

Application of Artificial Intelligence for Fraudulent Banking Operations Recognition


 ,
,  and
and 
Abstract
1. Introduction
- -
- Developed several machine learning models using various methodologies and strategies.
- -
- Compared and assessed the models from the previous stage using both quantitative and visual criteria.
- -
- Analyzed the results obtained and drew a conclusion about the research objective.
2. Related Works
3. Materials and Methods
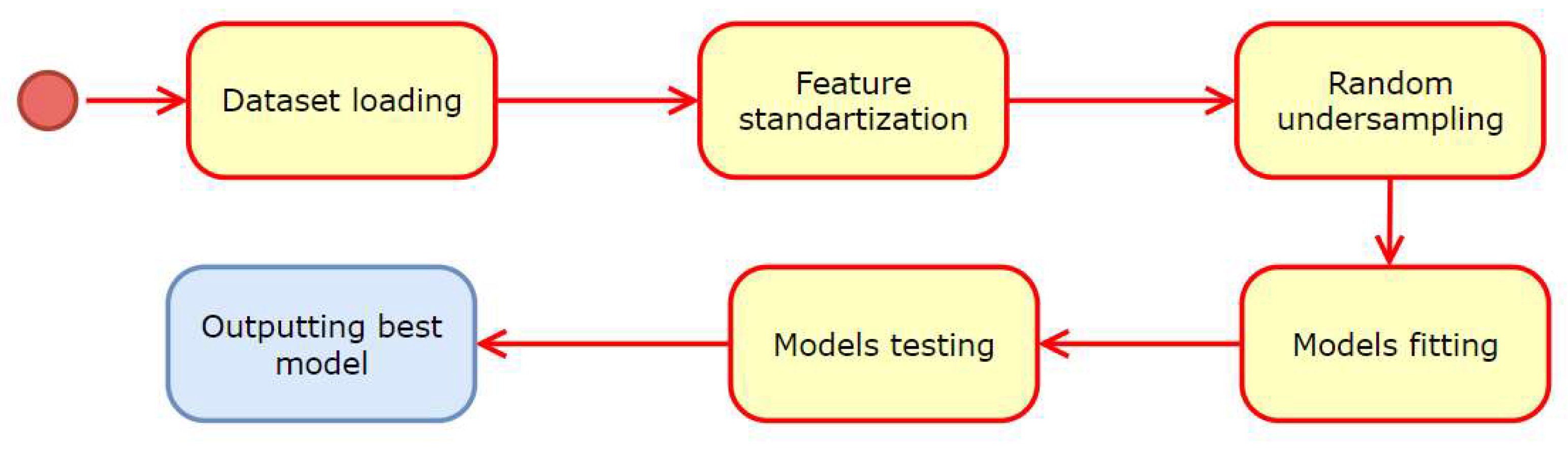
- Selecting the dataset using Kaggle datasets.
- Loading the dataset into the program (using a library such as pandas or NumPy to load the dataset into the program).
- Splitting the dataset into training and testing sets (using a library such as scikit-learn).
- Standardizing the features in the training and testing sets using a standard scaler.
- Imbalanced learning to randomly undersample the majority class in the training set to balance the class distribution.
- Selecting a set of candidate models to evaluate.
- For each model, fitting the model to the training data using hyperparameter tuning (using a library such as scikit-learn), which involves using cross-validation to find the best hyperparameters for each model.
- Using a library such as scikit-learn to evaluate each model on the testing data using an appropriate evaluation metric.
- Recording each model’s evaluation metric and hyperparameters for comparison.
- Selecting the model with the best evaluation metric on the testing data.
- Outputting the best model and its hyperparameters and evaluation metric for further use in production or research.
- Machine learning algorithms,
- Evaluation metrics,
- Data preprocessing technique.
