Comparing Swarm Intelligence Algorithms for Dimension Reduction in Machine Learning


Abstract
:1. Introduction
- 1.
- a generation procedure to generate the next candidate subset;
- 2.
- an evaluation function to evaluate the subset under examination;
- 3.
- a validation procedure to either choose the subset or abandon it.
2. Related Works
3. Materials and Methods
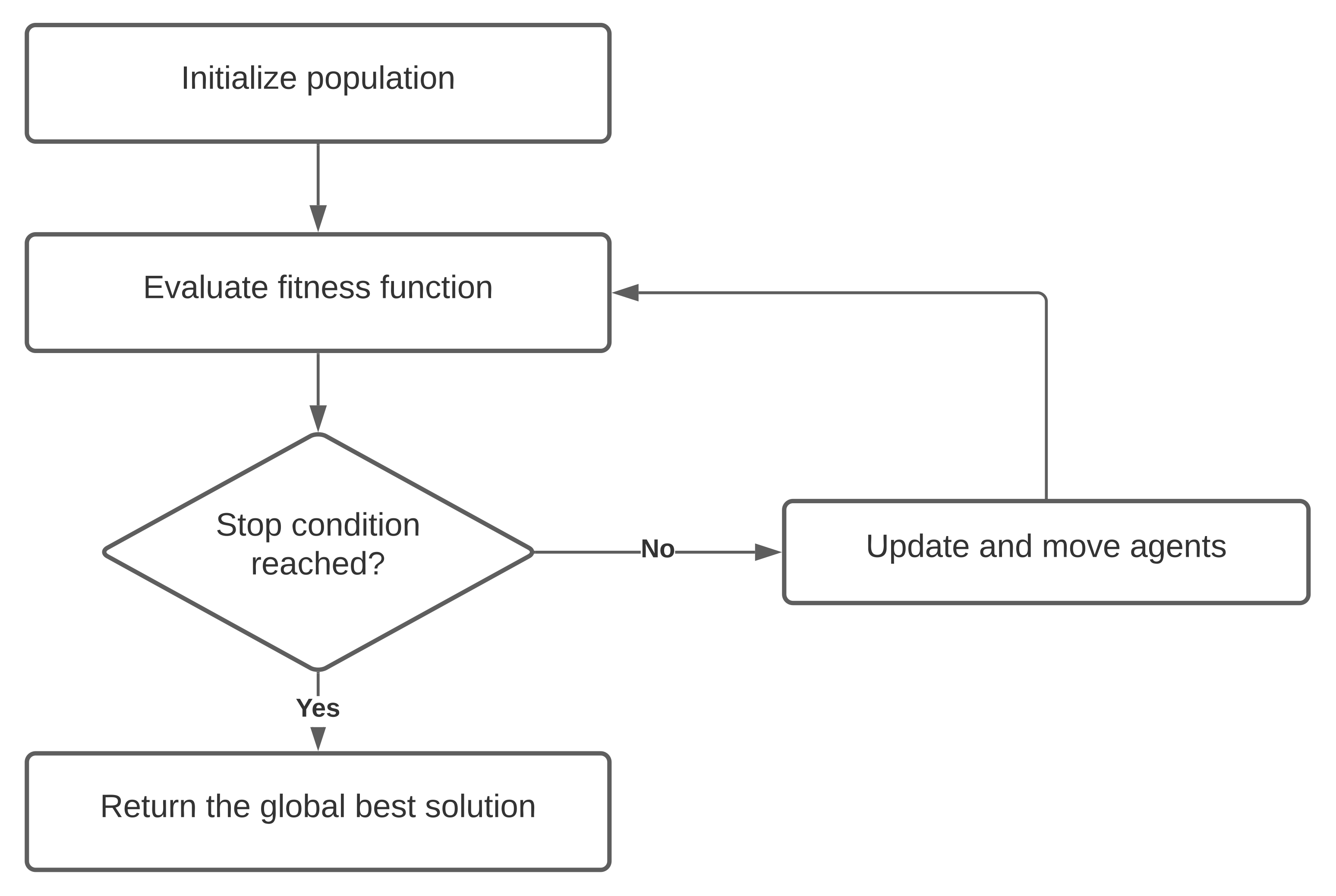
3.1. Swarm Intelligence
- Agents share information among each other.
- Self organization and autonomy of each agent.
- Adaptability and a fast response to environment change.
- It can be easily parallelized for practical and real-time problems.
