



AI-Based User Empowerment for Empirical Social Research

 , , , ,
, , , ,  , and
, and
Abstract
1. Introduction and Motivation
2. Related Work and Remaining Challenges
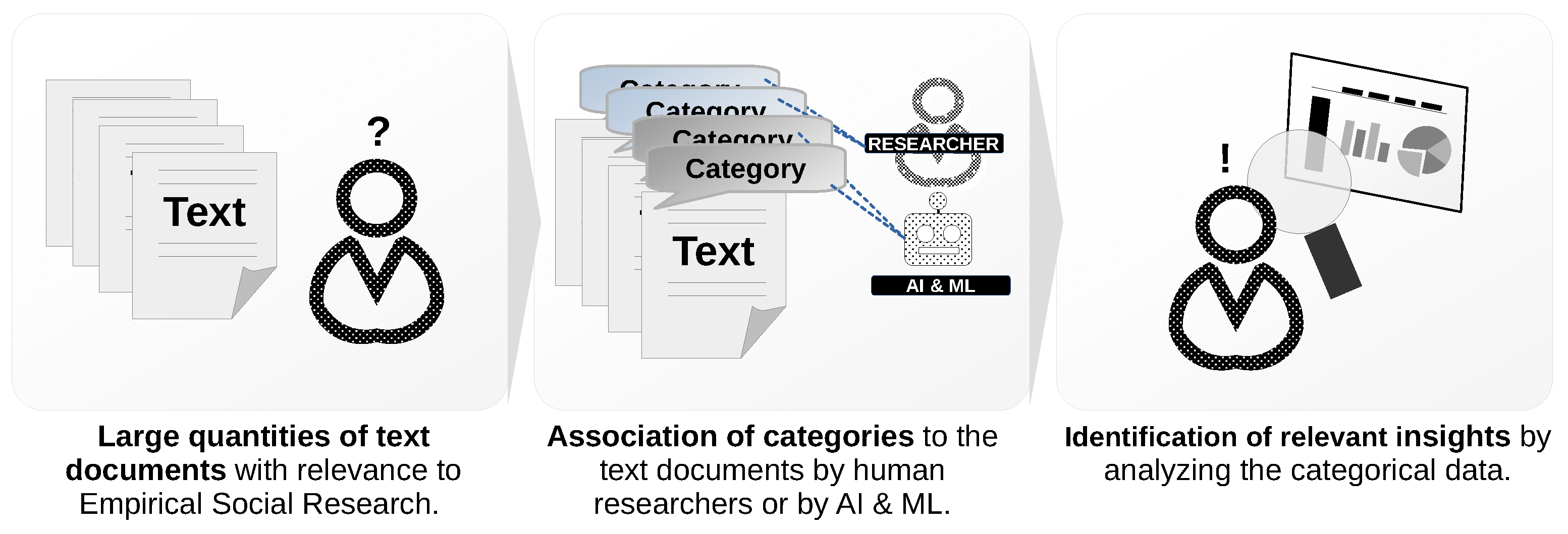
2.1. Empirical Social Research and Qualitative Content Analysis
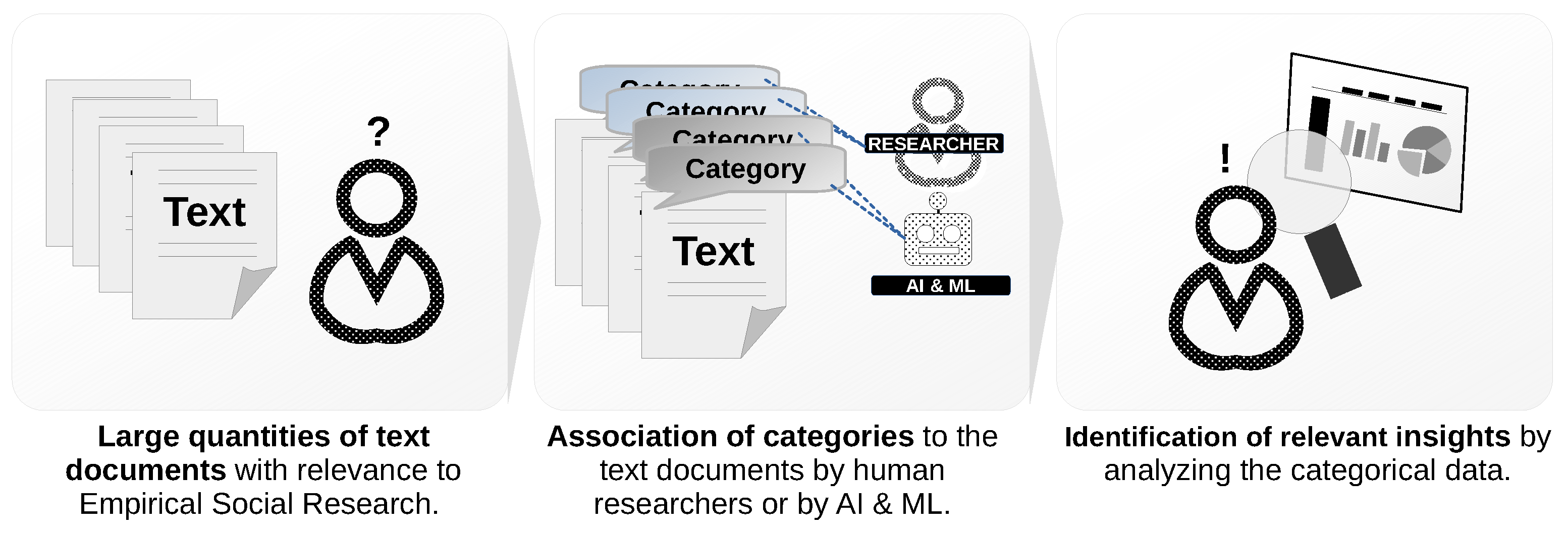
2.2. Machine Learning-Based Text Categorization (MLTC)
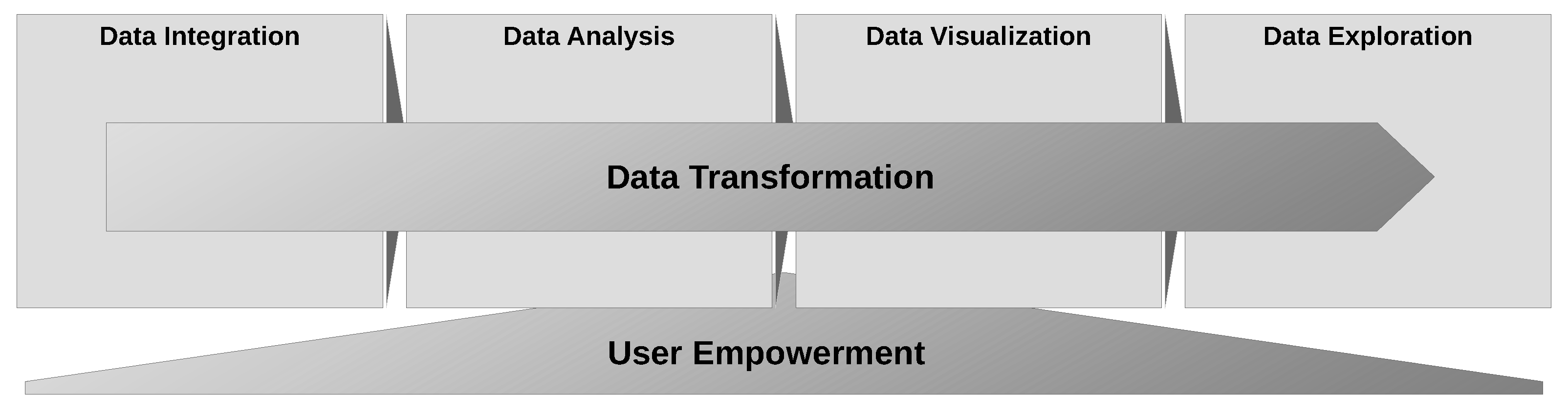
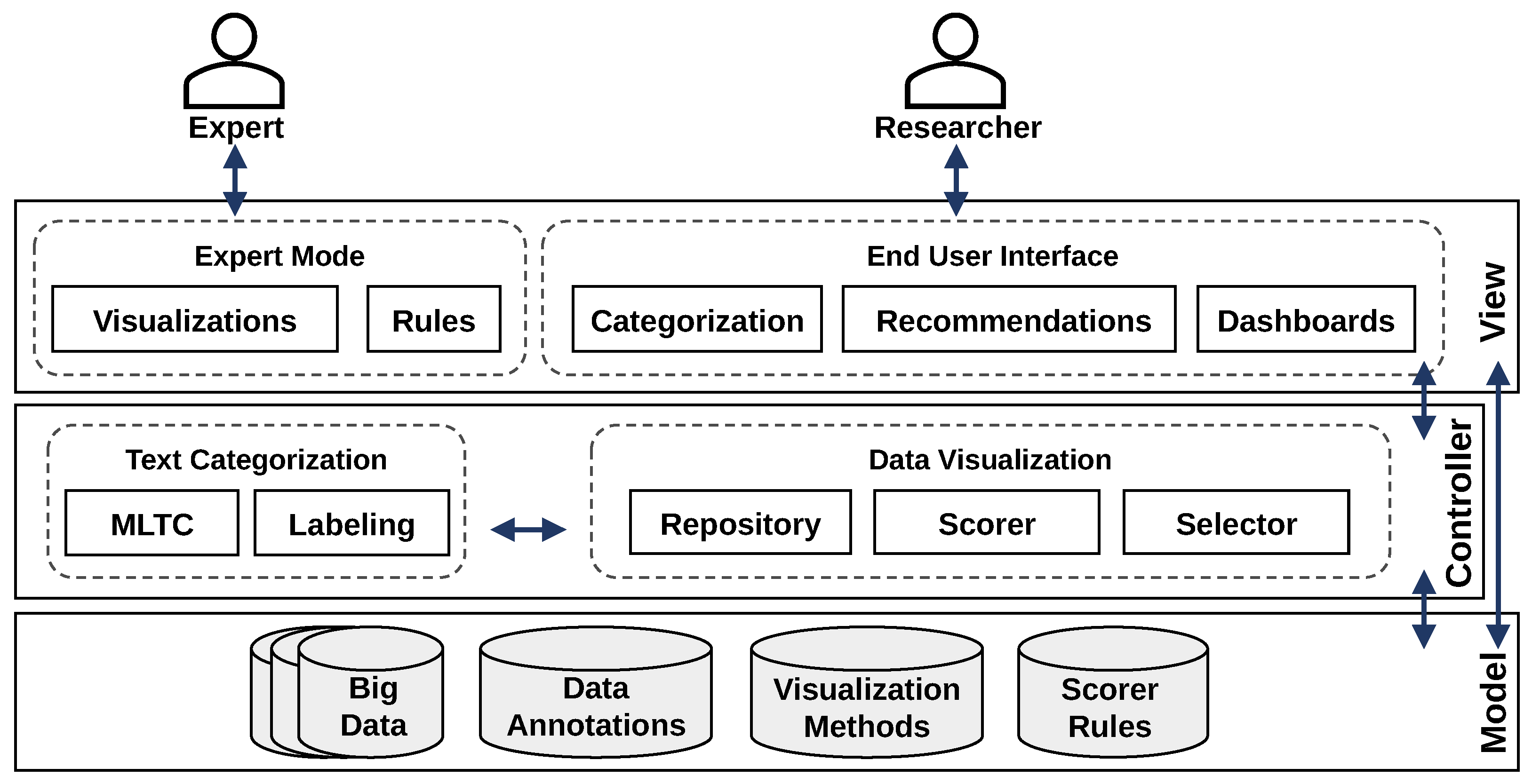
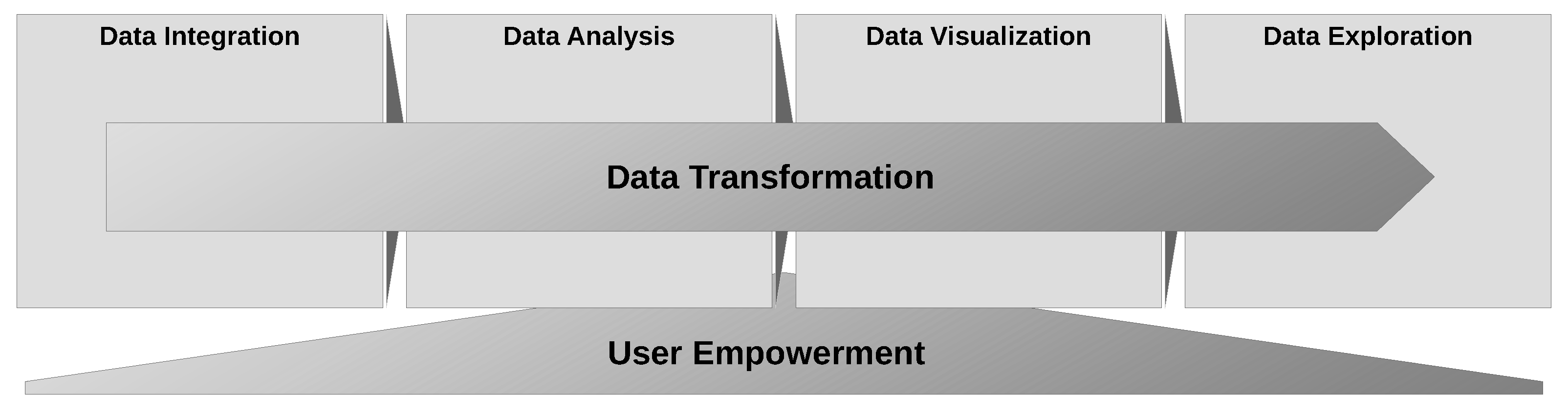
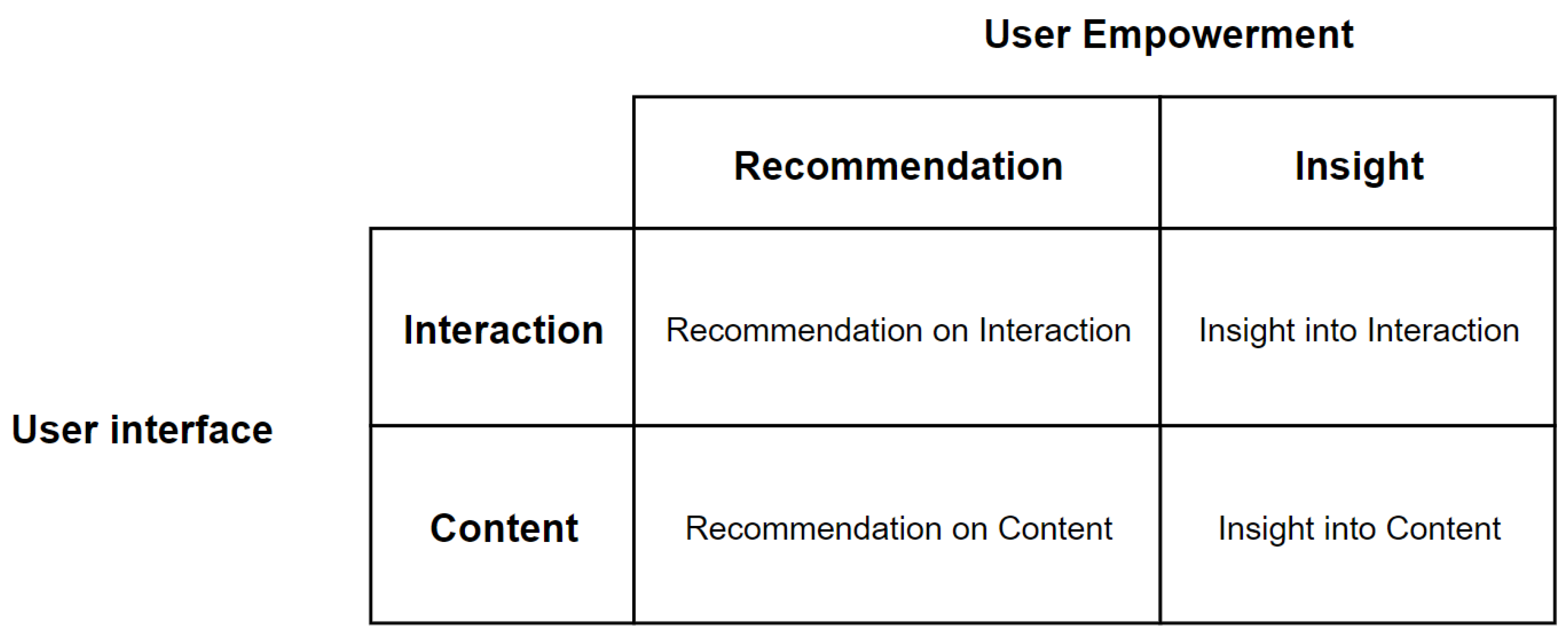
2.3. AI2VIS4BigData and User Empowerment
2.4. Discussion and Remaining Challenges
- (RC1) Application Domain: neither text categorization nor other social research-related application domains were assessed for AI2VIS4BigData or IVIS4BigData-related research.
