

Supporting Meteorologists in Data Analysis through Knowledge-Based Recommendations

 , , , , and
, , , , and
Abstract
:1. Introduction and Motivation
2. State-of-the-Art
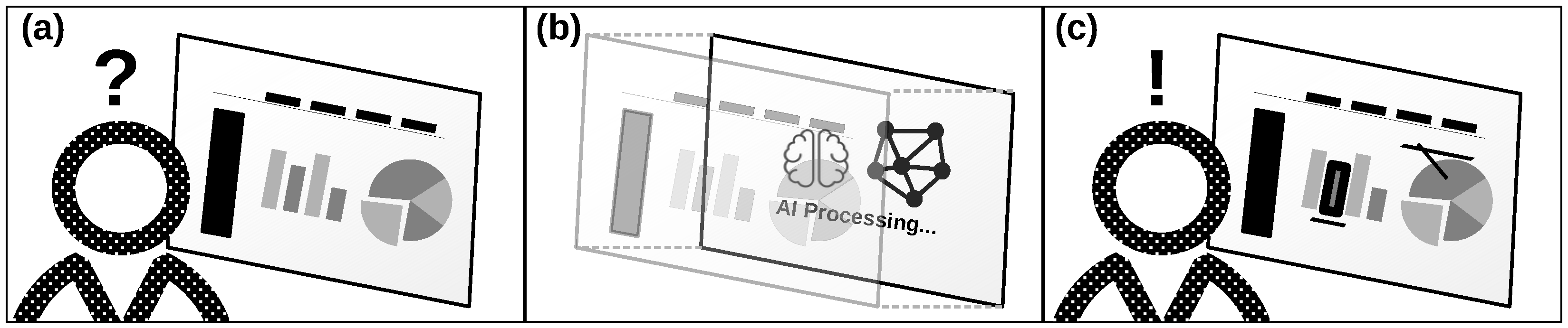
2.1. AI2VIS4BigData Reference Model
- (a)
- (b)
- The application of AI on the available information targets to identify areas of relevance or promising next data processing steps [5].