3.1. Machine Learning Algorithms
3.2. Stacked Generalization of Machine Learning Models
3.3. Metrics for Model Assessment
3.4. Data Preprocessing Techniques
4. Results
4.1. Dataset Selection
- Credit Card Fraud Detection with 150.83 Mb (https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud (accessed on 15 November 2022)). This dataset presents 284,807 transactions that occurred in two days, and only 492 of them have frauds. It means that this dataset is highly unbalanced.
- Credit Card Fraud with 76.28 Mb (https://www.kaggle.com/datasets/dhanushnarayananr/credit-card-fraud (accessed on 15 November 2022)). This dataset is simulated, which is why the accuracy in one of the solutions (URL: https://www.kaggle.com/datasets/dhanushnarayananr/credit-card-fraud/discussion/335338 (accessed on 15 November 2022)) is one.
- Fraud Detection—Credit Card with 102.92 Mb (https://www.kaggle.com/datasets/yashpaloswal/fraud-detection-credit-card (accessed on 15 November 2022)). This dataset is obtained from the first dataset by removing missing values. This is why the first dataset was used in the study.
4.2. Experiment Design
- Scikit Learn is an open-source machine learning library that supports both supervised and unsupervised learning. Scikit Learn also provides various tools to adapt models, preprocess data, select models, and assess models, among many other services [45].