- (RC2) MLTC: the MLTC component is not yet integrated into a user-empowering IS.
- (RC3) Data Exploration User Empowerment: there exists no example application for empowering users for the data exploration process step of the AI2VIS4BigData reference model.
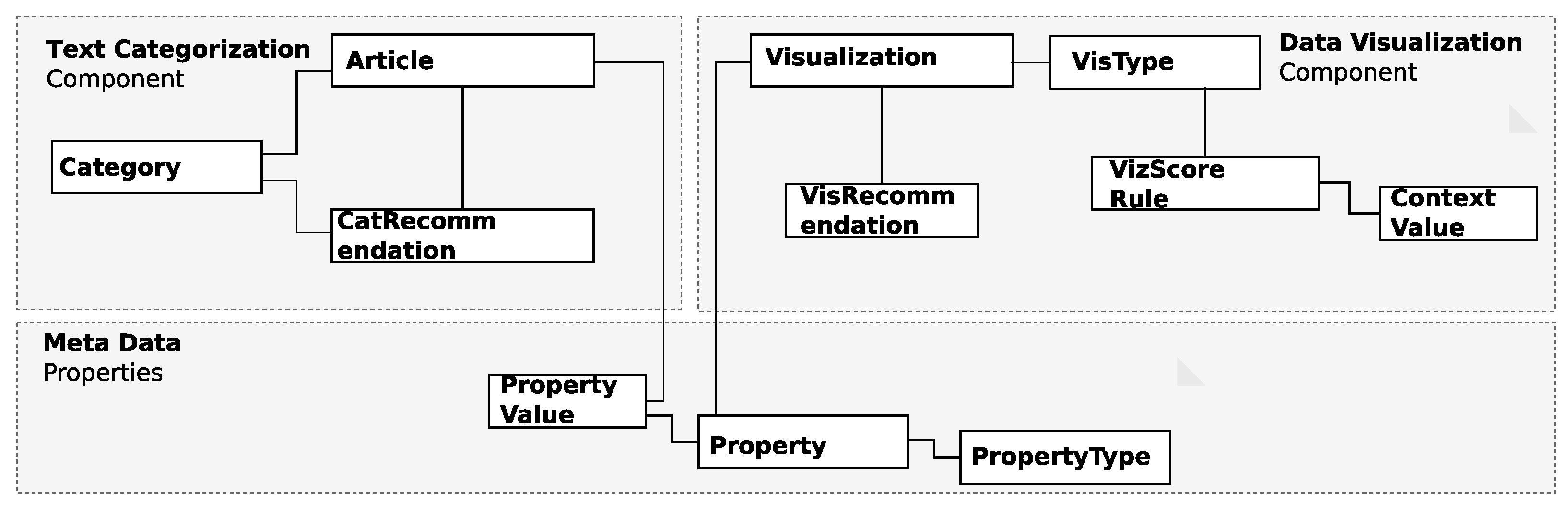
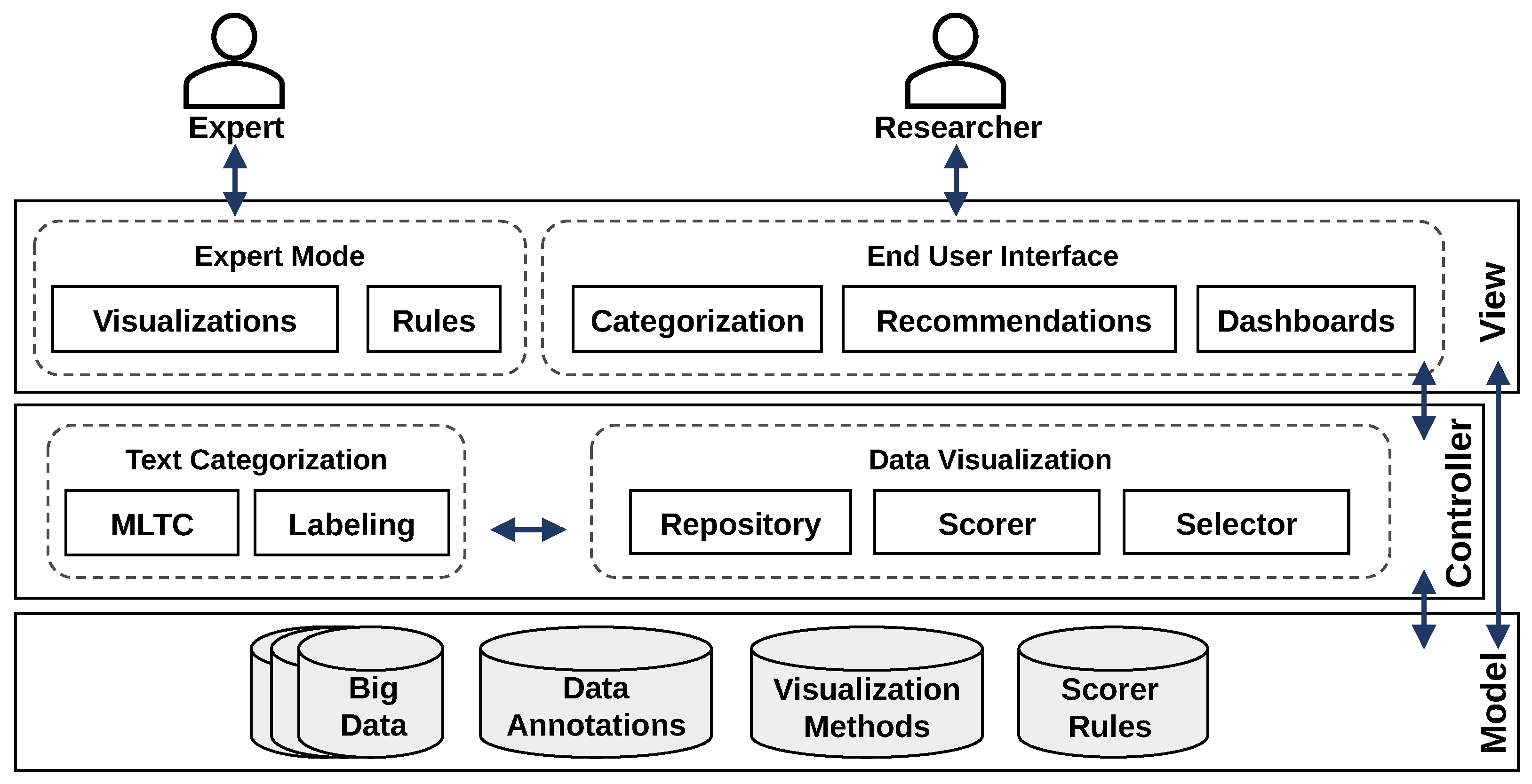
3. Conceptual Modeling
- (For RC1) Section 3.1 will derive the requirements and Section 3.4 will design a conceptual architecture for an IS that uses AI and ML for empowering its users in categorizing data and analyzing categorized data.
- (For RC2) Section 3.2 describes the design of an MLTC-based component for integration into a user-empowering IS.
- (For RC3) Section 3.3 describes the design of user-empowering data exploration component as exemplary AI2VIS4BigData reference implementation.
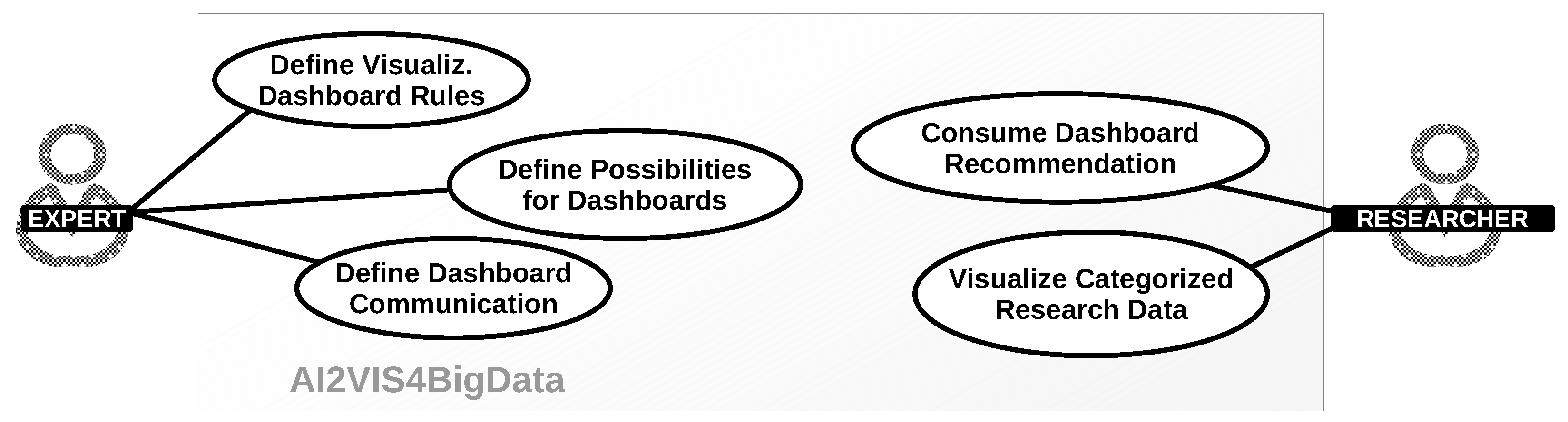
3.1. Use Context and Use Cases
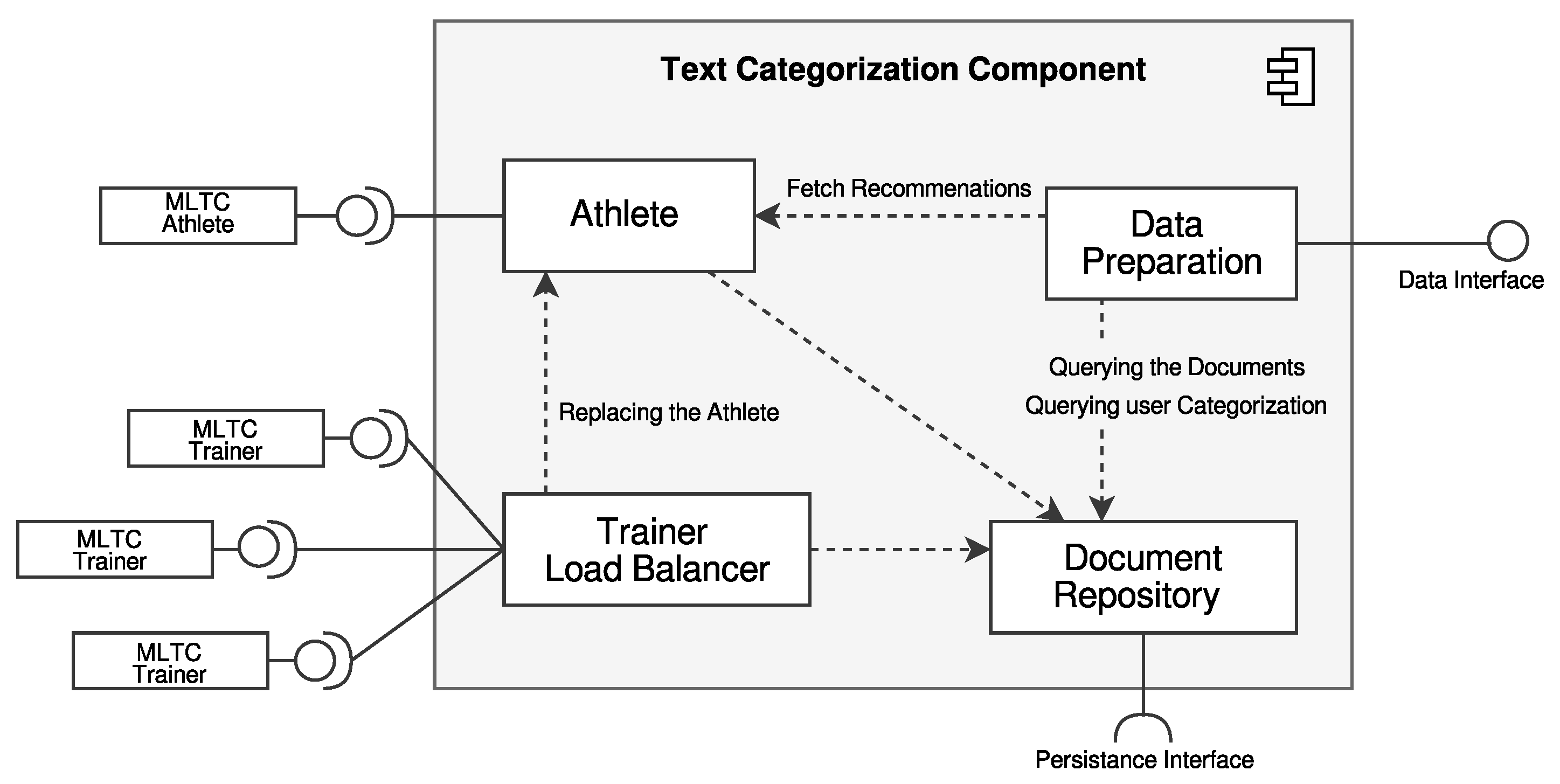
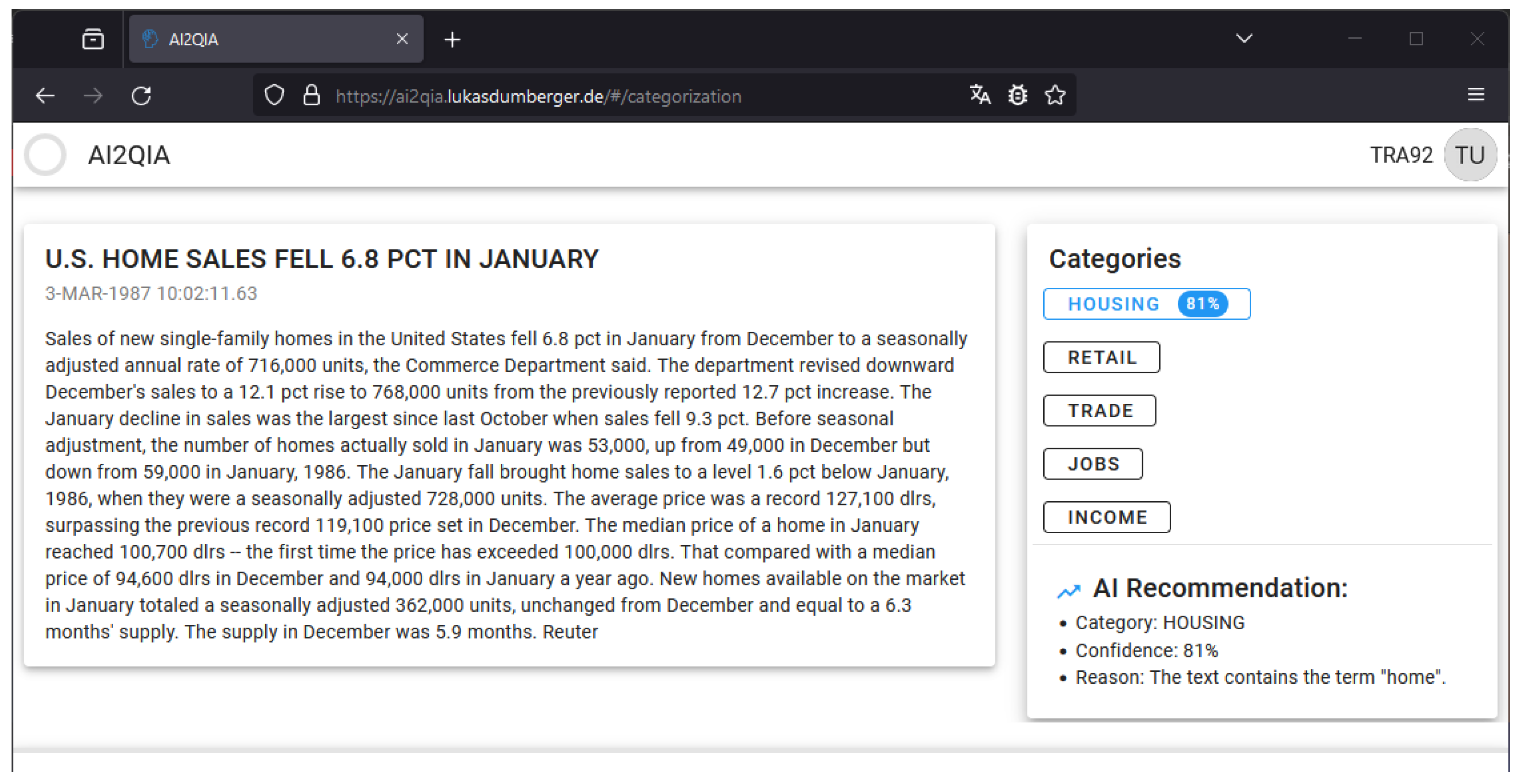
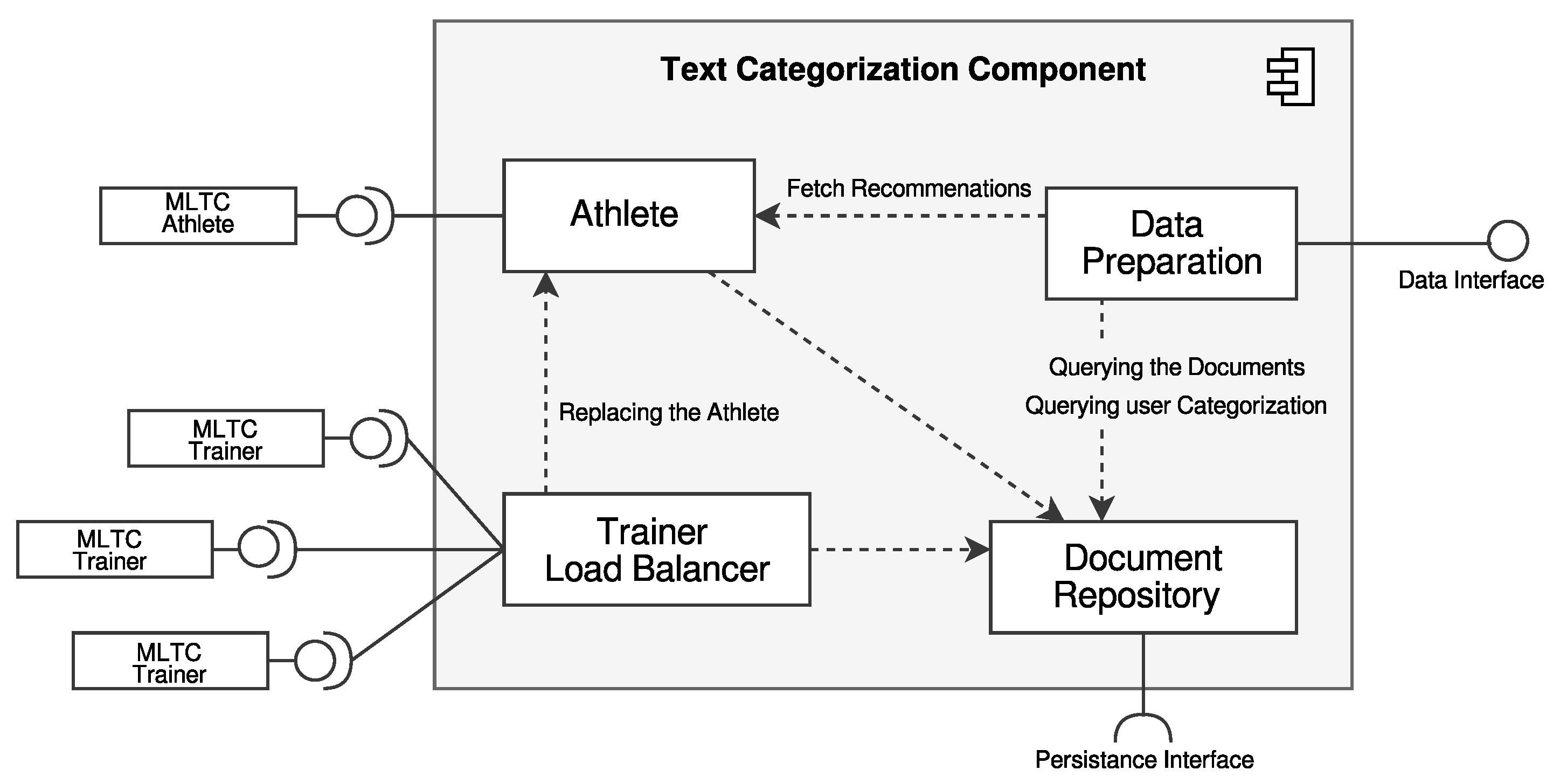
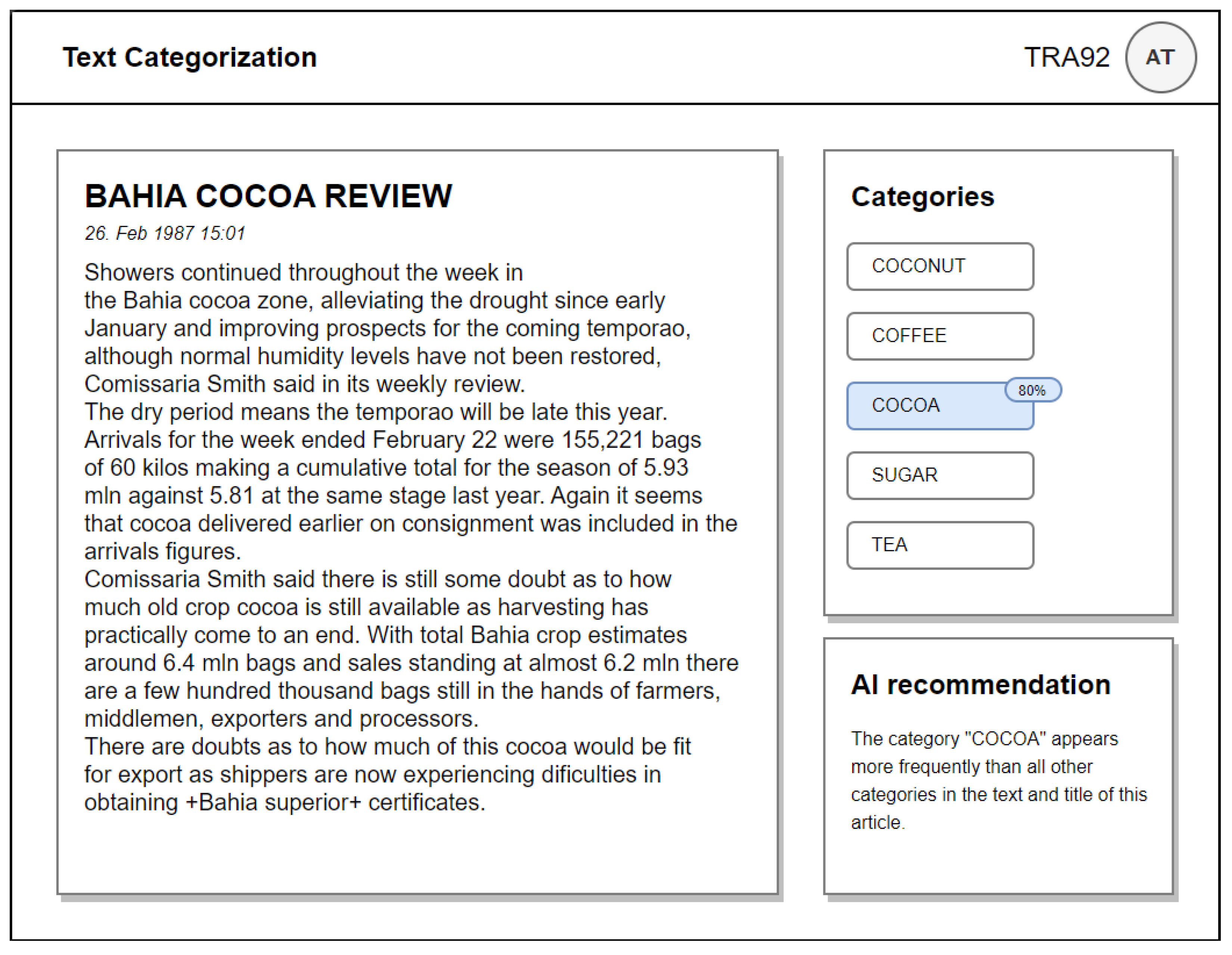
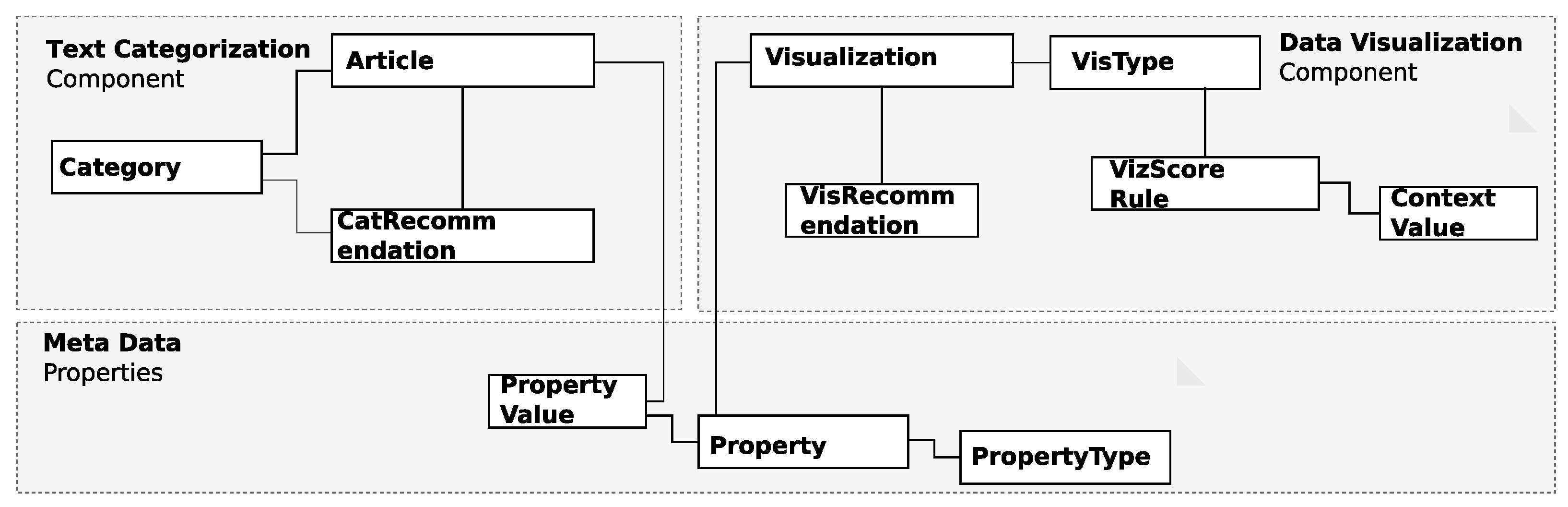
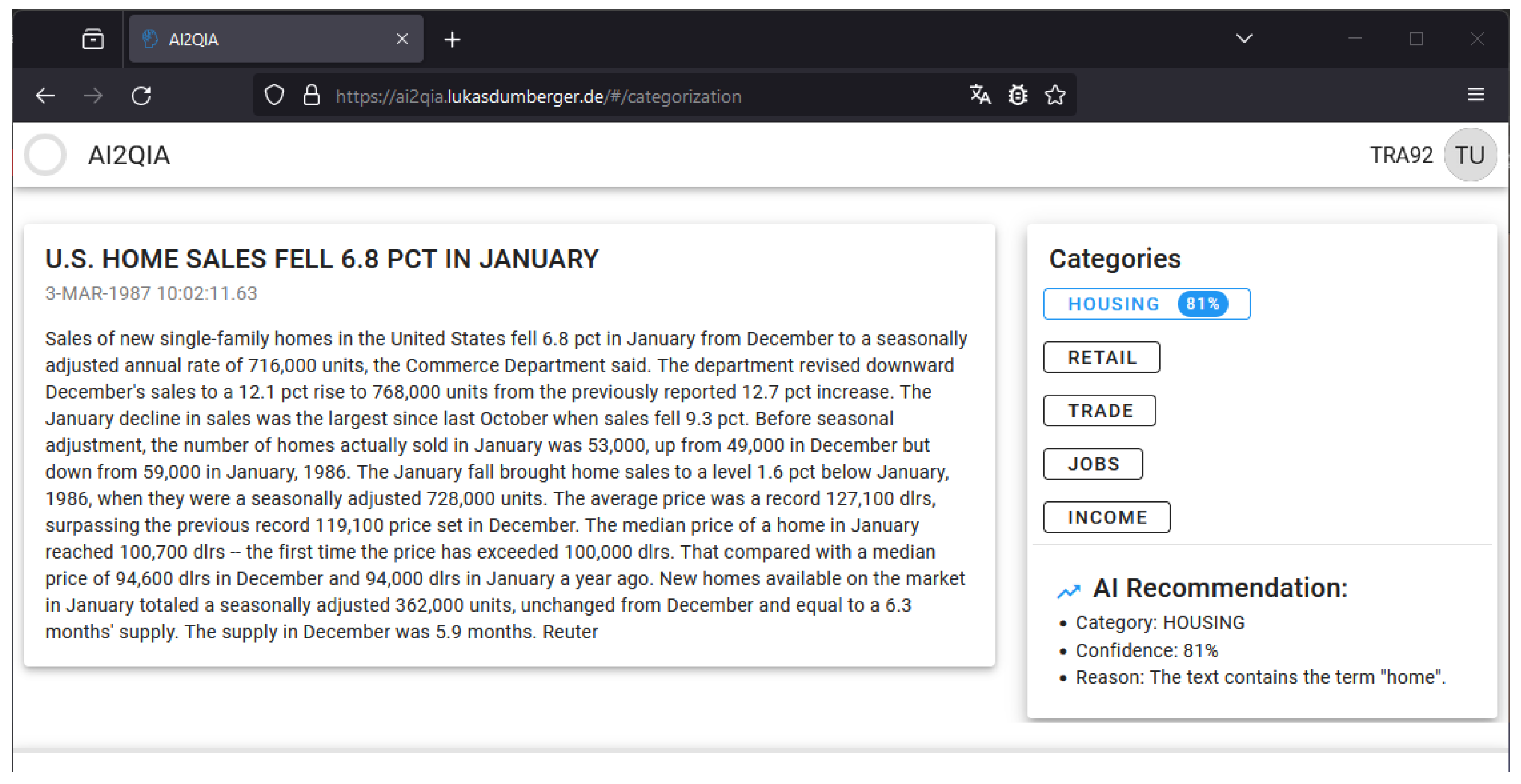
3.2. ML-Based Text Categorization Component
