Modelling Early Word Acquisition through Multiplex Lexical Networks and Machine Learning


Abstract
1. Introduction
2. Materials and Methods
2.1. Predicting Normative Word Acquisition with Machine Learning
2.2. Psycholinguistic Data
- Word frequency, representing how commonly a given word occurs in language [23,38]. A network investigation of the mental lexicon by Steyvers et al. [39] showed that high frequency words tended not only to be acquired early on during cognitive development but also to reside in the core of semantic network representations of the mental lexicon. These results highlighted the interplay between frequency, word learning and mental lexicon structure. Furthermore, a recent large-scale study of Kuperman et al. [40] found that word frequency was the most important predictor for the age of acquisition of over 30,000 English words, spanning from early childhood up to adulthood. Although the current paper focuses mainly on early childhood, word frequency is still expected to play an important role for early word learning prediction, as also reported by previous investigations [16,17,18]. The large-scale Opensubtitles dataset [38], including frequency norms from parsing over 2.7 million sentences from movie subtitles, was used as a proxy for quantifying word frequencies of English words. Importantly, the Opensubtitles dataset was found to be superior to other frequency norms from text corpora in explaining variance in reaction time from lexical decision tasks in English [41]. For this reason, the Opensubtitles dataset is suitable for further psycholinguistic investigations.
- Word length, counting the number of characters composing a given word. Kuperman et al. [40] found that word length strongly correlated (negatively) with the age of acquisition norms of 30,000 words, highlighting a tendency for shorter words to be acquired at earlier developmental stages. Empirical confirmations of the positive effect of short length over early word acquisition were found in previous investigations [16,17,18]. During learning, children also displayed a tendency to imitate shorter words with an increased likelihood [42], further underlining the importance of word length for the cognitive processes regulating early language development.
- Polysemy norms, counting the number of context-dependent definitions a word can have [23]. Polysemy represents a language ambiguity related to meaning, so that the same word (e.g., “character”) can have different meanings according to its context of use (e.g., “character” can be related to “nature” but also to “font”). Recent investigations highlighted a tendency for children to learn words with low polysemy early on during language acquisition [43]. Polysemy was also related to the explosive emergence of language cores in a network representation of the mental lexicon [31], ultimately decreasing the semantic network distance of concepts in networks of semantic associations [13] and potentially impacting language processing [11]. Polysemy is of relevance to early word learning also because it positively correlates with the number of semantic associations a given concept can feature (cf. [31]). Recent studies [10,21] reported a tendency for children to learn novel words filling gaps in semantic networks. Therefore, polysemy is expected to encapsulate additional insights over word learning. In fact, polysemous words might better fill semantic gaps due to their richer contextual diversity. For a review about the relevance of context diversity in early word learning, the interested reader should refer to [17,44]. Polysemy here was quantified in terms of the number of different meanings attributed to a word by the curated WordData dictionary maintained by Wolfram Research and obtained by the intersection of several large-scale dictionaries. The documentation of WordData is available online [45] (last accessed: 01-23-2019). The same data was used also in a previous investigation [31].
- Being a noun, encoded as a binary variable. Previous studies showed that word category influenced early word acquisition in English [17] as well as in other languages [18]. By using networks of free associations, Hills et al. [17] showed that nouns with more associations/larger degrees tended to be learned earlier. The authors related this finding to a wider contextual diversity helping children in capturing the meaning of concepts. The same study also found the opposite effect for words not being nouns (e.g., verbs and adjectives), for which a reduced contextual diversity favoured early acquisition, instead. Word classes were computed from the CHILDES dataset.
