1. Introduction
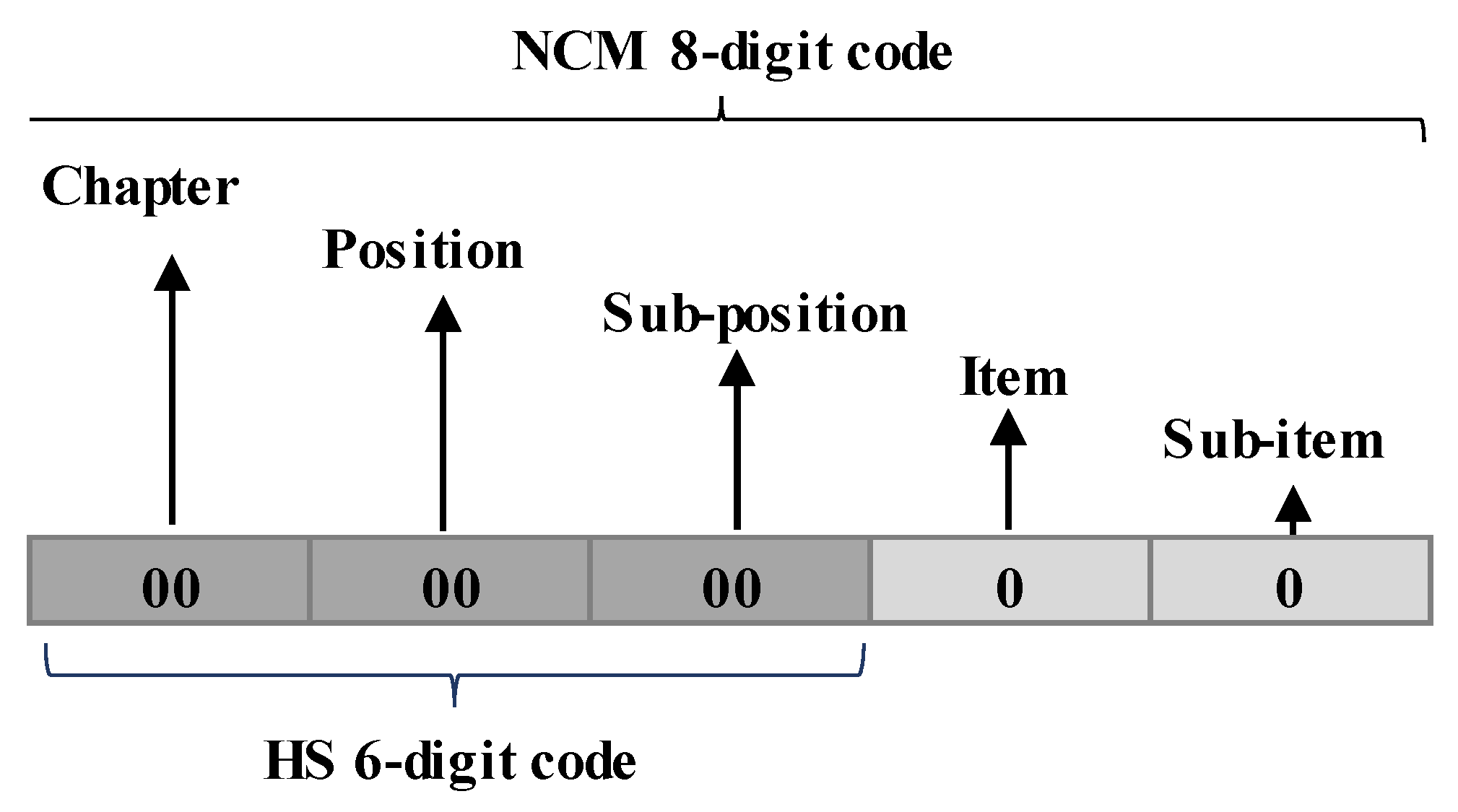
The Mercosur Common Nomenclature (MCN or NCM) is a system used by the South American trade bloc Mercosur to categorize goods in international trade and to facilitate customs control [
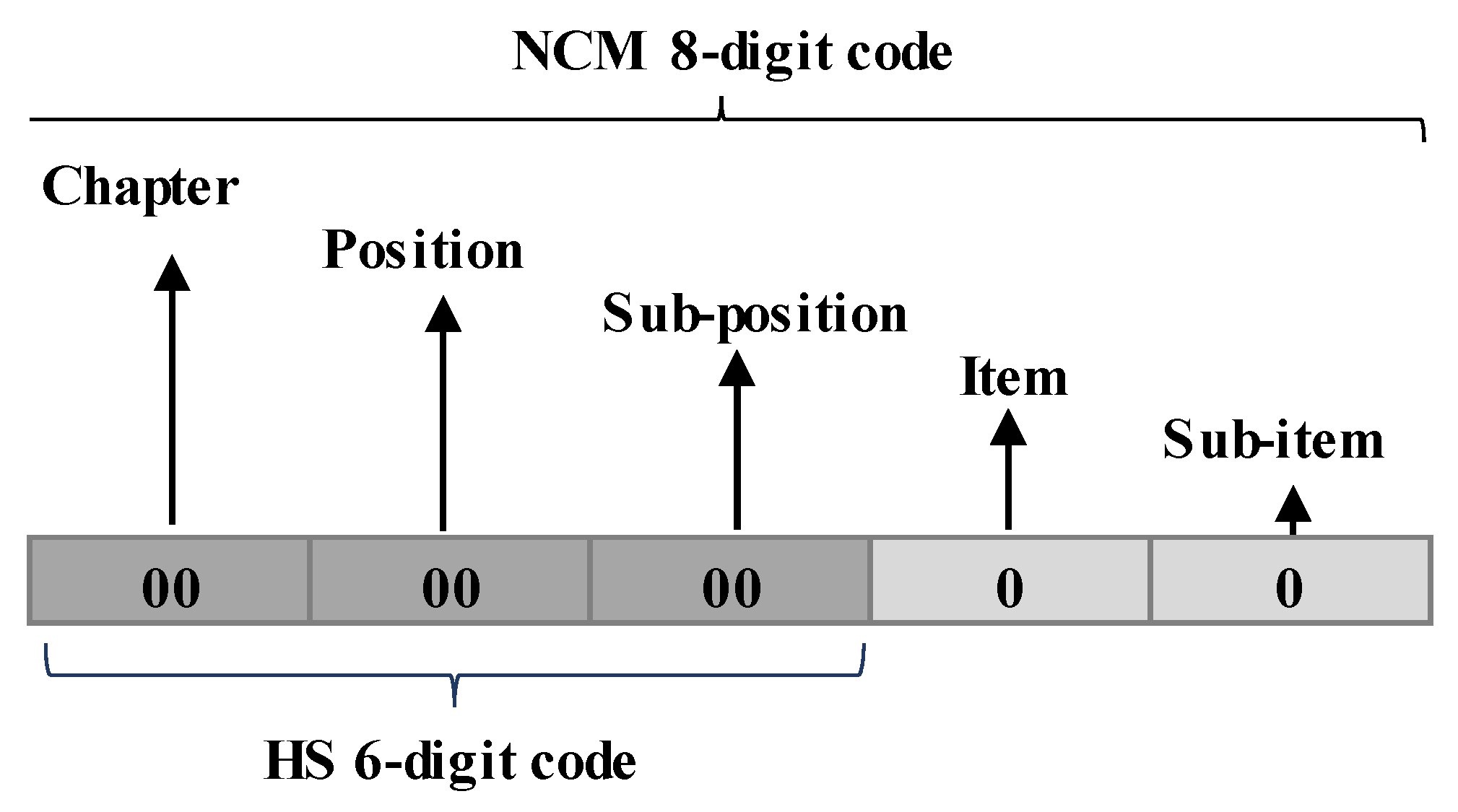
1]. The MCN is divided into 96 parts called “chapters”. These contain more than 10,000 unique MCN codes. An MCN code is an eight-digit numeric code than represents the goods and is required in the process of importing products in Brazil.
