
Arabic Tweets-Based Sentiment Analysis to Investigate the Impact of COVID-19 in KSA: A Deep Learning Approach



Abstract
1. Introduction
- Building an annotated dataset for Arabic (Saudi dialect and MSA) for sentiment analysis before and during the COVID-19 pandemic.
- Building a suitable pre-trained Arabic word embedding for Arabic datasets applying deep learning algorithms.
- Evaluating various deep learning algorithms for classifying the polarity of tweets and comparing it with the state-of-the-art techniques in the literature.
- Identifying and comparing the Arabic tweets sentiment analysis before and during the COVID-19 pandemic in Saudi Arabia.
2. Review of Literature
2.1. Arabic Sentiment Analysis Using the Traditional Machine Learning Approaches
2.2. Arabic Sentiment Analysis Using the Deep Learning Approaches
2.3. Sentiment Analysis Related to COVID-19
2.4. Differences and Similarities of the Study over Previous COVID-19 Sentiment Analysis
- The proposed research focuses on Arabic tweets’ sentiments related to, during and prior to COVID-19 in Saudi Arabia.
- The dataset was collected from three specific regions in Saudi Arabia (with Saudi dialect and MSA), which are Riyadh, Jeddah, and Dammam.
- The Arabic tweets were analyzed for sentiment in two periods: before and during the COVID-19 pandemic in Saudi Arabia.
- The BiLSTM deep learning algorithm was chosen to classify Arabic sentiment analysis and it had not been investigated earlier for the said problem.
- Multiple word embedding techniques are employed and the performance of these techniques compared in the developed dataset.
- 1.
- The proposed research aims to study sentiment analysis related to the COVID-19 era, such as the related works in the section on sentiment analysis related to COVID-19.
- 2.
- Deep learning algorithms are carried out for Arabic sentiment analysis.
- 3.
- Twitter is the source of the dataset.
3. Methodology
3.1. Data Collection
- For the Riyadh region, this command was used with the corona (كورونا) keyword: “twint-g = “24.63333,46.71667,50 km” -s كورونا --since “2020-3-2” -o file.csv –csv”.
- For Dammam region this command was used with the corona (كورونا) keyword since the epidemic started: “twint-g = “26.39222,49.97778,50 km” -s كورونا --since “2020-3-2” -o dammam_corona_file.csv –csv”.
- For the Jeddah region this command was used with the corona keywords since the epidemic started: “twint-g = “21.54472,39.17611,50 km” -s كورونا --since “2020-3-2” -o jeddah_corona._file.csv –csv”.
3.2. Data Preprocessing
3.2.1. Data Annotation
- The author’s viewpoint, not the annotator’s, should be considered when annotating the tweets. In addition, the label (positive, negative, or neutral) should be chosen based on the tweet’s context.
- The news should be labelled as neutral even if it contains positive or negative information because news is not considered subjective.
- If it is not clear to which label the tweet belongs, do not guess; instead, send it to the chat group and discuss it with other annotators, then choose the label with the most votes.
- Because the mentions and hashtag signs were deleted, the subject of the tweet may not always be evident, but the sentiment could still be identified.
- Delete tweets that contain advertisements or are incomplete due to download issues or other factors.
- Delete tweets that contained non-Saudi dialects because the focus of this study was on sentiment analysis of Saudi dialects and MSA dialect tweets.
3.2.2. Data Cleaning
- 1.
- Removing the Arabic diacritics, Table 3 shows the diacritic marks in the Arabic language.
- 2.
- Removing hashtags, user mentions, and URLs.
- 3.
- Removing punctuation marks, such as full stops and commas, is ineffective in detecting polarity.
- 4.
- Removing repeated tweets because there is no need to classify repeated tweets; it is enough to classify one.
- 5.
- Removing non-Arabic and commercial tweets.
- 6.
- Removing the elongation and repeating letters such as the word “مهههههم” to become “مهم”.
- 7.
- After removing the repeated letters, some words may be affected, especially if the words have double letters in the original, such as “الله” becoming after removing the double letters “اله”, spell checking is important in these situations. In addition, the mistakes or abbreviations by users during writing need to be corrected.
- 8.
- Tokenization is one of the NLP tasks that divides a string of words into semantically relevant tokens by whitespace or punctuation characters.
- 9.
- Normalization is the method of reducing letters to their most basic form. The Arabic language is rich morphologically, so it needs normalization. The normalization form for some Arabic letters is presented in Table 4.
- 10.
- Stop word removal: Stop words are employed to structure language but do not contribute to its content. Some of the Arabic stop words, such as الذي, هذا, من.
- 11.
- Light stemming is a way of removing suffixes and prefixes from words without shrinking them to their root, such as the word “مرفوض” after applying light stemming will be “رفض”. Compared to the root stemming approach, light stemming was revealed to have good outcomes with text classification problems [46]. Furthermore, light stemming has been shown to be effective in several studies [47,48,49]. However, the light stemmer algorithm proposed by Motaz Saad [50], was applied in this study. The number of tweets before and after preprocessing is summarized in Table 5. In addition, the examples of tweets before and after preprocessing are presented in Table 6.