3.2. Particle Swarm Optimization
3.3. Artificial Bee Colony
| Algorithm 1: PSO |
 /* Notes: ; -U(0, fi) represents a vector of random numbers uniformly distributed in [0, fi], which is randomly generated at each iteration and for each particle ; -× is component-wise multiplication ; -w, c1 and c2 are parameters to control exploration and exploitation. Usually, w decreases linearly with the number of iterations (mostly when optimizing hyperparameters like in [19]), but in this research, we used a fixed value - 0.5˙ */ |
| Algorithm 2: ABC |
 |
3.4. Invasive Weed Optimization
| Algorithm 3: IWO |
 |
3.5. Bat Algorithm
3.6. Gray Wolf Optimizer
| Algorithm 4: BA |
 |
| Algorithm 5: GWO |
 |
3.7. Summarizing Algorithms
4. Feature Selection
4.1. Decision Tree Classifier
4.2. Search Space Representation
4.3. Fitness Function
5. Results
5.1. Datasets
5.2. Data Preprocessing
5.3. Results
5.4. Comparing Algorithms
5.5. Limitations
6. Conclusions and Future Works
Future Works
- Try the optimization with other machine learning algorithms, for example, support vector machine or neural networks;
- Improve IWO or ABC using tips from previous section;
- Try different population sizes;
- Do parameter tuning;
- Implement and compare other SI methods;
- Try combining algorithms.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| SI | Swarm intelligence |
| FS | Feature selection |
| PSO | Particle Swarm Optimization |
| ABC | Artificial Bee Colony |
| IWO | Invasive Weed Optimization |
| BA | Bat Algorithm |
| GWO | Grey Wolf Optimizer |
References
- Brezočnik, L.; Fister, I.; Podgorelec, V. Swarm Intelligence Algorithms for Feature Selection: A Review. Appl. Sci. 2018, 8, 1521. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Trevino, R.P.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. ACM Comput. Surv. 2017, 50. [Google Scholar] [CrossRef] [Green Version]
- Saeys, Y.; Inza, I.; Larrañaga, P. A review of feature selection techniques in bioinformatics. Bioinformatics 2007, 23, 2507–2517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 2015 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015; pp. 1200–1205. [Google Scholar] [CrossRef]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Cox, M.A.A.; Cox, T.F. Multidimensional Scaling. In Handbook of Data Visualization; Springer: Berlin/Heidelberg, Germay, 2008; pp. 315–347. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis. In Encyclopedia of Statistics in Behavioral Science; American Cancer Society: Atlanta, GA, USA, 2005. [Google Scholar] [CrossRef]
- Park, C.H.; Park, H. A comparison of generalized linear discriminant analysis algorithms. Pattern Recognit. 2008, 41, 1083–1097. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, B.H.; Xue, B.; Zhang, M. A survey on swarm intelligence approaches to feature selection in data mining. Swarm Evol. Comput. 2020, 54, 100663. [Google Scholar] [CrossRef]
- Rostami, M.; Berahmand, K.; Nasiri, E.; Forouzandeh, S. Review of swarm intelligence-based feature selection methods. Eng. Appl. Artif. Intell. 2021, 100, 104210. [Google Scholar] [CrossRef]
- Beni, G.; Wang, J. Swarm Intelligence in Cellular Robotic Systems. In Robots and Biological Systems: Towards a New Bionics? Springer: Berlin/Heidelberg, Germany, 1993; pp. 703–712. [Google Scholar] [CrossRef]
- Fister, I., Jr.; Yang, X.; Fister, I.; Brest, J.; Fister, D. A Brief Review of Nature-Inspired Algorithms for Optimization. arXiv 2013, arXiv:1307.4186. [Google Scholar]
- Hassanien, A.; Emary, E. Swarm Intelligence: Principles, Advances, and Applications; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Panigrahi, B.; Shi, Y.; Lim, M. Handbook of Swarm Intelligence: Concepts, Principles and Applications; Adaptation, Learning, and Optimization; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 1942–1948. [Google Scholar] [CrossRef]
