

DRCCT: Enhancing Diabetic Retinopathy Classification with a Compact Convolutional Transformer




Abstract
1. Introduction
2. Literature Review
3. Transformers for Diabetic Retinopathy
3.1. Vision Transformer
3.2. Main Components of a Vision Transformer
3.2.1. The Vision Transformer Encoder
3.2.2. Patch Embedding
3.2.3. Position Encoding
3.2.4. Attention Mechanism
3.2.5. Self-Attention
3.2.6. Multi-Head Self-Attention Mechanism
3.3. Compact Convolutional Transformers for DR Detection
3.3.1. Convolutional Tokenization
3.3.2. CCT Encoder
3.3.3. Sequence Pooling
3.3.4. Classification Tasks
4. Work Done
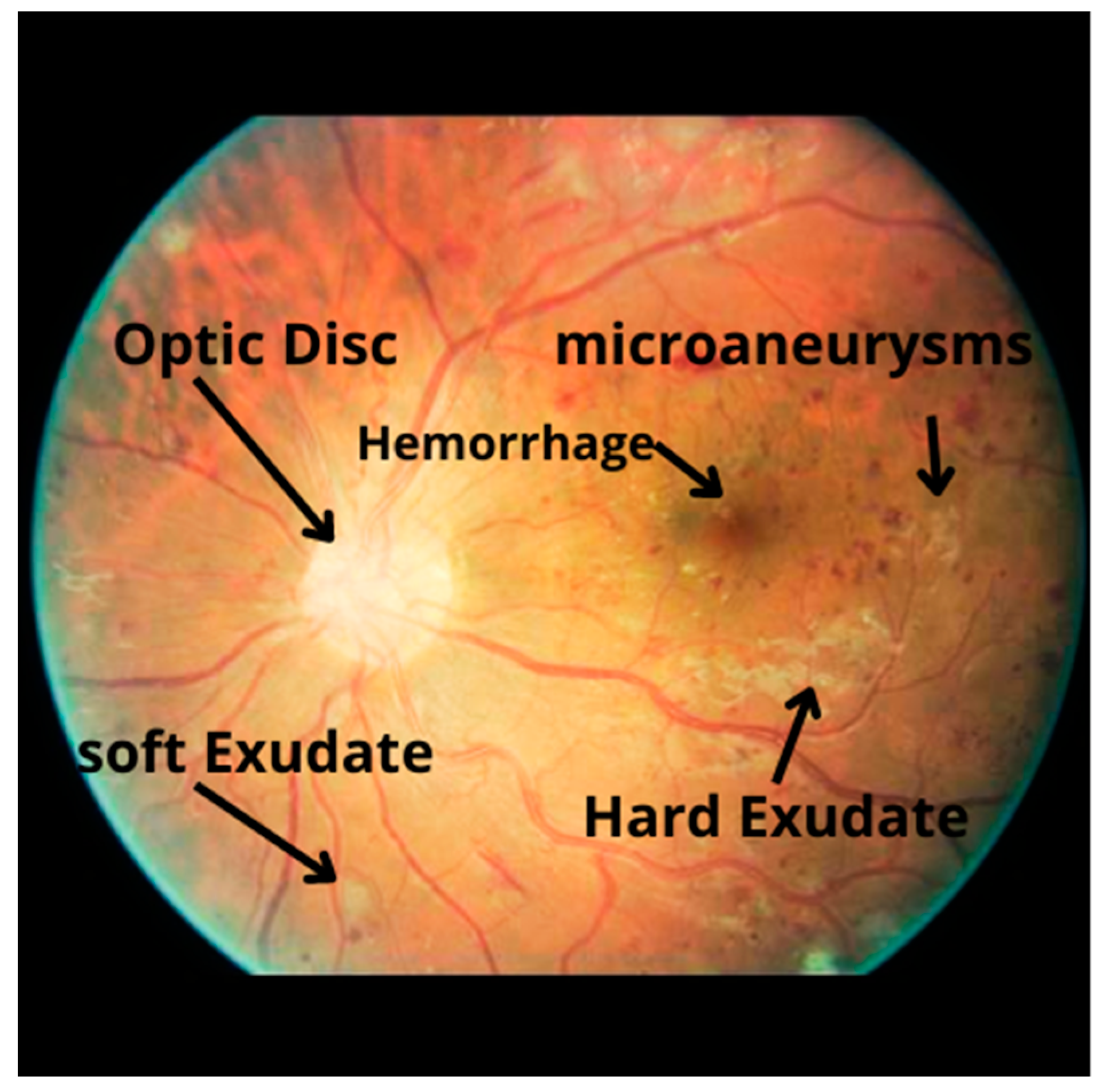
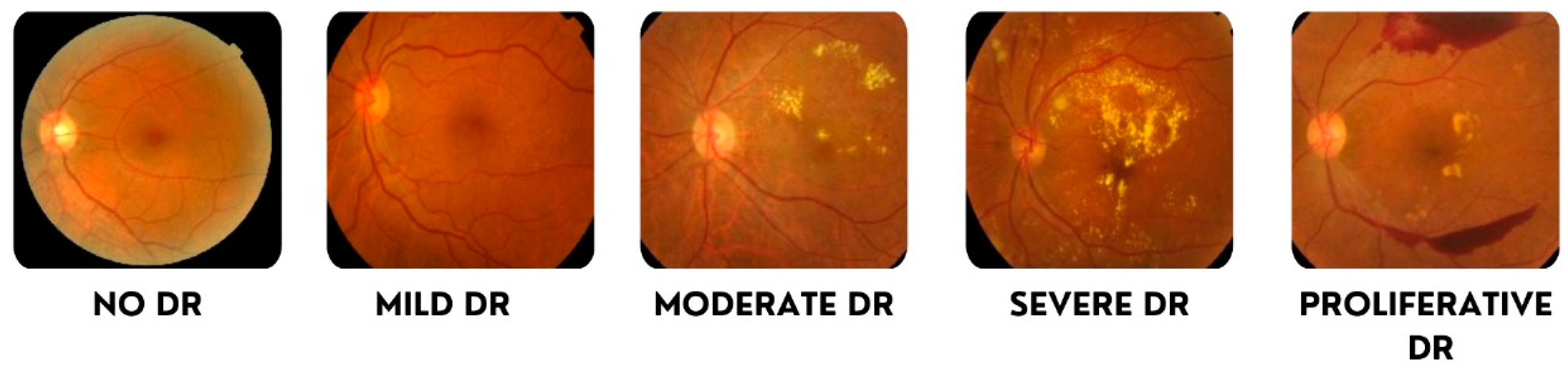
4.1. Data Undestading
- 0: No DR
- 1: Mild
- 2: Moderate
- 3: Severe
- 4: Proliferative DR
4.2. Image Preprocessing
4.2.1. Feature Extraction
4.2.2. Noise Reduction
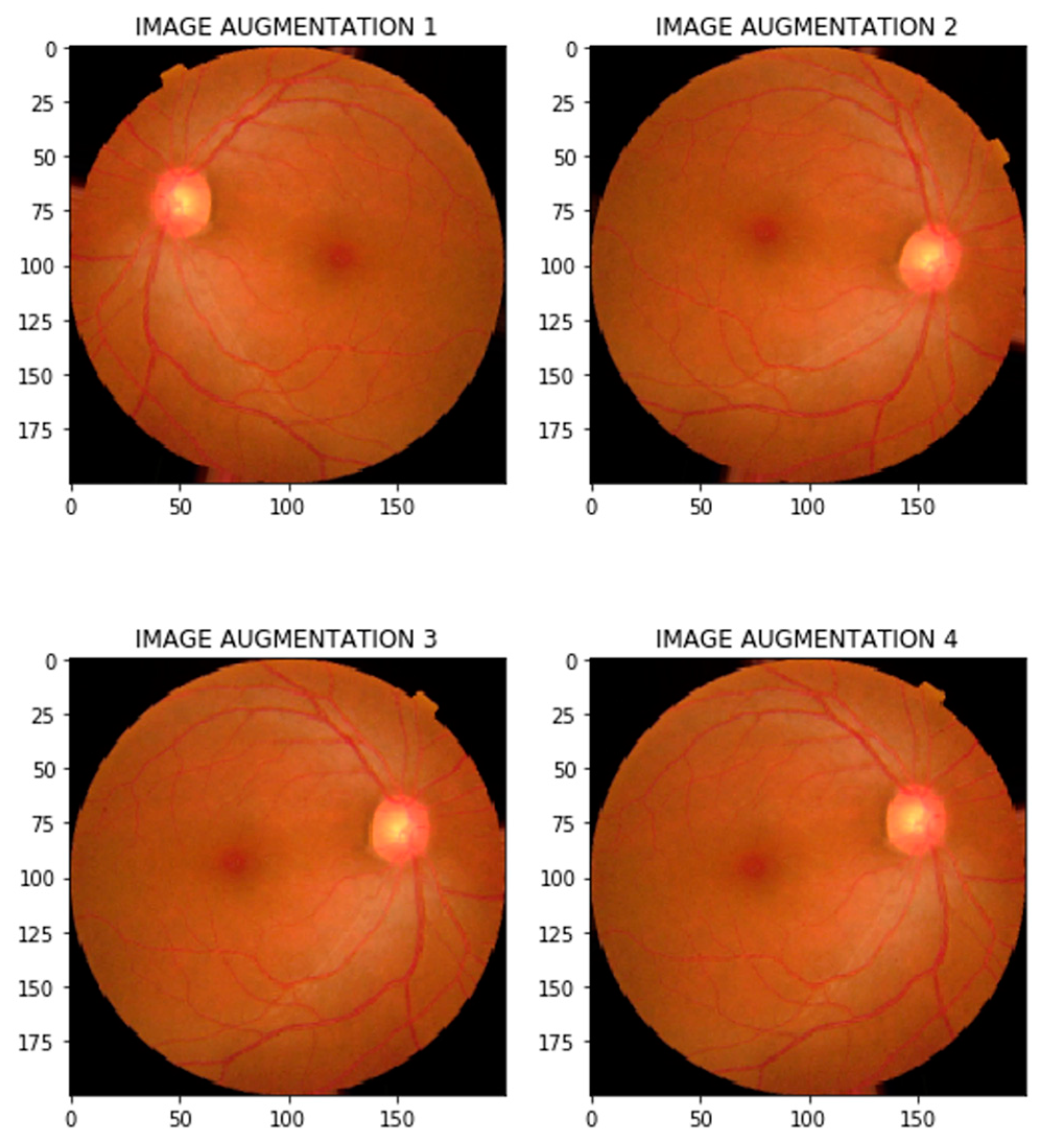
4.2.3. Data Augmentation
4.2.4. Data Balancing
4.3. Modeling Bulding
- Input Layer:
- CCT Tokenizer:
- Element-Wise Addition (tf.operators_add):
- Layer Normalization 1:
- Stabilizes training and accelerates convergence by normalizing token sequences.
- Stochastic Depth:
- Add:
- Layer Normalization 2:
5. Results and Discussion
5.1. Training and Validation Accuracy
5.2. Confusion Matrix Analysis
5.3. Model Testing and Metrics
- Testing Loss: 0.462828
- Testing Accuracy: 96.93%
- Average Confidence (AC): 98.25%
- Testing F1-Score: 96.96%
- Testing Recall (Sensitivity): 98.89%
5.4. Training and Validation Loss
5.5. Advanced Optimization Strategies
5.5.1. Optimizer
5.5.2. Cost Function
5.5.3. Learning Rate Adjustment
5.5.4. Regularization Techniques
5.6. Results Overview
5.7. Comparative Study of Results
6. Conclusions and Perspectives
6.1. Summary of Findings
6.2. Limitations
6.3. Future Directions in Securing AI-Driven Healthcare Systems
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bidwai, P.; Gite, S.; Pahuja, K.; Kotecha, K. A Systematic Literature Review on Diabetic Retinopathy Using an Artificial Intel-Ligence Approach. Big Data Cogn. Comput. 2022, 6, 152. [Google Scholar] [CrossRef]
- Subramanian, S.; Mishra, S.; Patil, S.; Shaw, K.; Aghajari, E. Machine Learning Styles for Diabetic Retinopathy Detection: A Review and Bibliometric Analysis. Big Data Cogn. Comput. 2022, 6, 154. [Google Scholar] [CrossRef]