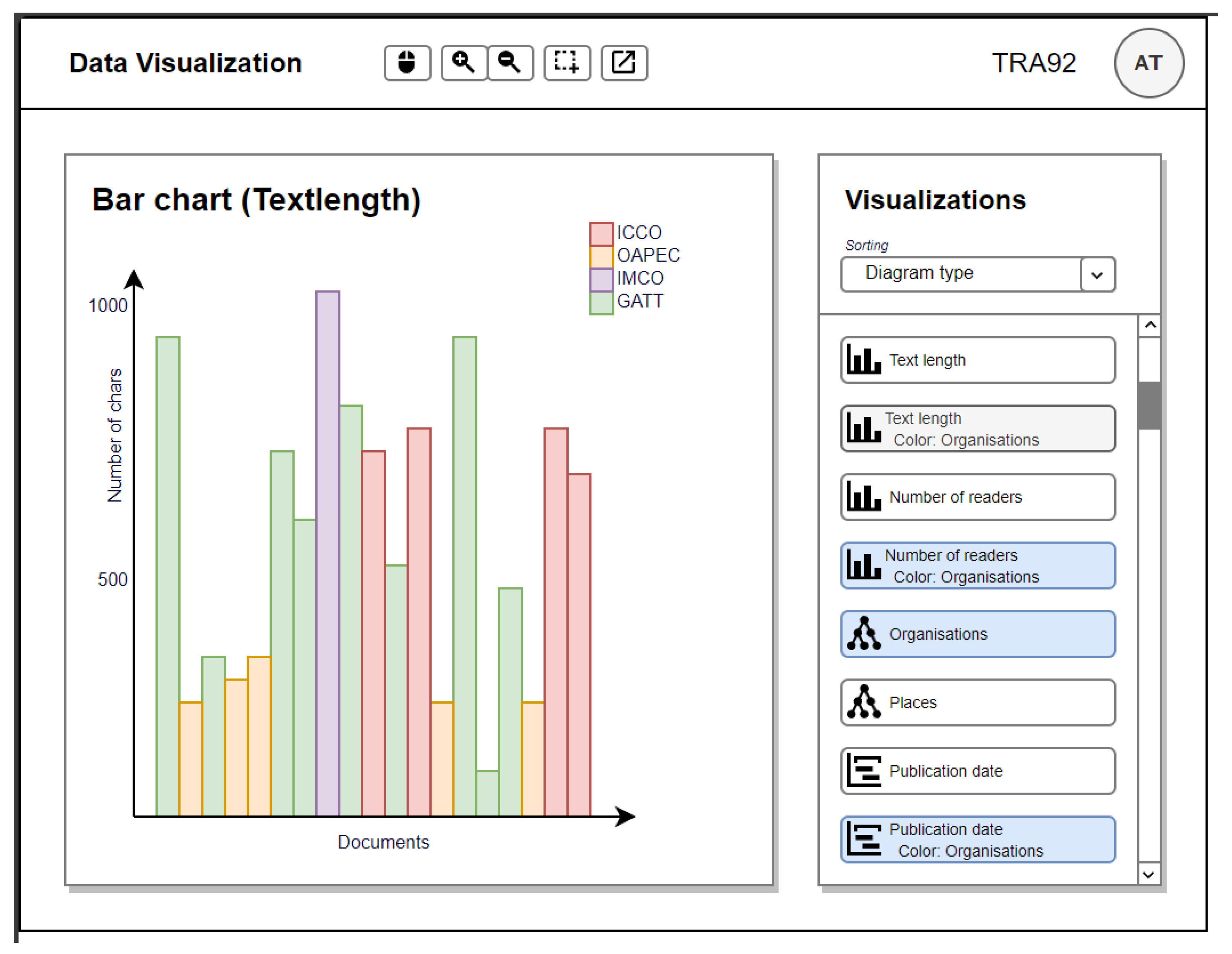
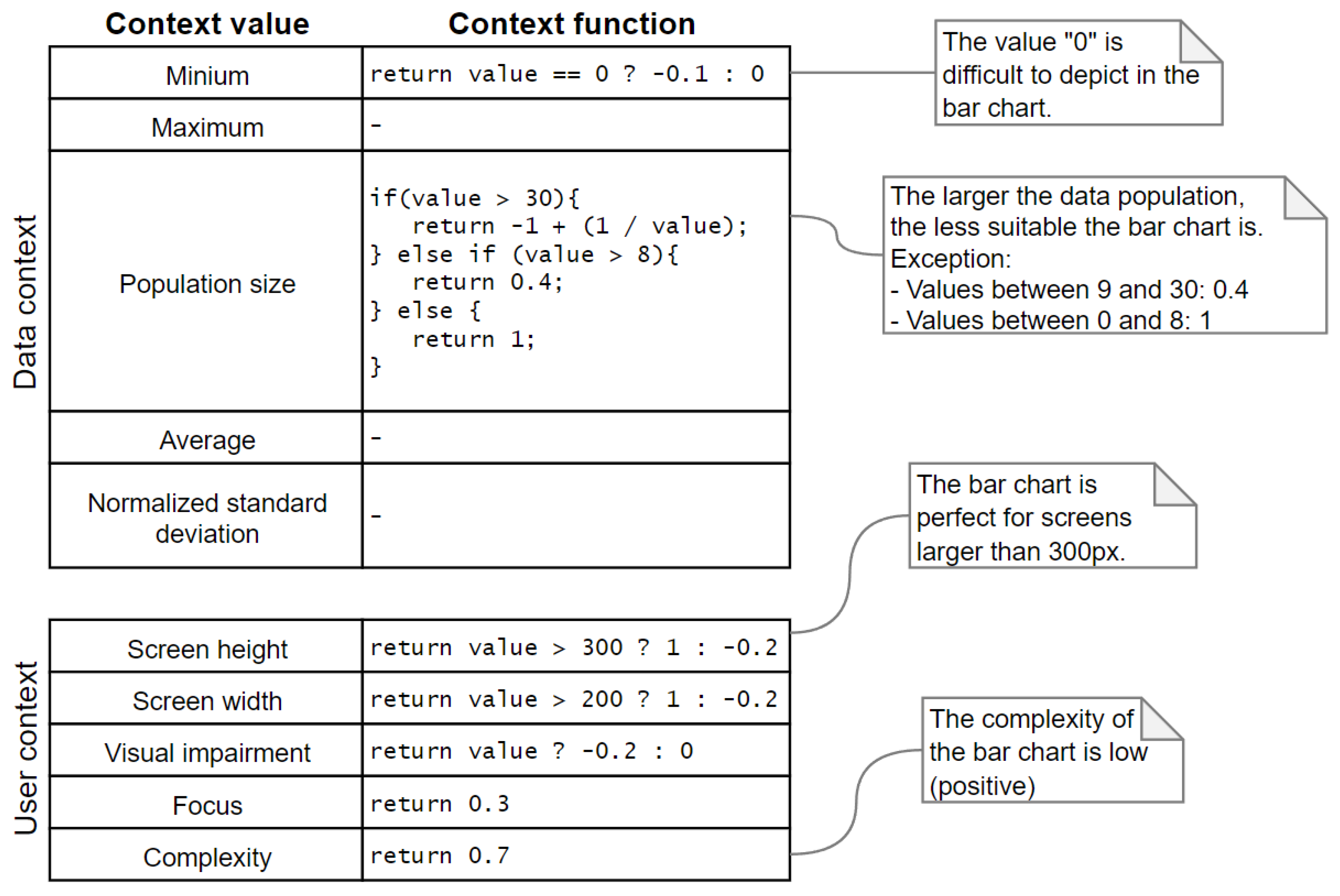
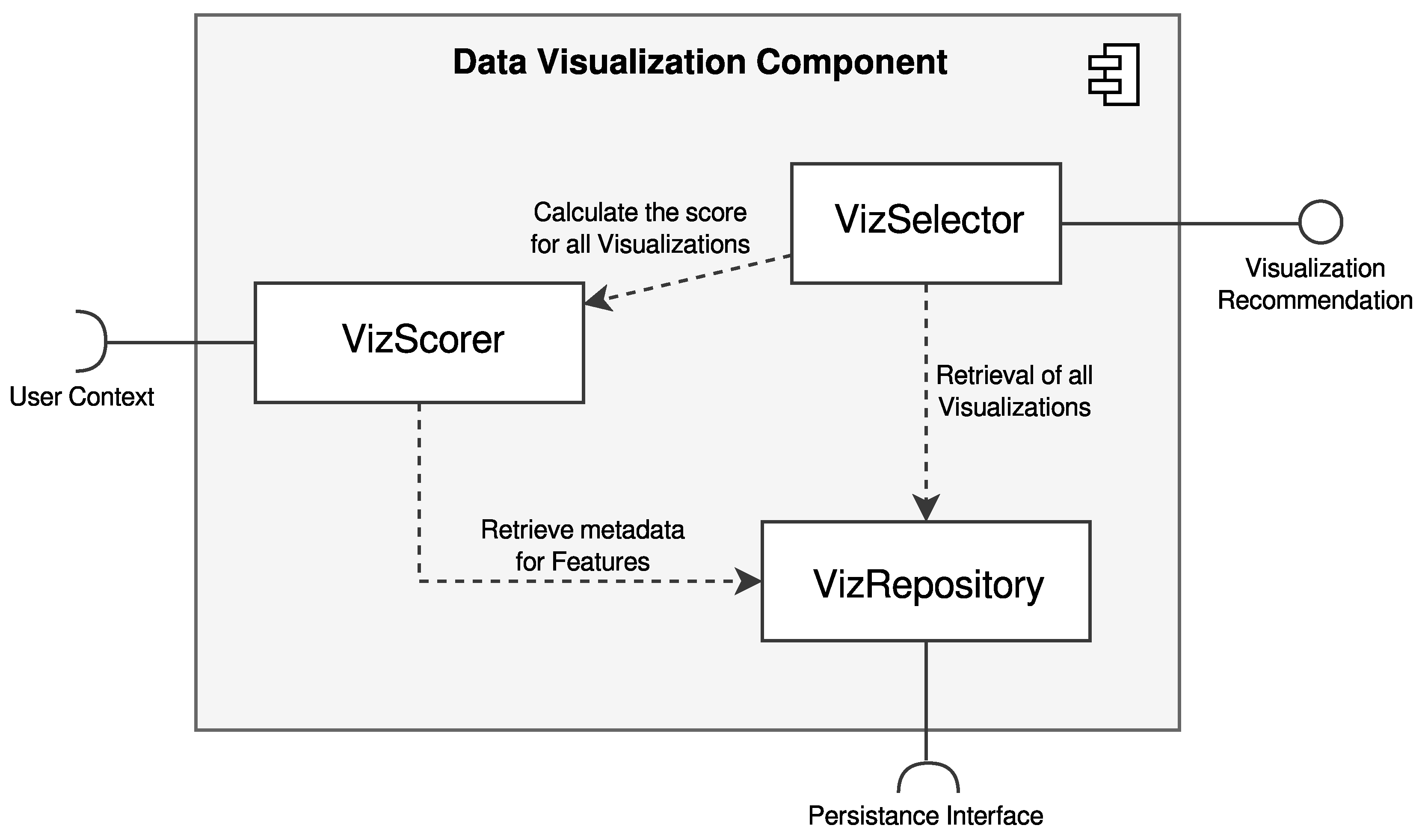
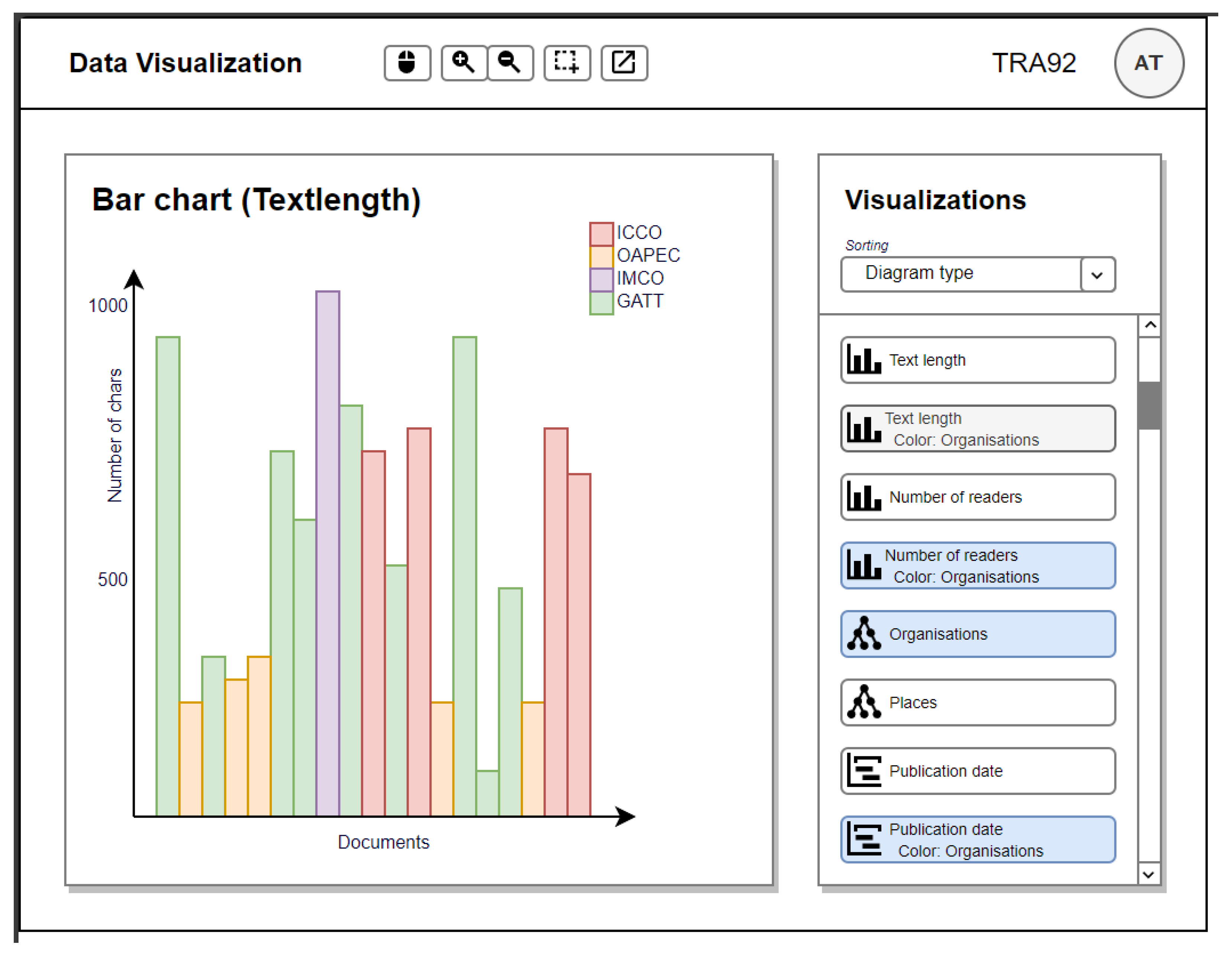
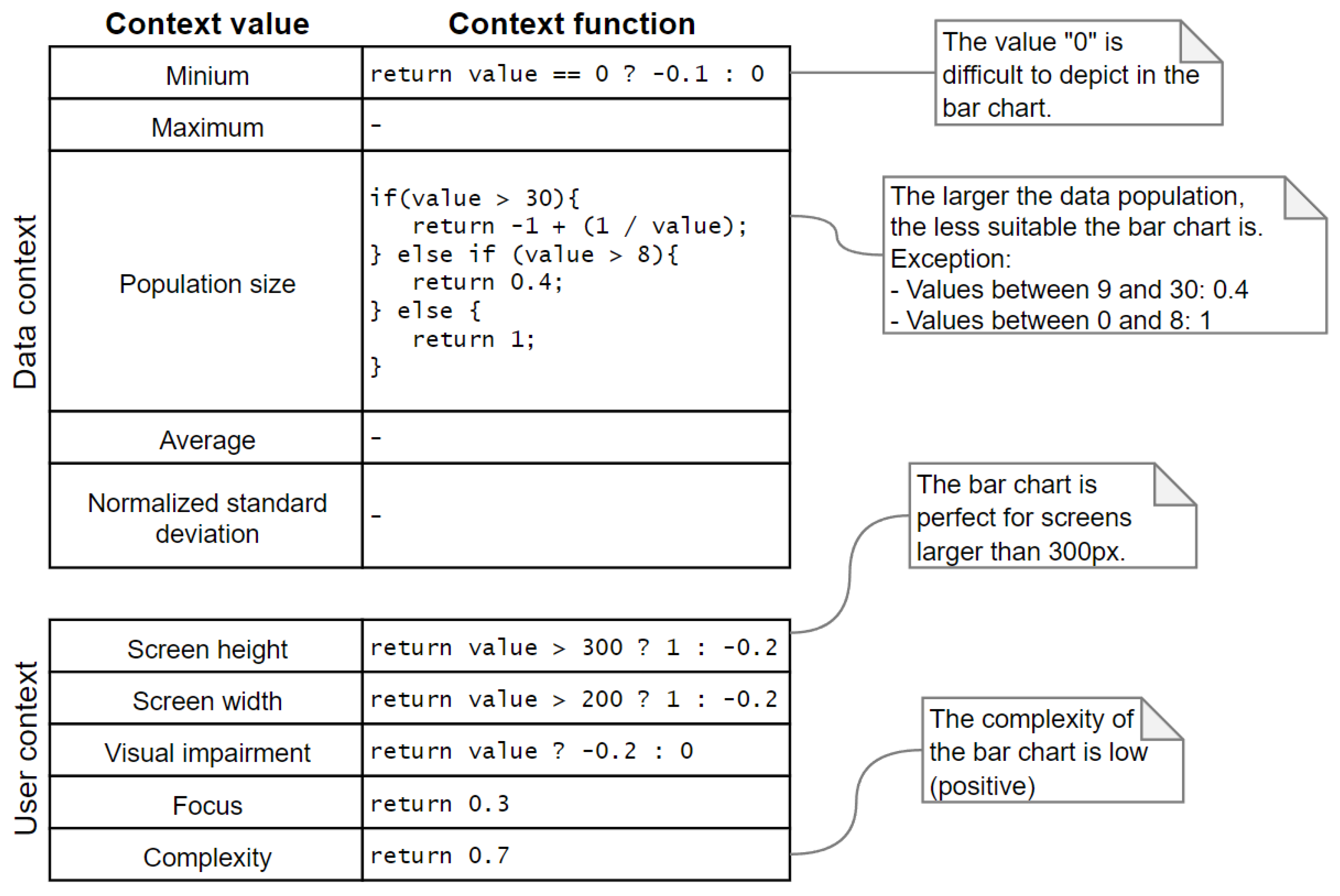
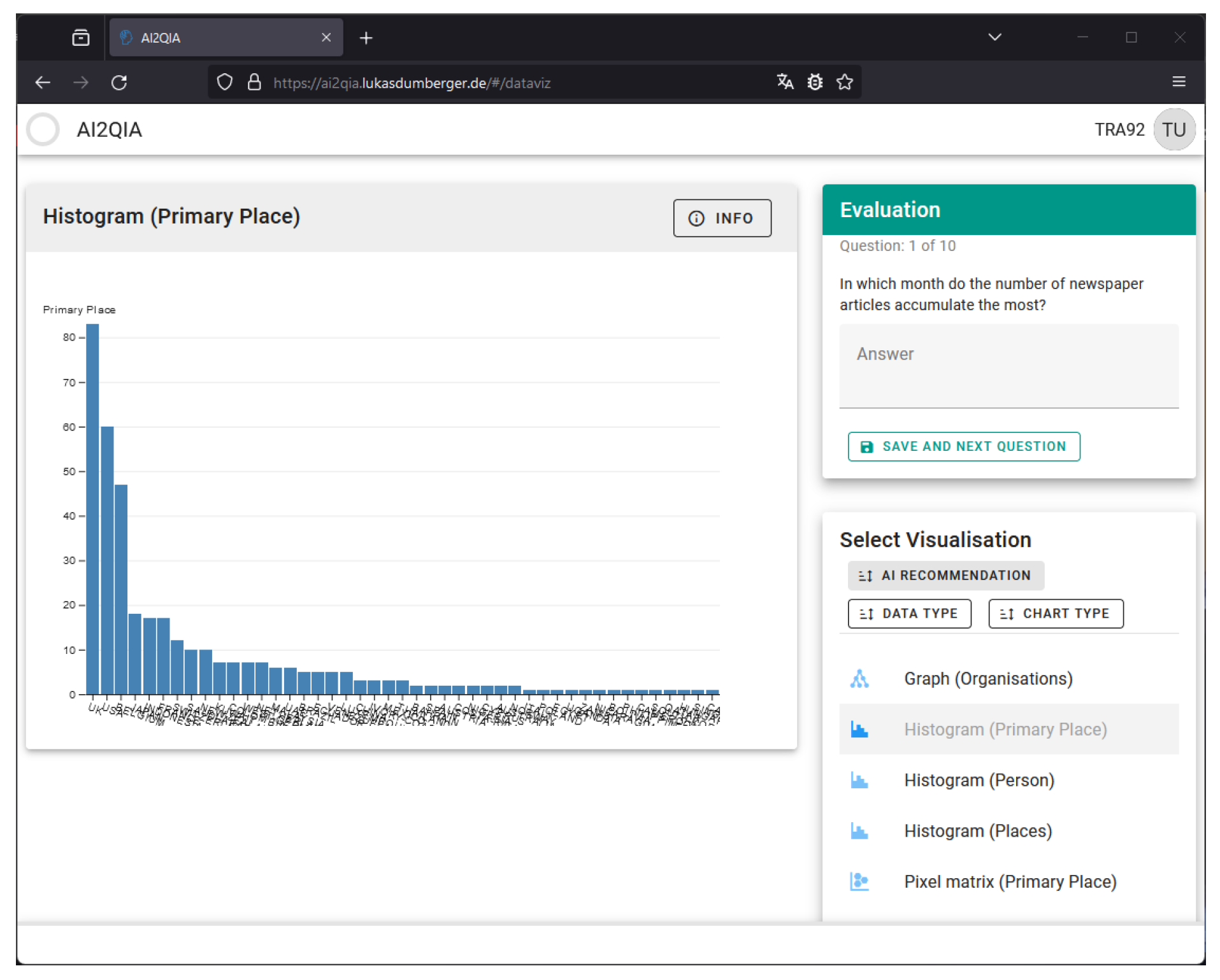
3.3. Expert System-Based Data Visualization Component
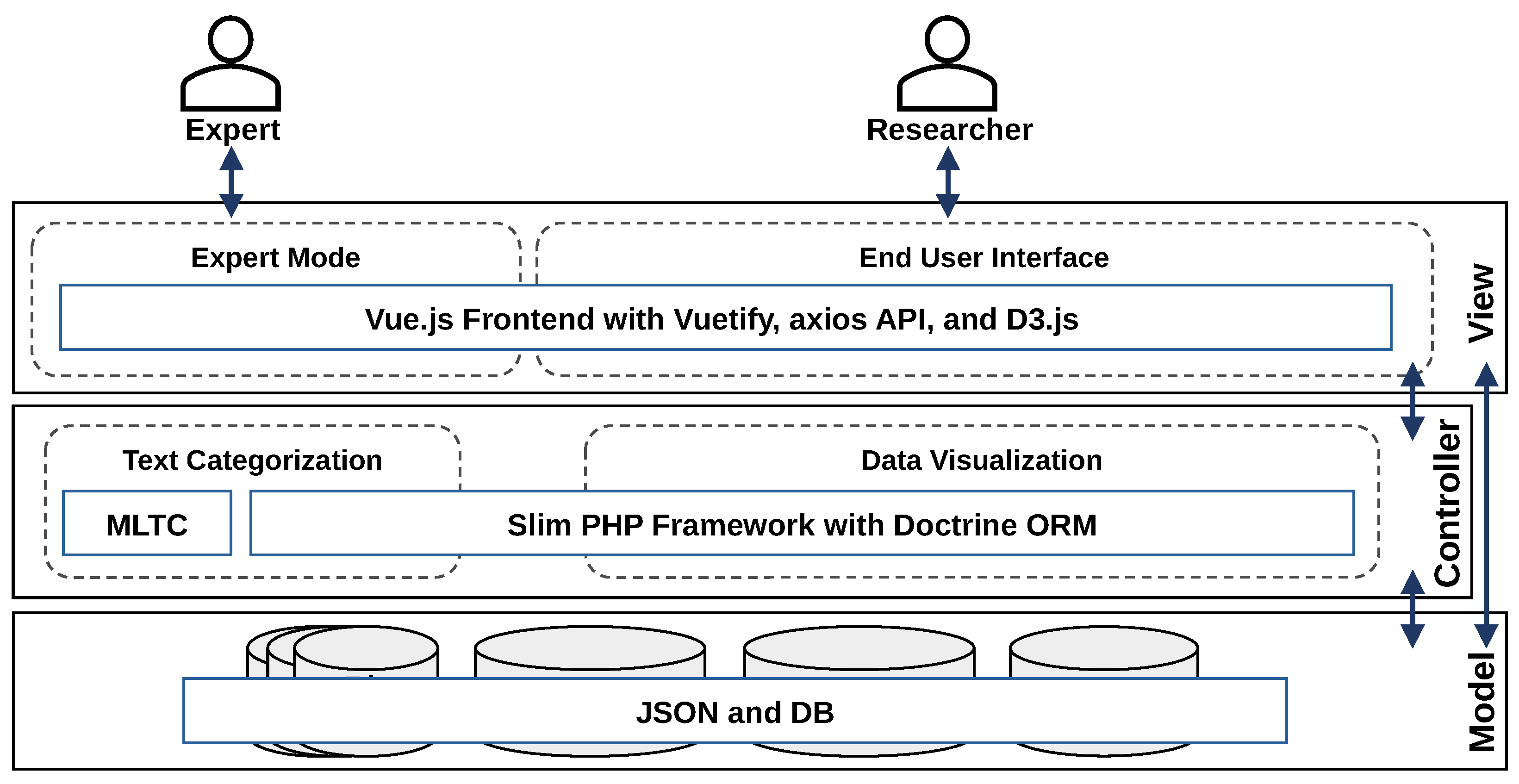
3.4. Conceptual Architecture
3.5. Discussion and Remaining Challenges
4. Proof-of-Concept Implementation
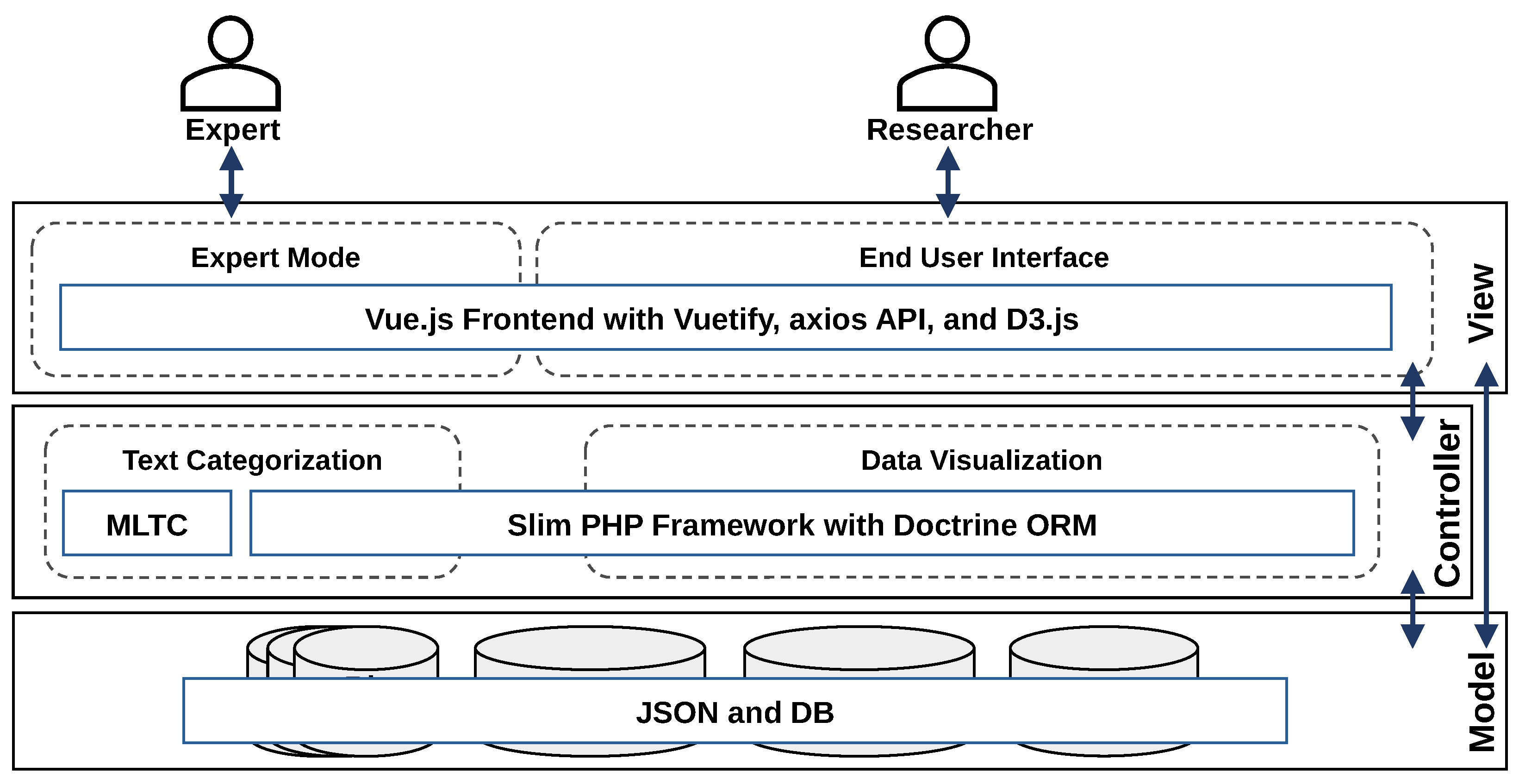
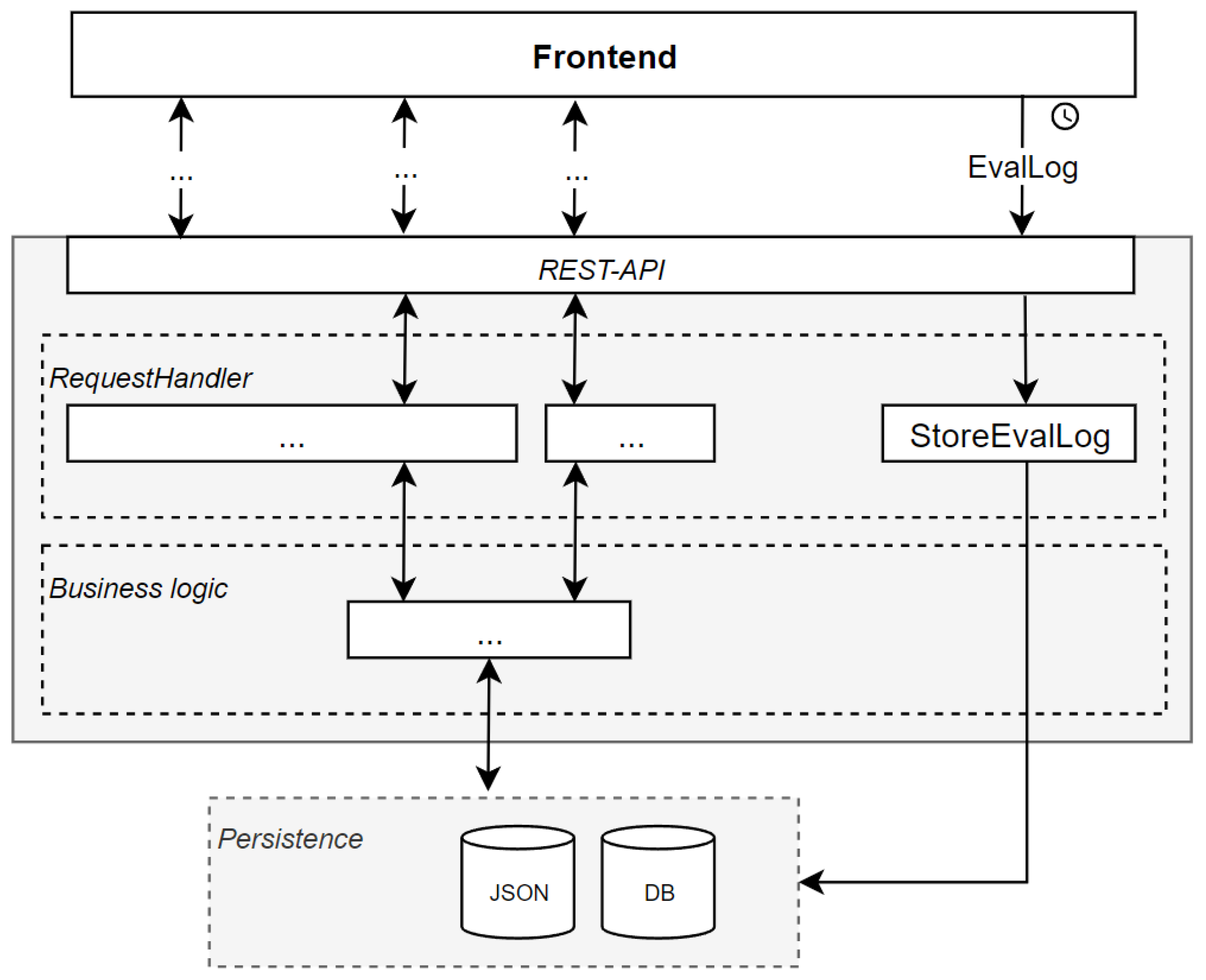
4.1. Technical Architecture
4.2. Implemented Text Categorization Component
| Listing 1. MLTC trainer example configuration. |
 |
| Listing 2. MLTC trainer training algorithm. |
 |
4.3. Implemented Data Visualization Component
4.4. Discussion and Remaining Challenges
5. Evaluation
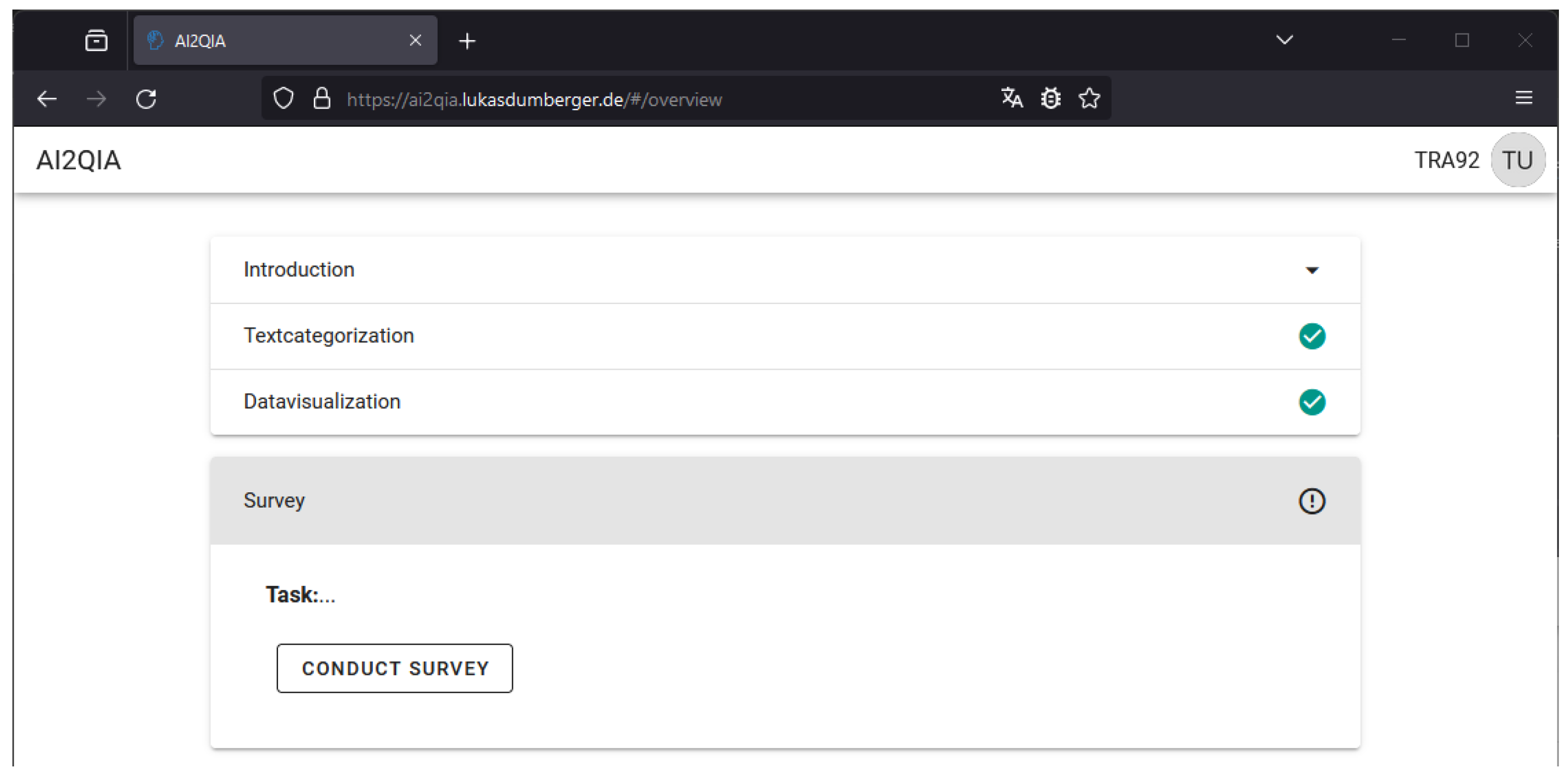
5.1. Qualitative Evaluation Using a Cognitive Walkthrough
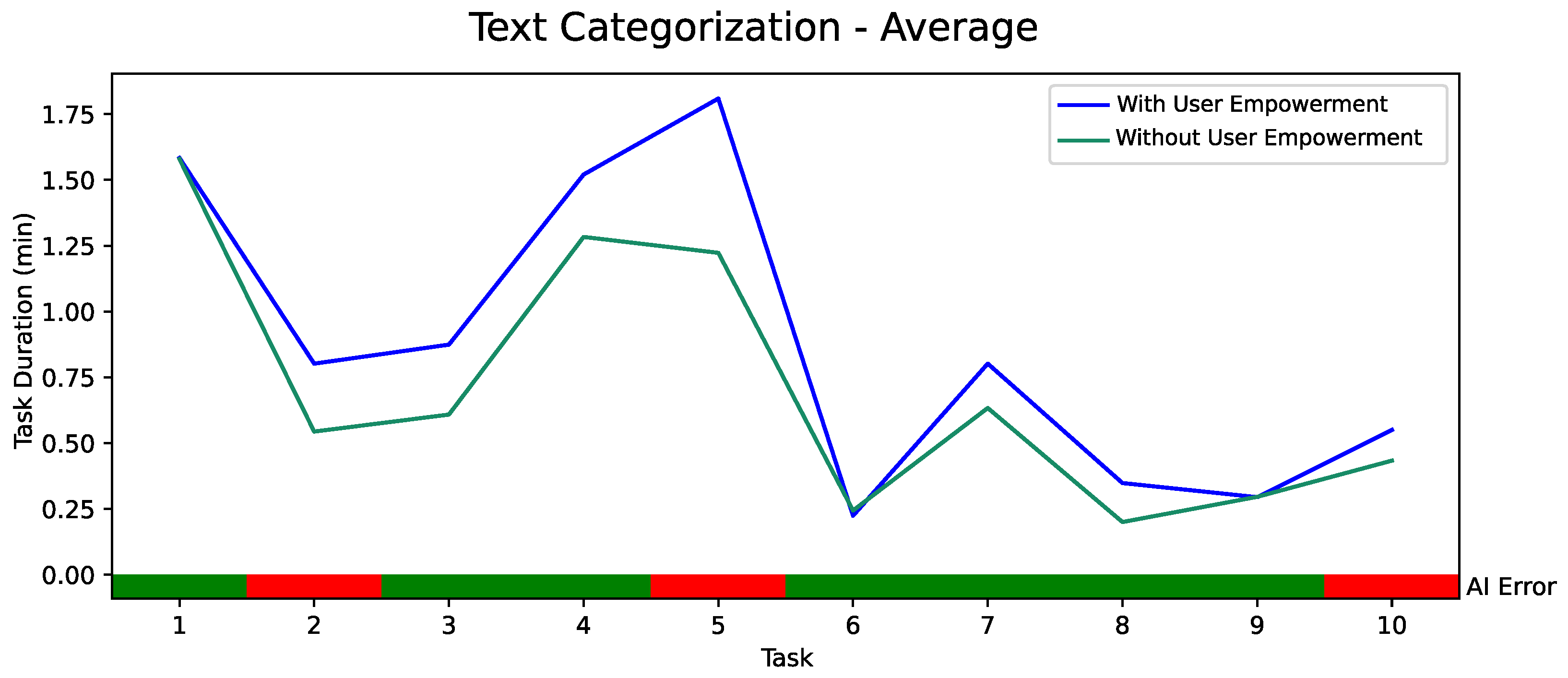
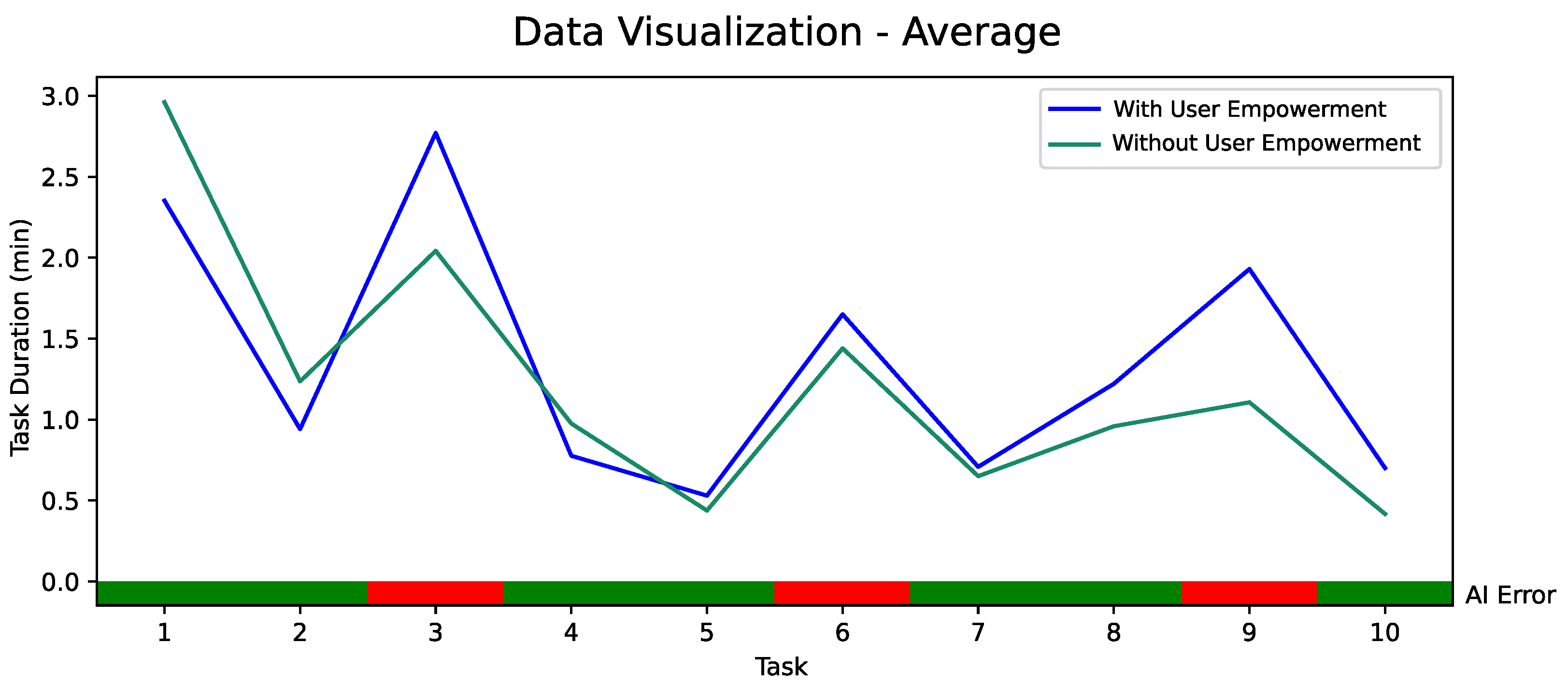
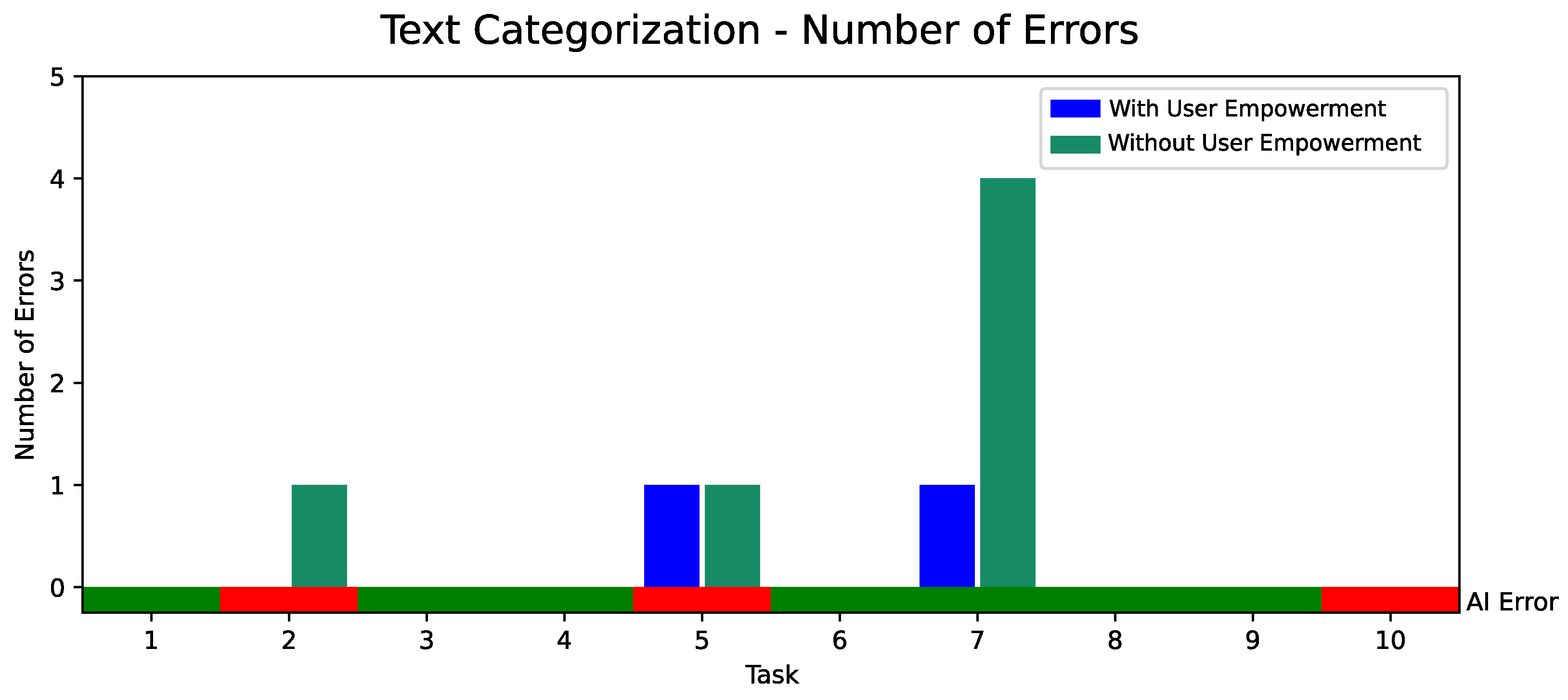
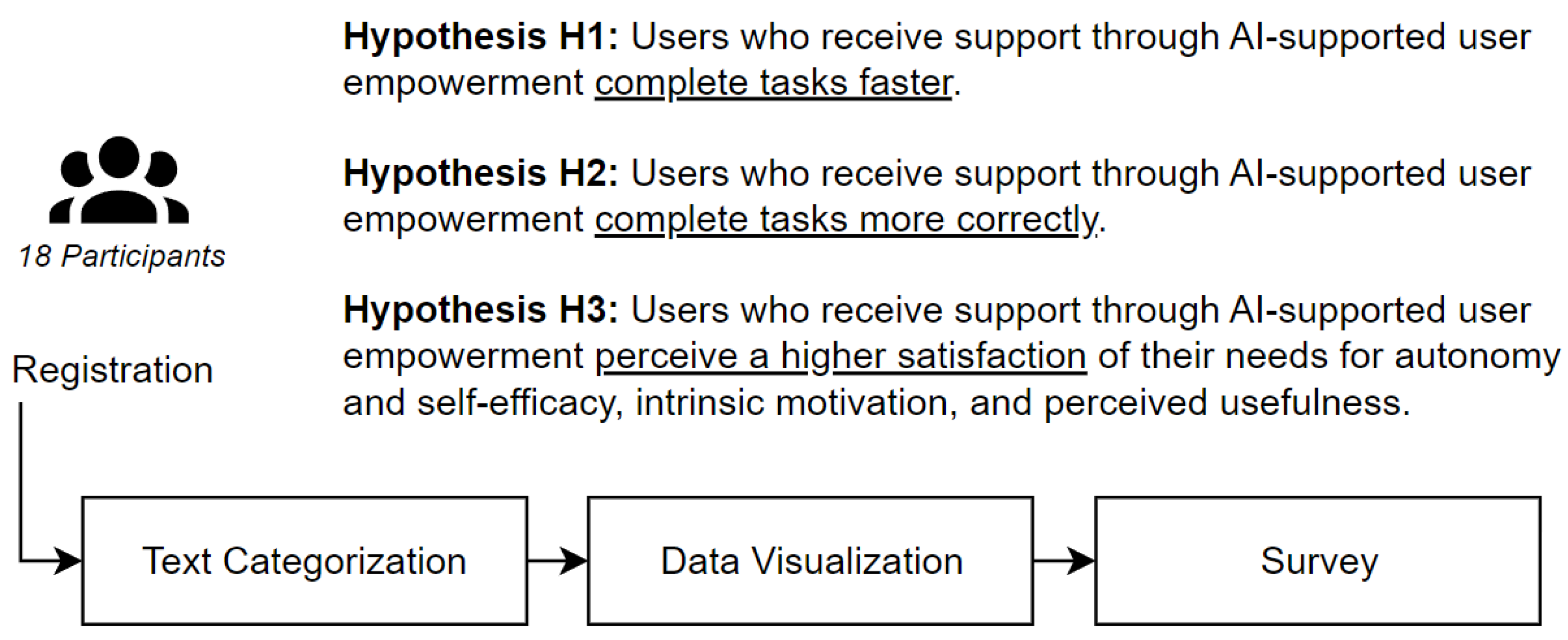
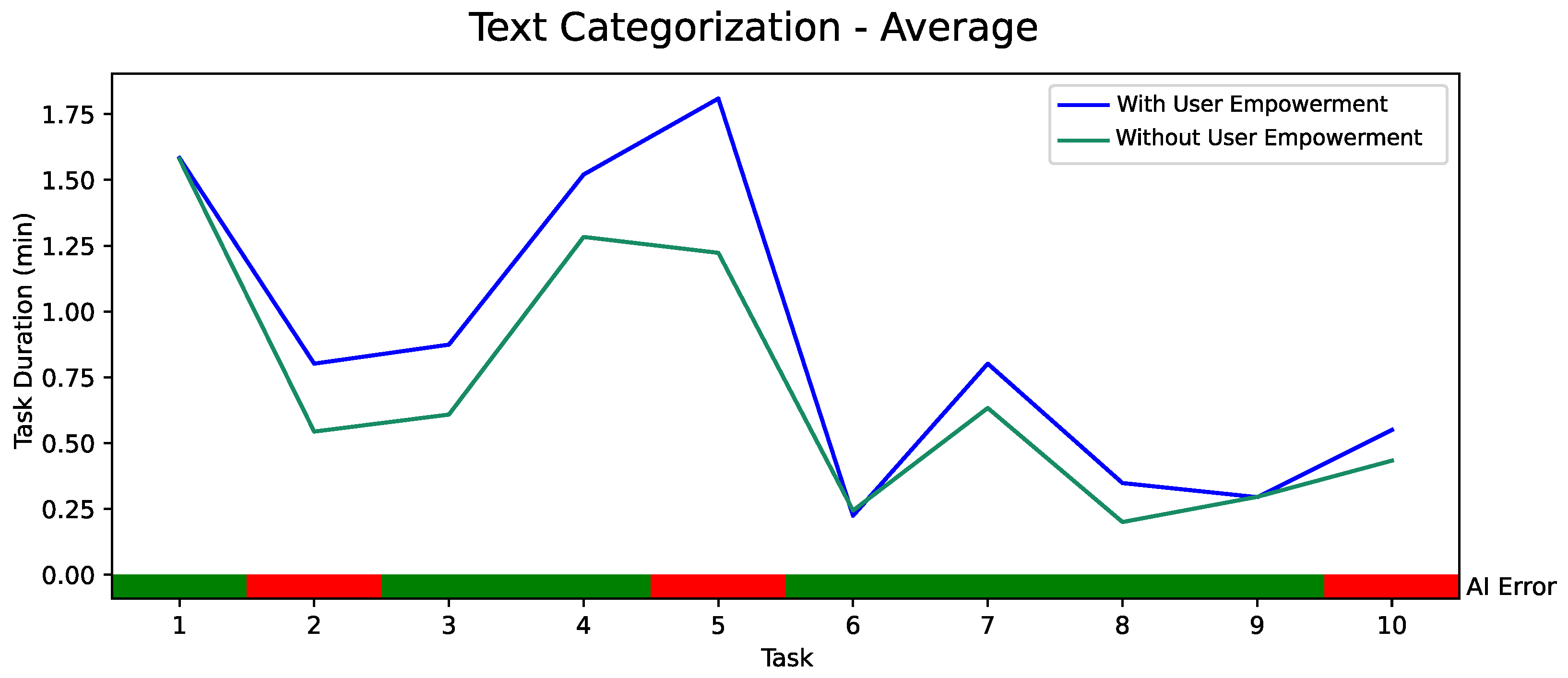
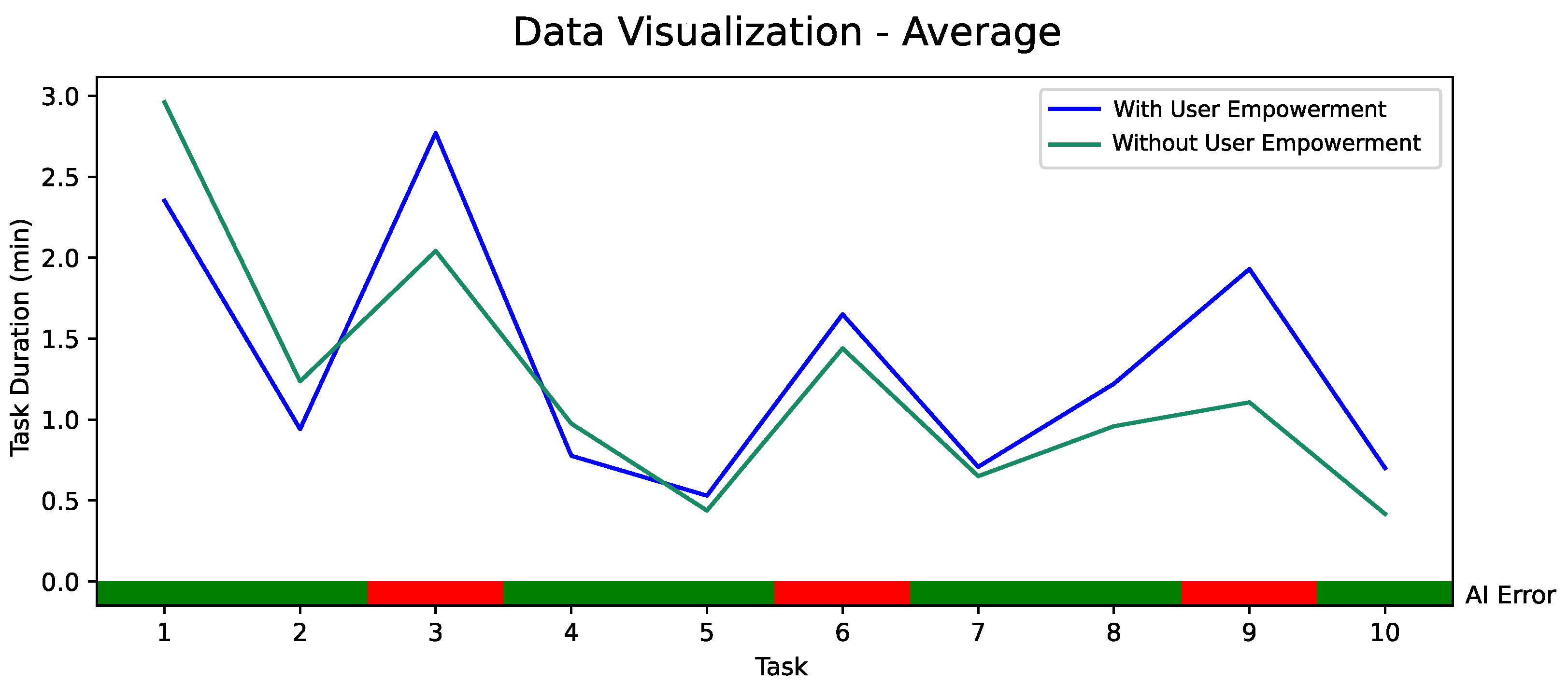
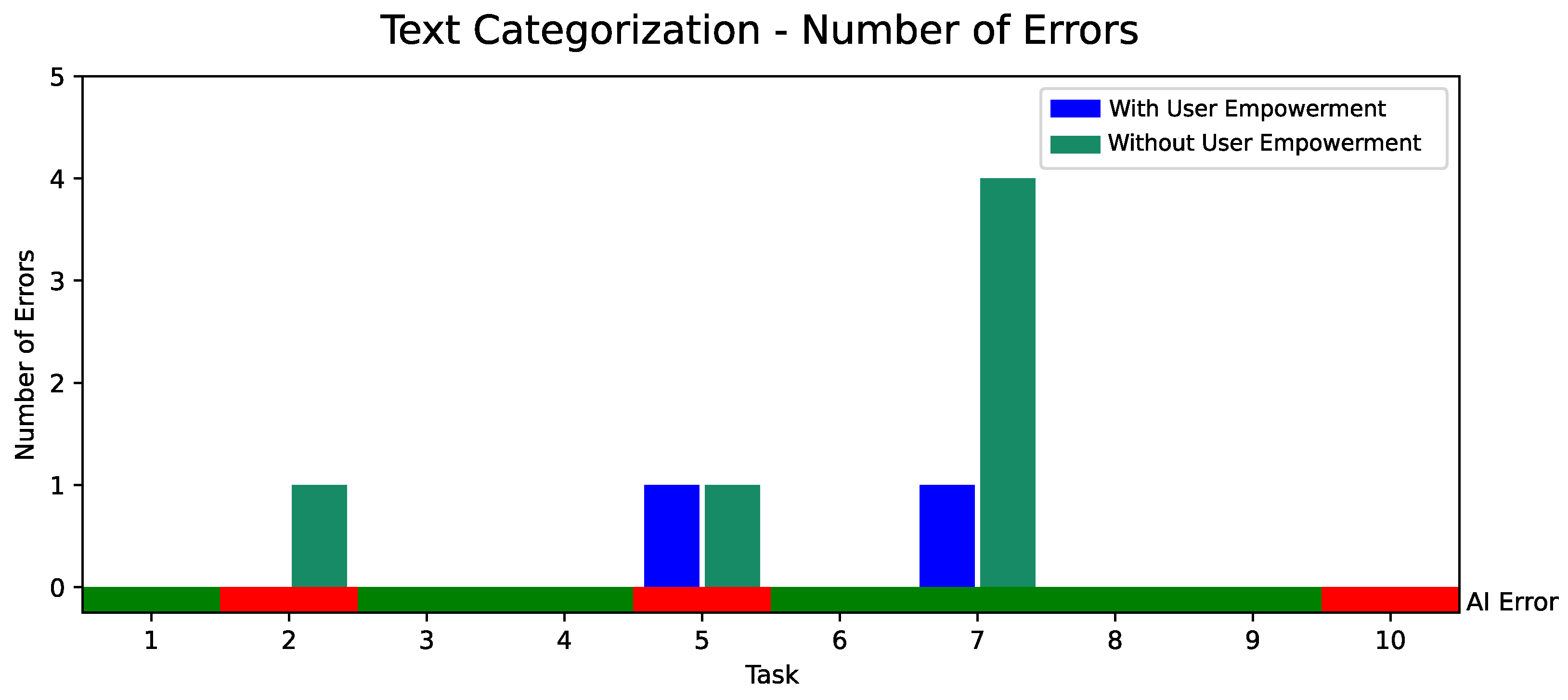
