1. Introduction
The rapid expansion of virtual learning environments, dramatically accelerated by the COVID-19 pandemic, has led to an unprecedented surge in online course enrollments, with some institutions reporting increases exceeding 300% [
1]. While this shift offers increased accessibility and flexibility, it has also amplified inherent challenges in online education, particularly regarding student engagement, assessment, and the delivery of personalized learning experiences. In online settings, students frequently experience reduced social presence and a sense of isolation, which negatively impacts their motivation, commitment, and overall learning outcomes [
2]. Moreover, traditional assessment methods, often reliant on standardized metrics, fail to capture the nuanced dynamics of digital engagement, and instructors struggle to provide timely, individualized feedback at scale. These issues underscore the urgent need for innovative, automated solutions that can support personalized feedback.
In response to these challenges, Artificial Intelligence (AI) technologies have emerged as promising tools for enhancing online education. In particular, deep learning (DL) techniques and large language models (LLMs) offer significant potential. Deep learning, which leverages large datasets to analyze complex educational data, has been suggested to offer the potential for superior accuracy in predicting student performance compared to traditional statistical methods [
3]. Models such as recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have proven effective in forecasting academic outcomes and identifying students at risk of dropout [
4]. Simultaneously, LLMs like OpenAI’s GPT-4 are revolutionizing automated, personalized feedback by generating natural language responses, understanding intricate prompts, and adapting their communication style to individual student needs [
5]. However, it is crucial to acknowledge that the application of DL and LLMs in education is not without challenges. Potential limitations include biases in training data, the “black box” nature of many deep learning models, and the risk of LLMs generating generic or contextually inappropriate feedback. Addressing these issues requires careful consideration and mitigation strategies, such as focusing on diverse and representative training data, incorporating interpretability techniques into model design, and implementing human oversight in the feedback generation process.
The significance of effective feedback for learning is well-established. The seminal work by Hattie and Timperley [
6] demonstrated that the type and modality of feedback are critical determinants of student performance, specifically, that corrective and detailed written feedback is more effective than simple praise or grades. Building on these insights, the field of Artificial Intelligence in Education (AIED) has been at the forefront of developing intelligent tutoring systems (ITS) and adaptive learning environments that leverage AI to automate and personalize feedback [
7,
8,
9,
10]. Early ITS approaches were based on rule-based systems and knowledge tracing, whereas modern methods have evolved to incorporate advanced techniques such as Bayesian networks and deep knowledge tracing, providing a more refined basis for adaptive feedback [
8]. This rich history in AIED research lays a robust foundation for integrating contemporary DL and LLM technologies to further enhance feedback mechanisms in online education.
In this study, we introduce the Adaptive Feedback System (AFS), a novel system designed to provide personalized and timely feedback to students in online courses. AFS utilizes a deep learning-based predictive model, specifically, a recurrent neural network (RNN) trained on historical student engagement and performance data from previous online courses in Digital Arts for Film and Video Games. This model analyzes key metrics, such as synchronous session attendance, digital content interaction, forum participation, and portfolio task completion, to identify students who could benefit from targeted interventions. The predictions are then interpreted by OpenAI’s GPT-4, which generates tailored feedback messages addressing individual student needs. For instance, AFS might offer encouraging messages and gamified incentives to students at risk of disengagement, while providing detailed, constructive criticism and targeted resources to those facing specific academic challenges. AFS is notably designed as a dynamic and adaptive system that continuously refines its feedback strategies based on ongoing student interactions.
The central research questions guiding this study are as follows: Can recurrent neural network-based deep learning models, applied to extensive datasets of quantitative learning analytics data, predict student performance in online environments more effectively than traditional methods? Furthermore, how effective are LLMs like OpenAI’s GPT-4 in interpreting these predictions and generating personalized feedback that enhances student engagement and learning outcomes? Finally, what is the overall impact of the integrated AFS on student performance and engagement in a real-world online course setting?
To address these questions and evaluate the effectiveness of AFS, this paper is structured as follows. First, we review relevant literature on AI in education—focusing on DL-based prediction models and LLMs for feedback—and critically discuss both their potential and limitations within educational contexts. Next, we detail the methodology of our study, including the experimental design, participant demographics, and data collection and analysis procedures. The Results section presents a comparative analysis of student performance and engagement metrics between the experimental group (using AFS) and a control group (receiving traditional feedback). The Discussion section interprets these findings in the context of established AIED research and broader educational literature, and the Conclusion section reflects on the challenges, limitations, and future directions for research in AI-enhanced feedback systems.
1.1. Personalized Feedback with ChatGPT
Building upon decades of research in the field of Artificial Intelligence in Education (AIED) on personalized and Adaptive Feedback Systems [
7,
9], recent studies have begun to explore the potential of large language models (LLMs) like ChatGPT to further enhance feedback in online learning environments. Wang et al. [
11] found that ChatGPT significantly enhances the quality of student argumentation by offering specific and timely feedback, key characteristics of effective feedback according to Hattie and Timperley [
6]. In contrast, Messer et al. [
12], in their systematic review of automated grading and feedback tools for programming education, offer a broader perspective, indicating that automated feedback tools, including those powered by LLMs, are generally effective in improving learning outcomes, reinforcing the more specific findings of Wang et al. [
11] and Meyer et al. [
13] explored the collaborative generation of feedback between students and AI, highlighting the potential of this collaboration to enrich educational feedback. Specifically, Li Wang et al. [
14] demonstrated that ChatGPT exhibits impressive accuracy (91.8%) and a retrieval rate of 63.2% when providing feedback on undergraduate student argumentation. However, they also found that the length of the arguments and the use of discourse markers significantly influenced the effectiveness of the feedback, suggesting that the quality of ChatGPT’s feedback may depend on the characteristics of the student’s input. Meyer et al. [
13] for their part, discovered that feedback generated by LLMs led to enhanced performance in text revisions, as well as increased motivation and positive emotions among high school students, indicating the potential multifaceted benefits of ChatGPT-based feedback beyond academic performance.
1.2. Deep Learning Models for Performance Prediction
In the field of learning analytics (LA) and educational data mining (EDM), deep learning has emerged as a powerful set of techniques for student performance prediction. Researchers have explored various deep learning models, including recurrent neural networks (RNNs) and, particularly, long short-term memory (LSTM) networks, due to their ability to model sequential learning data [
4]. These models have proven effective in predicting academic performance and in identifying students at risk of dropping out of courses [
3]. For example, Messer et al. [
12] used neural network algorithms and LSTM to analyze large volumes of data for the purpose of predicting performance in programming education, although their primary focus was the review of automated feedback tools. Alnasyan et al. [
15], while not directly focused on prediction, also found that the integration of generative AI, which often employs underlying deep learning models, can improve the academic performance and motivation of business students, suggesting that accurate performance prediction, enabled by deep learning, could be a valuable component for more adaptive and personalized educational systems. In addition to RNNs and LSTMs, other deep learning architectures, such as convolutional neural networks (CNNs) and multilayer perceptron (MLP) networks, have also been investigated for prediction tasks in LA/EDM, each with strengths and weaknesses depending on the data type and specific prediction task.
1.3. Evaluation of LLM-Based Educational Applications and Their Implicit Comparison with Traditional Feedback Methods
While several studies have directly compared feedback generated by deep learning models with traditional feedback methods (search for direct comparison studies to add here if you find them), research on LLMs in education often adopts an approach of evaluating the effectiveness and potential of LLMs per se in various educational roles, leaving the comparison with traditional methods implicit. For example, Hellas et al. [
16] investigated LLM responses to beginner programmers’ help requests, demonstrating the models’ effectiveness in providing helpful assistance, compared to the assistance traditionally expected from a human tutor or conventional educational resources. Shaikh et al. [
17] analyzed the potential of LLMs for sentiment analysis in student feedback, finding that these models can effectively identify students’ emotions and attitudes, a task that would traditionally require laborious qualitative human analysis. Golchin et al. [
18] examined the use of LLMs as evaluators in MOOCs, finding that they can provide accurate and consistent assessments, suggesting a scalable and automated alternative to human assessment in massive courses.
Extance [
19] offers a broader analysis of the growing use of ChatGPT in the educational field, highlighting both its potential and risks. A case study at Arizona State University showed that LLM-based chatbots can foster creativity and help students generate more ideas than they would normally consider, suggesting an improvement over traditional methods of individual or small group brainstorming. Furthermore, tools like Khanmigo, developed by Khan Academy in collaboration with OpenAI, use GPT-4 to offer personalized tutoring, guiding students through problems without giving direct answers, promoting “productive struggle” in learning, in a style that emulates individualized human tutoring, but with the scalability potential of AI.
Nevertheless, Extance [
19] also highlights the risks associated with the use of LLMs, such as the possibility of students over-relying on these tools to complete tasks without fully understanding the underlying concepts, which could be a greater problem than dependence on “solutions” from traditional sources like web search engines. Privacy concerns are also mentioned, as data entered into these platforms are stored and used to train future models, a risk not present with traditional feedback methods. Additionally, LLMs are prone to errors and “hallucinations”, where they can generate incorrect or fictitious information, requiring human validation and oversight that would not be necessary with feedback generated by human experts. Despite these challenges, Extance [
19] argues that the careful integration and proper supervision of LLMs in education can offer significant benefits, such as the ability to provide immediate and personalized feedback and improve access to high-quality tutoring, especially in resource-limited contexts, where personalized human tutoring is often infeasible.
1.4. Challenges and Opportunities
Despite these promising advances, significant challenges persist that require careful attention, including data privacy management and ethical dilemmas related to publishing AI-generated works. Furthermore, revisiting a historical concern in the field of AIED, the interpretability of complex deep learning models remains a crucial challenge to ensure transparency and trust in these educational systems [
20]. Specifically, concerns about data privacy are highlighted by Lund et al. [
21] and UNESCO [
20], who emphasize the need to safeguard student information in AI environments. UNESCO [
20] and Farrokhnia et al. [
22] also point to biases in AI-generated feedback as a significant risk, underscoring the need for human intervention to mitigate these biases and ensure academic integrity and educational equity, fundamental principles in AIED. Jeon and Lee [
23] emphasize the need for rigorous methods to translate these findings into effective educational practices and understand their potential long-term impacts. Finally, UNESCO [
20] also underscores the importance of validation of AI tools by educational institutions to ensure their effectiveness and fairness, aligning with AIED’s tradition of rigorous evaluation of technology-based educational interventions.
Table 1 summarizes the key challenges and opportunities in the use of deep learning models and LLMs in education.
While advances in the use of LLMs and deep learning in education are promising, further research is needed to address current limitations and maximize their potential, especially in the context of the AIED tradition and its ethical and pedagogical principles. This study seeks to fill some of these gaps by integrating the interpretation, still not sufficiently explored, of performance predictions made with deep learning models through personalized and timely feedback using LLMs.
