
A Survey on Databases for Multimodal Emotion Recognition and an Introduction to the VIRI (Visible and InfraRed Image) Database



Abstract
:1. Introduction
Method and Keywords
2. Literature Survey
2.1. Historical Evolution and Current Trends
2.2. Challenges in MER
2.2.1. Limitation in the Background or Emotional Categories of DBs
2.2.2. Real-Time Implementation
2.2.3. Dataset Categorization
2.2.4. Emotional Annotation
2.3. Multimodal (2+) Databases
2.3.1. AMIGOS
2.3.2. ASCERTAIN
2.3.3. CALLAS Expressivity Corpus
2.3.4. CLAS
2.3.5. CMU-MOSEI
2.3.6. DEAP
2.3.7. DECAF
2.3.8. emoFBVP
2.3.9. EU Emotion Stimulus
2.3.10. HEU
2.3.11. MAHNOB-HCI
2.3.12. MELD
2.3.13. MMSE/BP4D+
2.3.14. MPED
2.3.15. MUStARD
2.3.16. NNIME
2.3.17. RAMAS
2.3.18. RECOLA
2.3.19. SLADE
2.4. Bi-Modal Databases
2.4.1. AVEC
2.4.2. BAUM-1 and BAUM-2
2.4.3. BioVid Emo
2.4.4. CHEAVD & CHEAVD 2.0
2.4.5. DREAMER
2.4.6. eNTERFACE’05
2.4.7. FABO
2.4.8. GEMEP-FERA 2011
2.4.9. HUMAINE
2.4.10. IEMOCAP
2.4.11. LIRIS-ACCEDE
2.4.12. RAVDESS
2.4.13. RML
2.4.14. SAL
2.4.15. SAVEE
2.4.16. SEED
2.4.17. SEMAINE
2.4.18. The USC CreativeIT
2.4.19. VAM
2.5. Unimodal Databases
2.5.1. AFEW
2.5.2. Berlin
2.5.3. CK/CK+
2.5.4. FER2013
2.5.5. JAFFE
2.5.6. MMI
2.5.7. NTUA
2.5.8. SFEW

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | Modalities | Language | Elicitation Method | Subjects | Size of Databases/No. of Samples | Emotion Description | Representation Work | Remarks | Posed/Spontaneous Induced/Natural |
|---|---|---|---|---|---|---|---|---|---|
| AMIGOS [94] | PS (EEG, GSR and ECG), Video and Depth Information | - | 16 emotional movie excerpts (of short duration, <250 s and of long duration, >14 min) in individual and group (4 people) context | 40 subjects (13 females and 27 males) | PS recordings in Matlab format: 3.60 GB, Frontal Face Videos: 192 GB, Full body RGB videos from Kinect: 203 GB, Full body depth videos from Kinect: 39.9 GB | Self-assessment by subject of valence, arousal, dominance, liking, familiarity and basic emotions (happy, sad, angry, disgust, surprise, fear and neutral). External annotation of valence and arousal. | [51,188] | Available. The data were recorded in individual settings and group settings to observe and analyze the impact of social context on person’s emotional state. | Spontaneous, Induced |
| ASCERTAIN [97] | PS (EEG, ECG and GSR), Facial activity | - | Emotions induced by watching 36 movie excerpts (ranging from 51–128 s) | 58 subjects (21 females and 37 males) | - | Self reports (for 36 videos for 58 subjects each): Arousal, Valence, Engagement, Liking, Familiarity; Personality scores for the Big 5 Personality traits: Extraversion, Agreeableness, Conscientiousness, Emotional Stability, Openness | [189] | Available. First database to connect personality traits and emotional states via physiological responses | Spontaneous, Induced |
| CALLAS Expressivity Corpus [98,99] | Speech, Facial expressions, Gestures | German Italian Greek | Set of 120 emotion instigating sentences were displayed for the users | 21 subjects (10 females and 11 males) | Approximately 5 h of recording | 3 emotion categories, positive, neutral and negative | [28] | Unreleased for public domain.DB created to understand nonverbal behaviors across different cultures. | Spontaneous, Induced |
| CLAS [100] | PS (ECG, EDA, PPG), 3D AD, metadata of the 62 participants | - | Test subjects were involved in some purposely designed interactive or perceptive task | 62 subjects (17 females and 45 males) | 30-minute recording of physiological signals for each subject. Compressed size: 2.03 GB, Uncompressed size: 13.9 GB | Low/high Arousal, Valence, High-Arousal Negative Valence (HANV) condition, and low/high Concentration. | [190] | ALB. Interactive tasks: solving sequences of math problems, Logic problems, and the Stroop test. Perceptive tasks: use of images and audio–video stimuli for eliciting emotions in the four quadrants of the arousal valence space | Spontaneous, Induced |
