Developing a Robust Defensive System against Adversarial Examples Using Generative Adversarial Networks



Abstract
1. Introduction
- Developing a novel (attacking) method for adversarial example generation, which learns the initial data distribution of common adversarial examples and shifts it to fool a pre-trained deep learning model.
- Creating new adversarial examples that can pass undetected to models trained on the initial common adversarial examples.
- Attaching a pre-trained CNN to a Pix2Pix GAN and learning the generation with the goal to fool the attached network, a technical feat which has not been done before.
- Implementing a novel iterative pipeline in order to strengthen the model, attack, and defense in an iterative manner. After each iteration the attacker generates stronger adversarial examples, while the robustness of the model increases through retraining and updating associated weights.
- Conducting extensive experiments to evaluate the performance of the proposed method, with demonstrating an application for visualization-based botnet detection systems.
2. Background and Preliminaries
2.1. Network Traffic Data Visualization
2.2. Adversarial Attacks in Deep Learning
- The adversaries can only attack at the test stage after the training has been done. Therefore, training data poisoning will not be examined.
- In this work, deep convolutional neural networks will be examined as the model under attack. While traditional machine learning models, such as like Support Vector Machines (SVM) [23] or Random Forest (RF) [24] can also deliver high accuracy, it has been shown that adversarial examples found in deep neural networks work effectively against these traditional models [25,26].
- Adversaries aim to compromise integrity, which can be defined using one of the performance metrics such as accuracy or F1-score.
- The goal of the attacker is adversarial falsification. If an adversary is trying to fool the model to misclassify as input as positive or negative, the attacks differ. In the case of botnet detection, the adversary can try to make a botnet be classified as non-malicious and launch a successful attack or make the normal data be classified as malicious and cause disastrous consequences.
- In this study, we assume that the attacker is launching attacks frequently and in an iterative manner.
- The adversary has full knowledge about model structure and its internals, that is, white-box attacks.
2.3. Generative Adversarial Networks
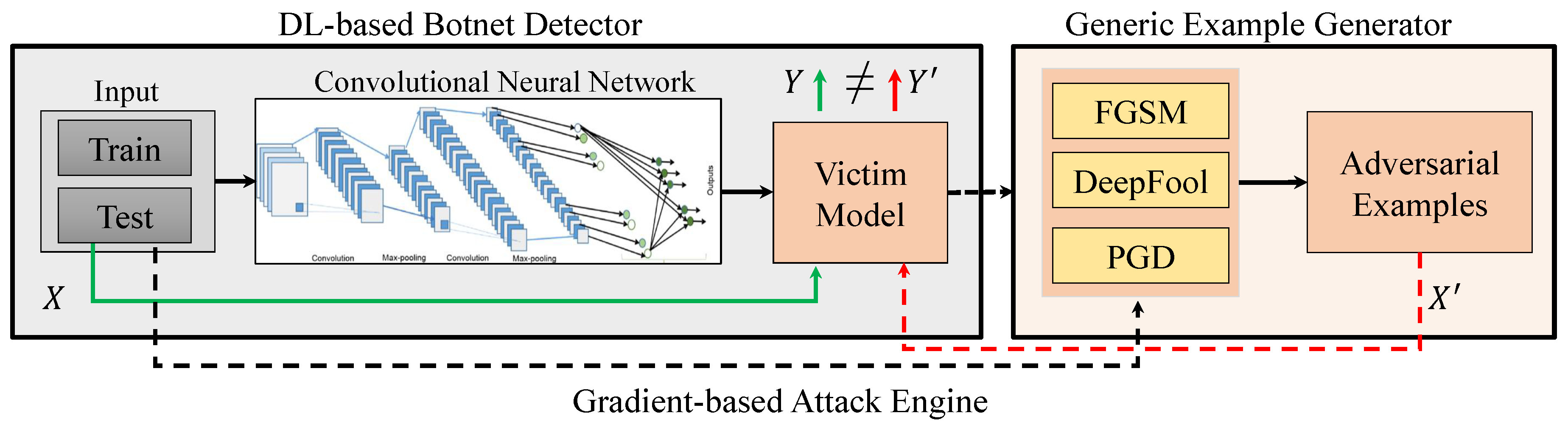
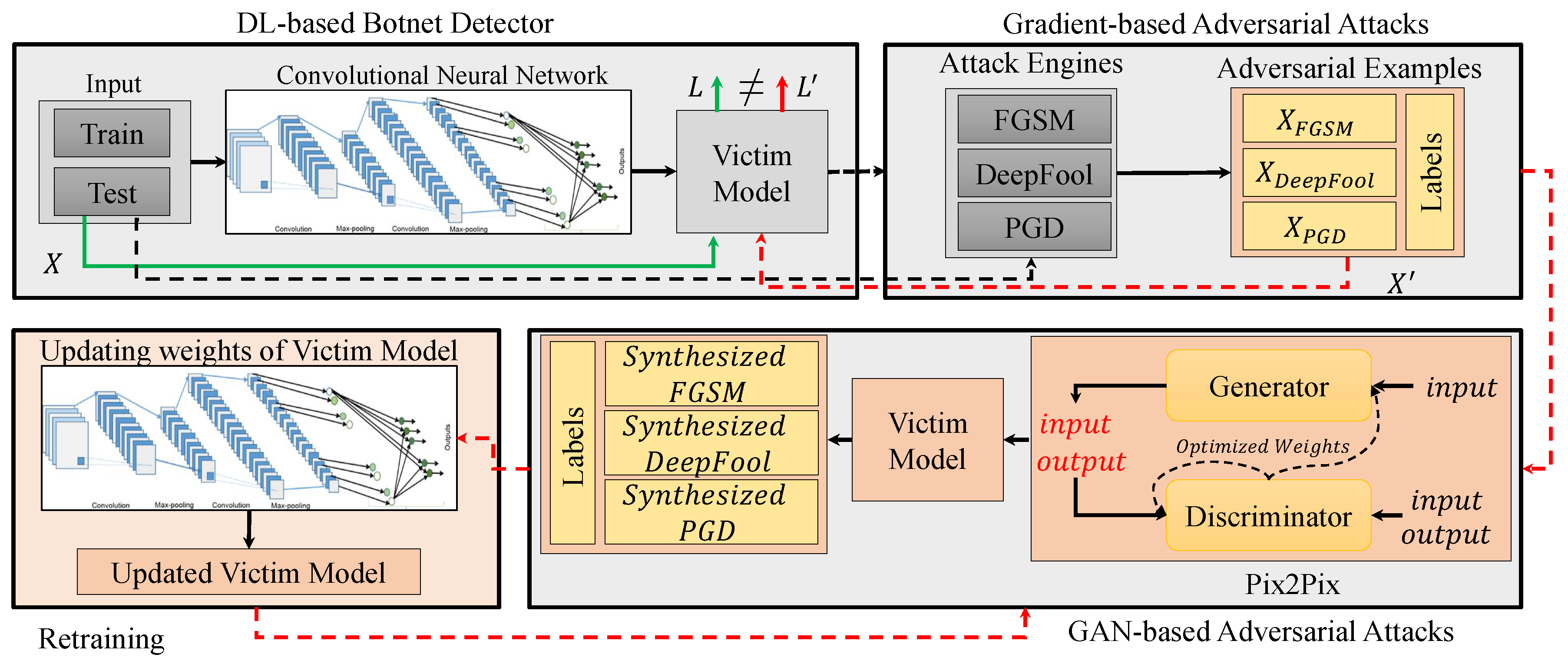
