

Evaluating the Effect of Surrogate Data Generation on Healthcare Data Assessment

 ,
,  ,
, 
 ,
,  and
and 
Abstract
1. Introduction
2. Methods for Surrogate Rehabilitative Data Generation
2.1. Image-Based Methods
2.2. One-Dimensional Methods
2.3. Shape-Preserving Technique
| Algorithm 1: Detection of Significant Transients for Spectrogram Data |
| I. Generate spectrogram of zero-mean signal II. For all time points compute mean and std cluster the means using k-means III. For all clusters remove members that are: < mean threshold % low energy > std threshold % energy not evenly spread remove clusters with few members IV. For valid clusters % members adjoining time points find start and end values of time points linearly interpolate signal between start/end times subtract from actual signal % transient only store differences % to be restored |
3. Generative Adversarial Network for Synthetic Clinical Data Generation
4. Effectiveness of Surrogate Data Generation
5. Conclusions and Recommendations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Brzezinski, D.; Minku, L.L.; Pewinski, T.; Stefanowski, J.; Szumaczuk, A. The impact of data difficulty factors on classification of imbalanced and concept drifting data streams. Knowl. Inf. Syst. 2021, 63, 1429–1469. [Google Scholar] [CrossRef]
- Cao, Y.; Jia, L.-L.; Chen, Y.; Lin, N.; Yang, C.; Zhang, B.; Liu, Z.; Li, X.; Dai, H. Recent advances of generative adversarial networks in computer vision. IEEE Access 2019, 7, 14985–15006. [Google Scholar] [CrossRef]
- Borji, A. Pros and cons of GAN evaluation measures. Comput. Vis. Image Understand 2019, 179, 41–65. [Google Scholar] [CrossRef]
- Wen, Q.; Sun, L.; Yang, F.; Song, X.; Gao, J.; Wang, X.; Xu, H. Time series data augmentation for deep learning: A survey. arXiv 2020, arXiv:2002.12478. [Google Scholar]
- Lancaster, G.; Iatsenkob, D.; Piddeac, A.; Ticcinelli, V.; Stefanovska, A. Surrogate data for hypothesis testing of physical systems. Phys. Rep. 2018, 748, 1–60. [Google Scholar] [CrossRef]
- Theiler, J.; Eubank, S.; Longtin, A.; Galdrikian, B.; Farmer, J.D. Testing for nonlinearity in time series: The method of surrogate data. Phys. D Nonlinear Phenom. 1991, 58, 1–4. [Google Scholar] [CrossRef]
- Schreiber, T.; Schmitz, R. Improved Surrogate Data for Nonlinearity Tests. Phys. Rev. Lett. 1996, 77, 635–638. [Google Scholar] [CrossRef]
- Cui, Z.; Chen, W.; Chen, Y. Multi-Scale Convolutional Neural Networks for Time Series Classification. arXiv 2016, arXiv:1603.06995. [Google Scholar]
- Le Guennec, A.; Malinowski, S.; Tavenard, R. Data Augmentation for time series classification using convolutional neural networks. In Proceedings of the 2nd ECML/PKDD Workshop on Advanced Analytics and Learning on Temporal Data, Riva Del Garda, Italy, 19–23 September 2016. [Google Scholar]
- Rashid, K.M.; Louis, J. Window-Warping: A time series data augmentation of IMU data for construction equipment activity identification. In Proceedings of the 36th International Symposium on Automation and Robotics in Construction (ISARC 2019), Banff, AB, Canada, 21–24 May 2019. [Google Scholar]