The process of classifying goods can constitute a real challenge due to the complexity involved in assigning the right code to each imported good given the substantial number of codes and the technical details involved in their specification. During the import process, one of the first documents required by Brazil is the Import Declaration in which the MCN code must be assigned to the product. In the case of a missing document or a misclassification of the MCN Code, the fines can be significant—thereby making classification a key challenge.
Since the proposition of the transformer model in [
2] the natural language processing (NLP) area has been hugely impacted by this model that does not need recurrences layers and is only based on attention mechanisms. The bidirectional encoder representations from transformers (BERT) model was proposed two years later by [
3] stacking only encoder layers from the transformers and achieving state of the art results in 11 natural language processing (NLP) tasks in the GLUE Benchmark thus allowing many NLP tasks to take advantage of this approach. Due to its transfer learning process, BERT models allow for less data and computing time to fine tune a model for a specific task, enhancing and facilitating its use for different purposes.
The Brazilian Revenue Service currently maintains Brazil’s international trade data in website called Siscori. This website contains all data relative to Brazilian imports and exports, including a detailed description of the goods and their respective NCM Code. The focus of this work is to use this international trade data to fine-tune a classifier in order to develop a tool that could improve foreign trade analysts’ performance when dealing with the classification of goods process. The multilingual BERT model proposed in [
3] and the Portuguese BERT (BERTimbau) proposed in [
4] will be used. In this article, an assessment of these models’ abilities to successfully categorize and attribute NCM codes will be made, as well as making an empirical comparison between the performance of the two models.
3. Procedures
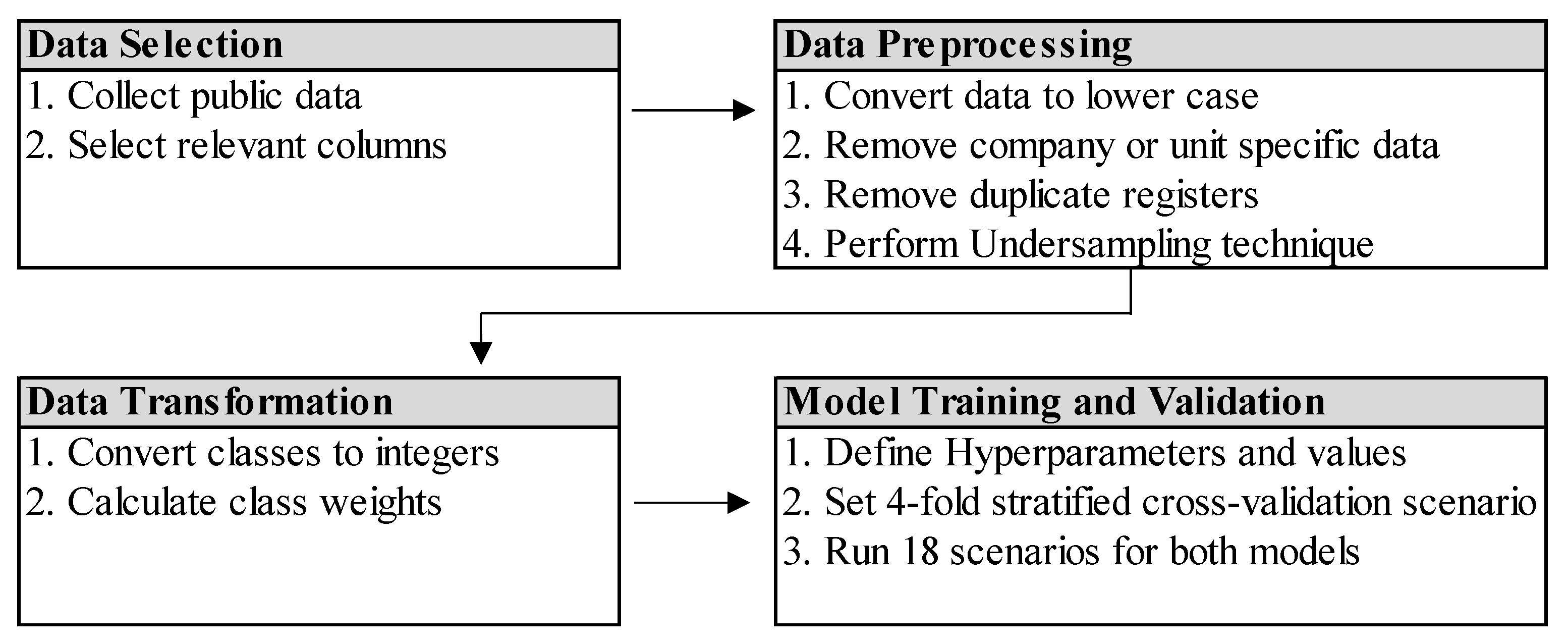
The starting point is obtaining the publicly available data provided by the Brazilian Revenue Service which is then run through the 18 scenarios for each model (Portuguese BERT and Multilingual BERT). Some steps were carried out in order to set up the initial data and preprocess it.
Figure 4 illustrates each step on data selection, preprocessing, transformation, and finally on model training and validation.
3.1. Data Selection
The data used in this work was obtained from “Siscori” [
14], the website provided by the Brazilian Revenue Service that currently contains all data on the import and export of goods from 2016 to 2021 (
Figure 5). The data records include a detailed description on the good (with a maximum of 250 characters), country of origin, country of destination, related costs, and the MCN code into which the good is classified, as well as other information that was not relevant to this work.