5.2. Quantitative Evaluation of AI-Based User Empowerment with 18 Participants
5.3. Discussion and Remaining Challenges
6. Summary and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hariri, R.H.; Fredericks, E.M.; Bowers, K.M. Uncertainty in big data analytics: Survey, opportunities, and challenges. J. Big Data 2019, 6, 1–16. [Google Scholar] [CrossRef]
- Berisha, B.; Mëziu, E.; Shabani, I. Big data analytics in Cloud computing: An overview. J. Cloud Comput. 2022, 11, 24. [Google Scholar] [CrossRef] [PubMed]
- Schreier, M. Qualitative Content Analysis in Practice; Sage Publications: Los Angeles, LA, USA, 2012; pp. 1–280. [Google Scholar]
- OECD. Artificial Intelligence in Society; OECD: Paris, France, 2019. [CrossRef]
- Reis, T.; Bruchhaus, S.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. AI-based User Empowering Use Cases for Visual Big Data Analysis. In Proceedings of the 7th Collaborative European Research Conference (CERC 2021), Cork, Ireland, 9–10 September 2021. [Google Scholar]
- Ruppert, E. Rethinking empirical social sciences. Dialogues Hum. Geogr. 2013, 3, 268–273. [Google Scholar] [CrossRef]
- Baur, N.; Blasius, J. Methoden der empirischen Sozialforschung: Ein Überblick. In Handbuch Methoden der Empirischen Sozialforschung; Springer: Berlin/Heidelberg, Germany, 2014; pp. 41–62. [Google Scholar]
