
LLMs in Education: Evaluation GPT and BERT Models in Student Comment Classification



Abstract
1. Introduction
2. Literature Review
2.1. Related Works
2.2. Transformers for Large Language Models
2.2.1. Generative Pretrained Transformer (GPT) Model
2.2.2. Bidirectional Encoder Representations from Transformers (BERT)
3. Research Methodology
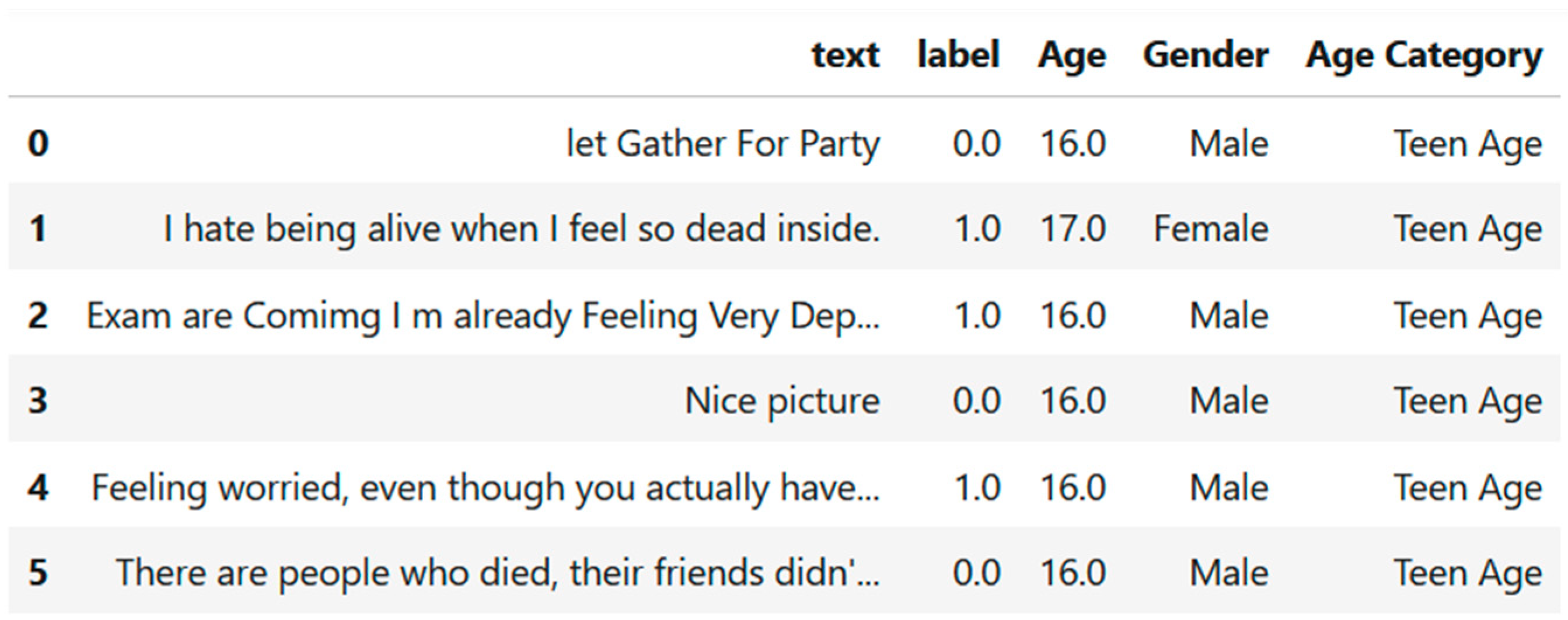
3.1. Dataset
3.2. Dataset Splitting and Preprocessing
3.3. Model Deployment and Fine-Tuning LLMs
3.3.1. gpt-4o-mini-2024-07-18
3.3.2. gpt-3.5-turbo-0125
3.3.3. gpt-neo-125m
3.3.4. bert-base-uncased
3.3.5. roberta-base
3.4. Evaluation Criteria
4. Results
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Vistorte, A.O.R.; Deroncele-Acosta, A.; Ayala, J.L.M.; Barrasa, A.; López-Granero, C.; Martí-González, M. Integrating artificial intelligence to assess emotions in learning environments: A systematic literature review. Front. Psychol. 2024, 15, 1387089. [Google Scholar] [CrossRef]
- Kim, K.-S.; Sin, S.-C.J.; Yoo-Lee, E.Y. Undergraduates’ Use of Social Media as Information Sources. Coll. Res. Libr. 2014, 75, 442–457. [Google Scholar] [CrossRef]
- Ali, K.; Dong, H.; Bouguettaya, A.; Erradi, A.; Hadjidj, R. Sentiment Analysis as a Service: A Social Media Based Sentiment Analysis Framework. In Proceedings of the 2017 IEEE 24th International Conference on Web Services (ICWS 2017), Honolulu, HI, USA, 25–30 June 2017; pp. 660–667. [Google Scholar] [CrossRef]
- Martín, H.R. Aprendiendo a Aprender: Mejora tu Capacidad de Aprender Descubriendo cómo Aprende tu Cerebro; Vergara: Barcelona, Spain, 2020. [Google Scholar]
- World Health Organization. Mental Health of Adolescents. Available online: https://www.who.int/es/news-room/fact-sheets/detail/adolescent-mental-health (accessed on 27 March 2024).
