An Enhanced Inference Algorithm for Data Sampling Efficiency and Accuracy Using Periodic Beacons and Optimization



Abstract
:1. Introduction
2. Methodology
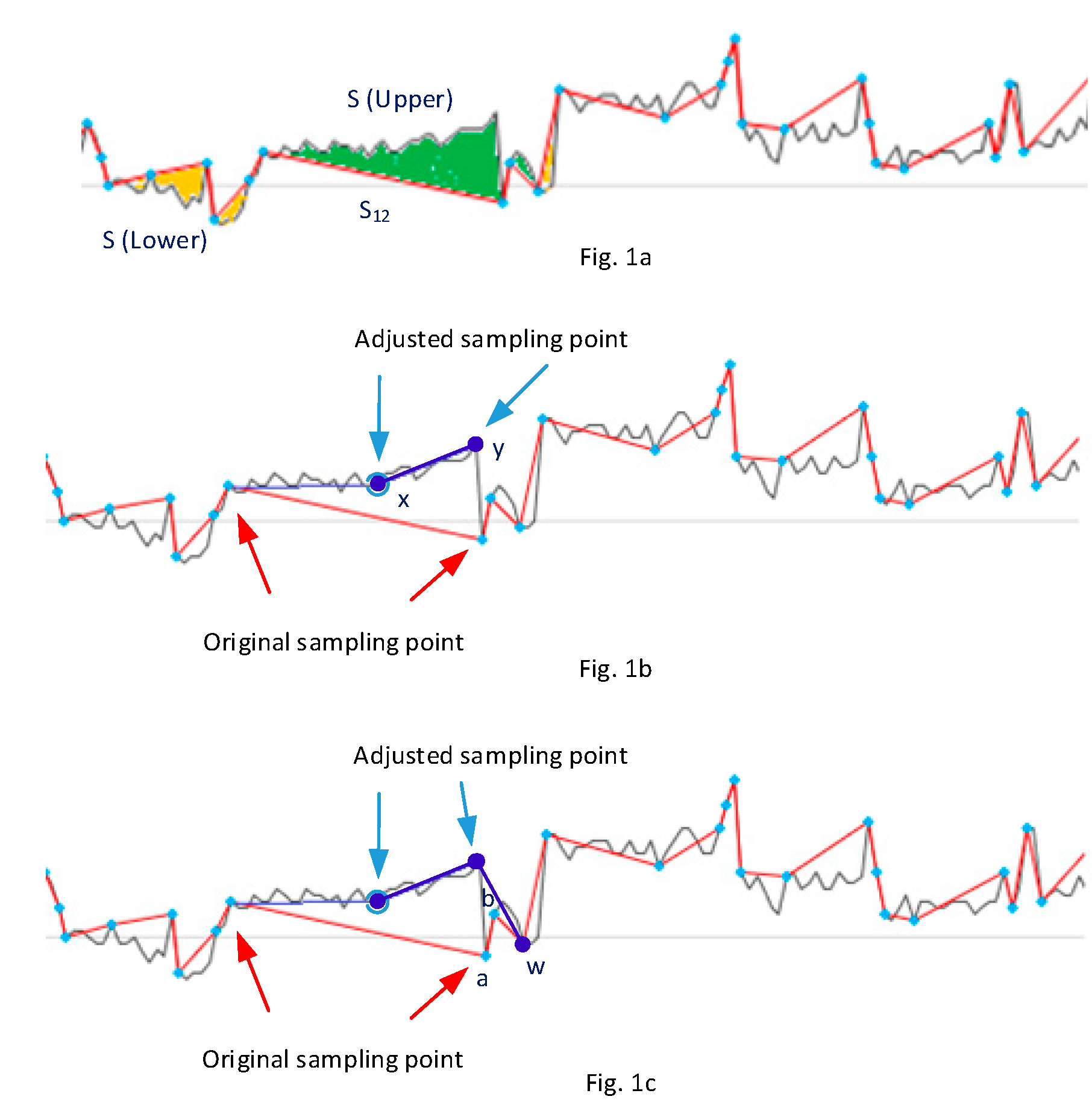
- Efficiency: Ratio of saved (reduced) data volume and actual transmitted data.
- Savings: Ratio of reduced data and sensed data (%).
- Accuracy: Ratio of total value of transmitted data and original data (%).
- Number of Sensed data: Total number of data points sensed by sensors. These data are used to take sample data for inferencing.
- Number of Transferred data: Total number of inferred data to be transferred to smart devices from the sensor after inference algorithm has been applied.
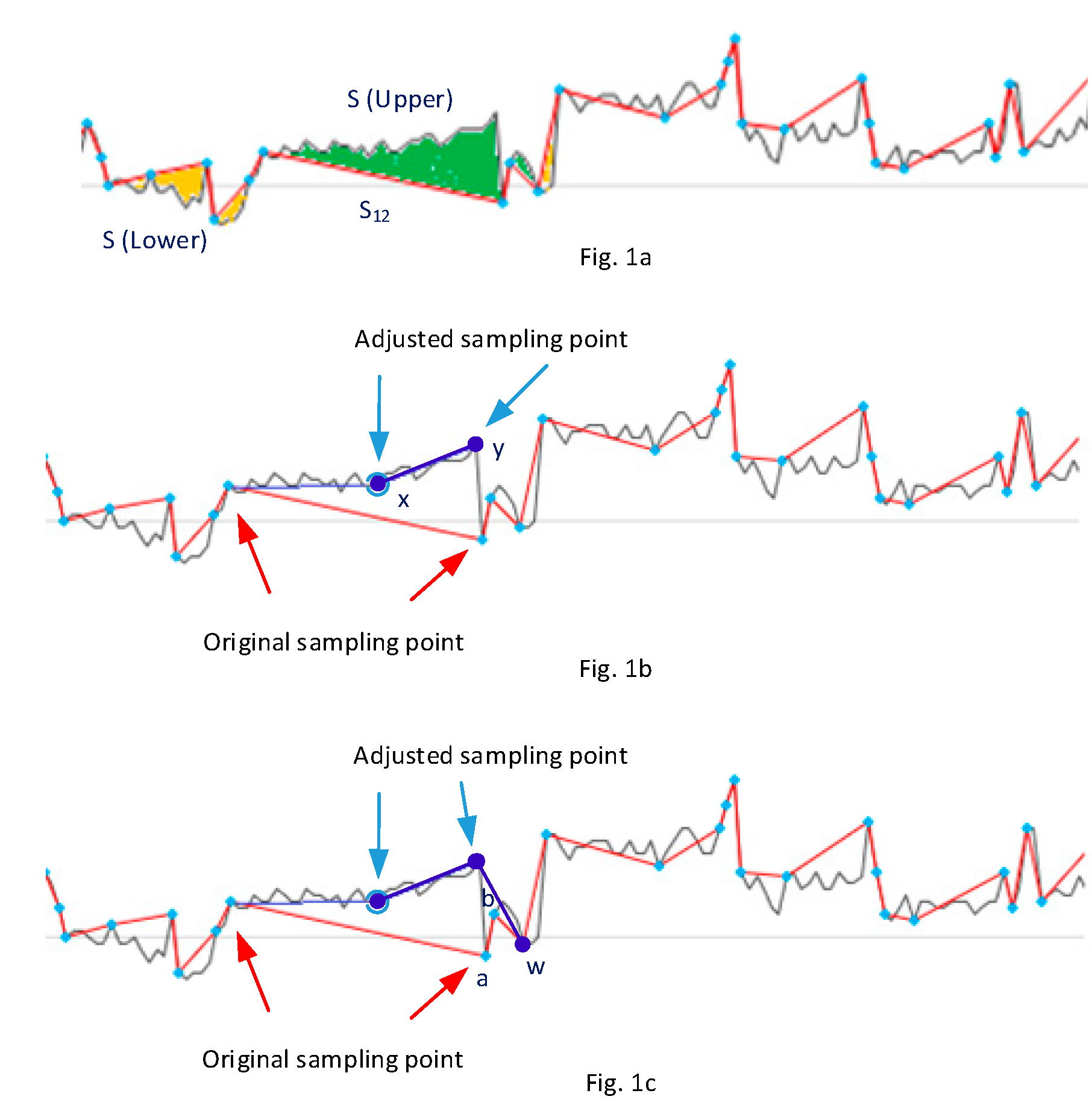
- Sum of original DPs: Total number of values of sensed data points, which is the same as the value of heart rate, e.g., DPn: 108 beats per minutes (BPM) = 108 for data point ‘n’.
- Sum of differences: Total values of gaps between the original DP values and the inferred DP values. These values are used to calculate the accuracy rates.