- (c)
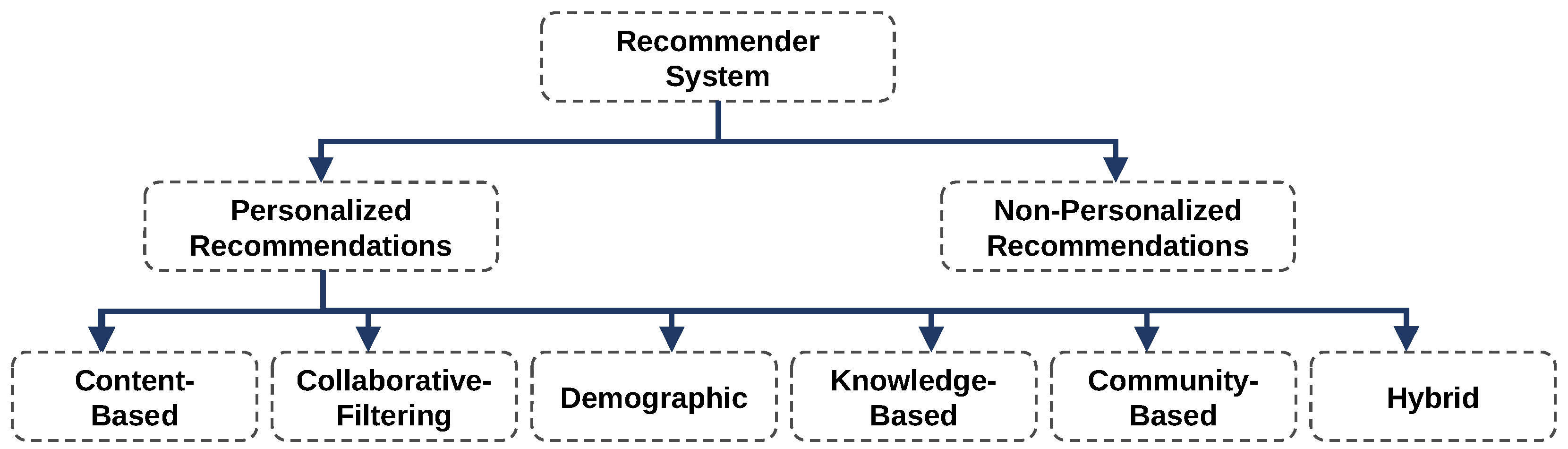
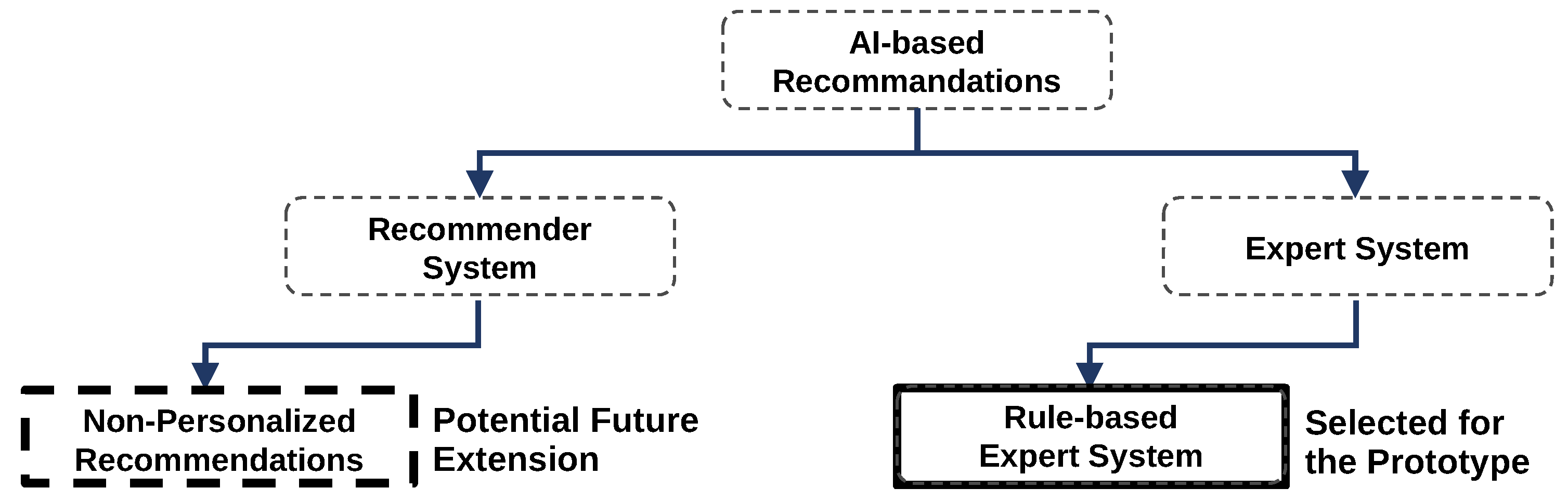
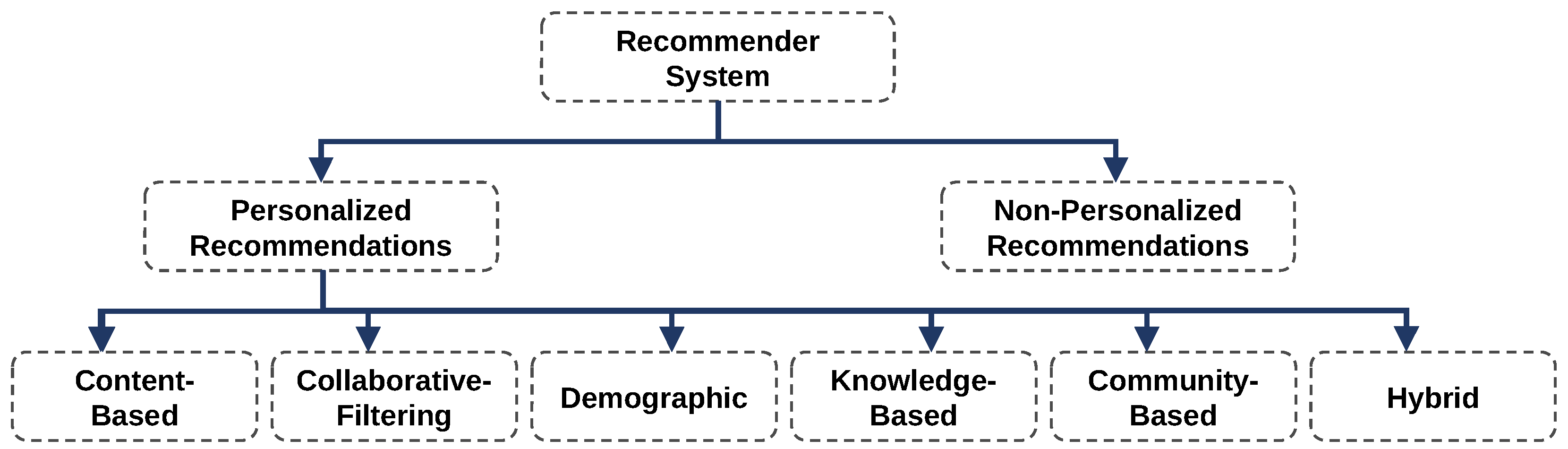
2.2. Expert and Recommender Systems for AI-Based Recommendations
2.3. Knowledge Representation and Symbolic AI
2.4. Discussion and Remaining Challenges
3. Conceptual Modeling
