
Deep Neural Network and Boosting Based Hybrid Quality Ranking for e-Commerce Product Search



Abstract
:1. Introduction
2. Related Works
2.1. Product Search
2.2. Word Embeddings
2.3. Learning to Rank for e-Commerce Search
3. Methodology
3.1. Preprocessing Step
3.2. Product Search Using Similarity Measure
3.3. Product Ranking Using Quality Indicators
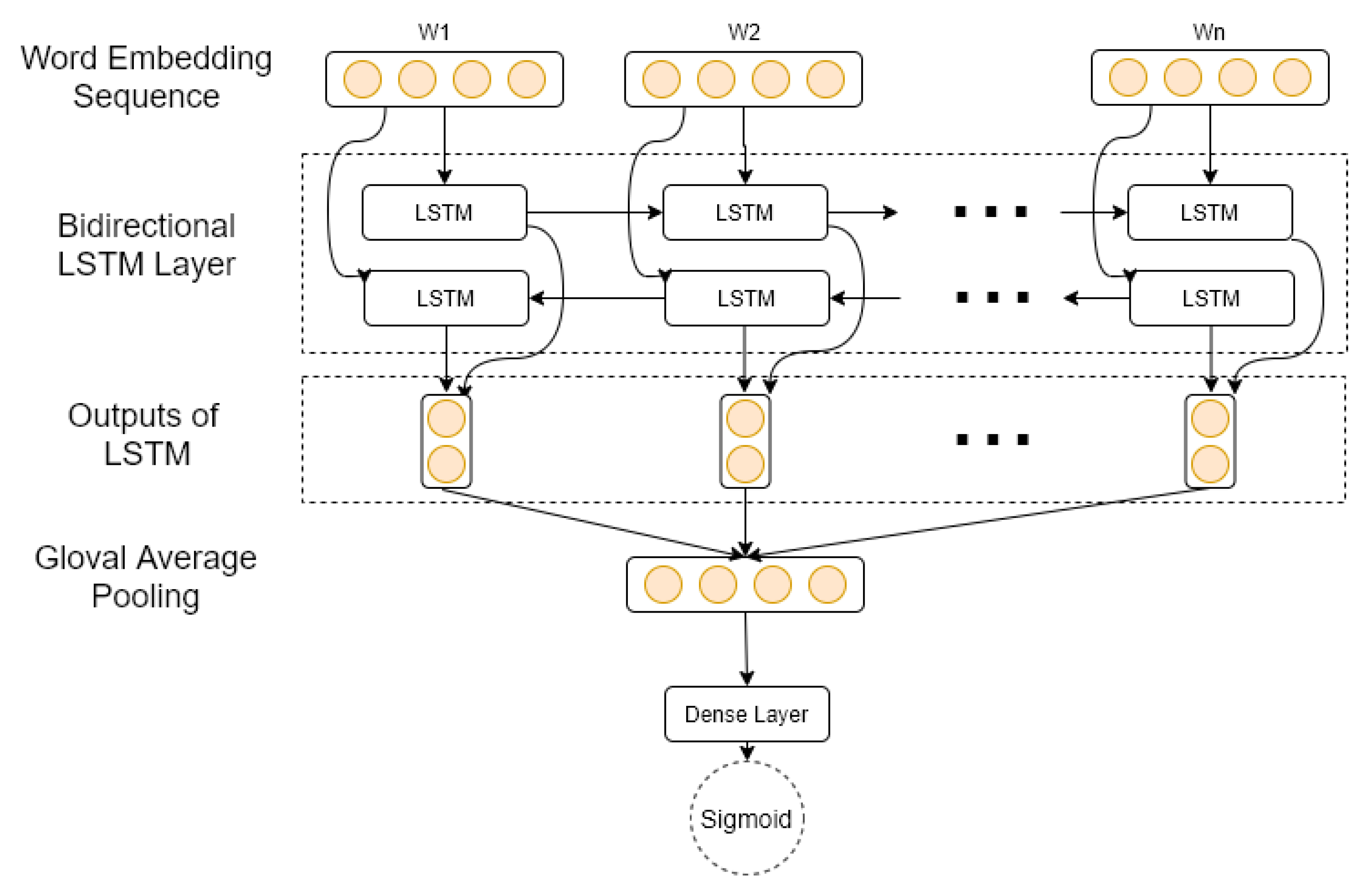
3.3.1. Reviews Sentiment
3.3.2. Popularity
3.3.3. Availability of Information
3.3.4. Product Price
3.3.5. LTR Model
3.3.6. Baseline Methods for Product Ranking
- AdaRank [43] is a representative pairwise model. It focuses more on the difficult queries and aims to directly optimize the performance measure NDCG based on a boosting approach.
