

Analysis of the Numerical Solutions of the Elder Problem Using Big Data and Machine Learning


Abstract
1. Introduction
2. Models and Scientific Questions
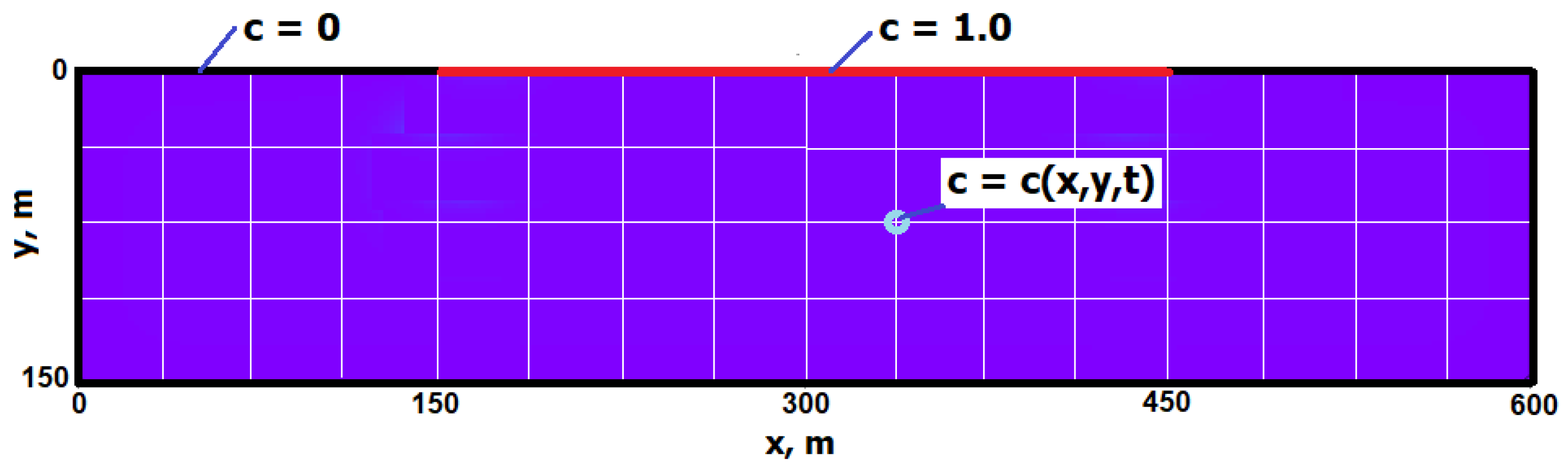
2.1. The Elder Problem
2.2. Existing Approaches to the Elder Problem
2.3. Background for Our Study
2.4. Numerical Solution
2.5. Perturbations
- Perturbations that are applied to the initial conditions (weak perturbations);
- Perturbations that are applied to the solutions in an early time year (strong perturbations).
2.6. The Steady-State Predicting Problem
2.7. Complexity Analysis
- The number of degrees of freedom (DoF) in a dataset.
- Metrics based on the principal component analysis (PCA) of a dataset. The singular value decomposition (SVD) is used as the computational technique for PCA.
3. Methods
3.1. Numerical Solvers for PDEs
- It can be used both on structured (squares) and unstructured (triangles) grids for complex geometries.
- It uses an integral formulation of conservation laws, which is the native form of conservation laws.
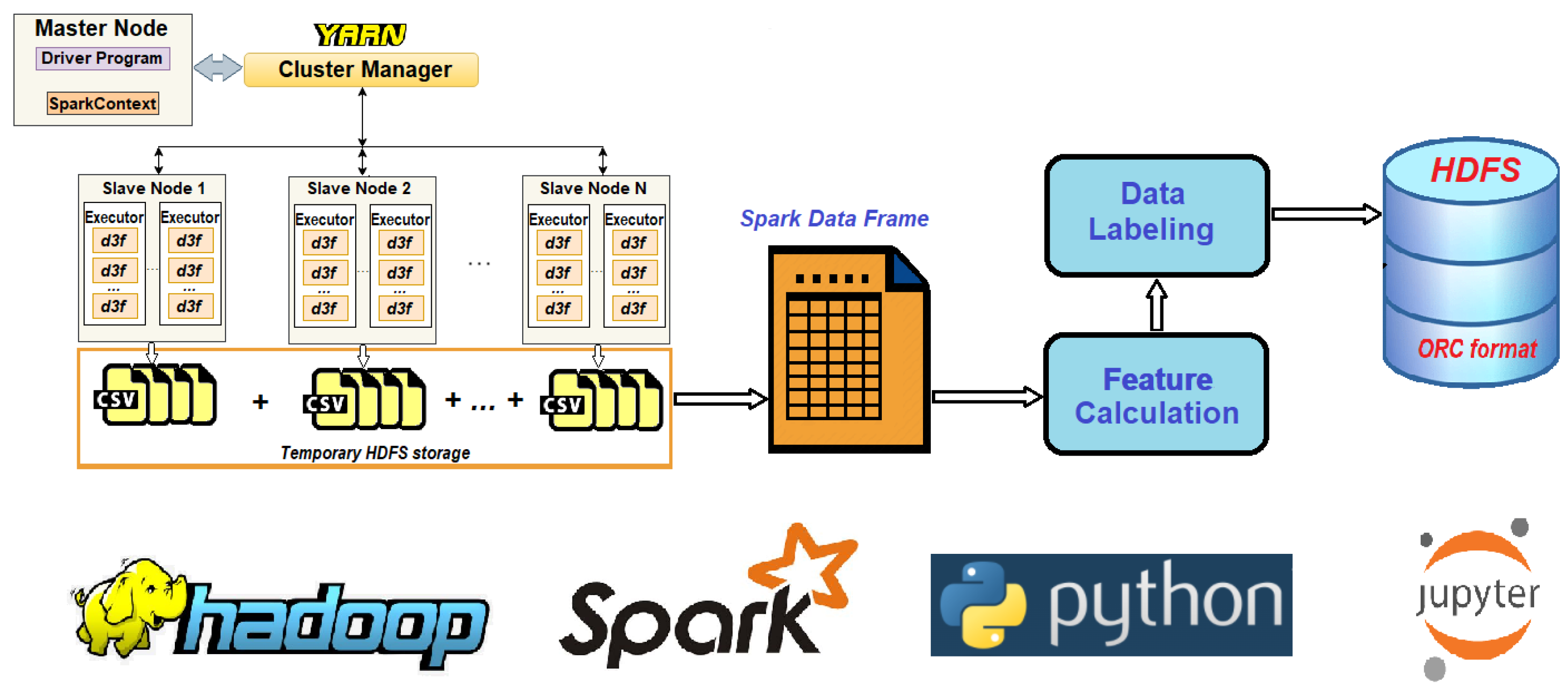
3.2. Big Data Setup for Large-Scale Simulations
- The implementation of a Big Data setup, allowing mass parallel runs of the legacy solver for numerical PDEs;
- The implementation of the pipelines for collecting, post-processing, and storing large amounts of data from numerical PDEs in the Big Data ecosystem;
- The implementation of machine learning pipelines for supervised (classification) and unsupervised (dimensionality reduction) models for the studied problem.
3.3. Machine Learning
- (i)
- A train set with correctly defined labels to fit a model;
- (ii)
- A validation dataset to estimate the model’s skill while tuning the model’s hyperparameters;
- (iii)
- A test set to obtain the performance metrics of a trained model.
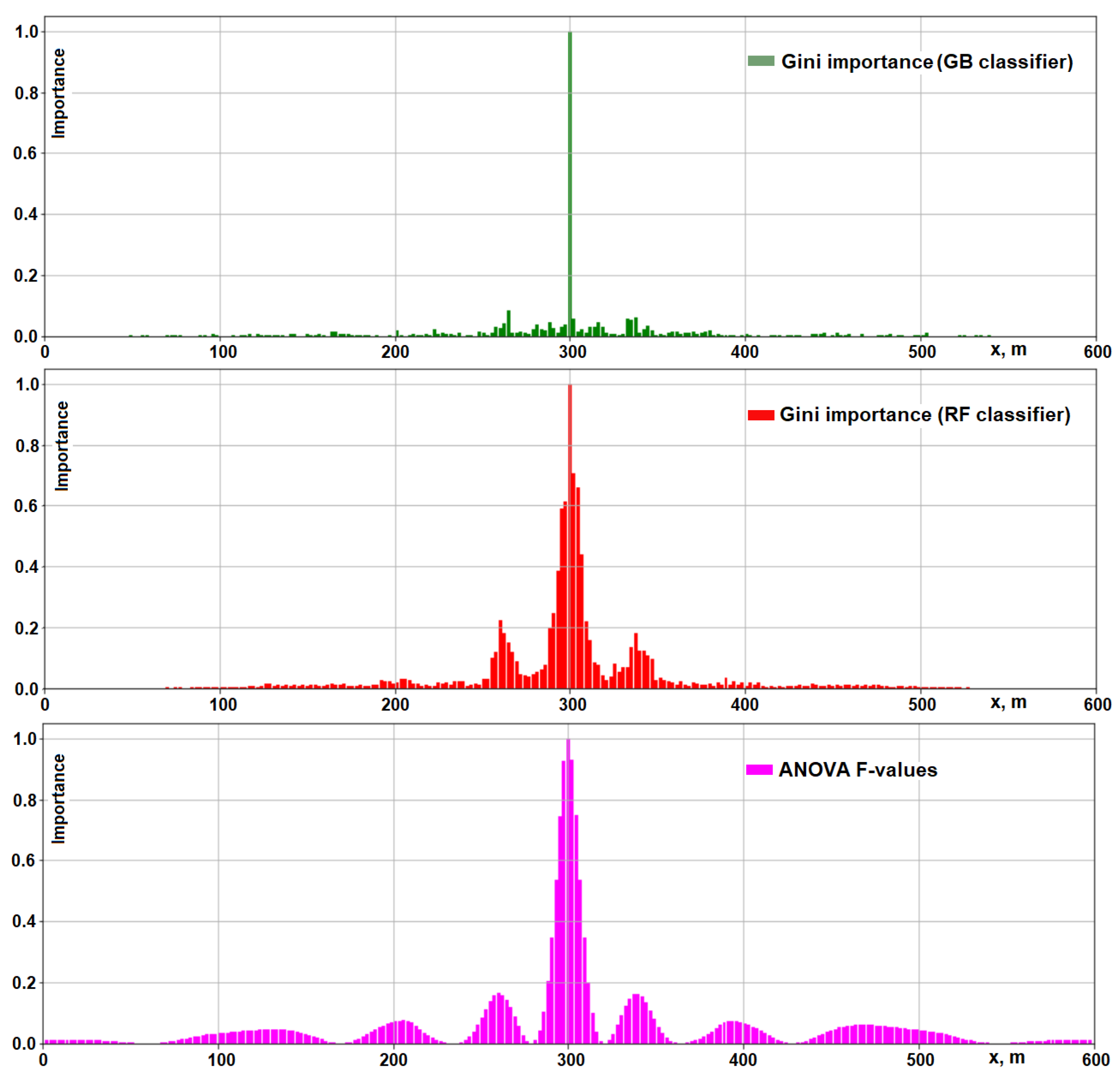
3.4. Feature Engineering
- Fully informed models (Type I);
- Partially informed models (Type II);
- Black-box models (Type III).
