OTNEL: A Distributed Online Deep Learning Semantic Annotation Methodology



Abstract
:1. Introduction and Motivation
2. Background and Related Work
2.1. Named Entity Disambiguation Approximations
- knowledge-based, also known as knowledge-rich, relying on lexical resources such as ontologies, machine-readable dictionaries, or thesauri;
- corpus-based, also known as knowledge-poor, which do not employ sense-labeled knowledge sources.
2.2. Early Approaches
2.3. Recent Deep Learning Approaches
2.4. Conclusions and Current Limitations
3. Materials and Methods
3.1. Notations and Terminology
- The Wikipedia articles are also referred to as Wikipedia entities, denoted as p.
- A text hyperlink to a Wikipedia page is denoted as a mention.
- Text hyperlink anchors within Wikipedia pointing to another page or article are referred to as anchors and denoted as a. Indices are used for referral to specific items in the anchor sequence as follows: a0 is the first anchor, i + 1 and so on. The number of anchors of a text input is cited as m.
- The notation pa refers to one of the candidate Wikipedia page senses of the anchor a.
- The set of linkable Wikipedia entities to an anchor a is denoted as Pg(a).
- The ensemble of inbound links to a given Wikipedia entity p is represented using in(p).
- The size of the Wikipedia entities ensemble is cited as |W|.
- link(a) refers to the cardinality of the count of an anchor’s indices as a mention.
- freq(a) denotes the total occurrence count of an anchor text within a corpus, including free text and hyperlinks.
- lp denotes the link probability of a text segment.
3.2. Knowledge Extraction
- Anchor ID: by keeping an identifier encoding for each text segment encountered as a hyperlink on the processed Wikipedia snapshot.
- Mention entity ID: the Wikipedia ID pointed to by a mention. Maintaining this information is necessary for deriving relatedness and commonness statistics.
- Source article ID: the Wikipedia article ID where an individual mention is encountered. This is necessary for relatedness calculations.
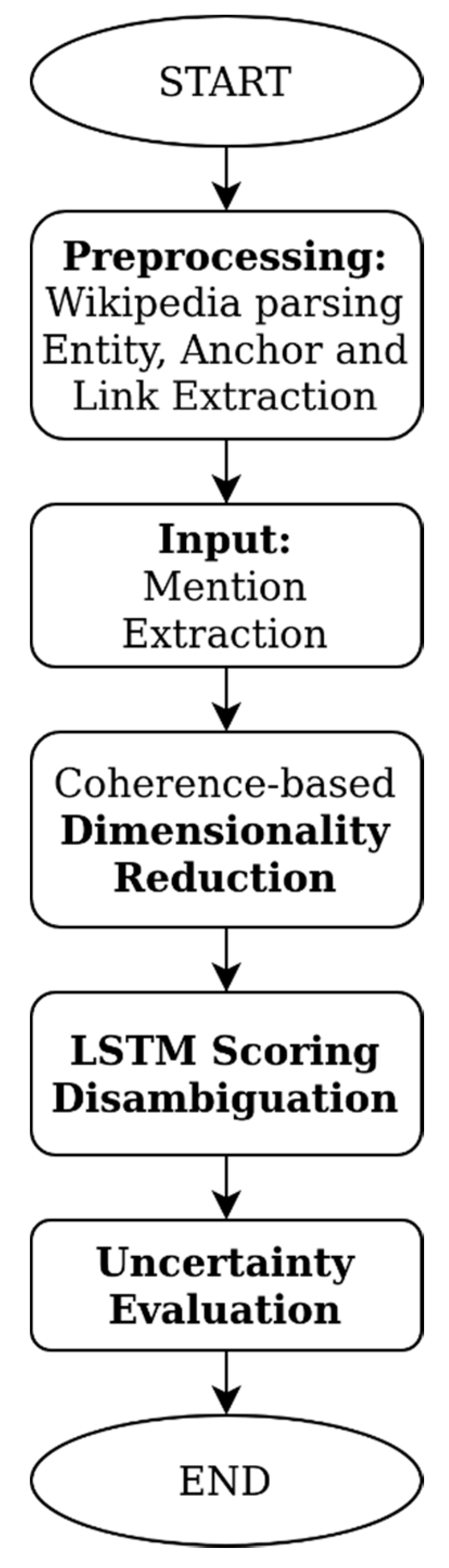
3.3. Methodology
3.3.1. Extraction, Transformation, and Loading
3.3.2. Coherence-Based Dimensionality Reduction
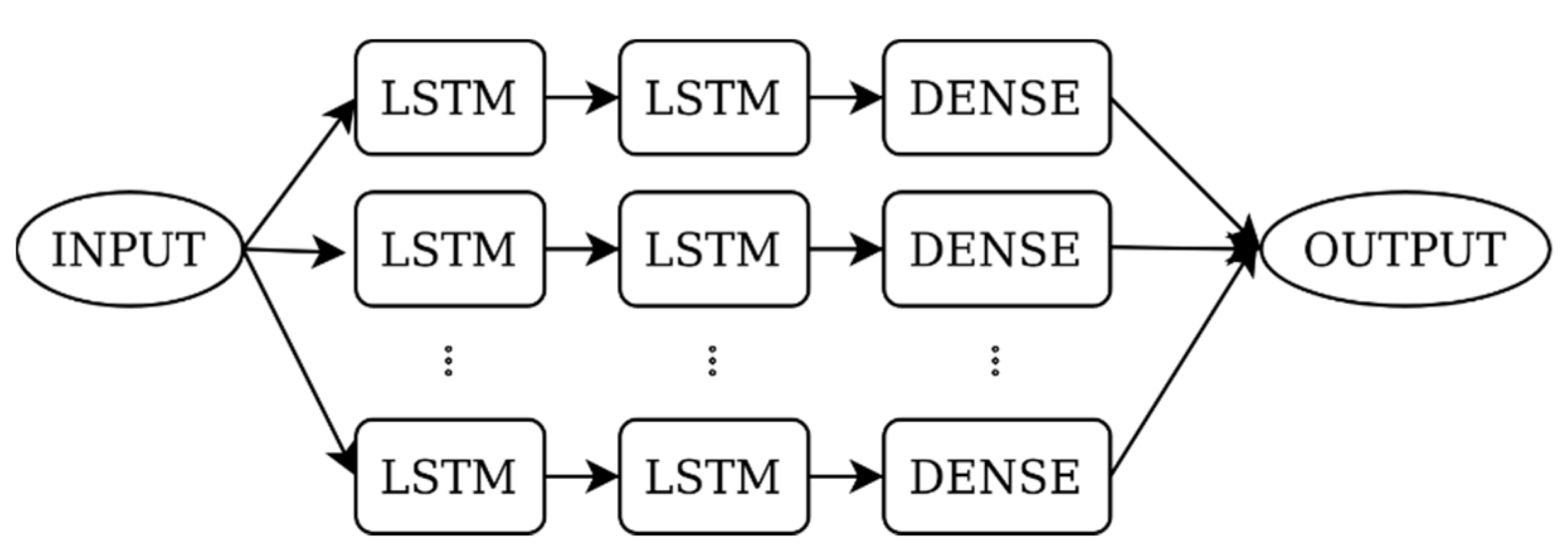
3.3.3. Named Entity Disambiguation
- class 1: the compatibility of the mention in the given context;
- class 0: the incompatibility of that mention in the given context.
