

Predicting the Price of Bitcoin Using Sentiment-Enriched Time Series Forecasting


Abstract
1. Introduction
- We propose a new hybrid method that integrates time series forecasting and sentiment analysis based on a fine-tuned BERT model, featuring a novel weighting scheme to aggregate multiple sentiment scores from a given period into a single sentiment score.
- We thoroughly investigate our approach, which spans, compared to previous research, both longer and more diverse price ranges and market scenarios, making the task more realistic but also much harder.
- Using this setup, we show that our approach outperforms previous ones. In particular, we empirically show that both our BERT model fine-tuned for sentiment analysis and our novel weighting scheme improve forecasts in terms of predictive accuracy (MAE and RMSE) compared to other setups. Moreover, we show that simpler models, particularly linear regression models, tend to perform best, while more complex models have issues with overfitting.
2. Related Work
2.1. Time Series Forecasting for Cryptocurrencies
2.2. Sentiment Analysis
2.3. Combining Time Series Forecasting with Sentiment Scores

{kind=link}
{kind=link}
{kind=link}
| Ref. | Year | Pred. Target | Granularity | Model | Additional Features |
|---|---|---|---|---|---|
| [55] | 2020 | binary | 1 min | random forest | VADER SA |
| [54] | 2022 | value | 30 min | stacking ensemble of LSTM, GRU | VADER SA, trading features |
| [56] | 2022 | value | 12 h | vector autoregression | VADER SA |
| [57] | 2018 | value | 1 day | linear regression | VADER SA, tweet volume, Google Trends |
| [58] | 2019 | value | 1 day | LSTM, vanilla RNN, linear regression, polynomial regression | VADER SA, tweet volume, Google Trends |
| [14] | 2019 | value | 1 day | 10 different models | VADER SA, Google Trends |
| [13] | 2020 | value | 1 day | LSTM, ARIMAX | VADER SA, tweet volume |
| [59] | 2022 | binary | 1 min | XGBoost | VADER SA, tweet volume, user-related features |
2.4. Research Gaps and Novel Contributions
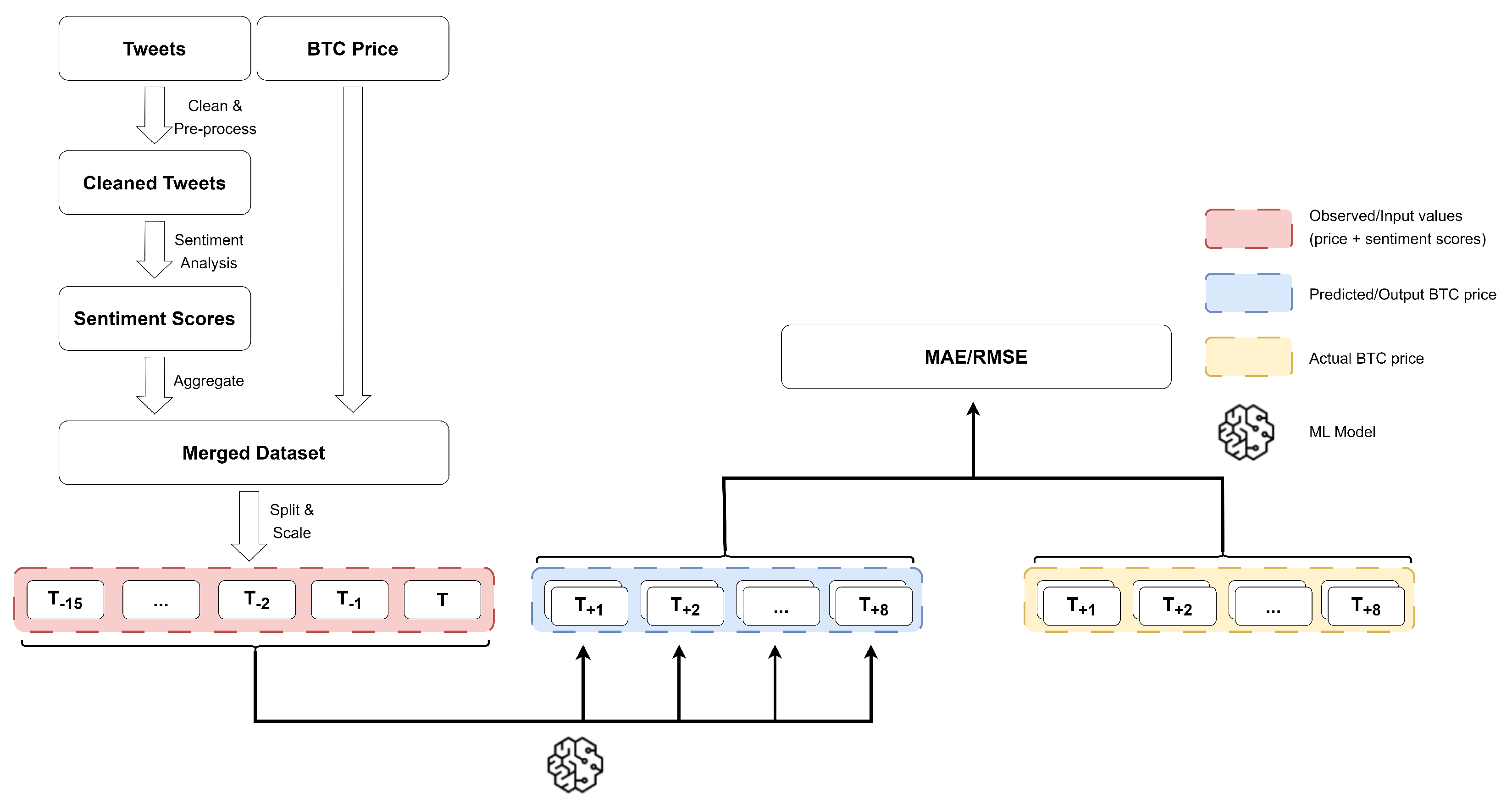
3. Methodology
3.1. Forecasting BTC Price
3.1.1. Baselines
3.1.2. Long Short-Term Memory Network
3.1.3. Temporal Convolutional Networks
3.1.4. D-Linear
3.1.5. Linear Regression
3.2. Sentiment Analysis
3.2.1. VADER Sentiment Analysis
3.2.2. BERT-Based Sentiment Analysis
3.3. Data Acquisition and Processing

3.3.1. Data Collection
3.3.2. Text Pre-Processing
3.3.3. Data Aggregation
3.3.4. Data Source Merging and Splitting
4. Evaluation and Discussion
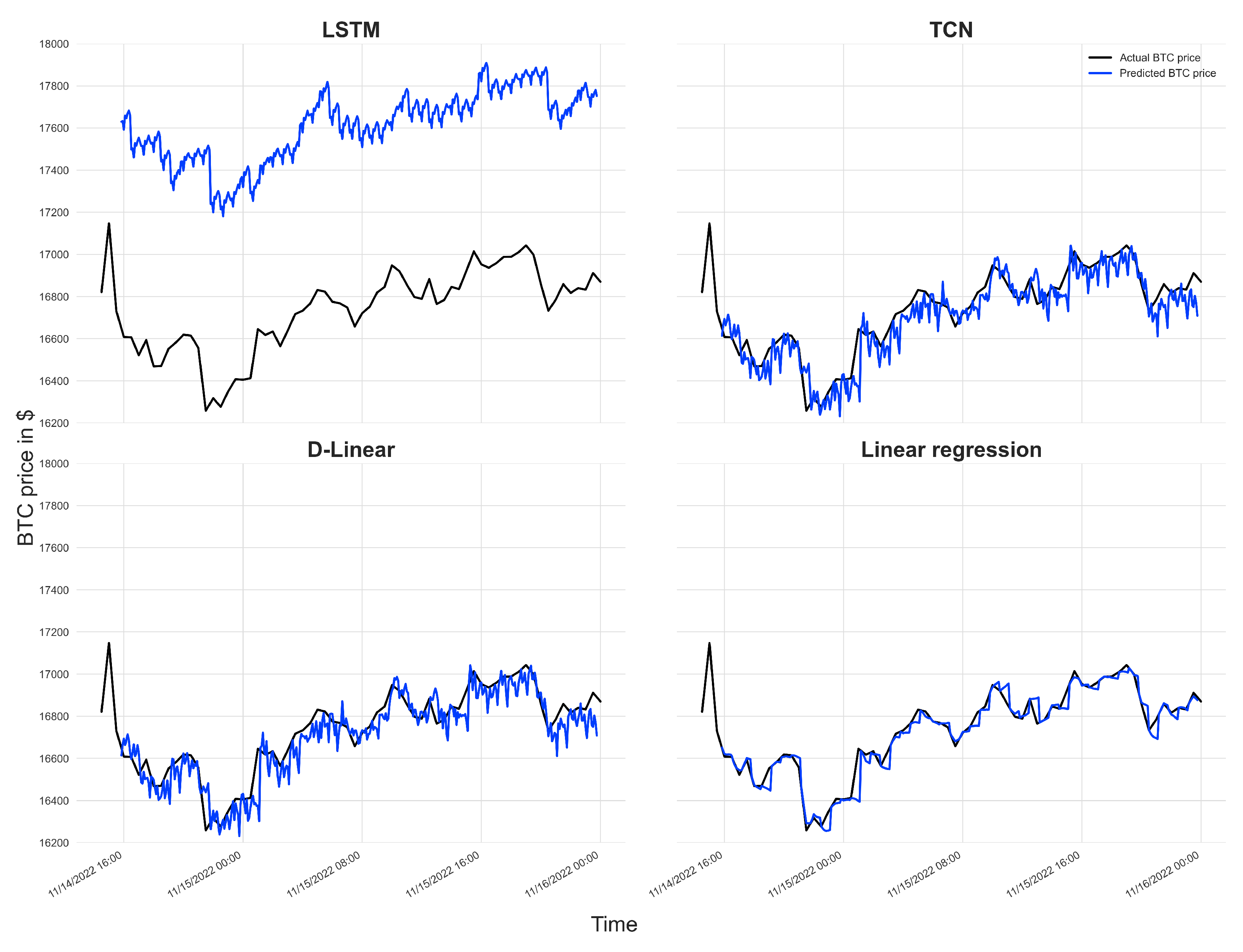
4.1. Model Comparison
4.2. Feature Comparison
4.3. Weighting Comparison
4.4. Comparison with Other Research Works
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AUC | Area Under Curve |