4. Results and Discussion
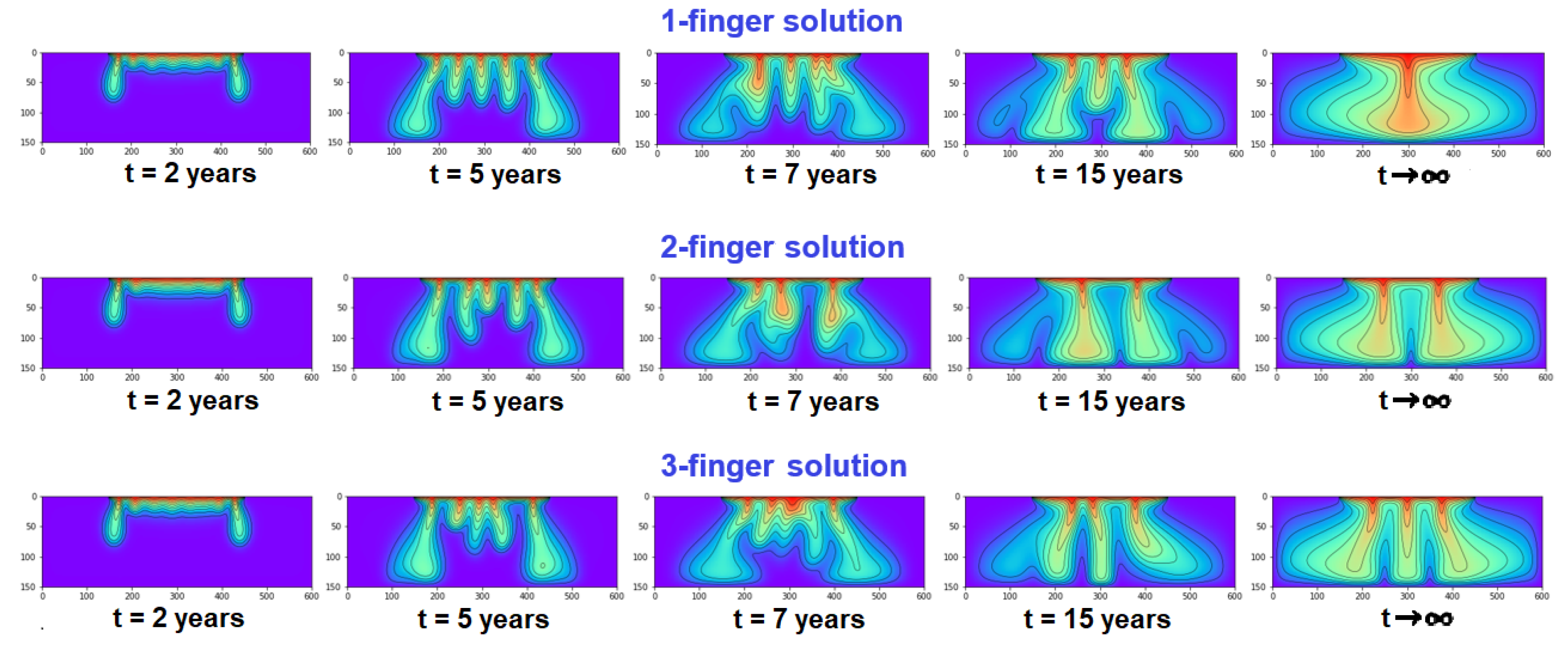
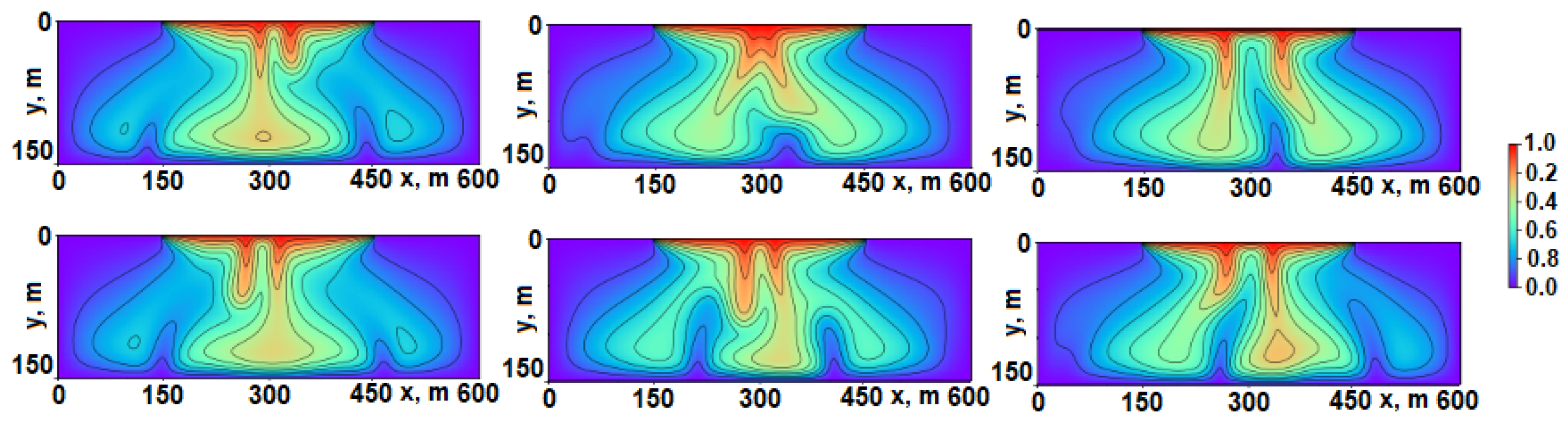
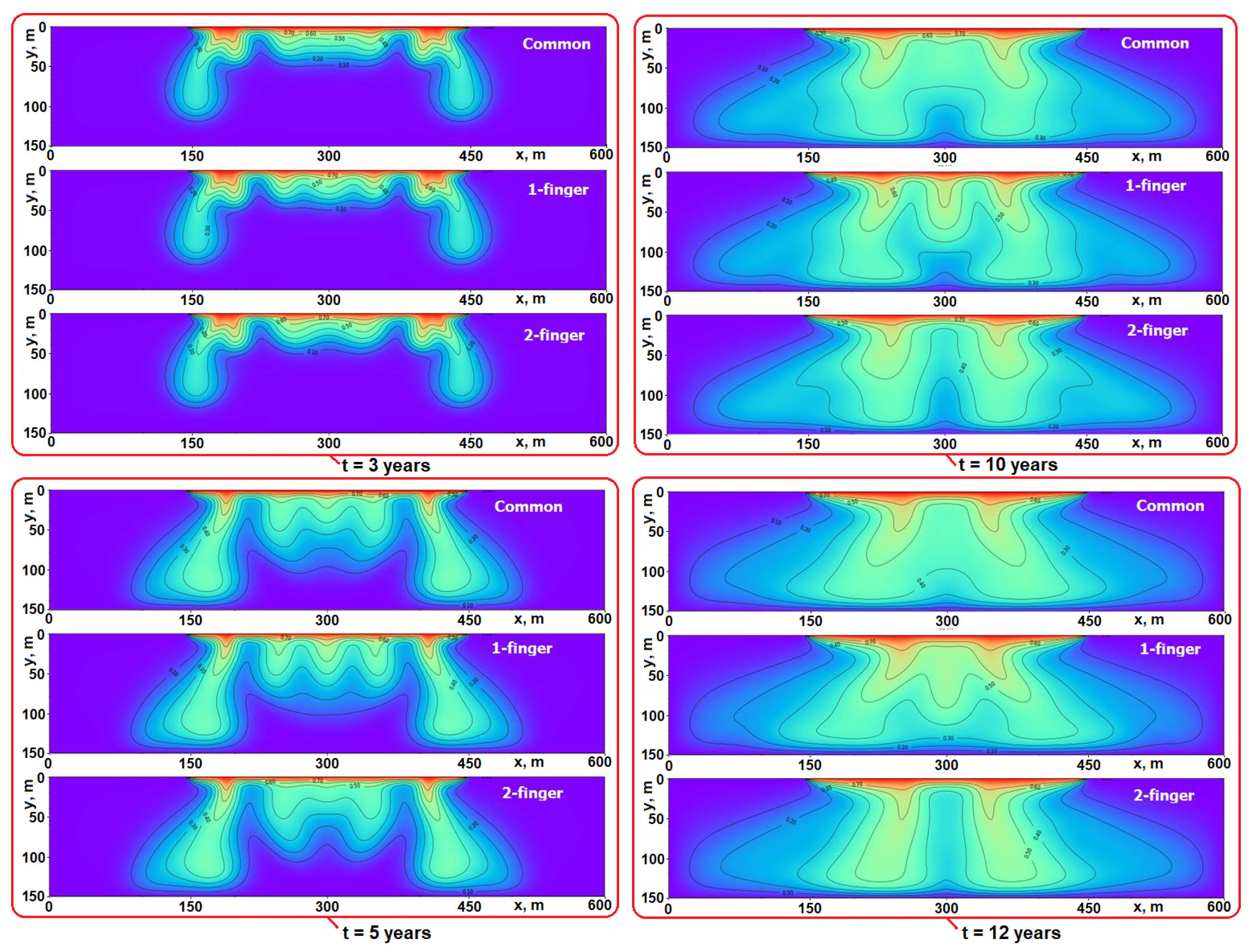
4.1. Unperturbed Solutions
4.2. Perturbed Solutions
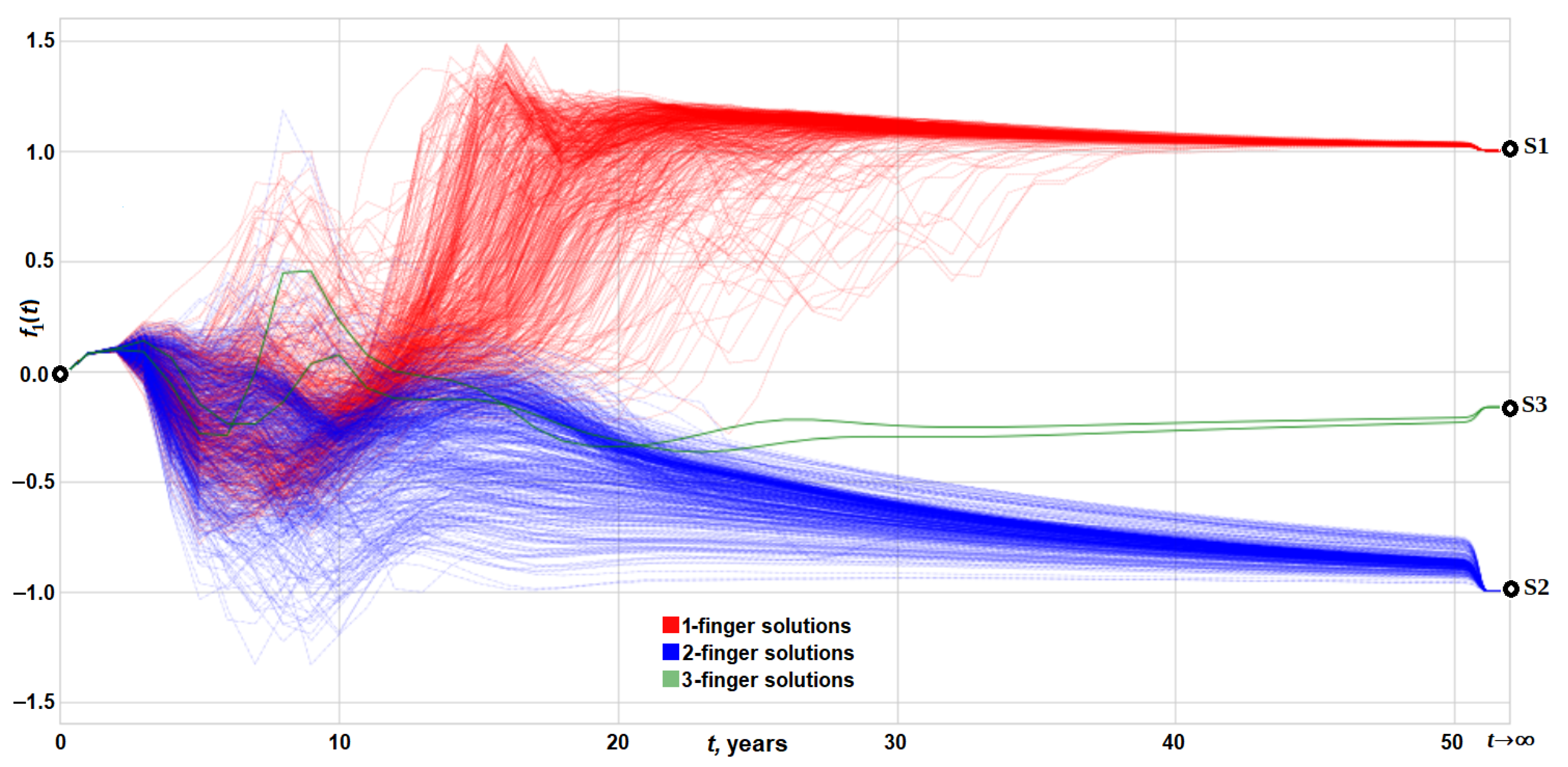
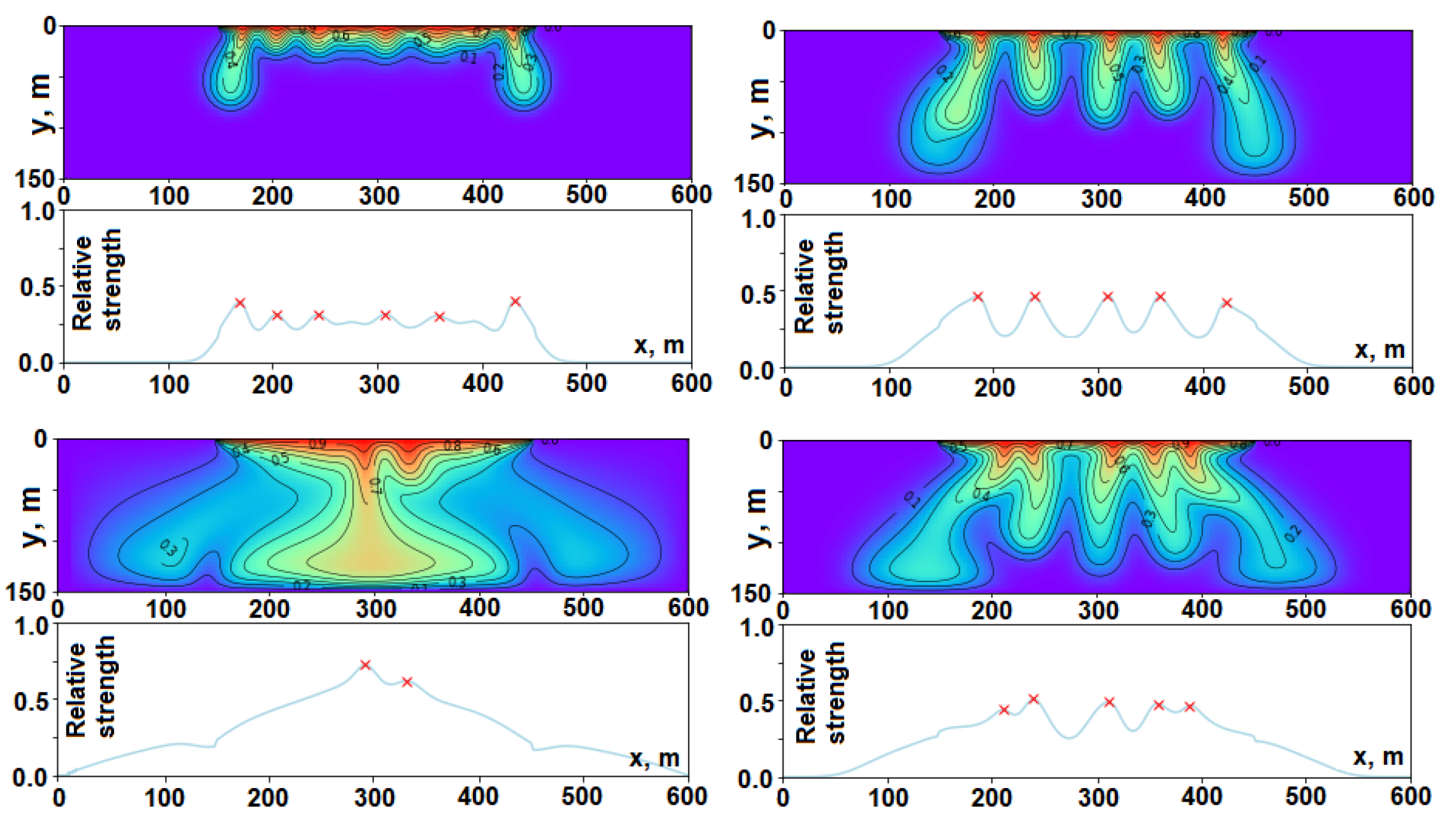
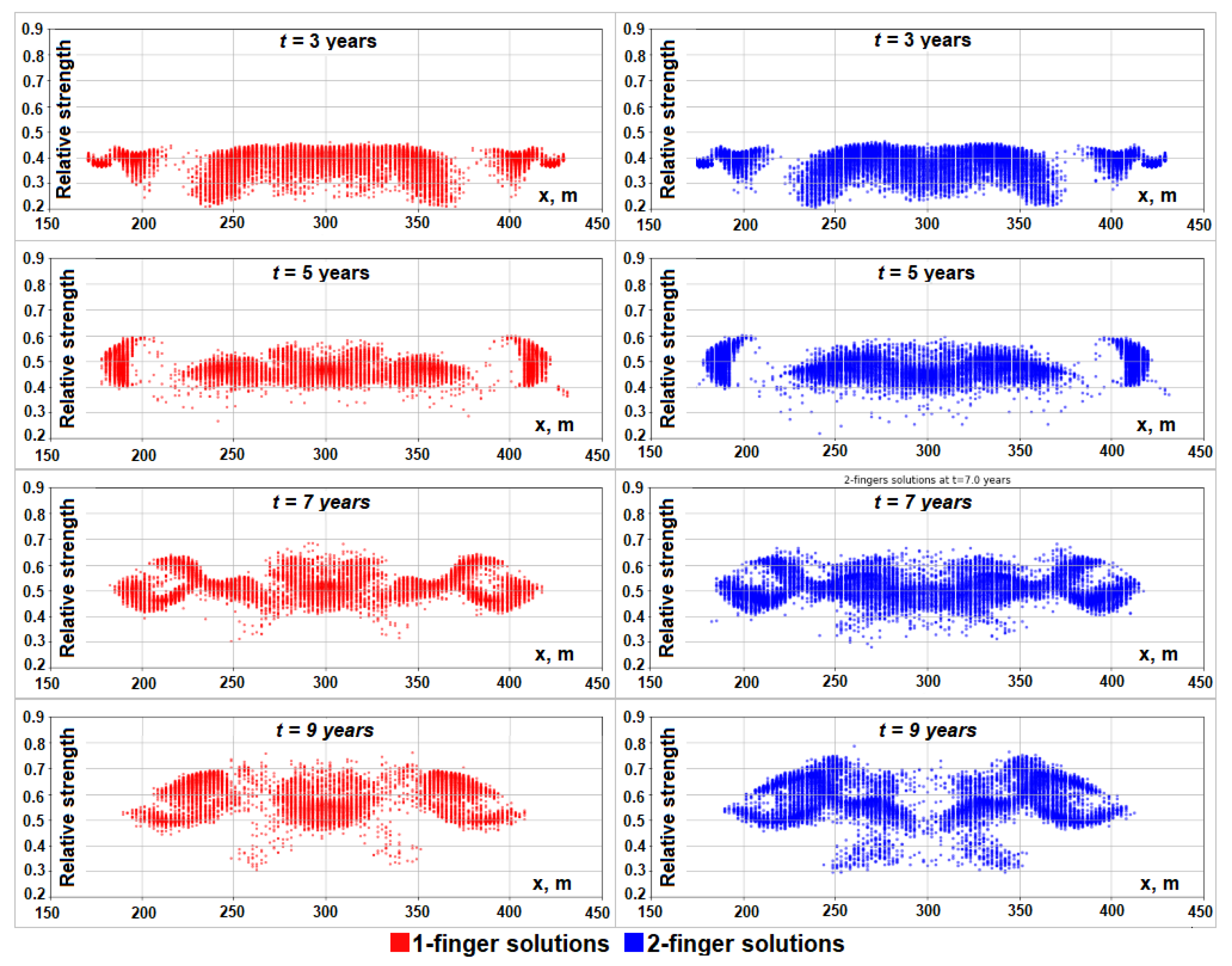