- Mahoney, J.L.; Durlak, J.A.; Weissberg, R.P. An update on social and emotional learning outcome research. Phi Delta Kappan 2018, 100, 18–23. [Google Scholar] [CrossRef]
- Shaheen, Z.; Wohlgenannt, G.; Filtz, E. Large Scale Legal Text Classification Using Transformer Models. arXiv 2010, arXiv:2010.12871. Available online: http://arxiv.org/abs/2010.12871 (accessed on 27 March 2024).
- Li, Q.; Zhao, S.; Zhao, S.; Wen, J. Logistic Regression Matching Pursuit algorithm for text classification. Knowledge-Based Syst. 2023, 277, 110761. [Google Scholar] [CrossRef]
- Wang, Y.; Li, X. Mining Product Reviews for Needs-Based Product Configurator Design: A Transfer Learning-Based Approach. IEEE Trans. Ind. Inform. 2021, 17, 6192–6199. [Google Scholar] [CrossRef]
- Kang, H.; Yoo, S.J.; Han, D. Senti-lexicon and improved Naïve Bayes algorithms for sentiment analysis of restaurant reviews. Expert Syst. Appl. 2012, 39, 6000–6010. [Google Scholar] [CrossRef]
- Paiva, E.; Paim, A.; Ebecken, N. Convolutional Neural Networks and Long Short-Term Memory Networks for Textual Classification of Information Access Requests. IEEE Lat. Am. Trans. 2021, 19, 826–833. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of deep learning: Concepts, CNN architectures, challenges, applications, future directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef]
- Sun, K.; Luo, X.; Luo, M.Y. A Survey of Pretrained Language Models. In Knowledge Science, Engineering and Management; Memmi, G., Yang, B., Kong, L., Zhang, T., Qiu, M., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 442–456. [Google Scholar]
- Pawar, C.S.; Makwana, A. Comparison of BERT-Base and GPT-3 for Marathi Text Classification; Springer: Singapore, 2022; pp. 563–574. [Google Scholar] [CrossRef]
- Qu, Y.; Liu, P.; Song, W.; Liu, L.; Cheng, M. A Text Generation and Prediction System: Pre-training on New Corpora Using BERT and GPT-2. In Proceedings of the 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), Beijing, China, 17–19 July 2020; pp. 323–326. [Google Scholar] [CrossRef]
- Yang, B.; Luo, X.; Sun, K.; Luo, M.Y. Recent Progress on Text Summarisation Based on BERT and GPT. In Proceedings of the 16th International Conference on Knowledge Science, Engineering and Management, Guangzhou, China, 16–18 August 2023; pp. 225–241. [Google Scholar] [CrossRef]
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New Avenues in Opinion Mining and Sentiment Analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Floridi, L.; Cowls, J. A Unified Framework of Five Principles for AI in Society. Harv. Data Sci. Rev. 2019, 1, 535–545. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. March 2023. Available online: https://cdn.openai.com/papers/gpt-4.pdf (accessed on 27 March 2024).
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 6–12 December 2020; in NIPS ’20. Curran Associates Inc.: Red Hook, NY, USA, 2020. [Google Scholar]
- Black, S.; Biderman, S.; Hallahan, E.; Anthony, Q.; Gao, L.; Golding, L.; He, H.; Leahy, C.; McDonell, K.; Phang, J.; et al. GPT-NeoX-20B: An Open-Source Autoregressive Language Model. In Proceedings of the BigScience Episode #5–Workshop on Challenges & Perspectives in Creating Large Language Models, Dublin, Ireland, 27 May 2022; Fan, A., Ilic, S., Wolf, T., Gallé, M., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 95–136. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies-Proceedings of the Conference; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. Available online: http://arxiv.org/abs/1907.11692 (accessed on 27 March 2024).
