
Federated Learning to Safeguard Patients Data: A Medical Image Retrieval Case



Abstract
1. Introduction
- Privacy: through the use of FL, we try to provide a distributed learning solution that is privacy oriented, as clients do not forward their information to a central server.
- Data quality and robustness: we carried out tests on the variation of the distribution of datasets held by individual clients, and we demonstrated that the proposed solution is robust as it does not depend on the quality of the data held by individual clients.
- Scalability: we carried out a study based on scalability by evaluating the performance of our solution as the number of FL clients varies.
- Medical domain: where data are often distributed across different hospitals, clinics, and research organizations. We proposed a way in which FL can be used in the medical domain. In this particular case, our goal was to define a system based on a neural network capable of recognizing a case of COVID-19 from other pathologies through the use of X-ray images.
1.1. General Data Protection Regulation
1.2. Challenges of Fl in Healthcare
2. Related Work
3. Federated Learning
3.1. Definition
- At least two different groups have shown interest in constructing a machine learning model together, and each group has data that it would want to utilize to train the model.
- During the process of training a model, each partner is responsible for keeping all of the data.
- The model might be encrypted and partly shared between parties, preventing third parties from re-engineering the data from a particular party. This would be accomplished by employing a method for encryption.
- The performance of the finished model is equivalent to that of an ideal model that was built with all data submitted to a single party throughout the construction process.
3.2. Horizontal Federated Learning
3.3. Vertical Federated Learning
3.4. Privacy
3.4.1. Data Anonymization
3.4.2. Secure Multi-Party Computation (SMC)
3.4.3. Differential Privacy
3.5. Federated Learning and Healthcare