- Pandas is an open-source library primarily intended to conveniently and efficiently handle labeled or relational data. It offers several data structures and functionalities that enable numerical data and time series processing. This library was developed on the foundation of the NumPy library and is known for its fast performance and high productivity for users [46].
- Matplotlib is an open-source library that enables data visualization and plotting for Python, and it supports its numerical extension NumPy. This library provides a feasible alternative to MATLAB and is compatible with different operating systems. Creators use the matplotlib API to embed graphs in GUI applications [47]. Because the program is implemented and stored in Kaggle, an online platform, the code of the software solution can be concurrently run in the browser of the application’s end user. This is why the need for personal computing power is not critical for running programs available to any modern computer with a sufficiently good Internet connection.
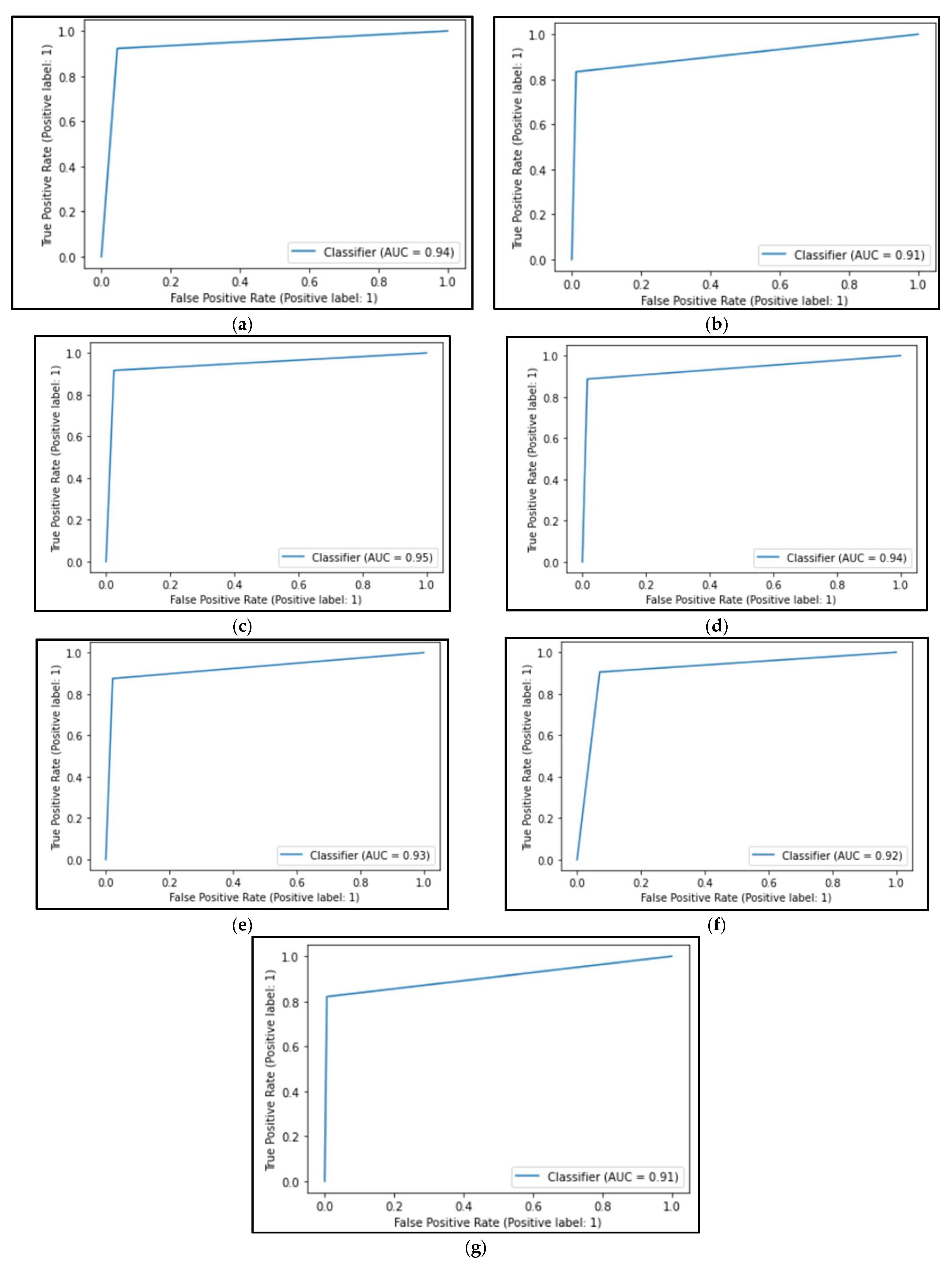
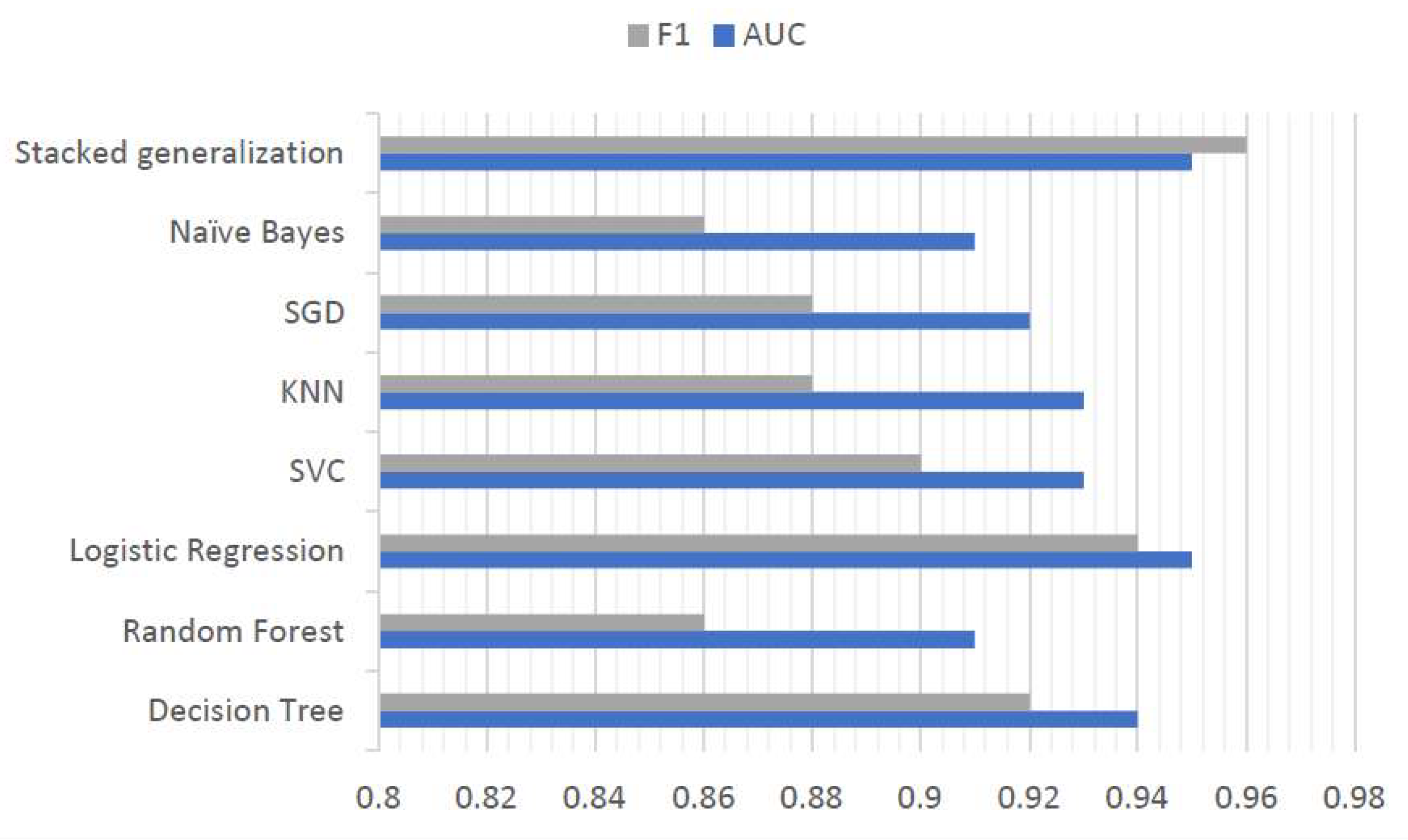
- The decision tree algorithm produced an AUC metric of 0.938.
- The logistic regression algorithm obtained an AUC value of 0.946.
