
Infusing Autopoietic and Cognitive Behaviors into Digital Automata to Improve Their Sentience, Resilience, and Intelligence


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Either single vendor-provided tools augmented by home-grown approaches to tweak the availability, performance, and security management; or
- Myriad third-party tools that manage multi-vendor cloud resources and provide end-to-end management of the distributed application components utilizing various local operation and management tools.
- The choice between the two approaches is between either single-vendor lock-in or the complexity of managing end-to-end application availability, performance, and security. While the single-vendor choice simplifies the operation and management using vendor-provided tools and services, migration from one vendor infrastructure to another vendor infrastructure is often expensive, time-consuming, and subject to sudden changes based on vendor policies, as some customers recently found out [12].
- The current state of software development does not support creating composable workflows using multiple vendor-provided tools and software modules without increasing cost and complexity. It requires using the APIs provided by these vendors to build the end-to-end workflow, which results in increased complexity and effort in assuring the quality of the composed workflow.
- As mentioned earlier, the distributed application, consisting of multiple components using resources managed by various local autonomous management systems operated and managed by multiple operators, acts as a complex adaptive system. Fluctuations in the resource demand or resource availability that impact a single component in the distributed system affect the overall application availability and performance. Local security breaches affect overall application security. Maintaining the stability and security of the application at desired levels of performance requires global knowledge sharing, coordination, and control while accommodating local autonomy and local constraints. This results in a “manager of managers” approach, where local management systems are managed by a global management system. This leads to the manager of managers conundrum, with the question “who manages the manager of managers?”.
- When the magnitude of fluctuations is small and the deviations are not far from the equilibrium values of availability, performance, and security, they could be corrected by making adjustments to the existing structure. However, if the magnitude of fluctuations is large enough to cause emergence properties of the CAS to appear, structural changes of the application are required (for example, auto-scaling, auto-failover, and live-migration of components) which would result in end-to-end service disruption during the period in which those structural changes are made. The larger the fluctuations, the shorter the time available for making the required changes without service disruption.
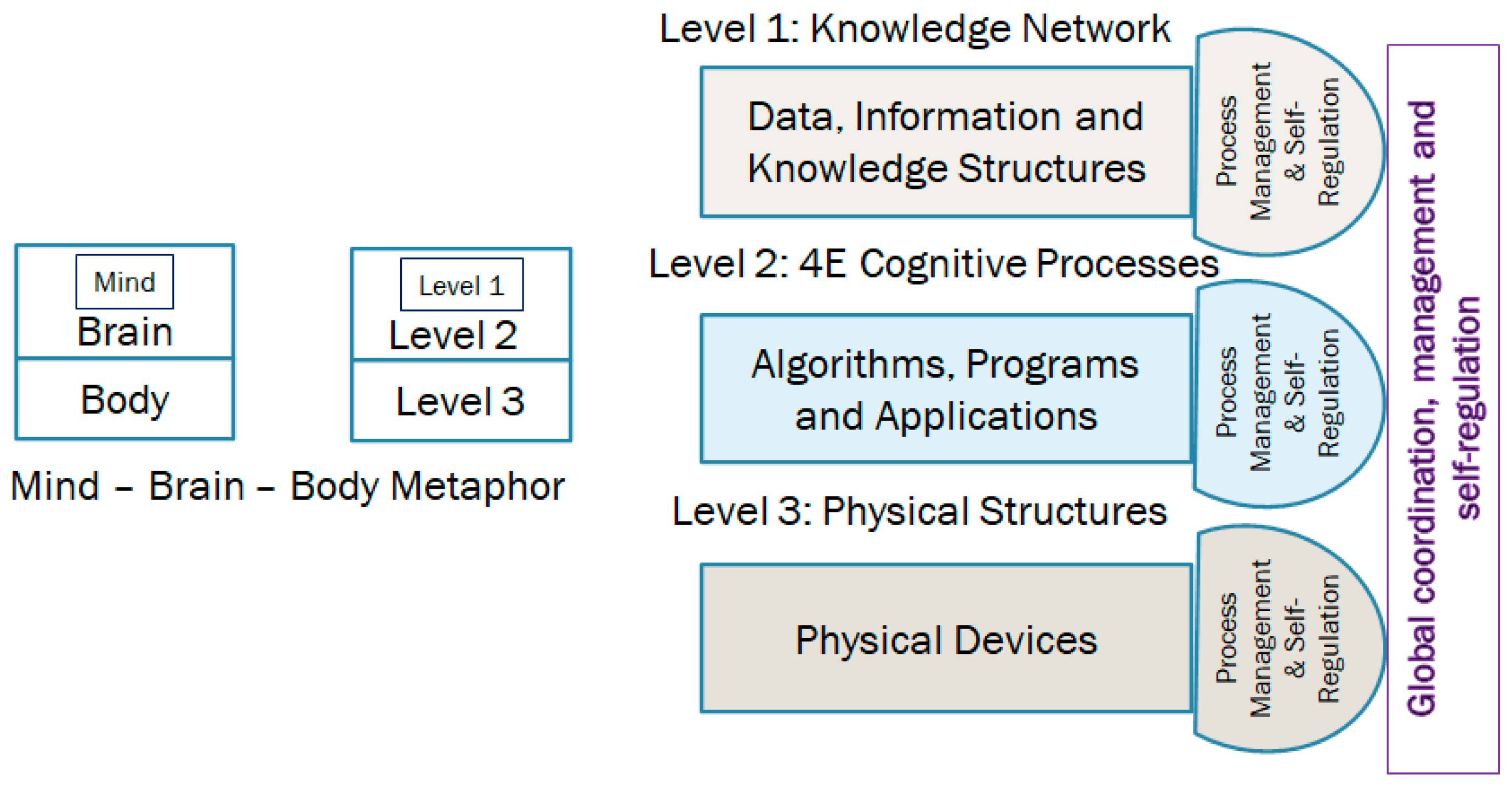
- The knowledge obtained from sub-symbolic computing is hidden in the neural networks, and the insights derived have to be integrated with symbolic computing structures to implement the changes dictated by the insights, such as the structural changes required to maintain stability and security. In this paper, we discuss super-symbolic computation, which integrates the knowledge from symbolic and sub-symbolic computing using a common knowledge representation schema that surpasses the current data-structure-based schemas [13]. This approach is very similar to how the mammalian neocortex uses the reptilian brain to sense and process information.
