1. Introduction
With the development of wireless communication technology, the requirements for intelligent computing have significantly increased. This can be attributed to the explosive popularity of wireless mobile terminals and further results in an extensive integration of various sensors in mobile devices, thus providing the powerful sensory and computing ability of devices. Under such conditions, the transmission of data, including images and videos, requires wide frequency bandwidth [
1]. The related studies have proven that data transmitted in this way contains a large amount of repeated and useless information, such as videos with limited motion activity captured by a traffic camera at a certain moment. Therefore, it is urgently needed to develop a mechanism to cognize data of interest to be transmitted [
2].
Fortunately, extensive research has been conducted on learning the network’s transmission data using artificial intelligence (AI) algorithms to realize intelligent networks [
3]. Existing studies have focused on data analysis by AI algorithms using data acquired by a network for the purpose of further optimizing communication, computation, and storage resources. For instance, the software can be used to define a network and realize network self-learning control strategies. However, enormous resources are required to acquire and transmit network data [
4].
Furthermore, when making decisions on network and intelligent applications, it is required to offload massive differentiated data to the cloud where data are processed by AI algorithms (e.g., deep learning) to obtain an optimal decision. However, a centralized model of cloud-related decision-making not only severely increases the pressure on traditional networks, but has also made it difficult for a cloud server to handle such complicated and differentiated multi-dimensional environmental information.
Due to different requirements of AI services, the demands for network latency and resources also differ. Thus, the future network needs to deploy communication, computing, and storage resources of the network in a dynamic and intelligent way. Using a multi-time scale, deployment and scheduling of a network can be realized with the resources including all smart terminal devices, edges, and cloud-computing servers in the network [
5]. Service cognition engines and resource cognition engines can be used to realize the cognition of business services and network resources, respectively.
Currently, it is still challenging to share and distribute multidimensional resources when a network is heterogeneous and business requirements are real-time and dynamic. According to existing studies, AI can better realize management of communication, computation, and storage resources, so it will be an important part of future 6G networks [
6]. Moreover, along with the development of intelligent devices, edge devices require the interaction of massive data and model parameters, which proves the bright future of distributed AI.
Moreover, in a 5G communication network, information exists in the form of codes. For instance, a large-scale MIMO antenna [
7] can better handle capacity, reduce latency, and enhance the transmission reliability. However, this system still requires man-make designs. Therefore, in a 6G network, it is necessary to realize an initial interaction of information [
8]. Namely, in a 6G communication system, intelligent devices should cognize a user’s demands using AI algorithms and collect valuable information of the user, and finally realize initial interaction with the user.
Thus, the future network will have the following features: (i) customized services: demands on network resources can be customized based on the needs of an intelligent service; (ii) value transmission: the future network is capable of realizing the transition from content transmission to value transmission; (iii) proactive interaction: the network system in the future will analyze human needs and interact with humans proactively and, thus, transmit both information and value while interacting.
However, the question is how to realize transmission and interaction of information value. The transmission of information can be realized based on the traditional Shannon information theory, i.e., the original information is transmitted after being coded, and it is decoded into the original information after being transmitted. Next, the question of how to realize the transmission of information value arises. Thus, it is necessary to measure information value.
To address these challenges, in this paper we propose the 6G MailBox Theory, namely, a cognitive information carrier to enable distributed algorithm embedding for intelligent networking, as shown in
Figure 1. There are some variations that include the word “cognitive information” and/or the word “mailbox”. Therefore, Cognitive Information Theory and Mailbox Theory are widely accepted too. Compared with the traditional mailbox, our proposed mailbox is an intelligent agent carrying information. Using mailbox theory, a smaller amount of data is required for transmission and higher reliability of decision-making can be achieved. Thus, with the information cognition based on the mailbox theory, the network will not only overcome the time and space constraints for information transmission in a traditional network, but will also realize the optimal joint decision-making.
In summary, the contributions of this paper are included as follows:
6G Network Architecture: In order to meet the requirements of intelligence, customization, and value transmission of a 6G network, a new type of network integrating distributed intelligent network, active interactive network, and cognitive information transmission have been proposed. The distributed intelligent network, proactive interaction network, and cognitive information transmission are introduced in detail.
6G Mailbox Theory: We propose the 6G mailbox theory and introduce its features, including polarity, traceability, dynamics, convergence, figurability, and dependence. Furthermore, the key technologies in realizing 6G mailbox theory are introduced, including extraction of information value based on knowledge graph, information cognition based on embedding distribution learning and blockchain-based safe transmission of cognitive information.
Performance Evaluation: In order to verify the proposed 6G mailbox theory, we establish a cognitive communication system assisted by deep learning, and the information is cognized and encoded by it with deep learning. The experimental results show that, compared with encoding of a traditional communication system, less data can be transmitted with the proposed cognitive communication system, while the transmission error is relatively small.
Driven by the three design issues of 6G cognitive information theory, the following sections are associated with three contributions of this article and are organized as
Figure 2.
Section 2 and
Section 3 summarize the evolution of 5G and 6G networking. On this basis,
Section 4 and
Section 5 propose an integration network architecture of distributed intelligent, active interact, and cognitive information transmission. Based on the new designed 6G network architecture, we introduced our novel 6G MailBox theory.
Section 6 proposes a concept of information fusion for data life cycle extensions.
Section 7 proposes information measurement based on cognitive computing, which is the central idea of 6G MailBox theory.
Section 8 introduces new technologies for information cognitive.
Section 9 presents the limits of cognitive information from the aspect of energy efficiency optimization. Based on the above theoretical and technique basis, our 6G MailBox theory will be realized as a cognitive information carrier to enable distributed algorithm embedding for intelligence networking. Finally,
Section 10,
Section 11 and
Section 12 introduce the establish and assessments of cognitive communication system, as well as some cognitive information applications for future usage of the mailbox theory.
2. Related Work
In this section, some relevant research on the evolution of the 6G network, including the evolution of communication networks, is introduced. 5G networks, mobile edge computing, and the application of intelligent algorithms in networks and information with the development of artificial intelligence are introduced as well.
2.1. The Evolution of 5G
Wireless-communication technologies for different application scenarios can be roughly divided into short-distance communication technologies and wide-area network communication technologies (e.g., cellular networks and low-power WAN). These technologies have promoted the development of mobile edge networks. The explanations of how technologies are fused, as well as the role that data-transmission can play, are elaborated in the following.
From the perspective of transmission distance, multi-scale sensor communication can be divided into two types: short distance communication and wide-area network (WAN) communication. The former includes Zigbee, Wi-Fi, Bluetooth, and Z-wave technologies, which are widely used in wireless access networks; whereas the latter include communication technology with low-rate service demand. The low-power WANs (LPWANs) [
9] can be divided into two categories: LPWANs, which work in an unauthorized spectrum, such as LoRa and SigFox, and the 2G/3G/4G cellular communication technologies, which are supported by 3GPP and work in an authorized spectrum, such as EC-GSM, LTE Cat-m, and NB-IoT [
10]. The data-transmission rates of these technologies are different, but they are all far lower than that of the current commercial 5G, which makes them suitable for applications with low transmission rates, such as smart electricity meters and large-scale sensor communications.
Currently, the emerging fifth generation of mobile communication (5G) network [
11] faces the challenging tasks of supporting thousands of users with a transmission rate of nearly 10 Mb/s. More specifically, the linking of hundreds of thousands of mobile devices for the deployment of large-scale sensor networks would require stronger spectrum efficiency, wider coverage, reinforced signaling efficiency, and significantly reduced communication distance compared to 4G networks.
Further, 5G applications can be divided into the three following categories:
Enhanced broadband mobile communication enables better user experience and access with wider bandwidth in order to support higher quality multimedia services and more living experience than 4G;
Massive IoT communication provides signaling control with a higher connectivity density and better real-time optimization and supports efficient access and management of massive IoT devices at low cost and power consumption;
Ultra-latency and ultra-reliability communication provides users with millisecond-level end-to-end latency and nearly a 100% guarantee for business reliability.
To satisfy the requirements of 5G for better performance, faster speed, better connection, higher reliability, shorter latency, and specific topological structures in application scenarios, many designs and techniques have been presented. For instance, for the purpose of improving the transmission rate, it has been proposed to spread the spectral range (e.g., millisecond-level communication) to deliver more information while improving the transmission rate. In addition, in order to enhance the spectral efficiency, the upper limit of transmission rate under the unit spectral resource of plots has been recommended using massive MIMO technology [
7] and high-order modulation technology.
Moreover, in order to enhance data traffic, it has been suggested to adopt a more compact plot arrangement and deploy more plots in each unit area to provide more capacity and more spectrum reuse. In addition, the full-spectrum access adopted by 5G involves the hybrid networking of 6 GHz and lower frequencies with higher frequencies, in which low frequencies are essential to 5G for seamless coverage, while higher ones are supplementary for the enhancement of rate at hot spot areas [
12]. These frequencies are combined to fully make use of their advantages and jointly satisfy the needs of 5G for seamless coverage, fast speed, and great capacity.
Further, to achieve the demands for ultralow latency, ultra-high reliability, and intelligence, 5G uses three main techniques in the wireless access network: separation of the control plane and the data plane based on a software-defined network, separation of up and down paths, elastic matching of wireless resources, and content distribution, and network integration in the core network. Furthermore, to make network services satisfy the needs and individualized services required by users, realize deep integration of networks and businesses, and provide better services, the network slicing technique has been proposed. To be specific, multiple end-to-end virtual sub-networks will be built pertinent to the actual needs in different business scenarios, and network slicing techniques can be used to virtualize network functions so that one or more network services can be provided neatly to meet the needs of the party requiring such slices [
13].
Moreover, for tasks characterized by extensive computation, extensive data, and latency sensitivity, such as the visual services of a wearable camera, using the mobile edge cloud computing has been recommended to move the business platform to the network edge and thus provide nearby mobile users with additional capacity for business computing and data caching.
Based on the presented analysis, the introduction of 5G technology will change our lives significantly [
14]. First, it will enhance the data transmission rate significantly while guaranteeing data reliability. Second, it will integrate more IoT devices, including different types of information devices, such as new-type sensors, embedded sensors, edge computing units, biosensors, and braincomputer interaction, and finally it realizes the automation and intelligent service in the physical world.
2.2. Mobile Edge Computing
It is anticipated that future wireless communication networks should be able to handle an unprecedented amount of big data, so it will be necessary to employ data-driven approaches to optimize new technologies towards improving performance.
The guaranteed growth in the amount of big data and mobile traffic is undoubtedly a great challenge to the existing communication technologies and frameworks, since it could lead to a shortage of computing and network resources. However, if data analysis and control logic are implemented on the cloud, it will be difficult to meet all business requirements for resource allocation and transmission delay. Namely, mobile edge computing is capable of supporting services with high performance, low delay, and high bandwidth, so it can accelerate the downloading speed of various contents, services, and applications on a network where users can enjoy an uninterrupted high-quality web experience. With the introduction of an MEC (Mobile Edge Computing), the effective fusion of wireless networks and Internet technology functions [
15], such as computing, storage, and processing, have been added to the wireless-network side to establish an open platform for embedded applications. The information interaction between a wireless network and a business server is performed through a wireless API by fusing the wireless network and business, thus upgrading the traditional wireless base-stations into intelligent base-stations. For the business level (e.g., IoT, video, healthcare [
16], retail, etc.), the MEC can provide customized and differentiated services to the industry, thus improving the network’s utilization efficiency and added value. Simultaneously, with strategical deployment (especially geographic location) of mobile edge computing, the advantages of low delay and high bandwidth can be achieved. The MEC can also obtain real-time wireless network information and accurate location information, therefore providing more accurate services.
2.3. Intelligent Algorithm for Network
By being based on artificial intelligence (AI), deep learning, as a method that has been studied extensively, can realize the learning process using neural networks. Theoretically, deep learning can operate in a data-driven way to relieve system designers from mathematical modeling and expert supervision [
17]. In addition, when massive data are available, deep learning can be used for image classification, speech recognition, and unmanned driving [
18]. The deep learning-based networks have a layered architecture and simulate the human brain’s functions when processing information. This enables the learning of data characteristics without requiring prior design of the original data characteristics. Under such conditions, massive original data, layer-by-layer extracted characteristics, and learning architecture can be used to establish a complicated non-linear mapping relation between input and output data. Through massive data training, a deep learning network adjusts the parameters of each network layer. It enables understanding an effective character representation of the data and improves the accuracy of classification or forecasting.
Furthermore, as the complexity of 5G networks is continuously increasing, making the development of theoretical models more difficult, so does the modeling and optimization of standard mathematical tools. Furthermore, with a rapid increase in the number of connected devices to the 5G network, more and more data needs to be processed, which can impact the design of communication networks [
19]. Nonetheless, recent progress in advanced techniques and the rapid acceleration of dedicated hardware facilities (e.g., GPU) for data processing, have made it practical to apply deep learning algorithms to wireless network optimization.
Bear in mind that deep learning has been widely used to enhance network performance [
20]. However, when deep learning is used in specific wireless communication businesses, it not only needs the high-speed processing required by network changes, but also faces complicated and diversified sources of data. Thus, to establish a deep learning model, it is needed not only to take reference from massive multi-type data to improve the prediction ability, but also to recognize and understand massive data to acknowledge the correlation between data elements. Nevertheless, due to the complexity and the large amount of data, such models and correlations are always ignored. Thus, deep learning algorithms are highly dependent on data. On the one hand massive data are required for training deep learning models; on the other hand, data quality is critical to the quality of the training model. Therefore, it has still been challenging to improve the quality and value of data simultaneously.
2.4. Information Intelligence
Based on the previous discussions, 5G communication using AI technologies can achieve fast transmission of information and processing where AI can be effectively utilized to extract wanted information from the massive data. Communication technologies and AI can integrate information from different regions, making the information and values more diversified. However, due to the improvement in digital communication systems in the physical world, it is necessary to interpret and use information transmitted by a communication system in a more profound way [
21]. The information carried by physical substances (such as sound, light, electricity, energy, and disk), has its own value.
In view of this, exploring the information value not only will relieve the burden of a communication system, but will also deliver the information of better value, which will bring a brand-new experience to the user [
22]. Moreover, the success of the digital information era is mainly attributed to Shannon’s information theory, which quantizes the information amount into entropy value based on the statistical probability of an event without taking into consideration the context of the information.
In the real world, the production, transmission, and application of information value are all affected by the intelligence and educational level of people. For instance, the human brain can have different connections and imaginations toward different things and information. However, by being limited by physical conditions, the processing of information value by humans is restricted by both time and space. In terms of time, people can hardly learn and summarize knowledge ceaselessly, and in terms of space, restrictions from physical and cultural differences make efficient and large-scale interaction of knowledge impossible. Hence, the main question is whether the existing communication systems and AI algorithms can realize the transmission of information value and knowledge.
3. Intelligence Networking for 6G
3.1. The Evolution of 6G
After evolution and development, communication technologies have evolved from human-body information transmission to simple signal communication via wired and wireless communication systems. In the current situation of widespread mobile-device usage, data transmission from devices to edge clouds mainly relies on the most widely used wireless/mobile-communication technologies. From the perspective of transmission fusion, existing technologies and related literature can be summarized in terms of which tasks or data are transferred to which computing node, i.e., what, where, how, and when to transmit. The question of how to transmit refers to determining what is currently the most widely used wireless/mobile communication network and technology. The questions of what, where, and when to transmit relates to the fusion and joint optimization of the network communication model and resources.
Due to the requirements for power consumption, coverage, transmission rate, cost, number of connected devices, and other related parameters, the IoT wireless communication technology has been a driving force in supporting different application scenarios, including short-range communication, low-power wide-area communication, and mobile cellular network communications. The mentioned communication technologies, with mobile cellular communication as the main research object, are established using multi-scale intelligent sensors all over the heterogeneous IoT where a communication network with the fusion application is gradually forming. As mobile cellular-communication technology continues to evolve towards the sixth generation (6G), wireless access technologies have followed different evolutionary paths.
These technologies focus on performance and efficiency in highly mobile environments. With the first generation (1G), the basic mobile voice-communication needs were realized, while for the second generation (2G), capacity and coverage expansion was the main motivation. The third generation (3G) technology opened the door to a mobile broadband experience with higher data-exploration speeds. The fourth generation (4G) technology provided a wide range of telecommunications services, including advanced mobile services provided by mobile and fixed networks. The 4G also supported packet switching with high mobility and high data rates. The fifth generation (5G) technology aimed at changing the world by connecting everything. It not only focused on new frequency bands, but also pursued requirements for higher performance, greater speed, multiple connections, higher reliability, lower latency, higher universality, and specific topological structures in application fields. As for the sixth generation (6G), pervasive AI and edge intelligence will be redefined [
23], i.e., an ultra-flexible architecture will be designed and realized to introduce human-like intelligence to all levels of network systems.
In recent years, 5G has entered the fast track of commercial deployment, and 3GPP has released the standard schedule of 5G. 5G has opened a new era of interconnectivity of everything. It has also penetrated a variety of industries, including transportation, agriculture, and energy. The 5G networks can realize ubiquitous information acquisition and meet the requirements for key performance indicators under the scenarios of enhanced mobile bandwidth, large-scale IoT, high reliability, and low latency. With the development of 5G academia, industry, and other research communities have begun to look beyond 5G, and it is expected that the key technologies of the 6G mobile communication networks will be made available in 2023 [
6]. 6G will have a brand-new architecture and the capability to support the digitalization of the whole world [
24]. Through the reconstruction of people and scenes in the physical world to the digital world, 6G will give IoT cognitive devices and strong intelligence and interactions in ubiquitous interconnection. While 6G research is still in its infancy, researchers from Europe, the United States, and China have started to study 6G networks. It has been recognized that each new generation of mobile global standards appears every 10 years, and therefore 6G is expected to emerge around 2030. Moreover, 6G will have features of on demand service, strong AI seamless embedding, flexibility, and simplicity.
Table 1 summarizes the wireless technologies from 1G to 5G in terms of peak data rates and presents driver applications used in 6G. The data rate of 5G mobile systems increased from 1 Kbps to 10 Kbps, 10 Mbps, 100 Mbps, and up to 10 Gbps. It is expected that the upcoming 6G systems will achieve the goal of increasing data rates by 100 times to about 1 TBps or even higher. This expectation is based on the realization of edge intelligent components, which will allow edge-computing networks to realize self-adaptation and self-learning.
3.2. 6G Network Architecture
Based on above discussion, 5G mobile communication is getting faster and faster, supporting the enhanced broadband mobile communication, massive IoT communication, and ultra-latency and ultra-reliability communication. However, there are still challenges in the way to realize 6G [
25], as stated below:
Intelligence requirements: In the future 6G network, with the development of the Internet of Things (IoT), UAV communication, and satellite communication, the various sensors that will be deployed in the space-are-ground integrated network and the data collected by these sensors will need to be transmitted, analyzed, and processed in real time. With the development of artificial intelligence (AI), sensing devices are becoming more and more intelligent. Thus, in order to meet the requirements of the space-are-ground integrated network, the network needs to be a distributed intelligent network with connection, perception, transmission, storage and analysis;
Customization requirements: With the constant development of new technologies, network architectures will be more and more customized to meet the personalized needs of users and applications. For example, with the development of industrial IoT, industrial equipment has become more and more dependent on communication networks, and different kinds of industrial equipment have different delay requirements for specific tasks. Thus, the 6G network needs to meet the personalized needs of users and different applications, and active cognition of the demand of users and applications can be realized by a future network, and then active interaction can be realized;
Transmission requirements: Demand for data traffic-based services is growing even faster. It is predicted by International Telecommunication Union (ITU) that by 2030, global mobile data traffic will be 100 times as much as current traffic. The deployment of future intelligent applications, such as holographic-type communication and mixed reality, will require higher reliability and lower delay. Therefore, in order to meet the increasing demand of communication, the future communication mode needs to be improved to realize the transmission of information value.
In order to meet the above requirements of 6G network, distributed intelligent network based on cloud-edge-terminal, demand centered active interaction and value based information transmission, are proposed:
(1) Distributed Intelligent Network. In the traditional communication systems, centralized control architecture is generally adopted, and there are problems in the scalability and management for this type of architecture, especially in the allusion to massive terminals and business requirements. Moreover, with the development of AI, terminals are becoming more and more intelligent, and the existing network experiences difficulties in supporting such applications. Therefore, in the 6G network, the following are required:
Intelligence of communication infrastructure is necessary, that is, intelligence should be embedded from access network to core network to meet the personalized access and service of intelligent applications at any time and at any place;
Intelligent management is needed. In consideration of more access equipment in a 6G network and wider network coverage area of a 6G network, how to manage these network resources is a challenging problem [
26]. The introduction of a intelligent network control and resource scheduling is an effective solution. It is predicted that network autonomy and self-optimization can be realized with the introduction of AI and digital twin technology;
For perception, transmission, storage, and analysis of large scale data, the realization of sinking from cloud centralized type to edge distributed type is required. Specifically, (i) the integration of perception and transmission is required, that is, the integration of data perception and transmission should be realized; (ii) the deep fusion of cloud edge-terminal communication, computing, and caching resources should be realized, that is, horizontal distributed collaboration, vertical hierarchical collaboration, and hybrid collaboration should be realized through aggregation and decoupling of communication, computing and caching resources.
(2) Proactive Interactive network. Traditional communication systems generally focus on network functions. However, with the rapid growth of IoT devices, such network architectures will become more and more complicated and it will be difficult for them to expand. Moreover, it may be difficult for such architectures to meet the personalized demand of users or services. Therefore, a personalized demand-centered network should be established in the 6G era, to realize demand-driven control and management. For example, for users’ personalized demand, a user-centered network can be established, where users can define network functions to implement on-demand resource scheduling. Moreover, in consideration of changes in user demand, the network will adjust dynamically in real time according to the changes of user demand, thus to realize proactive interaction. This design requires the use of AI technology to unify the network layout. However, this design brings security concerns. As users pay more and more attention to personal data, security, and privacy issues, the protection of user data should be realized in a 6G network, and user data should be autonomous and controllable.
(3) Cognitive Information Transmission. Most traditional communication technologies are based on Shannon information theory, which excludes semantic modeling and analysis of information. With such communication systems, the transmission of the number of bits of information can be ensured, without concern for semantic characteristics or the value of information. However, this kind of transmission may produce a large amount of redundant data transmission, resulting in the waste of communication and computing resources. Therefore, more attention should be paid to the content of the transmitted information in the 6G network, and the semantic features of the information should be extracted and transmitted. Furthermore, with the development of deep learning, feature extraction technology is becoming more and more advanced. Therefore, different from traditional encoding and decoding mode, the cognition of information can be realized by extracting and mining the features of information content.
Based on the discussion above, we propose the 6G mailbox theory, i.e., a cognitive information carrier to enable distributed algorithm embedding for intelligence. With this network, value-centered transmission, service customization, and active interaction can be realized. Specifically, the 6G network will become an intelligent agent with self-organization, self-learning, self-adaptation, and continuous evolution capabilities. Intelligent dynamic deployment and sharing of communication, computing, and caching resources can be realized, data transmission can be secure and reliable, and differential adaptation can be conducted based on user demand. Therefore, in a 6G network, with a decentralized intelligent network architecture and transmission of information value, transmission of signaling can be greatly reduced to meet the requirements of intelligent services on ultra-low delay and ultra-high reliability.
4. Distributed Intelligent Network
In this section, we introduce the distributed intelligent network with a fusion of the cloud-edge-terminal. With the rapid development of AI chips, embedding intelligent algorithms in network infrastructures (access networks, edge infrastructures, core networks, and cloud infrastructures) is becoming a new reality. In a 6G network, the intelligence of networks can be realized by making full use of the sensing, communication, computing, and storage capabilities of network nodes. Unlike the traditional network, with separate transmission and computing, 6G will be more complex and highly distributed. It will be based on the integration of transmission, computing, caching, and intelligence. In this network, the distributed communication, computing, and caching resources perceive and transform into each other where cloud, edge cloud, and users are effectively collaborating with each other intelligently. Thus, in this way, not only the utilization of network communication, computing, and caching resources can be improved, but fast scheduling of services and resources is also realized to satisfy users experience.
Specifically, the architecture can be divided into resource cognition engine, service cognition engine, and network orchestration management layer. The resource cognition engine is responsible for perception and forwarding of heterogeneous communication, computing, and storage resources. The service cognition engine is responsible for the decomposition and scheduling of general and intelligence services. Based on the resource cognition engine and service cognition engine, the distributed intelligent control [
27], layout, and scheduling of the network are realized in a network orchestration layer. This aims to meet the demand of users and also make use of the complicated network environment. For example, the overall perception and measurement can be conducted by existing multidimensional communication, computing, and caching resources in a 6G network according to the service demand of users, so as to reasonably allocate and schedule services. Next, we introduce the realization of transmission and computing integration with the fusion of communication, computing, and caching resources through the cloud-edge-terminal collaboration.
As a supplement and extension of the limited terminal and spectrum resources, the aim is to reduce the cloud service access and transmission delay. Under these conditions, edge caching represents an efficient technology in the trade-off optimization scheme for cost and storage resources. The edge caching focuses on the three following questions: where to cache, how to cache, and what to cache. Specifically, to provide end-users with more accurate real-time processing and high-quality services, the personalized intelligent caching policy should be designed according to a user’s data as perceived and acquired by an edge network. This includes personal information, business requirements, location, mobility, epidemicity, and historical information. To achieve this, the most appropriate content and optimal caching placement node (edge cloud) should be selected, where caching content should be transmitted using the distributed data-transmission technology and placed on the computing nodes of an optimal edge cloud. Therefore, this section focuses mainly on the mainstream edge-caching strategies, which are as follows.
(1) Content caching and distribution: where content that can be cached and shared is determined based on the popularity of the content requested, user mobility, and type of content.
(2) Task caching [
28]: in the current era hardware devices, AI, and 5G communication technologies are becoming increasingly popular, and computing tasks frequently appear in the request results and service process of terminals. If a user requests a computing task that is not cached by an edge cloud, then it will be offloaded to the edge cloud to be completed before returning to the user. If a computing task is cached, the edge cloud will execute it directly and returns the result to the user. If results of the computing task have been cached on the edge cloud, then the results can be returned directly to the user. Therefore, task caching is often closely related to computing offloading.
(3) Collaborative caching: in a collaborative environment, users are served by a set of collaborative caching servers, i.e., edge clouds, which can share user request information. When the cooperating agents do not cache the user access request object, they obtain the corresponding request object from the web server on behalf of the user. Therefore, it is necessary to ensure that the acting caches in the caching architecture can effectively cooperate to improve the performance of the caching system. This requires collaborative filtering of content and tasks, data synchronization, and fusion storage technologies.
4.1. Communication, Computing and Caching Integration
The main question that arises is how to understand the mailbox theory. According to the aforementioned discussions, the mailbox theory should be applied to the entire communication system. To simplify this explanation, consider the mailbox theory from the aspect of terminals and communication, computing, and caching (3C) integration, as shown in
Figure 3. First, for terminal 3C integration, algorithms shall be embedded into terminals and terminal business data. To be specific, for intelligent terminal services, key performance indexes include capacity, latency, reliability, link count, and cost-effectiveness. The user service quality refers to the user’s satisfaction at the network level. Such satisfaction is associated with the realization status of the user’s expectation on a business, the user’s personal preference and environment, and the business itself. Specifically, a model between the user’s experience (service quality) and the network KPIs can be expressed as follows:
, where
f denotes a non-linear function that can be solved using AI algorithms.
The heterogeneity of services should also need to be considered, which means that different services require different storage capacities and computing resources. For instance, for simple push notifications, it is only needed to consider the communicating and computing abilities of a user’s device. However, in virtual reality (VR) games, the communicating, computing, and storing abilities of devices are all critical. Thus, a model between service KPIs and communicating, computing, and caching resources should be built.
For services, such as augmented reality (AR) games, the demands of services (i.e., the demand of the service for 3C resources) can be expressed as , where denotes the required computation amount, s denotes the required transmission amount, and o represents the caching amount. For instance, earlier caching can be made for scene rendering of VR games. Thus, modeling between service KPIs and 3C can be expressed as , hence the relation between the KPI and 3C can be obtained. However, the theories for explaining the integration of communicating, computing, and caching are yet to be determined. The information theory should explain the integration of terminal 3C businesses and limits of communicating, computing, and caching resources.
In the field of wireless-communication systems, network optimization problems have been extensively studied using an appropriate network configuration or a method of maximizing system performance. The network-optimization problem involves a wide range of wireless network-related research. Typical applications include resource allocation and management, system reconfiguration, task scheduling, and user QoS optimization. As shown in
Figure 4, a typical network-optimization process in a wireless-communication system includes the five following steps:
Network-resource perception. The transmission data fused in the network-optimization process includes: communication resources, such as channel state information, interference, noise, user or sensor position, spectrum, and time slice occupancy information; QoS information, such as delay and energy consumption rate and mobile state; computing resources; and storage resources at the node, edge cloud, remote cloud, and so on;
Network-status analysis. The optimization objective and model to be adopted can be determined by analyzing the perceived network-resource data. Currently, the most widely used analytical methods include human analysis and intervention, and automatic analysis and prediction based on AI. However, artificial analysis by domain experts is both costly and inefficient. In contrast, if an AI-based automatic-analysis method is adopted, then the network-optimization process becomes more intelligent, and this method is also conducive to the establishment of effective models with low complexity in various unmeasurable environments;
Mathematical representation and establishment of the model. Through the analysis of network resources and conditions, mathematical formulas can be derived to express the index data that needs to be optimized in the future, i.e., an optimization model containing objective functions and several constraints can be developed. The optimization objectives of the model can be, for instance, throughput, spectrum utilization, user-perceived delay, energy consumption and gain, facility deployment costs, or other parameters;
Collaborative optimization and algorithm execution. Collaborative optimization can be achieved using multiple performance-index parameters. Currently, the most commonly used methods for solving optimization problems are mathematical derivation-based methods, heuristic algorithms, and self-learning algorithms based on machine learning. The former adopts a mathematical derivation process, such as the Lagrange-multiplier or gradient-descent methods. These methods are ideal for solving problems involving explicit and convex objective functions. Heuristic algorithms adopt the heuristic neighborhood search process to find an optimal solution. Heuristic algorithms include the genetic algorithm, simulated annealing, particle swarm optimization, and the firefly algorithm. These algorithms do not require a derivative of an objective function. However, if the optimization complexity is sufficiently high, then they can usually provide high quality solutions to complicated optimization problems. In the case of self-learning algorithms that are based on machine learning, the game-theory technologies, such as the noncooperative game, cooperative game, and Bayesian game, have been successfully used to solve optimization problems using interactive learning with functional nodes and automatic configuration strategies;
Performance evaluation and decision making. Depending on the optimization results, settings and operations can be reconfigured by the system to adjust the performance. Possible configuration actions and decisions can include computation offloading, content caching, network sharing, task scheduling, routing planning, resource allocation, etc. After the configuration is completed, data perception and analysis are conducted based on decision execution results by the system to evaluate the algorithm’s performance. Then, the optimization process is repeated to keep the system in an appropriate working state.
