
Deep Learning and YOLOv8 Utilized in an Accurate Face Mask Detection System




Abstract
1. Introduction
2. Materials and Methods
2.1. Face Mask Identification with Deep Learning
2.2. YOLOv8 Architecture
3. Results
3.1. Face Mask Dataset (FMD) and Medical Mask Dataset (MMD)
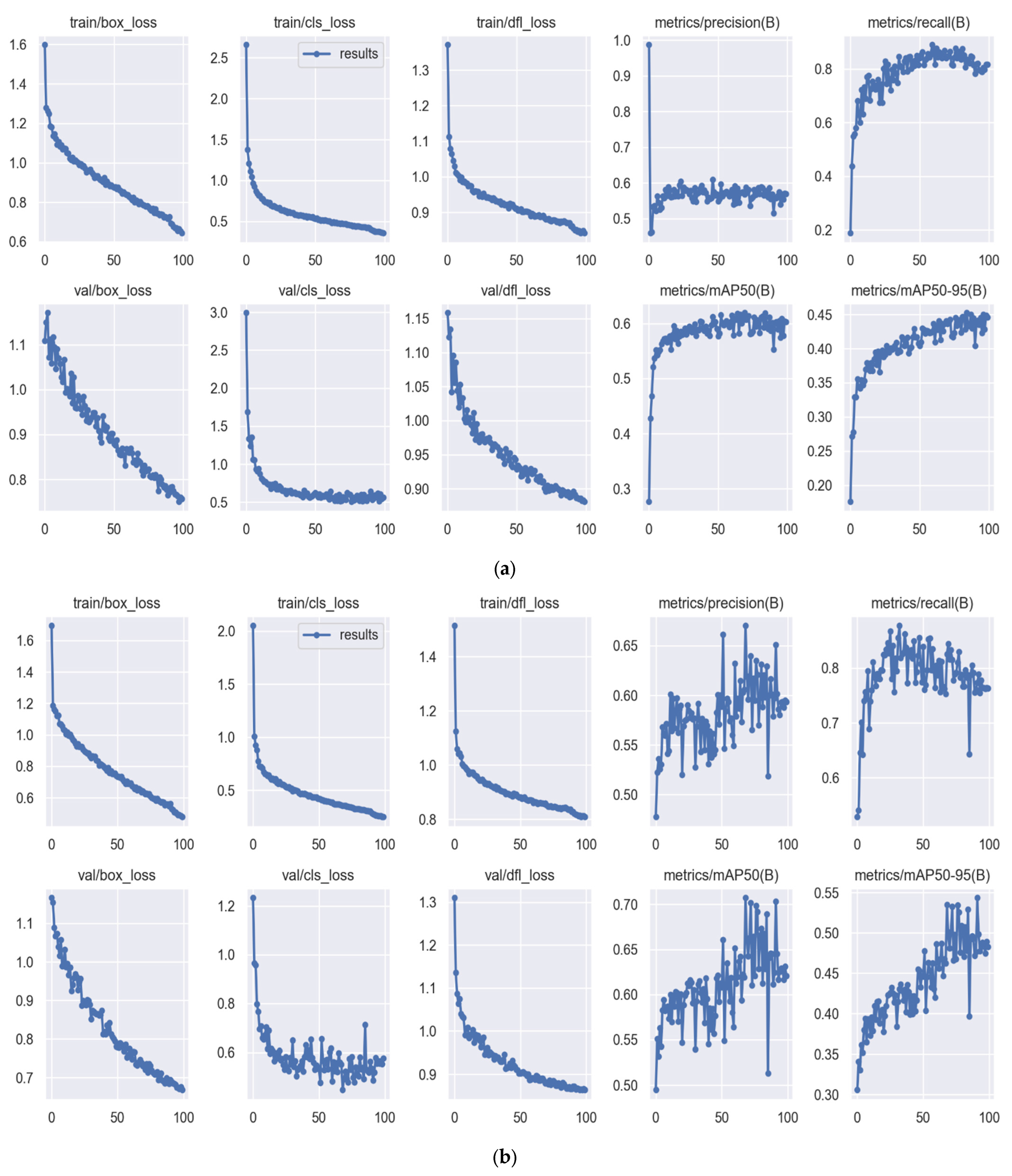
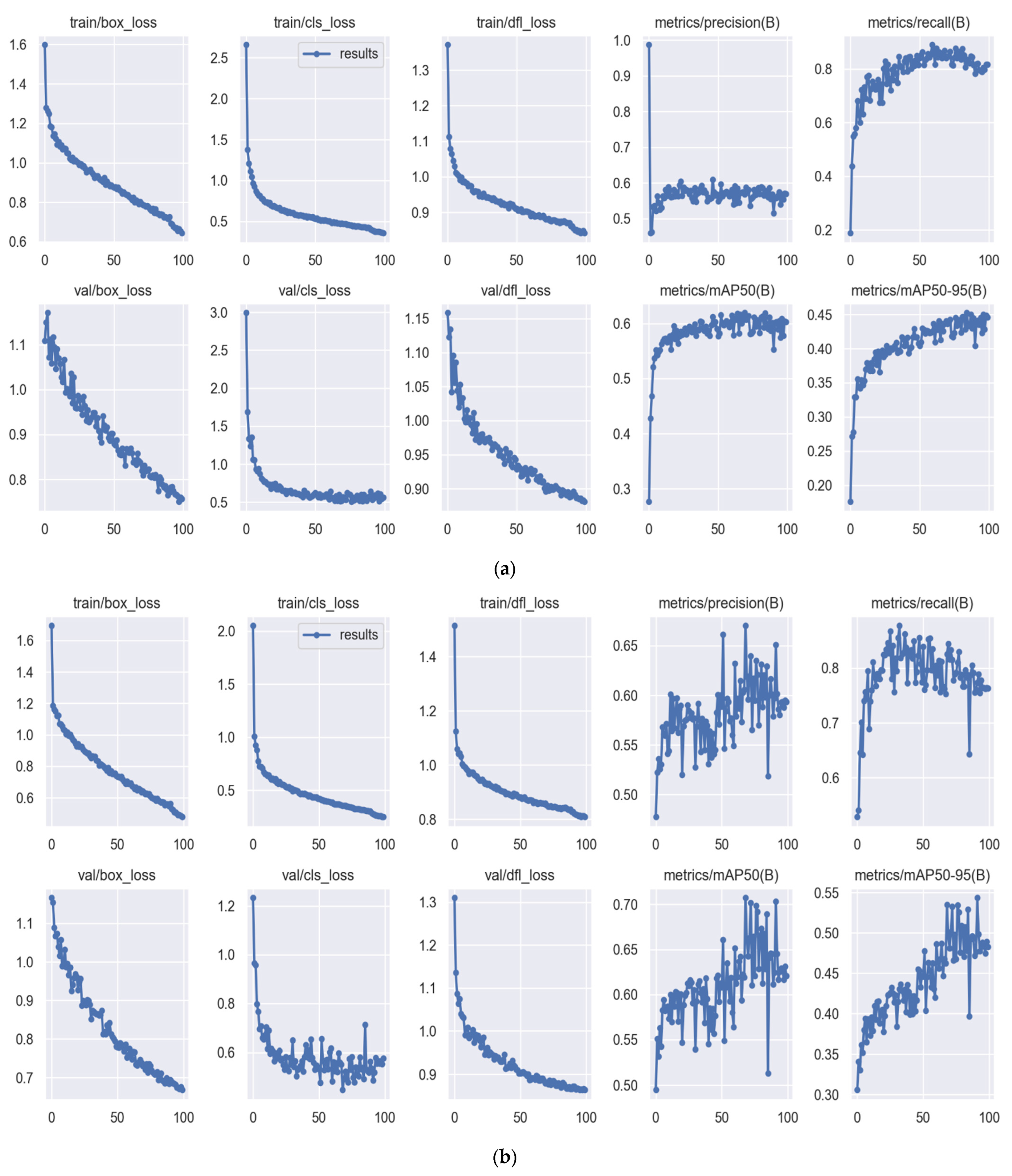
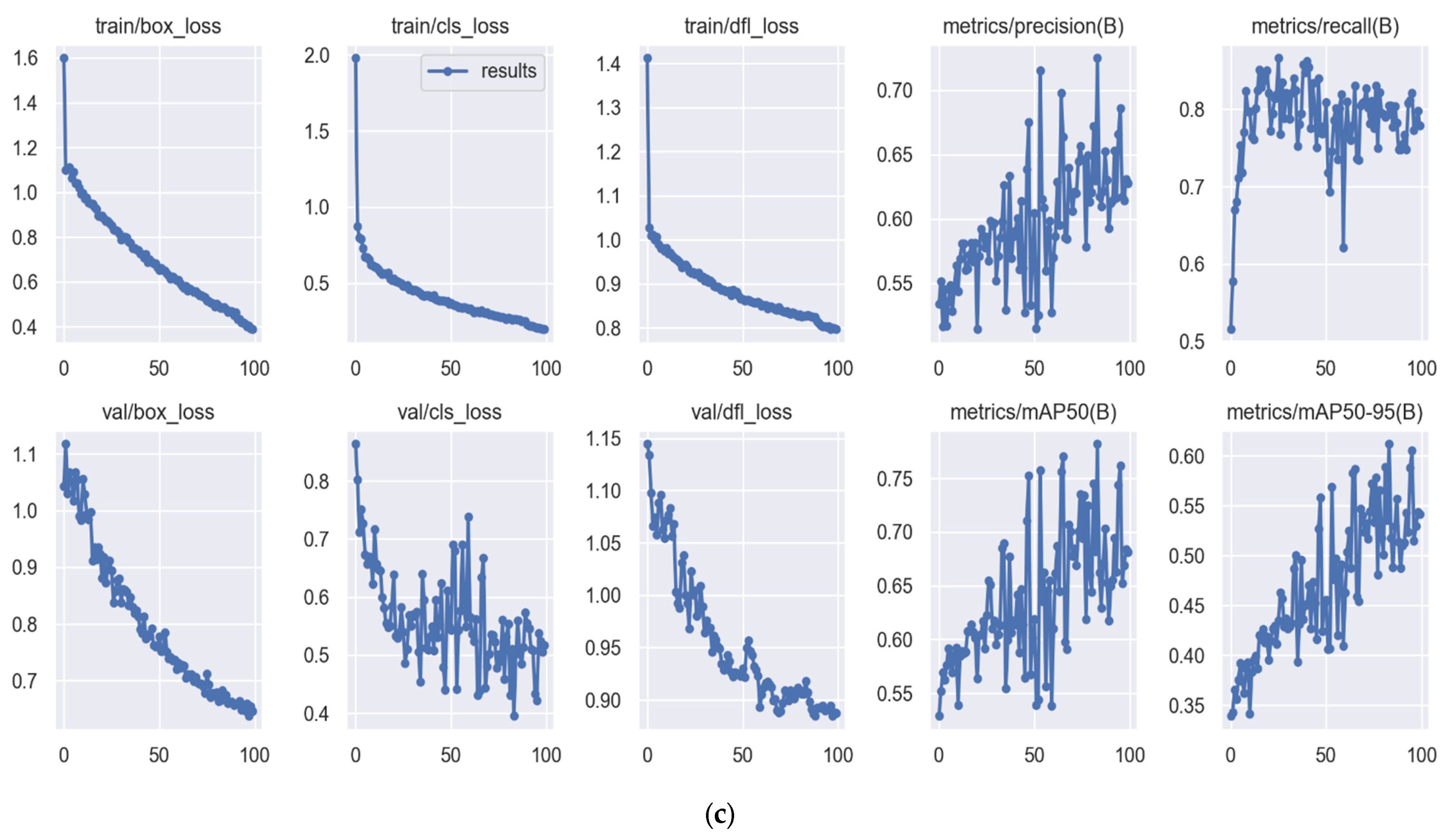
3.2. Training Result
4. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nowrin, A.; Afroz, S.; Rahman, M.S.; Mahmud, I.; Cho, Y.Z. Comprehensive Review on Facemask Detection Techniques in the Context of COVID-19. IEEE Access 2021, 9, 106839–106864. [Google Scholar] [CrossRef]
- Cao, Z.; Shao, M.; Xu, L.; Mu, S.; Qu, H. Maskhunter: Real-Time Object Detection of Face Masks during the COVID-19 Pandemic. IET Image Process. 2020, 14, 4359–4367. [Google Scholar] [CrossRef]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. Fighting against COVID-19: A Novel Deep Learning Model Based on YOLO-v2 with ResNet-50 for Medical Face Mask Detection. Sustain. Cities Soc. 2021, 65, 102600. [Google Scholar] [CrossRef] [PubMed]
- Wei, Z.; Chang, M.; Zhong, Y. Fruit Freshness Detection Based on YOLOv8 and SE Attention Mechanism. Acad. J. Sci. Technol. 2023, 6, 195–197. [Google Scholar] [CrossRef]
- Razavi, M.; Alikhani, H.; Janfaza, V.; Sadeghi, B.; Alikhani, E. An Automatic System to Monitor the Physical Distance and Face Mask Wearing of Construction Workers in COVID-19 Pandemic. SN Comput. Sci. 2022, 3, 27. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, P.; Louis, P.C.; Wheless, L.E.; Huo, Y. WearMask: Fast in-Browser Face Mask Detection with Serverless Edge Computing for COVID-19. Electron. Imaging 2023, 35, HPCI-229. [Google Scholar] [CrossRef]