4. Approach
4.1. Dataset
4.2. Dataset Distribution
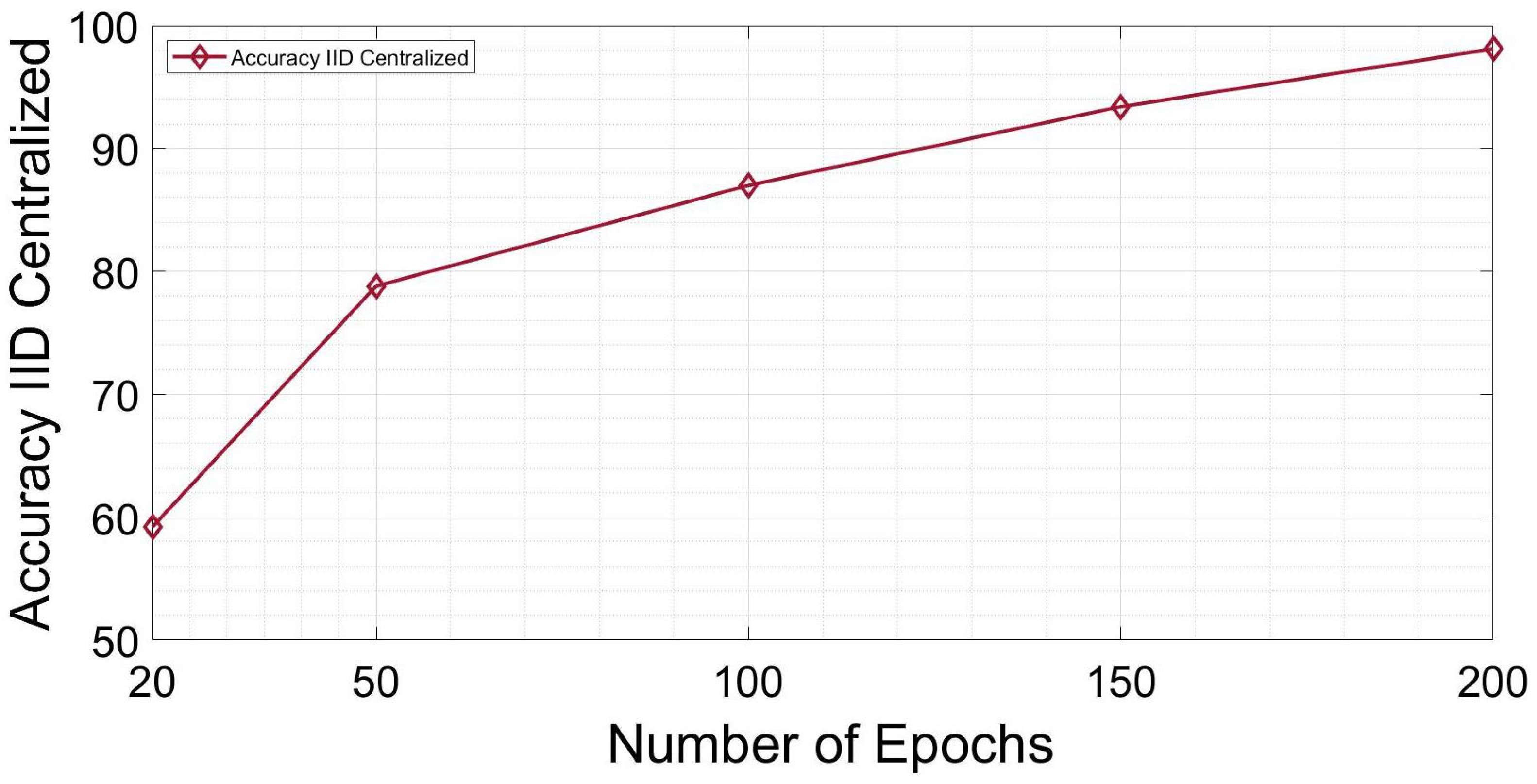
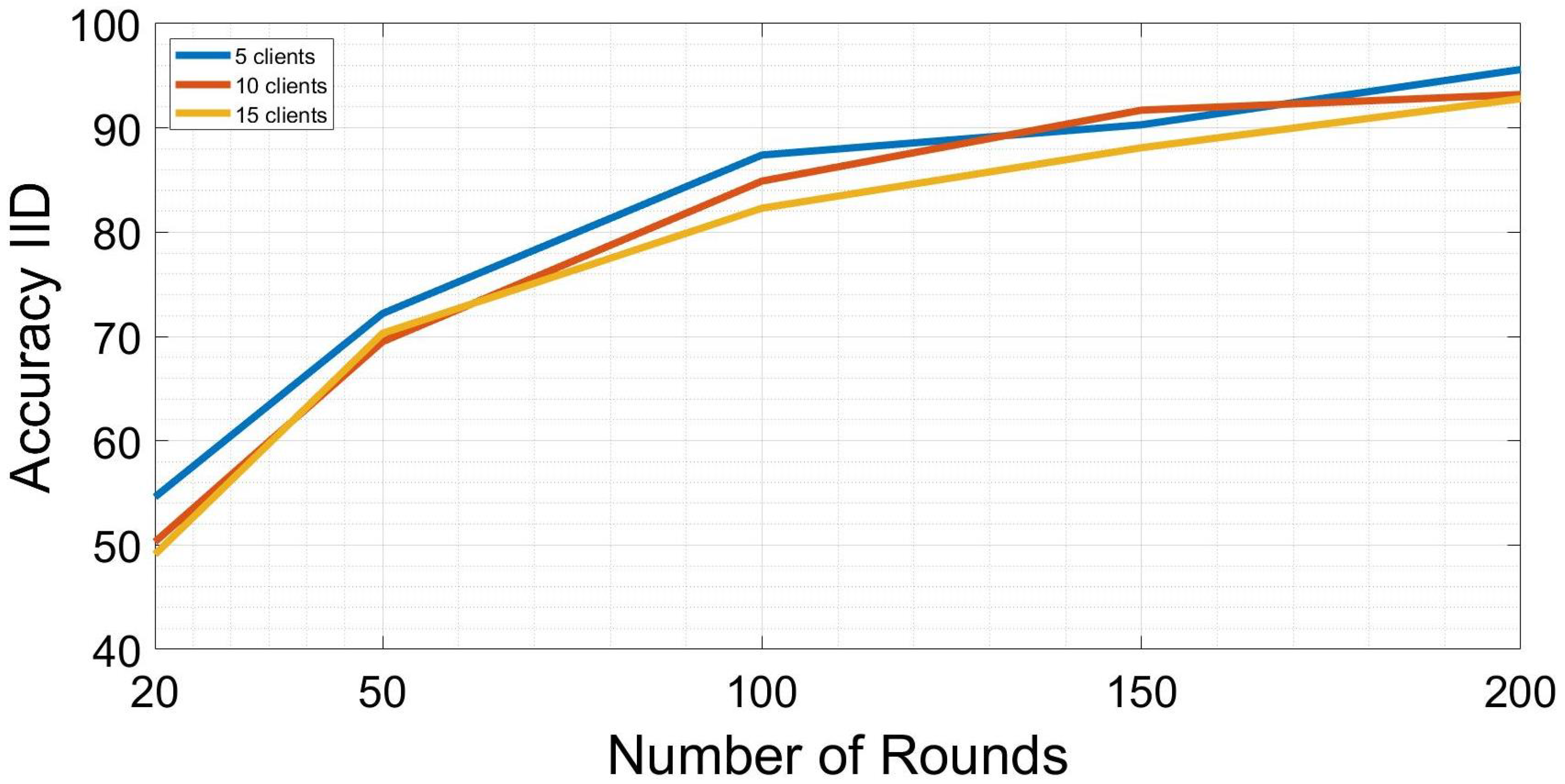
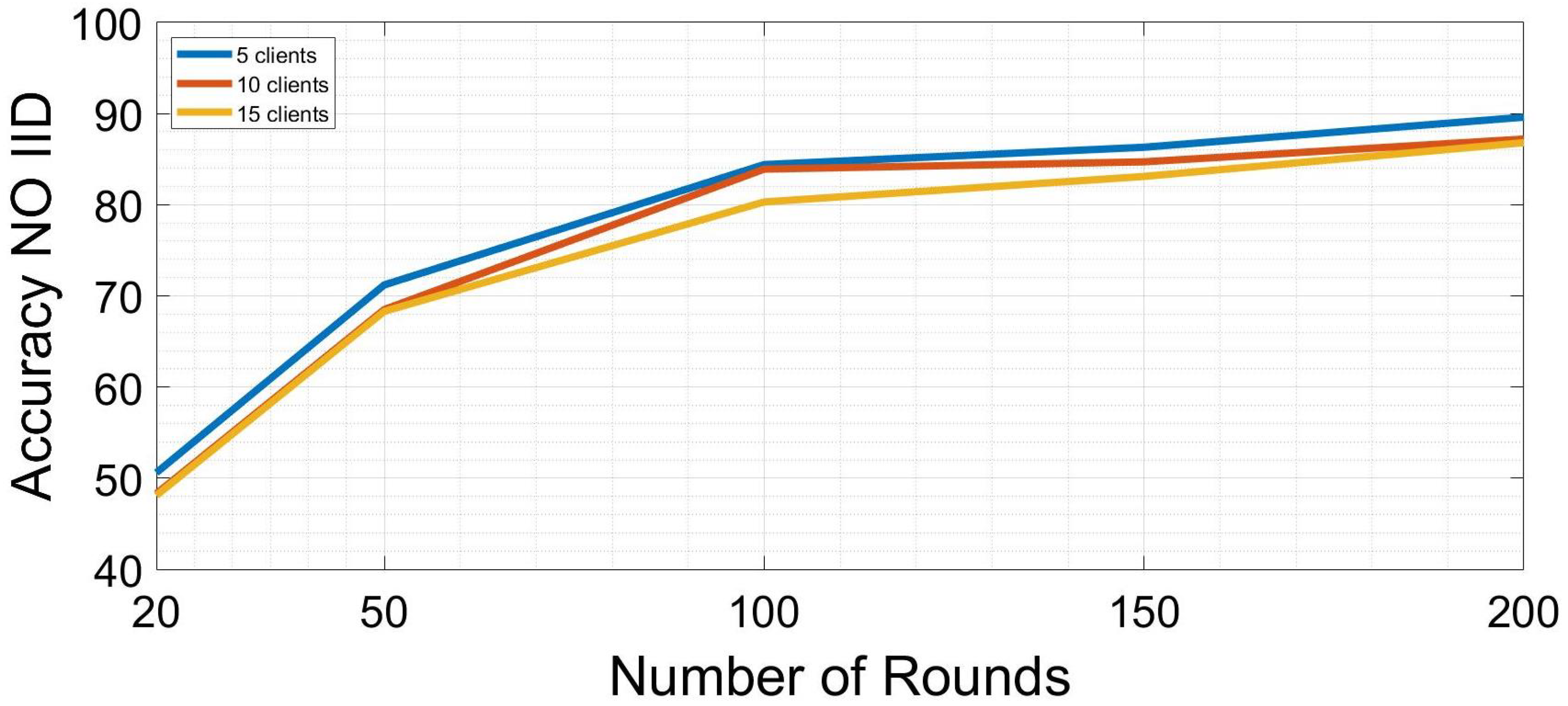
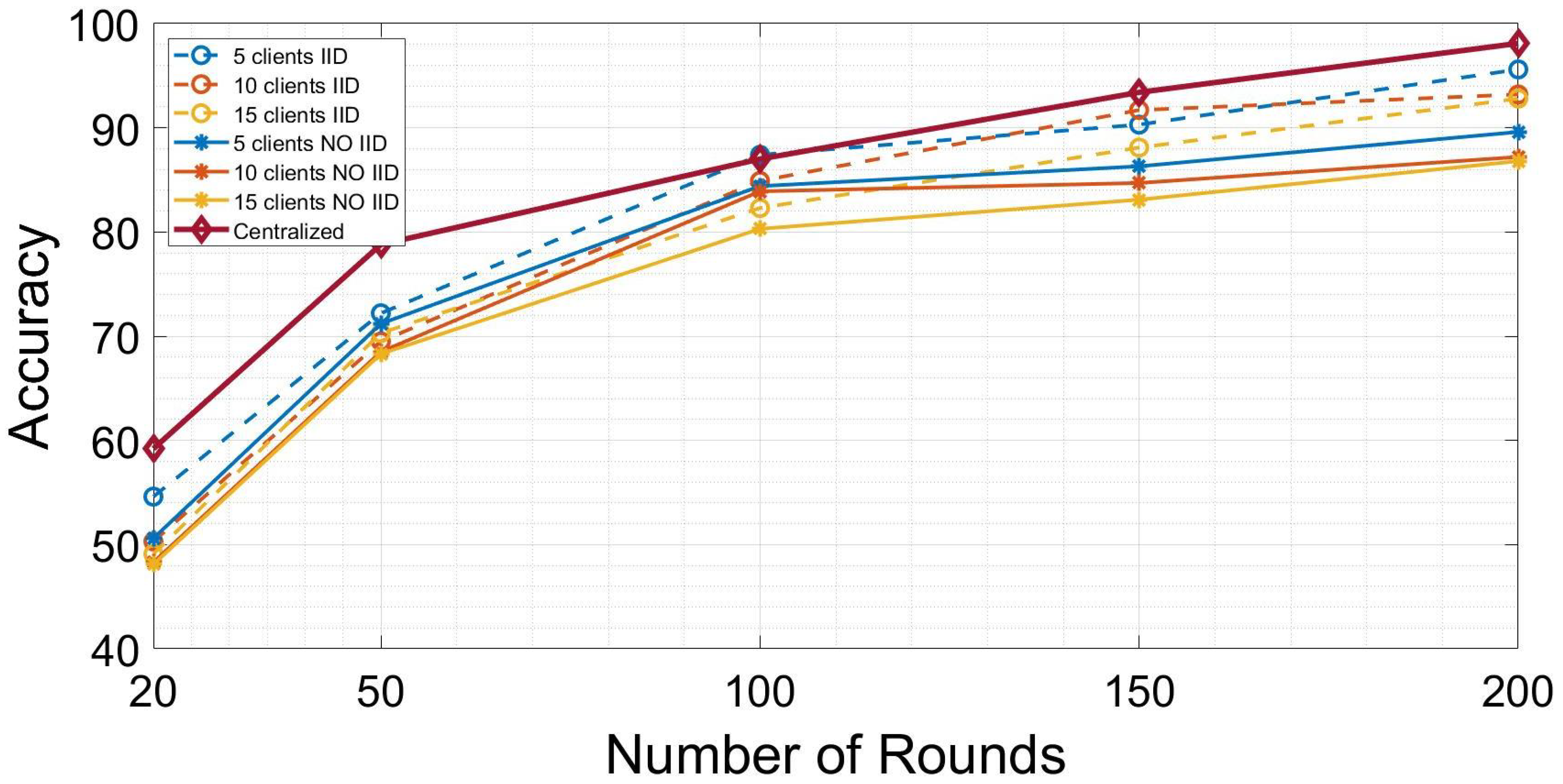
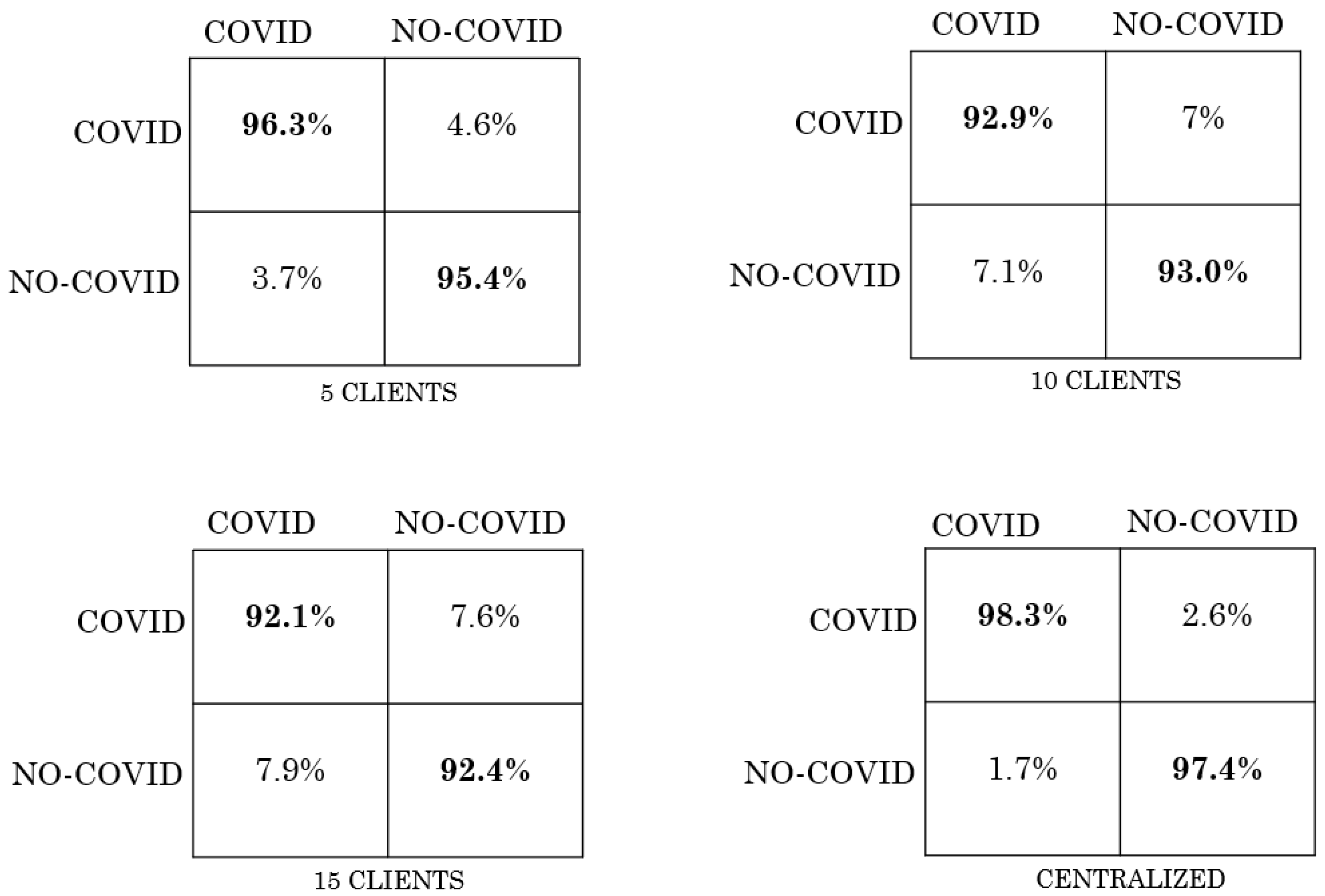
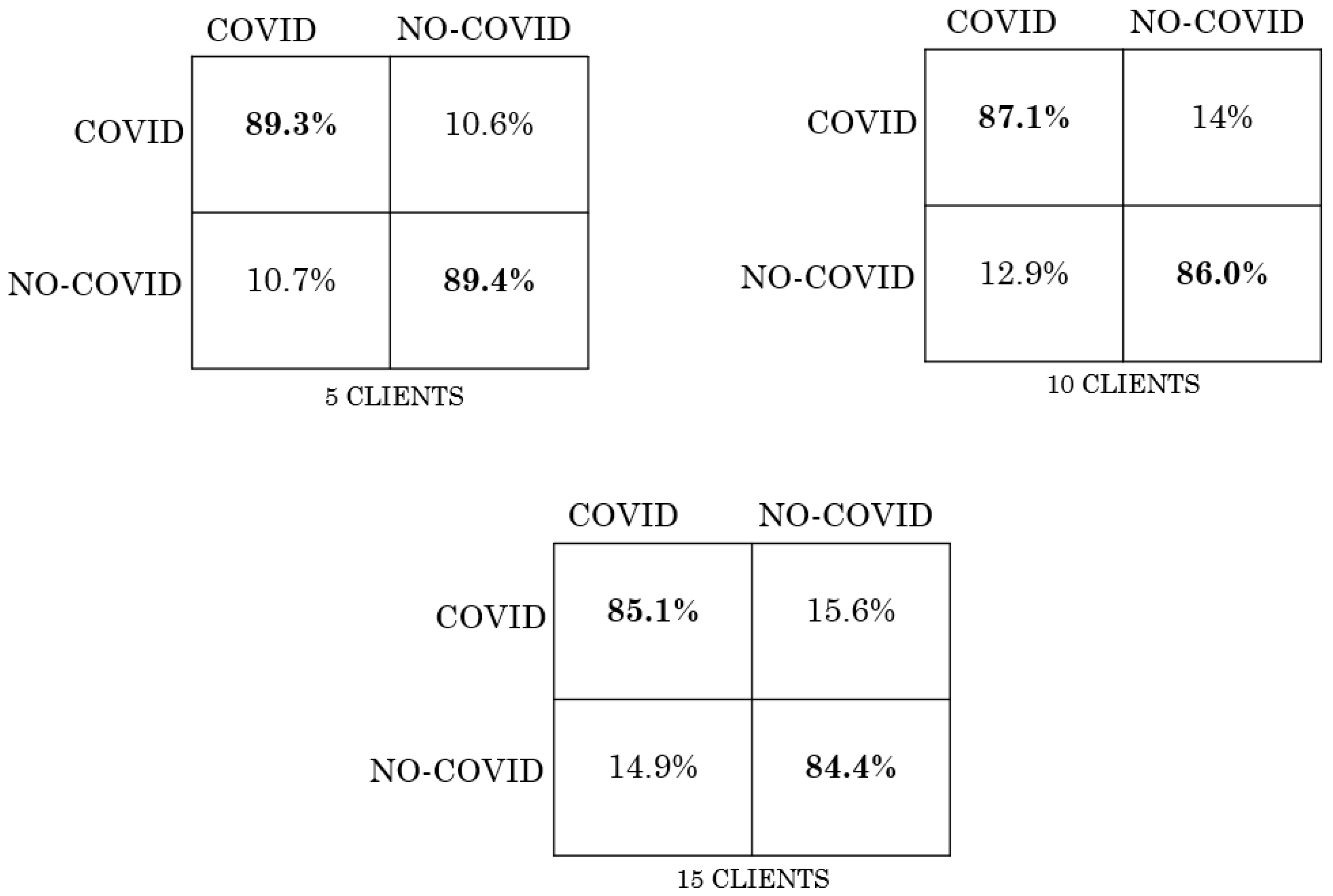
5. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Ceroni, A.; Gadiraju, U.; Matschke, J.; Wingert, S.; Fisichella, M. Where the Event Lies: Predicting Event Occurrence in Textual Documents. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 2016, Pisa, Italy, 17–21 July 2016; Perego, R., Sebastiani, F., Aslam, J.A., Ruthven, I., Zobel, J., Eds.; ACM: New York, NY, USA, 2016; pp. 1157–1160. [Google Scholar] [CrossRef]
- Ceroni, A.; Gadiraju, U.K.; Fisichella, M. Improving Event Detection by Automatically Assessing Validity of Event Occurrence in Text. In Proceedings of the 24th ACM International Conference on Information and Knowledge Management, CIKM 2015, Melbourne, VIC, Australia, 19–23 October 2015; Bailey, J., Moffat, A., Aggarwal, C.C., de Rijke, M., Kumar, R., Murdock, V., Sellis, T.K., Yu, J.X., Eds.; ACM: New York, NY, USA, 2015; pp. 1815–1818. [Google Scholar] [CrossRef]
- Banabilah, S.; Aloqaily, M.; Alsayed, E.; Malik, N.; Jararweh, Y. Federated learning review: Fundamentals, enabling technologies, and future applications. Inf. Process. Manag. 2022, 59, 103061. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Poor, H.V. Federated learning for internet of things: A comprehensive survey. IEEE Commun. Surv. Tutorials 2021, 23, 1622–1658. [Google Scholar] [CrossRef]
- Nguyen, D.C.; Pham, Q.V.; Pathirana, P.N.; Ding, M.; Seneviratne, A.; Lin, Z.; Dobre, O.; Hwang, W.J. Federated learning for smart healthcare: A survey. ACM Comput. Surv. (CSUR) 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Viorescu, R. 2018 reform of EU data protection rules. Eur. J. Law Public Adm. 2017, 4, 27–39. [Google Scholar] [CrossRef]