2. Methodology
The primary aim of this experimental study is to assess the effectiveness of integrating advanced technologies, such as deep learning and large language models (LLMs), in enhancing student performance in a Digital Art for Film and Video Games course. The specific objectives of this study are as follows:
Evaluate the accuracy of student performance predictions using deep learning models trained on historical student data.
Determine the impact of personalized feedback generated by LLMs, such as GPT-4, on enhancing academic performance and student engagement.
Compare participation and performance metrics between a control group and an experimental group that receives performance predictions and personalized recommendations.
Explore the feasibility of integrating technological tools into daily educational routines to facilitate effective and timely communication that supports educational decision-making.
Identify challenges and opportunities associated with implementing these technologies in an educational setting, including ethical and privacy considerations.
2.1. Participants
The participants in this study were students enrolled in a Digital Art for Film and Video Games Specialized Course, offered as part of Academy by PolygonUs, a highly competitive, non-traditional educational program specifically designed to address the immediate needs of the digital art industry. This program operates within an informal education context, focusing on developing high-impact digital skills relevant to the film and video game industries. The course employs a flipped classroom methodology, delivered 100% virtually through PolygonUs’s custom-built Learning Content Management System (LCMS). Instruction includes three weekly synchronous online sessions, complemented by asynchronous pre-recorded lectures and practical activities. The 16-month program is structured into four levels, encompassing 22 industry-specific courses, including technical art skills, industry-focused English, and power skills. Notably, 80% of the curriculum is practical, emphasizing hands-on project development and portfolio building, while 20% is theoretical, delivered primarily through pre-recorded sessions on the LCMS. Throughout the program, students present their work to industry professionals for feedback and portfolio refinement, preparing them for direct entry into the digital art job market.
A significant characteristic of the student population in this program is their high level of motivation. All participants are scholarship recipients, having been selected through a rigorous admission process from a pool of approximately 3600 applicants competing for limited scholarship positions. This highly selective admission process ensures that admitted students demonstrate a strong intrinsic motivation and commitment to pursuing a career in digital art. Furthermore, as part of the admission process, all applicants undergo a structured interview designed to assess their motivation and commitment to the program, in addition to the aforementioned diagnostic technical test. This multi-faceted selection process aims to identify and enroll students with a high aptitude and intrinsic drive for digital art skill development.
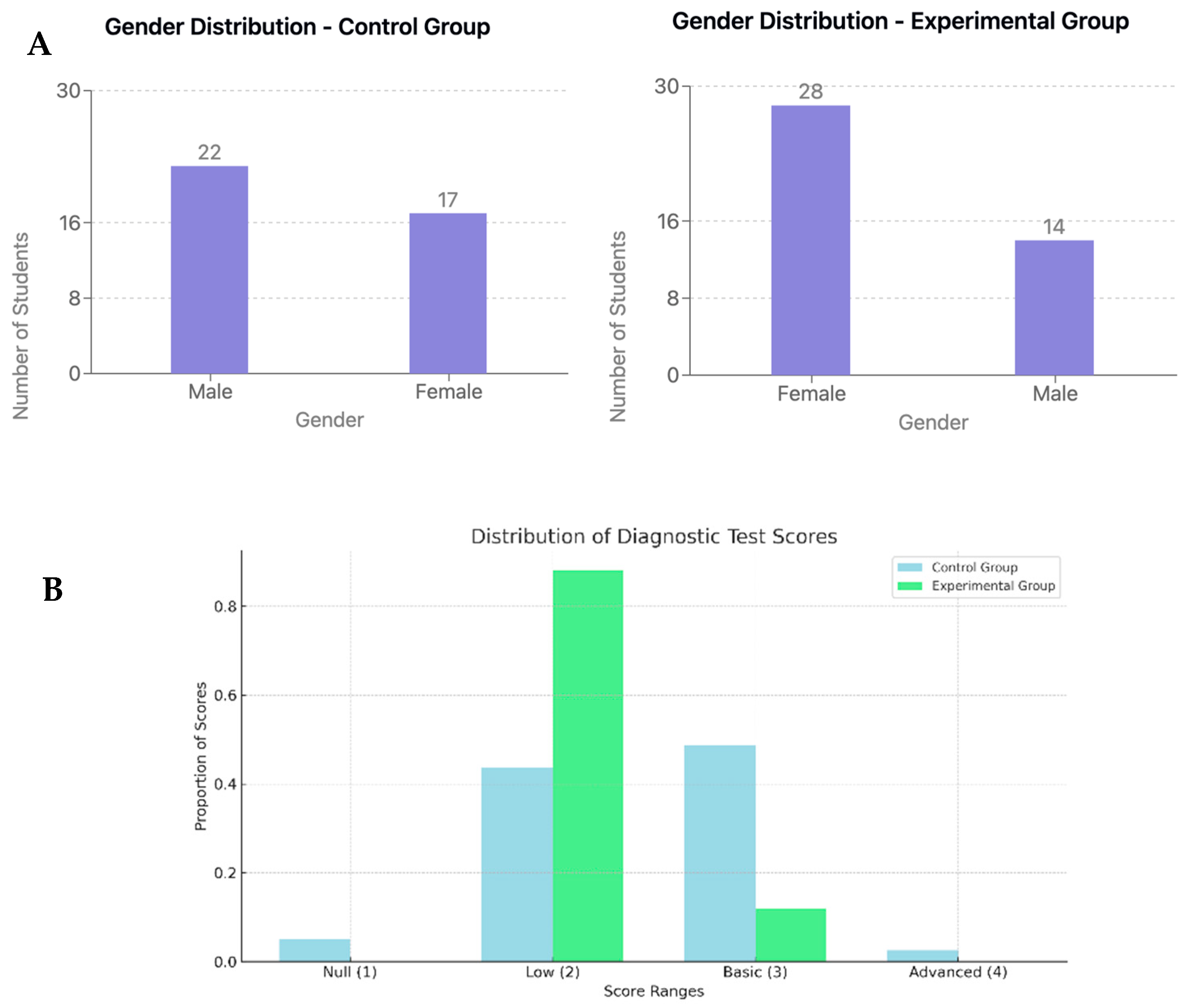
Due to institutional scheduling and enrollment dynamics inherent in this industry-driven and scholarship-based program, participants were not randomly assigned to groups; instead, existing cohorts were utilized. The control group consisted of 39 students enrolled in the 2022 iteration of the course, while the experimental group comprised 42 students enrolled in the 2023 iteration. As illustrated in
Figure 1A, initial demographic analysis revealed some gender imbalances between the groups. The control group had a higher proportion of female students compared to the experimental group. Furthermore, as shown in
Figure 1B, analysis of initial diagnostic test scores indicated that the control group exhibited slightly higher baseline performance levels compared to the experimental group at the beginning of the course. The age range of participants was broadly similar across groups, with the control group ranging from 17 to 43 years and the experimental group from 17 to 36 years.
Prior to the course commencement, all participants undertook a diagnostic technical test designed to assess their foundational skills in character concept design, a core skill in the Digital Art for Film and Video Games domain. This test required students to submit an initial character concept, which was evaluated by program instructors to determine their entry-level proficiency. The majority of students in both groups were categorized as having a “low and basic level of performance” based on this diagnostic assessment, indicating limited prior experience in character design upon entering the program. A small number of students in each group demonstrated “advanced level” skills at the outset of the training (see
Figure 1B for detailed distribution of diagnostic test scores). It is important to note that these pre-existing group differences are acknowledged as a limitation of the quasi-experimental design and will be statistically addressed through covariance analysis in subsequent data analysis stages to mitigate potential confounding effects.
To statistically assess the significance of these baseline differences in diagnostic test scores between the experimental and control groups, a Chi-square test of independence was performed. This test examined the distribution of students across different proficiency levels (low, basic, and advanced) as determined by the diagnostic character concept test. The Chi-square test revealed a statistically significant difference in the distribution of baseline knowledge between the two groups (χ2 = 18.49, df = 2, p < 0.001).
Specifically, as depicted in
Figure 1B, the experimental group presented a higher frequency of students categorized at the low proficiency level in the diagnostic test compared to the Control Group. Conversely, the control group exhibited a greater proportion of students classified as having basic and advanced baseline knowledge. These findings quantitatively confirm the initial observation that the experimental group, on average, commenced the course with a lower level of prior technical skills in digital art compared to the control group.
These statistically confirmed differences in baseline knowledge, while acknowledging an initial disadvantage for the experimental group, also present a significant opportunity to rigorously evaluate the potential of adaptive and personalized learning interventions. Specifically, these pre-existing disparities underscore the importance and potential impact of the AI-powered feedback system implemented in the experimental group to level the playing field. This initial disadvantage allows us to examine whether the personalized feedback can effectively mitigate these initial gaps in skills and knowledge and potentially enable the experimental group to achieve comparable, or even superior, performance outcomes compared to the control group.
Therefore, rather than being a confounding factor, these baseline differences become a critical context for assessing the true value and effectiveness of AI-driven personalized learning in addressing diverse student needs and promoting equitable educational outcomes. The subsequent sections of this methodology will detail the identical instructional design applied to both groups, alongside a comprehensive description of the AI-driven feedback system uniquely introduced to the experimental group, setting the stage for analyzing the intervention’s impact within this context of initial group differences.
2.2. Design and Procedure
Due to the logistical constraints inherent in random assignment within real-world, scholarship-based educational programs, this research employed a quasi-experimental design. However, to maximize methodological validity, the study focused on maintaining strict procedural equivalence between the experimental group and the control group. Consequently, both groups received identical instruction in all aspects of the course: the same curricular content, the same instructors, and the same pedagogical methodology based on a flipped classroom approach that integrated synchronous online sessions, pre-recorded asynchronous lectures, and weekly feedback from industry experts.
The only systematic and planned difference between the groups was the implementation of the Adaptive Feedback System (AFS), exclusive to the experimental group. This system provided students in the experimental cohort with personalized weekly messages containing performance predictions and specific recommendations for improvement. While the control group participated in the program between August 2022 and August 2023 and the experimental group between April 2023 and May 2024, it is crucial to emphasize that the content and delivery of instruction were rigorously standardized across both cohorts.
This quasi-experimental design, while acknowledging the limitations of non-randomization, strengthens the ecological validity of the study by evaluating the AI-based intervention within the authentic setting of a demanding, industry-oriented digital arts program. By minimizing procedural variations beyond the AFS intervention, this design aims to isolate the specific effect of the AI-powered feedback while preserving the authenticity of the real-world educational context.
