
Deep Learning for Highly Accurate Hand Recognition Based on Yolov7 Model




Abstract
1. Introduction
2. Materials and Methods
2.1. Hand Recognitions with Convolutional Neural Network (CNN)
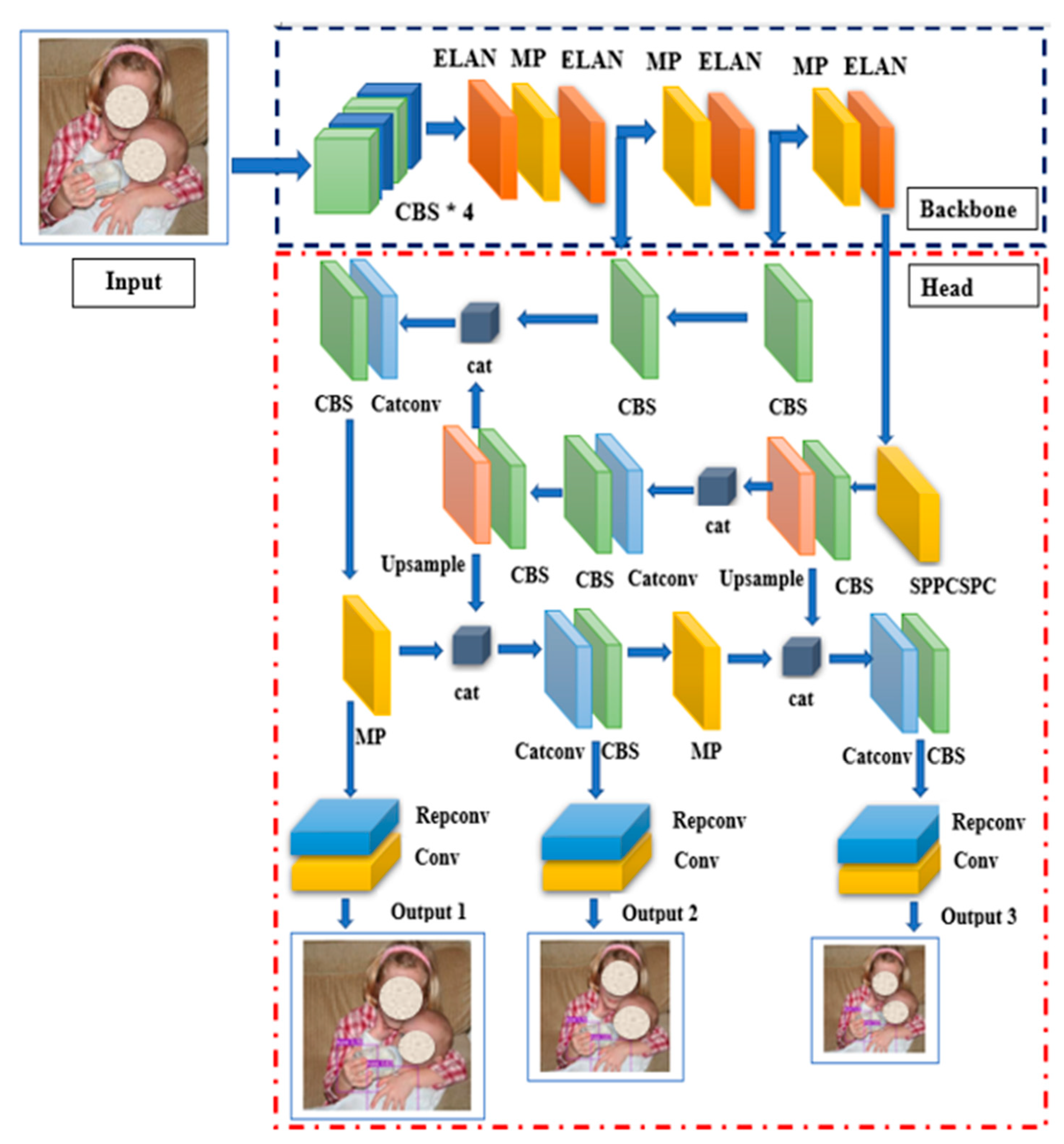
2.2. Yolov7 Architecture
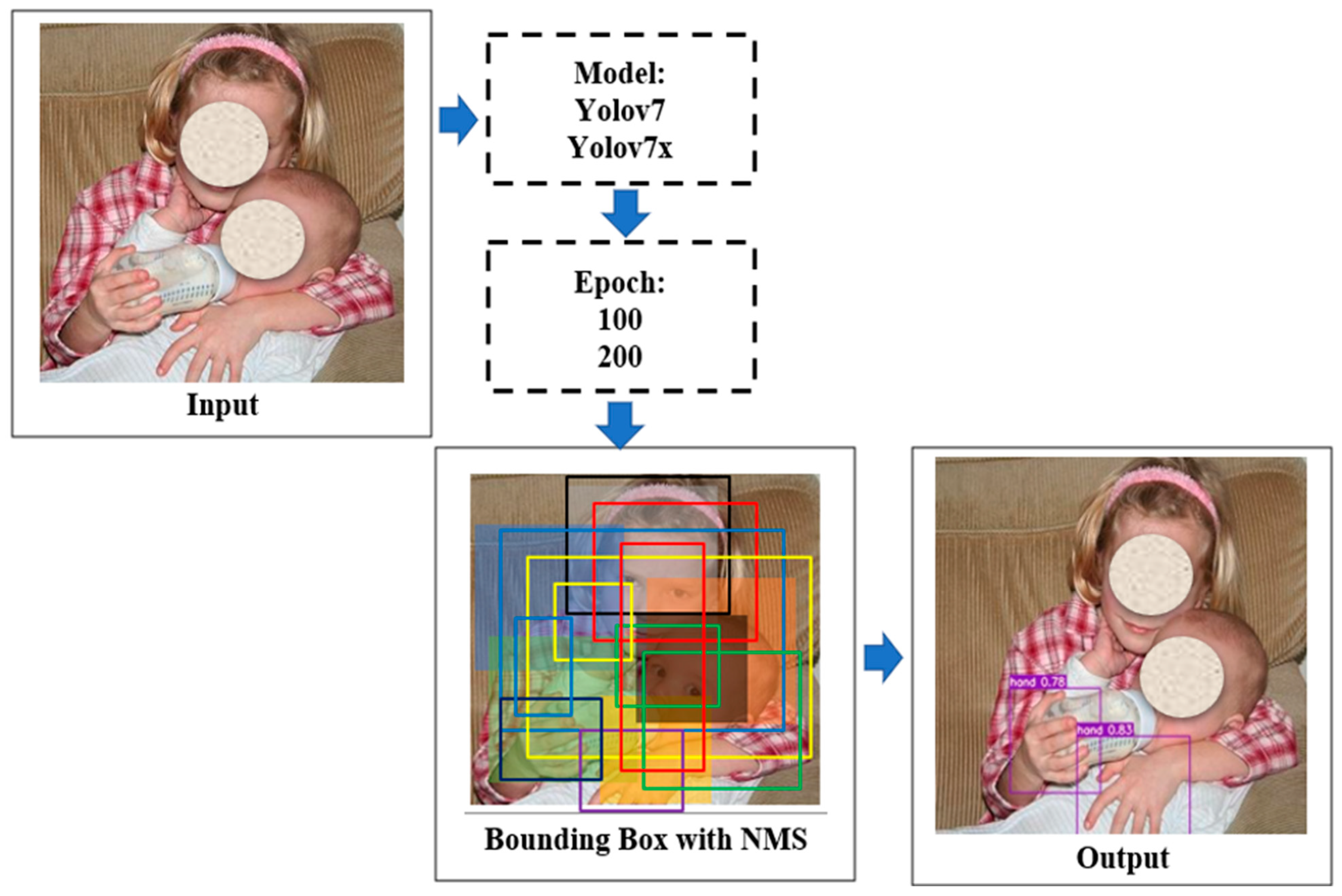
3. Results
3.1. Oxford Hand Dataset
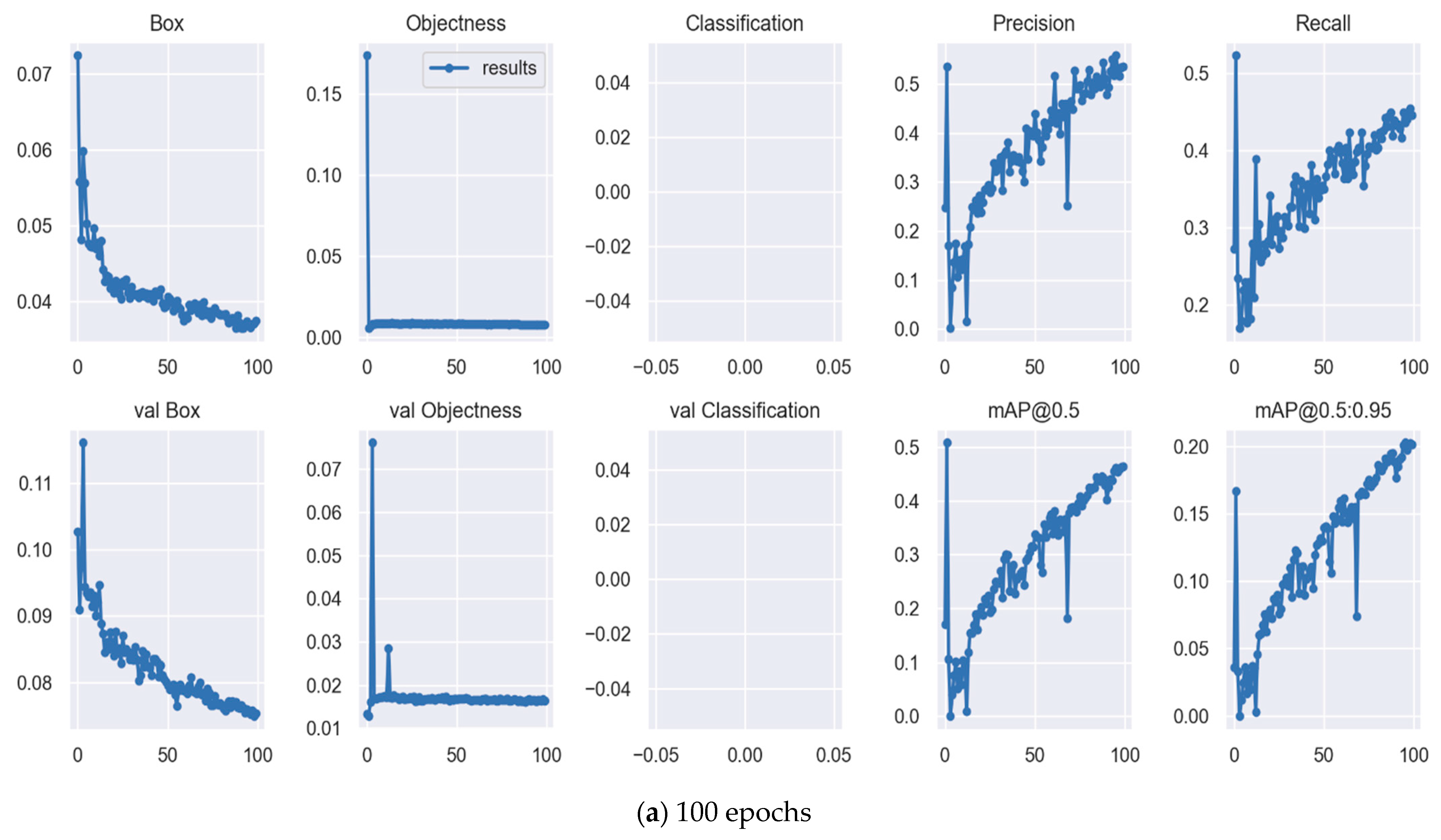
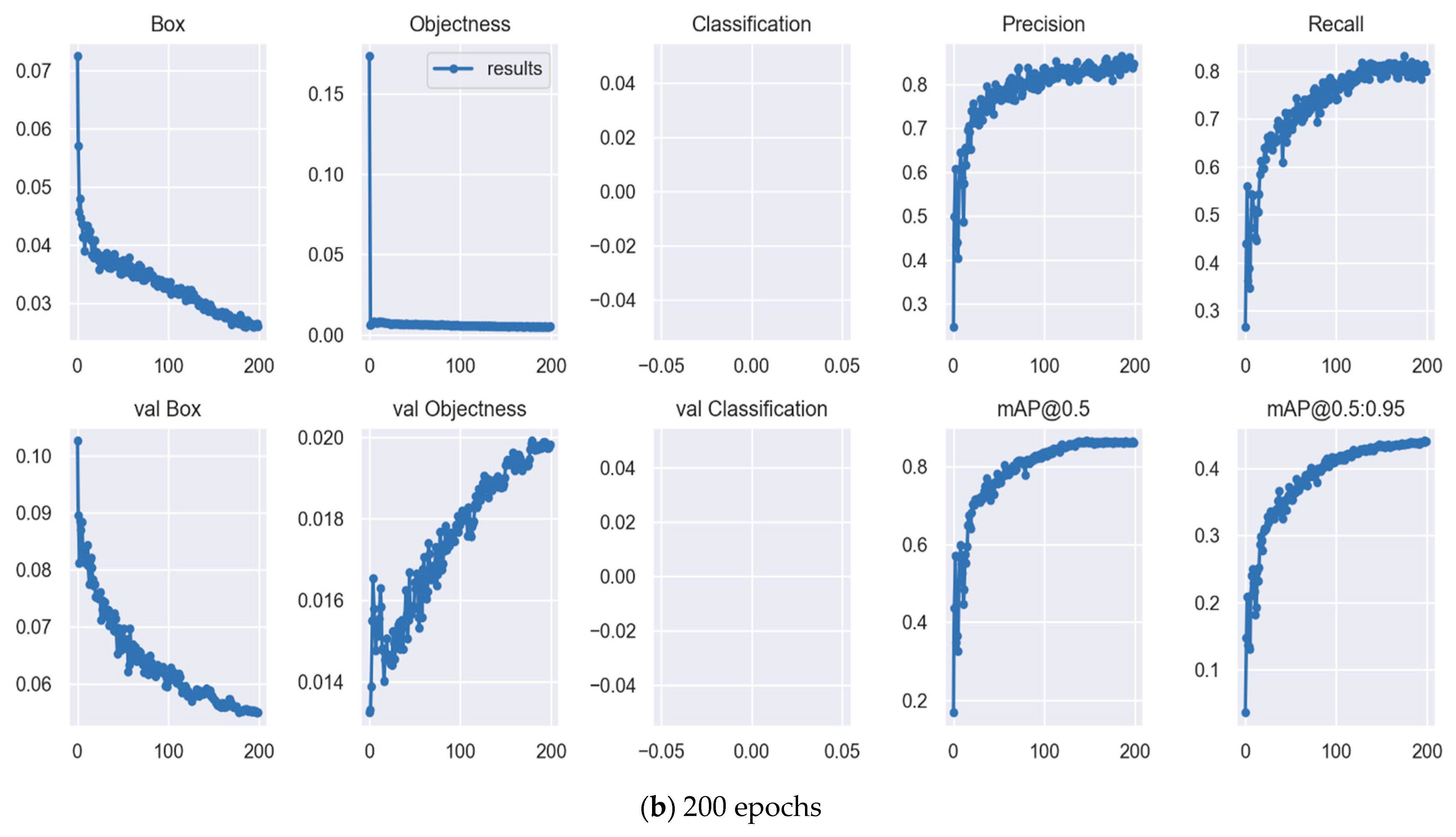
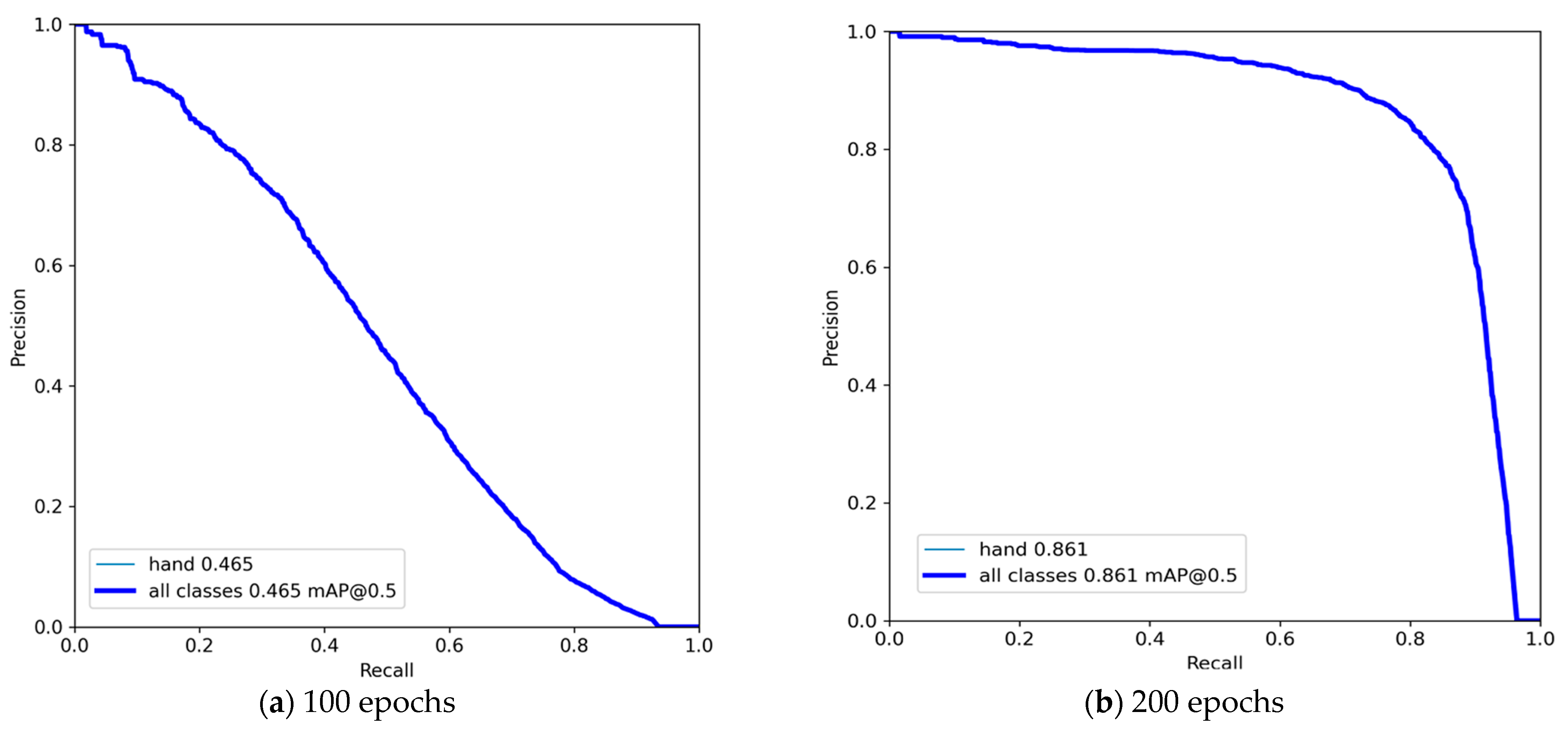
3.2. Training Result
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Xu, C.; Cai, W.; Li, Y.; Zhou, J.; Wei, L. Accurate Hand Detection from Single-Color Images by Reconstructing Hand Appearances. Sensors 2020, 20, 192. [Google Scholar] [CrossRef] [PubMed]
- Narasimhaswamy, S.; Wei, Z.; Wang, Y.; Zhang, J.; Nguyen, M.H. Contextual Attention for Hand Detection in the Wild. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Dewi, C.; Chen, R.-C. Decision Making Based on IoT Data Collection for Precision Agriculture. In Intelligent Information and Database Systems: Recent Developments; Huk, M., Maleszka, M., Szczerbicki, E., Eds.; ACIIDS 2019. Studies in Computational Intelligence; Springer: Cham, Switzerland, 2020; Volume 830, pp. 31–42. [Google Scholar]
- Dewi, C.; Christanto, J. Henoch Combination of Deep Cross-Stage Partial Network and Spatial Pyramid Pooling for Automatic Hand Detection. Big Data Cogn. Comput. 2022, 6, 85. [Google Scholar] [CrossRef]