2. Current Computing Models
2.1. Symbolic Computing
- Current business services demand non-stop operation, and their performance is adjusted in real-time to meet rapid fluctuations in service demand or available resources. A business application software providing these services contains many components which are often distributed across multiple geographies, and requires hardware (fuel for computation in the form of CPU and memory) owned or operated by different providers managing infrastructure from multiple vendors. The current state-of-the-art requires a myriad of tools and processes to deploy and maintain the stability of the application. The result is complexity in managing local non-deterministic fluctuations in the demand for or the availability of the fuel impacting the end-to-end service quality.The solution today is either a single hardware infrastructure provider lock-in or the complexity of many third-party tools. Besides, the speed with which the quality of service has to be adjusted to meet the demand is becoming faster than the time it takes to orchestrate various infrastructure components such as virtual machine (VM) or container images, network plumbing, application configurations, middleware, etc. It takes time and effort to reconfigure distributed plumbing, which results in increased cost and complexity.The afore-mentioned Church–Turing thesis’ boundaries are challenged when rapid non-deterministic fluctuations in the demand for or the availability of finite resources drive the need for structural readjustment in real-time without interrupting service transactions in progress. An autopoietic application would know to readjust the structure of the system (“self”) with required resources and maintain its stability. This is analogous to how living organisms maintain homeostasis without having to interrupt critical functions.