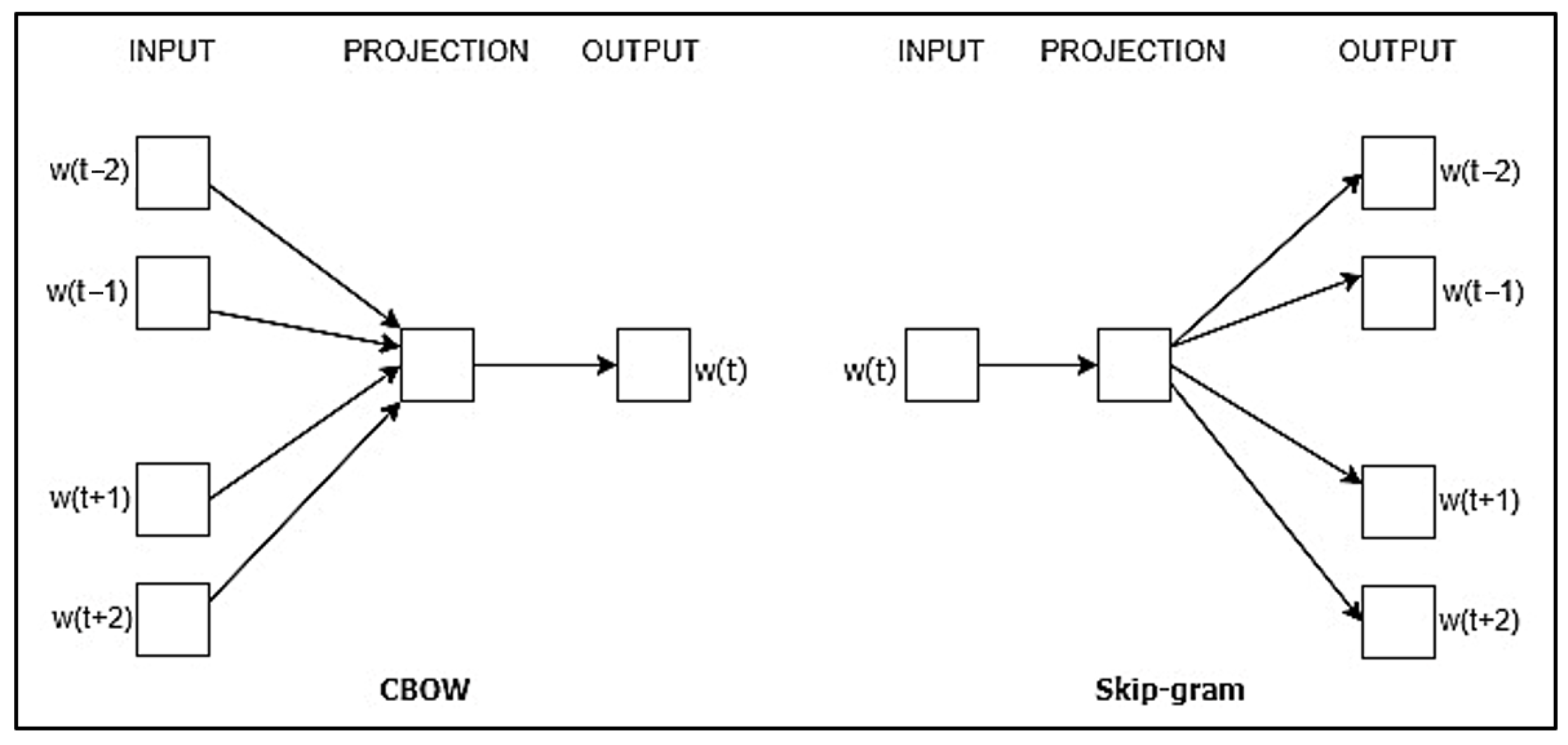
3.3. Word Embedding
3.3.1. Word2vec
3.3.2. FastText
3.4. Description of the Proposed Deep Learning Techniques
3.4.1. Convolutional Neural Network (CNN)
3.4.2. Long Short-Term Memory Network (LSTM)
- Forget Gate:
- Input Gate:
- Output Gate:
- Forward LSTM
- Bi-directional LSTM
Bi-Directional Long Short-Term Memory (BiLSTM)
3.5. Evaluation Metrics
- Accuracy: The result of dividing the number of true classified outcomes by the whole of classified instances. The accuracy is computed by the equation [65]:
- Recall: The percentage of positive tweets that are properly determined by the model in the dataset. The recall calculated by [65]:
- Precision: The proportion of true positive tweets among all forecasted positive tweets. The equation of precision measure calculated by [65]:
- F-score: A harmonic mean of precision and recall. The F-score measure equation is [65]:
4. Experiment Results and Discussion
4.1. Word Embedding Experiments
4.1.1. Word Embedding Results of the Datasets before the COVID-19 Pandemic Period
4.1.2. Word Embedding Results of the Datasets during the COVID-19 Pandemic Period
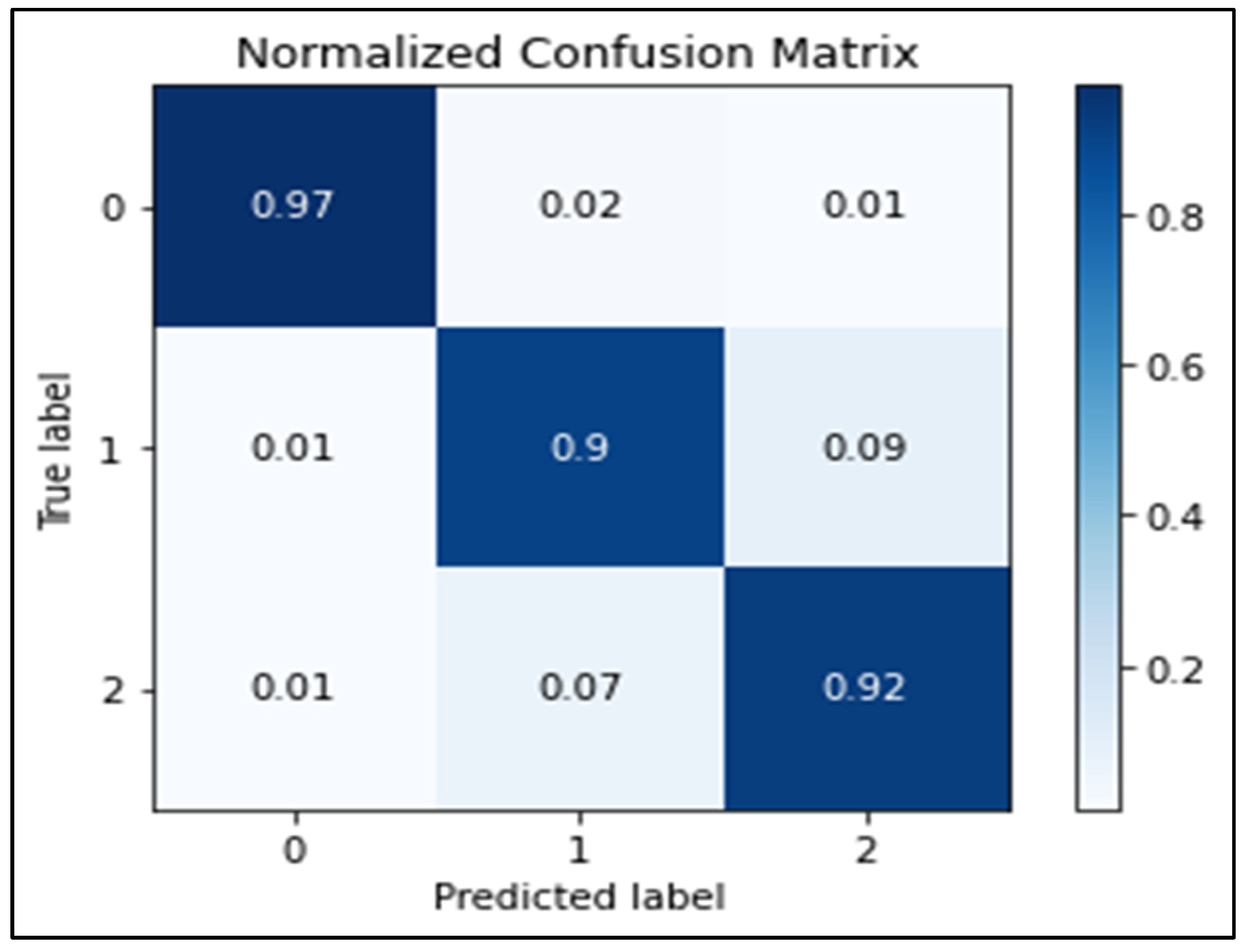
4.2. Deep Learning Algorithms Results
4.3. Word Cloud
