
HAMCap: A Weak-Supervised Hybrid Attention-Based Capsule Neural Network for Fine-Grained Climate Change Debate Analysis



Abstract
:1. Introduction
2. Related Works
2.1. Capsule Neural Networks for NLP
2.2. Reinforcement Learning-Based Data Augmentation
2.3. NLP Technologies for Climate Change
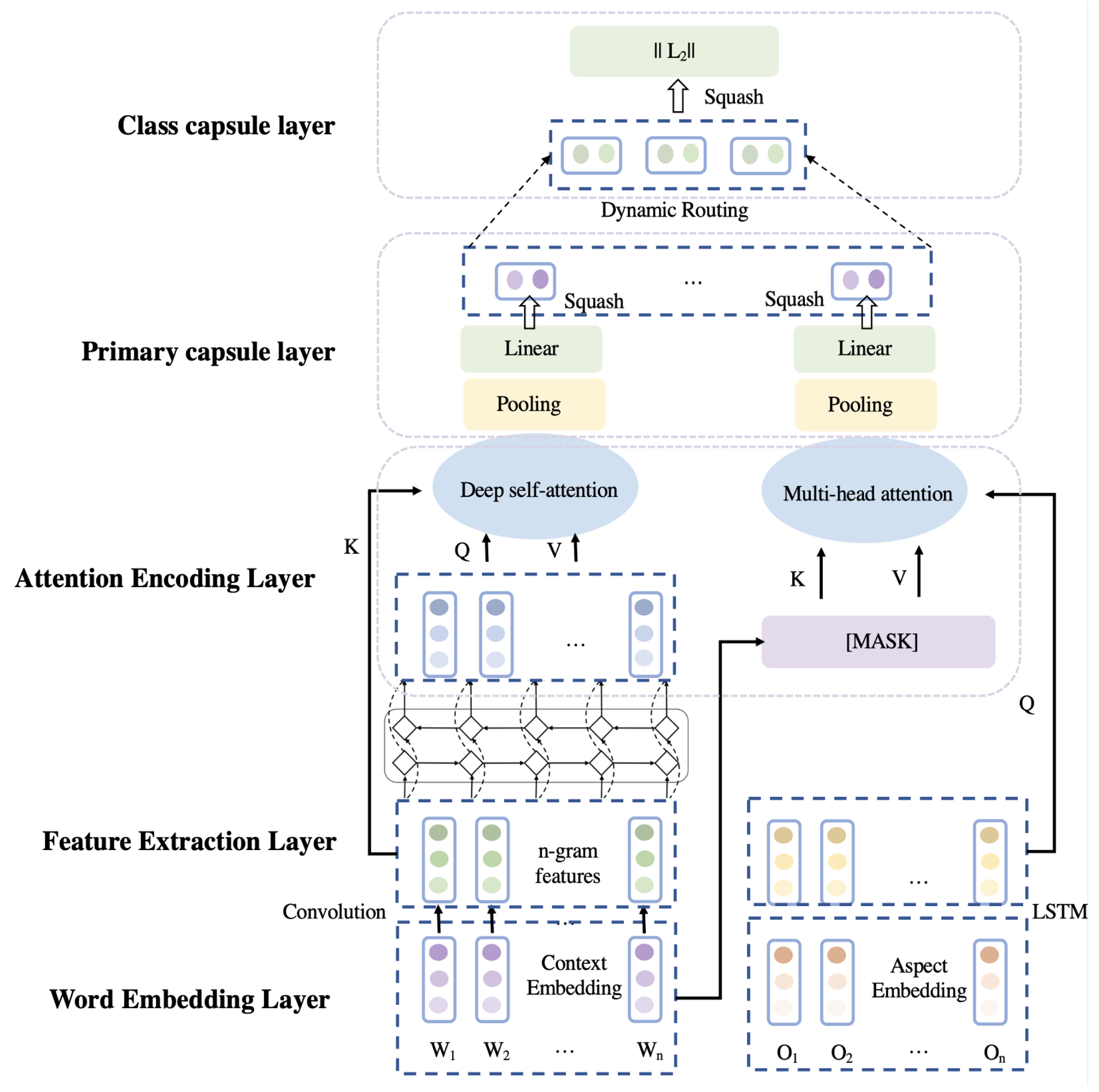
3. Model
3.1. Hybrid Attention-Based CapNet
3.1.1. Task Definition
3.1.2. Word Embedding Layer
3.1.3. Feature Extraction Layer
3.1.4. Hybrid Attention Mechanism
3.1.5. Capsule Neural Networks
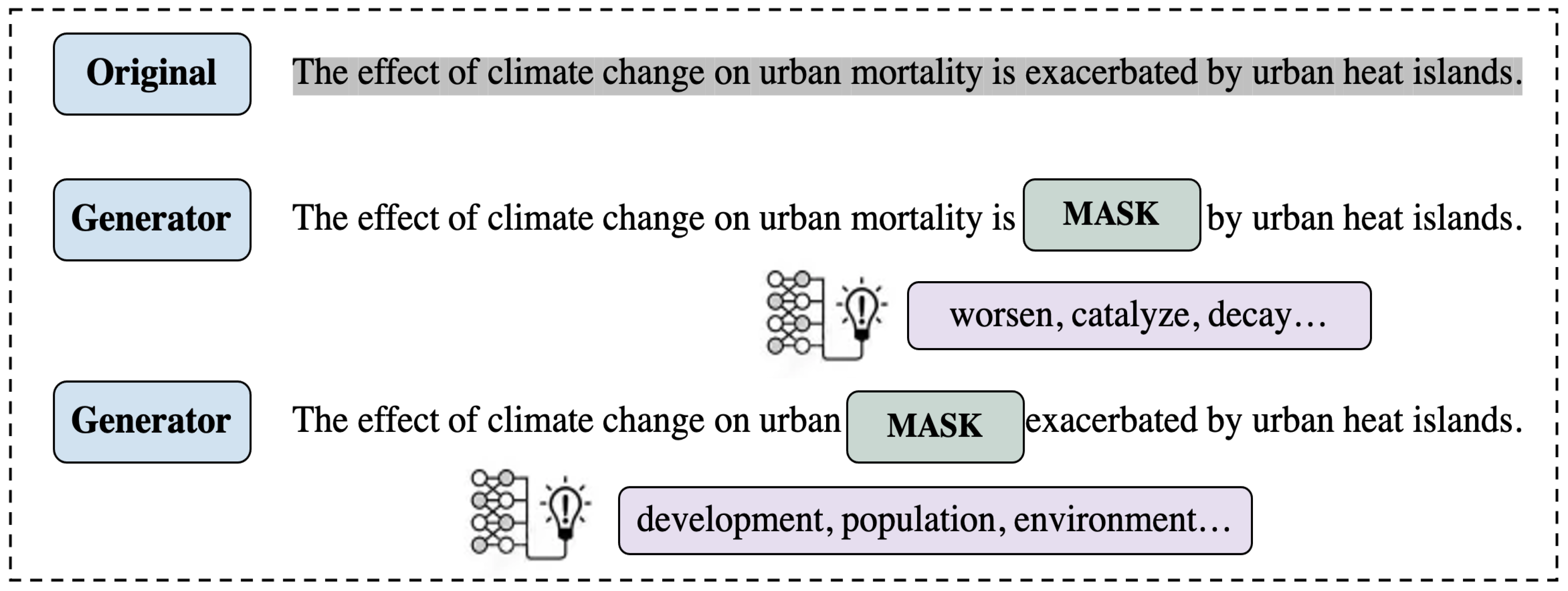
3.2. Reinforcement Learning Data Augmentation
4. Experiments
4.1. Dataset
4.2. Implement Details
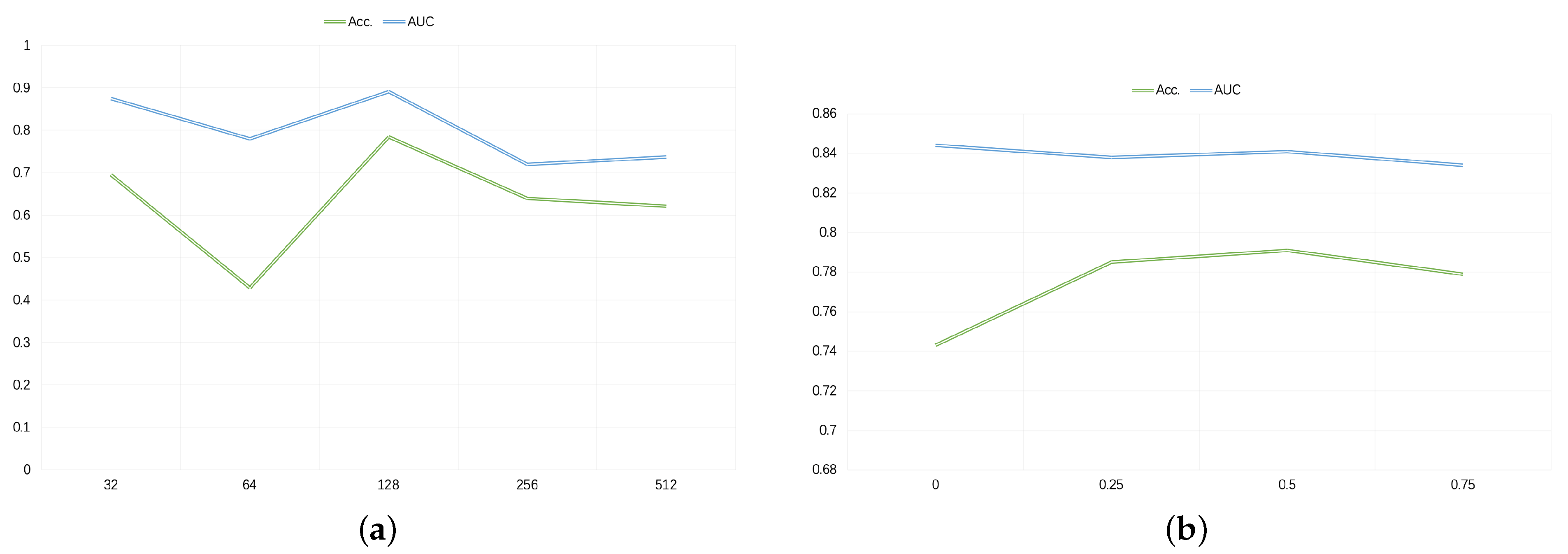
4.2.1. Parameter Settings
4.2.2. Baselines
4.3. Experimental Results
4.4. Analysis
4.4.1. Hybrid Attention Capsule Neural Network
4.4.2. Data Augmentation Mechanism Analysis
5. Topic Mining and Interpretation
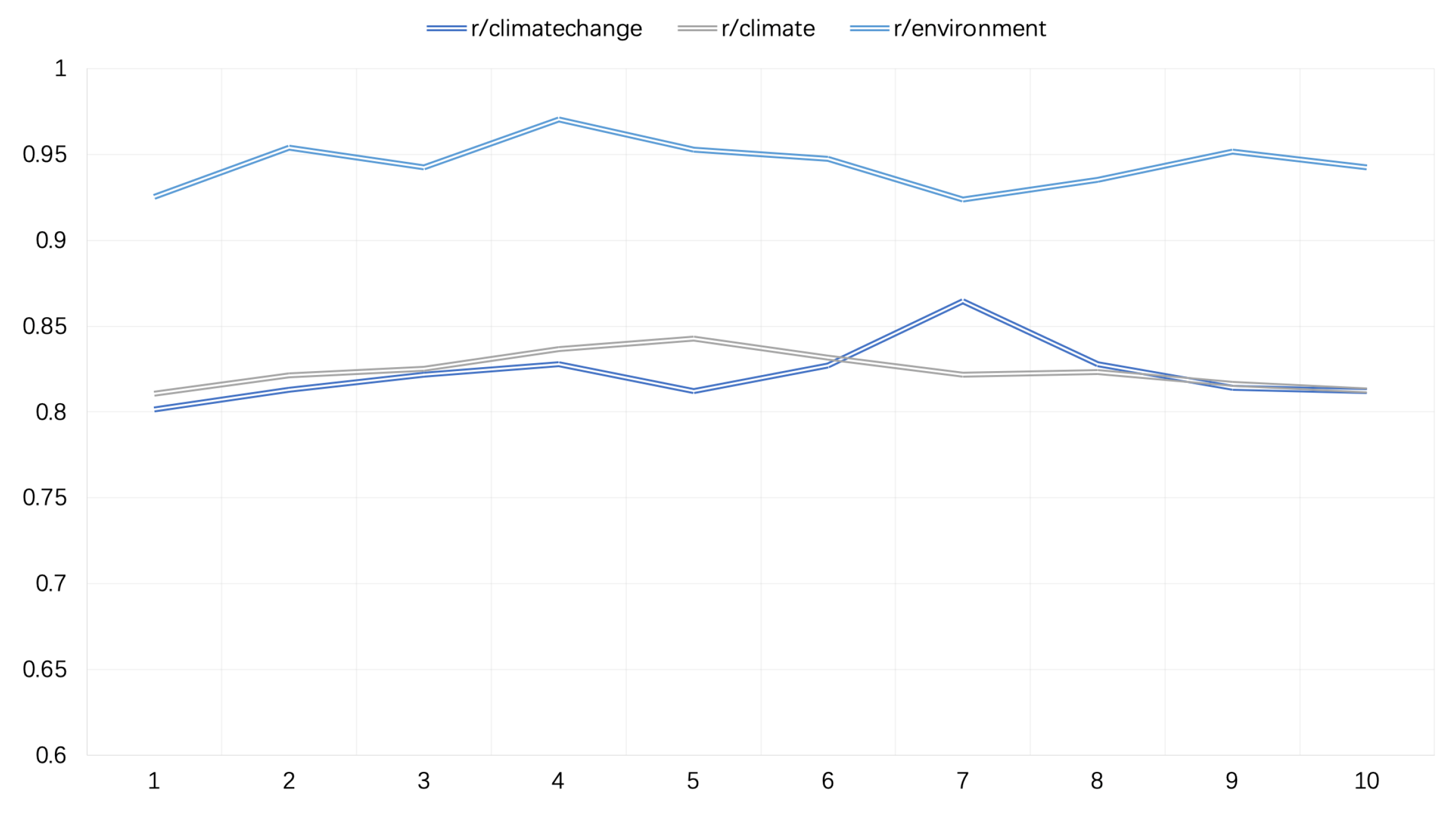
5.1. Topic Mining of Different r/Subreddits
5.2. Topic Mining of Different Sentiment Polarities
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Post: “I’m afraid climate change is going to kill me! Help!” | ||
| Positive | “Since the end of the last ice age sea levels rose by 120 m and temperatures warmed by a minimum of 4 degrees but maybe as much as 7. We not only survived but civilization as we know it emerged. And that was before we had advanced technology. We will be ok”. | Climate change is an irresistible result of natural development, whether it is caused by the development of modern society or not. Climate change is not going to harm or kill humans, and technological developments will hinder this dire trend. |
| Negative | “This post is 3 years old and still being used as an argument that ‘everything is fine’. Way to disillusion yourself”. | Believing that climate change is destroying the environment and human beings and showing a continuous deterioration. |