- Mohammed, A.A.Q.; Lv, J.; Islam, M.D.S. A Deep Learning-Based End-to-End Composite System for Hand Detection and Gesture Recognition. Sensors 2019, 19, 5282. [Google Scholar] [CrossRef]
- Rapp, A.; Curti, L.; Boldi, A. The Human Side of Human-Chatbot Interaction: A Systematic Literature Review of Ten Years of Research on Text-Based Chatbots. Int. J. Hum. Comput. Stud. 2021, 151, 102630. [Google Scholar] [CrossRef]
- Ashiquzzaman, A.; Lee, H.; Kim, K.; Kim, H.Y.; Park, J.; Kim, J. Compact Spatial Pyramid Pooling Deep Convolutional Neural Network Based Hand Gestures Decoder. Appl. Sci. 2020, 10, 7898. [Google Scholar] [CrossRef]
- Shin, J.; Matsuoka, A.; Hasan, M.A.M.; Srizon, A.Y. American Sign Language Alphabet Recognition by Extracting Feature from Hand Pose Estimation. Sensors 2021, 21, 5856. [Google Scholar] [CrossRef] [PubMed]
- Knights, E.; Mansfield, C.; Tonin, D.; Saada, J.; Smith, F.W.; Rossit, S. Hand-Selective Visual Regions Represent How to Grasp 3D Tools: Brain Decoding during Real Actions. J. Neurosci. 2021, 41, 5263–5273. [Google Scholar] [CrossRef]
- Kang, P.; Li, J.; Fan, B.; Jiang, S.; Shull, P.B. Wrist-Worn Hand Gesture Recognition While Walking via Transfer Learning. IEEE J. Biomed. Health Inform. 2022, 26, 952–961. [Google Scholar] [CrossRef]
- Qiang, B.; Zhai, Y.; Zhou, M.; Yang, X.; Peng, B.; Wang, Y.; Pang, Y. SqueezeNet and Fusion Network-Based Accurate Fast Fully Convolutional Network for Hand Detection and Gesture Recognition. IEEE Access 2021, 9, 77661–77674. [Google Scholar] [CrossRef]