| CMU-MOSEI [103] | language (spoken text), visual features (gestures and facial expressions) and audio features (intonations and prosody) | English | - | 1000 speakers (43% females and 57% males) | 3228 videos acquired from YouTube Total Video hours: 65 h, 53 min and 36 s | Each sentence annotation for a sentiment on a [−3, 3] Likert scale of: [−3: highly negative, −2 negative, −1 weakly negative, 0 neutral, +1 weakly positive, +2 positive, +3 highly positive]. Ekman emotions of happiness, sadness, anger, fear, disgust, and surprise annotated on a [0, 3] Likert scale for the presence of emotion x: [0: no evidence of x, 1: weakly x, 2: x, 3: highly x]. | [191] | Available. The corpus consist of 23,453 sentences, 250 distinct topics and 447,143 words. | Spontaneous, Natural |
| DEAP [104] | EEG, PS, Face | - | Each contributor watched 40 excerpts of one-minute duration music videos and the outcome was recorded in terms of their responses. | 32 subjects | Online ratings, video list, participant ratings and participant questionnaire (.ods, .xls and .csv formats). PS: Original BioSemi (.bdf) format (5.8 Gb). Face videos: avi format (15.3 Gb) | Intensity of arousal, valence liking for the video, dominance and familiarity with the videos on a continuous scale of 1–9. a discrete rating of 1–5 was used for appraising the familiarity | [34,36,86] | Available. Out of the total 32 participants, the face video of 22 were recorded. | Spontaneous, Induced |
| DECAF [105] | BS (204 MEG gradiometers, 102 MEG magnetometers), Face(NIR), PS (3-channels ECG, B-hEOG, B-tEMG) | - | 40 music videos as employed in DEAP DB [104], 36 Hollywood movie clips | 30 subjects (14 females and 16 males) | 14 GB of preprocessed data | Valence–arousal ratings by each participant | [192] | Available. DECAF also contains time continuous emotion annotations for movie clips from seven users | Spontaneous, Induced |
| emoFBVP [86] | Face, Speech, Body Gesture, Physiological signals | English | Professional actors acted the 23 emotions categories and filled and evaluation form to rate their confidence level with expressing each emotion on a scale of 1 to 5. | 10 professional actors | 6 recordings (3 in seated and 3 in standing positions) for each actor enacting for 23 different emotions. | 23 emotions in 3 intensities (Happy, Sad, Anger, Disgust, Fear, Surprise, Boredom, Interest, Agreement, Disagreement, Neutral, Pride, Shame, Triumphant, Defeat, Sympathy, Antipathy, Admiration, Concentration, Anxiety, Frustration, Content and Contempt). | [86,178] | Not yet released. The actors rated themselves for the acted emotion categories. Paper says database is freely available but website displays database is coming soon! | Posed, Induced |
| EU Emotion Stimulus [106] | Face, Speech, Body gestures, Contextual social scenes | English Swedish Hebrew | Facial expression specific scenes: 249 clips Body gesture specific scenes: 82 clips contextual social science specific scene: 87 clips Speech stimuli: 2364 recordings | 19 professional actors | 418 visual clips (2–52 s) | 21 emotions/mental states: neutral, afraid, angry, ashamed, bored, disappointed, disgusted, excited, frustrated, happy, hurt, interested, jealous, joking, kind, proud, sad, sneaky, surprised, unfriendly, and worried. | [10] | Available. Presents emotional and mental state data for face, body gestures and social sciences contextual scenes not available previously. | Spontaneous, Induced |
| HEU [107] | HEU-part 1: Face and Body Gesture HEU-part 2: (Face, Body Gesture, and Speech) | Chinese, English, Thai, Korean | - | Total: 9951 subjects (HEU-part1: 8984, HEU-part2: 967) | 19,004 video clips | 10 emotions: Anger, bored, confused, disappointed, disgust, fear, happy, neutral, sad, surprise | - | Available. Consists of multi-view postures of face and body, multiple local occlusion and illumination and expression intensity. | Posed, Induced |