- The SVC algorithm showed an AUC of 0.936.
- The k-nearest neighbors algorithm showed an AUC value of 0.927.
- The algorithm based on stochastic gradient descent had an AUC value of 0.917.
- The naïve Bayes algorithm showed an AUC value of 0.908.
- The random forest algorithm had an AUC value of 0.911.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jansen, J.; Leukfeldt, R. How people help fraudsters steal their money: An analysis of 600 online banking fraud cases. In Proceedings of the Workshop on Socio-Technical Aspects in Security and Trust, Verona, Italy, 13 July 2015; pp. 24–31. [Google Scholar] [CrossRef]
- Top 5 Banking Fraud Prevention Methods, SailPoint. Available online: https://www.sailpoint.com/identity-library/top-5-banking-fraud-prevention-methods/ (accessed on 15 November 2022).
- Law, B. Bank Fraud—Definitions & Penalties, Berry Law. 24 October 2017. Available online: https://jsberrylaw.com/blog/bank-fraud-definition-penalties/ (accessed on 15 November 2022).
- Scopus. Search “Fraudulent Banking”. Available online: https://www.scopus.com/results/results.uri?sort=plf-f&src=s&st1=fraudulent+banking&sid=d19e2a93c0ea9fab26cd4a3bf34ff777&sot=b&sdt=b&sl=33&s=ALL%28fraudulent+AND+banking%29&origin=searchbasic&editSaveSearch=&sessionSearchId=d19e2a93c0ea9fab26cd4a3bf34ff777&limit=10 (accessed on 15 November 2022).
