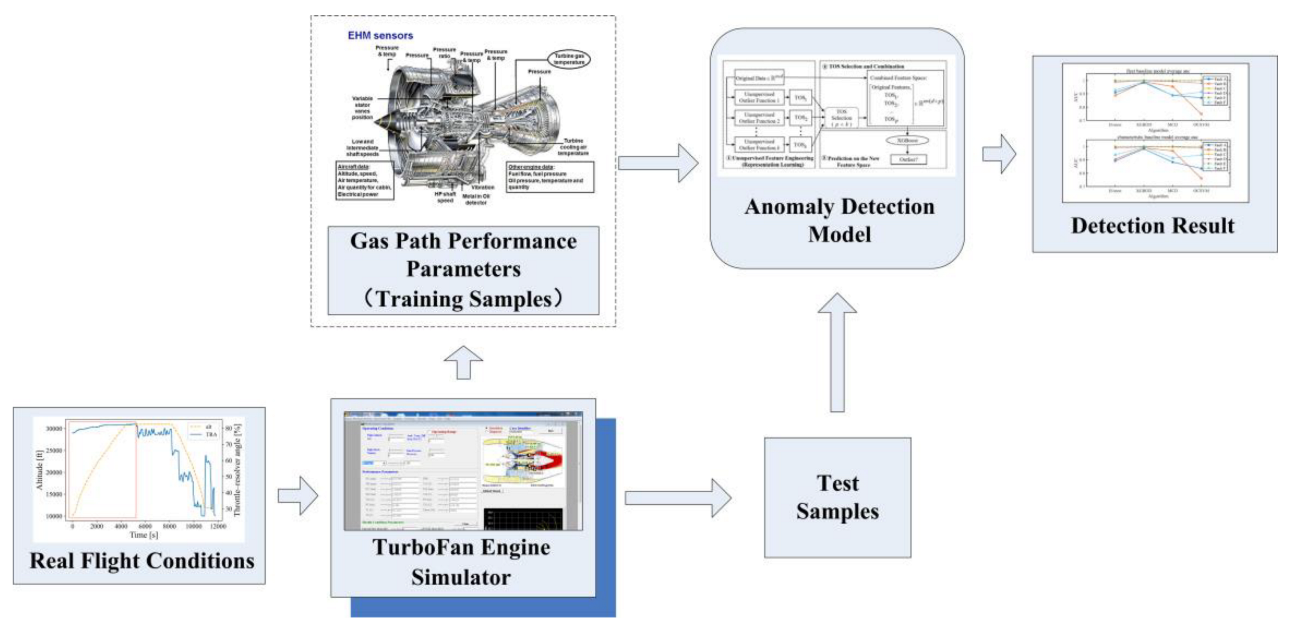
4.1. Simulation Process
All simulation data are obtained using TurboFan Engine Simulator. By inputting a specific working condition, the simulation software can calculate the performance parameters under the condition.
First a fleet of engines is simulated. The system’s components will experience degradation due to wear and tear resulting from usage. It is most often a slow phenomenon, which is detected relative to past performance on the same engine. It is very difficult to detect an efficiency drop in absolute value, because each unit of the fleet has slightly different initial wear at the engine sub-component due to manufacturing and assembly tolerances, which leads to differences in the health parameters of each engine component in the fleet, such as efficiency and flow.