- Pfitzner, B.; Steckhan, N.; Arnrich, B. Federated learning in a medical context: A systematic literature review. ACM Trans. Internet Technol. 2021, 21, 1–31. [Google Scholar] [CrossRef]
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. arXiv 2016, arXiv:1602.05629. [Google Scholar] [CrossRef]
- Younis, R.; Fisichella, M. FLY-SMOTE: Re-Balancing the Non-IID IoT Edge Devices Data in Federated Learning System. IEEE Access 2022, 10, 65092–65102. [Google Scholar] [CrossRef]
- Liu, Q.; Huang, S.; Opadere, J.; Han, T. An edge network orchestrator for mobile augmented reality. In Proceedings of the IEEE INFOCOM 2018-IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 756–764. [Google Scholar]
- Nilsson, A.; Smith, S.; Ulm, G.; Gustavsson, E.; Jirstrand, M. A performance evaluation of federated learning algorithms. In Proceedings of the Second Workshop on Distributed Infrastructures for Deep Learning, Rennes, France, 10–11 December 2018; pp. 1–8. [Google Scholar]
- Luping, W.; Wei, W.; Bo, L. CMFL: Mitigating communication overhead for federated learning. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 954–964. [Google Scholar]
- Spirovska, K.; Didona, D.; Zwaenepoel, W. Paris: Causally consistent transactions with non-blocking reads and partial replication. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 304–316. [Google Scholar]
- Wang, S.; Tuor, T.; Salonidis, T.; Leung, K.K.; Makaya, C.; He, T.; Chan, K. Adaptive federated learning in resource constrained edge computing systems. IEEE J. Sel. Areas Commun. 2019, 37, 1205–1221. [Google Scholar] [CrossRef]
- Yao, X.; Huang, C.; Sun, L. Two-stream federated learning: Reduce the communication costs. In Proceedings of the 2018 IEEE Visual Communications and Image Processing (VCIP), Taichung, Taiwan, 9–12 December 2018; pp. 1–4. [Google Scholar]
- Feki, I.; Ammar, S.; Kessentini, Y.; Muhammad, K. Federated learning for COVID-19 screening from Chest X-ray images. Appl. Soft Comput. 2021, 106, 107330. [Google Scholar] [CrossRef]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Bagheri, M.; Summers, R.M. Chestx-ray8: Hospital-scale chest x-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2097–2106. [Google Scholar]