In the following, we present a brief overview of existing research covering: fusion and joint optimization of caching at different nodes, communication, and computing (3C fusion) at the forefront of network communication and transmission fields from the perspectives of traditional algorithms and AI technologies.
4.2. Fusion of Terminal Caching, Communication and Computing
The fusion of terminal caching, communication, and computing is also known as terminal 3C fusion. This means that data fusion and analysis are conducted on caching, communication, and computing resources on the user side (sensors and devices), which provides the best resource-allocation scheme to achieve the optimal network experience to users. Since the terminal devices are dispersed, two scenarios (i.e., single end-user and multiple end-users) are considered, and either a distributed or centralized 3C fusion model is established when the data transmission or network communication is conducted.
(1) 3C fusion for a single terminal. In 3C fusion for a single user device, computing tasks or services are targeted. First, a task that a user is executing is described at the current moment, and then 3C resource modeling is optimized based on the task data. For intelligent services, the key performance indicators include channel capacity, transmission delay, transmission reliability, number of connected devices, and the cost-effectiveness of the transmission. The user’s service quality refers to the user’s satisfaction with a certain service. However, the satisfaction level depends on the user’s expectation of the service, which is related to the user’s personal preferences, environment, and data related to the task.
Specifically, the 3C fusion process for a single terminal can be divided into the following steps: (1) User experience and service modeling. The modeling function between the user’s experience (quality of service) and services provided by the edge-cloud server is a non-linear function, which can be modeled by a neural network. (2) Service and 3C fusion modeling: The demand for a service (i.e., requirements of computing tasks on caching, computing, and communication resources) can be described as a relation function between the service and amount of computation, transmission, and caching. At this point, the relationship between each of the key performance indicators of a task (such as transmission delay) and 3C can be obtained. (3) Optimal 3C fusion and configuration: The configuration problems of terminal 3C resources, computing, storage, and communication resources are allocated to the terminal to make the service quality at the terminal as high as possible. To achieve this goal, a mathematical description of the terminal performance (e.g., communication capacity, computing capacity, storage capacity, service demand, dump energy, and user data) should be determined first. In practice, due to the wide time variability and complexity in the service demand, link state, channel capacity, equipment load, and other parameters of a terminal, an on-line dynamic adaptive algorithm can be adopted in the mobile terminals to realize real-time configuration of caching, communication, and computing resources. Specifically, the goal of optimal 3C fusion and configurations is to minimize the task delay. The constraint is that the energy consumed by a terminal should not exceed the battery capacity, caching should not exceed the caching capacity, and the computing capacity should not exceed the remaining maximum amount of computing. To ensure the user experience in the process of iterative optimization, the pre-computing mechanism can be used; the requirements of a task and ability of network node for 3C resources at the next time can be predicted according to the status of the terminal equipment at the current time, and then the preliminary matching can be performed. (4) 3C offloading at a single terminal. When a terminal fails to meet the requirements of a task, a collaboration between the fusion of 3C terminal resources and edge cloud should be considered, i.e., the terminal meets the requirements through the transformation of caching, communication, and computing resources. Specifically, to achieve a collaborative optimization between the terminal and edge cloud, the goal of the single terminal 3C offloading is to minimize the user’s delay. This delay consists of three parts: wireless-transmission delay, computing delay, and delay in the optical transmission. Then, the energy consumption at the terminal can be obtained, including the energy consumption of data transmission and energy consumption of local computing. Using a combination with the corresponding offloading and caching strategies, the constraint conditions are the same as those in an optimal 3C fusion and configuration. For this optimization problem, a stable caching, communication, and computing resource-allocation scheme for a single terminal is given.
(2) 3C fusion for multi-terminal. In a multi-terminal scenario, if collaboration between terminals is not initiated, a model similar to the single-terminal model should be considered; otherwise, a mobile device can share the communication, computing, and storage resources with another device through collaboration between their terminals, such as a D2D connection between devices, which is conducive to an increase in the overall system throughput and reduction in delay.
Specifically, research on multi-terminal 3C fusion has several main directions, which are as follows. (1) Multi-user modeling and collaborative optimization of 3C resources. In a multi-terminal collaboration scenario, the offloading of resources to other terminals via D2D communication increases the delay in data transmission. Therefore, it is necessary to study a trade-off between transmission, computing, and caching, i.e., the trade-off between the collaboration gain and overhead. (2) Adaptive collaborative optimization of 3C resources based on AI. For realizing the collaboration of caching, computing, and communication resources in a multi-terminal scenario, not only should the resources of a terminal be considered, but also the resources of other devices that are connected to the user. If the mobility of a terminal is high, then its connection with other terminals can be broken, resulting in dynamic changes in the caching, computing, and communication resources, which makes the configuration of resources more difficult. However, this problem can be solved using AI technology to predict terminal mobility from two perspectives, the spatial information and terminal context information, and then applying reallocation to 3C resources. (3) 3C collaborative optimization with a combination of multi-dimensional perception and AI. More data can be perceived by decentralizing the caching, computing, and communication to a mobile terminal. Specifically, two types of data, the business data and terminal data, can be perceived. The business data includes the data content, such as AR game or HD video, and type and size of the business data. The terminal data includes the communication ability, computing, and storage ability of a terminal device, as well as the context data of an end-user, including age, occupation, and social information. Considering that the optimization problem of the user’s context information is generally non-convex and non-linear, using the traditional optimization scheme to solve it will result in high complexity and time consumption. Therefore, a method of reinforced deep learning can be adopted, and an offline deep neural network and on-line reinforced learning can be combined to obtain an optimal 3C resource allocation. (4) 3C offloading for multiple terminals. Through cooperation between terminals, the caching, computing, and communication resources of the terminals can be reasonably allocated to achieve a better service quality at the terminals. Since centralized algorithms consume more 3C resources, a distributed algorithm can be used to achieve optimal collaboration between terminals. However, a scheme for 3C fusion of a single terminal can be adopted in a distributed single-terminal computing offloading algorithm.
4.3. Fusion of Edge Caching, Communication and Computing
In recent years, edge-cloud computing has provided users with short-delay and high-performance computing services by deploying computing nodes or servers on the network edge to meet the computing requirements of delay-sensitive tasks. There are two main advantages of using the edge cloud. First, compared to local computing, the limited computing capacity of mobile devices can be overcome using edge-cloud computing. Second, compared to offloading computing on a remote cloud, in edge cloud computing, excessive delays caused by offloading task content on the remote cloud can be avoided. As a result, edge cloud computing commonly achieves a better trade-off for delay sensitive and computing-intensive tasks.
In a MEC system, an increase in the number of user devices and diversity of applications lead to the exponential growth of mobile services. Therefore, the ability to effectively offload large amounts of raw data in a communication system is essential. However, the computing, storage, and communication capabilities of MEC nodes are limited, and thus the fusion and configuration of 3C edge resources should be considered to achieve an optimal offloading strategy. Currently, the main types of 3C edge fusion methods are; (1) Traditional pattern-recognition methods. In these methods, description and modeling are conducted based on 3C resources on the edge cloud and terminal devices, and optimization is conducted to perform the computing-offloading. (2) 3C edge fusion based on AI. Since AI can provide analysis, training, and learning abilities for making network-transmission decisions, machine learning (ML) can be applied to 3C fusion at an intelligent edge. In the following, several mainstream 3C edge fusion and offloading methods are briefly introduced.
(1) Traditional 3C edge fusion and optimization methods: At present, existing studies on 3C edge-cloud fusion using the traditional modeling method focus on the four following aspects. (1) Content unloading or edge caching. Various caching strategies have been proposed to reduce delay and energy costs when a user obtains the request [
29,
30]. (2) Computing offloading. The main design problem is to decide when and how to offload the user’s tasks from the user’s device to the edge cloud and which tasks should be offloaded from the user’s device to the edge cloud to save energy and reduce computing delay [
31]. For instance, in [
32], the authors propose a task-scheduling scheme for edge–cloud computing when a user is mobile. (3) Mobile edge computing and offloading. The main concern is the deployment of edge clouds near base-stations [
33] and design of optimal solutions to reduce energy costs and delays while simultaneously considering the communication and computing resources [
34]. (4) 3C edge fusion and optimization. In [
28], a new concept of computing task caching was proposed, where joint optimization of edge-cloud computing, caching, and communication resources was achieved, and an innovative caching scheme and an offloading scheme for computing tasks were developed.
(2) 3C edge fusion and offloading based on machine learning: To obtain an effective inference function from a labeled 3C resource data for training, statistical rules can be used in a 3C edge fusion method based on supervised learning [
35]. Its purpose is to develop an analysis method that can predict output results based on the input 3C resource data. Supervised learning consists of two steps: learning and prediction. First, an analysis method is established by supervised learning, and then classifier parameters are optimized to obtain the optimal global prediction solution. The support vector machine (SVM) and support vector regression (SVR) are typical representatives of supervised learning algorithms, which are commonly used for discrete value classification and continuous value regression, respectively.
In the 3C edge fusion method based on unsupervised learning [
36], a label of input data is unknown, and the goal is to determine features and structures hidden in the data to achieve prediction and reasoning functions. One of the most widely used unsupervised learning algorithms is the K-means algorithm, which attempts to divide data of unknown classes into several disjoint clusters. These methods are relatively simple and suitable for practical applications, but their performances are dependent on training data. For instance, mobile users can form clusters based on location, service requirements, available resources, and other functions. The MEC server selection and offloading decisions are made by clusters rather than individuals, which can significantly reduce the number of participants more effectively.
(3) 3C edge fusion and offloading based on deep learning: Deep learning is a representation (or feature) learning method based on a multi-layer neural network that allows computing models to automatically extract features required for prediction or classification from a large amount of raw data. By using multilayer concatenation for feature extraction and transformation, deep learning can discover complex structures and learn hidden features from a large amount of the original data. However, deep learning is regarded as a black box, so certain training skills and experience are needed in the practical model training because there is no complete theoretical guidance for model training. It is necessary to use computing offloading of an edge cloud in a 3C fusion scheme based on deep learning because a large amount of data is necessary for training with complicated computing, and a MEC server can provide available computing resources and raw data [
37].
(4) 3C edge fusion and offloading based on reinforcement learning: Reinforcement learning focuses on how to learn from own experience and chooses the best behavior through continuous interactions with the system environment [
38]. The Markov decision-making process is a simple reinforced learning method that can be used for offloading decisions in a stochastic dynamic environment, such as the decision on whether to offload and which MEC servers to select. When considering mobile users, their energy can be saved, and their computing power can be enhanced by using offloading. However, the additional overhead caused by the allocated workload transmission and computing resource consumption should also be considered. Therefore, the first query should be whether to offload. If the decision is yes, then an appropriate MEC server should be selected, and the workload for offloading should be determined [
39].
(5) 3C edge fusion and offloading based on deep reinforcement learning: Traditional reinforcement learning requires handcrafted features to learn about optimal decision making, as well as low dimensional state spaces. However, with the implementation of deep learning, useful features can be directly extracted by learning high-dimensional raw data. Thus, reinforced deep learning can be used to make optimal decisions in the context of real-world complexity. The Deep Q network was proposed as a typical form of reinforced deep learning [
40]. By using end-to-end reinforced learning and deep learning, the deep Q network can directly learn about the optimal decisions from high-dimensional raw data. Thus, reinforced deep learning can be used to learn successful strategies directly from higher-dimensional raw data generated from edge networks without handcrafting features. It can acquire real-time transmission data for training within the edge network. This computing-intensive learning method can be executed in an edge-cloud server to expedite the training process.
4.4. Cloud-Edge-Terminal Caching, Communication, and Computing
Terminals such as smartphones, robots, wearable devices, and other local devices can acquire AI-application data. Due to the relatively low computing and storage capacity of a terminal, when a user’s requests are too many, or a computing task is complex, it is not appropriate to process data at the terminal. As an intermediate layer, the edge cloud can handle part of a computing task. The cognitive computing layer at the edge consists of several edge nodes with certain computing power. Edge nodes can be deployed on a gateway, a router, and other servers. However, the computing power of the edge layer is weaker than that of the cloud-computing layer. The cloud focuses more on inputting the computing resources, realizing high-precision computing and analysis, and providing the best computing services, rather than handling all the computing tasks [
41].
Due to the different computing capabilities of terminal devices, edge-computing nodes, and a cloud data center, the order of the computing delay for the same computing task at these three locations in descending order is as follows: local terminal, edge node, cloud center. However, although edge-computing nodes have higher computing power than local devices, there are still computing bottlenecks when they are dealing with many concurrent computing tasks or highly-complex computing tasks. To mitigate a sharp reduction in the edge-computing speed, during 3C fusion and optimization, complex computing tasks can be offloaded to a remote cloud for execution to reduce the computing delay. Besides, when considering the communication delay (data volume and data-transmission rate), it is also necessary to comprehensively select the destination of computing offloading. Therefore, in a cloud-edge-terminal-based 3C fusion scheme [
42], not only the performance limits of terminals and edge cloud should be considered, but also the resources cognitive engine and datacognitive engine of a cloud. Elastic matching is also conducted using network resources according to the network resources, interference, energy demand, and load conditions. Moreover, with the help of an historical data record, a prediction is conducted for the edge-network data, such as user behaviors and data traffic, and network resources or data are allocated in advance. This can effectively improve the efficiency of network communication and transmission.
5. Proactive Interaction Network Based on Digital Twin
Furthermore, a new theory is needed to realize tight coupling between the communication system and AI and the change from data transmission to value transmission. The future 6G should not only realize faster transmission, lower transmission latency, and better reliability, with terahertz-order (THz) communication, integrated sky-earth communication, visible light communication (VLC) and AI, but also the transmission of data value and support for the interaction of values. Thus, it is necessary for 6G communication systems to realize the integration of algorithms into data and computing platform (i.e., computing power), that is, algorithms should be embedded into the generation, acquisition, transmission, integration, and visualization of data, to realize the transmission of data values. This theory is described as the mailbox theory, that is, with the introduction of a mailbox, the deep integration of algorithms, data, and computing powers in 6G communication systems is realized.
Today, AI chips are more powerful than previously, and intelligent applications based on deep learning are used more extensively. In addition, a larger number of devices are accessing the network. The future network will introduce the seamless connection between the network, the physical world, and humans, realizing the seamless connection between the physical space, information space, and human world. Thus, future networks need to integrate AI algorithms into the cloud-edge network; namely, they need to deploy an AI algorithm not only at the cloud, but also at the edge cloud and terminal to realize better real-time interaction between the physical and information spaces.
As discussed above, if the function of proactive interaction is to be realized in 6G networks, real-time interaction between physical space and information space is required. In fact, it is difficult for devices in physical space to interact with information space in real time. In order to make the network have the function of proactive interaction, based on digital twin technology, the digital twin network (DTN) is designed with four key elements (network twin data, model, mapping, and interaction), to realize efficient interaction between physical space and information space. 6G networks include three layers: (i) The first layer is the physical communication layer, including the entity unit of the network, that is, the network entity with communication, caching, computing, and intelligence mentioned in intelligent networks. (ii) The second layer is a digital twin layer. Firstly, a network entity unit operates data and historical data to form the data source of a digital twin layer, then a model is established based on data source, and in combination with application requirements, and interaction of the model are realized. (iii) The third layer is the information layer, namely the information transmission in 6G network.
However, most of the existing AI algorithms have been deployed on the cloud, and these algorithms have been designed by humans, which means that well-marked dataset and training layers shall be established, but they have poor robustness and generalization ability. Moreover, their training processes are conducted in a centralized way, and such a cloud-based way can hardly meet the requirements of applications showing strong interaction in the physical world. Therefore, deploying algorithms at the edge cloud and terminals will not only provide better interaction with the physical world, but also better adapt to the changes in the environment and to users relying on multi-agent learning.
6. Data Life Cycle Extensions for Information Value
There are many types of sensors, such as thermosensitive, photosensitive, gas-sensitive, force-sensitive, magneto-sensitive, humidity-sensitive, acoustic, radiation-sensitive, color, and taste sensors. Specifically, radar, sonar, other acoustics, infrared/thermal imaging camera, TV cameras, sonobuoys, seismic sensors, magnetic sensors; electronic support measures (ESMs), phased array, MEMS, accelerometers, and global positioning system (GPS) are included. These sensors produce diversified types of data, such as text, video, infrared/image, ultrasonic, two-dimensional radar scan, lidar point cloud, gas, and temperature and humidity.
After the sensor data are acquired, possible application scenarios can be smart electricity meters, quality evaluation, security monitoring, and other services directly deployed on edge network or intelligent services deployed in the cloud, including smart cities, autonomous driving, knowledge mining, privacy protection, and pricing mechanisms.
However, to realize these services, the existing intelligent IoT architecture based on data fusion is faced with the following challenges:
Multi-modal data IntelliSense. Currently, optimization of the underlying data-acquisition device is required by an increasing number of big-data platforms with the purpose of using richer sensors to obtain more diverse data. A system that relies on a single sensor for data acquisition is likely to have the following problems: (1) Due to the limited sensor performance, the perception range is limited and the data type is single. (2) There can be a loss of data due to the failure of a sensor at some perceptual point. (3) There can be a system failure because a sensor is not available. (4) There is one-sidedness for perception due to single-perspective information. Therefore, the adoption of a multi-modal sensor would be essential to solve the above problems. Compared with a single sensor, multi-modal sensors have the advantages of multi-dimensional perception, multi-authentication, and enhanced information security [
43]. Nonetheless, systems with multi-modal sensors also need to address the following challenges: (1) How to expand the breadth and depth of the space coverage, massiveness, and diversification of ready data. (2) How to enhance the robustness in the architecture of the intelligent IoT, sensor reliability, and data security. (3) How to ensure the time uniformity of data perception. (4) How to solve the computing and communication complexity of the multi-dimensional perception system. (5) How to avoid information uncertainty caused by multivariate data;
Edge-network intelligence. The edge network is composed of smartphones, tablets, computers, and various sensor nodes connected to the core network through the edge-computing carrier [
44]. Heterogeneous edge-computing carriers include the edge server, nanocluster, edge gateway, raspberry PI, base-station, and other access points. The functions of the edge network include providing device access and network management for hardware facilities, providing data acquisition and storage for application services, and providing model-based reasoning and algorithm decision-making for local computing. To make the edge network more intelligent, a combination of AI technology and edge networks is the future direction in intelligent edge networks. Data generation, data acquisition, and data transmission are three important challenges for edge-network intelligence. (1) Data generation can be realized through the fusion of multi-modal data IntelliSense and data-generation enhancement technology. (2) Data acquisition includes necessary processes of sensor fusion, such as data cleaning, data filtering, data integration, data conversion, and data pre-processing [
45]. (3) Communication challenges, such as efficient communication algorithms toward limited resources, centralized and decentralized data-fusion-based edge-AI system architecture, transmission clock synchronization, and transmission security should be solved for data transmission [
46];
Cognitive computing and data intelligence. After ensuring safe and effective storage of the data obtained from the edge network, the cognitive computing capability of the big-data system of the intelligent IoT is reflected in a combination of edge computing and cloud computing. Cognitive computing provides users with data intelligence, including automatic labeling of data, fine-grained quality assessment, multi-dimensional cross-domain semantic understanding, multi-model real-time scheduling, lightweight, efficient and secure parallel computing, data security, and privacy protection. This requires the system to provide large amounts of data, deploy machine-learning algorithms, realize reliable industry models, and so on. Traditional data-analysis technologies include sketching and streaming, dimensionality reduction, numerical linear algebra, and compressed sensing for sensor data. The emergence of AI technology has also prompted the development of more advanced data-fusion algorithms, including data association, state estimation, decision fusion, covariance consistency, and distributed data fusion [
43,
47]. In summary, realizing cognitive computing and data intelligence needs to address the following challenges: (1) Data integration, storage, and synchronization. (2) Data security and privacy. (3) Data mining and information value enhancement. (4) Multidimensional data fusion and decision fusion [
48];
Application and service intelligence. After the system has a large amount of data and in-depth analysis results, the information needs to be fed back to the user. These applications include data visualization, personalized service and recommendations, information distribution and sharing, big-data control platforms, intelligent authority, and exploratory analysis. With the development of human-computer interaction technology, the multidimensional visualization of data seems to be particularly important in heterogeneous intelligent IoT applications, which is a service that is very friendly to users. Moreover, reactions, experience, feelings, opinions, suggestions, and other data generated by users in the service process can be used as a supplement to the system’s perception data, and they are also the feedback of the system’s computing intelligence. In this way, the three systems—infrastructure, AI, and visualization—are closely integrated, and a virtuous cycle is formed [
49]. To realize intelligent applications and services, the following challenges need to be addressed: (1) heterogeneous smart IoT applications, (2) multi-dimensional visualization fusion for data display, and (3) human-enhanced fusion.
6.1. Data Fusion for Data Acquisition
Data fusion for data acquisition refers to the combination of sensor data and data generated from distributed data sources to make the integrated data more accurate, more complete, and more reliable than the data acquired independently. Therefore, it is also called multi-sensor data fusion. Note that the data sources for fusion processing are not specifically generated by the same sensor. A fusion process can identify direct fusion, indirect fusion, and the fusion of the output of the first two. Direct fusion refers to the fusion of a series of heterogeneous or homogeneous sensor data, soft measurements, and historical values of the sensor data. Indirect fusion uses information sources, such as the environmental and priori knowledge input by humans. Sensor fusion refers to the integration of multimodal data into a unified format. Furthermore, the fusion of the output resulting from multiple sensors is also known as “multi-sensor integration”. It means the synergistic use of sensor data to accomplish a task with a system [
50]. Sensor fusion refers to the fusion of multi-modal data into a unified format. Multi-sensor integration means the synergistic use of multi-modal data, in which case a unified format is not required. As shown in
Figure 5, data-acquisition fusion is summarized in this subsection based on three technologies: data cleaning, data filtering, and data integration.
6.2. Data Fusion for Data Transmission
The technology with which data are transferred from one location to another is called communication technology, and the process is called data transmission. After many years of evolution and development, communication technology has evolved from human-body information transmission to simple signal communication via wired and wireless communications. For the current situation of widespread mobile-device usage, the transmission of data from devices to edge clouds mainly relies on the most widely used wireless mobile-communication technology. From the perspective of transmission fusion, existing technologies and the literature can be summarized as when and how which tasks or data are transferred to which node for computing, i.e., what, where, how, and when to transmit. (1) How to transmit relies on what is the most widely used wireless mobile communication network and technology at present. (2) What, where, and when to transmit requires fusion and joint optimization of the network communication model and resources.
With the development of wireless-communication technology, popularization of the mobile Internet has led to a growth in data volume, and unstructured data accounts for the largest proportion. In data-transmission fusion, an efficient integration of massive amounts of data is a necessary condition to realize real-time and fast transmission.
With the traditional transmission method, structured and unstructured data are processed and transmitted separately with different transmission rates. However, in most cases, the types of data describing the same scene and event are diversified, i.e., the data perceived at the same time have a strong correlation and cannot be simply processed separately. Therefore, it is necessary to design a new network architecture that can fuse a variety of data for transmission and analysis so that the data describing a single event at a particular time can be synchronously transmitted and processed.
Specifically, the data generated by different subsystems or subnets are uniformly extracted. Then, the features of the unstructured data are matched to the corresponding fields in the structured data to generate compound fields. Then, the packet-length information and encoding format are combined into a packet header, which is spliced with structured and unstructured data to form semi-structured data for the transmission. When the sync node receives semi-structured data, it parses the packet header and extracts each compound field, in turn, to obtain two kinds of complete data in reverse. Thus, the fusion and transmission of unstructured data and structured data are completed.
This new fusion-transmission mode is conducive to the unified extraction, processing, and centralized storage of data that are scattered in various fields and systems, which makes it very convenient for synchronous data transmission, synchronous processing, data exchange, and data sharing.
6.3. Data Fusion for Data Storage
Multi-modal data acquired by sensors in the perception layer are transmitted to the edge-cloud server through the network, processing, or computing, and integrated storage, packaging, and uploading to the cloud data center are conducted to the multi-modal data by the edge-cloud server, thus forming a complete closed-loop of data processing to ensure high-quality data storage for data analysis. This process not only tests the storage resources of these servers, but also relies on the data fusion and storage mechanisms deployed by them.
As shown in
Figure 3, data-fusion storage of the edge cloud and the cloud server includes the following aspects: (1) Distributed fusion storage. This includes clock/data synchronization between the sensor and the edge cloud and the clock synchronization between sensors. Distributed fusion storage occurs in real-time with the acquisition frequency of the sensor. (2) Edge caching and fusion storage. Collaborative caching at the edge effectively optimizes offloading and sharing of computing tasks and the results. (3) Centralized fusion storage in the cloud. Data fusion, synchronization, and applications are conducted to cloud services as per the user’s requirements. The whole process, as shown in
Figure 6, guarantees that an efficient data-fusion storage is conducted by the system in a secure, stable, and extensible environment.
6.3.1. Data Synchronization
To realize collaborative caching and data updating at the edge, it is essential to realize a data synchronization-and-sharing mechanism at the edge cloud. In addition to the use of database-synchronization technology (full-volume synchronization, incremental synchronization based on a trigger, full-volume synchronization based on a file-storage system, and so on) on the server side, data synchronization in the era of big data shows more concern for all-dimensional synchronization from the bottom to the top (from data acquisition and perception to data transmission and then to data storage). The mainstream methods of data synchronization and sharing [
51] are: (1) Timing-sync Protocol for Sensor Networks (TPSNs). (2) Flooding Time Synchronization Protocol (FTSP). (3) Continuous Clock Synchronization (CCS). (4) Reference Broadcast Synchronization (RBS). (5) Asynchronous Diffusion Protocol (ADP). (6) Average TimeSynch (ATS), and (7) Firefly-Based Synchronization (FBS). These mechanisms focus on the trigger type, clock frequency, connection type of the perception layer, mobility features, structure, and stability of the network layer, and so on. Based on these mechanisms, updating data transmission and caching can be better carried out between the edge cloud and the terminal devices in order to achieve an efficient and timely data synchronization and sharing between the edge-cloud servers.
6.3.2. Fusion Storage
As shown in the previous subsections, after fusion of data acquisition and transmission, the data acquired by sensors are stored in the cloud and edge cloud for further analysis. However, storage resources are still limited on the server side. Therefore, fusion storage should be conducted on the data, i.e., a distributed storage system should be adopted to store high-quality heterogeneous sensor data in real time [
52]. A distributed file system can effectively solve the problem of data storage and management. It extends a fixed file system to a multi-location multi-file system, in which many nodes form a file system network. Each node can be distributed in different locations, and communication and data transmission between the nodes can be conducted through the network. A distributed storage system is based on stream data access mode, and can process large-size data files. Furthermore, with this system, a one-time writing, a multiple-times reading, and processing of unstructured, semi-structured, and structured data can be realized. This method of data storage and management is very suitable for edge-cloud servers and cloud data centers distributed around the world; and, with the advent of 5G and the era of the Internet of everything, it is more suitable for future terminal requirements. Currently popular distributed storage systems include Google File System (GFS), Hadoop Distributed File System (HDFS), Lustre, Ceph, GridFS, mogileFS, Taobao FileSystem (TFS), and FastDFS. In the distributed storage system, the data cleaning and data integration technology can also be used to conduct further fusion on the data acquired at terminals to save storage resources and to improve the quality of the data.
6.4. Data Fusion for Data Analysis
For IoT applications, the best manifestation of service intelligence is the ability to analyze and process massive amounts of heterogeneous data. As an information-processing technology, the function of data-fusion technology in the data-analysis stage is embodied in the use of computers to automatically analyze and synthesize certain observation information obtained as per time sequence under certain criteria to complete the required decision-making and evaluation tasks. Therefore, data fusion is an indispensable and effective means for data analysis and intelligent decision-making in heterogeneous environments.
With the development of 5G technology, edge intelligence (edge cloud and terminal intelligence) has become an important evolutionary direction to improve service quality. The real-time analysis and mining of data are pushed in the direction of depth by edge intelligence and cloud intelligence. Therefore, research on data analysis and fusion can be summarized in four aspects: (1) what to fuse (data type and fusion type), (2) where to fuse (fusion location), (3) when to fuse (fusion target), and (4) how to fuse (fusion technologies). As shown in
Figure 7, we review existing data-fusion technologies according to the above four aspects: (1) data type (structured data, unstructured data, and semi-structured data), (2) fusion target (improving data quality, multi-source data integration, in-depth information mining, and enhancing decision making and evaluation), (3) fusion technologies (the statistical method and the deep-learning method in machine learning), (4) fusion location (terminal fusion and analysis, edge cloud fusion and analysis, cloud fusion and analysis), (5) fusion type (data in data out, data in feature out, feature in feature out, feature in decision out, and decision in decision out).