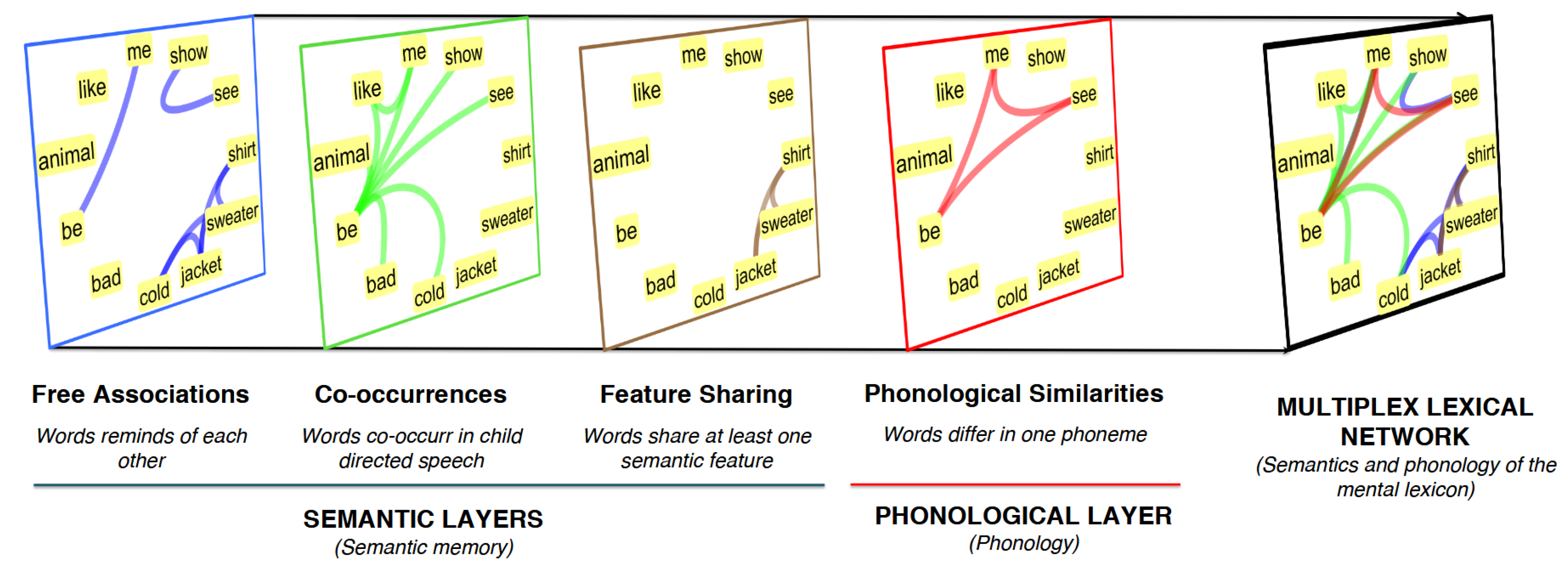
2.3. Multiplex Lexical Network
- Free associations built from the University of South Florida association norms [34]. In this layer, links between words indicate which words reminded of each other in a free association task (cf. [12,14,34]). Idiosyncratic associations were filtered out. Although free associations might contain both semantic and phonological associations, previous work on this layer has pointed out that its link overlaps with phonological similarities is negligible [19], so that it can be considered mainly a semantic layer in the current multiplex lexical network.
- Co-occurrences built from child-directed speech from the CHILDES dataset [19]. In this layer, links between words indicate which words co-occurred in the same 5-g more than T times. The threshold T was chosen to be 45 in order for the co-occurrence layer to have analogous link density compared to the other semantic layers. Co-occurrences in this multiplex lexical network capture some information about the syntactic structure of speech and some semantic features of concepts [4,9].
- Semantic feature sharing built from the McRae feature norms [47]. In this layer, words are linked if sharing at least one semantic feature (e.g., “being an animate object”).
- Phonological similarities built from phonological International Phonetic Alphabet (IPA) transcriptions of words. In this layer, two words are connected if they differ by the addition/substitution/deletion of one phoneme. Phonological similarities capture some of the phonological information available in the mental lexicon [7,8,15,22,48].
2.4. Cognitive Interpretation of Network Measures
- At the local scale of observation, word degree over the whole multiplex structure was chosen. This is the sum of the degrees of a word across all the multiplex layers [46]. For instance, with reference to Figure 1, the word “show” has multiplex degree equal to 2, since it has one free association link, one co-occurrence link, no feature sharing link and no phonological similarity. Degree is a local feature of words because it neglects the global network structure and it focuses on identifying the amount of lexical associations for a given word. On phonological networks, degree is also called neighbourhood density and it is informative of psycholinguistic data about lexical decision tasks, word confusability and memory retrieval [7,8,22]. On semantic networks, degree is similarly informative about memory retrieval from semantic memory in fluency tasks [12]. Multiplex degree (multidegree) combines phonological and semantic information [19].
- At the meso-scale level of observation, multiplex PageRank versatility was chosen. This variant of PageRank for multiplex networks was introduced by De Domenico and colleagues [50] in order to quantify the likelihood for a random walker navigating a multiplex network to visit a given node. The random walk explores a multiplex network by randomly crossing links within a given layer and teleporting from layer to layer. As a result, the exploration process is a good proxy of the community structure of a multiplex network, providing information on how central a given node is based on the centrality of its neighbours. On multiplex networks, versatility PageRank identifies those nodes acting as brokerage nodes for the flow of information across two layers (cf. [50]). An example in Figure 1 is the word “be”, which is well connected in both the phonological and co-occurrence layers. Single-layer PageRank versatility was reported to predict fluency data from semantic network structure [51].