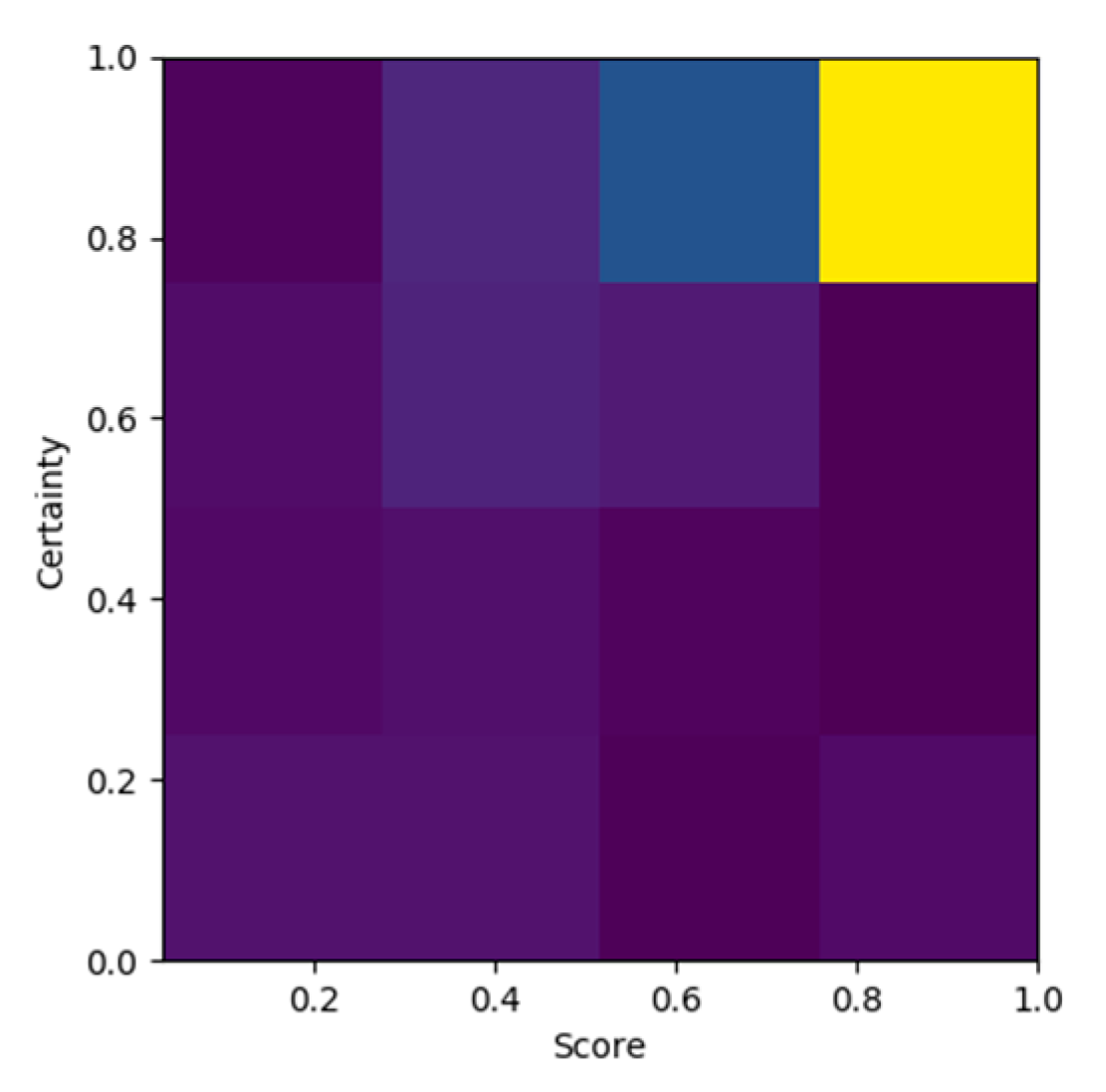
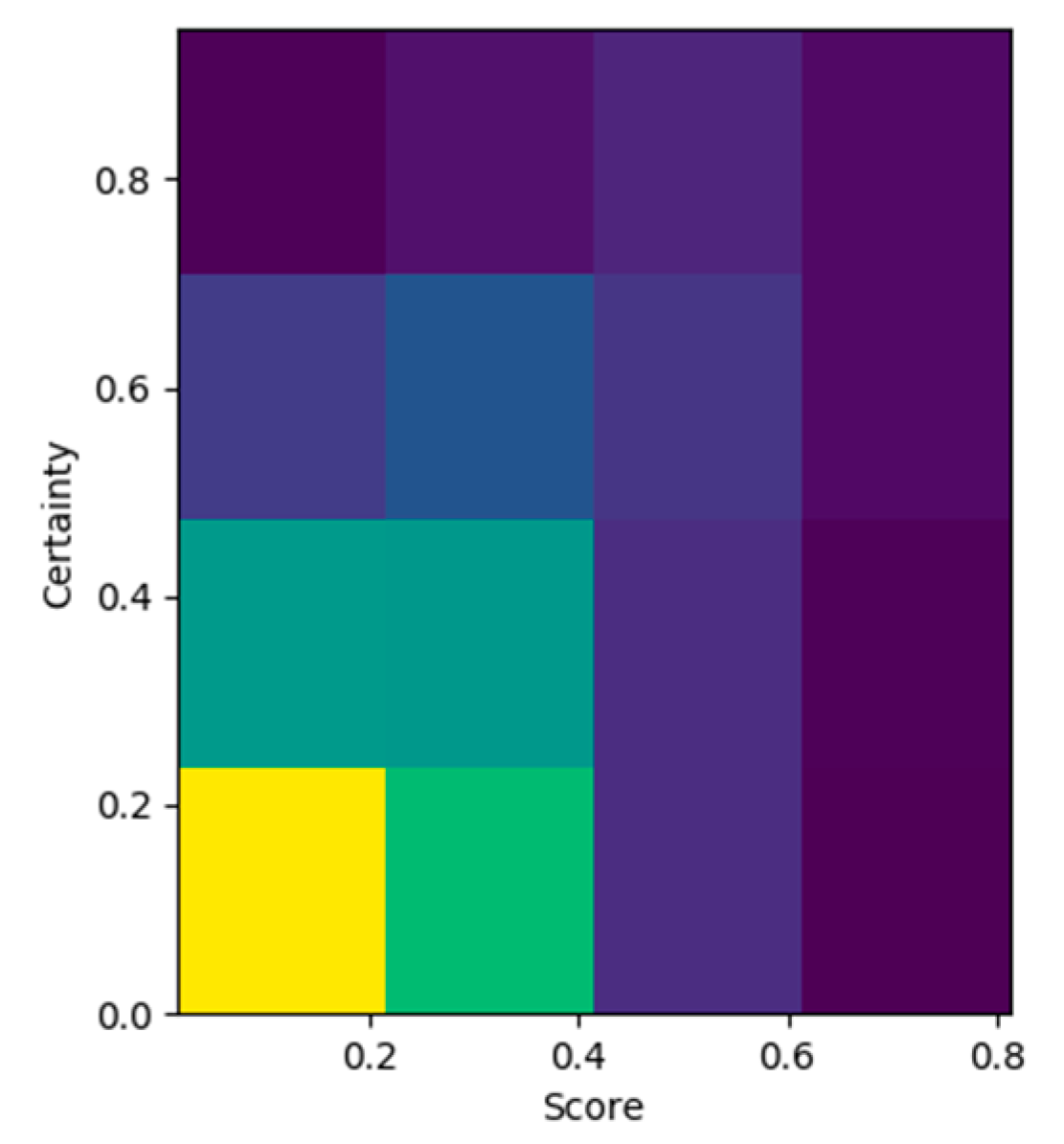
3.3.4. Quantification of Uncertainty
3.4. Evaluation Process
4. Results
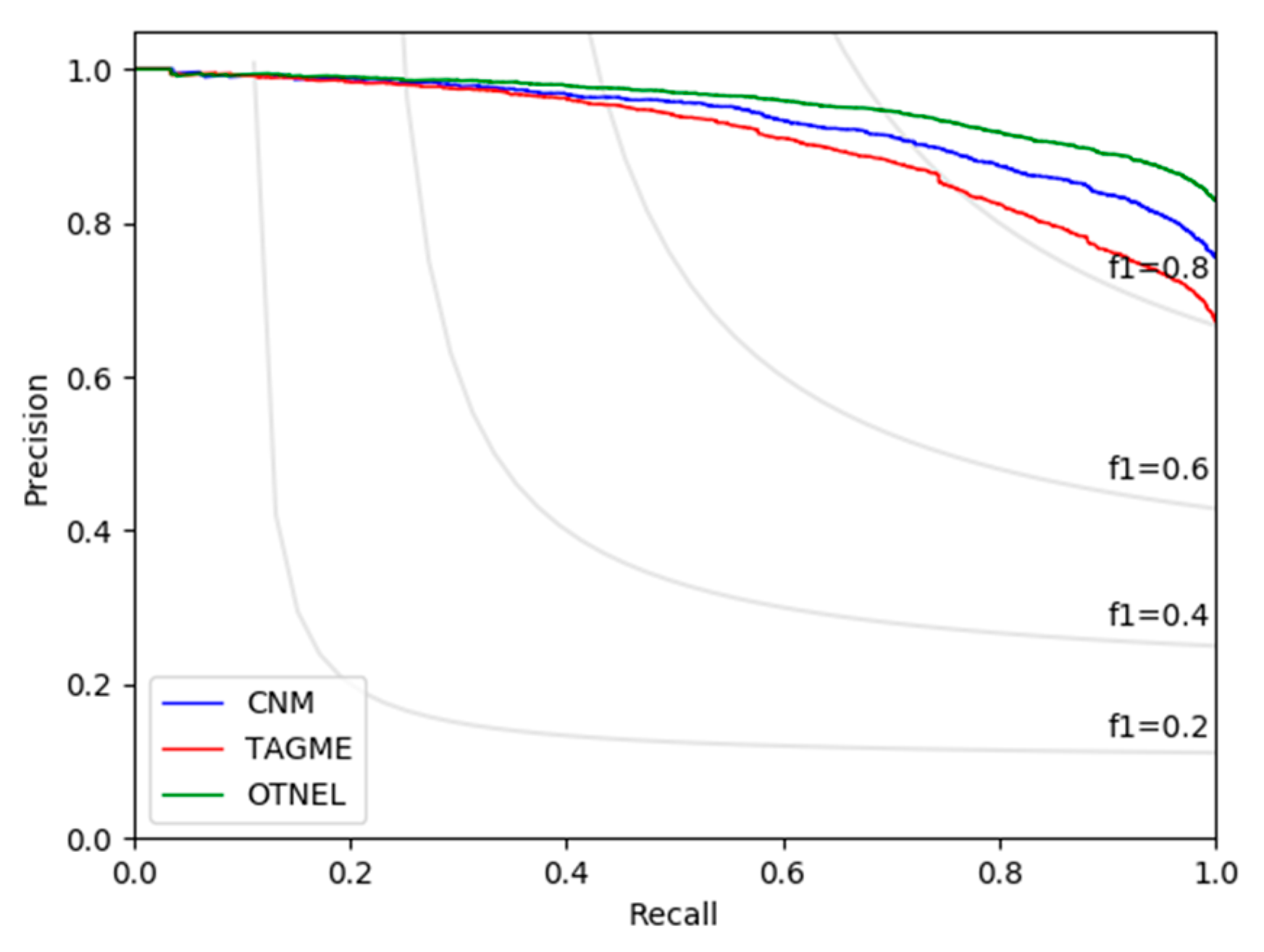
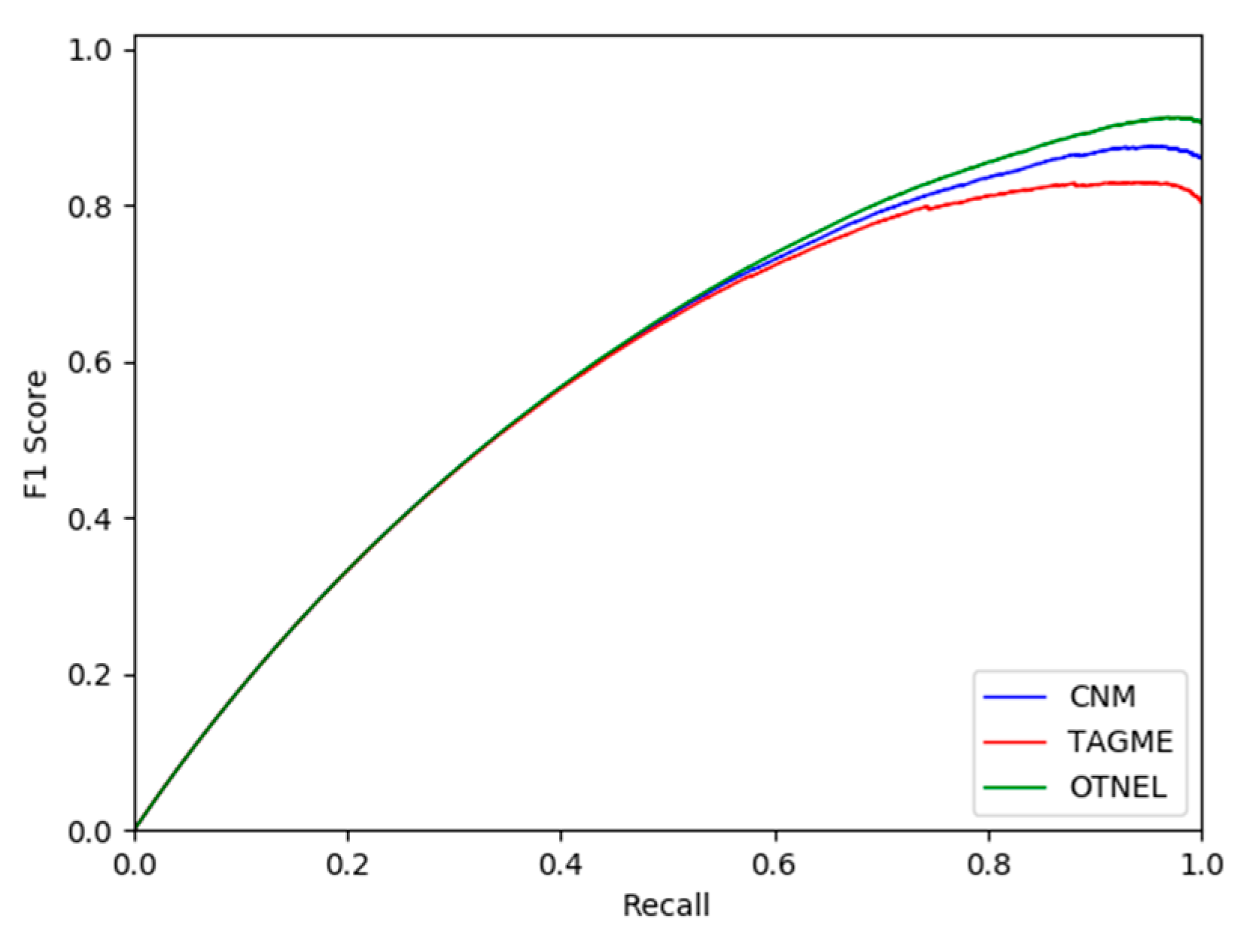
4.1. Experimental Analysis Discussion
4.2. Quantification of Certainty Evaluation
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Khalid, M.A.; Jijkoun, V.; de Rijke, M. The impact of named entity normalization on information retrieval for question answering. In Advances in Information Retrieval; Macdonald, C., Ounis, I., Eds.; Springer: Berlin, Germany, 2008; Volume 4956, pp. 705–710. [Google Scholar]
- Chang, A.X.; Valentin, I.S.; Christopher, D.M.; Eneko, A. A comparison of Named-Entity Disambiguation and Word Sense Disambiguation. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portoroz, Slovenia, 23–28 May 2016; pp. 860–867. [Google Scholar]
- Dorssers, F.; de Vries, A.P.; Alink, W. Ranking Triples using Entity Links in a Large Web Crawl—The Chicory Triple Scorer at WSDM Cup 2017. Available online: https://arxiv.org/abs/1712.08355 (accessed on 28 August 2020).
- Artiles, J.; Amigó, E.; Gonzalo, J. The role of named entities in web people search. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; Volume 2, pp. 534–542. [Google Scholar]
