

Arabic Toxic Tweet Classification: Leveraging the AraBERT Model

 ,
,  and
and
Abstract
:1. Introduction
- We curated a publicly accessible dataset consisting of 31,836 Arabic tweets, meticulously annotated as toxic or non-toxic. This novel dataset is a standardized resource crafted for the explicit purpose of toxic tweet classification, aiming to fill the gap in toxic content analysis for Arabic texts.
- Automated Annotation and Expertise: The dataset is annotated using Google’s Perspective API combined with the expertise of three native Arabic speakers and linguists, ensuring a comprehensive and accurate labeling process.
- Model Evaluation: Seven different models, including LSTM, GRU, CNN, and multilingual BERT, are evaluated to determine their performance in toxic tweet classification. The fine-tuned AraBERT model emerges as the top performer, surpassing other models with an impressive accuracy of 0.9960.
- Superior Performance: The accuracy achieved by the AraBERT model outperforms similar approaches reported in the recent literature, highlighting its effectiveness in accurately identifying toxic content in Arabic tweets.
- Advancement in Arabic Toxic Tweet Classification: This study signifies a significant advancement in Arabic toxic tweet classification, shedding light on the importance of addressing toxicity in social media platforms while considering the diverse languages and cultures involved.
2. Related Work
3. Background
3.1. LSTM
3.2. CNNs
3.3. GRU
3.4. AraBERT
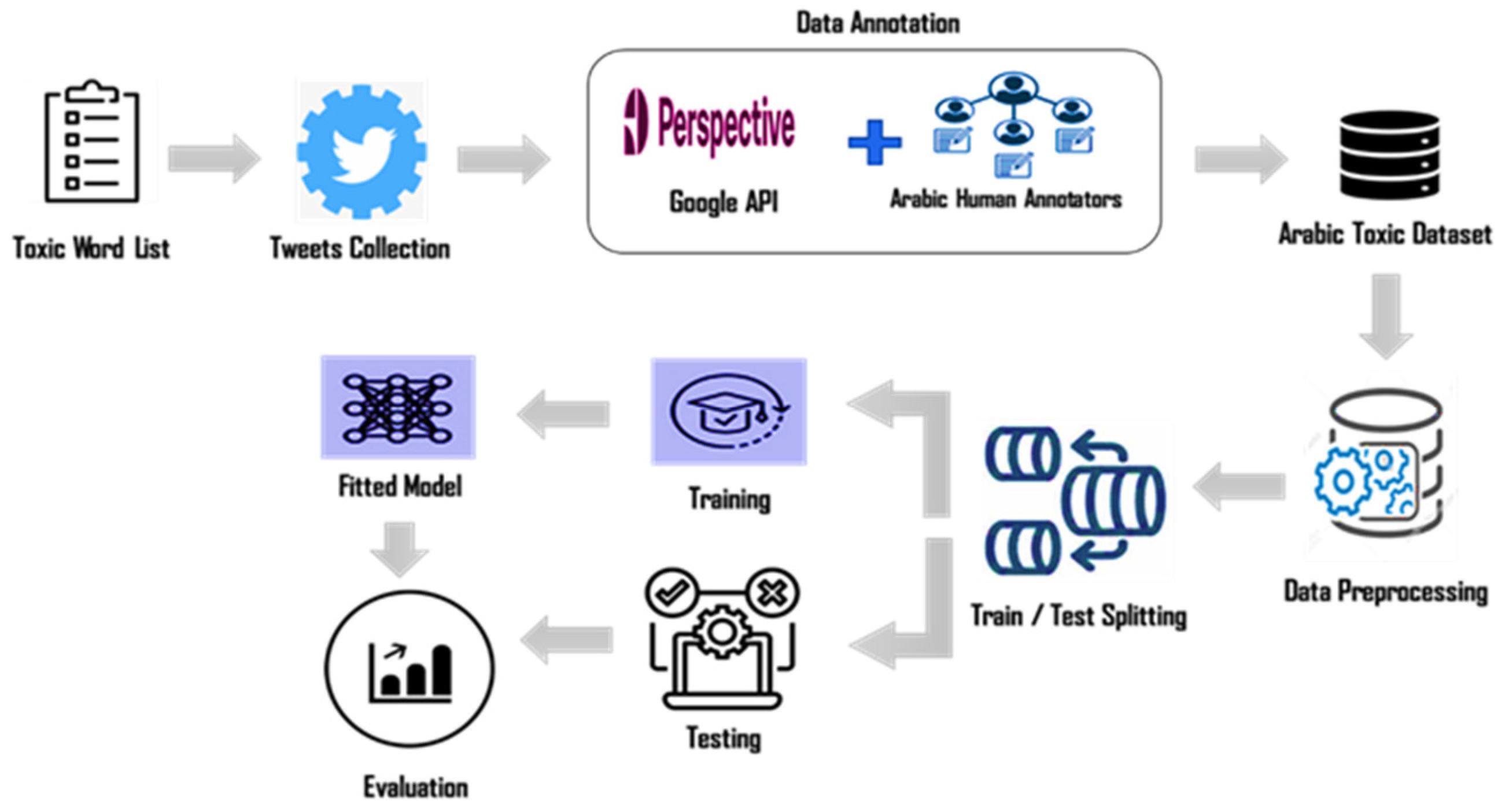
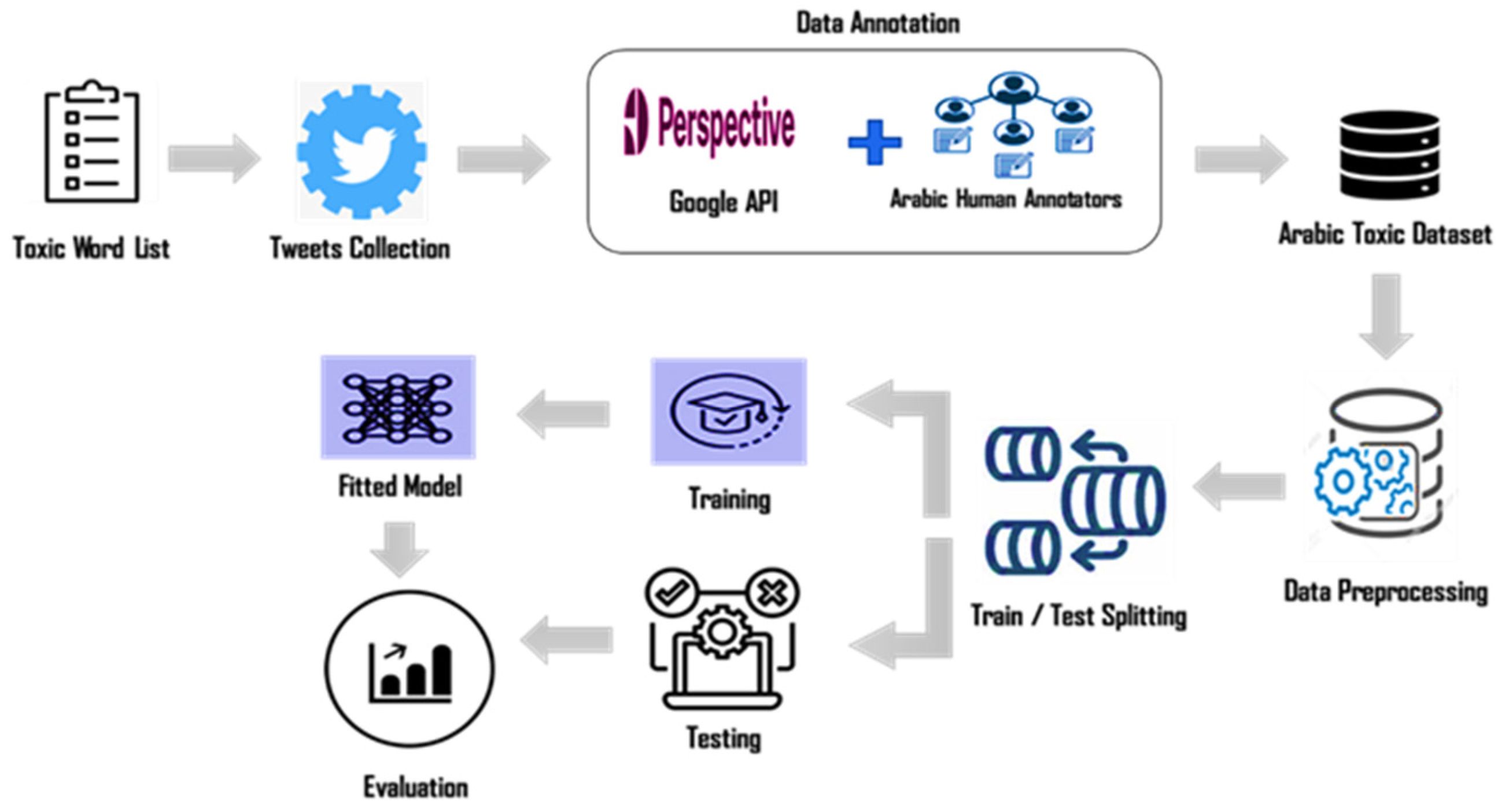
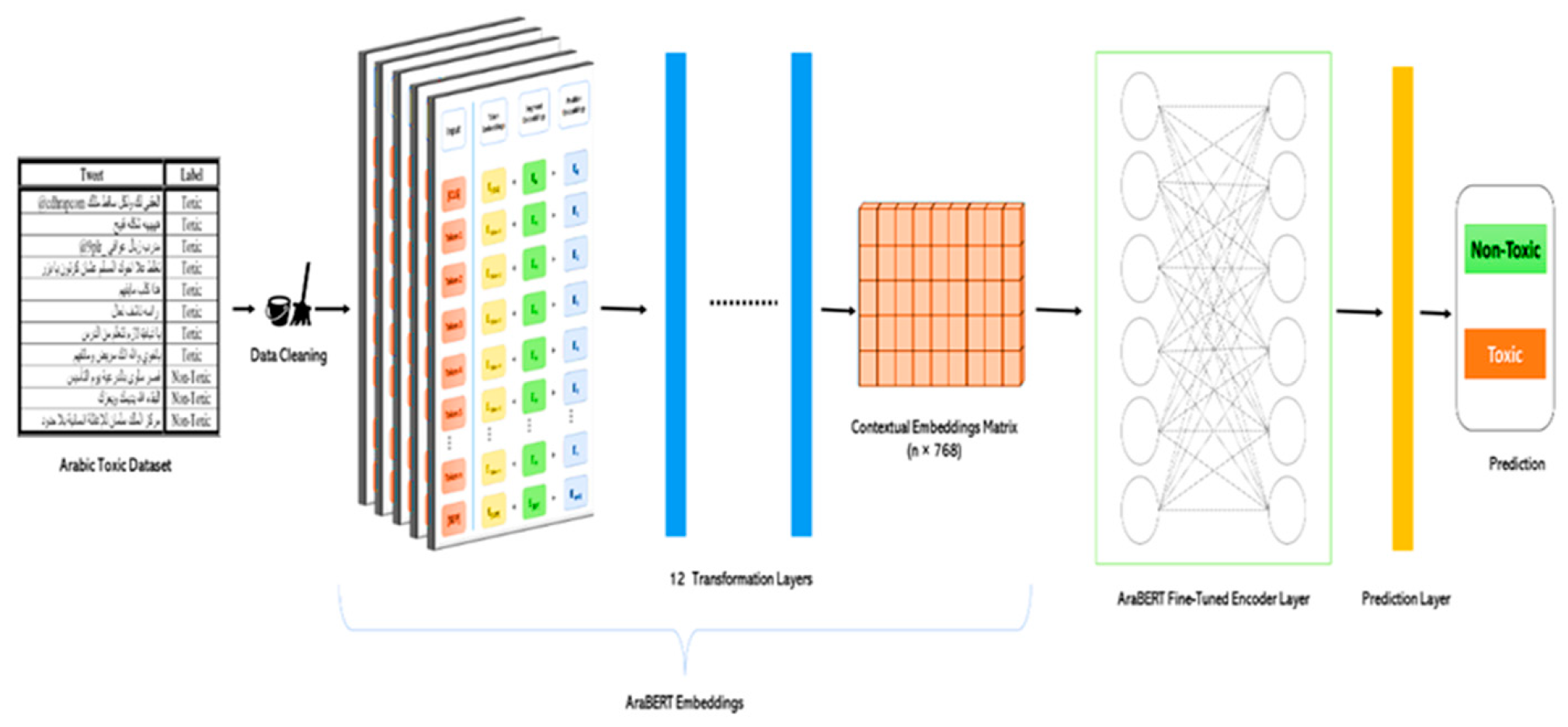
4. Methodology
| Algorithm 1: Methodology Steps: Dataset Creation, Preprocessing, and Classification. |
| Input: Arabic toxic word list |
| Output: Tweet label (toxic, non-toxic) |
|
| Output: Displayed classification performance metrics (accuracy, precision, recall, F1 score). |
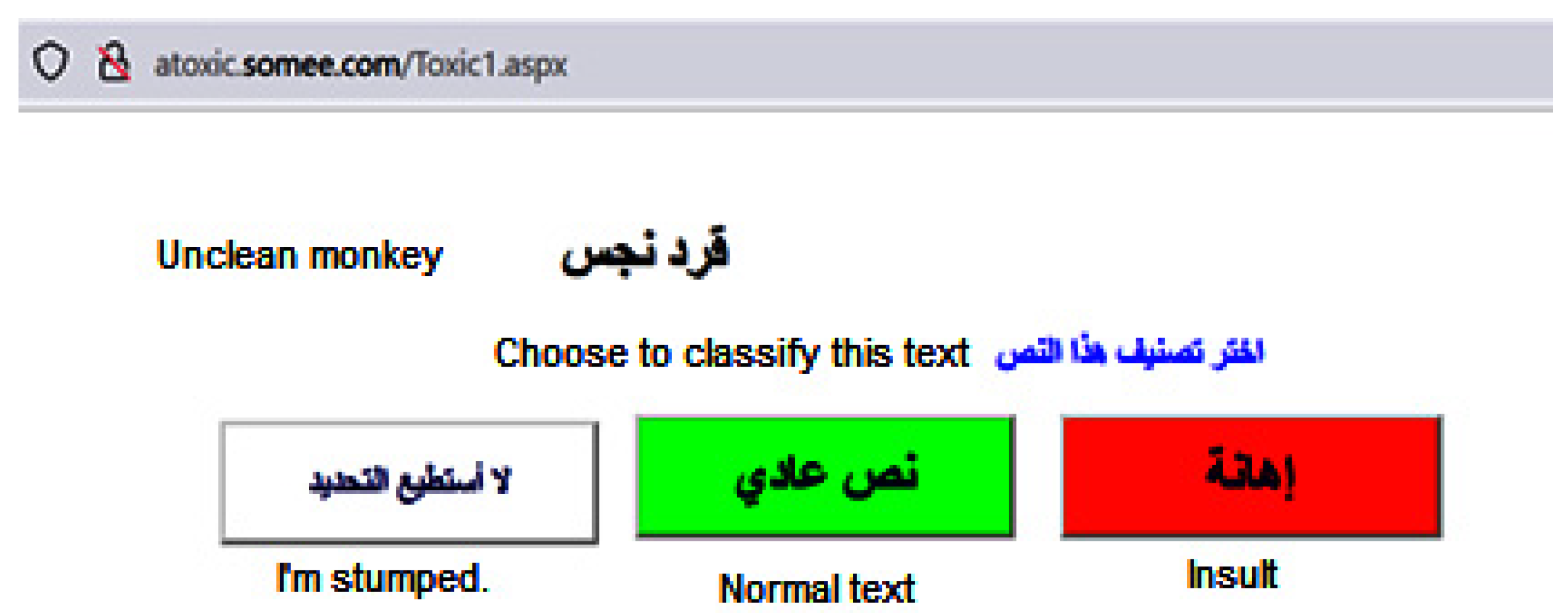
4.1. Dataset Creation Phase
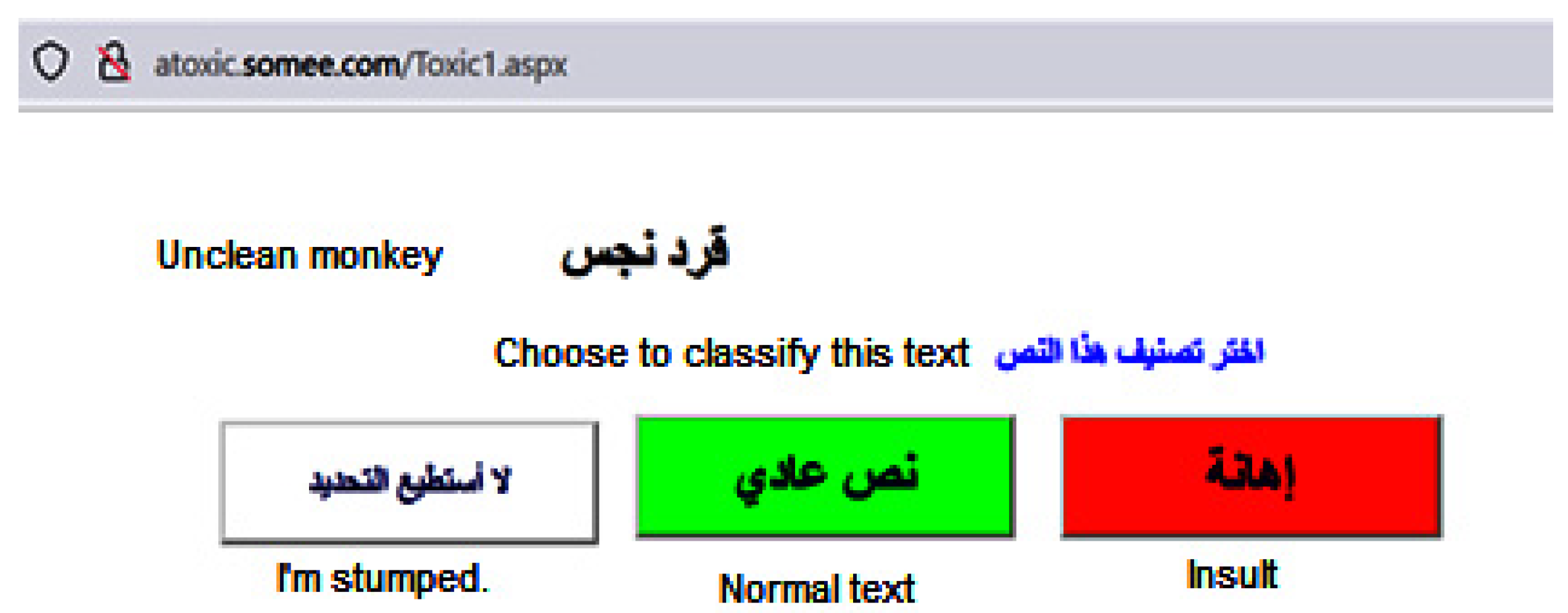
- Full-screen mode: The text is displayed in a full-screen view, maximizing the visibility and readability of the content.
