Big Data and Actuarial Science



Abstract
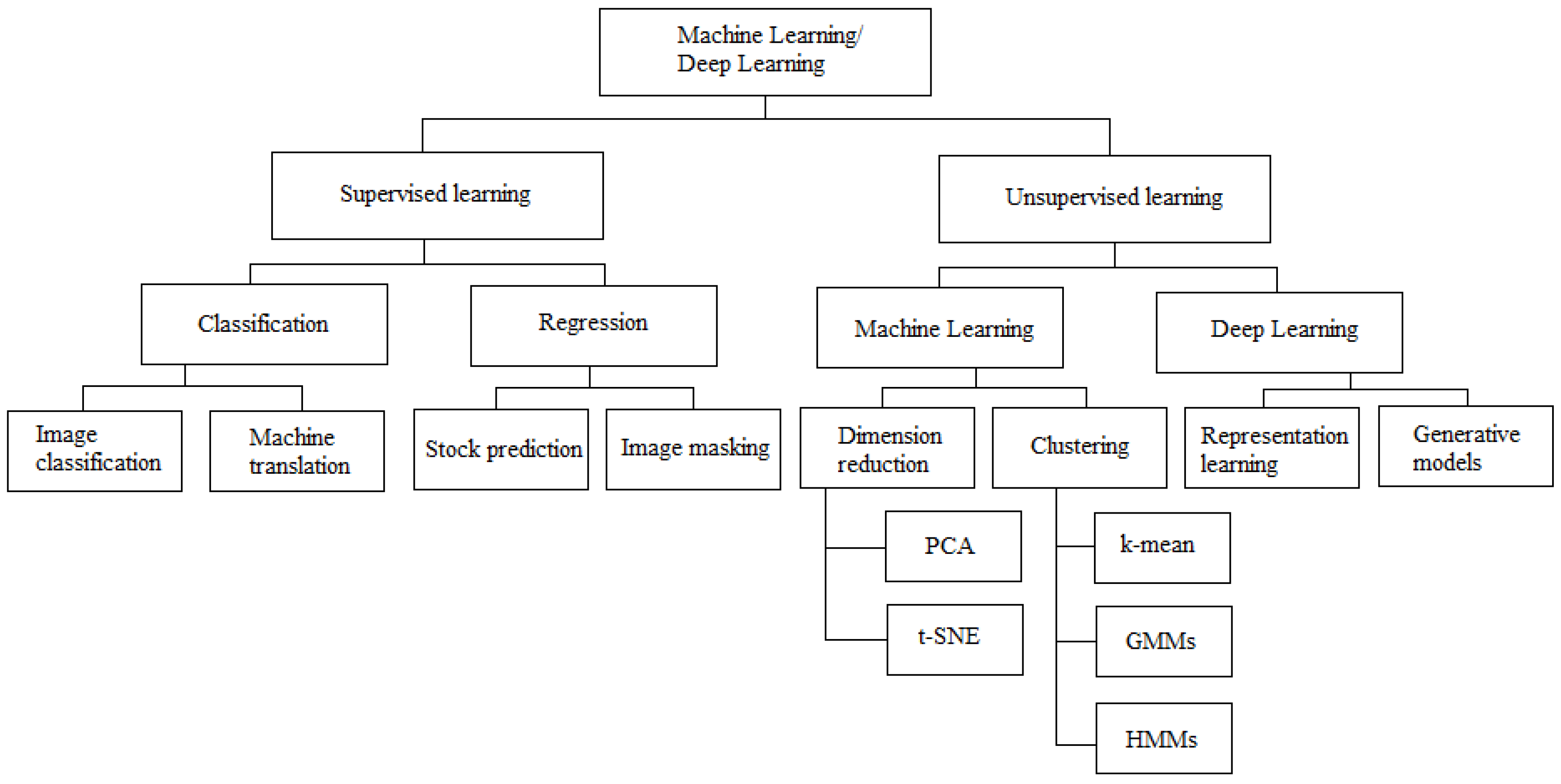
1. Introduction
2. Big Data
3. Big Data Application and Insurance
3.1. Automobile Insurance
3.2. Mortality Modelling
3.3. Healthcare
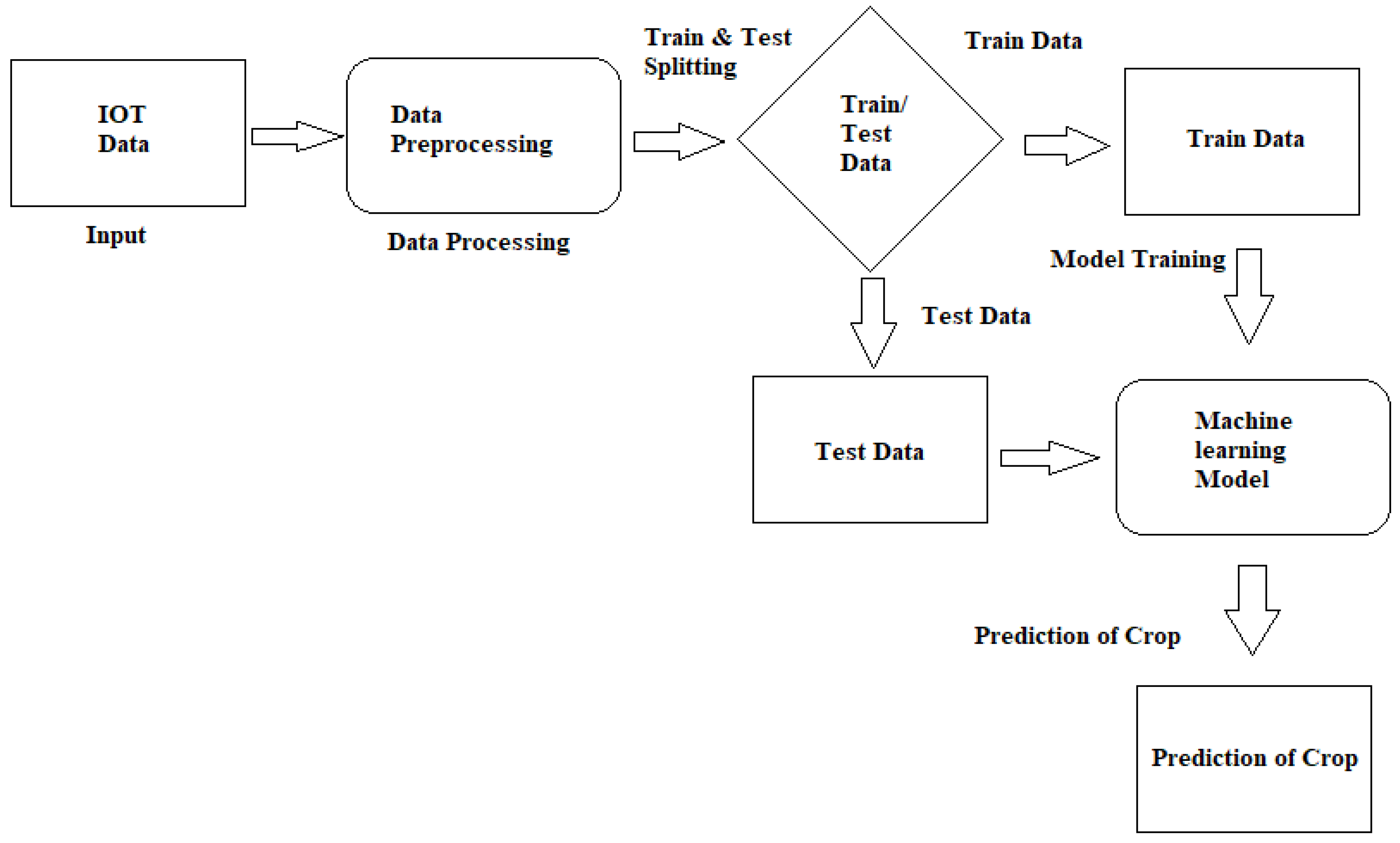
3.4. Harvest Risk
3.5. Catastrophe Risk
3.5.1. Hurricanes
3.5.2. Tornadoes
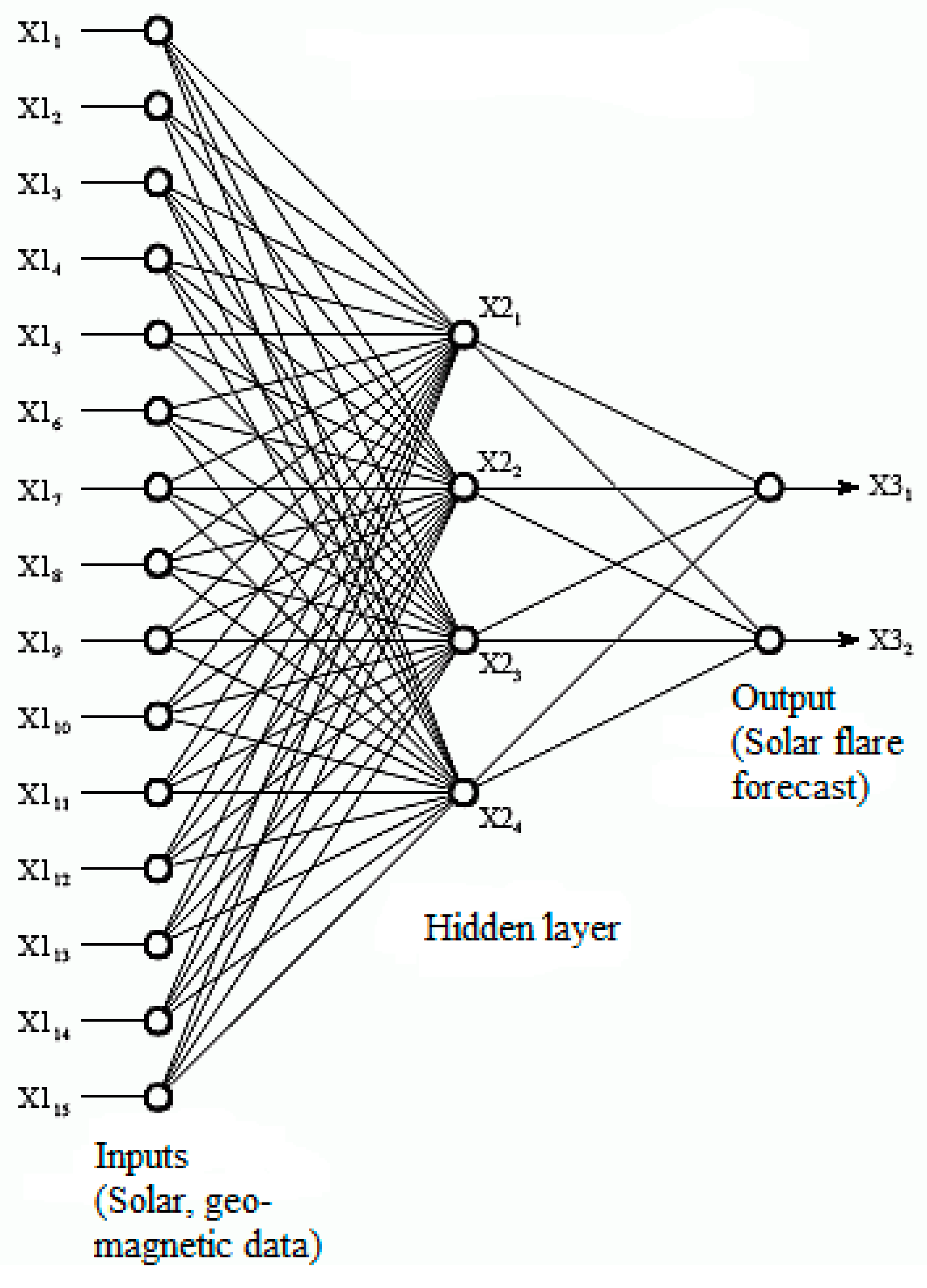
3.5.3. Geomagnetic Events
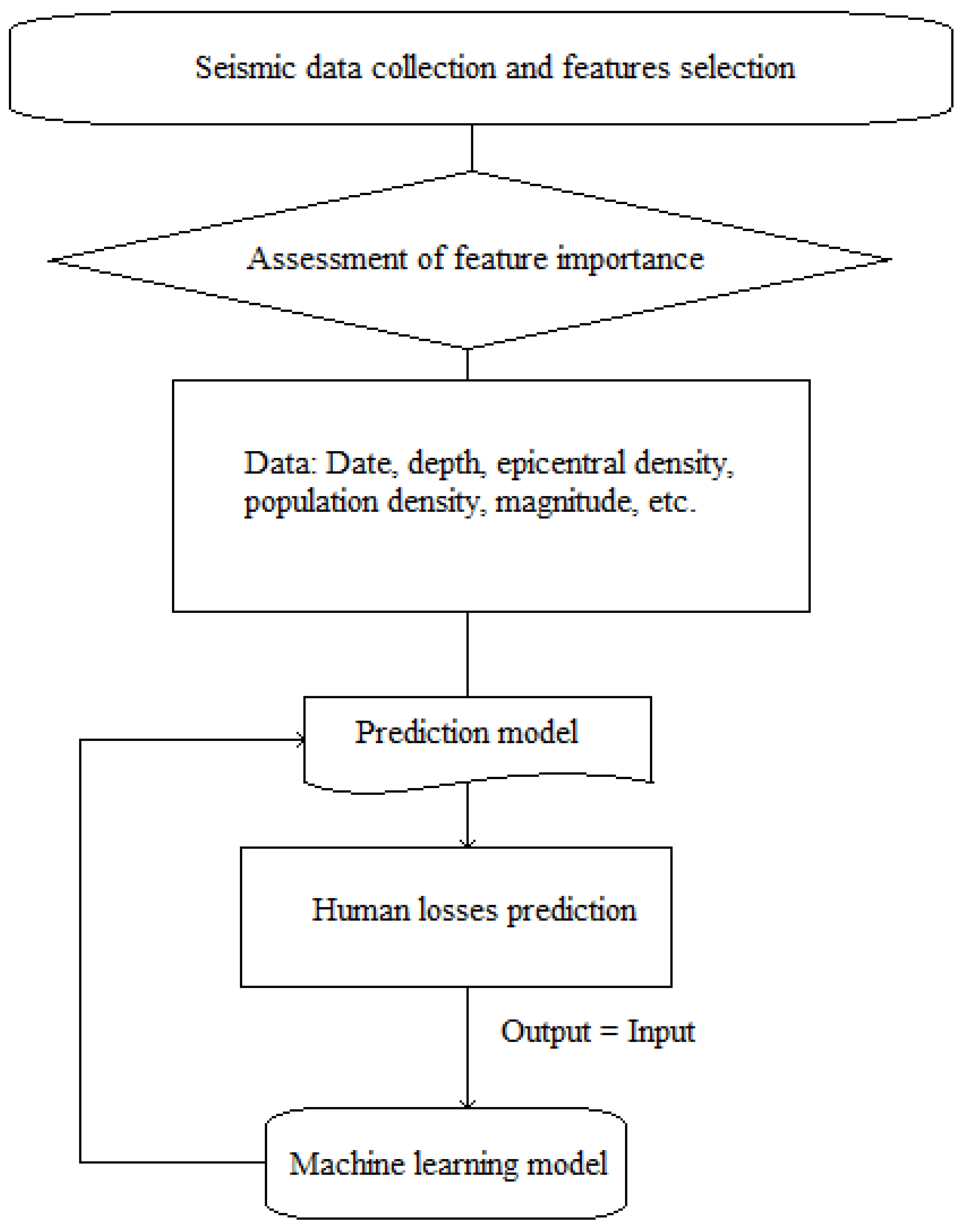
3.5.4. Earthquakes
3.5.5. Floods
3.5.6. Fires
3.6. Climate Risk
3.7. Cyber Risk
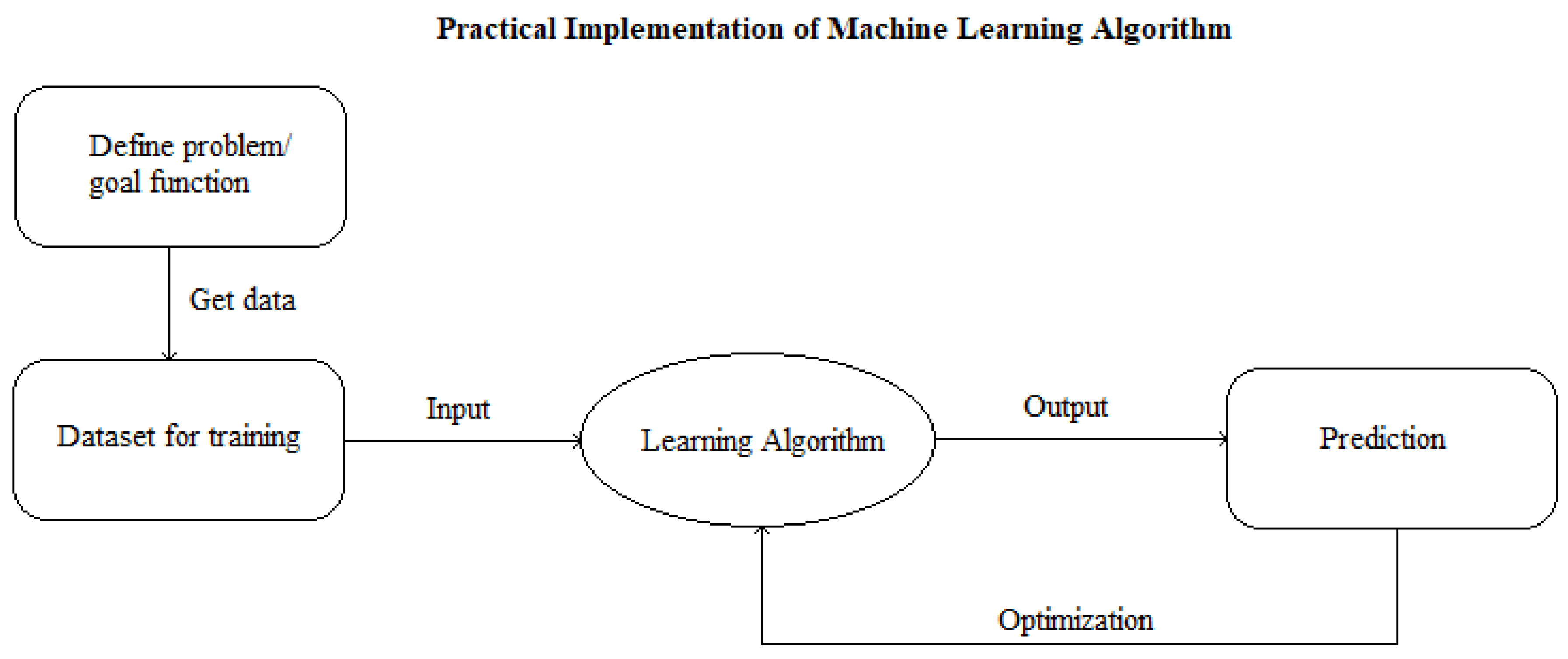
4. Summary
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Global Insurance Premiums Exceed $5 Trillion for the First Time. Available online: https://www.captive.com/news/2019/07/09/global-insurance-premiums-exceed-5-trillion (accessed on 16 December 2020).
- GDP (Current US$). World Development Indicators. World Bank. Available online: https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal) (accessed on 15 October 2019).
- Encyclopedia Britannica, Historical Development of Insurance. Available online: https://www.britannica.com/topic/insurance/Historical-development-of-insurance (accessed on 16 December 2020).
- Johnston, H.W. Burial places and funeral ceremonies. In The Private Life of the Romans; Johnston, M., Ed.; Scott, Foresman and Company: Chicago, IL, USA; Atlanta, GA, USA, 1903; pp. 475–476. Available online: https://en.wikipedia.org/wiki/Actuarial_science#CITEREFJohnston1932 (accessed on 16 December 2020).