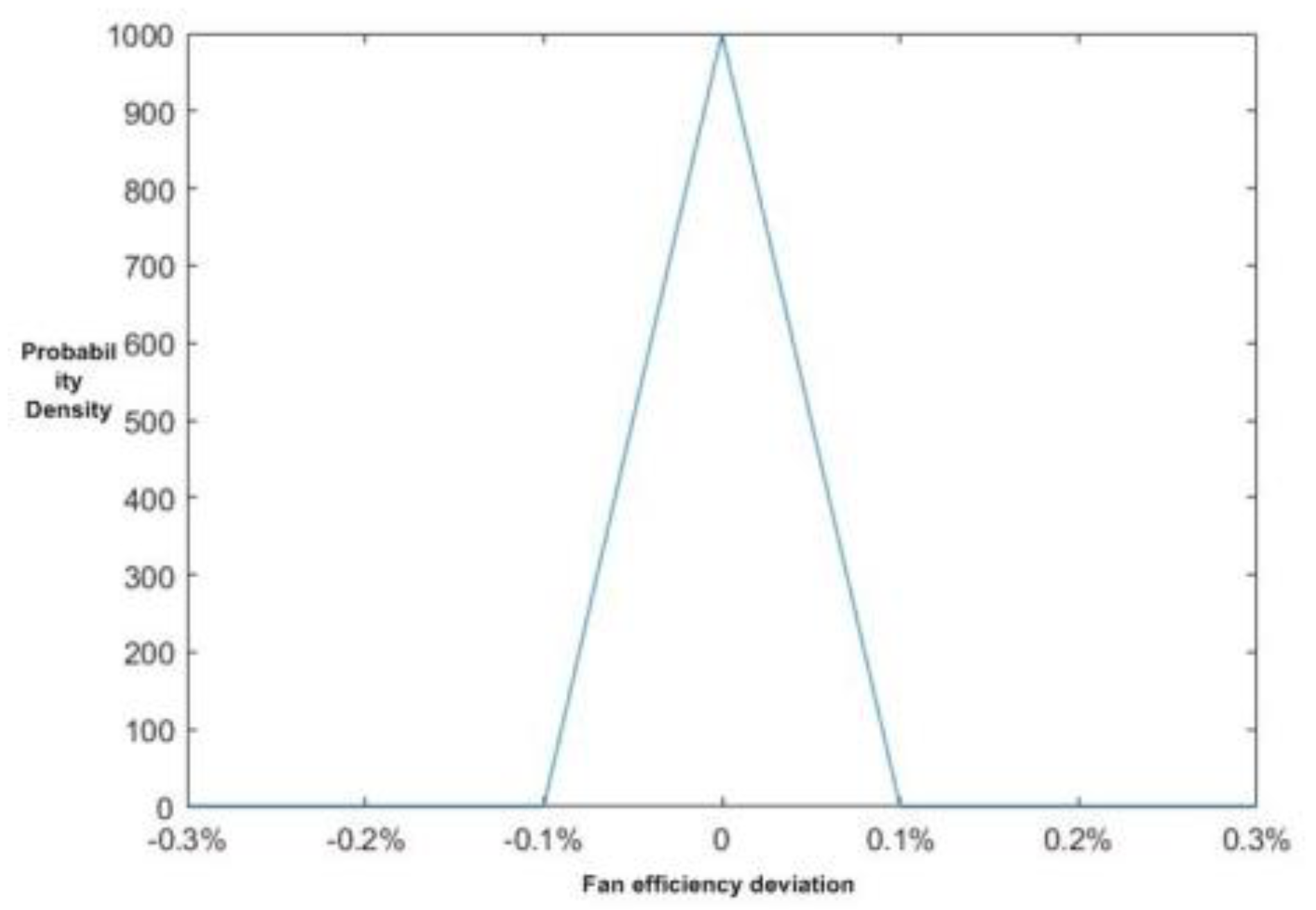
For the above reasons, each engine in the startup fleet can be distinguished based on the difference in the initial health parameters. Assuming that the deviation between the health parameters of a specific engine unit and the baseline value conform to a triangular distribution, the maximum and minimum deviation values of the parameters of each component are shown in
Table 4.
Based on the triangular distribution of the parameters, this paper adopts the Monte Carlo idea to randomly select values, and generates 100 sets of unit body health parameter deviation values, and uses this to distinguish each specific engine.
Figure 5 shows the triangular distribution of Fan efficiency deviation.
After obtaining the fleet data, the next step is to simulate different take-off conditions for each individual engine. Each set of different takeoff conditions simulation represents a specific flight. The simulation method is the same as the fleet data. Assuming that the parameters of the take-off condition also conform to the triangular distribution, the maximum and minimum deviation values are shown in
Table 5.
