

Impulsive Aggression Break, Based on Early Recognition Using Spatiotemporal Features


Abstract
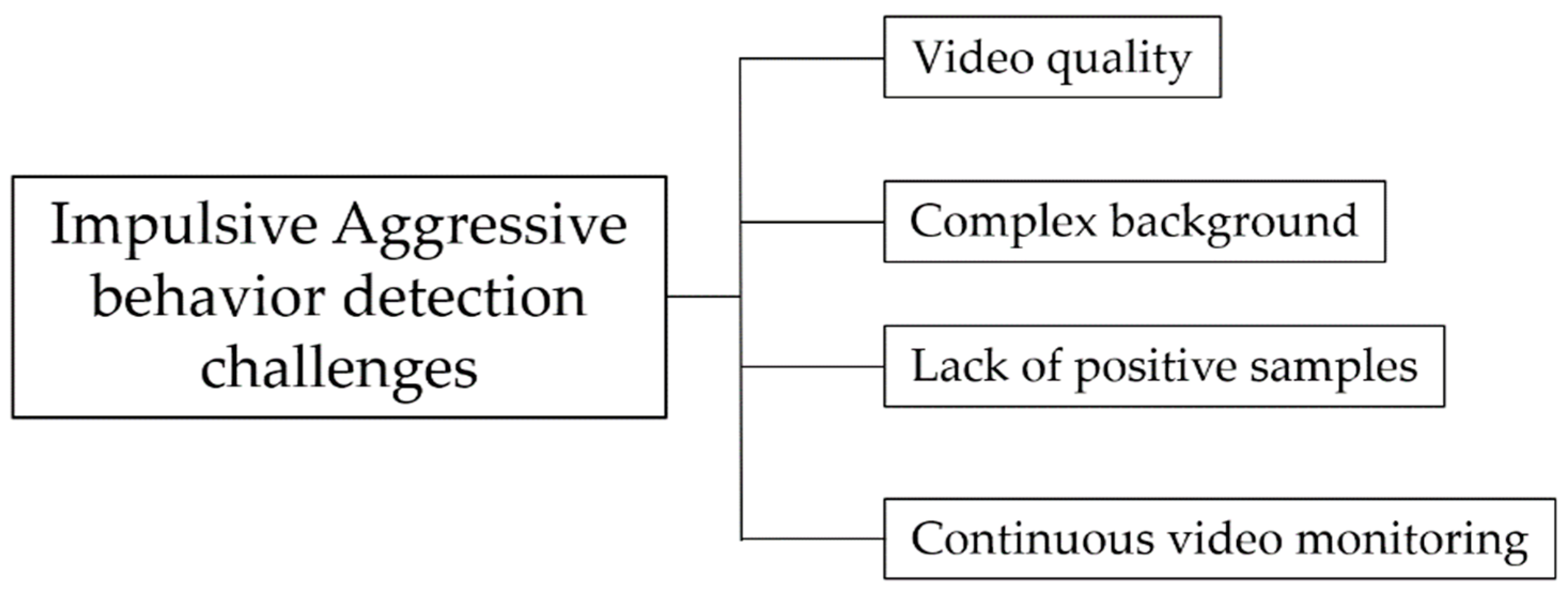
:1. Introduction
2. Literature Review
2.1. Handcrafted Features
2.2. Deep Learning
3. Proposed Work
3.1. Feature Engineering
3.1.1. Preprocessing Step
3.1.2. Spatiotemporal (ST) Feature Vector
- Temporal features: Optical flow is a commonly used method for temporal feature extraction. It represents the luminance variation of the motion region. The optical flow methods are made up of two types: sparse optical flow and dense optical flow. Sparse optical flow extracts motion features around points of interest as edges within the frame, while dense optical flow extracts motion features for all points in the frame. Dense optical flow shows a higher accuracy at the cost of being computationally expensive. After identifying the motion region in the video frame, the dense optical flow components and are extracted using the Gunnar method [48] for reliable accuracy. The temporal feature is the magnitude of vectors u and v for all pixels calculated using Equation (3).
3.1.3. STPCA Feature Vector
- //. Center data by subtracting input feature from its mean.
- //. Compute covariance matrix, where N is number of features.
- Determined //. Compute eigenvalues.
- Select eigenvalues for PCA n features which sustain the needed variance.
- //. Compute the eigenvectors matrix according to their eigenvalues.
- PCA features = .
