ML models, whether classification or regression, can be of type white-box or black-box, depending on their availability and constraints:
3.2. Identified Datasets
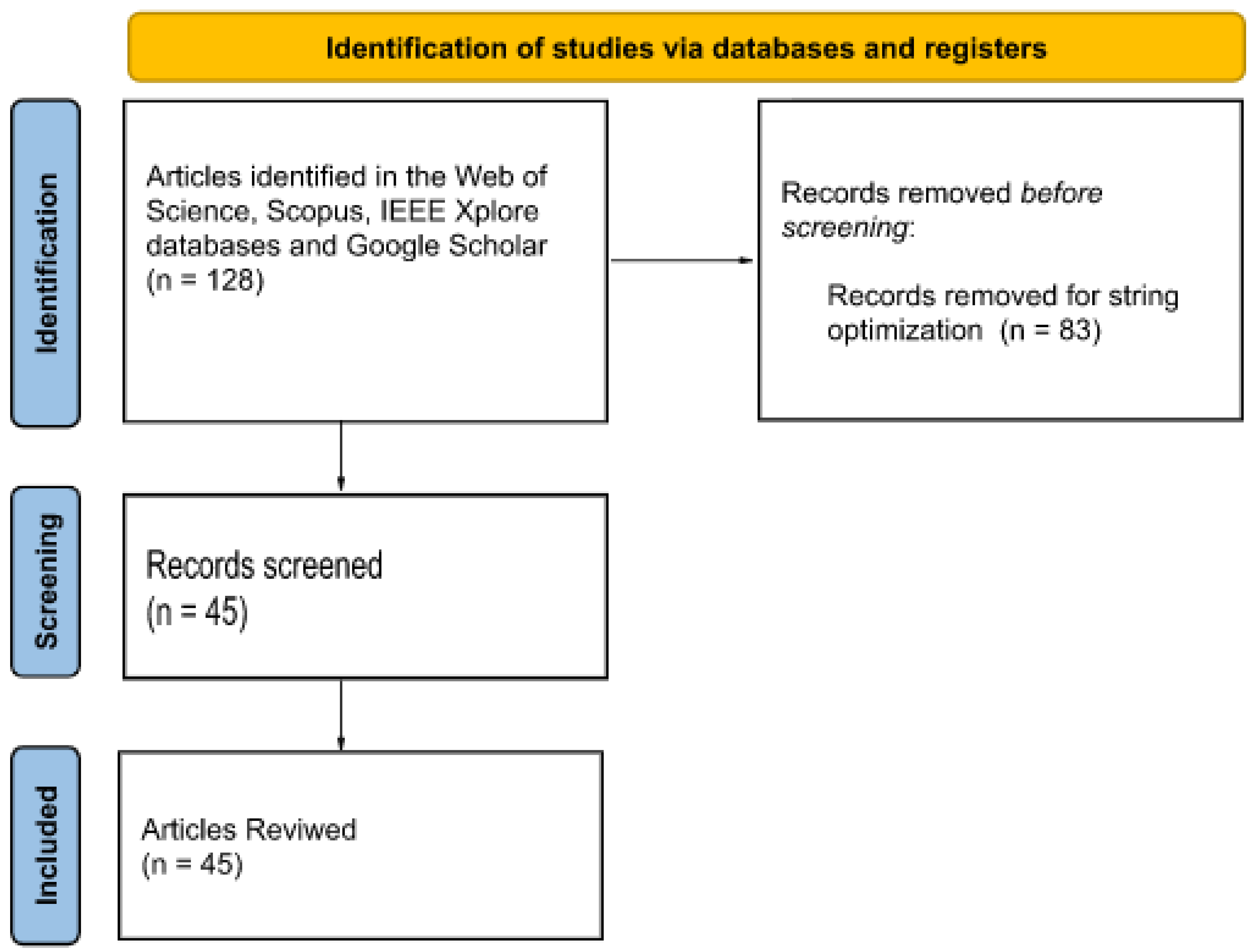
A survey of the datasets used in the works was conducted, listed in
Table 2. These datasets mostly are known to include demographic annotations, allowing for assessing unfairness and bias in their data, and can be used to test and validate techniques aimed at resolving these issues. Other datasets do not have demographic data, as it aims to identify bias and unfairness in image generation, reconstruction, enhancement, and super-resolution, not necessarily associated with demographic sensitive issues [
44]. Some datasets address crime-related issues such as Propublica Correctional Offender Management Profiling for Alternative Sanctions (COMPAS), Communities and Crime (Communities), and Florida Department of Corrections (FDOC).
The COMPAS [
79] dataset describes a binary classification task, which shows whether an inmate will re-offend within two years, has sensitive attributes such as race, age, and gender. This is one of the most widely used datasets for bias and fairness experiments, with a controversial and relevant topic.
Similar to COMPAS, the Communities dataset [
80] compares socioeconomic situations of US citizens in the 1990s and crime rate, identifying the per capita rate of violent crime in each community.