3. Methodology
3.1. Victim Model
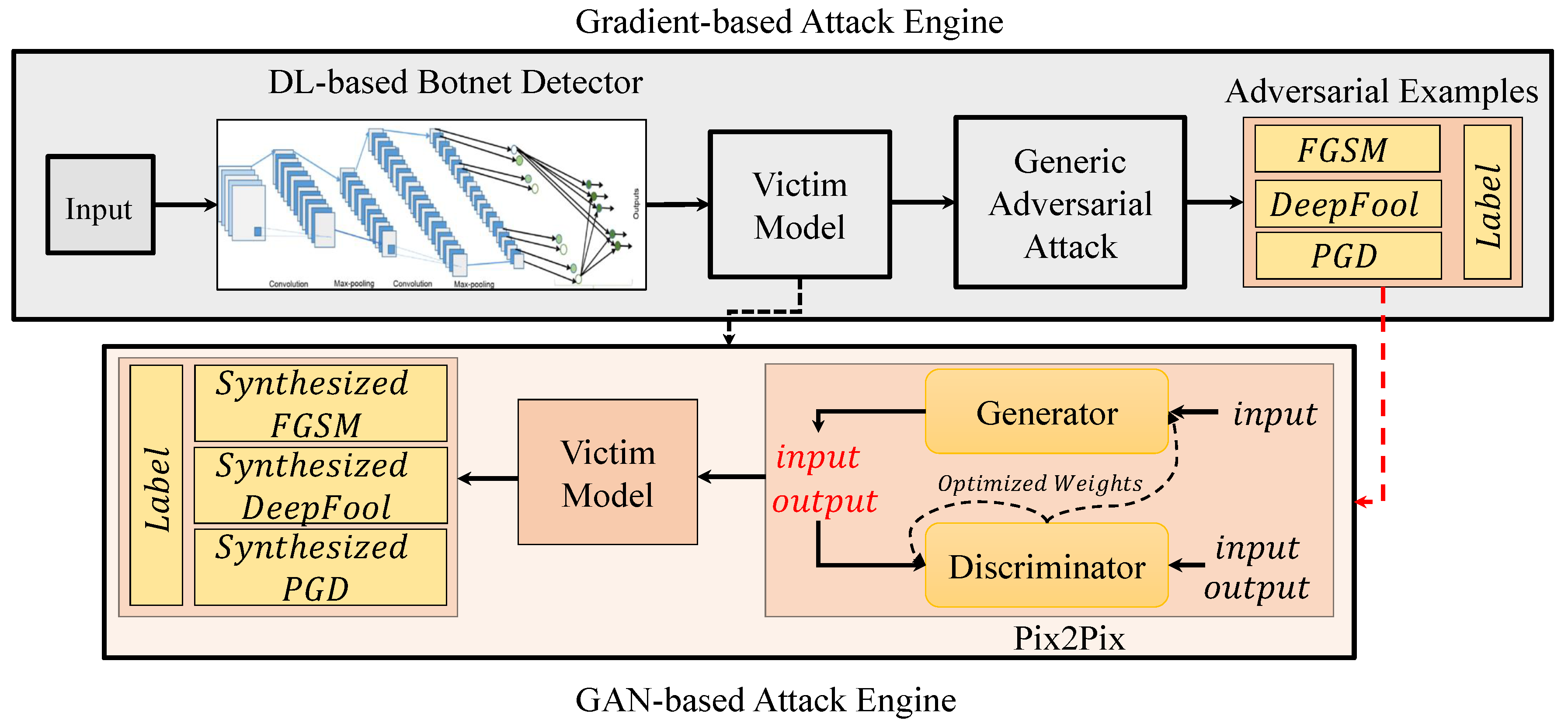
3.2. Attack Engines
3.2.1. Gradient-Based Attack Engine
- FGSM: FGSM is a fast method introduced by Goodfellow et al. in 2015 [12], which updates each feature in the direction of the sign of the gradient. This perturbation can be created after performing back-propagation. Being fast makes this attack a predominant attack in real world scenarios. FGSM can be formulated using (2).Here, X is the clean sample, is the adversarial example, J is the classification loss, Y is the label of the clean sample, and is a tunable parameter that controls the magnitude of the perturbation. Note that, in FGSM only direction of the gradient is important not its magnitude.
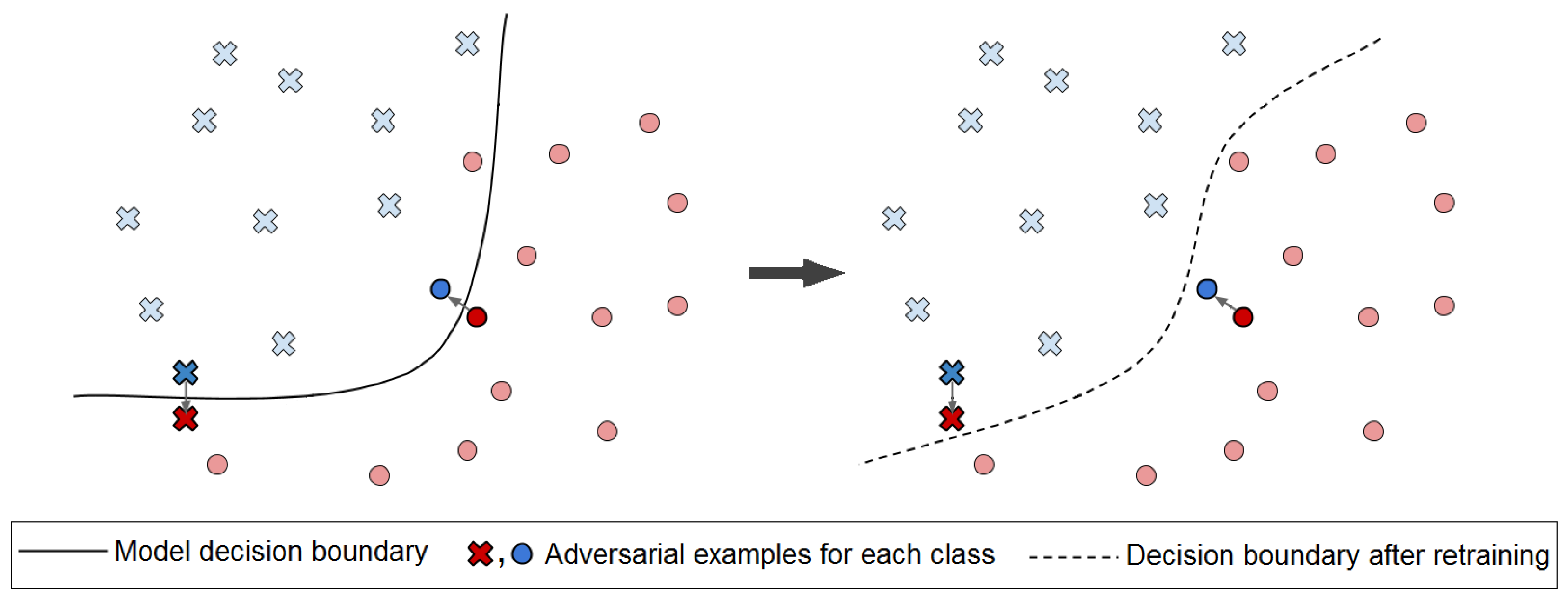
- DeepFool: This attack is introduced by Moosavi-Dezfooli et al. [8] as an untargeted iterative attack based on the distance metric. In this attack the closest distance from the clean input to the decision boundary is found. Decision boundaries are the boundaries that divide different classes in the hyper-plane created by the classifier. Perturbations are created in a manner that pushes the adversarial example outside of the boundary, causing it to be misclassified as another class, as demonstrated in Algorithm 1.