3. Algorithm Development
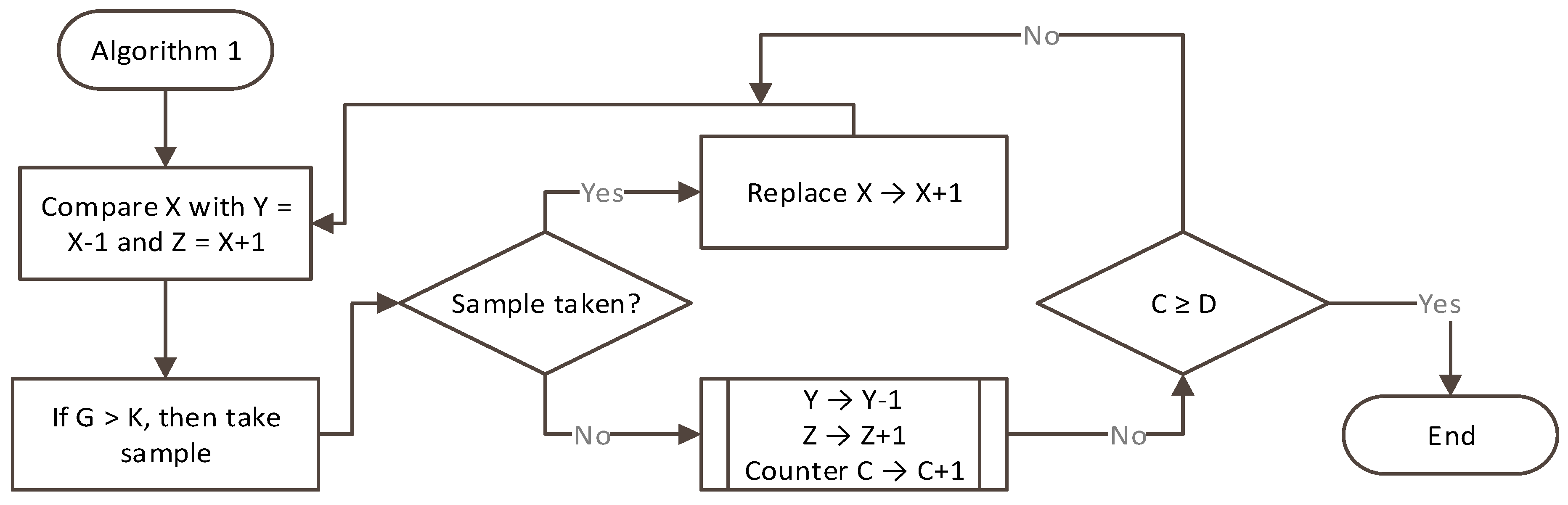
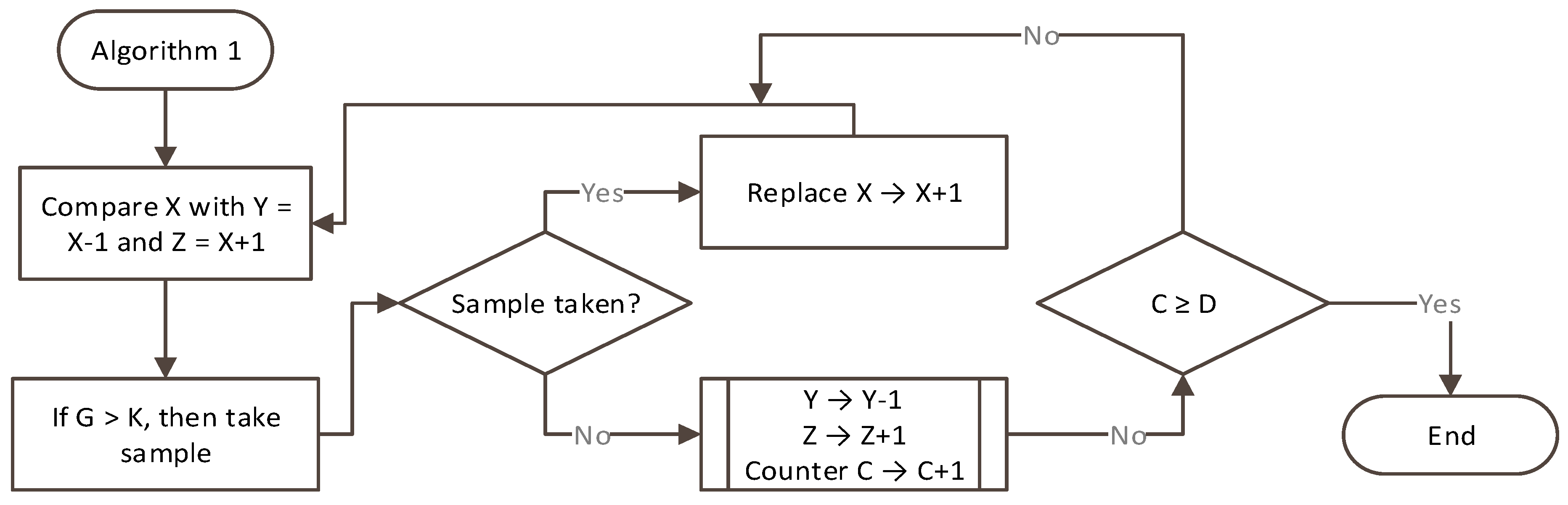
- Compare the value of data point at X with Y = X − 1 and Z = X + 1. When the value G (gap between X and (X − 1 or X + 1)) is larger than a value of K (this can be percentile, e.g., 2%, 5%, etc., and it determines “fine” or “coarse” method of the inference), the data point is selected as a sample, and moved to the next (i.e., data point at X + 1 to compare with X and X + 2).
- If a sample is not selected, then it will compare with X − 2 and X + 2. When the gap is larger than K, it will be selected as a sample data point. Counter C increments until a pre-defined value D, which determines the distance to neighbor data points.
- If a sample is not selected, then do the same till X and Y.
- If a sample is not selected and C is larger than D, then it ignores X, so move the data point X to X+1 to compare with Y and Z.
| Algorithm 1. Creation of sample data collection |
