Keyword Search over RDF: Is a Single Perspective Enough?



Abstract
1. Introduction
2. Related Work
2.1. Background: RDF
2.2. Keyword Search over RDF Datasets
2.3. Visualization of RDF Search Results
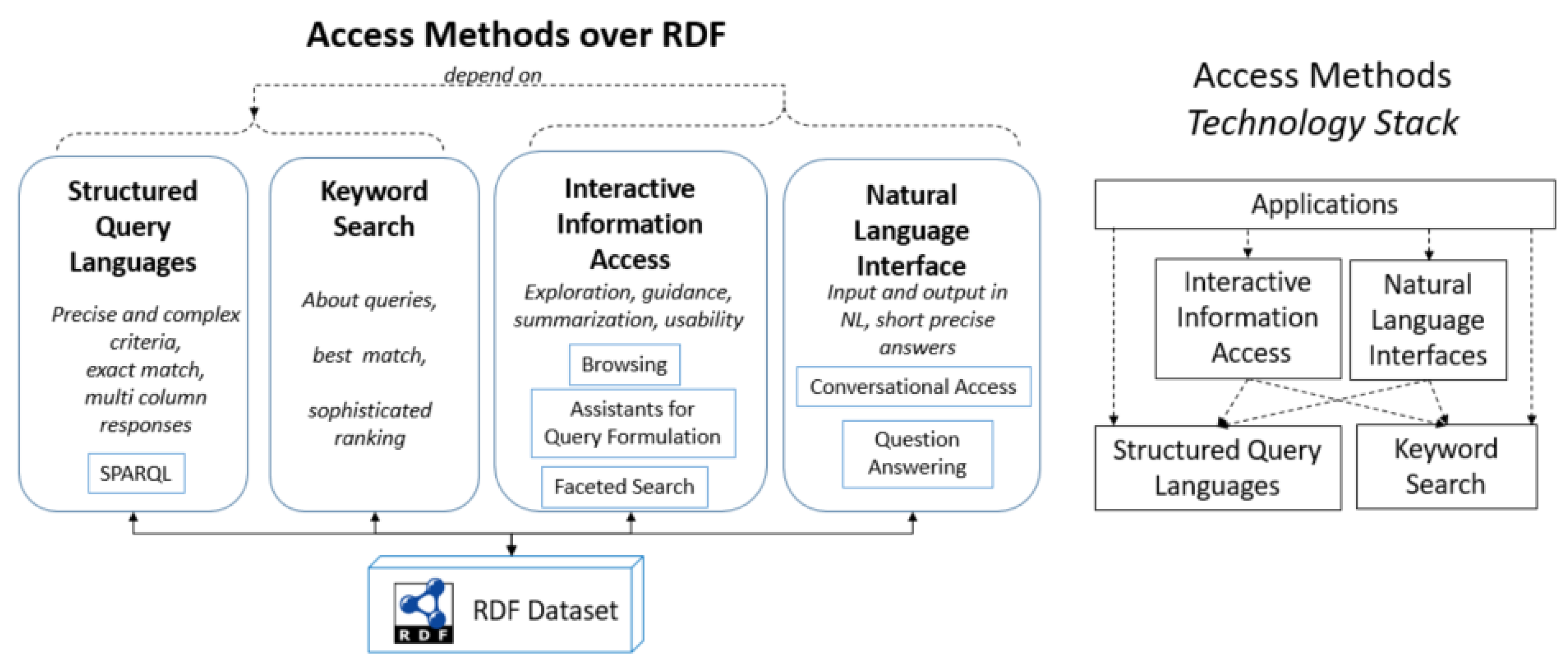
3. Multi-Perspective Presentation of Search Results: Rationale and Architecture
3.1. Rationale
- No Clear Unit of Retrieval and Presentation. In RDF data, there is not the notion of document or web page as is the case in web searching. Therefore, the retrieval, presentation and visualization of RDF data is challenging due to the complex, interlinked, and multi-dimensional nature of this data type [25].
- No Clear Information Need. The user query is just an attempt to formulate his/her information need. Some user needs require a single fact, others a list of entities or a set of facts, other how a set of entities are connected, other have an exploratory nature, and so on.