3.1. Meteorological Use Context and Requirements
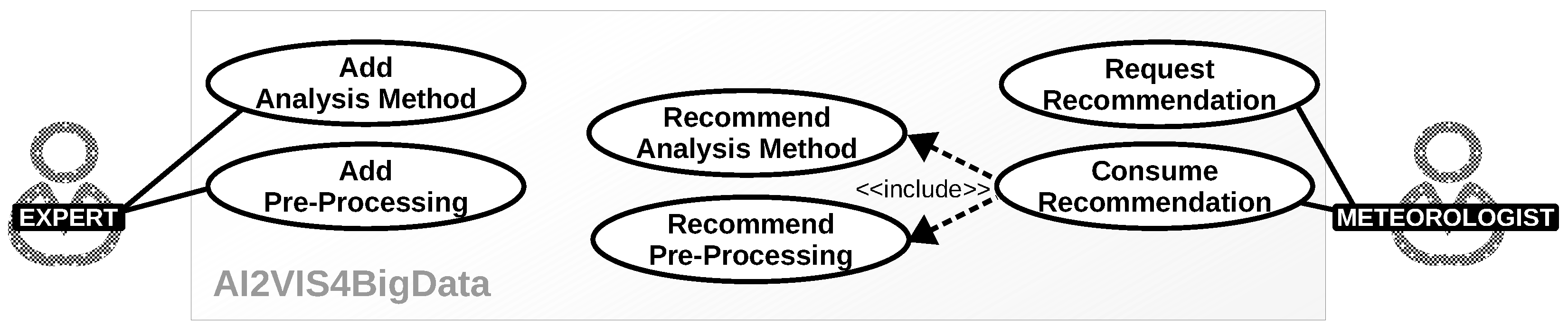
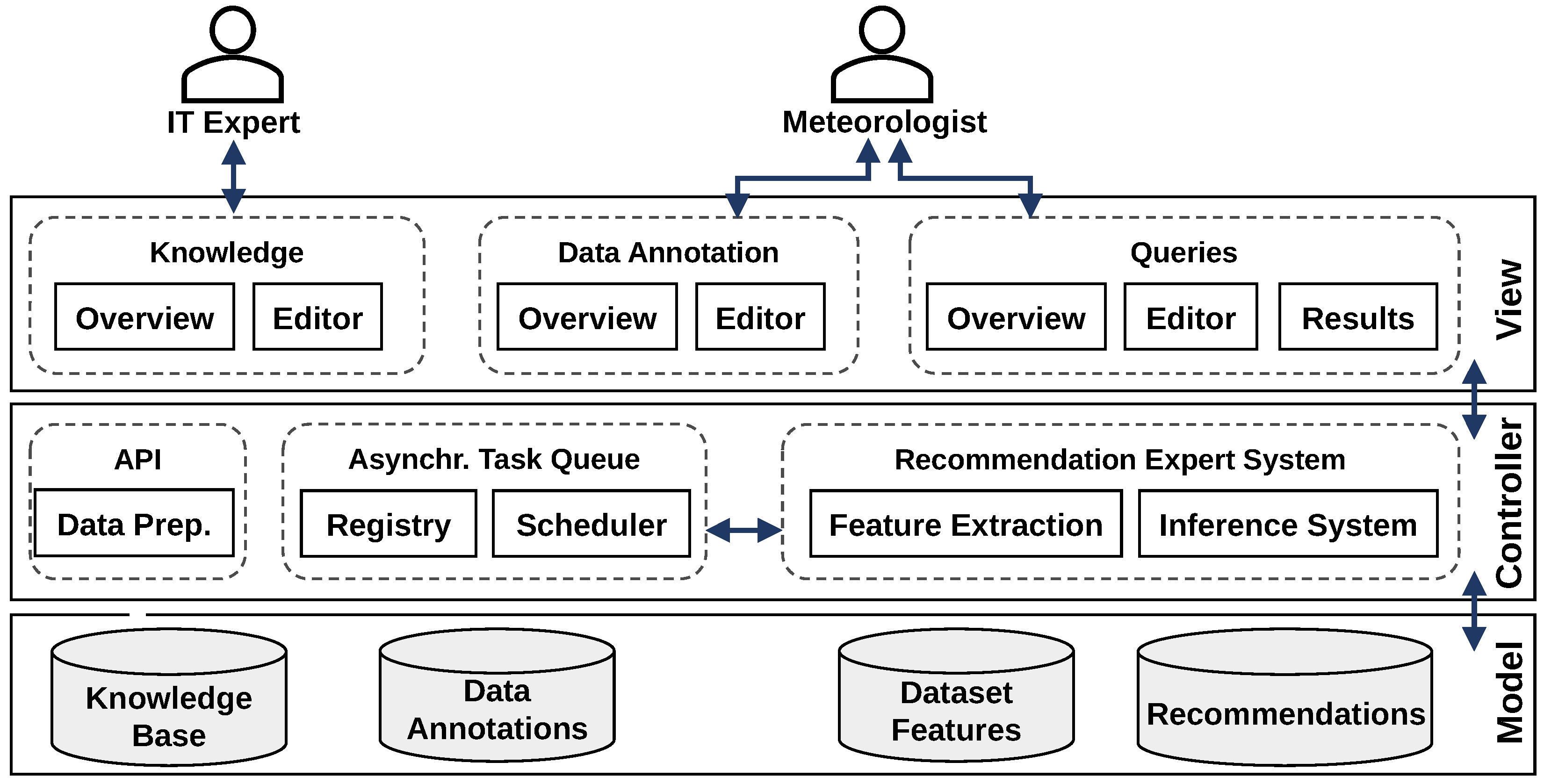
3.2. Modeling the Recommendation System for Meteorologists
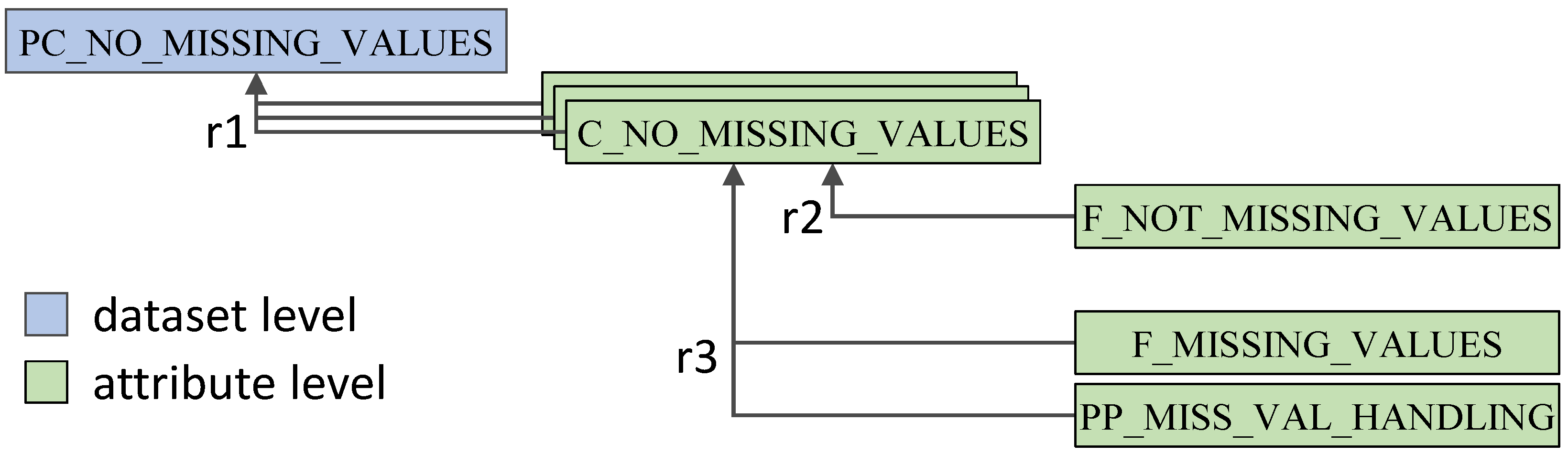
3.3. Modeling the Knowledge Base for Data Analysis Methods
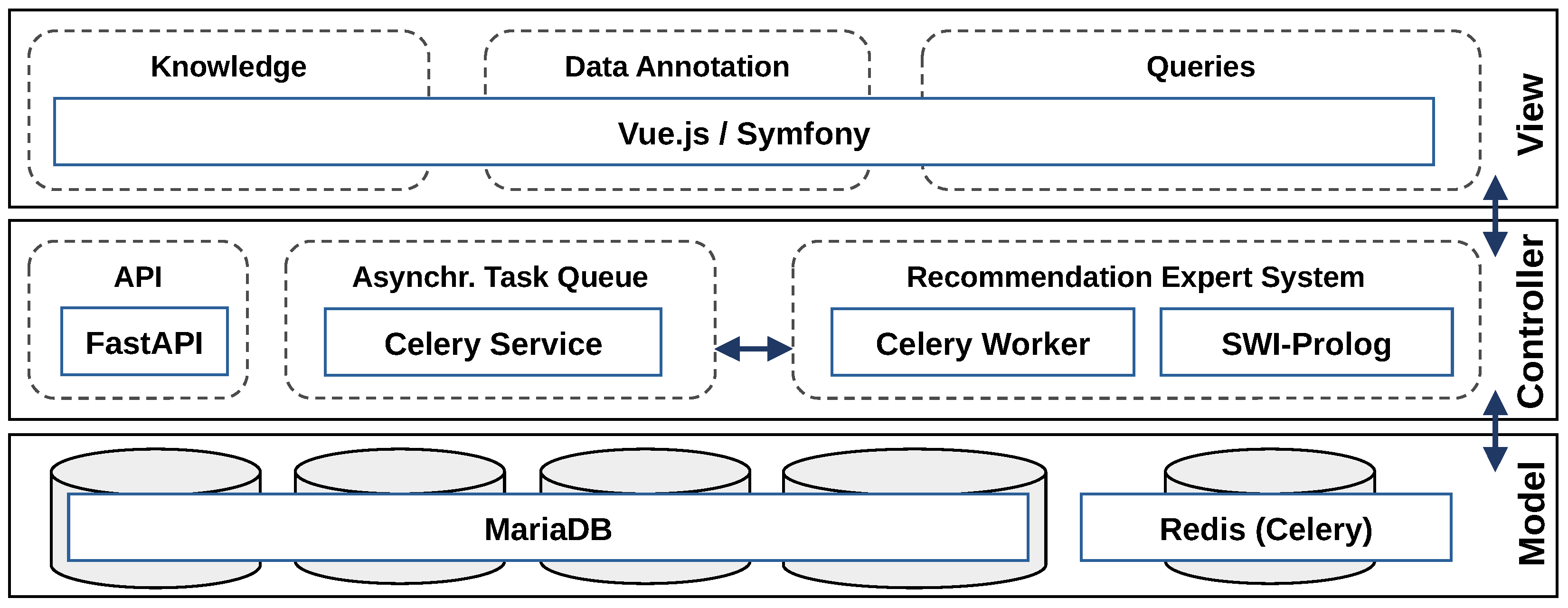
3.4. Integrating the Concept in AI2VIS4BigData