| BERT | Bidirectional Encoder Representations from Transformers |
| BTC | Bitcoin |
| ED | Emotion Detection |
| ES | Exponential Smoothing |
| FFT | Fast Fourier Transform |
| GRU | Gated Recurrent Unit |
| LSTM | Long Short-Term Memory |
| LR | Linear regression |
| MAE | Mean Absolute Error |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| NLP | Natural Language Processing |
| RMSE | Root Mean Squared Error |
| RNN | Recurrent Neural Network |
| SA | Sentiment Analysis |
| TCN | Temporal Convolutional Network |
| VADER | Valence Aware Dictionary and sEntiment Reasoner |
References
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System. 2008. Available online: https://bitcoin.org/bitcoin.pdf (accessed on 1 December 2022).
- Patel, M.M.; Tanwar, S.; Gupta, R.; Kumar, N. A Deep Learning-based Cryptocurrency Price Prediction Scheme for Financial Institutions. J. Inf. Secur. Appl. 2020, 55, 102583. [Google Scholar] [CrossRef]
- Peterson, T. To the moon: A history of Bitcoin price manipulation. J. Forensic Investig. Account. 2021, 13, 2. [Google Scholar] [CrossRef]
- Sovbetov, Y. Factors influencing cryptocurrency prices: Evidence from bitcoin, ethereum, dash, litcoin, and monero. J. Econ. Financ. Anal. 2018, 2, 1–27. [Google Scholar]
- Schilling, L.; Uhlig, H. Some simple bitcoin economics. J. Monet. Econ. 2019, 106, 16–26. [Google Scholar] [CrossRef]
- Karau, S. Monetary Policy and Bitcoin. J. Int. Money Financ. 2023, 137, 102880. [Google Scholar] [CrossRef]
- Vujičić, D.; Jagodić, D.; Ranđić, S. Blockchain technology, bitcoin and ethereum: A brief overview. In Proceedings of the 2018 17th International Symposium INFOTEH-JAHORINA (INFOTEH), East Sarajevo, Bosnia and Herzegovina, 21–23 March 2018; p. 6. [Google Scholar] [CrossRef]
- Ciaian, P.; Rajcaniova, M.; d’Artis Kancs. The economics of BitCoin price formation. Appl. Econ. 2016, 48, 1799–1815. [Google Scholar] [CrossRef]
- Mudassir, M.; Bennbaia, S.; Unal, D. Time-Series Forecasting of Bitcoin Prices Using High-Dimensional Features: A ML Approach; Springer: Berlin/Heidelberg, Germany, 2020; p. 15. [Google Scholar] [CrossRef]
- Pano, T.; Kashef, R. A Complete VADER-Based Sentiment Analysis of Bitcoin (BTC) Tweets during the Era of COVID-19. Big Data Cogn. Comput. 2020, 4, 33. [Google Scholar] [CrossRef]
- Vella Critien, J.; Gatt, A.; Ellul, J. Bitcoin price change and trend prediction through twitter sentiment and data volume. J. Financ. Innov. 2022, 8, 45. [Google Scholar] [CrossRef]
- Pant, D.R.; Neupane, P.; Poudel, A.; Pokhrel, A.K.; Lama, B.K. Recurrent Neural Network Based Bitcoin Price Prediction by Twitter Sentiment Analysis. In Proceedings of the 2018 IEEE 3rd International Conference on Computing, Communication and Security (ICCCS), Kathmandu, Nepal, 25–27 October 2018; pp. 128–132. [Google Scholar] [CrossRef]