| Positive | “The climate of the earth is in constant change no matter what the cause be it volcano, radiation from space, solar fluctuations etc. There are thousands of things that will kill you that are greater than climate change such as car accidents, burning candles at home, smoking, drugs etc. Climate change danger from CO2 is much less that most household dangers so you need to get this all in perspective. Sure we must do things to prevent climate change the best we can but over population of the earth is a much bigger threat to man’s existence. Too much population for us to produce food for!” | Admitting that climate change is ongoing and has some adverse effects. This change is brought about by the development of human society and will continue to pose threats. Therefore, measures need to be taken for intervention and protection. This deterioration is controllable. |
| Neutral | “Scientists said that the youngers are more delayed effect in comparison with the older people for sensitivity on NO2 and AMI”. | Only states scientific data and expresses no personal perspective. |
Appendix B
| Parameter | Value |
| Dropout | 0.1 |
| Batch_size | 32/64 |
| Maximum-sequence-length | 100 |
| Learning rate | 1e-3/2e-5 |
| L2-regularization | 1e-4 |
| Convolutional kernel numbers | 250 |
| Hidden layer dimension | 300 |
| Output capsule dimension | 16 |
| Dynamic routing iteration | 7 |
| Multi-head attention | 8 |
| Optimizer | Adam |
| Adam_beta1 | 0.9 |
| Adam_beta2 | 0.999 |
Appendix C
| Notation and Acronym | Explanation |
| w/ | With |
| w/o | Without |
| r/ | Specific reddit or subreddit |
| CC | Climate change |
| CapNets | Capsule neural networks |
| DA | Data augmentation |
| CV | Computer Vision |
| PCM | Partial context mask mechanism |
| RL | Reinforcement Learning |
| LLM | Large language model |
References