- Aamir, M.; Rahman, Z.; Ahmed Abro, W.; Tahir, M.; Mustajar Ahmed, S. An Optimized Architecture of Image Classification Using Convolutional Neural Network. Int. J. Image Graph. Signal Process. 2019, 11, 30–39. [Google Scholar] [CrossRef]
- Ur Rehman, M.; Ahmed, F.; Khan, M.A.; Tariq, U.; Alfouzan, F.A.; Alzahrani, N.M.; Ahmad, J. Dynamic Hand Gesture Recognition Using 3D-CNN and LSTM Networks. Comput. Mater. Contin. 2022, 70, 4675–4690. [Google Scholar] [CrossRef]
- Guan, Y.; Aamir, M.; Hu, Z.; Abro, W.A.; Rahman, Z.; Dayo, Z.A.; Akram, S. A Region-Based Efficient Network for Accurate Object Detection. Trait. Signal 2021, 38, 481–494. [Google Scholar] [CrossRef]
- Chang, C.W.; Santra, S.; Hsieh, J.W.; Hendri, P.; Lin, C.F. Multi-Fusion Feature Pyramid for Real-Time Hand Detection. Multimed. Tools Appl. 2022, 81, 11917–11929. [Google Scholar] [CrossRef]
- Alam, M.M.; Islam, M.T.; Rahman, S.M.M. Unified Learning Approach for Egocentric Hand Gesture Recognition and Fingertip Detection. Pattern Recognit. 2022, 121, 108200. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X.; Wang, J. An Attention Mechanism-Improved YOLOv7 Object Detection Algorithm for Hemp Duck Count Estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- Chen, J.; Liu, H.; Zhang, Y.; Zhang, D.; Ouyang, H.; Chen, X. A Multiscale Lightweight and Efficient Model Based on YOLOv7: Applied to Citrus Orchard. Plants 2022, 11, 3260. [Google Scholar] [CrossRef]
