
Lung Cancer Risk Prediction with Machine Learning Models



Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Dataset Description
- Gender [41]: This feature shows if the person’s sex is male or female.
- Age (years) [42]: This feature captures the person’s age.
- Smoking [43]: This feature indicates if the participant is a smoker or not.
- Yellow fingers [44]: This feature refers to whether the participant has yellow fingers or not.
- Anxiety [45]: This feature shows if the participant is anxious or not.
- Peer pressure [46]: This feature captures if the participant feels peer pressure or not.
- Chronic disease [47]: This feature expresses if the participant suffers from a chronic disease or not.
- Fatigue [48]: This feature manifests if the participant suffers from fatigue or not.
- Allergy [49]: This feature refers to whether the participant has an allergy or not.
- Wheezing [50]: This feature declares if the participant suffers from wheezing or not.
- Alcohol [51]: This feature shows if the participant consumes alcohol or not.
- Coughing [52]: This feature refers to whether the participant suffers from coughing or not.
- Shortness of breath [53]: This feature refers to whether the participant has shortness of breath or not.
- Swallowing difficulty [54]: This feature indicates if the participant has difficulty swallowing or not.
- Chest pain [55]: This feature captures whether the participant has chest pain or not.
- Lung Cancer: This feature shows if the participant has been diagnosed with lung cancer or not.All the features are nominal except for age, which is numerical.
3.2. Data Preprocessing
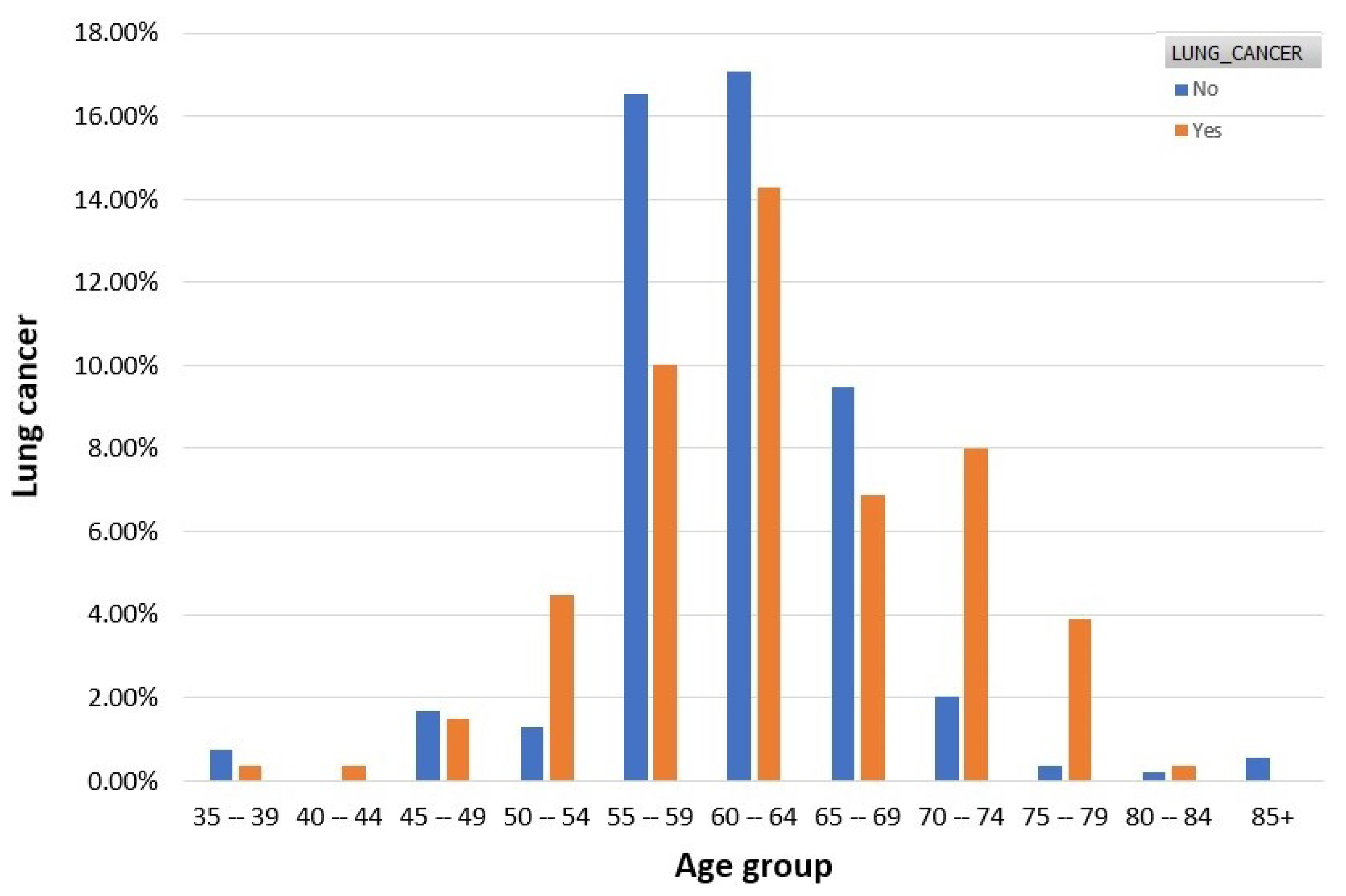
3.3. Features Analysis
3.4. Machine Learning Models
3.5. Evaluation Metrics
4. Results and Discussion