Algorithm 1: The process of generating adversarial examples based on DeepFool method [8]. - 1
- input: Image classifier f
- 2
- output: Perturbation
- 3
- Initialize
- 4
- while do
- 5
- 6
- 7
- 8
- end while
- 9
- return
- PGD: This attack is proposed by Madry et al. [31] as an iterative adversarial attack that creates adversarial examples based on applying FGSM on a data point , in an iterative manner, that is obtained by adding a random perturbation of magnitude to the original input x. Then the perturbed output is projected to a valid constrained space. The projection is conducted by finding the closet point to the current point within a feasible region. This attack can be formulated based on the following equation.where is the perturbed input at iteration and S denotes the set of feasible perturbations for x.
3.2.2. GAN-Based Attack Engine
3.3. Defense Mechanism
4. Evaluation and Discussion
4.1. Dataset
4.2. Experimental Setup
4.3. Evaluation Metrics
4.4. Results
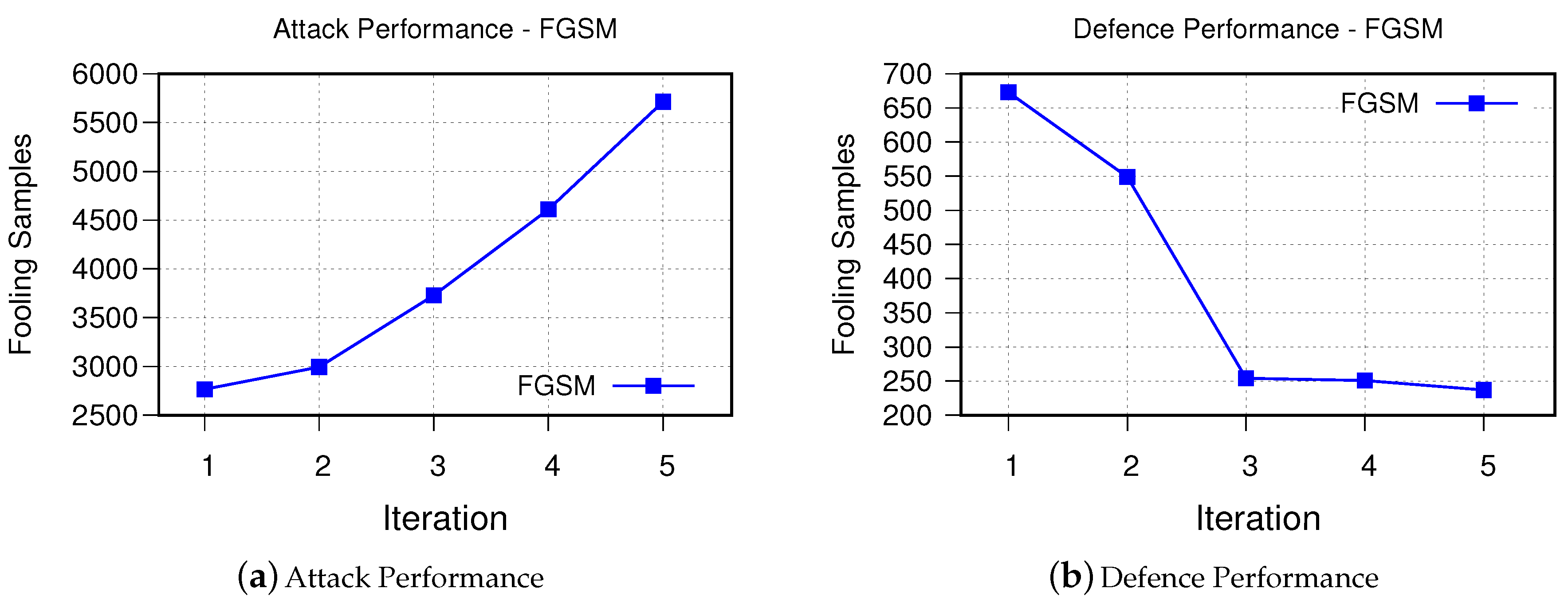
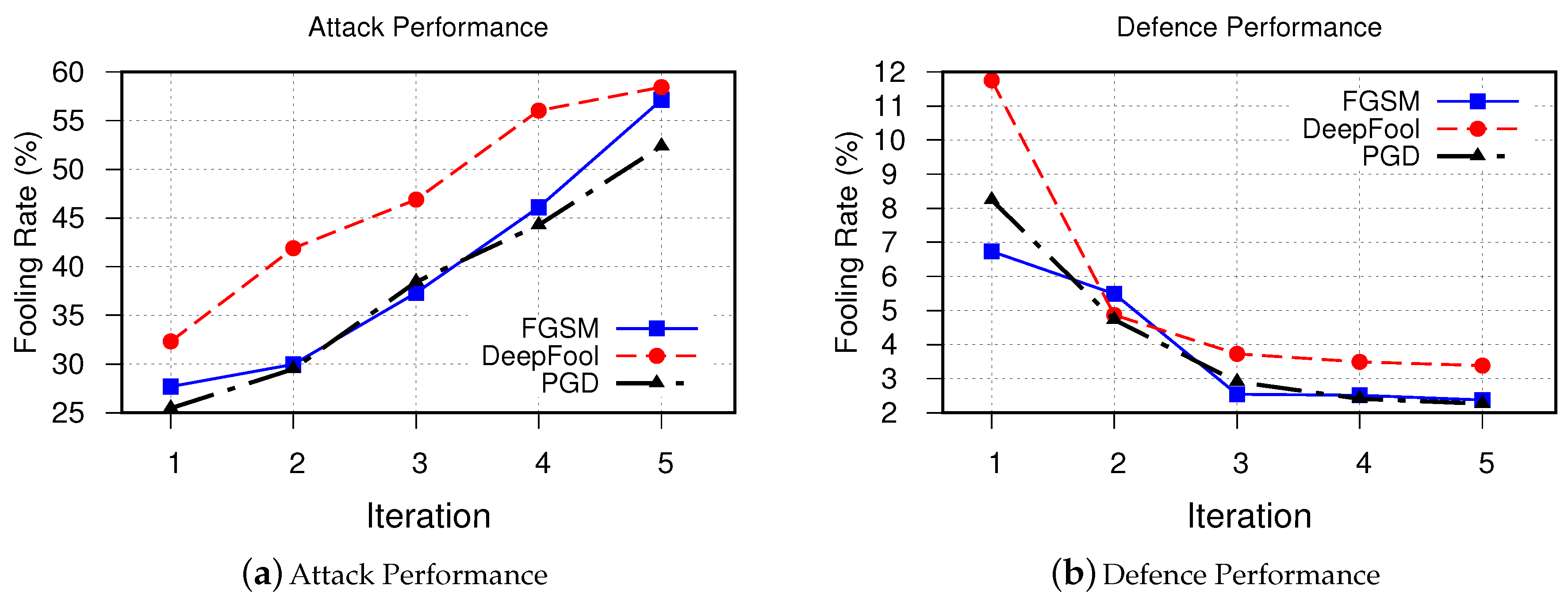
- FGSMFigure 6 demonstrates performance of proposed method in generating stronger adversarial examples, which are used to improve the performance of the victim model to defend against FGSM-based adversarial examples. As can be seen, after each iteration it was able to synthesize more samples that are fooling the victim model. Retraining the model using these synthesized examples, on the other hand, as it was expected improves the decision boundaries of the victim model such that fooling rate drops from 673 to 237 samples only after five iterations.