- Dardas, N.H.; Georganas, N.D. Real-Time Hand Gesture Detection and Recognition Using Bag-of-Features and Support Vector Machine Techniques. IEEE Trans. Instrum. Meas. 2011, 60, 3592–3607. [Google Scholar] [CrossRef]
- Girondel, V.; Bonnaud, L.; Caplier, A. A Human Body Analysis System. EURASIP J. Adv. Signal Process. 2006, 2006, 61927. [Google Scholar] [CrossRef]
- Sigal, L.; Sclaroff, S.; Athitsos, V. Skin Color-Based Video Segmentation under Time-Varying Illumination. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 862–877. [Google Scholar] [CrossRef]
- Mittal, A.; Zisserman, A.; Torr, P. Hand Detection Using Multiple Proposals. Bmvc 2011, 2, 5. [Google Scholar]
- Karlinsky, L.; Dinerstein, M.; Harari, D.; Ullman, S. The Chains Model for Detecting Parts by Their Context. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Rastgoo, R.; Kiani, K.; Escalera, S. Real-Time Isolated Hand Sign Language Recognition Using Deep Networks and SVD. J. Ambient Intell. Humaniz. Comput. 2022, 13, 591–611. [Google Scholar] [CrossRef]
- Bandini, A.; Zariffa, J. Analysis of the Hands in Egocentric Vision: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Núñez, J.C.; Cabido, R.; Pantrigo, J.J.; Montemayor, A.S.; Vélez, J.F. Convolutional Neural Networks and Long Short-Term Memory for Skeleton-Based Human Activity and Hand Gesture Recognition. Pattern Recognit. 2018, 76, 80–94. [Google Scholar] [CrossRef]