- Eyiokur, F.I.; Kantarcı, A.; Erakın, M.E.; Damer, N.; Ofli, F.; Imran, M.; Križaj, J.; Salah, A.A.; Waibel, A.; Štruc, V.; et al. A Survey on Computer Vision Based Human Analysis in the COVID-19 Era. Image Vis. Comput. 2023, 130, 104610. [Google Scholar] [CrossRef]
- Dewi, C.; Christanto, H.J. Automatic Medical Face Mask Recognition for COVID-19 Mitigation: Utilizing YOLO V5 Object Detection. Rev. D’intelligence Artif. 2023, 37, 627–638. [Google Scholar] [CrossRef]
- Dewi, C.; Shun Chen, A.P.; Juli Christanto, H. YOLOv7 for Face Mask Identification Based on Deep Learning. In Proceedings of the 2023 15th International Conference on Computer and Automation Engineering (ICCAE), Sydney, Australia, 3–5 March 2023; IEEE: Piscataway, NJ, USA; pp. 193–197. [Google Scholar]
- Alsalamah, M.S.I. Automatic Face Mask Identification in Saudi Smart Cities: Using Technology to Prevent the Spread of COVID-19. Inf. Sci. Lett. 2023, 12, 2411–2422. [Google Scholar] [CrossRef]
- Maradey-Lázaro, J.G.; Rincón-Quintero, A.D.; Garnica, J.C.R.; Segura-Caballero, D.O.; Sandoval-Rodríguez, C.L. Development of a Monitoring System for COVID-19 Monitoring in Early Stages. Period. Eng. Nat. Sci. 2023, 11, 48–61. [Google Scholar] [CrossRef]
- Wu, X.; Sahoo, D.; Hoi, S.C.H. Recent Advances in Deep Learning for Object Detection. Neurocomputing 2020, 396, 39–64. [Google Scholar] [CrossRef]
- Singh, S.; Ahuja, U.; Kumar, M.; Kumar, K.; Sachdeva, M. Face Mask Detection Using YOLOv3 and Faster R-CNN Models: COVID-19 Environment. Multimed. Tools Appl. 2021, 80, 19753–19768. [Google Scholar] [CrossRef]