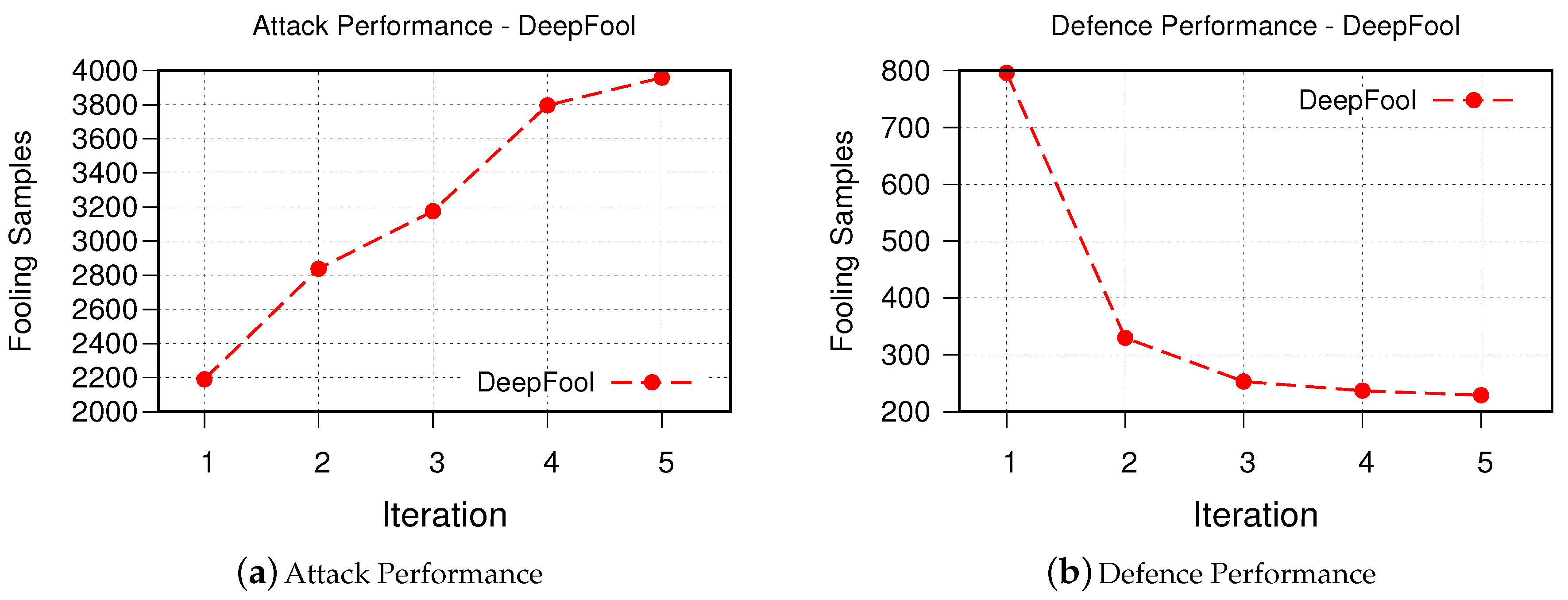
- DeepFool The obtained results for iterative attack and defense based on DeepFool are shown in Figure 7. Although the fooling rate of the DeepFool algorithm was only 67.73%, the GAN-based algorithm is able to generate similar number of successful synthesized adversarial examples as FGSM. This is promising as it demonstrates that our GAN-based approach is able to generate new and strong adversarial examples with even fewer number of samples. Similarly, the robustness of the retrained victim model is improved.
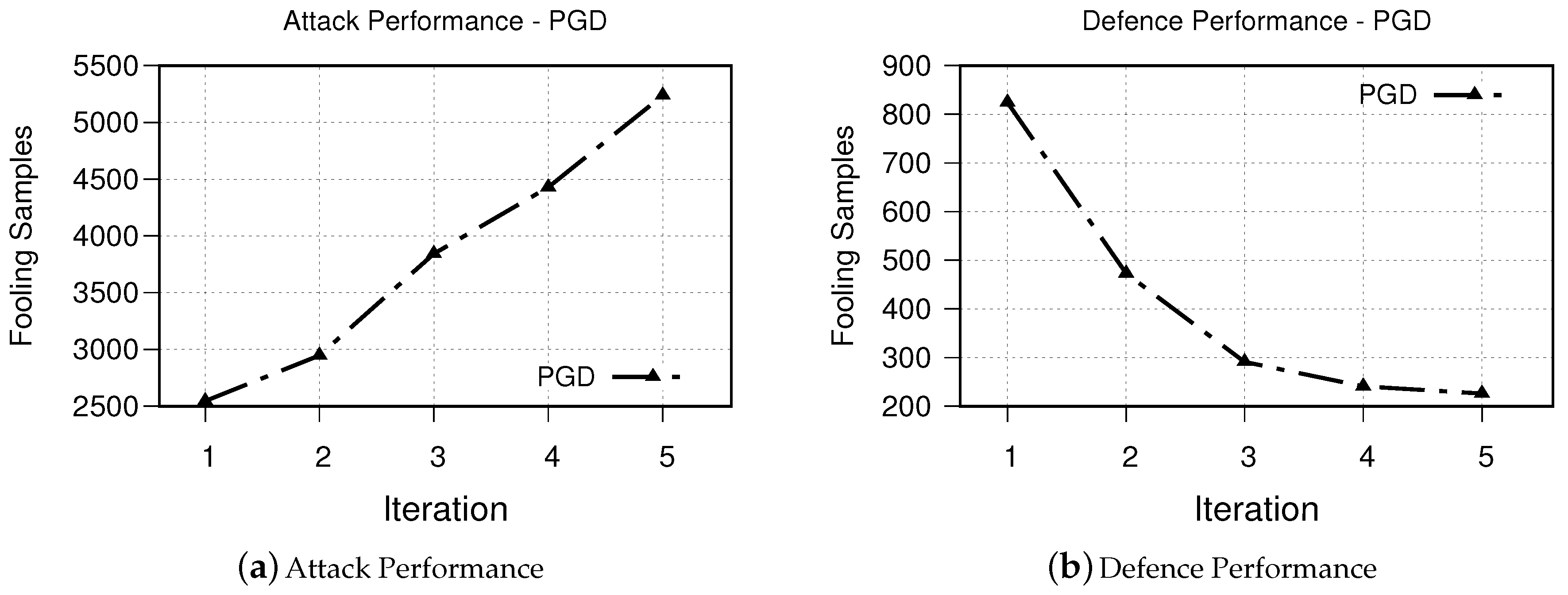
- PGD The obtained results for iterative attack and defense based on PGD is shown in Figure 8. The obtained results from our experiments demonstrates a similar trend to that of both FGSM and DeepFool methods.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Silva, S.S.; Silva, R.M.; Pinto, R.C.; Salles, R.M. Botnets: A survey. Comput. Netw. 2013, 57, 378–403. [Google Scholar] [CrossRef]
- Manyika, J.; Chui, M.; Bisson, P.; Woetzel, J.; Dobbs, R.; Bughin, J.; Aharon, D. Unlocking the Potential of the Internet of Things; McKinsey Global Institute: Washington, DC, USA, 2015. [Google Scholar]
- Taheri, S.; Salem, M.; Yuan, J.S. Leveraging Image Representation of Network Traffic Data and Transfer Learning in Botnet Detection. Big Data Cogn. Comput. 2018, 2, 37. [Google Scholar] [CrossRef]
- Vinayakumar, R.; Alazab, M.; Srinivasan, S.; Pham, Q.V.; Padannayil, S.K.; Simran, K. A Visualized Botnet Detection System based Deep Learning for the Internet of Things Networks of Smart Cities. IEEE Trans. Ind. Appl. 2020. [Google Scholar] [CrossRef]
- Chen, B.; Ren, Z.; Yu, C.; Hussain, I.; Liu, J. Adversarial examples for CNN-based malware detectors. IEEE Access 2019, 7, 54360–54371. [Google Scholar] [CrossRef]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), San Sebastian, Spain, 7–8 July 2016; pp. 372–387. [Google Scholar]
- Papernot, N.; McDaniel, P.; Goodfellow, I.; Jha, S.; Celik, Z.B.; Swami, A. Practical black-box attacks against machine learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and Communications Security, Abu Dhabi, UAE, 2–6 April 2017; pp. 506–519. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Frossard, P. Deepfool: A simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Wang, B.; Yao, Y.; Viswanath, B.; Zheng, H.; Zhao, B.Y. With great training comes great vulnerability: Practical attacks against transfer learning. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1281–1297. [Google Scholar]
- Yuan, X.; He, P.; Zhu, Q.; Li, X. Adversarial examples: Attacks and defenses for deep learning. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2805–2824. [Google Scholar] [CrossRef] [PubMed]