- Blanco, R.; Ottaviano, G.; Meij, E. Fast and Space-Efficient Entity Linking for Queries. In Proceedings of the Eighth ACM International Conference on Web Search and Data Mining (WSDM’15), Shanghai, China, 31 January–6 February 2015; pp. 179–188. [Google Scholar]
- Dietz, L.; Kotov, A.; Meij, E. Utilizing Knowledge Graphs in Text-centric Information Retrieval. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining (WSDM’17), Cambridge, UK, 6–10 February 2017; pp. 815–816. [Google Scholar]
- Chair-Carterette, B.G.; Chair-Diaz, F.G.; Chair-Castillo, C.P.; Chair-Metzler, D.P. Entity linking and retrieval for semantic search. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining (WSDM’14), New York, NY, USA, 24–28 February 2014; pp. 683–684. [Google Scholar]
- Navigli, R. Word sense disambiguation. ACM Comput. Surv. 2009, 41, 1–69. [Google Scholar] [CrossRef]
- Gale, W.A.; Church, K.W.; Yarowsky, D. A method for disambiguating word senses in a large corpus. Lang. Resour. Eval. 1992, 26, 415–439. [Google Scholar] [CrossRef] [Green Version]
- Mihalcea, R.; Csomai, A. Wikify! Linking Documents to Encyclopedic Knowledge. In Proceedings of the Sixteenth ACM Conference on Conference on Information and Knowledge Management, Lisbon, Portugal, 6–10 November 2007; pp. 233–242. [Google Scholar]
- Silviu, C. Large-Scale Named Entity Disambiguation Based on Wikipedia Data. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Prague, Czech Republic, 28–30 June 2007; pp. 708–716. [Google Scholar]
