
Quantum-Cognitive Neural Networks: Assessing Confidence and Uncertainty with Human Decision-Making Simulations



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
1.1. Motivation and Literature Review
1.2. Objectives and Outline
- To explore whether the QT-NN can replicate essential cognitive processes inherent in human decision-making, including ambiguity handling and contextual evaluation.
- To examine whether the QT-NN can outperform conventional ML models in classifying image datasets, while providing evidence of enhanced flexibility of the quantum approach and its ability to adapt to complex data patterns.
2. Methodology
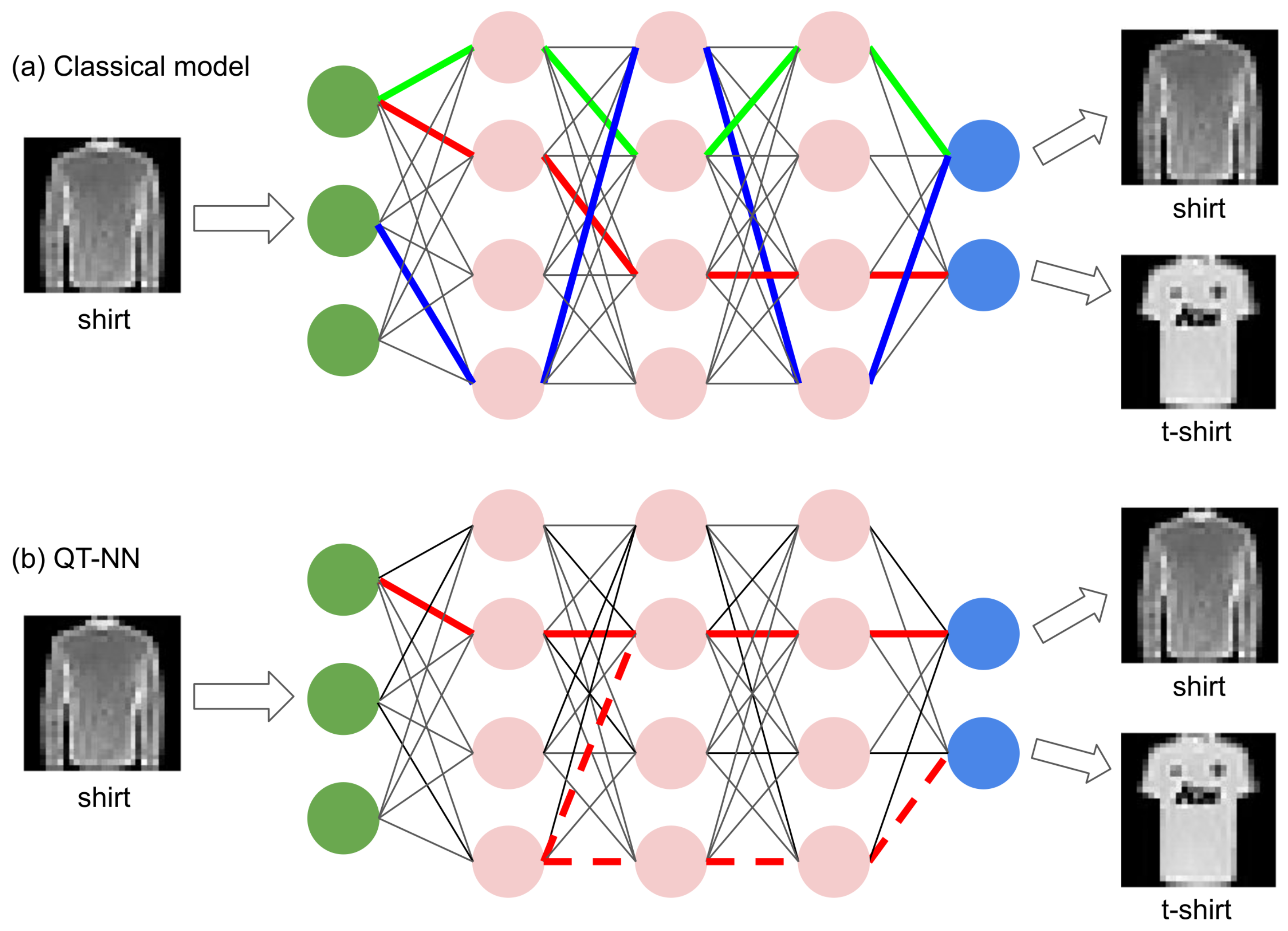
2.1. Quantum-Tunnelling Neural Network
2.2. Benchmarking Testbed
2.3. Statistical Analysis
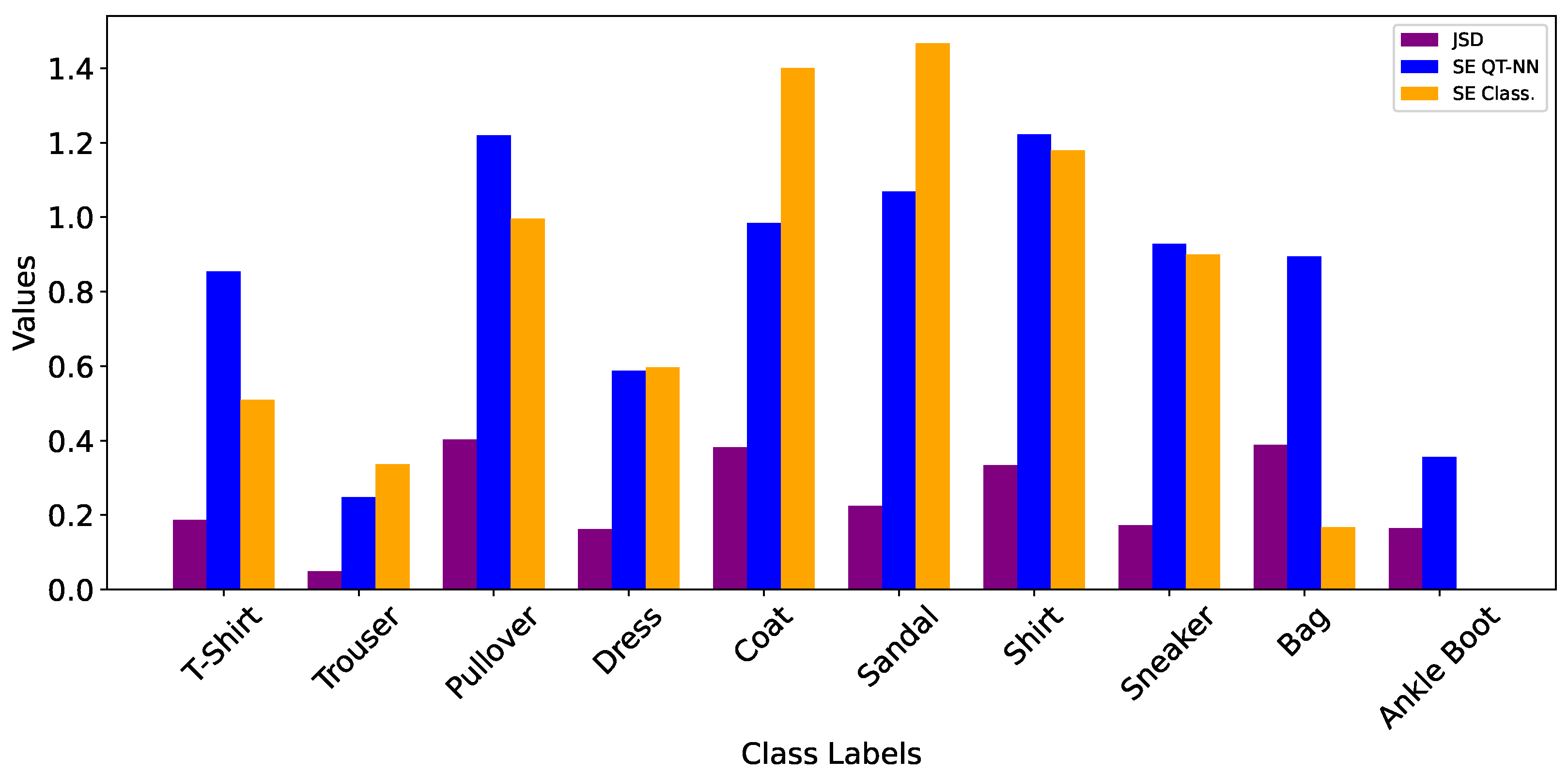
2.4. Model of Uncertainty
3. Results
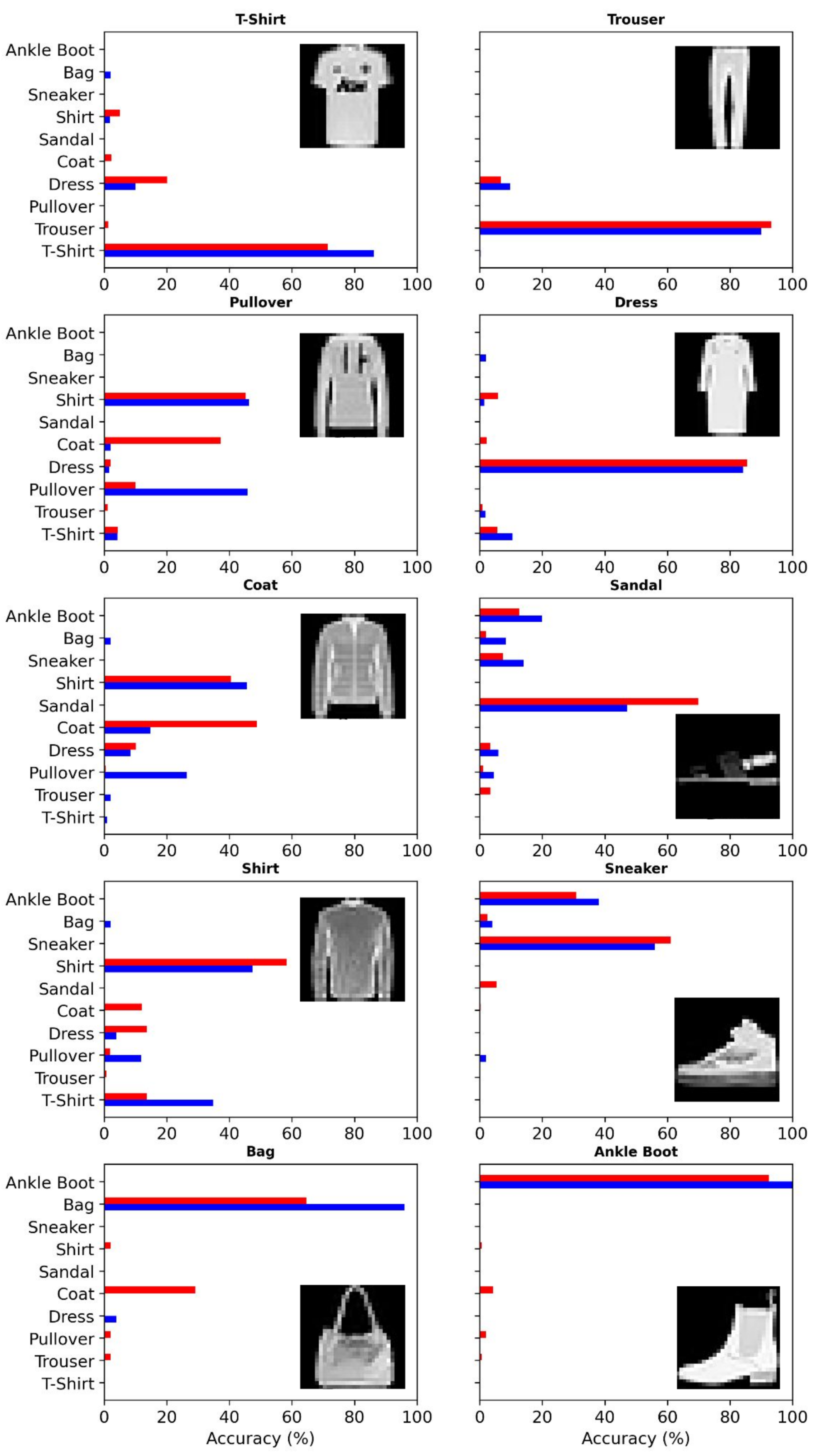
3.1. Comparison of the Outputs of QT-NN and the Classical Model
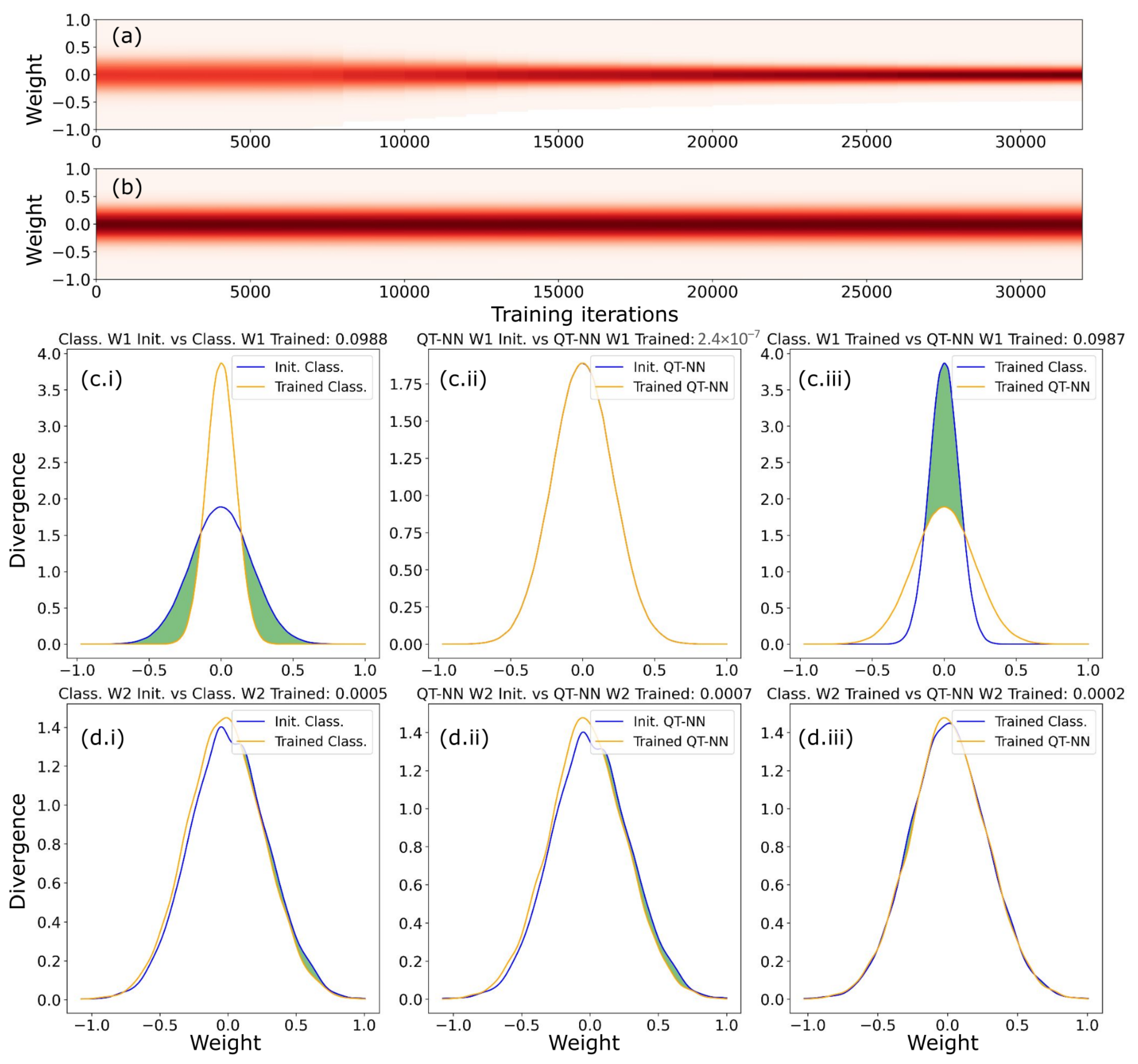
3.2. Trained Weight Distribution Comparison
4. Discussion
4.1. Modelling of Human Judgement
4.2. Practical Applications and Future Work
4.3. Further Challenges and Opportunities
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | artificial intelligence |
| BNN | Bayesian neural network |
| DNN | deep neural network |
| JSD | Jensen–Shannon divergence |
| KLD | Kullback–Leibler divergence |
| ML | machine learning |
| MNIST | Modified National Institute of Standards and Technology database |
| QBNN | quantum–Bayesian neural network |
| QCT | quantum cognition theory |
| QNN | quantum neural network |
| QT | quantum tunnelling |
| QT-NN | quantum tunnelling neural network |
| ReLU | rectified linear unit |
| SE | Shannon entropy |
References
- Busemeyer, J.R.; Bruza, P.D. Quantum Models of Cognition and Decision; Oxford University Press: New York, NY, USA, 2012. [Google Scholar]
- Sniazhko, S. Uncertainty in decision-making: A review of the international business literature. Cogent Bus. Manag. 2019, 6, 1650692. [Google Scholar] [CrossRef]
- Gu, Y.; Gu, S.; Lei, Y.; Li, H. From uncertainty to anxiety: How uncertainty fuels anxiety in a process mediated by intolerance of uncertainty. Neural Plast. 2020, 2020, 8866386. [Google Scholar] [CrossRef]
- Strogatz, S.H. Nonlinear Dynamics and Chaos. With Applications to Physics, Biology, Chemistry, and Engineering, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Lucero, K.S.; Chen, P. What do reinforcement and confidence have to do with it? A systematic pathway analysis of knowledge, competence, confidence, and intention to change. J. Eur. CME. 2020, 9, 1834759. [Google Scholar] [CrossRef]
- Hüllermeier, E.; Waegeman, W. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Mach. Learn. 2021, 110, 457–506. [Google Scholar] [CrossRef]