- Customizable buttons: Three buttons are provided, allowing experts to easily select the type of annotation they want to apply to the text.
- I love raising dogs.
- The teacher is sick today.
4.2. Preprocessing Phase
- Cleaning: Punctuation, additional whitespace, diacritics, and non-Arabic characters are eliminated in this step.
- Stop word elimination: Many terms in the text-preprocessing task have no essential meaning but are used frequently in a document. They do not help improve the performance because they do not provide much information for the classification task. Stop words should be eliminated before the feature selection process.
- Normalization: Many normalization methods are used, including stemming, to make all words acquire the same form. We can perform normalization using various techniques (e.g., regular expressions). The normalization steps are as follows:
- Different forms of “ا” (“أ,” “إ,” and “آ”) are replaced with “ا.”
- “ئ” and “ى” at the end of the word are replaced by “ي.”
- “ه” at the end of the word is replaced by “ة.”
- Repeated letters are replaced with a single letter (e.g., “جوووووول” converted to “جول” it means (Goal)).
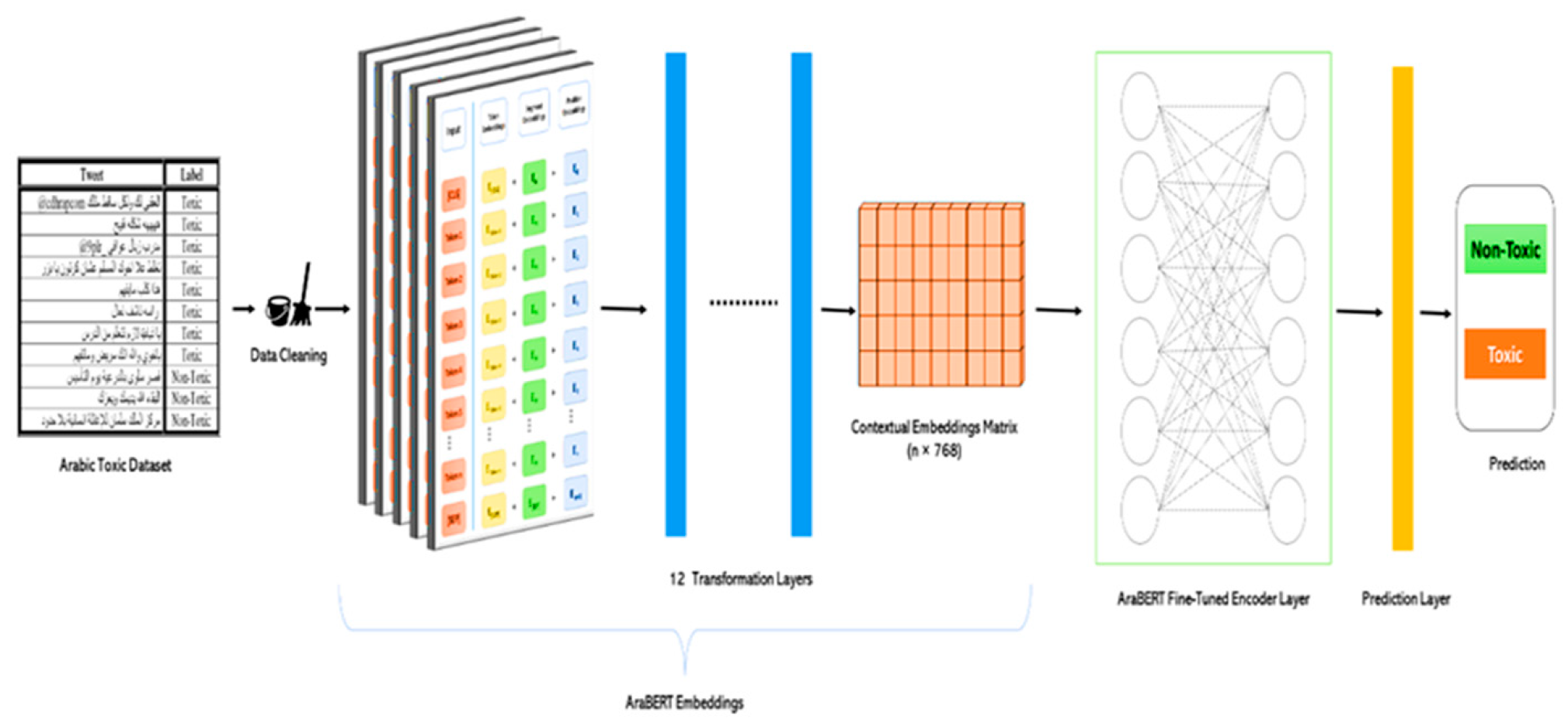
4.3. Classification Phase Using the AraBERT Model
4.4. Model Training and Fine-Tuning
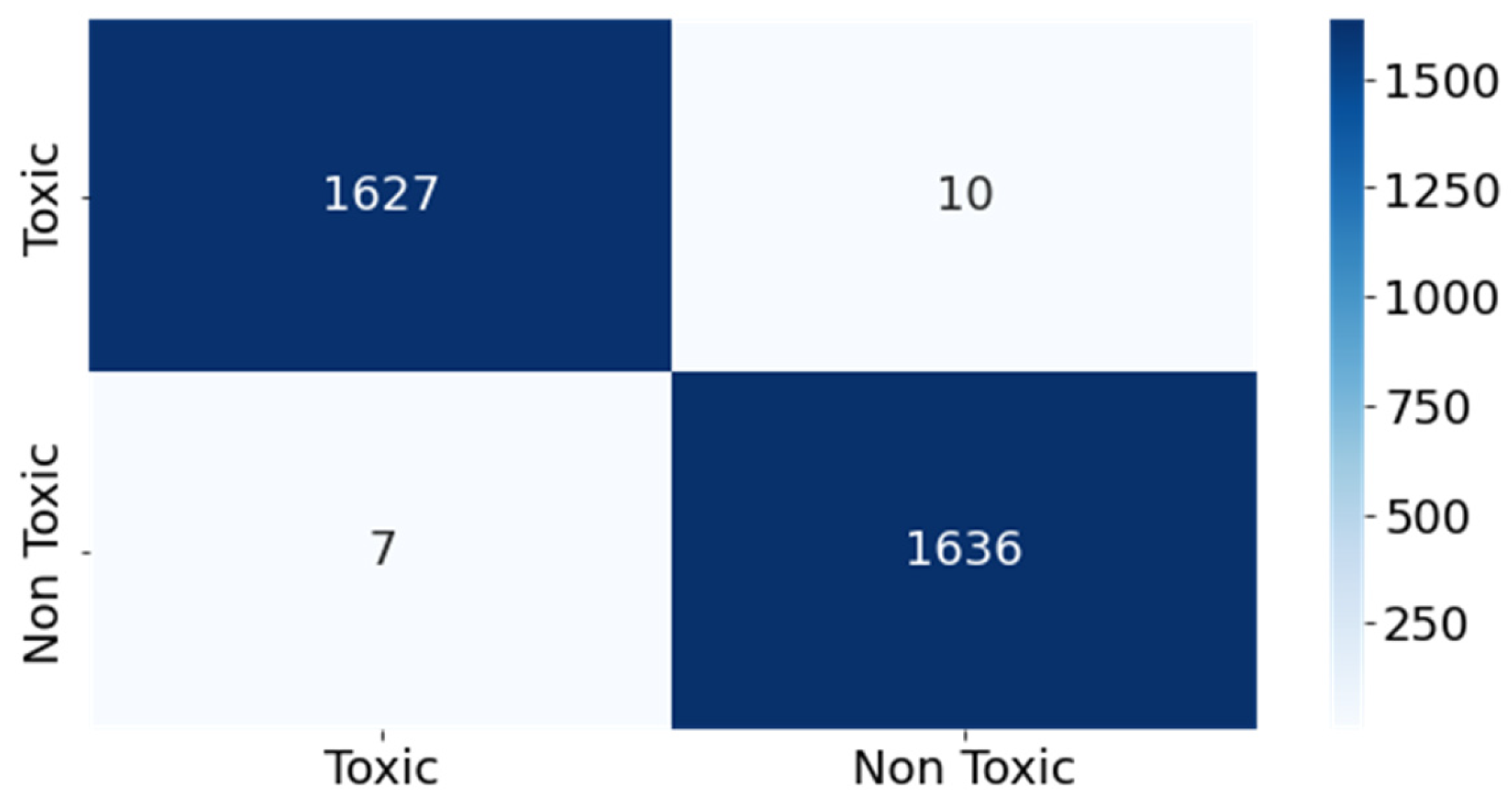
5. Results
6. Discussion
7. Limitations
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sheth, A.; Shalin, V.L.; Kursuncu, U. Defining and detecting toxicity on social media: Context and knowledge are key. Neurocomputing 2022, 490, 312–318. [Google Scholar] [CrossRef]
- Singh, I.; Goyal, G.; Chandel, A. AlexNet architecture based convolutional neural network for toxic comments classification. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 7547–7558. [Google Scholar] [CrossRef]
- Chakrabarty, N. A Machine Learning Approach to Comment Toxicity Classification; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–10. [Google Scholar]
- Omar, A.; Mahmoud, T.M.; Abd-El-Hafeez, T.; Mahfouz, A. Multi-label Arabic text classification in Online Social Networks. Inf. Syst. 2021, 100, 101785. [Google Scholar] [CrossRef]
- Omar, A.; Mahmoud, T.M.; Abd-El-Hafeez, T. Building Online Social Network Dataset for Arabic Text Classification. In The International Conference on Advanced Machine Learning Technologies and Applications (AMLTA2018); Springer-Advances in Intelligent Systems and Computing: Cham, Switzerland, 2018; pp. 486–495. [Google Scholar]
- Aldjanabi, W.; Dahou, A.; Al-Qaness, M.A.A.; Elaziz, M.A.; Helmi, A.M.; Damaševičius, R. Arabic offensive and hate speech detection using a cross-corpora multi-task learning model. Informatics 2021, 8, 69. [Google Scholar] [CrossRef]
- Mubarak, H.; Darwish, K.; Magdy, W.; Elsayed, T.; Al-Khalifa, H. Overview of OSACT4 Arabic Offensive Language Detection Shared Task. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, with a Shared Task on Offensive Language Detection; European Language Resource Association: Marseille, France, 2020; pp. 48–52. [Google Scholar]