The FDOC [
62] dataset, on the other hand, contains sentences with the types of charges, which can be violent charges (murder, manslaughter, sex crimes, and other violent crimes); robbery; burglary; other property charges (including theft, fraud, and damage); drug-related charges; and other charges (including weapons and other public order offenses). The dataset uses Florida Department of Law Enforcement (FDLE) criminal history records for recidivism information within 3 years. They have the attributes such as the major crime category, the offender’s age of admission and release, time served in prison, number of crimes committed prior to arrest, race, marital status, employment status, gender, education level, and if recidivist whether they were supervised after release.
Addressing issues concerning the selection process and approval of individuals, the Student [
81] dataset has the data collected during 2005 and 2006 in two public schools in Portugal. The dataset was built from two sources: school reports, based on sheets of work including some tributes with the three grades of the period and number of school absences; and questionnaires, used to complement the previous information. It also includes demographic data with mother’s education, family income, social/emotional situation, alcohol consumption, and variables that can affect student performance.
Another theme found in the selected datasets involves financial issues of bank credit such as Bank marketing (Bank), German credit (German), and Credit. Wage forecasting was found with the Adult dataset and product pricing was found with the Boston housing price (Boston) dataset.
The Bank dataset is related to the marketing campaigns of a Portuguese bank between the years 2008 to 2013. The goal of the classification is to predict whether a customer will make a deposit subscription [
50].
Similarly, the German [
80] dataset has 1000 items and 20 categorical attributes. Each entry in this dataset represents an individual who receives credit from a bank. According to the set of attributes, each individual is evaluated on his or her credit risk.
The Credit [
82] dataset, on the other hand, contains payment data from a Taiwanese bank (a cash and credit card issuer) for identifying the bank’s credit card holders who would potentially receive a loan, including demographic annotations such as education level, age, and gender.
One of the most prominent datasets, Adult [
80] includes 32,561 full cases representing adults from the 1994 US census. The task is to predict whether an adult’s salary is above or below
$50,000 based on 14 characteristics. The sensitive attribute ’gender’ is embedded in the samples.
For real estate pricing, the Boston dataset has data extracted from the Boston Standard Metropolitan Statistical Area (SMSA) in 1970 and each of the 506 samples represents data obtained on 14 characteristics for households. The classification of this model aims to predict the property value of the region using attributes such as crime rate, proportion of residential land, and average number of rooms per household, among others [
76].
The datasets found also highlights applications in the health domain, either to predict patients’ financial expenses, as in the dataset Medical Expenditure Panel Survey (MEPS), or to identify possible health risks for patients as in the datasets: MEPS, Heart Disease (Heart), Multiparameter Intelligent Monitoring in Intensive Care (MIMIC II), Weight, and Drugs.
The MEPS [
83] dataset contains data on families and individuals in the United States, with their medical providers and employers, with information on the cost and use of health care or insurance.
To identify and prevent diseases, the Heart [
76] dataset contains 76 attributes, but all published experiments refer to the use of a subset of 14 of them. The target attribute refers to the presence of heart disease in the patient and can be 0 (no presence) to 4. Experiments aim to classify the presence or absence of heart disease.
Similarly to Heart, the MIMIC II [
54] dataset contains vital signs captured from patient monitors and clinical data from tens of thousands of Intensive Care Unit (ICU) patients. It has demographic data such as patient gender and age, hospital admissions and discharge dates, room tracking, dates of death (in or out of hospital), ICD-9 codes, unique code for healthcare professional and patient type, as well as medications, lab tests, fluid administration, notes, and reports.
The Weight [
84] dataset contains data for estimating obesity levels in individuals from the countries of Mexico, Peru, and Colombia, based on their eating habits and physical condition. It has 17 attributes and 2111 samples, labeled with the level of obesity which can be Low Weight, Normal Weight, Overweight Level I, Overweight Level II, Obesity Type I, Obesity Type II and Obesity Type III. The sensitive attributes are gender, age, weight, height, and smoking, among others.
To predict narcotic use, the Drug [
85] dataset was collected from an online survey including personality traits (NEO-FFI-R), impulsivity (BIS-11), sensation seeking (ImpSS), and demographic information. The dataset contains information on the use of 18 central nervous system psychoactive drugs such as amphetamines, cannabis, cocaine, ecstasy, legal drugs, LSD, and magic mushrooms, among others, including demographic attributes such as gender, education level, and age group.
In the image enhancement and face recognition domain, bias may not be associated with demographic features, the datasets that have demographic information were identified, among them: Labeled Faces in the Wild (LFW), Large-scale CelebFaces Attributes (CelebA), MORPH Longitudinal Database (MORPH), MovieLens 1M and Visual Question Answering (VQA). The dataset Animal FacesHQ (AFHQ) deals with the identification of animals, and the bias is associated with implicit features of the images, as well as the dataset Correlated and Imbalanced MNIST (CI-MNIST). Synthetic datasets were also found as an alternative.