- Incomplete Data. The underlying dataset is in most cases incomplete [34] (also demonstrated by the number of papers that aim at completing the missing data [35]), therefore the retrieved triples cannot be considered neither complete, nor appropriately ranked. However, the provision of more than one method, each consuming different proportions of the list of top hits (and of their context), increases the probability that one method achieves to return something that is useful for the user’s information need.
- There is not a single presentation method appropriate for all kinds of information needs. An established method on how to present RDF results for arbitrary query types does not exist yet, and it seems that a single approach cannot suit all possible requirements. Different kinds of information needs need different ways to present the results.
3.2. Architecture
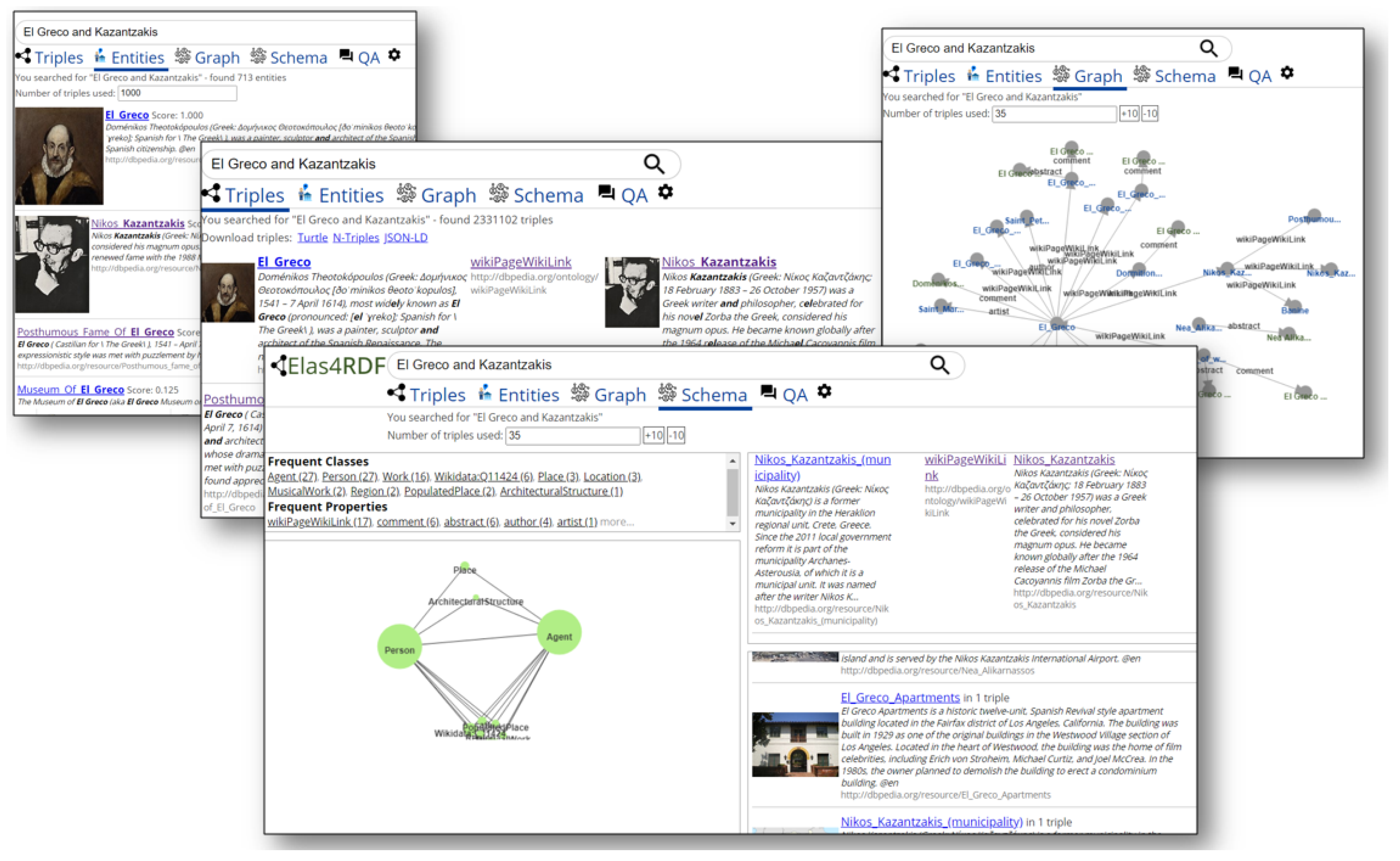
4. The Fundamental Perspectives of Keywords Search Results
4.1. Triples Tab
4.2. Entities Tab
4.3. Graph Tab
4.4. Schema Tab
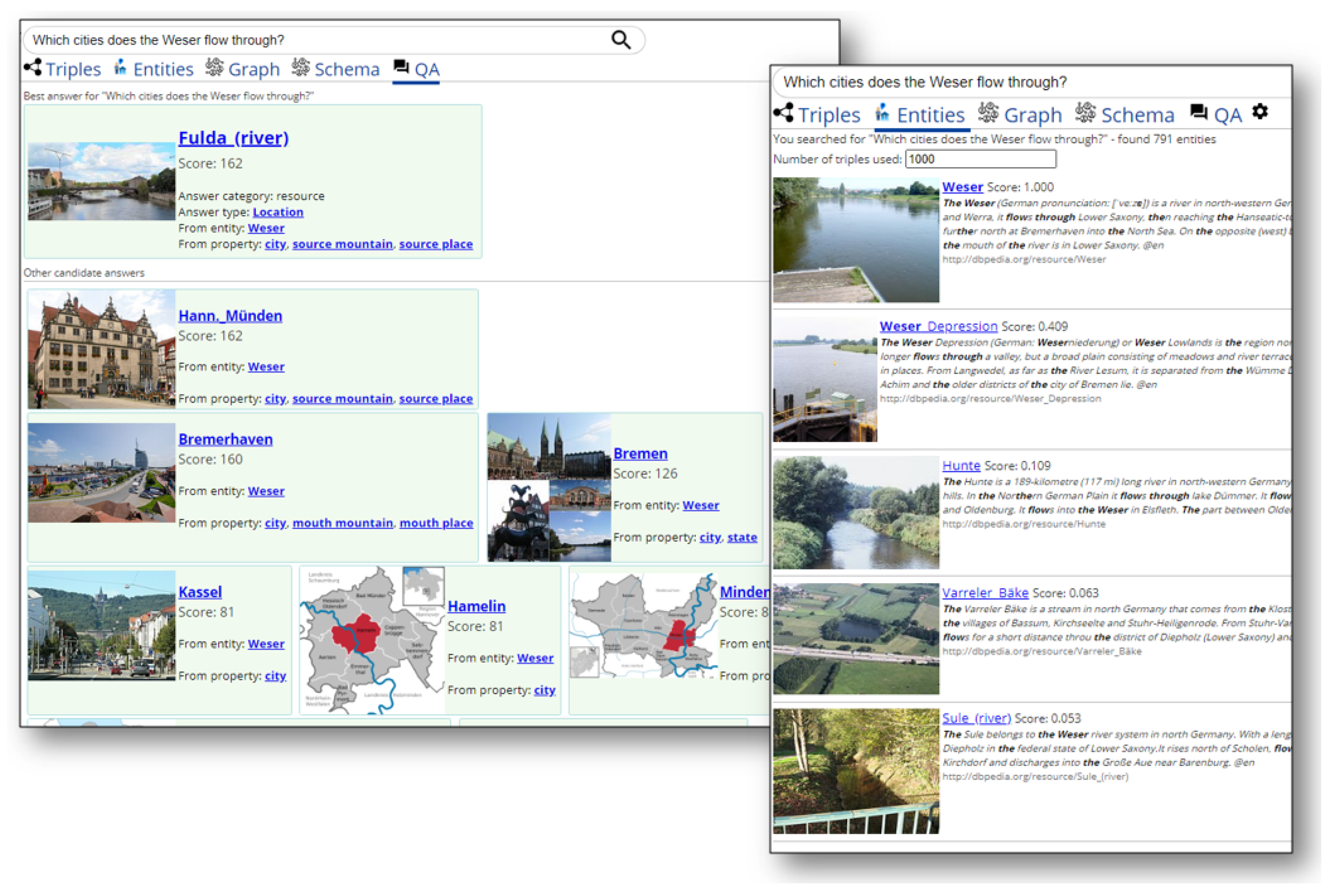
4.5. Question Answering (QA) Tab
4.6. Tabs’ Roles and Extra Tabs
5. Evaluation
5.1. Comparing the Functionality with Related Systems
5.2. Efficiency
5.3. Evaluation of Effectiveness
5.4. Evaluation with Users
5.4.1. Information-Seeking Tasks
5.4.2. Participants, Questionnaire and Results
- E1
- How would you rate the Triples tab?: Very Useful (40%), Useful (44%), Little Useful (16%), Not Useful (0%)
- E2
- How would you rate the Entities tab?: Very Useful (44%), Useful (28%), Little Useful (24%), Not Useful (4%)
- E3
- How would you rate the Graph tab?: Very Useful (32%), Useful (52%), Little Useful (12%), Not Useful (4%)
- E4
- How would you rate the Schema tab?: Very Useful (16%), Useful (40%), Little Useful (36%), Not Useful (8%)
- E5
- How would you rate the QA tab?: Very Useful (16%), Useful (36%), Little Useful (40%), Not Useful (8%)
- E6