- Mulki, H.; Haddad, H.; Ali, C.B.; Alshabani, H. L-HSAB: A Levantine Twitter Dataset for Hate Speech and Abusive Language. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1 August 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 111–118. [Google Scholar] [CrossRef]
- Haddad, H.; Mulki, H.; Oueslati, A. T-hsab: A tunisian hate speech and abusive dataset. In Proceedings of the International Conference on Arabic Language Processing, Nancy, France, 6–17 October 2019; pp. 251–263. [Google Scholar]
- Alsafari, S.; Sadaoui, S. Semi-Supervised Self-Training of Hate and Offensive Speech from Social Media. Appl. Artif. Intell. 2021, 35, 1621–1645. [Google Scholar] [CrossRef]
- Muaad, A.Y.; Davanagere, H.J.; Al-antari, M.A.; Benifa, J.V.B.; Chola, C. AI-Based Misogyny Detection from Arabic Levantine Twitter Tweets. Comput. Sci. Math. Forum 2022, 2, 15. [Google Scholar] [CrossRef]
- Farha, I.A.; Magdy, W. Multitask Learning for Arabic Offensive Language and Hate-Speech Detection. In Proceedings of the 4th Workshop on Open-Source Arabic Corpora and Processing Tools, Marseille, France, 12 May 2020; pp. 86–90. [Google Scholar]
- Alshalan, R.; Al-Khalifa, H. A deep learning approach for automatic hate speech detection in the saudi twittersphere. Appl. Sci. 2020, 10, 8614. [Google Scholar] [CrossRef]
- Albayari, R.; Abdallah, S. Instagram-Based Benchmark Dataset for Cyberbullying Detection in Arabic Text. Data 2022, 7, 83. [Google Scholar] [CrossRef]
- Althobaiti, M.J. BERT-based Approach to Arabic Hate Speech and Offensive Language Detection in Twitter: Exploiting Emojis and Sentiment Analysis. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 972–980. [Google Scholar] [CrossRef]
- Mubarak, H.; Hassan, S.; Chowdhury, S.A. Emojis as Anchors to Detect Arabic Offensive Language and Hate Speech. arXiv 2022, arXiv:220106723. [Google Scholar] [CrossRef]
- Reynolds, K.; Kontostathis, A.; Edwards, L. Using machine learning to detect cyberbullying. In Proceedings of the 2011 10th International Conference on Machine Learning and Applications and Workshops, Honolulu, HI, USA, 18–21 December 2011; pp. 241–244. [Google Scholar]
- Dinakar, K.; Jones, B.; Havasi, C.; Lieberman, H.; Picard, R. Common sense reasoning for detection, prevention, and mitigation of cyberbullying. ACM Trans. Interact. Intell. Syst. 2012, 2, 1–30. [Google Scholar] [CrossRef]
- Nahar, V.; Li, X.; Pang, C.; Zhang, Y. Cyberbullying detection based on text-stream classification. In Proceedings of the 11th Australasian Data Mining Conference (AusDM 2013), Canberra, Australia, 13–15 November 2013. [Google Scholar]
- Dadvar, M.; Trieschnigg, D.; Ordelman, R.; De Jong, F. Improving cyberbullying detection with user context. In Advances in Information Retrieval, Proccedings of the 35th European Conference on IR Research, ECIR 2013, Moscow, Russia, 24–27 March 2013; Proceedings 35; Springer: Berlin/Heidelberg, Germany, 2013; pp. 693–696. [Google Scholar]
- Feng, W.; Huang, W.; Ren, J. Class imbalance ensemble learning based on the margin theory. Appl. Sci. 2018, 8, 815. [Google Scholar] [CrossRef]
- Chavan, V.S.; Shylaja, S.S. Machine learning approach for detection of cyber-aggressive comments by peers on social media network. In Proceedings of the 2015 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Kochi, India, 10–13 August 2015; pp. 2354–2358. [Google Scholar]