- Barker, R. The use of proactive communication through knowledge management to create awareness and educate clients on e-banking fraud prevention. S. Afr. J. Bus. Manag. 2020, 51, a1941. [Google Scholar] [CrossRef]
- Abidoye, A.P.; Kabaso, B. Hybrid machine learning: A tool to detect phishing attacks in communication networks. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 559–569. [Google Scholar] [CrossRef]
- Shah, S.S.H.; Ahmad, A.R.; Jamil, N.; Khan, A.U.R. Memory forensics-based malware detection using computer vision and machine learning. Electronics 2022, 11, 2579. [Google Scholar] [CrossRef]
- Maulana, L.R.; Fajar, A.N.; Meyliana. Extending the design of smart mobile application to detect fraud theft of E-banking access using big data analytic and SOA. In Proceedings of the 2021 IEEE 5th International Conference on Information Technology, Information Systems and Electrical Engineering (ICITISEE), Purwokerto, Indonesia, 24–25 November 2021; pp. 360–364. [Google Scholar] [CrossRef]
- Khalaf Al Hattali, S.S.; Hussain, S.M.; Frank, A. Design and development for detection and prevention of ATM skimming frauds. Indones. J. Electr. Eng. Comput. Sci. 2019, 17, 1224–1231. [Google Scholar] [CrossRef]
- Tsai, C.; Su, P. The application of multi-server authentication scheme in internet banking transaction environments. Inf. Syst. e-Bus. Manag. 2021, 19, 77–105. [Google Scholar] [CrossRef]
- Hammi, B.; Zeadally, S.; Adja, Y.C.E.; Giudice, M.D.; Nebhen, J. Blockchain-based solution for detecting and preventing fake check scams. IEEE Trans. Eng. Manag. 2022, 69, 3710–3725. [Google Scholar] [CrossRef]
- Abdul Rani, M.I.; Syed Mustapha Nazri, S.N.F.; Zolkaflil, S. A systematic literature review of money mule: Its roles, recruitment and awareness. J. Financ. Crime 2023. ahead-of-print. [Google Scholar] [CrossRef]
- Ileberi, E.; Sun, Y.; Wang, Z. A machine learning based credit card fraud detection using the GA algorithm for feature selection. J. Big Data 2022, 9, 24. [Google Scholar] [CrossRef]
- Chaquet-Ulldemolins, J.; Gimeno-Blanes, F.-J.; Moral-Rubio, S.; Muñoz-Romero, S.; Rojo-álvarez, J.-L. On the Black-Box Challenge for Fraud Detection Using Machine Learning (I): Linear Models and Informative Feature Selection. Appl. Sci. Switz. 2022, 12, 3328. [Google Scholar] [CrossRef]
- Kasasbeh, B.; Aldabaybah, B.; Ahmad, H. Multilayer perceptron artificial neural networks-based model for credit card fraud detection, Indones. J. Electr. Eng. Comput. Sci. 2022, 26, 362–373. [Google Scholar] [CrossRef]
- Nguyen, N.; Duong, T.; Chau, T.; Nguyen, V.-H.; Trinh, T.; Tran, D.; Ho, T. A Proposed Model for Card Fraud Detection Based on CatBoost and Deep Neural Network. IEEE Access 2022, 10, 96852–96861. [Google Scholar] [CrossRef]
- Esenogho, E.; Mienye, I.D.; Swart, T.G.; Aruleba, K.; Obaido, G. A Neural Network Ensemble with Feature Engineering for Improved Credit Card Fraud Detection. IEEE Access 2022, 10, 16400–16407. [Google Scholar] [CrossRef]
- Sharma, P.; Banerjee, S.; Tiwari, D.; Patni, J.C. Machine learning model for credit card fraud detection-A comparative analysis. Int. Arab J. Inf. Technol. 2021, 18, 789–796. [Google Scholar] [CrossRef]
- Benchaji, I.; Douzi, S.; El Ouahidi, B. Credit card fraud detection model based on LSTM recurrent neural networks. J. Adv. Inf. Technol. 2021, 12, 113–118. [Google Scholar] [CrossRef]
- Mehbodniya, A.; Alam, I.; Pande, S.; Neware, R.; Rane, K.P.; Shabaz, M.; Madhavan, M.V. Financial Fraud Detection in Healthcare Using Machine Learning and Deep Learning Techniques. Secur. Commun. Netw. 2021, 2021, 9293877. [Google Scholar] [CrossRef]
- Cauteruccio, F.; Terracina, G.; Ursino, D. Generalizing identity-based string comparison metrics: Framework and techniques. Knowl.-Based Syst. 2020, 187, 104820. [Google Scholar] [CrossRef]