The LFW [
63] dataset contains 13,233 images of faces of 5749 distinct people and 1680 individuals are in two or more images. LFW is applied to face recognition problems and the images were annotated for demographic information such as gender, ethnicity, skin color, age group, hair color, eyeglass wearing, among other sensitive attributes.
The CelebA [
86] dataset contains 202,599 face images with 10,177 individuals and 40 annotated attributes per image such as gender, Asian features, skin color, age group, head color, and eye color, among other sensitive attributes, just as LFW is also used for face recognition problems.
The MORPH dataset contains over 400,000 images of almost 70,000 individuals. The images are 8-bit color and sizes can vary. MORPH has annotations for age, sex, race, height, weight, and eye coordinates.
The MovieLens 1M [
28] dataset contains a set of movie ratings from the MovieLens website, a movie recommendation service of 1 million reviews from 6000 users for 4000 movies, with demographics such as gender, age, occupation, and zip code, plus data from the movies and the ratings.
The VQA [
48] dataset contains natural language questions about images. It has 250,000 images, 760,000 questions, and about 10 million answers. The questions have a sensitive criterion from the point of view of the questioner and can be a simple question or a difficult one, creating a bias. The images can also be very complex, making it difficult to identify the question element. The VizWiz dataset has the same proposal as the VQA for object recognition and assistive technologies, collected from users with visual impairment. CLEVR has a similar proposal to VQA and VizWiz but was generated automatically by algorithms containing images with three basic shapes (spheres, cubes, and cylinders) in two different sizes (small and large) and eight different colors and includes questions and answers with the elements contained in the images. The combination of VQA, VizWiz, and CLEVR gave origin to another dataset of questions and answers, annotated with the sensitive attribute of the visual conditions of the user who asked the question, which could be normal vision, visually impaired, or robot.
The AFHQ [
44] dataset consists of 15,000 high-quality images of animal faces at 512 × 512 resolution. It includes three domains of cat, dog, and wildlife, each providing 5000 images, it also contains three domains and several images of various breeds (larger than eight) for each domain. All images are aligned vertically and horizontally to have the eyes in the center. Low-quality images were discarded. The work by Jalal et al. [
44] used only images of cats and dogs.
The CI-MNIST [
75] dataset is a variant of the MNIST dataset with additional artificial attributes for eligibility analysis. For an image, the label indicates eligibility or ineligibility, respectively, given that it is even or odd. The dataset varies the background colors as a protected or sensitive attribute, where blue denotes the nonprivileged group and red denotes the privileged group. The dataset is designed to evaluate bias mitigation approaches in challenging situations and address different situations. The dataset has 50,000 images for the training set, 10,000 images for validation and testing, with the eligible images representing 50 percent of each of these. Various background colors, colored boxes added at some top of the image of varying sizes were used to allow the impact of the colors, positions, and sizes of the elements contained in the image to be analyzed.
The dataset might also be generated synthetically [
67] using a normal distribution of the data. It created an attribute that was binary-sensitive and had the Bernouilli distribution.
The use of the datasets examined in this Section can be seen in the
Section 3.5 associated with mitigation techniques.
3.3. Fairness Metrics
Machine learning models increasingly provide approaches to quantify bias and inequality in classification operations as a methodology for measuring bias and fairness [
57]. While many metrics have been developed, when it comes to long-term decisions, the models and scientific community have produced poor outcomes. Some existing metrics for measuring model bias are insufficient, either because they only evaluate the individual or the group, or because they are unable to predict a model’s behavior over time. The authors offer the metric DP as a solution, which, when applied to a model, ensures that the average classification of individuals in each group converges to the same point, achieving a balance between accuracy, bias, and fairness for the groups classified by the model.
One of the metrics used to evaluate the model was DP, which assures that decisions are unrelated to sensitive attributes [
58]. EO metric was used to guarantee parity between positive and negative evaluations, and Equality of Opportunity metric was employed to ensure that individuals meet the same criteria and are treated equally. Each of these metrics assures that groups are treated fairly and that the model’s quality does not deteriorate or become biased over time [
57].
The metrics for assessing fairness should apply the same treatment to multiple groups; however, if one of the metrics identifies bias, other metrics can charge that the model is fair.
Five metrics for assessing fairness were established from the review of the works: EO, Equality of Opportunity, DP, Individual Differential Fairness, and MDFA.
As a basis for the fairness metrics, it is important to define true positive (TP), false positive (FP), true negative (TN), and false negative (FN). These values are obtained from the rights and wrongs of the model’s prediction relative to the target or ground truth provided by the dataset. Positive values are defined as the positive class that the model should predict, as opposed to negative values. For example, if the model should predict whether an individual will reoffend, the positive class will be 1, which indicates that the individual will reoffend, and the negative class will be 0. Therefore, if the positive classes are correct, they will be computed in TP, while the errors will be computed in FP. On the other hand, hits for negative classes will be computed in TN and errors in FN.