- Serafini, G.; Yi, P.; Zhang, Q.; Brambilla, M.; Wang, J.; Hu, Y.; Li, B. Sentiment-Driven Price Prediction of the Bitcoin based on Statistical and Deep Learning Approaches. In Proceedings of the 2020 International Joint Conference on Neural Networks IJCNN, Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Wołk, K. Advanced social media sentiment analysis for short-term cryptocurrency price prediction. Expert Syst. 2020, 37, e12493. [Google Scholar] [CrossRef]
- Vyas, P.; Vyas, G.; Dhiman, G. RUemo—The Classification Framework for Russia-Ukraine War-Related Societal Emotions on Twitter through Machine Learning. Algorithms 2023, 16, 69. [Google Scholar] [CrossRef]
- Zhou, B.; Zou, L.; Mostafavi, A.; Lin, B.; Yang, M.; Gharaibeh, N.; Cai, H.; Abedin, J.; Mandal, D. VictimFinder: Harvesting rescue requests in disaster response from social media with BERT. Comput. Environ. Urban Syst. 2022, 95, 101824. [Google Scholar] [CrossRef]
- Mateen, M. Regulation in the Cryptocurrency Industry. Ph.D. Thesis, University of Missouri–Kansas City, Kansas City, MO, USA, 2023. Available online: https://mospace.umsystem.edu/xmlui/handle/10355/95309 (accessed on 18 April 2023).
- Fu, S.; Wang, Q.; Yu, J.; Chen, S. FTX collapse: A Ponzi story. arXiv 2022, arXiv:2212.09436. [Google Scholar]
- Boutsoukis, A. Near Real-Time Cryptocurrency Sentiment Analysis. 2023. Available online: https://repository.ihu.edu.gr/xmlui/bitstream/handle/11544/30143/a.boutsoukis_ds.pdf (accessed on 12 January 2023).
- Akyildirim, E.; Aysan, A.F.; Cepni, O.; Darendeli, S.P.C. Do investor sentiments drive cryptocurrency prices? Econ. Lett. 2021, 206, 109980. [Google Scholar] [CrossRef]
- Kim, H.J.; Hong, J.S.; Hwang, H.C.; Kim, S.M.; Han, D.H. Comparison of Psychological Status and Investment Style between Bitcoin Investors and Share Investors. Front. Psychol. 2020, 11, 502295. [Google Scholar] [CrossRef]
- Das, N.; Sadhukhan, B.; Chatterjee, T.; Chakrabarti, S. Effect of public sentiment on stock market movement prediction during the COVID-19 outbreak. Soc. Netw. Anal. Min. 2022, 12, 92. [Google Scholar] [CrossRef]
- Gurdgiev, C.; O’Loughlin, D. Herding and anchoring in cryptocurrency markets: Investor reaction to fear and uncertainty. J. Behav. Exp. Financ. 2020, 25, 100271. [Google Scholar] [CrossRef]
- Nandwani, P.; Verma, R. A review on sentiment analysis and emotion detection from text. Soc. Netw. Anal. Min. 2021, 11, 81. [Google Scholar] [CrossRef]
- Barberis, N.; Shleifer, A.; Vishny, R. A Model of Investor Sentiment. J. Financ. Econ. 1998, 49, 307–343. [Google Scholar] [CrossRef]
