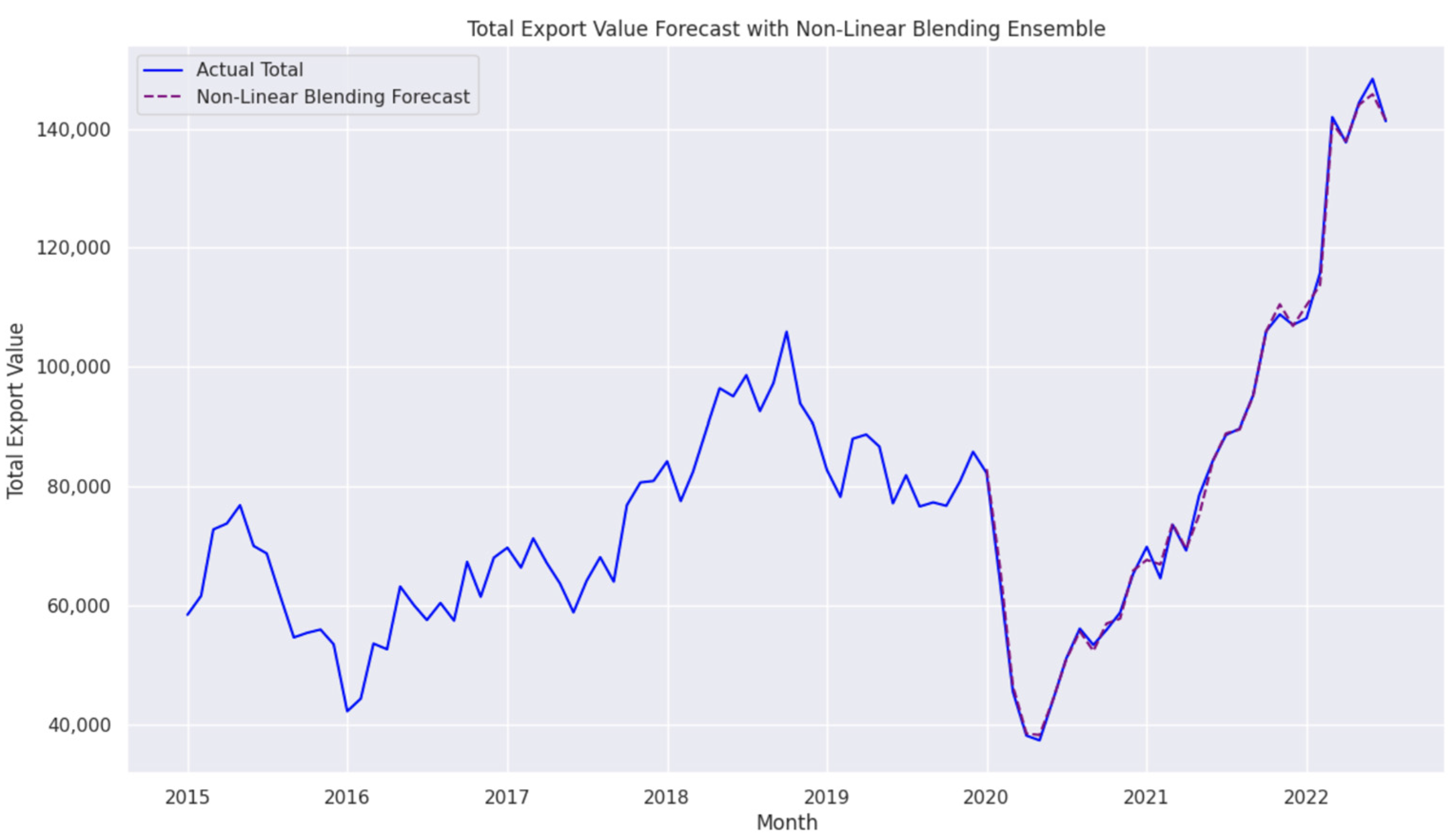
4.3.2. Forecasting Performance of the Ensemble Blending Model
- The model effectively captured key export trends, particularly during the post-2020 recovery phase, highlighting its ability to track complex economic fluctuations with high accuracy.
- The alignment between predicted and actual export values indicates that the Blending model successfully models temporal dependencies and adapts to market shifts.
- This performance further validates the model’s ability to balance short-term accuracy and long-term stability, making it a robust choice for economic forecasting.
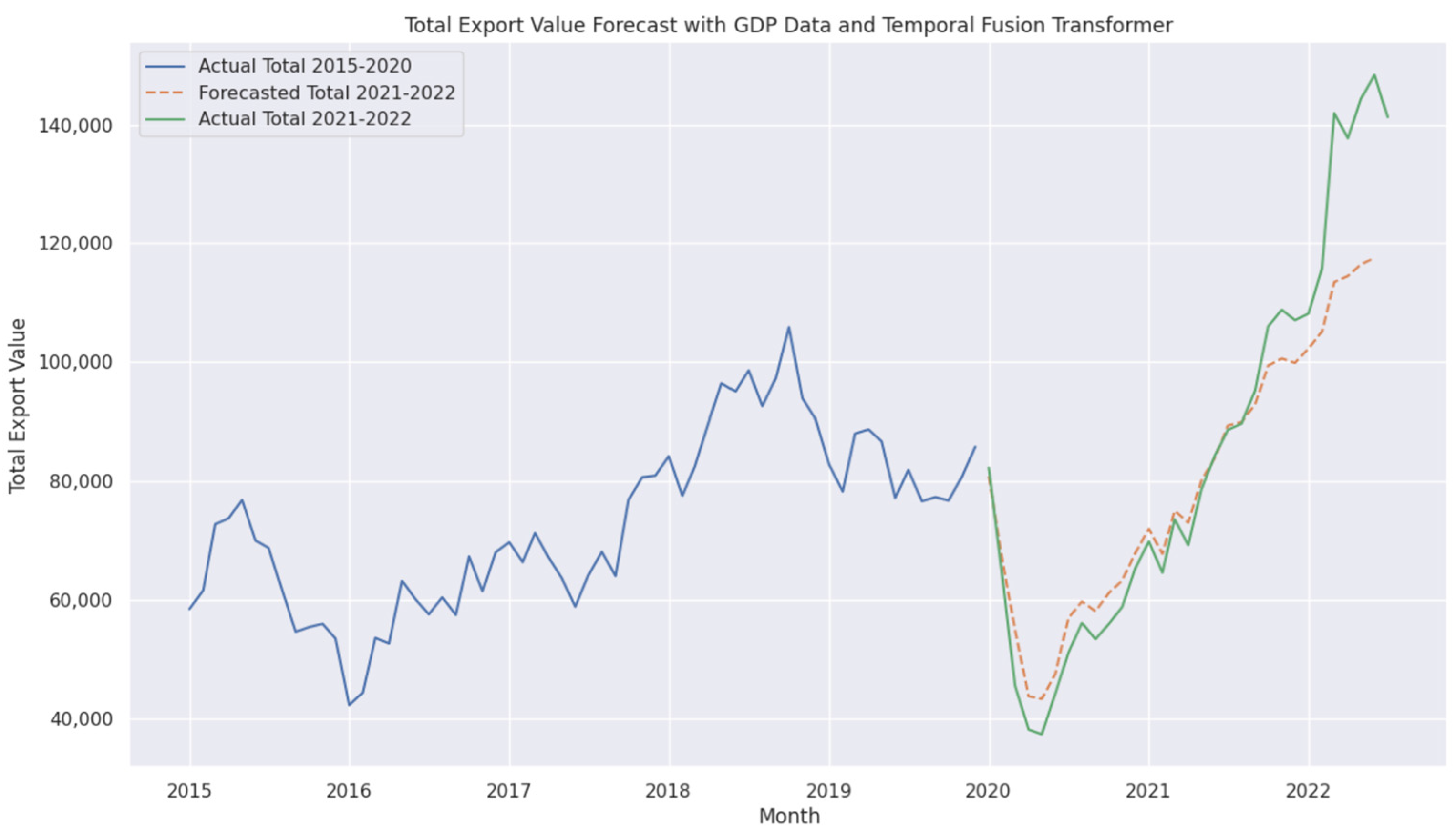
4.4. Performance of Temporal Fusion Transformer (TFT) with GDP
- is the final prediction of the TFT model.