4.1. Experiments Setup
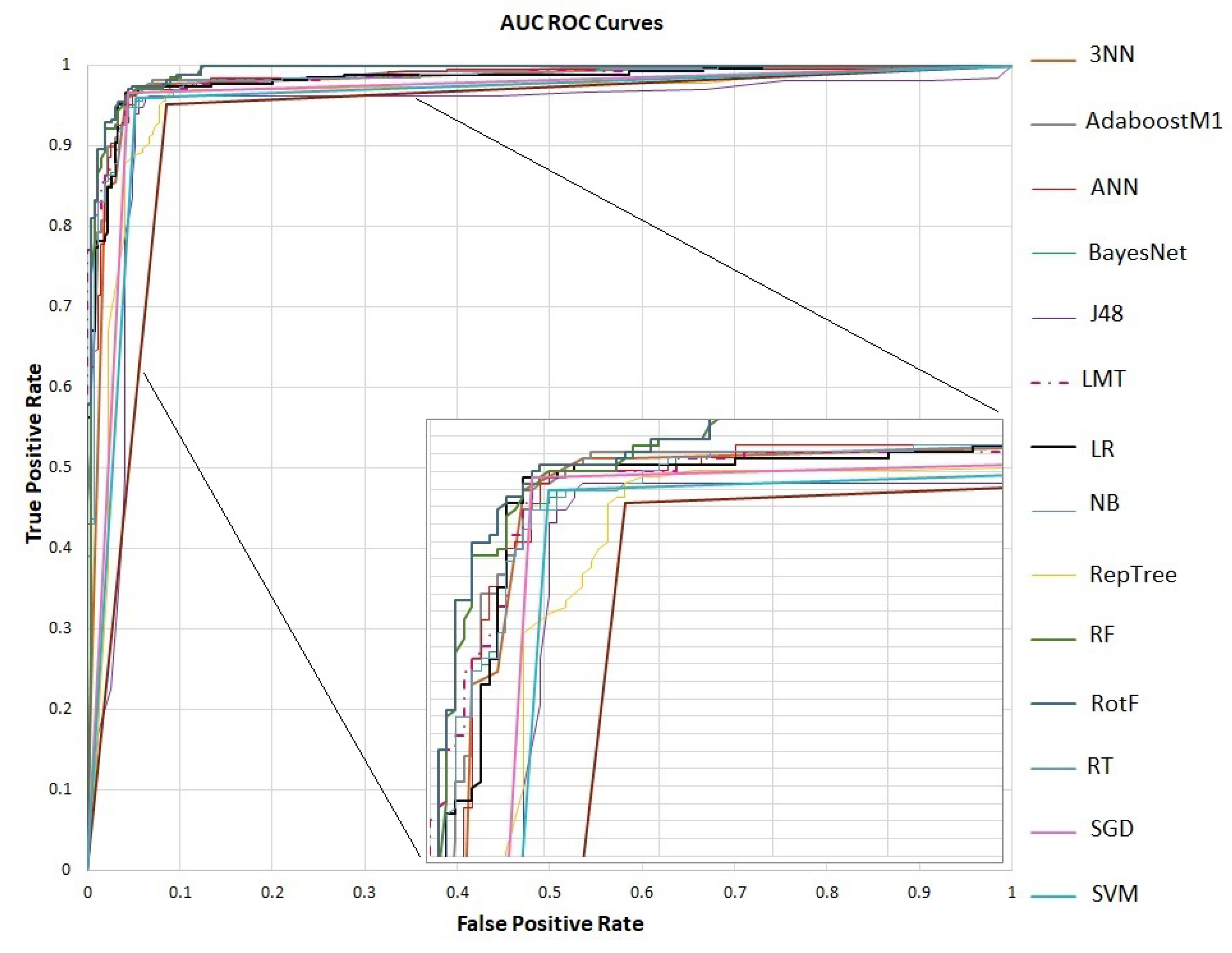
4.2. Evaluation
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Schiller, H.B.; Montoro, D.T.; Simon, L.M.; Rawlins, E.L.; Meyer, K.B.; Strunz, M.; Vieira Braga, F.A.; Timens, W.; Koppelman, G.H.; Budinger, G.S.; et al. The human lung cell atlas: A high-resolution reference map of the human lung in health and disease. Am. J. Respir. Cell Mol. Biol. 2019, 61, 31–41. [Google Scholar] [CrossRef] [PubMed]
- Hervier, B.; Russick, J.; Cremer, I.; Vieillard, V. NK cells in the human lungs. Front. Immunol. 2019, 10, 1263. [Google Scholar] [CrossRef] [PubMed]
- Barroso, A.T.; Martín, E.M.; Romero, L.M.R.; Ruiz, F.O. Factors affecting lung function: A review of the literature. Arch. De Bronconeumol. 2018, 54, 327–332. [Google Scholar] [CrossRef]
- Mirza, S.; Clay, R.D.; Koslow, M.A.; Scanlon, P.D. COPD guidelines: A review of the 2018 GOLD report. In Mayo Clinic Proceedings; Elsevier: Amsterdam, The Netherlands, 2018; Volume 93, pp. 1488–1502. [Google Scholar]
- Dotan, Y.; So, J.Y.; Kim, V. Chronic bronchitis: Where are we now? Chronic Obstr. Pulm. Dis. J. COPD Found. 2019, 6, 178. [Google Scholar] [CrossRef]
- Stern, J.; Pier, J.; Litonjua, A.A. Asthma epidemiology and risk factors. In Seminars in Immunopathology; Springer: Berlin/Heidelberg, Germany, 2020; Volume 42, pp. 5–15. [Google Scholar]
- Bell, S.C.; Mall, M.A.; Gutierrez, H.; Macek, M.; Madge, S.; Davies, J.C.; Burgel, P.R.; Tullis, E.; Castaños, C.; Castellani, C.; et al. The future of cystic fibrosis care: A global perspective. Lancet Respir. Med. 2020, 8, 65–124. [Google Scholar] [CrossRef]
- Mandell, L.A.; Niederman, M.S. Aspiration pneumonia. N. Engl. J. Med. 2019, 380, 651–663. [Google Scholar] [CrossRef]