4. Proof-of-Concept Implementation
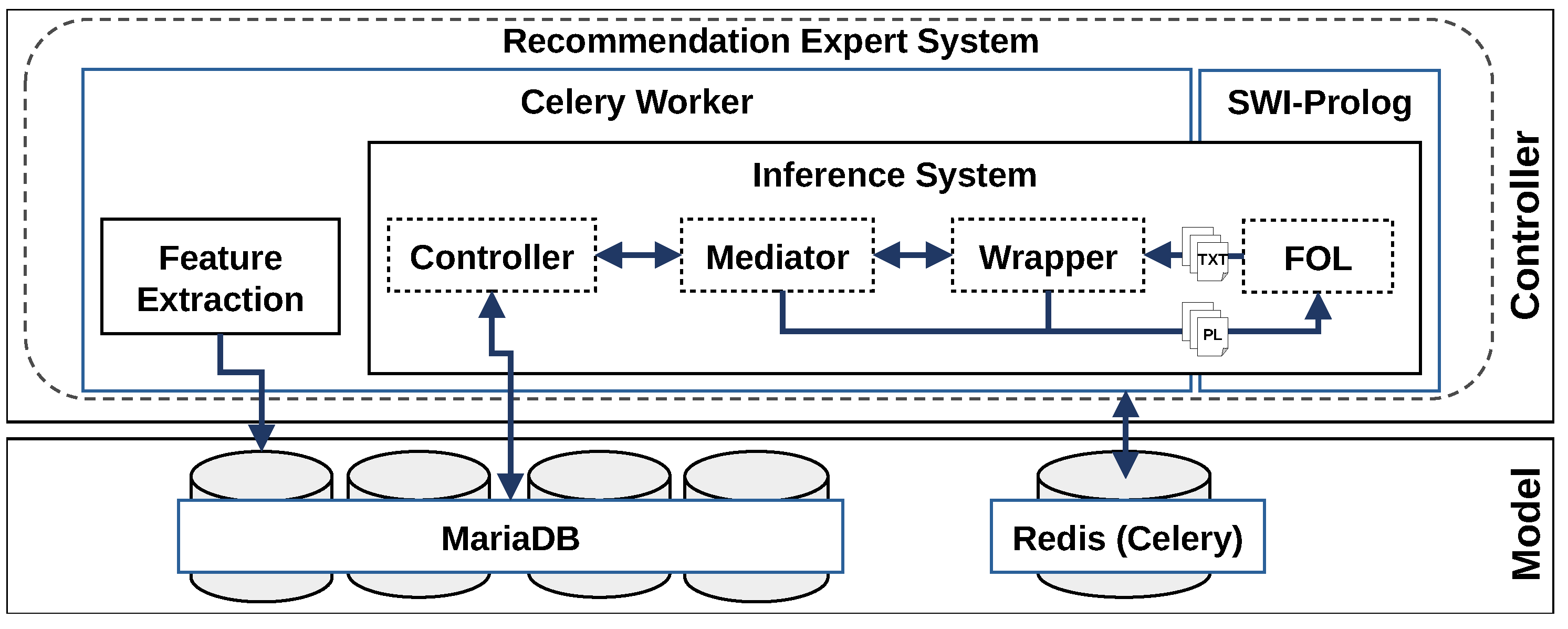
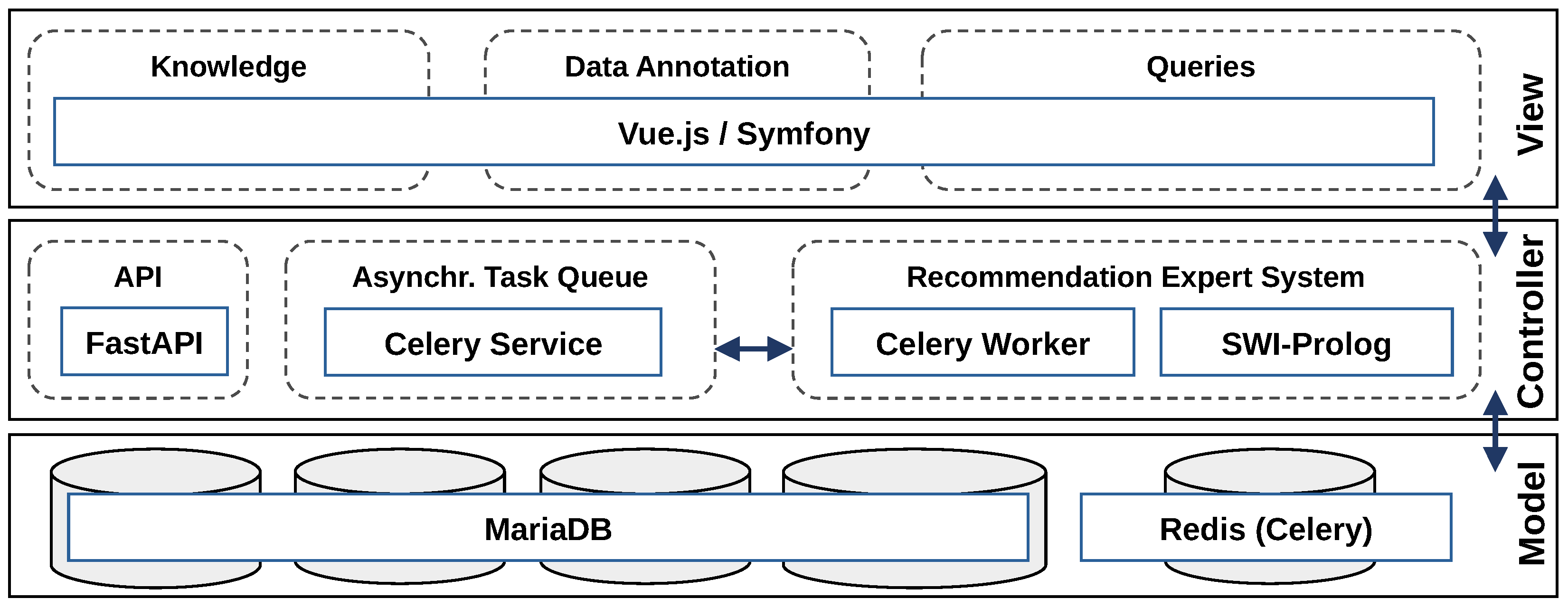
4.1. Technical Architecture
4.2. Knowledge Base Implemetation
| Listing 1. KB for analysis method PCA with three preconditions. |
 |
| Listing 2. KB for precondition “no missing value”. |
 |
| Listing 3. KB for precondition “numeric attributes”. |