Since this paper makes use of the BERT model to train a classifier that aims to classify descriptions on its respective MCN code, only the product description and MCN code columns were selected for this work. Although the amount of NCM codes is over 10,000 and is currently divided into 96 chapters, the focus of the classifier developed in this paper will be to predict MCN codes inside a single chapter.
Regarding the choice of this chapter, reference [
15] presents a classifier to the harmonized system (HS) codes using background nets which focuses on Chapters 22 and 90 since both of these chapters are more prone to classification errors in daily classification tasks made by international business analysts than any other chapter. Reference [
15] states that the accuracy for Chapter 90 has shown to be much lower than Chapter 22, which the authors consider to have direct relation with two main factors. The first one is related to short record descriptions that do not contain sufficient information for the model to learn properly and also high level descriptions that frequently refer directly to the HS nomenclature itself, this makes learning difficult when dealing with specific descriptions in new instances.
Reference [
16] presents a classifier for NCM codes using the naïve Bayes algorithm and focuses on Chapters 22 and 90 as these are most susceptible to practical errors. Reference [
16] shows three scenarios in their work with different difficult levels: the first one on Chapter 22 with data from a single company; the second one also on Chapter 22 but with data from companies randomly selected; and finally, the third one on Chapter 90 containing data also from different companies randomly collected. According to [
16] it is also important to take into account that the fact when comparing to the harmonized system, that the NCM system has a deeper hierarchy which leads to the difference in performance between classifiers. In addition to this, according to [
16], Portuguese is also a more complex language than English that has more regular and uniform sentences allowing the models prediction to be more accurate. Given that the difference in the amount of NCM codes in Chapter 90 is more than 10 times the amount of NCM codes in Chapter 22, this paper will focus only on Chapter 90 since it tends to have more difficulties involved. As mentioned, the Siscori website provides Brazilian import data from 2016 to 2021, and the import data from January 2019 through August 2021 was selected in this experiment, making a total of 7,645,573 records
3.2. Data Pre-Processing
Since the data was obtained from the official sources, there was some noise that needed to be removed in a cleaning process before beginning to train the model. At first, as shown in
Figure 3, most of the goods described are in upper case and only a few of them come cased as regular sentences, so initially all records were converted to lower case.
Using regular expressions, production and manufacturing dates were removed, as well as product batches and their abbreviations and numbers, since these data are not relevant to the distinction between classes and can interfere in the training. Additionally, codes and terms related to billing and part number (PN) were removed, since they are specific codes for each company. In addition, extra white space and some special characters present in the sentences that would not contribute to the learning process were also removed.
After the data cleaning phase records that had duplicate descriptions, this is data which most likely come from the same importing companies, were also removed. After the cleaning and removal of duplicate records, the database was reduced from 7,645,573 records to a total of 3,481,090.
Since the processing of this amount of data would still be significant an undersampling technique was carried out with imblearn’s RandomUnderSampler. Given that the dataset was unbalanced, the undersampling process for this research kept a ratio of 1:300 samples between the minority and majority classes. The minority class presented only 4 records so the majority class would present 1200 records giving the chosen ratio with the samples being selected randomly. After the undersampling process, the database was reduced from 3,481,090 to 265,818 records keeping the original number of classes of 325. All the pre-processing steps are summarized in
Table 2.
3.3. Data Transformation
The classifiers were implemented in Python and the main library used to fine-tune the BERT model was simple transformers, by Thilina Rajapakse [
17]. For multiclass classification, the format of training and testing data required by the library states that classes must be provided as integers starting from 0 to n. Therefore, a simple transformation of the MCN codes and adaptation of the column names according to the documentation was performed. The MCN codes and their respective indexes were also stored in a dictionary, for later referral after the prediction process.
For this work, the selected multilingual BERT model proposed by [
3] was the uncased version on the base form (12 layers). Regarding Portuguese BERT (BERTimbau), since only the cased version was available it was chosen also on its base form. In this case, it is important to emphasize that, for the BERT model to perform tasks called downstream¸ such as classification, the simple transformer library provides models with a classification layer already implemented on top of it. Besides that, simple transformers allow the model to be supplied with a list of weights to be assigned to each class in the case of unbalanced datasets. As the database contains real Brazilian import data and presents a considerable difference in the amount of some goods in relation to others with respect to MCN codes, it is clearly a highly unbalanced base. To make use of this configuration allowed by simple transformers, the weights were calculated inversely proportional to the number of records per class and provided to the model as a parameter, to be used in the loss calculation during training and evaluation, thus minimizing the effects of the unbalanced dataset.
At this point, it is important to emphasize that some steps are necessary so that the texts and classes are provided in the proper format for a BERT model. The first requirement is that the input texts are converted to tokens using the same tokenizer used to originally train BERT, namely the WordPiece embeddings, defined in [
10].
BERT also expects special tokens in the texts: for classification tasks, the token ‘[CLS]’ is needed at the beginning of each sentence, and by default the token of ‘[SEP]’ is needed at the end. In addition, it is important to emphasize that BERT can be supplied with variable length sentences, but these must be spaced or truncated to a fixed length and, for this, ‘[PAD]’ tokens are used, which indicate empty spaces. Finally, it is also necessary to provide a so-called attention mask, responsible for identifying and separating the tokens from the paddings, consisting of a list with a value of 0 for the tokens of ‘[PAD]’ and value 1 for everything else. All these steps are provided by the simple transformers library implementation and do not need extra work to get this working.
3.4. Hyperparameter Tuning
Having defined the parameters referred to the model itself, in addition to parameters such as seed to allow the replication of results later, some hyperparameters used in the BERT model were defined as well. Reference [
3] specify that most hyperparameters used in fine tuning are the same as in pre-training, except for batch size, learning rate, and number of training epochs. Along these lines, the authors suggest some values that, based on the experiments, have shown to work well for different types of tasks. Reference [
3] suggests values for batch size as 16 or 32, for learning rate as 5 × 10
−5, 3 × 10
−5, 2 × 10
−5, as well as training epochs of 2, 3, and 4. The authors also reiterate that, during their experiments, it was noticed that, for large databases (+100,000 labeled data), the model was far less sensitive to the changes of these parameters than on smaller databases. Because the fine-tuning process is relatively fast, Ref. [
3] also recommends carrying out an exhaustive search among these parameters in order to find those that best fit the model. Therefore, a grid search was performed on the training of the classifier of Chapter 90 comprising all 18 scenarios for each BERT model (multilingual and Portuguese).