- Su, J.; Vargas, D.V.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. In Proceedings of the International Conference on Learning Representation ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Grosse, K.; Papernot, N.; Manoharan, P.; Backes, M.; McDaniel, P. Adversarial examples for malware detection. In Proceedings of the European Symposium on Research in Computer Security, Oslo, Norway, 11–15 September 2017; pp. 62–79. [Google Scholar]
- Osadchy, M.; Hernandez-Castro, J.; Gibson, S.; Dunkelman, O.; Pérez-Cabo, D. No bot expects the DeepCAPTCHA! Introducing immutable adversarial examples, with applications to CAPTCHA generation. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2640–2653. [Google Scholar] [CrossRef]
- Buckman, J.; Roy, A.; Raffel, C.; Goodfellow, I. Thermometer encoding: One hot way to resist adversarial examples. In Proceedings of the International Conference on Learning Representation ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; Van Der Maaten, L. Countering adversarial images using input transformations. In Proceedings of the International Conference on Learning Representation ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Song, Y.; Kim, T.; Nowozin, S.; Ermon, S.; Kushman, N. Pixeldefend: Leveraging generative models to understand and defend against adversarial examples. In Proceedings of the International Conference on Learning Representation ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Athalye, A.; Carlini, N.; Wagner, D. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of the 35th International Conference on Machine Learning, Vienna, Austria, 25–31 July 2018; Volume 80, pp. 274–283. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–28 July 2017; pp. 1125–1134. [Google Scholar]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the 2017 International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; pp. 712–717. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Yosinski, J.; Clune, J.; Bengio, Y.; Lipson, H. How transferable are features in deep neural networks? In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3320–3328. [Google Scholar]
- Dong, Y.; Pang, T.; Su, H.; Zhu, J. Evading defenses to transferable adversarial examples by translation-invariant attacks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 July 2019; pp. 4312–4321. [Google Scholar]
- Pan, Z.; Yu, W.; Yi, X.; Khan, A.; Yuan, F.; Zheng, Y. Recent progress on generative adversarial networks (GANs): A survey. IEEE Access 2019, 7, 36322–36333. [Google Scholar] [CrossRef]
- Tolosana, R.; Vera-Rodriguez, R.; Fierrez, J.; Morales, A.; Ortega-Garcia, J. DeepFakes and Beyond: A Survey of Face Manipulation and Fake Detection. arXiv 2020, arXiv:2001.00179. [Google Scholar]