4.3. Identification of Transient Fingers, Their Positions, and Strengths
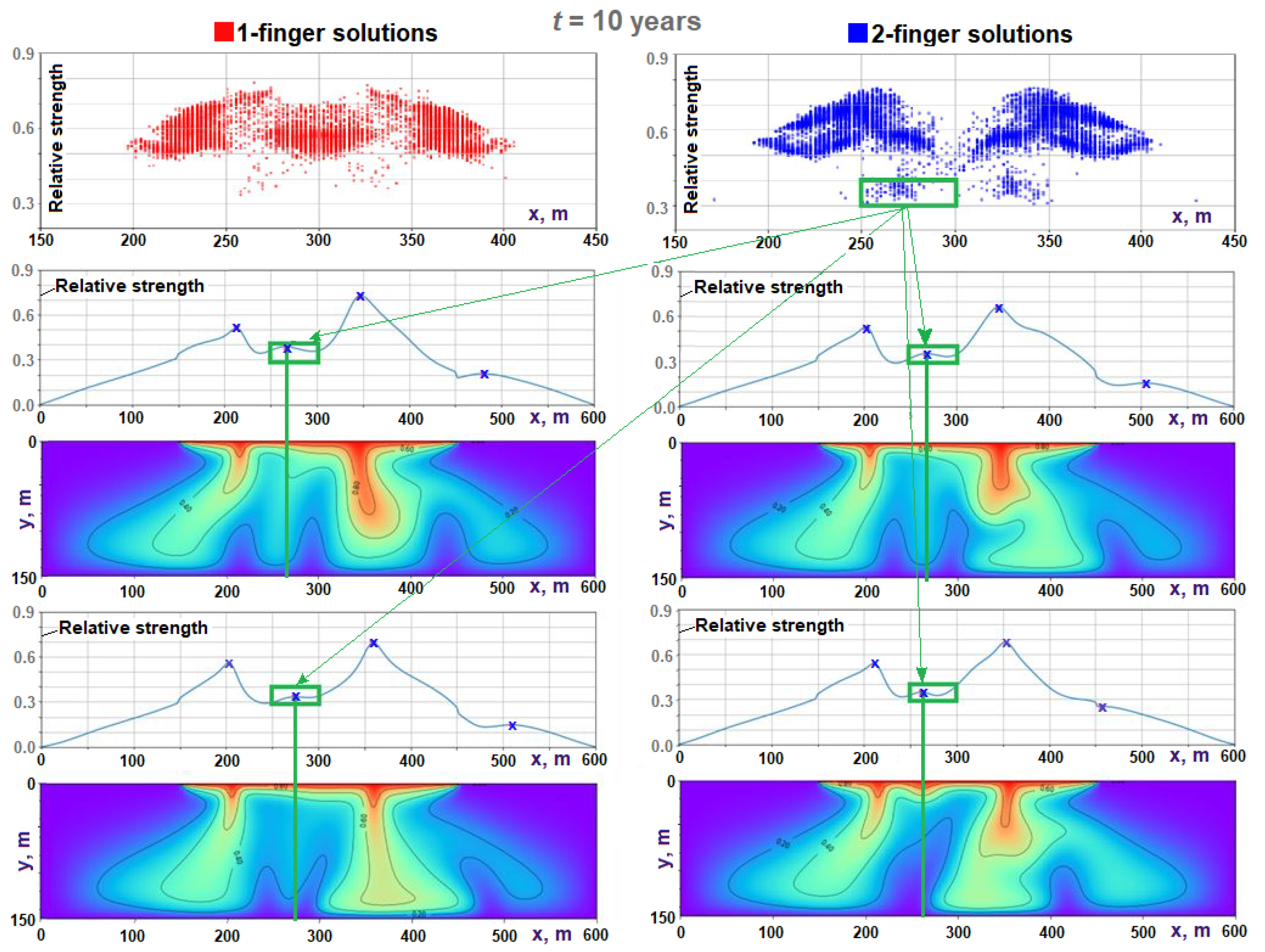
4.4. Interactive Visualization of Transient Solutions and Their Fingers
- The positions and strengths of all one- and two-finger solutions in an ensemble at time t are visualized on separate plots.