- Current business processes and their automation assume trusted relationships between the participants in various transactions. Information processing and communication structures in turn assume “trusted relationships” between their components. Unfortunately, global connectivity and non-deterministic fluctuations caused by participants make it necessary to verify trust before completing transactions. On the one hand, assuming a complete lack of trust between participants (whether they are people, service components, or devices) increases the effort to manage risk in every transaction to assure the safety and security of the transaction. On the other hand, assuming complete trust between the participants increases the security risk. What we need is a mechanism that trusts but verifies just as living beings do. They use cognition as a means to represent knowledge about the participants and the risk associated with them and use this knowledge in any interaction to manage the transactions.For example, a cognitive application would manage its own security and privacy, with appropriate knowledge, independent of hardware infrastructure security mechanisms using its own autopoietic behaviors. This is analogous to a living organism fighting harmful viruses with its own immune system. The knowledge of immune system processes is embedded as a part of the “Self” in the genome.
2.2. Sub-Symbolic Computing
3. General Theory of Information and the Science of Information Processing Structures
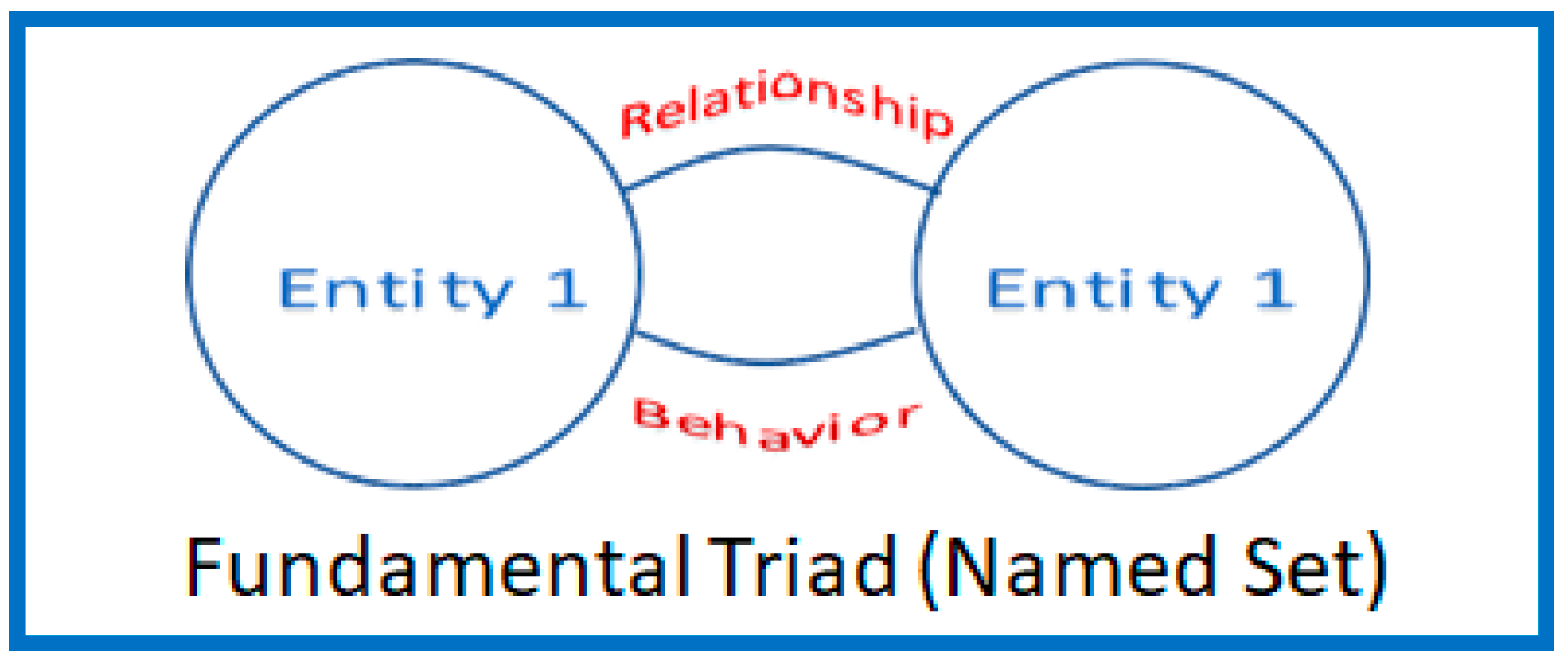
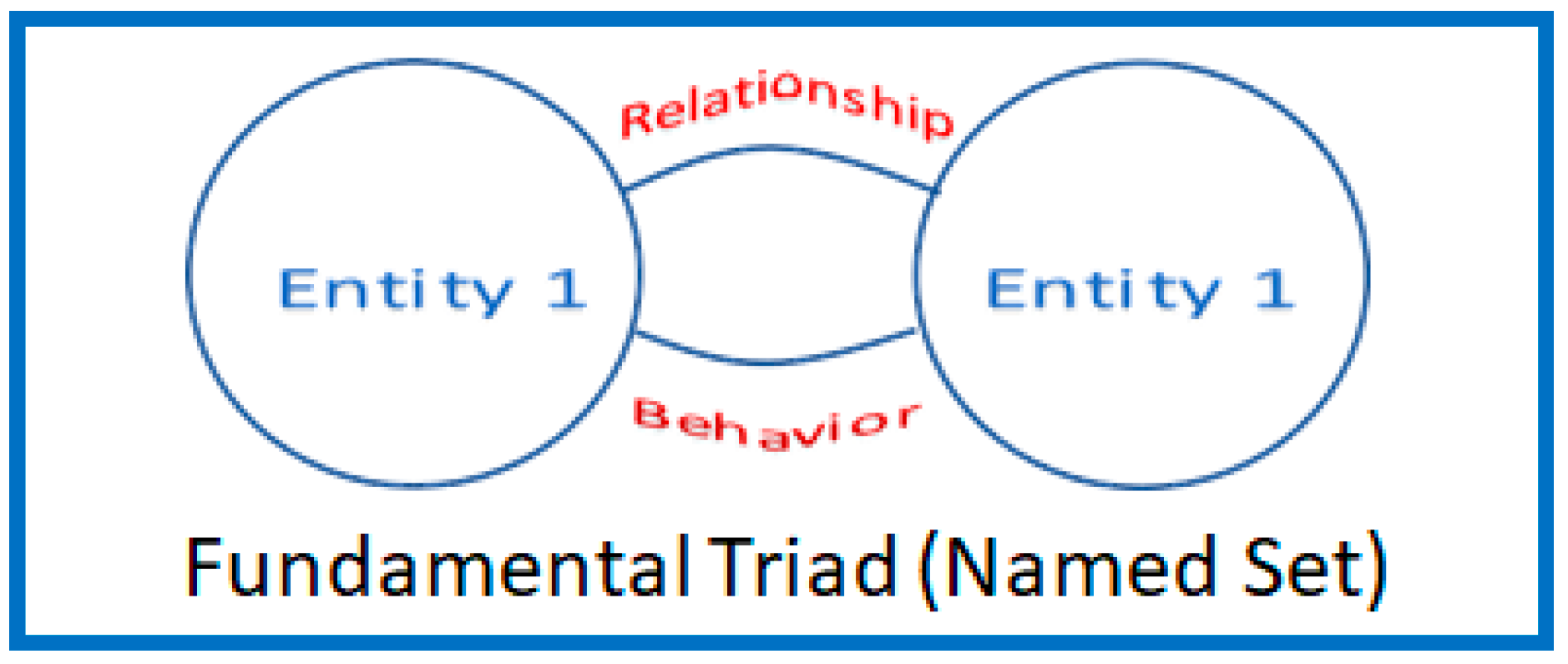
3.1. Fundamental Triad or a Named Set
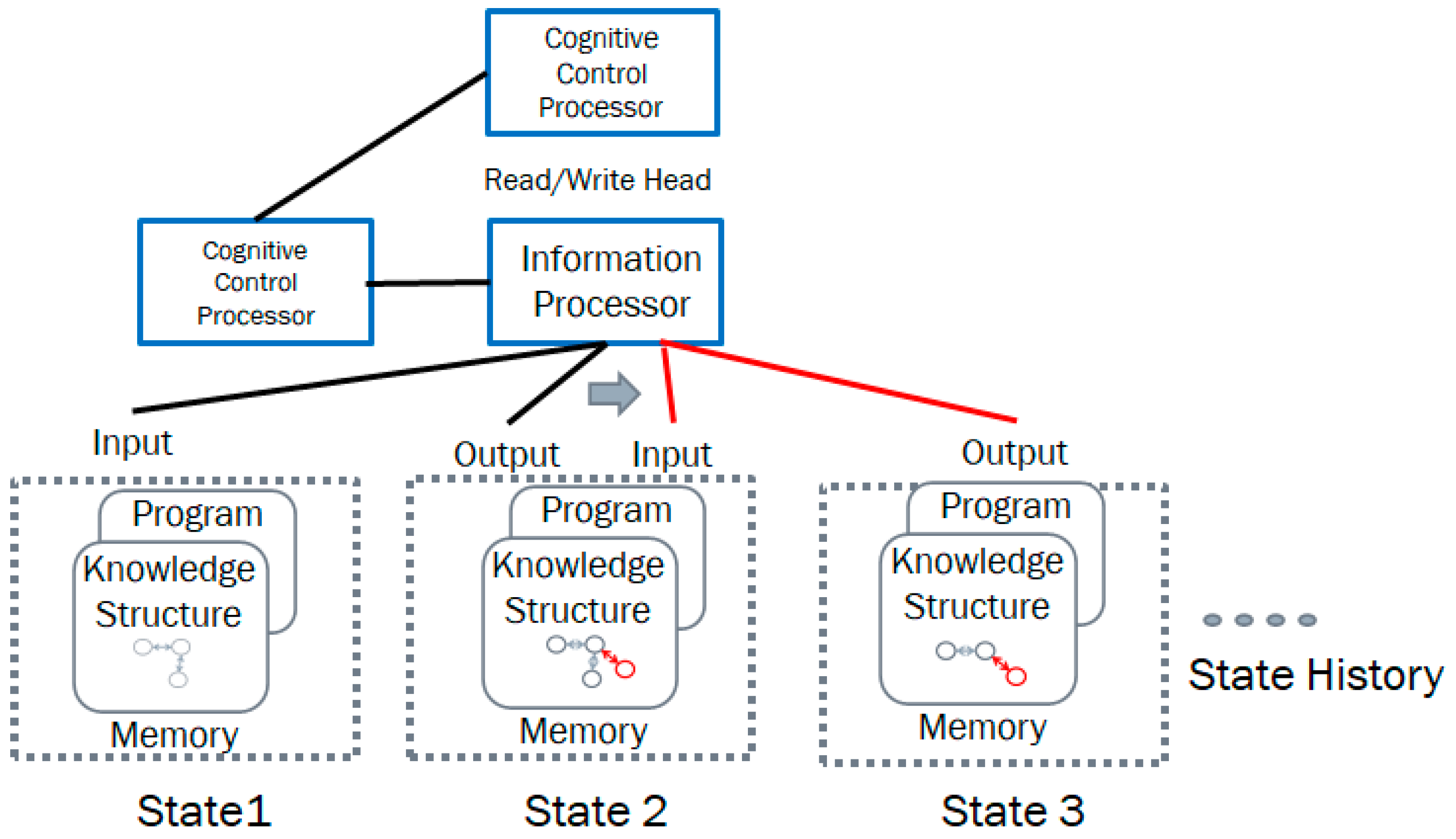
3.2. Knowledge Structure
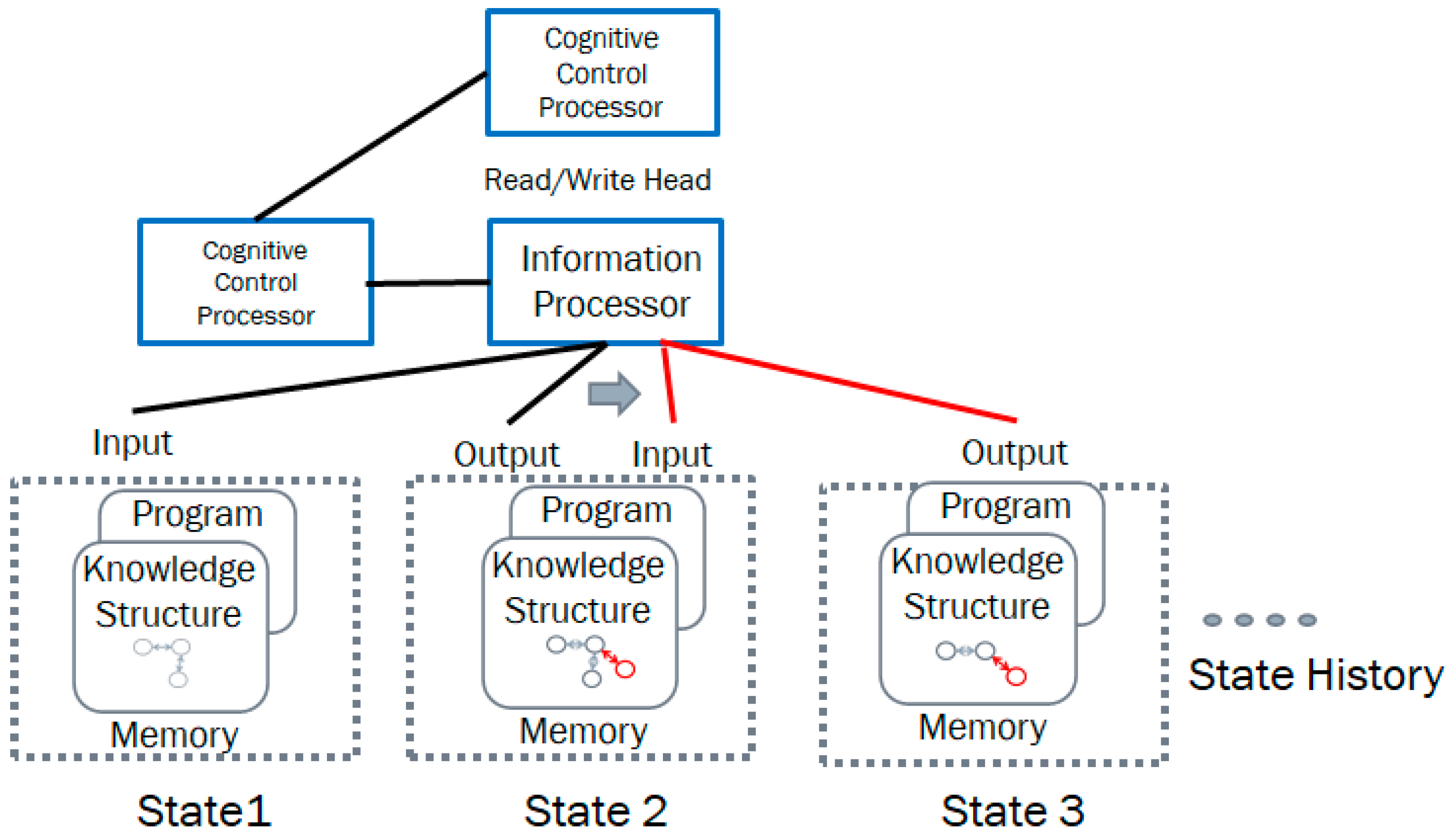
3.3. Structural Machine
- The unified control device CM regulates the state of the machine.
- The unified processor performs the transformation of the processed structures and their actions (operations) depending on the state of the machine and the state of the processed structures.
- The functional space, which in turn consists of three components:
- The input space which contains the input knowledge structure.
- The output space which contains the output knowledge structure.
- The processing space in which the input knowledge structure is transformed into the output structure.
3.4. Oracles and Self-Managing Computing Structures
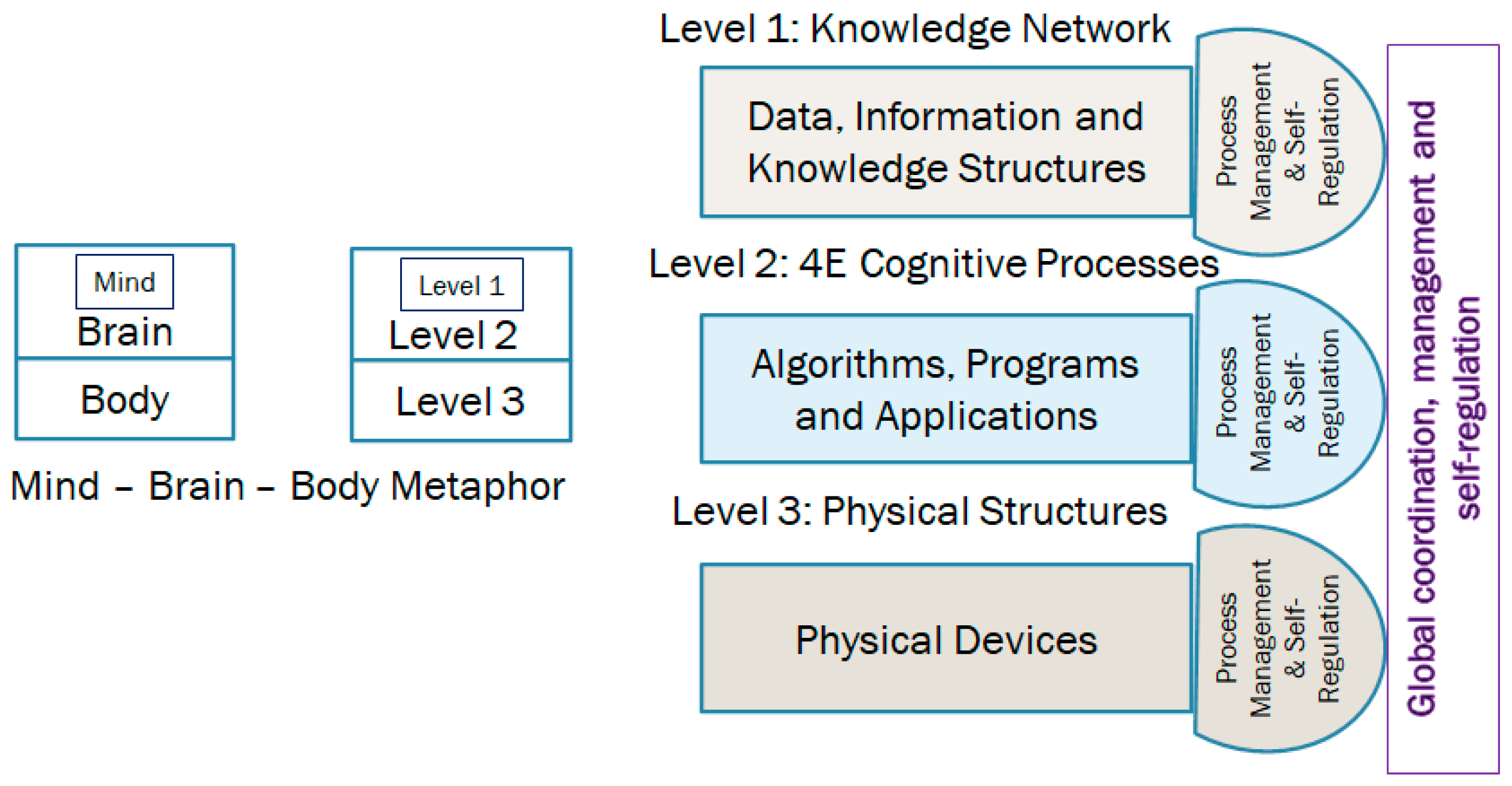
3.5. Triadic Automata and Autopoietic Machines with Cognitive Behaviors
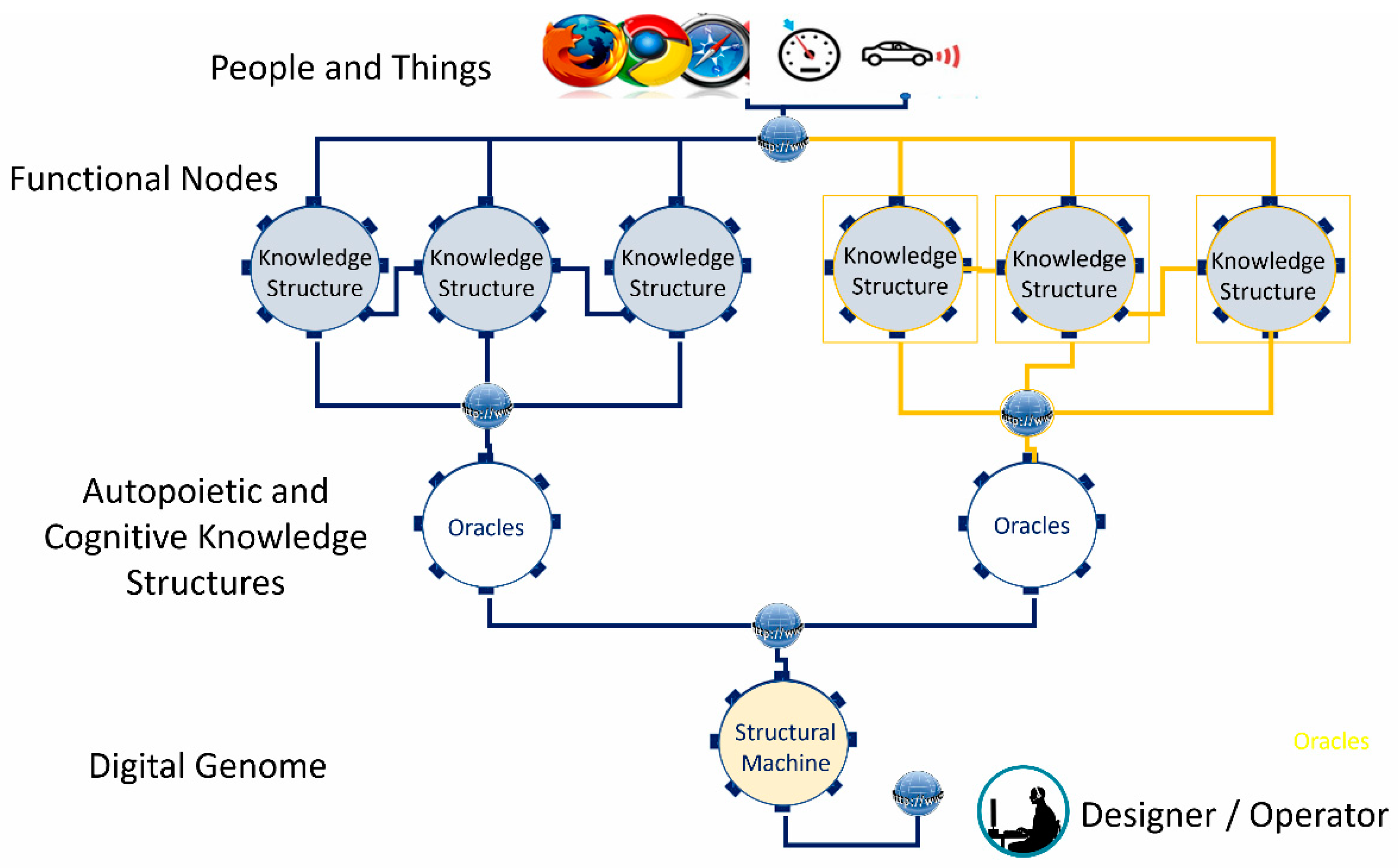
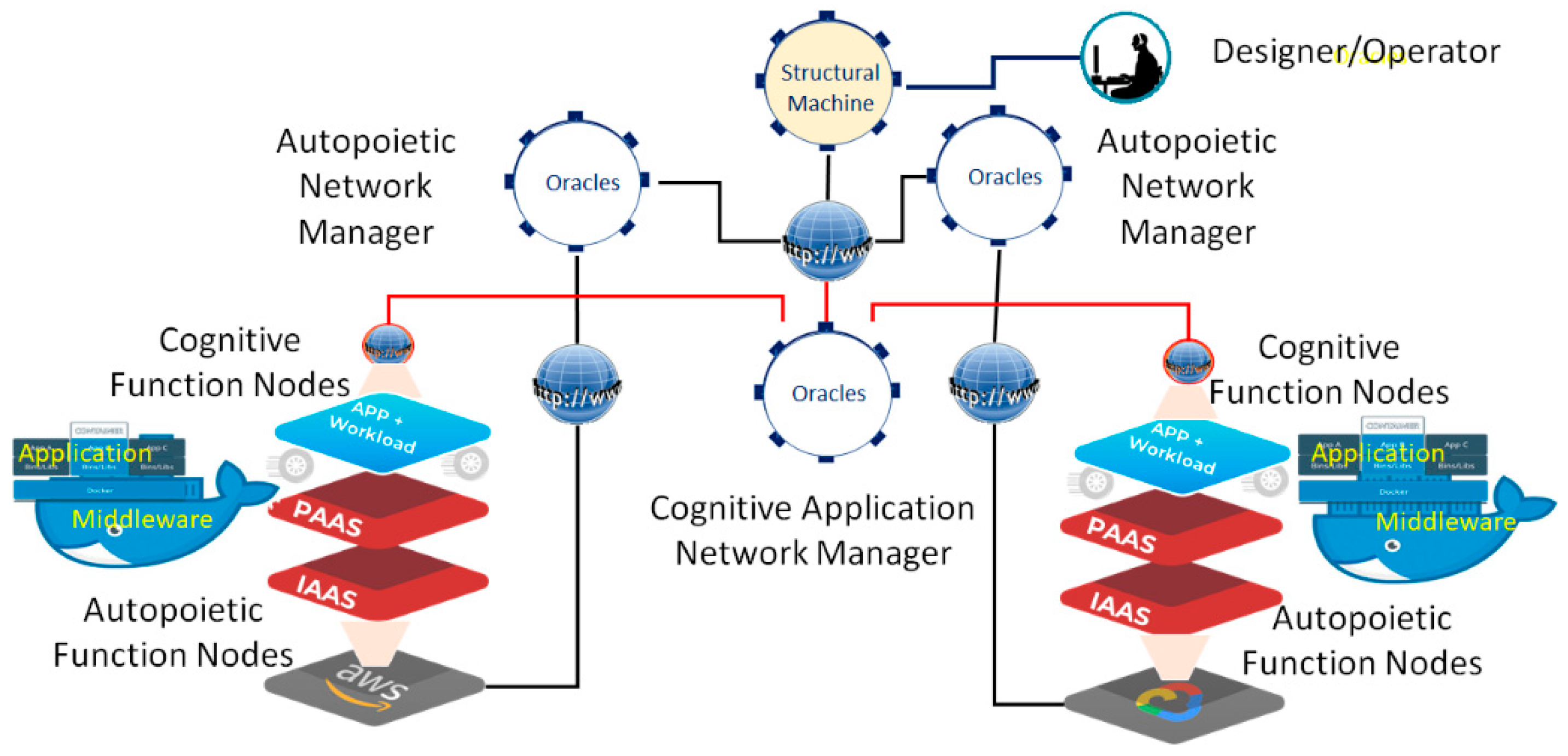
4. Infusing Autopoietic and Cognitive Behaviors into Existing Information Technology Use Cases
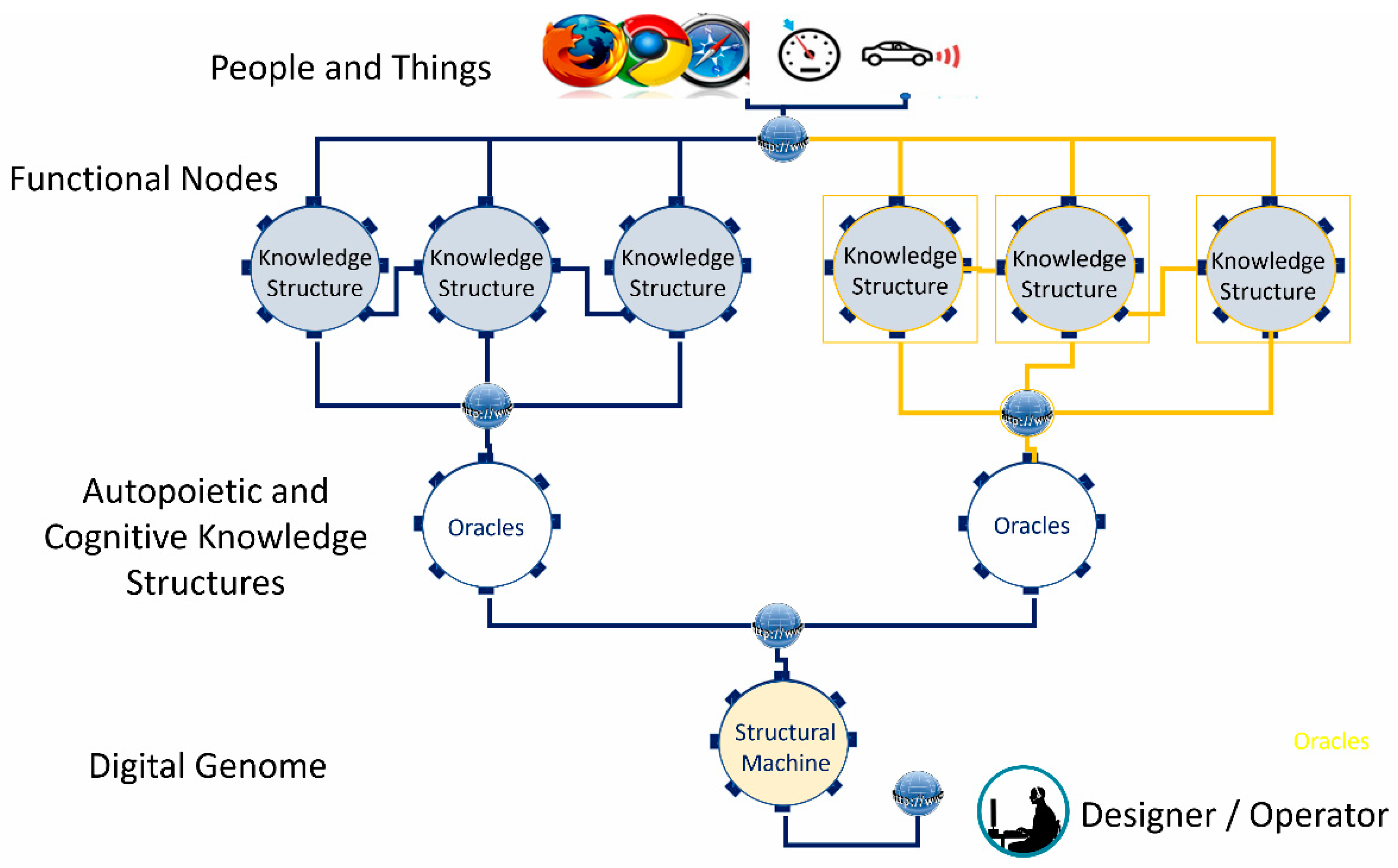
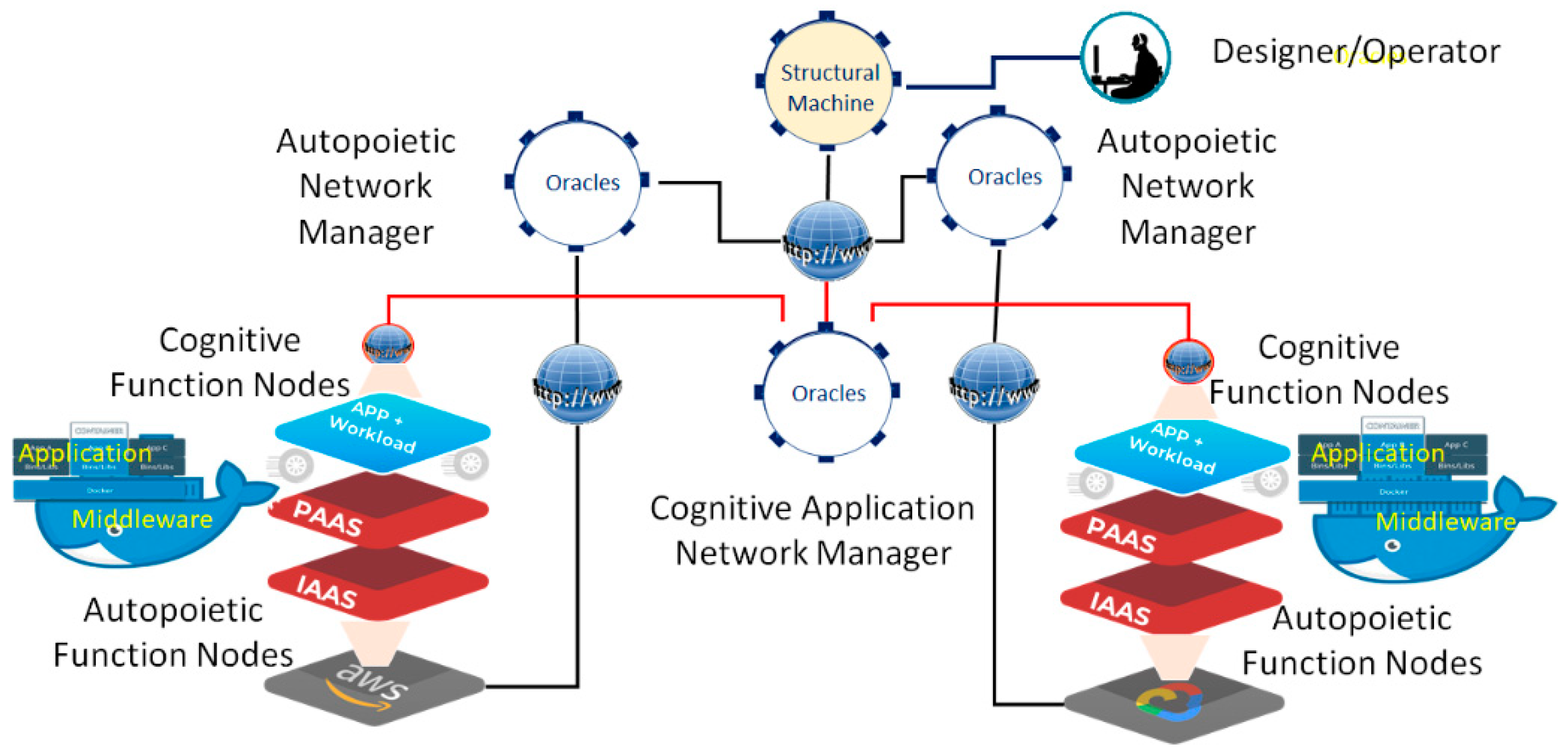
- The Digital Genome Node: Contains both the cognitive “reasoning” processes and the autopoietic “life” processes to configure, monitor, and manage the downstream resources (e.g., IaaS, PaaS, and application component workloads, which include both programs in executable form and associated data). Operations defined [15,17] in the digital genome provide the required behaviors, such as