- Hutto, C.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. Proc. Int. AAAI Conf. Web Soc. Media 2014, 8, 216–225. [Google Scholar] [CrossRef]
- Al-Shabi, M. Evaluating the performance of the most important Lexicons used to Sentiment analysis and opinions Mining. IJCSNS 2020, 20, 1. [Google Scholar]
- Baly, R.; El-Khoury, G.; Moukalled, R.; Aoun, R.; Hajj, H.; Shaban, K.B.; El-Hajj, W. Comparative Evaluation of Sentiment Analysis Methods Across Arabic Dialects. Procedia Comput. Sci. 2017, 117, 266–273. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; (Long and ShortPapers). Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Vu, T.; Nguyen, A.T. BERTweet: A pre-trained language model for English Tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 9–14. [Google Scholar]
- Liu, Z.; Zhu, Z.; Gao, J.; Xu, C. Forecast Methods for Time Series Data: A Survey. IEEE Access 2021, 9, 91896–91912. [Google Scholar] [CrossRef]
- Lindemann, B.; Müller, T.; Vietz, H.; Jazdi, N.; Weyrich, M. A survey on long short-term memory networks for time series prediction. Procedia Cirp 2021, 99, 650–655. [Google Scholar] [CrossRef]
- Gers, F.A.; Eck, D.; Schmidhuber, J. Applying LSTM to Time Series Predictable through Time-Window Approaches. In Proceedings of the Artificial Neural Networks—ICANN 2001, Vienna, Austria, 21–25 August 2001; Dorffner, G., Bischof, H., Hornik, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2130, pp. 669–676. [Google Scholar] [CrossRef]
- Jaquart, P.; Köpke, S.; Weinhardt, C. Machine learning for cryptocurrency market prediction and trading. J. Financ. Data Sci. 2022, 8, 331–352. [Google Scholar] [CrossRef]
- Uras, N.; Marchesi, L.; Marchesi, M.; Tonelli, R. Forecasting Bitcoin closing price series using linear regression and neural networks models. Peerj Comput. Sci. 2020, 6, e279. [Google Scholar] [CrossRef]
- Hamayel, M.J.; Owda, A.Y. A Novel Cryptocurrency Price Prediction Model Using GRU, LSTM and bi-LSTM Machine Learning Algorithms. AI 2021, 2, 477–496. [Google Scholar] [CrossRef]
- Dimitriadou, A.; Gregoriou, A. Predicting Bitcoin Prices Using Machine Learning. Entropy 2023, 25, 777. [Google Scholar] [CrossRef] [PubMed]
- Birjali, M.; Kasri, M.; Hssane, A.B. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl. Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Balci, S.; Demirci, G.M.; Demirhan, H.; Sarp, S. Sentiment Analysis Using State of the Art Machine Learning Techniques. In Proceedings of the Digital Interaction and Machine Intelligence—Proceedings of MIDI’2021 - 9th Machine Intelligence and Digital Interaction Conference, Warsaw, Poland, 9–10 December 2021; Biele, C., Kacprzyk, J., Kopec, W., Owsinski, J.W., Romanowski, A., Sikorski, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2022; Volume 440, pp. 34–42. [Google Scholar] [CrossRef]