- LSTM (X) represents the LSTM Encoder output for the input sequence X.
- Transformer (·) applies the attention mechanism for long-range dependencies.
- Dense (·) represents fully connected layers for final predictions.
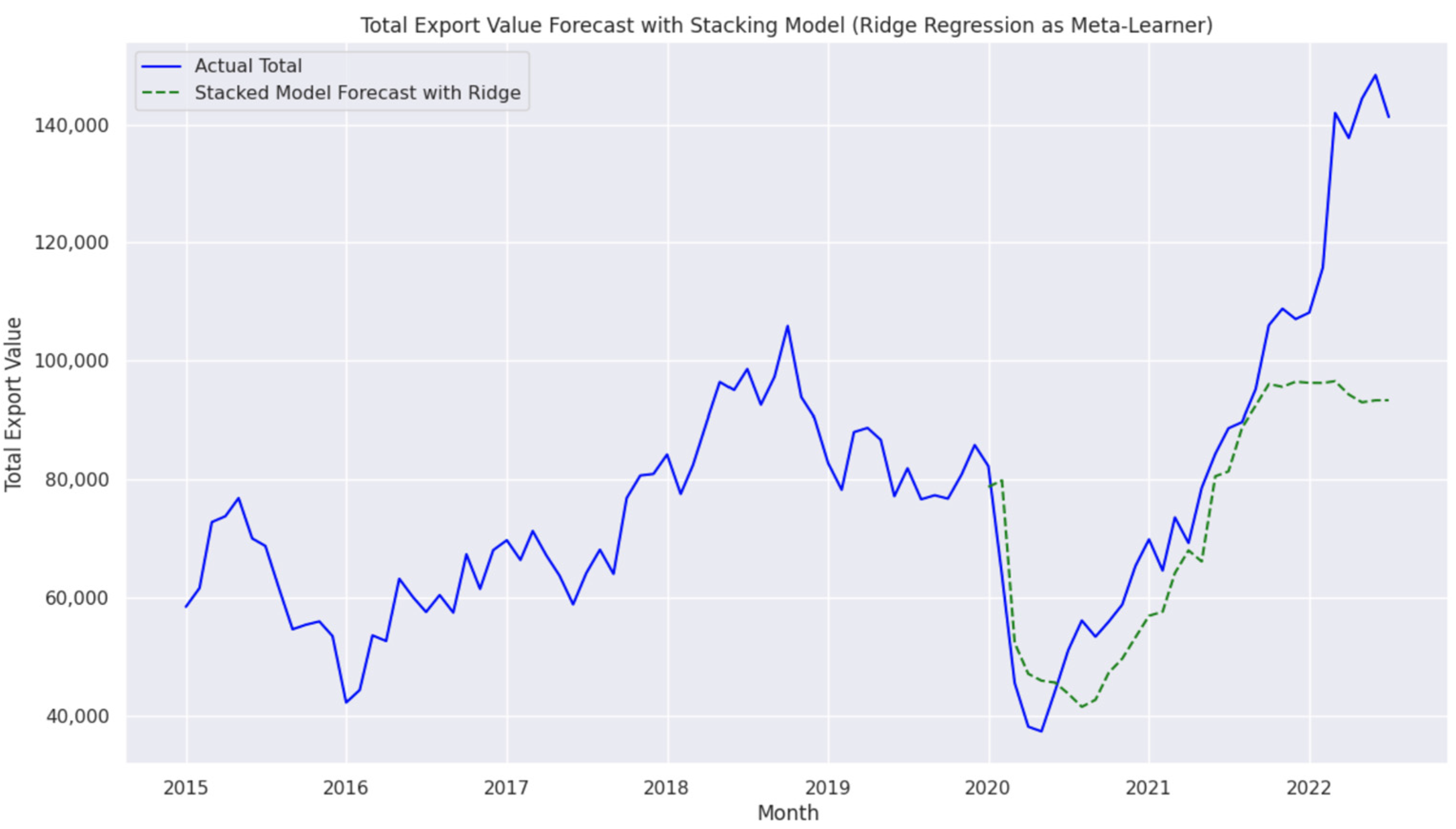
4.5. Performance of Ensemble Stacking
- is the final prediction of the Stacking approach.
- are the predictions from Random Forest, XGBoost, and AdaBoost, respectively.
- Ridge(.) represents the Ridge Regressor as the meta-learner, applying regularization to prevent overfitting.
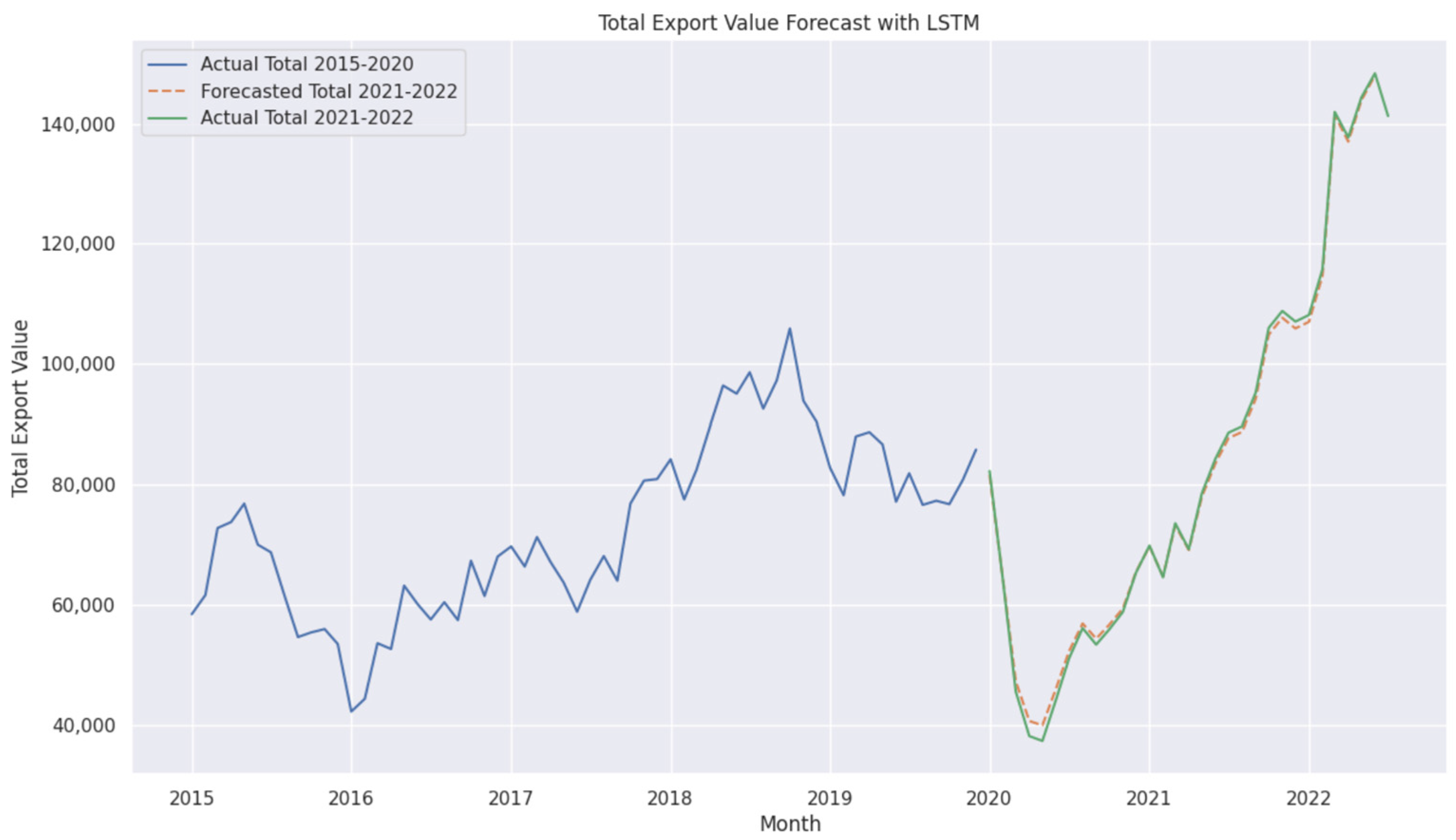
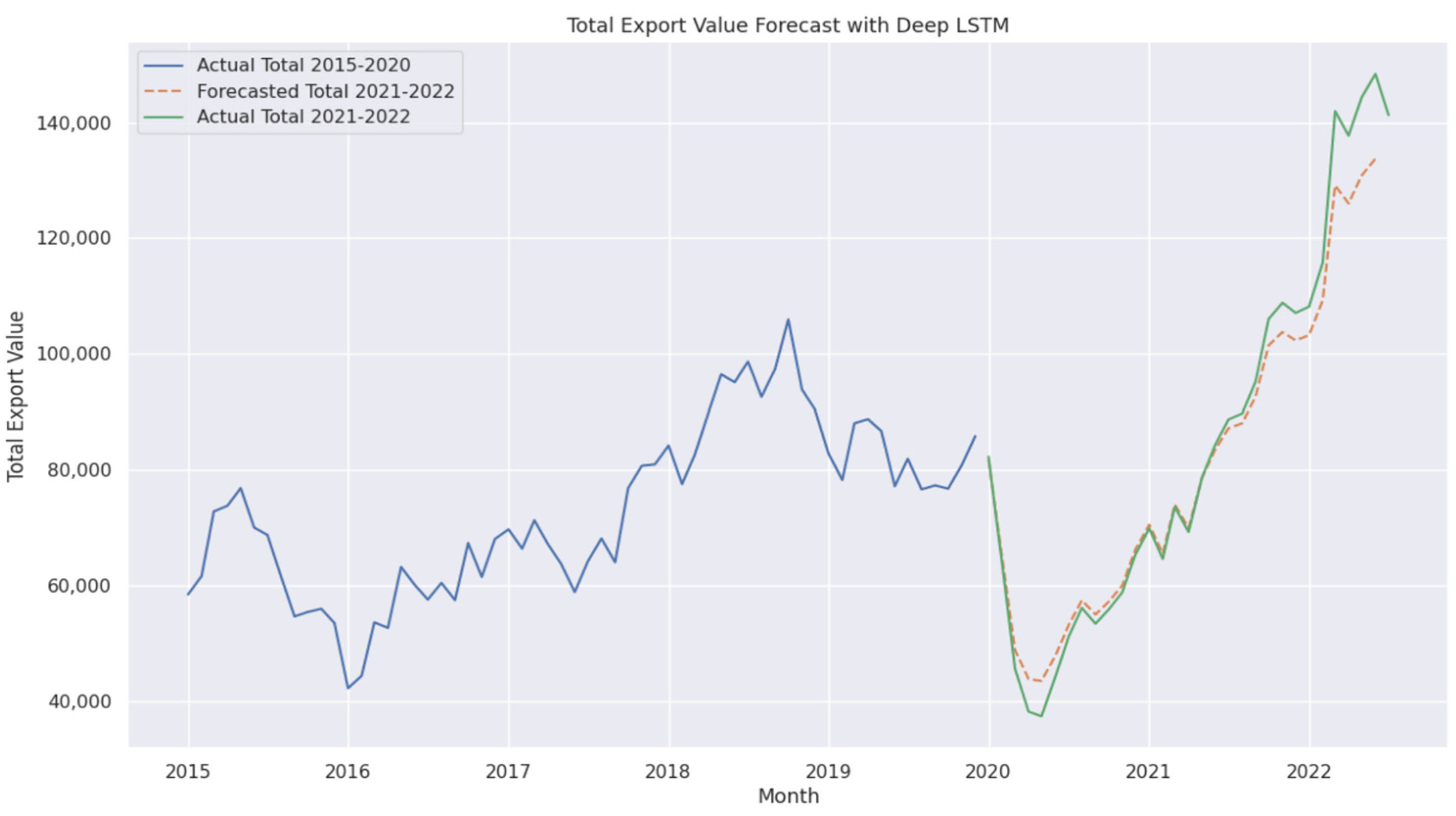
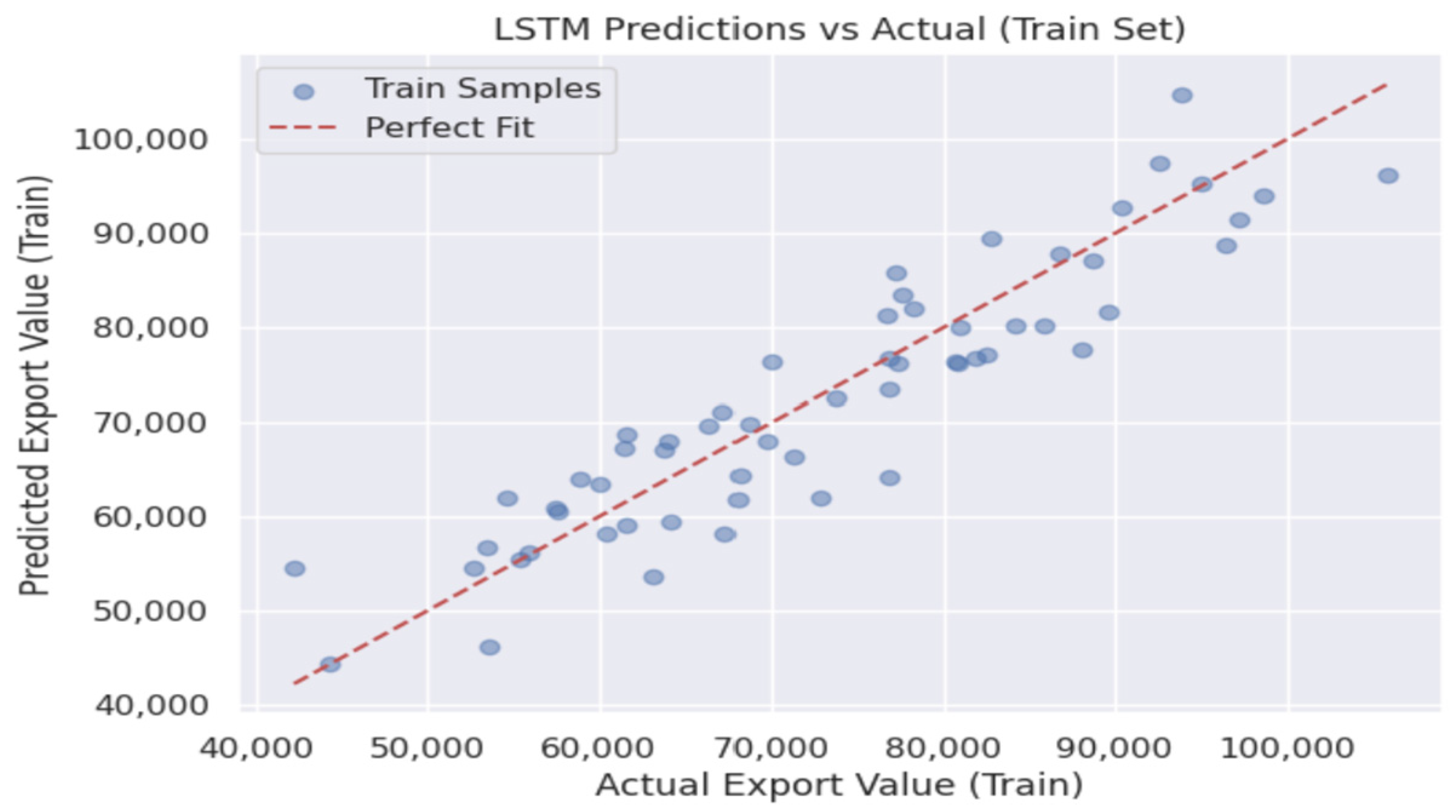
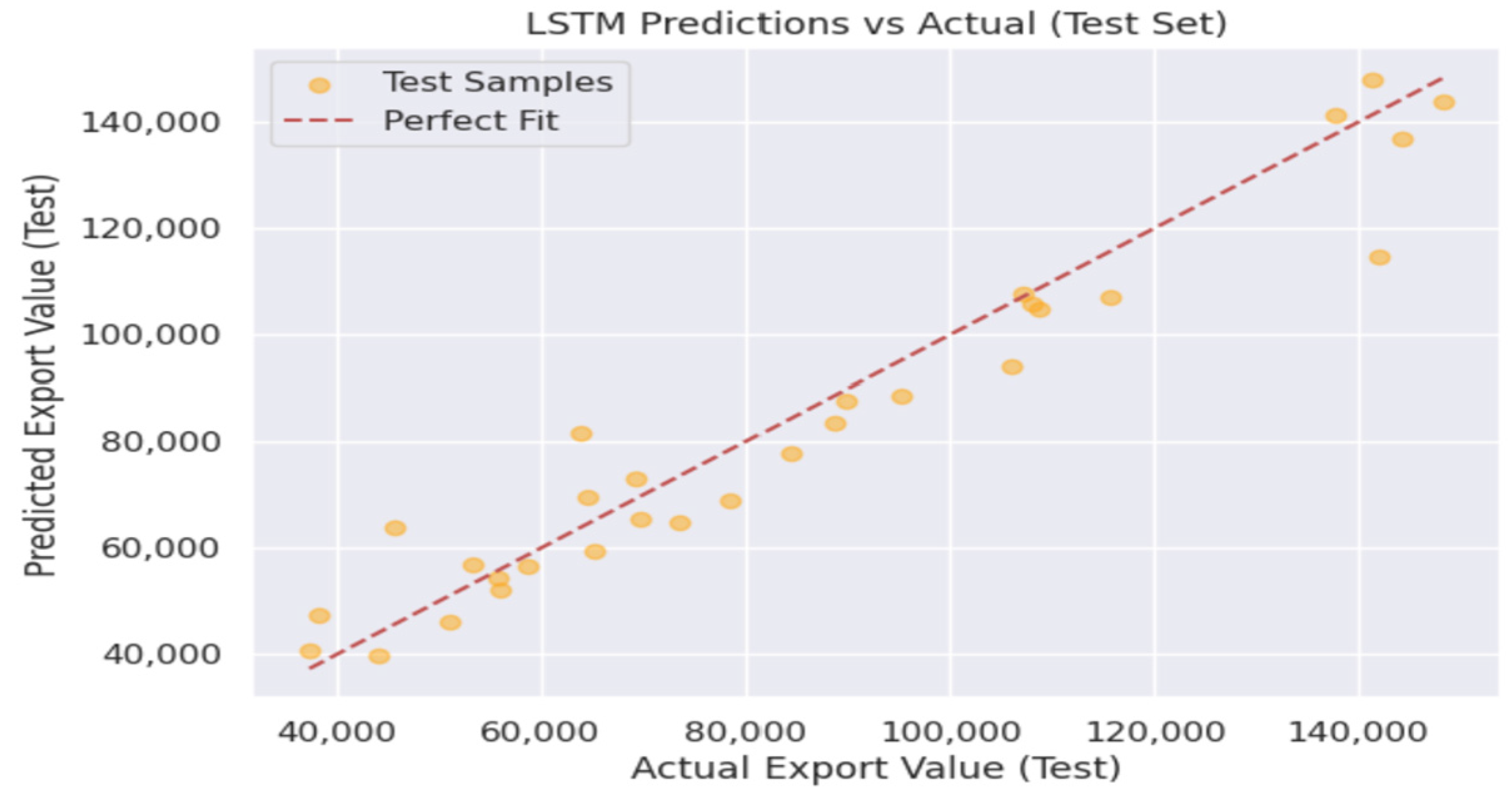
4.6. Performance of LSTM and Deep LSTM
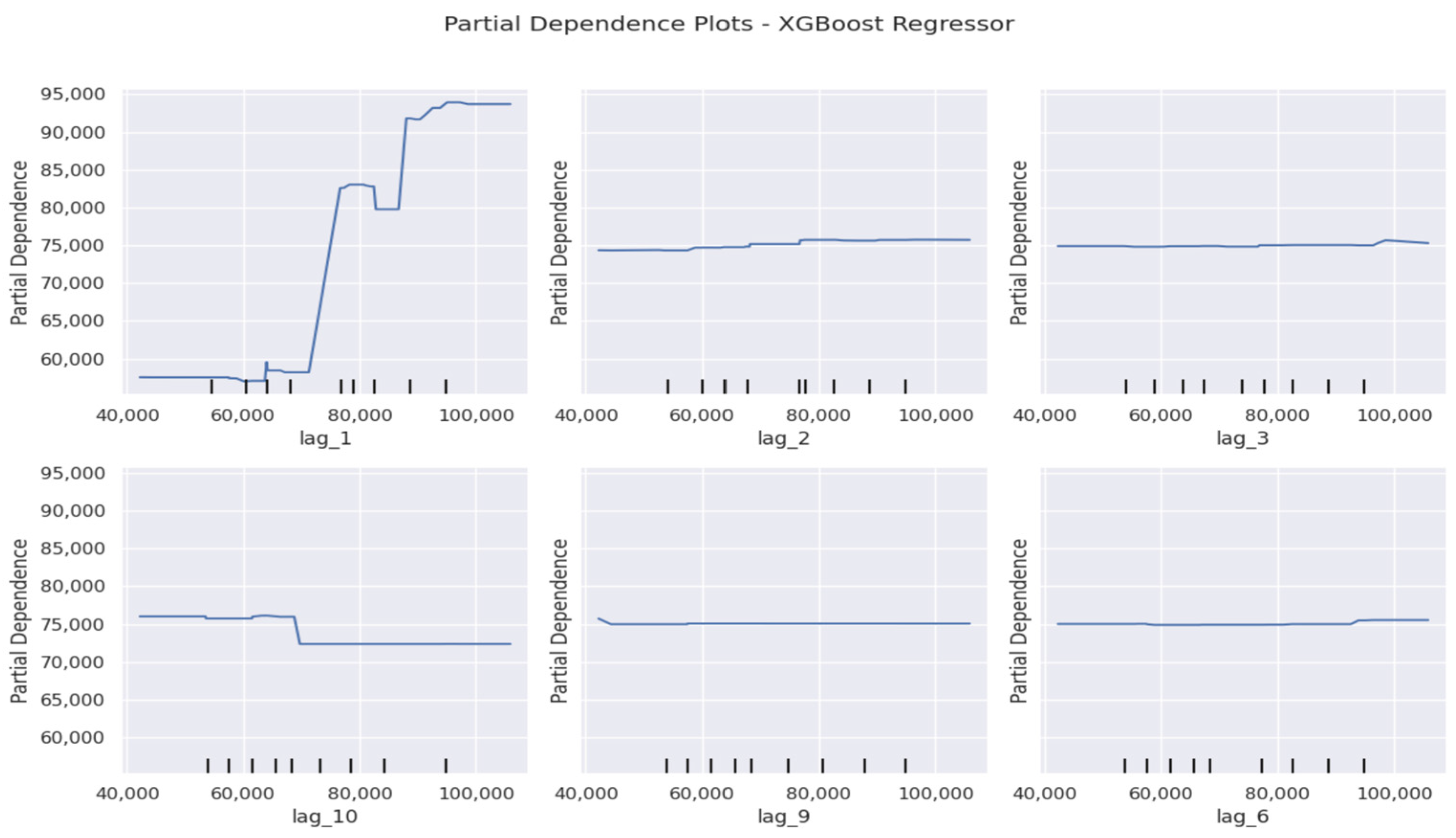
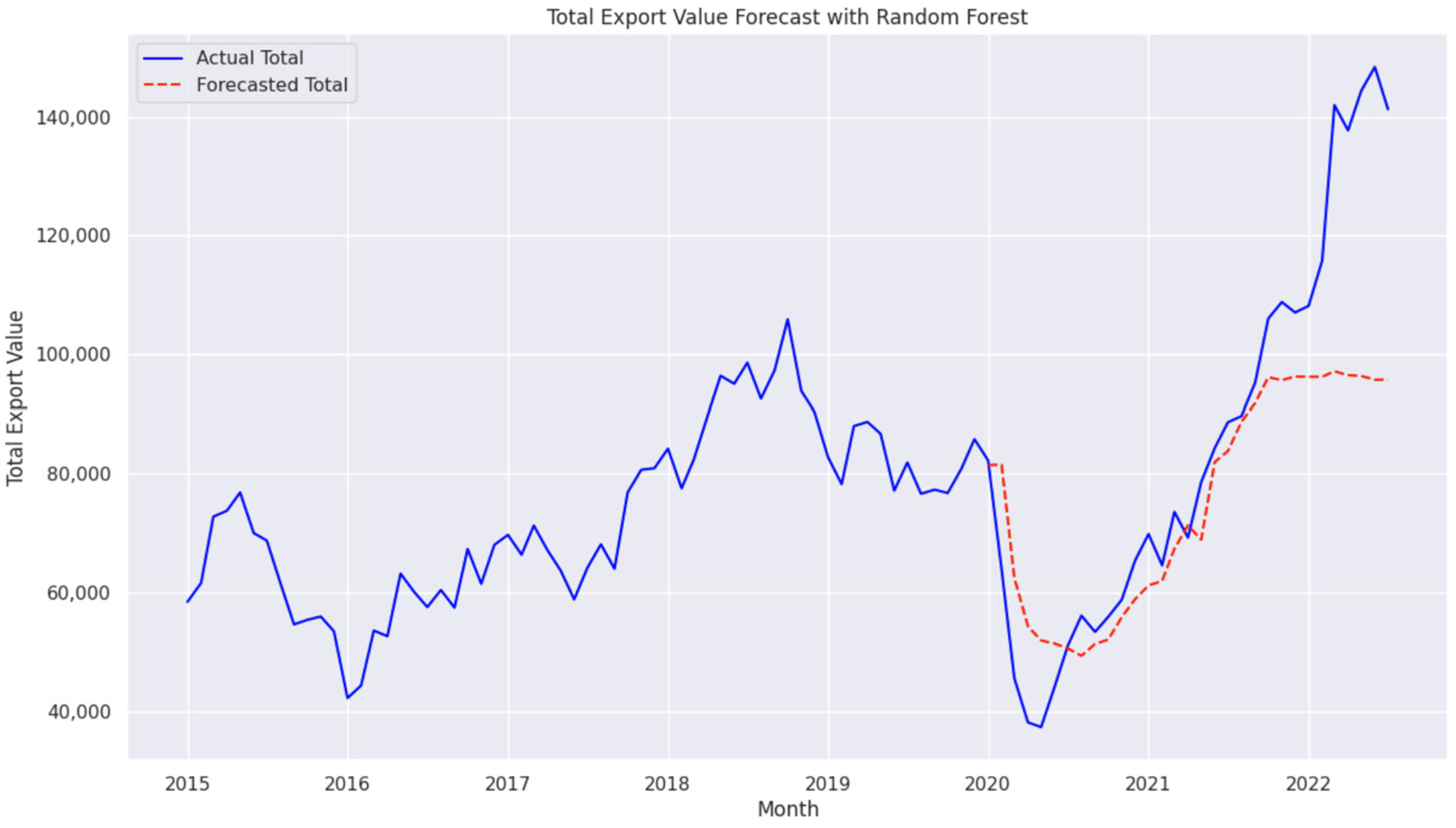
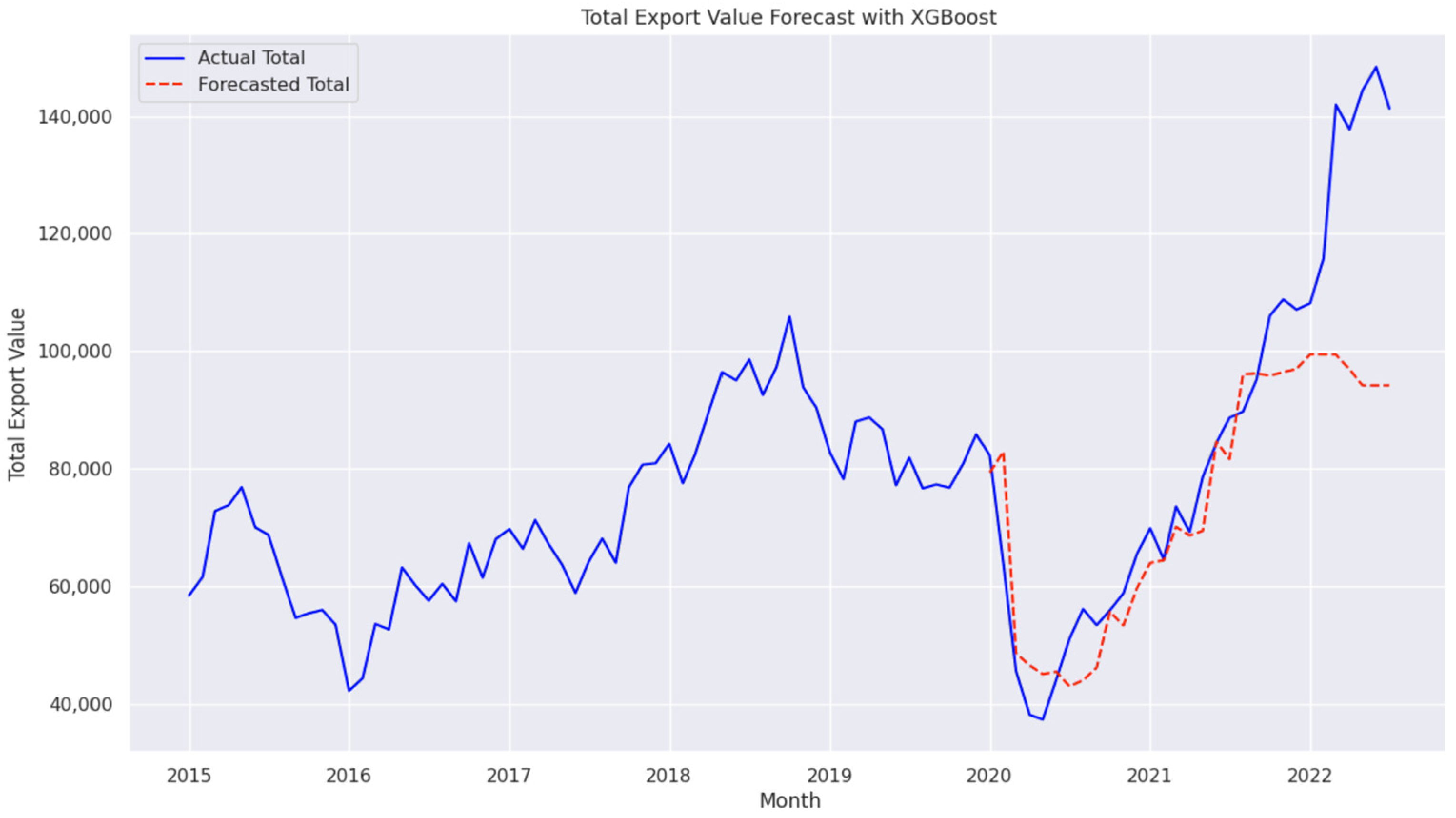