- Ojagh, S.; Cauteruccio, F.; Terracina, G.; Liang, S.H.L. Enhanced air quality prediction by edge-based spatiotemporal data pre-processing. Comput. Electr. Eng. 2021, 96, 107572. [Google Scholar] [CrossRef]
- Arora, M.; Bhardwaj, I. Artificial Intelligence in Collaborative Information System. Int. J. Mod. Educ. Comput. Sci. (IJMECS) 2022, 14, 44–55. [Google Scholar] [CrossRef]
- Junejo, M.; Laghari, A.; Jumani, A.; Karim, S.; Khuhro, M. Quality of Experience Assessment of Banking Service. Int. J. Inf. Eng. Electron. Bus. (IJIEEB) 2020, 12, 39–50. [Google Scholar] [CrossRef]
- Gupta, P.; Varshney, A.; Khan, M.R.; Ahmed, R.; Shuaib, M.; Alam, S. Unbalanced Credit Card Fraud Detection Data: A Machine Learning-Oriented Comparative Study of Balancing Techniques. Procedia Comput. Sci. 2023, 218, 2575–2584. [Google Scholar] [CrossRef]
- Navaneethakrishnan, P.; Viswanath, R. Fraud Detection on Credit Cards Using Artificial Intelligence Methods. Ilkogr. Online-Elem. Educ. Online 2020, 19, 2086–2096. [Google Scholar]
- Khan, M.; Mahmood, W. Technology Adoption in Pakistani Banking Industry using UTAUT. Int. J. Inf. Technol. Comput. Sci. (IJITCS) 2022, 14, 32–42. [Google Scholar] [CrossRef]
- Zimba, A. A Bayesian Attack-Network Modeling Approach to Mitigating Malware-Based Banking Cyberattacks. Int. J. Comput. Netw. Inf. Secur. (IJCNIS) 2022, 14, 25–39. [Google Scholar] [CrossRef]
- Elhassan, R.; Yousif, A.; Suliman, T. Assessment of Knowledge Management Application in Banking Sector of Sudan: Case Study Farmer’s Commercial Bank. Int. J. Inf. Eng. Electron. Bus. (IJIEEB) 2021, 13, 1–19. [Google Scholar] [CrossRef]
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Credit Card Fraud Detection. Available online: https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud (accessed on 15 November 2022).
- Charbuty, B.; Abdulazeez, A. Classification based on decision tree algorithm for machine learning. J. Appl. Sci. Technol. Trends 2021, 2, 20–28. [Google Scholar] [CrossRef]
- Polimis, K.; Rokem, A.; Hazelton, B. Confidence intervals for random forests in python. J. Open Source Softw. 2017, 2, 124. [Google Scholar] [CrossRef]
- Mood, C. Logistic regression: Why we cannot do what we think we can do, and what we can do about it. Eur. Sociol. Rev. 2010, 26, 67–82. [Google Scholar] [CrossRef]
- Aldino, A.A.; Saputra, A.; Nurkholis, A.; Setiawansyah, S. Application of Support Vector Machine (SVM) Algorithm in Classification of Low-Cape Communities in Lampung Timur. Build. Inform. Technol. Sci. (BITS) 2021, 3, 325–330. [Google Scholar] [CrossRef]
- Isnain, A.R.; Supriyanto, J.; Kharisma, M.P. Implementation of K-Nearest Neighbor (K-NN) Algorithm For Public Sentiment Analysis of Online Learning. Indones. J. Comput. Cybern. Syst. 2021, 15, 121–130. [Google Scholar] [CrossRef]
- Do, T.N.; Tran-Nguyen, M.T. ImageNet Challenging Classification with the Raspberry Pis: A Federated Learning Algorithm of Local Stochastic Gradient Descent Models. In Future Data and Security Engineering. Big Data, Security and Privacy, Smart City and Industry 4.0 Applications; FDSE 2022; Communications in Computer and Information Science; Springer: Singapore, 2022; Volume 1688. [Google Scholar] [CrossRef]
- Zhang, Y.; Sakhanenko, L. The naive Bayes classifier for functional data. Stat. Probab. Lett. 2019, 152, 137–146. [Google Scholar] [CrossRef]
- Chukhray, N.; Shakhovska, N.; Mrykhina, O.; Lisovska, L.; Izonin, I. Stacking Machine Learning Model for the Assessment of R&D Product’s Readiness and Method for Its Cost Estimation. Mathematics 2022, 10, 1466. [Google Scholar] [CrossRef]
- Muppalaneni, N.B.; Ma, M.; Gurumoorthy, S.; Kannan, R.; Vasanthi, V. Machine learning algorithms with ROC curve for predicting and diagnosing the heart disease. In Soft Computing and Medical Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 63–72. [Google Scholar]