- Loan, A. Institutional Bases of the Spontaneous Order: Surety and Assurance. Hum. Stud. Rev. 1991, 7, 92. Available online: https://www.researchgate.net/publication/235899483_Institutional_Bases_of_the_Spontaneous_Order_Surety_and_Assurance (accessed on 17 December 2020).
- Practice areas. In The Official Guide to Becoming an Actuary; Institute and Faculty of Actuaries: London, UK, 2017; Available online: https://silo.tips/download/the-official-guide-to-becoming-an-actuary (accessed on 17 December 2020).
- Deloitte Insights, 2021 Insurance Outlook. Available online: https://www2.deloitte.com/us/en/pages/financial-services/articles/insurance-industry-outlook.html (accessed on 17 December 2020).
- Pearson, R. Insuring the Industrial Revolution: Fire Insurance in Great Britain, 1700–1850; Modern Economic and Social History Series; Ashgate Publishing Company: Burlington, VT, USA, 2004; Volume XI, 434p. [Google Scholar]
- Halley, E. An estimate of the degrees of mortality of mankind, drawn from curious tables of the births and funerals at the city of Breslaw, with an attempt to ascertain the price of annuities upon lives. Philos. Trans. R. Soc. Lond. 1693, 17, 596–610. [Google Scholar] [CrossRef]
- Bellhouse, D.A. A new look at Halley’s life table. J. R. Stat. Soc. A 2011, 174 Pt 3, 823–832. Available online: http://www.medicine.mcgill.ca/epidemiology/hanley/c609/Material/BellhouseHalleyTable2011JRSS.pdf (accessed on 17 December 2020). [CrossRef]