- Barta, J.A.; Powell, C.A.; Wisnivesky, J.P. Global epidemiology of lung cancer. Ann. Glob. Health 2019, 85, 8. [Google Scholar] [CrossRef]
- Bradley, S.H.; Kennedy, M.; Neal, R.D. Recognising lung cancer in primary care. Adv. Ther. 2019, 36, 19–30. [Google Scholar] [CrossRef]
- Athey, V.L.; Walters, S.J.; Rogers, T.K. Symptoms at lung cancer diagnosis are associated with major differences in prognosis. Thorax 2018, 73, 1177–1181. [Google Scholar] [CrossRef]
- Duma, N.; Santana-Davila, R.; Molina, J.R. Non–small cell lung cancer: Epidemiology, screening, diagnosis, and treatment. In Mayo Clinic Proceedings; Elsevier: Amsterdam, The Netherlands, 2019; Volume 94, pp. 1623–1640. [Google Scholar]
- Romaszko, A.M.; Doboszyńska, A. Multiple primary lung cancer: A literature review. Adv. Clin. Exp. Med. 2018, 27, 725–730. [Google Scholar] [CrossRef]
- No Tobacco ’22. Available online: https://www.lung.org/media/press-releases/no-tobacco-%E2%80%9922 (accessed on 6 August 2022).
- Wadowska, K.; Bil-Lula, I.; Trembecki, Ł.; Śliwińska-Mossoń, M. Genetic markers in lung cancer diagnosis: A review. Int. J. Mol. Sci. 2020, 21, 4569. [Google Scholar] [CrossRef] [PubMed]
- Thakur, S.K.; Singh, D.P.; Choudhary, J. Lung cancer identification: A review on detection and classification. Cancer Metastasis Rev. 2020, 39, 989–998. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Xiao, Z.; Tang, C.; Deng, Y.; Huang, H.; He, Z. Recent advances in biosensor for detection of lung cancer biomarkers. Biosens. Bioelectron. 2019, 141, 111416. [Google Scholar] [CrossRef] [PubMed]
- Artificial Intelligence/Machine Learning (AI/ML)-Based: Software as a Medical Device (SaMD) Action Plan. Available online: https://www.fda.gov/media/145022/download (accessed on 30 July 2022).