 |
4.3. Recommendation Workflow
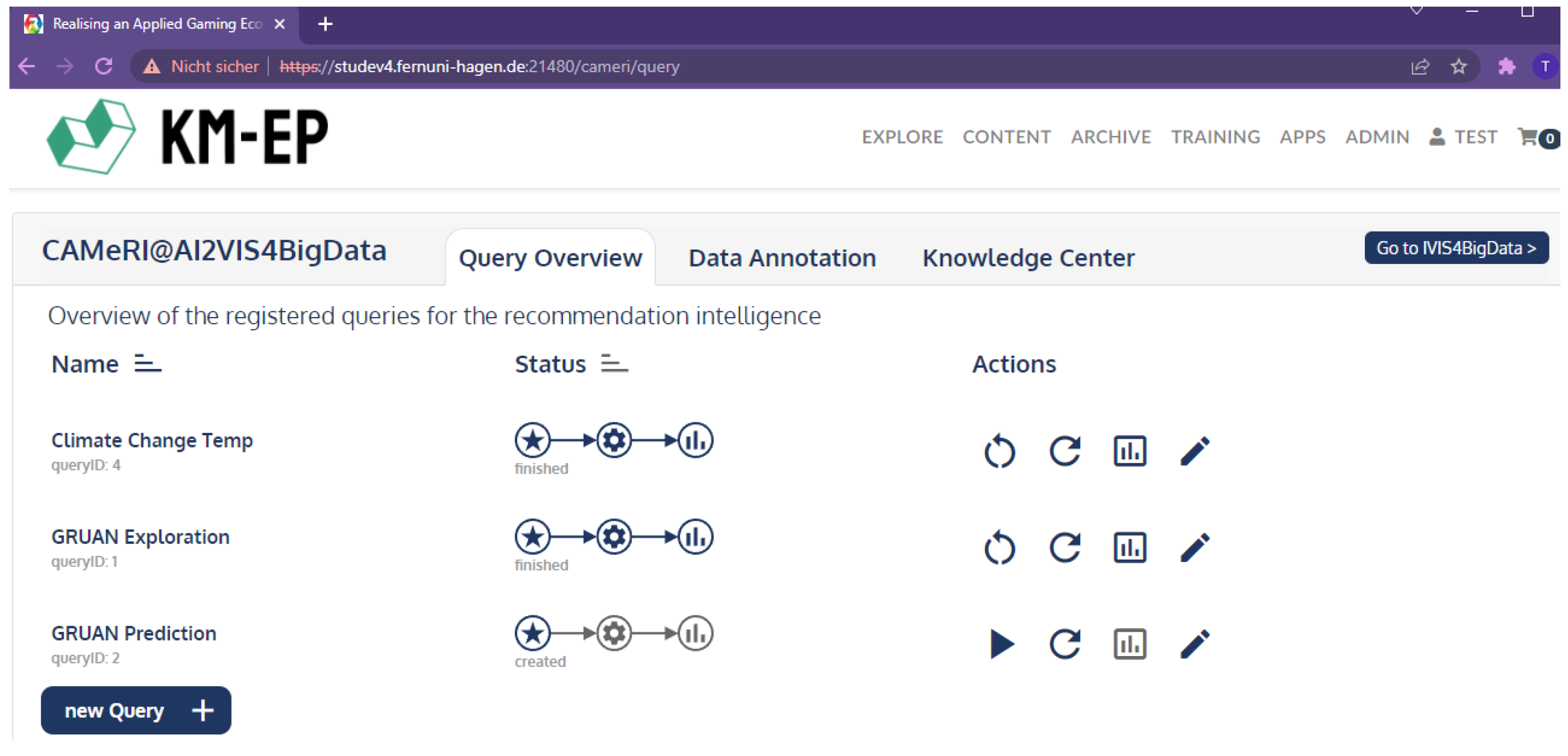
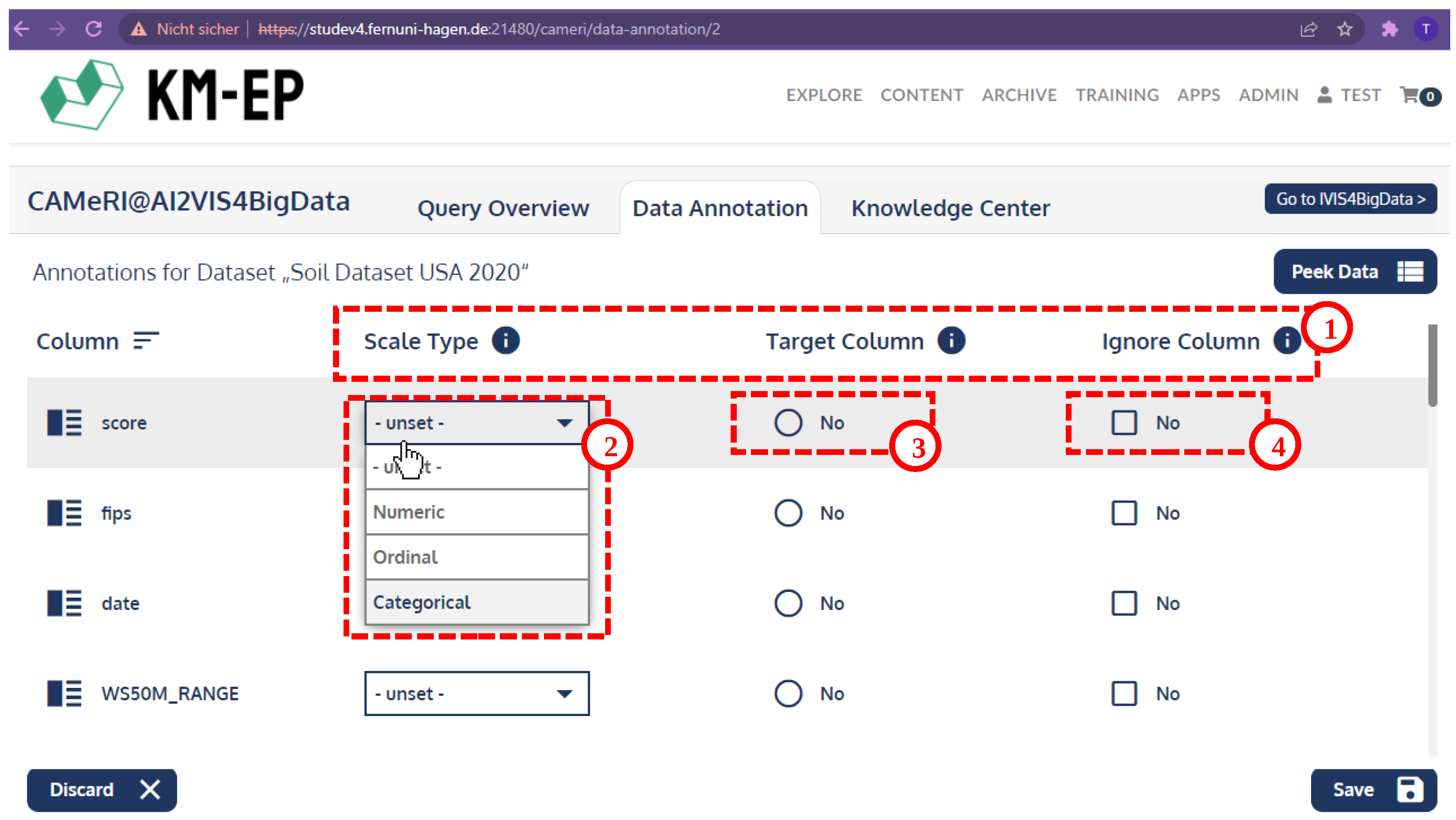
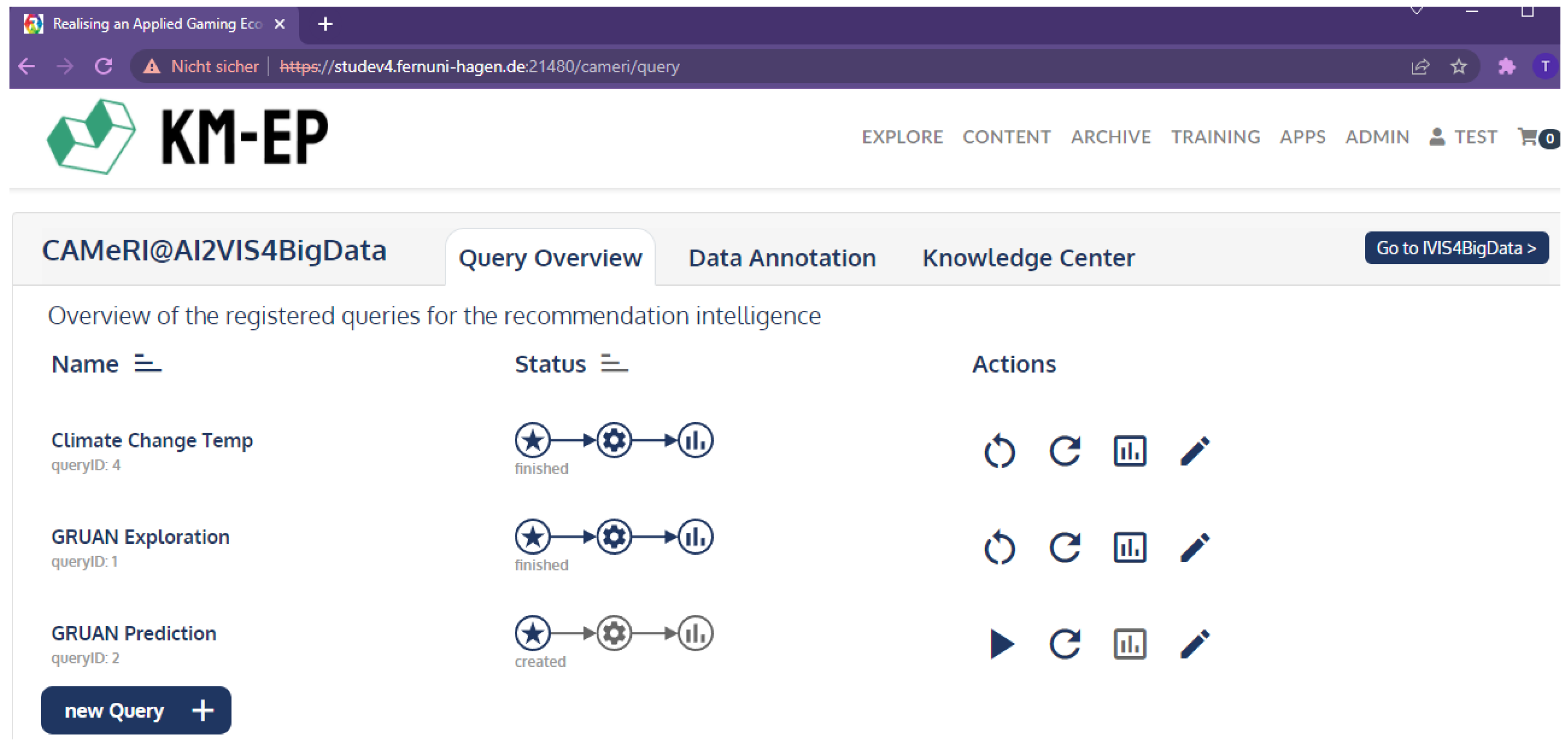
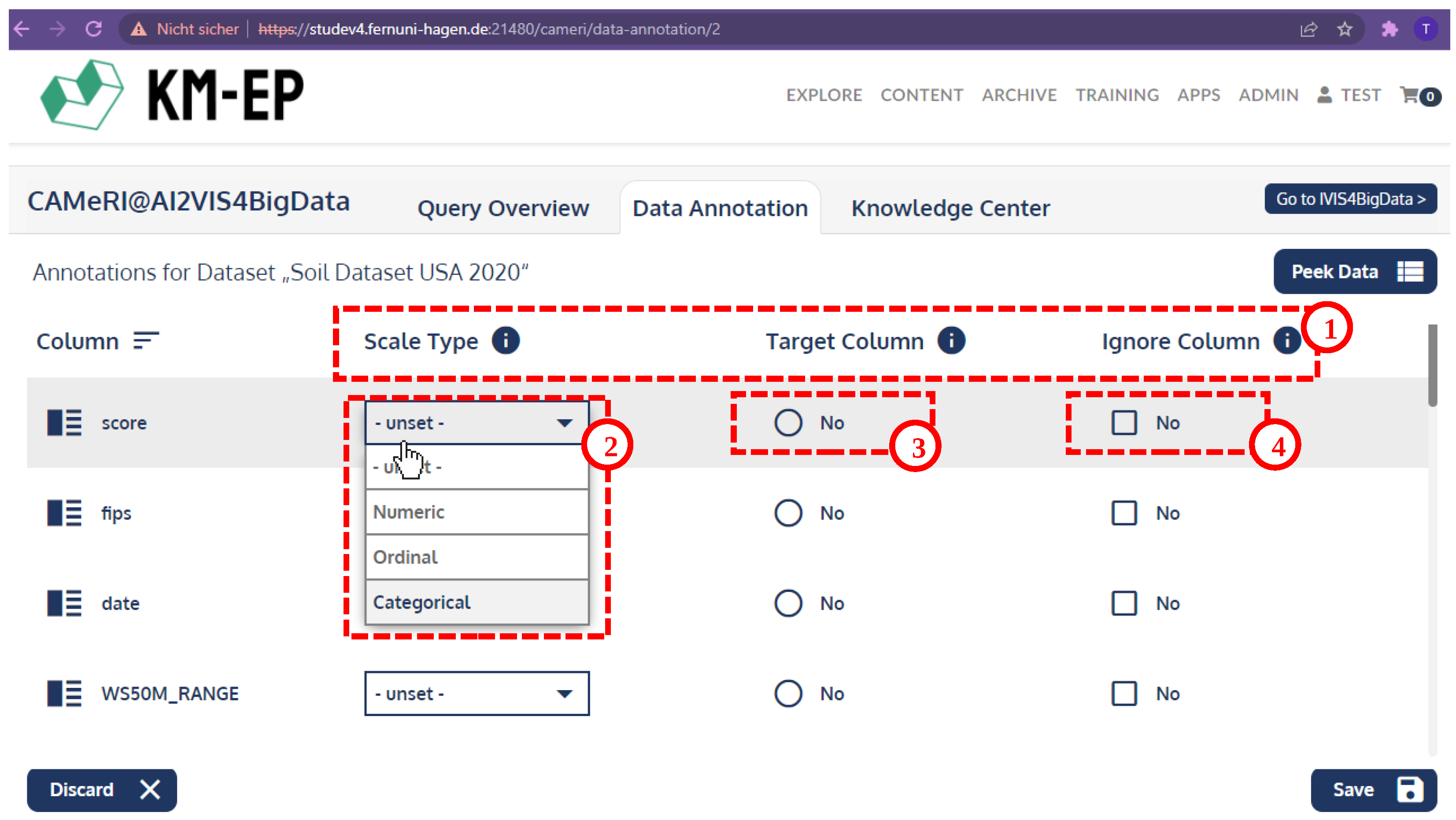
4.4. User Interface
5. Evaluation
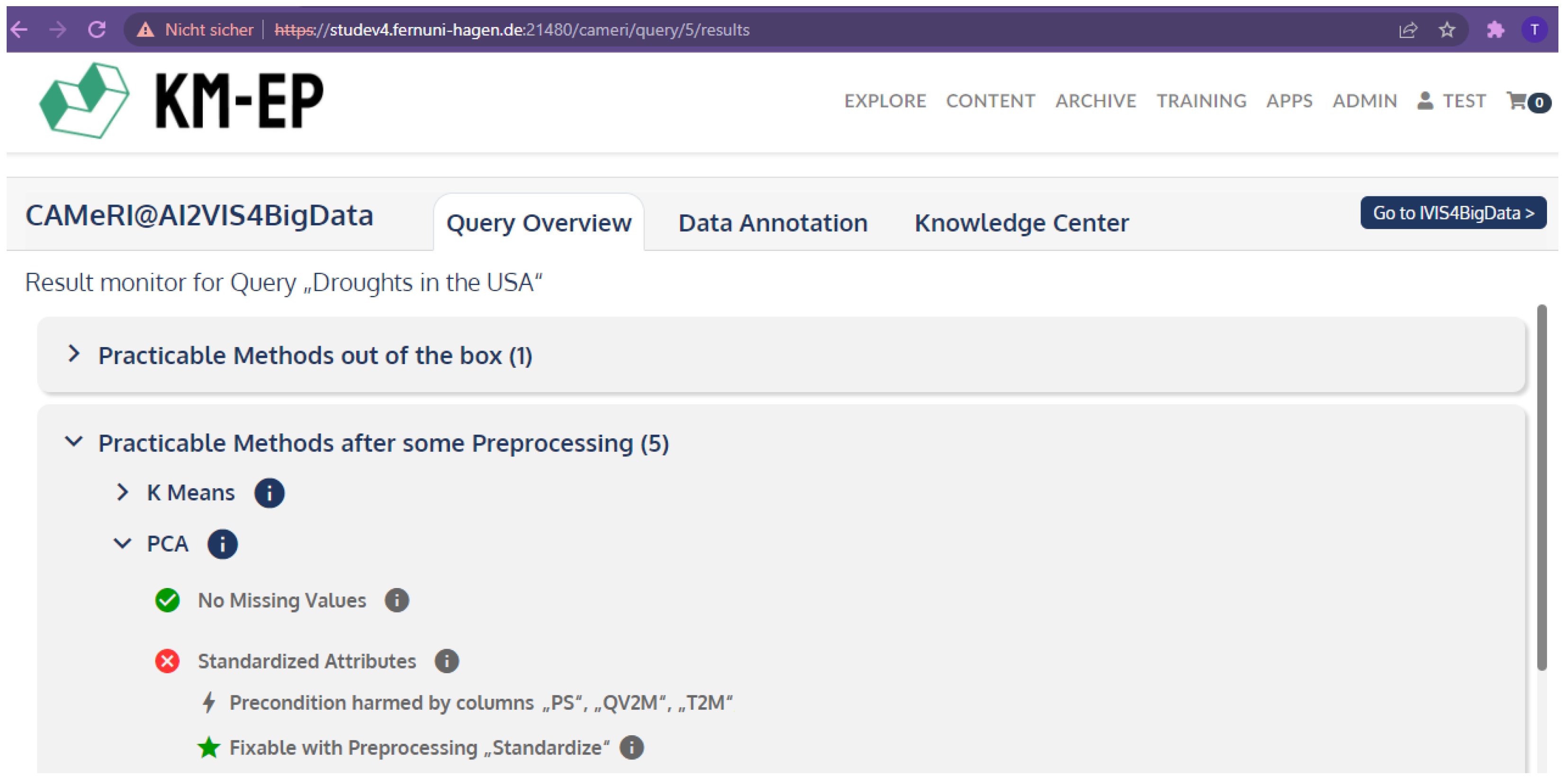
5.1. Qualitative Evaluation of Recommendations
- (a)
- Soil Dataset USA 2020 was released on the data science platform kaggle.com (https://www.kaggle.com/cdminix/us-drought-meteorological-data, (accessed on 8 September 2022)) by the author Christoph Minixhofer. It consists of 22 million entries with 21 attributes each. It is compiled from three different sources (NASA LaRC POWER Project, U.S. Drought Monitor, and Harmonized World Soil Database).