| 1. /* To create a collection of sample data points as from the original data points array that is .*/ |
| 2. function retrievePredefinedValues( ) |
| 3. K → retrieve pre-defined threshold values for FM and CM from inference threshold database dbI 4. D → retrieve pre-defined threshold values for distance to neighboring data point from dbI |
| 5. return K,D |
| 6. end function |
| 7. function createSampleDataPoints (X,C) |
| 8. Y = X − C // to store the value of neighbor data point—one prior data point |
| 9. Z = X + C // to store the value of next consecutive data point |
| 10. G → Calculategap |
| 11. if ( G > K ) then |
| 12. Add X to // add to collection of sample data array after inference |
| 13. end if |
| 14. end function |
| 15. -----------------------------Algorithm 1 Logic----------------------------- |
| 16. K → retrievePredefinedValues( ) |
| 17. D → retrievePredefinedValues( ) 18. select X from [ ] // an array of original sample data |
| 19. until ( X < N ) do loop // executed for the N-1 times for a pair of adjacent data points |
| 20. integer C //declare the counter to compare with the pre-defined value D 21. C = 1 // initialize the counter to compare with the pre-defined value D |
| 22. createSampleDataPoints(X,C) |
| 23. if ( G < K ) then |
| 24. until ( C < D ) do loop // a pre-defined value D to determines the distance to neighbor data points |
| 25. C = C+1 // increment counter C |
| 26. createSampleDataPoints (X,C) |
| 27. end until |
| 28. end if |
| 29. X = X+1 //select next data point from —an array of original sample data |
| 30. end until |
| 31. -----------------------------End of Algorithm 1 Logic----------------------------- |
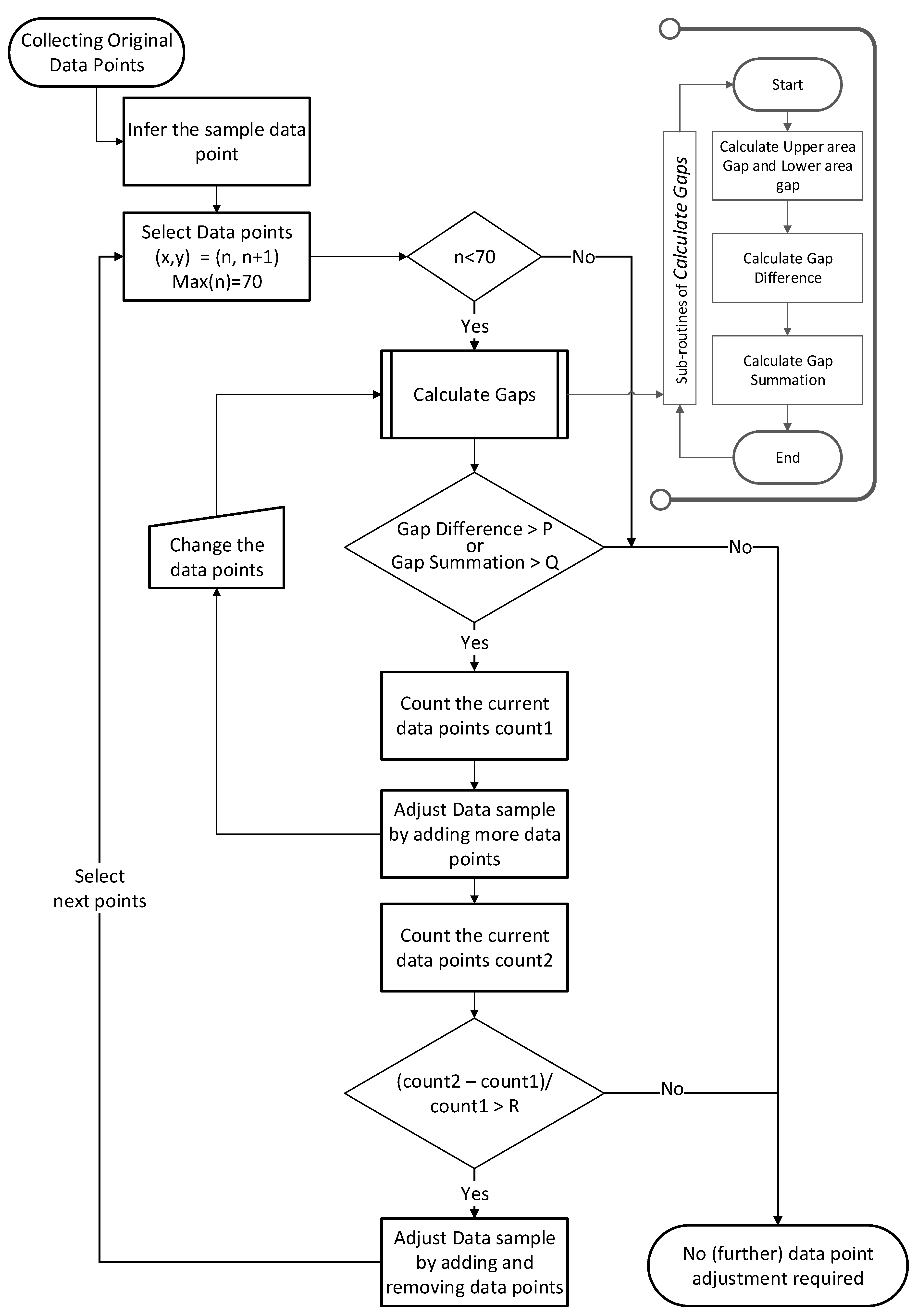
| Algorithm 2. Calculation and comparison of Gap area |
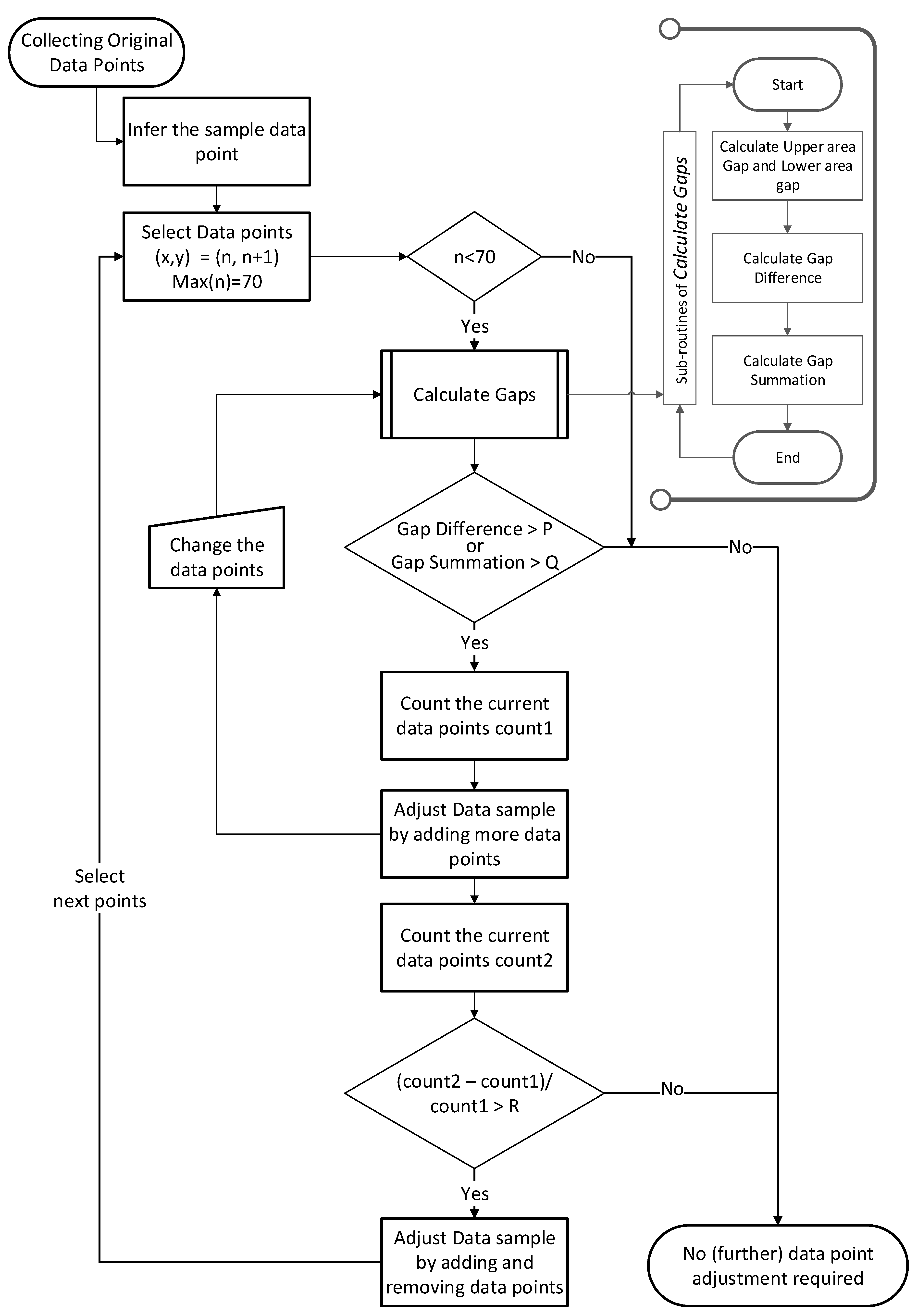
| 1. // Calculates the Gap area and compares the outcome with the inference threshold database values |
| 2. function retrieveThresholdValue() |
| 3. P → find pre-defined threshold data from inference threshold database dbI |