- Mahler, M.; Auza, C.; Albesa, R.; Melus, C.; Wu, J.A. Regulatory aspects of artificial intelligence and machine learning-enabled software as medical devices (SaMD). In Precision Medicine and Artificial Intelligence; Elsevier: Amsterdam, The Netherlands, 2021; pp. 237–265. [Google Scholar]
- Dritsas, E.; Trigka, M. Data-Driven Machine-Learning Methods for Diabetes Risk Prediction. Sensors 2022, 22, 5304. [Google Scholar] [CrossRef] [PubMed]
- Dritsas, E.; Alexiou, S.; Konstantoulas, I.; Moustakas, K. Short-term Glucose Prediction based on Oral Glucose Tolerance Test Values. In Proceedings of the International Joint Conference on Biomedical Engineering Systems and Technologies—HEALTHINF, Vienna, Austria, 9–11 February 2022; Volume 5, pp. 249–255. [Google Scholar]
- Dritsas, E.; Fazakis, N.; Kocsis, O.; Fakotakis, N.; Moustakas, K. Long-Term Hypertension Risk Prediction with ML Techniques in ELSA Database. In Proceedings of the International Conference on Learning and Intelligent Optimization, Athens, Greece, 20–25 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 113–120. [Google Scholar]
- De Felice, F.; Polimeni, A. Coronavirus disease (COVID-19): A machine learning bibliometric analysis. In Vivo 2020, 34, 1613–1617. [Google Scholar] [CrossRef] [PubMed]
- Dritsas, E.; Trigka, M. Machine Learning Methods for Hypercholesterolemia Long-Term Risk Prediction. Sensors 2022, 22, 5365. [Google Scholar] [CrossRef]
- Dritsas, E.; Alexiou, S.; Moustakas, K. COPD Severity Prediction in Elderly with ML Techniques. In Proceedings of the 15th International Conference on PErvasive Technologies Related to Assistive Environments, Corfu, Greece, 29 June–1 July 2022; pp. 185–189. [Google Scholar]
- Dritsas, E.; Trigka, M. Stroke Risk Prediction with Machine Learning Techniques. Sensors 2022, 22, 4670. [Google Scholar] [CrossRef] [PubMed]
- Dritsas, E.; Alexiou, S.; Moustakas, K. Cardiovascular Disease Risk Prediction with Supervised Machine Learning Techniques. In Proceedings of the ICT4AWE, Online, 23–25 April 2022; pp. 315–321. [Google Scholar]
- Spann, A.; Yasodhara, A.; Kang, J.; Watt, K.; Wang, B.; Goldenberg, A.; Bhat, M. Applying machine learning in liver disease and transplantation: A comprehensive review. Hepatology 2020, 71, 1093–1105. [Google Scholar] [CrossRef]
- Konstantoulas, I.; Kocsis, O.; Dritsas, E.; Fakotakis, N.; Moustakas, K. Sleep Quality Monitoring with Human Assisted Corrections. In Proceedings of the International Joint Conference on Computational Intelligence (IJCCI), Online, 25–27 October 2021; pp. 435–444. [Google Scholar]
- Konerman, M.A.; Beste, L.A.; Van, T.; Liu, B.; Zhang, X.; Zhu, J.; Saini, S.D.; Su, G.L.; Nallamothu, B.K.; Ioannou, G.N.; et al. Machine learning models to predict disease progression among veterans with hepatitis C virus. PLoS ONE 2019, 14, e0208141. [Google Scholar] [CrossRef]
- Yu, C.S.; Lin, Y.J.; Lin, C.H.; Wang, S.T.; Lin, S.Y.; Lin, S.H.; Wu, J.L.; Chang, S.S. Predicting metabolic syndrome with machine learning models using a decision tree algorithm: Retrospective cohort study. JMIR Med. Inf. 2020, 8, e17110. [Google Scholar] [CrossRef]
- Dritsas, E.; Trigka, M. Machine Learning Techniques for Chronic Kidney Disease Risk Prediction. Big Data Cogn. Comput. 2022, 6, 98. [Google Scholar] [CrossRef]
- Singh, G.A.P.; Gupta, P. Performance analysis of various machine learning-based approaches for detection and classification of lung cancer in humans. Neural Comput. Appl. 2019, 31, 6863–6877. [Google Scholar] [CrossRef]
- Patra, R. Prediction of lung cancer using machine learning classifier. In Proceedings of the International Conference on Computing Science, Communication and Security, Gujarat, India, 26–27 March 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 132–142. [Google Scholar]
- Radhika, P.; Nair, R.A.; Veena, G. A comparative study of lung cancer detection using machine learning algorithms. In Proceedings of the 2019 IEEE International Conference on Electrical, Computer and Communication Technologies (ICECCT), Prague, Czech Republic, 20–22 February 2019; pp. 1–4. [Google Scholar]
- Bartholomai, J.A.; Frieboes, H.B. Lung cancer survival prediction via machine learning regression, classification, and statistical techniques. In Proceedings of the 2018 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Louisville, KY, USA, 6–8 December 2018; pp. 632–637. [Google Scholar]
- Faisal, M.I.; Bashir, S.; Khan, Z.S.; Khan, F.H. An evaluation of machine learning classifiers and ensembles for early stage prediction of lung cancer. In Proceedings of the 2018 3rd International Conference on Emerging Trends in Engineering, Sciences and Technology (ICEEST), Thrissur, Kerala, India, 18–20 January 2018; pp. 1–4. [Google Scholar]
- Vieira, E.; Ferreira, D.; Neto, C.; Abelha, A.; Machado, J. Data Mining Approach to Classify Cases of Lung Cancer. In World Conference on Information Systems and Technologies; Springer: Berlin/Heidelberg, Germany, 2021; pp. 511–521. [Google Scholar]
- Lung Cancer Prediction Dataset. Available online: https://www.kaggle.com/datasets/mysarahmadbhat/lung-cancer (accessed on 3 July 2022).