Each engine randomly generates 1000 sets of condition parameter values for flights simulation. After the simulation calculation is completed, the performance data of 100 engines is obtained, and 1000 flights are simulated for each engine. The gas path parameters calculated with the aid of the performance model do not contain noise, but in practice the sensor will inevitably introduce measurement noise. Therefore, a certain amount of Gaussian noise is added to the gas path parameters to simulate actual measurement noise.
4.2. Data Preprocessing and Fault Injection
The baseline model of engine can reflect the basic functional relationships of engine performance parameters in a healthy state. When the engine is in a healthy state, the performance parameter deviation value obtained by subtracting the baseline value from the actual measurement value should theoretically fluctuate around 0. The abnormal detection of the engine performance parameter can be realized by analyzing the deviation value sequence.
The performance measurement deltas (
) of each parameter needs to be calculated to facilitate the detection of the algorithm. The formula is as follows:
where
Y represents the value of the parameter, and
Y0 the nominal value at a typical taking-off condition when the engine is at a clean and new condition. (That is, using the Random Forest algorithm for parameter regression).
The health parameter deviation is calculated as follows:
where
f0 = 1 meaning the engine is at a clean and new condition. The interrelation among the health parameters deviations and the measurements deltas is expressed through a multi variable regression model, which is obtained by linearizing of the engine performance model at a typical taking-off operating point.
In this paper, two kinds of baseline values Y0 are calculated. One is to randomly select 400 sets of data from all health status data of the fleet to calculate a baseline value. The other is based on the first 400 health data of each engine, a total of 20 engines’ personalized baseline values was established separately.
Component faults are simulated by deviating of the corresponding health parameters from their nominal values, i.e., the flow and efficiency deviations of each module. To demonstrate the proposed information fusion mechanism, a typical set of fault scenarios has been examined, which covers different possible faults in all individual components (given in
Table 6).
For each fault case, a series of
n = 400 measurement sets from the taking-off operating point has been recorded for following, including 20 fleet samples and 20 single engine samples. They were randomly selected from the fleet data without putting it back. The first 360 sets are health status data, and the last 40 sets are abnormal conditions (Inject according to the failure mode of
Table 4).
4.3. Results Analysis and Comparison
In the detection, four binary classifiers, IForest, XGBOD, MCD, OCSVM (one class support vector machine), are chosen as detection algorithms. The algorithms will output two indicators to measure classification accuracy: AUC and Precision. AUC is the area under the ROC curve, its value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example. As for precision, it is the probability of how many real positive examples are in the sample predicted to be positive.
This article compares the test results from the following three aspects:
The deviation values obtained from the two baseline models are input into the isolation forest, MCD, XGBOD, OCSVM algorithm. The AUC value and accuracy rate of the abnormal detection of six abnormal modes is calculated by the algorithm model. Since each algorithm has been tested many times, the calculation result is the average of multiple tests. After detection, the comparison of AUC and precision is shown in the figure below.