2.3. Measurements
This study employed a comprehensive measurement system designed to evaluate multiple dimensions of student performance throughout the four levels of the program. In order to robustly and thoroughly capture the impact of the AI-powered Adaptive Feedback System, the following key performance indicators (KPIs) were recorded and analyzed recurrently at each program level. These measured variables served as key input features for the deep learning model used to generate student performance predictions within the Adaptive Feedback System:
Cognitive Learning (Quiz Scores): To measure knowledge acquisition and conceptual understanding, a total of 84 quizzes were administered throughout the program. These formative assessments, primarily composed of multiple-choice and short-answer questions, were systematically repeated in each of the four levels, with 21 quizzes administered per level. The average quiz scores, calculated for each level (Average Quiz Score), provided a granular measure of cognitive learning gains at each stage of the program.
Behavioral Engagement (Session Engagement): Student engagement with learning materials was quantified by tracking attendance and interaction in both recorded and live sessions, conducted at each level of the program. The percentage of recorded sessions accessed (Recorded Percentage) and the percentage of live sessions attended (Live Percentage) served as indicators of behavioral engagement per level. It was hypothesized that the AFS would increase engagement in both learning modalities at each level.
Social Learning and Collaboration (Forum Activity): Participation in collaborative learning was evaluated by quantifying forum activity across four key evaluation periods within each level of the program, resulting in a total of 16 forum activity evaluations throughout the program. The frequency and quality of contributions (Forums 1 to Forums 4, Forum Percentage), measured in each evaluation period within each level, indicated the level of social learning and collaborative engagement per level. It was expected that the AFS would foster greater participation and quality in forums at each level of the program.
Practical Skill Mastery (Practical Activities Scores): To assess the development of practical skills, numerous industry-deliverable challenges were designed and implemented as practical activities in each course and level of the program. These practical activities, based on real industry requirements, were evaluated by industry experts through personalized feedback and quantitatively scored using predefined rubrics. An average score of practical activities per level (Average of Practical Activities) was recorded. This KPI measured the progress in mastering industry-relevant practical skills at each level of the program.
Practical Skill Mastery (Portfolio Assessment Scores): To evaluate the ability to apply skills in complex projects and demonstrate mastery of industry-level competencies, portfolio submissions delivered by students at the end of each level of the program were evaluated, resulting in a total of eight portfolio evaluations throughout the program. Industry experts assigned scores in two portfolio evaluations per level (Evaluation 1, Evaluation 2), and their percentage average (Evaluations Percentage) was calculated to obtain a measure of practical skill mastery in portfolio projects at the end of each level. It was anticipated that the AFS would improve portfolio quality and, therefore, scores in these evaluations at each level of the program.
The collection and analysis of these KPIs, systematically repeated at each of the four program levels, provided a rich and granular database to exhaustively evaluate student performance and the impact of the AI-powered Adaptive Feedback System across multiple dimensions of learning.
It is important to note that while all variables were collected for pedagogical and evaluation purposes, only a subset was selected as input features for the predictive model, based on their availability in the early stages of each program level. Specifically, the portfolio evaluation scores were excluded from model training due to their late availability in the course timeline, which would have introduced data leakage. However, these scores were retained as valuable outcome indicators to assess skill mastery at the end of each level.
2.4. Data Collection
To ensure transparent and replicable data collection, this study relied on both automated data logging and expert evaluation procedures. Automated data collection was facilitated by a proprietary Learning Content Management System (LCMS) platform, developed by PolygonUs for its Academy educational programs. This LCMS was instrumented to automatically capture student activity data relevant to the study’s metrics. Specifically, the following data streams were automatically recorded via the LCMS API:
Student Performance in Quizzes: The LCMS automatically logged and stored individual student scores for each quiz administered within the platform (Q1Punta to Q21Punta), allowing for the calculation of average quiz scores (Average Quiz Score).
Student Engagement in Sessions: The LCMS tracked student access and participation in learning sessions, automatically recording attendance in live sessions (Live Percentage) and engagement with recorded sessions (Recorded Percentage) based on platform login and session activity logs.
Student Activity in Forums: The LCMS automatically logged student posts and interactions within the platform’s forum modules, enabling the quantification of forum activity based on frequency and timestamps of contributions (Forums 1 to Forums 4).
Data collected via the LCMS was securely stored in an Amazon Web Services (AWS) database infrastructure. Weekly data reports were generated and extracted from this AWS database, providing structured datasets for feeding the AI-powered Adaptive Feedback System (AFS). Importantly, the data stored in the AWS database could not be modified, ensuring the integrity and auditability of the collected data. These data were queried through a secure web interface and integrated into the Python 3.11 algorithm that executed the predictive model weekly.
In addition to automated data, expert-assessed data were collected for metrics related to practical skill mastery. Industry experts, defined as senior artists with extensive experience in the digital art production pipeline, including areas such as concept art, 3D modeling, texturing, rendering, animation, retopology, UVs, and compositing with After Effects, conducted evaluations of student portfolio submissions and practical activity deliverables. These experts, trained by the PolygonUs education team for this purpose, performed the evaluations using standardized rubrics integrated within the LCMS platform. Practical activities, consisting of industry-deliverable challenges, were reviewed by experts every 15 days, given the practical nature of the program. Additionally, final projects, designed to integrate knowledge from each level, were also evaluated by experts at the end of each level. Students received personalized feedback from experts in 2 h sessions, twice a week. The experts provided both quantitative scores (recorded as Evaluation 1, Evaluation 2, Average of Practical Activities) and detailed qualitative feedback comments for each student submission, enhancing the quality of the assessment data. This expert evaluation data were then queried through the secure web interface and used to generate the portfolio and practical activity evaluation metrics.
Data collection for all metrics was performed periodically and continuously throughout the four levels of the program, allowing for the longitudinal analysis of student performance and engagement. The complete data flow, from student interaction in the LCMS to data integration into the prediction algorithm and feedback communication through the website and other channels, is illustrated in
Figure 2.
2.5. Adaptive Feedback System (AFS): Architecture and Implementation
The Adaptive Feedback System (AFS) developed in this study was designed as a multi-layered architecture that integrates predictive modeling and automated feedback generation in a scalable, secure, and pedagogically informed manner. This section outlines the four core layers of the system and their interconnections:
2.5.1. Data Collection Layer
This layer interfaces directly with the Learning Content Management System (LCMS) through its API, retrieving the following:
Engagement metrics (live attendance, recorded class access, forum participation);
Performance metrics (quiz scores).
Data are anonymized at collection and securely stored in AWS databases, with Google Sheets serving as an intermediary interface for real-time visualization and instructor access. The system ensured that the AWS-stored data could not be altered post-capture, thus preserving the auditability of performance logs.
2.5.2. Prediction Layer
The system’s prediction layer utilized a deep learning model (a feedforward neural network with dropout regularization) trained to estimate the probability of each student passing the course. The model used four behavioral and performance variables as input and was optimized using binary cross-entropy loss and the Adam optimizer. Weekly inference runs produced class probability predictions, which were later used to generate feedback messages.
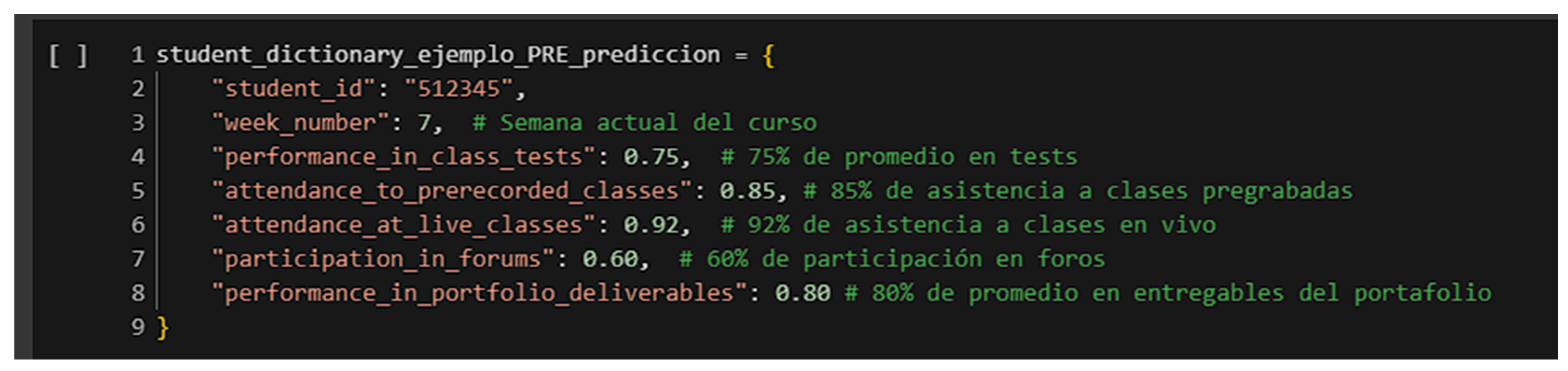
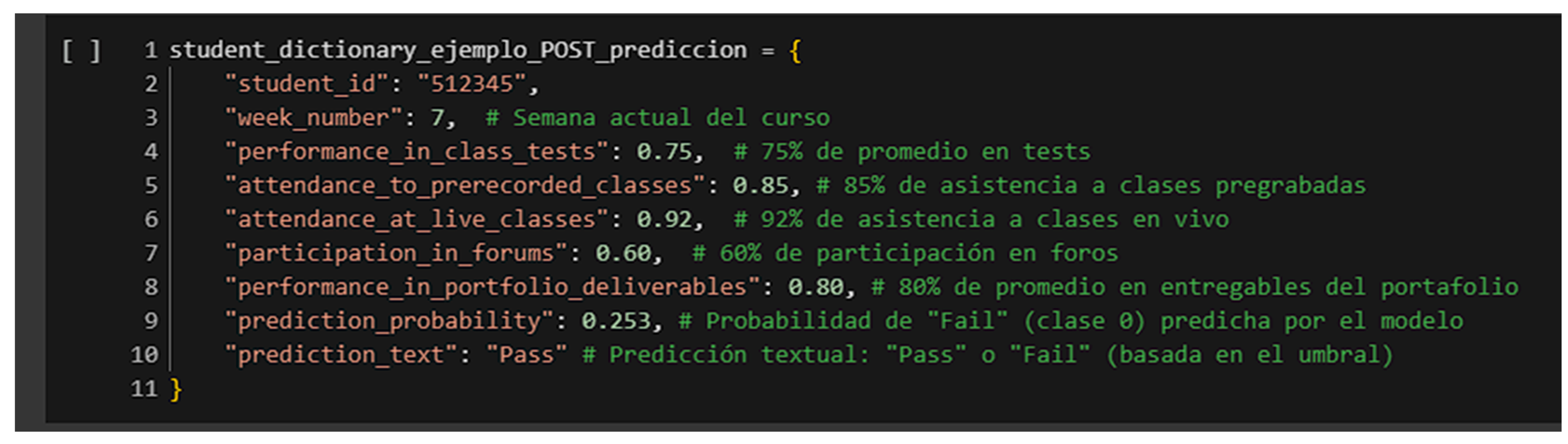
To illustrate the data flow through the prediction layer:
Original input from LCMS: quiz = 63.91%; recorded attendance = 82.5%; live attendance = 66.7%; and forum activity = 41.3%.