- Mazen, F.M.A.; Seoud, R.A.A.; Shaker, Y.O. Deep Learning for Automatic Defect Detection in PV Modules Using Electroluminescence Images. IEEE Access 2023, 11, 57783–57795. [Google Scholar] [CrossRef]
- Lemke, M.K.; Apostolopoulos, Y.; Sönmez, S. Syndemic Frameworks to Understand the Effects of COVID-19 on Commercial Driver Stress, Health, and Safety. J. Transp. Health 2020, 18, 100877. [Google Scholar] [CrossRef]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Kang, J.; Zhao, L.; Wang, K.; Zhang, K. Research on an Improved YOLOV8 Image Segmentation Model for Crop Pests. Adv. Comput. Signals Syst. 2023, 7, 1–8. [Google Scholar]
- Patel, S.H.; Kamdar, D. Accurate Ball Detection in Field Hockey Videos Using YOLOV8 Algorithm. Int. J. Adv. Res. Ideas Innov. Technol. 2023, 9, 411–418. [Google Scholar]
- Wang, G.; Chen, Y.; An, P.; Hong, H.; Hu, J.; Huang, T. UAV-YOLOv8: A Small-Object-Detection Model Based on Improved YOLOv8 for UAV Aerial Photography Scenarios. Sensors 2023, 23, 7190. [Google Scholar] [CrossRef]
- Ultralytics YOLOv8. Available online: https://github.com/ultralytics/ultralytics?ref=blog.roboflow.com (accessed on 12 May 2023).
- Ge, S.; Li, J.; Ye, Q.; Luo, Z. Detecting Masked Faces in the Wild with LLE-CNNs. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2016; Volume 2017. [Google Scholar]
- Ejaz, M.S.; Islam, M.R.; Sifatullah, M.; Sarker, A. Implementation of Principal Component Analysis on Masked and Non-Masked Face Recognition. In Proceedings of the 1st International Conference on Advances in Science, Engineering and Robotics Technology 2019, ICASERT 2019, Dhaka, Bangladesh, 3–5 May 2019. [Google Scholar]