- The rectangular selector (in green in Figure 8) is used to specify the selection criteria.
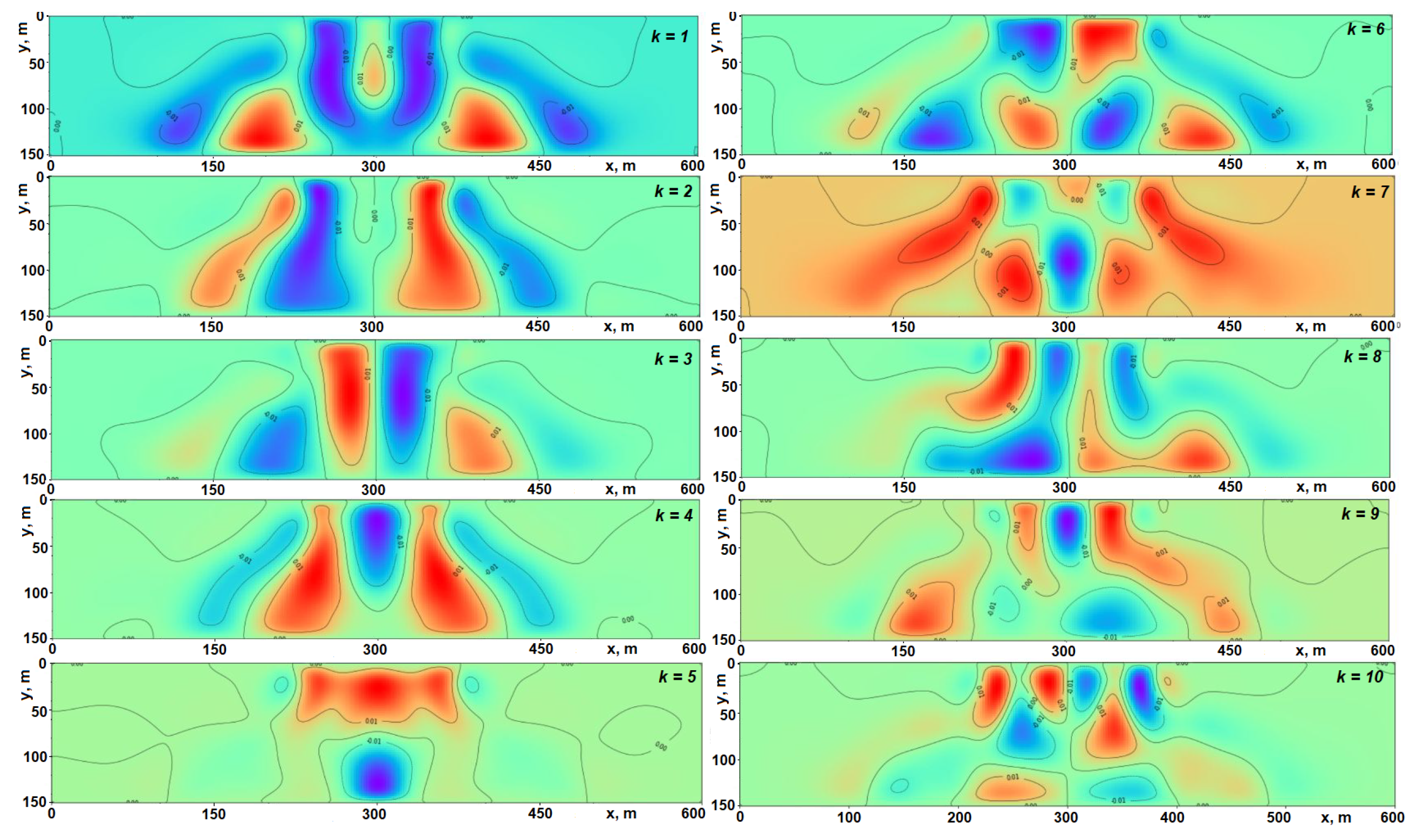
4.5. Complexity Analysis of Transient Solutions
- Create a subset of a dataset () that consists of both one-finger and two-finger solutions at time t.