- Vyas, P.; Reisslein, M.; Rimal, B.P.; Vyas, G.; Basyal, G.P.; Muzumdar, P. Automated Classification of Societal Sentiments on Twitter With Machine Learning. IEEE Trans. Technol. Soc. 2022, 3, 100–110. [Google Scholar] [CrossRef]
- Hoque, M.U.; Lee, K.; Beyer, J.L.; Curran, S.R.; Gonser, K.S.; Lam, N.S.N.; Mihunov, V.V.; Wang, K. Analyzing Tweeting Patterns and Public Engagement on Twitter During the Recognition Period of the COVID-19 Pandemic: A Study of Two U.S. States. IEEE Access 2022, 10, 72879–72894. [Google Scholar] [CrossRef]
- Aslam, N.; Xia, K.; Rustam, F.; Hameed, A.; Ashraf, I. Using Aspect-Level Sentiments for Calling App Recommendation with Hybrid Deep-Learning Models. Appl. Sci. 2022, 12, 8522. [Google Scholar] [CrossRef]
- Balaji, P.; Haritha, D. An Ensemble Multi-Layered Sentiment Analysis Model (EMLSA) for Classifying the Complex Datasets. Int. J. Adv. Comput. Sci. Appl. 2023, 14. [Google Scholar] [CrossRef]
- Loria, S. textblob Documentation. Release 0.15 2018, 2, 269. [Google Scholar]
- Gujjar, J.P.; Kumar, H.P. Sentiment analysis: Textblob for decision making. Int. J. Sci. Res. Eng. Trends 2021, 7, 1097–1099. [Google Scholar]
- Aljedaani, W.; Rustam, F.; Mkaouer, M.W.; Ghallab, A.; Rupapara, V.; Washington, P.B.; Lee, E.; Ashraf, I. Sentiment analysis on Twitter data integrating TextBlob and deep learning models: The case of US airline industry. Knowl.-Based Syst. 2022, 255, 109780. [Google Scholar] [CrossRef]
- Aslam, N.; Rustam, F.; Lee, E.; Washington, P.B.; Ashraf, I. Sentiment Analysis and Emotion Detection on Cryptocurrency Related Tweets Using Ensemble LSTM-GRU Model. IEEE Access 2022, 10, 39313–39324. [Google Scholar] [CrossRef]
- Zhang, L.; Wang, S.; Liu, B. Deep learning for sentiment analysis: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1253. [Google Scholar] [CrossRef]
- Dos Santos, C.; Gatti, M. Deep convolutional neural networks for sentiment analysis of short texts. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 69–78. [Google Scholar]
- Zou, Y.; Gui, T.; Zhang, Q.; Huang, X.J. A lexicon-based supervised attention model for neural sentiment analysis. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 21–25 August 2018; pp. 868–877. [Google Scholar]
- Pérez, J.M.; Giudici, J.C.; Luque, F. Pysentimiento: A Python Toolkit for Sentiment Analysis and SocialNLP tasks. arXiv 2021, arXiv:2106.09462. [Google Scholar]
- Swathi, T.; Kasiviswanath, N.; Rao, A. An optimal deep learning-based LSTM for stock price prediction using twitter sentiment analysis. Appl. Intell. 2022, 52, 13675–13688. [Google Scholar] [CrossRef]