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. In Artificial Neural Networks and Machine Learning–ICANN 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 44–51. [Google Scholar]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; Volume 30. [Google Scholar]
- Zhao, W.; Peng, H.; Eger, S.; Cambria, E.; Yang, M. Towards scalable and reliable capsule networks for challenging nlp applications. arXiv 2019, arXiv:1906.02829. [Google Scholar]
- Ranasinghe, T.; Hettiarachchi, H. Emoji Powered Capsule Network to Detect Type and Target of Offensive Posts in Social Media; INCOMA Ltd.: Varna, Bulgaria, 2019. [Google Scholar]
- Liu, J.; Lin, H.; Liu, X.; Xu, B.; Ren, Y.; Diao, Y.; Yang, L. Transformer-based capsule network for stock movement prediction. In Proceedings of the First Workshop on Financial Technology and Natural Language Processing, Macao, China, 12 August 2019; pp. 66–73. [Google Scholar]
- Du, C.; Sun, H.; Wang, J.; Qi, Q.; Liao, J.; Wang, C.; Ma, B. Investigating capsule network and semantic feature on hyperplanes for text classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 456–465. [Google Scholar]
- Xiao, L.; Zhang, H.; Chen, W.; Wang, Y.; Jin, Y. Mcapsnet: Capsule network for text with multi-task learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4565–4574. [Google Scholar]
- Su, J.; Yu, S.; Luo, D. Enhancing aspect-based sentiment analysis with capsule network. IEEE Access 2020, 8, 100551–100561. [Google Scholar] [CrossRef]
- Lin, H.; Meng, F.; Su, J.; Yin, Y.; Yang, Z.; Ge, Y.; Zhou, J.; Luo, J. Dynamic context-guided capsule network for multimodal machine translation. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 1320–1329. [Google Scholar]
- Verma, S.; Zhang, Z.-L. Graph capsule convolutional neural networks. arXiv 2018, arXiv:1805.08090. [Google Scholar]
- Wu, Y.; Li, J.; Wu, J.; Chang, J. Siamese capsule networks with global and local features for text classification. Neurocomputing 2020, 390, 88–98. [Google Scholar] [CrossRef]