- Did you find it useful that the system offers multiple perspective of the search results?: Very much (48%), Fair (48%), Not that Useful (4%), Not Useful (0%)
- E7
- Mark the perspective(s) that you think are redundant: Triples Tab (0%), Entities Tab (8%), Graph Tab (8%), Schema Tab (40%) QA Tab (16%) All tabs are useful, none is redundant (44%)
- E8
- Have you used DBpedia before: Never (40%), Only a few times (without using SPARQL) (16%), Quite a lot (I have used SPARQL to query it) (44%).
- E9
- How would you rate the entire system? Very Useful (32%), Useful (60%), Little Useful (8%), Not Useful (0%)
- E10
- You can report here errors, problems, or recommendations. (free text of unlimited length)
5.4.3. Results Analysis and Discussion
〈 {GraphTab (84%), TriplesTab (84%)}, EntitiesTab (72%), SchemaTab (56%), QATab(52%) 〉.
〈 QATab (48%), SchemaTab (44%), EntitiesTab (28%), {GraphTab (16%), TriplesTab (16%)} 〉.
〈 TriplesTab (65%), GraphTab (65%), EntitiesTab (52%), SchemaTab (37%), QATab (33%) 〉
where a perspective with score X means that it will have an average rating greater than X, with 95% confidence.〈 TriplesTab (2.84), GraphTab (2.73), EntitiesTab (2.69), SchemaTab (2.30), QATab (2.27) 〉
5.4.4. Log Analysis
5.4.5. Discussion: Related Systems
6. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| TF-IDF | Term Frequency - Inverse Document Frequency |
| KB | Knowledge Base |
| OLAP | Online Analytical Processing |
| QA | Question Answering |
| RDF | Resource Description Framework |
| REST | Representational State Transfer |
| SPARQL | SPARQL Protocol and RDF Query Language |
References
- Mountantonakis, M.; Tzitzikas, Y. Large-scale Semantic Integration of Linked Data: A Survey. ACM Comput. Surv. (CSUR) 2019, 52, 103. [Google Scholar] [CrossRef]
- Wishart, D.S.; Feunang, Y.D.; Guo, A.C.; Lo, E.J.; Marcu, A.; Grant, J.R.; Sajed, T.; Johnson, D.; Li, C.; Sayeeda, Z.; et al. DrugBank 5.0: A major update to the DrugBank database for 2018. Nucleic Acids Res. 2018, 46, D1074–D1082. [Google Scholar] [CrossRef] [PubMed]