- Xie, Y.; Meng, W.Y.; Li, R.Z.; Wang, Y.W.; Qian, X.; Chan, C.; Yu, Z.F.; Fan, X.X.; Pan, H.D.; Xie, C.; et al. Early lung cancer diagnostic biomarker discovery by machine learning methods. Transl. Oncol. 2021, 14, 100907. [Google Scholar] [CrossRef]
- Stapelfeld, C.; Dammann, C.; Maser, E. Sex-specificity in lung cancer risk. Int. J. Cancer 2020, 146, 2376–2382. [Google Scholar] [CrossRef] [PubMed]
- de Groot, P.M.; Wu, C.C.; Carter, B.W.; Munden, R.F. The epidemiology of lung cancer. Transl. Lung Cancer Res. 2018, 7, 220. [Google Scholar] [CrossRef] [PubMed]
- O’Keeffe, L.M.; Taylor, G.; Huxley, R.R.; Mitchell, P.; Woodward, M.; Peters, S.A. Smoking as a risk factor for lung cancer in women and men: A systematic review and meta-analysis. BMJ Open 2018, 8, e021611. [Google Scholar] [CrossRef] [PubMed]
- Al-Bander, B.; Fadil, Y.A.; Mahdi, H. Multi-Criteria Decision Support System for Lung Cancer Prediction; IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2021; Volume 1076, p. 012036. [Google Scholar]
- Hu, T.; Xiao, J.; Peng, J.; Kuang, X.; He, B. Relationship between resilience, social support as well as anxiety/depression of lung cancer patients: A cross-sectional observation study. J. Cancer Res. Ther. 2018, 14, 72. [Google Scholar]
- Leshargie, C.T.; Alebel, A.; Kibret, G.D.; Birhanu, M.Y.; Mulugeta, H.; Malloy, P.; Wagnew, F.; Ewunetie, A.A.; Ketema, D.B.; Aderaw, A.; et al. The impact of peer pressure on cigarette smoking among high school and university students in Ethiopia: A systemic review and meta-analysis. PLoS ONE 2019, 14, e0222572. [Google Scholar] [CrossRef]
- Schabath, M.B.; Cote, M.L. Cancer progress and priorities: Lung cancer. Cancer Epidemiol. Prev. Biomarkers 2019, 28, 1563–1579. [Google Scholar] [CrossRef]
- Avancini, A.; Sartori, G.; Gkountakos, A.; Casali, M.; Trestini, I.; Tregnago, D.; Bria, E.; Jones, L.W.; Milella, M.; Lanza, M.; et al. Physical activity and exercise in lung cancer care: Will promises be fulfilled? Oncologist 2020, 25, e555–e569. [Google Scholar] [CrossRef]
- Kantor, E.D.; Hsu, M.; Du, M.; Signorello, L.B. Allergies and asthma in relation to cancer risk. Cancer Epidemiol. Prev. Biomarkers 2019, 28, 1395–1403. [Google Scholar] [CrossRef] [PubMed]
- Alsharairi, N.A. The effects of dietary supplements on asthma and lung cancer risk in smokers and non-smokers: A review of the literature. Nutrients 2019, 11, 725. [Google Scholar] [CrossRef] [PubMed]
- Brenner, D.R.; Fehringer, G.; Zhang, Z.F.; Lee, Y.C.A.; Meyers, T.; Matsuo, K.; Ito, H.; Vineis, P.; Stucker, I.; Boffetta, P.; et al. Alcohol consumption and lung cancer risk: A pooled analysis from the International Lung Cancer Consortium and the SYNERGY study. Cancer Epidemiol. 2019, 58, 25–32. [Google Scholar] [CrossRef] [PubMed]
- Harle, A.S.; Blackhall, F.H.; Molassiotis, A.; Yorke, J.; Dockry, R.; Holt, K.J.; Yuill, D.; Baker, K.; Smith, J.A. Cough in patients with lung cancer: A longitudinal observational study of characterization and clinical associations. Chest 2019, 155, 103–113. [Google Scholar] [CrossRef] [PubMed]
- Phillips, M.; Bauer, T.L.; Pass, H.I. A volatile biomarker in breath predicts lung cancer and pulmonary nodules. J. Breath Res. 2019, 13, 036013. [Google Scholar] [CrossRef]
- Brady, G.C.; Roe, J.W.; O’Brien, M.; Boaz, A.; Shaw, C. An investigation of the prevalence of swallowing difficulties and impact on quality of life in patients with advanced lung cancer. Support. Care Cancer 2018, 26, 515–519. [Google Scholar] [CrossRef]