- Lerzynski, G. Ethical Implications of Digitalization in Healthcare. In Digitalization in Healthcare; Springer: Berlin/Heidelberg, Germany, 2021; pp. 163–170. [Google Scholar]
- Liu, B.; Yan, B.; Zhou, Y.; Yang, Y.; Zhang, Y. Experiments of federated learning for covid-19 chest x-ray images. arXiv 2020, arXiv:2007.05592. [Google Scholar]
- Li, Z.; Xu, X.; Cao, X.; Liu, W.; Zhang, Y.; Chen, D.; Dai, H. Integrated CNN and federated learning for COVID-19 detection on chest X-ray images. IEEE/ACM Trans. Comput. Biol. Bioinform. 2022. early access. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Cheng, Y.; Kang, Y.; Chen, T.; Yu, H. Federated learning. Synth. Lect. Artif. Intell. Mach. Learn. 2019, 13, 1–207. [Google Scholar]
- Yang, Q.; Fan, L.; Yu, H. Federated Learning: Privacy and Incentive; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12500. [Google Scholar]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.C.; Yang, Q.; Niyato, D.; Miao, C. Federated learning in mobile edge networks: A comprehensive survey. IEEE Commun. Surv. Tutorials 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Segal, A.; Marcedone, A.; Kreuter, B.; Ramage, D.; McMahan, H.B.; Seth, K.; Bonawitz, K.A.; Patel, S.; Ivanov, V. Practical Secure Aggregation for Privacy-Preserving Machine Learning. In Proceedings of the CCS, Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Phong, L.T.; Aono, Y.; Hayashi, T.; Wang, L.; Moriai, S. Privacy-Preserving Deep Learning via Additively Homomorphic Encryption. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1333–1345. [Google Scholar] [CrossRef]
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. Adv. Neural Inf. Process. Syst. 2017, 4427–4437. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics (PMLR), Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Ramage, D.; Richtárik, P. Federated optimization: Distributed machine learning for on-device intelligence. arXiv 2016, arXiv:1610.02527. [Google Scholar]