4.4. Further Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sarkodie, S.A.; Owusu, P.A. Investigating the cases of novel coronavirus disease (COVID-19) in China using dynamic statistical techniques. Heliyon 2020, 6, e03747. [Google Scholar] [CrossRef] [PubMed]
- Iacus, S.M.; Natale, F.; Santamaria, C.; Spyratos, S.; Vespe, M. Estimating and projecting air passenger traffic during the COVID-19 coronavirus outbreak and its socio-economic impact. Saf. Sci. 2020, 129, 104791. [Google Scholar] [CrossRef]
- Rosenberg, H.; Syed, S.; Rezaie, S. The Twitter pandemic: The critical role of Twitter in the dissemination of medical information and misinformation during the COVID-19 pandemic. Can. J. Emerg. Med. 2020, 22, 418–421. [Google Scholar] [CrossRef] [PubMed]
- Malla, S.J.; Alphonse, P.J.A. COVID-19 outbreak: An ensemble pre-trained deep learning model for detecting informative tweets. Appl. Soft Comput. 2021, 107, 107495. [Google Scholar] [CrossRef] [PubMed]
- Pang, B.; Lee, L. Opinion Mining and Sentiment Analysis. Found. Trends Inf. Retr. 2008, 2, 1–135. [Google Scholar] [CrossRef]
- Internet World Users by Language Top 10 Languages. Available online: https://www.internetworldstats.com/stats7.htm (accessed on 2 July 2022).