- At the global level of observation, where the whole network structure is measured, multiplex closeness centrality was chosen. Closeness centrality quantifies the average network distance of a node from all the other nodes in the same connected component of a network [52]. The multiplex variant exploits network distances combining links from different layers. No explicit cost for traversing semantic/phonological layers is considered. However, multiplex closeness still depends on inter-layer link–link correlations, so that this metric considers an implicit coupling between layers even when no explicit transition costs are considered. With reference to Figure 1, the word “be” is the one with the highest closeness centrality, since it is at lower network distance from most of the other network nodes. Notice that network distance indicates the smallest amount of associations connecting two nodes and it has been used for predicting data from both semantic [11] and phonological [48] relatedness tasks. More recently, network distance was used also as a predictor of knowledge acquisition [26], creativity [24,53] and picture naming performance in patients with aphasia [22,28].
2.5. Interpreting the Adopted Research Methodology
3. Results
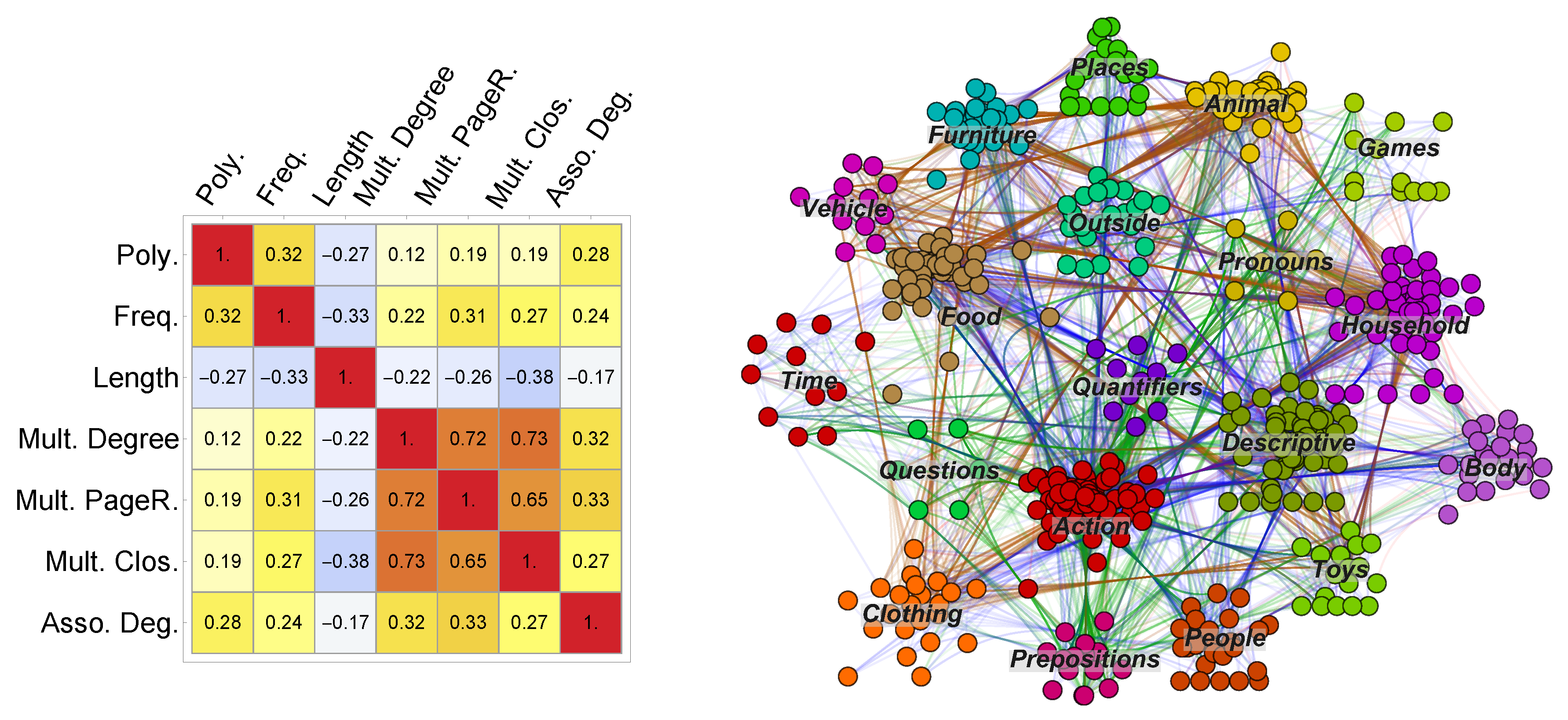
3.1. Psycholinguistic and Network Features Are Correlated
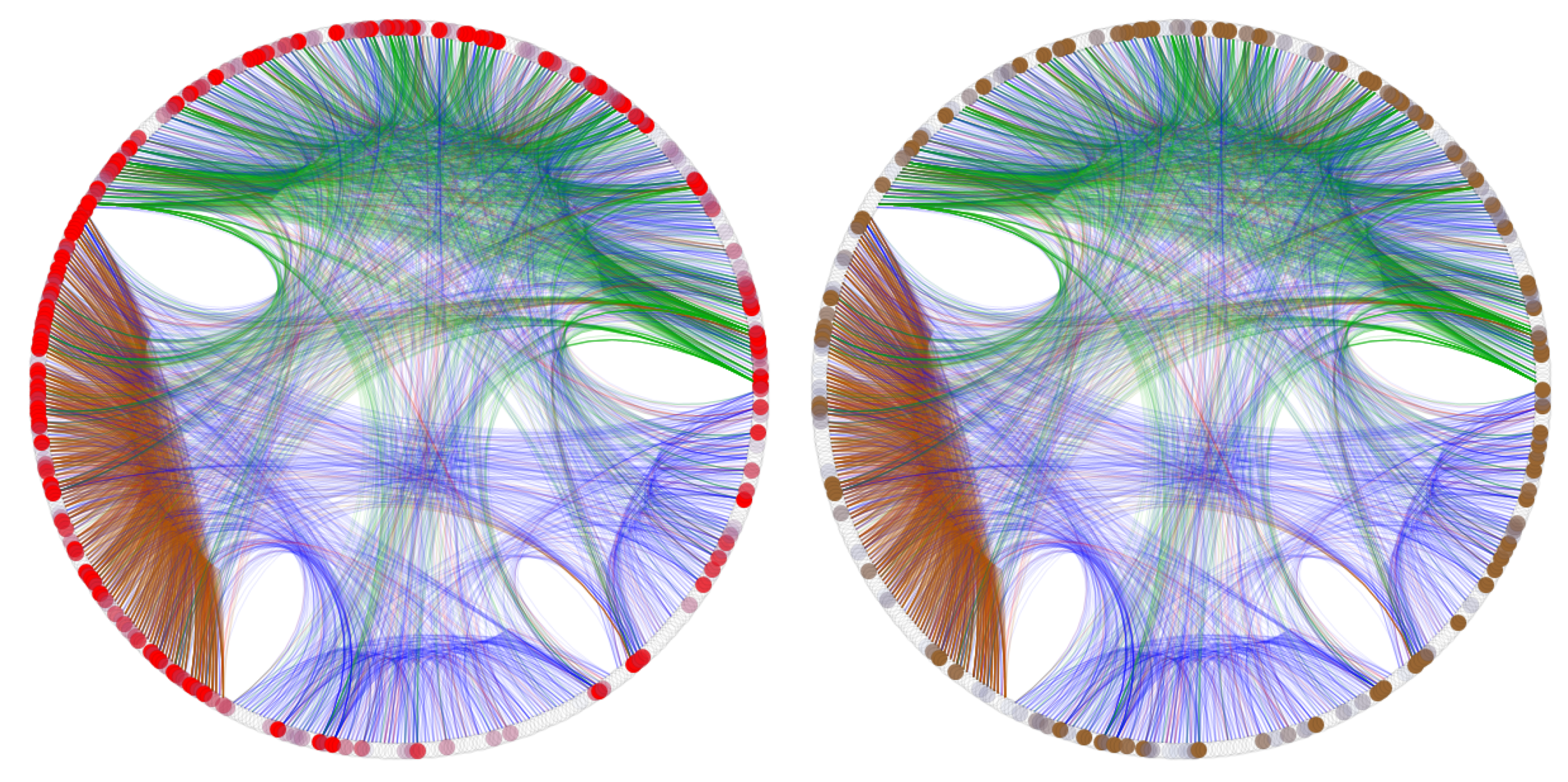
3.2. Multiplex Lexical Structure Reflects Conceptual Categories
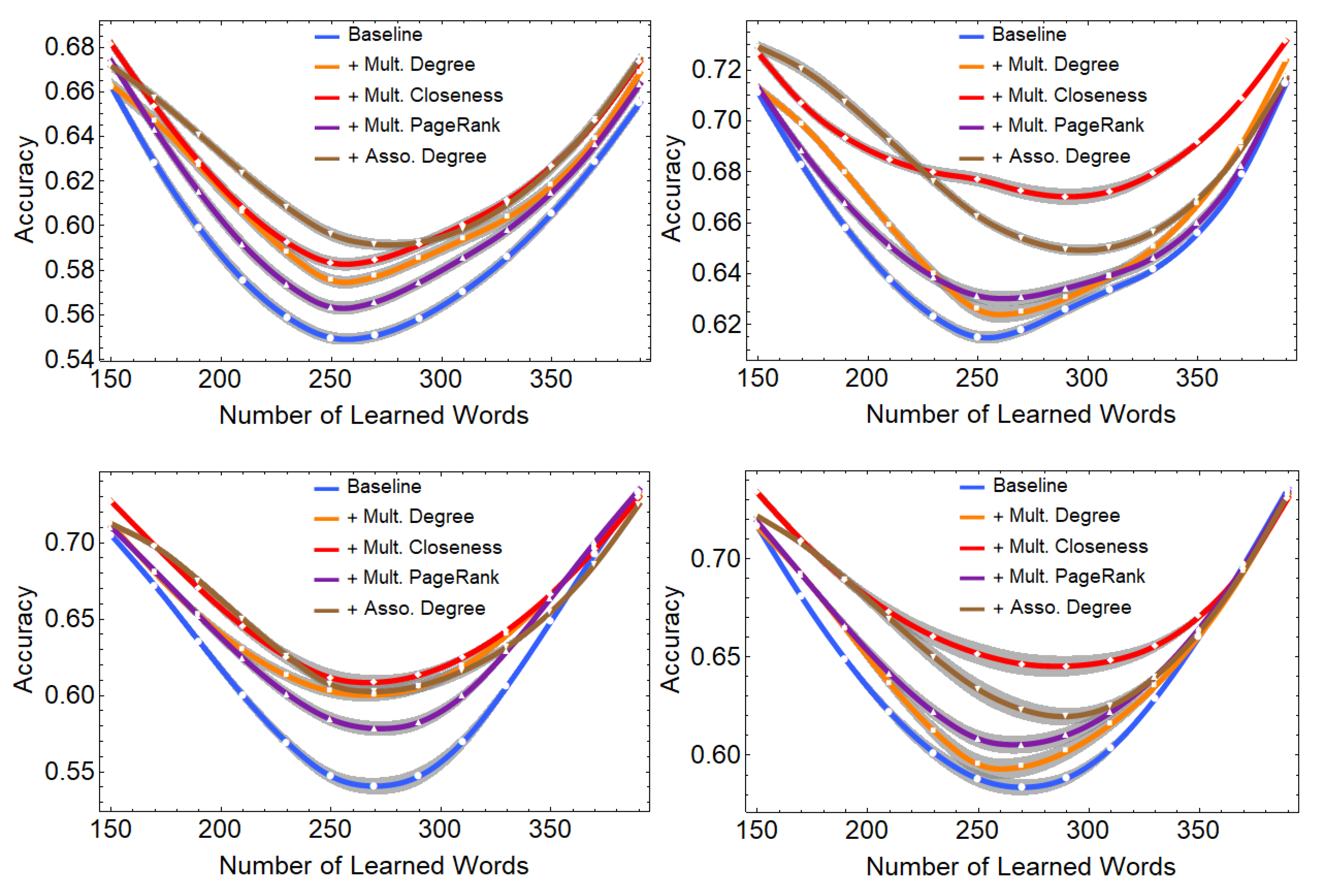
3.3. Machine Learning Highlights the Influence of the Global Mental Lexicon Structure on Word Learning
4. Discussion
5. Conclusions
Supplementary Materials
Funding
Acknowledgments
Conflicts of Interest
References
- Aitchison, J. Words in the Mind: An Introduction to the Mental Lexicon; John Wiley & Sons: New York, NY, USA, 2012. [Google Scholar]
- Thomas, M.S.; Laurillard, D. Computational Modeling of Learning and Teaching; Handbook of Educational Neuroscience; Wiley-Blackwell: Oxford, UK, 2013. [Google Scholar]