- Malinowska, K. The relationship between chest pain and level of perioperative anxiety in patients with lung cancer. Pol. J. Surg. 2018, 90, 23–27. [Google Scholar] [CrossRef]
- Maldonado, S.; López, J.; Vairetti, C. An alternative SMOTE oversampling strategy for high-dimensional datasets. Appl. Soft Comput. 2019, 76, 380–389. [Google Scholar] [CrossRef]
- Dritsas, E.; Fazakis, N.; Kocsis, O.; Moustakas, K.; Fakotakis, N. Optimal Team Pairing of Elder Office Employees with Machine Learning on Synthetic Data. In Proceedings of the 2021 12th International Conference on Information, Intelligence, Systems & Applications (IISA), Chania, Crete, Greece, 12–14 July 2021; pp. 1–4. [Google Scholar]
- Gnanambal, S.; Thangaraj, M.; Meenatchi, V.; Gayathri, V. Classification algorithms with attribute selection: An evaluation study using WEKA. Int. J. Adv. Netw. Appl. 2018, 9, 3640–3644. [Google Scholar]
- Darst, B.F.; Malecki, K.C.; Engelman, C.D. Using recursive feature elimination in random forest to account for correlated variables in high dimensional data. BMC Genet. 2018, 19, 1–6. [Google Scholar] [CrossRef]
- Berrar, D. Bayes’ theorem and naive Bayes classifier. In Encyclopedia of Bioinformatics and Computational Biology: ABC of Bioinformatics; Elsevier: Amsterdam, The Netherlands, 2019; pp. 403–412. [Google Scholar]
- McLachlan, S.; Dube, K.; Hitman, G.A.; Fenton, N.E.; Kyrimi, E. Bayesian networks in healthcare: Distribution by medical condition. Artif. Intell. Med. 2020, 107, 101912. [Google Scholar] [CrossRef] [PubMed]
- Nusinovici, S.; Tham, Y.C.; Yan, M.Y.C.; Ting, D.S.W.; Li, J.; Sabanayagam, C.; Wong, T.Y.; Cheng, C.Y. Logistic regression was as good as machine learning for predicting major chronic diseases. J. Clin. Epidemiol. 2020, 122, 56–69. [Google Scholar] [CrossRef] [PubMed]
- Truong, X.L.; Mitamura, M.; Kono, Y.; Raghavan, V.; Yonezawa, G.; Truong, X.Q.; Do, T.H.; Tien Bui, D.; Lee, S. Enhancing prediction performance of landslide susceptibility model using hybrid machine learning approach of bagging ensemble and logistic model tree. Appl. Sci. 2018, 8, 1046. [Google Scholar] [CrossRef]
- Pisner, D.A.; Schnyer, D.M. Support vector machine. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 101–121. [Google Scholar]
- Netrapalli, P. Stochastic gradient descent and its variants in machine learning. J. Indian Inst. Sci. 2019, 99, 201–213. [Google Scholar] [CrossRef]
- Jimoh, I.A.; Ismaila, I.; Olalere, M. Enhanced Decision Tree-J48 with SMOTE Machine Learning Algorithm for Effective Botnet Detection in Imbalance Dataset. In Proceedings of the 2019 15th International Conference on Electronics, Computer and Computation (ICECCO), Abuja, Nigeria, 10–12 December 2019; pp. 1–8. [Google Scholar]
- Joloudari, J.H.; Hassannataj Joloudari, E.; Saadatfar, H.; Ghasemigol, M.; Razavi, S.M.; Mosavi, A.; Nabipour, N.; Shamshirband, S.; Nadai, L. Coronary artery disease diagnosis; ranking the significant features using a random trees model. Int. J. Environ. Res. Public Health 2020, 17, 731. [Google Scholar] [CrossRef] [PubMed]
- Naghibi, S.A.; Dolatkordestani, M.; Rezaei, A.; Amouzegari, P.; Heravi, M.T.; Kalantar, B.; Pradhan, B. Application of rotation forest with decision trees as base classifier and a novel ensemble model in spatial modeling of groundwater potential. Environ. Monit. Assess. 2019, 191, 1–20. [Google Scholar] [CrossRef]