- Kruskal, B.; Liberman, M. The Symmetric Time-Warping Problem: From Continuous to Discrete, Time Warps, String Edits, and Macromolecules: The Theory and Practice of Sequence Comparison; Addison-Wesley Publishing Company, INC: Boston, MA, USA, 1983. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. Classification with deep convolutional neural networks. In Proceedings of the Conference on Neural Information Processing Systems (NIPS12), Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Weiss, K.; Khoshgoftaar, T.M.; Wang, D.D. A survey of transfer learning. Big Data 2016, 3, 9. [Google Scholar] [CrossRef]
- Lee, T.K.M.; Chan, H.W.; Leo, K.-H.; Chew, E.; Zhao, L.; Sanei, S. Surrogate rehabilitative time series data for image-based deep learning. In Proceedings of the European Signal Processing Conference EUSIPCO 2019, A Coruna, Spain, 2–6 September 2019. [Google Scholar]
- Aldrich, C. A Comparative Analysis of Image Encoding of Time Series for Anomaly Detection. In Time Series Analysis—Recent Advances, New Perspectives and Applications; IntechOpen: London, UK, 2023. [Google Scholar] [CrossRef]
- Byeon, Y.H.; Pan, S.B.; Kwak, K.C. Intelligent deep models based on scalograms of electrocardiogram signals for biometrics. Sensors 2019, 19, 935. [Google Scholar] [CrossRef] [PubMed]
- Tsai, Y.C.; Chen, J.H.; Wang, J.J. Predict Forex Trend via Convolutional Neural Networks. Intell. Syst. 2020, 29, 941–958. [Google Scholar] [CrossRef]
- Wang, Z.; Oates, T. Encoding Time Series as Images for Visual Inspection and Classification Using Tiled Convolutional Neural Networks. In Proceedings of the 29th AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Lee, T.K.M.; Chan, H.W.; Leo, K.-H.; Chew, E.; Zhao, L.; Sanei, S. Surrogate Data for Deep Learning Architectures in Rehabilitative Edge Systems. In Proceedings of the 24th Conference on Signal Processing: Algorithms, Architectures, Arrangements, and Applications, SPA 2020, Poznań, Poland, 23–25 September 2020. [Google Scholar]
- Grattan, E.S.; Velozo, C.A.; Skidmore, E.R.; Page, S.J.; Woodbury, M.L. Interpreting Action Research Arm Test Assessment Scores to Plan Treatment. OTJR 2019, 39, 64–73. [Google Scholar] [CrossRef] [PubMed]
- Golyandina, N.; Zhigljavski, A. Singular Spectrum Analysis for Time Series, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Lee, T.K.M.; Chan, H.W.; Leo, K.-H.; Chew, E.; Zhao, L.; Sanei, S. Improving Rehabilitative Assessment with Statistical and Shape Preserving Surrogate Data and Singular Spectrum Analysis. In Proceedings of the IEEE International Conference on Signal Processing Algorithms, Architecture, Arrangements, and Applications, SPA 2022, Poznan, Poland, 21–22 September 2022. [Google Scholar]
- Allen, M.R.; Smith, L.A. Monte Carlo SSA: Detecting irregular oscillations in the Presence of Colored Noise. J. Clim. 1996, 9, 3373–3404. [Google Scholar] [CrossRef]