- Baronchelli, A.; Ferrer-i Cancho, R.; Pastor-Satorras, R.; Chater, N.; Christiansen, M.H. Networks in cognitive science. Trends Cognit. Sci. 2013, 17, 348–360. [Google Scholar] [CrossRef] [PubMed]
- Beckage, N.M.; Colunga, E. Language networks as models of cognition: Understanding cognition through language. In Towards a Theoretical Framework for Analyzing Complex Linguistic Networks; Springer: New York, NY, USA, 2016; pp. 3–28. [Google Scholar]
- Siew, C.S.; Wulff, D.U.; Beckage, N.; Kenett, Y. Cognitive Network Science: A review of research on cognition through the lens of network representations, processes, and dynamics. PsyArXiv 2018, 9. [Google Scholar] [CrossRef]
- Thomas, M.S.; McLelland, J. Connectionist Models of Cognition; Cambridge University Press: Cambridge, UK, 2008. [Google Scholar]
- Vitevitch, M.S. What can graph theory tell us about word learning and lexical retrieval? J. Speech Lang. Hear. Res. 2008, 51, 408–422. [Google Scholar] [CrossRef]
- Vitevitch, M.S.; Siew, C.S.; Castro, N. Spoken Word Recognition; The Oxford Handbook of Psycholinguistics; MIT Press: Cambridge, MA, USA, 2018; p. 31. [Google Scholar]
- Beckage, N.; Smith, L.; Hills, T. Small worlds and semantic network growth in typical and late talkers. PLoS ONE 2011, 6, e19348. [Google Scholar] [CrossRef] [PubMed]
- Hills, T.T.; Siew, C.S. Filling gaps in early word learning. Nat. Hum. Behav. 2018, 2, 622. [Google Scholar] [CrossRef]
- Kenett, Y.N. Going the extra creative mile: The role of semantic distance in creativity–Theory, research, and measurement. In The Cambridge Handbook of the Neuroscience of Creativity; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]
- De Deyne, S.; Navarro, D.J.; Storms, G. Better explanations of lexical and semantic cognition using networks derived from continued rather than single-word associations. Behav. Res. Methods 2013, 45, 480–498. [Google Scholar] [CrossRef] [PubMed]
- Sigman, M.; Cecchi, G.A. Global organization of the Wordnet lexicon. Proc. Natl. Acad. Sci. USA 2002, 99, 1742–1747. [Google Scholar] [CrossRef]