- Goldani, M.H.; Momtazi, S.; Safabakhsh, R. Detecting fake news with capsule neural networks. Appl. Soft Comput. 2021, 101, 106991. [Google Scholar] [CrossRef]
- Chen, D.; Chen, X.; Lu, P.; Wang, X.; Lan, X. Cnfrd: A few-shot rumor detection framework via capsule network for COVID-19. Int. J. Intell. Syst. 2023, 2023, 2467539. [Google Scholar] [CrossRef]
- Du, C.; Sun, H.; Wang, J.; Qi, Q.; Liao, J.; Xu, T.; Liu, M. Capsule network with interactive attention for aspect-level sentiment classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5489–5498. [Google Scholar]
- Yang, M.; Zhao, W.; Chen, L.; Qu, Q.; Zhao, Z.; Shen, Y. Investigating the transferring capability of capsule networks for text classification. Neural Netw. 2019, 118, 247–261. [Google Scholar] [CrossRef]
- Fei, H.; Ji, D.; Zhang, Y.; Ren, Y. Topic-enhanced capsule network for multi-label emotion classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1839–1848. [Google Scholar] [CrossRef]
- Deng, J.; Cheng, L.; Wang, Z. Self-attention-based bigru and capsule network for named entity recognition (2020). arXiv 2002, arXiv:2002.00735. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M.; Furht, B. Text data augmentation for deep learning. J. Big Data 2021, 8, 1–34. [Google Scholar] [CrossRef]
- Jiang, J.; Chen, X.; Huang, Z.; Li, X.; Du, Y. Deep reinforcement learning-based approach for rumor influence minimization in social networks. Appl. Intell. 2023, 53, 20293–20310. [Google Scholar] [CrossRef]
- Liu, R.; Xu, G.; Jia, C.; Ma, W.; Wang, L.; Vosoughi, S. Data boost: Text data augmentation through reinforcement learning guided conditional generation. arXiv 2020, arXiv:2012.02952. [Google Scholar]
- Pan, B.; Yang, Y.; Zhao, Z.; Zhuang, Y.; Cai, D.; He, X. Discourse marker augmented network with reinforcement learning for natural language inference. arXiv 2019, arXiv:1907.09692. [Google Scholar]