- Cauteruccio, F.; Kou, Y. Investigating the emotional experiences in eSports spectatorship: The case of League of Legends. Inf. Process. Manag. 2023, 60, 103516. [Google Scholar] [CrossRef]
- Eljasik-Swoboda, T. Bootstrapping Explainable Text Categorization in Emergent Knowledge-Domains. Ph.D. Thesis, FernUniversität in Hagen, Hagen, Germany, 2021. [Google Scholar] [CrossRef]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. (CSUR) 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Reis, T.; Kreibich, A.; Bruchhaus, S.; Krause, T.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. An Information System Supporting Insurance Use Cases by Automated Anomaly Detection. Big Data Cogn. Comput. 2023, 7, 4. [Google Scholar] [CrossRef]
- Dakhel, A.M.; Majdinasab, V.; Nikanjam, A.; Khomh, F.; Desmarais, M.C.; Jiang, Z.M.J. Github copilot ai pair programmer: Asset or liability? J. Syst. Softw. 2023, 203, 111734. [Google Scholar] [CrossRef]
- Shoufan, A. Exploring Students’ Perceptions of CHATGPT: Thematic Analysis and Follow-Up Survey. IEEE Access 2023, 11, 38805–38818. [Google Scholar] [CrossRef]
- Abras, C.; Maloney-Krichmar, D.; Preece, J. User-Centered Design; Sage Publications: Los Angeles, LA, USA, 2004. [Google Scholar]
- Mahatody, T.; Sagar, M.; Kolski, C. State of the art on the cognitive walkthrough method, its variants and evolutions. Int. J. Hum. Comput. Interact. 2010, 26, 741–785. [Google Scholar] [CrossRef]
- Salazar, K. How to Conduct a Cognitive Walkthrough Workshop; Nielsen Norman Group: Fremont, CA, USA, 2022. [Google Scholar]
- Fischer, G.; Nakakoji, K. Beyond the macho approach of artificial intelligence: Empower human designers—Do not replace them. Knowl. Based Syst. 1992, 5, 15–30. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
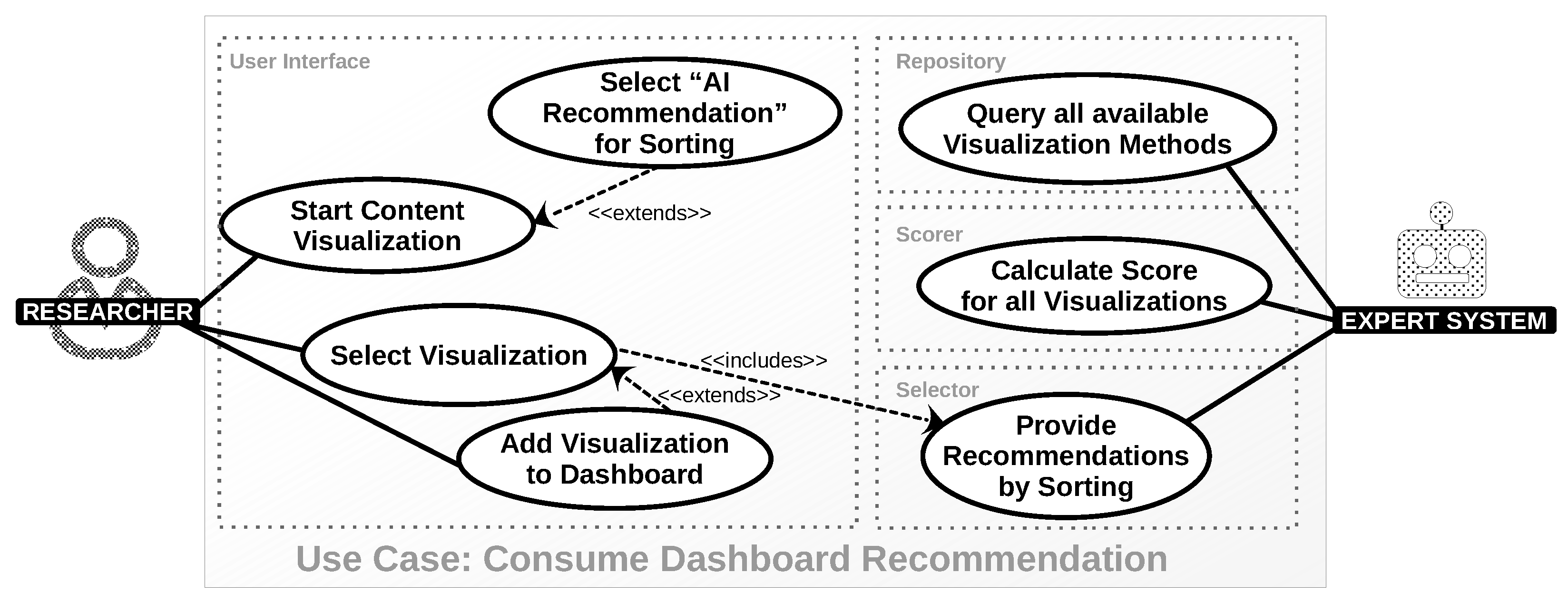
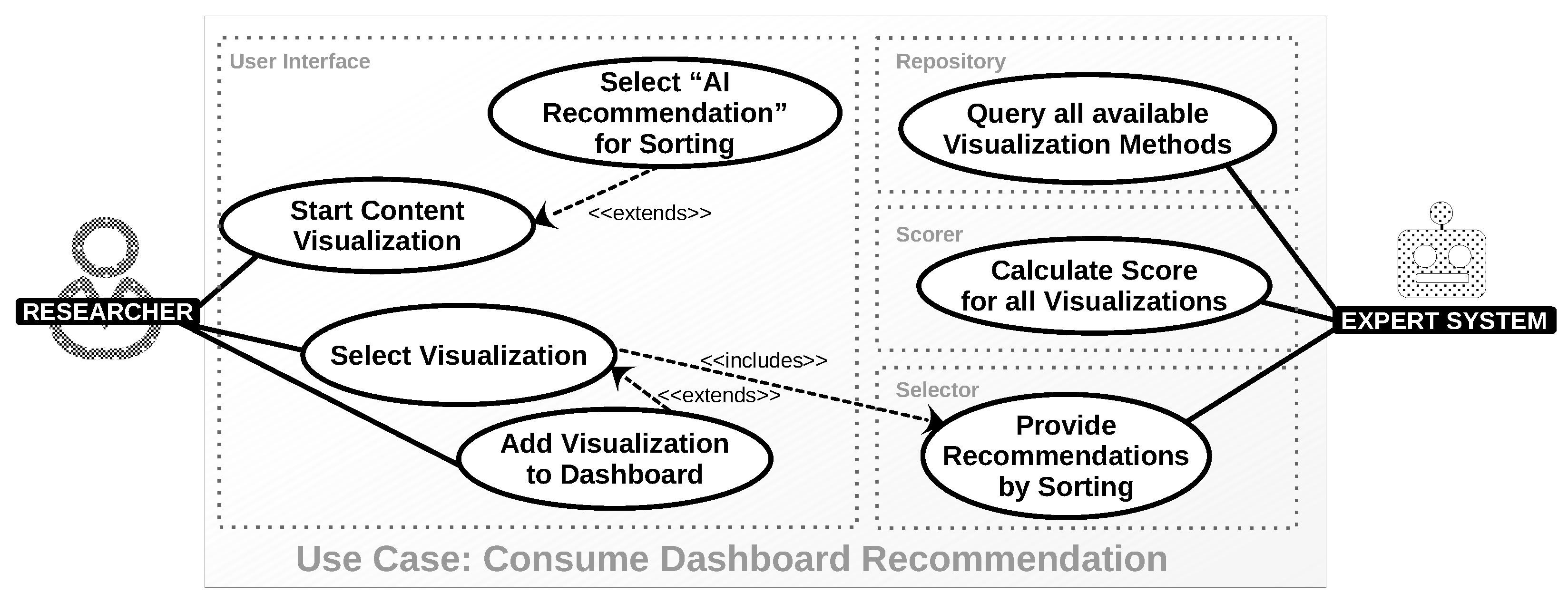
| Use Case: Consume Dashboard Recommendation | |
|---|---|
| Brief Description | Communicate AI-created recommendations regarding visualization methods that are suitable for the present data via the system’s user interface. |
| Actors | Researcher (end user), Expert System |
| Trigger | End user chooses to start the content visualization (button in the system’s UI). |