- Hammad, M.; Al-awadi, M. Sentiment Analysis for Arabic Reviews in Social Networks Using Machine Learning. In Information Technology: New Generations; Latifi, S., Ed.; Springer International Publishing: Cham, Switzerland, 2016; pp. 131–139. [Google Scholar]
- Abdelminaam, D.S.; Neggaz, N.; Gomaa, I.A.E.; Ismail, F.H.; Elsawy, A.A. Arabicdialects: An efficient framework for Arabic dialects opinion mining on twitter using optimized deep neural networks. IEEE Access 2021, 9, 97079–97099. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Alharbi, A.; Kalkatawi, M.; Taileb, M. Arabic Sentiment Analysis Using Deep Learning and Ensemble Methods. Arab. J. Sci. Eng. 2021, 46, 8913–8923. [Google Scholar] [CrossRef]
- Musleh, D.A.; Alkhales, T.A.; Almakki, R.A.; Alnajim, S.E.; Almarshad, S.K.; Alhasaniah, R.S.; Aljameel, S.S.; Almuqhim, A.A. Twitter arabic sentiment analysis to detect depression using machine learning. Comput. Mater. Contin. 2022, 71, 3463–3477. [Google Scholar] [CrossRef]
- Alharbi, L.M.; Qamar, A.M. Arabic Sentiment Analysis of Eateries’ Reviews: Qassim region Case study. In Proceedings of the 2021 IEEE 4th National Computing Colleges Conference, NCCC 2021, Taif, Saudi Arabia, 27–28 March 2021. [Google Scholar] [CrossRef]
- Alsalman, H. An Improved Approach for Sentiment Analysis of Arabic Tweets in Twitter Social Media. In Proceedings of the 2020 3rd International Conference on Computer Applications and Information Security: 0–3, Riyadh, Saudi Arabia, 19–21 March 2020. [Google Scholar] [CrossRef]
- Alyami, S.N.; Olatunji, S.O. Application of Support Vector Machine for Arabic Sentiment Classification Using Twitter-Based Dataset. J. Inf. Knowl. Manag. 2020, 19, 1–13. [Google Scholar] [CrossRef]
- Almouzini, S.; Khemakhem, M.; Alageel, A. Detecting Arabic Depressed Users from Twitter Data. Procedia Comput. Sci. 2019, 163, 257–265. [Google Scholar] [CrossRef]
- Elshakankery, K.; Ahmed, M.F. HILATSA: A hybrid Incremental learning approach for Arabic tweets sentiment analysis. Egypt. Informatics J. 2019, 20, 163–171. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Al-Ayyoub, M.; Jararweh, Y.; Qawasmeh, O. Enhancing Aspect-Based Sentiment Analysis of Arabic Hotels’ reviews using morphological, syntactic and semantic features. Inf. Process. Manag. 2019, 56, 308–319. [Google Scholar] [CrossRef]
- Maghfour, M.; Elouardighi, A. Standard and Dialectal Arabic Text Classification for Sentiment Analysis; Springer International Publishing: Berlin/Heidelberg, Germany, 2018; Volume 11163, ISBN 9783030008550. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.Z.; Lahcen, A.A.; Belfkih, S. ASA: A framework for Arabic sentiment analysis. J. Inf. Sci. 2020, 46, 544–559. [Google Scholar] [CrossRef]
- Hazım, W.; Gwad, G.; Mahmood, I.; Ismael, I.; Gültepe, Y. Twitter Sentiment Analysis Classification in the Arabic Language using Long Short-Term Memory Neural Networks. Int. J. Eng. Adv. Technol. 2020, 9, 235–239. [Google Scholar] [CrossRef]
- Ombabi, A.H.; Ouarda, W.; Alimi, A.M. Deep learning CNN–LSTM framework for Arabic sentiment analysis using textual information shared in social networks. Soc. Netw. Anal. Min. 2020, 10, 53. [Google Scholar] [CrossRef]
- Al Omari, M.; Al-Hajj, M.; Sabra, A.; Hammami, N. Hybrid CNNs-LSTM Deep Analyzer for Arabic Opinion Mining. In Proceedings of the 2019 6th International Conference on Social Networks Analysis, Management and Security, Granada, Spain, 22–25 October 2019; pp. 364–368. [Google Scholar] [CrossRef]
- Al-Dabet, S.; Tedmori, S. Sentiment analysis for Arabic language using attention-based simple recurrent unit. In Proceedings of the 2019 2nd International Conference on New Trends in Computing Sciences, Amman, Jordan, 9–11 October 2019. [Google Scholar] [CrossRef]
- Baali, M.; Ghneim, N. Emotion analysis of Arabic tweets using deep learning approach. J. Big Data 2019, 6, 89. [Google Scholar] [CrossRef]
- Abu Kwaik, K.; Saad, M.; Chatzikyriakidis, S.; Dobnik, S. LSTM-CNN Deep Learning Model for Sentiment Analysis of Dialectal Arabic. In Arabic Language Processing: From Theory to Practice; Springer: Cham, Switzerland, 2019; Volume 1108. [Google Scholar] [CrossRef]
- Mohammed, A.; Kora, R. Deep learning approaches for Arabic sentiment analysis. Soc. Netw. Anal. Min. 2019, 9, 52. [Google Scholar] [CrossRef]