replication, transcription, and translation, to deploy appropriate downstream networks and their component functions just as cellular organisms do. By “life” processes we mean the structure, its initial state information, knowledge about resources, and processes to configure, monitor, and manage based on known-best-practice knowledge encapsulated in executable form. Examples are executable programs to configure, monitor, and manage IaaS, PaaS resources, and application business process executables as workloads and associated data using local resource managers provided by multiple vendors.
- Autopoietic Network Node: Contains knowledge about the autopoietic “life” processes that deal with configuring, monitoring, and managing the resources using replication, transcription of policies, and best practices to execute them. The autopoietic network node contains the knowledge structures that configure, monitor, and manage downstream autopoietic function nodes that are designed to configure, monitor, and manage the local resources.
- Autopoietic Function Node: Contains knowledge about the autopoietic “life” processes that deal with configuring, monitoring, and managing the local resources using replication, transcription of policies, and best practices to execute them. For example, if the resources are available in a public cloud, the autopoietic node deploys the executable programs that use local management programs such as Kubernetes, and containers or scripts that provision, monitor, and manage the resources. The IaaS autopoietic managers configure, monitor, and manage the cloud IaaS services using various scripts or tools. The PaaS autopoietic manager configures, monitors, and manages PaaS services in the local environment. For example, Dockers and Kubernetes are configured and managed in the local environment using local scripts or tools. The knowledge structures in these nodes are designed to capture local resources and manage them. Databases, web servers, and other middleware are examples of PaaS managed by the autopoietic PaaS function node.
- Cognitive Network Node: Contains knowledge about the application-specific “life” processes that deal with configuring, monitoring, and managing the application workloads and associated data using replication, transcription of policies, and best practices to execute them. The cognitive network node contains the knowledge structures that configure, monitor, and manage downstream application components as cognitive function nodes that are designed to configure, monitor, and manage the application executables and associated data. For example, the cognitive function has the knowledge about the components of the application such as the web component, application logic component, and database component, as well as where to deploy, monitor, and manage them based on best-practice policies when fluctuations point to potential instabilities. When a local component fails, the cognitive function node has the knowledge to recover with auto-failover or to configure based on recovery position objective (RPO) and recovery time objective (RTO), or to recover without service description or auto-scale to maintain stability using replication and managing the data to maintain service while replicating, etc.