Normalized input vector for the model: [0.6391, 0.825, 0.667, 0.413].
Output: Probability of success = 0.698 → classified as “likely to pass” (threshold = 0.6048).
To improve interpretability and transparency, a logistic regression model and several baseline classifiers (decision tree and random forest) were also tested, as reported in
Section 3.4. Model performance was evaluated using metrics such as F1 score, ROC-AUC, and cross-validation scores. The final neural network model achieved a ROC-AUC of 0.945 and was selected based on its ability to generalize across cohorts while avoiding overfitting.
2.5.3. Feedback Generation Layer
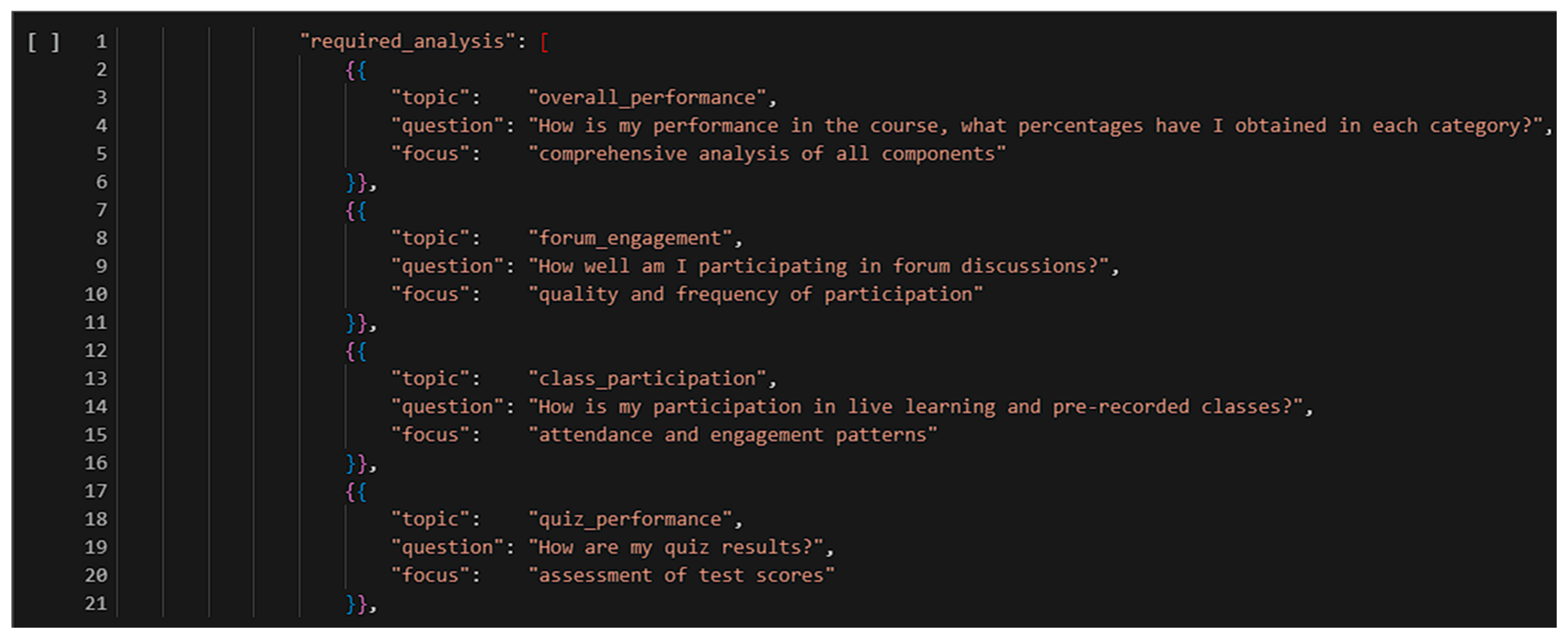
The feedback layer was powered by GPT-4, which received structured prompts engineered using a chain-of-thought style and context-aware variables. Prompts were designed to generate multi-part feedback that included:
A motivational greeting;
An interpretation of the AI prediction;
Detailed analyses of quiz scores, session engagement, and forum activity;
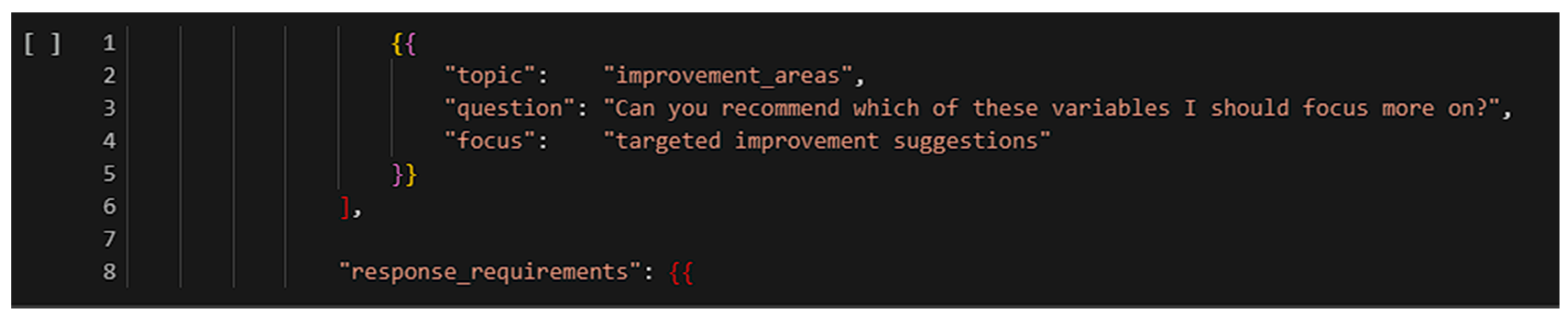
A list of personalized recommendations.
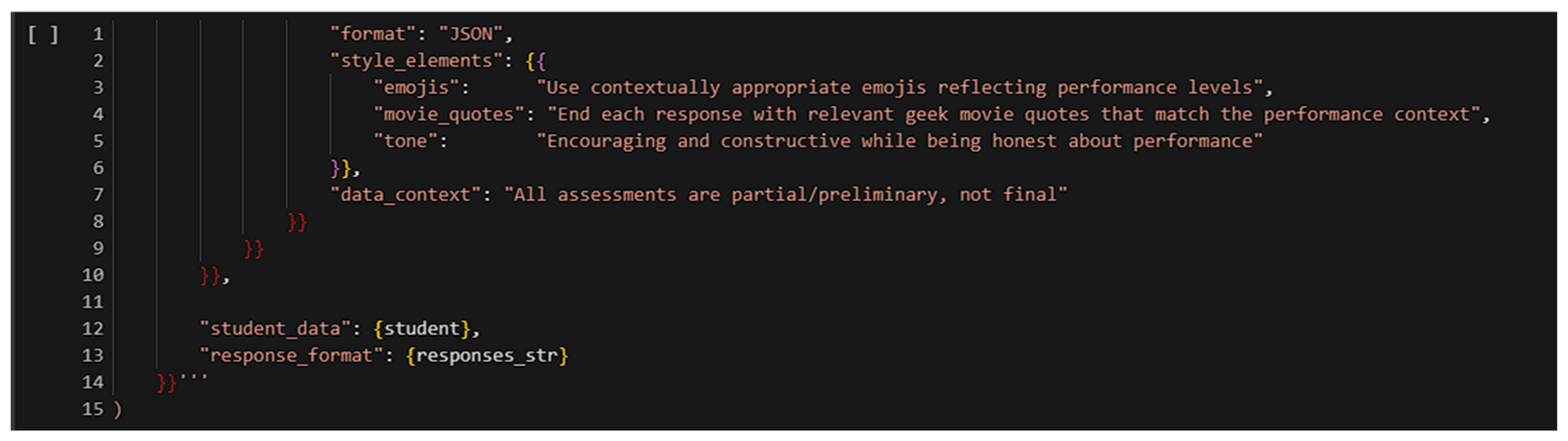
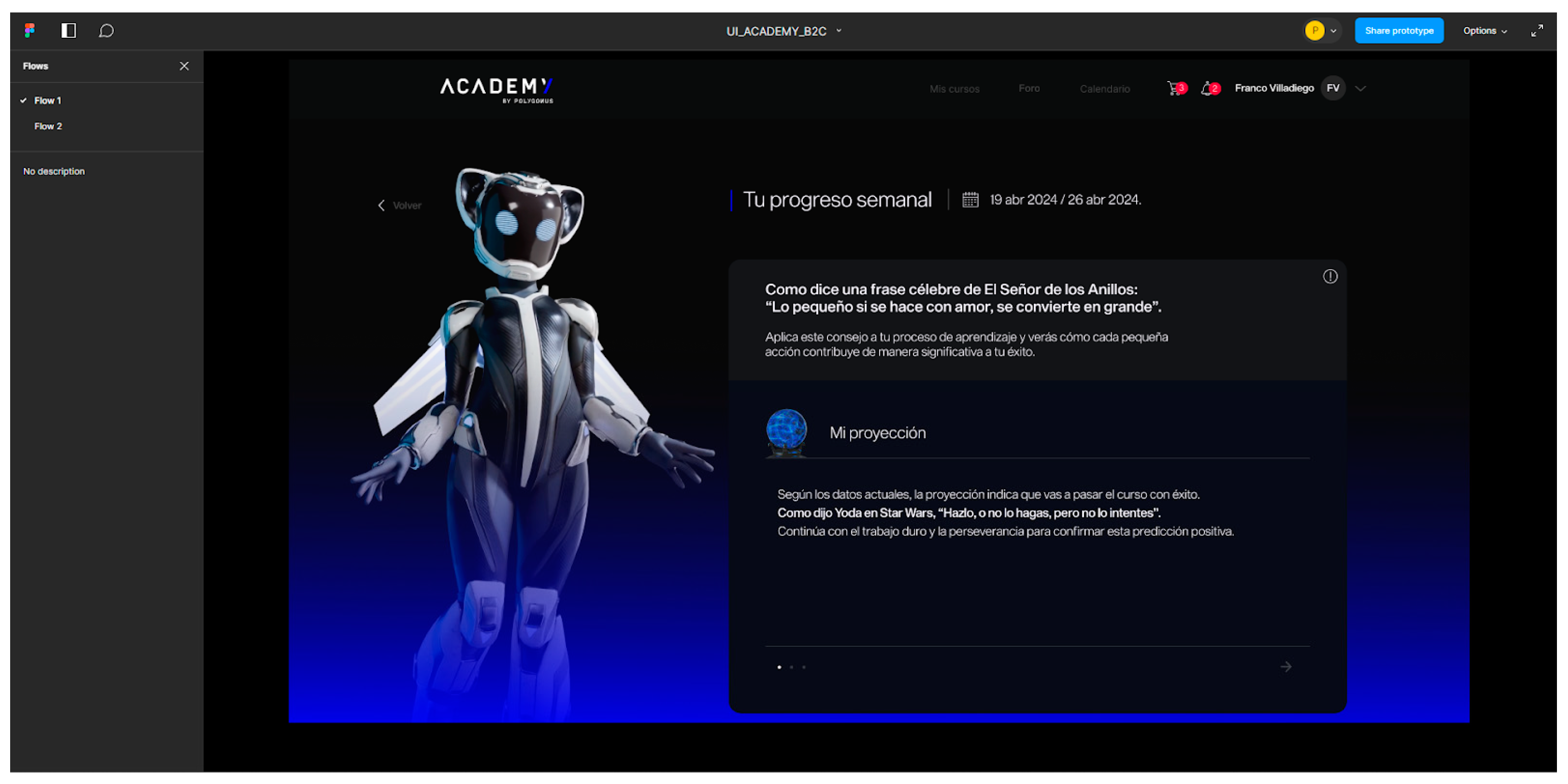
Pop culture preferences (e.g., Star Wars, Marvel) and mentor archetypes (e.g., Yoda, Dumbledore) were used to personalize tone and content style. Prompts were crafted to follow pedagogical best practices, and output quality was reviewed by the education team. Importantly, GPT-4 operated as a one-way feedback generator—students could not interact with the AI. In cases where feedback contained errors or ambiguity, human team members manually reviewed and corrected the messages.