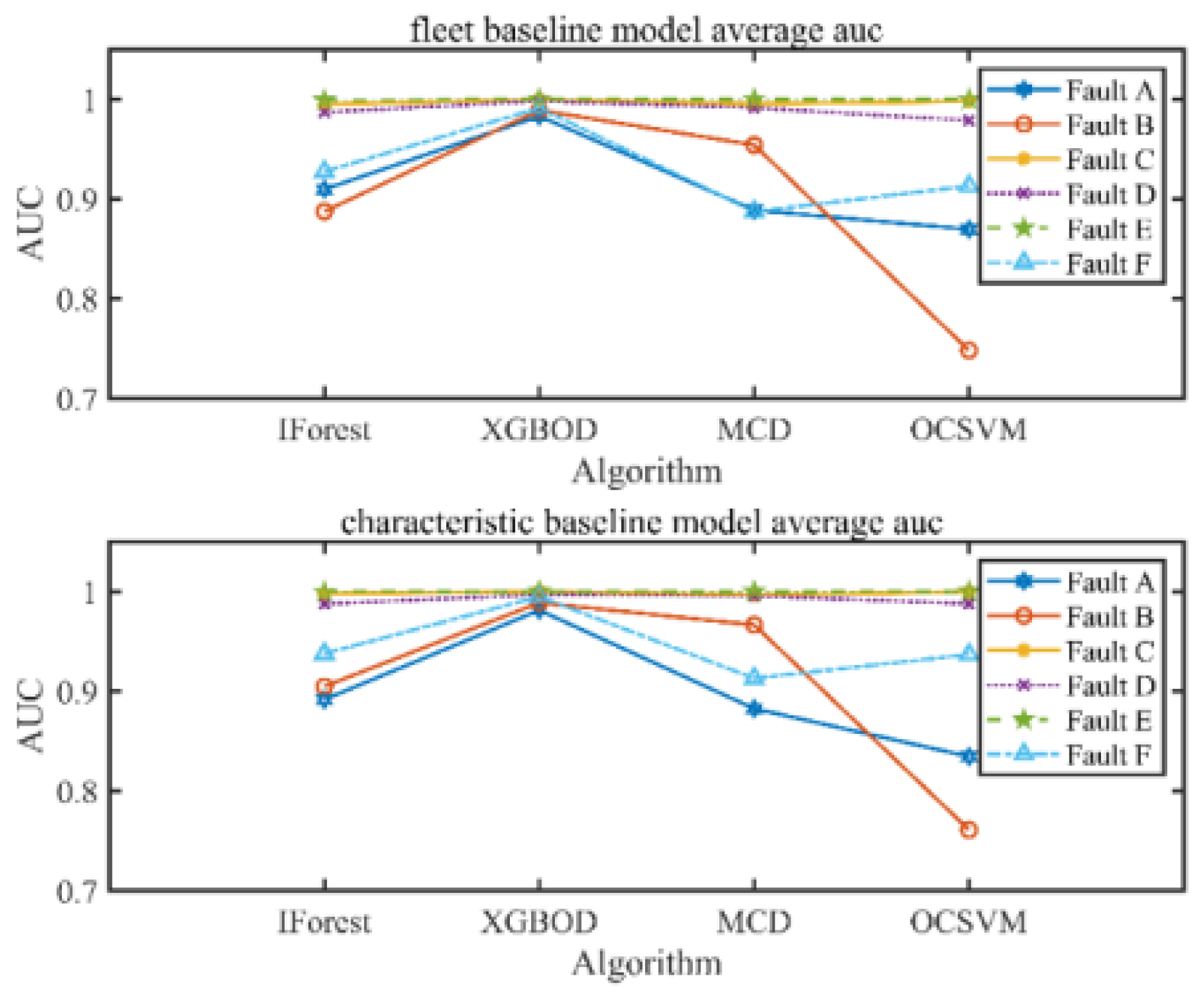
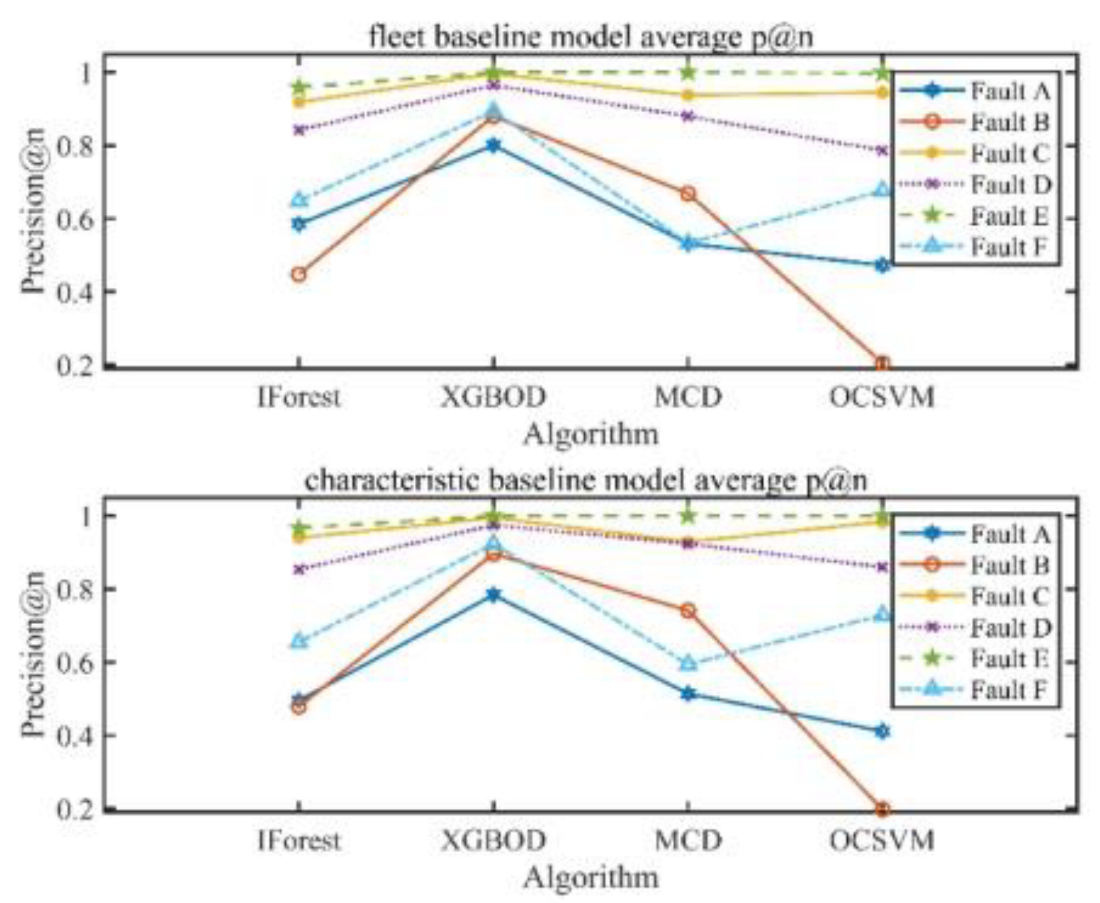
It can be seen from
Figure 6 and
Figure 7 that only three faults (i.e., fault C, D and E) have relatively high detection accuracy. The remaining fault cases are misdiagnosed. Among the four anomaly detection algorithms, XGBOD is an ensemble learning algorithm, so the overall effect is the best. The overall anomaly detection effect of MCD and IForest is not much different. In abnormal modes A and F, IForest is better than MCD. In abnormal mode B, MCD is better than IForest. OCSVM has the worst anomaly detection effect overall.