- LambdaMart [30] is a tree boosting algorithm that extends multiple additive regression trees (MART) by introducing a weighting term for each pair of data, as to how LambdaRank extends RankNet with the listwise measure.
4. Experiments
4.1. Dataset
4.1.1. Query Extraction
4.1.2. Evaluation Metrics
- Precision (PR): the fraction of the products retrieved that are relevant to the query.
- Recall (RE): the fraction of the products relevant to the query that are successfully retrieved.
- F-score (FS): the weighted harmonic mean of the precision and recall.
- Normalized discounted cumulative gain (NDCG@k): assesses the overall order of the ranked elements at truncation level k with a much higher emphasis on the top-ranked elements. NDCG for a query q is defined as follows:where is the ideal value of , and is the label of the i-th listed product.
- Expected reciprocal rank (ERR@k) [50]: a cascade-based metric that is commonly used for graded relevance.where n is the number of items in the ranked list; r is the position of the document; and R is a mapping from relevance degree to relevance probability.
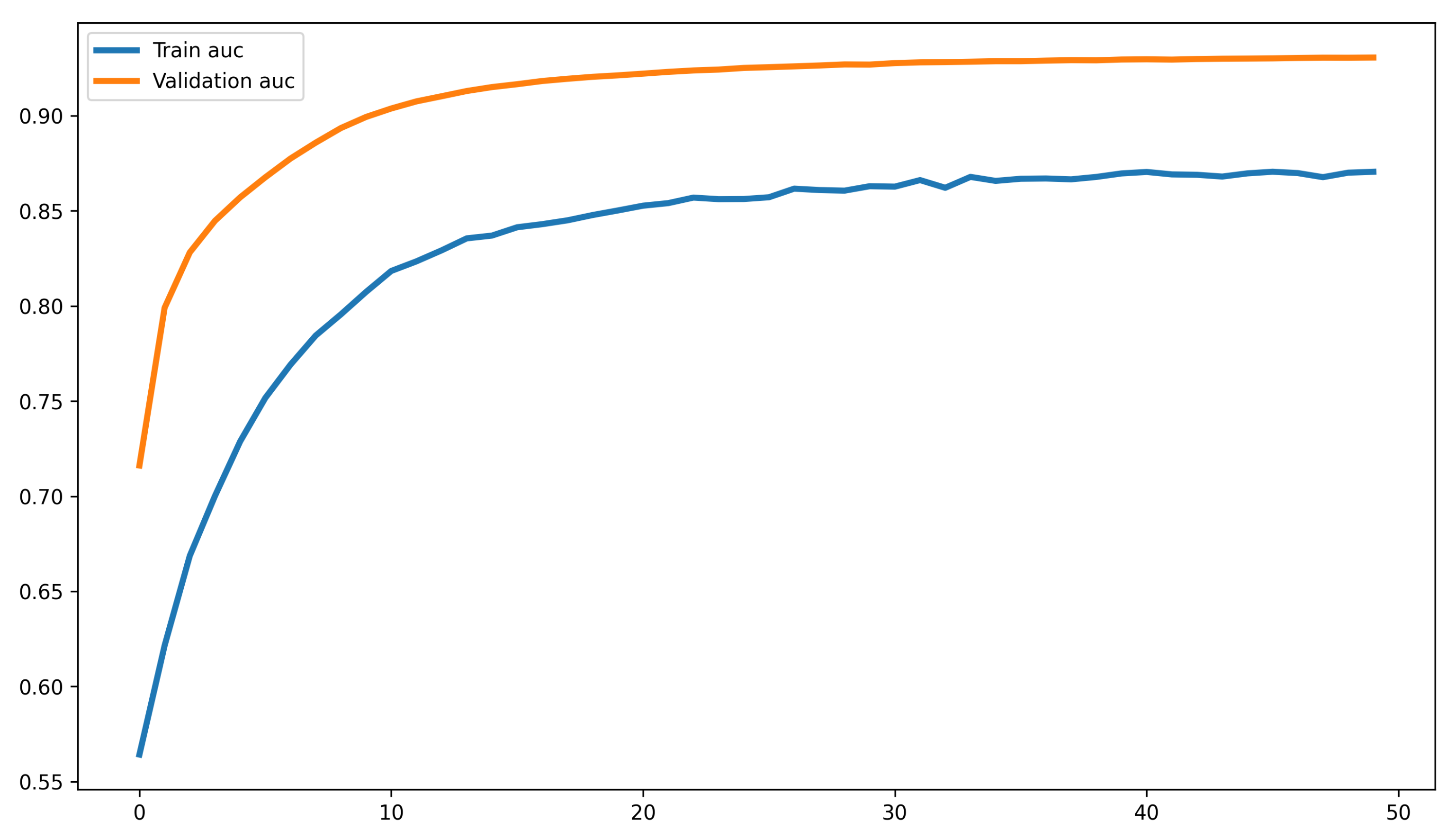
4.2. Results and Discussions
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| MDPI | Multidisciplinary Digital Publishing Institute |
| DOAJ | Directory of open access journals |
| TLA | Three letter acronym |
| LD | Linear dichroism |
References
- Kaabi, S.; Jallouli, R. Overview of E-commerce Technologies, Data Analysis Capabilities and Marketing Knowledge. In Digital Economy, Emerging Technologies and Business Innovation; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 183–193. [Google Scholar]