Prompt design was aligned with formative assessment principles and cognitive scaffolding strategies to enhance self-regulated learning.
2.5.4. Delivery and Notification Mechanism
Once generated, the feedback messages were stored in the student profile and made available through the platform every Friday. Additionally, a short WhatsApp notification was automatically sent to each student, summarizing the feedback in under 200 characters and linking back to the platform. Although the system tracked delivery, it did not verify whether students consciously engaged with the messages. This limitation is acknowledged and discussed in
Section 4.6.
Figure 3 illustrates the complete architecture of the AFS, from data acquisition to predictive modeling and feedback delivery. For further details on the practical application of the predictive model, see
Appendix A.
2.6. Model Selection Process
To estimate the likelihood of academic success and generate personalized feedback, multiple machine learning models were trained and evaluated on a dataset comprising 445 labeled instances. The selected input variables reflect behavioral indicators: performance in in-class tests, attendance to prerecorded sessions, attendance to live classes, and participation in discussion forums. The target variable was a binary label (pass/fail) based on the final course outcomes.
Four different classifiers were implemented: logistic regression, decision tree, random forest, and a compact-architecture neural network. Models were trained using an 80/20 split for training and test sets and evaluated using standard metrics such as precision, recall, F1 score, and area under the ROC curve (ROC-AUC). To estimate generalization capacity, a five-fold cross-validation with three repetitions was applied.
To support reproducibility,
Table 2 presents a detailed summary of the hyperparameters used for the neural network.
2.7. Ethical Considerations
This study was conducted with the formal approval of Academy by PolygonUS, the organization responsible for the “Academy” training program. Given the nature of the research carried out in the real-world context of an educational program within a private company, obtaining this institutional approval was a fundamental step to ensure the feasibility and ethical conduct of the study. Additionally, this research was undertaken as part of the first author’s doctoral candidacy at the Universitat Politècnica de València (UPV), framing the study within a rigorous academic context and with implicit ethical oversight.
All participants provided their informed consent prior to participating in the study. They were provided with detailed information about the research objectives, the nature of the intervention (AFS), the data collection procedures, and the intended use of the data. They were explicitly guaranteed the confidentiality of their personal and academic data, ensuring that their information remained anonymous and protected. They were also clearly informed about their right to withdraw from the study at any time, without any negative consequences for their participation in the educational program.
To protect participant privacy, the collected data were anonymized at the point of collection, removing any personally identifiable information. The anonymized data were securely stored on encrypted servers, complying with data protection regulations. Access to the data were restricted solely to the principal investigators of the study.
3. Results
This section presents the results obtained after implementing the Adaptive Feedback System (AFS) based on deep learning—specifically, a pre-trained recurrent neural network (RNN) with historical data and GPT-4. The system provided weekly personalized feedback to the experimental group (n = 42) throughout all four learning blocks or levels of the program, while the control group (n = 39) followed the same four learning blocks or levels program without this intervention. Key findings include (1) a cumulative effect resulting in a significant performance difference in the fourth learning block (+12.63 percentage points); (2) a notable reduction in performance disparities between students with varying levels of prior knowledge in the experimental group (−56.5%) versus an increase in the control group (+103.3%); (3) a particularly beneficial effect for students with low prior knowledge; (4) an overcoming effect where up to 42.9% of students surpassed initial negative predictions; and (5) an especially positive impact on components related to active participation. These results remained robust across various complementary analyses.
3.1. Initial Characteristics of the Groups
The experimental (
n = 42) and control (
n = 39) groups presented significant differences in their initial characteristics, an important factor to consider in this quasi-experimental design, as shown in
Table 3.
Chi-square tests confirmed statistically significant differences in both gender distribution (χ2 = 4.63, p = 0.031) and prior knowledge level (χ2 = 20.87; p < 0.001). These results coincide with the diagnostic assessment described in the methodology (χ2 = 18.49; df = 2; p < 0.001).
These differences, while representing a methodological limitation, offer an opportunity to evaluate the capacity of the AFS to mitigate initial knowledge gaps, aligning with the literature on adaptive educational systems [
7,
9], which suggests their leveling potential. To address these differences statistically, analysis of covariance (ANCOVA) will be employed in subsequent sections.
3.2. Evolution of Academic Performance
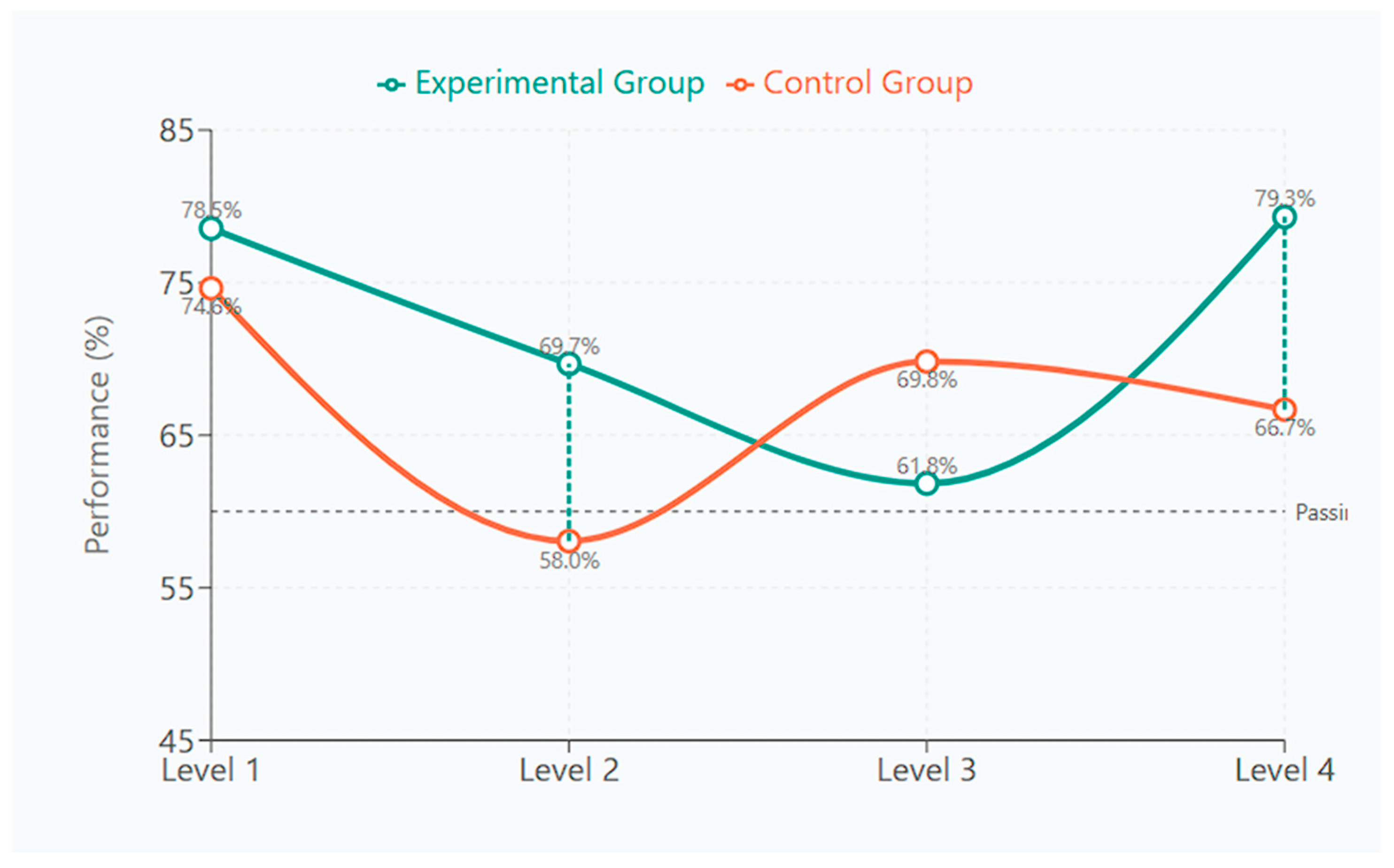
At Level 2, both groups experienced a decrease in performance, but the experimental group maintained a significantly higher level (69.67% vs. 58.05%;
p = 0.017) with a small to moderate effect size (η
2 = 0.073), as shown in
Table 4.
Level 3 presented an interesting reversal, with the control group recovering (69.82%) while the experimental group continued to decline (61.83%). This difference, however, did not reach statistical significance (p = 0.102).
The most striking difference emerged at Level 4, where the experimental group showed a dramatic recovery (79.30%), exceeding even their initial performance, while the control group declined to 66.67%. This difference was highly significant (p < 0.001) with a large effect size (η2 = 0.183).
This performance pattern across all four levels indicates a cumulative effect of the AFS, which becomes most evident in the program’s final stage. This aligns with prior research on the variable and cumulative impact of Adaptive Feedback Systems [
11,
13].