6.4.1. Data Types
At present, the amount of unstructured and semi-structured information is becoming increasingly large (according to statistics, semi-structured and unstructured data account for more than 80% of all information). A feature of semi-structured data is that they have a certain structure, but the semantics are not quite certain (for example, tags in web pages can indicate some incomplete structured information). Unstructured information (such as large-scale text information, corpus, picture, video, and audio) mostly refers to the information that users are interested in, which is not organized and is scattered in various parts of the text. Users must review and understand the information to mine the hidden meaning of the information. Generally, unstructured information cannot be clearly expressed with a unified structure, and thus it is difficult to conduct information structuring and information extraction following a unified pattern, which is fundamentally different from the information organization and management based on structured data. Therefore, in the research on data analysis and mining, the data type greatly influences the choice of the fusion technology. The fusion and analysis based on different data types are divided into the following three aspects in this paper:
Fusion and analysis for structured data: Structured data refers to the data logically expressed and realized by a two-dimensional table structure. They strictly follow the data format and length specification and are mainly stored and managed by a relational database. The general feature is that the data are with a row as a unit. A row of data represents the information of an entity, and the attribute of each row of data is the same. Application scenarios of fusion and analysis for structured data include Enterprise resource planning (ERP), financial system, medical HIS database, education all-in-one card, administrative approval of the government, and other core databases. Structured data are mainly divided into numerical value data and type data. The fusion of structured data mainly relies on statistical methods and tree-based algorithms (such as the decision tree, Bayes, support vector machine, and random forest). This is because there is no need for tree-based algorithms to assume that type variables are continuous, and there is no need to make any assumption at the level of type variables. Branching can be conducted with them as required to find out each state. There are also some studies exploring how to separately handle the numerical value variable and the type variable. The use of neural networks is suggested to learn these features.
Fusion and analysis for semi-structured data: Semi-structured data are a form of structured data, but they do not comply with a relational database or the structure of the data model associated with the form of other data tables. However, they contain relevant tags that are used to separate semantic elements and to conduct the layering for records and fields. Therefore, it is also called a self-describing structure. In semi-structured data, entities belonging to the same type can have different attributes, and the sequence of these attributes is not important after data fusion. Common semi-structured data include XML, JSON, mail, HTML, statements, resource library, and so on. Typical scenarios of fusion and analysis for semi-structured data include mail systems, WEB cluster, teaching resource library, data-mining systems, and archive system. The fusion for semi-structured data mainly depends on data-integration technology, model-extraction technology, and the data-description pattern (tree-based description, graph-based description, relation-based description, logic-based description, and object-based description).
Fusion and analysis for unstructured data: Unstructured data refer to data with an irregular or incomplete data structure, data without a predefined data model, and data that are not easily represented by a two-dimensional logical table of the database. These data mainly include video, audio, picture, image, document, text, etc. Technically, it is more difficult for unstructured information to be standardized and understood than for structured and semi-structured information. Therefore, the application fields of fusion and analysis for the unstructured data are also more abundant and diversified, such as medical imaging systems, educational video on demand, video monitoring, file servers, media resource management, intelligent retrieval, knowledge mining, content protection, and the value-added development and utilization of information. Unstructured data fusion mainly relies on semi-supervised machine learning, reinforced learning, representation learning, deep learning, and tagless learning due to their complex characteristics and performance requirements on data-mining technology.
6.4.2. Data-Fusion Technologies
In previous subsections we have shown that data-fusion technologies can be diversified for different data types and fusion targets. They can be divided into nine categories from two perspectives of low-level and high-level information fusion: data association, state estimation, decision fusion, classification, prediction, unsupervised machine learning, dimension reduction, statistical inference, analysis, and visualization [
47]. Discussion on the advantages and disadvantages of mainstream data-fusion technologies (including K-Means, probabilistic data association (PDA), joint probabilistic data associations, distributed multiple hypothesis tests, state estimations, covariance consistency methods, decision fusion techniques, and distributed data fusion) was conducted in a previous study [
43].
Summarization is conducted for data-fusion technology in this paper with two major categories (statistical methods and deep-learning methods) in machine learning as shown in
Table 2, and the following methods/technologies are introduced: statistical method (clustering, correlation analysis, dimension reduction, regression analysis, decision tree, Bayesian network, and support vector machine), deep learning, reinforced learning, and label-less learning technology.
(1) Data fusion and analysis based on statistical methods:
(1) Regression analysis: A regression algorithm is a combination method that constantly reduces the gap between the predicted value and the actual value to obtain the optimal input characteristics. Here, a linear-regression algorithm is used in the model training of continuous values, and a logistic regression algorithm is used in the model training of a discrete value or category prediction.
(2) Instance-based learning: The final model of the instance-based algorithm is highly dependent on the original data. In the process of prediction, the similarity criterion is generally used to find similarities between data of the sample to be predicted and the original sample, and, finally, the prediction result is obtained.
(3) Rule-based algorithm: This classification method is an extension of regression analysis and can play an important role in solving some problems.
(4) Decision tree: With the decision-tree algorithm, a tree containing many decision paths is established according to the eigenvalues of the original data. For the sample to be predicted, the path decision is made according to each node in the tree, and the prediction result is finally obtained.
(5) Bayes: This is an algorithm to solve classification and regression problems using the Bayes theorem, and it can be used for decision fusion.
(6) Cluster analysis: The clustering algorithm divides the input sample data into different core groups and then discovers some rules among the data according to the results.
(7) Correlation rules: The correlation-rules algorithm refers to obtaining a rule that can explain a certain association relation in the observed training sample, i.e., obtaining the relevant knowledge on the dependent relation between events and time and correlation and fusion of multi-source data.
(8) Dimension reduction: To some extent, the dimension-reduction algorithm is like the clustering algorithm, with both aiming to discover the structure in the original data. The difference is that the dimension-reduction algorithm tries to summarize and describe most of the content represented by the original information with lower-dimensional information.
(9) Support vector machine (SVM): A commonly used supervised-learning algorithm maps data from a low-dimensional space to a high-dimensional space so that linear non-fractional data in a low-dimensional space can be dividable in a high-temperature space, which is mainly used to solve classification problems.
(10) Decision fusion: This is an optimization means or strategy, which usually combines several simple machine learning algorithms for reliable decision-making. As an example, for classification problems, multiple classifiers are established, and then methods, such as adopting a voting mechanism, are used to avoid unreliable results. In this way the reliability and accuracy of the algorithm can be effectively improved.
(2) Data fusion and analysis based on deep learning:
Deep learning can learn data characteristics, and the performance is more prominent when processing unstructured data, such as image data, text data, and voice data. In heterogeneous IoT, fusion and analysis are performed on a large amount of structured and unstructured data, and the corresponding pattern can be established.
(1) Artificial neural network (ANN): An ANN is a mathematical model abstracted with inspiration from the structure and function of the human brain. It has been widely used in the field of pattern recognition, image processing, intelligent control, combinatorial optimization, robotics, and expert systems. Specifically, there are many similarities between an ANN and the human brain. The basic structure has a set of connected input and output units with several hidden layers in the middle, and the nodes between each connection are associated with weights. In the training and learning stages, these weights can be adjusted according to the class label of the predicted input tuples and the correct class label.
(2) Convolutional neural network (CNN): A CNN is a kind of feedforward neural network. Compared with a traditional feedforward neural network, a method of weight sharing is adopted to reduce the number of weights in the network and reduce the complexity of the computing. The structure of this network is similar to that of biological neural networks. As a supervised learning method, CNN is widely used in voice recognition and image detection and recognition. CNN is a good choice for data-fusion technologies that need to understand data, describe characteristics of a data set, discover relationships and patterns existing in the data, establish models, and make predictions.
(3) Recurrent neural network (RNN): Each time point of the RNN corresponds to a three-layer ANN, and thus the training of the RNN is similar to that of the ANN. RNN is a neural network where the data characteristics of a time sequence are considered, where information remembered from the past can be used in the computation of output data at the current time. This method is suitable for applications where data fusion and prediction are required.
(4) Stacked auto-encoder (SAE): The auto-encoder can be regarded as a special ANN. There are only input sample data during the network-training stage, but there is no corresponding tag data. The input data is reconstructed by using the output data of the auto-encoder, and a comparison is made with the original input data. After many iterations, the objective function value is gradually minimized, i.e., the reconstructed input data is as close as possible to the original input data. An auto-encoder is self-supervised learning and is categorized as unsupervised learning. An SAE is a neural network consisting of several hidden layers between the input layer and the output layer where each hidden layer corresponds to an auto-encoder.
(5) Reinforcement learning: Reinforcement learning is a method where the model gives some feedback when the data input is conducted. The supervised learning algorithm simply determines whether the input data obtains the correct output to evaluate the model. In contrast, with reinforced learning, users are expected to take appropriate action to extract useful information from the input data to improve accuracy. Under reinforced learning, it is necessary to formulate a strategy that can correlate with the prediction model and corresponding actions will be taken with that strategy. Input data directly affects the model after feedback, and associated adjustments are made by the model according to the feedback results. Some application scenarios are dynamic systems and robot behavior controlling. Common deep learning algorithms include Monte Carlo learning, Q-L, strategy gradient algorithm, reinforcement deep learning, and so on.
(6) Label-less learning: A new fusion method is proposed in [
68] for a large amount of emotion-recognition applications with label-less data, i.e., label-less learning technology. For a small amount of multi-modal data with labels, the principle of entropy is applied to supplement automatic label data without human intervention in the model’s training. Based on the low entropy multimodal data mutual authentication algorithm, the unlabeled data is tagged independently and added to the training model, which further improves the accuracy of the model and realizes the utilization of unlabeled data.
6.4.3. Data-Fusion Targets
Diverse intelligent IoT applications need to rely on the analysis and mining of heterogeneous multi-source data sets. The data fusion targets for these applications are summarized and mainly include the following aspects:
Improving data quality: Preprocessing (with the data cleaning and filtering technologies) is applied to various quality related problems caused by the environment and hardware, such as data loss, errors, redundancy, noise, etc.; and the data integrity, reliability, and analyzing efficiency are improved;
Multi-source data integration: Multiple segments of information from a single sensor or information provided by different types of sensors are fused (with the data-generation and integration technology), redundancies and contradictions of information that may exist between multiple sensors are eliminated, and complementation is conducted to mine the correlation between the data and deep meaning of data;
Deep information mining: Data types include structured, semi-structured, and unstructured data. For semi-structured and unstructured data, which account for 80% of all data, there is still a lot of room for the adoption of more intelligent algorithms to conduct deep analysis and mining. This is more dependent on strong feature-extraction support provided by data-fusion technology based on AI;
Strengthening decision-making and evaluation: For intelligent IoT, distributed hardware and software systems lead to a condition where each subnet or each layer of the computing unit has its own analytical and decision-making capabilities. However, for decisions or services provided by the system to really meet the needs of users is still a very difficult challenge. Therefore, reinforced learning or tagless learning schemes can be adopted to conduct fusion for historical decisions and remarks, or centralized fusion can be conducted to distributed decision-making. Both methods can effectively enhance the decision-making effect, and the service quality can be better evaluated.
The appropriate fusion algorithm can be intelligently selected according to the fusion target and fusion level, fusion can be conducted for multi-source data, and more efficient deep information mining and analysis can be done on this basis to obtain a more accurate representation or estimation for the specific target and application.
6.4.4. Data-Fusion Locations
Due to the development of hardware foundation, communication technology, and computing technology, data intelligence shows the development from cloud intelligence to edge intelligence and then to terminal intelligence. Different fusion technologies provide data-preparation functions with different performances for different levels of data analysis. The data-fusion location is taken as the classification standard in this paper, and the following three aspects are discussed.
Terminal data fusion and analysis: Terminal devices are the important hardware foundation of data generation and acquisition. As a computing unit exposed to data for the first time (although its storage, communication, and computing capacity are limited), the amount of data can be enriched with the use of data perception and generation technology, while the quality of data can be improved by data-cleaning and data-filtering technologies. On this basis, some analysis models established at the cloud can be used to obtain computing results efficiently and be put into the application as soon as possible;
Edge-cloud data fusion and analysis: The edge cloud is the computing and resource storage unit nearest to the IoT terminals. As a higher-level management system, the edge cloud can provide higher computing, storage, and communication capabilities. Therefore, with the edge cloud, fusion and analysis can be conducted to more data, and data-integration technology provides strong support for the integration and fusion of distributed data sources. In addition, the edge cloud can prepare better quality data for the cloud and more efficient services for terminals based on data-transmission fusion (3C resource fusion) and data-fusion storage;
Cloud data fusion and analysis: Because there are massive historical data and a large amount of real-time data in the cloud, in addition to using statistical methods or supervised machine-learning algorithms for the fusion and analysis of structured data, a greater proportion consists of conducting deep information mining for a large number of semi-structured and unstructured data based on AI technologies such as deep learning, reinforced learning, and label-less learning. Moreover, feature-level fusion for different data and decision-level fusion based on computing results also provide stronger decision-making and service for terminals.
6.5. Data Life Cycle Extensions
Based on the application of data fusion for data life cycle extensions in the previous six subsections, a general architecture of data fusion for an intelligent infrastructure-AI-visualization integration system is proposed in this paper, as shown in
Figure 8. In the future, this cross-domain fusion system will be one of the development directions of the new generation of AI+IoT. In this system, users are no longer only exposed to hardware devices and invisible and intangible algorithm modules, but can feel the overall system intelligence and personalized applications on the service side. The general architecture proposed in this paper mainly includes the following important modules:
Data fusion: As a module that can play an important role from low-level to high-level, it can provide three subsystems of infrastructure, AI, and visualization with different degrees of diverse data;
Infrastructure system: This subsystem is used as the hardware foundation of the edge-computing network, and is responsible for providing the other two subsystems with real-time and efficient multi-source data-acquisition functions;
AI system: As the intelligence center of the whole system, this subsystem can provide the edge-computing network and cloud-based visualization and application system with algorithms, including statistics, machine learning, and deep learning, and can assist in realizing deep information mining and analysis;
Visualization and application system: The function of this subsystem is to visually display the data of the infrastructure system to the users. This subsystem can do more prediction, simulation, and visualization based on the analysis results of the AI system. It is an important user-interaction interface that provides personalized services and contains feedback results;
Edge-computing network: The function of this module is to push the AI intelligence closer to the users, i.e., to achieve more efficient data acquisition and analysis at the IoT edge. With the help of other modules, it can provide edge intelligence to provide a highly efficient, self-learning, and human-in-the-loop system;
Goal and state transition: In general, the goal of this cross-domain fusion system is to achieve real-time data acquisition (infrastructure system and edge computing network), deep data analysis (AI system), visualization and simulation (visualization and application system), real-time prediction (AI system), decision making (AI system), and intelligent services (visualization and application system). The function of data-fusion technology in the system is data fusion for data generation, acquisition, transmission, storage, analysis, and application. On this basis, the state transitions between each module include multi-modal data perception and preparation, edge network intelligence, human-computer interactions and feedback, cognitive computing and data intelligence, and application and service intelligence.
7. Information Measurement Based on Cognitive Computing
In 5G communication networks, information exists in the form of codes, while in 6G communication networks, the transmission of information will change from the traditional transmission of data to the transmission of values. More details are provided in the following.
7.1. Value Transmission Based on Semantic Information
In current information systems, information exists in the form of codes and bits. A bit can be stored directly using a semiconductor device or can be modulated and transmitted directly as an electromagnetic wave. With the development of communication technology, including the application of massive multiple-input and multiple-output (MIMO) systems and usage of terahertz or higher frequency spectrum, network throughput has been improved, the reliability of communication transmission has been enhanced, and communication delay has been reduced. Nevertheless, there are still problems in the transmission process, including those related to a great proportion of data transmission and difficulty in proactive interaction with humans. In the future, communication networks will not only transmit data but also provide users with messages of the best value. Next, future communication networks need to recognize in advance a user and the environment to collect data proactively and transmit useful information in advance.
Based on the above discussion, as opposed to traditional information transmission, future networks need to recognize information and realize the conversion from information to knowledge and from knowledge to value. In the traditional Shannon information theory, correct transmission of information can be achieved based on a uniform channel coding scheme, i.e., by using the channel coding information can be delivered from the sending side to the receiving side. In future systems, the value of information should be transmitted, in contrast to traditional information transmission. Thus, it is necessary to recognize that the information. values, and knowledge can be easily understood in the real world, but there are no universal standards to measure the implied knowledge and values behind the information.
Particularly, information is analyzed first. Information consists of the motion states of things and the way the state changes. In this regard, information is specific, general, extensive, effective, and time-sensitive. Further, information can be divided into three information layers:
Grammar information: This information consists of information on the state and logical structure of the expression of information. Information represented by the motion of things exists objectively and can be observed by everyone in a proper form, such as a picture, a paragraph, or a string of codes, and such an expression can be entirely seen by everyone;
Semantic information: This information consists of the digestion of connotation or messages represented by a state or a logical structure of a thing that can be digested by people having such cognition or comprehension. For instance, the meaning of certain words or messages of codes is not understandable to everyone;
Pragmatic information: This is the much deeper information level, and people know not only the meaning of information, but also its function and know how to use it. For instance, personnel use such a function; personnel definitely know the structure, connotation, application, and purpose of information and can develop an application or use such information to realize the goal.
7.2. Data Transmission Centered on Information Value
Next, the measurements of information value are explained. To measure the information value, it is needed first to consider the value of data. It has been proven that Shannon’s three theorems can be used to develop a limit coding method and determine the rate of data transmission in a communication system. With the development of 5G networks, the upgrading of communication technology and devices has been approaching Shannon’s limits. However, as the number of IoT devices increase, it becomes a great challenge to import massive data into the core network, and network blocking and service quality declination can easily occur.
To further optimize the network performance in the next generation communication networks, it is necessary to determine how to choose and transmit data with the best value among all massive data. Consequently, this paper proposes using data-value-based information cognition, and the essential idea is to conduct modeling analysis of data transmitted through the communication network to obtain the value properties of each data package; thus, it is needed not only to consider the effectiveness and reliability of data transmission but also to evaluate the contribution of user data on the demanded task, i.e., the information value.
Therefore, the transmission of cognitive information should be considered. In order to transmit such information in a distributed intelligent network, we propose a 6G mailbox, as shown in
Figure 9. It can be simply understood as a twin intelligent agent that integrates communication, computing, and caching capabilities, and it is an intelligent agent with self-organization, self-learning, self-adaptation, and continuous evolution capabilities. The communication system based on the Mailbox does not simply encode or decode information anymore; it is encoding and decoding based on information value. Next, the characteristics of mailbox theory will be introduced.
7.3. The Features of the Mailbox Theory
In this paper, the mailbox theory is used to realize the assembly process from information to value and, in the process where the value takes shape, time, and energy will be consumed. As soon as data have been generated, the abundant information contained in these data will be extracted constantly (based on the mailbox theory and along with the packing, transmission, digestion, and evolution of data). Different cognitive abilities of subjects provide a diversified interpretation of information, and thus endow diversified values to the original data. As shown in
Figure 10, in the process of interpreting information, data show different attributes, including polarity, dependence, figurability, convergence, dynamics, and traceability, whose details are introduced next:
Polarity: This information indicates positive or negative polarity in the view of impact. Positive information makes people excited and promotes the progress of people, while severely negative information depresses people and even makes them anxious or depressed. In our previous work [
69], mental health data of the public in the pandemic period were collected using Jin Dong’s health platform. The results have found that more than 50% of people who browsed negative news and paid close attention to the pandemic showed depression symptoms. This represents the negative polarity of information. In contrast, moderately negative information can stimulate the potentiality of people. So, when determining the attributes of information, polarity shall be considered to relieve the impact of negative information and promote its conversion toward positive information.
Dependence: This information shows two dependences. The first is the dependence on the carrier. Information is not a real object and thus needs to rely on media or another material carrier for expression, but does not exist independently. Additionally, dependence can be found between different parts of information. For instance, multiple conclusions can be extended or derived from one principle, and principles can be generated from each other. In the process of cognition, new information can be generated from old information, and a dependence network can take shape among different pieces of information and get connected with each other to make information stronger and more stable when being transmitted.
Figurability: Information can turn into knowledge after being processed and validated. Information can be treated in different ways when being transmitted and interpreted by different people; it can gain different values and create different results. For instance, when facing a historical building, scientists may think about its structure and mechanical analysis and bring new thoughts to the laboratory, while artists will analyze its aesthetic values and get inspiration for future paintings. Therefore, the information shows the property of figurability, and an information block can, after being commented and analyzed, be built into multiple information blocks; the more it is built, the more expanded values it will inspire.
Convergence: The sharp increase in data size brings the exponential growth of data value, and such a value is kept in the memory of people based on their cognitive ability. Analysis of the cognitive ability of humans has proven that the human brain can effectively eliminate redundant data and convert it into limited knowledge and then obtain a value based on that knowledge. A reflection on the cognitive process of information in the communication network shows that although massive data are accepted by physical space, the knowledge contained in information in the same dimensional and scale space constantly converge with the increase in data size. When data are extracted, in a higher space, into a knowledge of higher value density, the knowledge converges into the expression of value. Special attention should be paid to the convergence of information that will not develop toward infinite high value density or low storage density, and convergence realizes the cognition toward redundant data while guaranteeing the intrinsic value of information.
Dynamics: At the beginning, when data are generated from information to the extracted knowledge, and finally, manifested as a value, the data change dynamically. First, cognitive information has multiple viewing angles, a subject of cognition directly determines the dynamics of information in the process of comprehension and transmission. Intrinsic value, based on such information, changes while staying constant and hence influences the shaping of knowledge. Then, due to the real-time attribute of a communication network and variation characteristics of the information flow, knowledge extracted from data in the process of cognizing such data shows real-time performance, and the knowledge keeps upgrading. Finally, in view of intrinsic characteristics of information, including polarity, dependence, convergence, and figurability, knowledge will not only be fixed when being generated, but will also be updated in real-time when being cognized by different subjects, so that the cognition will be realized by different subjects.
Traceability: Based on the mailbox theory there are certain problems, such as problems where the information and data cannot be determined, and no validation or protection mechanism exists when the information is being packed or transmitted. To validate the identity of a sender and protect knowledge privacy, the existing blockchain technology is used to realize the credit mechanism guarantee system in the process of information cognition. On the one hand, blockchain technology can realize the tracking of data and information source and thus shows great significance in defending the communication network safety and guaranteeing the data value. On the other hand, for a subject issuing such information, effective privacy protection is critically important. Using a distributed memory database, the security level for data protection can be improved significantly. Tracking the data can be expanded to the verification of data value, which can guarantee a safe network communication environment.
8. Key Technology for Information Cognitive
According to the above analysis, the mailbox theory needs to cognize information as the principle shown in
Figure 11. However, how to cognize the information and extract the value of that information is still challenging. To solve this problem, this paper recommends the following three possible technologies.
8.1. Extraction of Information Value Based on Knowledge Graph
A knowledge graph can be used to find delivered information and realize the conversion from information to knowledge. To be specific, a knowledge graph is used to describe objective things in the real world by using a graphic structure consisting of many nodes and edges. Nodes denote entities (namely, concrete things) or concepts (namely, abstract things), while edges represent internode relations that connect things or concepts. Particularly, nodes can save the value of their own attributes, which are used to record the internal characteristics of things, while the inter-edge relations are used to reflect the external connection of things.
In the knowledge graph, the triple of node-relation-node can be deemed as a data record, where the first node represents a subject, the edge denotes the predicate, and the end node stands for an object. The subject, predicate, and object constitute a record, and the set made of massive records includes the knowledge graph. Generally, the transformation process from the original data to the knowledge graph includes steps of knowledge acquisition and extraction, knowledge fusion (including entity dis-ambiguity and anaphora resolution), knowledge representation, and knowledge reasoning.
Knowledge acquisition is used to acquire knowledge about related entities and relations from different sources [
70]. Particularly, the original data constituting the knowledge graph generally come from three sources: structured data, semi-structured data, and nonstructured data. Different knowledge acquisition methods can be adopted for different sources. Structured data are stored in a relational database and have a certain data structure and relation name and inter-project correspondence, so it is needed only to convert the data into the resource description framework (RDF). The semi-structured data generally have a certain data structure but need to be further extracted and organized due to irregular formats. For instance, for web data, specific text contents can be extracted from web data and stored as structured data.
Knowledge acquisition of non-structured data can be divided into three steps generally: (i) entity extraction or entity identification. Here, an entity represents a concept, thing, human, or place name in the objective world. (ii) Relation extraction, which is to analyze the relation of entities based on the text data using multiple techniques; (iii) Attribute extraction, which is to identify the attribute information of an entity or relation. As for the identification of an entity, traditional algorithms mainly rely on statistical models. Today, many algorithms are using LSTM to realize the further acquisition of semantic information. As for relation extraction, automatic extraction of specific semantic relations between different entities can be realized to compensate for missing relations in the graph. However, an error can easily be made when the aforementioned extraction methods are used. To solve this problem, an end-to-end neural network model has been proposed to identify entities and extract relations and attributes.
Knowledge fusion is to recognize the same entity from different knowledge bases and thus solve the integration problem of multi-source heterogeneous data. Particularly, the same entity will most likely show different attributes and relation descriptions for different knowledge bases, and two knowledge bases may differ from each other in all aspects. Knowledge fusion is used to unify multiple descriptions of an entity to obtain complete information about the entity. The fusion process generally includes extraction and fusion of things-in-itself, entity alignments, entity linking, and attribute fusion.
Entity alignment is the core of knowledge fusion. It needs to compute the similarities between entities by methods that include clustering and knowledge embedding. In these methods, knowledge embedding is used extensively. It trains, with models, entities, and relations in the knowledge base so that all the information about the entities and relations can be expressed by vectors, and then mathematical methods can be used to compute the similarity between entities. Entity alignment realizes the only entity in the knowledge graph and, using the many-to-many mapping tables between entities, the entity connection matches the corresponding entities in the knowledge graph and further learns the real information expressed by the user. There have been many knowledge fusion methods, such as open source knowledge fusion, multiple knowledge graph fusion, multimode knowledge fusion, and multi-source knowledge cooperative reasoning.
Knowledge representation refers to the description and convention of data with the purpose of enabling a computer to understand knowledge like a human by using the knowledge graph in all fields. Knowledge representation has been widely studied, such as the word vector embedding, which means the purpose of learning is to express specific information (such as semantic information) as a lower-dimensional vector using a certain method so that it can be used in all algorithms. Knowledge representation learning can, for the purpose of the triple information (entities and relations included) in a large knowledge base, conduct iterative training on entities and relations with models, manifest all semantic information with lower-dimensional vectors, and At present, algorithm models that conduct representation learning on entities and relations in a knowledge graph can be roughly divided into two types: (i) distance-based translation models, where an end entity is considered as a vector path of the first entity and relation, and a scoring function is set up by computing the Euclidean distance and other vector distances. Generally, the smaller the vector distance is, the higher the value of the scoring function will be, and the higher probability that the triple is correct will be. This type of model is generally Trans algorithms. (ii) Semantics-based matching model represented by a structure-mapping engine, and this type of algorithm constitutes a classification model.
Knowledge seasoning is to further explore the tacit knowledge based on the existing knowledge graph to enrich and expand the knowledge base. Generally, in the process of seasoning, support of associated rules is required. New knowledge can be obtained from knowledge seasoning. Since entities, entity attributes, and relations are diversified, people can hardly fully list all the seasoning rules, and some of the complicated seasoning rules are always summarized manually. The exploration of seasoning rules mainly depends on the abundant co-concurrences among entities and relations. The object of knowledge seasoning can be an entity, entity attribute, inter-entity relation, or hierarchical structure of concepts in the ontology base. The seasoning of the knowledge graph can be divided into symbol-based seasoning and statistics-based seasoning.
The symbol-based seasoning is generally used to apply seasoning rules to the knowledge graph to derive a new entity relation by triggering the antecedent of rules. In this work, seasoning rules are considered to be owned by a knowledge seasoning language, set by humans, or obtained by a machine learning technique. Although symbol-based seasoning includes all types of optimization methods to improve seasoning efficiency, it cannot keep pace with the speed of data growth, especially when the data size is beyond the handling capacity of the memory-based server. To cope with this challenge, researchers combined description logic and seasoning to improve the efficiency and expandability of seasoning, and many achievements have been realized. For instance, the Cloud SEC is a real-time lateral movement test method that was proposed for the evidence seasoning network of the edge cloud environment.
The symbol-based seasoning is generally used to apply seasoning rules to the knowledge graph so as to derive new entity relations by triggering the antecedent of rules. In this work, seasoning rules are considered to be owned by knowledge seasoning language, set by humans, or obtained by a machine learning technique. Although symbol-based seasoning includes all types of optimization methods to improve seasoning efficiency, it cannot keep pace with the speed of data growth, especially when the data size is beyond the handling capacity of the memory-based server. To cope with this challenge, researchers combined description logic and seasoning to improve the efficiency and expandability of seasoning, and many achievements have been realized. For instance, the CloudSEC is a real-time lateral movement test method that was proposed for the evidence seasoning network of the edge cloud environment.
Statistics-based seasoning can be divided into learning based on the entity relationship and induction based on models. The learning based on entity relationships is to learn the relationship between entities in the knowledge graph using statistical methods or neural network methods and has been studied extensively. The related research can be roughly divided into two categories: methods based on representation learning and methods based on graph characteristics. The methods based on representation learning map entities and relations in the knowledge graph jointly combine into a low-dimensional continuous vector space to depict their potential semantic features.