| 4. Q → find pre-defined threshold data from inference threshold database dbI |
| 5. R → find pre-defined threshold data from inference threshold database dbI |
| 6. return P,Q,R |
| 7. end function |
| 8. function calculateGapArea(first,last) |
| 9. → calculateUppergapVolume(first,last) |
| 10. → calculateLowergapVolume(first,last) |
| 11. → |
| 12. → |
| 13. return , |
| 14. end function |
| 15. -----------------------------Algorithm 2 Logic------------------------------ |
| 16. for i in 1 .. n-1 loop |
| 17. integer count1, count 2 // to keep the count of the Sample data points after the inference |
| 18. , → CalculateGap(n, n+1) |
| 19. P → retrieveThresholdValue() |
| 20. count1 → counti |
| 21. if ( orthen |
| 22. //if the gap difference or gap summation is larger than the pre-defined P and Q respectively 23. call Algorithm 3 |
| 24. call Algorithm 4 |
| 25. end if |
| 26. end for loop |
| 27. -----------------------------End of Algorithm 2 Logic-------------------- |
| Algorithm 3. Adjustment of data points sample based on gap difference and summation |
| 1. function adjustDataSample1() |
| 2. if ( x in SDO[ ] and y in SDO[ ] ) then |
| 3. until <= P ) or ( <= Q) do loop |
| 4. add () data point in SDI[ ] from SDO[ ] |
| 5. end until |
| 6. end if |
| 7. end function |
| 8. -----------------------------Algorithm 3 Logic----------------------------- |
| 9. adjustDataSample1([x,y]) |
| 10. count2 → I |
| 11. -----------------------------End of Algorithm 3 Logic-------------------- |
| Algorithm 4. Adjustment of data points sample based on total number of data points |
| 1. function adjustDataSample2() |
| 2. remove () data point from SDI[ ] |
| 3. add () data point in SDI[ ] from SDO[ ] |
| 4. end function |
| 5. -----------------------------Algorithm 4 Logic----------------------------- |
| 6. if () > R) then |
| 7. // compare the total number of data points between X & Y with before and after the sample adjustment 8. adjustDataSample2(w, [a,b]) |
| 9. end if |