- De Deyne, S.; Kenett, Y.N.; Anaki, D.; Faust, M.; Navarro, D. Large-scale network representations of semantics in the mental lexicon. In Big Data in Cognitive Science: From Methods to Insights; CRC Press: Boca Raton, FL, USA, 2016; pp. 174–202. [Google Scholar]
- Stella, M.; Brede, M. Patterns in the English language: phonological networks, percolation and assembly models. J. Stat. Mech. Theory Exp. 2015, 2015, P05006. [Google Scholar] [CrossRef]
- Hills, T.T.; Maouene, M.; Maouene, J.; Sheya, A.; Smith, L. Longitudinal analysis of early semantic networks: Preferential attachment or preferential acquisition? Psychol. Sci. 2009, 20, 729–739. [Google Scholar] [CrossRef]
- Hills, T.T.; Maouene, J.; Riordan, B.; Smith, L.B. The associative structure of language: Contextual diversity in early word learning. J. Mem. Lang. 2010, 63, 259–273. [Google Scholar] [CrossRef]
- Braginsky, M.; Yurovsky, D.; Marchman, V.A.; Frank, M.C. From uh-oh to tomorrow: Predicting age of acquisition for early words across languages. In Proceedings of the 38th annual conference of the Cognitive Science Society, Philadelphia, PA, USA, 10–13 August 2016; pp. 1691–1696. [Google Scholar]
- Stella, M.; Beckage, N.M.; Brede, M. Multiplex lexical networks reveal patterns in early word acquisition in children. Sci. Rep. 2017, 7, 46730. [Google Scholar] [CrossRef] [PubMed]
- Stella, M.; De Domenico, M. Distance entropy cartography characterises centrality in complex networks. Entropy 2018, 20, 268. [Google Scholar] [CrossRef]
- Sizemore, A.E.; Karuza, E.A.; Giusti, C.; Bassett, D.S. Knowledge gaps in the early growth of semantic feature networks. Nat. Hum. Behav. 2018, 2, 682. [Google Scholar] [CrossRef] [PubMed]
- Vitevitch, M.S.; Castro, N. Using network science in the language sciences and clinic. Int. J. Speech-Lang. Pathol. 2015, 17, 13–25. [Google Scholar] [CrossRef] [PubMed]
- Ferrer-i Cancho, R.; Vitevitch, M.S. The origins of Zipf’s meaning-frequency law. J. Assoc. Inf. Sci. Technol. 2018, 69, 1369–1379. [Google Scholar] [CrossRef]