- (b)
- City Temperatures World was released on kaggle.com (https://www.kaggle.com/berkeleyearth/climate-change-earth-surface-temperature-data, (accessed on 8 September 2022)) as well. The data set was published by the organization Berkely Earth (http://berkeleyearth.org/, (accessed on 8 September 2022)). It contains 8.2 million measurements of average temperatures in 3448 cities with seven attributes each from 1900 to 2013.
- (c)
- GRUAN Radio Data is a data set authored by the Copernicus Climate Change Service (C3S) that was released on their website (https://cds.climate.copernicus.eu/cdsapp#!/dataset/insitu-observations-gruan-reference-network, (accessed on 8 September 2022)). The data was captured by radiosondes during 36,733 flights of meteorological balloons. The measurements were clustered into five bins per flight and averaged for 23 attributes to ease the evaluation.
5.2. Initial Qualitative Evaluation via Cognitive Walkthrough
- (1)
- Complete the data annotation for Soil Dataset USA 2020 data set;
- (2)
- Create a new query for Soil Dataset USA 2020 data set that includes the whole knowledge base;
- (3)
- Execute the query from (2);
- (4)
- Review the applicability of PCA for the query results.
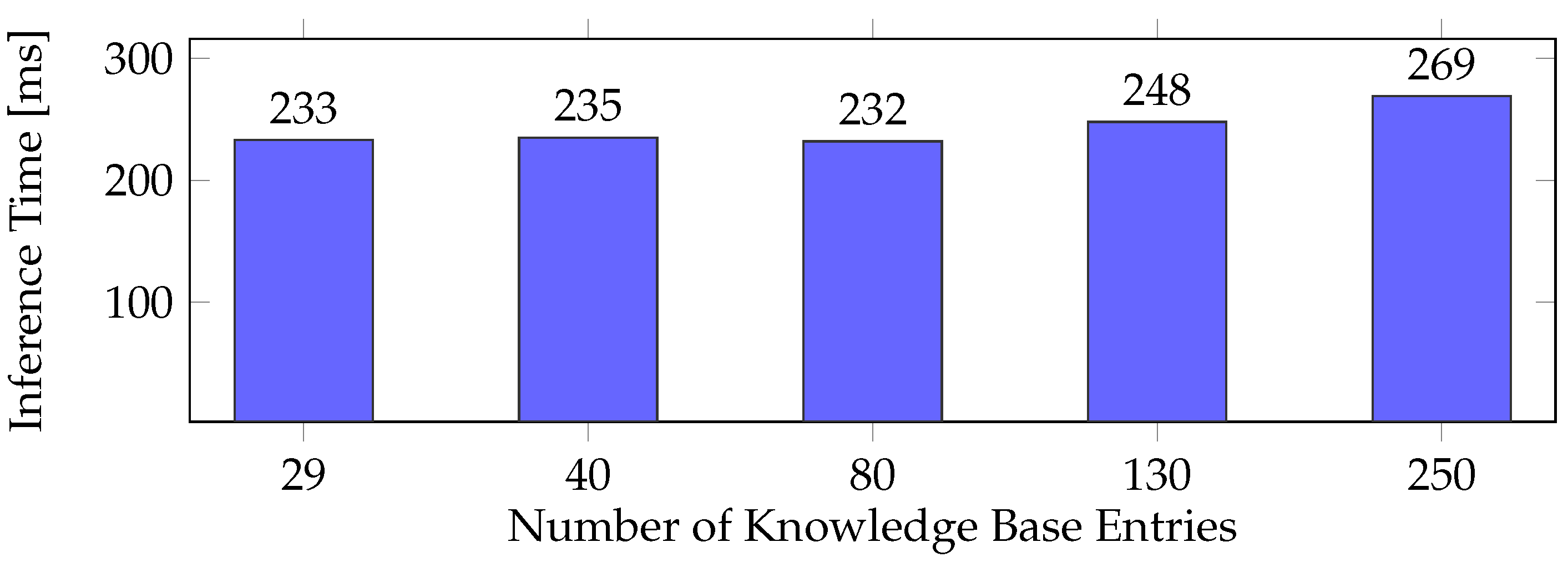
5.3. Quantitative System Performance Evaluation
6. Summary and Outlook
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mangal, P.; Rajesh, A.; Misra, R. Big data in climate change research: Opportunities and challenges. In Proceedings of the 2020 International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 17–19 June 2020; pp. 321–326. [Google Scholar]
- Yamaç, S.S. Artificial intelligence methods reliably predict crop evapotranspiration with different combinations of meteorological data for sugar beet in a semiarid area. Agric. Water Manag. 2021, 254, 106968. [Google Scholar] [CrossRef]
- Laney, D. 3D Data Management: Controlling Data Volume, Velocity, and Variety; Technical Report; META Group: Brussels, Belgium, 2001. [Google Scholar]
- Reis, T.; Bornschlegl, M.X.; Hemmje, M.L. AI2VIS4BigData: Qualitative Evaluation of an AI-Based Big Data Analysis and Visualization Reference Model. In Advanced Visual Interfaces. Supporting Artificial Intelligence and Big Data Applications; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12585, pp. 136–162. [Google Scholar] [CrossRef]
- Reis, T.; Bruchhaus, S.; Vu, B.; Bornschlegl, M.X.; Hemmje, M.L. Towards Modeling AI-based User Empowerment for Visual Big Data Analysis. In Proceedings of the Second Workshop on Bridging the Gap between Information Science, Information Retrieval and Data Science (BIRDS 2021), Virtual Event, 19 March 2021; pp. 67–75. [Google Scholar]
- Fischer, G.; Nakakoji, K. Beyond the macho approach of artificial intelligence: Empower human designers—Do not replace them. Knowl.-Based Syst. 1992, 5, 15–30. [Google Scholar] [CrossRef]
- Reis, T.; Bruchhaus, S.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. AI-based User Empowering Use Cases for Visual Big Data Analysis. In Proceedings of the 7th Collaborative European Research Conference (CERC 2021), Cork, Ireland, 9–10 September 2021. [Google Scholar]
- Reis, T.; Steffl, A.; Bruchhaus, S.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. A Service-based Information System for AI-supported Health Informatics. In Proceedings of the 2022 IEEE 5th International Conference on Big Data and Artificial Intelligence (BDAI), Fuzhou, China, 8–10 July 2022; pp. 99–104. [Google Scholar] [CrossRef]
- Ravi, M.; Negi, A.; Chitnis, S. A Comparative Review of Expert Systems, Recommender Systems, and Explainable AI. In Proceedings of the 2022 IEEE 7th International conference for Convergence in Technology (I2CT), Pune, India, 7–9 April 2022; pp. 1–8. [Google Scholar]
- Ochmann, J.; Zilker, S.; Laumer, S. The evaluation of the black box problem for AI-based recommendations: An interview-based study. In Proceedings of the International Conference on Wirtschaftsinformatik, Essen, Germany, 9 March 2021; pp. 232–246. [Google Scholar]
- Tan, C.F.; Wahidin, L.S.; Khalil, S.N.; Tamaldin, N.; Hu, J.; Rauterberg, M. The application of expert system: A review of research and applications. ARPN J. Eng. Appl. Sci. 2016, 11, 2448–2453. [Google Scholar]
- Villegas-Ch, W.; Sánchez-Viteri, S.; Román-Cañizares, M. Academic activities recommendation system for sustainable education in the age of COVID-19. Informatics 2021, 8, 29. [Google Scholar] [CrossRef]
- Akram, M.; Rahman, I.A.; Memon, I. A review on expert system and its applications in civil engineering. Int. J. Civ. Eng. Built Environ. 2014, 1, 24–29. [Google Scholar]
- Tanwar, P.; Prasad, T.V.; Aswal, M.S. Comparative study of three declarative knowledge representation techniques. Int. J. Comput. Sci. Eng. 2010, 2, 2274–2281. [Google Scholar]