- Calculate the SVD of the dataset.
- Approximate with 95% precision and save the number of principal components k needed for this approximation.
- Calculate the average solution of the .
- Create a subset of a dataset consisting of only one-finger solutions at time t.
- Repeat steps 3–4 for the dataset, using the set of PCs obtained at step 3.
- Create a subset of a dataset consisting of only two-finger solutions at time t.
- Repeat steps 3–4 for the dataset using the set of PCs obtained at step 3.
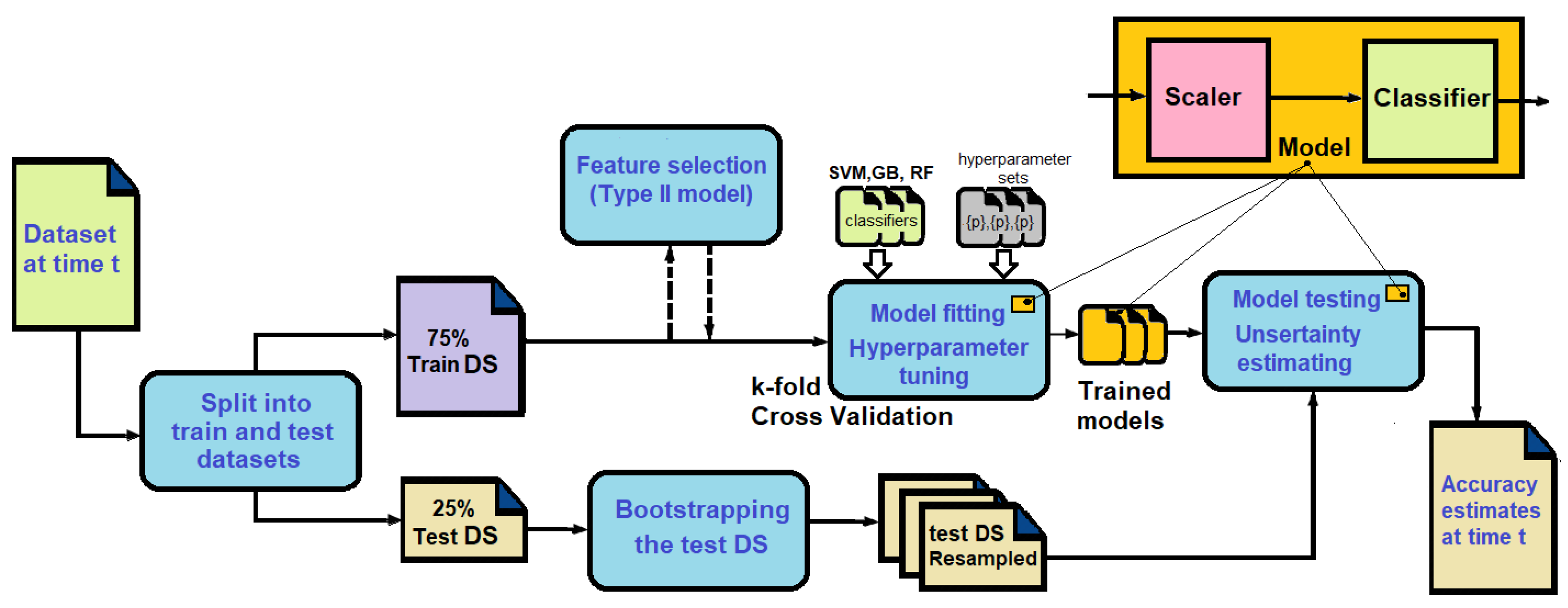
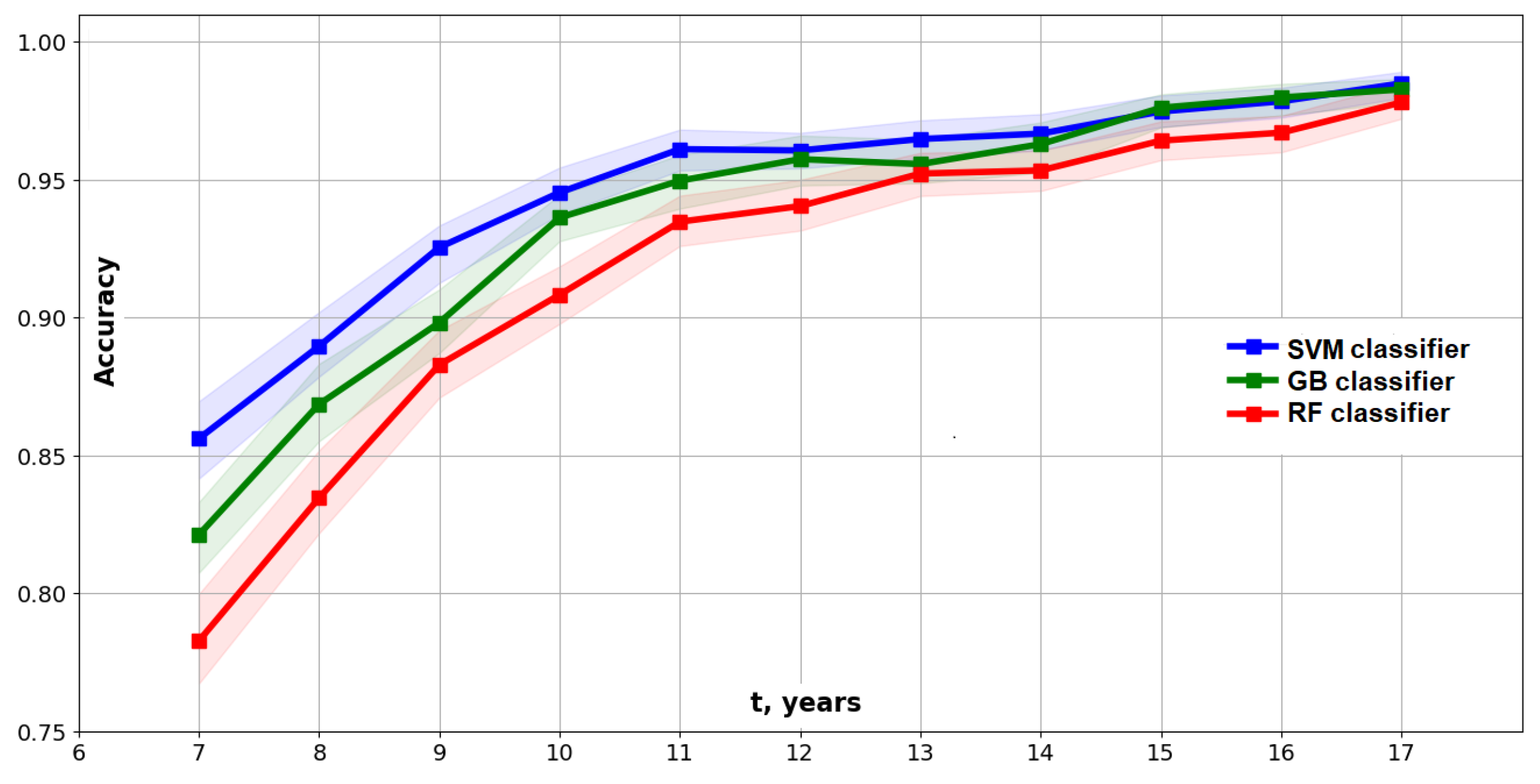
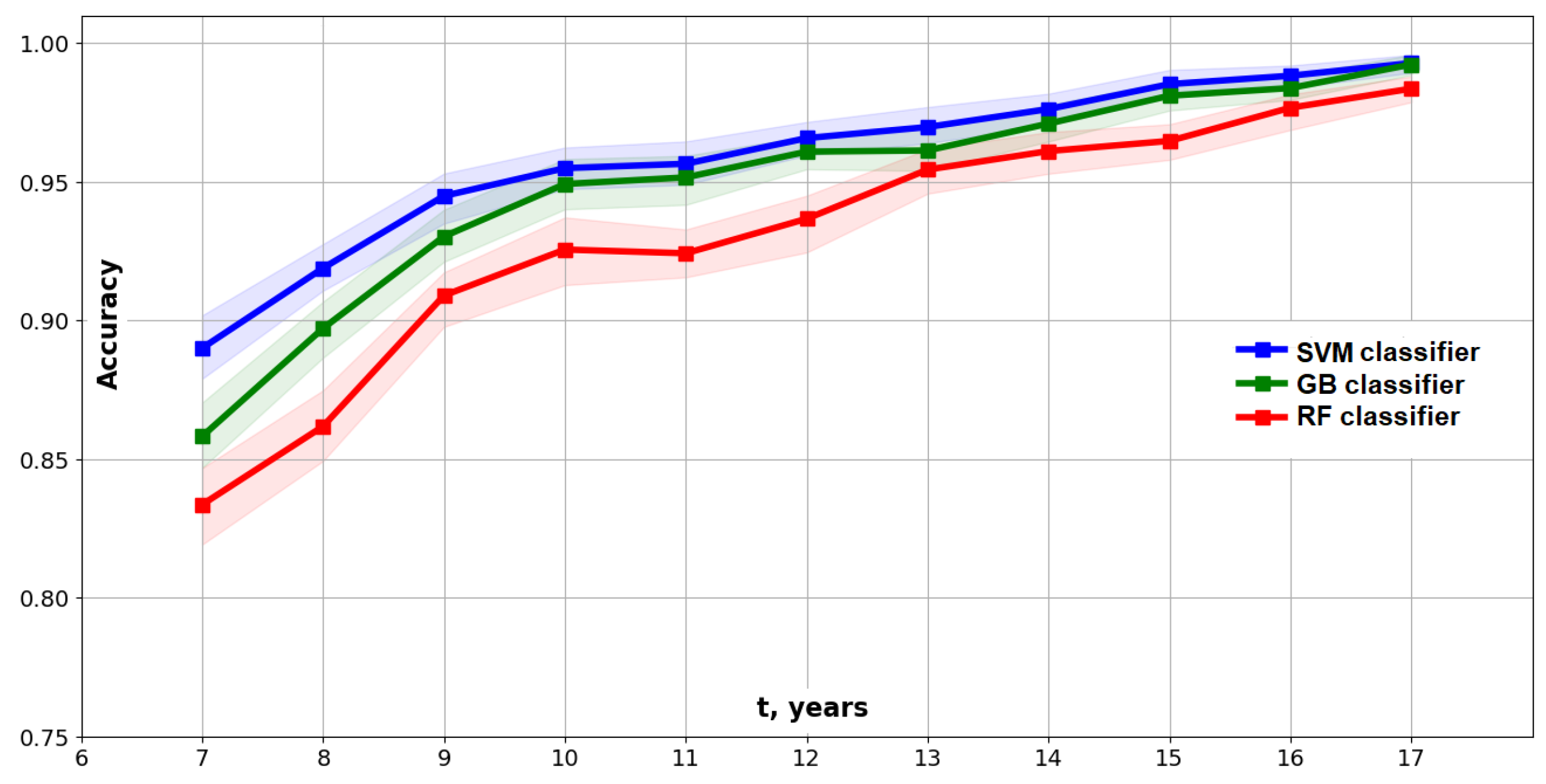
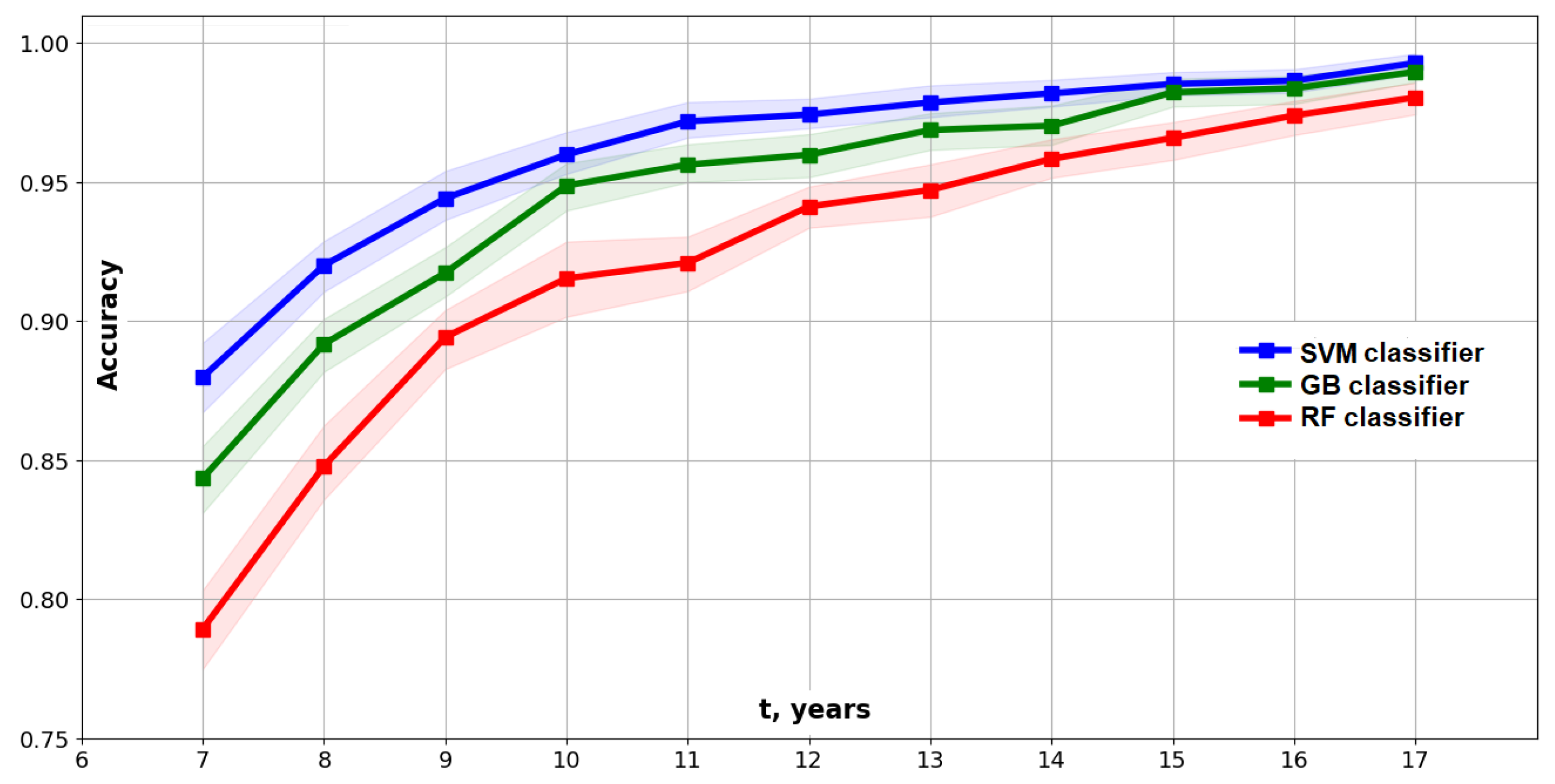
4.6. Predictive Modeling for the Elder Problem
- Data at time t are queried from HDFS and are transformed into a Pandas data frame.
- The dataset at time t is randomly divided into training (75%) and testing (25%) datasets.
- The k-fold cross-validation schema with folds is used to search for the best parameters in the hyperparameter spaces. This means that a small internal pipeline is fitted k times on the training datasets, and is evaluated k times on the validation datasets. This block returns the best model and combinations of hyperparameters found on the grid.
- The features of the training, validation, and testing datasets are scaled using the Standard Scaler, which removes the mean and performs scaling to unit variance.
- In the case of the Type II model, there is a feature selection step selecting the 18 most important features from the original feature set.
- Bootstrap is used to create resampled datasets from the test dataset.