- Grattan-Guinness, I. Landmark Writings in Western Mathematics 1640–1940; Elsevier: Amsterdam, The Netherlands, 2005. [Google Scholar]
- Dunnigton, W.G. Gauss: The Titan of Science; The Mathematical Association of America (Incorporated): Washington, DC, USA, 2004. [Google Scholar]
- Frees, E.W. Stochastic Life Contingencies with Solvency Considerations. Trans. Soc. Actuar. 1990, 42, 91–148. [Google Scholar]
- Shapiro, A.F.; Jain, L.C. (Eds.) Intelligent and Other Computational Techniques in Insurance: Theory and Applications; World Scientific: Singapore, 2003. [Google Scholar]
- KPMG. How Augmented and Virtual Reality Are Changing the Insurance Landscape. Seizing the Opportunity. 2016. Available online: https://members.aixr.org/storage/how-augmented-and-virtual-reality-changing-insurance-landscape%20(1).pdf (accessed on 17 December 2020).
- Corlosquet-Habart, M.; Jansen, J. Big Data for Insurance Companies; ISTE Ltd.: London, UK; John Wiley and Sons, Inc.: New York, NY, USA, 2018; Volume 1. [Google Scholar]
- European Insurance and Occupational Pensions Authority (EIOPA). Big Data Analytics in Motor and Health Insurance; Publications Office of the European Union: Luxembourg, 2019. [Google Scholar]
- BearingPoint Institute. The Smart Insurer: Embedding Big Data in Corporate Strategy. Available online: https://www.bearingpoint.com/en-us/our-success/thought-leadership/the-smart-insurer-embedding-big-data-in-corporate-strategy/ (accessed on 17 December 2020).