- Cognitive Function Node: Contains knowledge about configuring, monitoring, and managing the local application function using the PaaS and IaaS resources made available with autopoietic function nodes.
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Von Neumann, J. Theory of Self-Reproducing Automata; Burks, A.W., Ed.; University of Illinois Press: Urbana, IL, USA, 1966; p. 71. [Google Scholar]
- Luisi, P.L. Autopoiesis: A review and a reappraisal. Naturwissenschaften 2003, 90, 49–59. [Google Scholar] [CrossRef] [PubMed]
- Copeland, B.J. The Church-Turing Thesis. In The Stanford Encyclopedia of Philosophy; Edward, N.Z., Ed.; Stanford University: Stanford, CA, USA, 2020; Available online: https://plato.stanford.edu/archives/sum2020/entries/church-turing/ (accessed on 30 December 2021).
- Church, A. A note on the Entscheidungsproblem. J. Symb. Log. 1936, 1, 40–41. [Google Scholar] [CrossRef] [Green Version]
- Turing, A.M. On computable numbers, with an application to the Entscheidungsproblem. Proc. Lond. Math. Soc. 1937, 2, 230–265. [Google Scholar]
- Gubbi, J.; Buyya, R.; Marusic, S.; Palaniswami, M. Internet of Things (IoT): A vision, architectural elements, and future directions. Future Gener. Comput. Syst. 2013, 29, 1645–1660. [Google Scholar] [CrossRef] [Green Version]
- Buyya, R.; Yeo, C.S.; Venugopal, S.; Broberg, J.; Brandic, I. Cloud computing and emerging IT platforms: Vision, hype, and reality for delivering computing as the 5th utility. Future Gener. Comput. Syst. 2009, 25, 599–616. [Google Scholar] [CrossRef]
- ANunet. Whitepaper: A Global Decentralized Framework. Available online: https://nunet-io.github.io/public/NuNet_Whitepaper.pdf (accessed on 30 December 2021).