- Gawlikowski, J.; Tassi, C.R.N.; Ali, M.; Lee, J.; Humt, M.; Feng, J.; Kruspe, A.; Triebel, R.; Jung, P.; Roscher, R.; et al. A survey of uncertainty in deep neural networks. Artif. Intell. Rev. 2023, 56, 1513–1589. [Google Scholar] [CrossRef]
- Guha, R.; Velegol, D. Harnessing Shannon entropy-based descriptors in machine learning models to enhance the prediction accuracy of molecular properties. J. Cheminform. 2023, 15, 54. [Google Scholar] [CrossRef]
- Wasilewski, J.; Paterek, T.; Horodecki, K. Uncertainty of feed forward neural networks recognizing quantum contextuality. J. Phys. A Math. Theor. 2024, 56, 455305. [Google Scholar] [CrossRef]
- Karaca, Y. Multi-chaos, fractal and multi-fractional AI in different complex systems. In Multi-Chaos, Fractal and Multi-Fractional Artificial Intelligence of Different Complex Systems; Karaca, Y., Baleanu, D., Zhang, Y.D., Gervasi, O., Moonis, M., Eds.; Academic Press: Cambridge, MA, USA, 2022; pp. 21–54. [Google Scholar] [CrossRef]
- Bobadilla-Suarez, S.; Guest, O.; Love, B.C. Subjective value and decision entropy are jointly encoded by aligned gradients across the human brain. Commun. Biol. 2020, 3, 597. [Google Scholar] [CrossRef] [PubMed]
- Maksymov, I.S. Quantum-tunneling deep neural network for optical illusion recognition. APL Mach. Learn. 2024, 2, 036107. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Pearson-Prentice Hall: Singapore, 1998. [Google Scholar]
- Kim, P. MATLAB Deep Learning With Machine Learning, Neural Networks and Artificial Intelligence; Apress: Berkeley, CA, USA, 2017. [Google Scholar]
- Franchi, G.; Bursuc, A.; Aldea, E.; Dubuisson, S.; Bloch, I. TRADI: Tracking Deep Neural Network Weight Distributions. In Proceedings of the Computer Vision—ECCV 2020, Glasgow, UK, 23–28 August 2020; pp. 105–121. [Google Scholar]
- Erhan, D.; Bengio, Y.; Courville, A.; Manzagol, P.A.; Vincent, P.; Bengio, S. Why does unsupervised pre-training help deep learning? J. Mach. Learn. Res. 2010, 11, 625–660. [Google Scholar]
- Jospin, L.V.; Laga, H.; Boussaid, F.; Buntine, W.; Bennamoun, M. Hands-on Bayesian neural networks–A tutorial for deep learning users. IEEE Comput. Intell. Mag. 2022, 17, 29–48. [Google Scholar] [CrossRef]
- Wang, D.B.; Feng, L.; Zhang, M.L. Rethinking Calibration of Deep Neural Networks: Do Not Be Afraid of Overconfidence. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–14 December 2021; Volume 34, pp. 11809–11820. [Google Scholar]
- Wei, H.; Xie, R.; Cheng, H.; Feng, L.; An, B.; Li, Y. Mitigating Neural Network Overconfidence with Logit Normalization. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 23631–23644. [Google Scholar]