- Fields, J.; Chovanec, K.; Madiraju, P. A Survey of Text Classification With Transformers: How Wide? How Large? How Long? How Accurate? How Expensive? How Safe? IEEE Access 2024, 12, 6518–6531. [Google Scholar] [CrossRef]
- Bansal, M.; Verma, S.; Vig, K.; Kakran, K. Opinion Mining from Student Feedback Data Using Supervised Learning Algorithms. In Third International Conference on Image Processing and Capsule Networks; Chen, J.I.-Z., Tavares, J.M.R.S., Shi, F., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 411–418. [Google Scholar]
- Shaik, T.; Tao, X.; Dann, C.; Xie, H.; Li, Y.; Galligan, L. Sentiment analysis and opinion mining on educational data: A survey. Nat. Lang. Process. J. 2023, 2, 100003. [Google Scholar] [CrossRef]
- Han, Z.; Wu, J.; Huang, C.; Huang, Q.; Zhao, M. A review on sentiment discovery and analysis of educational big-data. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 10, 1328. [Google Scholar] [CrossRef]
- Yan, C.; Liu, J.; Liu, W.; Liu, X. Sentiment Analysis and Topic Mining Using a Novel Deep Attention-Based Parallel Dual-Channel Model for Online Course Reviews. Cogn. Comput. 2023, 15, 304–322. [Google Scholar] [CrossRef]
- Du, B. Research on the factors influencing the learner satisfaction of MOOCs. Educ. Inf. Technol. 2023, 28, 1935–1955. [Google Scholar] [CrossRef]
- Ren, Y.; Tan, X. Research on the Method of Identifying Students’ Online Emotion Based on ALBERT. In Proceedings of the 2021 International Conference on Intelligent Computing, Automation and Applications (ICAA), Nanjing, China, 25–27 June 2021; pp. 646–650. [Google Scholar] [CrossRef]
- Fouad, S.; Alkooheji, E. Sentiment Analysis for Women in STEM using Twitter and Transfer Learning Models. In Proceedings of the 17th IEEE International Conference on Semantic Computing, ICSC 2023, Laguna Hills, CA, USA, 1–3 February 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023; pp. 227–234. [Google Scholar] [CrossRef]
- Hameed, M.Y.; Al-Hindi, L.; Ali, S.; Jensen, H.K.; Shoults, C.C. Broadening the Understanding of Medical Students’ Discussion of Radiology Online: A Social Listening Study of Reddit. Curr. Probl. Diagn. Radiol. 2023, 52, 377–382. [Google Scholar] [CrossRef]
- Zhou, M.; Mou, H. Tracking public opinion about online education over COVID-19 in China. Educ. Technol. Res. Dev. 2022, 70, 1083–1104. [Google Scholar] [CrossRef]
- Jyothsna, R.; Rohini, V.; Paulose, J. Sentiment Analysis of Stress Among the Students Amidst the Covid Pandemic Using Global Tweets. In Ambient Intelligence in Health Care; Swarnkar, T., Patnaik, S., Mitra, P., Misra, S., Mishra, M., Eds.; Springer Nature: Singapore, 2023; pp. 317–324. [Google Scholar]
- World Health Organization. Anxiety Disorders. Available online: https://www.who.int/news-room/fact-sheets/detail/anxiety-disorders (accessed on 5 April 2024).
- World Health Organization. Depressive Disorder. Available online: https://www.who.int/news-room/fact-sheets/detail/depression (accessed on 13 April 2024).