- Pham, B.T.; Prakash, I.; Singh, S.K.; Shirzadi, A.; Shahabi, H.; Bui, D.T. Landslide susceptibility modeling using Reduced Error Pruning Trees and different ensemble techniques: Hybrid machine learning approaches. Catena 2019, 175, 203–218. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Palimkar, P.; Shaw, R.N.; Ghosh, A. Machine learning technique to prognosis diabetes disease: Random forest classifier approach. In Advanced Computing and Intelligent Technologies; Springer: Berlin/Heidelberg, Germany, 2022; pp. 219–244. [Google Scholar]
- Polat, K.; Sentürk, U. A novel ML approach to prediction of breast cancer: Combining of mad normalization, KMC based feature weighting and AdaBoostM1 classifier. In Proceedings of the 2018 2nd International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Ankara, Turkey, 19–21 October 2018; pp. 1–4. [Google Scholar]
- Masih, N.; Naz, H.; Ahuja, S. Multilayer perceptron based deep neural network for early detection of coronary heart disease. Health Technol. 2021, 11, 127–138. [Google Scholar] [CrossRef]
- Cunningham, P.; Delany, S.J. k-Nearest neighbour classifiers-A Tutorial. ACM Comput. Surv. 2021, 54, 1–25. [Google Scholar] [CrossRef]
- Zaman, M.; Lung, C.H. Evaluation of machine learning techniques for network intrusion detection. In Proceedings of the NOMS 2018-2018 IEEE/IFIP Network Operations and Management Symposium, Taipei, Taiwan, 23–27 April 2018; pp. 1–5. [Google Scholar]
- Weka Tool. Available online: https://www.weka.io/ (accessed on 3 July 2022).
- Vial, A.; Stirling, D.; Field, M.; Ros, M.; Ritz, C.; Carolan, M.; Holloway, L.; Miller, A.A. The role of deep learning and radiomic feature extraction in cancer-specific predictive modelling: A review. Transl. Cancer Res. 2018, 7, 803–816. [Google Scholar] [CrossRef]
- Xu, Y.; Goodacre, R. On splitting training and validation set: A comparative study of cross-validation, bootstrap and systematic sampling for estimating the generalization performance of supervised learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
| Random Forest | Gain Ratio | ||
|---|---|---|---|
| Feature | Ranking | Feature | Ranking |
| Age | 0.3462 | Allergy | 0.3951 |
| Allergy | 0.2809 | Alcohol | 0.3699 |
| Alcohol | 0.2665 | Swallow Difficulty | 0.3256 |
| Wheezing | 0.2567 | Wheezing | 0.3081 |
| Coughing | 0.2442 | Peer Pressure | 0.2920 |
| Swallow Difficulty | 0.2327 | Coughing | 0.2473 |
| Peer Pressure | 0.2245 | Age | 0.1561 |
| Chronic Disease | 0.1662 | Chronic Disease | 0.1177 |
| Chest Pain | 0.0958 | Chest Pain | 0.0438 |
| Anxiety | 0.0774 | Yellow Fingers | 0.0291 |
| Smoking | 0.0753 | Anxiety | 0.0290 |
| Yellow Fingers | 0.0725 | Smoking | 0.0220 |
| Shortness of Breath | 0.0431 | Shortness of Breath | 0.0133 |
| Gender | −0.0053 | Gender | 0.0025 |
| Fatigue | −0.0334 | Fatigue | 0.0003 |
| Feature | Lung Cancer | Feature | Lung Cancer | ||
|---|---|---|---|---|---|
| Gender | No | Yes | Allergy | No | Yes |
| Female | 26.11% | 23.15% | No | 49.07% | 19.07% |
| Male | 23.89% | 26.85% | Yes | 0.93% | 30.93% |
| Smoking | No | Yes | Wheezing | No | Yes |
| No | 30.00% | 21.30% | No | 47.41% | 19.81% |
| Yes | 20.00% | 28.70% | Yes | 2.59% | 30.19% |
| Yellow Fingers | No | Yes | Alcohol | No | Yes |
| No | 29.81% | 19.81% | No | 48.70% | 19.44% |
| Yes | 20.19% | 30.19% | Yes | 1.30% | 30.56% |
| Anxiety | No | Yes | Coughing | No | Yes |
| No | 33.52% | 23.70% | No | 45.00% | 18.70% |
| Yes | 16.48% | 26.30% | Yes | 5.00% | 31.30% |