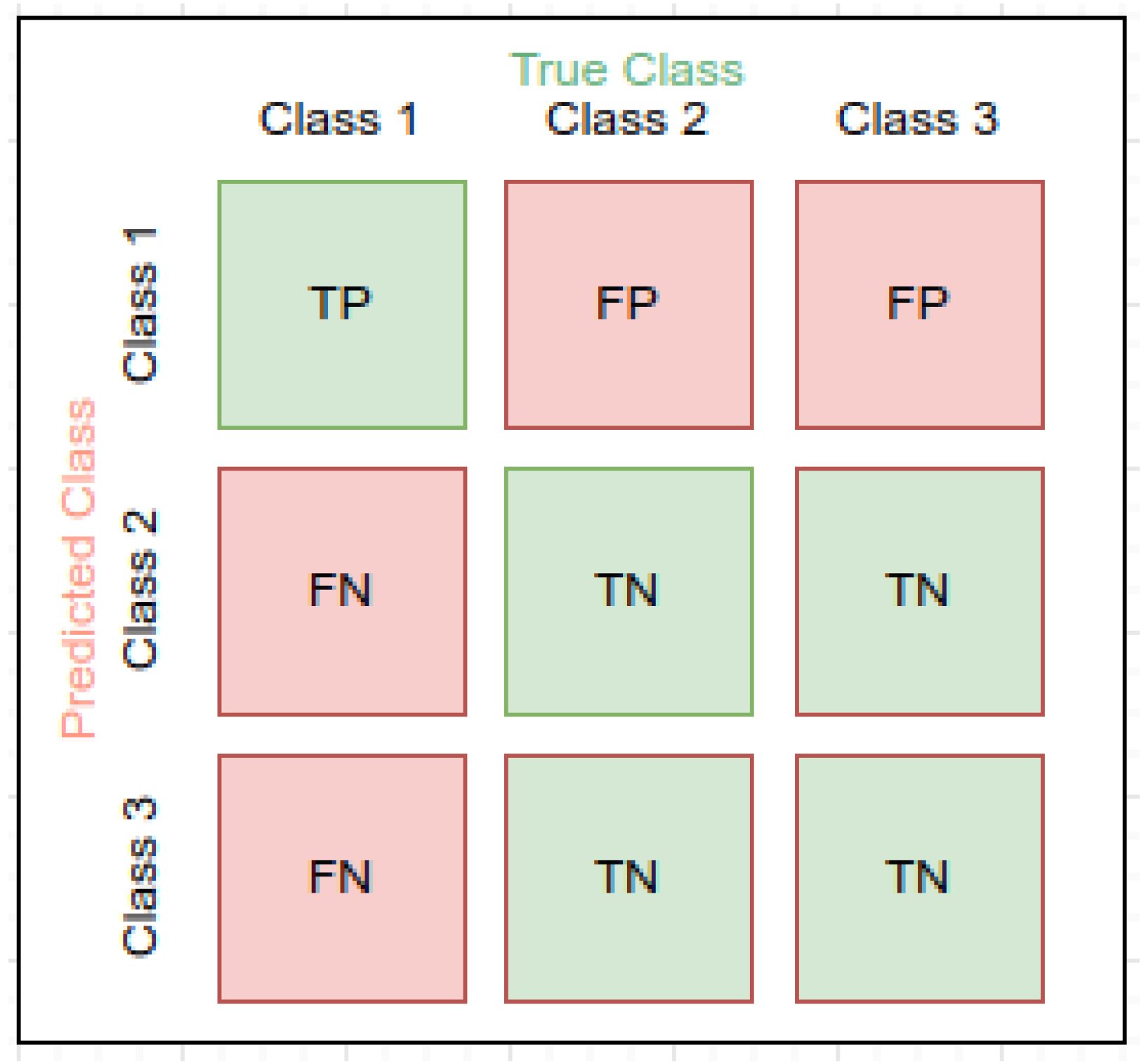
For a multiclass problem there is no positive and negative class, just consider the values for each individual class, observe
Figure 5.
In the example, the scenario for calculating the values of Class 1 is illustrated, TP is the value of the correct prediction, consistent with the target. The TN are the sum of the classes that do not involve Class 1, neither in the prediction nor in the target. The FP is the sum of the classes falsely predicted as Class 1, while the FN are the sum of the classes predicted as other classes that should have been predicted as Class 1.
This process should be performed for all classes and the overall TP, FP, TN, and FN of the model should be averaged over the individual values.
To understand the fairness metrics, which use the TP, FP, TN, and FN, the statistical metrics must also be defined as per
Table 3.
The objective of the metric EO is to ensure that the probability that an individual in a positive class receives a good result and the probability that an individual in a negative class wrongly receives a positive result for the protected and unprotected groups are the same. That is, the TPR and FPR of the protected and unprotected groups must be the same [
31].