- Jaradeh, M.Y.; Oelen, A.; Farfar, K.E.; Prinz, M.; D’Souza, J.; Kismihók, G.; Stocker, M.; Auer, S. Open Research Knowledge Graph: Next Generation Infrastructure for Semantic Scholarly Knowledge. In Proceedings of the 10th International Conference on Knowledge Capture, Marina del Rey, CA, USA, 19–22 November 2019; pp. 243–246. [Google Scholar]
- Dimitrov, D.; Baran, E.; Fafalios, P.; Yu, R.; Zhu, X.; Zloch, M.; Dietze, S. TweetsCOV19–A Knowledge Base of Semantically Annotated Tweets about the COVID-19 Pandemic. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management (CIKM 2020), Virtual Event, Ireland, 19–23 October 2020. [Google Scholar]
- Tzitzikas, Y.; Manolis, N.; Papadakos, P. Faceted exploration of RDF/S datasets: A survey. J. Intell. Inform. Syst. 2017, 48, 329–364. [Google Scholar] [CrossRef]
- Papadaki, M.E.; Tzitzikas, Y.; Spyratos, N. Analytics over RDF Graphs. In Proceedings of the International Workshop on Information Search Integration, and Personalization, Heraklion, Greece, 9–10 May 2019; pp. 37–52. [Google Scholar]
- Kritsotakis, V.; Roussakis, Y.; Patkos, T.; Theodoridou, M. Assistive Query Building for Semantic Data. In Proceedings of the SEMANTICS Posters&Demos, Vienna, Austria, 10–13 September 2018. [Google Scholar]
- Kadilierakis, G.; Fafalios, P.; Papadakos, P.; Tzitzikas, Y. Keyword Search over RDF using Document-centric Information Retrieval Systems. In Proceedings of the Extended Semantic Web Conference (ESWC’2020), Heraklion, Crete, Greece, 31 May–4 June 2020. [Google Scholar]
- Hasibi, F.; Nikolaev, F.; Xiong, C.; Balog, K.; Bratsberg, S.E.; Kotov, A.; Callan, J. DBpedia-Entity V2: A Test Collection for Entity Search. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 1265–1268. [Google Scholar]
- Kadilierakis, G.; Nikas, C.; Fafalios, P.; Papadakos, P.; Tzitzikas, Y. Elas4RDF: Multi-perspective Triple-centered Keyword Search over RDF using Elasticsearch. In Proceedings of the Extended Semantic Web Conference (ESWC’2020), Heraklion, Crete, Greece, 31 May–4 June 2020. [Google Scholar]