By comparing and matching the distributed representations of entities and relations, relations between entities in the knowledge graph can be established, and a possible edge can be predicted using the graph features observed in the knowledge graph by the graph-features-based method. This method can explore seasoning rules automatically from the knowledge graph and show a clear seasoning mechanism. The model induction method is to learn the model-level information of the thing-in-itself from the knowledge graph or to enrich the existing thing-in-itself, including the concept hierarchy and attribute hierarchy. For instance, a knowledge bridge-map network model has been proposed. This model bridges the cross-pattern semantic relations between vision and text knowledge via the graph and with fine granularity and searches for the required knowledge via the self-adaptive information selecting model.
Based on the above descriptions, it can be concluded that the knowledge graph cannot only describe the multi-dimensional features of entities, but can also reinforce the comprehension of information in view of its rich content of semantic information. Therefore, it has been widely used in personalized recommendations, information searching, and smart question and answer systems. Take the recommendation system as an example. In this system, entities can be searched via the knowledge graph based on a user’s preference and relations of things in order to make things match the users’ preference. So, the knowledge graph is a potential technology capable of cognizing information. Moreover, it should be noted that in the mailbox theory, different applications need to acquire the data of specific domains to extract and transmit data, and the shift learning based on knowledge graph can be used to realize the shift between different entities. Thus, it is clear that using the knowledge graph shows potential advantages in cognizing information.
8.2. Information Cognition Based on Distributed Learning
Traditional cloud-based learning needs to gather the information acquired from the cloud dataset center for uniform training. By using distributed learning, such as federal learning, not only will the learning and seasoning ability of the network and devices be improved and the pressure of a cloud server and load of network flow be reduced, but also data privacy can be protected. This is because federal learning uses the cloud network only for simple network initialization and convergence and assigns other work to the edge network server and nodes for completion. However, it is necessary to improve the robustness of data in distributed learning and consider distributed resource allocation and scheduling. As a new learning method, federal learning has been extensively studied. It is not only capable of realizing distributed learning, but can also protect a user’s data privacy. Federal learning mainly includes two structure types:
(1) Server-Client structure: In this structure, clients denote slave nodes of a network that hold and store data in their place, while the server represents a central node that does not hold any private data of clients, but takes part in the computation of a model as a convergence center of the slave node’s model, helps a client solve its data and network heterogeneous problems, and accelerates the convergence of the model. Model learning process of this structure consists of four steps:
Initial nodes of the system. In this stage, a server initializes the distribution of its model parameters, and clients establish a federal agreement with the server and reach a consensus on the federal learning model. Then, the server broadcasts the initialized parameters to establish the initial state of the whole system;
Local shift of client nodes. After receiving model parameters from the server, the client nodes use the local data training model to make the model learn the characteristics of local data. Considering the heterogeneous characteristics of the client node system and the diversified data characteristics, and learning effects of the model between nodes, when the server node recycles the model, a client uses local data to make a change in the consensus model status, that is, the client node realizes a local shift and, in the process of state shift, the client node reports its model shift state to the server;
Server convergence. Under the classification of the time length model or model data quantity standard, the server converges the collected model parameters. Then, by washing and analyzing massive model data of the node client, a convergence model containing no private data of the client can be obtained;
System state nodes shift. After combined convergence of models in the previous step, the server rebroadcasts a new model and a client gets the new model sent by the server and continues to use its local data for training. In this way, the overall shift of the system’s state nodes is realized. The final results of federal learning can be obtained as soon as the consensus model converges to the expected target.
(2) Peer-to-peer network structure: The peer-to-peer network structure has no obvious central node as all nodes share equal rights of autonomy in the network and communicate and exchange information on model parameters with each other directly. The scope of the interaction between nodes can be deemed as their action scope and other nodes in the action node are regarded as neighboring nodes. A node can be both a server and a client of a neighboring node and thus has a great similarity with the server client structure. The server-client structure can be considered as a special peer-to-peer network structure with a large action scope. Without the support of a server, the peer-to-peer network has greater difficulties and higher cost of internode communication, and more difficult convergence of model compared to Server-Client structure.
Both of the above two models involve distributed learning of data. Using this learning framework, communication efficiency is improved and the classification of data is involved. To improve the communication efficiency of both the client and server in federal learning, methods for structure upgrading have been proposed to reduce the communication cost. As for the heterogeneity of data, different nodes in federal learning have different geographical locations, so data samples can be different. Consequently, data held by different nodes generally have different distribution characteristics.
Moreover, according to the distribution coincidence degree of data, federal learning can be divided into horizontal federal learning and vertical federal learning. Data collected by nodes establish a sample matrix space with sample ID and sample characteristics. When the data of different nodes show low similarity in the sample ID but a high similarity in the sample characteristics, federal learning will make a transverse alignment of characteristics. When the data of different nodes show high similarity in the sample ID, but low similarity in the sample characteristics, vertical alignment of sample IDs will be performed to expand the characteristic dimensions of sample IDs. This federal learning is denoted as vertical federal learning. Both horizontal and vertical federal learning types aim to solve the problems of network data heterogeneity and missing single-node data and to compensate for the defects of sparse node information.
Moreover, with the development of AI chips, a large number of lightweight-class AI models have been embedded into mobile devices and collaboration at the cloud has been required for information processing. Collaboration at the cloud edge of the information-based cognition is a challenging task. This is because storing the cognition of information at the cloud edge requires balancing the energy consumption of edge devices, server load, information cognition precision, cognition delay, and AI model. Moreover, to realize a cognitive system capable of balancing the cloud and edges, it is necessary for the cognitive system to support the granularity of the on-line classification of information.
8.3. Blockchain-Based Safe Transmission of Cognitive Information
Blockchain adopts a distributed storage and accounting method that consists of multiple network nodes distributed at different geographical addresses. Moreover, data sharing and synchronization in blockchain are decentralized [
71]. The nodes do not differentiate the server–client relation, and each node can demand or provide services. Nodes can directly exchange resources with each other without bridging by a server, and users can use and share resources with each other directly. That is, in the distributed network of blockchain, all nodes have equal status, which is similar to the mailbox theory. In the cognitive information theory, each piece of information is packed as a mailbox and stored in a distributed way.
Blockchain is a dynamic network, where new nodes come all the time while the former nodes exit. The constantly incoming new nodes bring new resources to the system and thus, the entire network is built and developed, and abundance and diversity of resources expand accordingly, while the dispersity, robustness, availability, and overall performance of the point-to-point network increase with the increase in node numbers. In the cognitive information theory, new cognitions can be added continuously to each mailbox to cognize the information further.
The privacy in blockchain relates to data transaction and identity privacy. The most common way used by transaction users to reinforce privacy is to hide transactions in a group where users exchange their funds, making the attacker unable to judge the user fund relation. Data transaction privacy protection includes all data-related processes in blockchain, i.e., data generation, validation, storage, and usage. Special data structures and consensus mechanisms are designed in blockchain to guarantee that data transaction is reliable, tamper-proof, and distributed uniformly to protect transaction records kept in the blockchain and information and value hidden behind such records.
The tamper-proof technology in blockchain is essential to build trust in a value internet. Blockchain represents a tamper-proof database. For instance, a database built by blockchain is a CRW database having only basic operations; create, read, and write. Take BitCoin as an example. BitCoin stores transaction records generated since its very birth, i.e., whenever a miner digs up the record of a block, or a user out-transfers or in-transfers a transaction, the related information is kept in each block on the chain. If a single chain wants to modify the record, no record can be generated since such modifications cannot be approved by the other blockchain records. Therefore, false information generated by each mining node cannot be recorded in the blockchain.
According to the characteristics of cognitive information, constant interaction with a user is required in the process of information cognition to continuously improve the value of information. However, in the process of this interaction, privacy information exists, so a safe, distributed learning-based network is required. In recent years, the blockchain has been widely studied, and it is distributed, tamper-proof, and capable of providing a new approach for the interaction between cognitive information. Moreover, the transformation process from information to value is similar to blockchain generation. Due to the collaboration between mailboxes, information value can be extracted and such extraction can go beyond the difference in culture and nationalities and finally realize an intelligent evolution of information cognition.
8.4. The Challenge of the Mailbox Thory
The proposed cognitive information shows polarity, dependence, figurability, convergence, dynamics, and traceability. Moreover, extraction of information value based on the knowledge graph, information cognition based on distributed learning, and safe transmission of blockchain-based cognitive information are all provided. However, there are certain challenges in the mailbox theory and they can be summarized as follows:
The extraction of information value based on the knowledge graph is limited. Namely, in the knowledge graph based information extraction, information value is extracted based on semantic information, which results in restrictions on the extraction of information value. Therefore, new information cognition theories are necessary to realize the real extraction of information value;
The direction of information value convergence is uncertain. Although it is expected that information converges at the information of higher value, the extraction of information value is still designed by humans, and the convergence direction is uncertain. Therefore, it is necessary to design a learning-based direction for information convergence;
Robustness of information value extraction. Generally, when distributed learning is used to extract information value, specific scenarios are considered. Therefore, the robustness of an algorithm for cognitive information is critically important in new, unseen scenarios. Furthermore, the fact that the value of information cognition can be used to create a new information value also deserves research attention.
9. Energy Consumption Optimization in Cognitive Information
In this section, the limits of cognitive information from the aspect of energy efficiency optimization are presented. Since cognitive algorithms are embedded in a terminal, an edge, and a cloud, cognitive information energy consumption and the terminal communication, computation, and storage are analyzed.
9.1. Energy Efficient Cognitive Information
The optimization problems in cognitive information have been widely studied. In traditional analysis, Shannon’s formula defines the theoretical limit of information transmission, and Landauer’s principle defines the lower limit of energy consumption for information processing. However, there have been no theories to explain the measurement of value. Specifically, the process of information transmission follows Shannon’s signaling capacity theory and, by measuring the changes in the information entropy in the process of information transmission, Shannon expresses the transmission capacity of a random signaling channel with a formula. In contrast, Landauer’s principle indicates that the micro computation of information in computing chips will generate heat, i.e., it will change the thermodynamic entropy of computing chips and the nearby region, there will be a lower limit of computation energy consumption, and the computation of a piece of information will be accompanied with specific minimum energy consumption.
Thus, according to the principle of thermodynamic entropy, the entropy increase of computing chips and the nearby region results from the process of computing. This can be realized through heat transfer, and thus the computing energy consumption can be presented in the form of heat energy. However, the aforementioned computation does not consider the value of information.
First, the energy consumed by transmission is calculated. According to Shannon’s formula, the maximum transmission rate of information
can be obtained as follows:
where
W denotes the transmission bandwidth,
is the transmission power,
represents the noise, and
h is the transmission distance. Therefore, the transmission power is expressed as:
The energy consumption denotes the energy consumed when handling computing information, and it mainly includes the energy consumed by the information processor. According to Landauer’s principle, the minimum energy required to wipe off 1 bit of information is obtained as:
where
k denotes the Boltzmann constant, and
;
T is the temperature in Kelvin degrees; thus, there is a lower limit in the processing of information. In addition, there is a certain space for optimization in the development of chip technology. Besides, there is a gap between the existing power consumption and Landauer’s limit.
Next, is the calculation of the computation energy consumption. It can be divided into energy consumed for information processing (including the processing of information value) and energy consumed by information communication. Therefore, the total computation amount for both processing and communication of information can be expressed as:
where
is the logical operand corresponding to each bit of information in communication, and
is the logical operand corresponding to each bit of information in the processing algorithm of computation. Thus, the computation energy consumption can be expressed as:
where
F is the fan-out coefficient of the gate circuit, and
is the activator.
Based on the above discussions, in the process of wireless communication, the communication energy consumption when the channel capacity is reached can be measured using the Shannon channel capacity formula. In the process of information computation, the computation energy consumed in the process of information processing can be measured using Landauer’s limits and transistor process technology. Although using the Shannon channel capacity formula and Landauer’s limits, the energy consumed in the processes of wireless communication and computation can be measured, the intrinsic relationship between the communication energy consumption and computation energy consumption, from the aspect of information value, is given. Finally, it is explained how to cognize the value of information, which is to screen transmitted data in advance first to improve the value density of data as much as possible and then transmit data of higher-value density through the channel. The density of data is expressed as follows:
where
denotes the size of the original data, and
is the data size after data are processed.
9.2. Energy Efficient Cognitive Information in Edge Device
The data-value-based information cognition is user-oriented data cognition, and it describes the contribution of information to the completion of a task. For instance, in the face cognition model, the evaluation of picture values is conducted at each user terminal, and then the communication resources are distributed in an optimal way based on the evaluation result. If the user data have contributed nothing to the training model, little communication resources will be assigned to the user, or reliable transmission will be guaranteed as much as possible.
Therefore, the 6G network needs to comprehensively consider, the effectiveness, reliability, and value indexes of a communication network. Thus, the existing communication technology should change accordingly and the traditional optimization model should change from the competition based on two indexes to that it is based on three indexes. In addition, the proposed mailbox theory is an assembly process from information to value, and this process exists in the whole communication network. The aforementioned terminal 3C integration is just a part of the information value chain.
Specifically, the communication system generally transmits information from a device via a wireless access network and the core network to the target user. Thus, cognitive information is processed as follows. The sending terminal roughly recognizes the data and reduces the transmission amount based on the computing ability of the terminal. Next, when the data are transmitted to the wired stage, data are further cognized where the transmission amount can be further reduced. Then, when the data are transmitted to the wireless network again, its amount reduces significantly so as the energy consumed by transmission. The aforementioned discussion proves that the data cognition process consumes the energy consumption of computing, improves the data value density, and reduces energy consumption in communication. Thus, it can be concluded that complex coupling exists between the value density of cognitive information, energy consumption of transmission, and computation energy consumption of information cognition.
From the aspect of a mobile terminal, the relation between the cognitive information value density, energy consumed by data transmission, and energy consumed by information cognition is proposed. First, the energy consumed by information cognition is determined. Namely, the more complex the cognitive computing, the denser the information value will be. Thus, in this paper, for the purpose of simplification, it is assumed that value density and computation complexity of data are positively correlated, i.e., the more complex the computation, the denser the data value will be. However, when the computing complexity reaches a certain value, the data value density drops. Therefore, the data value density can be expressed as follows:
where
denotes a non-linear dull increasing function.
Further, assume that the complexity of computation adopted for data value is denoted as
, then, the computation for data value is as follows:
where
denotes the energy coefficient associated with the chip structure,
is the CPU frequency of a mobile device, and
is the data size. The communication energy consumption, after data processing, is needed to transmit only the processed data
. Assume that the transmitting power of a mobile device is denoted as
, and the uploading power is denoted as
, then the energy consumption of data transmission is calculated by:
Therefore, the main goal is to improve the value of information transmission to the maximum extent under the minimum energy consumption (i.e., communication and computing energy consumption), which is expressed as follows:
Based on the above-described optimization problems, complex coupling relationships among terminal communication, computing, caching, and data value.
10. Customized UAV Networking Enabled Edge Intelligence
As is well-known, there is a large amount of diversified data in the heterogeneous Internet of Things, including the designed drone network. Multiple sensors indicate that it is needed to conduct numerous analyses on massive data. Thus, is there a way to embed distributed intelligent algorithms into a different stage of the data value chain? Multi-level data fusion can be a potential research direction.
Section 6 proposes a brand new concept of data fusion for data life cycle extensions. Using the deep fusion of the data value chain, applications, and human-machine interaction as a motivation, a general architecture that uses different data-fusion technologies is proposed. The authors believe that using data fusion for data life cycle extensions can help to improve data intelligence from low level to high level in six aspects: data fusion for data generation, acquisition, transmission, storage, analytics, and application. Thus, a new and unique solution for a “people-oriented” user service and experience can be achieved.
This section gives an innovative enabling technology and application, i.e., customized UAV networking enabled edge intelligence.
As an IoT equipment carried within computers and sensors, UAVs are widely used in many fields, such as military, monitoring, logistics, aerial photography, smart city, and so on. Compared with the traditional manned aircraft, UAVs have the advantages of small size, good mobility, convenient secondary transformation, and low cost. Since the 1990s, UAV technology has developed rapidly; new materials have increased the endurance of UAVs; evolved communication technology has improved the data transmission speed of UAVs; advanced flight control technology have enabled UAVs to fly completely or intermittently according to a set program. However, in the above-mentioned UAV network functions, UAVs are only used for cruising, monitoring, transportation and other simple aircraft functions, and the surplus computing and storage resources of its airborne computer are idle. As a mobile air IoT device, the UAV network is the most typical structure of the IoT-Edge network extension. How to provide more computing, storage, and communication resources for IoT devices when UAVs perform flight, monitoring, and edge services is an important research topic to explore and inspire edge intelligence.
UAVs with mobile characteristics can become one of the potential choices of mobile edge computing nodes. It is an extension function of a UAV network and it is compatible with edge computing upwards and provides airborne resources downwards. In the new MEC network architecture assisted by customized UAVs, the traditional MEC base station can still exist, and UAVs can also be used as backup base stations when the fixed base station is damaged. In the UAV cluster flight scenario controlled by a ground station and with a change of UAV trajectory, it can also provide a higher-performance in computing offloading or storage services. Therefore, there are more suitable and low-cost mobile edge computing nodes in the key monitoring areas of complex terrain or crowd gathering places such as desert, wilderness, and ocean.
This section will discuss the above vision through the following two important research directions:
(1) Path planning and obstacle avoidance of customized UAV networking enabled edge intelligence. As air flight equipment, safe flight is the primary premise and basic guarantee for UAVs to provide many airborne services including computing and offloading. Among them, there are three open problems that need to be solved: (1) In order to improve the accuracy of obstacle recognition, many researchers use a variety of sensor devices to seek higher perception efficiency, and propose a variety of pattern recognition algorithms for target segmentation and location, (2) Considering the uncertainty of flight time, path length, and flight energy consumption, path planning in multi obstacle environment is a typical NP hard problem, (3) Achieving dynamic path planning and obstacle avoidance in the environment of coexistence of dynamic and static obstacles has high performance requirements for the time precision and distance precision of path planning for UAV in flight.
(2) Dynamic path planning and computation offloading of customized UAV networking enabled edge intelligence. Although the MEC network with UAVs has many advantages, there are still some unavoidable challenges in its implementation and application. Specifically, the traditional MEC network provides a computation offloading service through fixed base stations that only need to consider the offloading characteristics and performance indicators of IoT devices. In the UAV-assisted MEC offloading scenario, the characteristics of IoT devices, UAV, and MEC networks need to be considered comprehensively. (1) In the research of cooperative computing offloading between the UAV and MEC base station, the design and implementation of network hardware and software architecture of UAV-assisted new MEC computing offloading algorithm is a practical problem of both engineering and academic research. (2) In order to meet the demand of computing the offloading delay, the process of joint optimization of dynamically changing network resources and states (the mobility characteristics of IoT devices and UAVs, trajectory changes, offloading service times, task computation and data volume, computing and communication resources of different computing nodes, etc.) is usually composed of multiple sub-modal optimization problems, which cannot be modeled by traditional centralized modeling. (3) Due to the limited energy of UAV, the system has to extend the flight time of UAV and improve the energy efficiency by dynamically planning the flight path and calculating the offloading strategy.
10.1. UAV-Assisted Data Value Cognition and Transmission
In order to validate the performance of the proposed mailbox theory described in
Section 8 and
Section 9, we use an UAV as an information carrier to do the data value cognition and transmission in an edge computing environment.
In this experiment, a quadrotor UAV with a diagonal wheelbase of 600 mm, 6S FOC governor, 4006 motor, and a maximum flight load of 4 kg is used. The airborne computer is an Intel Core i7 mini computer with an Intel i7-8565u processor, four core eight thread 1.8–4.6 GHz, 8G memory, 128G storage, 2.4/5.8G dual band WiFi gigabit network card, and Ubuntu 18.04 operating system. The edge server is equipped with Ubuntu 16.04.7 LTS, 32G memory, 3T storage, i7-7800X processor and two GTX 1080 Ti graphics cards.
First, the UAV equipped with an airborne computer is connected to the public network through WIFI to realize data transmission to the edge server. Five shufflenet models with different network complexities are deployed to the airborne computer to recognize the value of edge devices. The parameter volumes of network models are 1030 K, 1122 K, 1162 K, 2093 K, and 2314 K, respectively. It will process the image data with data volumes ranging from 61 KB to 2289 KB. Then, the UAV transmits the data to the edge server after value cognition, and finally calculates the data transmission delay with or without value cognition.
Figure 12 compares the delay of data transmission with or without value cognition. When the data volume is small, the delay of data transmission without value cognition is shorter; when the amount of data increases to 1099 KB, the data transmission delay after value cognition is much shorter.
Figure 13 compares the image value cognition time of network models with different complexities. The model with low network complexity performs shorter delay of value cognition while the model with high network complexity performs longer delay. Furthermore, cognition delay increases with the increase of data volume as shown in
Figure 12.
10.2. Case Study of Digital Twin
With the support of IoT, cloud computing and AI, “Digital Twin” is the future trend of a smart city. It is the “clone” of a physical city in the digital world. This is based on the sensor data of the IoT, accurately mapping and co-evolving with the physical city. To realize the digital twin city, we need to obtain a 3D model of the physical world through UAV tilt photography or lidar mapping, network GIS data or artificial modeling. On this basis, real-time city state mapping and urban simulation can be carried out. Realtime city state mapping needs to obtain location information of the crowd in the city through a variety of sensors and AI technology, combined with edge computing and cloud computing, and displays it in real time in its digital twin city. Urban simulation needs to run crowd simulation and traffic flow simulation in digital city, which can provide reference for various decision-making of governmental departments. In this section, we carried out the campus crowd simulation experiment.
In the experiment, the downloaded GIS data are imported into the 3D modeling software Blender to obtain the main campus 3D model for Huazhong University of Science and Technology, including roads, buildings, and so on. On this basis, the crowd simulation software MassMotion is used to simulate crowd activities in the real world, including classes in the teaching building, sports in the playground, dining in the canteen, etc.
Figure 14 shows the experimental result of a digital twin. The bottom layer is the real photos and 3D model of the main university campus, and the top layer is the real photos and simulation screenshots of the second floor of its canteen. The experiment simulates the process of people queuing up for lunch. The orange models in the picture represent the simulated people (agents). The color lines on the floor represent the total number of people passing through this location during lunch time, increasing from dark blue, light blue, green, yellow, orange to red.
11. A Deep Learning-Assisted Cognitive Information Communication System
In order to verify the 6G mailbox theory proposed in this paper, we establish a deep learning assisted cognitive information communication system.
11.1. Traditional Communication System Architecture
The traditional communication system mainly includes the following five parts: information source, transmitter, channel, receiver, and sink. The information source refers to original data, such as sound signal, picture, audio and video that a user needs to transmit, and corresponding preprocessing is required at the information source. The transmitter mainly completes encoding and modulation of data, such as source encoding, channel encoding, encryption, channel multiplexing and spectrum spreading, to improve the effectiveness, reliability, and security of data transmission. The channel is the physical transmission medium of user data in nature, including wired and wireless channels. The receiver completes a series of decoding processes completed by the user after receiving the data, including despreading, demultiplexing, decryption, channel decoding, source decoding, etc., and restores the transmitted original signals. Sink is the receiving end of signals. Thus, in the whole communication process, the sending end mainly completes encoding and modulation of signals, while the receiving end mainly completes the corresponding decoding and demodulation.
11.2. Cognitive Communication System Architecture
We design the architecture of a cognitive communication system assisted by deep learning, which includes encoder, channel, and decoder. Thus, the encoder cognizes information and the decoder decodes the information that has been cognized. Specifically, a cognitive communication system for image transmission based on U-Net architecture has been designed. That is, the information transmitted by this system are images, and encoding and decoding are conducted to the images.
Encoder: The encoding part consists of a deep residual module and maximum pooling layer. The deep residual module includes input, batch normalization (BN) layer, ReLU activation function, two 3 × 3 convolution operations, identity mapping unit, and output. By adding an identity mapping unit, the input of the deep residual module is directly transmitted to the network layer in the back. This is to effectively reduce the influence of gradient degradation in the process of network training and to promote the transmission of information to solve the problem of information loss in traditional networks to a certain extent. The maximum pooling layer is used for the down-sampling operation of images, with a step size of 2. Its purpose is to reduce the size of the feature map as the number of channels in the feature map increases with the decrease of the size. Specifically, the number of channels for an input image is 32. Before entering the encoding part, the image will go through a 3 × 3 convolution layer, BN layer and ReLu activation function, and the number of its channels will become 64. In the encoding part, down-sampling is conducted three times, and the number of channels is 64, 128 and 256, respectively. The size of the feature map of the latter submodule is equal to 1/2 of that of the former, that is, the size of the feature map is 160 × 160, 80 × 80, 40 × 40, 20 × 20, and 10 × 10, respectively.
Channel: Channel connects the encoder and decoder. In order to achieve uniform training of cognitive systems, we define the channel as salt-and-pepper noise and uniform training is carried out. In other words, the salt-and-pepper noise is added to the encoded image after output.
Decoder: The decoder part contains the same four deep residual modules and up-sampling operations. Up-sampling is conducted to the feature map from the channel part. After each up-sampling, the number of channels in the feature map is halved, and the size of the feature map is doubled. Finally, the feature map with the same size as the original image is obtained. In the decoder part, up-sampling is conducted four times and the number of channels is 256, 128, 64, and 32 respectively. The classifier is composed of 1 × 1 convolution layer and Sigmod activation function. The convolution operation of 1 × 1 is conducted on the feature maps from the decoder, to reduce the number of feature maps. The Sigmod activation function is used to calculate the category of each pixel in the feature map and finally the multi-channel feature map is mapped to the corresponding categories.
Loss function: In this experiment, the loss function we used is cross-entropy loss function, which is defined as follows:
where
M is the set of pixels in the segmentation image,
N is the set of pixels in the labelling segmentation tags,
is the true category of pixel
i in the segmentation image and pixel
j in labelling segmentation tags,
is the predicted value of pixel
i in the segmentation image and pixel
j in the labelling segmentation tags. In the process of network training, if cross-entropy loss function is used for optimization, then the problem of gradient disappearance in the network can be solved effectively, and the network can run stably.
11.3. Performance Analysis
Experiment setting: In this experiment, we use the Oxford-IIIT Pet dataset, which contains 7390 images of dogs and cats, and use the dataset for segmentation of pet images. Furthermore, the network parameters are set as follows; The encoder consists of three deep residual modules and a maximum pooling layer. In the maximum pooling layer, down-sampling is conducted with a step size of 2. In the process of each down-sampling, the number of feature channels doubles. Each step of the decoding process includes a depth residual module and up-sampling where the number of feature channels is halved. In the last layer, 1 × 1 convolution and Sigmod function are used to map each eigenvector to the required class number.
Evaluating metrics: Cross-entropy loss and percentage of average pixel error are used as evaluation indices. The percentage of average pixel error is the proportion of cases where the predicted pixels of an image are different from the pixels of real labels. It can be seen from the definition of the average error of pixels that the smaller the average error of pixels, the more accurate the transmission.
Experimental result: In the experiment, all data sets have been used to divide training sets and test sets. The training and testing situations with different numbers of images have been compared and in each case, the ratio of training set to test set is 3:1. With the well trained model, different numbers of images have been used as the input to predict the results. As shown in
Figure 15, the loss function of our cognitive system becomes smaller with the increase of training pictures, indicating the stability of our cognitive system. Moreover,
Figure 16 also shows that our system is stable. Furthermore, compared with traditional communication systems, less image data can be transmitted with our communication system based on deep learning, but the transmission error is very small.
12. Cognitive Information Applications
12.1. Wise Medical
With the maturity and commercial use of 5G technology shown in
Figure 17, the real-time and efficient application of wise medical has become the future development direction in the health field. In wise medical, data-fusion technology is used for medical image registration and retrieval [
72], multi-source image-feature fusion, multi-sensor fusion of medical apparatus and instruments or body area network, and multi-modal patient-data fusion, diagnosis, and treatment. In [
73], the authors studied multi-sensor fusion and multi-modal image registration and used different data-fusion technologies to transform the patient data and image features to identify organ structures. In [
74], different methods were used for feature extraction and fusion, and the results were conducive to medical image retrieval. Moreover, in [
75], the authors used fusion technologies to conduct deep information mining for multi-source medical images and obtained image data of high quality. In [
76], the medical-decision fusion for images of different forms of organs was presented, and good qualitative and quantitative diagnostic results were achieved.
12.2. Industrial Applications
Complex industrial manufacturing, including industrial control [
77], mobile robots, and remotely operated robots, is one of the applications of data-fusion technology. It has stipulated in Industry 4.0 [
78] that information technology is used to promote industrial transformation, i.e., industrial intelligence. In the face of such massive infrastructure construction and production potential, the automation, intelligence, and safety of industrial control systems denote important components to ensure national security and social livelihood [
79]. To obtain data, operation feedback, and system status of physical equipment or sensors, the multi-dimensional data-fusion technology is applied to the quantitative analysis, industrial prediction, safety monitoring, and system energy saving [
80].
12.3. Traffic Control
Due to the widespread application of AI technology, highly complicated, diverse, and automated unmanned operations have appeared in transportation systems. These operations greatly rely on environmental data acquired by sensors. Therefore, data-fusion technology can be applied to vehicle positioning, tracking, navigation, as well as ground and air-traffic control [
81,
82]. Among them, the ground traffic control applications mainly focus on an infrastructure’s data perception [
83], autonomous vehicle navigation, and traffic flow control [
84]. The air traffic control applications include path planning [
85], obstacle avoidance, and 3D modeling. A typical application is Microsoft Bing 3D Cities, established using UAV aerial photography technology and automatic data segmentation and fusion technology [
86].