In contrast, the metric Equality of Opportunity must satisfy equal opportunity in a binary classifier (Z). As a result, the probability of an individual in a positive class receiving a good outcome must be the same for both protected and unprotected groups. That is, the TPR for both the protected and unprotected groups must be the same [
31].
According to the fairness metric Demographic Parity (DP), also known as Statistical Parity, the probability of an outcome being positive [
31]. For this, the formula below should be applied.
The Disparate Impact (DI) fairness metric compares the proportion of individuals who receive a favorable outcome for two groups, a protected group and an unprotected group. This measure must equal to 1 to be fair.
The K-Nearest Neighbors Consistency (KNNC) fairness metric, on the other hand, is the only individual fairness metric used by the authors of Ref. [
64]; it measures the similarity of sensitive attribute labels for similar instances [
50].
Different metrics were used as fairness metrics by the authors of Ref. [
64], including Absolute Balanced Accuracy Difference (ABAD), Absolute Average Odds Difference (AAOD), Absolute Equal Opportunity Rate Difference (AEORD) and Statistical Parity Difference (SPD). The Differences metrics are calculated from the difference of the ’Disparity’ metrics between two classes.
The ABAD is the difference in balanced accuracy in protected and unprotected groups, defined by Equation (
6).
The AAOD is the absolute difference in TPR and FPR between different protected groups, defined by Equation (
7).
AEORD is the difference in recall scores (TPR) between the protected and unprotected groups. A value of 0 indicates equality of opportunity, defined by Equation (
8).
Finally, SPD is the difference in SD between a protected and an unprotected group, defined by Equation (
9).
In addition to fairness metrics, some works use classification metrics such as accuracy, precision, recall and F1-score [
48] as criteria for identifying bias. In addition to fairness metrics, some works use classification metrics such as accuracy, precision, recall and F1-score [
48] as criteria for identifying bias. Measures of bias linked to the accuracy of model predictions are designed to check for unexpected differences in accuracy between groups. A less accurate prediction for one group compared to another contains systematic error, which disproportionately affects one group over the other [
7].
Accuracy is the ratio between the number of true negatives and true positives to the total number of observations. Precision is the proportion of correct positive identifications. Recall is the proportion of true positives correctly identified. The F1-score is the weighted average of Precision and Recall. The formulas for each can be seen in Equations (
10)–(
13)
Other cases used the number of positive (NIP) and negative (NIN) instances as the criteria for fairness metrics, as well as the base rate (BR) also known as prior probabilities are the unconditional probabilities, it is a probability with respect to all samples (N) [
50]. The formulas for each can be seen in Equations (
14)–(
16)
All reported fairness metrics can be seen in
Table 4.
3.5. Mitigation Techniques and Models
As previously noted, bias and unfairness mitigation techniques can be of the types: preprocessing, in-processing, and postprocessing. While preprocessing mitigation techniques focus on rebalancing the data, in-processing mitigation focuses on the model and its regularization with a bias correction term in the loss function or implicit in the model as with adversarial networks, where the model predicts the sensitive attribute [
6].
The preprocessing mitigation technique aims to alter the dataset in a way that positively impacts the fairness metrics, and FairDAGs library is proposed as an acyclic graph generator that describes the data flow during preprocessing [
53]. The purpose is to identify and mitigate bias in the distribution and distortions that may arise with protected groups, while allowing direct observation of changes in the dataset. The four types of treatment are: bias by filtering the data, standardizing missing values, changes in the proportion of the dataset after replacement of NaN values, and, for NLP systems, filtering out extraneous names or words that the computer may not recognize. The results showed that DAG was able to identify and represent differences in the data that occurred during preprocessing, as well as correct imbalances in the datasets examined.
Preprocessing may have a different purpose, such as removing sensitive data from the model for a banking system, ensuring the removal of customer data after the output without affecting the ML model [
50]. The goal is the generation of synthetic data from the representation of the original data in order to preserve privacy while maintaining the usefulness of that original data. The synthetic data is generated by the Trusted Model Executor (TME), which is an AIF360 tool. At the end, the bias in the synthetic dataset was evaluated by comparing it with the original datasets in order to validate the TME.
Also using AIF360 to perform preprocessing operations, a study examined that smartwatches distinguish between men and women in the identification of cardiovascular problems, evaluating more characteristics of the former group than the latter [
54]. In view of the above, there should be a correction to fit the needs of both genders the removal of sensitive data, with the rebalancing of the dataset distribution and processing operations. It also adjusts nonrepresentative data for accurate assessment of user health. The mitigation technique in preprocessing used was Reweighting. At the end, the Vital-ECG was developed, a watchlike device that detects heart rate, blood pressure, skin temperature and other body variables without distinction of gender and with superior predictions.
Still in the area of data generation, another study generated a new dataset that has no disparity of distribution, quality or noise, ensuring that all classes are treated equally [
64]. To do this, it used the VAE-GAN architecture which, although it showed great improvements in model impartiality, the use of synthetic data during training limited its ability to generalize real data, reducing accuracy and precision. To minimize the trade-off, the model trained with artificial data used transfer learning techniques to perform an adjustment of the weights with real data.