- Finally, we calculate the prediction accuracy and estimate the uncertainty using the resampled datasets for each of the models. Namely, we estimate the mean values and 95% confidence intervals for this accuracy.
- ∗
- SMV hyperparameters:where C is the regularization parameter, that is, the penalty for each misclassified data point, and is the kernel coefficient for the radial basis function (RBF) kernel;
- ∗
- RF hyperparameters:where is the number of estimators (trees) in the forest, is the maximum depth of the tree, is the minimum number of samples required to split an internal node, and is the minimum number of samples at a leaf node;
- ∗
- GB hyperparameters:where is the number of boosting stages to perform, is the maximum number of nodes in the tree, and is the parameter controlling the contribution of each model in the ensemble prediction. and have the same meaning as the RF classifier.
- The projection of a current solution on the vectoris a linear combination of steady-state solutions and satisfying the conditions below:After inserting (10) into (11) and solving the system of two linear equations, we obtain the coefficients and . Originally, the vector was designed to automate the labeling of steady-state solutions in large ensembles of solutions. Then, we calculated the projections of all transient solutions on this vector and used them as a feature in the Type I model.
- The projection of a current solution on vector orthogonal to is defined as follows:where and .
- Descriptive statistics (mean, standard deviation, and maximum) of a difference between a current perturbed solution and an unperturbed solution :where .