3.5. Hardware and Platform
Since transformers allow parallelization their use with the proper hardware is very important. For this work, the code was developed in the Python language and was executed in a notebook on Google Colab, an interactive environment that is easy to configure and share. For the execution of the experiments used in this research, Google Colab Pro version was used due to the availability of fast GPUs and large amounts of RAM. In this case, all 36 scenarios in this experiment were run on Google Colab Pro and a Tesla P100 PCIe 16 GB GPU was assigned for the notebook.
3.6. Model Training and Validation
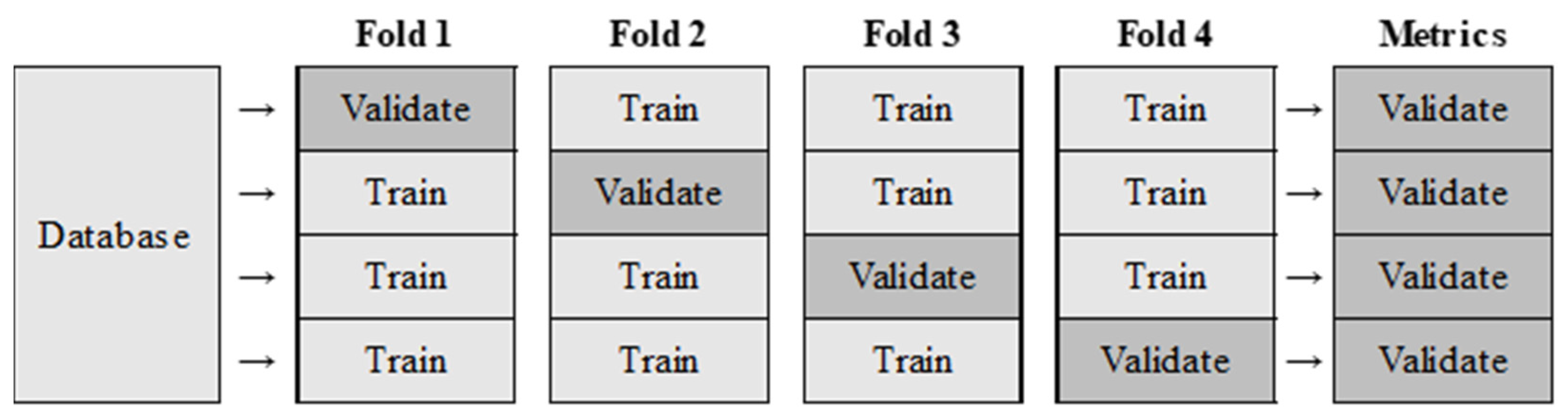
In order to evaluate the classifier, the training and validation processes were performed using k-fold cross-validation. This is illustrated in
Figure 6 in a 4-fold cross-validation which was the number of folds used in this paper’s experiments. In [
9], it is stated that in k-fold cross-validation where the database comprises N instances then these should be divided into k equal parts, where k is usually a small number, such as 5 or 10. With the database separated into parts a series of k executions is performed using one of the k parts as a test base and the other (k − 1) parts as a training base.
Thus, after k executions, reference [
9] defines that the total number of correctly classified instances is divided by the total number of instances N, resulting in an overall accuracy of the model. One of the variations of cross-validation is the stratified cross-validation, which—according to [
8]—uses a representation proportional to each class in the different folds and generally provides less pessimistic results. As the database used is quite unbalanced, the stratified cross-validation was run in all experiments with the different hyperparameters to ensure more consistent results. Other scenarios and applications described can be found in [
18].
3.7. Metrics Selection
To analyze the performance of the classifier, three different metrics were used, as some are more adequate to the characteristics of the database used in this work: accuracy, cross-entropy loss, and Matthews correlation coefficient (MCC).
3.7.1. Accuracy
Accuracy represents the number of instances correctly classified in relation to the total number of instances evaluated. According to [
19], although accuracy has been shown to be the simplest and most widespread measure in the scientific literature, it presents some problems in cases in which the performance of unbalanced databases is evaluated. According to the authors, there is an accuracy problem in not being able to distinguish well between different distributions of incorrect classifications.
3.7.2. Cross-Entropy Loss
The cross-entropy loss configures a loss function commonly used in classification tasks, being a performance measure of models, whose output involves probability values. In this case, the cross-entropy loss increases as the predicted probability diverges from the real one, and therefore the objective is for its value to be as close to zero as possible. To calculate the cross-entropy loss in the multiclass case, according to [
20] the expression can be written for each instance, where (
k) has the value 0 or 1, indicating whether the class
k is the correct classification for the prediction
(k), in the form
Class-balanced loss introduces a weight factor that is inversely proportional to the number of instances of a class and is used precisely to address the problem of unbalanced databases [
21]. Thus, as this work deals with this case of unbalance and the simple transformers library allows the supply of a vector of weights for the model, these weights are used as multipliers in the cross-entropy loss function.
3.7.3. Matthews Correlation Coefficient
The Matthews correlation coefficient (
MCC) is calculated directly from the confusion matrix, and its values range between −1 and +1. A +1 coefficient represents a perfect prediction, 0 an average prediction, and −1 an inverse prediction. For binary classifications,
MCC comprises the following expression based on the binary confusion matrix values
Since the focus of this work is a multiclass classification problem, reference [
22] presents its generalized form for the multiclass case, in which
Ckl are the elements of the confusion matrix
Reference [
23] refers to the MCC in their work as a performance measure of a multiclass classifier, and point out that, in the most general case, the
MCC presents a good harmonization between discrimination, consistency, and consistent behaviors with a varied number of classes and unbalanced databases. In addition, reference [
19] shows that the behavior of the
MCC remains consistent both in cases of binary and multiclass classifiers.
In their work evaluating binary classifications, reference [
23] points out that due to its mathematical properties, the
MCC can give better, more reliable score on imbalanced datasets. Reference [
23] reiterates the fact that the
MCC criterion is direct and intuitive regarding its score: for a high score, it means that the classifier correctly predicts most negative classes and most positive classes, regardless of their proportions in the dataset. The work of [
23] focuses on binary classification and shows that the main differential and advantages of the
MCC are that it benefits and penalizes for each class, since a good performance of the classifier will occur when it has a good predictive power for each of the classes together. In this sense, regardless of the number of instances of a class being much lower than another (in the case of unbalanced datasets), the
MCC maintains its overall performance evaluation power consistently.