4.7. Performance of Random Forest and XGBoost
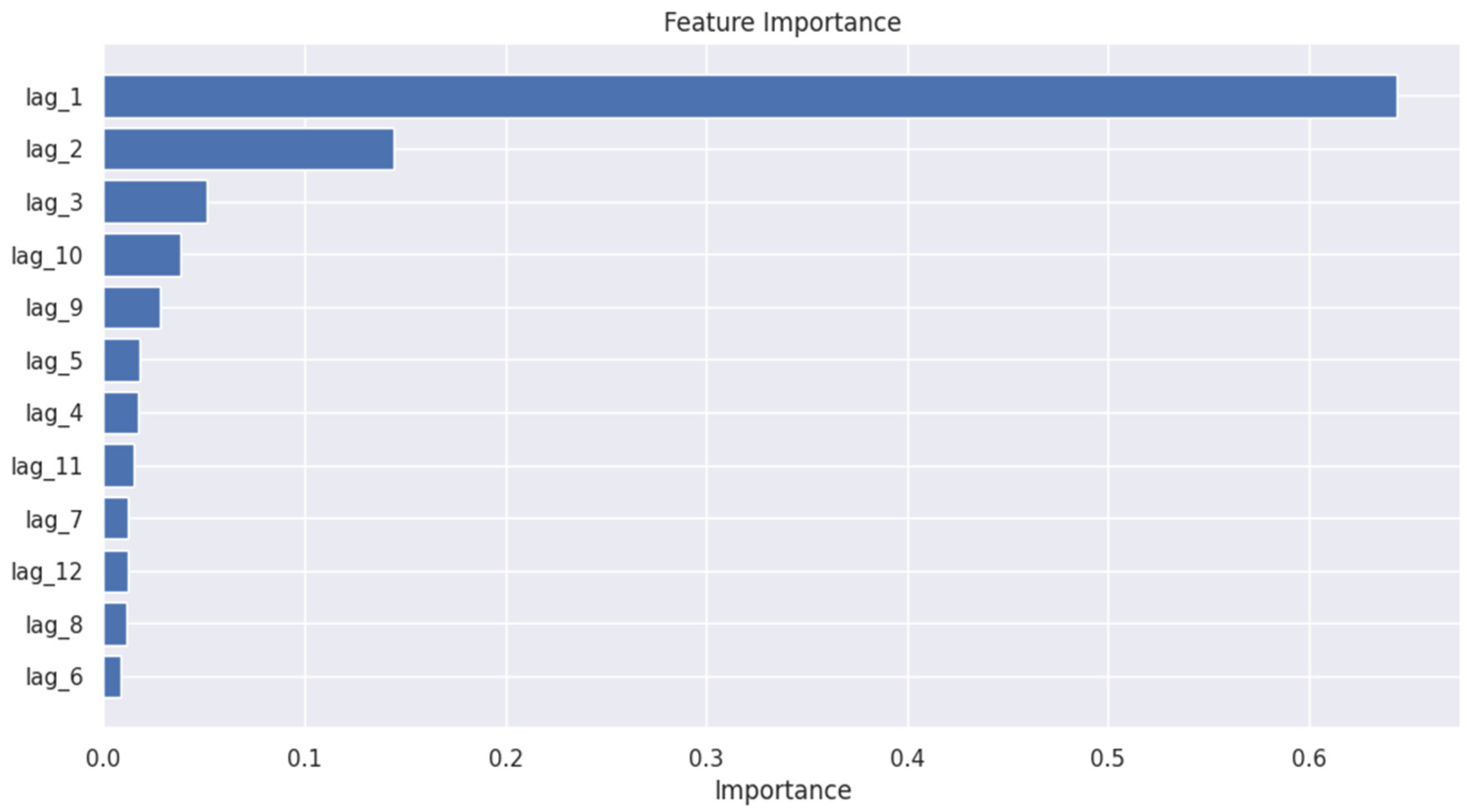
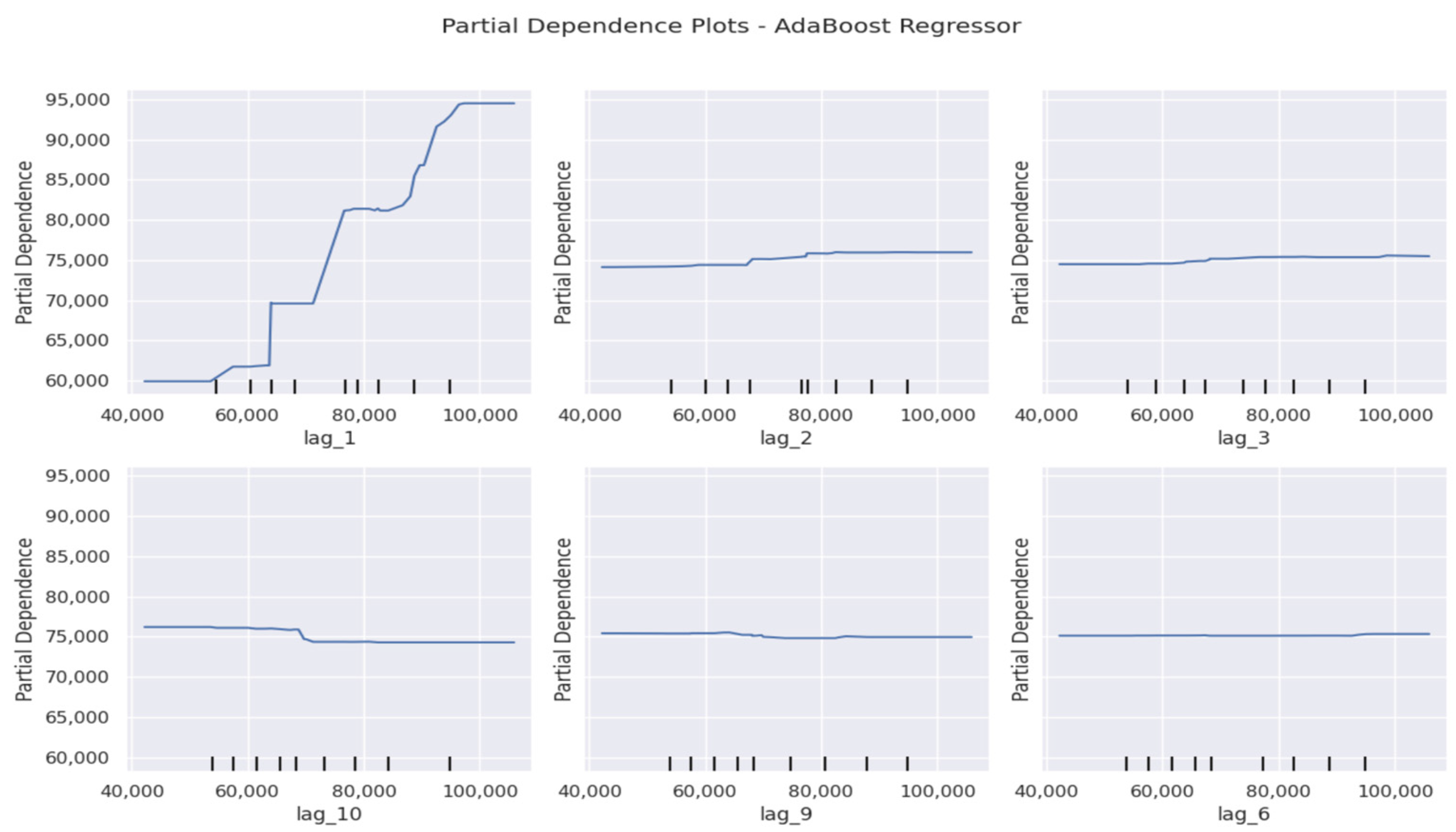
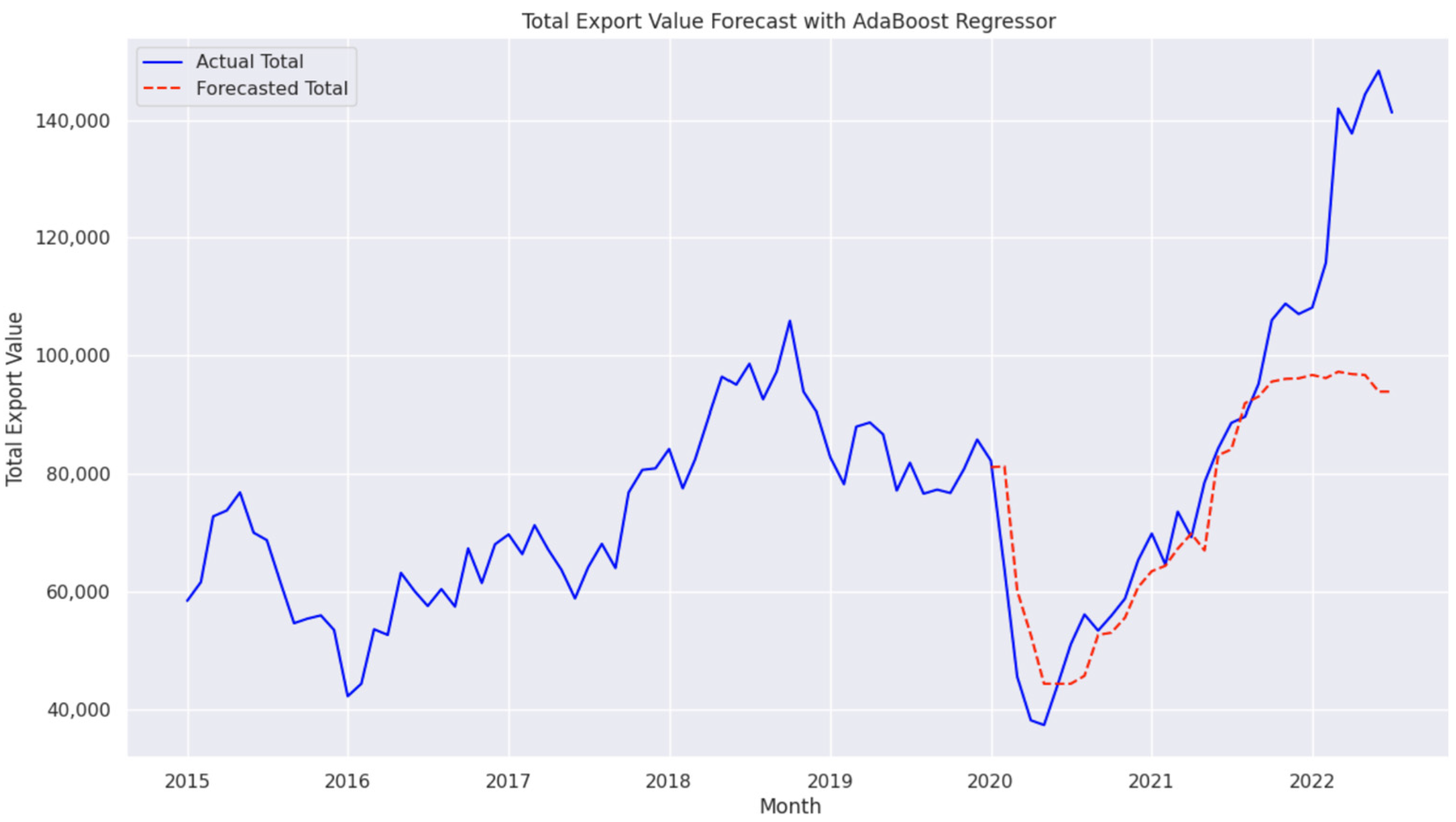
4.8. Performance of AdaBoost Regressor
4.9. Performance of Transformers with GDP
5. Discussion
5.1. AI’s Role in Economic Forecasting
5.2. Impact of GDP Data on Forecasting Accuracy
5.3. Integration with the Existing Literature
5.4. Methodological Strengths and Weaknesses
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hasanov, F.J.; Javid, M.; Joutz, F.L. Saudi non-oil exports before and after covid-19: Historical impacts of determinants and scenario analysis. Sustainability 2022, 14, 2379. [Google Scholar] [CrossRef]
- Available online: https://www.vision2030.gov.sa/ar/overview (accessed on 30 March 2025).