3.1.4. STPCA + LDA Feature Vector
- //Center data
- //. Compute within-class covariance, where
- //. Compute eigenvectors
- LDA features = input features
3.1.5. Classification
3.2. Learned Features
4. Results and Discussion
4.1. Feature Engineering Results
4.2. Learned Feature Results
4.3. Comparison with the Literature
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Barsade, S.G. The ripple effect: Emotional contagion and its influence on group behavior. Adm. Sci. Q. 2002, 47, 644–675. [Google Scholar] [CrossRef]
- Hatfield, E.; Carpenter, M.; Rapson, R.L. Emotional contagion as a precursor to collective emotions. In Collective Emotions: Perspectives from Psychology, Philosophy, and Sociology; OUP Oxford: Oxford, UK, 2014; pp. 108–122. [Google Scholar]
- Slutkin, G.; Ransford, C. Violence is a contagious disease: Theory and practice in the USA and abroad. In Violence, Trauma, and Trauma Surgery: Ethical Issues, Interventions, and Innovations; Springer: New York, NY, USA, 2020; pp. 67–85. [Google Scholar]
- Green, M.W. The Appropriate and Effective Use of Security Technologies in US Schools: A Guide for Schools and Law Enforcement Agencies; US Department of Justice, Office of Justice Programs, National Institute of Justice: Washington, DC, USA, 1999.
- Khalid, S.; Khalil, T.; Nasreen, S. A survey of feature selection and feature extraction techniques in machine learning. In Proceedings of the 2014 Science and Information Conference, London, UK, 27–29 August 2014; IEEE: New York, NY, USA, 2014; pp. 372–378. [Google Scholar]
- Buhrmester, V.; Münch, D.; Arens, M. Analysis of explainers of black box deep neural networks for computer vision: A survey. Mach. Learn. Knowl. Extr. 2021, 3, 966–989. [Google Scholar] [CrossRef]
- Lin, C.E. Introduction to Motion Estimation with Optical Flow. 2020. Available online: https://nanonets. com/blog/optical-flow (accessed on 11 September 2023).
- Lejmi, W.; Khalifa, A.B.; Mahjoub, M.A. Fusion strategies for recognition of violence actions. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017. [Google Scholar]
- Khan, M.; Tahir, M.A.; Ahmed, Z. Detection of violent content in cartoon videos using multimedia content detection techniques. In Proceedings of the 2018 IEEE 21st International Multi-Topic Conference (INMIC), Karachi, Pakistan, 1–2 November 2018; pp. 1–5. [Google Scholar]