- Ye, Y.; Pei, H.; Wang, B.; Chen, P.-Y.; Zhu, Y.; Xiao, J.; Li, B. Reinforcement-learning based portfolio management with augmented asset movement prediction states. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1112–1119. [Google Scholar]
- Cao, R.; Lee, R.K.-W. Hategan: Adversarial generative-based data augmentation for hate speech detection. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6327–6338. [Google Scholar]
- Chen, H.; Xia, R.; Yu, J. Reinforced counterfactual data augmentation for dual sentiment classification. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online, 7–11 November 2021; pp. 269–278. [Google Scholar]
- Xiang, K.; Fujii, A. Dare: Distill and reinforce ensemble neural networks for climate-domain processing. Entropy 2023, 25, 643. [Google Scholar] [CrossRef] [PubMed]
- Stede, M.; Patz, R. The climate change debate and natural language processing. In Proceedings of the 1st Workshop on NLP for Positive Impact, Bangkok, Thailand, 5 August 2021; pp. 8–18. [Google Scholar]
- Mallick, T.; Bergerson, J.D.; Verner, D.R.; Hutchison, J.K.; Levy, L.-A.; Balaprakash, P. Analyzing the impact of climate change on critical infrastructure from the scientific literature: A weakly supervised nlp approach. arXiv 2023, arXiv:2302.01887. [Google Scholar]
- Schäfer, M.S.; Hase, V. Computational methods for the analysis of climate change communication: Towards an integrative and reflexive approach. Wiley Interdiscip. Rev. Clim. Chang. 2023, 14, e806. [Google Scholar] [CrossRef]
- Schweizer, V.J.; Kurniawan, J.H.; Power, A. Semi-automated literature review for scientific assessment of socioeconomic climate change scenarios. In Proceedings of the Companion Proceedings of the Web Conference 2022, Virtual Event, Lyon, France, 25–29 April 2022; pp. 789–799. [Google Scholar]