- Milne, D.N.; Witten, I.H. Learning to link with wikipedia. In Proceedings of the 17th ACM Conference on Information and Knowledge Management (CIKM’08), Hong Kong, China, 2–6 November 2008; pp. 509–518. [Google Scholar]
- Milne, D.; Witten, I.H. An Effective, Low-Cost Measure of Semantic Relatedness obtained from Wikipedia Links. In Proceedings of the AAAI Workshop on Wikipedia and Artificial Intelligence (WIKIAI), Chicago, IL, USA, 13 July 2008; pp. 25–30. [Google Scholar]
- Sayali, K.; Amit, S.; Ganesh, R.; Soumen, C. Collective annotation of Wikipedia entities in web text. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’09), Paris, France, 28 June–1 July 2009; pp. 457–466. [Google Scholar]
- Paolo, F.; Ugo, S. TAGME: On-the-fly annotation of short text fragments (by wikipedia entities). In Proceedings of the 19th ACM International Conference on Information and Knowledge Management (CIKM’10), Toronto, Canada, 26–30 October 2010; pp. 1625–1628. [Google Scholar]
- Johannes, H.; Mohamed, A.Y.; Ilaria, B.; Hagen, F.; Manfred, P.; Marc, S.; Bilyana, T.; Stefan, T.; Gerhard, W. Robust Disambiguation of Named Entities in Text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP 2011), Edinburgh, UK, 27–31 July 2011; pp. 782–792. [Google Scholar]