- The features described above but taken with a time lag of 1 year:
- Features , taken with a time lag of 2 years, are described as follows:
5. Conclusions
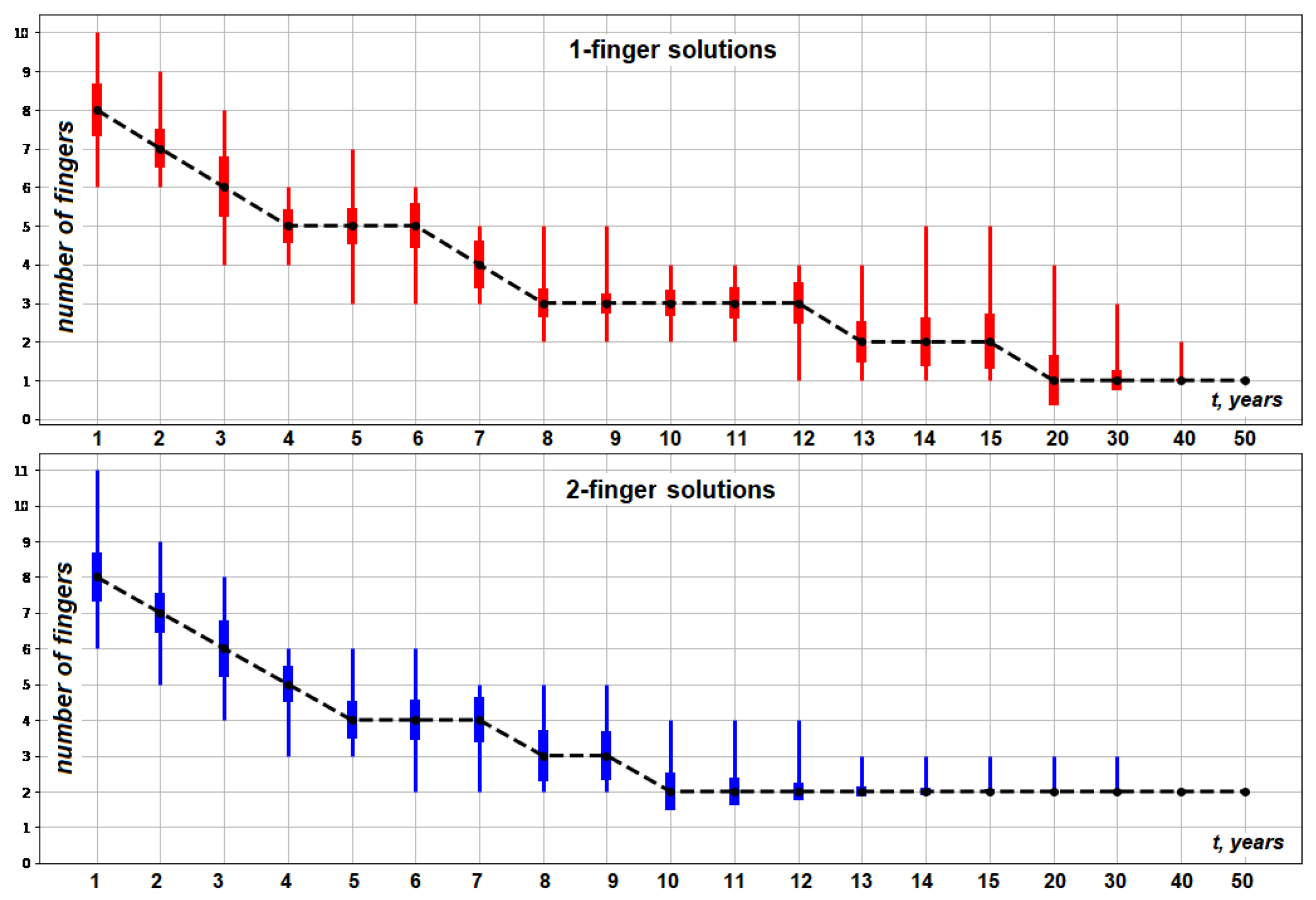
- A low-order model such as the 18-feature model in this study only has limited capabilities for predicting the full dynamics of the studied system at any given time.
- At the early time years, the system is nearly unpredictable when using such a low-dimensional (10–20 DoF) model. During this time, we observe quickly growing fingers and the increasing complexity of solutions.
- At the time years, we observe the highest complexity of solutions and less than 95% predictability.
- Prediction at the 95% level of accuracy with the 18-feature models becomes possible at the time years, when the complexity is significantly decreased. The fingers become more stable and start asymptotically moving to the fingers of a steady-state solution.
- It might be possible to predict the full dynamics of the Elder problem at time years using models of the order that are higher than 18 features (but that are still low-dimensional models).
- Investigation of predictability at the transient period years using models of the higher order, as indicated above;
- More accurate characterizations of transient fingers and their parameters;
- Nonlinear dimensionality reduction for numerical solutions to the Elder problem;
- Complexity analysis based on other complexity measures/approaches;
- Investigation of Deep Learning models for the Elder problem.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PDE | Partial differential equation; |
| FVM | Finite volume method; |
| FDM | Finite difference method; |
| FEM | Finite element method; |
| Rayleigh number; | |
| SUTRA | Saturated and/or unsaturated fluid flow, and solute/energy transport; |
| DMO | Dynamic mesh optimization; |
| HDFS | Hadoop file system; |
| ORC | Optimized row columnar; |
| CSV | Comma-separated values; |
| ML | Machine learning; |
| PC | Principal component; |
| PCA | Principal components analysis; |
| SVD | Singular value decomposition; |
| DoF | Degrees of freedom; |
| SVM | Support vector machines; |
| RBF | Radial basis function; |
| RF | Random forest; |
| GB | Gradient boosting; |
| ANOVA | Analysis of variation. |
References
- Elder, J.W. Transient convection in a porous medium. J. Fluid Mech. 1967, 27, 609–623. [Google Scholar] [CrossRef]
- Diersch, J.G.; Kolditz, O. Variable-density flow and transport in porous media: Approaches and challenges. Adv. Water Resour. 2002, 25, 899–944. [Google Scholar] [CrossRef]
- Voss, C.I.; Souza, W.R. Variable density flow and solute transport simulation of regional aquifers containing a narrow freshwater-saltwater transition zone. Water Resour. 1987, 26, 2097–2106. [Google Scholar] [CrossRef]
- Nield, D.A.; Bejan, A. Convection in Porous Media, 4th ed.; Spinger: Berlin/Heidelberg, Germany, 2013; ISBN 978-1-4614-5540-0. [Google Scholar] [CrossRef]
- Johannsen, K. On the validity of the Boussinesq approximation for the Elder problem. Comput. Geosci. 2003, 7, 169–182. [Google Scholar] [CrossRef]
- Frolkovič, P.; De Schepper, H. Numerical modelling of convection dominated transport coupled with density driven flow in porous media. Adv. Water Resour. 2001, 24, 63–72. [Google Scholar] [CrossRef]
- Elder, J.; Simmons, C.T.; Diersch, H.-J.; Frolkovic, P.; Holzbecher, E.; Johannsen, K. The Elder Problem. Fluids 2017, 2, 11. [Google Scholar] [CrossRef]
- Simmons, C.T.; Narayan, K.A.; Wooding, R.A. On a test case for density-dependent groundwater flow and solute transport models: The salt lake problem. Water Resour. Res. 1999, 35, 3607–3620. [Google Scholar] [CrossRef]
- van Reeuwijk, M.; Mathias, S.A.; Simmons, C.T.; Ward, J.D. Insights from a pseudospectral approach to the Elder problem. Water Resour. Res. 2009, 45, 1–13. [Google Scholar] [CrossRef]
- SUTRA: A Model for 2D or 3D Saturated-Unsaturated, Variable-Density Ground-Water Flow with Solute or Energy Transport. Available online: https://www.usgs.gov/software/sutra-model-2d-or-3d-saturated-unsaturated-variable-density-ground-water-flow-solute-or (accessed on 23 December 2022).
- Oldenburg, C.; Pruess, K. Dispersive transport dynamics in a strongly coupled groundwater–brine flow system. Water Resour. Res. 1995, 31, 289–302. [Google Scholar] [CrossRef]
- Kolditz, O.R.; Ratke, H.-J.; Diersch, W. Coupled groundwater flow and transport: 1. Verification of variable density flow and transport models. Adv. Water Resour. 1998, 21, 7–46. [Google Scholar] [CrossRef]
- Prasad, A.; Simmons, C.T. Unstable density-driven flow in heterogeneous porous media: A stochastic study of the Elder “short heater” problem. Water Resour. Res. 2003, 39, 4-1–4-21. [Google Scholar] [CrossRef]
- Johannsen, K. The Elder problem—bifurcations and steady state solutions. Dev. Water Sci. 2002, 47, 485–492. [Google Scholar] [CrossRef]
- Woods, J.A.; Teubner, M.D.; Simmons, C.T.; Narayan, K. Numerical error in groundwater flow and solute transport simulation. Water Resour. Res. 2003, 39, 1–13. [Google Scholar] [CrossRef]
- Thornea, D.T.; Sukopa, M.C. Lattice Boltzmann model for the elder problem. Dev. Water Sci. 2004, 55 Pt 2, 1549–1557. [Google Scholar] [CrossRef]
- Musuuza, J.L.; Radu, F.A.; Radu, F.A.; Attinger, S.; Attinger, S. The effect of dispersion on the stability of density-driven flows in saturated homogeneous porous media. Adv. Water Resour. 2011, 34, 417–432. [Google Scholar] [CrossRef]
- Ataie-Ashtiani, B.; Simmons, C.T.; Werner, A.D. Influence of Boundary Condition Types on Unstable Density-Dependent Flow. Groundwater 2014, 52, 378–387. [Google Scholar] [CrossRef]
- Simmons, C.T.; Elder, J.W. The Elder Problem. Groundwater 2017, 55, 926–930. [Google Scholar] [CrossRef]
- Yan, M.; Lu, C.; Yang, J.; Xie, Y.; Luo, J. Impact of Low- or High-Permeability Inclusion on Free Convection in a Porous Medium. Geofluids 2019, 2019, 8609682. [Google Scholar] [CrossRef]
- Shafabakhsh, P.; Fahs, M.; Ataie-Ashtiani, B.; Simmons, C.T. Unstable Density-Driven Flow in Fractured Porous Media: The Fractured Elder Problem. Fluids 2019, 4, 168. [Google Scholar] [CrossRef]
- Bahlali, M.L.; Salinas, P.; Jackson, M.D. Efficient numerical simulation of density-driven flows: Application to the 2- and 3-D Elder problem. Water Resour. Res. 2022, 58, e2022WR032307. [Google Scholar] [CrossRef]
- Xie, Y.; Simmons, C.; Werner, A.; Diersch, J.G. Prediction and uncertainty of free convection phenomena in porous media. Water Resour. Res. 2012, 48, 1944–7973. [Google Scholar] [CrossRef]
- Kutz, J.N. Data-Driven Modeling & Scientific Computation: Methods for Complex Systems & Big Data; Oxford University Press: Oxford, UK, 2013; ISBN 978-0-19-966034-6. [Google Scholar]
- Brunton, S.; Kutz, J.N. Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control; Oxford University Press: Oxford, UK, 2022; ISBN 9781009089517. [Google Scholar] [CrossRef]
- Apache Hadoop. Available online: https://hadoop.apache.org/ (accessed on 23 December 2022).