- Deloitte Insights. Sector spotlight: Insurance. In Global Risk Management, 11th ed.; 2019; Available online: https://www2.deloitte.com/content/dam/insights/us/articles/4222_Global-risk-management-survey/DI_global-risk-management-survey.pdf (accessed on 17 December 2020).
- Big Data and Insurance: Implications for Innovation, Competition and Privacy. March 2018. Available online: https://www.genevaassociation.org/research-topics/cyber-and-innovation-digitalization/big-data-and-insurance-implications-innovation (accessed on 17 December 2020).
- Berthelé, E. Using Big Data in Insurance. In Big Data for Insurance Companies; John Wiley: New York, NY, USA, 2018; pp. 131–161. [Google Scholar] [CrossRef]
- OECD. The Impact of Big Data and Artificial Intelligence (AI) in the Insurance Sector; OECD: Paris, France, 2020; Available online: http://www.oecd.org/finance/Impact-Big-Data-AI-in-the-Insurance-Sector.htm (accessed on 17 December 2020).
- SNS Telecom & IT. Big Data in the Insurance Industry: 2018–2030—Opportunities, Challenges, Strategies & Forecasts. August 2018. Available online: https://www.snstelecom.com/bigdatainsurance (accessed on 17 December 2020).
- Corbett, P.; Schroeck, M.; Shockley, R. Analytics: The Real-World Use of Big Data in Insurance. Executive Report, IBM Institute for Business Value. 2018. Available online: https://www.ibm.com/downloads/cas/LKMQWLPY (accessed on 17 December 2020).
- PWC’s HR Technology Survey. 2020. Available online: https://www.pwc.com/us/en/library/workforce-of-the-future/hr-tech-survey.html (accessed on 17 December 2020).
- Topol, E.J. The Patient Will See You Now: The Future of Medicine Is in Your Hands; Basic Books: New York, NY, USA, 2015. [Google Scholar]
- Swiss Re. Wearables: New technology—New risks. In Trend Spotlight; Swiss Re.: Zurich, Switzerland, 2016. [Google Scholar]
- Meyers, G.; Van Hoyweghen, I. Enacting Actuarial Fairness in Insurance: From Fair Discrimination to Behaviour-based Fairness. Sci. Cult. 2017, 1–29. [Google Scholar] [CrossRef]
- Available online: https://www.capgemini.com/2018/08/bigtech-firms-take-measured-steps-toward-the-insurance-sector/ (accessed on 23 August 2018).
- World Insurance Report (WIR) 2018: Digital Agility is Key for Insurers as BigTechs Ponder Entering the Market from Capgemini in Collaboration with Efma. Available online: https://www.capgemini.com/news/world-insurance-report-2018-as-more-customers-buy-insurance-from-bigtechs-digital-agility-is-key-for-traditional-insurers/ (accessed on 17 December 2020).
- SOA. 2019. Available online: https://www.soa.org/globalassets/assets/files/resources/research-report/2019/emerging-analytics-techniques-applications.pdf (accessed on 17 December 2020).
- Big Data and the Role of the Actuary. Available online: https://www.actuary.org/sites/default/files/files/publications/BigDataAndTheRoleOfTheActuary.pdf (accessed on 17 December 2020).
- Sondergeld, E.T.; Purushotham, M.C. Top Acturial Technologies of 2019; Society of Actuaries: Itasca, IL, USA, April 2019. Available online: https://www.soa.org/globalassets/assets/files/resources/research-report/2019/actuarial-innovation-technology.pdf (accessed on 17 December 2020).
- Guo, L. Applying Data Mining Techniques in Property/Casualty Insurance. CAS Forum. 2003. Available online: https://www.casact.org/pubs/forum/03wforum/03wf001.pdf (accessed on 17 December 2020).
- Wedel, M.; Kannan, P.K. Marketing Analytics for Data-Rich Environments. J. Mark. 2016, 80. [Google Scholar] [CrossRef]
- Deloitte Insights. 2020 Insurance Outlook. 3 December 2019. Available online: https://www2.deloitte.com/us/en/insights/industry/financial-services/financial-services-industry-outlooks/insurance-industry-outlook.html (accessed on 17 December 2020).
- BearingPoint Institute. The Smart Insurer: More than Just Big Data. Available online: https://www.bearingpoint.com/en/our-success/thought-leadership/the-smart-insurer-embedding-big-data-in-corporate-strategy/ (accessed on 17 December 2020).
- Bakratsas, M.; Basaras, P.; Katsaros, D.; Tassiulas, L. Hadoop MapReduce performance on SSDs for analyzing social networks. Big Data Res. 2017. [Google Scholar] [CrossRef]
- Billot, R.; Bothorel, C.; Lenca, P. Introduction to Big Data and Its Applications in Insurance. In Big Data for Insurance Companies; Wiley: New York, NY, USA, 2018; pp. 1–25. [Google Scholar]
- Kunce, J.; Chatterjee, S. A Machine-Learning Approach to Parameter Estimation, Casualty Actuarial Society Monograph Series 6, CAS. 2017. Available online: https://www.casact.org/pubs/monographs/papers/06-Kunce-Chatterjee.pdf (accessed on 17 December 2020).
- Noll, A.; Salzmann, R.; Wüthrich, M.V. Case Study: French Motor Third-Party Liability Claims. Swiss Association of Actuaries, 2018. Available online: https://ssrn.com/abstract=3164764 (accessed on 17 December 2020).
- Zappa, D.; Clemente, G.P.; Borrelli, M.; Savelli, N. Text Mining in Insurance: From Unstructured Data to Meaning. Variance, 2019. Available online: https://www.variancejournal.org/articlespress/articles/Text_Mining-Zappa-Borrelli-Clemente-Savelli.pdf (accessed on 17 December 2020).
- Report on the Use of Big Data by Financial Institutions. Joint Committee of the ESAs: 15 March 2018. Available online: https://www.esma.europa.eu/sites/default/files/library/jc-2016-86_discussion_paper_big_data.pdf (accessed on 17 December 2020).
- P&C Insurance Trends to Watch in 2019. CB Insights, 4 February 2019. Available online: www.cbinsights.com/research/insurance-trends-2019/ (accessed on 17 December 2020).
- Bellina, R.; Ly, A.; Taillieu, F. A European Insurance lEader Works with Milliman to Process Raw Telematics Data and Detect Driving Behavior. Milliman White Paper. May 2018. Available online: https://www.milliman.com/en/insight/a-european-insurance-leader-works-with-milliman-to-process-raw-telematics-data-and-detect (accessed on 17 December 2020).
- Huang, Y.; Meng, S. Automobile insurance classification ratemaking based on telematics driving data. Decis. Support Syst. 2019, 127, 113156. [Google Scholar] [CrossRef]
- Tselentis, D.I.; Yannis, G.; Vlahogianni, E.I. Innovative motor insurance schemes: A review of current practices and emerging challenges. Accid. Anal. Prev. 2017, 98, 139–148. [Google Scholar] [CrossRef]
- Baecke, P.; Bocca, L. The value of vehicle telematics data in insurance risk selection processes. Decis. Support Syst. 2017, 98, 69–79. [Google Scholar] [CrossRef]
- Paefgen, J.; Staake, T.; Thiesse, F. Evaluation and aggregation of pay-as-you-drive insurance rate factors: A classification analysis approach. Decis. Support Syst. 2013, 56, 192–201. [Google Scholar] [CrossRef]
- Paefgen, J.; Staake, T.; Fleisch, E. Multivariate exposure modeling of accident risk: Insights from Pay-as-you-drive insurance data. Transp. Res. Part A Policy Pract. 2014, 61, 27–40. [Google Scholar] [CrossRef]
- Husnjak, S.; Peraković, D.; Forenbacher, I.; Mumdziev, M. Telematics System in Usage Based Motor Insurance. Procedia Eng. 2015, 100, 816–825. [Google Scholar] [CrossRef]
- Richman, R. AI in Actuarial Science. Presented at the Actuarial Society of South Africa’s 2018 Convention, Cape Town, South Africa, 24–25 October 2018. [Google Scholar]
- KPMG. The Chaotic Middle. The Autonomous Vehicle and Disruption in Automobile Insurance, White Paper. June 2017. Available online: https://assets.kpmg/content/dam/kpmg/us/pdf/2017/06/chaotic-middle-autonomous-vehicle-paper.pdf (accessed on 17 December 2020).