- Kenett, Y.N.; Levy, O.; Kenett, D.Y.; Stanley, H.E.; Faust, M.; Havlin, S. Flexibility of thought in high creative individuals represented by percolation analysis. Proc. Natl. Acad. Sci. USA 2018, 115, 867–872. [Google Scholar] [CrossRef] [PubMed]
- Stella, M.; Ferrara, E.; De Domenico, M. Bots increase exposure to negative and inflammatory content in online social systems. Proc. Natl. Acad. Sci. USA 2018, 115, 12435–12440. [Google Scholar] [CrossRef]
- Siew, C.S. Using network science to analyze concept maps of psychology undergraduates. Appl. Cognit. Psychol. 2018. [Google Scholar] [CrossRef]
- Amancio, D.R. Authorship recognition via fluctuation analysis of network topology and word intermittency. J. Stat. Mech. Theory Exp. 2015, 2015, P03005. [Google Scholar] [CrossRef]
- Castro, N.; Stella, M. The multiplex structure of the mental lexicon influences picture naming in people with aphasia. PsyArXiv 2018. [Google Scholar] [CrossRef]
- Wulff, D.U.; Hills, T.; Mata, R. Structural differences in the semantic networks of younger and older adults. PsyArXiv 2018. [Google Scholar] [CrossRef]
- Stella, M.; Brede, M. Mental lexicon growth modelling reveals the multiplexity of the English language. In Complex Networks VII; Springer: New York, NY, USA, 2016; pp. 267–279. [Google Scholar]
- Stella, M.; Beckage, N.M.; Brede, M.; De Domenico, M. Multiplex model of mental lexicon reveals explosive learning in humans. Sci. Rep. 2018, 8, 2259. [Google Scholar] [CrossRef] [PubMed]
- Stella, M. Cohort And Rhyme Priming Emerge From The Multiplex Network Structure Of The Mental Lexicon. Complexity 2018, 2018, 6438702. [Google Scholar] [CrossRef]
- MacWhinney, B. The CHILDES Project: Tools for Analyzing Talk, Volume II: The Database; Psychology Press: London, UK, 2014. [Google Scholar]
- Nelson, D.L.; McEvoy, C.L.; Schreiber, T.A. The University of South Florida free association, rhyme, and word fragment norms. Behav. Res. Methods Instrum. Comput. 2004, 36, 402–407. [Google Scholar] [CrossRef] [PubMed]