3.3. Performance Transitions Between Consecutive Levels Across the Program
The analysis of transitions between consecutive levels reveals important patterns in how students progressed through the four-level program, as shown in
Table 5.
In the transition from Level 1 to 2, both groups experienced a decrease in performance, with the decline being significantly smaller in the experimental group (−8.88% vs. −16.56%; p = 0.032). A significantly higher proportion of students in the experimental group managed to improve their performance (31.0% vs. 2.6%; p < 0.001).
In the transition from Level 2 to 3, the patterns reversed. The control group showed a significant recovery (+11.77%), while the experimental group continued its downward trend (−7.84%, p < 0.001).
The most striking difference occurred in the transition from Level 3 to 4. The experimental group showed a dramatic improvement (+17.47%), while the control group experienced a slight decline (−3.15%, p < 0.001). A vast majority of experimental group students improved their performance (84.8% vs. 30.3% in the control group, p < 0.001).
These transition patterns across all four levels suggest that the AFS had different effects at different stages of the program. The system appeared to provide initial resilience (Level 1 to 2), faced challenges in the middle stage (Level 2 to 3), but showed its greatest impact in the final transition (Level 3 to 4). This pattern of delayed effectiveness across a four-level program has been documented in other studies of AI-mediated educational interventions [
11,
12].
3.4. Model Results and Selection Rationale
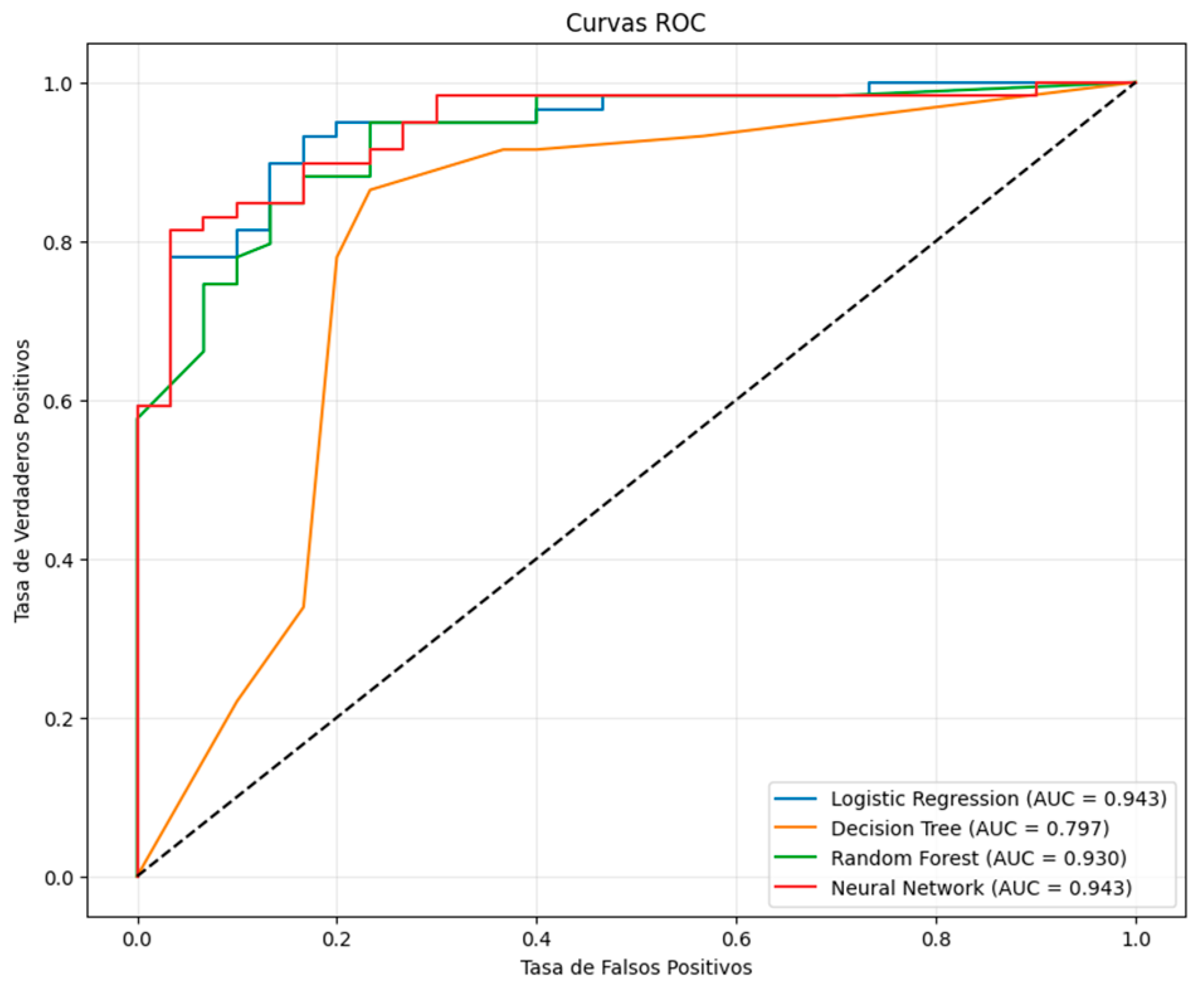
Table 6 summarizes the performance metrics obtained by each model on the test set. The neural network achieved the highest F1 score (0.923) and ROC-AUC (0.946), closely followed by logistic regression (F1 = 0.917; ROC-AUC = 0.942) and the random forest, with differences likely not statistically significant. In contrast, the decision tree showed comparatively lower performance.
Figure 4 presents the ROC curves for the four evaluated models. Both the neural network and logistic regression display curves approaching the ideal, with a slight advantage observed for the former.
Interpretability was also assessed through feature importance analysis. For logistic regression, decision tree, and random forest models, feature importance was computed using model-specific internal mechanisms (e.g., coefficient magnitudes or impurity-based scores).
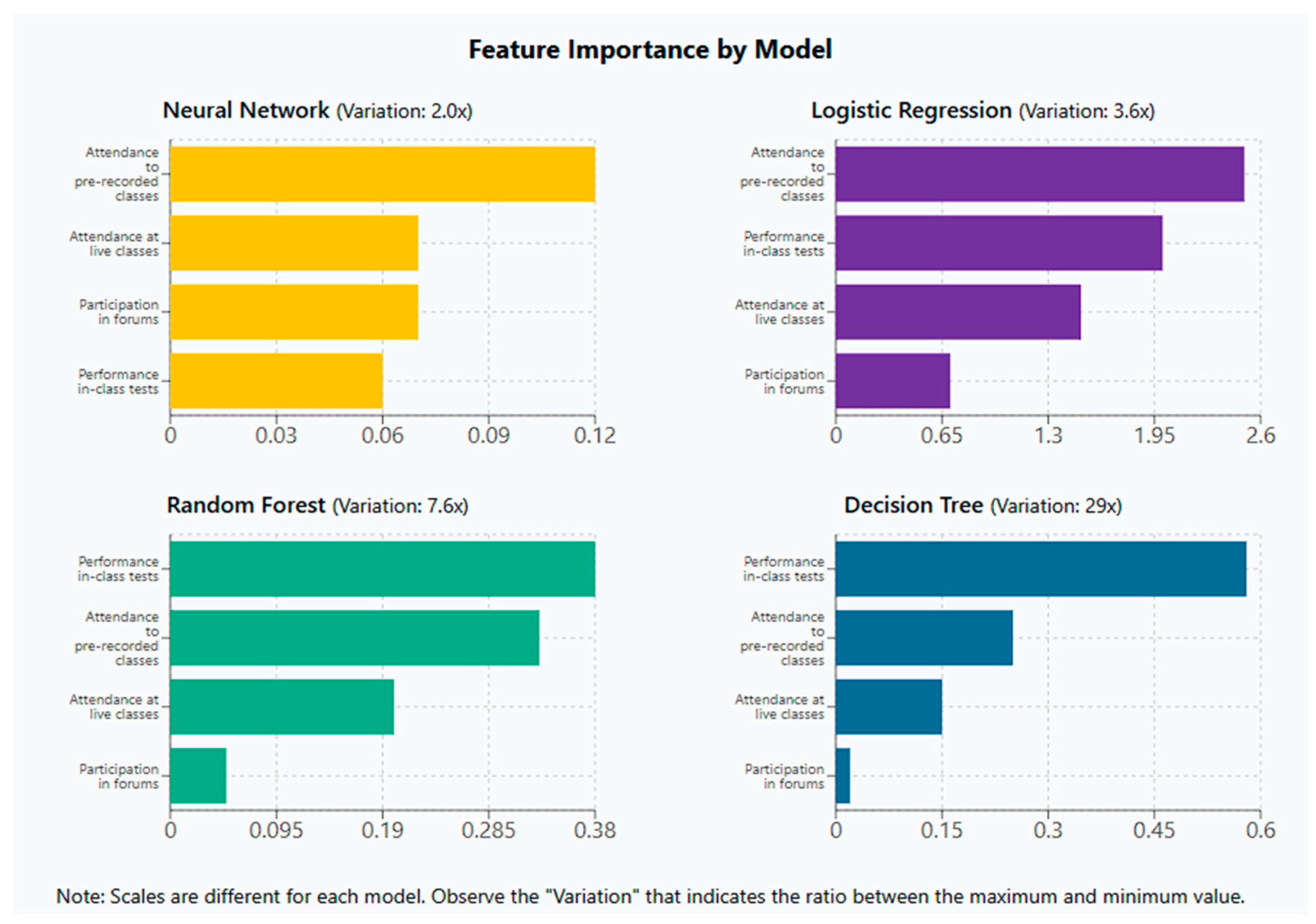
Figure 5 shows the relative importance assigned to each feature across these models. The results reveal distinct distribution patterns: logistic regression exhibits a 3.6-fold difference between its most and least influential variables; the random forest model shows a 7.6-fold variation; and the decision tree displays the most imbalanced distribution, with a nearly 29-fold difference between performance in in-class tests and forum participation.
For the neural network, interpretability was addressed using SHAP values derived from a KernelExplainer. This model-agnostic approach estimates the marginal contribution of each input feature to the model’s output. As seen in
Figure 5, the neural network distributes importance more evenly, with only a twofold variation between the most and least influential variables. While more modest than in other models, this behavior may be desirable in educational contexts where student performance depends on a diverse set of factors. Nevertheless, a clear feature hierarchy remains identifiable within the network.
Interestingly, the models differ in identifying the most influential variable: both logistic regression and the neural network prioritize attendance to pre-recorded sessions, while the tree-based models emphasize performance in in-class tests. This divergence reflects the different inductive biases of the algorithms when modeling student behavior.