- Chen, W.; Gao, L.; Li, X.; Shen, W. Lightweight Convolutional Neural Network with Knowledge Distillation for Cervical Cells Classification. Biomed. Signal Process. Control 2022, 71, 103177. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.; Liu, Y.; Yu, H. Various Generative Adversarial Networks Model for Synthetic Prohibitory Sign Image Generation. Appl. Sci. 2021, 11, 2913. [Google Scholar] [CrossRef]
- Loey, M.; Manogaran, G.; Taha, M.H.N.; Khalifa, N.E.M. A Hybrid Deep Transfer Learning Model with Machine Learning Methods for Face Mask Detection in the Era of the COVID-19 Pandemic. Meas. J. Int. Meas. Confed. 2021, 167, 108288. [Google Scholar] [CrossRef] [PubMed]
- Nieto-Rodríguez, A.; Mucientes, M.; Brea, V.M. System for Medical Mask Detection in the Operating Room through Facial Attributes. In Pattern Recognition and Image Analysis, Proceedings of the 2015 Iberian Conference on Pattern Recognition and Image Analysis, Santiago de Compostela, Spain, 17–19 June 2015; Paredes, R., Cardoso, J., Pardo, X., Eds.; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9117. [Google Scholar]
- Khalid, S.; Oqaibi, H.M.; Aqib, M.; Hafeez, Y. Small Pests Detection in Field Crops Using Deep Learning Object Detection. Sustainability 2023, 15, 6815. [Google Scholar] [CrossRef]
- Yang, W.; Wu, J.; Zhang, J.; Gao, K.; Du, R.; Wu, Z.; Firkat, E.; Li, D. Deformable Convolution and Coordinate Attention for Fast Cattle Detection. Comput. Electron. Agric. 2023, 211, 108006. [Google Scholar] [CrossRef]
- Sharma, N.; Baral, S.; Paing, M.P.; Chawuthai, R. Parking Time Violation Tracking Using YOLOv8 and Tracking Algorithms. Sensors 2023, 23, 5843. [Google Scholar] [CrossRef]
- Bbox Label Tool. Available online: https://github.com/puzzledqs/BBox-Label-Tool (accessed on 9 January 2024).