- Turban, E.; King, D.; Lee, J.K.; Liang, T.P.; Turban, D.C. E-Commerce: Mechanisms, Platforms, and Tools. In Electronic Commerce: A Managerial and Social Networks Perspective; Springer Texts in Business and Economics; Springer International Publishing: Cham, Swizterland, 2015; pp. 51–99. [Google Scholar] [CrossRef]
- Moraes, F.; Yang, J.; Zhang, R.; Murdock, V. The role of attributes in product quality comparisons. In Proceedings of the 2020 Conference on Human Information Interaction and Retrieval, Vancouver, BC, Canada, 14–18 March 2020; pp. 253–262. [Google Scholar] [CrossRef] [Green Version]
- Carmel, D.; Haramaty, E.; Lazerson, A.; Lewin-Eytan, L.; Maarek, Y. Why do people buy seemingly irrelevant items in voice product search? On the relation between product relevance and customer satisfaction in ecommerce. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 79–87. [Google Scholar] [CrossRef] [Green Version]
- Ahuja, A.; Rao, N.; Katariya, S.; Subbian, K.; Reddy, C.K. Language-agnostic representation learning for product search on e-commerce platforms. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 7–15. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, H.T.; Duong, P.H.; Cambria, E. Learning short-text semantic similarity with word embeddings and external knowledge sources. Knowl. Based Syst. 2019, 182, 104842. [Google Scholar] [CrossRef]
- Lample, G.; Conneau, A.; Ranzato, M.; Denoyer, L.; Jégou, H. Word translation without parallel data. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Fan, Z.P.; Li, G.M.; Liu, Y. Processes and methods of information fusion for ranking products based on online reviews: An overview. Inf. Fusion 2020, 60, 87–97. [Google Scholar] [CrossRef]
- Robertson, S.E.; Walker, S.; Jones, S.; Hancock-Beaulieu, M.; Gatford, M. Okapi at TREC-3. 1994. Available online: https://www.researchgate.net/publication/221037764_Okapi_at_TREC-3 (accessed on 12 August 2021).