- Ahmed, A.; Xi, R.; Hou, M.; Shah, S.A.; Hameed, S. Harnessing big data analytics for healthcare: A comprehensive review of frameworks, implications, applications, and impacts. IEEE Access 2023, 11, 112891–112928. [Google Scholar] [CrossRef]
- Alreshidi, I.; Moulitsas, I.; Jenkins, K.W. Advancing aviation safety through machine learning and psychophysiological data: A systematic review. IEEE Access 2024, 12, 5132–5150. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, A. Sampling for big data profiling: A survey. IEEE Access 2020, 8, 72713–72726. [Google Scholar] [CrossRef]
- Jarrah, M.; Derbali, M. Predicting saudi stock market index by using multivariate time series based on deep learning. Appl. Sci. 2023, 13, 8356. [Google Scholar] [CrossRef]
- Yoo, T.-W.; Oh, I.-S. Time series forecasting of agricultural products’ sales volumes based on seasonal long short-term memory. Appl. Sci. 2020, 10, 8169. [Google Scholar] [CrossRef]
- Dave, E.; Leonardo, A.; Jeanice, M.; Hanafiah, N. Forecasting Indonesia exports using a hybrid model arima-lstm. Procedia Comput. Sci. 2021, 179, 480–487. [Google Scholar] [CrossRef]
- Sirisha, U.M.; Belavagi, M.C.; Attigeri, G. Profit prediction using arima, sarima and lstm models in time series forecasting: A comparison. IEEE Access 2022, 10, 124715–124727. [Google Scholar] [CrossRef]
- Reza, S.; Ferreira, M.C.; Machado, J.J.; Tavares, J.M.R. A multi head attention-based transformer model for traffic flow forecasting with a comparative analysis to recurrent neural networks. Expert Syst. Appl. 2022, 202, 117275. [Google Scholar] [CrossRef]
- Islam, M.; Shuvo, S.S.; Shohan, J.A.; Faruque, O. Forecasting of pv plant output using interpretable temporal fusion transformer model. In Proceedings of the 2023 North American Power Symposium (NAPS), Asheville, NC, USA, 15–17 October 2023; pp. 1–6. [Google Scholar]