- Melotti, G.; Premebida, C.; Bird, J.J.; Faria, D.R.; Gonçalves, N. Reducing overconfidence predictions in autonomous driving perception. IEEE Access 2022, 10, 54805–54821. [Google Scholar] [CrossRef]
- Bouteska, A.; Harasheh, M.; Abedin, M.Z. Revisiting overconfidence in investment decision-making: Further evidence from the U. S. market. Res. Int. Bus. Financ. 2023, 66, 102028. [Google Scholar] [CrossRef]
- Mukhoti, J.; Kirsch, A.; van Amersfoort, J.; Torr, P.H.; Gal, Y. Deep Deterministic Uncertainty: A New Simple Baseline. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 24384–24394. [Google Scholar] [CrossRef]
- Weiss, M.; Gómez, A.G.; Tonella, P. Generating and detecting true ambiguity: A forgotten danger in DNN supervision testing. Empir. Softw. Eng. 2023, 146. [Google Scholar] [CrossRef]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 427–436. [Google Scholar] [CrossRef]
- Guo, C.; Pleiss, G.; Sun, Y.; Weinberger, K.Q. On calibration of modern neural networks. In Proceedings of the 34th International Conference on Machine Learning–Volume 70. JMLR.org, Sydney, NSW, Australia, 6–11 August 2017; ICML’17. pp. 1321–1330. [Google Scholar]
- Moon, J.; Kim, J.; Shin, Y.; Hwang, S. Confidence-aware learning for deep neural networks. In Proceedings of the 37th International Conference on Machine Learning, Virtual Event, 13–18 July 2020; ICML’20. pp. 7034–7044. [Google Scholar]
- Wang, J.; Ai, J.; Lu, M.; Liu, J.; Wu, Z. Predicting neural network confidence using high-level feature distance. Inf. Softw. Technol. 2023, 159, 107214. [Google Scholar] [CrossRef]
- Rafiei, F.; Shekhar, M.; Rahnev, D. The neural network RTNet exhibits the signatures of human perceptual decision-making. Nat. Hum. Behav. 2024, 8, 1752–1770. [Google Scholar] [CrossRef]
- Liu, S.; Xiao, T.P.; Kwon, J.; Debusschere, B.J.; Agarwal, S.; Incorvia, J.A.C.; Bennett, C.H. Bayesian neural networks using magnetic tunnel junction-based probabilistic in-memory computing. Front. Nanotechnol. 2022, 4. [Google Scholar] [CrossRef]
- Wan, K.H.; Dahlsten, O.; Kristjánsson, H.; Gardner, R.; Kim, M.S. Quantum generalisation of feedforward neural networks. Npj Quantum Inf. 2017, 3, 36. [Google Scholar] [CrossRef]
- Beer, K.; Bondarenko, D.; Farrelly, T.; Osborne, T.J.; Salzmann, R.; Scheiermann, D.; Wolf, R. Training deep quantum neural networks. Nat. Commun. 2020, 11, 808. [Google Scholar] [CrossRef]
- Yan, P.; Li, L.; Jin, M.; Zeng, D. Quantum probability-inspired graph neural network for document representation and classification. Neurocomputing 2021, 445, 276–286. [Google Scholar] [CrossRef]
- Zhao, C.; Gao, X.S. QDNN: Deep neural networks with quantum layers. Quantum Mach. Intell. 2021, 3, 15. [Google Scholar] [CrossRef]