- Das, S.; Sarker, A.; Mahmud, T. Violence detection from videos using hog features. In Proceedings of the 2019 4th International Conference on Electrical Information and Communication Technology (EICT), Khulna, Bangladesh, 20–22 December 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar]
- Salman, M.; Yar, H.; Jan, T.; Rahman, K.U. Real-time Violence Detection in Surveillance Videos using RPi. In Proceedings of the 5th International Conference on Next Generation Computing, Chiang Mai, Thailand, 20–21 December 2019. [Google Scholar]
- Lamba, S.; Nain, N. Detecting anomalous crowd scenes by oriented Tracklets’ approach in active contour region. Multimed. Tools Appl. 2019, 78, 31101–31120. [Google Scholar] [CrossRef]
- Nadeem, M.S.; Franqueira, V.N.; Kurugollu, F.; Zhai, X. WVD: A new synthetic dataset for video-based violence detection. In Proceedings of the Artificial Intelligence XXXVI: 39th SGAI International Conference on Artificial Intelligence, Cambridge, UK, 17–19 December 2019. [Google Scholar]
- Jahagirdar, A.; Nagmode, M. A Novel Human Action Recognition and Behaviour Analysis Technique using SWFHOG. Int. J. Adv. Comput. Sci. Appl. 2020, 11. [Google Scholar] [CrossRef]
- Mahmoodi, J.; Salajeghe, A. A classification method based on optical flow for violence detection. Expert Syst. Appl. 2019, 127, 121–127. [Google Scholar] [CrossRef]
- Chen, S.; Li, T.; Niu, Y.; Cai, G. Fighting Detection Based on Hybrid Features. In Fuzzy Information and Engineering; John Wiley & Sons, Inc.: New York, NY, USA, 2020; pp. 37–50. [Google Scholar]
- Yao, C.; Su, X.; Wang, X.; Kang, X.; Zhang, J.; Motion, J.R. Direction Inconsistency-Based Fight Detection for Multiview Surveillance Videos. Wirel. Commun. Mob. Comput. 2021, 2021, 9965781. [Google Scholar] [CrossRef]
- Khalil, T.; Bangash, J.I.; Khan, A.W.; Lashari, S.A.; Khan, A.; Ramli, D.A. Detection of Violence in Cartoon Videos Using Visual Features. Procedia Comput. Sci. 2021, 192, 4962–4971. [Google Scholar] [CrossRef]
- Tian, Q.; Arbel, T.; Clark, J.J. Shannon information based adaptive sampling for action recognition. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; IEEE: New York, NY, USA, 2016; pp. 967–972. [Google Scholar]
- Wang, W.; Cheng, Y.; Liu, Y. A new method for violence detection based on the three dimensional scene flow. In Proceedings of the Three-Dimensional Image Acquisition and Display Technology and Applications, Beijing, China, 22–24 May 2018; Volume 10845, pp. 150–155. [Google Scholar]