4. Experimental Results
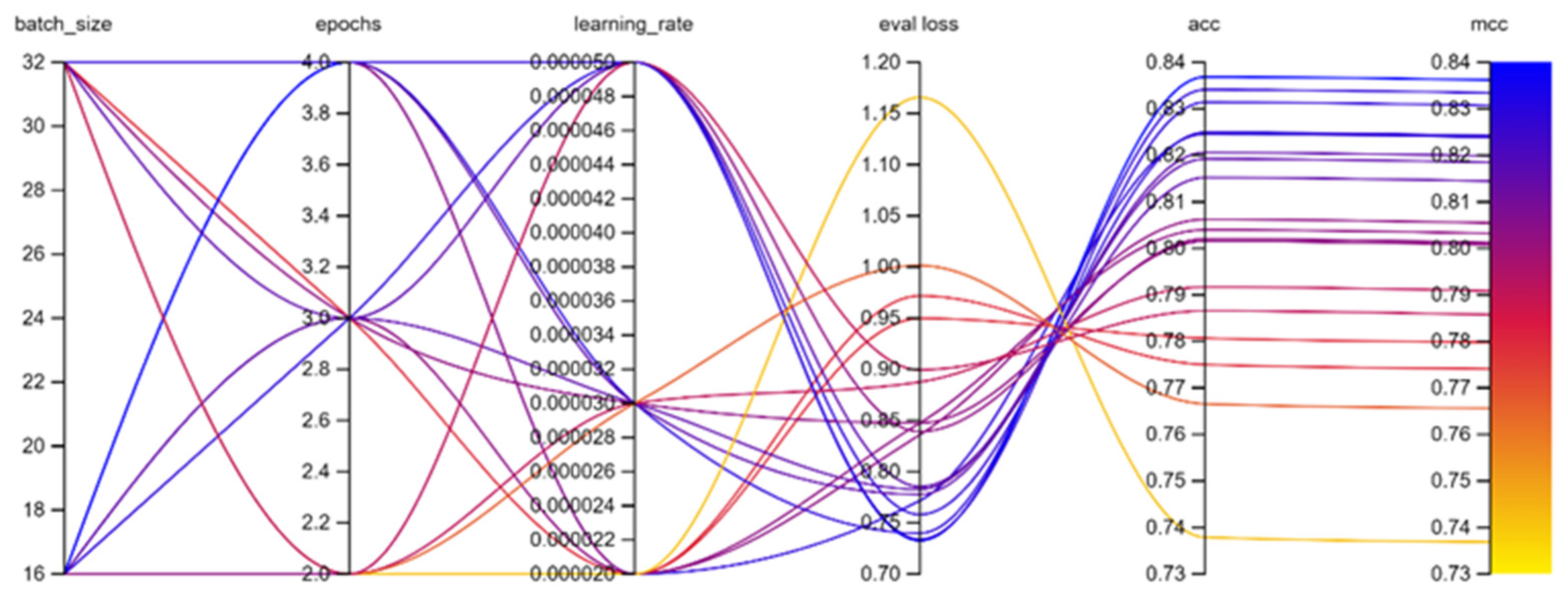
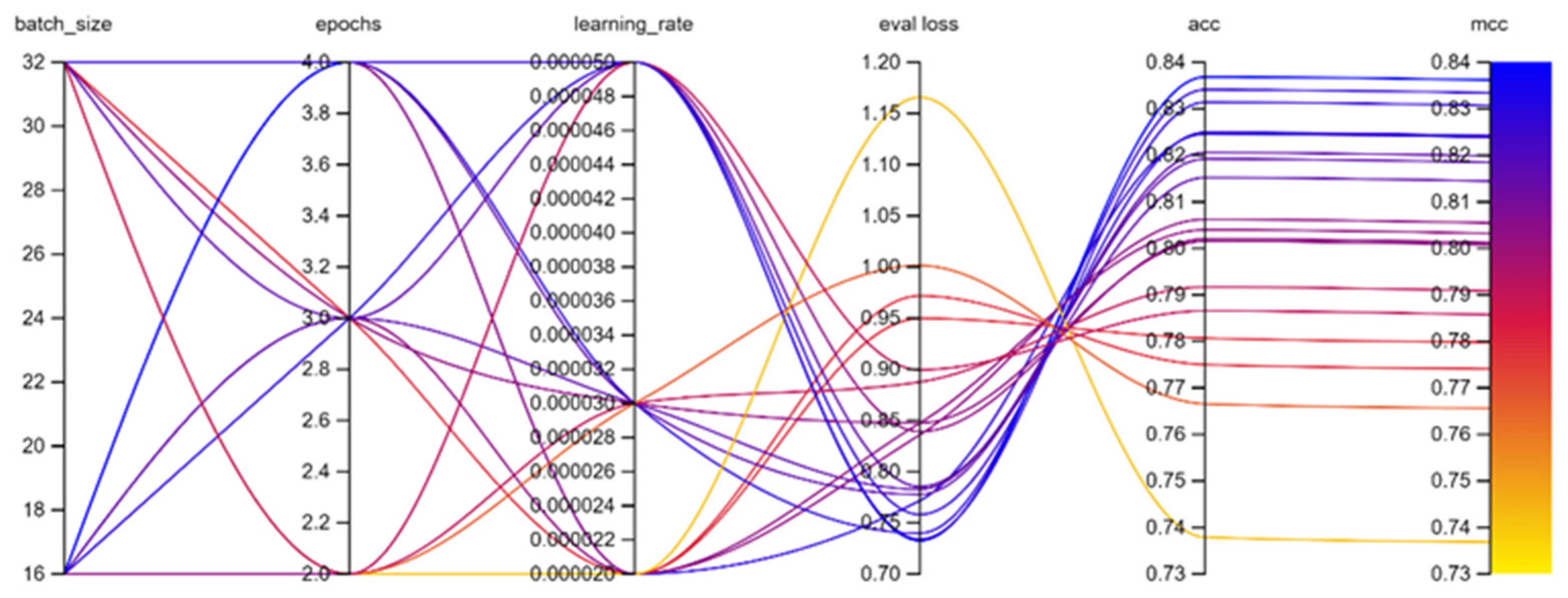
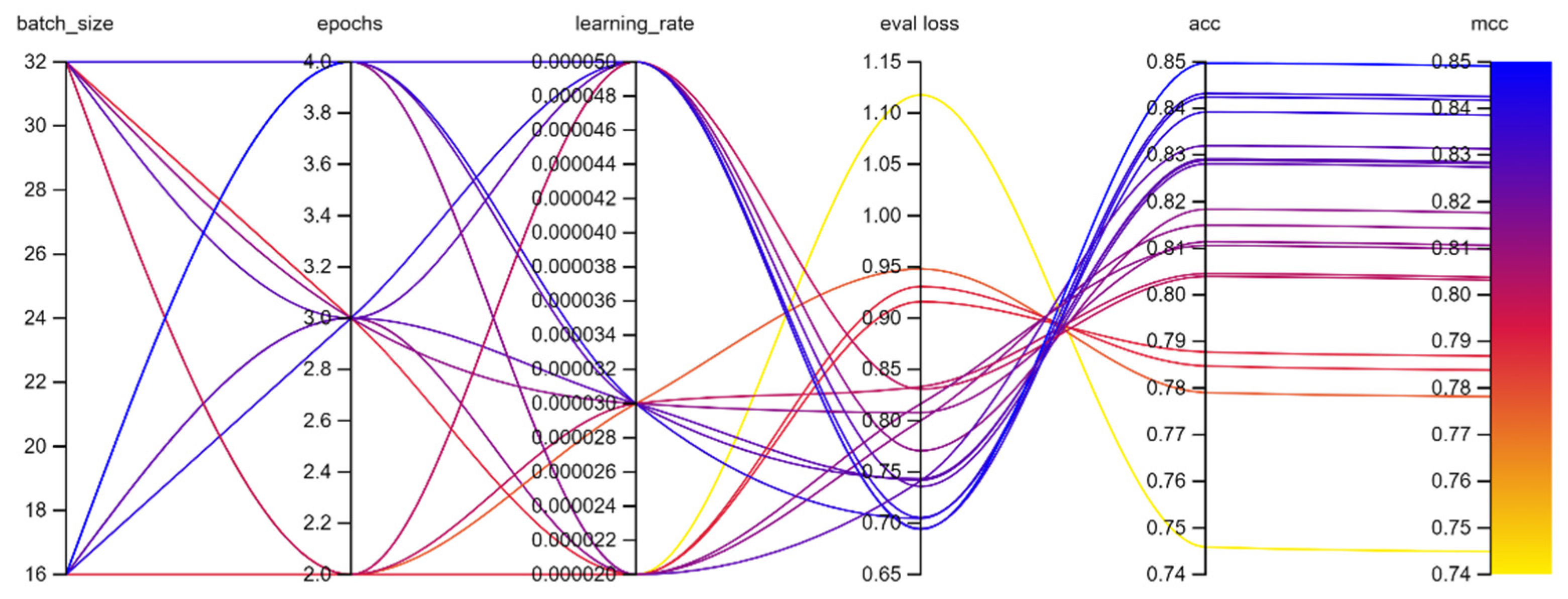
Both multilingual BERT and Portuguese BERT experiments were carried out on a grid search comprising all 18 scenarios that encompasses the combinations of parameters for batch size, epochs, and learning rate suggested in [
3]. A 4-fold stratified cross-validation was performed and the results presented on
Table 2 and
Table 3 for cross-entropy loss, accuracy, and Matthews correlation coefficient are averaged among each fold. Both
Table 2 and
Table 3 are sorted by the highest
MCC result first, since it is the most suitable metric for the unbalanced database.
The experiments performed by the authors, regarding multilingual BERT, demonstrated that the best result regarding
MCC metric was the one presented where the batch size hyperparameter was set to 16, learning rate to 5 × 10
−5 and total epochs of 4. This best combination of hyperparameter resulted on a
MCC of 0.8362, an accuracy result of 0.8369 and a cross-entropy value of 0.7326 as shown on
Table 3.
In the work of [