- Xia, Z.; Xu, F. Time-Space Dimension Reduction of Millimeter-Wave Radar Point-Clouds for Smart-Home Hand-Gesture Recognition. IEEE Sens. J. 2022, 22, 4425–4437. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C.; Zhuang, Y.-C.; Christanto, H.J. Yolov5 Series Algorithm for Road Marking Sign Identification. Big Data Cogn. Comput. 2022, 6, 149. [Google Scholar] [CrossRef]
- Cheng, Y.T.; Patel, A.; Wen, C.; Bullock, D.; Habib, A. Intensity Thresholding and Deep Learning Based Lane Marking Extraction and Lanewidth Estimation from Mobile Light Detection and Ranging (LiDAR) Point Clouds. Remote Sens. 2020, 12, 1379. [Google Scholar] [CrossRef]
- Chen, R.-C.; Manongga, W.E.; Dewi, C. Automatic Digit Hand Sign Detection With Hand Landmark. In Proceedings of the 2022 International Conference on Machine Learning and Cybernetics (ICMLC), Toyama, Japan, 9–11 September 2022. [Google Scholar]
- Bose, S.R.; Kumar, V.S. In-Situ Recognition of Hand Gesture via Enhanced Xception Based Single-Stage Deep Convolutional Neural Network. Expert Syst. Appl. 2022, 193, 116427. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.C.; Yu, H. Weight Analysis for Various Prohibitory Sign Detection and Recognition Using Deep Learning. Multimed. Tools Appl. 2020, 79, 32897–32915. [Google Scholar] [CrossRef]
- Dong, X.; Zhao, Z.; Wang, Y.; Zeng, T.; Wang, J.; Sui, Y. FMCW Radar-Based Hand Gesture Recognition Using Spatiotemporal Deformable and Context-Aware Convolutional 5-D Feature Representation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–11. [Google Scholar] [CrossRef]