- Carlson, M.T.; Sonderegger, M.; Bane, M. How children explore the phonological network in child-directed speech: A survival analysis of children’s first word productions. J. Mem. Lang. 2014, 75, 159–180. [Google Scholar] [CrossRef] [PubMed]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; The MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Pranckevičius, T.; Marcinkevičius, V. Comparison of naive bayes, random forest, decision tree, support vector machines, and logistic regression classifiers for text reviews classification. Baltic J. Mod. Comput. 2017, 5, 221. [Google Scholar] [CrossRef]
- Barbaresi, A. Language-Classified Open Subtitles (LACLOS): Download, Extraction, and Quality Assessment. Ph.D. Thesis, BBAW, Berlin, Germany, 2013. [Google Scholar]
- Steyvers, M.; Tenenbaum, J.B. The large-scale structure of semantic networks: Statistical analyses and a model of semantic growth. Cognit. Sci. 2005, 29, 41–78. [Google Scholar] [CrossRef] [PubMed]
- Kuperman, V.; Stadthagen-Gonzalez, H.; Brysbaert, M. Age-of-acquisition ratings for 30,000 English words. Behav. Res. Methods 2012, 44, 978–990. [Google Scholar] [CrossRef]
- Brysbaert, M.; New, B. Moving beyond Kučera and Francis: A critical evaluation of current word frequency norms and the introduction of a new and improved word frequency measure for American English. Behav. Res. Methods 2009, 41, 977–990. [Google Scholar] [CrossRef]
- Zamuner, T.S.; Thiessen, A. A phonological, lexical, and phonetic analysis of the new words that young children imitate. Can. J. Linguist./Rev. Can. Linguist. 2018, 1–24. [Google Scholar] [CrossRef]
- Casas, B.; Català, N.; Ferrer-i Cancho, R.; Hernández-Fernández, A.; Baixeries, J. The polysemy of the words that children learn over time. arXiv, 2016; arXiv:1611.08807. [Google Scholar]
- Engelthaler, T.; Hills, T.T. Feature biases in early word learning: network distinctiveness predicts age of acquisition. Cognit. Sci. 2017, 41, 120–140. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://reference.wolfram.com/language/note/WordDataSourceInformation.html (accessed on 24 January 2019).