| MAHNOB-HCI [85] | 32 Channel EEG PS, Face, Audio, EM, Body movements | English | Participants were shown emotional videos and pictures | 27 subjects (16 females and 11 males) | Emotion Elicitation exp: 4 readings each for 27 participants, Implicit tagging exp: 3 readings each for 27 participants | Emotional keyworker, Arousal, Valence and Predictability on a Likert scale(1–9) | [86,108] | Available. Subjects from different cultural backgrounds. | Spontaneous, Induced |
| MELD [109] | Video, Audio, Text | English | - | Characters from TV show “Friends” (84% of time, there were 6 Actors) | 13,000 utterances from 1433 dialogues. Each utterance is 3.59 s | 7 emotions: Anger, Disgust, Sadness, Joy, Neutral, Surprise and Fear; 3 sentiments: positive, negative and neutral | [111] | Available. Each utterance (combination of audio, video and text) is annotated with sentiment and emotion labels. | Posed, Induced |
| MMSE/BP4D+ [112] | High-resolution 3D model sequences, 2D RGB videos, Thermal videos, PS(RR, BP, EDA, and HR) | - | Participants conducted 10 activities, under the supervision of a professional actor. The activities included 4 methods: cold pressor, designed physical experiences, interpersonal conversations and watching of a film clip. | 140 subjects (82 females and 58 male) | 10TB high quality data | 10 Emotions: Happiness/amusement, surprise, sadness, startle surprise, skeptical, embarrassment, fear nervous, physical pain, angry, disgust. | [113,114] | Available. Ethnic/Racial Ancestries include Black, White, Asian (including East Asian and Middle East Asian), Hispanic/Latino, and others (e.g., Native American). | Spontaneous, Induced |
| MPED [115] | PS(EEG, GSR, RR, ECG). | - | Each participant watched 28 video clips describing seven different emotions. | 23 Chinese volunteers (13 females and 10 males) | 5684 s | 7 emotions: Joy, funny, anger, disgust, fear, sad and neutrality | [116] | Available. 28 videos for elicitation were manually annotated and were chosen from a group of 1500 videos to reduce the influence of culture | Spontaneous, Induced |
| MUStARD [117] | Video, Audio, Text | English | - | Characters from 4 TV shows: “Friends”, “The Golden Girls”, “The Big Bang Theory” and “Sarcasmaholics Anonymous” | 690 one-utterance videos | Sarcasm and non-sarcasm | [119,120] | Available. Each audiovisual utterance goes along with the conversational context for additional information. | Posed, Induced |
| NNIME [121] | Audio, Video, ECG | Chinese | Dyadic spoken interaction between subjects designed by a professional director | 44 subjects (22 females, 20 males) | 11 h of audio, video, and electrocardiogram data | 6 emotions: Angry, happy, sad, neutral, disappointed, surprise | [122] | Available. Consist of both discrete (6 emotion categories) and continuous (activation and valence) emotion annotation | Posed, Natural |
| RAMAS [123] | Face, Speech, Motion-capture, PS (EDA and PG) | Russian | The subjects actors played out interactive dyadic scenarios involving each of the six emotional categories. | Ten semi-professional actors (5 females and 5 males) | Approximately 7 h of high quality Videos | 6 emotions: angry, disgust, happy, sad, scared, surprised; 2 social interaction characteristics: domination and submission | [125] | ALB | Posed, Induced |
| RECOLA [126] | Speech, Face, ECG, EDA | French | 23 teams of two were asked to complete a collaborative task involving social and emotional behaviors. | 46 subjects (27 females and 19 males) | 9.5 h of audio, visual, and physiological (electrocardiogram, and electrodermal activity) recording. | Continuous dimensions of valence and arousal. | [8,35,127,193] | Available. 34 participants out of 46 gave their consent to share their data. | Spontaneous, Induced |