| Preconditions | There is at least one visualization method in the system. There is at least one scoring rule in the system. The system has categorized data upon which the recommendation can be applied. |
| Results | Visualization methods in the system’s UI are sorted according to the expert system’s recommendation and communicated as such to the end user. |
| Sequence Description | Create recommendations by the expert system. Then start end-user activities: Start Content Visualization. Select “AI Recommendation” for Sorting (if not selected). Select available visualization. Add it to the dashboard. |
| Task | Evaluation | |||
|---|---|---|---|---|
| Description | Required Actions | Identified Actions (Avg.) | Problems (Total) | Problem Rate |
| (1) Perform a registration | 5 | 3 | 2 | 40% |
| (2) Categorize text data | 3 | 2 | 1 | 33% |
| (3) Visualize categorized data | 8 | 6 | 2 | 25% |
| (4) Respond to an integrated survey | 5 | 4 | 1 | 20% |
| Total | 21 | 15 | 6 | 25.6% |
| Text Categorization Component | Data Visualization Component | |
|---|---|---|
| Task: | Categorize newspaper articles. | Create visualizations to answer given questions. |
| AI support: | AI-created category recommendations are provided to the user. | AI selects ten of 25 visualizations as most suitable for the user. |
| Simulated AI failure: | AI recommends wrong category. | Non-recommended visualizations are required to answer a certain question. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reis, T.; Dumberger, L.; Bruchhaus, S.; Krause, T.; Schreyer, V.; Bornschlegl, M.X.; Hemmje, M.L. AI-Based User Empowerment for Empirical Social Research. Big Data Cogn. Comput. 2024, 8, 11. https://doi.org/10.3390/bdcc8020011
Reis T, Dumberger L, Bruchhaus S, Krause T, Schreyer V, Bornschlegl MX, Hemmje ML. AI-Based User Empowerment for Empirical Social Research. Big Data and Cognitive Computing. 2024; 8(2):11. https://doi.org/10.3390/bdcc8020011
Chicago/Turabian StyleReis, Thoralf, Lukas Dumberger, Sebastian Bruchhaus, Thomas Krause, Verena Schreyer, Marco X. Bornschlegl, and Matthias L. Hemmje. 2024. "AI-Based User Empowerment for Empirical Social Research" Big Data and Cognitive Computing 8, no. 2: 11. https://doi.org/10.3390/bdcc8020011
APA StyleReis, T., Dumberger, L., Bruchhaus, S., Krause, T., Schreyer, V., Bornschlegl, M. X., & Hemmje, M. L. (2024). AI-Based User Empowerment for Empirical Social Research. Big Data and Cognitive Computing, 8(2), 11. https://doi.org/10.3390/bdcc8020011