- Deepak, K.; Vignesh, L.K.P.; Srivathsan, G.; Roshan, S.; Chandrakala, S. Statistical Features-Based Violence Detection in Surveillance Videos. In Cognitive Informatics and Soft Computing; Springer: Singapore, 2020; pp. 197–203. [Google Scholar]
- Deepak, K.; Vignesh, L.K.P.; Chandrakala, S.J. Autocorrelation of gradients based violence detection in surveillance videos. ICT Express 2020, 6, 155–159. [Google Scholar]
- Febin, I.P.; Jayasree, K.; Joy, P.T. Violence detection in videos for an intelligent surveillance system using MoBSIFT and movement filtering algorithm. Pattern Anal. Appl. 2020, 23, 611–623. [Google Scholar] [CrossRef]
- Pujol, F.A.; Mora, H.; Pertegal, M.L. A soft computing approach to violence detection in social media for smart cities. Soft Comput. 2020, 24, 11007–11017. [Google Scholar] [CrossRef]
- Lohithashva, B.H.; Aradhya, V.M. Violent video event detection: A local optimal oriented pattern based approach. In Proceedings of the Applied Intelligence and Informatics: First International Conference, AII 2021, Nottingham, UK, 30–31 July 2021; Proceedings 1. pp. 268–280. [Google Scholar]
- Serrano, I.; Deniz, O.; Espinosa-Aranda, J.L.; Bueno, G. Fight recognition in video using hough forests and 2D convolutional neural network. IEEE Trans. Image Process. 2018, 27, 4787–4797. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.U.; Haq, I.U.; Rho, S.; Baik, S.W.; Lee, M.Y. Cover the violence: A novel Deep-Learning-Based approach towards violence-detection in movies. Appl. Sci. 2019, 9, 4963. [Google Scholar] [CrossRef]
- Lejmi, W.; Khalifa, A.B.; Mahjoub, M.A. A Novel Spatio-Temporal Violence Classification Framework Based on Material Derivative and LSTM Neural Network. Trait. Du Signal 2020, 37, 687–701. [Google Scholar] [CrossRef]
- Su, Y.; Lin, G.; Zhu, J.; Wu, Q. Human interaction learning on 3d skeleton point clouds for video violence recognition. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. pp. 74–90. [Google Scholar]
- She, Q.; Mu, G.; Gan, H.; Fan, Y. Spatio-temporal SRU with global context-aware attention for 3D human action recognition. Multimed. Tools Appl. 2020, 79, 12349–12371. [Google Scholar] [CrossRef]
- Sharma, S.; Sudharsan, B.; Naraharisetti, S.; Trehan, V.; Jayavel, K. A fully integrated violence detection system using CNN and LSTM. Int. J. Electr. Comput. Eng. 2021, 11, 2088–8708. [Google Scholar] [CrossRef]