- Choi, S.; Salamin, Y.; Roques-Carmes, C.; Dangovski, R.; Luo, D.; Chen, Z.; Horodynski, M.; Sloan, J.; Uddin, S.Z.; Soljačić, M. Photonic probabilistic machine learning using quantum vacuum noise. Nat. Commun. 2024, 15, 7760. [Google Scholar] [CrossRef]
- Hiesmayr, B.C. A quantum information theoretic view on a deep quantum neural network. AIP Conf. Proc. 2024, 3061, 020001. [Google Scholar] [CrossRef]
- Pira, L.; Ferrie, C. On the interpretability of quantum neural networks. Quantum Mach. Intell. 2024, 6, 52. [Google Scholar] [CrossRef]
- Peral-García, D.; Cruz-Benito, J.; García-Peñalvo, F.J. Systematic literature review: Quantum machine learning and its applications. Comput. Sci. Rev. 2024, 51, 100619. [Google Scholar] [CrossRef]
- van de Schoot, R.; Depaoli, S.; King, R.; Kramer, B.; Märtens, K.; Tadesse, M.G.; Vannucci, M.; Gelman, A.; Veen, D.; Willemsen, J.; et al. Bayesian statistics and modelling. Nat. Rev. Methods Prim. 2021, 1, 1. [Google Scholar] [CrossRef]
- Monteiro, C.A.; Filho, G.I.S.; Costa, M.H.J.; de Paula Neto, F.M.; de Oliveira, W.R. Quantum neuron with real weights. Neural Netw. 2021, 143, 698–708. [Google Scholar] [CrossRef]
- Pan, X.; Lu, Z.; Wang, W.; Hua, Z.; Xu, Y.; Li, W.; Cai, W.; Li, X.; Wang, H.; Song, Y.P.; et al. Deep quantum neural networks on a superconducting processor. Nat. Commun. 2023, 14, 4006. [Google Scholar] [CrossRef]
- Qiu, P.H.; Chen, X.G.; Shi, Y.W. Detecting entanglement with deep quantum neural networks. IEEE Access 2019, 7, 94310–94320. [Google Scholar] [CrossRef]
- Bai, Q.; Hu, X. Superposition-enhanced quantum neural network for multi-class image classification. Chin. J. Phys. 2024, 89, 378–389. [Google Scholar] [CrossRef]
- Nielsen, M.; Chuang, I. Quantum Computation and Quantum Information; Oxford University Press: New York, NY, USA, 2002. [Google Scholar]
- Maronese, M.; Destri, C.; Prati, E. Quantum activation functions for quantum neural networks. Quantum Inf. Process. 2023, 21, 128. [Google Scholar] [CrossRef]
- Parisi, L.; Neagu, D.; Ma, R.; Campean, F. Quantum ReLU activation for Convolutional Neural Networks to improve diagnosis of Parkinson’s disease and COVID-19. Expert Syst. Appl. 2022, 187, 115892. [Google Scholar] [CrossRef]
- Tanaka, G.; Yamane, T.; Héroux, J.B.; Nakane, R.; Kanazawa, N.; Takeda, S.; Numata, H.; Nakano, D.; Hirose, A. Recent advances in physical reservoir computing: A review. Neural Newt. 2019, 115, 100–123. [Google Scholar] [CrossRef]
- Marcucci, G.; Pierangeli, D.; Conti, C. Theory of neuromorphic computing by waves: Machine learning by rogue waves, dispersive shocks, and solitons. Phys. Rev. Lett. 2020, 125, 093901. [Google Scholar] [CrossRef] [PubMed]