- Mangaonkar, A.; Hayrapetian, A.; Raje, R. Collaborative detection of cyberbullying behavior in Twitter data. In Proceedings of the 2015 IEEE International Conference on Electro/Information Technology (EIT), DeKalb, IL, USA, 21–23 May 2015; pp. 611–616. [Google Scholar]
- Van Hee, C.; Lefever, E.; Verhoeven, B.; Mennes, J.; Desmet, B.; De Pauw, G.; Daelemans, W.; Hoste, V. Detection and fine-grained classification of cyberbullying events. In Proceedings of the International Conference Recent Advances in Natural Language Processing, Hissar, Bulgaria, 7–9 September 2015; pp. 672–680. [Google Scholar]
- Ptaszynski, M.; Masui, F.; Nitta, T.; Hatakeyama, S.; Kimura, Y.; Rzepka, R.; Araki, K. Sustainable cyberbullying detection with category-maximized relevance of harmful phrases and double-filtered automatic optimization. Int. J. Child-Comput. Interact. 2016, 8, 15–30. [Google Scholar] [CrossRef]
- Singh, V.K.; Huang, Q.; Atrey, P.K. Cyberbullying detection using probabilistic socio-textual information fusion. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; pp. 884–887. [Google Scholar]
- Al-Garadi, M.A.; Varathan, K.D.; Ravana, S.D. Cybercrime detection in online communications: The experimental case of cyberbullying detection in the Twitter network. Comput. Hum. Behav. 2016, 63, 433–443. [Google Scholar] [CrossRef]
- Zhao, R.; Zhou, A.; Mao, K. Automatic detection of cyberbullying on social networks based on bullying features. In Proceedings of the 17th International Conference on Distributed Computing and Networking, Singapore, 4–7 January 2016; pp. 1–6. [Google Scholar]
- Sugandhi, R.; Pande, A.; Agrawal, A.; Bhagat, H. Automatic monitoring and prevention of cyberbullying. Int. J. Comput. Appl. 2016, 8, 17–19. [Google Scholar] [CrossRef]
- Hosseinmardi, H.; Rafiq, R.I.; Han, R.; Lv, Q.; Mishra, S. Prediction of cyberbullying incidents in a media-based social network. In Proceedings of the 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), San Francisco, CA, USA, 18–21 August 2016; pp. 186–192. [Google Scholar]
- Zhang, X.; Tong, J.; Vishwamitra, N.; Whittaker, E.; Mazer, J.P.; Kowalski, R.; Hu, H.; Luo, F.; Macbeth, J.; Dillon, E. Cyberbullying detection with a pronunciation based convolutional neural network. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 740–745. [Google Scholar]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.; Carvalho, J.; Oliveira, S.; Coheur, L.; Paulino, P.; Simão, A.V.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Haidar, B.; Chamoun, M.; Serhrouchni, A. A Multilingual System for Cyberbullying Detection: Arabic Content Detection using Machine Learning. Adv. Sci. Technol. Eng. Syst. J. 2017, 2, 275–284. [Google Scholar] [CrossRef]
- Haidar, B.; Chamoun, M.; Serhrouchni, A. Arabic cyberbullying detection: Using deep learning. In Proceedings of the 2018 7th International Conference on Computer and Communication Engineering (ICCCE), Kuala Lumpur, Malaysia, 19–20 September 2018; pp. 284–289. [Google Scholar]