- Hasan, M.; Abedin, M.Z.; Hajek, P.; Coussement, K.; Sultan, M.N.; Lucey, B. A blending ensemble learning model for crude oil price forecasting. Ann. Oper. Res. 2024, 1–31. [Google Scholar] [CrossRef]
- Pavlyshenko, B. Using stacking approaches for machine learning models. In Proceedings of the 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), Lviv, Ukraine, 21–25 August 2018; pp. 255–258. [Google Scholar]
- Carta, S.; Podda, A.S.; Reforgiato Recupero, D.; Stanciu, M.M. Explainable ai for financial forecasting. In International Conference on Machine Learning, Optimization, and Data Science, 7th International Conference, LOD 2021, Grasmere, UK, October 4–8, 2021, Revised Selected Papers, Part II; Springer: Cham, Switzerland, 2021; pp. 51–69. [Google Scholar]
- e Silva, L.C.; de Freitas Fonseca, G.; Andre, P.; Castro, L. Transformers and attention-based networks in quantitative trading: A comprehensive survey. In Proceedings of the 5th ACM International Conference on AI in Finance (ICAIF ′24), Brooklyn, NY, USA, 14–17 November 2024; Association for Computing Machinery: New York, NY, USA, 2024; pp. 822–830. [Google Scholar]
- Baumeister, C.; Guérin, P. A comparison of monthly global indicators for forecasting growth. Int. J. Forecast. 2021, 37, 1276–1295. [Google Scholar] [CrossRef]
- Kozik, R.; Pawlicki, M.; Choraś, M. A new method of hybrid time window embedding with transformer-based traffic data classification in iot-networked environment. Pattern Anal. Appl. 2021, 24, 1441–1449. [Google Scholar] [CrossRef]
- Exports Value by Harmonized System. 2024. Available online: https://datasource.kapsarc.org/explore/dataset/exports-value-by-harmonized-system/information/?disjunctive.hs_section&disjunctive.hs_chapter&sort=time_period (accessed on 30 March 2025).