- Shamshad, F.; Khan, S.; Zamir, S.W.; Khan, M.H.; Hayat, M.; Khan, F.S.; Fu, H. Transformers in Medical Imaging: A Survey. Med. Image Anal. 2023, 88, 102802. [Google Scholar] [CrossRef] [PubMed]
- Touati, M.; Nana, L.; Benzarti, F. A Deep Learning Model for Diabetic Retinopathy Classification. In Digital Technologies and Applications, Proceedings of the ICDTA 2023, Fez, Morocco, 27–28 January 2023; Motahhir, S., Bossoufi, B., Eds.; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2023; Volume 669, p. 669. [Google Scholar]
- Touati, M.; Nana, L.; Benzarti, F. Enhancing diabetic retinopathy classification: A fusion of ResNet50 with attention mechanism. In Proceedings of the IEEE/IFAC 10th International Conference on Control, Decision and Information Technologies (CoDIT), Valletta, Malta, 1–4 July 2024. [Google Scholar]
- Sheikh, S.; Qidwai, U. Using MobileNetV2 to Classify the Severity of Diabetic Retinopathy. Int. J. Simul.-Syst. Sci. Technol. 2020, 21, 16.1–16.6. [Google Scholar] [CrossRef]
- Gao, J.; Leung, C.; Miao, C. Diabetic Retinopathy Classification Using an Efficient Convolutional Neural Network. In Proceedings of the 2019 IEEE International Conference on Agents (ICA), Jinan, China, 18–21 October 2019. [Google Scholar]
- Wang, S.; Wang, X.; Hu, Y.; Shen, Y.; Yang, Z.; Gan, M.; Lei, B. Diabetic retinopathy diagnosis using multichannel generative adversarial network with semisupervision. IEEE Trans. Autom. Sci. Eng. 2020, 18, 574–585. [Google Scholar] [CrossRef]
- Yaqoob, M.K.; Ali, S.F.; Bilal, M.; Hanif, M.S.; Al-Saggaf, U.M. ResNet-based deep features and random forest classifier for diabetic retinopathy detection. Sensors 2021, 21, 3883. [Google Scholar] [CrossRef] [PubMed]
- Dharmana, M.M.; Aiswarya, M.S. Pre-diagnosis of Diabetic Retinopathy using Blob Detection. In Proceedings of the 2020 Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 15–17 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 98–101. [Google Scholar]
- Toledo-Cortés, S.; De La Pava, M.; Perdomo, O.; González, F.A. Hybrid Deep Learning Gaussian Process for Diabetic Retinopathy Diagnosis and Uncertainty Quantification. In Proceedings of the International Workshop on Ophthalmic Medical Image Analysis, Lima, Peru, 8 October 2020; Springer: Cham, Switzerland, 2020; pp. 206–215. [Google Scholar]