- Mehtab, S.; Sen, J. A Robust Predictive Model for Stock Price Prediction Using Deep Learning and Natural Language Processing. arXiv 2019, arXiv:1912.07700,. [Google Scholar] [CrossRef]
- Ye, Z.; Wu, Y.; Chen, H.; Pan, Y.; Jiang, Q. A Stacking Ensemble Deep Learning Model for Bitcoin Price Prediction Using Twitter Comments on Bitcoin. Mathematics 2022, 10, 1307. [Google Scholar] [CrossRef]
- Sattarov, O.; Jeon, H.S.; Oh, R.; Lee, J.D. Forecasting Bitcoin Price Fluctuation by Twitter Sentiment Analysis. In Proceedings of the 2020 International Conference on Information Science and Communications Technologies (ICISCT), Tashkent, Uzbekistan, 4–6 November 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Oikonomopoulos, S.; Tzafilkou, K.; Karapiperis, D.; Verykios, V.S. Cryptocurrency Price Prediction using Social Media Sentiment Analysis. In Proceedings of the 13th International Conference on Information, Intelligence, Systems & Applications, IISA 2022, Corfu, Greece, 18–20 July 2022; Bourbakis, N.G., Tsihrintzis, G.A., Virvou, M., Eds.; IEEE: Piscataway, NJ, USA, 2022; pp. 1–8. [Google Scholar] [CrossRef]
- Abraham, J.; Higdon, D.W.; Nelson, J.; Ibarra, J. Cryptocurrency Price Prediction Using Tweet Volumes and Sentiment Analysis. Smu Data Sci. Rev. 2018, 1, 1. [Google Scholar]
- Mittal, A.; Dhiman, V.; Singh, A.; Prakash, C. Short-Term Bitcoin Price Fluctuation Prediction Using Social Media and Web Search Data. In Proceedings of the 2019 Twelfth International Conference on Contemporary Computing (IC3), Noida, India, 8–10 August 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Edgari, E.; Thiojaya, J.; Qomariyah, N.N. The Impact of Twitter Sentiment Analysis on Bitcoin Price during COVID-19 with XGBoost. In Proceedings of the 2022 5th International Conference on Computing and Informatics (ICCI), New Cairo, Cairo, Egypt, 9–10 March 2022; pp. 337–342. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Lea, C.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal Convolutional Networks: A Unified Approach to Action Segmentation. In Proceedings of the Computer Vision–ECCV 2016 Workshops, Amsterdam, The Netherlands, 8–10 and 15–16 October 2016. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are Transformers Effective for Time Series Forecasting? arXiv 2022, arXiv:2205.13504. [Google Scholar] [CrossRef]
- Herzen, J.; Lässig, F.; Piazzetta, S.G.; Neuer, T.; Tafti, L.; Raille, G.; Pottelbergh, T.V.; Pasieka, M.; Skrodzki, A.; Huguenin, N.; et al. Darts: User-Friendly Modern Machine Learning for Time Series. J. Mach. Learn. Res. 2022, 23, 1–6. [Google Scholar]
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic Differentiation in Pytorch. 2017. Available online: https://openreview.net/pdf?id=BJJsrmfCZ (accessed on 9 April 2023).