- Omara, E.; Ismail, N.; Network, L. Deep Convolutional Network For Arabic sentiment Analysis. In Proceedings of the 2018 International Japan-Africa Conference on Electronics, Communications and Computations (JAC-ECC), Alexandria, Egypt, 17–19 December 2018; IEEE: New York, NY, USA; pp. 155–159. [Google Scholar]
- Abdullah, M.; Hadzikadicy, M.; Shaikhz, S. SEDAT: Sentiment and Emotion Detection in Arabic Text Using CNN-LSTM Deep Learning. In Proceedings of the 17th IEEE International Conference on Machine Learning and Applications, Orlando, FL, USA, 17–20 December 2018; pp. 835–840. [Google Scholar] [CrossRef]
- Heikal, M.; Torki, M.; El-Makky, N. Sentiment Analysis of Arabic Tweets using Deep Learning. Procedia Comput. Sci. 2018, 142, 114–122. [Google Scholar] [CrossRef]
- Alayba, A.M.; Palade, V.; England, M.; Iqbal, R. A combined CNN and LSTM model for Arabic sentiment analysis. In Machine Learning and Knowledge Extraction; Springer: Cham, Switzerland, 2018; Volume 11015. [Google Scholar] [CrossRef]
- Alabdulkreem, E. Prediction of depressed Arab women using their tweets. J. Decis. Syst. 2021, 30, 102–117. [Google Scholar] [CrossRef]
- Alharbi, N.H.; Alkhateeb, J.H. Sentiment Analysis of Arabic Tweets Related to COVID-19 Using Deep Neural Network. In Proceedings of the 2021 International Congress of Advanced Technology and Engineering, Taiz, Yemen, 4–5 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–11. [Google Scholar] [CrossRef]
- Rustam, F.; Khalid, M.; Aslam, W.; Rupapara, V.; Mehmood, A.; Choi, G.S. A performance comparison of supervised machine learning models for Covid-19 tweets sentiment analysis. PLoS ONE 2021, 16, e0245909. [Google Scholar] [CrossRef]
- Aljameel, S.S.; Alabbad, D.A.; Alzahrani, N.A.; Alqarni, S.M.; Alamoudi, F.A.; Babili, L.M.; Aljaafary, S.K.; Alshamrani, F.M. A sentiment analysis approach to predict an individual’s awareness of the precautionary procedures to prevent COVID-19 outbreaks in Saudi Arabia. Int. J. Environ. Res. Public Health 2021, 18, 218. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep Sentiment Classification and Topic Discovery on Novel Coronavirus or COVID-19 Online Discussions: NLP Using LSTM Recurrent Neural Network Approach. IEEE J. Biomed. Heal. Informatics 2020, 24, 2733–2742. [Google Scholar] [CrossRef]
- Imran, A.S.; Daudpota, S.M.; Kastrati, Z.; Batra, R. Cross-Cultural Polarity and Emotion Detection Using Sentiment Analysis and Deep Learning on COVID-19 Related Tweets. IEEE Access 2020, 8, 181074–181090. [Google Scholar] [CrossRef]
- Alhumoud, S. Arabic Sentiment Analysis using Deep Learning for COVID-19 Twitter Data. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2020, 20, 132. [Google Scholar]
- Samuel, J.; Ali, G.G.M.N.; Rahman, M.M.; Esawi, E.; Samuel, Y. COVID-19 public sentiment insights and machine learning for tweets classification. Information 2020, 11, 314. [Google Scholar] [CrossRef]
- Xue, J.; Chen, J.; Hu, R.; Chen, C.; Zheng, C.; Su, Y.; Zhu, T. Twitter discussions and emotions about the COVID-19 pandemic: Machine learning approach. J. Med. Internet Res. 2020, 22, e20550. [Google Scholar] [CrossRef]
- Alanezi, M.A.; Hewahi, N.M. Tweets Sentiment Analysis during COVID-19 Pandemic. In Proceedings of the 2020 International Conference on Data Analytics for Business and Industry: Way Towards a Sustainable Economy, Sakheer, Bahrain, 26–27 October 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Alhuri, L.A.; Aljohani, H.R.; Almutairi, R.M.; Haron, F. Sentiment Analysis of COVID-19 on Saudi Trending Hashtags Using Recurrent Neural Network. In Proceedings of the International Conference on Developments in eSystems Engineering, Liverpool, UK, 14–17 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 299–304. [Google Scholar] [CrossRef]
- Vyas, P.; Reisslein, M.; Rimal, B.P.; Vyas, G.; Basyal, G.P.; Muzumdar, P. Automated Classification of Societal Sentiments on Twitter With Machine Learning. IEEE Trans. Technol. Soc. 2022, 3, 100–110. [Google Scholar] [CrossRef]
- Rahman, M.M.; Islam, M.N. Exploring the Performance of Ensemble Machine Learning Classifiers for Sentiment Analysis of COVID-19 Tweets. In Sentimental Analysis and Deep Learning; Shakya, S., Balas, V.E., Kamolphiwong, S., Du, K.-L., Eds.; Springer: Singapore, 2022; pp. 383–396. [Google Scholar]
- Twitter. Twitter Website. Available online: https://twitter.com/ (accessed on 20 November 2022).