- Haidar, B.; Chamoun, M.; Serhrouchni, A. Arabic cyberbullying detection: Enhancing performance by using ensemble machine learning. In Proceedings of the 2019 International Conference on Internet of Things (Ithings) and Ieee Green Computing and Communications (Greencom) and IEEE Cyber, Physical and Social Computing (Cpscom) and IEEE Smart Data (Smartdata), Atlanta, GA, USA, 14–17 July 2019; pp. 323–327. [Google Scholar]
- Mouheb, D.; Abushamleh, M.H.; Abushamleh, M.H.; Al Aghbari, Z.; Kamel, I. Real-time detection of cyberbullying in arabic twitter streams. In Proceedings of the 2019 10th IFIP International Conference on New Technologies, Mobility and Security (NTMS), Canary Islands, Spain, 24–26 June 2019; pp. 1–5. [Google Scholar]
- Mouheb, D.; Albarghash, R.; Mowakeh, M.F.; Al Aghbari, Z.; Kamel, I. Detection of Arabic cyberbullying on social networks using machine learning. In Proceedings of the 2019 IEEE/ACS 16th International Conference on Computer Systems and Applications (AICCSA), Abu Dhabi, United Arab Emirates, 3–7 November 2019; pp. 1–5. [Google Scholar]
- AlHarbi, B.Y.; AlHarbi, M.S.; AlZahrani, N.J.; Alsheail, M.; Alshobaili, J.; Ibrahim, D.M. Automatic cyber bullying detection in Arabic social media. Int. J. Eng. Res. Technol. 2019, 12, 2330–2335. [Google Scholar]
- Rachid, B.A.; Azza, H.; Ghezala, H.H.B. Classification of cyberbullying text in Arabic. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Kanan, T.; Aldaaja, A.; Hawashin, B. Cyber-bullying and cyber-harassment detection using supervised machine learning techniques in Arabic social media contents. J. Internet Technol. 2020, 21, 1409–1421. [Google Scholar]
- Farid, D.; El-Tazi, N. Detection of cyberbullying in tweets in Egyptian dialects. Int. J. Comput. Sci. Inf. Secur. IJCSIS 2020, 18, 34–41. [Google Scholar]
- AlHarbi, B.Y.; AlHarbi, M.S.; AlZahrani, N.J.; Alsheail, M.M.; Ibrahim, D.M. Using machine learning algorithms for automatic cyber bullying detection in Arabic social media. J. Inf. Technol. Manag. 2020, 12, 123–130. [Google Scholar]
- ArunKumar, K.E.; Kalaga, D.V.; Kumar, C.M.S.; Kawaji, M.; Brenza, T.M. Comparative analysis of Gated Recurrent Units (GRU), long Short-Term memory (LSTM) cells, autoregressive Integrated moving average (ARIMA), seasonal autoregressive Integrated moving average (SARIMA) for forecasting COVID-19 trends. Alex. Eng. J. 2022, 61, 7585–7603. [Google Scholar] [CrossRef]
- Alatawi, H.S.; Alhothali, A.M.; Moria, K.M. Detecting White Supremacist Hate Speech Using Domain Specific Word Embedding with Deep Learning and BERT. IEEE Access 2021, 9, 106363–106374. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In Proceedings of the EMNLP 2014—2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar] [CrossRef]
- Antoun, W.; Baly, F.; Hajj, H. AraBERT: Transformer-based Model for Arabic Language Understanding. arXiv 2020, arXiv:2003.00104. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019—Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, no. Mlm, 2019. pp. 4171–4186. [Google Scholar]
- Omar, A.; Mahmoud, T.M.; Abd-El-Hafeez, T. Comparative Performance of Machine Learning and Deep Learning Algorithms for Arabic Hate Speech Detection in OSNs; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 1. [Google Scholar] [CrossRef]