- Ferdiansyah, F.; Othman, S.H.; Zahilah Raja Md Radzi, R.; Stiawan, D.; Sazaki, Y.; Ependi, U. A LSTM-Method for Bitcoin Price Prediction: A Case Study Yahoo Finance Stock Market. In Proceedings of the 2019 International Conference on Electrical Engineering and Computer Science (ICECOS), Batam, Indonesia, 2–3 October 2019; pp. 206–210. [Google Scholar] [CrossRef]
- Guo, H.; Zhang, D.; Liu, S.; Wang, L.; Ding, Y. Bitcoin price forecasting: A perspective of underlying blockchain transactions. Decis. Support Syst. 2021, 151, 113650. [Google Scholar] [CrossRef]
- Sharma, A.; Bhuriya, D.; Singh, U. Survey of stock market prediction using machine learning approach. In Proceedings of the 2017 International conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; Volume 2, pp. 506–509. [Google Scholar] [CrossRef]
- Awan, M.J.; Rahim, M.S.M.; Nobanee, H.; Munawar, A.; Yasin, A.; Zain, A.M. Social Media and Stock Market Prediction: A Big Data Approach. Comput. Mater. Contin. 2021, 67, 2569–2583. [Google Scholar] [CrossRef]
- Gardner, E.S.G.; Acar, Y. Fitting the damped trend method of exponential smoothing. J. Oper. Res. Soc. 2019, 70, 926–930. [Google Scholar] [CrossRef]
- Chatfield, C. The Holt-Winters Forecasting Procedure. J. R. Stat. Soc. Ser. (Appl. Stat.) 1978, 27, 264–279. [Google Scholar] [CrossRef]
- Musbah, H.; El-Hawary, M.; Aly, H. Identifying Seasonality in Time Series by Applying Fast Fourier Transform. In Proceedings of the 2019 IEEE Electrical Power and Energy Conference (EPEC), Montreal, QC, Canada, 16–18 October 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Brigham, E.O.; Morrow, R.E. The fast Fourier transform. IEEE Spectr. 1967, 4, 63–70. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Schneider, A.; Hommel, G.; Blettner, M. Linear Regression Analysis Part 14 of a Series on Evaluation of Scientific Publications. Dtsch. Ärzteblatt Int. 2010, 107, 776–782. [Google Scholar] [CrossRef]
- Ekaputri, A.P.; Akbar, S. Financial News Sentiment Analysis using Modified VADER for Stock Price Prediction. In Proceedings of the 2022 9th International Conference on Advanced Informatics: Concepts, Theory and Applications (ICAICTA), Tokoname, Japan, 28–29 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Hutto, C. GitHub—cjhutto/vaderSentiment: VADER Sentiment Analysis. Available online: https://github.com/cjhutto/vaderSentiment (accessed on 24 November 2022).
- Nakov, P.; Ritter, A.; Rosenthal, S.; Sebastiani, F.; Stoyanov, V. SemEval-2016 task 4: Sentiment analysis in Twitter. arXiv 2019, arXiv:1912.01973. [Google Scholar]
- del Arco, F.M.P.; Strapparava, C.; Lopez, L.A.U.; Martín-Valdivia, M.T. EmoEvent: A multilingual emotion corpus based on different events. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 1492–1498. [Google Scholar]
- Binance. Binance API. 2022. Available online: https://www.binance.com/en/binance-api (accessed on 15 October 2022).
- Kash. Bitcoin Tweets. 2021. Available online: https://www.kaggle.com/datasets/kaushiksuresh147/bitcoin-tweets (accessed on 1 November 2022).
- Lopez, F. Language Detection Library in Python. 2017. Available online: https://github.com/fedelopez77/langdetect (accessed on 20 November 2022).