- Du, W.; Han, Y.S.; Chen, S. Privacy-preserving multivariate statistical analysis: Linear regression and classification. In Proceedings of the 2004 SIAM International Conference on Data Mining (SIAM), Lake Buena Vista, FL, USA, 22–24 April 2004; pp. 222–233. [Google Scholar]
- Wan, L.; Ng, W.K.; Han, S.; Lee, V.C.S. Privacy-Preservation for Gradient Descent Methods; Association for Computing Machinery: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Gascón, A.; Schoppmann, P.; Balle, B.; Raykova, M.; Doerner, J.; Zahur, S.; Evans, D. Secure Linear Regression on Vertically Partitioned Datasets. IACR Cryptol. ePrint Arch. 2016, 2016, 892. [Google Scholar]
- Sanil, A.P.; Karr, A.F.; Lin, X.; Reiter, J.P. Privacy preserving regression modelling via distributed computation. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, DC, USA, 22–25 August 2004; pp. 677–682. [Google Scholar]
- Vaidya, J.; Clifton, C. Privacy Preserving Association Rule Mining in Vertically Partitioned Data. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD ’02, Edmonton, AB, Canada, 23–26 July 2002; Association for Computing Machinery: New York, NY, USA, 2002; pp. 639–644. [Google Scholar] [CrossRef]
- Du, W.; Atallah, M. Privacy-Preserving Cooperative Statistical Analysis. In Proceedings of the Seventeenth Annual Computer Security Applications Conference, New Orleans, LA, USA, 10–14 December 2001. [Google Scholar]
- Hardy, S.; Henecka, W.; Ivey-Law, H.; Nock, R.; Patrini, G.; Smith, G.; Thorne, B. Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption. arXiv 2017, arXiv:1711.10677. [Google Scholar]
- Nock, R.; Hardy, S.; Henecka, W.; Ivey-Law, H.; Patrini, G.; Smith, G.; Thorne, B. Entity resolution and federated learning get a federated resolution. arXiv 2018, arXiv:1803.04035. [Google Scholar]
- Fisichella, M.; Lax, G.; Russo, A. Partially-federated learning: A new approach to achieving privacy and effectiveness. Inf. Sci. 2022, 614, 534–547. [Google Scholar] [CrossRef]