- Ponte, J.M.; Croft, W.B. A Language Modeling Approach to Information Retrieval. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998. [Google Scholar] [CrossRef]
- Van Gysel, C.; de Rijke, M.; Kanoulas, E. Learning Latent Vector Spaces for Product Search. In Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Indianapolis, IN, USA, 24–28 October 2016; pp. 165–174. [Google Scholar] [CrossRef] [Green Version]
- Ai, Q.; Zhang, Y.; Bi, K.; Chen, X.; Croft, W.B. Learning a Hierarchical Embedding Model for Personalized Product Search. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 645–654. [Google Scholar] [CrossRef]
- Ai, Q.; Hill, D.N.; Vishwanathan, S.V.N.; Croft, W.B. A Zero Attention Model for Personalized Product Search. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 379–388. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Cheng, Z.; Nie, L.; Xu, X.S.; Kankanhalli, M. Multi-modal Preference Modeling for Product Search. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Korea, 22–26 October 2018; pp. 1865–1873. [Google Scholar] [CrossRef]
- Bi, K.; Ai, Q.; Zhang, Y.; Croft, W.B. Conversational Product Search Based on Negative Feedback. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 359–368. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.; Rao, N.; Subbian, K. Learning Robust Models for e-Commerce Product Search. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 6861–6869. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; Volume 2, pp. 3111–3119. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Shen, S.; Dong, Z.; Ye, J.; Ma, L.; Yao, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A Primer in BERTology: What We Know About How BERT Works. Trans. Assoc. Comput. Linguist. 2020, 8, 842–866. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- Liu, T.Y. Learning to Rank for Information Retrieval. Found. Trends Inf. Retr. 2009, 3, 225–331. [Google Scholar] [CrossRef]
- Burges, C.; Shaked, T.; Renshaw, E.; Lazier, A.; Deeds, M.; Hamilton, N.; Hullender, G. Learning to rank using gradient descent. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 89–96. [Google Scholar] [CrossRef]
- Burges, C.J.C.; Ragno, R.; Le, Q.V. Learning to rank with nonsmooth cost functions. In Proceedings of the 19th International Conference on Neural Information Processing Systems, Doha, QA, Canada, 12–15 November 2006; pp. 193–200. [Google Scholar]
- Burges, C.J. From RankNet to LambdaRank to LambdaMART: An Overview; Technical Report MSR-TR-2010-82. Available online: https://www.microsoft.com/en-us/research/uploads/prod/2016/02/MSR-TR-2010-82.pdf (accessed on 12 August 2021).
- Mitra, B.; Craswell, N. Neural Models for Information Retrieval. arXiv 2017, arXiv:1705.01509. [Google Scholar]
- Wu, C.; Yan, M.; Si, L. Ensemble Methods for Personalized E-Commerce Search Challenge at CIKM Cup 2016. arXiv 2017, arXiv:1708.04479. [Google Scholar]
- Karmaker Santu, S.K.; Sondhi, P.; Zhai, C. On Application of Learning to Rank for E-Commerce Search. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 475–484. [Google Scholar] [CrossRef] [Green Version]
- Wu, L.; Hu, D.; Hong, L.; Liu, H. Turning Clicks into Purchases: Revenue Optimization for Product Search in E-Commerce. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 365–374. [Google Scholar] [CrossRef]
- Lee, H.C.; Rim, H.C.; Lee, D.G. Learning to rank products based on online product reviews using a hierarchical deep neural network. Electron. Commer. Res. Appl. 2019, 36, 100874. [Google Scholar] [CrossRef]
- Bird, S.; Loper, E. NLTK: The Natural Language Toolkit. In Proceedings of the ACL Interactive Poster and Demonstration Sessions; Association for Computational Linguistics: Barcelona, Spain, 2004; pp. 214–217. [Google Scholar]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Bell, A.; Senthil Kumar, P.; Miranda, D. The Title Says It All: A Title Term Weighting Strategy For eCommerce Ranking. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 2233–2241. [Google Scholar] [CrossRef]
- Bi, K.; Teo, C.H.; Dattatreya, Y.; Mohan, V.; Croft, W.B. A Study of Context Dependencies in Multi-page Product Search. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2333–2336. [Google Scholar] [CrossRef] [Green Version]