- Jitsakul, W.; Whasphuttisit, J. Forecasting the export value of smes using time series analysis. In Proceedings of the 2022 7th International Conference on Business and Industrial Research (ICBIR), Bangkok, Thailand, 19–20 May 2022; pp. 671–676. [Google Scholar]
- Haque, M.I. Assessing the progress of exports diversification in saudi arabia: Growth-share matrix approach. Probl. Perspect. Manag. 2020, 18, 118. [Google Scholar]
- Al-Fattah, S.M. A new artificial intelligence gannats model predicts gasoline demand of saudi arabia. J. Pet. Sci. Eng. 2020, 194, 107528. [Google Scholar] [CrossRef]
- Gross Domestic Product by Kind of Economic Activity at Current Prices Quarterly. 2024. Available online: https://datasource.kapsarc.org/explore/dataset/saudi-arabia-gross-domestic-product-by-kind-of-economic-activity-at-current-pric/information// (accessed on 30 March 2025).
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and machine learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef]
- Batarseh, F.; Gopinath, M.; Nalluru, G.; Beckman, J. Application of machine learning in forecasting international trade trends. arXiv 2019, arXiv:1910.03112. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2017; Volume 30. [Google Scholar]
- Foumani, N.M.; Tan, C.W.; Webb, G.I.; Salehi, M. Improving position encoding of transformers for multivariate time series classification. Data Min. Knowl. Discov. 2024, 38, 22–48. [Google Scholar] [CrossRef]
- Peng, B.; Alcaide, E.; Anthony, Q.; Albalak, A.; Arcadinho, S.; Biderman, S.; Cao, H.; Cheng, X.; Chung, M.; Grella, M.; et al. RWKV: Reinventing RNNs for the Transformer Era. In Findings of the Association for Computational Linguistics: EMNLP; Association for Computational Linguistics: Singapore, 2023; pp. 14048–14077. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Sagheer, A.; Kotb, A. Time Series Forecasting of Petroleum Production using Deep LSTM Recurrent Networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Lim, B.; Arık, S.Ö.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for interpretable multi-horizon time series forecasting. Int. J. Forecast. 2021, 37, 1748–1764. [Google Scholar] [CrossRef]
- Chatzimparmpas, A.; Martins, R.M.; Kucher, K.; Kerren, A. Empirical Study: Visual Analytics for Comparing Stacking to Blending Ensemble Learning. In Proceedings of the 2021 23rd International Conference on Control Systems and Computer Science (CSCS), Bucharest, Romania, 26–28 May 2021; pp. 1–8. [Google Scholar]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS′17), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hu, Y.; Wei, R.; Yang, Y.; Li, X.; Huang, Z.; Liu, Y.; He, C.; Lu, H. Performance Degradation Prediction Using LSTM with Optimized Parameters. Sensors 2022, 22, 2407. [Google Scholar] [CrossRef] [PubMed]
- Maccarrone, G.; Morelli, G.; Spadaccini, S. GDP Forecasting: Machine Learning, Linear or Autoregression? Front. Artif. Intell. 2021, 4, 757864. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | MSE | RMSE | MAD | MAPE | MAD as % of Mean |
|---|---|---|---|---|---|
| Advanced Transformer | 246,510 | 496 | 452 | 0.73% | 0.53% |
| Transformer | 259,862 | 509 | 482 | 0.76% | 0.57% |
| Ensemble Blending | 1,698,952 | 2130 | 931 | 1.23% | 1.10% |
| LSTM | 1,180,754 | 1086 | 892 | 1.44% | 1.05% |
| Transformer with GDP | 5,474,217 | 2339 | 2000 | 2.67% | 2.36% |
| Deep LSTM | 31,972,707 | 5654 | 3884 | 4.519% | 4.59% |
| TFT with GDP | 80,225,739 | 8956 | 5395 | 5.48% | 6.37% |
| XGBRegressor | 416,618,498 | 20,411 | 13,155 | 13.36% | 15.53% |
| AdaBoostRegressor | 428,840,065 | 20,708 | 13,515 | 14.10% | 15.96% |
| Random Forest | 428,208,024 | 20,693 | 14,008 | 15.39% | 16.54% |
| Ensemble Stacking | 469,002,748 | 21,656 | 15,301 | 16.45% | 18.07% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aloudah, M.; Alajmi, M.; Sagheer, A.; Algosaibi, A.; Almarri, B.; Albelwi, E. AI-Powered Trade Forecasting: A Data-Driven Approach to Saudi Arabia’s Non-Oil Exports. Big Data Cogn. Comput. 2025, 9, 94. https://doi.org/10.3390/bdcc9040094
Aloudah M, Alajmi M, Sagheer A, Algosaibi A, Almarri B, Albelwi E. AI-Powered Trade Forecasting: A Data-Driven Approach to Saudi Arabia’s Non-Oil Exports. Big Data and Cognitive Computing. 2025; 9(4):94. https://doi.org/10.3390/bdcc9040094
Chicago/Turabian StyleAloudah, Musab, Mahdi Alajmi, Alaa Sagheer, Abdulelah Algosaibi, Badr Almarri, and Eid Albelwi. 2025. "AI-Powered Trade Forecasting: A Data-Driven Approach to Saudi Arabia’s Non-Oil Exports" Big Data and Cognitive Computing 9, no. 4: 94. https://doi.org/10.3390/bdcc9040094
APA StyleAloudah, M., Alajmi, M., Sagheer, A., Algosaibi, A., Almarri, B., & Albelwi, E. (2025). AI-Powered Trade Forecasting: A Data-Driven Approach to Saudi Arabia’s Non-Oil Exports. Big Data and Cognitive Computing, 9(4), 94. https://doi.org/10.3390/bdcc9040094