| 10. -----------------------------End of Algorithm 4 Logic----------------------------- |
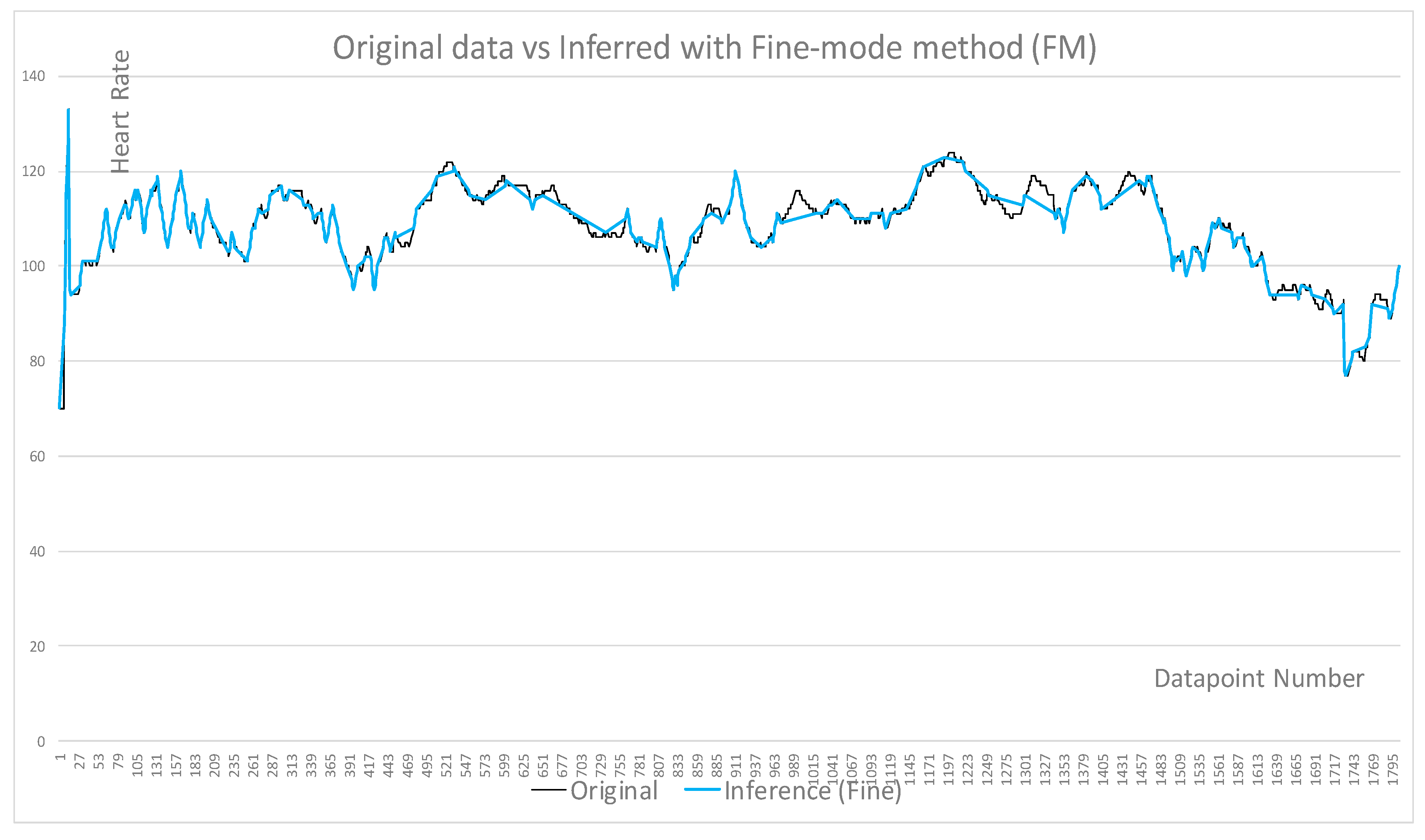
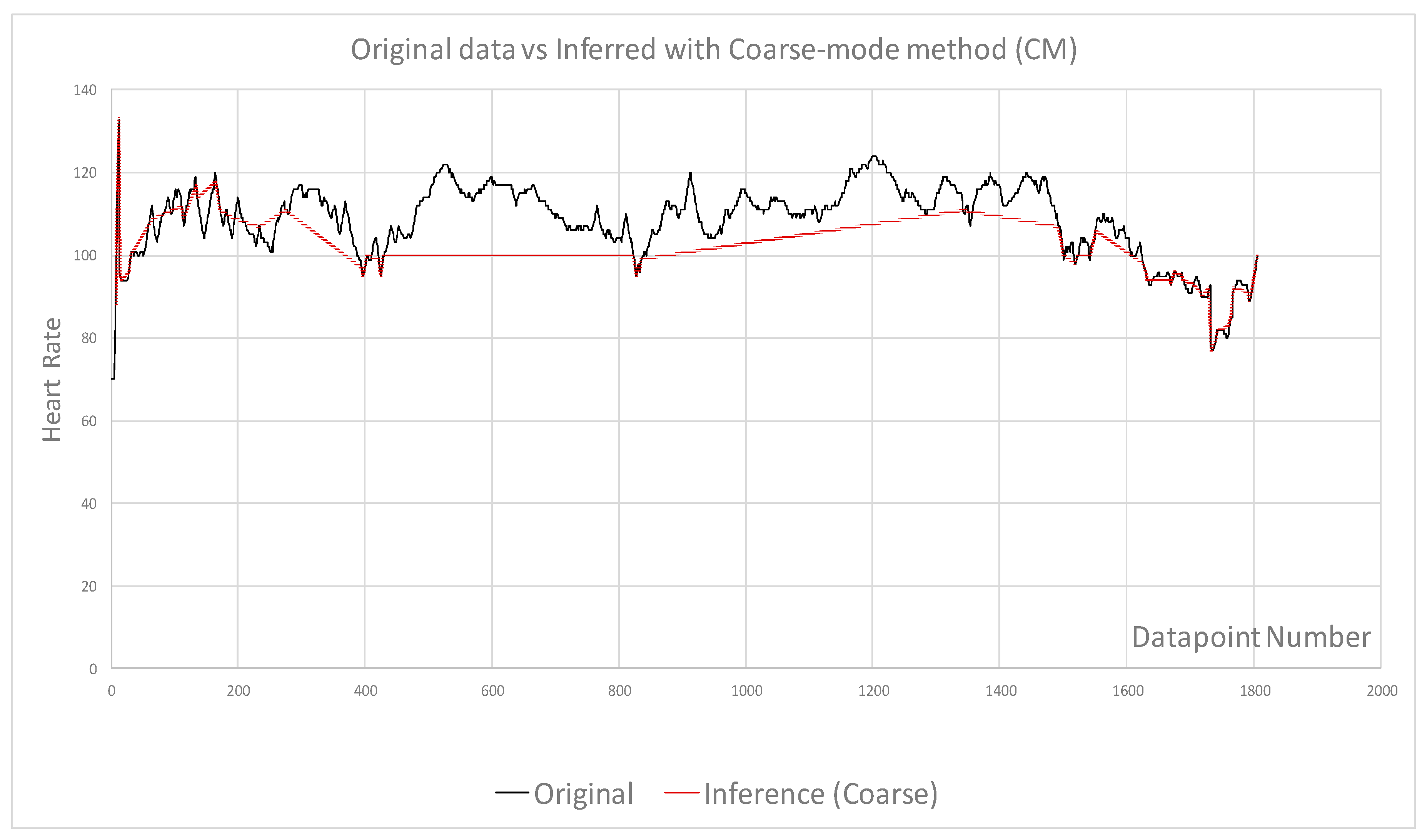
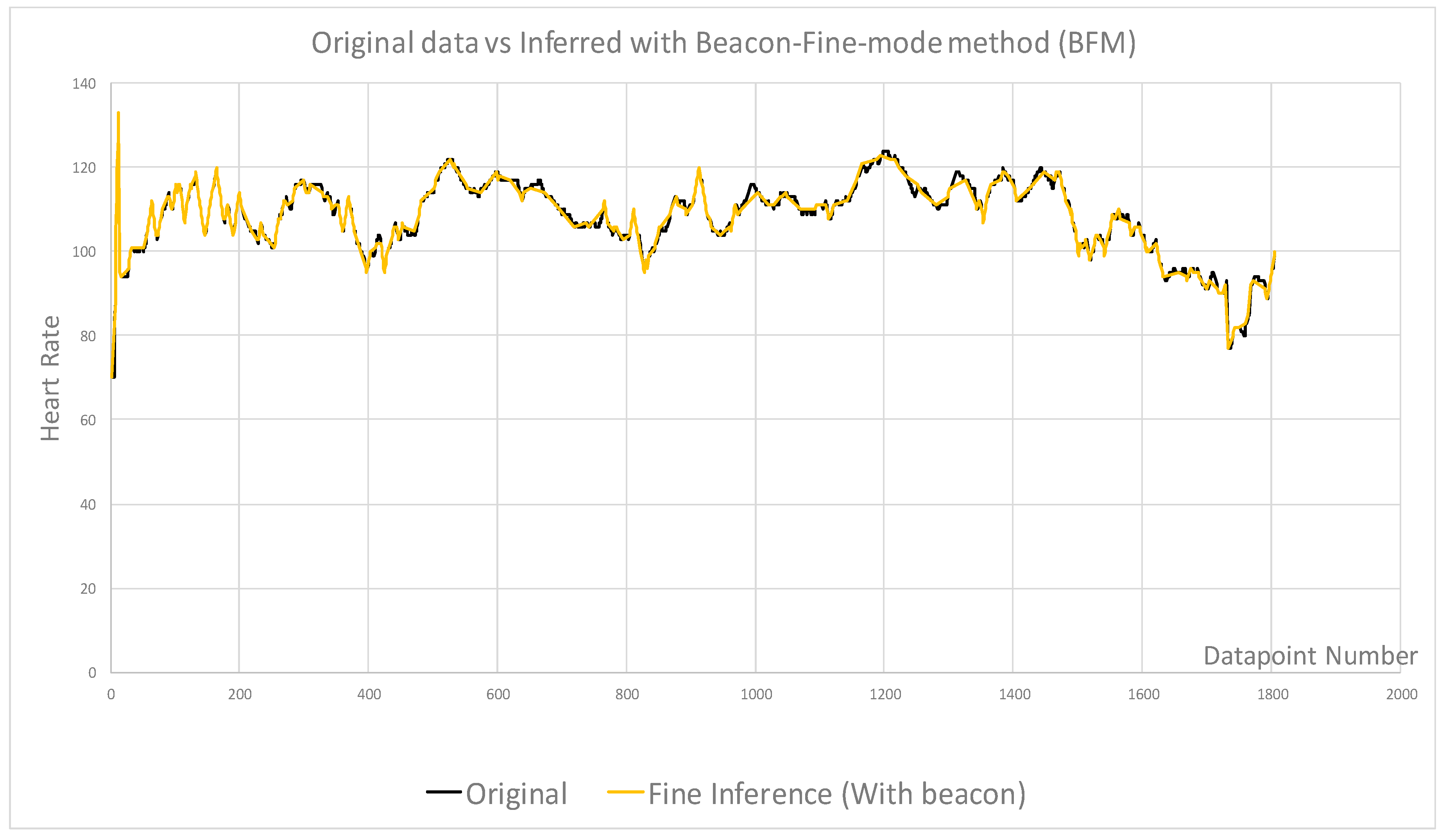
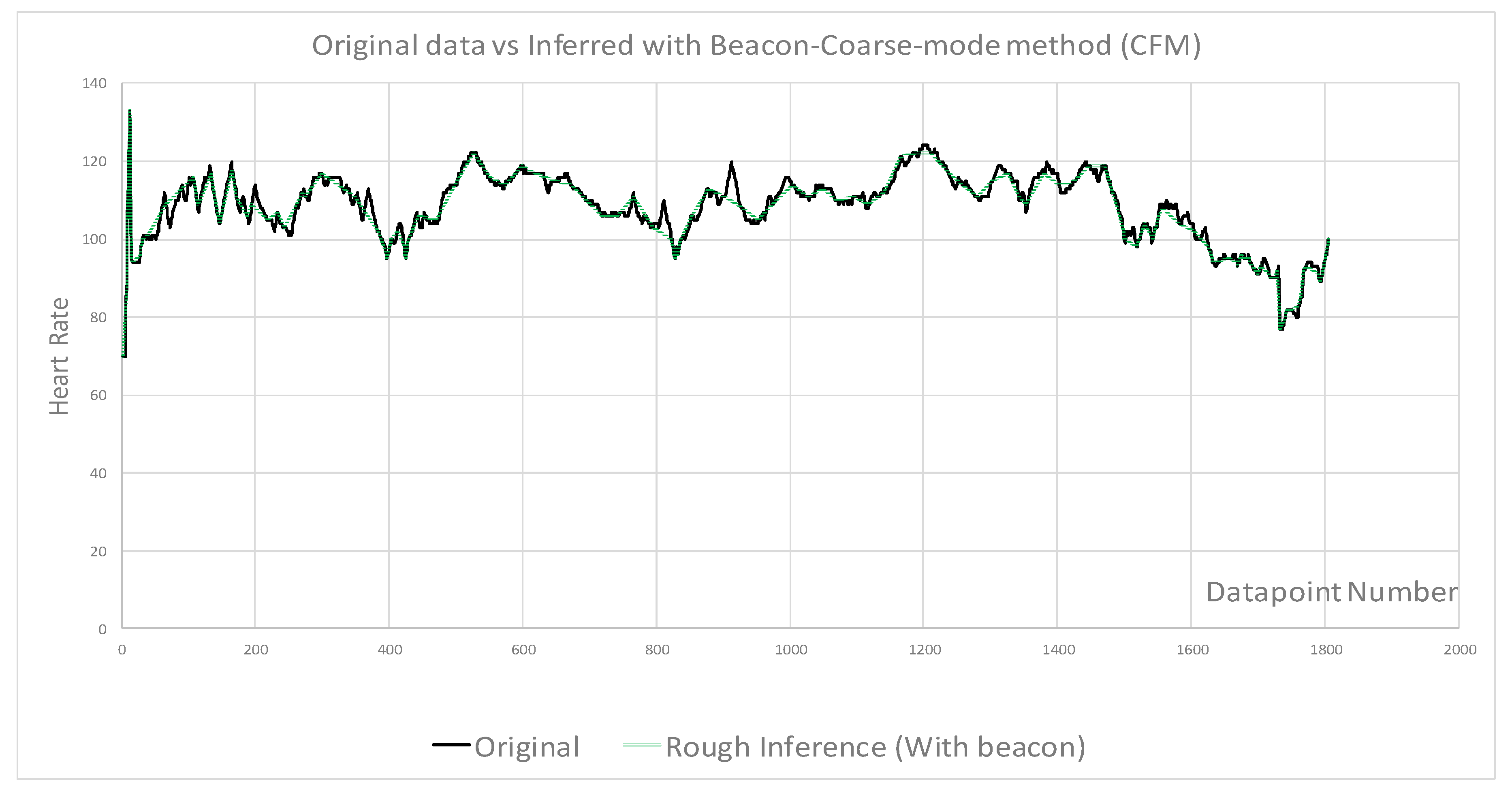
4. Testing Results and Discussion
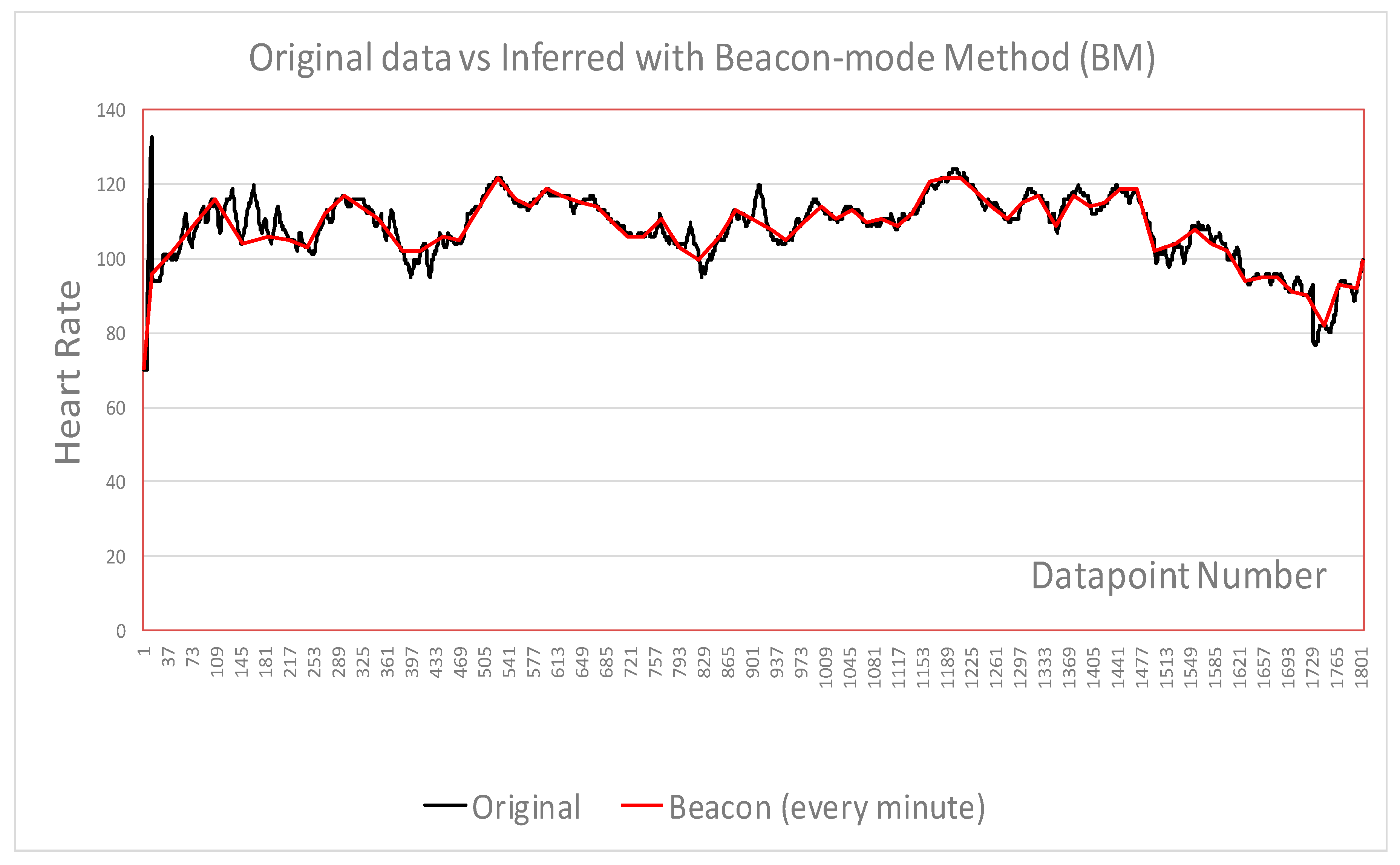
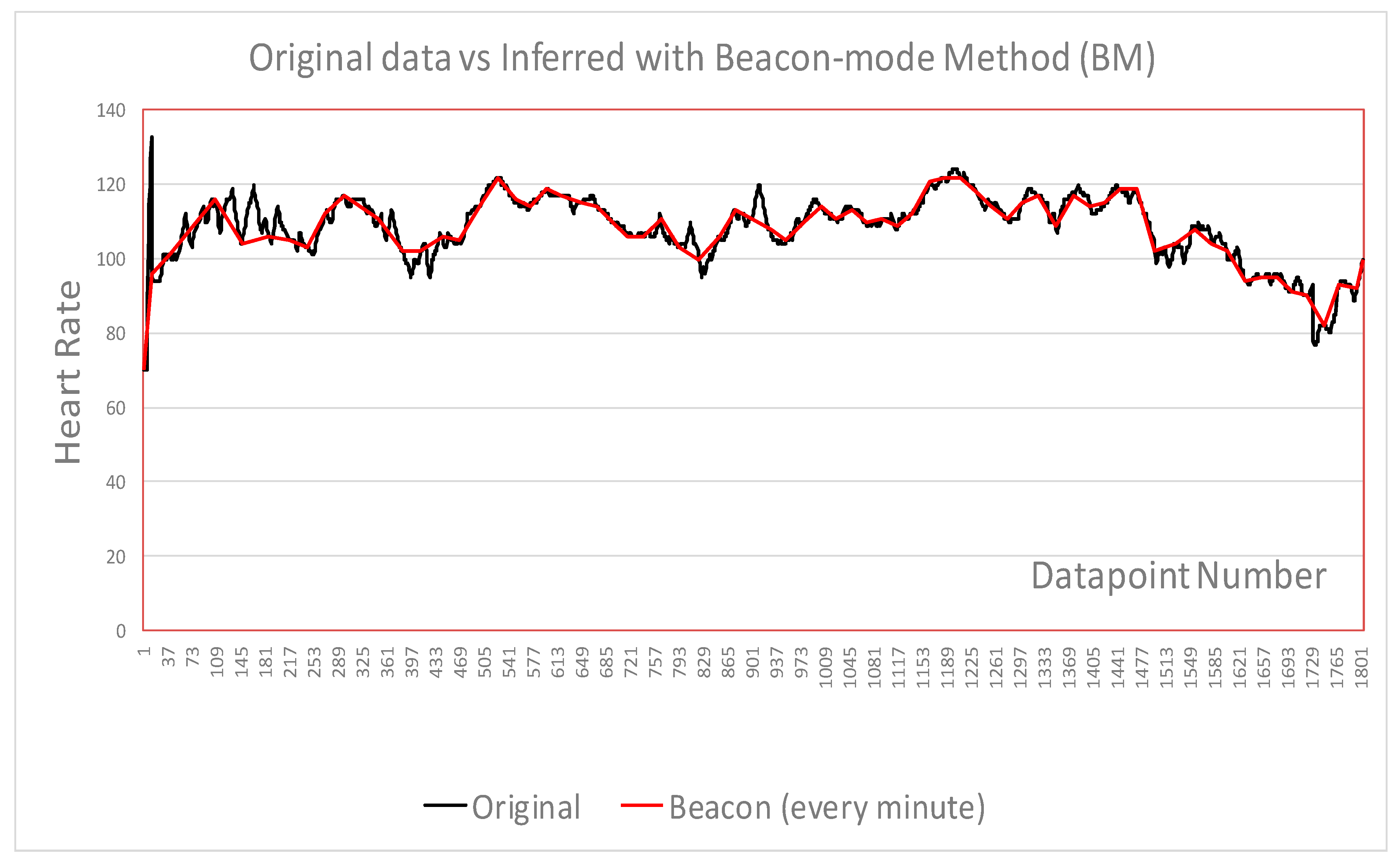
- Original data points monitored over 90 min and selected 1800 data points as raw data. to be used for inferencing with algorithms to apply based on sensing every second
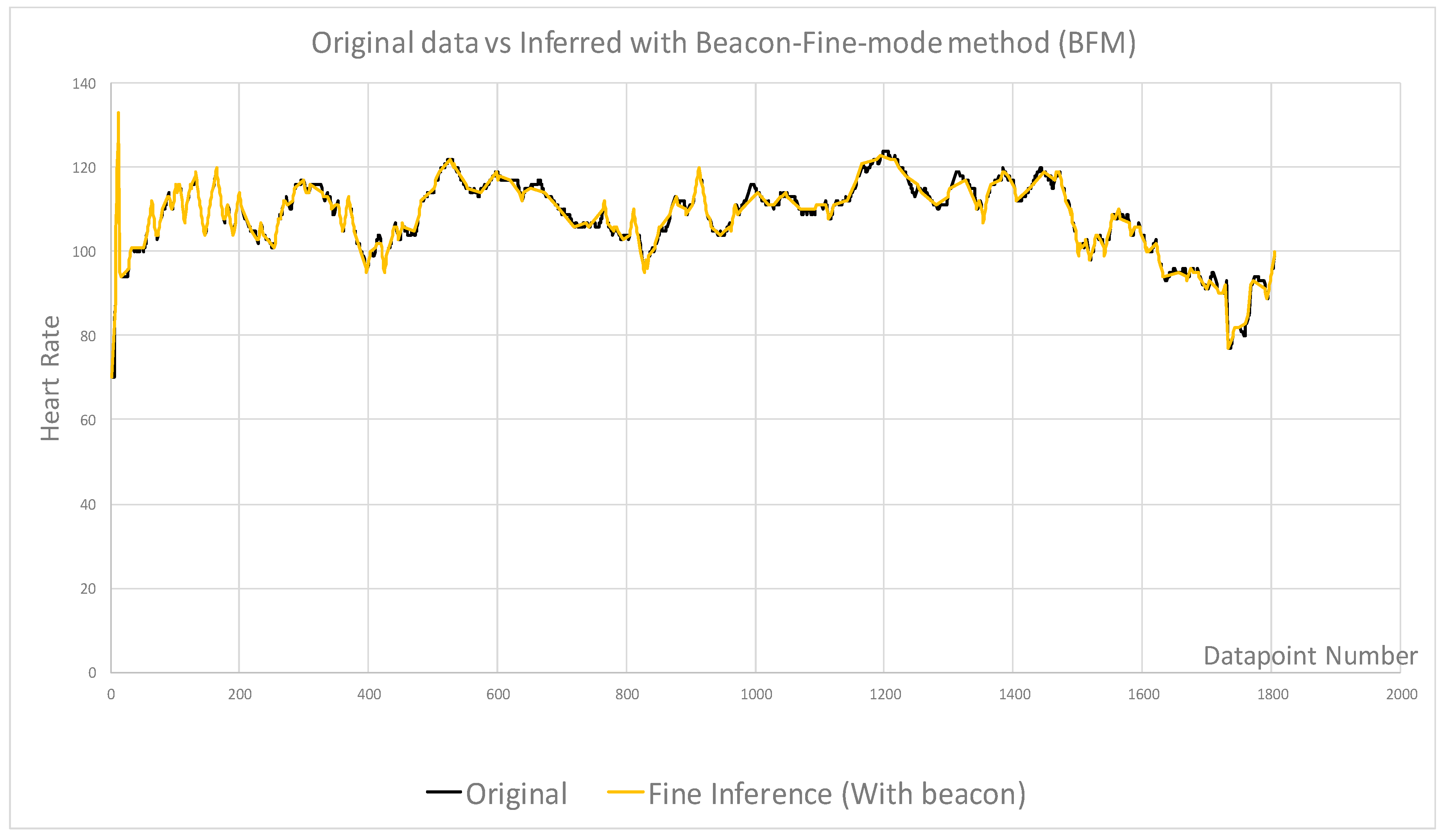
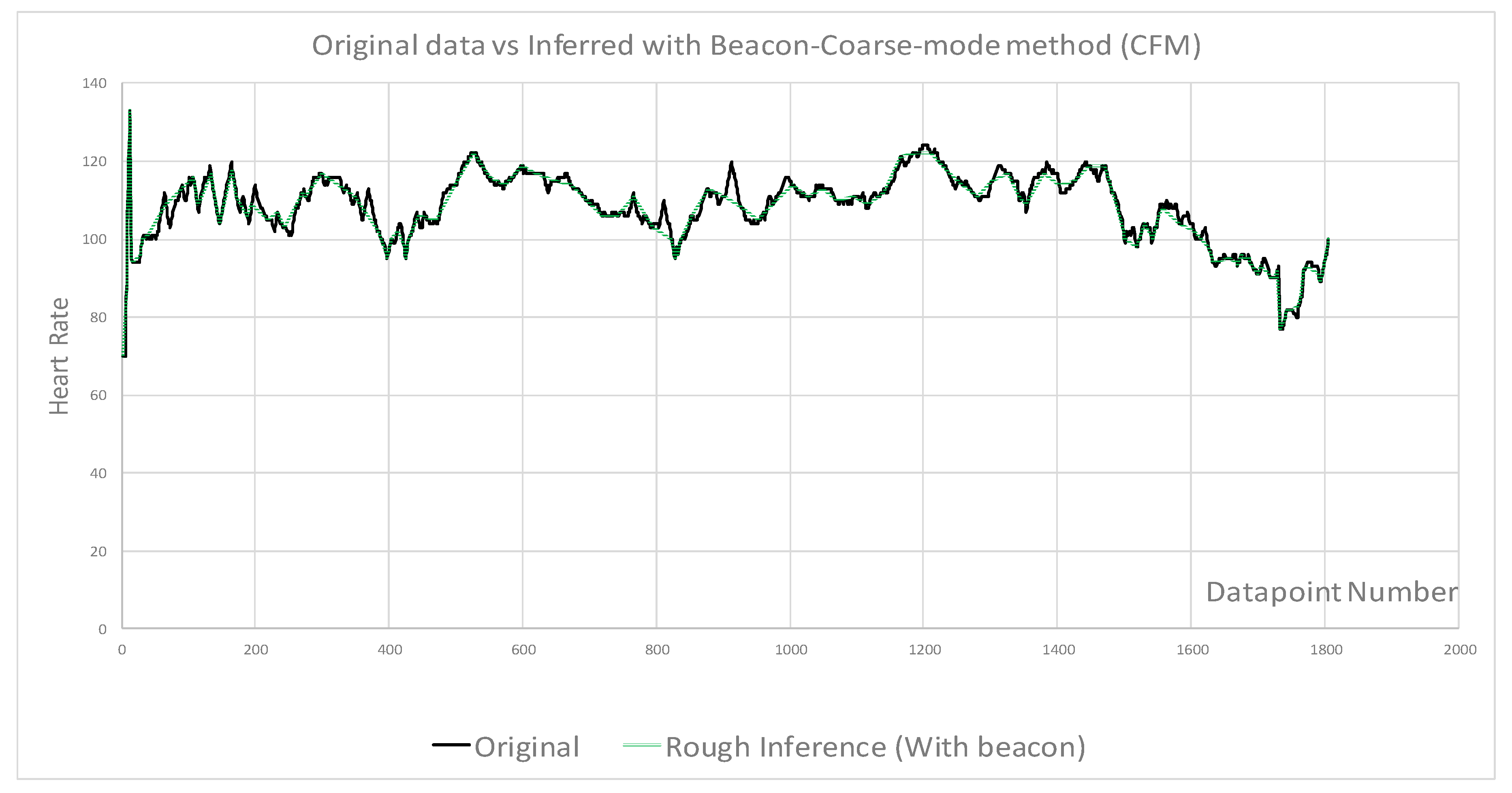
- Beacon samples selected as baseline to compare with no beacon samples
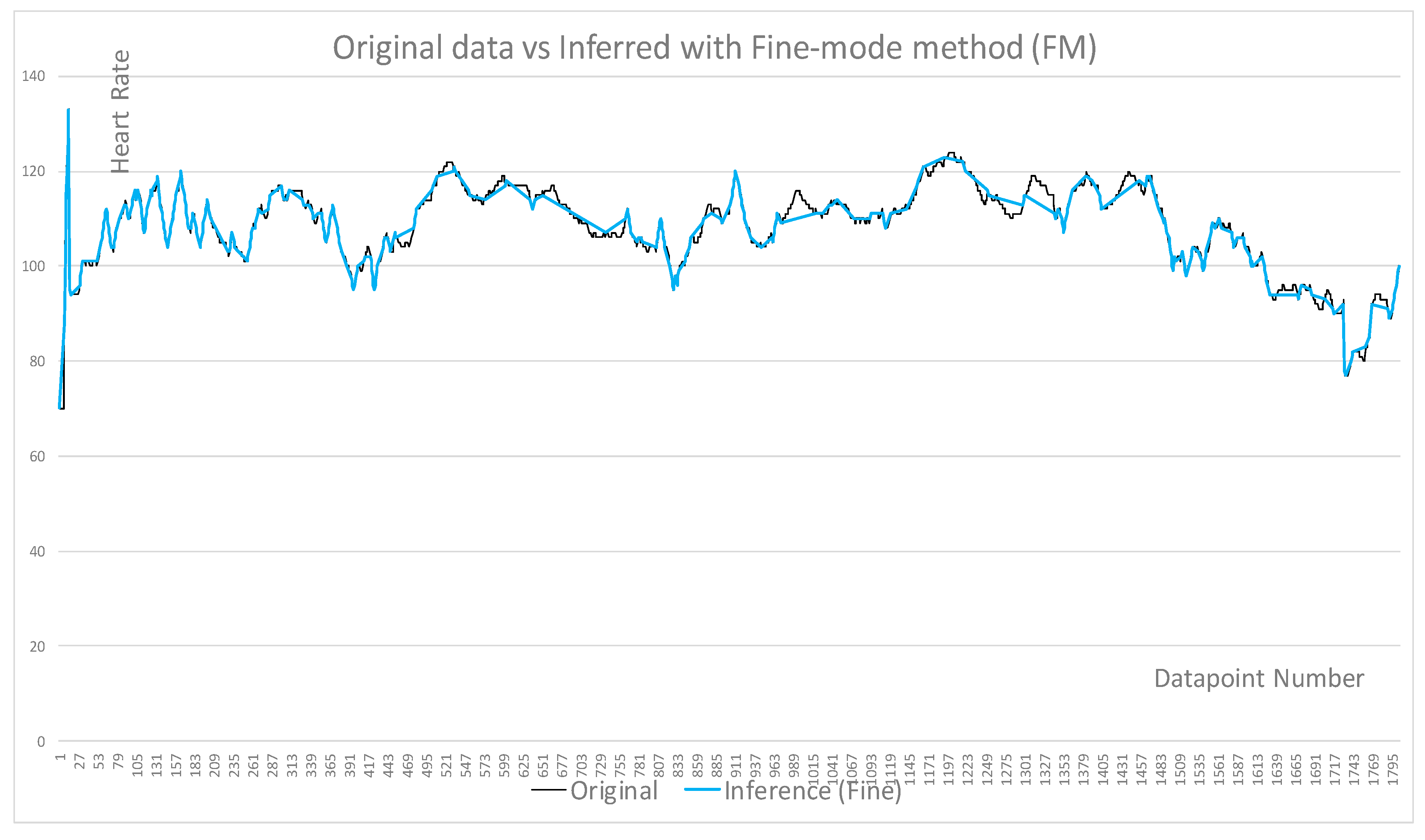
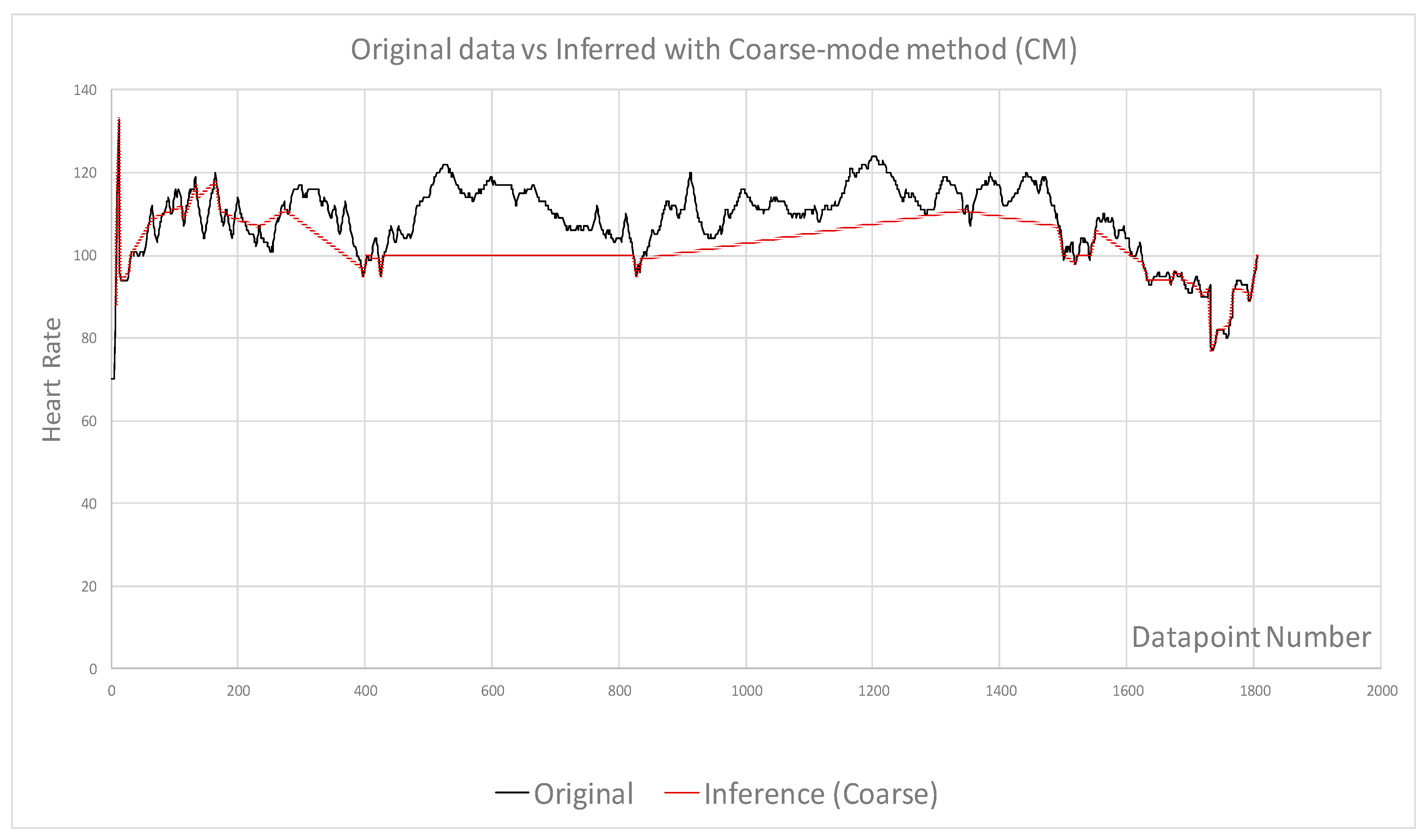
- Fine and coarse inference level were used to select samples
- Beacon data points combined with fine and coarse samples for comparison
- Algorithms 3 and 4 are applied to the original data for sampling with further adjustment.