In the area of computer vision, face recognition and analysis models generally exhibit demographic biases, even in models where accuracy is high [
63]. The reason is usually due to datasets with under-represented categories, whether for identifying identity, gender, or expressions of the human face. Biases can be in relation to age, gender, and skin tone. Therefore, a bias mitigation technique was proposed with a dataset of facial images, where to increase demographic diversity, a style transfer approach using Generative Adversarial Networks (GANs) was used to create additional images by transferring multiple demographic attributes to each image in a biased set. Two literature reviews highlighted preprocessing techniques to mitigate data bias, such as Synthetic Minority Oversampling Technique (SMOTE) and uses Data Augmentation [
63,
76]. The authors defined open questions on the topic, such as the fact that metrics can be conflicting, indicating a model that is fair in one metric and unfair in another. Also dealing with bias in face recognition, another research assessed the performance of diversity in Lenovo’s internal facial recognition system, named LeFace [
70]. The algorithm developed is a semiautomatic data collection, cleaning, and labeling system. The training data is diverse in terms of race, age, gender, poses, lighting, and so on. This data system cleans and labels the face data with an algorithm that evaluates data balancing before applying data augmentation to obtain a balanced training dataset. Furthermore, LeFace employs an attention method to provide balanced data to the network during the training phase. The Racial Faces in the Wild (RFW) database was used to assess the algorithm’s capacity to recognize different races. It is divided into four classes: African, Asian, Caucasian, and Indian.
Also in the domain of computer vision, the authors of Ref. [
44] present several intuitive notions of group fairness, applied to image enhancement problems. Due to the uncertainty in defining the clusters, since, for the author, there are no ground truth identities in the clusters, and the sensitive attributes are not well-defined.
Concerning the impacts of fairness metrics on the preprocessing mitigation process, the metric Demographic Parity is strongly dependent on clusters, which is problematic for generating images of people in the data augmentation process, because the classes of the sensitive attribute ’race’ are ill-defined [
44]. In CPR, implemented using Langevin dynamics, this phenomenon does not occur, and it can be seen in the results obtained that, for any choice of protected clusters, the expected properties are displayed.
The fairness metrics identified in the works that addressed preprocessing are in
Table 5, as are the datasets in
Table 6.
The in-processing mitigation technique was identified in a larger number of works [
28,
55,
56,
58,
59,
60,
62,
65,
75].
One study proposes an in-processing solution in the holistic and often subjective methods that may contain biases in the student selection process in schools [
55]. From this perspective, learning algorithms capable of admitting a diverse student population were developed, even for groups with historical disadvantages. The study examined the impact of characteristics such as income, color, and gender on student admission rates.
Another in-process mitigation solution for group bias used the logistic regression technique to develop the model [
65]. The solution used was Pareto Optimal, which aims to ensure a better accuracy loss function while keeping the fairness metrics at the threshold set at 80%. The author states that the in-processing solution, where the algorithm is adjusted during learning, would be a natural solution, because the preprocessing algorithms would be altering the original data, hurting ethical norms; however, it is possible to work with data balance without altering the users’ data.
Table 6.
Datasets used in preprocessing techniques.
Table 6.
Datasets used in preprocessing techniques.
One in-processing mitigation model used a new classification approach for datasets based on the sensitive attribute ’race’, with the aim of increasing prediction accuracy and reducing racial bias in crime recidivism [
62]. The recidivism prediction models were evaluated by the type of crime, including ’violent crimes’, ’property’, ’drug’, and ’other’. For the ’all crimes’, ’Caucasian data set’, and ’African American data set’ groups, the results still contained bias, although lower than the baseline data. The ratios obtained were 41:59, 34:66, and 46:54.
A study focused on bias mitigation in deep learning models for classification and the need for a systematic analysis of different bias mitigation techniques in-processing with MLP and CNN [
75]. Using a dataset that allows the creation of different bias sets, the authors performed an analysis of the mitigation models recently proposed in the literature. Then, they showed the correlation between eligibility and sensitive attributes, the possible presence of bias even without sensitive attributes, and the importance of the initial choice of architecture for model performance.
In contrast, another work focused on the ways in which bias can occur in recommender systems, while addressing the lack of systematic mapping to address unfairness and bias in the current literature [
28]. In the experiments, sources of unfairness that can occur in recommendation tasks were mapped, while evaluating whether existing bias mitigation approaches successfully improve different types of fairness metrics. It also presents a mitigation strategy in which the algorithm learns the difference between predicted and observed ratings in subgroups, identifying which is biased and correcting the prediction. The results show that fairness increased in most use cases, but performance for MSE and MAE vary in each case.