- Tzutalin Labellmg. Available online: https://github.com/csq20081052/labelImg (accessed on 13 January 2022).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Yuan, Y.; Xiong, Z.; Wang, Q. An Incremental Framework for Video-Based Traffic Sign Detection, Tracking, and Recognition. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1918–1929. [Google Scholar] [CrossRef]
- Kang, H.; Chen, C. Fast Implementation of Real-Time Fruit Detection in Apple Orchards Using Deep Learning. Comput. Electron. Agric. 2020, 168, 105108. [Google Scholar] [CrossRef]
- Larxel Face Mask Detection. Available online: https://www.kaggle.com/datasets/andrewmvd/face-mask-detection (accessed on 9 January 2024).
- Mikolaj Witkowski Medical Mask Dataset. Available online: https://www.kaggle.com/datasets/mloey1/medical-face-mask-detection-dataset (accessed on 9 January 2024).
- Chen, R.-C.; Zhuang, Y.-C.; Chen, J.-K.; Dewi, C. Deep Learning for Automatic Road Marking Detection with Yolov5. In Proceedings of the 2022 International Conference on Machine Learning and Cybernetics (ICMLC), Toyama, Japan, 9–11 September 2022. [Google Scholar]
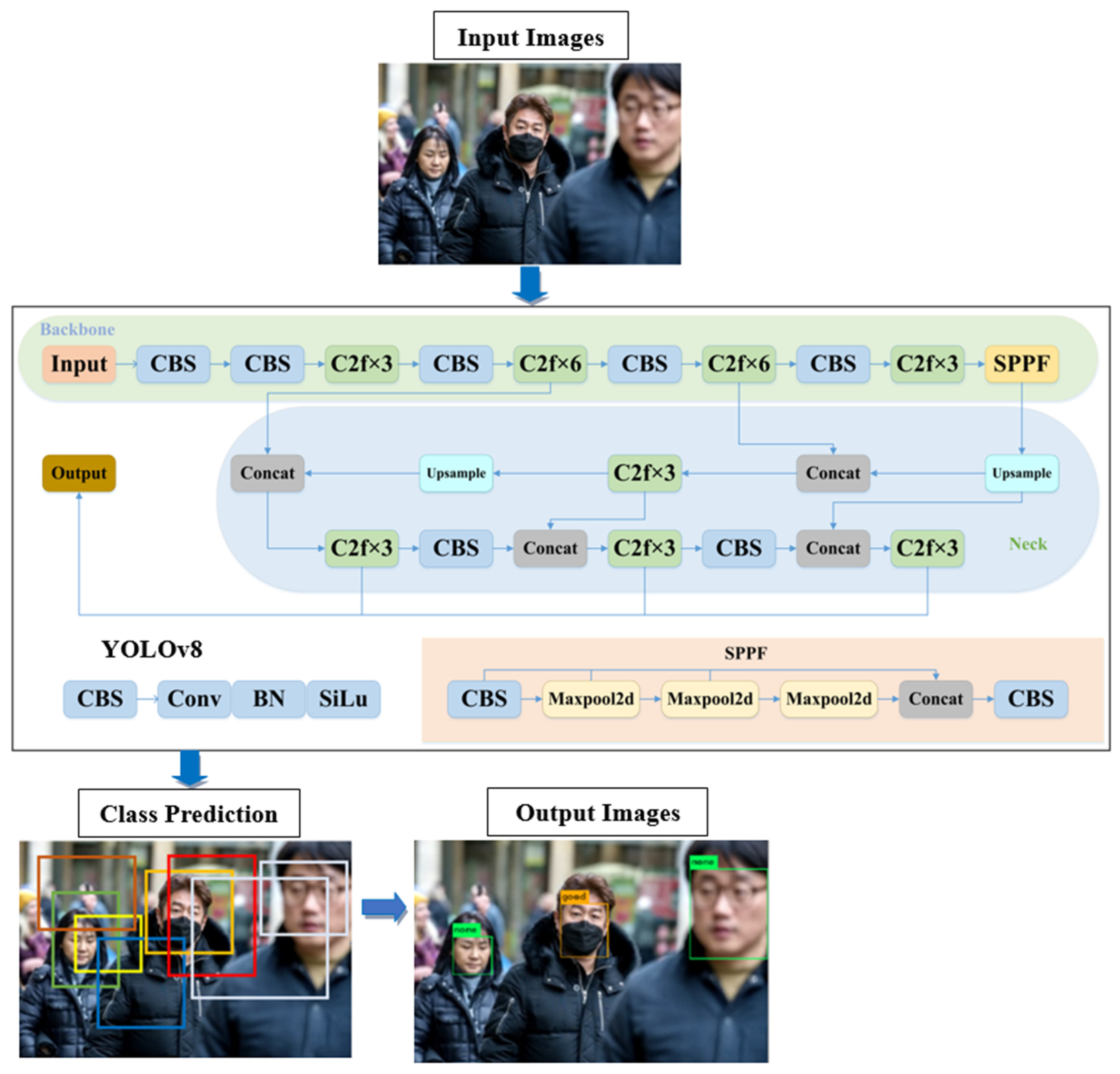








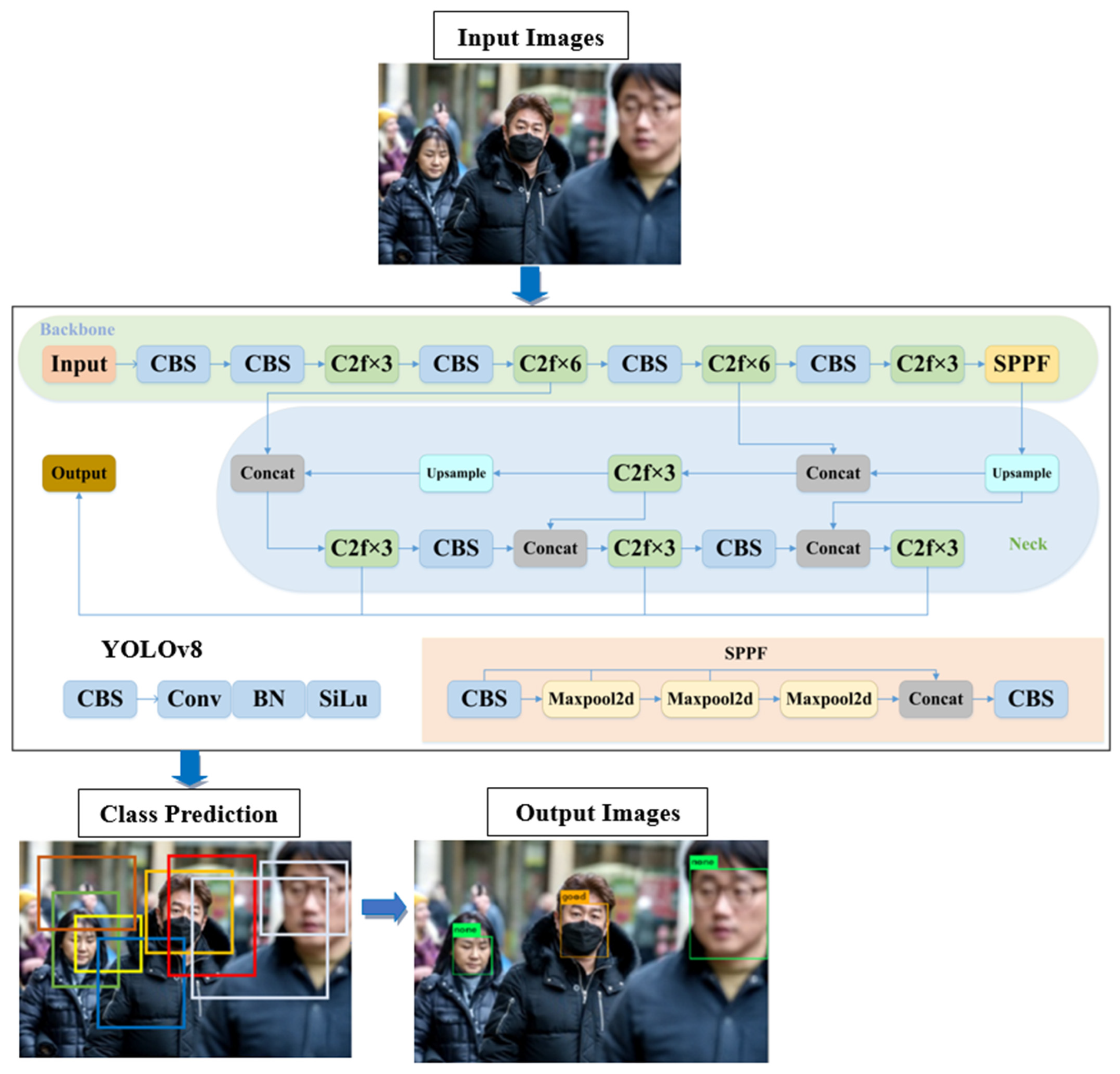{kind=link}
{kind=link}
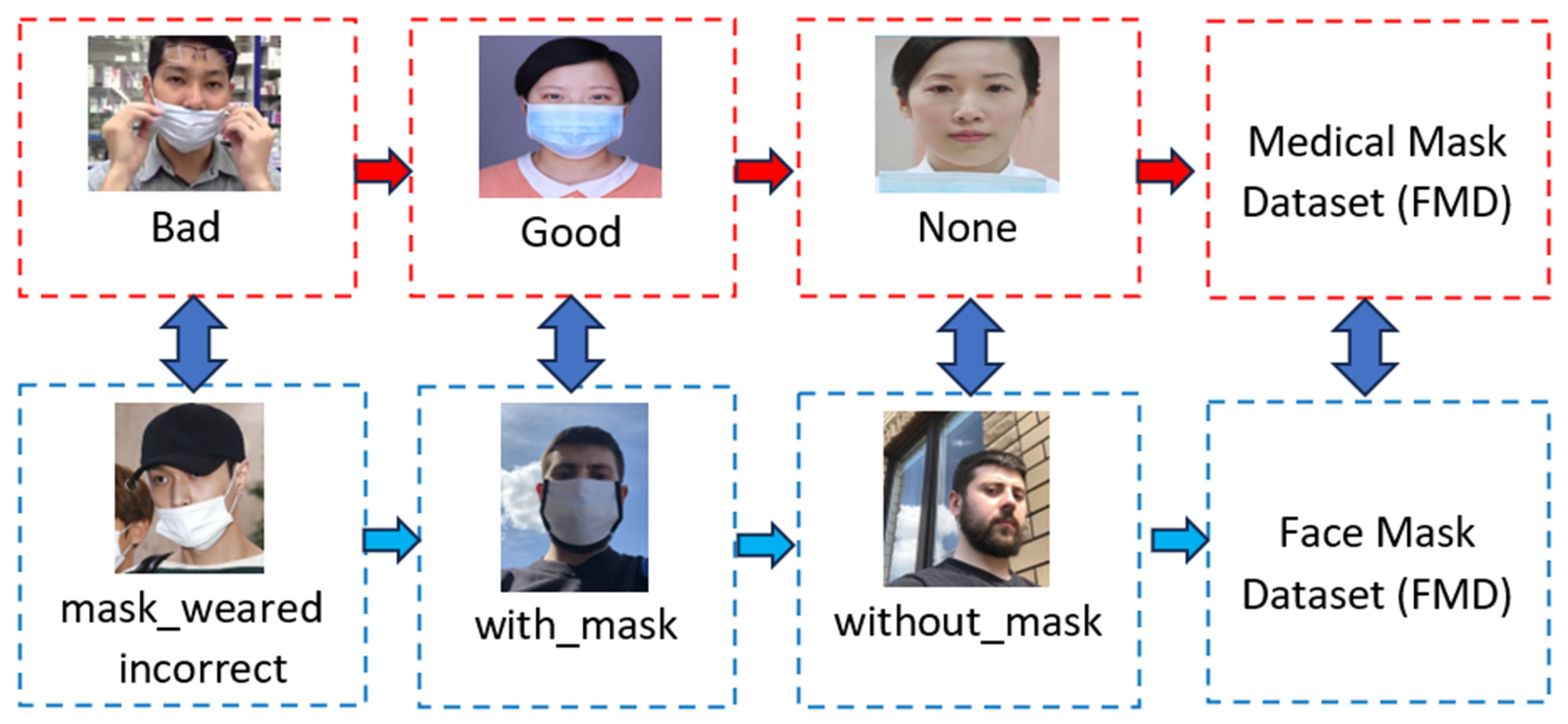{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Class | Images | Labels | P | R | mAP@.5 |
|---|---|---|---|---|---|---|
| YOLO V5s | all | 507 | 2661 | 0.639 | 0.832 | 0.662 |
| bad | 507 | 260 | 0.508 | 0.815 | 0.492 | |
| good | 507 | 2123 | 0.933 | 0.945 | 0.963 | |