- Ultralytics Yolo V5. Available online: https://github.com/ultralytics/yolov5 (accessed on 13 January 2021).
- Long, J.W.; Yan, Z.R.; Peng, L.; Li, T. The Geometric Attention-Aware Network for Lane Detection in Complex Road Scenes. PLoS ONE 2021, 16, e0254521. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Zeng, X. Deep Learning-Based Workers Safety Helmet Wearing Detection on Construction Sites Using Multi-Scale Features. IEEE Access 2022, 10, 718–729. [Google Scholar] [CrossRef]
- Jiang, L.; Liu, H.; Zhu, H.; Zhang, G. Improved YOLO v5 with Balanced Feature Pyramid and Attention Module for Traffic Sign Detection. MATEC Web Conf. 2022, 355, 03023. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, K. Online Predictive Connected and Automated Eco-Driving on Signalized Arterials Considering Traffic Control Devices and Road Geometry Constraints under Uncertain Traffic Conditions. Transp. Res. Part B Methodol. 2021, 145, 80–117. [Google Scholar] [CrossRef]
- Dewi, C.; Chen, R.-C. Combination of Resnet and Spatial Pyramid Pooling for Musical Instrument Identification. Cybern. Inf. Technol. 2022, 22, 104. [Google Scholar] [CrossRef]
- Arcos-García, Á.; Álvarez-García, J.A.; Soria-Morillo, L.M. Evaluation of Deep Neural Networks for Traffic Sign Detection Systems. Neurocomputing 2018, 316, 332–344. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Deng, X.; Zhang, Y.; Yang, S.; Tan, P.; Chang, L.; Yuan, Y.; Wang, H. Joint Hand Detection and Rotation Estimation Using CNN. IEEE Trans. Image Process. 2018, 27, 1888–1900. [Google Scholar] [CrossRef]