12.4. Remote Sensing and Mapping
Remote sensing refers to non-contact, remote-detection technology [
87]. In this method, extraction, judgment, processing, analysis, and application are conducted on electromagnetic-wave information, such as electric field, magnetic field, electromagnetic wave, and seismic wave, of an object with sensors or remote sensors where target objects are detected far away from the target without any contact. With the introduction of multi-modal data fusion, a remote-sensing and mapping technology can be used in 3D modeling and classification [
88] for topography [
89], climate [
90] ecology, species [
88], and so on.
12.5. Military Applications
Thus far, data fusion has been widely used by the military, where it originated [
91]. Military applications require dynamic target detection, identification, and tracking with the properties of high accuracy, large scale, and automation. Due to the complexity and uncertainty in scenes and military operations, it is difficult to accurately judge and respond to real scenes or entities from a human perspective. Therefore, a large-scale, multi-source data fusion [
92] using sensors and computing nodes deployed by the military for applications, such as battlefield situation assessment, combined heaven and earth surveillance, target acquisition, strategic defense, early warning, battle-damage quantitative measurement [
93], army management and military decision making, and modernized military information systems, has been used [
94].
12.6. Smart Cities
The concept of a “Smart City” was proposed by IBM in 2010. The emphasis was put on building people-oriented and sustainable cities based on IoT, cloud computing, and AI technologies. The application of data-fusion technology in smart cities is diversified. It includes smart living (e.g., smart health, smart homes, and smart communities) [
95], smart urban-area management (e.g., urban planning, smart municipal, and smart buildings), smart environment (e.g., climate monitoring, ecological protection, and urban waste management), smart industry (e.g., smart manufacturing, smart maintenance, and smart agriculture) [
96], smart economics (e.g., intelligent commerce, intelligent supply chain, and financial and security transactions) [
97], smart human mobility (e.g., positioning services, intelligent transportation systems, and management of big data on the population), and smart infrastructure (e.g., urban infrastructure planning and management, intelligent IoT, and intelligent communication) [
47]. The main features of these applications are interdisciplinary, cross-time domain, cross-regional big-data fusion, and intelligent services.
12.7. 5G/6G+AIoT (AI+IoT)
In 2017, Legrand popularized the concept of combining AI and IoT technologies (AIoT) and proposed the concept of intelligent IoT with AIoT as a core. In 2019, GSMA released a report on intelligent connectivity [