- Vo, H.H.; Verma, A. New deep neural nets for fine-grained diabetic retinopathy recognition on hybrid color space. In Proceedings of the 2016 IEEE International Symposium on Multimedia (ISM), San Jose, CA, USA, 11–13 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 209–215. [Google Scholar]
- Vani, K.S.; Praneeth, P.; Kommareddy, V.; Kumar, P.R.; Sarath, M.; Hussain, S.; Ravikiran, P. An Enhancing Diabetic Retinopathy Classification and Segmentation based on TaNet. Nano Biomed. Eng. 2024, 16, 85–100. [Google Scholar] [CrossRef]
- Alwakid, G.; Gouda, W.; Humayun, M.; Jhanjhi, N.Z. Enhancing diabetic retinopathy classification using deep learning. Digit. Health 2023, 9, 20552076231203676. [Google Scholar] [CrossRef] [PubMed]
- Nazih, W.; Aseeri, A.O.; Atallah, O.Y.; El-Sappagh, S. Vision transformer model for predicting the severity of diabetic retinopathy in fundus photography-based retina images. IEEE Access 2023, 11, 117546–117561. [Google Scholar] [CrossRef]
- Al-Hammuri, K.; Gebali, F.; Kanan, A.; Chelvan, I.T. Vision transformer architecture and applications in digital health: A tutorial and survey. Vis. Comput. Ind. Biomed. Art 2023, 6, 14. [Google Scholar] [CrossRef]
- Khan, I.U.; Raiaan, M.A.K.; Fatema, K.; Azam, S.; Rashid, R.u.; Mukta, S.H.; Jonkman, M.; De Boer, F. A Computer-Aided Diagnostic System to Identify Diabetic Retinopathy, Utilizing a Modified Compact Convolutional Transformer and Low-Resolution Images to Reduce Computation Time. Biomedicines 2023, 11, 1566. [Google Scholar] [CrossRef]
- Bashir, I.; Sajid, M.Z.; Kalsoom, R.; Ali Khan, N.; Qureshi, I.; Abbas, F.; Abbas, Q. RDS-DR: An Improved Deep Learning Model for Classifying Severity Levels of Diabetic Retinopathy. Diagnostics 2023, 13, 3116. [Google Scholar] [CrossRef]
- Berbar, M. Features extraction using encoded local binary pattern for detection and grading diabetic retinopathy. Health Inf. Sci. Syst. 2022, 10, 14. [Google Scholar] [CrossRef] [PubMed]
- R., Y.; Raja Sarobin M., V.; Panjanathan, R.; S., G.J.; L., J.A. Diabetic Retinopathy Classification Using CNN and Hybrid Deep Convolutional Neural Networks. Symmetry 2022, 14, 1932. [Google Scholar] [CrossRef]