- Alshamsi, A.S. Predicting car insurance policies using random forest. In Proceedings of the 2014 10th International Conference on Innovations in Information Technology (IIT), Abu Dhabi, UAE, 9–11 November 2014. [Google Scholar]
- Wang, H.D. Research on the Features of Car Insurance Data Based on Machine Learning. Procedia Comput. Sci. 2020, 166, 582–587. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, W. Leveraging deep learning with LDA-based text analytics to detect automobile insurance fraud. Decis. Support Syst. 2018, 105, 87–95. [Google Scholar] [CrossRef]
- Subudhi, S.; Panigrahi, S. Effect of Class Imbalanceness in Detecting Automobile Insurance Fraud. In Proceedings of the 2nd International Conference on Data Science and Business Analytics, Changsha, China, 21–23 September 2018; IEEE: New York, NY, USA, 2018. [Google Scholar]
- Institute and Faculty of Actuaries (IFoA). Longevity Bulletin. Big Data Health. 2016. Available online: https://www.actuaries.org.uk/system/files/field/document/Longevity%20Bulletin%20Issue%209.pdf (accessed on 17 December 2020).
- LLMA. Longevity Pricing Framework, A Framework for Pricing Longevity Exposures Developed by the Life & Longevity Markets Association (LLMA). 2010. Available online: www.llma.org (accessed on 17 December 2020).
- Silverman, S.; Simpson, P. Case Study: Modelling Longevity Risk for Solvency II. Milliman Research Report. October 2011. Available online: https://www.milliman.com/-/media/products/reveal/modelling-longevity-risk.ashx (accessed on 17 December 2020).
- Booth, H.; Tickle, L. Mortality modelling and forecasting: A review of methods. Ann. Actuar. Sci. 2008, 3, 3–43. [Google Scholar] [CrossRef]
- Deprez, P.; Shevchenko, P.; Wüthrich, M. Machine learning techniques for mortality modeling. Eur. Actuar. J. 2017, 7, 337–352. [Google Scholar] [CrossRef]
- Kopinsky, M. Predicting Group Long Term Disability Recovery and Mortality Rates Using Tree Models, SOA. 2017. Available online: https://www.soa.org/globalassets/assets/Files/Research/Projects/2017-gltd-recovery-mortality-tree.pdf (accessed on 17 December 2020).
- Hainaut, D. A neural-network analyzer for mortality forecast. Astin Bull. 2018, 48, 481–508. [Google Scholar] [CrossRef]
- Shang, K. Individual Cancer Mortality Prediction; Insurance and Social Protection Area: Madrid, Spain, 2017; Available online: www.fundacionmapfre.org (accessed on 17 December 2020).
- Mehta, N.; Pandit, A.; Shukla, S. Transforming Healthcare with Big Data Analytics and Artificial Intelligence: A Systematic Mapping Study. J. Biomed. Inform. 2019, 100, 103311. [Google Scholar] [CrossRef]
- Chawla, N.V.; Davis, D.A. Bringing Big Data to Personalized Healthcare: A Patient-Centered Framework. J. Gen. Intern. Med. 2013, 28 (Suppl. S3), S660–S665. [Google Scholar] [CrossRef]
- Raghupathi, W.; Raghupathi, V. Big data analytics in healthcare: Promise and potential. Health Inf. Sci. Syst. 2014, 2, 3. [Google Scholar] [CrossRef] [PubMed]
- Belle, A.; Thiagarajan, R.; Soroushmehr, S.M.R.; Navidi, F.; Beard, D.A.; Najarian, K. Big Data Analytics in Healthcare. In BioMed Research International; Hindawi Publishing Corporation: New York, NY, USA, 2015; p. 370194. [Google Scholar] [CrossRef]
- Lander, E.S.; Linton, L.M.; Birren, B.; Nusbaum, C.; Zody, M.C.; Baldwin, J.; Devon, K.; Dewar, K.; Doyle, M.; FitzHugh, W.; et al. Initial sequencing and analysis of the human genome. Nature 2001, 409, 860–921. Available online: http://hdl.handle.net/2027.42/62798 (accessed on 17 December 2020). [PubMed]
- Drmanac, R.; Sparks, A.B.; Callow, M.J.; Halpern, A.L.; Burns, N.L.; Kermani, B.G.; Carnevali, P.; Nazarenko, I.; Nilsen, G.B.; Yeung, G.; et al. Human genome sequencing using unchained base reads on self-assembling DNA nanoarrays. Science 2010, 327, 78–81. [Google Scholar] [CrossRef] [PubMed]
- Bates, D.W.; Saria, S.; Ohno-Machado, L.; Shah, A.; Escobar, G. Big Data in Health Care: Using Analytics to Identify and Manage High-Risk and High-Cost Patients. Health Aff. 2014, 33, 1123–1131. [Google Scholar] [CrossRef] [PubMed]
- Feldman, B.; Martin, E. Big Data in Healthcare Hype and Hope. Comput. Sci. 2012, 360, 122–125. [Google Scholar]
- Kandula, S.; Shaman, J. Reappraising the utility of Google Flu Trends. PLoS Comput. Biol. 2019, 15, e1007258. [Google Scholar] [CrossRef]
- Horn, J.W.; Xi, Z.; Riina, R.; Peirson, J.A.; Yang, Y.; Dorsey, B.L.; Berry, P.E.; Davis, C.C.; Wurdack, K.J. Evolutionary bursts inEuphorbia(Euphorbiaceae) are linked with photosynthetic pathway. Evolution 2014, 68, 3485–3504. [Google Scholar] [CrossRef]
- Brandt, N.; Gunnarsson, T.P.; Bangsbo, J.; Pilegaard, H. Exercise and exercise training-induced increase in autophagy markers in human skeletal muscle. Physiol. Rep. 2018, 6, e13651. [Google Scholar] [CrossRef]
- Schileo, E.; Dall’Ara, E.; Taddei, F.; Malandrino, A.; Schotkamp, T.; Baleani, M.; Viceconti, M. An accurate estimation of bone density improves the accuracy of subject-specific finite element models. J. Biomech. 2008, 41, 2483–2491. [Google Scholar] [CrossRef]
- Irigaray, T.Q.; Pacheco, J.T.B.; Grassi-Oliveira, R.; Fonseca, R.P.; Leite, J.C.D.C.; Kristensen, C.H. Child maltreatment and later cognitive functioning: A systematic review. Psicol. Reflexão Crítica 2013, 26, 376–387. [Google Scholar] [CrossRef]
- Hammer, L.B.; Kossek, E.E.; Bodner, T.; Crain, T. Measurement development and validation of the Family Supportive Supervisor Behavior Short-Form (FSSB-SF). J. Occup. Health Psychol. 2013, 18, 285–296. [Google Scholar] [CrossRef] [PubMed]
- Kerfoot, E.D.; Lamata, P.; Niederer, S.A.; Hose, R.; Spaan, J.A.E.; Smith, N. Share and enjoy: Anatomical models database--generating and sharing cardiovascular model data using web services. Med. Biol. Eng. Comput. 2013, 51, 1181–1190. [Google Scholar] [CrossRef] [PubMed]
- Morris, P.D.; Narracott, A.; von Tengg Kobligk, H.; Soto, D.A.S.; Hsiao, S.; Lungu, A.; Evans, P.; Bressloff, N.W.; Lawford, P.V.; Hose, D.R.; et al. Computational fluid dynamics modelling in cardiovascular medicine. Heart 2016, 102, 18–28. [Google Scholar] [CrossRef] [PubMed]
- Lio, P.; Shavit, Y. CytoHiC: A cytoscape plugin for visual comparison of Hi-C networks. Bioinformatics 2013, 29, 1206–1207. [Google Scholar] [CrossRef]
- Evans, M.A.; Johri, A. Facilitating guided participation through mobile technologies: Designing creative learning environments for self and others. J. Comput. High. Educ. 2008, 20, 92–105. [Google Scholar] [CrossRef]
- Marco, V.; Josef, K.; Clapworthy, G.J.; Saulo, M. Fast realistic modelling of muscle fibres. In Computer Vision, Imaging and Computer Graphics; Csurka, G., Kraus, M., Laramee, R.S., Richard, P., Braz, J., Eds.; Theory and Application; Communications in Computer and Information Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 359. [Google Scholar] [CrossRef]
- Jyun, J.-G.; Kim, G.; Lee, J.-E.; Kim, Y.; Shim, W.B.; Lee, J.-H.; Shin, H.; Lee, J.D.; Park, B.-G. Single-Crystalline Si STacked ARray (STAR) NAND Flash Memory. IEEE Trans. Electron Devices 2011, 58, 1006–1014. [Google Scholar] [CrossRef]
- Viceconti, M.; Henney, A.; Morley-Fletcher, E. In silico clinical trials: How computer simulation will transform the biomedical industry. Int. J. Clin. Trials 2016, 3, 37. [Google Scholar] [CrossRef]
- Diana, A.; Griffin, J.; Oberoi, J.; Yao, J. Machine-Learning Methods for Insurance Applications-A Survey. Society of Actuaries, 2019. Available online: https://www.soa.org/resources/research-reports/2019/machine-learning-methods/ (accessed on 17 December 2020).