- Maksymov, I.S. Analogue and physical reservoir computing using water waves: Applications in power engineering and beyond. Energies 2023, 16, 5366. [Google Scholar] [CrossRef]
- Onen, M.; Emond, N.; Wang, B.; Zhang, D.; Ross, F.M.; Li, J.; Yildiz, B.; del Alamo, J.A. Nanosecond protonic programmable resistors for analog deep learning. Science 2022, 377, 539–543. [Google Scholar] [CrossRef] [PubMed]
- Ye, N.; Cao, L.; Yang, L.; Zhang, Z.; Fang, Z.; Gu, Q.; Yang, G.Z. Improving the robustness of analog deep neural networks through a Bayes-optimized noise injection approach. Commun. Eng. 2023, 2, 25. [Google Scholar] [CrossRef]
- McQuarrie, D.A.; Simon, J.D. Physical Chemistry—A Molecular Approach; Prentice Hall: New York, NY, USA, 1997. [Google Scholar]
- Griffiths, D.J. Introduction to Quantum Mechanics; Prentice Hall: Upper Saddle River, NJ, USA, 2004. [Google Scholar]
- Maksymov, I.S. Quantum-inspired neural network model of optical illusions. Algorithms 2024, 17, 30. [Google Scholar] [CrossRef]
- Atmanspacher, H.; Filk, T.; Römer, H. Quantum Zeno features of bistable perception. Biol. Cybern. 2004, 90, 33–40. [Google Scholar] [CrossRef]
- Khrennikov, A. Quantum-like brain: “Interference of minds”. Biosystems 2006, 84, 225–241. [Google Scholar] [CrossRef] [PubMed]
- Pothos, E.M.; Busemeyer, J.R. Quantum Cognition. Annu. Rev. Psychol. 2022, 73, 749–778. [Google Scholar] [CrossRef] [PubMed]
- Galam, S. Sociophysics: A Physicist’s Modeling of Psycho-Political Phenomena; Springer: New York, NY, USA, 2012. [Google Scholar]
- Maksymov, I.S.; Pogrebna, G. Quantum-mechanical modelling of asymmetric opinion polarisation in social networks. Information 2024, 15, 170. [Google Scholar] [CrossRef]
- Maksymov, I.S.; Pogrebna, G. The physics of preference: Unravelling imprecision of human preferences through magnetisation dynamics. Information 2024, 15, 413. [Google Scholar] [CrossRef]
- Benedek, G.; Caglioti, G. Graphics and Quantum Mechanics–The Necker Cube as a Quantum-like Two-Level System. In Proceedings of the 18th International Conference on Geometry and Graphics, Milan, Italy, 3–7 August 2018; pp. 161–172. [Google Scholar]
- Georgiev, D.D.; Glazebrook, J.F. The quantum physics of synaptic communication via the SNARE protein complex. Prog. Biophys. Mol. 2018, 135, 16–29. [Google Scholar] [CrossRef] [PubMed]
- Georgiev, D.D. Quantum Information and Consciousness; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Georgiev, D.D. Causal potency of consciousness in the physical world. Int. J. Mod. Phys. B 2024, 38, 2450256. [Google Scholar] [CrossRef]