- Sulikowski, P.; Zdziebko, T.; Turzyński, D. Modeling online user product interest for recommender systems and ergonomics studies. Concurr. Comput. Pract. Exp. 2019, 31, e4301. [Google Scholar] [CrossRef]
- Gabrani, G.; Sabharwal, S.; Singh, V.K. Artificial intelligence based recommender systems: A survey. In Proceedings of the International Conference on Advances in Computing and Data Sciences, Ghaziabad, India, 11–12 November 2016; pp. 50–59. [Google Scholar]
- Sulikowski, P.; Zdziebko, T.; Coussement, K.; Dyczkowski, K.; Kluza, K.; Sachpazidu-Wójcicka, K. Gaze and Event Tracking for Evaluation of Recommendation-Driven Purchase. Sensors 2021, 21, 1381. [Google Scholar] [CrossRef]
- Yang, C.; De Baets, B.; Lachat, C. From DIKW pyramid to graph database: A tool for machine processing of nutritional epidemiologic research data. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5202–5205. [Google Scholar]
- Malhotra, M.; Nair, T.R.G. Evolution of knowledge representation and retrieval techniques. Int. J. Intell. Syst. Appl. 2015, 7, 18. [Google Scholar] [CrossRef]
- OECD. Artificial Intelligence in Society. 2019. Available online: https://doi.org/10.1787/eedfee77-en (accessed on 8 September 2022).
- Ortega, A.; Fierrez, J.; Morales, A.; Wang, Z.; Ribeiro, T. Symbolic AI for XAI: Evaluating LFIT inductive programming for fair and explainable automatic recruitment. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual Conference, 5–9 January 2021; pp. 78–87. [Google Scholar]
- Ahmad, J.; Farman, H.; Jan, Z. Deep learning methods and applications. In Deep Learning: Convergence to Big Data Analytics; Springer: Singapore, 2019; pp. 31–42. [Google Scholar]
- Abras, C.; Maloney-Krichmar, D.; Preece, J. User-centered design. In Encyclopedia of Human-Computer Interaction; Sage Publications: Thousand Oaks, CA, USA, 2004. [Google Scholar]
- Wu, W.; Peng, M. A data mining approach combining K-means clustering with bagging neural network for short-term wind power forecasting. IEEE Internet Things J. 2017, 4, 979–986. [Google Scholar] [CrossRef]
- Kovač-Andrić, E.; Brana, J.; Gvozdić, V. Impact of meteorological factors on ozone concentrations modelled by time series analysis and multivariate statistical methods. Ecol. Inform. 2009, 4, 117–122. [Google Scholar] [CrossRef]
- Fowler, M. Patterns of Enterprise Application Architecture; Addison-Wesley Longman Publishing Co., Inc.: Hoboken, NJ, USA, 2002. [Google Scholar]
- Wharton, C.; Rieman, J.; Lewis, C.; Polson, P. The cognitive walkthrough method: A practitioner’s guide. In Usability Inspection Methods; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1994; pp. 105–140. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precondition | KM | PCA | LR | KNN | SVM | RF |
|---|---|---|---|---|---|---|
| supervised | X | X | X | X | ||
| numeric attributes | X | X | X | X | ||
| numeric source attributes | X | |||||
| categorical target attributes | X | X | X | |||
| normalized source attributes | X | X | ||||
| standardized attributes | X | X | ||||
| no missing values | X | X | X | X | X |
| Task | Evaluator “IT Manager” | Evaluator “Software Designer” | |||||
|---|---|---|---|---|---|---|---|
| Description | Required Actions | Identified Actions | Problems | Problem Rate | Identified Actions | Problems | Problem Rate |
| (1) Complete data annotation | 6 | 6 | 2 | 33% | 6 | 1 | 17% |
| (2) Create a new query | 8 | 8 | 0 | 0% | 8 | 1 | 13% |
| (3) Execute the query from (2) | 3 | 3 | 0 | 0% | 3 | 1 | 33% |
| (4) Review the applicability of PCA | 4 | 4 | 0 | 0% | 4 | 1 | 25% |
| Total | 21 | 21 | 2 | 10% | 21 | 4 | 19% |
| Test Data | Measured Duration [s] | ||
|---|---|---|---|
| Data Set | Data Points | Feature Extraction | Inference |
| Soil Dataset USA 2020 | 462,000,000 | 30.938 | 0.283 |
| City Temperatures World | 57,400,000 | 5.498 | 0.279 |
| GRUAN Radio Data | 4,224,295 | 0.558 | 0.266 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reis, T.; Funke, T.; Bruchhaus, S.; Freund, F.; Bornschlegl, M.X.; Hemmje, M.L. Supporting Meteorologists in Data Analysis through Knowledge-Based Recommendations. Big Data Cogn. Comput. 2022, 6, 103. https://doi.org/10.3390/bdcc6040103
Reis T, Funke T, Bruchhaus S, Freund F, Bornschlegl MX, Hemmje ML. Supporting Meteorologists in Data Analysis through Knowledge-Based Recommendations. Big Data and Cognitive Computing. 2022; 6(4):103. https://doi.org/10.3390/bdcc6040103
Chicago/Turabian StyleReis, Thoralf, Tim Funke, Sebastian Bruchhaus, Florian Freund, Marco X. Bornschlegl, and Matthias L. Hemmje. 2022. "Supporting Meteorologists in Data Analysis through Knowledge-Based Recommendations" Big Data and Cognitive Computing 6, no. 4: 103. https://doi.org/10.3390/bdcc6040103
APA StyleReis, T., Funke, T., Bruchhaus, S., Freund, F., Bornschlegl, M. X., & Hemmje, M. L. (2022). Supporting Meteorologists in Data Analysis through Knowledge-Based Recommendations. Big Data and Cognitive Computing, 6(4), 103. https://doi.org/10.3390/bdcc6040103