- OSINT Team. Twint Tool. 2022. Available online: https://github.com/twintproject/twint (accessed on 19 February 2022).
- Wahbeh, A.; Al-Kabi, M.; Al-Radaideh, Q.; Al-Shawakfa, E.; Alsmadi, I. The Effect of Stemming on Arabic Text Classification. Int. J. Inf. Retr. Res. 2011, 1, 54–70. [Google Scholar] [CrossRef]
- Aldayel, H.K.; Azmi, A.M. Arabic tweets sentiment analysis-A hybrid scheme. J. Inf. Sci. 2016, 42, 782–797. [Google Scholar] [CrossRef]
- Altaher, A. Hybrid approach for sentiment analysis of Arabic tweets based on deep learning model and features weighting. Int. J. Adv. Appl. Sci. 2017, 4, 43–49. [Google Scholar] [CrossRef]
- Abuaiadah, D.; Rajendran, D.; Jarrar, M. Clustering Arabic tweets for sentiment analysis. In Proceedings of the IEEE/ACS International Conference on Computer Systems and Applications, Hammamet, Tunisia, 30 October–3 November 2017; pp. 449–456. [Google Scholar] [CrossRef]
- Motazsaad. Light Stemmer Algorithm. 2022. Available online: https://github.com/motazsaad/arabic-light-stemmer (accessed on 1 March 2022).
- Yu, T.; Hidey, C.; Rambow, O.; McKeown, K. Leveraging Sparse and Dense Feature Combinations for Sentiment Classification. arXiv 2017, arXiv:1708.03940. [Google Scholar]
- Giatsoglou, M.; Vozalis, M.G.; Diamantaras, K.; Vakali, A.; Sarigiannidis, G.; Chatzisavvas, K.C. Sentiment analysis leveraging emotions and word embeddings. Expert Syst. Appl. 2017, 69, 214–224. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers; Association for Computational Linguistics: Valencia, Spain, 2017; pp. 427–431. [Google Scholar] [CrossRef]
- Hosomi, N.; Sakti, S.; Yoshino, K.; Nakamura, S. Deception Detection and Analysis in Spoken Dialogues based on FastText. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Honolulu, HI, USA, 12–15 November 2018; pp. 139–142. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1746–1751. [Google Scholar] [CrossRef]
- Ombabi, A.H.; Lazzez, O.; Ouarda, W.; Alimi, A.M. Deep Learning Framework based on Word2Vec and CNN for Users Interests Classification. In Proceedings of the 2017 Sudan Conference on Computer Science and Information Technology (SCCSIT), Elnihood, Sudan, 17–19 November 2017. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Elzayady, H.; Badran, K.M.; Salama, G.I. Arabic Opinion Mining Using Combined CNN-LSTM Models. Int. J. Intell. Syst. Appl. 2020, 12, 25–36. [Google Scholar] [CrossRef]
- Wang, J. An LSTM Approach to Short Text Sentiment Classification with Word Embeddings. In Proceedings of the 30th Conference on Computational Linguistics and Speech Processing (ROCLING 2018), Hsinchu, Taiwan, 4–5 October 2018; pp. 214–223. [Google Scholar]
- Das, S.; Das, D.; Kolya, A.K. Sentiment classification with GST tweet data on LSTM based on polarity-popularity model. Sadhana Acad. Proc. Eng. Sci. 2020, 45, 140. [Google Scholar] [CrossRef]
- Luo, F.-L. Machine Learning for Future Wireless Communications; Wiley-IEEE Press: Chichester, UK, 2020; p. 2546. ISBN 9781119562252. [Google Scholar]
- Khalil, E.A.H.; El Houby, E.M.F.; Mohamed, H.K. Deep Learning Approach in Sentiment Analysis: A Review. In Proceedings of the 15th International Conference on Computer Engineering and Systems, Cairo, Egypt, 15–16 December 2020. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Soliman, A.B.; Eissa, K.; El-Beltagy, S.R. AraVec: A set of Arabic Word Embedding Models for use in Arabic NLP. Procedia Comput. Sci. 2017, 117, 256–265. [Google Scholar] [CrossRef]
- Fouad, M.M.; Mahany, A.; Aljohani, N.; Abbasi, R.A.; Hassan, S.U. ArWordVec: Efficient word embedding models for Arabic tweets. Soft Comput. 2020, 24, 8061–8068. [Google Scholar] [CrossRef]