The selection of the neural network as the core model for the Adaptive Feedback System (AFS) was not based solely on its marginal performance advantages or on its more balanced feature attribution. Instead, it was primarily motivated by its greater flexibility for future scalability. Neural networks are better equipped to integrate heterogeneous variables (e.g., sociodemographic data or learning styles) and to uncover nonlinear relationships—capabilities that are critical for the next phase of system development.
Furthermore, this performance was achieved without requiring specialized computational infrastructure: training was completed in approximately 16 s using only a free Google Colab instance. This computational efficiency underscores the feasibility of deploying advanced models in educational environments with limited technological resources, facilitating broader accessibility and adoption.
3.5. Analysis by Learning Components
To understand how the AFS affected different aspects of learning throughout the four-level program, we analyzed its impact on six key components.
Table 7 presents the evolution of these components across all four levels.
This comprehensive analysis reveals several important patterns:
Test performance: The experimental group maintained higher test scores throughout all four levels, with the gap widening at Level 2 (84.14% vs. 49.87%) and Level 4 (82.45% vs. 74.06%).
Pre-recorded classes: The experimental group consistently showed higher attendance, with the largest difference at Level 1 (95.50% vs. 75.82%) and Level 2 (87.50% vs. 53.49%).
Live classes: After an initial advantage at Level 1 (59.12% vs. 26.13%), the experimental group fell behind at Levels 2 and 3 but showed a dramatic recovery at Level 4 (73.70% vs. 43.48%).
Forum participation: The experimental group showed substantially higher participation at Level 1 (61.90% vs. 5.13%) and Level 2 (60.71% vs. 28.38%), a slight drop at Level 3, and recovered at Level 4 (70.45% vs. 60.67%).
Portfolio components: The control group initially performed better in the portfolio assessment (Level 1), but by Level 4, the experimental group showed superior performance in both submissions (74.33% vs. 70.39%) and assessment (79.30% vs. 67.27%).
The observed evolution of these components across the four levels is consistent with the hypothesis that the AFS may have contributed to improvements in multiple aspects of learning, although alternative explanations cannot be ruled out due to the study’s quasi-experimental design. By Level 4, the experimental group showed superior performance across all components, with the most notable differences in live class attendance (+30.21 points), portfolio assessment (+12.03 points), and forum participation (+9.79 points).
These findings indicate that the AFS, when sustained across a four-level program, can have a comprehensive positive impact on multiple dimensions of learning, particularly those related to active participation and engagement.
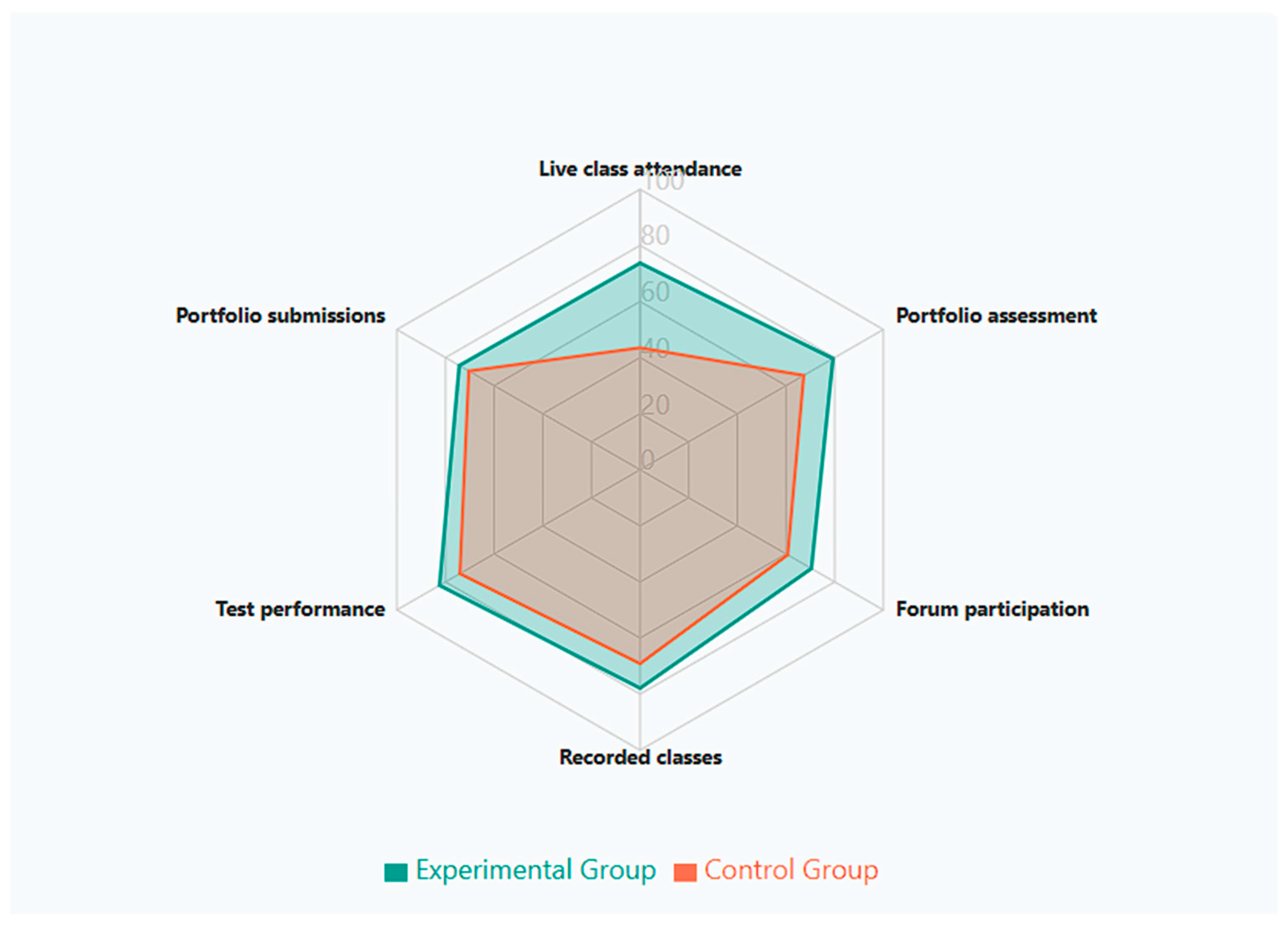
Figure 6 provides a multidimensional visualization of learning components at Level 4, clearly illustrating how the experimental group (green area) consistently outperformed the control group (orange area) across all dimensions. This radar representation highlights the comprehensive nature of the AFS’s impact, with the most substantial differences observed in live class attendance (+30.2pp), portfolio assessment (+12.0pp), and forum participation (+9.8pp). The pattern revealed in this visualization reinforces our finding that adaptive feedback had the greatest impact on components related to active engagement and participation.
3.6. Understanding the Overcoming Effect: Predictive Model Efficacy
The core contribution of this study revolves around what we have termed the Overcoming Effect—the ability of students receiving adaptive feedback to surpass negative predictions and alter their expected learning trajectory across a four-level program.
Figure 7 conceptualizes this phenomenon.
The conceptual model illustrates how adaptive feedback transforms predicted academic trajectories across all four levels. When students receive risk predictions accompanied by personalized and actionable weekly feedback, they can modify their academic behavior, generating a progressive divergence between the initially predicted trajectory (red dotted line) and the actual trajectory (green line). The green shaded area represents the “Overcoming Effect,” highlighting the ability of the AFS to positively transform initial expectations and enhance academic achievement, particularly for students initially identified as at-risk.
Table 8 presents the quantitative evolution of this Overcoming Effect across all four levels of the program.
The predictive accuracy of the model improved progressively throughout the four-level program, reaching its peak at Level 4 (78.6%). This increase suggests that the model was learning and adapting with more data, a finding aligned with the literature on the potential for improvement of deep learning models with continuous feedback [
3].
A particularly interesting finding is the steady increase in the percentage of students who managed to surpass an initial negative prediction across all four levels. At Level 1, only 16.7% of students in the experimental group with an initial failure prediction managed to pass. This figure consistently increased through each level, reaching 42.9% at Level 4. This pattern may be indicative of what we describe as the overcoming effect—a phenomenon in which students, upon receiving information about their risk along with specific recommendations, appear to modify their academic behavior and exceed the initial expectations of the model.
The correlation analysis between the probability of passing assigned by the model and the final performance showed a moderate but significant correlation (r = 0.62, p < 0.001), indicating that, despite the initial limitations, the assigned probabilities had predictive value for final performance across the entire four-level program.
3.7. Educational Gap Reduction Effect Across the Four-Level Program
One of the most significant findings of this study was the AFS’s capacity to reduce educational gaps between students with different levels of prior knowledge as they progressed through all four levels of the program, as shown in
Table 9.
The tracking of educational gaps across all four levels reveals a fascinating pattern. At Level 1, the experimental group showed a larger initial gap between students with basic and low prior knowledge (14.36pp vs. 6.98pp in the control group). This gap widened at Levels 2 and 3 for both groups.
However, at Level 4, a dramatic reversal occurred: the experimental group’s gap narrowed significantly to 6.24pp (a 56.5% reduction from Level 1), while the control group’s gap continued to widen to 14.19pp (a 103.3% increase from Level 1).
At Level 4, students with low prior knowledge in the experimental group achieved a performance of 78.36%, while their counterparts in the control group only achieved 58.31%, a difference of 20.05 percentage points. This interaction was statistically significant (F = 4.75,
p = 0.033), suggesting that the AFS was particularly beneficial for students with lower levels of prior knowledge in the long term, a finding that reinforces the potential of Adaptive Feedback Systems to promote educational equity [
15].
3.8. Retention and Completion Across All Four Levels
Of the original participants, 78.6% of the experimental group (33 of 42) and 84.6% of the control group (33 of 39) completed all four levels of the program. This difference in completion rates was not statistically significant (χ2 = 0.51, p = 0.477).
In the experimental group, the completion rate was lower among students with basic prior knowledge (60.0%, 3 of 5) than among those with low prior knowledge (81.1%, 30 of 37). In the control group, the completion rate was similar between students with basic prior knowledge (84.2%, 16 of 19) and low prior knowledge (82.4%, 14 of 17).
Follow-up interviews with students who did not complete all four levels indicated that most dropouts were due to personal circumstances (such as changes in work schedules or family responsibilities) and time constraints related to the program’s demanding schedule, rather than factors related to the educational intervention itself. This finding aligns with research on dropout factors in online and blended learning environments [
13,
15], which consistently identify external factors as primary drivers of non-completion.
3.9. Robustness Analysis Across Different Thresholds
To verify the consistency of the findings, analyses were conducted with different passing thresholds, as presented in
Table 10.
The predictive accuracy improved notably with a more demanding threshold (70%), suggesting that the model is more effective at identifying students with very high or very low performance, but has difficulties in the intermediate ranges, a finding consistent with research on the variable accuracy of predictive models according to the classification threshold [
12].