- Chatterjee, R.; Halder, R. Discrete Wavelet Transform for CNN-BiLSTM-Based Violence Detection. In Advances in Systems, Control and Automations; Springer: Singapore, 2021; pp. 41–52. [Google Scholar]
- Patel, M. Real-Time Violence Detection Using CNN-LSTM. arXiv 2021, arXiv:2107.07578. [Google Scholar]
- Asad, M.; Yang, J.; He, J.; Shamsolmoali, P.; He, X. Multi-frame feature-fusion-based model for violence detection. Vis. Comput. 2021, 37, 1415–1431. [Google Scholar] [CrossRef]
- Imah, E.M.; Laksono, I.K.; Karisma, K.; Wintarti, A. Detecting violent scenes in movies using Gated Recurrent Units and Discrete Wavelet Transform. Regist. J. Ilm. Teknol. Sist. Inf. 2022, 8, 94–103. [Google Scholar] [CrossRef]
- Vijeikis, R.; Raudonis, V.; Dervinis, G. Efficient violence detection in surveillance. Sensors 2022, 22, 2216. [Google Scholar] [CrossRef]
- Lejmi, W.; Khalifa, A.B.; Mahjoub, M.A. An Innovative Approach Towards Violence Recognition Based on Deep Belief Network. In Proceedings of the 2022 8th International Conference on Control, Decision and Information Technologies (CoDIT), Istanbul, Turkey, 17–20 May 2022. [Google Scholar]
- Aktl, Ş.; Ofli, F.; Imran, M.; Ekenel, H.K. Fight detection from still images in the wild. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 550–559. [Google Scholar]
- Da Silva, A.V.B.; Pereira, L.F.A. Handcrafted vs. Learned Features for Automatically Detecting Violence in Surveillance Footage. In Anais do XLIX Seminário Integrado de Software e Hardware; SBC: Porto Alegre, Brazil, 2022; pp. 82–91. [Google Scholar]
- Rendón-Segador, F.J.; Álvarez-García, J.A.; Salazar-González, J.L.; Tommasi, T. Crimenet: Neural structured learning using vision transformer for violence detection. Neural Netw. 2023, 161, 318–329. [Google Scholar] [CrossRef]
- Savadogo, W.A.R.; Lin, C.C.; Hung, C.C.; Chen, C.C.; Liu, Z.; Liu, T. A study on constructing an elderly abuse detection system by convolutional neural networks. J. Chin. Inst. Eng. 2023, 46, 1–10. [Google Scholar] [CrossRef]
- Verma, A.; Meenpal, T.; Acharya, B. Human interaction recognition in videos with body pose traversal analysis and pairwise interaction framework. IETE J. Res. 2023, 69, 46–58. [Google Scholar] [CrossRef]
- Huszár, V.D.; Adhikarla, V.K.; Négyesi, I.; Krasznay, C. Toward Fast and Accurate Violence Detection for Automated Video Surveillance Applications. IEEE Access 2023, 11, 18772–18793. [Google Scholar] [CrossRef]