- Battiston, F.; Nicosia, V.; Latora, V. The new challenges of multiplex networks: Measures and models. Eur. Phys. J. Spec. Top. 2017, 226, 401–416. [Google Scholar] [CrossRef]
- McRae, K.; Cree, G.S.; Seidenberg, M.S.; McNorgan, C. Semantic feature production norms for a large set of living and nonliving things. Behav. Res. Methods 2005, 37, 547–559. [Google Scholar] [CrossRef] [PubMed]
- Goldstein, R.; Vitevitch, M.S. The influence of closeness centrality on lexical processing. Front. Psychol. 2017, 8, 1683. [Google Scholar] [CrossRef] [PubMed]
- Stella, M.; Brede, M. Investigating the phonetic organisation of the English language via phonological networks, percolation and Markov models. In Proceedings of ECCS 2014; Springer: New York, NY, USA, 2016; pp. 219–229. [Google Scholar]
- De Domenico, M.; Solé-Ribalta, A.; Omodei, E.; Gómez, S.; Arenas, A. Ranking in interconnected multilayer networks reveals versatile nodes. Nat. Commun. 2015, 6, 6868. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Steyvers, M.; Firl, A. Google and the mind: Predicting fluency with PageRank. Psychol. Sci. 2007, 18, 1069–1076. [Google Scholar] [CrossRef]
- Borgatti, S.P. Centrality and network flow. Soc. Netw. 2005, 27, 55–71. [Google Scholar] [CrossRef]
- Kenett, Y.N. What can quantitative measures of semantic distance tell us about creativity? Curr. Opin. Behav. Sci. 2019, 27, 11–16. [Google Scholar] [CrossRef]
- Roy, B.C.; Frank, M.C.; DeCamp, P.; Miller, M.; Roy, D. Predicting the birth of a spoken word. Proc. Natl. Acad. Sci. USA 2015, 112, 12663–12668. [Google Scholar] [CrossRef]
- Karuza, E.A.; Thompson-Schill, S.L.; Bassett, D.S. Local patterns to global architectures: influences of network topology on human learning. Trends Cognit. Sci. 2016, 20, 629–640. [Google Scholar] [CrossRef] [PubMed]
- Fenson, L.; Dale, P.S.; Reznick, J.S.; Bates, E.; Thal, D.J.; Pethick, S.J.; Tomasello, M.; Mervis, C.B.; Stiles, J. Variability in early communicative development. Monogr. Soc. Res. Child. Dev. 1994, 59, 1–173. [Google Scholar] [CrossRef] [PubMed]
- Csardi, G.; Nepusz, T. The igraph software package for complex network research. InterJournal Complex Syst. 2006, 1695, 1–9. [Google Scholar]
- Newman, M.E. Modularity and community structure in networks. Proc. Natl. Acad. Sci. USA 2006, 103, 8577–8582. [Google Scholar] [CrossRef]
- Xu, F.; Tenenbaum, J.B. Word learning as Bayesian inference. Psychol. Rev. 2007, 114, 245. [Google Scholar] [CrossRef] [PubMed]
- Newman, M. Networks; Oxford University Press: Oxford, UK, 2018. [Google Scholar]
- Fortunato, S.; Latora, V.; Marchiori, M. Method to find community structures based on information centrality. Phys. Rev. E 2004, 70, 056104. [Google Scholar] [CrossRef] [PubMed]
- Vosoughi, S.; Roy, B.; Frank, M.; Roy, D. Contributions of prosodic and distributional features of caregivers’ speech in early word learning. In Proceedings of the Annual Meeting of the Cognitive Science Society, Portland, OR, USA, 11–14 August 2010; Volume 32. [Google Scholar]
- Brysbaert, M.; Warriner, A.B.; Kuperman, V. Concreteness ratings for 40 thousand generally known English word lemmas. Behav. Res. Methods 2014, 46, 904–911. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reshuffled Feature | Relative Decrease in Accuracy | p-Value |
|---|---|---|
| Closeness Centrality | −9% | |
| Is-a-noun Flag | −6% | |
| Word Length | −2% | |
| Polysemy Score | −2% | |
| Frequency | −1% |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Stella, M. Modelling Early Word Acquisition through Multiplex Lexical Networks and Machine Learning. Big Data Cogn. Comput. 2019, 3, 10. https://doi.org/10.3390/bdcc3010010
Stella M. Modelling Early Word Acquisition through Multiplex Lexical Networks and Machine Learning. Big Data and Cognitive Computing. 2019; 3(1):10. https://doi.org/10.3390/bdcc3010010
Chicago/Turabian StyleStella, Massimo. 2019. "Modelling Early Word Acquisition through Multiplex Lexical Networks and Machine Learning" Big Data and Cognitive Computing 3, no. 1: 10. https://doi.org/10.3390/bdcc3010010
APA StyleStella, M. (2019). Modelling Early Word Acquisition through Multiplex Lexical Networks and Machine Learning. Big Data and Cognitive Computing, 3(1), 10. https://doi.org/10.3390/bdcc3010010