- Toyoda, S.; Niki, N. Information Visualization for Chronic Patient’s Data. In ISIP; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Kareem, S.; Ahmad, R.; Sarlan, A. Framework for the identification of fraudulent health insurance claims using association rule mining. In Proceedings of the 2017 IEEE Conference on Big Data and Analytics (ICBDA), Kuching, Malaysia, 16–17 November 2017; pp. 99–104. [Google Scholar] [CrossRef]
- Dhieb, N.; Ghazzai, H.; Besbes, H.; Massoud, Y. A Secure AI-Driven Architecture for Automated Insurance Systems: Fraud Detection and Risk Measurement. IEEE Access 2020, 8. [Google Scholar] [CrossRef]
- Wang, Y.; Kung, L.; Byrd, T. Big data analytics: Understanding its capabilities and potential benefits for healthcare organizations. Technol. Forecast. Soc. Chang. 2018, 126, 3–13. [Google Scholar] [CrossRef]
- Hartmann, B.; Owen, R.; Gibbs, Z. Predicting High-Cost Health Insurance Members through Boosted Trees and Oversampling: An Application Using the HCCI Database. 2018. Available online: https://hartman.byu.edu/docs/files/HartmanOwenGibbs_HighCostClaims.pdf (accessed on 17 December 2020).
- Boodhun, N.; Jayabalan, M. Risk Prediction in Life Insurance Industry using Supervised Learning Algorithms. Complex Intell. Syst. 2018. [Google Scholar] [CrossRef]
- The International Actuarial Association. Impact of Personalised Medicine and Genomics on the Insurance Industry. April 2017. Available online: http://www.actuaries.org/LIBRARY/Papers/HC_Personalised_Medicine_Paper_Final.pdf (accessed on 17 December 2020).
- Hulsen, T.; Jamuar, S.S.; Moody, A.R.; Karnes, J.H.; Varga, O.; Hedensted, S.; Spreafico, R.; Hafler, D.A.; McKinney, E.F. From Big Data to Precision Medicine. Front. Med. 2019, 6, 34. [Google Scholar] [CrossRef] [PubMed]
- Cirillo, D.; Valencia, A. Big data analytics for personalized medicine. Curr. Opin. Biotechnol. 2019, 58, 161–167. [Google Scholar] [CrossRef] [PubMed]
- McKinney, S.M.; Sieniek, M.; Godbole, V.; Godwin, J.; Antropova, N.; Ashrafian, H.; Back, T.; Chesus, M.; Corrado, G.S.; Darzi, A.; et al. International evaluation of an AI system for breast cancer screening. Nature 2020, 577, 89–94. [Google Scholar] [CrossRef] [PubMed]
- Perez, M.V.; Mahaffey, K.W.; Hedlin, H.; Rumsfeld, J.S.; Garcia, A.; Ferris, T.; Balasubramanian, V.; Russo, A.M.; Rajmane, A.; Cheung, L.; et al. Large-Scale Assessment of a Smartwatch to Identify Atrial Fibrillation. N. Engl. J. Med. 2020, 381, 1909–1917. [Google Scholar] [CrossRef]
- Kamilaris, A.; Antón, A.; Bonmatí, A.; Torrellas, M.; Prenafeta Boldú, F. Estimating the Environmental Impact of Agriculture by Means of Geospatial and Big Data Analysis: The Case of Catalonia; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Pretty, J. Agricultural sustainability: Concepts, principles and evidence. Philos. Trans. R. Soc. B Biol. Sci. 2007, 363, 447–465. [Google Scholar] [CrossRef]
- Nandyala, C.S.; Kim, H.-K. Big and Meta Data Management for U-Agriculture Mobile Services. Int. J. Softw. Eng. Its Appl. 2016, 10, 257–270. [Google Scholar] [CrossRef]
- Hashem, I.A.T.; Yaqoob, I.; Anuar, N.B.; Mokhtar, S.; Gani, A.; Khan, S.U. The rise of “big data” on cloud computing: Review and open research issues. Inf. Syst. 2015, 47, 98–115. [Google Scholar] [CrossRef]
- Chedad, A.; Moshou, D.; Aerts, J.M.; Van Hirtum, A.; Ramon, H.; Berckmans, D. Recognition system for pig cough based on probabilistic neural networks. J. Agric. Eng. Res. 2001, 79, 449–457. [Google Scholar] [CrossRef]
- Kempenaar, C.; Been, T.; Booij, J.; Van Evert, F.; Michielsen, J.-M.; Kocks, C. Advances in Variable Rate Technology Application in Potato in The Netherlands. Potato Res. 2017, 60, 295–305. [Google Scholar] [CrossRef]
- Becker-Reshef, I.; Justice, C.; Sullivan, M.; Vermote, E.; Tucker, C.J.; Anyamba, A.; Small, J.; Pak, E.; Masuoka, E.; Schmaltz, J.; et al. Monitoring Global Croplands with Coarse Resolution Earth Observations: The Global Agriculture Monitoring (GLAM) Project. Remote. Sens. 2010, 2, 1589–1609. [Google Scholar]
- Giuliani, G.; Nativi, S.; Obregon, A.; Beniston, M.; Lehmann, A. Spatially enabling the Global Framework for Climate Services: Reviewing geospatial solutions to efficiently share and integrate climate data & information. Clim. Serv. 2017, 8, 44–58. [Google Scholar] [CrossRef]
- Karmas, A.; Karantzalos, K.; Athanasiou, S. Online analysis of remote sensing data for agricultural applications. In Proceedings of the OSGeo’s European Conference on Free and Open Source Software for Geospatial, Portland, OR, USA, 8–13 September 2014. [Google Scholar]
- Yu, M.K.; Ma, J.; Fisher, J.; Kreisberg, J.F.; Raphael, B.; Ideker, T. Visible Machine Learning for Biomedicine. Cell 2018, 173, 1562–1565. [Google Scholar] [CrossRef] [PubMed]
- Mucherino, A.; Papajorgji, P.J.; Pardalos, P. Data Mining Agriculture; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Shirsath, P.; Vyas, S.; Aggarwal, P.K.; Rao, K. Designing weather index insurance of crops for the increased satisfaction of farmers, industry and the government. Clim. Risk Manag. 2019, 25, 100189. [Google Scholar] [CrossRef]
- Sykuta, M. Big Data in Agriculture: Property Rights, Privacy and Competition in Ag Data Services. Int. Food Agribus. Manag. Rev. 2016, 19, 1–18. [Google Scholar]
- Kshetri, N. Big data׳s impact on privacy, security and consumer welfare. Telecommun. Policy 2014, 38, 1134–1145. [Google Scholar] [CrossRef]
- Ashok, T.; Suresh, V.P. Prediction of Crops based on Environmental Factors using IoT & Machine Learning Algorithms. Int. J. Innov. Technol. Explor. Eng. 2019, 9, 5395–5401. [Google Scholar]
- Lane, M.; Mahul, O. Catastrophe Risk Pricing—An Empirical Analysis; Policy Research Working Paper; World Bank: Washington, DC, USA, 2008; WPS: 4765. [Google Scholar]
- Li, M.; Powers, I.Y. The role of catastrophe modeling in insurance rating. Risk Manag. 2007, 54, 10. [Google Scholar]
- Bougen, P.D. Catastrophe risk. Econ. Soc. 2003, 32, 253–274. [Google Scholar] [CrossRef]
- Logic Mark and Accord. Making Sense of Big Data in Insurance (White Paper). 2013. Available online: https://cdn1.marklogic.com/wp-content/uploads/2018/01/making-sense-big-data-in-insurance-130913.pdf (accessed on 17 December 2020).