- FastText. 2022. Available online: https://fasttext.cc/docs/en/crawl-vectors.html (accessed on 13 September 2022).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tweets | Sentiment |
|---|---|
 | 1 |
 | −1 |
 | 0 |
| Tweets | Sentiment |
|---|---|
 | 1 |
 | −1 |
 | 0 |
| Diacritic Marks | Characters |
|---|---|
| Fatha |  |
| Tashdeed |  |
| Tanwin Fath |  |
| Damma |  |
| Tanwin Damm |  |
| Kasra |  |
| Tanwin Kasr |  |
| Sukun |  |
| Letter | Normalized Form |
|---|---|
| إ,أ,آ,ا | ا |
| ى | ي |
| ئ | ء |
| ؤ | ء |
| ة | ه |
| كـ | ك |
| Files | Before Cleaning | After Cleaning | ||
|---|---|---|---|---|
| Before COVID-19 | During COVID-19 | Before COVID-19 | During COVID-19 | |
| Riyadh File | 23,307 | 44,073 | 13,487 | 25,860 |
| Jeddah File | 17,788 | 51,386 | 13,244 | 20,912 |
| Dammam File | 7521 | 13,139 | 6887 | 9613 |
| Tweets before Processing | Tweets after Processing |
|---|---|
 |  |
 |  |
| Word Embedding Model | Hyper-Parameters | Algorithms | Datasets before COVID-19 Period | |||||
|---|---|---|---|---|---|---|---|---|
| Architecture | Vector Size | Window Size | Riyadh Dataset | Jeddah Dataset | Dammam Dataset | All Datasets | ||
| ArWordVec | SG | 300 | 3 | CNN | 92.18 | 87.27 | 80.86 | 88.99 |
| 300 | 5 | 91.92 | 87.35 | 81.11 | 88.94 | |||
| 500 | 3 | 92.24 | 87.23 | 81.20 | 89.14 | |||
| 500 | 5 | 92.10 | 86.96 | 80.90 | 88.71 | |||
| CBOW | 300 | 5 | 92.43 | 86.72 | 79.43 | 88.72 | ||
| 500 | 3 | 92.34 | 87.03 | 80.55 | 89.05 | |||
| 500 | 5 | 92.06 | 86.72 | 80.34 | 89.01 | |||
| AraVec | SG | 100 | 3 | 92.09 | 87.70 | 80.60 | 89.21 | |
| 300 | 3 | 92.80 | 88.35 | 83.39 | 89.69 | |||
| CBOW | 100 | 3 | 92.06 | 86.66 | 76.80 | 88.47 | ||
| 300 | 3 | 92.00 | 87.29 | 81.43 | 89.23 | |||
| FastText | CBOW | 300 | - | 92.24 | 87.62 | 79.95 | 88.76 | |
| ArWordVec | SG | 300 | 3 | BiLSTM | 91.28 | 85.83 | 80.61 | 88.37 |
| 300 | 5 | 91.76 | 86.02 | 80.78 | 88.04 | |||
| 500 | 3 | 90.92 | 86.50 | 81.29 | 88.42 | |||
| 500 | 5 | 91.38 | 85.70 | 81.08 | 88.09 | |||
| CBOW | 300 | 5 | 91.03 | 86.22 | 81.29 | 88.04 | ||
| 500 | 3 | 91.75 | 87.04 | 81.10 | 88.35 | |||
| 500 | 5 | 91.27 | 86.63 | 81.34 | 87.67 | |||
| AraVec | SG | 100 | 3 | 91.19 | 85.00 | 81.70 | 87.68 | |
| 300 | 3 | 91.99 | 86.83 | 82.25 | 88.74 | |||
| CBOW | 100 | 3 | 91.49 | 86.94 | 81.96 | 88.07 | ||
| 300 | 3 | 91.88 | 87.41 | 83.14 | 88.56 | |||
| FastText | CBOW | 300 | - | 91.05 | 84.57 | 80.10 | 87.49 | |
| Word Embedding Model | Hyper-Parameters | Algorithms | Datasets during COVID-19 Period | |||||
|---|---|---|---|---|---|---|---|---|
| Architecture | Vector Size | Window Size | Riyadh Dataset | Jeddah Dataset | Dammam Dataset | All Datasets | ||
| ArWordVec | SG | 300 | 3 | CNN | 78.27 | 81.62 | 70.19 | 77.52 |
| 300 | 5 | 78.19 | 81.38 | 70.27 | 77.84 | |||
| 500 | 3 | 78.02 | 80.87 | 69.95 | 77.73 | |||
| 500 | 5 | 77.83 | 81.35 | 70.82 | 77.17 | |||
| CBOW | 300 | 5 | 78.12 | 80.99 | 69.85 | 77.61 | ||
| 500 | 3 | 77.90 | 80.98 | 70.11 | 77.70 | |||
| 500 | 5 | 78.31 | 80.87 | 70.61 | 77.80 | |||
| AraVec | SG | 100 | 3 | 78.71 | 81.00 | 71.78 | 77.84 | |
| 300 | 3 | 79.52 | 82.77 | 72.28 | 78.98 | |||
| CBOW | 100 | 3 | 77.78 | 81.12 | 70.43 | 77.17 | ||
| 300 | 3 | 78.25 | 81.64 | 70.84 | 77.69 | |||
| FastText | CBOW | 300 | 78.49 | 81.70 | 71.05 | 78.53 | ||
| ArWordVec | SG | 300-3 | 3 | BiLSTM | 76.49 | 79.54 | 67.75 | 75.58 |
| 300-5 | 5 | 76.27 | 79.41 | 67.78 | 75.99 | |||
| 500-3 | 3 | 76.32 | 79.64 | 68.54 | 76.39 | |||
| 500-5 | 5 | 76.61 | 79.67 | 68.05 | 76.12 | |||
| CBOW | 300-5 | 5 | 77.00 | 79.63 | 68.29 | 76.69 | ||
| 500-3 | 3 | 77.22 | 80.08 | 68.45 | 76.69 | |||