- Lawani, A.; Reed, M.R.; Mark, T.; Zheng, Y. Reviews and price on online platforms: Evidence from sentiment analysis of Airbnb reviews in Boston. Reg. Sci. Urban Econ. 2019, 75, 22–34. [Google Scholar] [CrossRef]
- Guo, Y.; Cheng, Z.; Nie, L.; Wang, Y.; Ma, J.; Kankanhalli, M. Attentive Long Short-Term Preference Modeling for Personalized Product Search. ACM Trans. Inf. Syst. (TOIS) 2019, 37, 19:1–19:27. [Google Scholar] [CrossRef] [Green Version]
- Schuster, M.; Paliwal, K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef] [Green Version]
- Xu, J.; Li, H. AdaRank: A boosting algorithm for information retrieval. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 391–398. [Google Scholar] [CrossRef]
- Ni, J.; Li, J.; McAuley, J. Justifying Recommendations using Distantly-Labeled Reviews and Fine-Grained Aspects. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 188–197. [Google Scholar] [CrossRef]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint Deep Modeling of Users and Items Using Reviews for Recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar] [CrossRef] [Green Version]
- Ling, G.; Lyu, M.R.; King, I. Ratings meet reviews, a combined approach to recommend. In Proceedings of the 8th ACM Conference on Recommender Systems, Foster City, Silicon Valley, CA, USA, 6–10 October 2014; pp. 105–112. [Google Scholar] [CrossRef]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 297–305. [Google Scholar] [CrossRef]
- Catherine, R.; Cohen, W. TransNets: Learning to Transform for Recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 288–296. [Google Scholar] [CrossRef] [Green Version]
- Rowley, J. Product search in e-shopping:a review and research propositions. J. Consum. Mark. 2000, 17, 20–35. [Google Scholar] [CrossRef]
- Chapelle, O.; Metlzer, D.; Zhang, Y.; Grinspan, P. Expected reciprocal rank for graded relevance. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, Hong Kong, China, 2–6 November 2009; pp. 621–630. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Electronics: | Toys and ames: |
| - electronics home audio speakers | - toys games hand puppets |
| - electronics camera photo accessories | - toys game room mini table games |
| Office Products: | Appliances: |
| - products office school supplies paper | - appliances dryer parts accessories |
| - products office school supplies education crafts | - laundry appliances dryers washers |
| Dataset | Embeddings | Precision@K | Recall@K | F1-Score@K |
|---|---|---|---|---|
| Appliances | Bert | 0.27 | 0.25 | 0.26 |
| FastText | 0.22 | 0.12 | 0.16 | |
| Electronics | Bert | 0.13 | 0.22 | 0.15 |
| FastText | 0.12 | 0.12 | 0.12 | |
| Office Products | Bert | 0.12 | 0.22 | 0.16 |
| FastText | 0.13 | 0.09 | 0.11 | |
| Toys and Games | Bert | 0.18 | 0.17 | 0.17 |
| FastText | 0.16 | 0.09 | 0.12 |
| Methods Categories | LambdaRank | AdaRank | LambdaMART | |||
|---|---|---|---|---|---|---|
| ERR@10 | NDCG@10 | ERR@10 | NDCG@10 | ERR@10 | NDCG@10 | |
| Appliances | 0.476 | 0.480 | 0.565 | 0.560 | 0.612 | 0.600 |
| Electronics | 0.487 | 0.490 | 0.571 | 0.570 | 0.627 | 0.650 |
| Office Products | 0.407 | 0.410 | 0.479 | 0.482 | 0.631 | 0.644 |
| Toys and Games | 0.477 | 0.489 | 0.508 | 0.492 | 0.603 | 0.554 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jbene, M.; Tigani, S.; Saadane, R.; Chehri, A. Deep Neural Network and Boosting Based Hybrid Quality Ranking for e-Commerce Product Search. Big Data Cogn. Comput. 2021, 5, 35. https://doi.org/10.3390/bdcc5030035
Jbene M, Tigani S, Saadane R, Chehri A. Deep Neural Network and Boosting Based Hybrid Quality Ranking for e-Commerce Product Search. Big Data and Cognitive Computing. 2021; 5(3):35. https://doi.org/10.3390/bdcc5030035
Chicago/Turabian StyleJbene, Mourad, Smail Tigani, Rachid Saadane, and Abdellah Chehri. 2021. "Deep Neural Network and Boosting Based Hybrid Quality Ranking for e-Commerce Product Search" Big Data and Cognitive Computing 5, no. 3: 35. https://doi.org/10.3390/bdcc5030035
APA StyleJbene, M., Tigani, S., Saadane, R., & Chehri, A. (2021). Deep Neural Network and Boosting Based Hybrid Quality Ranking for e-Commerce Product Search. Big Data and Cognitive Computing, 5(3), 35. https://doi.org/10.3390/bdcc5030035