- Mohammadi, H.; Nazerfard, E. Video violence recognition and localization using a semi-supervised hard attention model. Expert Syst. Appl. 2023, 212, 118791. [Google Scholar] [CrossRef]
- Elkhashab, Y.R.; El-Behaidy, W.H. Violence Detection Enhancement in Video Sequences Based on Pre-trained Deep Models. Int. J. Bull. Inform. 2023, 5, 23–28. [Google Scholar] [CrossRef]
- Islam, M.; Dukyil, A.S.; Alyahya, S.; Habib, S. An IoT Enable Anomaly Detection System for Smart City Surveillance. Sensors 2023, 23, 2358. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Farnebäck, G. Two-frame motion estimation based on polynomial expansion. In Proceedings of the Image Analysis: 13th Scandinavian Conference, SCIA 2003, Halmstad, Sweden, 29 June–2 July 2003. [Google Scholar]
- Zivkovic, Z.; Van Der Heijden, F. Efficient adaptive density estimation per image pixel for the task of background subtraction. Pattern Recognit. Lett. 2006, 27, 773–780. [Google Scholar] [CrossRef]
- Song, F.; Guo, Z.; Mei, D. Feature selection using principal component analysis. In Proceedings of the 2010 International Conference on System Science, Engineering Design and Manufacturing Informatization, Yichang, China, 12–14 November 2010; IEEE: New York, NY, USA, 2010; Volume 1, pp. 27–30. [Google Scholar]
- Gu, Q.; Li, Z.; Han, J. Linear discriminant dimensionality reduction. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2011, Athens, Greece, 5–9 September 2011. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Dallora, A.L.; Berglund, J.S.; Brogren, M.; Kvist, O.; Ruiz, S.D.; Dübbel, A.; Anderberg, P. Age assessment of youth and young adults using magnetic resonance imaging of the knee: A deep learning approach. JMIR Med. Inform. 2019, 7, e162. [Google Scholar] [CrossRef]
- Yun, K.; Honorio, J.; Chattopadhyay, D.; Berg, T.L.; Samaras, D. Two-person interaction detection using body-pose features and multiple instance learning. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; IEEE: New York, NY, USA, 2012; pp. 28–35. [Google Scholar]
- Bermejo Nievas, E.; Deniz Suarez, O.; Bueno García, G.; Sukthankar, R. Violence detection in video using computer vision techniques. In Proceedings of the Computer Analysis of Images and Patterns: 14th International Conference, CAIP 2011, Seville, Spain, 29–31 August 2011. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
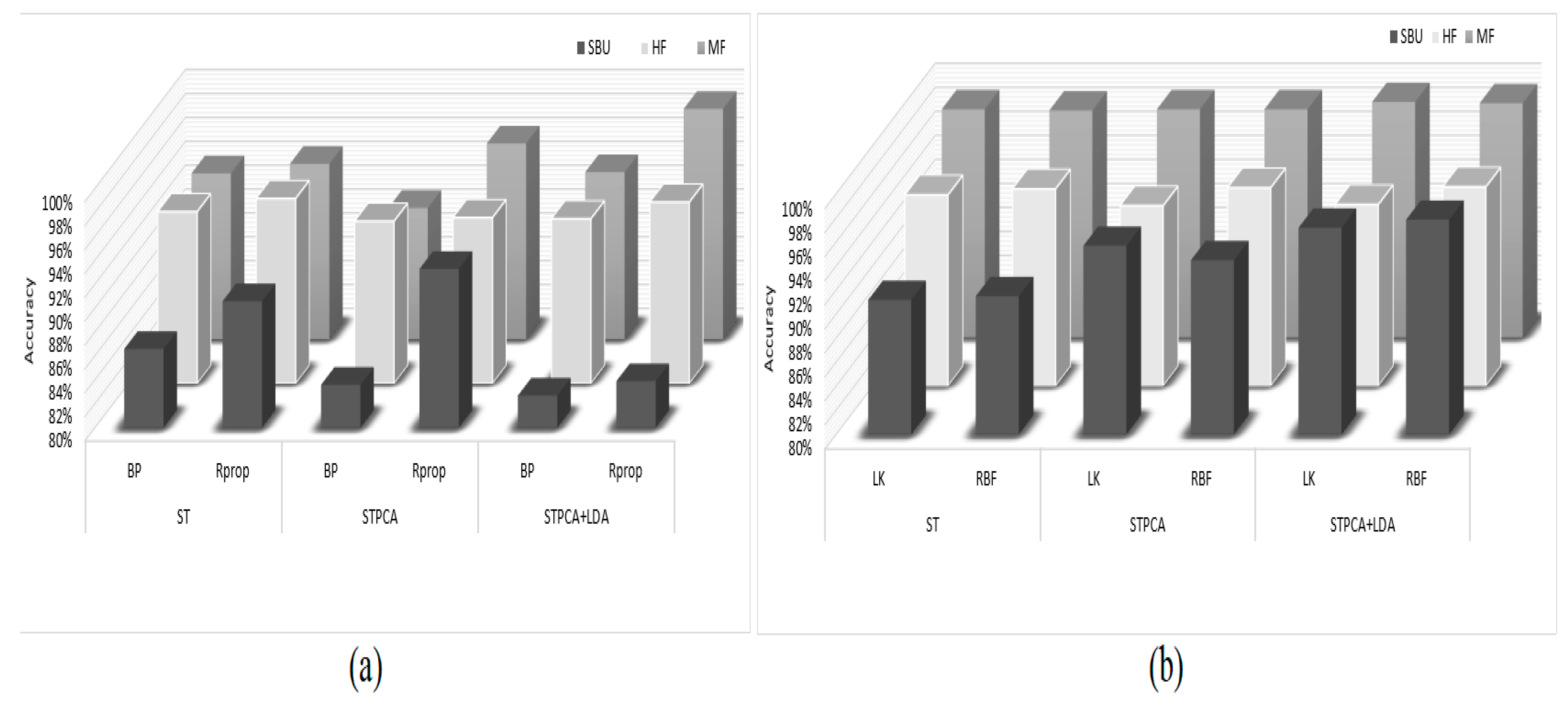
| SBU | HF | MF | ||
|---|---|---|---|---|