- Twitter. Twitter API Wiki/Twitter API Documentation. 2010. Available online: http://apiwiki.twitter.com/w/page/22554679/Twitter-API-Documentation (accessed on 1 January 2022).
- Google and Jigsaw. Perspective API. 2017. Available online: https://perspectiveapi.com (accessed on 1 February 2022).
- Han, X.; Tsvetkov, Y. Fortifying Toxic Speech Detectors Against Veiled Toxicity. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 7732–7739. [Google Scholar] [CrossRef]
- Almerekhi, H.; Kwak, H.; Salminen, J.; Jansen, B.J. PROVOKE: Toxicity trigger detection in conversations from the top 100 subreddits. Data Inf. Manag. 2022, 6, 100019. [Google Scholar] [CrossRef]
- Pavlopoulos, J.; Thain, N.; Dixon, L.; Androutsopoulos, I. ConvAI at SemEval-2019 Task 6: Offensive Language Identification and Categorization with Perspective and BERT. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MI, USA, 6–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 571–576. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Platform | Language | Size | Balancing |
|---|---|---|---|---|
| [17] | Formspring | English | 3915 | 0.142 |
| [18] | YouTube Formspring | English | - | - |
| [19] | Twitter, MySpace | English | 1,570,000 | - |
| [20] | YouTube | English | 4626 | 0.097 |
| [21] | English | 4865 | 0.019 | |
| [22] | Kaggle | English | 2647 | 0.272 |
| [23] | English | 1340 | 0.152 | |
| [24] | Ask FM | Dutch | 85,485 | 0.067 |
| [25] | Schoolboard Bulletins (BBS) | Japanese | 2222 | 0.128 |
| [26] | English | 4865 | 0.186 | |
| [27] | English | 10,007 | 0.06 | |
| [28] | English | 1762 | 0.388 | |
| [29] | Train-Formspring and MySpace Test-Twitter | English | 3279 | 0.12 |
| [30] | English | 1954 | 0.29 | |
| [31] | Formspring | English | 13,000 | 0.066 |
| [32] | Formspring | English | 13,160 | 0.194 |
| Study | Dataset | Feature Representation | Classifier | Performance | |||||
|---|---|---|---|---|---|---|---|---|---|
| Platform | Size | Classes | Acc | P | R | F | |||
| [33] | Arabic = 35,273 English = 91,431 | Yes/No | Tweet to SentiStrength Feature Vector | Naïve Bayes SVM | 93.4 | 94.1 | 92.7 | ||
| [34] | Large = 34,890 Small = 4913 | Yes/No | Word embedding | FFNN | 94.5 | ||||
| [35] | 34,890 | Bully Non-bully | Bagging, boosting (KNN, SVM, NB) | 93.3 | 93.5 | 92.0 | |||
| [36] | Real-Time Classification | TF-IDF | |||||||
| [37] | YouTube and Twitter | 25,000 | TF-IDF | Naïve Bayes (NB) | 95.9 | 92.9 | 92.5 | 92.7 | |
| [38] | YouTube Twitter | training (100,327) testing (2020) | TF-IDF | PMI, Chi-square Entropy | 81.0, 62.1, 39.1 | ||||
| [39] | Aljazeera.net. (test) Twitter | 32K | CB, NCB | Word embedding TF-IDF, n- gram, Bow | CNN, RNN | 84.0 | |||
| [40] | Facebook and Twitter. | 6138 | Positive/ Negative | TF-IDF | KNN, SVM, NB, random forests, and J48 | 94.5 | 94.4 | 94.4 | |
| [41] | Bullying/No bullying | Sentiment analysis, emojis and user history | 85.0 | ||||||
| [42] | 151,000 | Sentiment analysis | Ridge regression (RR) and logistic regression (LR) | ||||||
| Ar-Keyword | En-Keyword | Translation | Sample Tweet |
|---|---|---|---|