A multiple regression analysis for performance across all four levels, controlling for multiple covariates, was statistically significant (F = 28.45, p < 0.001, adjusted R2 = 0.763), explaining approximately 76% of the variance. After controlling all covariates, the effect of the group was statistically significant (β = 0.214, p = 0.018), reinforcing the conclusion that the AFS had a substantial impact on student performance throughout the four-level program.
These results suggest that the integration of a deep learning model (RNN) and GPT-4 within the AFS has the potential to support improved academic performance. However, further studies are needed to confirm the robustness and generalizability of these effects in generating personalized feedback across multi-level educational programs. Beyond overall performance gains, the system showed particularly positive outcomes in reducing educational gaps and enabling students to overcome initial negative predictions—findings that align with recent literature on the potential of AI technologies to foster more equitable and personalized learning environments [
3,
11,
13].
4. Discussion
4.1. Interpretations and Alignment with the Previous Literature
The results of this research provide substantial evidence on the potential of Adaptive Feedback Systems (AFS) based on deep learning and LLMs in online educational environments. A key outcome is the cumulative effect observed throughout the four levels of the program, becoming more evident in advanced stages. This is consistent with studies in adaptive feedback [
11,
13] that also report a long-term buildup of positive effects:
Students become accustomed to incorporating iterative feedback into their self-regulated learning strategies;
The system “learns” more about each student, thus refining its predictive power;
Repeatedly receiving feedback prompts progressive behavioral changes that accumulate over time.
The fact that the experimental group managed to reduce educational gaps and even outperform the control group by Level 4—despite starting with lower prior knowledge—points toward the equity-promoting potential of AFS-like interventions. Such findings echo pedagogical scaffolding principles [
24,
25] wherein adaptive and differentiated support helps level the playing field for students with varying backgrounds.
4.2. Delayed Recovery and the Overcoming Effect
An intriguing pattern that emerged is the delayed improvement in the experimental group, where performance dipped at Level 3 but rebounded significantly at Level 4. This dip-then-spike trajectory may be explained by a combination of increasing course difficulty during the mid-levels and the time it takes for students to internalize the suggestions consistently. Similar phenomena have been documented in prolonged adaptive feedback interventions, where students sometimes display a temporary plateau or regression before fully capitalizing on personalized recommendations [
12].
Within this context, the overcoming effect—students surpassing initially negative predictions—was seen in up to 42.9% of learners by the final stage. Instead of demotivating at-risk students, early alerts seem to trigger behavior changes that reverse their predicted trajectory. This contrasts with concerns that risk labeling may lead to self-fulfilling prophecies and instead shows how timely, actionable feedback can empower students to outperform the system’s early forecasts.
4.3. Stronger Impact on Active Participation
Breaking down learning components revealed the strongest gains in active participation metrics, notably live class attendance (+30.21) and forum engagement (+9.79). Such findings support the view that social presence and interactive engagement are crucial predictors of success in online education [
2]. By making students aware of how attendance and forum posts correlate with performance, the AFS seemed to foster a more proactive approach, encouraging them to attend synchronous sessions and contribute to collaborative discussions.
4.4. Potential Biases and Model Transparency
Although the Adaptive Feedback System (AFS) demonstrated high predictive accuracy (up to 78.6% in later stages), several interpretability issues and potential biases warrant attention. The system integrates two main components: (1) a compact deep learning model (specifically, a recurrent neural network) that forecasts student performance based on behavioral features, and (2) a GPT-4-based module that generates individualized feedback messages.
A major concern lies in the opacity of neural network models, which tend to function as black boxes. This makes it difficult for instructors and learners to understand how specific inputs—such as forum participation or attendance—contribute to the predicted outcomes. As Lipton [
26] emphasizes, the lack of transparency can hinder trust and complicate efforts to detect fairness issues, biases, or model drift. While our current implementation prioritized performance, we mitigated this limitation by integrating SHAP (Shapley additive explanations) into the interpretability workflow. SHAP offers model-agnostic explanations by estimating the marginal contribution of each input feature to a prediction. This aligns with current efforts in educational AI to balance performance with interpretability [
12,
15].
On the feedback generation side, large language models such as GPT-4 may inherit and reproduce cultural, demographic, or linguistic biases embedded in their training data. This risk is especially relevant in educational settings, where the framing and tone of recommendations can significantly affect student engagement. Prior studies have raised concerns that unmonitored LLM outputs may reinforce inequities or yield inconsistent advice across student profiles [
21,
22,
24].
Although our content review process did not identify overtly biased feedback during deployment, this limitation suggests a critical need for future safeguards. These may include content audits, prompt engineering guidelines, and co-design sessions with educators to ensure feedback remains aligned with pedagogical intent and equity standards. Moreover, emerging studies propose combining human-in-the-loop strategies with automated moderation to increase transparency and ethical oversight in generative educational systems [
16,
19].
4.5. Generic or Uncontextualized Feedback
If the input data passed to GPT-4 does not adequately capture the nuances of a student’s context—such as low digital literacy, language barriers, or fluctuating motivation—the resulting feedback may lack personalization. This risk increases when the system is scaled to large cohorts, where real-time prompt monitoring and manual review become less feasible.
To address this issue, the system integrated explainable AI (XAI) techniques, specifically the SHAP (Shapley additive explanations) method. SHAP allowed the academic team to visualize which features had the greatest influence on each prediction made by the model, improving transparency and enabling more pedagogically informed interventions.
Although we did not conduct structured interviews or surveys specifically focused on the AI, anecdotal evidence of student engagement was observed in discussion forums and support chats. Some students referred directly to the AI-generated messages—calling it “the Oracle”—and requested manual edits when they felt the feedback did not reflect their actual progress. While informal, these instances suggest partial student appropriation and perceived relevance of the system.
Looking ahead, the next version of the system will include a conversational agent that allows students to reply directly to feedback via WhatsApp. This two-way interaction channel will not only enhance personalization but also enable the collection of valuable data on how students perceive, interpret, and act upon the feedback provided.
Based on these insights, we recommend that future research combines XAI outputs with more systematic qualitative analysis (e.g., surveys, interviews, behavioral trace analysis) to evaluate how students engage with AI-generated feedback and how it influences their learning trajectories.
4.6. Limitations
Despite the promising outcomes, this study has certain limitations that call for cautious interpretation.
4.6.1. Quasi-Experimental Design and Cohort Differences
The study employed a quasi-experimental design involving different cohorts (2022 for the control group and 2023 for the experimental group), which limits internal validity and restricts the ability to establish causal relationships. Although statistical controls were applied using ANCOVA to adjust for baseline disparities in prior knowledge and gender composition, unmeasured external factors—such as curricular updates or increased exposure to AI technologies in 2023—may have influenced the results. Nonetheless, since the control group did not receive AI-generated feedback, the potential impact of these external factors was likely reduced. In light of this limitation, findings are interpreted as consistent with the hypothesis that the Adaptive Feedback System may have contributed to the improvements observed, rather than as definitive proof of causality.
4.6.2. Sample Size and Power Analysis
While the experimental and control groups had 42 and 39 students, respectively, such sample sizes might limit generalizability. Future studies should consider larger cohorts or multi-institutional settings, ideally accompanied by a power analysis to ensure the sample is sufficient to detect meaningful differences.
4.6.3. Contextual Scope
Participants were part of a highly selective digital art program, which may not represent the full spectrum of online learners. Their motivation levels, scholarship context, and professional aspirations could have amplified the receptiveness to AI-driven feedback.
4.6.4. Model Overfitting or Narrow Feature Selection
Although cross-validation was performed, high accuracy values (particularly early in the pipeline) may raise concerns about potential overfitting. Moreover, the predictors used (attendance, quiz scores, forum activity, etc.) might not capture broader factors (e.g., emotional well-being, socio-economic conditions) that also shape student success.
4.6.5. Ethical and Privacy Considerations
AI systems handling student data must comply with stringent privacy regulations and ensure informed consent. Institutions adopting such systems should implement robust data protection measures and remain vigilant against inadvertently reinforcing biases, in alignment with guidelines [
21].
5. Conclusions
5.1. Main Contributions
This study empirically demonstrates that integrating deep learning (RNN) and GPT-4 for personalized, weekly feedback can significantly enhance online learning outcomes. Notably, we identified the overcoming effect, wherein students who were initially projected to fail changed their learning trajectories through actionable feedback. The findings reinforce the notion that predictive analytics should be viewed not merely as a detection tool for at-risk students, but as an intervention that can actively redirect learners’ academic paths.
Additionally, the research shows that such AI-powered feedback can close educational gaps, a critical advance in ensuring more equitable outcomes. By providing differential support to those with lower prior knowledge, AFS aligned with Vygotskyian scaffolding principles and effectively improved engagement and participation.
5.2. Practical Implications
For Educational Institutions: Adopting Adaptive Feedback Systems can bolster student engagement and performance, especially among those starting with lower skills. This has strong potential for promoting inclusion and equity in online courses.
For EdTech Developers: The demonstrated synergy between an RNN for predictions and GPT-4 for messaging can guide future product roadmaps. Emphasis on interpretability, data security, and robust prompting strategies will be crucial to maximize effectiveness.
For Policymakers: Balancing innovation with ethical frameworks is essential. Policymakers could incentivize institutions to pilot similar AI interventions, but accountability, transparency, and fairness during deployment must be ensured.
5.3. Future Directions
Looking ahead, several promising avenues exist for refining and expanding the potential of the Adaptive Feedback System (AFS). First, longitudinal research examining whether the observed improvements persist beyond the immediate course cycle—such as follow-up performance one year later—would provide insight into the sustainability of the system’s impact. Second, cross-domain studies could explore the adaptability of the AFS across diverse subject areas (e.g., STEM or humanities), assessing whether domain-specific customization is necessary.
Another key direction involves integrating multimodal data, such as video engagement and affective indicators, to improve the system’s predictive power and relevance—provided strict ethical and privacy safeguards are enforced. Importantly, we have already implemented explainable AI (XAI) methods such as SHAP to interpret feature contributions in the prediction model, and we plan to expand the use of such tools to increase transparency and foster trust among users.
Future iterations of the AFS will also incorporate a conversational agent that allows students to respond to feedback directly via WhatsApp. This two-way interaction will enable the collection of behavioral and perceptual data, providing valuable insight into how students interpret and react to feedback. Such data can inform continuous improvements to the system’s tone, structure, and personalization strategies.
Researchers may also explore differentiated feedback modalities—such as textual vs. visual formats, or directive vs. motivational tones—to identify what styles best support various learner profiles. Finally, embedding a co-design process with both educators and students will help adapt the system’s frequency, delivery methods, and pedagogical voice to the needs of real-world learning environments, ensuring continued relevance and effectiveness.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}