- Big Data Analytics Is Shaking up the Insurance Business? HPC, 2016. Available online: www.datanami.com (accessed on 17 December 2020).
- Schruek, M.; Shockley, R. Analytics: Real World Use of Big Data in Insurance. IBM, 2015. Available online: m.ibm.com (accessed on 17 December 2020).
- TIBCO Blog. 4 Ways Big Data Is Transforming the Insurance Industry. 2015. Available online: https://www.tibco.com/blog/2015/07/20/4-ways-big-data-is-transforming-the-insurance-industry/ (accessed on 17 December 2020).
- Nguyen, L.; Yang, Z.; Li, J.; Pan, Z.; Cao, G.; Jin, F. Forecasting People’s Needs in Hurricane Events from Social Network. IEEE Trans. Big Data 2019. [Google Scholar] [CrossRef]
- Hangan, H.; Refan, M.; Jubayer, C.; Parvu, D.; Kilpatrick, R. Big Data from Big Experiments. The WindEEE Dome. In Whither Turbulence and Big Data in the 21st Century; Springer: Berlin, Germany, 2016; pp. 215–230. [Google Scholar]
- Cox, T.S.; Hoi, C.S.H.; Leung, C.K.; Marofke, C.R. An Accurate Model for Hurricane Trajectory Prediction. In Proceedings of the 2018 IEEE 42nd Annual Computer Software and Applications Conference (COMPSAC), Tokyo, Japan, 23–27 July 2018. [Google Scholar] [CrossRef]
- Zhu, Y.; Ozbay, K.; Xie, K.; Yang, H. Using Big Data to Study Resilience of Taxi and Subway Trips for Hurricanes Sandy and Irene. Transp. Res. Rec. J. Transp. Res. Board 2016, 2599, 70–80. [Google Scholar] [CrossRef]
- Camara, R.C.; Cuzzocrea, A.; Grasso, G.M.; Leung, C.K.; Powell, S.B.; Souza, J.; Tang, B. Fuzzy Logic-Based Data Analytics on Predicting the Effect of Hurricanes on the Stock Market. In Proceedings of the 2018 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), New Orleans, LA, USA, 23–26 June 2018. [Google Scholar] [CrossRef]
- Aladangady, A.; Aron-Dine, S.; Dunn, W.E.; Feiveson, L.; Lengermann, P.; Sahm, C. The Effect of Hurricane Matthew on Consumer Spending, Feds Notes. 2017. Available online: https://ssrn.com/abstract=3056155 (accessed on 17 December 2020).
- Chen, Z.; Sharma, P.; Sutley, E.J. Deep learning of Tornado Disaster Scenes using Unmanned-Aerial-Vehicle (UAV) Images. In Proceedings of the American Geophysical Union, Fall Meeting 2019, San Francisco, CA, USA, 9–13 December 2019. [Google Scholar]
- Elsner, J.B.; Fricker, T.; Schroder, Z. Increasingly Powerful Tornadoes in the United States. Geophys. Res. Lett. 2018. [Google Scholar] [CrossRef]
- Lian, J.; McGuire, M.P.; Moore, T.W. Funnel Cloud: A cloud-based system for exploring tornado events. Int. J. Digit. Earth 2017, 10, 1030–1054. [Google Scholar] [CrossRef]
- Srebrov, B.; Kounchev, O.; Simeonov, G. Chapter 19—Big Data for the Magnetic Field Variations in Solar-Terrestrial Physics and Their Wavelet Analysis. In Knowledge Discovery in Big Data from Astronomy and Earth Observation, Astrogeoinformatics; Elsevier: Amsterdam, The Netherlands, 2020; pp. 347–370. [Google Scholar]
- Pashova, L.; Srebrov, B.; Kounchev, O. Investigation of Strong Geomagnetic Storms Using Multidisciplinary Big Data Sets; IEEE: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- Blagoveshchensky, D.; Sergeeva, M. Impact of geomagnetic storm of 7–8 September 2017 on ionosphere and HF propagation: A multi-instrument study. Adv. Space Res. 2019, 63, 239–256. [Google Scholar] [CrossRef]
- Astafyeva, E.; Yasyukevich, Y.; Maksikov, A.; Zhivetiev, I. Geomagnetic storms super-storms and their impacts on GPS-based navigation systems. Space Weather 2014, 12, 508–525. [Google Scholar] [CrossRef]
- Gvishiani, A.; Soloviev, A.; Krasnoperov, R.; Lukianova, R. Automated Hardware and Software System for Monitoring the Earth’s Magnetic Environment. Data Sci. J. 2016, 15, 18. [Google Scholar] [CrossRef]
- Belehaki, A.; Tsagouri, I.; Kutiev, I.; Marinov, P.; Zolesi, B.; Pietrella, M.; Themelis, K.; Elias, P.; Tziotziou, K. The European Ionosonde Service: Nowcasting and forecasting ionospheric conditions over Europe for the ESA Space Situational Awareness services. J. Space Weather Space Clim. 2015, 5, A25. [Google Scholar] [CrossRef]
- Lemmerer, B.; Unger, S. Modeling and pricing of space weather derivatives. Risk Manag. 2019, 21, 265–291. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, K.; Quian, K.; Du, M.; Guo, S. Tornado: Enabling Blockchain in Heterogeneous Internet of Things through a Space-Structured Approach. IEEE Internet Things J. 2020, 7, 1273–1286. [Google Scholar] [CrossRef]
- Kagan, Y.Y. Earthquake size distribution and earthquake insurance. Commun. Stat. Stoch. Models 1997, 13, 775–797. [Google Scholar] [CrossRef]
- Brillinger, D.R. Earthquake risk and insurance. Environmetrics 1993, 4, 1–21. [Google Scholar] [CrossRef]
- Mouyiannou, A.; Styles, K.E. From Structural Performance to Loss Estimation for (Re) Insurance Industry Needs: An Overview of the Vulnerability Estimation Approaches within Earthquake Catastrophe Models. In Proceedings of the COMPDYN 2017 6th ECCOMAS Thematic Conference on Computational Methods in Structural Dynamics and Earthquake Engineering, Rhodes Island, Greece, 15–17 July 2017. [Google Scholar]
- Tiampo, K.F.; Kazemian, J.; Ghofrani, H.; Kropivnitskaya, Y.; Michel, G. Insights into seismic hazard from big data analysis of ground motion simulations. Int. J. Saf. Secur. Eng. 2019, 9, 1–12. [Google Scholar] [CrossRef]
- Crichton, D. Role of Insurance in Reducing Flood Risk. Geneva Pap. Risk Insur. Issues Pract. 2007, 33, 117–132. [Google Scholar] [CrossRef]
- Andre, C.; Monfort, C.; Bouzit, M.; Vinchon, C. Contribution of insurance data to cost assessment of coastal flood damage to residential buildings: Insights gained from Johanna (2008) and Xynthia (2010) storm events. Nat. Hazards Earth Syst. Sci. 2013, 13, 2003–2012. [Google Scholar] [CrossRef]
- Schumann, G.J.-P. Fight floods on a global scale. Nature 2013, 507, 169. [Google Scholar] [CrossRef]
- Browne, J.L.; Kayode, G.A.; Arhinful, D.; Fidder, S.A.J.; E Grobbee, D.; Klipstein-Grobusch, K. Health insurance determines antenatal, delivery and postnatal care utilisation: Evidence from the Ghana Demographic and Health Surveillance data. BMJ Open 2016, 6, e008175. [Google Scholar] [CrossRef]