- Engel, J.; Agrawal, K.K.; Chen, S.; Gulrajani, I.; Donahue, C.; Roberts, A. Gansynth: Adversarial neural audio synthesis. arXiv 2019, arXiv:1902.08710. [Google Scholar]
- De Cao, N.; Kipf, T. MolGAN: An implicit generative model for small molecular graphs. arXiv 2018, arXiv:1805.11973. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. In Proceedings of the International Conference on Learning Representation ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Garcia, S.; Grill, M.; Stiborek, J.; Zunino, A. An empirical comparison of botnet detection methods. Comput. Secur. 2014, 45, 100–123. [Google Scholar] [CrossRef]
- Papernot, N.; Faghri, F.; Carlini, N.; Goodfellow, I.; Feinman, R.; Kurakin, A.; Xie, C.; Sharma, Y.; Brown, T.; Roy, A.; et al. Technical Report on the CleverHans v2.1.0 Adversarial Examples Library. arXiv 2018, arXiv:1610.00768. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train | Test | |
|---|---|---|
| Normal | 34,144 | 7376 |
| Botnet | 15,856 | 2624 |
| Total | 50,000 | 10,000 |
| True Label | |||
|---|---|---|---|
| Botnet | Normal | ||
| Predicted Label | Botnet | True Positive (TP) | False Positive (FP) |
| Normal | False Negative (FN) | True Negative (TN) | |
| Confusion Matrix | Accuracy Rate (%) | F1 Score (%) | |||
|---|---|---|---|---|---|
| Predicted Label | 99.99 | 99.98 | |||
| Botnet | Normal | ||||
| True Label | Botnet | TP = 2624 | FN = 0 | ||
| Normal | FP = 1 | TN = 7375 | |||
| Attack | Fooling Rate (%) | Distortion Rate (%) |
|---|---|---|
| FGSM | 99.69 | 39.73 |
| DeepFool | 67.73 | 43.93 |
| PGD | 99.98 | 18.93 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taheri, S.; Khormali, A.; Salem, M.; Yuan, J.-S. Developing a Robust Defensive System against Adversarial Examples Using Generative Adversarial Networks. Big Data Cogn. Comput. 2020, 4, 11. https://doi.org/10.3390/bdcc4020011
Taheri S, Khormali A, Salem M, Yuan J-S. Developing a Robust Defensive System against Adversarial Examples Using Generative Adversarial Networks. Big Data and Cognitive Computing. 2020; 4(2):11. https://doi.org/10.3390/bdcc4020011
Chicago/Turabian StyleTaheri, Shayan, Aminollah Khormali, Milad Salem, and Jiann-Shiun Yuan. 2020. "Developing a Robust Defensive System against Adversarial Examples Using Generative Adversarial Networks" Big Data and Cognitive Computing 4, no. 2: 11. https://doi.org/10.3390/bdcc4020011
APA StyleTaheri, S., Khormali, A., Salem, M., & Yuan, J.-S. (2020). Developing a Robust Defensive System against Adversarial Examples Using Generative Adversarial Networks. Big Data and Cognitive Computing, 4(2), 11. https://doi.org/10.3390/bdcc4020011