- Ozsahin, D.U.; Taiwo Mustapha, M.; Mubarak, A.S.; Said Ameen, Z.; Uzun, B. Impact of feature scaling on machine learning models for the diagnosis of diabetes. In Proceedings of the 2022 International Conference on Artificial Intelligence in Everything (AIE), Lefkosa, Cyprus, 2–4 August 2022; pp. 87–94. [Google Scholar] [CrossRef]
- Shamsudin, H.; Yusof, U.K.; Jayalakshmi, A.; Khalid, M.N.A. Combining oversampling and undersampling techniques for imbalanced classification: A comparative study using credit card fraudulent transaction dataset. In Proceedings of the 2020 IEEE 16th International Conference on Control & Automation (ICCA), Singapore, 9–11 October 2020; pp. 803–808. [Google Scholar] [CrossRef]
- Nagpal, A.; Gabrani, G. Python for Data Analytics, Scientific and Technical Applications. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 140–145. [Google Scholar] [CrossRef]
- Pimentel, J.F.; Murta, L.; Braganholo, V.; Freire, J. A Large-Scale Study About Quality and Reproducibility of Jupyter Notebooks. In Proceedings of the 2019 IEEE/ACM 16th International Conference on Mining Software Repositories (MSR), Montreal, QC, Canada, 25–31 May 2019; pp. 507–517. [Google Scholar] [CrossRef]
- Wang, A.Y.; Wang, D.; Drozdal, J.; Muller, M.; Park, S.; Weisz, J.; Liu, X.; Wu, L.; Dugan, C. Documentation matters: Human-centered AI system to assist data science code documentation in computational notebooks. ACM Trans. Comput.-Hum. Interact. 2022, 29, 17. [Google Scholar] [CrossRef]
- Cutler, J.; Dickenson, M.; Cutler, J.; Dickenson, M. Introduction to Machine Learning with Python. In Computational Frameworks for Political and Social Research with Python; Springer: Berlin/Heidelberg, Germany, 2020; pp. 129–142. [Google Scholar]
- Moruzzi, G.; Moruzzi, G. Plotting with matplotlib. In Essential Python for the Physicist; Springer: Berlin/Heidelberg, Germany, 2020; pp. 53–69. [Google Scholar]
- Credit Fraud || Dealing with Imbalanced Datasets. Available online: https://www.kaggle.com/code/janiobachmann/credit-fraud-dealing-with-imbalanced-datasets (accessed on 15 November 2022).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fraudulent Banking Approach | Threat |
|---|---|
| Phishing [5,6] | The attacker steals login credentials or other personal information by tricking the victim into entering them on a fake banking website or through a fake email or text message. |
| Malware [7] | Malicious software is used to steal login credentials or other personal information and may be used to take control of the victim’s computer or manipulate banking transactions. |
| Social Engineering [8] | Attackers use psychological manipulation to trick victims into disclosing sensitive information or performing transactions they would not normally. This may include pretexting, baiting, or quid pro quo tactics. |
| Skimming [9] | Attackers install devices on ATMs or other card readers to steal card information. This information is then be used to create counterfeit cards or make unauthorized transactions. |
| Account Takeover [10] | Attackers access a victim’s account by stealing login credentials or other means. Once in the account, they make unauthorized transactions, change account details, or otherwise manipulate the account for their gain. |
| Fake Checks [11] | Attackers send fake checks to victims, asking them to deposit them and send back a portion of the funds. The check eventually bounces, leaving the victim responsible for the funds they sent to the attacker. |
| Money Mules [12] | Attackers recruit unwitting victims to help launder money by having them receive and send funds on their behalf. The victims say they are performing legitimate work but participating in illegal activities. |