- Mao, H.; Schwarzkopf, M.; Venkatakrishnan, S.B.; Meng, Z.; Alizadeh, M. Learning scheduling algorithms for data processing clusters. In Proceedings of the ACM Special Interest Group on Data Communication, Los Angeles, CA, USA, 21–25 August 2017; ACM Press: New York, NY, USA, 2019; pp. 270–288. [Google Scholar]
- Ghafouri, S.; Saleh-Bigdeli, A.A.; Doyle, J. Consolidation of Services in Mobile Edge Clouds using a Learning-based Framework. In Proceedings of the 2020 IEEE World Congress on Services (IEEE SERVICES 2020), Beijing, China, 7–11 July 2020; IEEE: New York, NY, USA, 2020; pp. 116–121. [Google Scholar]
- Brandherm, F.; Wang, L.; Mühlhäuser, M. A learning-based framework for optimizing service migration in mobile edge clouds. In Proceedings of the 2nd International Workshop on Edge Systems, Analytics, and Networking, New York, NY, USA, 25 March 2019; pp. 12–17. [Google Scholar]
- Cut Off from the Cloud: How Free Speech-Touting Parler Became a Tech Industry Pariah. 13 January 2021. Available online: computerweekly.com (accessed on 30 December 2021).
- Burgin, M.; Mikkilineni, R. From Symbolic Computation to Super-Symbolic Computation, EasyChair Preprint No. 6559. 2021. Available online: https://easychair.org/publications/preprint_open/PMjC (accessed on 30 December 2021).
- Burgin, M. Theory of Information: Fundamentality, Diversity, and Unification; World Scientific: Singapore, 2010. [Google Scholar]
- Burgin, M. Triadic Automata and Machines as Information Transformers. Information 2020, 11, 102. [Google Scholar] [CrossRef] [Green Version]
- Burgin, M.; Mikkilineni, R.; Phalke, V. Autopoietic Computing Systems and Triadic Automata: The Theory and Practice. Adv. Comput. Commun. 2020, 1, 16–35. [Google Scholar] [CrossRef]
- Burgin, M.; Mikkilineni, R. From Data Processing to Knowledge Processing: Working with Operational Schemas by Autopoietic Machines. Big Data Cogn. Comput. 2021, 5, 13. [Google Scholar] [CrossRef]
- Burgin, M.; Mikkilineni, R. Symbiotic information processing: A methodological analysis. In Proceedings of the Theoretical and Foundational Problems in Information Studies (TFP), is4si Summit 2021, Online, 12–19 September 2021. [Google Scholar]
- Cockshott, P.; MacKenzie, L.M.; Michaelson, G. Computation and Its Limits; Oxford University Press: New York, NY, USA, 2012; p. 215. [Google Scholar]
- Yanai, I.; Martin, L. The Society of Genes; Harvard University Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Stanislas, D. Consciousness and the Brain: Deciphering How the Brain Codes Our Thoughts; Tantor Audio: New York, NY, USA, 2014. [Google Scholar]
- Stanislas, D. Reading in the Brain: The New Science of How We Read Revised and Updated; Penguin Books: New York, NY, USA, 2010; p. 10. [Google Scholar]
- Damasio, A. Self Comes to Mind. Pantheon, a Division of Random House; Pantheon: New York, NY, USA, 2010. [Google Scholar]
- Hawkins, J. A Thousand Brains: A New Theory of Intelligence; Basic Books: New York, NY, USA, 2021. [Google Scholar]
- Mikkilineni, R.; Burgin, M. Structural Machines as Unconventional Knowledge Processors. Proceedings 2020, 47, 26. [Google Scholar] [CrossRef]
- Burgin, M. The General Theory of Information as a Unifying Factor for Information Studies: The Noble Eight-Fold Path. Proceedings 2017, 1, 164. [Google Scholar] [CrossRef] [Green Version]
- Burgin, M. Theory of Named Sets; Nova Science Publisher Inc.: New York, NY, USA, 2011. [Google Scholar]
- Burgin, M. Theory of Knowledge: Structures and Processes; World Scientific Books: Singapore, 2016. [Google Scholar]
- Burgin, M. Data, Information, and Knowledge. Information 2004, 7, 47–57. [Google Scholar]
- Mikkilineni, R.; Morana, G.; Burgin, M. Oracles in Software Networks: A New Scientific and Technological Approach to Designing Self-Managing Distributed Computing Processes. In Proceedings of the 2015 European Conference on Software Architecture Workshops (ECSAW ‘15), Croatia, Balkans, 7–11 September 2015; ACM: New York, NY, USA, 2015. [Google Scholar]
- Burgin, M.; Mikkilineni, R. Cloud computing based on agent technology, superrecursive algorithms, and DNA. Int. J. Grid Util. Comput. 2018, 9, 193–204. [Google Scholar] [CrossRef]
- Mikkilineni, R.; Comparini, A.; Morana, G. The Turing o-Machine and the DIME Network Architecture: Injecting the Architectural Resiliency into Distributed Computing. Turing100, The Alan Turing Centenary, EasyChair Proceedings in Computing. 2012. Available online: https://easychair.org/publications/paper/gBD (accessed on 21 December 2021).
- Burgin, M. Superecursive Algorithms; Springer: New York, NY, USA, 2005. [Google Scholar]
- Burgin, M.; Mikkilineni, R. On the Autopoietic and Cognitive Behavior, EasyChair Preprint No. 6261, Version 2. 2021. Available online: https://easychair.org/publications/preprint_open/tkjk (accessed on 21 December 2021).

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mikkilineni, R. Infusing Autopoietic and Cognitive Behaviors into Digital Automata to Improve Their Sentience, Resilience, and Intelligence. Big Data Cogn. Comput. 2022, 6, 7. https://doi.org/10.3390/bdcc6010007
Mikkilineni R. Infusing Autopoietic and Cognitive Behaviors into Digital Automata to Improve Their Sentience, Resilience, and Intelligence. Big Data and Cognitive Computing. 2022; 6(1):7. https://doi.org/10.3390/bdcc6010007
Chicago/Turabian StyleMikkilineni, Rao. 2022. "Infusing Autopoietic and Cognitive Behaviors into Digital Automata to Improve Their Sentience, Resilience, and Intelligence" Big Data and Cognitive Computing 6, no. 1: 7. https://doi.org/10.3390/bdcc6010007
APA StyleMikkilineni, R. (2022). Infusing Autopoietic and Cognitive Behaviors into Digital Automata to Improve Their Sentience, Resilience, and Intelligence. Big Data and Cognitive Computing, 6(1), 7. https://doi.org/10.3390/bdcc6010007