- Mohassel, P.; Zhang, Y. Secureml: A system for scalable privacy-preserving machine learning. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; pp. 19–38. [Google Scholar]
- Kilbertus, N.; Gascón, A.; Kusner, M.; Veale, M.; Gummadi, K.; Weller, A. Blind justice: Fairness with encrypted sensitive attributes. In Proceedings of the International Conference on Machine Learning (PMLR), Stockholm, Sweden, 10–15 July 2018; pp. 2630–2639. [Google Scholar]
- Agrawal, D.; Aggarwal, C.C. On the design and quantification of privacy preserving data mining algorithms. In Proceedings of the 20th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Santa Barbara, CA, USA, 21–23 May 2001; pp. 247–255. [Google Scholar]
- Mohassel, P.; Rindal, P. ABY3: A Mixed Protocol Framework for Machine Learning. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, CCS ’18, Toronto, Canada, 15–19 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 35–52. [Google Scholar] [CrossRef]
- Araki, T.; Furukawa, J.; Lindell, Y.; Nof, A.; Ohara, K. High-Throughput Semi-Honest Secure Three-Party Computation with an Honest Majority. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS’16, Vienna, Austria, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 805–817. [Google Scholar] [CrossRef]
- Furukawa, J.; Lindell, Y.; Nof, A.; Weinstein, O. High-throughput secure three-party computation for malicious adversaries and an honest majority. In Proceedings of the Annual international conference on the theory and applications of cryptographic techniques, Paris, France, 30 April–4 May 2017; pp. 225–255. [Google Scholar]
- Mohassel, P.; Rosulek, M.; Zhang, Y. Fast and Secure Three-Party Computation: The Garbled Circuit Approach. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, CCS’15, Denver, CO, USA, 12–16 October 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 591–602. [Google Scholar] [CrossRef]