- Luccioni, A.; Palacios, H. Using natural language processing to analyze financial climate disclosures. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Loureiro, M.L.; Alló, M. Sensing climate change and energy issues: Sentiment and emotion analysis with social media in the UK and Spain. Energy Policy 2020, 143, 111490. [Google Scholar] [CrossRef]
- Swarnakar, P.; Modi, A. Nlp for climate policy: Creating a knowledge platform for holistic and effective climate action. arXiv 2021, arXiv:2105.05621. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Parsa, M.S.; Shi, H.; Xu, Y.; Yim, A.; Yin, Y.; Golab, L. Analyzing climate change discussions on reddit. In Proceedings of the 2022 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2022. [Google Scholar]
- Chen, Z.; Qian, T. Transfer capsule network for aspect level sentiment classification. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 547–556. [Google Scholar]
- Ma, D.; Li, S.; Zhang, X.; Wang, H. Interactive attention networks for aspect-level sentiment classification. arXiv 2017, arXiv:1709.00893. [Google Scholar]
- Majumder, N.; Poria, S.; Gelbukh, A.; Akhtar, M.S.; Cambria, E.; Ekbal, A. Iarm: Inter-aspect relation modeling with memory networks in aspect-based sentiment analysis. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3402–3411. [Google Scholar]
- Tang, D.; Qin, B.; Liu, T. Aspect level sentiment classification with deep memory network. arXiv 2016, arXiv:1605.08900. [Google Scholar]
- Chen, P.; Sun, Z.; Bing, L.; Yang, W. Recurrent attention network on memory for aspect sentiment analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 452–461. [Google Scholar]
- Wang, Y.; Huang, M.; Zhu, X.; Zhao, L. Attention-based lstm for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 606–615. [Google Scholar]
- He, R.; Lee, W.S.; Ng, H.T.; Dahlmeier, D. Exploiting document knowledge for aspect-level sentiment classification. arXiv 2018, arXiv:1806.04346. [Google Scholar]