| none | 507 | 278 | 0.476 | 0.736 | 0.496 | |
| YOLO V5m | all | 507 | 2661 | 0.639 | 0.832 | 0.672 |
| bad | 507 | 260 | 0.508 | 0.815 | 0.492 | |
| good | 507 | 2123 | 0.933 | 0.945 | 0.964 | |
| none | 507 | 278 | 0.476 | 0.736 | 0.496 | |
| YOLO7x | all | 456 | 2154 | 0.625 | 0.932 | 0.635 |
| bad | 456 | 72 | 0.612 | 0.944 | 0.163 | |
| good | 456 | 1733 | 0.942 | 0.965 | 0.977 | |
| none | 456 | 349 | 0.772 | 0.885 | 0.494 | |
| YOLO7 | all | 456 | 2154 | 0.609 | 0.931 | 0.632 |
| bad | 456 | 72 | 0.166 | 0.941 | 0.168 | |
| good | 456 | 1733 | 0.939 | 0.978 | 0.986 | |
| none | 456 | 349 | 0.722 | 0.874 | 0.742 | |
| YOLOv8n | all | 456 | 2154 | 0.579 | 0.834 | 0.619 |
| bad | 456 | 72 | 0.142 | 0.687 | 0.152 | |
| good | 456 | 1733 | 0.891 | 0.969 | 0.982 | |
| none | 456 | 349 | 0.702 | 0.845 | 0.723 | |
| YOLOv8s | all | 456 | 2154 | 0.651 | 0.774 | 0.704 |
| bad | 456 | 72 | 0.217 | 0.681 | 0.367 | |
| good | 456 | 1733 | 0.968 | 0.975 | 0.99 | |
| none | 456 | 349 | 0.768 | 0.754 | 0.754 | |
| YOLOv8m | all | 456 | 2154 | 0.716 | 0.829 | 0.784 |
| bad | 456 | 72 | 0.355 | 0.681 | 0.5 | |
| good | 456 | 1733 | 0.983 | 0.972 | 0.991 | |
| none | 456 | 349 | 0.811 | 0.834 | 0.861 |
| Model | Class | Images | Labels | P | R | mAP@.5 |
|---|---|---|---|---|---|---|
| YOLO V5s | all | 507 | 2661 | 0.615 | 0.837 | 0.662 |
| bad | 507 | 260 | 0.475 | 0.777 | 0.48 | |
| good | 507 | 2123 | 0.932 | 0.958 | 0.97 | |
| none | 507 | 278 | 0.471 | 0.791 | 0.522 | |