- Accuracy trades off with efficiency
- BM produces the best efficiency with a reasonable accuracy rate
- Combining BM with other methods can improve the accuracy, however the efficiency will decrease
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- European Standardization Organization (CEN). SSCC-CG Final Report: Smart and Sustainable Cities and Communities Coordination Group; CEN-CENELEC: Brussels, Belgium, 2015. [Google Scholar]
- Brain, M. A Typical Mote—How Motes Work. Available online: http://computer.howstuffworks.com/mote4.htm (accessed on 24 December 2018).
- Konishi, T.; Kubo, T.; Watanabe, K.; Ikeda, K. Variational Bayesian Inference Algorithms for Infinite Relational Model of Network Data. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2176–2181. [Google Scholar] [CrossRef] [PubMed]
- Ma, F.; Liu, W.; Li, T. A Bayesian Inference Method under Data-Intensive Computing. In Proceedings of the 2012 International Conference on Computer Science and Service System, Nanjing, China, 11–13 August 2012; pp. 2017–2020. [Google Scholar]
- Zhang, W.; Dong, H.; Guo, G.; Yu, L. Distributed Sampled-Data Filtering for Sensor Networks with Nonuniform Sampling Periods. IEEE Trans. Ind. Inform. 2014, 10, 871–881. [Google Scholar] [CrossRef]
- Zhang, H.L.; Liu, J.; Li, T.; Xue, Y.; Xu, S.; Chen, J. Extracting sample data based on poisson distribution. In Proceedings of the 2017 International Conference on Machine Learning and Cybernetics (ICMLC), Ningbo, China, 9–12 July 2017; pp. 374–378. [Google Scholar]
- Kang, J. An Inference System Framework for Personal Sensor Devices in Mobile Health and Internet of Things Networks. Ph.D. Thesis, School of IT, Deakin University, Burwood, Australia, 2017; p. 275. [Google Scholar]
- Kang, J.J.; Larkin, H.; Luan, T.H. Enhancement of Sensor Data Transmission by Inference and Efficient Data Processing. In Applications and Techniques in Information Security; Batten, L., Li, G., Eds.; Springer: Singapore, 2016; pp. 81–92. [Google Scholar]
- NHMRC: National Statement on Ethical Conduct in Human Research (2007)—Updated 2018; Australian Government National Health and Medical Research Council: Canberra, Australia, 2018.
- Nielsen, R. Parse Heart Rate 2016. Available online: http://www.mhsoft.com/home.html (accessed on 24 December 2018).
- Mazumdar, S. From data integrity to inference integrity. In Proceedings of the 2017 2nd International Conference on Telecommunication and Networks (TEL-NET), Noida, India, 10–11 August 2017; p. 1. [Google Scholar]
- Chen, Y.; Li, L.; Chen, Z. An Approach to Verifying Data Integrity for Cloud Storage. In Proceedings of the 2017 13th International Conference on Computational Intelligence and Security (CIS), Hong Kong, China, 15–18 December 2017; pp. 582–585. [Google Scholar]
- Hiremath, S.; Kunte, S. A novel data auditing approach to achieve data privacy and data integrity in cloud computing. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Mysuru, India, 15–16 December 2017; pp. 306–310. [Google Scholar]
- Shah, S.A.R.; Sangwook, B.; Jaikar, A.; Seo-Young, N. An adaptive load monitoring solution for logically centralized SDN controller. In Proceedings of the 2016 18th Asia-Pacific Network Operations and Management Symposium (APNOMS), Kanazawa, Japan, 5–7 October 2016; pp. 1–6. [Google Scholar]
- Sidki, L.; Ben-Shimol, Y.; Sadovski, A. Fault tolerant mechanisms for SDN controllers. In Proceedings of the 2016 IEEE Conference on Network Function Virtualization and Software Defined Networks (NFV-SDN), Palo Alto, CA, USA, 7–10 November 2016; pp. 173–178. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| O | Number of original sample data |
| I | The total number of sample data after each adjustment in the sample data |
| dbI | Inference Database |
| D | Pre-defined value for distance to neighbor data point |
| G | Gap between X and its neighboring data point value |
| K | Threshold value of FM and CM |
| N | Total number of original data points. According to the Figure 4, N = Total number of DP |
| n | Total number of sampling data points. According to the Figure 4, n = Total number of Inferred DP |
| P | Pre-defined threshold data for decision making in comparison with gap difference |
| Q | Pre-defined threshold data for decision making in comparison with gap summation |
| R | Pre-defined threshold data for decision making |
| Collection of sample data after inference | |
| Collection of original sample data | |
| The upper gap after inference has been applied for the first and last data point (x and y) | |
| The lower gap after inference has been applied for the first and last data point | |
| Absolute value of difference between the original and inferred gap for the first and last data point | |
| Absolute value of summation of original and inferred gap for the first and last data point | |
| Data points to be added to from | |
| X | Current selected Data points to be compared for gaps |
| Data point to be removed from |
| Variance Rate | Original | BM | FM | CM | BFM | BCM |
|---|---|---|---|---|---|---|
| Data points | 1800 | 70 | 449 | 139 | 496 | 202 |
| Savings (%) | n/a | 96.0 | 75.1 | 92.1 | 72.3 | 88.5 |
| Efficiency | n/a | 24.3 | 3 | 11.9 | 2.6 | 7.91 |
| Accuracy (%) | n/a | 97.5 | 99.0 | 94.1 | 99.5 | 98.3 |
| Figures | Figure 4 | Figure 4 | Figure 5 | Figure 6 | Figure 7 | Figure 8 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kang, J.J.; Fahd, K.; Venkatraman, S. An Enhanced Inference Algorithm for Data Sampling Efficiency and Accuracy Using Periodic Beacons and Optimization. Big Data Cogn. Comput. 2019, 3, 7. https://doi.org/10.3390/bdcc3010007
Kang JJ, Fahd K, Venkatraman S. An Enhanced Inference Algorithm for Data Sampling Efficiency and Accuracy Using Periodic Beacons and Optimization. Big Data and Cognitive Computing. 2019; 3(1):7. https://doi.org/10.3390/bdcc3010007
Chicago/Turabian StyleKang, James Jin, Kiran Fahd, and Sitalakshmi Venkatraman. 2019. "An Enhanced Inference Algorithm for Data Sampling Efficiency and Accuracy Using Periodic Beacons and Optimization" Big Data and Cognitive Computing 3, no. 1: 7. https://doi.org/10.3390/bdcc3010007
APA StyleKang, J. J., Fahd, K., & Venkatraman, S. (2019). An Enhanced Inference Algorithm for Data Sampling Efficiency and Accuracy Using Periodic Beacons and Optimization. Big Data and Cognitive Computing, 3(1), 7. https://doi.org/10.3390/bdcc3010007