Some studies have in common the fact that their models were trained in order to mitigate bias from only adjusting the weights of their proposed models [
28,
55,
62,
65,
69,
75]. An attempt to mitigate the bias by neutralizing the sensitive attribute in the model showed to be possible to make a classification model fairer by removing bias only in its output layer, in a process that occurs during its construction [
66]. To this end, a technique was developed where training samples with different sensitive attributes are neutralized, causing the model’s dependence on sensitive attributes to be reduced. The main advantage demonstrated by the method is the small loss of accuracy in exchange for improved fairness metrics, without requiring access to the sensitive attributes in the database. In addition, the authors argue that it is possible to increase the quality of the technique by combining it with others, for example, by using a fairer basis than the one used in the experiments.
In another work, the classification detects the item with the highest probability of belonging to the ’target’ class of the model; however, there are cases where numerous items have very close probabilities and bias the model, causing an error to propagate across multiple levels [
69]. To avoid this, there is a need for a threshold with a minimum degree for the data to be classified and triggers a recalculation of the maximum node probability. The sensitive cost then performs its own probability calculation on the data with the highest degree of membership. These calculations avoid bias caused by using a single probability or overoptimal adjustment caused by using data with no prior context. Hierarchical Precision and Hierarchical Precision, which evaluates the relationship between all descendants of the class and includes Hierarchical F1, Hierarchical Recall, and Hierarchical Precision, were used as metrics. The threshold is adaptive, without requiring user parameters, since metrics exist throughout the classification. Even with fewer samples, it produced results that were superior to the state of the art.
In other works, the neutralization of sensitive attributes in an attempt to mitigate model bias is more direct [
56,
58,
59,
60] by identifying it beforehand, similar to the investigation of the authors Chiappa and Isaac [
51], which addresses a new perspective on the concept of fairness by determining whether an attribute is sensitive by evaluating it in a Causal Bayesian Networks model. This model examines the direct effects of one characteristic on another and determines whether a sensitive attribute ’A’ influences the output ’Y’ of a model, producing correlation plots that strive to understand whether decisions made were made fairly.
A pre-existing biased model must be updated to become fair, minimizing unfairness without causing abrupt structural changes [
56]. The study uses an adversarial learning technique with the distinction that the generating model is the original network; however, the adversarial model comprises an extra hidden layer, rather than a second model, to predict which sensitive attribute influenced the generator’s decision. The main element of this competition model is that if the discriminator finds the sensitive attribute that influenced the decision the most, it demonstrates dependence on the generator model, suggesting bias. The generator moves away from the sensitive attributes and performs a classification that does not depend on them, eventually lowering the discriminator’s hit rate until it completely loses its predictive ability. The network architecture has three parts: adding an adversarial layer on top of the network, balancing the distribution of classes across the minisets, and adapting sensitive attributes until they are no longer present.
The technique was developed for classification tasks but can be used for any neural network with biases starting with sensitive attributes [
56], and it achieved better results compared to the state of the art with the metrics addressed.
In the same way as Adel et al. [
56], Amend and Spurlock [
59] also uses adversarial network for sensitive attribute identification and examines metrics and combinations of techniques for bias mitigation. The study was conducted using basic ANN models and a Split model, which forms the basic model by permuting attribute classes as training criteria in order to identify which one is sensitive. Another model is based on the Classifier-Adversarial Network (CAN) architecture; in that model, the adversarial network predicts the sensitive attribute based on the output of the basic model. Finally, there is the CAN with Embedding (CANE) architecture, which takes as input the output of the basic model as well as the weights created in the penultimate layer. They demonstrated that the models from the Basic RNA architecture can improve accuracy, but not bias. Meanwhile, the models of the CAN and CANE architectures improved accuracy and reduce bias, with CANE being better than CAN.
Still involving adversarial network, the Adversarial Fairness Local Outlier Factor (AFLOF) method is proposed for outlier detection, combining adversarial algorithms with the Local Outlier Factor (LOF) algorithm, which returns a value indicating whether an instance is an outlier, aiming to achieve a fairer and more assertive result than LOF and FairLOF [
47]. It works with the sensitive attributes Gender, Age, and Race. It also uses the AUC-ROC score to measure outlier detection. It results in a fairer and more assertive performance for outlier detection than the previous methods cited, thus achieving a breakthrough in the study of fairness. Research on fairness and bias in machine learning focuses only on neural networks, with few publications for other classification techniques [
61]. As a result, the author investigated Adversarial Gradient Tree Boosting to rank data and noted that while the adversary progressively loses the reference of the sensitive attribute that led to that prediction.
Another contribution is the adversarial learning method for generic classifiers, such as decision trees [
61]. Comparing numerous state-of-the-art models with the one provided in the work, which covers two fairness metrics. They used varied decision trees in the model given that they make rankings, which are then sent through a weighted average to an adversary, who predicts which sensitive attribute was significant to the final decision. While the adversary is able to detect the sensitive attribute, a gradient propagation occurs, updating the weights in the decision trees and trying to prevent the sensitive attribute from having a direct impact on the ranking.