| Peer Pressure | No | Yes | Shortness of Breath | No | Yes |
| No | 48.15% | 23.15% | No | 11.67% | 17.41% |
| Yes | 1.85% | 26.85% | Yes | 38.33% | 32.59% |
| Chronic Disease | No | Yes | Shallow Difficulty | No | Yes |
| No | 41.85% | 23.70% | No | 49.07% | 24.07% |
| Yes | 8.15% | 26.30% | Yes | 0.93% | 25.93% |
| Fatigue | No | Yes | Chest Pain | No | Yes |
| No | 15.93% | 15.00% | No | 32.59% | 20.37% |
| Yes | 34.07% | 35.00% | Yes | 17.41% | 29.63% |
| Models | Parameters |
|---|---|
| NB | useKernelEstimator: False useSupervisedDiscretization: True |
| BayesNet | estimator: simpleEstimator search Algorithm: K2 useADTree: True |
| SGD | epochs = 500 epsilon = 0.001 lambda = learningRate = 0.01 lossFunction: Hinge loss (SVM) |
| SVM | eps = 0.001 gamma = 0.0 kernel type: linear loss = 0.1 |
| LR | ridge = useConjugateGradientDescent: False |
| ANN | hidden layers: `a’ learning rate: 0.3 momentum: 0.2 training time: 500 |
| KNN | K = 3 Search Algorithm: LinearNNSearch with Euclidean |
| J48 | reducedErrorPruning: False savelnstanceData: False subtreeRaising: True |
| LMT | errorOnProbabilities: False fastRegression: True numInstances = 15 useAIC: False |
| RF | maxDepth = 0 numIterations = 100 numFeatures = 0 |
| RT | maxDepth = 0 minNum = 1.0 minVarianceProp = 0.001 |
| DT (RepTree) | maxDepth = −1 minNum = 2.0 minVarianceProp = 0.001 |
| RotF | classifier: Random Forest numberOfGroups: False projectionFilter: PrincipalComponents |
| AdaBoostM1 | classifier: Random Forest resume: False useResampling: False |
| Accuracy | Precision | Recall | F-Measure | AUC | |
|---|---|---|---|---|---|
| NB | 0.950 | 0.950 | 0.950 | 0.950 | 0.982 |
| BayesNet | 0.950 | 0.950 | 0.950 | 0.950 | 0.982 |
| SGD | 0.960 | 0.960 | 0.960 | 0.960 | 0.960 |
| SVM | 0.954 | 0.954 | 0.954 | 0.954 | 0.954 |
| LR | 0.963 | 0.963 | 0.963 | 0.963 | 0.983 |
| ANN | 0.946 | 0.946 | 0.946 | 0.946 | 0.983 |
| 3NN | 0.960 | 0.959 | 0.959 | 0.959 | 0.978 |
| J48 | 0.948 | 0.948 | 0.948 | 0.948 | 0.938 |
| LMT | 0.959 | 0.959 | 0.959 | 0.959 | 0.985 |
| RF | 0.952 | 0.952 | 0.952 | 0.952 | 0.991 |
| RT | 0.933 | 0.933 | 0.933 | 0.933 | 0.933 |
| DT(RepTree) | 0.937 | 0.937 | 0.937 | 0.937 | 0.955 |
| RotF | 0.971 | 0.971 | 0.971 | 0.971 | 0.993 |
| AdaBoostM1 | 0.954 | 0.954 | 0.954 | 0.954 | 0.985 |
| Accuracy | Recall | Precision | ||||
|---|---|---|---|---|---|---|
| Proposed Models | [38] | Proposed Models | [38] | Proposed Models | [38] | |
| SVM | 95.4% | 90.9% | 95.4% | 91.6% | 95.4% | 90.3% |
| ANN | 94.6% | 92% | 94.6% | 94.2% | 94.6% | 90.8% |
| NB | 95% | 88.7% | 95% | 86.2% | 95% | 91% |
| DT | 93.7% | 87.4% | 93.7% | 91.2% | 93.7% | 85.2% |
| KNN | 95.2% | 85.5% | 95.2% | 87.4% | 95.2% | 84.7% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dritsas, E.; Trigka, M. Lung Cancer Risk Prediction with Machine Learning Models. Big Data Cogn. Comput. 2022, 6, 139. https://doi.org/10.3390/bdcc6040139
Dritsas E, Trigka M. Lung Cancer Risk Prediction with Machine Learning Models. Big Data and Cognitive Computing. 2022; 6(4):139. https://doi.org/10.3390/bdcc6040139
Chicago/Turabian StyleDritsas, Elias, and Maria Trigka. 2022. "Lung Cancer Risk Prediction with Machine Learning Models" Big Data and Cognitive Computing 6, no. 4: 139. https://doi.org/10.3390/bdcc6040139
APA StyleDritsas, E., & Trigka, M. (2022). Lung Cancer Risk Prediction with Machine Learning Models. Big Data and Cognitive Computing, 6(4), 139. https://doi.org/10.3390/bdcc6040139