| ST | BP | 86.6% | 94.4% | 93.9% |
| Rprop | 90.6% | 95.5% | 94.7% | |
| STPCA | BP | 83.6% | 93.6% | 91% |
| Rprop | 93.3% | 93.9% | 96.4% | |
| STPCA + LDA | BP | 82.7% | 93.8% | 94% |
| Rprop | 83.9% | 95.2% | 99.3% |
| SBU | HF | MF | ||
|---|---|---|---|---|
| ST | LK | 91.2% | 95.9% | 99% |
| RBF | 91.5% | 96.4% | 98.9% | |
| STPCA | LK | 95.7% | 95% | 99% |
| RBF | 94.5% | 96.50% | 99% | |
| STPCA + LDA | LK | 97.2% | 95.1% | 99.6% |
| RBF | 97.87% | 96.57% | 99.5% |
| SBU_Dataset | HF_Dataset | MF_Dataset | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TR_t | ACC | F1 | Pr | TPR | TR_t | ACC | F1 | Pr | TPR | TR_t | ACC | F1 | Pr | TPR | |
| ST | 1.31 m | 91.5% | 0.897 | 0.89 | 0.9 | 22.08 m | 96.4% | 0.964 | 0.965 | 0.96 | 4.4 m | 98.9% | 0.989 | 0.984 | 0.99 |
| STPCA | 1.08 m | 94.5% | 0.93 | 0.93 | 0.92 | 9.45 m | 96.5% | 0.964 | 0.97 | 0.96 | 3.55 m | 99.07% | 0.99 | 0.98 | 0.99 |
| STPCA_LDA | 1.06 m | 97.8% | 0.974 | 0.97 | 0.977 | 9.3 m | 96.57% | 0.965 | 0.97 | 0.96 | 3.51 m | 99.6% | 0.99 | 0.99 | 1 |
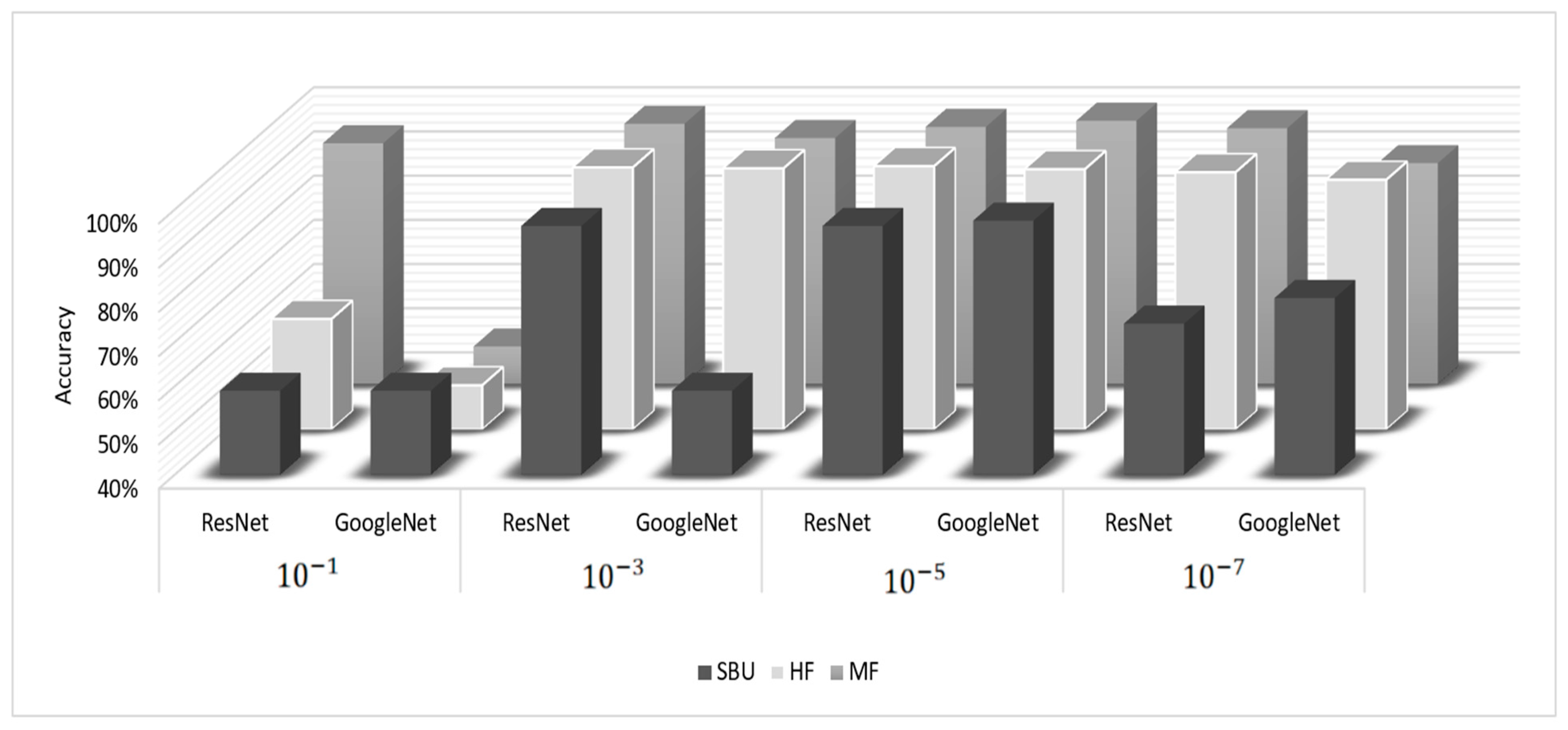
| Learning Rate | Model | SBU | HF | MF |
|---|---|---|---|---|
| ResNet | 59.0% | 65.0% | 94.5% | |
| GoogleNet | 59.0% | 50.0% | 48.5% | |
| ResNet | 96.3% | 99.3% | 98.9% | |
| GoogleNet | 59.0% | 99.1% | 95.7% | |
| ResNet | 96.3% | 99.6% | 98.2% | |
| GoogleNet | 97.5% | 98.9% | 99.6% | |
| ResNet | 74.2% | 98.2% | 97.9% | |
| GoogleNet | 80% | 96.5% | 90.0% |
| SBU_Dataset | HF_Dataset | MF_Dataset | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ATR_t | ACC | F1 | Pr | TPR | ATR_t | ACC | F1 | Pr | TPR | ATR_t | ACC | F1 | Pr | TPR | |
| ResNet | 14.1 m | 96.36% | 0.95 | 0.96 | 0.94 | 2.81 h | 99.6% | 0.99 | 0.99 | 0.99 | 46.37 m | 98.28% | 0.98 | 0.96 | 1 |
| GoogleNet | 5.26 m | 97.5% | 0.97 | 0.97 | 0.97 | 1.46 h | 98.9% | 0.98 | 0.98 | 0.99 | 21.86 m | 99.6% | 0.99 | 0.99 | 0.99 |
| SBU_Dataset | HF_Dataset | MF_Dataset | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TR_t | ACC | F1 | Pr | TPR | TR_t | ACC | F1 | Pr | TPR | TR_t | ACC | F1 | Pr | TPR | |
| GoogleNet | 5.26 m | 97.5% | 0.97 | 0.97 | 0.97 | 1.46 h | 98.9% | 0.98 | 0.98 | 0.99 | 21.86 m | 99.6% | 0.99 | 0.99 | 0.99 |
| STPCA_LDA | 1.06 m | 97.8% | 0.974 | 0.97 | 0.977 | 9.3 m | 96.57% | 0.965 | 0.97 | 0.96 | 3.51 m | 99.6% | 0.99 | 0.99 | 1 |
| Author | Method | Acc |
|---|---|---|
| Lejmi et al. [37] | DBN | 65.5% |
| Lejmi et al. [28] | LSTM | 84.62% |