- Le, T.H.N.; Quach, K.G.; Zhu, C.; Duong, C.N.; Luu, K.; Savvides, M. Robust Hand Detection and Classification in Vehicles and in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yang, L.; Qi, Z.; Liu, Z.; Liu, H.; Ling, M.; Shi, L.; Liu, X. An Embedded Implementation of CNN-Based Hand Detection and Orientation Estimation Algorithm. Mach. Vis. Appl. 2019, 30, 1071–1082. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Epoch | Class | Images | Labels | P | R | mAP@0.5 | Training Time (hours) | Size (MB) |
|---|---|---|---|---|---|---|---|---|---|
| Yolov7x | 100 | All | 1205 | 2487 | 0.536 | 0.446 | 0.465 | 4.522 | 142.1 |
| Yolov7x | 200 | All | 1205 | 2487 | 0.847 | 0.799 | 0.861 | 8.616 | 142.1 |
| Yolov7 | 100 | All | 1205 | 2487 | 0.591 | 0.509 | 0.539 | 2.599 | 74.8 |
| Yolov7 | 200 | All | 1205 | 2487 | 0.774 | 0.663 | 0.742 | 5.313 | 74.8 |
| Model | Epoch | Class | Images | Labels | P | R | mAP@0.5 |
|---|---|---|---|---|---|---|---|
| Yolov7x | 100 | All | 1205 | 2487 | 0.532 | 0.46 | 0.459 |
| Yolov7x | 200 | All | 1205 | 2487 | 0.844 | 0.8 | 0.863 |
| Yolov7 | 100 | All | 1205 | 2487 | 0.597 | 0.521 | 0.55 |
| Yolov7 | 200 | All | 1205 | 2487 | 0.732 | 0.672 | 0.736 |
| Model | Epoch | Inference | NMS | Total | FPS | Layers | Parameters | Gradient | GFLOPS |
|---|---|---|---|---|---|---|---|---|---|
| Yolov7x | 100 | 8.8 | 1.3 | 10.10 | 99.010 | 362 | 70,782,444 | 0 | 188 |