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1. [Google Scholar] [CrossRef]
- Karaboga, D.; Basturk, B. A powerful and efficient algorithm for numerical function optimization: Artificial bee colony (ABC) algorithm. J. Glob. Optim. 2007, 39, 459–471. [Google Scholar] [CrossRef]
- Brownlee, J. Clever Algorithms: Nature-inspired Programming Recipes; Lulu.com: Morrisville, NC, USA, 2011. [Google Scholar]
- Ossai, C.I. A Data-Driven Machine Learning Approach for Corrosion Risk Assessment—A Comparative Study. Big Data Cogn. Comput. 2019, 3, 28. [Google Scholar] [CrossRef] [Green Version]
- Mehrabian, A.; Lucas, C. A novel numerical optimization algorithm inspired from weed colonization. Ecol. Inform. 2006, 1, 355–366. [Google Scholar] [CrossRef]
- Karimkashi, S.; Kishk, A.A. Invasive Weed Optimization and its Features in Electromagnetics. IEEE Trans. Antennas Propag. 2010, 58, 1269–1278. [Google Scholar] [CrossRef]
- Yang, X.S. A New Metaheuristic Bat-Inspired Algorithm. In Nature Inspired Cooperative Strategies for Optimization (NICSO 2010); Springer: Berlin/Heidelberg, Germany, 2010; pp. 65–74. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Teng, Z.J.; Lv, J.L.; Guo, L.W. An improved hybrid grey wolf optimization algorithm. Soft Comput. 2019, 23, 6617–6631. [Google Scholar] [CrossRef]
- Trabelsi Ben Ameur, S.; Sellami, D.; Wendling, L.; Cloppet, F. Breast Cancer Diagnosis System Based on Semantic Analysis and Choquet Integral Feature Selection for High Risk Subjects. Big Data Cogn. Comput. 2019, 3, 41. [Google Scholar] [CrossRef] [Green Version]
- Al-Tashi, Q.; Abdul Kadir, S.J.; Rais, H.M.; Mirjalili, S.; Alhussian, H. Binary Optimization Using Hybrid Grey Wolf Optimization for Feature Selection. IEEE Access 2019, 7, 39496–39508. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H.; Setiono, R.; Zhao, Z. Feature Selection: An Ever Evolving Frontier in Data Mining. In Proceedings of the Fourth International Workshop on Feature Selection in Data Mining, Hyderabad, India, 21 June 2010; Volume 10, pp. 4–13. [Google Scholar]
- Liu, H.; Zhao, Z. Manipulating Data and Dimension Reduction Methods: Feature Selection. In Computational Complexity: Theory, Techniques, and Applications; Springer: New York, NY, USA, 2012; pp. 1790–1800. [Google Scholar] [CrossRef]
- Xue, B.; Zhang, M.; Browne, W.N. A Comprehensive Comparison on Evolutionary Feature Selection Approaches to Classification. Int. J. Comput. Intell. Appl. 2015, 14, 1550008. [Google Scholar] [CrossRef]
- Quinlan, J. C4.5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Stein, G.; Chen, B.; Wu, A.S.; Hua, K.A. Decision Tree Classifier for Network Intrusion Detection with GA-Based Feature Selection. In Proceedings of the 43rd Annual Southeast Regional Conference, New York, NY, USA, 14–18 March 2005; pp. 136–141. [Google Scholar] [CrossRef]
- Emary, E.; Zawbaa, H.M.; Hassanien, A.E. Binary grey wolf optimization approaches for feature selection. Neurocomputing 2016, 172, 371–381. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; pp. 4104–4108. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2017. Available online: http://archive.ics.uci.edu/ml (accessed on 3 July 2021).


{kind=link}
{kind=link}
{kind=link}
| ID | Inspiration | Exploration | Exploitation | Aim Points | Num of Parameters |
|---|---|---|---|---|---|
| PSO | birds | high | low | 2 | 3 |
| ABC | honey bees | low | medium | 2 | 1 |
| IWO | weeds | low | high | 1 | 4 |
| BA | bats | medium | high | 1 | 4 |
| GWO | wolves | high | medium | 3 | 0 |