| YOLO V5m | all | 507 | 2661 | 0.626 | 0.886 | 0.671 |
| bad | 507 | 260 | 0.481 | 0.858 | 0.523 | |
| good | 507 | 2123 | 0.931 | 0.957 | 0.972 | |
| none | 507 | 278 | 0.465 | 0.845 | 0.509 | |
| YOLO7x | all | 456 | 2154 | 0.625 | 0.932 | 0.635 |
| bad | 456 | 72 | 0.612 | 0.944 | 0.163 | |
| good | 456 | 1733 | 0.942 | 0.965 | 0.977 | |
| none | 456 | 349 | 0.772 | 0.885 | 0.494 | |
| YOLO7 | all | 456 | 2154 | 0.609 | 0.931 | 0.632 |
| bad | 456 | 72 | 0.166 | 0.941 | 0.168 | |
| good | 456 | 1733 | 0.939 | 0.978 | 0.986 | |
| none | 456 | 349 | 0.722 | 0.874 | 0.742 | |
| YOLOv8n | all | 456 | 2154 | 0.579 | 0.839 | 0.619 |
| bad | 456 | 72 | 0.148 | 0.712 | 0.152 | |
| good | 456 | 1733 | 0.893 | 0.969 | 0.981 | |
| none | 456 | 349 | 0.695 | 0.836 | 0.725 | |
| YOLOv8s | all | 456 | 2154 | 0.652 | 0.773 | 0.706 |
| bad | 456 | 72 | 0.22 | 0.681 | 0.367 | |
| good | 456 | 1733 | 0.965 | 0.975 | 0.99 | |
| none | 456 | 349 | 0.77 | 0.665 | 0.762 | |
| YOLOv8m | all | 456 | 2154 | 0.716 | 0.829 | 0.784 |
| bad | 456 | 72 | 0.355 | 0.681 | 0.5 | |
| good | 456 | 1733 | 0.983 | 0.972 | 0.991 | |
| none | 456 | 349 | 0.811 | 0.834 | 0.861 |
| Process | Model | Layers | Parameters | GFLOPs | Speed (ms) | Inference (ms) | Post-Process Per Image |
|---|---|---|---|---|---|---|---|
| Train | Yolov8s | 168 | 11,126,745 | 28.4 | 0.7 | 85.1 | 0.3 |
| Train | Yolov8n | 168 | 3,006,233 | 8.1 | 0.6 | 36.6 | 0.3 |
| Train | Yolov8m | 218 | 25,841,497 | 78.227 | 0.6 | 178 | 0.3 |
| Val | Yolov8s | 168 | 11,126,745 | 28.4 | 1 | 131.8 | 0.5 |