- Chitambar, E.; Gour, G. Quantum resource theories. Rev. Mod. Phys. 2019, 91, 025001. [Google Scholar] [CrossRef]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Pope, P.E.; Zhu, C.; Abdelfattah, M.; Goldblum, M.; Goldstein, T. The Intrinsic Dimension of Images and Its Impact on Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Simard, P.Y.; Steinkraus, D.; Platt, J.C. Best practices for convolutional neural networks applied to visual document analysis. In Proceedings of the Seventh International Conference on Document Analysis and Recognition, Edinburgh, Scotland, UK, 3–6 August 2003; pp. 958–963. [Google Scholar] [CrossRef]
- Deng, L. The MNIST database of handwritten digit images for machine learning research. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Kayed, M.; Anter, A.; Mohamed, H. Classification of Garments from Fashion MNIST Dataset Using CNN LeNet-5 Architecture. In Proceedings of the 2020 International Conference on Innovative Trends in Communication and Computer Engineering (ITCE), Aswan, Egypt, 8–9 February 2020; pp. 238–243. [Google Scholar] [CrossRef]
- Rudolph, M.S.; Lerch, S.; Thanasilp, S.; Kiss, O.; Shaya, O.; Vallecorsa, S.; Grossi, M.; Holmes, Z. Trainability barriers and opportunities in quantum generative modeling. Npj Quantum Inf. 2024, 10, 116. [Google Scholar] [CrossRef]
- Csiszar, I. I-divergence geometry of probability distributions and minimization problems. Ann. Probab. 1975, 3, 146–158. [Google Scholar] [CrossRef]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multi-Model Inference; Spriger: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Wanjiku, R.N.; Nderu, L.; Kimwele, M. Dynamic fine-tuning layer selection using Kullback–Leibler divergence. Eng. Rep. 2023, 5, e12595. [Google Scholar] [CrossRef]
- Endres, D.M.; Schindelin, J.E. A new metric for probability distributions. IEEE Trans. Inf. Theory 2003, 49, 1858–1860. [Google Scholar] [CrossRef]
- Nielsen, F. On the Jensen–Shannon symmetrization of distances relying on abstract means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef] [PubMed]
- Stehman, S.V. Selecting and interpreting measures of thematic classification accuracy. Remote Sens. Environ. 1997, 62, 77–89. [Google Scholar] [CrossRef]
- Go, J.; Baek, B.; Lee, C. Analyzing Weight Distribution of Feedforward Neural Networks and Efficient Weight Initialization. In Proceedings of the Structural, Syntactic, and Statistical Pattern Recognition, Lisbon, Portugal, 18–20 August 2004; pp. 840–849. [Google Scholar]
- Nguyen, A.; Clune, J.; Bengio, Y.; Dosovitskiy, A.; Yosinski, J. Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3510–3520. [Google Scholar] [CrossRef]
- Yosinski, J. How AI Detectives Are Cracking Open the Black Box of Deep Learning. Science, 6 July 2017. Available online: https://www.science.org/content/article/how-ai-detectives-are-cracking-open-black-box-deep-learning (accessed on 4 December 2024).