| Verma et al. [42] | TNN/PIF | 93.9% |
| She et al. [30] | GCA-ST_SRU | 94% |
| Jahagirdar and Nagmode [14] | SWFHOG_FNN | 95.74% |
| Pujol et al. [24] | LE + HOA + HSGA_SVM | 97.85% |
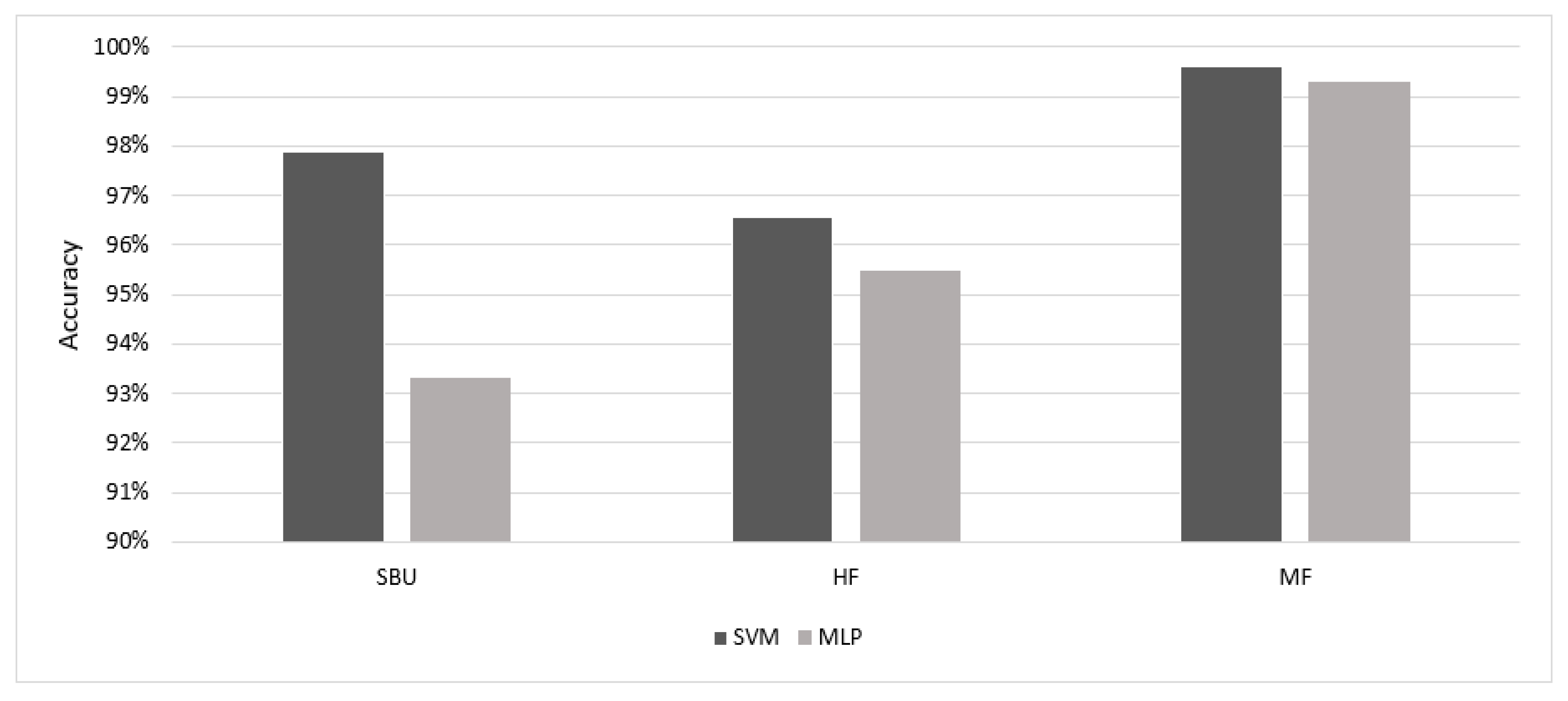
| Learned features | GoogleNet | 97.5% |
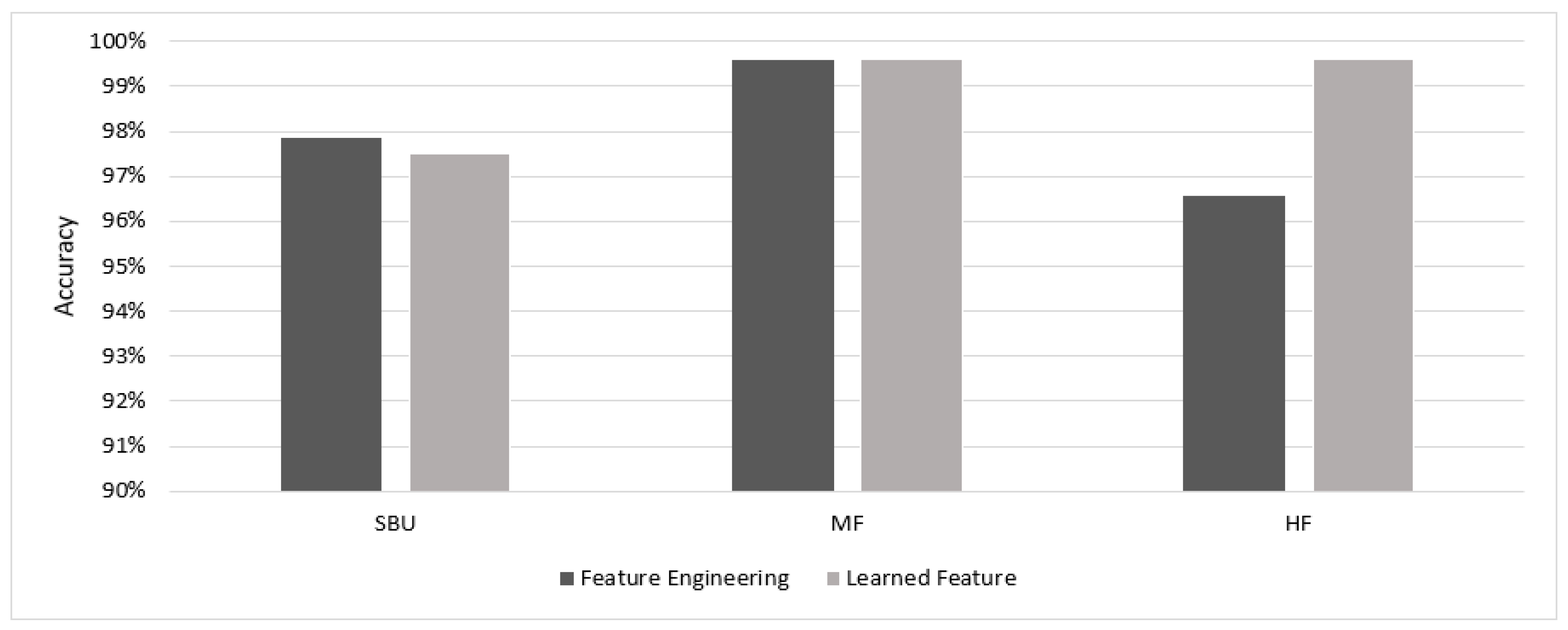
| Feature engineering | STPCA + LDA-SVM | 97.87% |
| Author | Method | Acc |
|---|---|---|
| Khan et al. [27] | MobileNet | 87% |
| Da Silva and Pereira [39] | VGG-19 | 88.4% |
| Patel [33] | ResNet-LSTM | 89.5% |
| Deepak et al. [22] | STACOG_SVM | 90.4% |
| Deepak et al. [21] | HoF + statistical features_SVM | 91.5% |
| Chen et al. [16] | optical flow_SVM | 92.7% |
| Chatterjee and Halder [32] | CNN-BiLSTM | 94.06% |
| Elkhashab et al. [45] | DenseNet_121-LSTM | 96% |
| Vijeikis et al. [36] | MobileNet-LSTM | 96.1% |
| Learned features | Resnet-50 | 99.6% |
| Feature engineering | STPCA + LDA-SVM | 96.57% |
| Author | Method | Acc |
|---|---|---|
| Imah et al. [35] | DWT-GRU | 96% |
| Sharma et al. [31] | Xception-LSTM | 98.32% |
| Su et al. [29] | SPIL | 98.5% |
| Febin et al. [23] | MoBSIFT_RF | 98.9% |
| Serrano et al. [26] | 2D-CNN | 99% |
| Asad et al. [34] | 2D-CNN-LSTM | 99.1% |
| Vijeikis et al. [36] | MobileNet-LSTM | 99.5% |
| Khan et al. [27] | MobileNet | 99.5% |
| Mohammadi and Nazerfard [44] | SSHA | 99.5% |
| Learned features | GoogleNet | 99.6% |
| Feature engineering | STPCA + LDA-SVM | 99.6% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Donia, M.M.F.; El-Behaidy, W.H.; Youssif, A.A.A. Impulsive Aggression Break, Based on Early Recognition Using Spatiotemporal Features. Big Data Cogn. Comput. 2023, 7, 150. https://doi.org/10.3390/bdcc7030150
Donia MMF, El-Behaidy WH, Youssif AAA. Impulsive Aggression Break, Based on Early Recognition Using Spatiotemporal Features. Big Data and Cognitive Computing. 2023; 7(3):150. https://doi.org/10.3390/bdcc7030150
Chicago/Turabian StyleDonia, Manar M. F., Wessam H. El-Behaidy, and Aliaa A. A. Youssif. 2023. "Impulsive Aggression Break, Based on Early Recognition Using Spatiotemporal Features" Big Data and Cognitive Computing 7, no. 3: 150. https://doi.org/10.3390/bdcc7030150
APA StyleDonia, M. M. F., El-Behaidy, W. H., & Youssif, A. A. A. (2023). Impulsive Aggression Break, Based on Early Recognition Using Spatiotemporal Features. Big Data and Cognitive Computing, 7(3), 150. https://doi.org/10.3390/bdcc7030150