- Dwork, C. Differential Privacy: A Survey of Results. In Proceedings of the 5th International Conference on Theory and Applications of Models of Computation, TAMC’08, Xi’an, China, 25–29 April 2008; pp. 1–19. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS’16, Vienna, Austria, 24–28 October 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 308–318. [Google Scholar] [CrossRef]
- Chaudhuri, K.; Monteleoni, C. Privacy-preserving logistic regression. In Proceedings of the NIPS, Vancouver, BC, Canada, 8–11 December 2008. [Google Scholar]
- McMahan, H.B.; Ramage, D.; Talwar, K.; Zhang, L. Learning Differentially Private Recurrent Language Models. arXiv 2017, arXiv:1710.06963. [Google Scholar] [CrossRef]
- Stochastic gradient descent with differentially private updates. In Proceedings of the2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013. [CrossRef]
- Agrawal, R.; Srikant, R. Privacy-Preserving Data Mining. SIGMOD Rec. 2000, 29, 439–450. [Google Scholar] [CrossRef]
- Geyer, R.C.; Klein, T.; Nabi, M. Differentially Private Federated Learning: A Client Level Perspective. arXiv 2017, arXiv:1712.07557. [Google Scholar] [CrossRef]
- Mbonihankuye, S.; Nkunzimana, A.; Ndagijimana, A. Healthcare data security technology: HIPAA compliance. Wirel. Commun. Mob. Comput. 2019, 2019, 1927495. [Google Scholar] [CrossRef]
- Ozturk, T.; Talo, M.; Yildirim, E.A.; Baloglu, U.B.; Yildirim, O.; Acharya, U.R. Automated detection of COVID-19 cases using deep neural networks with X-ray images. Comput. Biol. Med. 2020, 121, 103792. [Google Scholar] [CrossRef]
- Cohen, J.P.; Morrison, P.; Dao, L. COVID-19 image data collection. arXiv 2020, arXiv:2003.11597. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Layer | Layer Type | Output Shape | Number of Trainable Parameters |
|---|---|---|---|
| 1 | Conv2d | [8, 256, 256] | 216 |
| 2 | Conv2d | [16, 128, 128] | 1152 |
| 3 | Conv2d | [32, 64, 64] | 4608 |
| 4 | Conv2d | [16, 66, 66] | 512 |
| 5 | Conv2d | [32, 256, 256] | 4608 |
| 6 | Conv2d | [64, 33, 33] | 18,432 |
| 7 | Conv2d | [32, 35, 35] | 2048 |
| 8 | Conv2d | [64, 35, 35] | 18,432 |
| 9 | Conv2d | [128, 17, 17] | 73,728 |
| 10 | Conv2d | [74, 19, 19] | 8192 |