| ساقط | Fallen | You are impolite, uneducated, paid, and a fallen Baathist | انت غير مؤدب وغير مثقف ومأجور وبعثي ساقط |
| قبيح | Ugly | God does not give you anything nice, an ugly face, a bad tongue, malicious eyes. | ربنا مش مديك اى حاجة حلوه وجه قبيح لسان عبيط عيون خبيثة |
| زبال | Trashy | Valverde is the least-losing coach in Barcelona’s history, scavenger | فالفيردي المدرب الأقل خسارة في تاريخ برشلونة يا زبال |
| بزر | Insignificant | Make a mistake about your Muslim brother because of cardboard, kid. | تغلط علا اخوك المسلم عشان كرتون يا بزر |
| سافل | Damn | Damn grant that’s bad | منحط سافل هذا ردي |
| خنزير | Pig | What is the saying of a donkey, a pig, a genus that is human beings? | علماني إيه قول حمار خنزير خرتيت أي جنس غير إنه يكون بني آدم |
| مريض | Sick | My brother, by God, you are sick and do not understand | ياخوي والله انك مريض وماتفهم |
| Toxicity Percentage | Tweet Count |
|---|---|
| ≥0.5 | 3470 |
| ≥0.35 and <0.5 | 9400 |
| ≥0.4 | 6600 |
| ≥0.35 and <0.4 | 6200 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
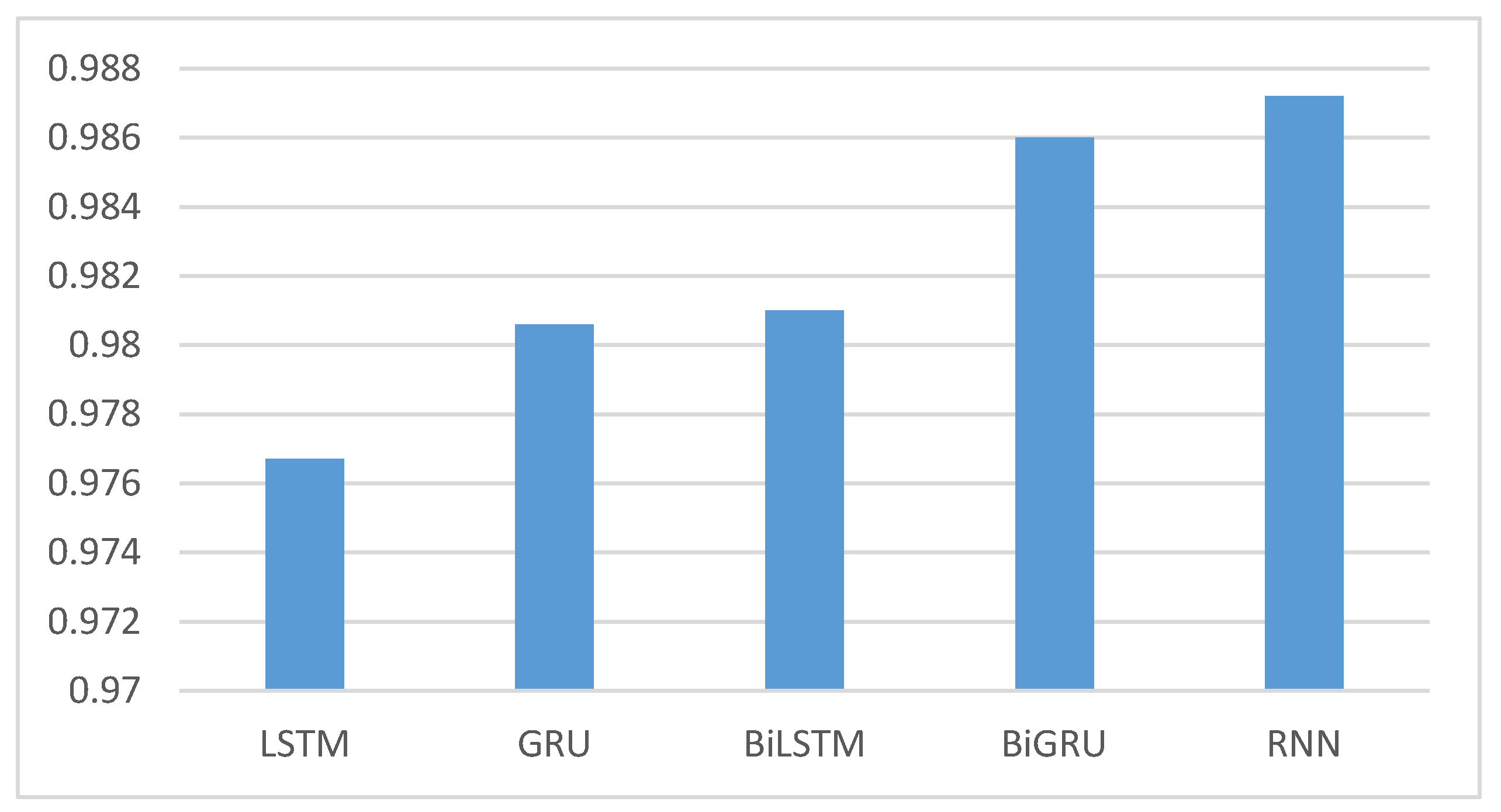
| LSTM | 0.9767 | 0.9623 | 0.9831 | 0.9763 |
| GRU | 0.9806 | 0.9796 | 0.9828 | 0.9803 |
| BiLSTM | 0.9810 | 0.9728 | 0.9851 | 0.9812 |
| BiGRU | 0.9860 | 0.9838 | 0.9880 | 0.9870 |
| RNN | 0.9872 | 0.9865 | 0.9890 | 0.9866 |
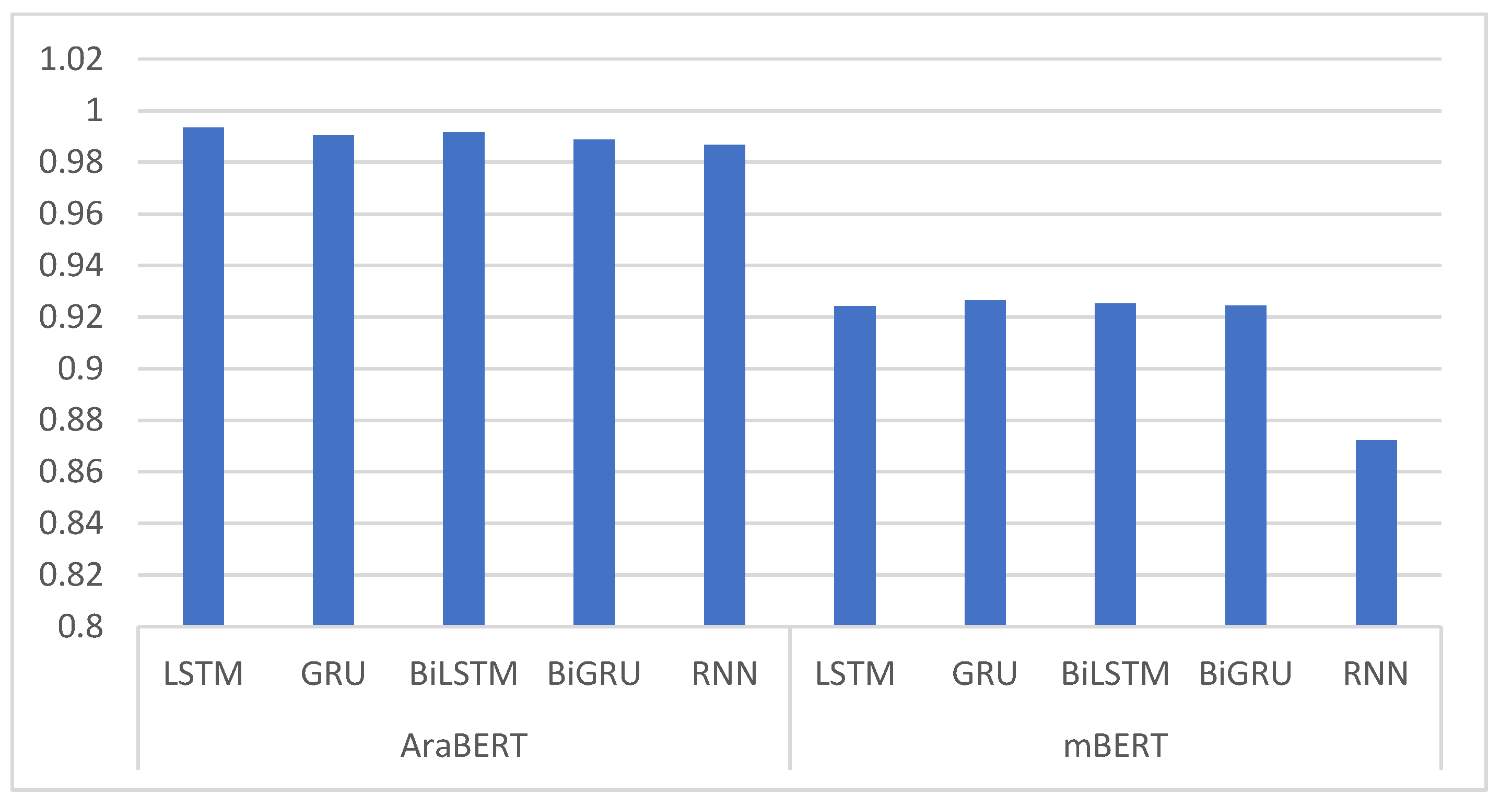
| Word Embedding | Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|---|
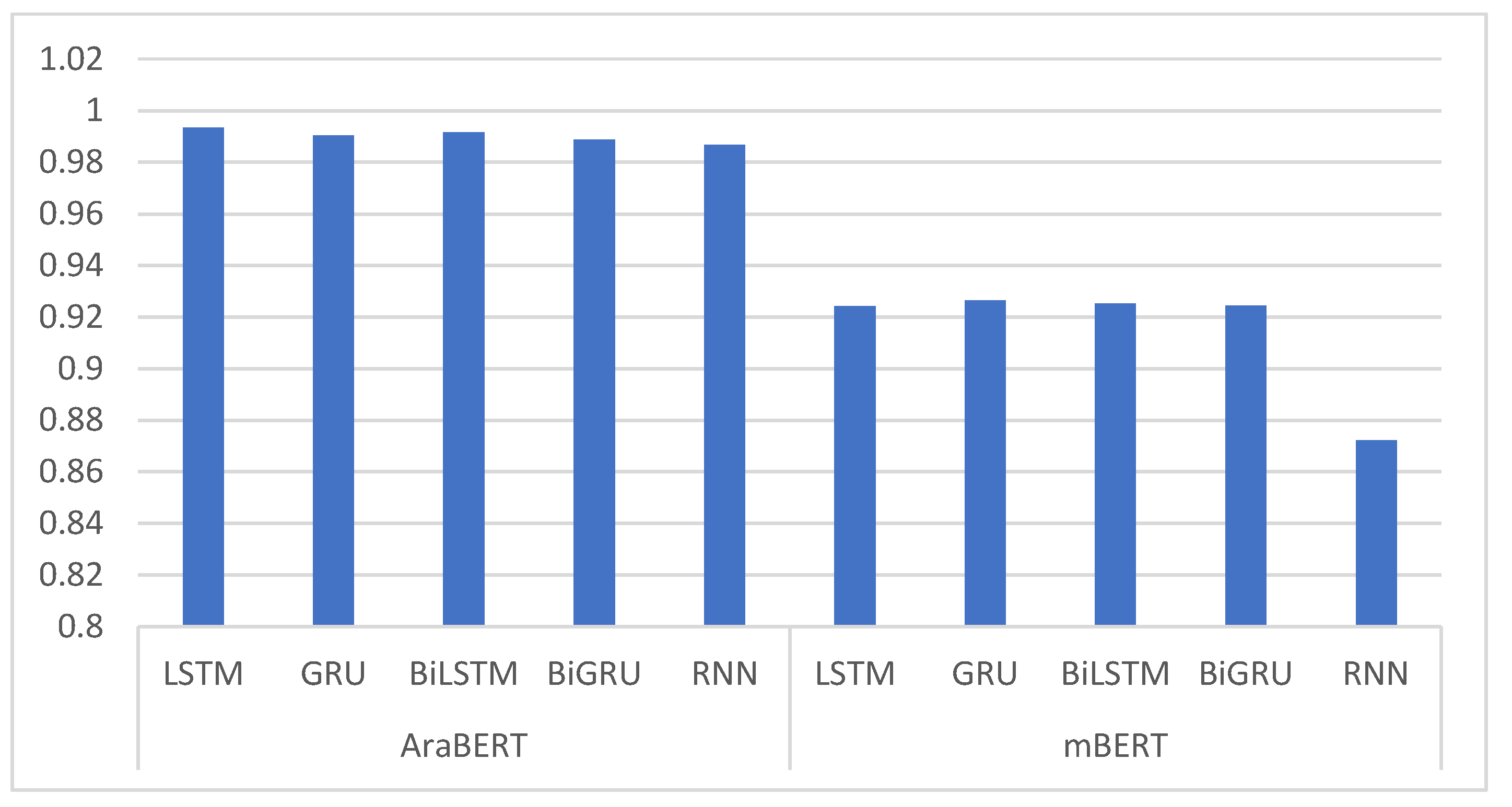
| AraBERT | LSTM | 0.9934 | 0.9923 | 0.9944 | 0.9930 |
| GRU | 0.9905 | 0.9895 | 0.9908 | 0.9900 | |
| BiLSTM | 0.9917 | 0.9905 | 0.9923 | 0.9911 | |
| BiGRU | 0.9888 | 0.9803 | 0.9901 | 0.9815 | |
| RNN | 0.9868 | 0.9808 | 0.9898 | 0.9838 | |
| mBERT | LSTM | 0.9242 | 0.9222 | 0.9262 | 0.9232 |
| GRU | 0.9264 | 0.9234 | 0.9272 | 0.9254 | |
| BiLSTM | 0.9252 | 0.9232 | 0.9284 | 0.9241 | |
| BiGRU | 0.9244 | 0.9235 | 0.9252 | 0.9241 | |
| RNN | 0.8723 | 0.8712 | 0.8742 | 0.8720 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
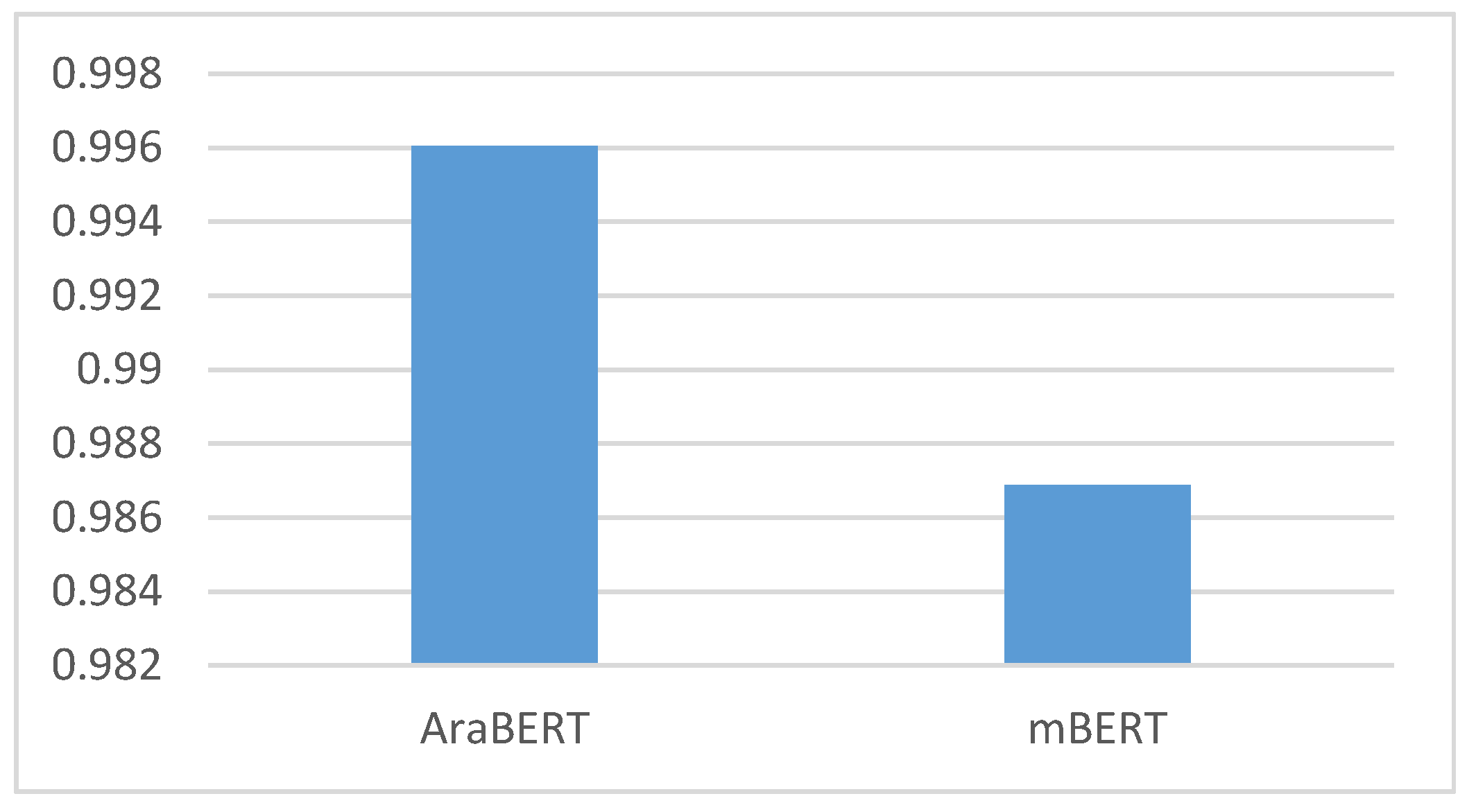
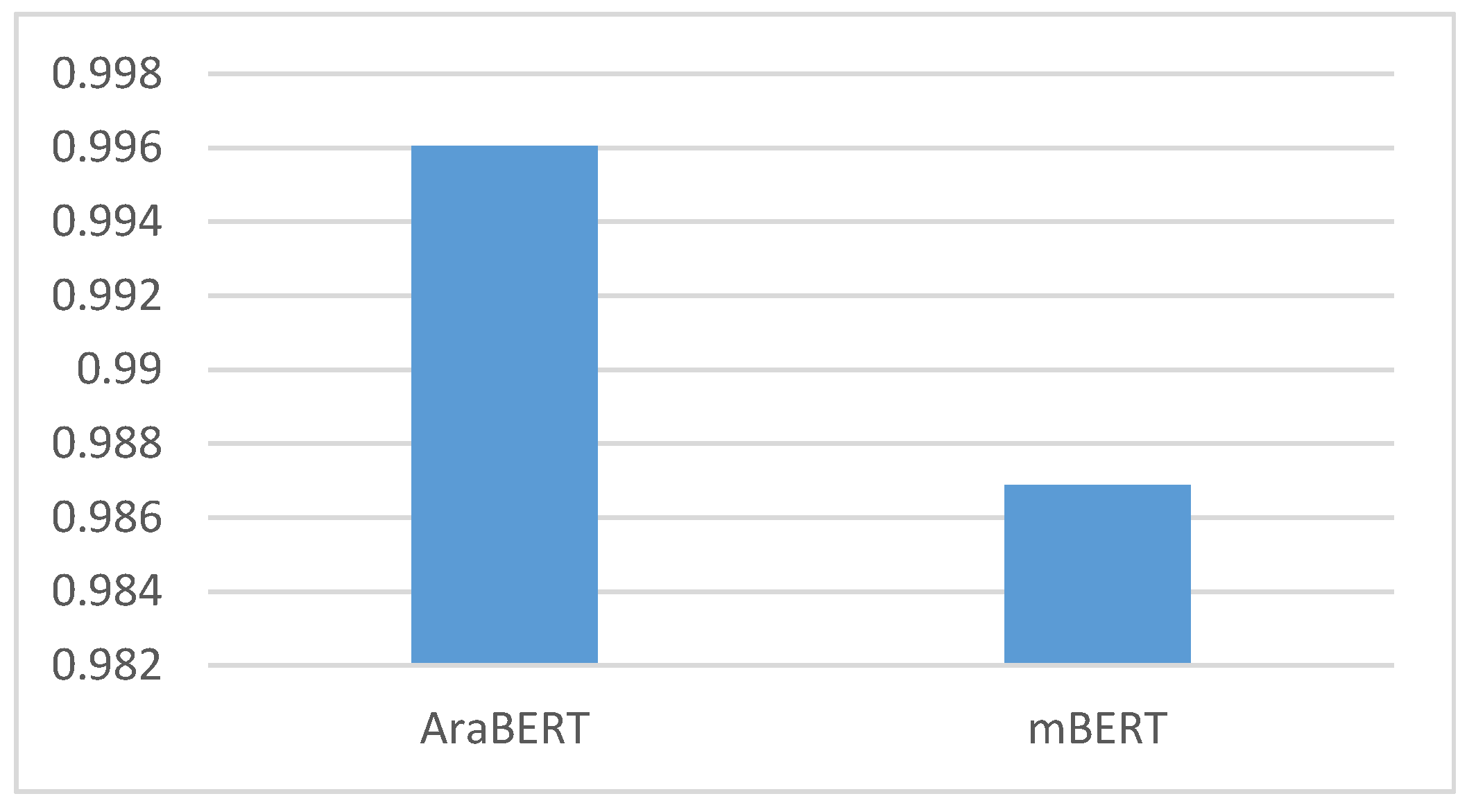
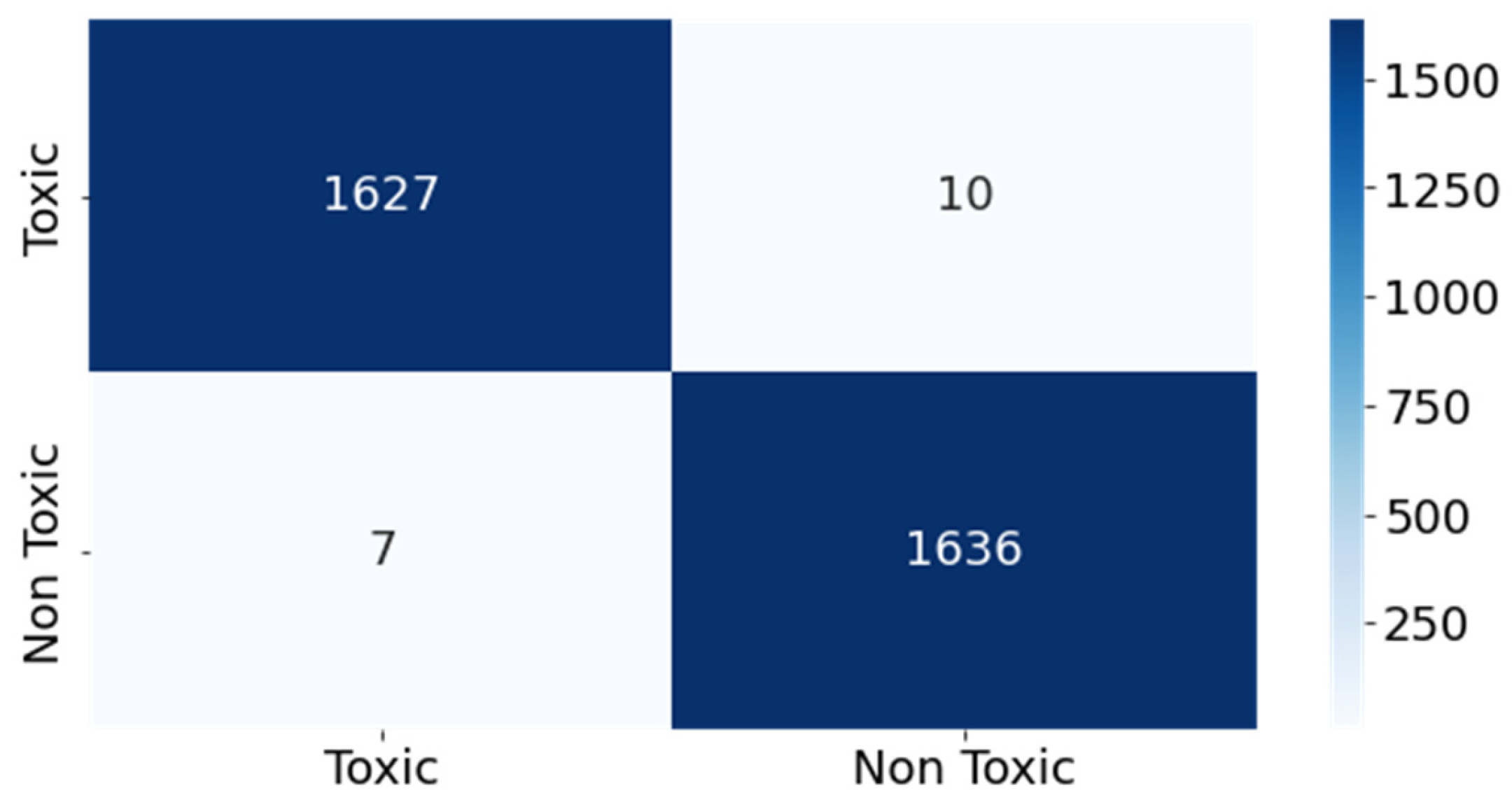
| AraBERT | 0.996037 | 0.99604 | 0.996035 | 0.996037 |
| mBERT | 0.98689 | 0.9869 | 0.986895 | 0.98689 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koshiry, A.M.E.; Eliwa, E.H.I.; Abd El-Hafeez, T.; Omar, A. Arabic Toxic Tweet Classification: Leveraging the AraBERT Model. Big Data Cogn. Comput. 2023, 7, 170. https://doi.org/10.3390/bdcc7040170
Koshiry AME, Eliwa EHI, Abd El-Hafeez T, Omar A. Arabic Toxic Tweet Classification: Leveraging the AraBERT Model. Big Data and Cognitive Computing. 2023; 7(4):170. https://doi.org/10.3390/bdcc7040170
Chicago/Turabian StyleKoshiry, Amr Mohamed El, Entesar Hamed I. Eliwa, Tarek Abd El-Hafeez, and Ahmed Omar. 2023. "Arabic Toxic Tweet Classification: Leveraging the AraBERT Model" Big Data and Cognitive Computing 7, no. 4: 170. https://doi.org/10.3390/bdcc7040170
APA StyleKoshiry, A. M. E., Eliwa, E. H. I., Abd El-Hafeez, T., & Omar, A. (2023). Arabic Toxic Tweet Classification: Leveraging the AraBERT Model. Big Data and Cognitive Computing, 7(4), 170. https://doi.org/10.3390/bdcc7040170