- Karimi, A.; Rossi, L.; Prati, A. Adversarial training for aspect-based sentiment analysis with bert. In Proceedings of the 2020 25th International conference on pattern recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 8797–8803. [Google Scholar]
- Xu, H.; Liu, B.; Shu, L.; Yu, P.S. Bert post-training for review reading comprehension and aspect-based sentiment analysis. arXiv 2019, arXiv:1904.02232. [Google Scholar]
- Xie, Q.; Dai, Z.; Hovy, E.; Luong, T.; Le, Q. Unsupervised data augmentation for consistency training. Adv. Neural Inf. Process. Syst. 2020, 33, 6256–6268. [Google Scholar]
- Wei, J.; Zou, K. Eda: Easy data augmentation techniques for boosting performance on text classification tasks. arXiv 2019, arXiv:1901.11196. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subreddits | r/climatechange | r/climateskeptics | r/climate | r/ClimateOffensive | r/environment |
|---|---|---|---|---|---|
| Non-empty Posts | 1798 | 2121 | 2847 | 863 | 5899 |
| Comments w/o DA | 58,201 | 208,423 | 74,274 | 10,394 | 579,245 |
| Comments w/ DA | 79,327 | 381,645 | 93,071 | 17,394 | 839,572 |
| Model | r/climatechange | r/climateskeptics | r/climate | r/ClimateOffensive | r/environment | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | |
| IAN | 69.73 | 63.45 | 68.32 | 66.19 | 70.23 | 67.99 | 70.11 | 68.43 | 69.14 | 65.80 |
| ATAE-LSTM | 63.13 | 61.97 | 70.23 | 68.23 | 70.88 | 68.12 | 69.83 | 66.42 | 63.46 | 61.78 |
| IARM | 77.31 | 75.67 | 74.14 | 71.56 | 79.23 | 77.24 | 72.28 | 70.13 | 69.10 | 66.43 |
| MemNet | 79.13 | 77.23 | 80.13 | 74.32 | 82.45 | 79.13 | 80.53 | 78.13 | 81.34 | 77.63 |
| RAM | 82.13 | 80.44 | 83.13 | 80.34 | 80.13 | 76.34 | 83.14 | 80.42 | 79.13 | 77.48 |
| TransCap | 80.13 | 79.24 | 80.68 | 78.41 | 81.49 | 80.24 | 79.13 | 77.14 | 81.45 | 79.34 |
| PRET+MULT | 69.42 | 67.31 | 70.31 | 70.14 | 75.42 | 70.14 | 74.24 | 70.24 | 74.25 | 70.11 |
| BAT | 87.24 | 85.42 | 89.24 | 86.76 | 88.35 | 86.43 | 87.42 | 83.53 | 87.64 | 84.75 |
| BERT-PT | 89.35 | 87.53 | 89.96 | ♠87.50 | 90.64 | 89.53 | 91.54 | ♠89.64 | 91.54 | 89.34 |