- Ohzeki, M.; Okada, S.; Terabe, M.; Taguchi, S. Optimization of neural networks via finite-value quantum fluctuations. Sci. Rep. 2018, 8, 9950. [Google Scholar] [CrossRef]
- Eilertsen, G.; Jönsson, D.; Ropinski, T.; Unger, J.; Ynnerman, A. Classifying the classifier: Dissecting the weight space of neural networks. In Proceedings of the European Conference on Artificial Intelligence (ECAI 2020), Santiago de Compostela, Spain, 29 August–8 September 2020; Volume 325, pp. 1119–1126. [Google Scholar]
- Billingsley, P. Probability and Measure, 3rd ed.; Wiley: New York, NY, USA, 1995. [Google Scholar]
- Biamonte, J.; Wittek, P.; Pancotti, N.; Rebentrost, P.; Wiebe, N.; Lloyd, S. Quantum machine learning. Nature 2017, 549, 195–202. [Google Scholar] [CrossRef]
- Bavelier, D.; Green, C.S.; Dye, M.W.G. Brain plasticity through the life span: Learning to learn and action video games. Annu. Rev. Neurosci. 2012, 35, 391–416. [Google Scholar] [CrossRef]
- Kornmeier, J.; Bach, M. The Necker cube–an ambiguous figure disambiguated in early visual processing. Vis. Res. 2005, 45, 955–960. [Google Scholar] [CrossRef]
- Inoue, M.; Nakamoto, K. Dynamics of cognitive interpretations of a Necker cube in a chaos neural network. Prog. Theor. Phys. 1994, 92, 501–508. [Google Scholar] [CrossRef]
- Gaetz, M.; Weinberg, H.; Rzempoluck, E.; Jantzen, K.J. Neural network classifications and correlation analysis of EEG and MEG activity accompanying spontaneous reversals of the Necker cube. Cogn. Brain Res. 1998, 6, 335–346. [Google Scholar] [CrossRef] [PubMed]
- Araki, O.; Tsuruoka, Y.; Urakawa, T. A neural network model for exogenous perceptual alternations of the Necker cube. Cogn. Neurodyn. 2020, 14, 229–237. [Google Scholar] [CrossRef]
- Joos, E.; Giersch, A.; Hecker, L.; Schipp, J.; Heinrich, S.P.; van Elst, L.T.; Kornmeier, J. Large EEG amplitude effects are highly similar across Necker cube, smiley, and abstract stimuli. PLoS ONE 2020, 15, e0232928. [Google Scholar] [CrossRef]
- Atmanspacher, H.; Filk, T. A proposed test of temporal nonlocality in bistable perception. J. Math. Psychol. 2010, 54, 314–321. [Google Scholar] [CrossRef]
- Khan, A.; Ahsan, M.; Bonyah, E.; Jan, R.; Nisar, M.; Abdel-Aty, A.H.; Yahia, I.S. Numerical solution of Schrödinger equation by Crank–Nicolson method. Math. Probl. Eng. 2022, 2022, 6991067. [Google Scholar] [CrossRef]
- Maksymov, I.S. Quantum Mechanics of Human Perception, Behaviour and Decision-Making: A Do-It-Yourself Model Kit for Modelling Optical Illusions and Opinion Formation in Social Networks. arXiv 2024, arXiv:2404.10554. [Google Scholar]
- Liang, Y.; Peng, W.; Zheng, Z.J.; Silvén, O.; Zhao, G. A hybrid quantum–classical neural network with deep residual learning. Neural Netw. 2021, 143, 133–147. [Google Scholar] [CrossRef] [PubMed]
- Domingo, L.; Djukic, M.; Johnson, C.; Borondo, F. Binding affinity predictions with hybrid quantum-classical convolutional neural networks. Sci. Rep. 2023, 13, 17951. [Google Scholar] [CrossRef]
- Gircha, A.I.; Boev, A.S.; Avchaciov, K.; Fedichev, P.O.; Fedorov, A.K. Hybrid quantum-classical machine learning for generative chemistry and drug design. Sci. Rep. 2023, 13, 8250. [Google Scholar] [CrossRef]
- Nguyen, N.; Chen, K.C. Bayesian quantum neural networks. IEEE Access 2022, 10, 54110–54122. [Google Scholar] [CrossRef]
- Sakhnenko, A.; Sikora, J.; Lorenz, J. Building Continuous Quantum-Classical Bayesian Neural Networks for a Classical Clinical Dataset. In Proceedings of the Recent Advances in Quantum Computing and Technology, Budapest, Hungary, 19–20 June 2024; ReAQCT ’24. pp. 62–72. [Google Scholar] [CrossRef]
- LeCun, Y. Security Council Debates Use of Artificial Intelligence in Conflicts, Hears Calls for UN Framework to Avoid Fragmented Governance. Video Presentation, 19 December 2024. Available online: https://press.un.org/en/2024/sc15946.doc.htm (accessed on 4 January 2025).