- Ghaffar Nia, N.; Kaplanoglu, E.; Nasab, A. Evaluation of artificial intelligence techniques in disease diagnosis and prediction. Discov. Artif. Intell. 2023, 3, 5. [Google Scholar] [CrossRef]
- Yang, Y.; Cai, Z.; Qiu, S.; Xu, P. Vision transformer with masked autoencoders for referable diabetic retinopathy classification based on large-size retina image. PLoS ONE 2024, 19, e0299265. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Kumar, N.S.; Karthikeyan, B.R. Diabetic Retinopathy Detection using CNN, Transformer and MLP based Architectures. In Proceedings of the 2021 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Hualien City, Taiwan, 16–19 November 2021; Available online: https://ieeexplore.ieee.org/abstract/document/9651024 (accessed on 28 December 2021).
- Wu, J.; Hu, R.; Xiao, Z.; Chen, J.; Liu, J. Vision Transformer-based recognition of diabetic retinopathy grade. Med. Phys. 2021, 48, 7850–7863. [Google Scholar] [CrossRef] [PubMed]
- Islam, K. Recent advances in vision transformer: A survey and outlook of recent work. arXiv 2022, arXiv:2203.01536. [Google Scholar] [CrossRef]
- Hassani, A.; Walton, S.; Shah, N.; Abuduweili, A.; Li, J.; Shi, H. Escaping the Big Data Paradigm with Compact Transformers. arXiv 2021, arXiv:2104.05704. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Wang, Z.; Yin, Y.; Shi, J.; Fang, W.; Li, H.; Wang, X. Zoom-in-net: Deep mining lesions for diabetic retinopathy detection. In Proceedings of the Medical Image Computing and Computer Assisted Intervention MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, 11–13 September 2017; Springer International Publishing: Cham, Switzerland, 2017. Part III. pp. 267–275. [Google Scholar]
- Jagielski, M.; Oprea, A.; Biggio, B.; Liu, C.; Nita-Rotaru, C.; Li, B. Manipulating Machine Learning: Poisoning Attacks and Countermeasures for Regression Learning. IEEE Secur. Priv. 2018, 16, 88–96. [Google Scholar]
- Nia, A.M.; Mozaffari-Kermani, M.; Sur-Kolay, S.; Raghunathan, A.; Jha, N.K. Energy-Efficient Long-Term Continuous Personal Health Monitoring. IEEE Trans. Multi-Scale Comput. Syst. 2015, 1, 85–98. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect | CNNs | RNNs | ViTs |