- Braun, M.L.; Buhmann, J.; Müller, K.-R. On relevant dimensions in kernel feature spaces. J. Mach. Learn. Res. 2008, 9, 1875–1908. [Google Scholar]
- Iwana, B.K.; Uchida, S. An empirical survey of data augmentation for time series classification with neural networks. PLoS ONE 2021, 16, e0254841. [Google Scholar] [CrossRef] [PubMed]
- Alarcón, G.; Martinez, J.; Kerai, S.V.; Lacruz, M.E.; Quiroga, R.Q.; Selway, R.P.; Richardson, M.P.; García Seoane, J.J.; Valentín, A. In vivo neuronal firing patterns during human epileptiform discharges replicated by electrical stimulation. Clin. Neurophysiol. 2012, 123, 1736–1744. [Google Scholar] [CrossRef]
- Belay, M.A.; Blakseth, S.S.; Rasheed, A.; Salvo Rossi, P. Unsupervised anomaly detection for IoT-based multivariate time series: Existing solutions, performance analysis and future directions. Sensors 2023, 23, 2844. [Google Scholar] [CrossRef]
- Lee, T.K.M.; Chan, H.W.; Leo, K.-H.; Chew, E.; Zhao, L.; Sanei, S. Intrinsic properties of human accelerometer data for machine learning. In Proceedings of the IEEE Workshop on Statistical Signal Processing, SSP 2023, Hanoi, Vietnam, 2–5 July 2023. [Google Scholar]
- Lee, T.K.M.; Chan, H.W.; Leo, K.-H.; Chew, E.; Zhao, L.; Sanei, S. Fidelitous augmentation of human accelerometric data for deep learning. In Proceedings of the IEEE International Conference on E-Health Networking, Application, and Services, Healthcom 2023, Chongqing, China, 15–17 December 2023. [Google Scholar]
- Migueles, J.H.; Cadenas-Sanchez, C.; Ekelund, U.; Delisle Nyström, C.; Mora-Gonzalez, J.; Löf, M.; Labayen, I.; Ruiz, J.R.; Ortega, F.B. Accelerometer data collection and processing criteria to assess physical activity and other outcomes: A systematic review and practical considerations. Sports Med. 2017, 47, 1821–1845. [Google Scholar] [CrossRef]
- Said, S.E.; Fuller, D.A. Testing for unit roots in autoregressive moving average models of unknown order. Biometrika 1984, 71, 599–607. [Google Scholar] [CrossRef]
- Kwiatkowski, D.; Phillips, P.C.B.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root. J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]
- McLeod, A.I.; Li, W.K. Diagnostic checking ARMA time series models using squared residual autocorrelations. J. Time Ser. Anal. 1983, 4, 269–273. [Google Scholar] [CrossRef]
- Boukhennoufa, I.; Jarchi, D.; Zhai, X.; Utti, V.; Sanei, S.; Lee, T.K.M.; Jackson, J.; McDonald-Maier, K.D. TS-SGAN—An approach to generate heterogeneous time series data for post-stroke rehabilitation assessment. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 2676–2687. [Google Scholar] [CrossRef] [PubMed]
- Allahyani, M.; Alsulami, R.; Alwafi, T.; Alafif, T.; Ammar, H.; Sabban, S.; Chen, X. SD2GAN: A Siamese dual discriminator generative adversarial network for mode collapse reduction. arXiv 2017, arXiv:1709.03831. [Google Scholar]