- Elbassuoni, S.; Ramanath, M.; Schenkel, R.; Weikum, G. Searching RDF graphs with SPARQL and keywords. IEEE Data Eng. Bull. 2010, 33, 16–24. [Google Scholar]
- Lin, X.; Zhang, F.; Wang, D. RDF Keyword Search Using Multiple Indexes. Filomat 2018, 32, 1861–1873. [Google Scholar] [CrossRef]
- Cheng, G.; Qu, Y. Searching linked objects with falcons: Approach, implementation and evaluation. Int. J. Semant. Web Inform. Syst. (IJSWIS) 2009, 5, 49–70. [Google Scholar] [CrossRef]
- Delbru, R.; Rakhmawati, N.A.; Tummarello, G. Sindice at semsearch 2010. In Proceedings of the 19th International World Wide Web Conference, Aleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Liu, X.; Fang, H. A study of entity search in semantic search workshop. In Proceedings of the 3rd International Semantic Search Workshop, Raleigh, NC, USA, 26–30 April 2010. [Google Scholar]
- Delbru, R.; Campinas, S.; Tummarello, G. Searching web data: An entity retrieval and high-performance indexing model. J. Web Semant. 2012, 10, 33–58. [Google Scholar] [CrossRef]
- Ouksili, H.; Kedad, Z.; Lopes, S.; Nugier, S. Using Patterns for Keyword Search in RDF Graphs. In Proceedings of the EDBT/ICDT Workshops, Venice, Italy, 21–24 March 2017. [Google Scholar]
- Elbassuoni, S.; Blanco, R. Keyword search over RDF graphs. In Proceedings of the 20th ACM international Conference on Information and Knowledge Management ACM, Glasgow, UK, 19–23 October 2011; pp. 237–242. [Google Scholar]
- Blanco, R.; Mika, P.; Vigna, S. Effective and efficient entity search in RDF data. In Proceedings of the International Semantic Web Conference, Bonn, Germany, 23–27 October 2011; pp. 83–97. [Google Scholar]
- Pérez-Agüera, J.R.; Arroyo, J.; Greenberg, J.; Iglesias, J.P.; Fresno, V. Using BM25F for semantic search. In Proceedings of the 3rd International Semantic Search Workshop ACM, Raleigh, NC, USA, April 2010; p. 2. Available online: https://dl.acm.org/doi/10.1145/1863879.1863881 (accessed on 27 August 2020).