| Methods | Algorithm | Pros | Cons |
|---|---|---|---|
| Machine Learning Algorithms | Random Forest | Performs well in handling high-dimensional data with complex relationships, missing values, and outliers. | Computationally expensive for massive datasets and challenging to interpret. |
| K-Nearest Neighbors | Easy to implement and works well on small datasets, handling nonlinear relationships. | Computationally expensive for large datasets sensitive to irrelevant features and distance metrics. | |
| Logistic Regression | Easy to implement and interpret, good performance in handling categorical features. | Assumes a linear relationship between features and target, and may not perform well on highly nonlinear data. | |
| Stochastic Gradient Descent Classifier | Performs well on large datasets and handles nonlinear relationships. | Sensitive to hyperparameters and initialization converges to a suboptimal solution. | |
| Naive Bayes | Fast and straightforward, performing well in handling categorical features. | Assumes independence between features. may not perform well on highly nonlinear data. | |
| Decision Tree | Easy to interpret and handles nonlinear relationships. Good performance on small to medium datasets. | Easily overfits the data and is sensitive to small changes in data. | |
| Support Vector Machine | Performs well on many problems, including nonlinear data, and handles high-dimensional data. | Computationally expensive for large datasets. Sensitive to choice of kernel function and hyperparameters. | |
| Metrics for model assessment | Area Under the Curve (AUC) | A widely-used metric for binary classification problems that is easy to interpret and robust to imbalanced datasets. | Does not provide information on optimal threshold for classification and unsuitable for multiclass classification problems. |
| Receiver Operating Characteristic (ROC) | Provides a visual representation of the trade-off between sensitivity and specificity, help select the optimal threshold for classification. | Challenging to interpret for datasets with many classes. | |
| Data pre-processing techniques | Standardization | Improves the performance of specific algorithms, such as distance metrics and coefficients’ interpretability in linear models. | Standardization is sensitive to outliers and leads to overfitting if applied to entire dataset (including test set). |
| Undersampling | Improves algorithms’ performance on imbalanced datasets and reduces computation time and memory usage. | Results in loss of important information from the dataset and increases risk of overfitting if the validation set is not representative of the test set. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mytnyk, B.; Tkachyk, O.; Shakhovska, N.; Fedushko, S.; Syerov, Y. Application of Artificial Intelligence for Fraudulent Banking Operations Recognition. Big Data Cogn. Comput. 2023, 7, 93. https://doi.org/10.3390/bdcc7020093
Mytnyk B, Tkachyk O, Shakhovska N, Fedushko S, Syerov Y. Application of Artificial Intelligence for Fraudulent Banking Operations Recognition. Big Data and Cognitive Computing. 2023; 7(2):93. https://doi.org/10.3390/bdcc7020093
Chicago/Turabian StyleMytnyk, Bohdan, Oleksandr Tkachyk, Nataliya Shakhovska, Solomiia Fedushko, and Yuriy Syerov. 2023. "Application of Artificial Intelligence for Fraudulent Banking Operations Recognition" Big Data and Cognitive Computing 7, no. 2: 93. https://doi.org/10.3390/bdcc7020093
APA StyleMytnyk, B., Tkachyk, O., Shakhovska, N., Fedushko, S., & Syerov, Y. (2023). Application of Artificial Intelligence for Fraudulent Banking Operations Recognition. Big Data and Cognitive Computing, 7(2), 93. https://doi.org/10.3390/bdcc7020093