The model called FAGTB performed well on accuracy and fairness metrics for the COMPAS, Adult, Bank, and Default datasets, outperforming other state-of-the-art models on several of them and considerably outperforming the network adversary Grari et al. [
61]. The study leaves certain questions unanswered for future research, such as an adversary using Deep Neural Decision Forests. If this method were used to retrieve the gradient, theoretically, the transparency of the model for the algorithm’s decision would be apparent because it consists only of trees. As a final caveat, they acknowledge that the algorithm handles distinct groups well, but the EO and DP fairness metrics do not measure bias between individuals, and is an aspect for improvement.
Following varied work with adversarial learning, the model Privileged Information is a technique that trains the model with all the features of the original dataset, including sensitive attributes, and then tests it without these attributes [
58]. The model is an in-processing type adjusted with the goal of mitigating unfairness and independent of sensitive attributes, while maintaining its ability to produce accurate predictions, thus respecting the protected information for decision-making. Note that in this case, the model fully fits the dataset in an attempt to mitigate bias. The author emphasizes the strength of his model in identifying the best predictor relative to other state-of-the-art work, having the sensitive attributes as optional, and still using Privileged Information.
In contrast, model bias is avoided by using only data with minimal or, if possible, no sensitive attributes by applying a noise conditioning operation to the data provided in the model, inducing the model to ignore sensitive attributes, reducing bias [
60]. The goal of the model is to create as accurate a representation as possible in the prediction, with fairness. The models used the techniques of logistic regression and Random Forest.
The fairness metrics identified in the works that addressed in-processing are in
Table 7, as are the datasets in
Table 8.
Mitigation solutions for post-processing were also found [
48,
67]. A study proposes a solution for an already formed model, seeking to identify whether certain groups receive discriminatory treatment due to their sensitive attributes [
67]. With the identification of discrimination for a group, it is verified whether the sensitive attributes are impacting the model, even if indirectly. The model has a neural network with four fully connected layers of 8 neurons, expressing the weights as a function of the features in order to minimize the maximum average discrepancy function between the sensitive attribute classes promoting unfairness mitigation. He applied his mitigation model to a Logistic Classification model. The work allows black-box type models to be mitigated for unfairness, but there is also understanding of the assigned treatment.
Other study uses the identification of biases in models developed to recognize the user, where the user can be a human with normal vision, a blind person, or a robot [
48]. The identification takes place when answering a question, so NLP is applied. Its bias can be seen in the most frequently asked question
what is this object?, as well as the low image quality compared to the others. Initially, annotations were assigned to the content of the images such as
boy,
package,
grass,
airplane, and
sky. Random Forest, KNN, Nave Bayes, and Logistic Regression techniques were used to develop the models. Logistic Regression produced the best results, with 99% on all metrics. The authors found that the algorithms readily recognized the bias in each dataset and provided a means of tracing the origin of the questions and images.
Table 7.
Fairness metrics used in in-processing techniques.
Table 7.
Fairness metrics used in in-processing techniques.
| Fairness Metric | References |
|---|
| DP | [44,47,58,59,61,66,70,75] |
| EOO | [47,58,59,65,70,75] |
| EO | [28,44,58,61,63,65,66,68,70,75] |
| Accuracy | [58,59,62,70,75] |
| DI | [56] |
| TPR | [58,63] |
| FPR | [56,58,61,62] |
| FNR | [56,61,62] |
| Race-Blind | [70] |
| AAOD | [64] |
| ABAD | [64] |
| AEORD | [64] |
| SPD | [64] |
| SP | [28] |
| Equal Opportunity Difference | [28] |
Table 8.
Datasets used in the in-processing techniques.
Table 8.
Datasets used in the in-processing techniques.
| Datasets | References |
|---|
| CI-MNIST | [75] |
| Adult | [47,56,58,59,60,65,66,75] |
| COMPAS | [56,58,60,65] |
| German | [60] |
| Bank | [60] |
| FDOC | [62] |
| FDLE | [62] |
| MovieLens 1M | [28] |
| MEPS | [66] |
| CelebA | [66] |
| Weight | [47] |
| Drug | [47] |
| Crime | [47] |
| Student | [47] |
| Credit | [47] |
The fairness metrics identified in the works that addressed postprocessing are in
Table 9, as are the datasets in
Table 10.
Table 9.
Fairness metrics used in postprocessing techniques.
Table 9.
Fairness metrics used in postprocessing techniques.
| Fairness Metric | References |
|---|
| DI | [67] |
| precision | [48] |
| recall | [48] |
| accuracy | [48] |
| F1-score | [48] |
Table 10.
Datasets used in postprocessing techniques.
Table 10.
Datasets used in postprocessing techniques.
| Datasets | References |
|---|
| Synthetic (normal distribution) | [67] |
| COMPAS | [67] |
| VQA | [48] |
| VizWiz | [48] |
| CLEVR | [48] |


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