| Val | Yolov8n | 168 | 3,006,233 | 8.1 | 1 | 62.2 | 0.5 |
| Val | Yolov8m | 218 | 25,841,497 | 78.7 | 0.7 | 210.1 | 0.3 |
| Reference | Dataset | Methodology | Classification | Detection | Result AP (%) |
|---|---|---|---|---|---|
| Dewi et al., 2023 [8] | FMD and MMD | YOLOv5m | Yes | Yes | All: 67.1%, bad: 52.3%, good: 97.2%, none: 50.9% |
| Dewi et al., 2023 [9] | FMD and MMD | YOLOv7 | Yes | Yes | All: 63.2%, bad: 16.8%, good: 98.6%, none: 74.2% |
| Proposed Method | FMD and MMD | YOLOv8m | Yes | Yes | All: 78.4%, bad: 50%, good: 99.1%, none: 86.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewi, C.; Manongga, D.; Hendry; Mailoa, E.; Hartomo, K.D. Deep Learning and YOLOv8 Utilized in an Accurate Face Mask Detection System. Big Data Cogn. Comput. 2024, 8, 9. https://doi.org/10.3390/bdcc8010009
Dewi C, Manongga D, Hendry, Mailoa E, Hartomo KD. Deep Learning and YOLOv8 Utilized in an Accurate Face Mask Detection System. Big Data and Cognitive Computing. 2024; 8(1):9. https://doi.org/10.3390/bdcc8010009
Chicago/Turabian StyleDewi, Christine, Danny Manongga, Hendry, Evangs Mailoa, and Kristoko Dwi Hartomo. 2024. "Deep Learning and YOLOv8 Utilized in an Accurate Face Mask Detection System" Big Data and Cognitive Computing 8, no. 1: 9. https://doi.org/10.3390/bdcc8010009
APA StyleDewi, C., Manongga, D., Hendry, Mailoa, E., & Hartomo, K. D. (2024). Deep Learning and YOLOv8 Utilized in an Accurate Face Mask Detection System. Big Data and Cognitive Computing, 8(1), 9. https://doi.org/10.3390/bdcc8010009