- Mirza, A.A.; Baig, M.; Beyari, G.M.; Halawani, M.A.; Mirza, A.A. Depression and Anxiety Among Medical Students: A Brief Overview. Adv. Med. Educ. Pract. 2021, 12, 393–398. [Google Scholar] [CrossRef]
- Hooda, M.; Saini, A. Academic Anxiety: An Overview. Int. J. Educ. Appl. Soc. Sci. 2017, 8, 807–810. [Google Scholar] [CrossRef]
- Şad, S.N.; Kış, A.; Demir, M.; Özer, N. Meta-Analysis of the Relationship between Mathematics Anxiety and Mathematics Achievement. Pegem J. Educ. Instr. 2016, 6, 371–392. [Google Scholar] [CrossRef]
- Namkung, J.M.; Peng, P.; Lin, X. The Relation Between Mathematics Anxiety and Mathematics Performance Among School-Aged Students: A Meta-Analysis. Rev. Educ. Res. 2019, 89, 459–496. [Google Scholar] [CrossRef]
- Barroso, C.; Ganley, C.M.; McGraw, A.L.; Geer, E.A.; Hart, S.A.; Daucourt, M.C. A meta-analysis of the relation between math anxiety and math achievement. Psychol. Bull. 2021, 147, 134–168. [Google Scholar] [CrossRef] [PubMed]
- Caviola, S.; Toffalini, E.; Giofrè, D.; Ruiz, J.M.; Szűcs, D.; Mammarella, I.C. Math Performance and Academic Anxiety Forms, from Sociodemographic to Cognitive Aspects: A Meta-analysis on 906,311 Participants. Educ. Psychol. Rev. 2022, 34, 363–399. [Google Scholar] [CrossRef]
- Latif, M.M.A. Sources of L2 writing apprehension: A study of Egyptian university students. J. Res. Read. 2015, 38, 194–212. [Google Scholar] [CrossRef]
- Nolan, K.; Bergin, S. The role of anxiety when learning to program: A systematic review of the literature. In Proceedings of the 16th Koli Calling International Conference on Computing Education Research, Koli, Finland, 24–27 November 2016; in Koli Calling ’16. Association for Computing Machinery: New York, NY, USA, 2016; pp. 61–70. [Google Scholar] [CrossRef]
- Rothman, D. Transformers for Natural Language Processing: Build Innovative Deep Neural; Pack Publishing Ltd.: Birmingham, UK, 2021; Available online: https://books.google.com.ec/books?hl=en&lr=&id=Cr0YEAAAQBAJ&oi=fnd&pg=PP1&ots=a9t6Rt3i21&sig=6AunRon2EtcpjTNULNgtdoA2ODI&redir_esc=y#v=onepage&q&f=false (accessed on 5 April 2024).
- Ravichandiran, S. Getting Started with Google BERT: Build and Train State-of-the-Art Natural Language Processing Models Using BERT; Packt Publishing Ltd.: Birmingham, UK, 2021. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Im, S.-K.; Chan, K.-H. Neural Machine Translation with CARU-Embedding Layer and CARU-Gated Attention Layer. Mathematics 2024, 12, 997. [Google Scholar] [CrossRef]
- Birhane, A.; Kasirzadeh, A.; Leslie, D.; Wachter, S. Science in the age of large language models. Nat. Rev. Phys. 2023, 5, 277–280. [Google Scholar] [CrossRef]
- Ataei, T.S.; Javdan, S.; Minaei-Bidgoli, B. Applying Transformers and Aspect-based Sentiment Analysis approaches on Sarcasm Detection. In Proceedings of the Second Workshop on Figurative Language Processing; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 67–71. [Google Scholar] [CrossRef]
- Schmidt, L.; Weeds, J.; Higgins, J.P.T. Data Mining in Clinical Trial Text: Transformers for Classification and Question Answering Tasks. arXiv 2021, arXiv:2001.11268. [Google Scholar] [CrossRef]
- Razno, M. Machine Learning Text Classification Model with NLP Approach. In Proceedings of the 3D International Conference Computational Linguistics And Intelligent Systems, Kharkiv, Ukraine, 18–19 April 2019; pp. 71–77. [Google Scholar]
- Fanni, S.C.; Febi, M.; Aghakhanyan, G.; Neri, E. Natural Language Processing. In Introduction to Artificial Intelligence; Klontzas, M.E., Fanni, S.C., Neri, E., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 87–99. [Google Scholar] [CrossRef]
- Parker, M.J.; Anderson, C.; Stone, C.; Oh, Y. A Large Language Model Approach to Educational Survey Feedback Analysis. Int. J. Artif. Intell. Educ. 2024, 1–38. [Google Scholar] [CrossRef]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://gluebenchmark.com/leaderboard (accessed on 10 May 2024).