16], for the experiment with Chapter 90 without duplicates—which is the most similar to this paper experiment—the classifier presented an average accuracy of 0.8338. In the same scenario, but with terms in English and considering the harmonized system (HS) classification, the classifier developed by [
15], obtained an average accuracy of 0.8330. The result from the multilingual BERT experiment of 0.8362 outperformed both works with a BERT model that was pretrained in 102 languages.
Figure 7 shows the hyperparameters optimization process on multilingual BERT experiment with 18 scenarios using weight and biases in [
24] to illustrate different scenarios.
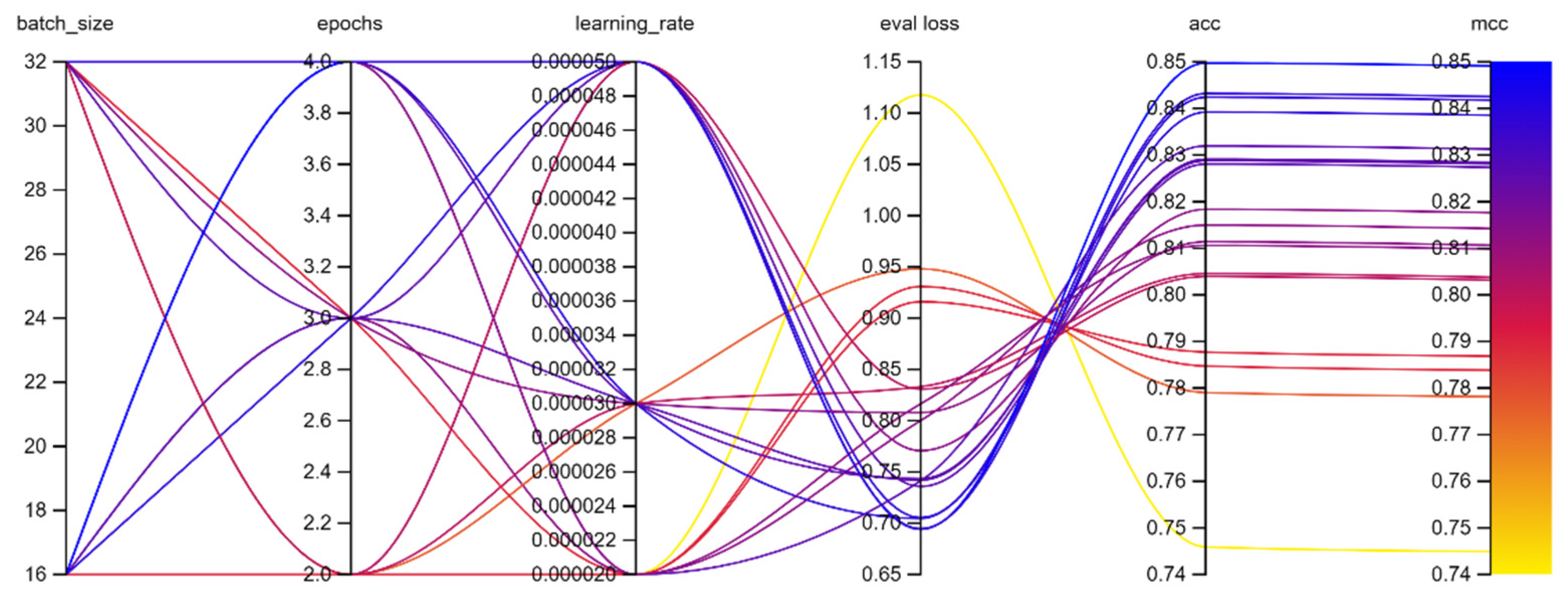
The experiments performed by the authors on Portuguese BERT were also carried out 18 times, for each possible combination of parameters as suggested in [
3]. The results showed that the greatest
MCC achieved was 0.8491 for a batch size value of 16, 4 epochs, and a learning rate of 5 × 10
−5. In this empirical comparison, a lower batch size and higher epochs and learning rates has shown to be the best combination for fine tuning a BERT model using this data for both the multilingual and Portuguese models. For the best-case scenario in the Portuguese BERT model experiment the
MCC presented a value of 0.8491, accuracy reached 0.8497, and cross-entropy loss was 0.6941.