- Dosso, D.; Silvello, G. A Scalable Virtual Document-Based Keyword Search System for RDF Datasets. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 965–968. [Google Scholar]
- Ilievski, F.; Beek, W.; van Erp, M.; Rietveld, L.; Schlobach, S. LOTUS: Adaptive text search for big linked data. In Proceedings of the European Semantic Web Conference, Crete, Greece, 29 May–2 June 2016; pp. 470–485. [Google Scholar]
- Johnson, T. Indexing linked bibliographic data with JSON-LD, BibJSON and Elasticsearch. Code4lib J. 2013, 19, 1–11. [Google Scholar]
- Bikakis, N.; Sellis, T. Exploration and visualization in the web of big linked data: A survey of the state of the art. arXiv 2016, arXiv:1601.08059. [Google Scholar]
- Dadzie, A.S.; Pietriga, E. Visualisation of linked data–reprise. Semant. Web 2017, 8, 1–21. [Google Scholar] [CrossRef]
- Skjæveland, M.G. Sgvizler: A javascript wrapper for easy visualization of sparql result sets. In Proceedings of the Extended Semantic Web Conference, Crete, Greece, 27–31 May 2012; pp. 361–365. [Google Scholar]
- Leskinen, P.; Miyakita, G.; Koho, M.; Hyvönen, E. Combining Faceted Search with Data-analytic Visualizations on Top of a SPARQL Endpoint. In Proceedings of the CEUR Workshop, Bolzano, Italy, 20–22 September 2018; pp. 53–63. [Google Scholar]
- Vargas, H.; Buil-Aranda, C.; Hogan, A.; López, C. RDF Explorer: A Visual SPARQL Query Builder. In Proceedings of the International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; pp. 647–663. [Google Scholar]
- Ilievski, F.; Beek, W.; Van Erp, M.; Rietveld, L.; Schlobach, S. LOTUS: Linked Open Text UnleaShed. In Proceedings of the 6th International Workshop on Consuming Linked Data, Bethlehem, PN, USA, 12 October 2015; p. 6. [Google Scholar]
- Rihany, M.; Kedad, Z.; Lopes, S. Keyword Search Over RDF Graphs Using WordNet. In Proceedings of the 1st International Conference on Big Data and Cyber-Security Intelligence BDCSIntell 2018, Hadath, Lebanon, 13–15 December 2018; pp. 75–82. [Google Scholar]
- Dosso, D.; Silvello, G. Search Text to Retrieve Graphs: A Scalable RDF Keyword-Based Search System. IEEE Access 2020, 8, 14089–14111. [Google Scholar] [CrossRef]
- Stab, C.; Nazemi, K.; Breyer, M.; Burkhardt, D.; Kohlhammer, J. Semantics visualization for fostering search result comprehension. In Proceedings of the Extended Semantic Web Conference, Crete, Greece, 27–31 May 2012; pp. 633–646. [Google Scholar]
- Kontiza, K.; Bikakis, A. Web Search Results Visualization: Evaluation of Two Semantic Search Engines. In Proceedings of the International Conference on Web Intelligence, Mining and Semantics (WIMS’14), Thessaloniki, Greece, 2–4 June 2014; pp. 1–12. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. LODsyndesis: Global scale knowledge services. Heritage 2018, 1, 23. [Google Scholar] [CrossRef]
- Belth, C.; Zheng, X.; Vreeken, J.; Koutra, D. What is Normal, What is Strange, and What is Missing in a Knowledge Graph: Unified Characterization via Inductive Summarization. In Proceedings of the Web Conference, Ljubljana, Slovenia, 20–24 April 2020; pp. 1115–1126. [Google Scholar]
- Oldman, D.; Tanase, D. Reshaping the Knowledge Graph by connecting researchers, data and practices in ResearchSpace. In Proceedings of the International Semantic Web Conference, Monterey, CA, USA, 8–12 October 2018; pp. 325–340. [Google Scholar]
- Dimitrakis, E.; Sgontzos, K.; Tzitzikas, Y. A survey on question answering systems over linked data and documents. J. Intell. Inform. Syst. 2019, 55, 1–27. [Google Scholar] [CrossRef]
- Cui, W.; Xiao, Y.; Wang, H.; Song, Y.; Hwang, S.W.; Wang, W. KBQA: Learning Question Answering over QA Corpora and Knowledge Bases. Proc. VLDB Endow. 2017, 10, 565–576. [Google Scholar] [CrossRef]