| HAMCap (ours) | ♠92.42 | ♠89.43 | ♠91.45 | 87.35 | ♠94.23 | ♠90.64 | 90.35 | 87.54 | ♠95.24 | ♠92.35 |
| r/subreddit | r/climatechange | r/climate | r/environment | |||
|---|---|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | Acc. | F1 | |
| Ori. | 92.42 | 89.43 | 94.23 | 89.64 | 95.24 | 92.35 |
| -Conv | 4.34↓ | 6.45↓ | 5.25↓ | 7.52↓ | 5.76↓ | ♣8.49↓ |
| -HAM | 7.73↓ | 8.89↓ | 7.35↓ | ♣9.21↓ | 7.32↓ | 9.35↓ |
| -PCM | 8.77↓ | 9.45↓ | ♣9.54↓ | 8.35↓ | 6.34↓ | 8.56↓ |
| -Cap | ♣8.95↓ | 9.66↓ | 6.44↓ | 7.34↓ | 8.44↓ | 8.86↓ |
| r/subreddit | r/climatechange | r/climate | r/environment | |||
|---|---|---|---|---|---|---|
| Acc. | F1 | Acc. | F1 | Acc. | F1 | |
| Collab. | 93.28 | 90.11 | 92.57 | 88.96 | 94.66 | 92.37 |
| w/o sele. | 7.53↓ | 6.45↓ | 7.13↓ | 5.73↓ | 9.45↓ | 7.48↓ |
| UDA | 2.56↓ | 4.89↓ | 4.35↓ | 2.21↓ | 5.32↓ | 3.35↓ |
| EDA | 14.73↓ | 16.25↓ | 12.51↓ | 13.79↓ | 15.40↓ | 16.56↓ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, K.; Fujii, A. HAMCap: A Weak-Supervised Hybrid Attention-Based Capsule Neural Network for Fine-Grained Climate Change Debate Analysis. Big Data Cogn. Comput. 2023, 7, 166. https://doi.org/10.3390/bdcc7040166
Xiang K, Fujii A. HAMCap: A Weak-Supervised Hybrid Attention-Based Capsule Neural Network for Fine-Grained Climate Change Debate Analysis. Big Data and Cognitive Computing. 2023; 7(4):166. https://doi.org/10.3390/bdcc7040166
Chicago/Turabian StyleXiang, Kun, and Akihiro Fujii. 2023. "HAMCap: A Weak-Supervised Hybrid Attention-Based Capsule Neural Network for Fine-Grained Climate Change Debate Analysis" Big Data and Cognitive Computing 7, no. 4: 166. https://doi.org/10.3390/bdcc7040166
APA StyleXiang, K., & Fujii, A. (2023). HAMCap: A Weak-Supervised Hybrid Attention-Based Capsule Neural Network for Fine-Grained Climate Change Debate Analysis. Big Data and Cognitive Computing, 7(4), 166. https://doi.org/10.3390/bdcc7040166