|---|---|---|---|
| Architecture | Convolutional layers | Sequential recurrent layers | Transformer encoder with self-attention |
| Data Processing | Local patterns, spatial hierarchies | Sequential information | Dependencies, global integration |
| Feature Learning | Local features, sequential learning | Global features, entire sequence | Local integration into patches, global integration |
| Receptive Field | Local | Local (sequential) | Global |
| Feature Engineering | More manual, learns from data | More manual, learns from data | Less manual, learns from data |
| Scalability | Average | Low (sequential processing) | High (parallel processing) |
| Classes | Train Set | Test Set |
|---|---|---|
| No DR | 2192 | 549 |
| Mild | 592 | 148 |
| Moderate | 1518 | 380 |
| Proliferative DR | 472 | 118 |
| Severe | 284 | 72 |
| Metric | No_DR | Mild | Moderate | Severe | Proliferate | Micro Avg | Macro Avg | Weighted Avg | Samples Avg |
|---|---|---|---|---|---|---|---|---|---|
| Precision | 0.99 | 0.96 | 0.98 | 0.96 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 |
| Recall | 0.97 | 0.99 | 0.92 | 1.00 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 |
| F1-Score | 0.98 | 0.98 | 0.95 | 0.98 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 |
| Support | 549 | 604 | 545 | 555 | 552 | 2805 | 2805 | 2805 | 2805 |
| Authors | Method | Performance | Our Model |
|---|---|---|---|
| Sheikh and Qidwai [6] | Transfer Learning of MobileNetV2 | 90.8% DR, 92.3% RDR | Likely superior, F1-score: 0.97 |
| Gao, J.; Leung, C and Miao, C [7] | DL/Efficient CNN | 90.5% accuracy | Exhibits a higher F1-score |
| Yaqoob et al. [9] | ResNet-50 with a Random Forest classifier | 96% on the Messidor-2, 75.09% EyePACS | Better than EyePACS, comparable to Messidor-2 |
| Dharmana and Aiswarya [10] | Significantly improved | 83% accuracy | Significantly better |
| Toledo-Cortés et al. [11] | Deep Learning/DLGP-DR, Inception-V3 | 93.23% sensitivity, 91.73% specificity, 0.9769 AUC | Enhanced sensitivity and specificity |
| Wang, S. et al. [8] | Deep Learning/GAN Discriminative model | EyePACS: 86.13% accuracy; Messidor: 84.23% accuracy; Messidor (2): 80.46% accuracy | Superior performance across metrics |