- Han, X.; Sun, L.; Zhao, J. Collective entity linking in web text: A graph-based method. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR’11), Beijing, China, 25–29 July 2011; pp. 765–774. [Google Scholar]
- Makris, C.; Simos, M.A. Novel Techniques for Text Annotation with Wikipedia Entities. In Proceedings of the Artificial Intelligence Applications and Innovations Evaluation—AIAI 2014, Rhodes, Greece, 19–21 September 2014. [Google Scholar]
- Ricardo, U.; Axel-Cyrille, N.N.; Michael, R.; Daniel, G.; Sandro, A.C.; Sören, A.; Andreas, B. AGDISTIS—Agnostic Disambiguation of Named Entities Using Linked Open Data. In Proceedings of the Twenty-first European Conference on Artificial Intelligence, Prague, Czech Republic, 18–24 August 2014; pp. 1113–1114. [Google Scholar]
- Piccinno, F.; Ferragina, P. From TagME to WAT: A new entity annotator. In Proceedings of the First International Workshop on Entity Recognition & Disambiguation (ERD’14), Gold Coast, Queensland, Australia, 11 July 2014; pp. 55–62. [Google Scholar]
- Sun, Y.; Lin, L.; Tang, D.; Yang, N.; Ji, Z.; Wang, X. Modeling mention, context and entity with neural networks for entity disambiguation. In Proceedings of the 24th International Conference on Artificial Intelligence (IJCAI’15), Buenos Aires, Argentina, 25–31 July 2015; pp. 1333–1339. [Google Scholar]