- Roumeliotis, K.I.; Tselikas, N.D.; Nasiopoulos, D.K. Unveiling Sustainability in Ecommerce: GPT-Powered Software for Identifying Sustainable Product Features. Sustainability 2023, 15, 12015. [Google Scholar] [CrossRef]
- Liu, X.; Zheng, Y.; Du, Z. Journal Pre-proof GPT understands, too. AI Open 2023, 5, 208–215. [Google Scholar] [CrossRef]
- Koroteev, M.V. BERT: A Review of Applications in Natural Language Processing and Understanding. arXiv 2021, arXiv:2103.11943. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations; International Conference on Learning Representations: New Orleans, LA, USA, 2019. [Google Scholar] [CrossRef]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. Available online: http://arxiv.org/abs/1910.01108 (accessed on 20 January 2024).
- Jiao, X.; Yin, Y.; Shang, L.; Jiang, X.; Chen, X.; Li, L.; Wang, F.; Liu, Q. TinyBERT: Distilling BERT for Natural Language Understanding. In Findings of the Association for Computational Linguistics: EMNLP 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 4163–4174. [Google Scholar]
- Wang, W.; Wei, F.; Dong, L.; Bao, H.; Yang, N.; Zhou, M. MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers. arXiv 2020, arXiv:2002.10957. [Google Scholar]
- Chan, K.-H.; Im, S.-K.; Ke, W. Multiple classifier for concatenate-designed neural network. Neural Comput. Appl. 2022, 34, 1359–1372. [Google Scholar] [CrossRef]
- Kaggle. Kaggle: Your Machine Learning and Data Science Community. Available online: https://www.kaggle.com/ (accessed on 8 April 2024).
- Jain, A.; Patel, H.; Nagalapatti, L.; Gupta, N.; Mehta, S.; Guttula, S.; Mujumdar, S.; Afzal, S.; Mittal, R.S.; Munigala, V. Overview and Importance of Data Quality for Machine Learning Tasks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 6–10 July 2020; pp. 3561–3562. [Google Scholar] [CrossRef]
- Meng, Z.; McCreadie, R.; Macdonald, C.; Ounis, I. Exploring Data Splitting Strategies for the Evaluation of Recommendation Models. In Proceedings of the Fourteenth ACM Conference on Recommender Systems, Virtual Event, 22–26 September 2020; ACM: New York, NY, USA, 2020; pp. 681–686. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D.; Nasiopoulos, D.K. LLMs in e-commerce: A comparative analysis of GPT and LLaMA models in product review evaluation. Nat. Lang. Process. J. 2024, 6, 100056. [Google Scholar] [CrossRef]
- Gorriz, J.M.; Clemente, R.M.; Segovia, F.; Ramirez, J.; Ortiz, A.; Suckling, J. Is K-fold cross validation the best model selection method for Machine Learning? arxiv 2024, arXiv:2401.16407. [Google Scholar]
- Han, X.; Zhang, Z.; Ding, N.; Gu, Y.; Liu, X.; Huo, Y.; Qiu, J.; Yao, Y.; Zhang, A.; Zhang, L.; et al. Pre-trained models: Past, present and future. AI Open 2021, 2, 225–250. [Google Scholar] [CrossRef]
- Tinn, R.; Cheng, H.; Gu, Y.; Usuyama, N.; Liu, X.; Naumann, T.; Gao, J.; Poon, H. Fine-tuning large neural language models for biomedical natural language processing. Patterns 2023, 4, 100729. [Google Scholar] [CrossRef]
- OpenAI. GPT-4o Mini: Advancing Cost-Efficient Intelligence. OpenAI Blog. Available online: https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence (accessed on 27 December 2024).
- OpenAI. Models—OpenAI API. Available online: https://platform.openai.com/docs/models (accessed on 12 April 2024).
- EleutherAI. GPT-Neo—EleutherAI. Available online: https://www.eleuther.ai/artifacts/gpt-neo (accessed on 11 April 2024).
- Bert-base-uncased Hugging Face. Available online: https://huggingface.co/bert-base-uncased (accessed on 28 September 2022).
- Hugging Face. Pretrained Models—Transformers 3.3.0 Documentation. Available online: https://huggingface.co/transformers/v3.3.1/pretrained_models.html (accessed on 10 April 2024).
- Hugging Face. BERT—Transformers 3.0.2 Documentation. Available online: https://huggingface.co/transformers/v3.0.2/model_doc/bert.html#berttokenizer (accessed on 9 April 2024).
- Hugging Face. FacebookAI/roberta-base Hugging Face. Available online: https://huggingface.co/FacebookAI/roberta-base (accessed on 10 April 2024).