- 2.
The influence of engine performance parameters on anomaly detection effect:
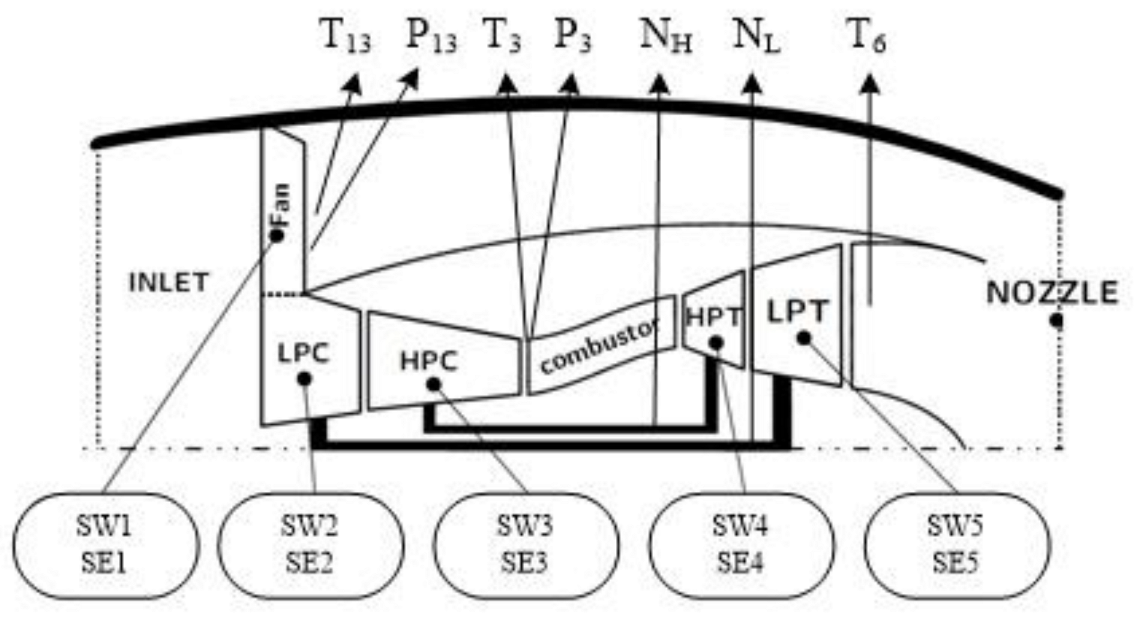
In the above, the deviation values of the nine performance parameters are all detected for abnormality. In the actual situation, the data collected by the sensor does not include the HPC inlet pressure and inlet temperature. Therefore, this section will compare the anomaly detection effects of the nine parameters and the seven parameters.