- Ikuya, Y.; Hiroyuki, S.; Hideaki, T.; Yoshiyasu, T. Joint Learning of the Embedding of Words and Entities for Named Entity Disambiguation. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 250–259. [Google Scholar]
- Ganea, O.-E.; Hofmann, T. Deep joint entity disambiguation with local neural attention. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017. [Google Scholar]
- Ivan, T.; Phong, L. Improving Entity Linking by Modeling Latent Relations between Mentions. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1, pp. 1595–1604. [Google Scholar]
- Priya, R.; Partha, T.; Vasudeva, V. ELDEN: Improved entity linking using densified knowledge graphs. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 1844–1853. [Google Scholar]
- Fang, Z.; Cao, Y.; Li, Q.; Zhang, D.; Zhang, Z.; Liu, Y. Joint Entity Linking with Deep Reinforcement Learning. In Proceedings of the World Wide Web Conference (WWW’19), San Francisco, CA, USA, 13–17 May 2019; pp. 438–447. [Google Scholar]
- Avirup, S.; Gourab, K.; Radu, F.; Wael, H. Neural Cross-Lingual Entity Linking. Proceedings of The Thirty-Second AAAI Conference on Artificial Intelligence (AAAI-18), New Orleans, LA, USA, 2–7 February 2018; pp. 5464–5472. [Google Scholar]
- Ilya, S.; Liat, E.-D.; Yosi, M.; Alon, H.; Benjamin, S.; Artem, S.; Yoav, K.; Dafna, S.; Ranit, A.; Noam, S. Fast End-to-End Wikification. Available online: https://arxiv.org/abs/1908.06785 (accessed on 28 August 2020).