- Weiss, G. WISDM Smartphone and Smartwatch Activity and Biometrics Dataset; UCI Machine Learning Repository: Bronx, NY, USA, 2019. [Google Scholar] [CrossRef]
- Myerson, R.B. Nash equilibrium and the history of economic theory. J. Econ. Lit. 1999, 37, 1067–1082. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, H.; Xuan, J.; Leung, D.Y.C. Powering future body sensor network systems: A review of power sources. Biosens. Bioelectron. 2020, 166, 112410. [Google Scholar] [CrossRef] [PubMed]
- Thabtah, F.; Hammoud, S.; Kamalov, F.; Gonsalves, A. Data imbalance in classification: Experimental evaluation. Inf. Sci. 2020, 513, 429–441. [Google Scholar] [CrossRef]




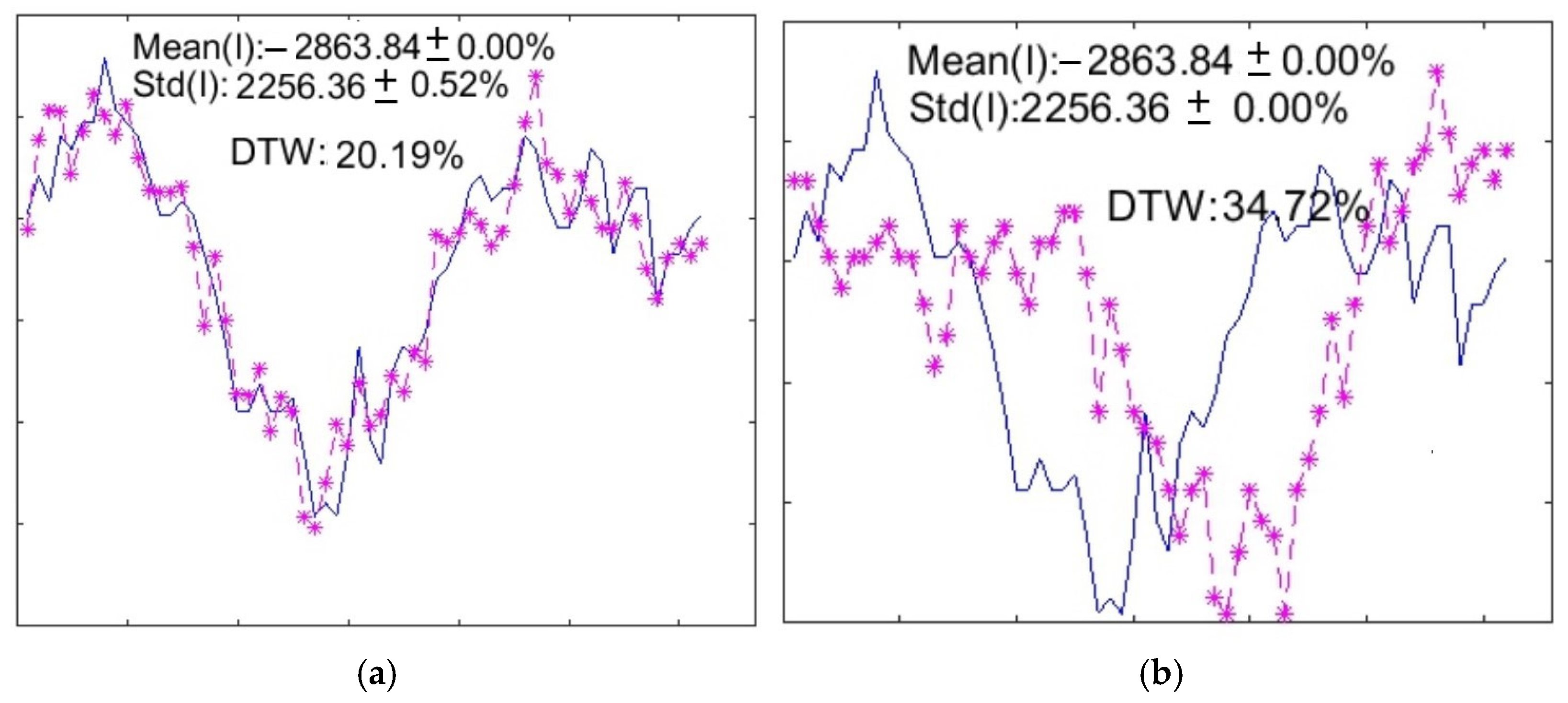





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Surrogate Generation Method | # Fold Surrogate Data | Line Graph | GAF | Wavelet Transform (WT) |
|---|---|---|---|---|
| No surrogate | Original data | 60.7% (5 min) | 57.6% (5 min) | 46.5% (58 min) |
| AAFT surrogates | 10-fold | 90.1% (16 min) | 86.7% (1:10 h) | 84.1% (2:08 h) |
| 100-fold | 100% (5:12 h) | 98.9% (18 h) | 98.5% (12:11 h) | |
| IAAFT surrogates | 10-fold | 97.1% (25 min) | 86.8% (1.6 h) | 82.2% (1:49 h) |
| 100-fold | 99.9% (5:06 h) | 99.1% (17 h) | 98.5% (10:02 h) |
| Model | Input | Number of Parameters | Training Accuracy | Validation Accuracy | Testing Accuracy |
|---|---|---|---|---|---|
| 2-D AlexNet + transfer learning | Image | 62,381,347 | 99.45% | 98.53% | 51.6% |
| 2-D CNN | Image | 99.851 | 98.87% | 98.20% | 39.1% |
| 1-D CNN | Time series | 141,735 | 99.98% | 98.86% | 90.7% |
| LSTM | Time series | 213,395 | 98.43% | 98.48% | 98.7% |
| Types of Activity | Activity Name |
|---|---|
| Using body | Walking, Jogging, Stair Climbing, Sitting, Standing, Kicking |
| Eating/Drinking | Soup, Chips, Pasta, Drinking, Eating Sandwich |
| Using hands only | Typing, Playing Catch, Dribbling, Writing, Clapping, Brushing Teeth, Folding Cloths |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanei, S.; Lee, T.K.M.; Boukhennoufa, I.; Jarchi, D.; Zhai, X.; McDonald-Maier, K. Evaluating the Effect of Surrogate Data Generation on Healthcare Data Assessment. Big Data Cogn. Comput. 2025, 9, 22. https://doi.org/10.3390/bdcc9020022
Sanei S, Lee TKM, Boukhennoufa I, Jarchi D, Zhai X, McDonald-Maier K. Evaluating the Effect of Surrogate Data Generation on Healthcare Data Assessment. Big Data and Cognitive Computing. 2025; 9(2):22. https://doi.org/10.3390/bdcc9020022
Chicago/Turabian StyleSanei, Saeid, Tracey K. M. Lee, Issam Boukhennoufa, Delaram Jarchi, Xiaojun Zhai, and Klaus McDonald-Maier. 2025. "Evaluating the Effect of Surrogate Data Generation on Healthcare Data Assessment" Big Data and Cognitive Computing 9, no. 2: 22. https://doi.org/10.3390/bdcc9020022
APA StyleSanei, S., Lee, T. K. M., Boukhennoufa, I., Jarchi, D., Zhai, X., & McDonald-Maier, K. (2025). Evaluating the Effect of Surrogate Data Generation on Healthcare Data Assessment. Big Data and Cognitive Computing, 9(2), 22. https://doi.org/10.3390/bdcc9020022