- Lu, X.; Pramanik, S.; Saha Roy, R.; Abujabal, A.; Wang, Y.; Weikum, G. Answering Complex Questions by Joining Multi-Document Evidence with Quasi Knowledge Graphs. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 105–114. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. DBpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Berlin, Germany, 2007; pp. 722–735. [Google Scholar]
- Moreno-Vega, J.; Hogan, A. GraFa: Scalable faceted browsing for RDF graphs. In International Semantic Web Conference; Springer: Berlin, Germany, 2018; pp. 301–317. [Google Scholar]
- Heim, P.; Hellmann, S.; Lehmann, J.; Lohmann, S.; Stegemann, T. RelFinder: Revealing Relationships in RDF Knowledge Bases. In Semantic Multimedia; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5887, pp. 182–187. [Google Scholar]
- Ferré, S. Sparklis: An expressive query builder for SPARQL endpoints with guidance in natural language. Semant. Web 2017, 8, 405–418. [Google Scholar] [CrossRef]
- Faulkner, L. Beyond the five-user assumption: Benefits of increased sample sizes in usability testing. Behav. Res. Methods Instrum. Comput. 2003, 35, 379–383. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Triple Retrieval | Entity Search | Graph View | Faceted Search | QA | Relation Finder | SPARQL Support | SUM |
|---|---|---|---|---|---|---|---|---|
| LOTUS [22] (no online demo) | Yes | No | No | No | No | No | No | 1/7 |
| GraFa [41] | No | No | No | Yes | No | No | No | 1/7 |
| RelFinder [42] | No | Partial (through auto completion) | Partial (only of related entities) | No | No | Yes | No | 1/7 |
| DBpedia Search & Find | Yes (no images) | No | No | Partial (simple) | No | No | Partial (query display) | 2/7 |
| SPARKLIS [43] | No | No | No | Yes (Very Expressive) | No | No | Yes | 2/7 |
| Elas4RDF | Yes | Yes | Yes | No | Yes | No | No | 4/7 |
| Perspective | Triples | Entities | Graph | Schema | QA |
|---|---|---|---|---|---|
| Without caching | 980 ms | 2582 ms | 1018 ms | 924 ms | 2869 ms |
| With caching | 145 ms | 124 ms | 91 ms | 175 ms | 118 ms |
| ID | Task |
|---|---|
| T1 | Is there any person that is fisherman, writer and poet? Provide at least 3 related names (or URIs). |
| T2 | Is there any writer and astronaut from Russia? Provide related names or URIs. |
| T3 | Find information that relates Albert Einstein with Stephen Hawking. |
| T4 | Find if El Greco was influenced by Michelangelo. |
| T5 | Is there any reference of Freud to the ancient Greece? |
| T6 | How is Mars related to Crete? |
| T7 | Find mathematicians related to Pisa. |
| T8 | Find painters of the Ancient Greece. |
| T9 | Are there drugs that contain aloe? |
| T10 | Which cities does the Weser flow through? |
| T11 | Find at least 5 rivers of Greece. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nikas, C.; Kadilierakis, G.; Fafalios, P.; Tzitzikas, Y. Keyword Search over RDF: Is a Single Perspective Enough? Big Data Cogn. Comput. 2020, 4, 22. https://doi.org/10.3390/bdcc4030022
Nikas C, Kadilierakis G, Fafalios P, Tzitzikas Y. Keyword Search over RDF: Is a Single Perspective Enough? Big Data and Cognitive Computing. 2020; 4(3):22. https://doi.org/10.3390/bdcc4030022
Chicago/Turabian StyleNikas, Christos, Giorgos Kadilierakis, Pavlos Fafalios, and Yannis Tzitzikas. 2020. "Keyword Search over RDF: Is a Single Perspective Enough?" Big Data and Cognitive Computing 4, no. 3: 22. https://doi.org/10.3390/bdcc4030022
APA StyleNikas, C., Kadilierakis, G., Fafalios, P., & Tzitzikas, Y. (2020). Keyword Search over RDF: Is a Single Perspective Enough? Big Data and Cognitive Computing, 4(3), 22. https://doi.org/10.3390/bdcc4030022