| 500-5 | 5 | 77.18 | 79.92 | 68.83 | 76.81 | |||
| AraVec | SG | 100 | 3 | 76.36 | 79.84 | 67.82 | 75.81 | |
| 300 | 3 | 77.78 | 80.75 | 69.77 | 77.19 | |||
| CBOW | 100 | 3 | 77.43 | 79.88 | 68.08 | 76.11 | ||
| 300 | 3 | 78.03 | 80.63 | 69.83 | 77.24 | |||
| FastText | CBOW | 300 | - | 75.51 | 79.25 | 67.27 | 74.87 | |
| Algorithms | Performance Metrics | Dataset before COVID-19 | Dataset during COVID-19 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Riyadh Dataset | Jeddah Dataset | Dammam Dataset | All Cities Dataset | Riyadh Dataset | Jeddah Dataset | Dammam Dataset | All Cities Dataset | ||
| CNN | Accuracy | 92.80 | 88.35 | 83.39 | 89.69 | 79.52 | 82.77 | 72.28 | 78.98 |
| Precision | 92.97 | 88.73 | 83.65 | 89.93 | 79.81 | 82.87 | 72.60 | 79.05 | |
| Recall | 93.06 | 88.77 | 83.81 | 90.03 | 79.66 | 83.01 | 72.39 | 79.18 | |
| F-score | 92.99 | 88.72 | 83.63 | 89.96 | 79.61 | 82.90 | 72.34 | 79.07 | |
| BiLSTM | Accuracy | 91.99 | 87.41 | 83.14 | 88.74 | 78.03 | 80.63 | 69.83 | 77.24 |
| Precision | 91.99 | 87.65 | 83.18 | 88.87 | 78.11 | 80.67 | 69.90 | 77.30 | |
| Recall | 92.25 | 87.88 | 83.63 | 89.16 | 78.20 | 80.93 | 69.99 | 77.48 | |
| F-score | 92.06 | 87.72 | 83.29 | 88.97 | 78.11 | 80.73 | 69.87 | 77.30 | |
| Dammam File (before COVID-19) | Jeddah File (before COVID-19) | Riyadh File (before COVID-19) | |||
|---|---|---|---|---|---|
| Sentiment Class | Number of Tweets | Sentiment Class | Number of Tweets | Sentiment Class | Number of Tweets |
| 1 | 3313 | 1 | 7385 | 1 | 9383 |
| −1 | 2811 | −1 | 4908 | −1 | 3218 |
| 0 | 796 | 0 | 951 | 0 | 886 |
| Dammam File (during COVID-19) | Jeddah File (during COVID-19) | Riyadh File (during COVID-19) | |||
|---|---|---|---|---|---|
| Sentiment Class | Number of Tweets | Sentiment Class | Number of Tweets | Sentiment Class | Number of Tweets |
| 1 | 2228 | 1 | 4111 | 1 | 5811 |
| −1 | 3473 | −1 | 9688 | −1 | 10,418 |
| 0 | 3925 | 0 | 7169 | 0 | 9713 |
| Ref | Dataset Source and Language | Datasets Size | Feature Used | Algorithm | The Best Result |
|---|---|---|---|---|---|
| [32] | Arabic Tweets | 30,000 Tweets After preprocessing 20,000 tweets | TFIDF and Word Embedding | LSTM and NB | LSTM: 98.9% accuracy |
| Proposed work | Arabic Tweets | 157,214 Tweets After preprocessing 90,187 Tweets | Word Embedding | BiLSTM, CNN | CNN: 93% accuracy BiLSTM: 92% accuracy |
| [37] | Arabic Tweets | 10 M Tweets After preprocessing 416,292 Tweets | ---- | SGRUs, SBGRU AraBERT, and the Ensemble deep learning algorithm | Ensemble deep learning algorithm: 90% accuracy |
| [41] | Arabic Tweets | 707,829 Tweets After preprocessing 8000 Tweets | Word Embedding | BiLSTM and GRU | GRU: 81% in terms of F1 score |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alqarni, A.; Rahman, A. Arabic Tweets-Based Sentiment Analysis to Investigate the Impact of COVID-19 in KSA: A Deep Learning Approach. Big Data Cogn. Comput. 2023, 7, 16. https://doi.org/10.3390/bdcc7010016
Alqarni A, Rahman A. Arabic Tweets-Based Sentiment Analysis to Investigate the Impact of COVID-19 in KSA: A Deep Learning Approach. Big Data and Cognitive Computing. 2023; 7(1):16. https://doi.org/10.3390/bdcc7010016
Chicago/Turabian StyleAlqarni, Arwa, and Atta Rahman. 2023. "Arabic Tweets-Based Sentiment Analysis to Investigate the Impact of COVID-19 in KSA: A Deep Learning Approach" Big Data and Cognitive Computing 7, no. 1: 16. https://doi.org/10.3390/bdcc7010016
APA StyleAlqarni, A., & Rahman, A. (2023). Arabic Tweets-Based Sentiment Analysis to Investigate the Impact of COVID-19 in KSA: A Deep Learning Approach. Big Data and Cognitive Computing, 7(1), 16. https://doi.org/10.3390/bdcc7010016