| Touati, Nana, and Benzarti [4] | Xception pretrained model | Training accuracy: 94%, Test accuracy: 89%, F1-score: 0.94 | Notable F1-score of 0.97 |
| Z. Wang, Y. Yin. [28] | Deep Learning/CNN+Attention Network | AUC 0.921/Acc 0.905 for normal/abnormal | Our model Likely superior based on metrics |
| Khan, I et al. [17] | Compact Convolution Network | Acc 90.17% | Significantly better, likely 97% accuracy |
| M. Berbar [19] | Residual–Dense System | 97% in classifying DR severity | Comparable or slightly better |
| Nazih et al. [15] | ViT CNN | F1-score: 0.825, accuracy: 0.825, B Acc: 0.826, AUC: 0.964, precision: 0.825, recall: 0.825, specificity: 0.956 | Significantly better, F1-score: 0.97 |
| Ijaz Bashir et al. [18] | Residual Block + CNN | Accuracy of 97.5% | Comparable, accuracy likely around 97% |
| Yasashvini R et al. [20] | Hybrid CNNs ResNet, and a hybrid CNN with DenseNet | The models achieved accuracy rates of 96.22%, 93.18%, and 75.61%, respectively | DRCCT Demonstrates a strong performance |
| Yaoming Yang et al. [22] | Vision transformers (ViT) combined with Masked Autoencoders (MAE) | Accuracy 93.42%, AUC 0.9853, sensitivity 0.973, specificity 0.9539 | Slightly better F1-score |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Touati, M.; Touati, R.; Nana, L.; Benzarti, F.; Ben Yahia, S. DRCCT: Enhancing Diabetic Retinopathy Classification with a Compact Convolutional Transformer. Big Data Cogn. Comput. 2025, 9, 9. https://doi.org/10.3390/bdcc9010009
Touati M, Touati R, Nana L, Benzarti F, Ben Yahia S. DRCCT: Enhancing Diabetic Retinopathy Classification with a Compact Convolutional Transformer. Big Data and Cognitive Computing. 2025; 9(1):9. https://doi.org/10.3390/bdcc9010009
Chicago/Turabian StyleTouati, Mohamed, Rabeb Touati, Laurent Nana, Faouzi Benzarti, and Sadok Ben Yahia. 2025. "DRCCT: Enhancing Diabetic Retinopathy Classification with a Compact Convolutional Transformer" Big Data and Cognitive Computing 9, no. 1: 9. https://doi.org/10.3390/bdcc9010009
APA StyleTouati, M., Touati, R., Nana, L., Benzarti, F., & Ben Yahia, S. (2025). DRCCT: Enhancing Diabetic Retinopathy Classification with a Compact Convolutional Transformer. Big Data and Cognitive Computing, 9(1), 9. https://doi.org/10.3390/bdcc9010009