- Gao, C.; Wang, M. Forest Fire Risk Assessment Based on Ecological and Economic Value—Take Yunnan Province as an Example. In Proceedings of the 7th Annual Meeting of Risk Analysis Council of China Association for Disaster Prevention, Changsha, China, 4–6 November 2016. [Google Scholar] [CrossRef]
- Tang, J. Big Data and Predictive Analytics in Fire Risk using Weather Data; ProQuest Dissertations Publishing; State University of New York at Buffalo: Buffalo, NY, USA, 2018. [Google Scholar]
- Byungkwan, J. Exploratory study on the based on big data for fire prevention of multiple shops. J. Ind. Converg. 2018, 16, 27–32. [Google Scholar]
- Eckstein, D.; Künzel, V.; Schäfer, L.; Winges, M. Global Climate Risk Index, Germanwatch, Briefing Paper. 2020. Available online: https://www.germanwatch.org/sites/germanwatch.org/files/20-2-01e%20Global%20Climate%20Risk%20Index%202020_16.pdf (accessed on 17 December 2020).
- Botzen, W.J.W.; van den Bergh, J.C.J.M. Insurance against Climate Change and Flooding in the Netherlands: Present, Future, and Comparison with Other Countries. Risk Anal. 2008, 28, 413–426. [Google Scholar] [CrossRef]
- Keucheyan, R. Insuring Climate Change: New Risks and the Financialization of Nature. Dev. Chang. 2018, 49, 484–501. [Google Scholar] [CrossRef]
- Zvedzdov, I.; Rath, S. Towards Socially Responsible (Re)Insurance Underwriting Practices: Readily Available ‘Big Data’ Contributions to Optimize Catastrophe Risk Management. 2016. Available online: https://ssrn.com/abstract=2737508 (accessed on 17 December 2020).
- Iuliia, P.; Aleksan, S. Big Data and Smallholder Farmers: Big Data Applications in the Agri-Food Supply Chain in Developing Countries. Int. Food Agribus. Manag. Rev. 2016, 18, 173–190. [Google Scholar]
- Mills, E.; Jones, R.B. An insurance perspective on U.S. electric grid disruption costs. Geneva Pap. Risk Insur. Issues Pract. 2016, 41, 555–586. [Google Scholar] [CrossRef][Green Version]
- Biener, C.; Eling, M.; Wirfs, J.H. Insurability of Cyber Risk: An Empirical Analysis. Geneva Pap. Risk Insur. Issues Pract. 2015, 40, 131–158. [Google Scholar] [CrossRef]
- Eling, M.; Schnell, W. What do we know about cyber risk and cyber risk insurance? J. Risk Finance 2016, 17, 474–491. [Google Scholar] [CrossRef]
- Gai, K.; Qiu, M.; Elnagdy, S.A. Security-Aware Information Classifications Using Supervised Learning for Cloud-Based Cyber Risk Management in Financial Big Data. In Proceedings of the IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS), New York, NY, USA, 9–10 April 2016. [Google Scholar] [CrossRef]
- Shaw, R. The 10 Best Machine Learning Algorithms for Data Science Beginners. 2019. Available online: https://www.dataquest.io/blog/top-10-machine-learning-algorithms-for-beginners/ (accessed on 25 November 2020).
- Shukla, P.; Iriondo, R.; Chen, S. Machine Learning Algorithms for Beginners with Code Examples in Python, towards AI. 2020. Available online: https://medium.com/towards-artificial-intelligence/machine-learning-algorithms-for-beginners-with-python-code-examples-ml-19c6afd60daa (accessed on 26 November 2020).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Technology | Category | Application | Efficiency |
|---|---|---|---|---|
| Markov Chain | IoT, Blockchain, Virtual reality, Quantum computing, Data mining | Catastrophe risk, Climate risk | Map the spatio-temporal patterns of tornadoes | Low |
| Monte Carlo | ||||
| Random Forest | ||||
| Clustering | Predict hurricane trajectories, solar flare forecasting, flood simulation | |||
| Support Vector | ||||
| Machines (SVMs) | ||||
| Digital elevation | ||||
| Models | Blockchain | |||
| K-nearest neighbor | Cloud computing, Data mining | Mortality Modelling | Simulate rates of human mortality based upon collected data and co-morbidity factors | High |
| SVM, Multivariate | ||||
| adaptive regression | ||||
| splines, Random | ||||
| Forest, Neural | ||||
| Network | Cybersecurity, Blockchain, Cloud computing, IoT, | |||
| Regression trees | Healthcare | Image processing, diagnosis, biomedical modeling, tumor recognition | High | |
| Lasso, Logistic | ||||
| regression, SVM, | ||||
| Random Forest | ||||
| Artificial and Deep | Blockchain, Cloud computing | Harvest risk | Smart farming, crop growth modeling, agro-meteorological statistical assessment, plant population, soil preparation, pest control | Medium-High |
| Neural Networks | ||||
| Support Vector | ||||
| Machines | ||||
| Quantum computing, Cybersecurity, Cloud computing | Cyber risk | Malware detection, modeling, monitoring, analysis, defense against threats to sensitive data and security systems | ||
| Random Forest | Medium | |||
| Gradient Boosting | ||||
| SVM, Logistic | ||||
| Regression | ||||
| K-Means | ||||
| Neural Networks | IoT, Blockchain, Data mining | Automobile | Achieve more enticing insurance packages, advertising tactics, fraud detection | High |
| Random Forest | ||||
| Light-GBM | ||||
| Latent Dirichlet | ||||
| Allocation-based | ||||
| text analytics | ||||
| Adaptive Synthetic | ||||
| Sampling, SVM | ||||
| Decision Tree, Multi- | ||||
| Layered Perceptron | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassani, H.; Unger, S.; Beneki, C. Big Data and Actuarial Science. Big Data Cogn. Comput. 2020, 4, 40. https://doi.org/10.3390/bdcc4040040
Hassani H, Unger S, Beneki C. Big Data and Actuarial Science. Big Data and Cognitive Computing. 2020; 4(4):40. https://doi.org/10.3390/bdcc4040040
Chicago/Turabian StyleHassani, Hossein, Stephan Unger, and Christina Beneki. 2020. "Big Data and Actuarial Science" Big Data and Cognitive Computing 4, no. 4: 40. https://doi.org/10.3390/bdcc4040040
APA StyleHassani, H., Unger, S., & Beneki, C. (2020). Big Data and Actuarial Science. Big Data and Cognitive Computing, 4(4), 40. https://doi.org/10.3390/bdcc4040040