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes: The Art of Scientific Computing, 3rd ed.; Cambridge University Press: Cambridge, MA, USA, 2007. [Google Scholar]
- Li, H.; Xu, Z.; Taylor, G.; Studer, C.; Goldstein, T. Visualizing the loss landscape of neural nets. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; NIPS’18. pp. 6391–6401. [Google Scholar]
- Trensch, G.; Morrison, A. A system-on-chip based hybrid neuromorphic compute node architecture for reproducible hyper-real-time simulations of spiking neural networks. Front. Neuroinform. 2022, 16, 884033. [Google Scholar] [CrossRef] [PubMed]
- Abbas, A.H.; Abdel-Ghani, H.; Maksymov, I.S. Classical and Quantum Physical Reservoir Computing for Onboard Artificial Intelligence Systems: A Perspective. Dynamics 2024, 4, 643–670. [Google Scholar] [CrossRef]
- Esaki, L. New phenomenon in narrow germanium p − n junctions. Phys. Rev. 1958, 109, 603–604. [Google Scholar] [CrossRef]
- Kahng, D.; Sze, S.M. A floating gate and its application to memory devices. Bell Syst. Tech. J. 1967, 46, 1288–1295. [Google Scholar] [CrossRef]
- Chang, L.L.; Esaki, L.; Tsu, R. Resonant tunneling in semiconductor double barriers. Appl. Phys. Lett. 1974, 12, 593–595. [Google Scholar] [CrossRef]
- Ionescu, A.M.; Riel, H. Tunnel field-effect transistors as energy-efficient electronic switches. Nature 2011, 479, 329–337. [Google Scholar] [CrossRef] [PubMed]
- Modinos, A. Field emission spectroscopy. Prog. Surf. Sci. 1993, 42, 45. [Google Scholar] [CrossRef]
- Rahman Laskar, M.A.; Celano, U. Scanning probe microscopy in the age of machine learning. APL Mach. Learn. 2023, 1, 041501. [Google Scholar] [CrossRef]
- Binnig, G.; Rohrer, H. Scanning tunneling microscopy—From birth to adolescence. Rev. Mod. Phys. 1987, 59, 615–625. [Google Scholar] [CrossRef]
- Feng, Y.; Tang, M.; Sun, Z.; Qi, Y.; Zhan, X.; Liu, J.; Zhang, J.; Wu, J.; Chen, J. Fully flash-based reservoir computing network with low power and rich states. IEEE Trans. Electron Devices 2023, 70, 4972–4975. [Google Scholar] [CrossRef]
- Kwon, D.; Woo, S.Y.; Lee, K.H.; Hwang, J.; Kim, H.; Park, S.H.; Shin, W.; Bae, J.H.; Kim, J.J.; Lee, J.H. Reconfigurable neuromorphic computing block through integration of flash synapse arrays and super-steep neurons. Sci. Adv. 2023, 9, eadg9123. [Google Scholar] [CrossRef] [PubMed]
- Yilmaz, Y.; Mazumder, P. Image processing by a programmable grid comprising quantum dots and memristors. IEEE Trans. Nanotechnol. 2013, 12, 879–887. [Google Scholar] [CrossRef]
- Kent, R.M.; Barbosa, W.A.S.; Gauthier, D.J. Controlling chaos using edge computing hardware. Nat. Commun. 2024, 15, 3886. [Google Scholar] [CrossRef] [PubMed]
- Bastiaans, K.M.; Benschop, T.; Chatzopoulos, D.; Cho, D.; Dong, Q.; Jin, Y.; Allan, M.P. Amplifier for scanning tunneling microscopy at MHz frequencies. Rev. Sci. Instrum. 2018, 89, 093709. [Google Scholar] [CrossRef]
- Marković, D.; Grollier, J. Quantum neuromorphic computing. Appl. Phys. Lett. 2020, 117, 150501. [Google Scholar] [CrossRef]
- van der Made, P. Learning How to Learn: Neuromorphic AI Inference at the Edge. BrainChip White Pap. 2022, 12. Available online: https://brainchip.com/learning-how-to-learn-neuromorphic-ai-inference-at-the-edge/ (accessed on 5 January 2024).


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Maksimovic, M.; Maksymov, I.S. Quantum-Cognitive Neural Networks: Assessing Confidence and Uncertainty with Human Decision-Making Simulations. Big Data Cogn. Comput. 2025, 9, 12. https://doi.org/10.3390/bdcc9010012
Maksimovic M, Maksymov IS. Quantum-Cognitive Neural Networks: Assessing Confidence and Uncertainty with Human Decision-Making Simulations. Big Data and Cognitive Computing. 2025; 9(1):12. https://doi.org/10.3390/bdcc9010012
Chicago/Turabian StyleMaksimovic, Milan, and Ivan S. Maksymov. 2025. "Quantum-Cognitive Neural Networks: Assessing Confidence and Uncertainty with Human Decision-Making Simulations" Big Data and Cognitive Computing 9, no. 1: 12. https://doi.org/10.3390/bdcc9010012
APA StyleMaksimovic, M., & Maksymov, I. S. (2025). Quantum-Cognitive Neural Networks: Assessing Confidence and Uncertainty with Human Decision-Making Simulations. Big Data and Cognitive Computing, 9(1), 12. https://doi.org/10.3390/bdcc9010012