| ID | Name | Attribute Types | Instances | Attributes |
|---|---|---|---|---|
| 1 | Arrhythmia | Categorical, Real | 452 | 279 |
| 2 | Chess (KR vs. KP) | Categorical | 3196 | 36 |
| 3 | Crowdsourced Mapping | Real | 10,546 | 29 |
| 4 | Hepatitis C Virus (HCV) | |||
| for Egyptian patients | Integer, Real | 1385 | 29 | |
| 5 | MEU-Mobile KSD | Integer, Real | 2856 | 71 |
| 6 | Phishing Websites | Integer | 2456 | 30 |
| 7 | QSAR androgen receptor | Integer | 1687 | 1024 |
| 8 | DBWorld e-mails | Integer | 64 | 4702 |
| 9 | Musk (Version 2) | Integer | 6598 | 168 |
| 10 | A study of Asian Religious | |||
| and Biblical Texts | Integer | 590 | 8265 | |
| 11 | Ozone Level Detection | Real | 2536 | 73 |
| 12 | Diabetic Retinopathy | Integer, Real | 1151 | 20 |
| 13 | Geographical Original of Music | Real | 1059 | 68 |
| 14 | Wall-Following Robot Navigation | Real | 5456 | 24 |
| 15 | Insurance Company Benchmark | Categorical, Integer | 9000 | 85 |
| 16 | Internet Advertisements | Integer, Real | 3279 | 1558 |
| 17 | Amazon Commerce reviews | Real | 1500 | 10,000 |
| Dataset ID | Original | PSO | IWO | ABC | BA | GWO |
|---|---|---|---|---|---|---|
| 1 | 0.357 | 0.643 | 0.714 | 0.643 | 0.643 | 0.643 |
| 2 | 0.997 | 0.992 | 0.997 | 0.994 | 0.997 | 0.997 |
| 3 | 0.874 | 0.895 | 0.886 | 0.890 | 0.892 | 0.896 |
| 4 | 0.274 | 0.343 | 0.368 | 0.365 | 0.357 | 0.357 |
| 5 | 0.642 | 0.710 | 0.682 | 0.682 | 0.685 | 0.699 |
| 6 | 0.961 | 0.964 | 0.961 | 0.961 | 0.962 | 0.969 |
| 7 | 0.875 | 0.931 | 0.920 | 0.917 | 0.937 | 0.931 |
| 8 | 0.727 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| 9 | 0.965 | 0.989 | 0.994 | 0.986 | 0.993 | 0.992 |
| 10 | 0.712 | 0.890 | 0.847 | 0.831 | 0.864 | 0.890 |
| 11 | 0.915 | 0.949 | 0.947 | 0.945 | 0.949 | 0.954 |
| 12 | 0.621 | 0.709 | 0.691 | 0.730 | 0.739 | 0.739 |
| 13 | 0.207 | 0.349 | 0.325 | 0.312 | 0.382 | 0.373 |
| 14 | 0.996 | 0.996 | 0.994 | 0.997 | 0.995 | 0.995 |
| 15 | 0.880 | 0.936 | 0.923 | 0.920 | 0.926 | 0.931 |
| 16 | 0.968 | 0.983 | 0.977 | 0.980 | 0.980 | 0.979 |
| 17 | 0.337 | 0.497 | 0.460 | 0.413 | 0.483 | 0.473 |
| Dataset ID | Original | PSO | IWO | ABC | BA | GWO |
|---|---|---|---|---|---|---|
| 1 | 279 | 118 | 126 | 140 | 102 | 77 |
| 2 | 73 | 36 | 42 | 43 | 41 | 28 |
| 3 | 28 | 15 | 17 | 18 | 12 | 19 |
| 4 | 28 | 13 | 12 | 14 | 11 | 13 |
| 5 | 71 | 36 | 39 | 36 | 38 | 39 |
| 6 | 30 | 22 | 22 | 20 | 20 | 21 |
| 7 | 1024 | 493 | 512 | 515 | 503 | 511 |
| 8 | 4702 | 2131 | 2271 | 2311 | 1971 | 2034 |
| 9 | 168 | 84 | 83 | 104 | 89 | 93 |
| 10 | 8266 | 4085 | 4118 | 4235 | 4101 | 4063 |
| 11 | 73 | 39 | 32 | 40 | 31 | 38 |
| 12 | 19 | 9 | 11 | 12 | 8 | 7 |
| 13 | 68 | 38 | 32 | 36 | 38 | 28 |
| 14 | 24 | 11 | 12 | 16 | 9 | 7 |
| 15 | 85 | 28 | 43 | 31 | 34 | 33 |
| 16 | 1558 | 732 | 784 | 776 | 681 | 751 |
| 17 | 10,000 | 4960 | 5012 | 4969 | 4958 | 4908 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kicska, G.; Kiss, A. Comparing Swarm Intelligence Algorithms for Dimension Reduction in Machine Learning. Big Data Cogn. Comput. 2021, 5, 36. https://doi.org/10.3390/bdcc5030036
Kicska G, Kiss A. Comparing Swarm Intelligence Algorithms for Dimension Reduction in Machine Learning. Big Data and Cognitive Computing. 2021; 5(3):36. https://doi.org/10.3390/bdcc5030036
Chicago/Turabian StyleKicska, Gabriella, and Attila Kiss. 2021. "Comparing Swarm Intelligence Algorithms for Dimension Reduction in Machine Learning" Big Data and Cognitive Computing 5, no. 3: 36. https://doi.org/10.3390/bdcc5030036
APA StyleKicska, G., & Kiss, A. (2021). Comparing Swarm Intelligence Algorithms for Dimension Reduction in Machine Learning. Big Data and Cognitive Computing, 5(3), 36. https://doi.org/10.3390/bdcc5030036