| 11 | Conv2d | [128, 19, 19] | 73,728 |
| 12 | Conv2d | [256, 9, 9] | 294,912 |
| 13 | Conv2d | [128, 11, 11] | 32,768 |
| 14 | Conv2d | [256, 11, 11] | 294,912 |
| Attribute | Description | ||
|---|---|---|---|
| Patient ID | Internal identifier | ||
| Offset | Number of days since the start of symptoms or hospitalization for each image. If a report indicates “after a few days”, then 5 days is assumed | ||
| Sex | Male (M), Female (F), or blank | ||
| Age | Age of the patient in years | ||
| Finding | Type of pneumonia | ||
| Survival | Yes or No | ||
| View | Posteroanterior (PA), Anteroposterior (AP), AP Supine (APS), or Lateral (L) for X-rays; Axial or Coronal for CT scans | ||
| Modality | CT, X-ray, or something else | ||
| Number of Layer | Layer Type | Output Shape | Number of Trainable Parameters |
| 15 | Conv2d | [128, 13, 13] | 256 |
| 16 | Conv2d | [256, 13, 13] | 294,912 |
| 17 | Conv2d | [2, 13, 13] | 4608 |
| 18 | Flatten | [338] | 0 |
| 19 | Linear | [2] | 678 |
| Scenario | IID | NO-IID |
|---|---|---|
| FL with 5 clients | 0.97 | 0.93 |
| FL with 10 clients | 0.9 | 0.87 |
| FL with 15 clients | 0.93 | 0.85 |
| Centralized | 0.98 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Singh, G.; Violi, V.; Fisichella, M. Federated Learning to Safeguard Patients Data: A Medical Image Retrieval Case. Big Data Cogn. Comput. 2023, 7, 18. https://doi.org/10.3390/bdcc7010018
Singh G, Violi V, Fisichella M. Federated Learning to Safeguard Patients Data: A Medical Image Retrieval Case. Big Data and Cognitive Computing. 2023; 7(1):18. https://doi.org/10.3390/bdcc7010018
Chicago/Turabian StyleSingh, Gurtaj, Vincenzo Violi, and Marco Fisichella. 2023. "Federated Learning to Safeguard Patients Data: A Medical Image Retrieval Case" Big Data and Cognitive Computing 7, no. 1: 18. https://doi.org/10.3390/bdcc7010018
APA StyleSingh, G., Violi, V., & Fisichella, M. (2023). Federated Learning to Safeguard Patients Data: A Medical Image Retrieval Case. Big Data and Cognitive Computing, 7(1), 18. https://doi.org/10.3390/bdcc7010018