| Yolov7x | 200 | 14.1 | 1.2 | 15.30 | 65.359 | 362 | 70,782,444 | 0 | 188 |
| Yolov7 | 100 | 8.9 | 1.2 | 10.10 | 99.010 | 314 | 36,481,772 | 6,194,944 | 103.2 |
| Yolov7 | 200 | 8.8 | 1.3 | 10.10 | 99.010 | 314 | 36,481,772 | 6,194,944 | 103.2 |
| Author | mAP (%) | Method |
|---|---|---|
| Mittal et al. [23] | 48.2 | Two-stage hypothesize-and-classify framework |
| Deng et al. [43] | 57.7 | Joint model |
| Le et al. [44] | 75.1 | Multiple-scale region-based fully convolutional networks (MS RFCN) |
| Li Yang et al. [45] | 83.2 | CNN, MobileNet |
| Our method | 86.3 | Yolov7x |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dewi, C.; Chen, A.P.S.; Christanto, H.J. Deep Learning for Highly Accurate Hand Recognition Based on Yolov7 Model. Big Data Cogn. Comput. 2023, 7, 53. https://doi.org/10.3390/bdcc7010053
Dewi C, Chen APS, Christanto HJ. Deep Learning for Highly Accurate Hand Recognition Based on Yolov7 Model. Big Data and Cognitive Computing. 2023; 7(1):53. https://doi.org/10.3390/bdcc7010053
Chicago/Turabian StyleDewi, Christine, Abbott Po Shun Chen, and Henoch Juli Christanto. 2023. "Deep Learning for Highly Accurate Hand Recognition Based on Yolov7 Model" Big Data and Cognitive Computing 7, no. 1: 53. https://doi.org/10.3390/bdcc7010053
APA StyleDewi, C., Chen, A. P. S., & Christanto, H. J. (2023). Deep Learning for Highly Accurate Hand Recognition Based on Yolov7 Model. Big Data and Cognitive Computing, 7(1), 53. https://doi.org/10.3390/bdcc7010053