- Apache Spark. Available online: https://spark.apache.org/ (accessed on 23 December 2022).
- Fein, E. d3f—Ein Programmpaket zur Modellierung von Dichtegetriebenen Strömungen; GRS: Braunschweig, Germany, 1998; ISBN 3-923875-97-5. [Google Scholar]
- Bastian, P.; Birken, K.; Johannsen, K.; Lang, S.; Eckstein, K.; Neuss, N.; Rentz-Reichert, H.; Wieners, C. UG—A Flexible Software Toolbox for Solving Partial Differential Equations. Comput. Vis. Sci. 1997, 1, 27–40. [Google Scholar] [CrossRef]
- Ferziger, J.; Perić, M.; Street, R. Computational Methods for Fluid Dynamics, 4th ed.; Springer: Cham, Switzerland, 2020; ISBN 978-3-319-99691-2. [Google Scholar]
- ISO Random (The GNU C Library). Available online: https://www.gnu.org/software/libc/manual/html_node/ISO-Random.html#index-rand (accessed on 23 December 2022).
- Ajibola, J.; Adam, A.; Ann Muggeridge, A. Gravity Driven Fingering and Mixing During CO2 Sequestration. In Proceedings of the the SPE Asia Pacific Oil & Gas Conference and Exhibition, Perth, Australia, 25–27 October 2016. [Google Scholar] [CrossRef]
- Aggarwal, C. (Ed.) Data Classification: Algorithms and Applications; Chapman & Hall/CRC: Boca Raton, FL, USA, 2014; ISBN 1466586745. [Google Scholar]
- Bishop, C. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006; ISBN 978-0-387-31073-2. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2018; ISBN 978-1461468486. [Google Scholar]
- Di Ciccio, T.; Efron, B. Bootstrap confidence intervals. Stat. Sci. 1996, 11, 189–228. [Google Scholar] [CrossRef]
- Ho, T.K.; Basu, M. Complexity measures of supervised classification problems. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 289–300. [Google Scholar] [CrossRef]
- Baumgartner, R.; Somorjai, R.L. Data complexity assessment in undersampled classification of high-dimensional biomedical data. Pattern Recognit. Lett. 2006, 27, 1383–1389. [Google Scholar] [CrossRef]
- Eldén, L. Matrix Methods in Data Mining and Pattern Recognition; Society for Industrial & Applied Mathematics: Philadelphia, PA, USA, 2007; ISBN 978-0-89871-626-9. [Google Scholar]
- Dulhare, U.; Ahmad, K.; Bin Ahmad, K.A. (Eds.) Machine Learning and Big Data: Concepts, Algorithms, Tools and Applications.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2020; ISBN 9781119654742. [Google Scholar]
- Pulliam, T.H.; Zingg, D.W. Fundamentals Algorithms in Computational Fluid Dynamics; Scientific Computation; Springer: Berlin, Germany, 2014. [Google Scholar] [CrossRef]
- Chakraverty, S.; Mahato, N.R.; Karunakar, P.; Rao, T.D. Advanced Numerical and Semi-Analytical Methods for Differential Equations; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Rapp, B. Microfluidics: Modeling, Mechanics and Mathematics; Elsevier Inc.: Amsterdam, The Netherlands, 2017. [Google Scholar] [CrossRef]
- HDFS Architecture Guide. Available online: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html (accessed on 23 December 2022).
- Apache ORC—High-Performance Columnar Storage for Hadoop. Available online: https://orc.apache.org/ (accessed on 23 December 2022).
- Brownlee, J. What Is the Difference Between Test and Validation Datasets? 2017. Available online: https://machinelearningmastery.com/difference-test-validation-datasets/ (accessed on 23 December 2022).
- Calvetti, D.; Somersalo, E. Mathematics of Data Science: A Computational Approach to Clustering and Classification; Society for Industrial & Applied Mathematics: Philadelphia, PA, USA, 2020; ISBN 9781611976366. [Google Scholar]
- Scikit-Learn—Machine Learning in Python. Available online: https://scikit-learn.org/ (accessed on 23 December 2022).
- Apache Spark MLlib. Available online: https://spark.apache.org/mllib/ (accessed on 23 December 2022).
- Project Jupyter. Available online: https://jupyter.org/ (accessed on 23 December 2022).
- Matplotlib: Visualization with Python. Available online: https://matplotlib.org/ (accessed on 23 December 2022).
- Duboue, P. The Art of Feature Engineering: Essentials for Machine Learning; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Univariate Feature Selection—Scikit-Learn 1.2.0 Documentation. Available online: https://scikit-learn.org/stable/modules/feature_selection.html#univariate-feature-selection (accessed on 23 December 2022).
- Scipy.Signal.Find_PEAKS—SciPy v1.9.1 Manual. Available online: https://docs.scipy.org/doc/scipy/reference/generated/scipy.signal.find_peaks.html (accessed on 23 December 2022).
- Tingle, M. Preventing Data Leakage in Your Machine Learning Model. Available online: https://towardsdatascience.com/preventing-data-leakage-in-your-machine-learning-model-9ae54b3cd1fb (accessed on 26 February 2023).
- Random Forest Classifier—Scikit-Learn 1.2.0 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html#sklearn.ensemble.RandomForestClassifier.feature_importances_ (accessed on 23 December 2022).
- Gradient Boosting Classifier—Scikit-Learn 1.2.0 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.GradientBoostingClassifier.html#sklearn.ensemble.GradientBoostingClassifier.feature_importances_ (accessed on 23 December 2022).


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Symbol | Value | Unit |
|---|---|---|---|
| Porosity | n | 0.1 | - |
| Molecular diffusion coefficient | · | ||
| Viscosity | 0.001 | kg· | |
| Permeability | K | ||
| Max. salt mass fraction | 20% | - | |
| Min. density | 1000.0 | kg· | |
| Max. density | 1200.0 | kg· | |
| Gravity | g | 9.81 | m· |
| l | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
|---|---|---|---|---|---|---|---|---|---|
| 3 | 5 | 9 | 17 | 33 | 65 | 129 | 257 | 513 | |
| 9 | 17 | 33 | 65 | 129 | 257 | 513 | 1025 | 2049 | |
| N | 27 | 85 | 297 | 1105 | 4257 | 16,705 | 66,177 | 263,425 | 1,051,137 |
| Parameter | Value |
|---|---|
| Number of nodes | 10 |
| CPU type | ×86_64, the mix of Intel and AMD CPUs |
| Total cores available | 208 (416 threads) |
| Total memory (RAM) available | 1792 GB |
| RAM per node | from 128 to 256 GB |
| HDFS storage available | 192 TB |
| Cluster manager | YARN |
| 0 | 25 | 50 | 75 | 100 | 125 | 150 | 175 | 200 | 225 | |
| Solution | S1 | S1 | S1 | S1 | S2 | S2 | S2 | S1 | S2 | S2 |
| 250 | 275 | 300 | 325 | 350 | 375 | 400 | 425 | 450 | 475 | |
| Solution | S1 | S3 | S3 | S2 | S2 | S2 | S1 | S1 | S1 | S1 |
| 0 | 25 | 50 | 75 | 100 | 125 | 150 | 175 | 200 | 225 | |
| 1.00 | 1.00 | 1.00 | 0.83 | 0.00 | 0.00 | 0.48 | 0.87 | 0.00 | 0.00 | |
| 0.00 | 0.00 | 0.00 | 0.17 | 1.00 | 1.00 | 0.52 | 0.00 | 1.00 | 1.00 | |
| 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.13 | 0.00 | 0.00 | |
| 250 | 275 | 300 | 325 | 350 | 375 | 400 | 425 | 450 | 475 | |
| 0.70 | 0.00 | 0.00 | 0.13 | 0.00 | 0.00 | 0.52 | 0.71 | 0.86 | 0.65 | |
| 0.30 | 0.22 | 0.04 | 0.57 | 0.87 | 0.86 | 0.33 | 0.29 | 0.14 | 0.35 | |
| 0.00 | 0.78 | 0.96 | 0.30 | 0.13 | 0.14 | 0.14 | 0.00 | 0.00 | 0.00 |
| Model Type | SVM Classifier | GB Classifier | RF Classifier |
|---|---|---|---|
| Type I | |||
| Type II | |||
| Type III |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khotyachuk, R.; Johannsen, K. Analysis of the Numerical Solutions of the Elder Problem Using Big Data and Machine Learning. Big Data Cogn. Comput. 2023, 7, 52. https://doi.org/10.3390/bdcc7010052
Khotyachuk R, Johannsen K. Analysis of the Numerical Solutions of the Elder Problem Using Big Data and Machine Learning. Big Data and Cognitive Computing. 2023; 7(1):52. https://doi.org/10.3390/bdcc7010052
Chicago/Turabian StyleKhotyachuk, Roman, and Klaus Johannsen. 2023. "Analysis of the Numerical Solutions of the Elder Problem Using Big Data and Machine Learning" Big Data and Cognitive Computing 7, no. 1: 52. https://doi.org/10.3390/bdcc7010052
APA StyleKhotyachuk, R., & Johannsen, K. (2023). Analysis of the Numerical Solutions of the Elder Problem Using Big Data and Machine Learning. Big Data and Cognitive Computing, 7(1), 52. https://doi.org/10.3390/bdcc7010052