98], where it was pointed out that the fusion of 5G, AI, big data, and IoT would lead to the development of the next generation of the super Internet. With the advent of 5G/6G, AIoT is no longer a simple AI+IoT. It is rather an integrated service [
99] for data, knowledge, and intelligence based on AI+IoT with the basic support of big data and cloud computing, a semiconductor as an algorithm carrier, network-security technology as an implementation guarantee, and 5G/6G as a catalyst. Therefore, the development of DF technology strongly promotes the deep cooperation of infrastructure, AI, and application and provides a new cross-domain fusion perspective [
100,
101].
13. Conclusions
In order to meet the requirements of intelligence, customization and value transmission of 6G networks, we first propose a new network integrating distributed intelligent network, active interactive network and cognitive information transmission. Based on this, a 6G mailbox theory, i.e., cognitive information carrier to enable distributed algorithm embedding for intelligence, has been proposed. Under the proposed mailbox theory, more valuable data can be transmitted in 6G networks. Furthermore, we introduce the features of the mailbox theory, including polarity, traceability, dynamics, convergence, figurability, and dependence. Key technologies based on knowledge graph, distributed learning and blockchain are introduced. Finally, we establish a cognitive communication system assisted by deep learning to verify our scheme.





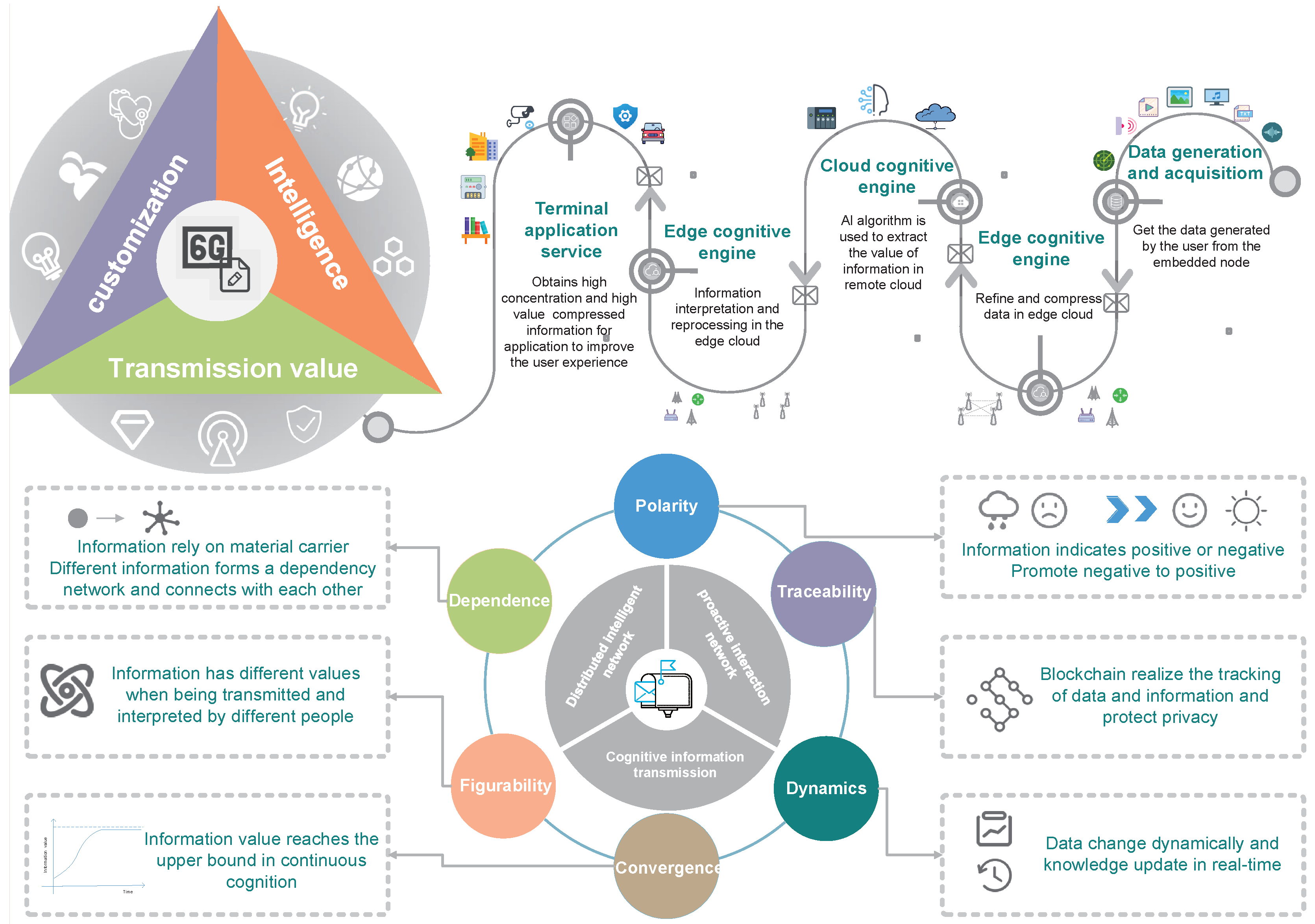
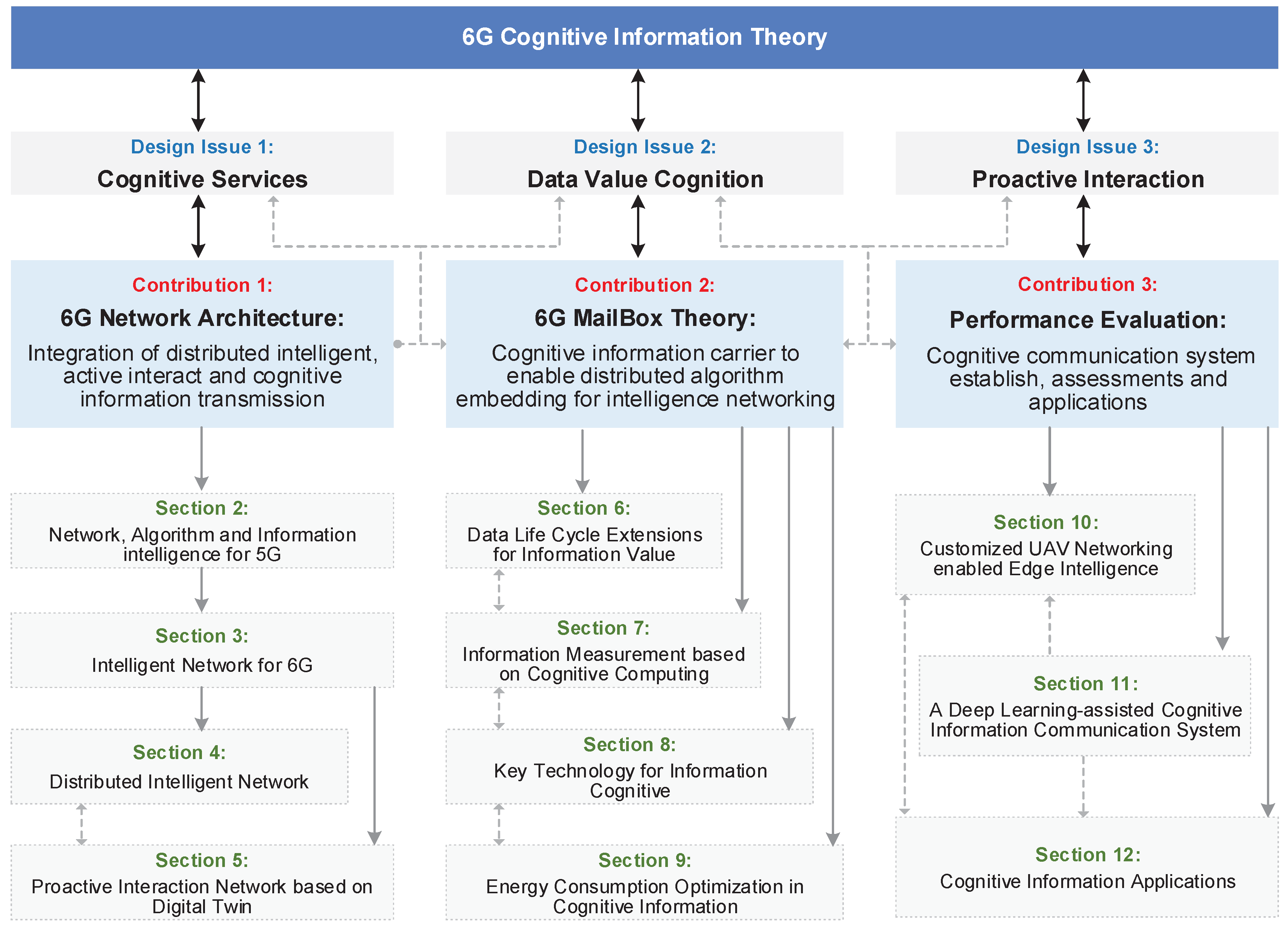
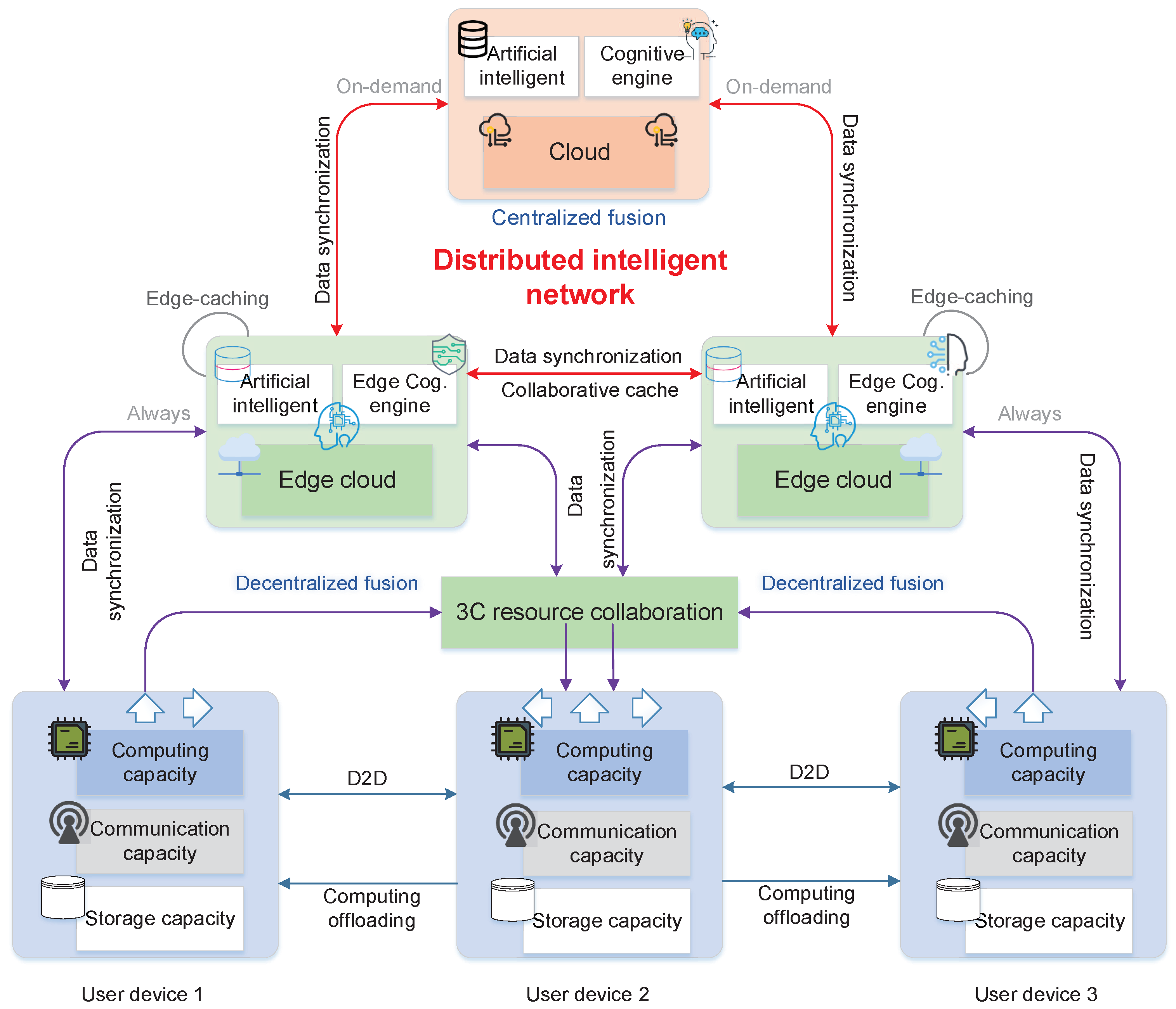
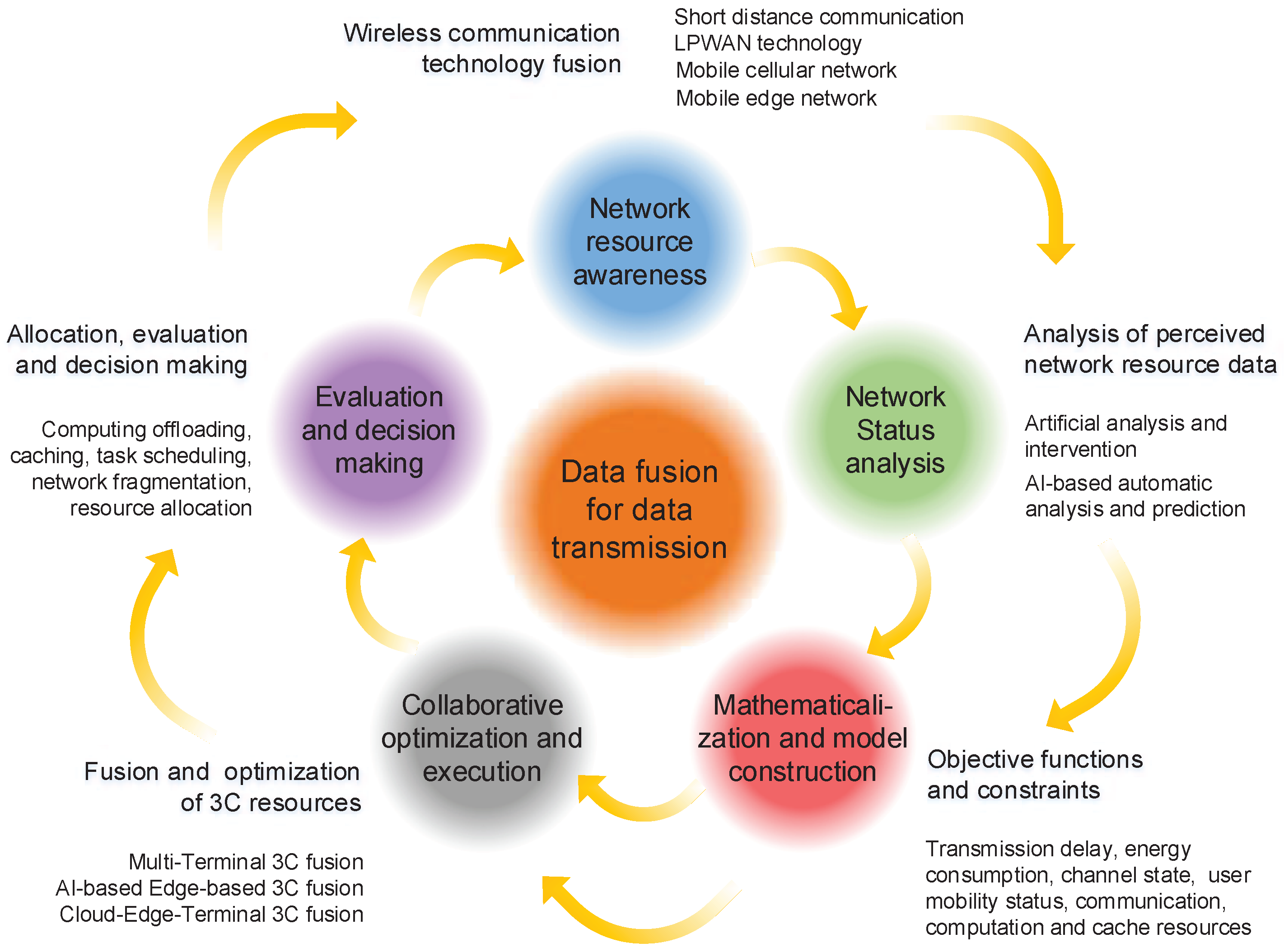
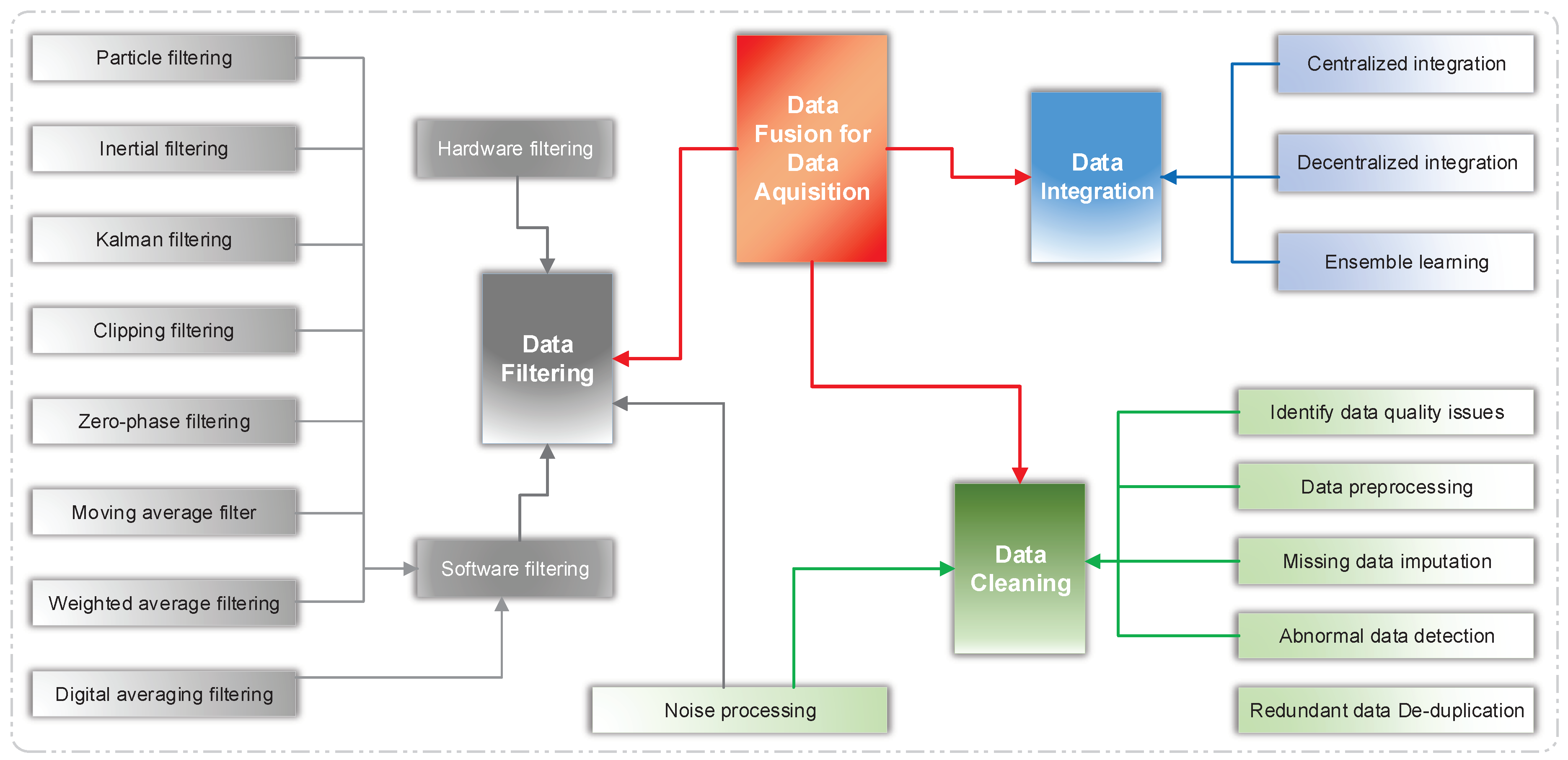
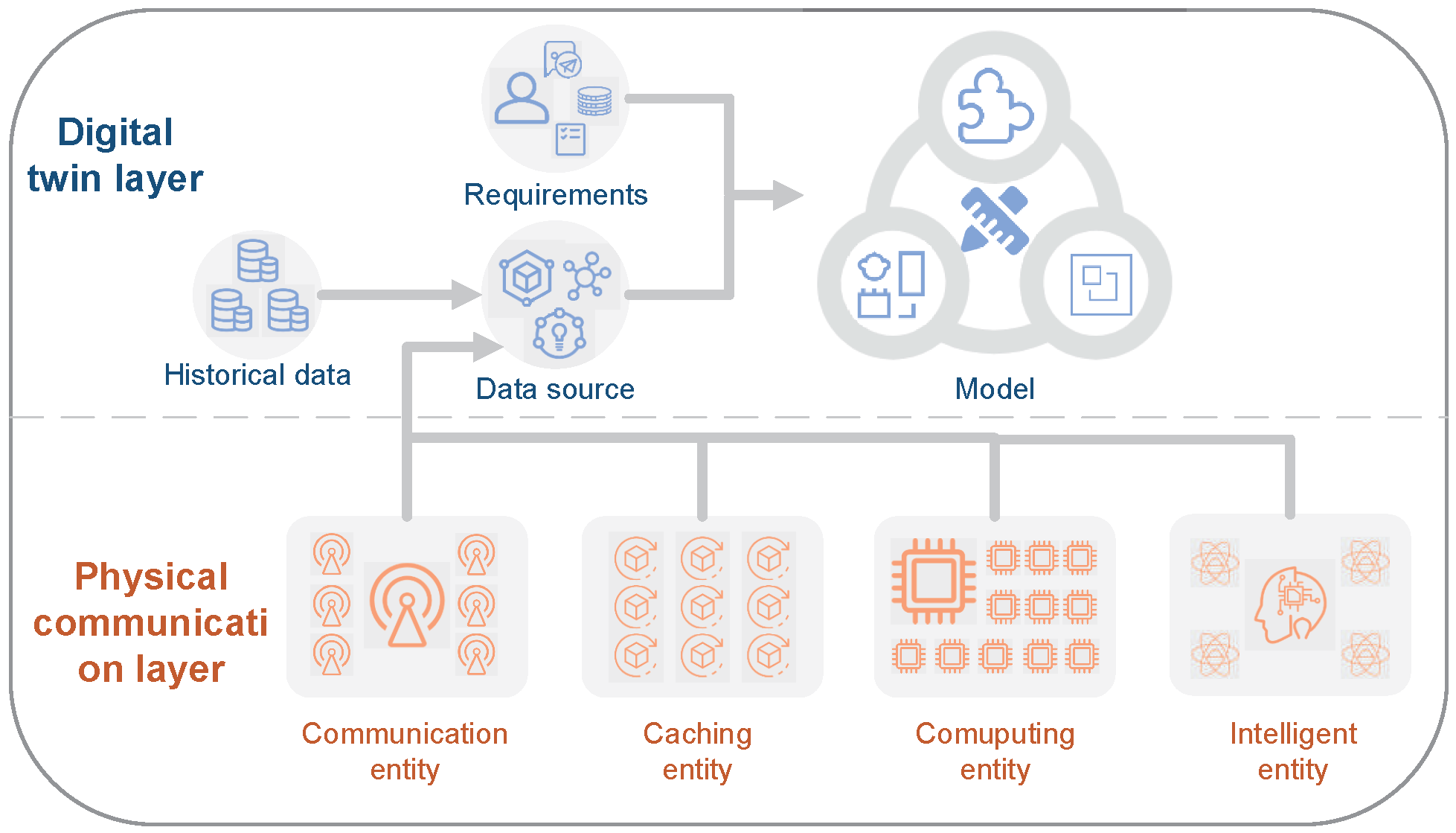
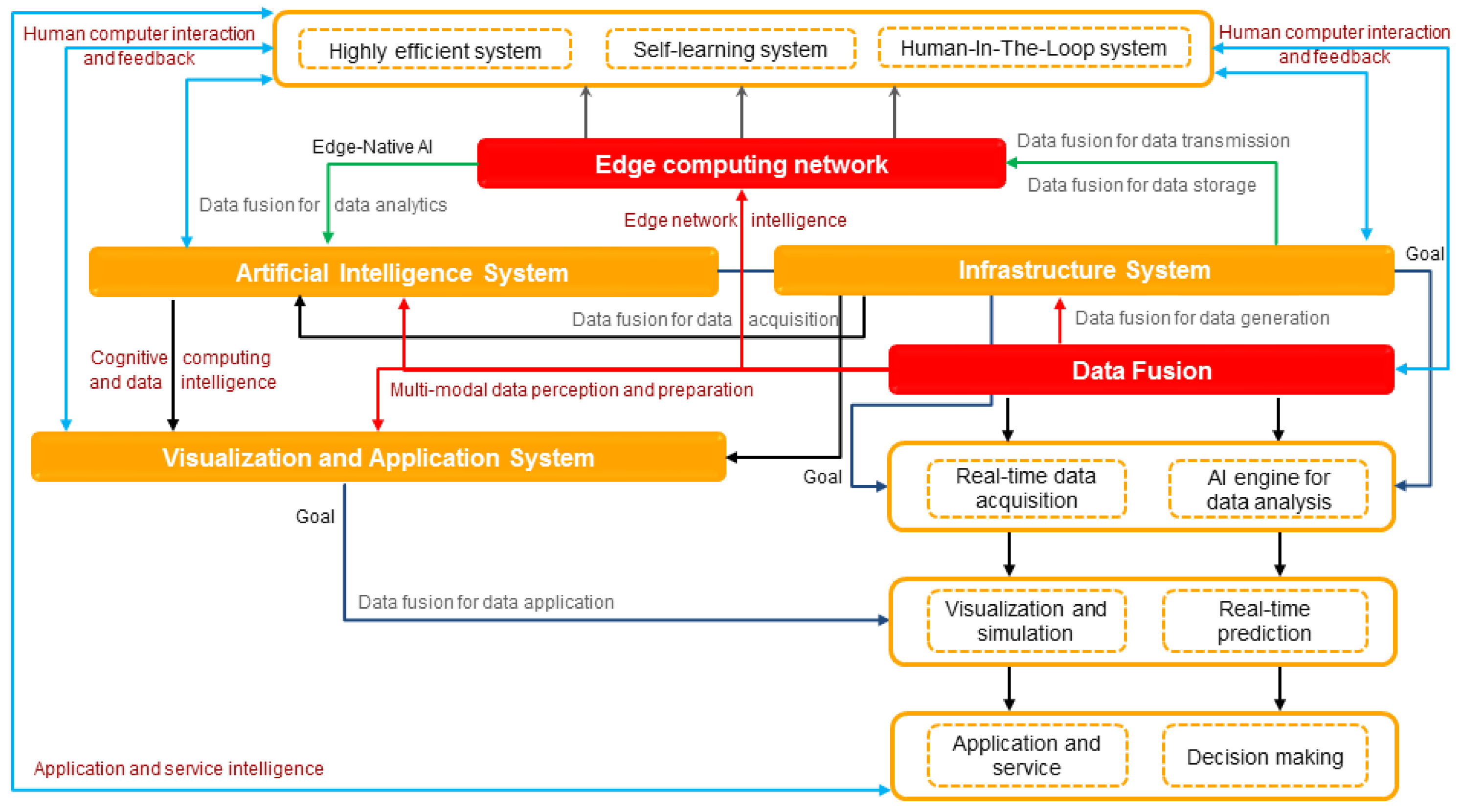
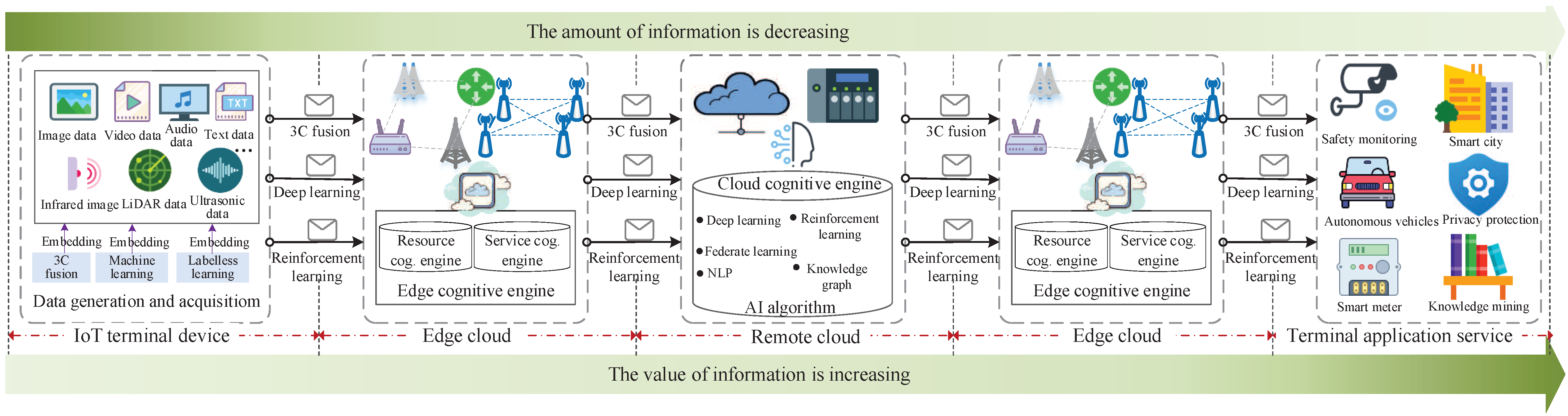
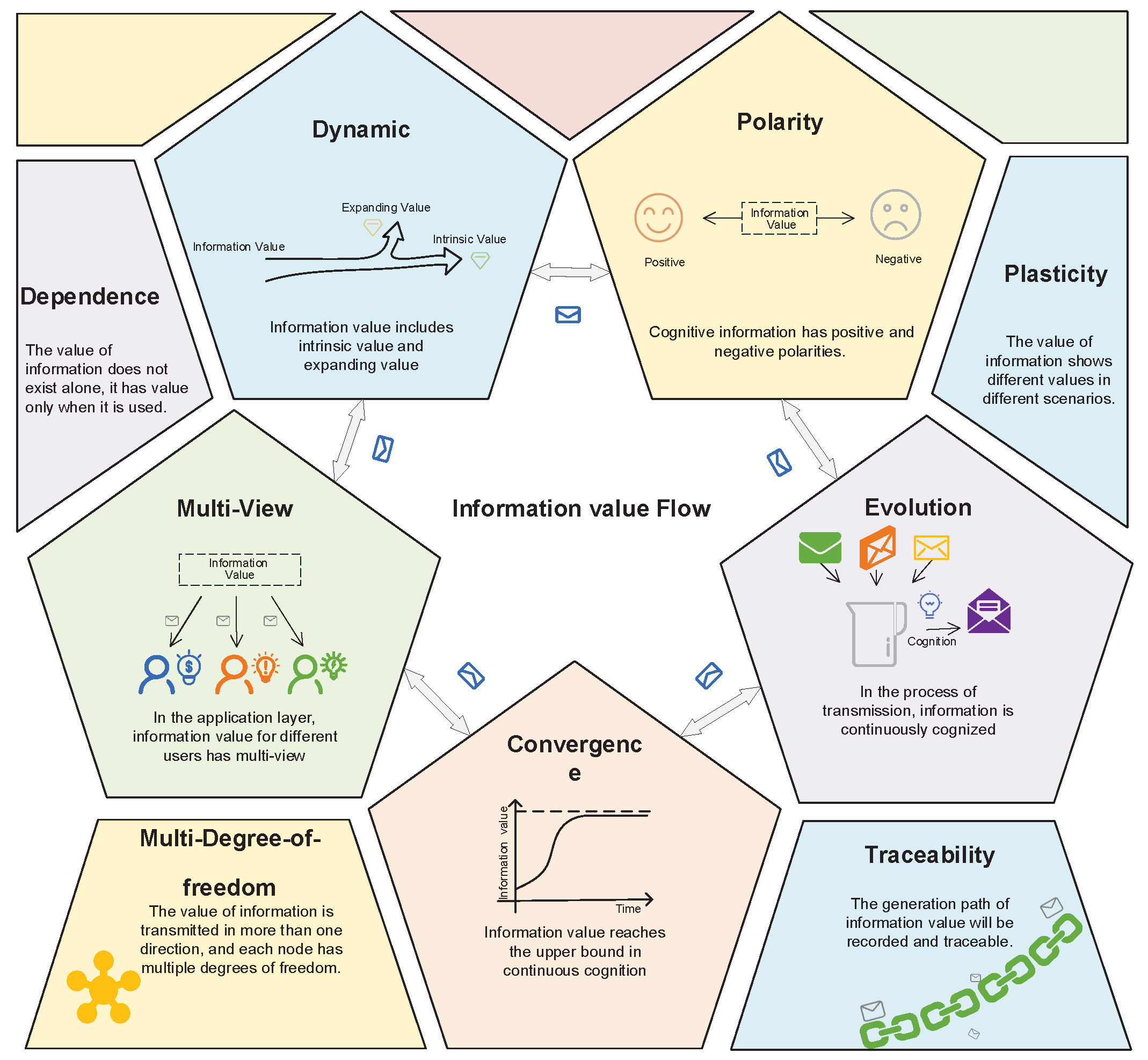
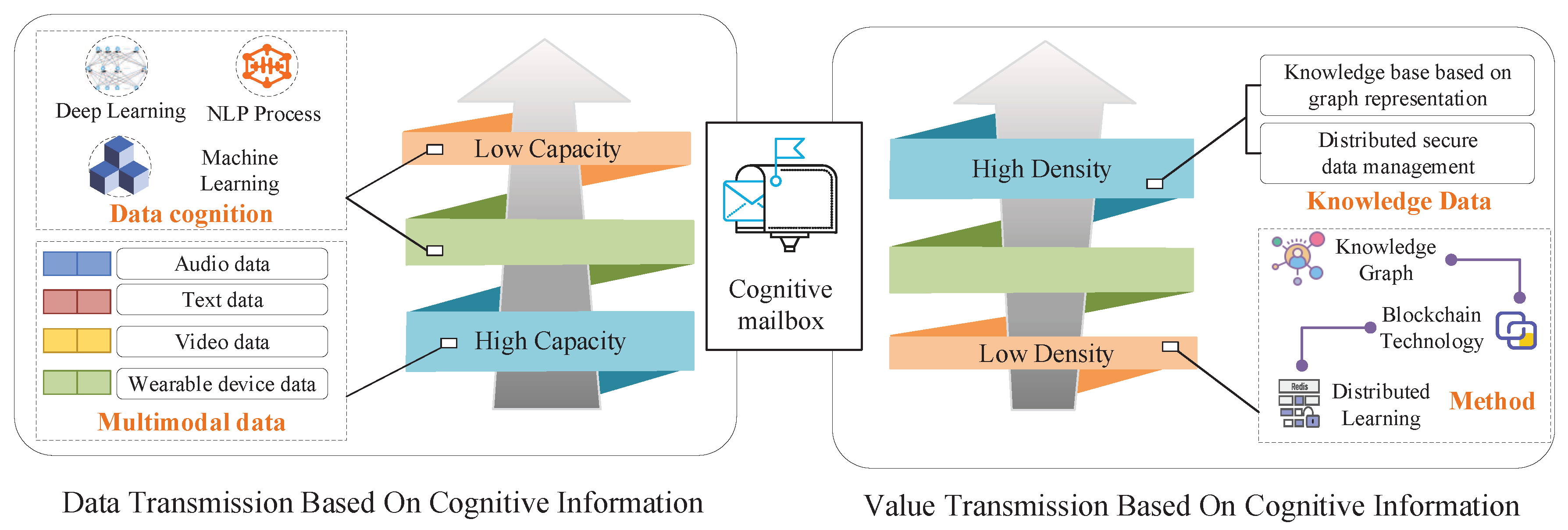
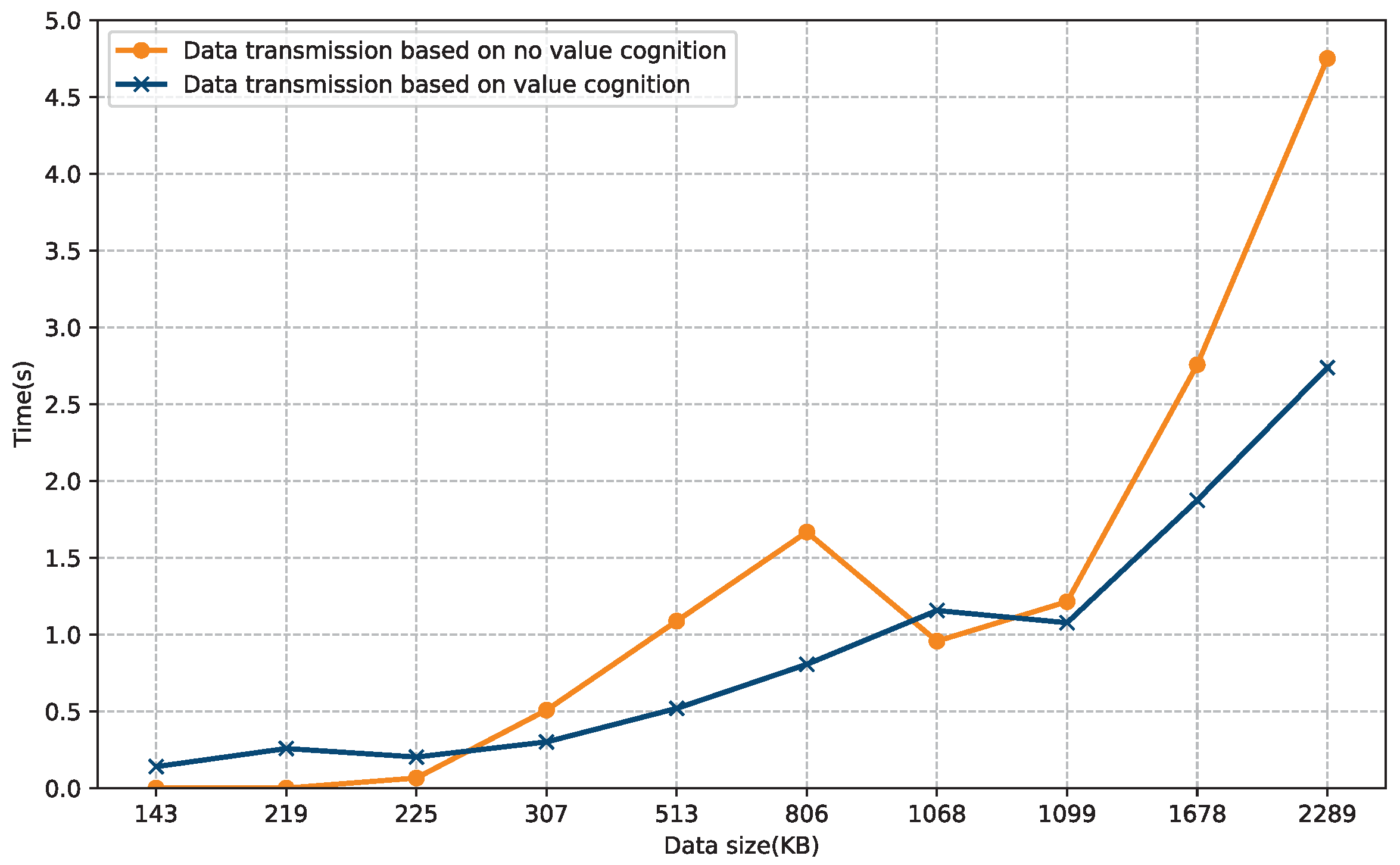
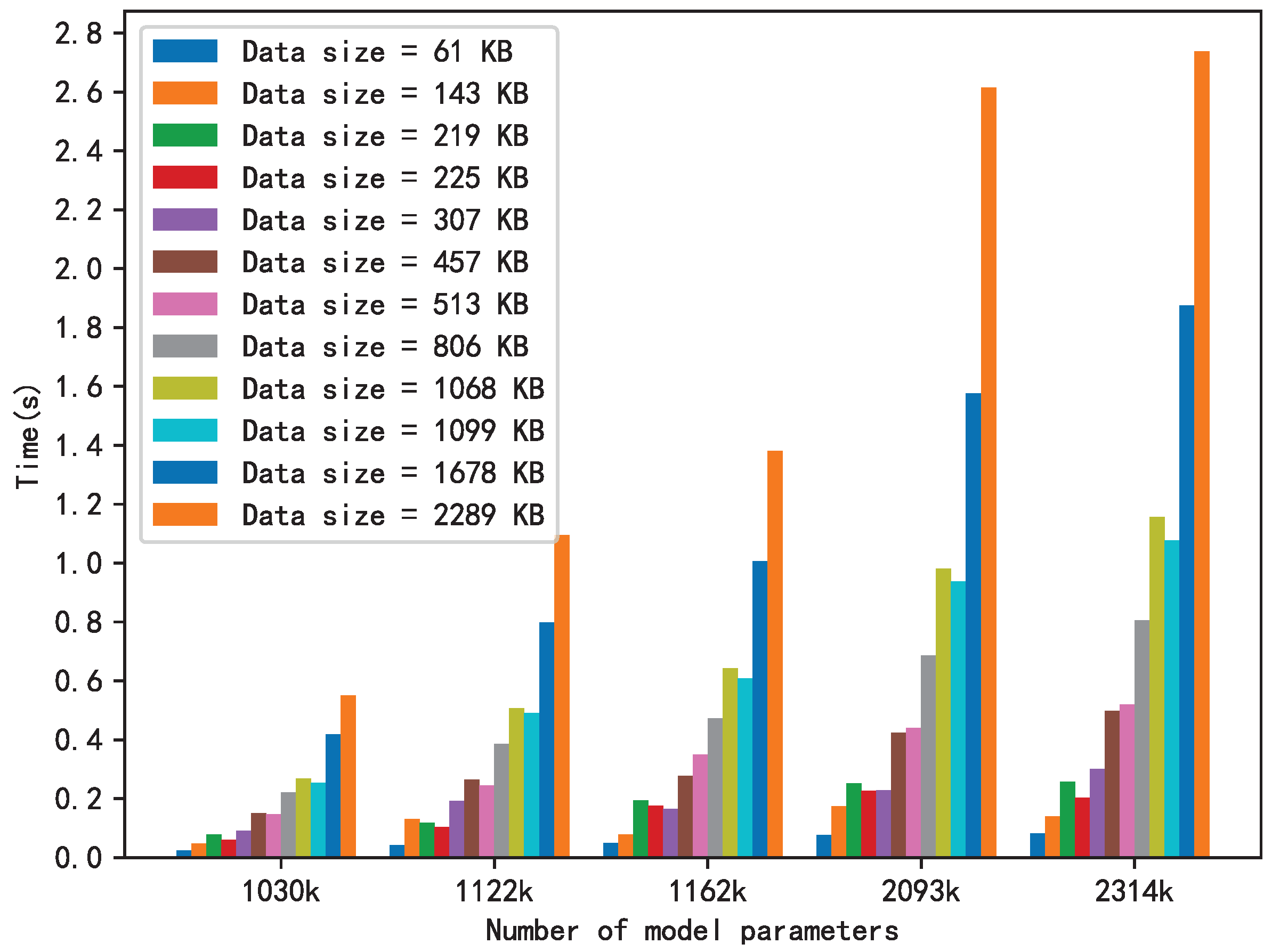
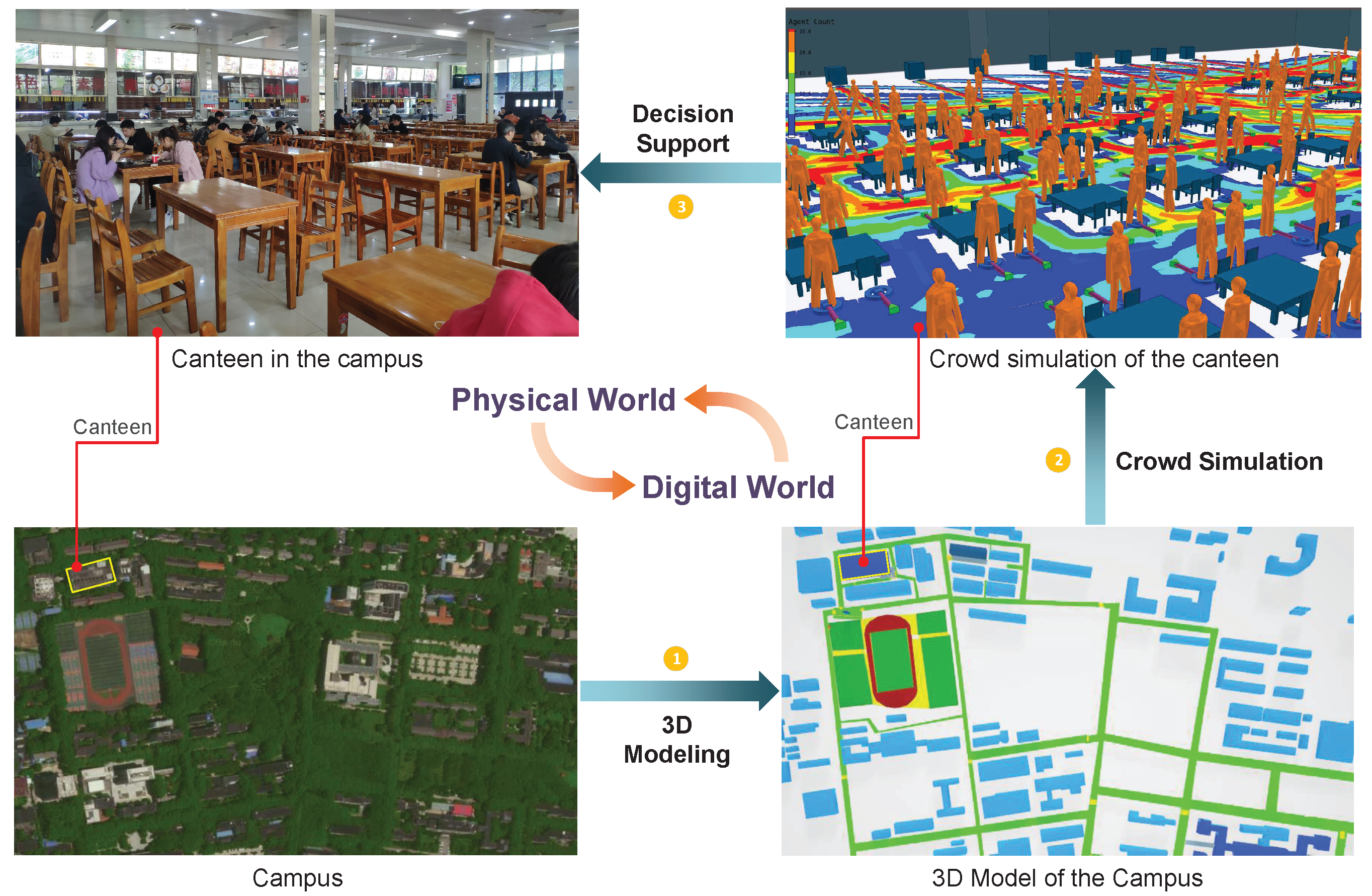
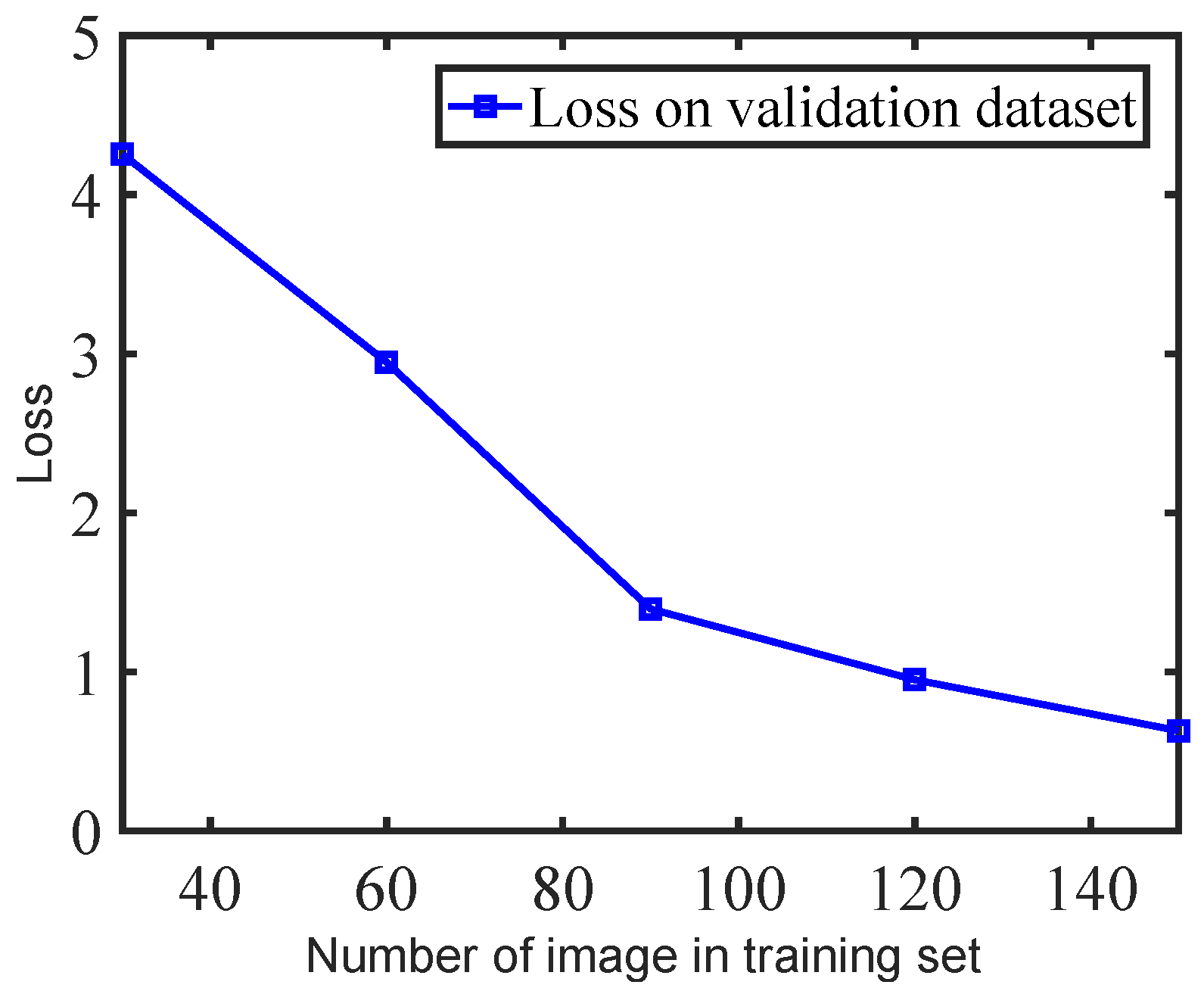
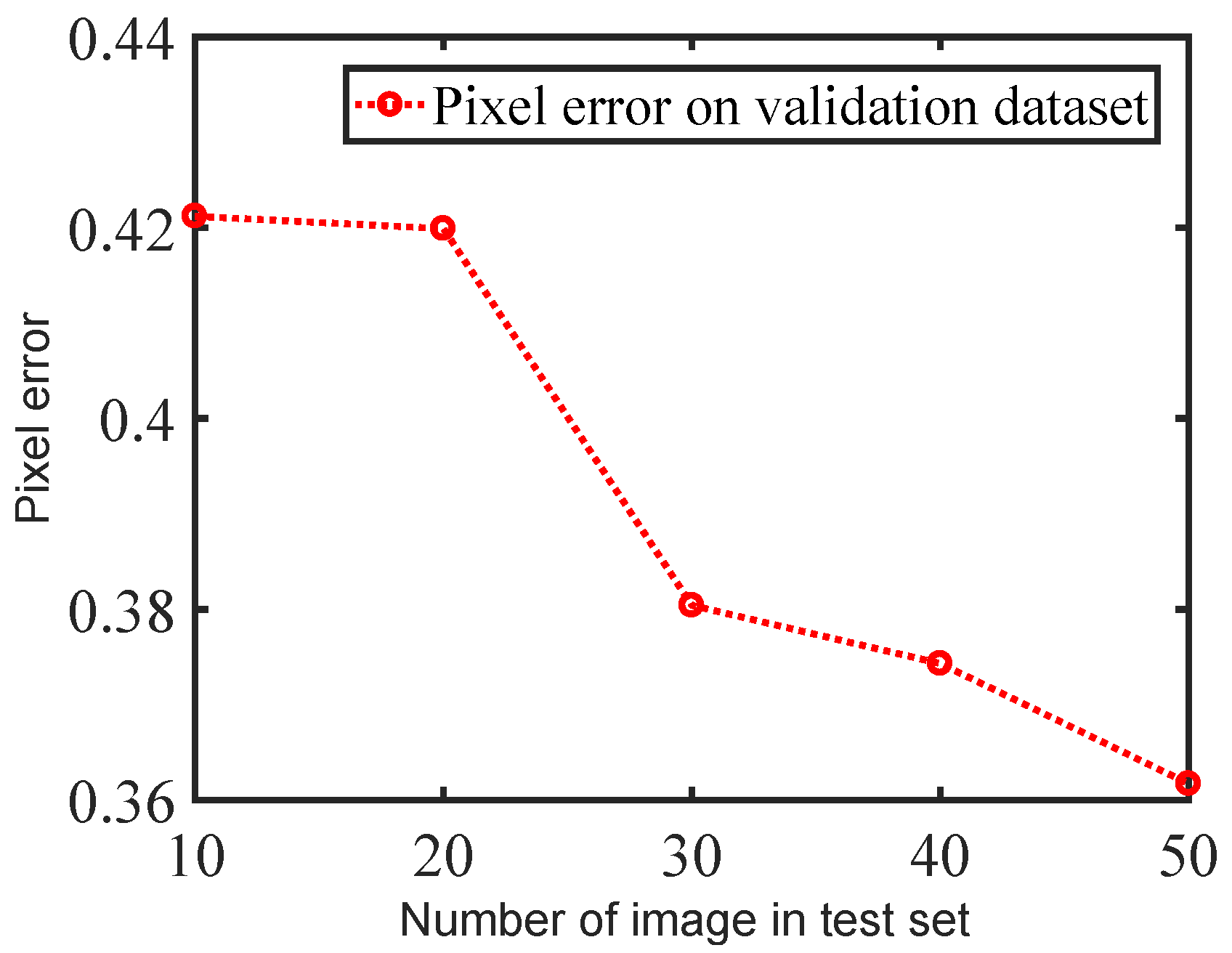
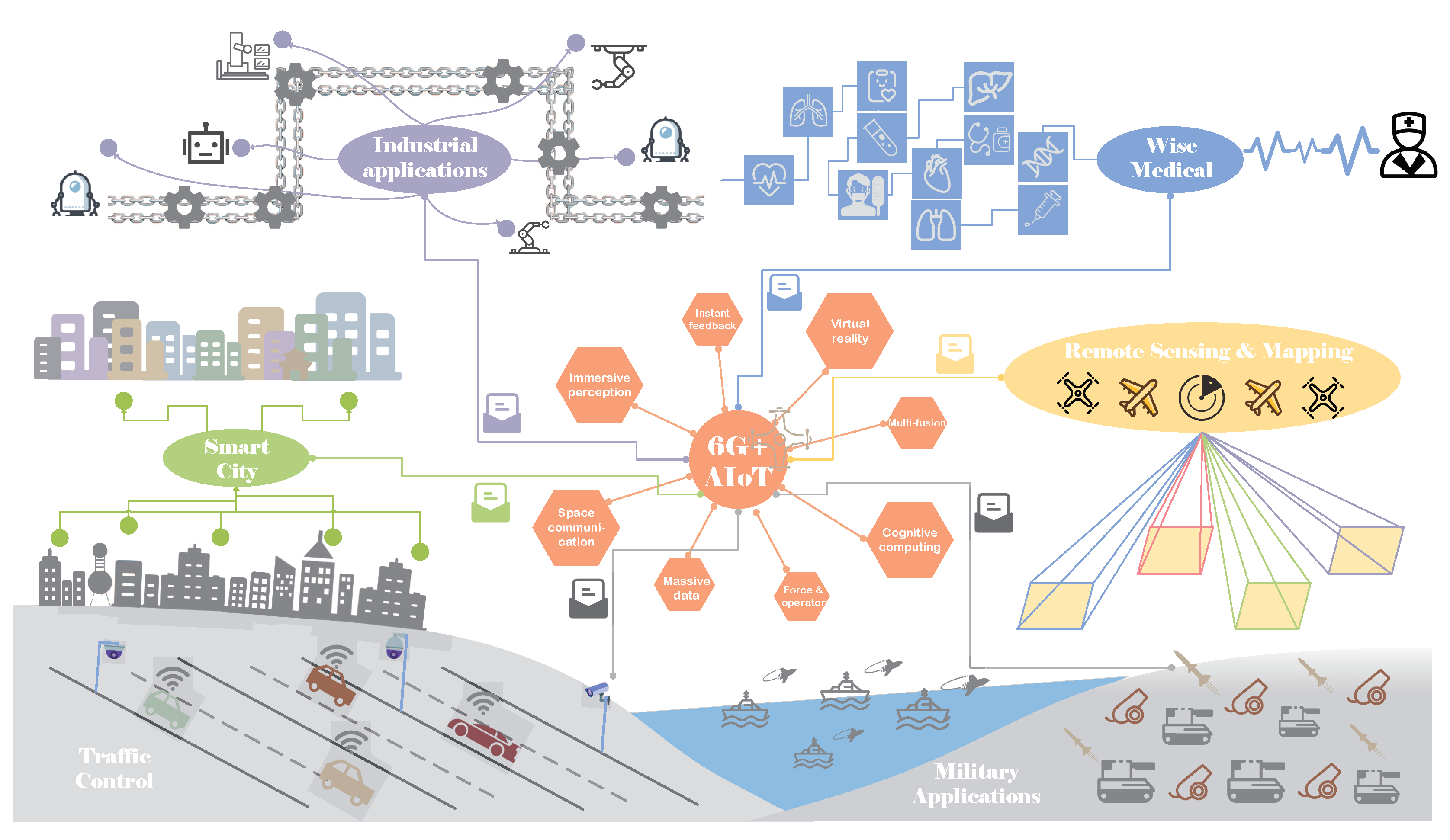

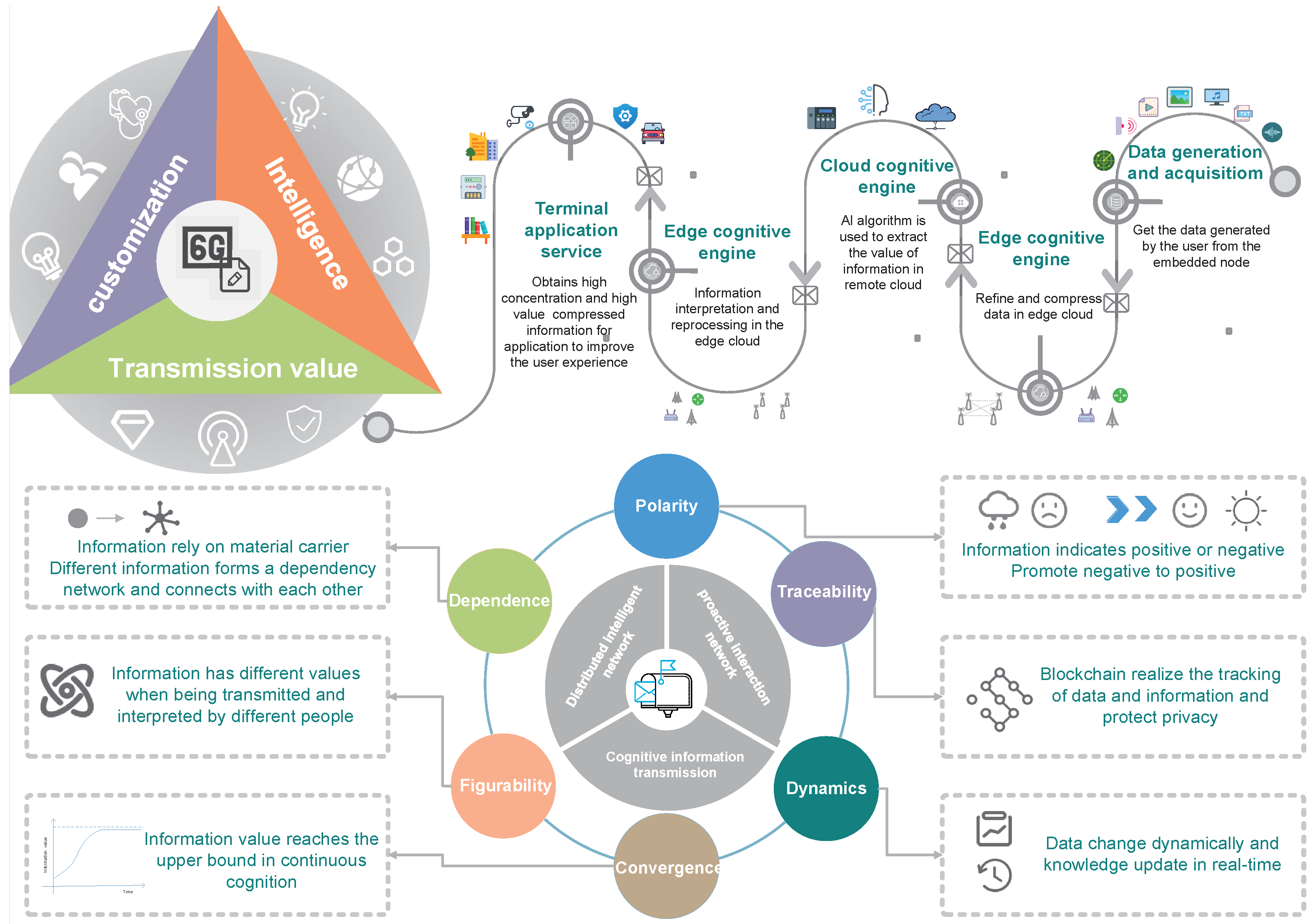{kind=link}
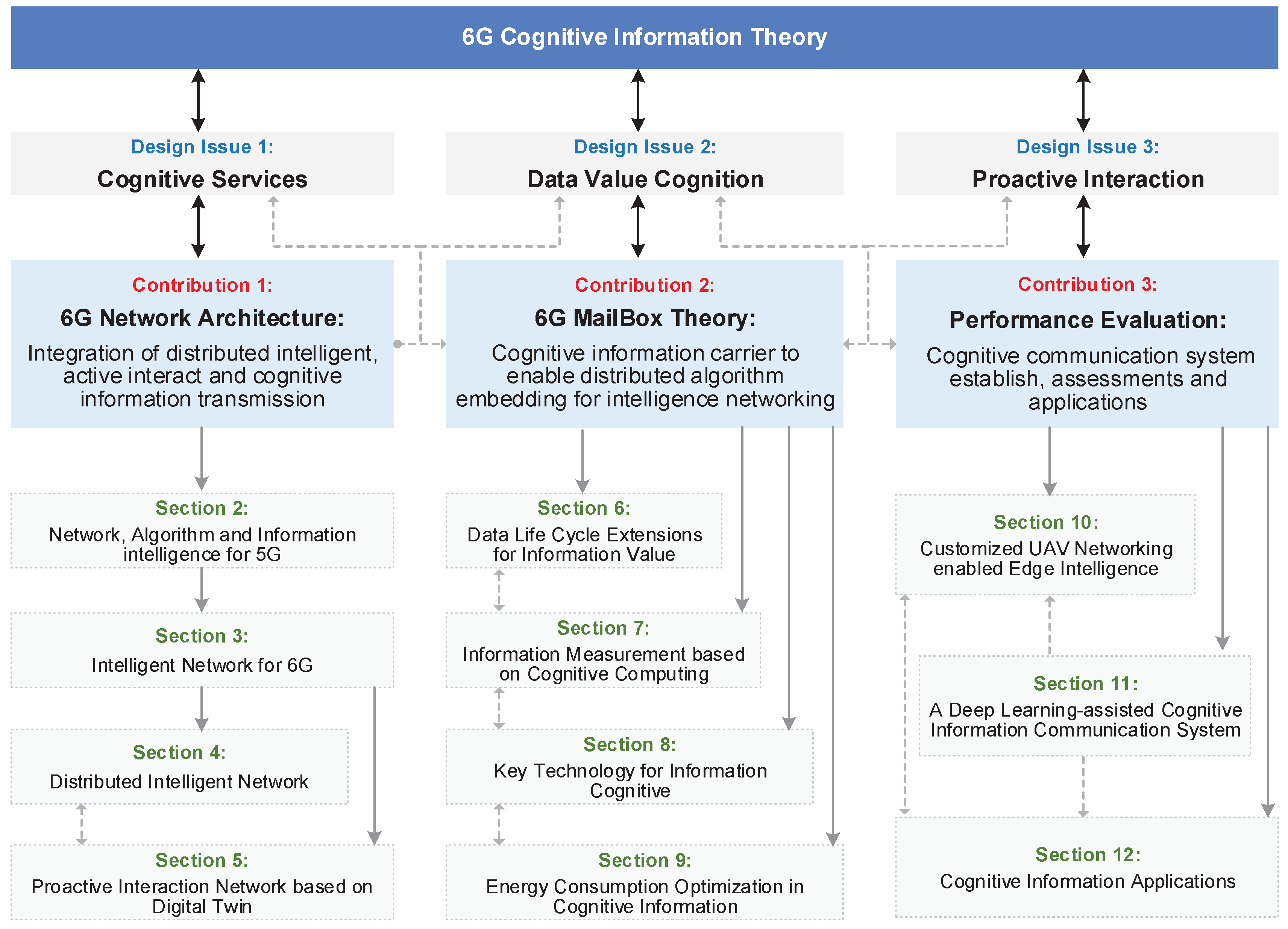{kind=link}
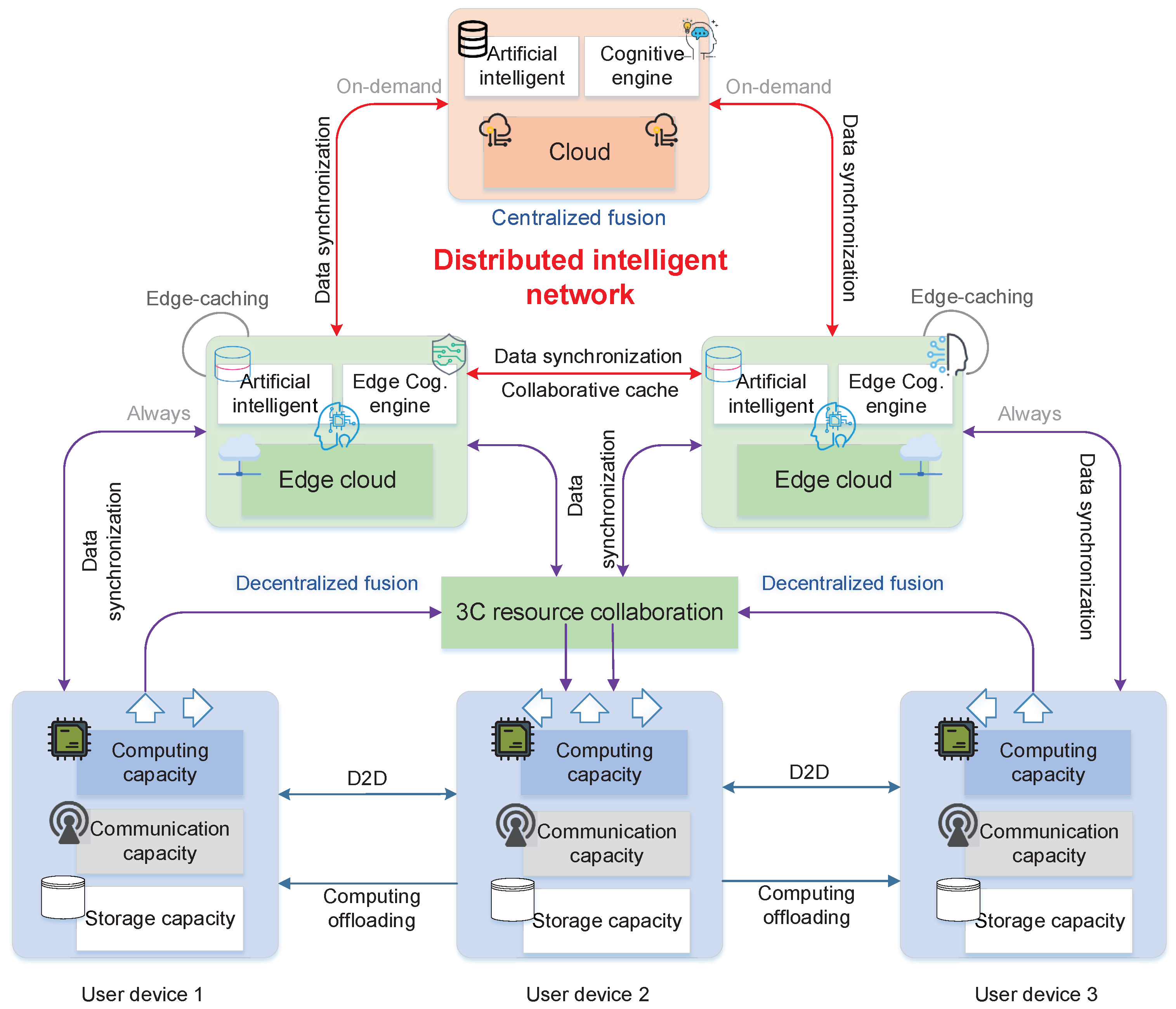{kind=link}
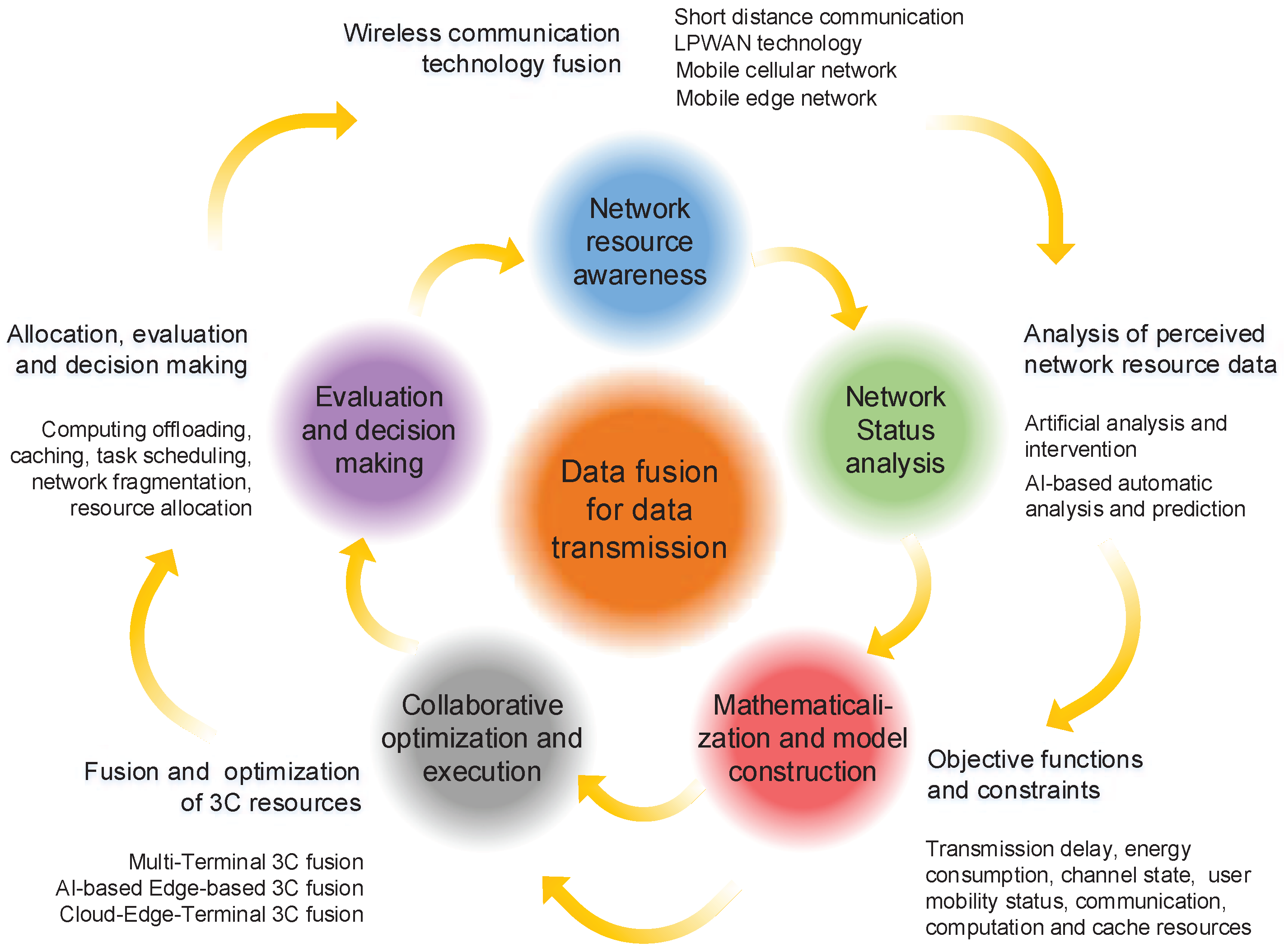{kind=link}
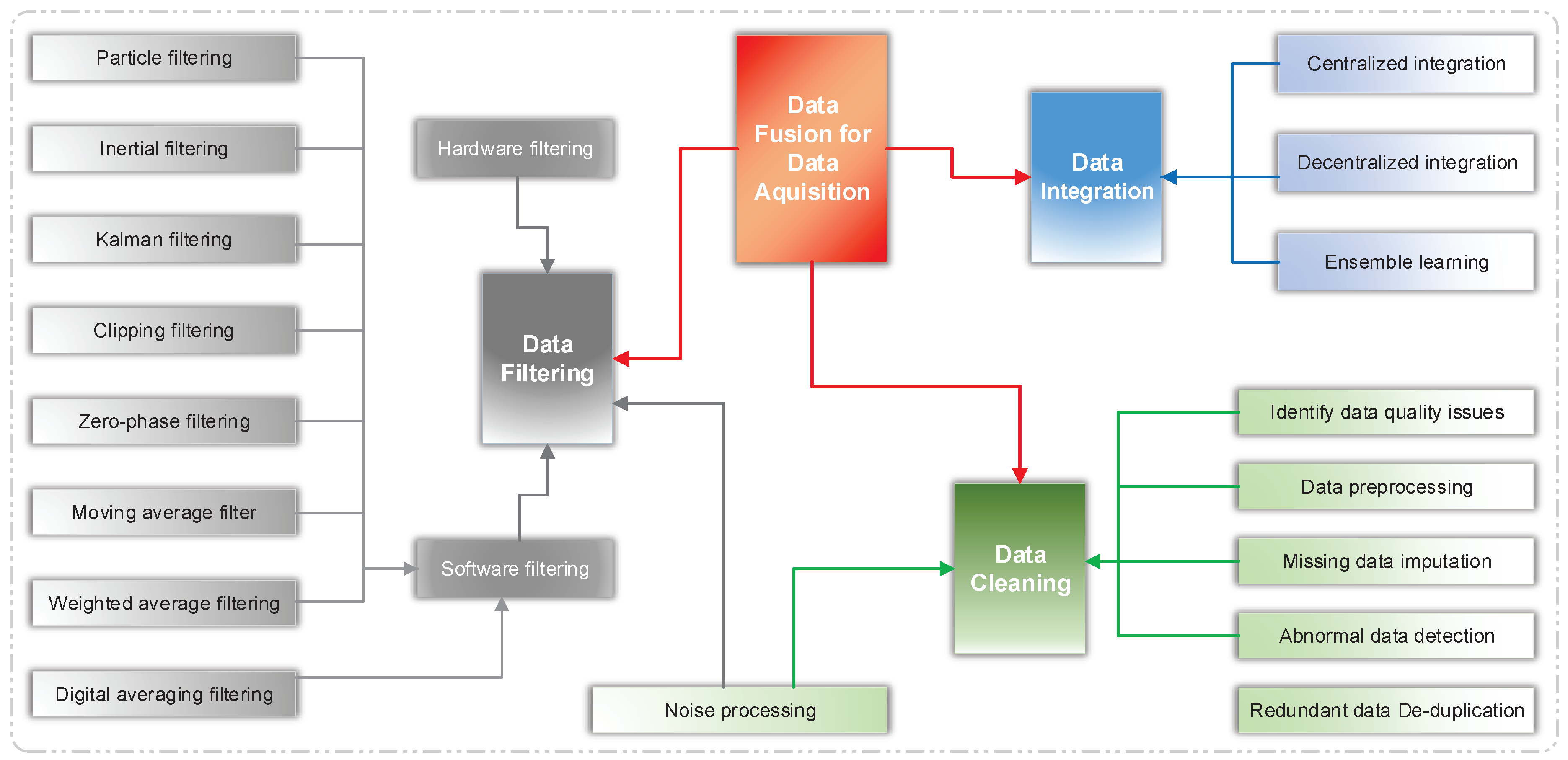{kind=link}
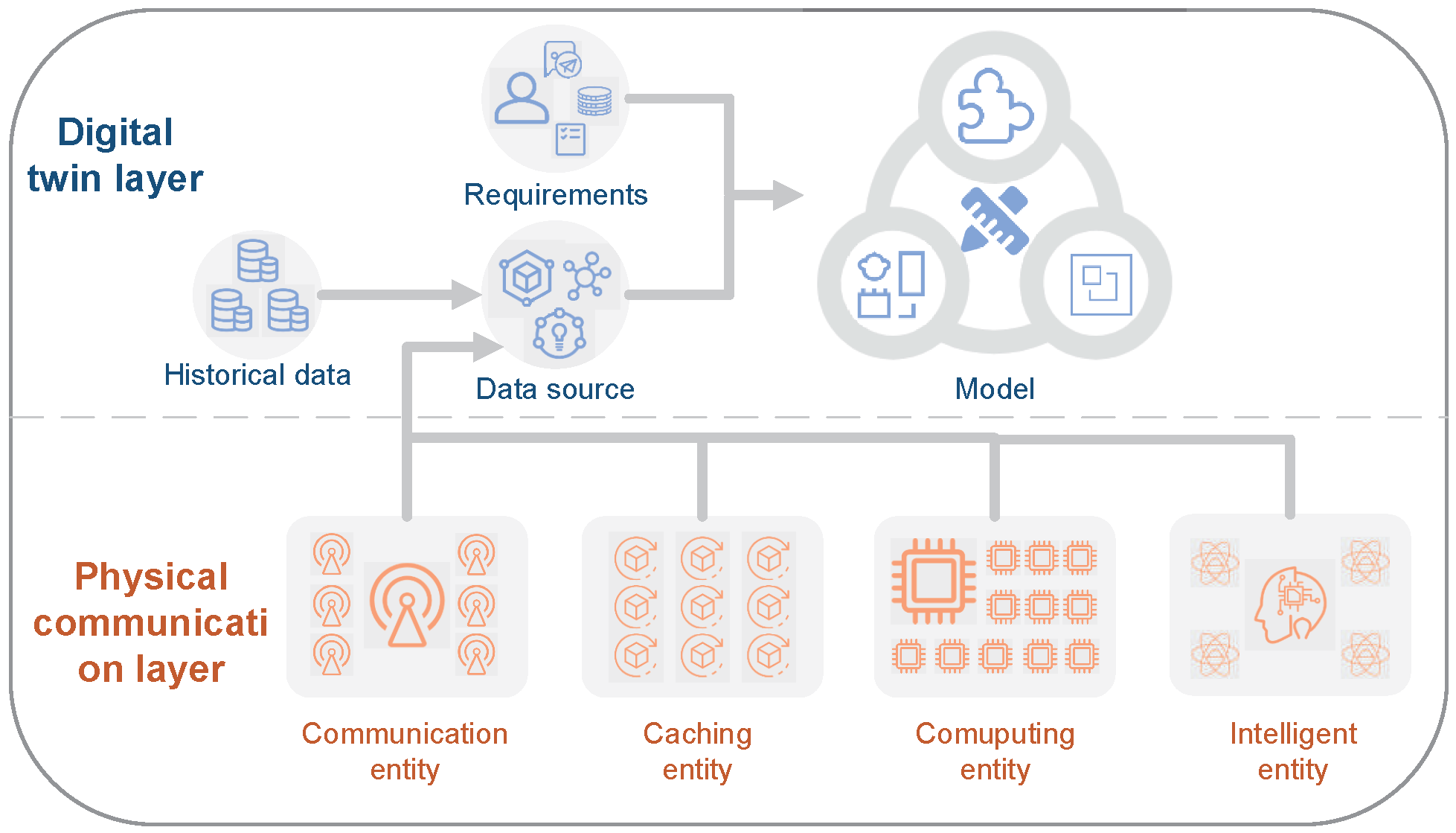{kind=link}
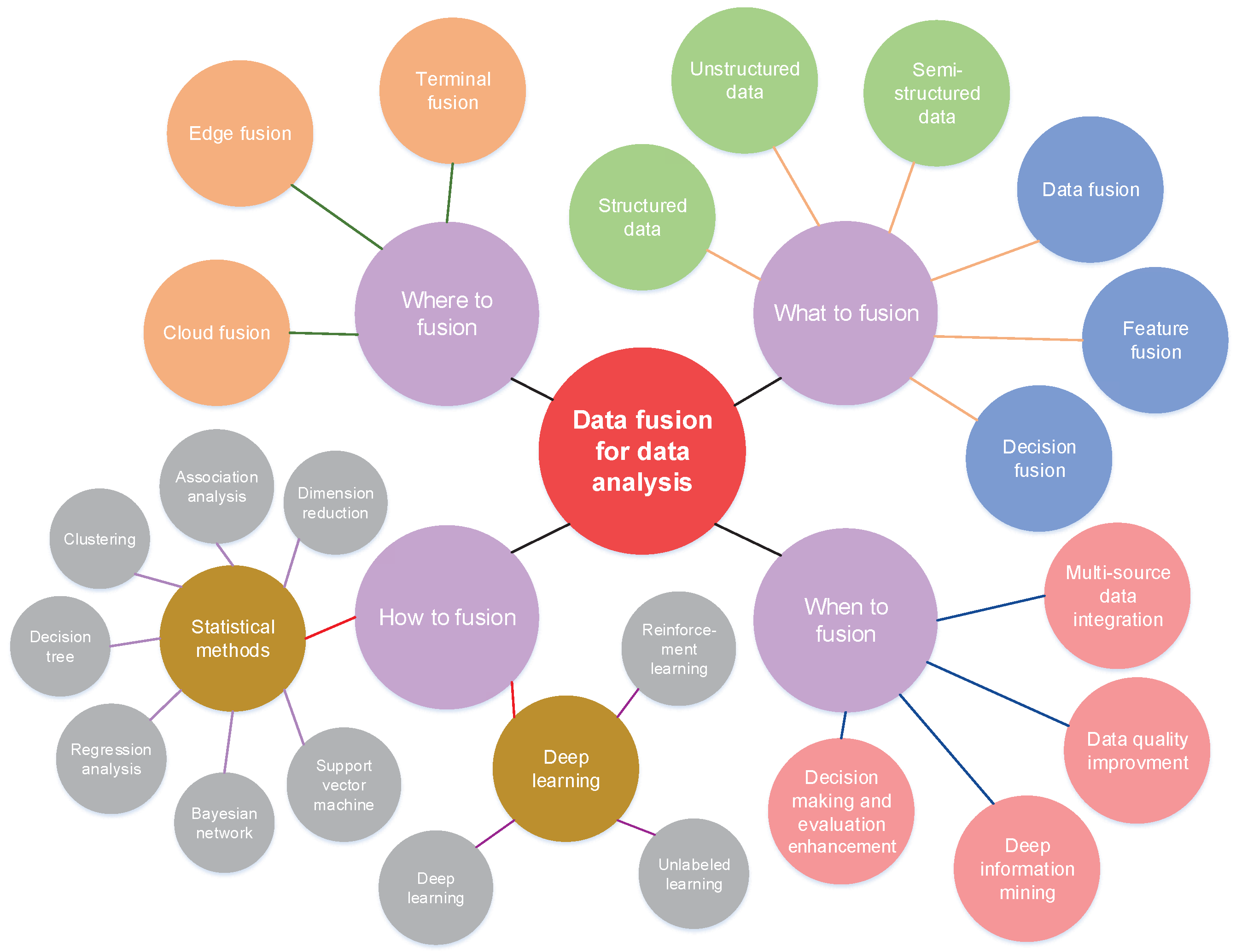{kind=link}
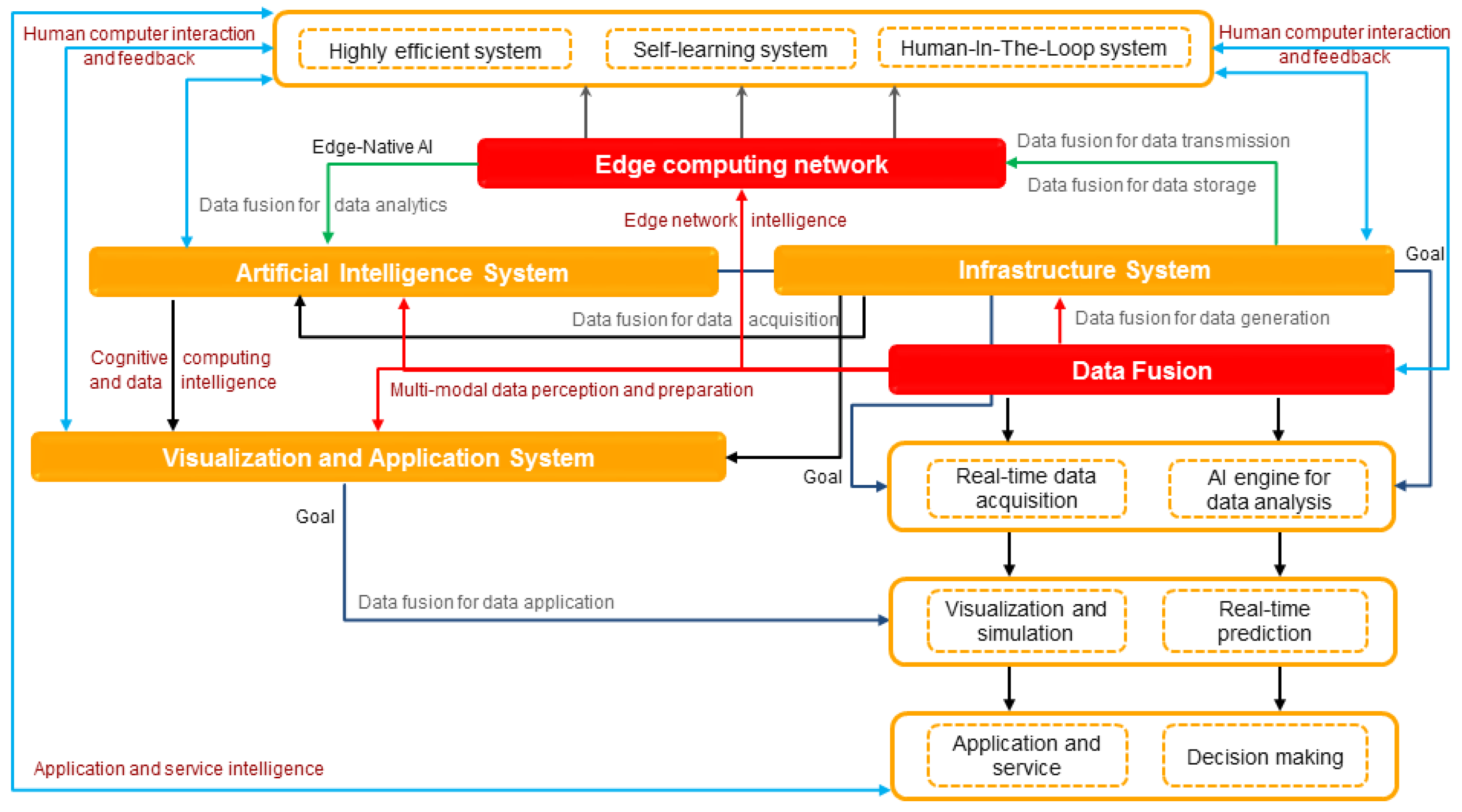{kind=link}
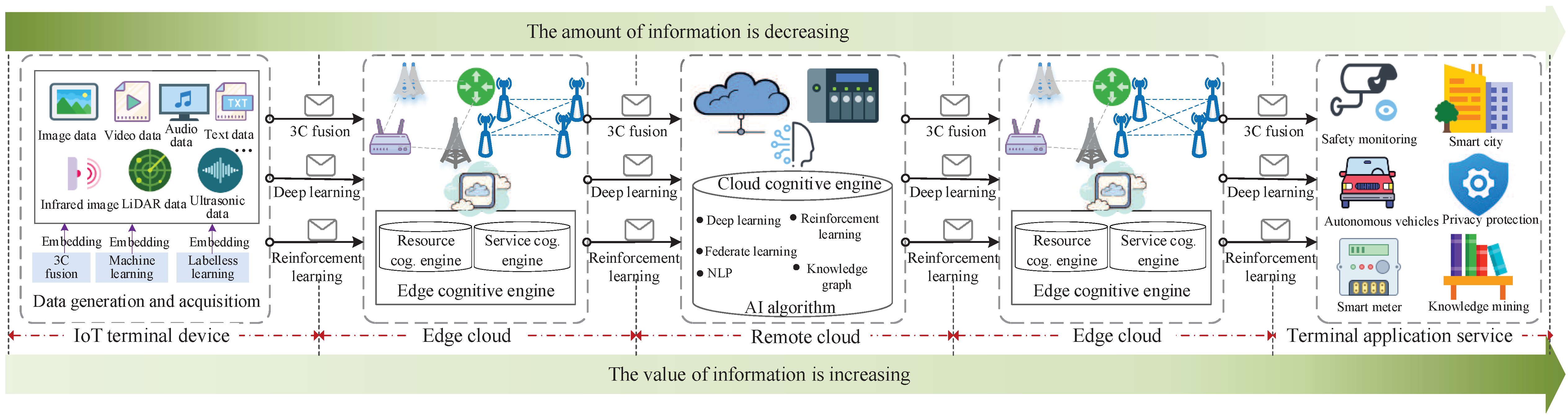{kind=link}
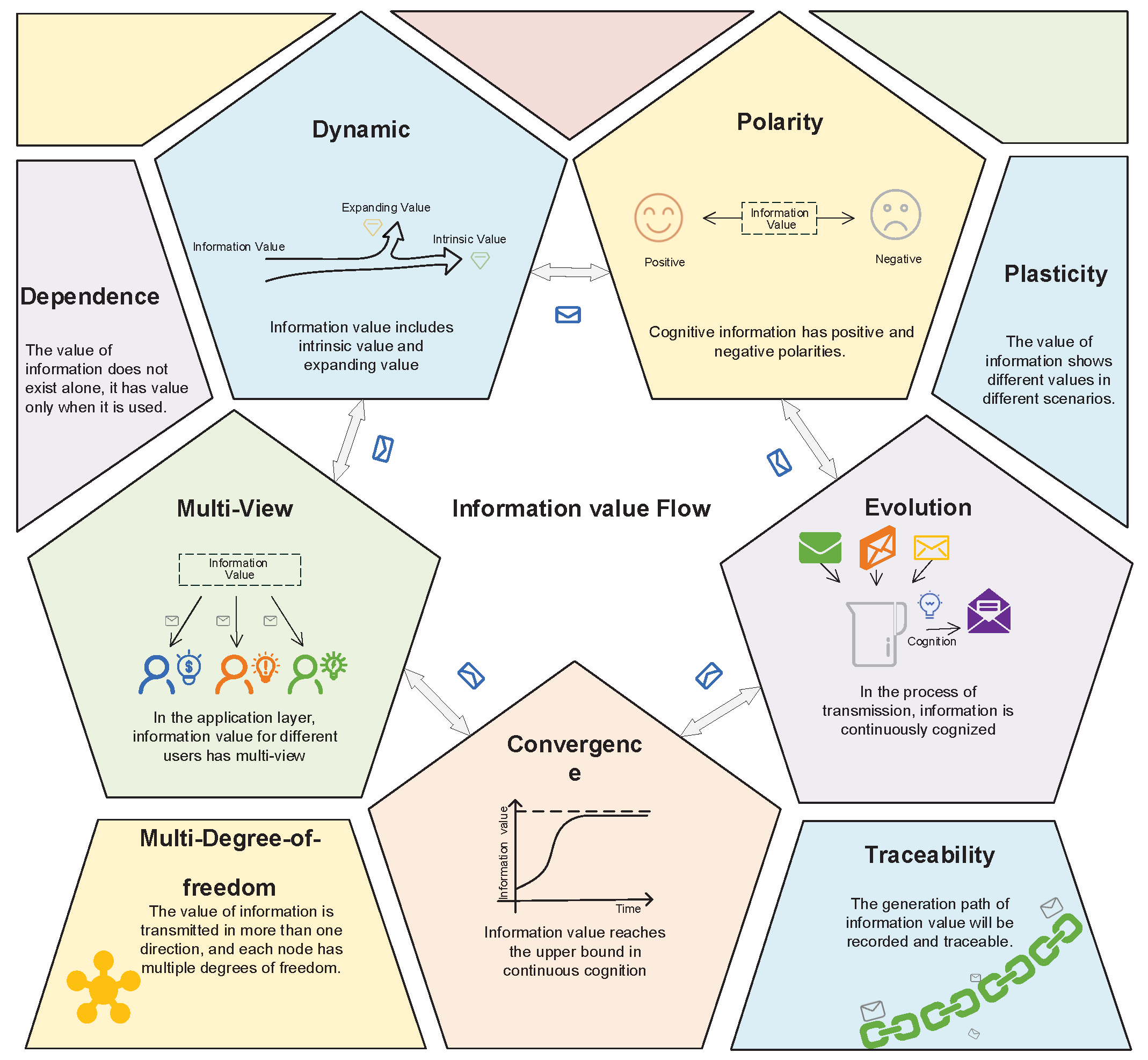{kind=link}
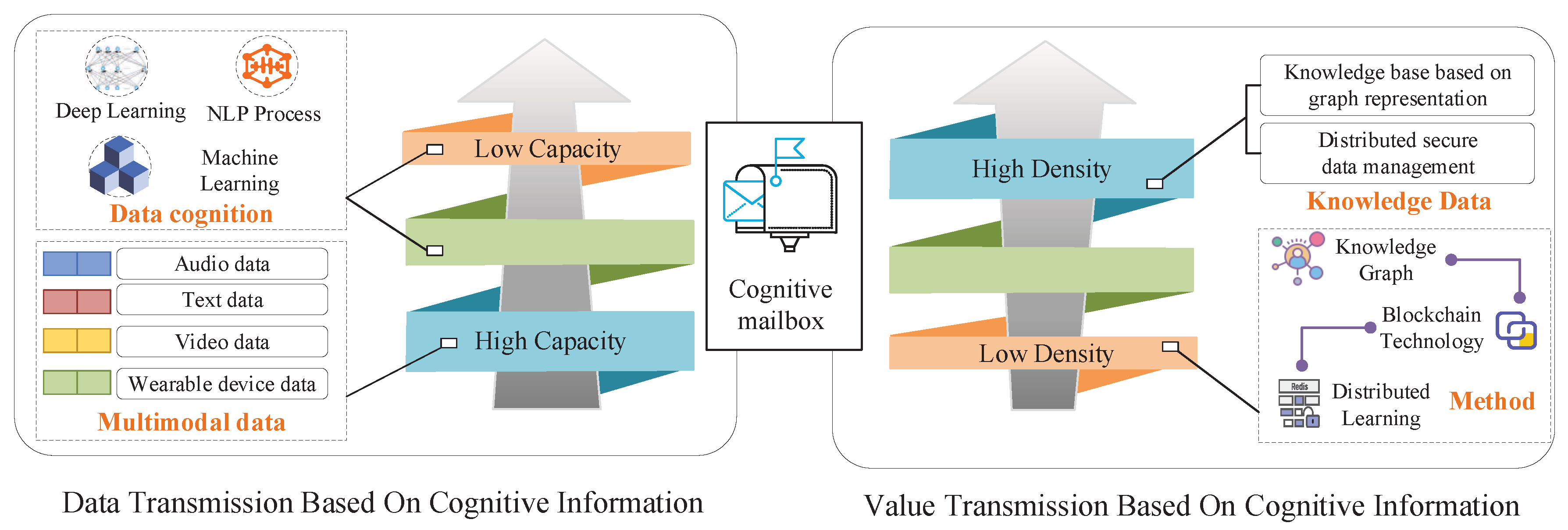{kind=link}
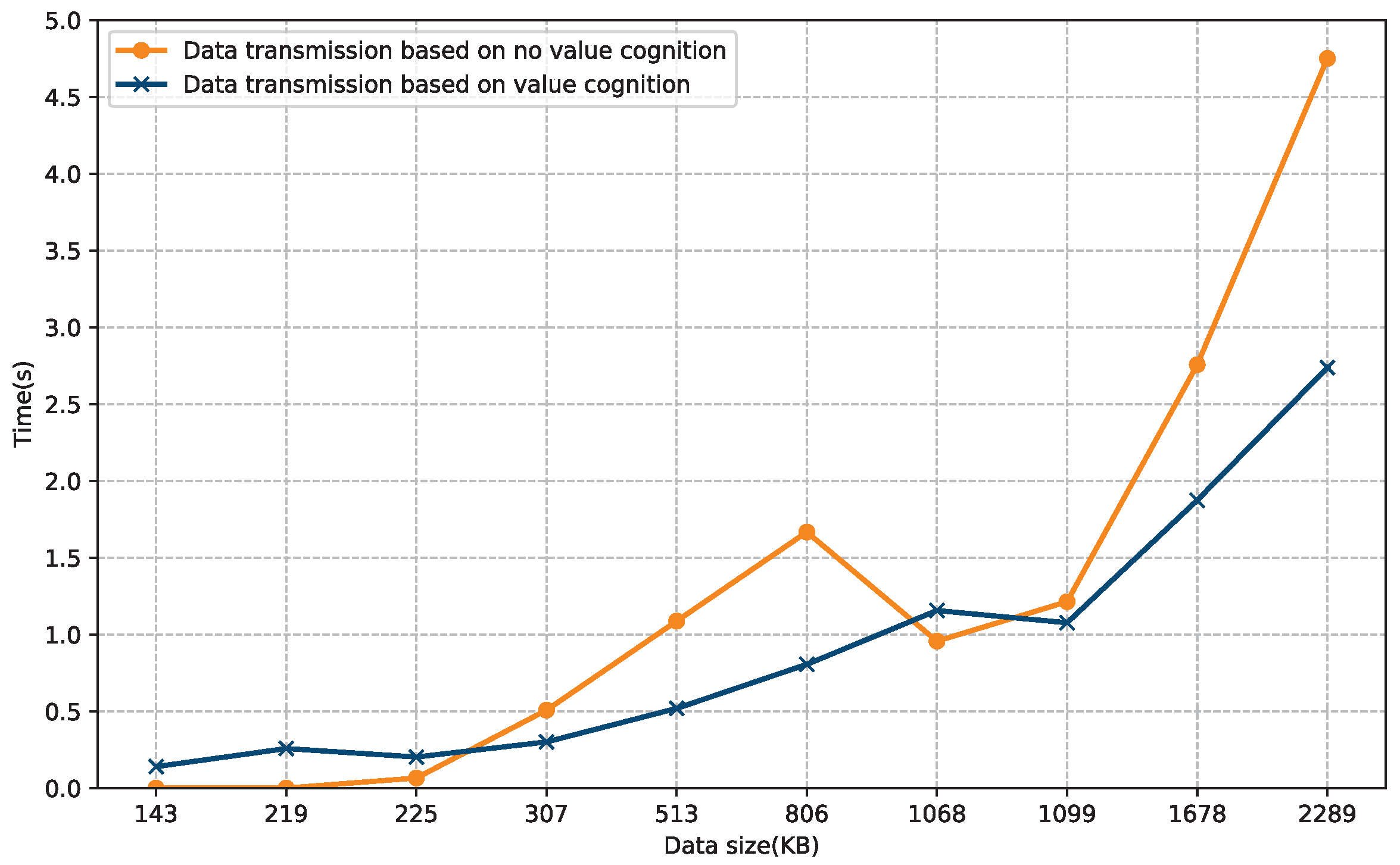{kind=link}
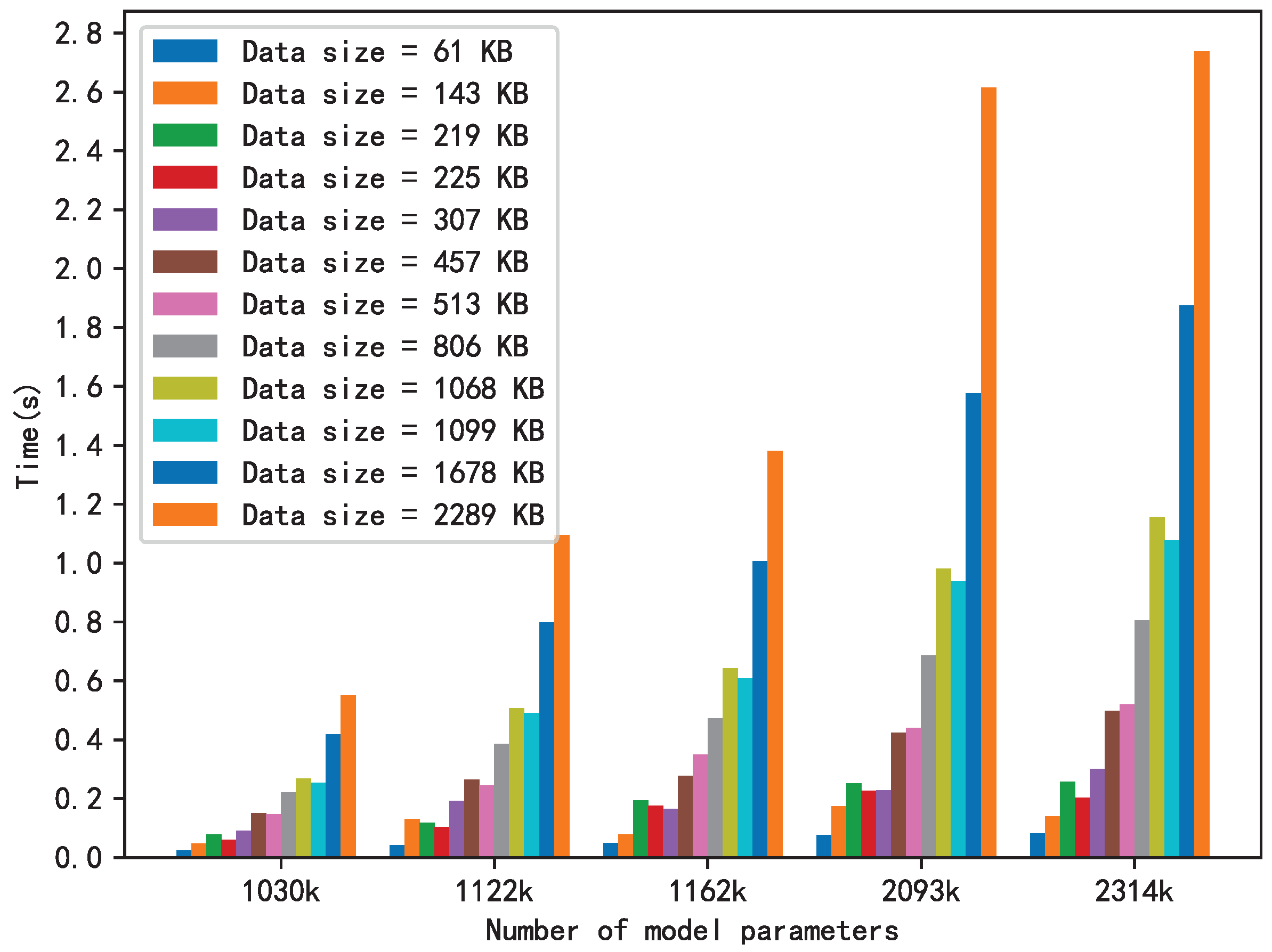{kind=link}
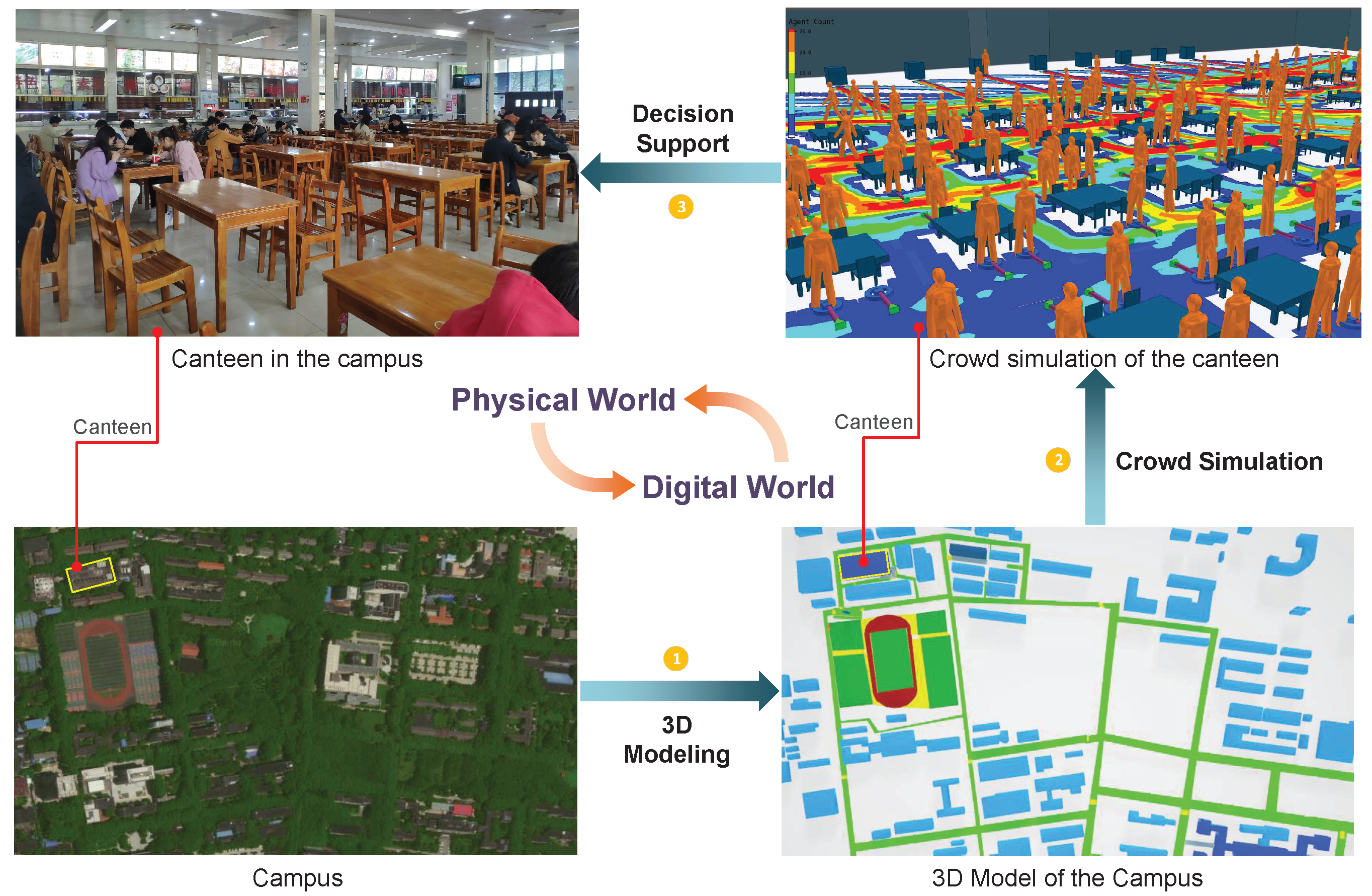{kind=link}
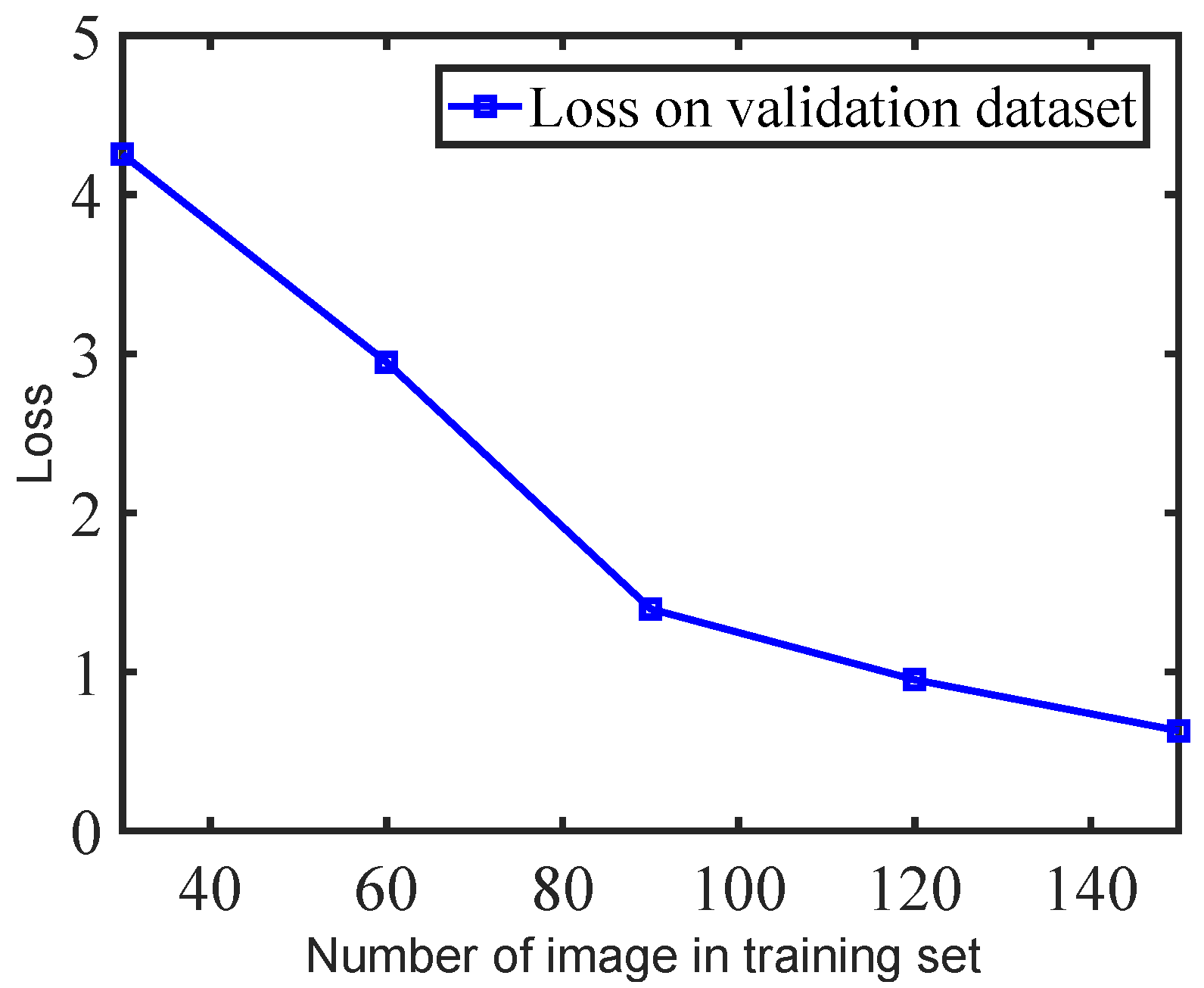{kind=link}
{kind=link}
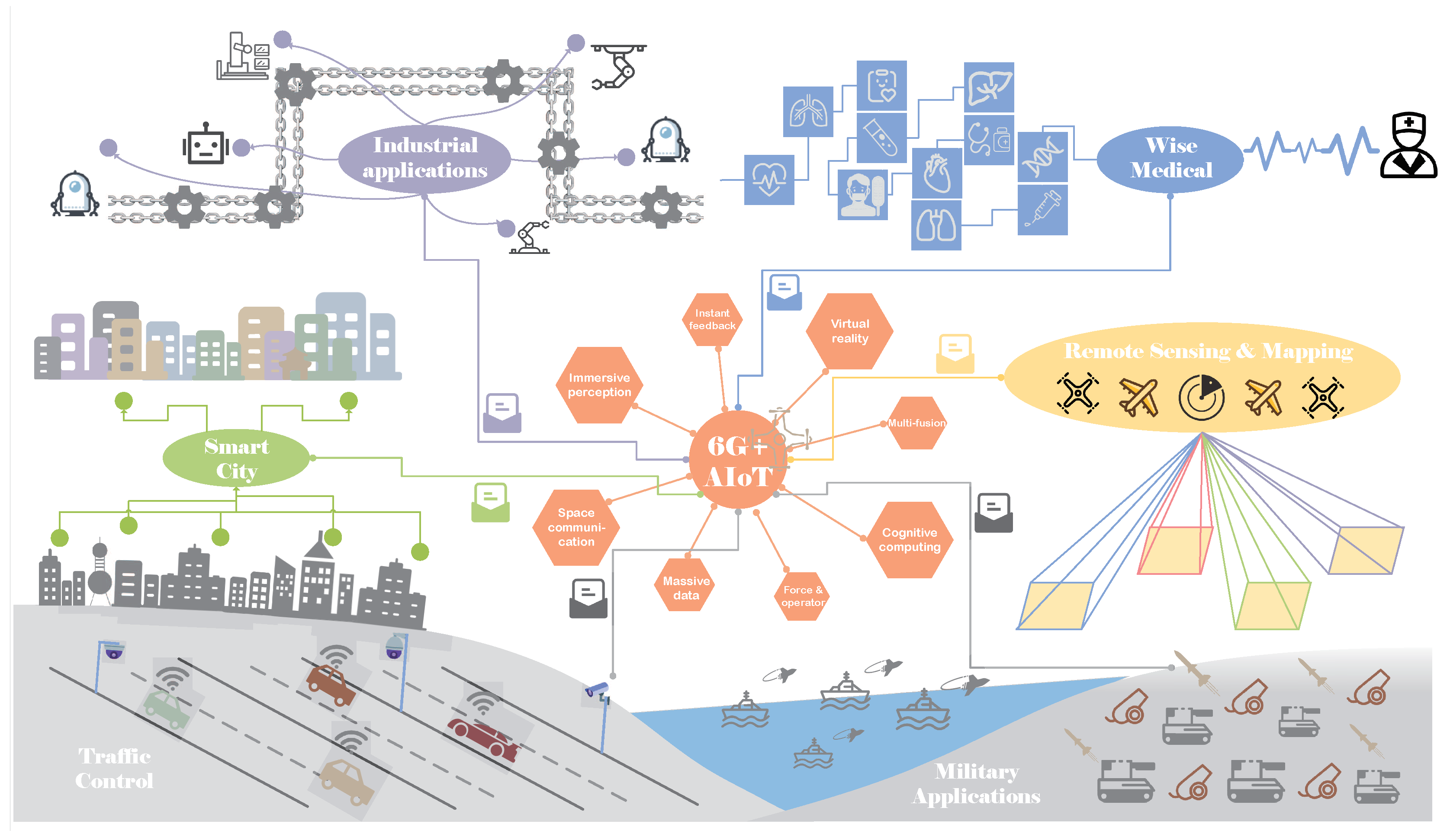{kind=link}