Table 7 and
Table 8 show the results.
The failure modes not accurately identified were failure mode A and B. For the failure mode B, the HPC fault with a simultaneous reduction in efficiency and flow capacity, which may affect LPC component, resulting in an evident LPC efficiency decrease. Due to the limited on-board performance measurement set, the measurements between the LPC and HPC are insufficient to characterize all fault information, for which they share a similar measurement observation pattern due to the failure.
- 3.
The influence of different levels of noise on the detection effect:
Besides the on-board sensor measurements limitation, the measurement noise can also introduce uncertainty into the health parameters estimation. Especially when the fault magnitude is relatively smaller, the failure signature maybe masked in the measurement noise, causing wrong diagnostics conclusions. Two types of noise are used to process the data here. The amount of noise is shown in
Table 9.
The test analysis for the above test results is given here. First, in the detection of different baseline model, the failure modes B, C, D, E and F show better effect with single engine baseline model. However, in the detection of failure mode A, the detection effect of the fleet baseline model is more accurate, which means that the failure mode A is less affected by the engine’s performance difference. The fan is the most exposed air path component of the engine. Compared to changes in internal flow and efficiency of components, changes in the external environment are more likely to affect the efficiency of the fan.
Second, most algorithms obtain better detection results when the input performance parameters are nine. However, the MCD algorithm performs even better when the input parameters are seven, which may be related to the internal calculation of the Mahalanobis distance. When the dimensionality of the data point increases, the calculated Mahalanobis distance will also increase. If the fault information can be reflected by only a few parameters, adding more parameter dimension may cover up the fault information which needs to be expressed by the value of distance, and it may lead to the misjudgment of the algorithm.
Third, the detection results of noise case are given in
Table 10. Indicator “Precision” is more obviously affected by noise, so it is selected as the observation target.
It can be observed that the detection ability of all algorithms decreases after the noise is doubled. Among them, the detection accuracy of failure modes C, D and F are significantly reduced, which are all turbine failure. This shows the flow and efficiency deviations of turbine component have less impact on the engine, which can be easily masked in the noise.
Based on the above results, the XGBOD algorithm has the highest detection accuracy. It makes good use of its advantages as an integrated algorithm, and performs well in the case of reduced parameters or increased noise. In contrast, the detection accuracy of IForest and OCSVM algorithms is not in a good level. Due to the lack of training data, the IForest failed to play its advantage in the detection of massive data. As for OCSVM, it is mainly good at single classification [
28], and it does not perform well on two classification problems.
In terms of failure modes, failure mode E has the highest detection accuracy. This shows that the reduced efficiency of the high-pressure compressor will seriously affect the performance of the whole engine. On the other hand, the detection rate of each algorithm for failure mode A is relatively low. The reason may be that the selected parameters cannot well represent the characteristics of the failure, or the failure itself has a small impact on engine’s performance.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}