Table 4 shows Portuguese BERT results for Chapter 90.
Results from the 18 different scenarios show that the Portuguese BERT outperforms the multilingual BERT
MCC. One of the reasons behind this is that Portuguese is a high-resource language to which the specific language model fits better than the BERT multilingual model. Additionally, since all the training data is in Portuguese the BERT Portuguese tends to adapt better to the specific details of the language, getting the inner details more frequently than models that can handle multiple languages at a time. In this case, the model also improves results when comparing to [
16] accuracy results for Chapter 90 with no duplicates and [
15] results for the same chapter and scenario 90 but for harmonized system (HS).
Figure 8 also presents the hyperparameter tuning process illustrated using weight and biases in [
24] for the Portuguese BERT model experiment.
Hence, in both Portuguese and multilingual BERT, the best result was achieved with the smallest batch size between the two options, which corresponds to the number of samples processed before updating the model. Additionally, the smallest learning rate between the three options has shown to be a better hyperparameter option than the others, and finally the number of epochs, which corresponds to the number of times that all the data goes into the model, has been shown to be the greatest possible between the three. Additionally, when considering the 18 scenarios, for both models the MCC fluctuated approximately 13% between the worst and the best value, confirming the importance of hyperparameter tuning to get better results.
Having presented the results, mainly about the Matthews correlation coefficient (MCC), it was noticed that it is now possible to train a relevant performance classifier with a low computational cost, mainly due to the knowledge transfer process that the BERT models allow. Thus, with the process of fine-tuning for the classification of product descriptions in their respective MCN codes, it was successfully executed leading to results such as 0.8491 for the MCC using the Portuguese pre-trained model in a task with 325 distinct classes. This pretraining process which has a high cost of training allows BERT models to have a relevant performance when compared to other existing traditional methods.
Finally, since both models
MCC’s result highlighting the relevance of the classifier and as the transformer-based methods work almost like a ‘black box’ regarding what really led to the models’ decision, the authors decided to apply the LIME (local interpretable model-agnostic explanations) proposed in [
13] to the Portuguese BERT model classifier. According to its authors, LIME is an explanation technique of any classifier (independent of its inner workings) which focus on presenting an interpretable model local around one prediction in which a human could easily understand and confirm the classifier prediction trust.
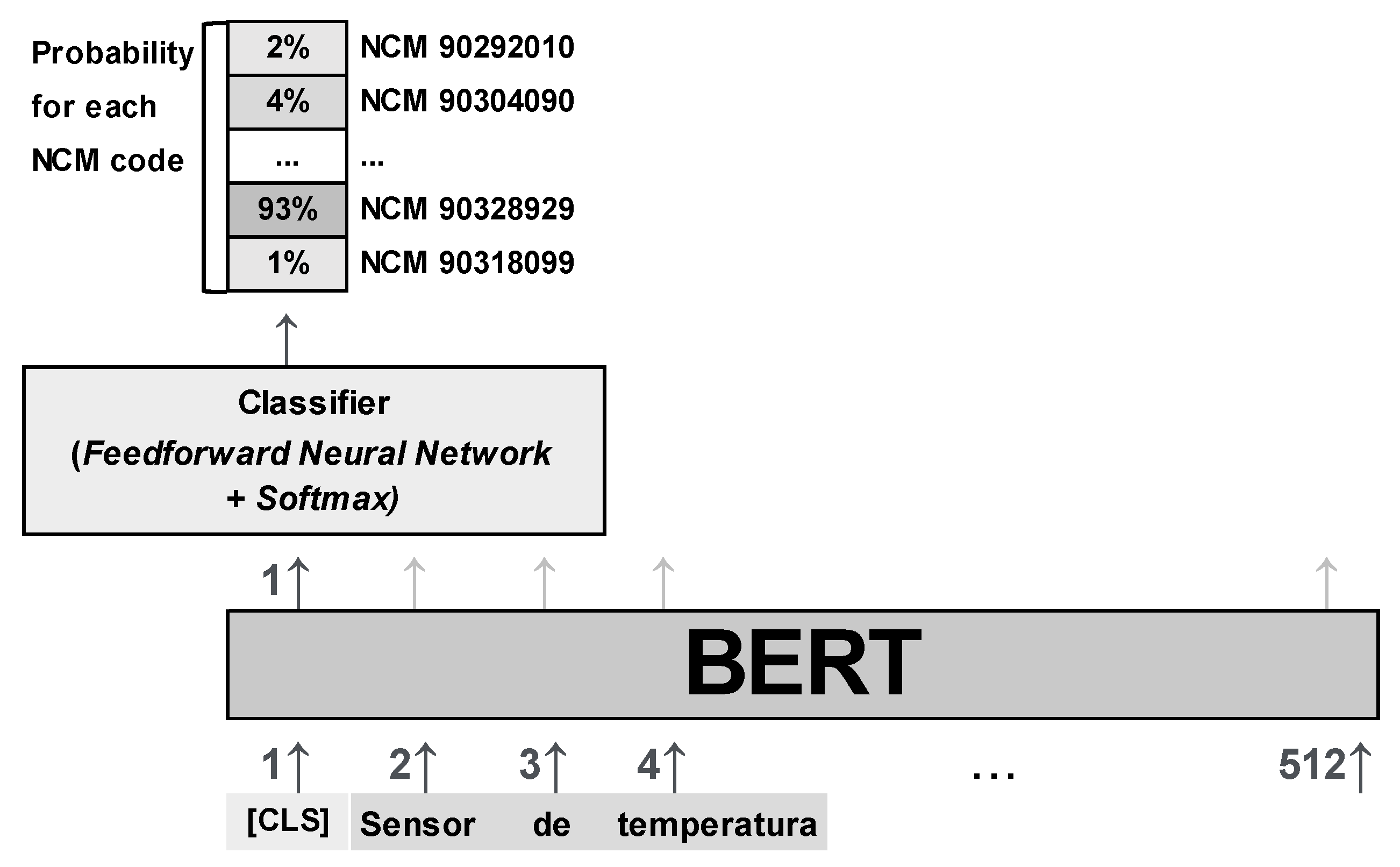
The Portuguese BERT classifier was selected to apply the LIME method since it outperformed the multilingual BERT in all proposed scenarios. Using the LIME package and loading the saved trained Portuguese BERT model, a new product description was collected from Siscori import data from November 2021, since the model was trained on data from January 2019 through August 2021 and an unseen instance should be selected to test the classifier performance. Once the simple transformers library required all classes to be integers from 0 to n and all MCN codes were replaced by a respective integer, all prediction probabilities refer to integers numbers represents each MCN code class.