- Wikimedia Update Feed Service. Available online: https://meta.wikimedia.org/wiki/Wikimedia_update_feed_service (accessed on 28 August 2020).
- Keras: The Python Deep Learning API. Available online: https://keras.io (accessed on 28 August 2020).
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation (OSDI’16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Farzad, A.; Mashayekhi, H.; Hassanpour, H. A comparative performance analysis of different activation functions in LSTM networks for classification. Neural Comput. Appl. 2017, 31, 2507–2521. [Google Scholar] [CrossRef]
- Christos, M.; Georgios, P.; Michael, A.S. Text Semantic Annotation: A Distributed Methodology Based on Community Coherence. Algorithms 2020, 13, 160. [Google Scholar] [CrossRef]
- Index of /Enwiki/. Available online: https://dumps.wikimedia.org/enwiki (accessed on 28 August 2020).
- Specs/wikitext/1.0.0 MediaWiki. Available online: https://www.mediawiki.org/wiki/Specs/wikitext/1.0.0 (accessed on 28 August 2020).
- Matei, Z.; Mosharaf, C.; Michael, J.F.; Scott, S.; Ion, S. Spark: Cluster computing with working sets. In Proceedings of the 2nd USENIX Conference on Hot Topics in Cloud Computing (HotCloud’10), Boston, MA, USA, 22 June 2010. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Recall | 1.0 | 0.9 | 0.8 | 0.6 | 0.4 | 0.2 |
|---|---|---|---|---|---|---|
| CNM 1 (Precision) | 0.7554 | 0.8362 | 0.8738 | 0.9337 | 0.9678 | 0.9866 |
| CNM 1 (F1) | 0.8606 | 0.8667 | 0.8351 | 0.7287 | 0.5659 | 0.3325 |
| TAGME (Precision) | 0.6720 | 0.7640 | 0.8242 | 0.9101 | 0.9619 | 0.9832 |
| TAGME (F1) | 0.8038 | 0.8264 | 0.8118 | 0.7222 | 0.5650 | 0.3323 |
| OTNEL 2 (Precision) | 0.8290 | 0.8897 | 0.9180 | 0.9589 | 0.9789 | 0.9896 |
| OTNEL 2 (F1) | 0.9065 | 0.8948 | 0.8548 | 0.7381 | 0.5678 | 0.3327 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Makris, C.; Simos, M.A. OTNEL: A Distributed Online Deep Learning Semantic Annotation Methodology. Big Data Cogn. Comput. 2020, 4, 31. https://doi.org/10.3390/bdcc4040031
Makris C, Simos MA. OTNEL: A Distributed Online Deep Learning Semantic Annotation Methodology. Big Data and Cognitive Computing. 2020; 4(4):31. https://doi.org/10.3390/bdcc4040031
Chicago/Turabian StyleMakris, Christos, and Michael Angelos Simos. 2020. "OTNEL: A Distributed Online Deep Learning Semantic Annotation Methodology" Big Data and Cognitive Computing 4, no. 4: 31. https://doi.org/10.3390/bdcc4040031
APA StyleMakris, C., & Simos, M. A. (2020). OTNEL: A Distributed Online Deep Learning Semantic Annotation Methodology. Big Data and Cognitive Computing, 4(4), 31. https://doi.org/10.3390/bdcc4040031