- Robertson, S.E.; Zaragoza, H. The Probabilistic Relevance Framework: BM25 and Beyond. Found. Trends Inf. Retr. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Muralidhar, N.; Muthiah, S.; Butler, P.; Jain, M.; Yu, Y.; Burne, K.; Li, W.; Jones, D.; Arunachalam, P.; McCormick, H.S.; et al. Using AntiPatterns to avoid MLOps Mistakes. arXiv 2021, arXiv:2107.00079. [Google Scholar]


| Metric | LSTM | TCN | D-Linear | LR | ES | FFT | Drift | Mean |
|---|---|---|---|---|---|---|---|---|
| MAE | 11.69 | 13.71 | 3.40 | 2.72 | 4.15 | 9.46 | 3.43 | 7.13 |
| RMSE | 12.22 | 14.19 | 4.22 | 3.33 | 5.01 | 10.04 | 3.97 | 7.51 |
| SA Method | Scores | Metric | LSTM | TCN | D-Linear | LR |
|---|---|---|---|---|---|---|
| VADER SA | All | MAE | 90.50 | 19.22 | 4.49 | 3.23 |
| RMSE | 90.67 | 19.69 | 5.48 | 3.96 | ||
| Compound | MAE | 25.81 | 12.84 | 3.46 | 2.71 | |
| RMSE | 26.17 | 13.37 | 4.23 | 3.31 | ||
| BERTweet SA | All | MAE | 53.32 | 22.72 | 4.75 | 3.14 |
| RMSE | 53.09 | 22.18 | 5.93 | 3.85 | ||
| Compound | MAE | 35.04 | 11.56 | 3.75 | 2.67 | |
| RMSE | 35.41 | 12.10 | 4.75 | 3.28 | ||
| BERTweet ED | All | MAE | 22.39 | 15.49 | 6.35 | 2.87 |
| RMSE | 22.94 | 16.07 | 8.02 | 3.52 |
| SA Method | Weighting | Metric | LSTM | TCN | D-Linear | LR |
|---|---|---|---|---|---|---|
| Vader SA | Mean | MAE | 90.50 | 19.22 | 4.49 | 3.23 |
| RMSE | 90.67 | 19.69 | 5.48 | 3.96 | ||
| User influence | MAE | 132.54 | 25.55 | 4.37 | 3.35 | |
| RMSE | 132.66 | 25.98 | 5.36 | 4.11 | ||
| BERTweet SA | Mean | MAE | 53.32 | 22.72 | 4.75 | 3.14 |
| RMSE | 53.09 | 22.18 | 5.93 | 3.85 | ||
| User influence | MAE | 53.09 | 10.13 | 4.53 | 3.01 | |
| RMSE | 53.33 | 10.78 | 5.68 | 3.69 | ||
| BERTweet ED | Mean | MAE | 22.39 | 15.49 | 6.35 | 2.87 |
| RMSE | 22.94 | 16.07 | 8.02 | 3.52 | ||
| User influence | MAE | 36.13 | 14.43 | 5.97 | 2.84 | |
| RMSE | 36.48 | 14.95 | 7.36 | 3.49 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frohmann, M.; Karner, M.; Khudoyan, S.; Wagner, R.; Schedl, M. Predicting the Price of Bitcoin Using Sentiment-Enriched Time Series Forecasting. Big Data Cogn. Comput. 2023, 7, 137. https://doi.org/10.3390/bdcc7030137
Frohmann M, Karner M, Khudoyan S, Wagner R, Schedl M. Predicting the Price of Bitcoin Using Sentiment-Enriched Time Series Forecasting. Big Data and Cognitive Computing. 2023; 7(3):137. https://doi.org/10.3390/bdcc7030137
Chicago/Turabian StyleFrohmann, Markus, Manuel Karner, Said Khudoyan, Robert Wagner, and Markus Schedl. 2023. "Predicting the Price of Bitcoin Using Sentiment-Enriched Time Series Forecasting" Big Data and Cognitive Computing 7, no. 3: 137. https://doi.org/10.3390/bdcc7030137
APA StyleFrohmann, M., Karner, M., Khudoyan, S., Wagner, R., & Schedl, M. (2023). Predicting the Price of Bitcoin Using Sentiment-Enriched Time Series Forecasting. Big Data and Cognitive Computing, 7(3), 137. https://doi.org/10.3390/bdcc7030137