The selected instance (product description) had its correct class as the MCN code 90.26.80.00. The chapter and position part, 90.26, stands for “instruments for measuring or controlling the flow, level, pressure or other variable characteristics of liquids or gases”. Regarding its sub-position, item, and sub-item, to make the entire MCN code, it refers to other instruments that are not classified in controlling the flow, level or pressure specifically.
Figure 9 shows the LIME explanation, in which the predicted class (with the highest prediction probability) is the integer 212 with 92%, which corresponds (taking into account the code to integer transformation) to the 90.26.80.00 class, which is the right one for this instance of product description. Other probabilities are spread in other classes, but the prediction is clear enough on the selected class.
Regarding the highlighted words in pink in
Figure 9 that led the classifier to decide for class 212 (90268000), are the words in Portuguese for “flow”, “measure”, “of”, “sensor”, “for”, “gas”, “on”, “respiratory”, and “expiration” in this order, opposing to “used”. All of the mentioned words that led the model to this class selection are words totally related to this specific MCN code in which the instance was classified. The words “flow” and “measure”, for example, are totally related to the chapter and position 90.26 and represents key words to distinguish between this position and others, while “respiratory” and “expiration” are probably the words used to distinguish between other sub-position, item, and sub-Item within the same position. LIME method provided an intuitive and interpretable sample in which the authors were able to infer based on what the BERT Portuguese model selected the class, and the prediction has proven to be suitable since the words that were more important to decision-making were truly related to the MCN code and could easily be used to distinguish it from other codes.
Concerning research limitations, since the training process for the BERT models’ classifiers are based on real import data, only products that were imported at least once will be part of the training process. This means that if a product with a specific MCN code never had a product imported to Brazil, it will not be among the training data which will make the classifier inadequate to predict those new products. Additionally, despite the Siscori website providing data from 2016 through 2021, not all of these data are suitable for use, since MCN codes are deprecated occasionally which would need extra cleaning and preprocessing when leading with data from early years such as 2016, since some MCN codes would not be active anymore, needing to be removed or have their code updated.
5. Conclusions
Given the difficulties in the classification of goods in Brazil and the expensive fines for classification errors, the use of the developed classifier as a starting point in this classification process is obviously an important and relevant result. Considering that Chapter 90 type goods have one of the greatest (classification) errors in the literature related to foreign trade, the classifier can be useful for supporting foreign trade analysts’ decisions when classifying goods, especially for goods and products that require more technical knowledge and details.
The trained classifier could also be used by authorities such as the Brazilian Revenue Service. For instance, during the process of customs checking the goods and products descriptions and associated MCN codes are verified. In this case, the classifier could complement, optimize, and improve the existing process, helping to predict what MCN code the good/product should be assigned to, allowing to compare the predicted code with the one provided from customers in the import declaration.
Regarding the model comparisons, as BERT multilingual documentation stated, specific-language methods tend to have better results particularly in feature-rich languages like Portuguese, which is clearly proven in the empirical comparison made in this paper. For the dataset and classification problem, which is the focus of this work, BERT Portuguese has been shown to be the better one between the two models. The Portuguese BERT outperformed multilingual BERT, meanwhile the results with multilingual BERT are encouraging considering the training in 102 languages and even outperformed related work on the same scenarios.
The knowledge transfer process in models such as BERT combined with the availability of import and export records by the Brazilian Revenue Service has made the development of classifiers like this possible. The possibility of fine-tuning the model, as well as its parallel nature, allow for a reduction in training time and make it feasible to run it on local machines or notebooks running in the cloud as shown in this research. In addition to this, the availability of open-source libraries and models allows the sharing of knowledge and the implementation of solutions using state-of-the-art technologies by developers worldwide, as is the case of the multilingual BERT proposed in [
3] and Portuguese BERT proposed by [
4].
For future work, the authors suggest the training of the Portuguese BERT model on other chapters with the aim of developing an ‘upper level’ classifier that is able to determine to which chapter a product description belongs to, so it can further be pipelined with chapter-specific classifiers. The Brazilian Revenue Service provides data from 2016 through 2021 from all MCN 96 chapters; thus, by extracting only the first two digits from each sample, it would be possible to train a classifier to distinguish between these 96 classes (chapters). This ‘upper level’ classifier would perform what a foreign trade analyst does when classifying into which chapter the good fits and the specific chapter classifier would then provide what a chapter specialist does by selecting the appropriate MCN code for the good.
As well as the development of the chapters classifier, the authors suggest the training of a classifier for each chapter, starting from the chapters that are most prone to errors, as reported in the literature. This could lead to a major improvement in foreign trade analysts’ daily work routine as done with Chapter 90 in this work. Since there are enough data available and relevant number of classes for each chapter, keeping a classifier specialized for each chapter would allow a more precise prediction on each specific subject.
Additionally, this work used both multilingual BERT and Portuguese BERT on its base form, with 12 layers, due to a reduction in computational cost when dealing with the base form since hyperparameter tuning and cross-validation highly increase the time to run the experiments. Reference [
4] also provides a Portuguese BERT model on its large form, with 24 layers, which according to their evaluation benchmarks proved to outperform the base form on all tasks. Considering the increase in classifier performance using the large form, the authors also suggest an experiment with Portuguese BERT large for future works on Chapter 90, as well as other relevant chapters for the industry.
In addition to the public data provided by the Brazilian Revenue Service and the explanation regarding each MCN code composition, [
6] also provides “Harmonized System Explanatory Notes” (HSENs) for each chapter and position. These notes explain in detail its scope as well as legal notes that help understand which goods do not belong to the chapter. The authors suggest research on different models or approaches that could take those notes into account and that could deal with these explanatory notes on what the chapters refer to. Since all these notes have a detailed explanation on each part, a search for a model that could take this written detailed explanation as input would be relevant for the field.
Finally, after the proposal of the transformers in [
2] and BERT in [
3], several other models were presented such as RoBERTa in [
25] and DistilBERT in [
26] which propose some changes from the original BERT model and could potentially have improved results or performance when used to build and train classifiers when compared to the ones presented in this work. The authors also are considering researching what the specific changes on those models are and their application to the Siscori data in order to train a classifier, as done in this paper to the multilanguage and Portuguese BERT models.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}