- Moré, J. Evaluación de la Calidad de los Sistemas de Reconocimiento de Sentimientos. Available online: https://openaccess.uoc.edu/bitstream/10609/148645/3/Modulo3_EvaluacionDeLaCalidadDeLosSistemasDeReconocimientoDeSentimientos.pdf (accessed on 25 September 2024).
- Li, X.; Zhang, H.; Ouyang, Y.; Zhang, X.; Rong, W. A Shallow BERT-CNN Model for Sentiment Analysis on MOOCs Comments. In Proceedings of the 2019 IEEE International Conference on Engineering, Technology and Education (TALE), Yogyakarta, Indonesia, 10–13 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Lopes, C.; Sahani, S.; Dubey, S.; Tiwari, S.; Yadav, N. Hopeful horizon: Forecast student mental health using data analytics & ml techniques. Int. J. Emerg. Technol. Innov. Res. 2023, 10, 116–125. Available online: https://universalcollegeofengineering.edu.in/wp-content/uploads/2024/03/3.3.1-comps-merged-49-58.pdf (accessed on 16 April 2024).
- Regulation (EU) 2024/1689. Official Journal (OJ) of the European Union; European Commission: Brussels, Belgium; Luxembourg, July 2024; Available online: https://artificialintelligenceact.eu/es/ai-act-explorer/ (accessed on 22 February 2025).
- Dyulicheva, Y. Learning Analytics in MOOCs as an Instrument for Measuring Math Anxiety. Vopr. Obraz./Educ. Stud. Mosc. 2021, 4, 243–265. [Google Scholar] [CrossRef]
- Wasil, A.R.; Venturo-Conerly, K.E.; Shingleton, R.M.; Weisz, J.R. A review of popular smartphone apps for depression and anxiety: Assessing the inclusion of evidence-based content. Behav. Res. Ther. 2019, 123, 103498. [Google Scholar] [CrossRef] [PubMed]
- Discord Company. Sobre Discord. Discord. Available online: https://discord.com/company (accessed on 15 March 2021).
- Twitch. Keeping Our Community Safe: Twitch 2020 Transparency Report|Twitch Blog. 2020. Available online: https://blog.twitch.tv/es-mx/2021/03/02/keeping-our-community-safe-twitch-2020-transparency-report/ (accessed on 12 March 2021).



{kind=link}
{kind=link}
{kind=link}
| Sentiment | Comment | Label |
|---|---|---|
| Normal | I haven’t showered yet, give me motivation to take a shower | 0 |
| Anxiety/depression | Feeling worried, even though you have a God who is ready to help you in any case | 1 |
| Anxiety/depression | I want to die. But I’m scared of dying painfully. I want to die peacefully. I hate waking up. I don’t want to feel this way. | 1 |
| Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| gpt-4o-mini-2024-07-18 | 0.9893 | 0.9896 | 0.9893 | 0.9894 |
| gpt-3.5-turbo-0125 | 0.9893 | 0.9893 | 0.9893 | 0.9893 |
| gpt-neo-125m | 0.9646 | 0.9144 | 0.8835 | 0.9643 |
| bert-base-uncased | 0.9713 | 0.9176 | 0.9211 | 0.9713 |
| roberta-base | 0.9813 | 0.9312 | 0.9662 | 0.9814 |
| 5-Fold | Model | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|---|
| Average | roberta-base | 0.9862 | 0.9446 | 0.9738 | 0.9863 |
| gpt-neo-125m | 0.9418 | 0.9015 | 0.7213 | 0.9383 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pilicita, A.; Barra, E. LLMs in Education: Evaluation GPT and BERT Models in Student Comment Classification. Multimodal Technol. Interact. 2025, 9, 44. https://doi.org/10.3390/mti9050044
Pilicita A, Barra E. LLMs in Education: Evaluation GPT and BERT Models in Student Comment Classification. Multimodal Technologies and Interaction. 2025; 9(5):44. https://doi.org/10.3390/mti9050044
Chicago/Turabian StylePilicita, Anabel, and Enrique Barra. 2025. "LLMs in Education: Evaluation GPT and BERT Models in Student Comment Classification" Multimodal Technologies and Interaction 9, no. 5: 44. https://doi.org/10.3390/mti9050044
APA StylePilicita, A., & Barra, E. (2025). LLMs in Education: Evaluation GPT and BERT Models in Student Comment Classification. Multimodal Technologies and Interaction, 9(5), 44. https://doi.org/10.3390/mti9050044