| SLADE [128] | PS (EEG, ECG, GSR and ST) | - | Audio-visual stimuli in the form of 40 movie excerpts (duration 1 min) | - | - | Valence-arousal ratings by each participant | - | Not publicly available. This DB was developed to facilitate the detection of stress levels end ER. | Spontaneous/ Induced |
| AVEC [129,130] | Face, Speech | German | Subjects performed HCI tasks while they were being recorded | 292 subjects | 340 video clips adding up to 240 h | The clips were annotated in 3 dimensions; arousal, valence and dominance, in continuous time and value | [20,131] | Not available publicly. Developed for emotion and depression recognition challenge. | Spontaneous, Induced |
| BAUM-1 [132] | Face, Speech | Turkish | Subjects watched images and video sequences to evoke target emotions. | 31 subjects (17 females and 14 males) | 1222 video clips | 6 emotions: happiness, anger, sadness, disgust, fear and surprise Intensity on a scale 0–5 | [23] | Available. Consists of emotional and mental states. Close to natural conditions such as background. | Spontaneous, Induced |
| BAUM-2 [194] | Face, Speech | English Turkish | - | 286 subjects (118 females and 168 males) | 1047 video clips | 7 emotions: anger, happiness, sadness, disgust, surprise, neutral and fear. Intensity of emotion in term of score between 1 and 5 | - | Available. Contains clips from movies and TV clips are more naturalistic. It is a multilingual database | Posed, Natural |
| BioVid Emo [133] | PPS (SCL, ECG, tEMG), Video | - | 15 standardized film clips of length 32 to 245 s were shown to the participants | 94 subjects (50 females and 44 males) | 430 .csv sheets; 5 sheets for each subject; each sheet contains PPS data of the participant’s chosen film clip 430 .mp4 videos of the .csv sheets | 5 emotions: amusement, sadness, anger, disgust and fear. | [134] | ALB. Originally 94 subjects were there but now only 86 remain due to missed or corrupted recordings. | Spontaneous, Induced |
| CHEAVD [135] | Audio, Video | Chinese | - | 238 speakers (47.5% female and 52.5% male) | 140 min of excerpts from 34 films, 2 television series, 2 television shows, 1 impromptu speech and 1 talk show | 26 non-prototypical emotional states, including the basic six: Angry, happy, sad, neutral, disgust, surprise | [137,138] | Available. Multi-emotion labels and fake/suppressed emotion labels. Highly Skewed | Posed/Induced |
| CHEAVD 2.0 [136] | Audio, Video | Chinese | - | 527 speakers (41.6% female and 58.4% male) | 474 min of excerpts from Chinese movies, soap operas and TV shows, 7030 samples | 8 emotions: neutral, angry, happy, sad, surprised, disgust, worried, anxious | [137,138] | Available. This DB was developed for the Multimodal Emotion Recognition Challenge (MEC) 2017 | Posed/Induced |
| DREAMER [139] | EEG & ECG | - | 18 movie clips (duration: 65–393 s) to elicit emotions | 23 subjects (9 females and 14 males) | - | Valence/arousal rated using a discrete scale of integers from 1 to 5 | [195,196] | Available. Signals were captured using portable, wearable, wireless, low-cost, and off-the-shelf equipment. | Spontaneous/ Induced |
| eNTERFACE’05 [143] | Face, Speech | English | Subjects were asked to hear six short stories evoking a particular emotion | 42 subjects (8 females and 34 males) | Total: 1166 videos (Anger: 200, Disgust: 189, Fear: 187, Happiness: 205, Sadness: 195, Surprise: 190) | 6 emotions: happiness, sadness, surprise, anger, disgust and fear. | [11,14,15,17,21,22,23,27] | Available. Subjects were from 14 different nationalities (Belgium, Turkey, France, Spain, Greece, Austria, Italy, Cuba, Slovakia, Brazil, USA, Croatia, Canada, and Russia), | Spontaneous, Induced |
| FABO [144] | Face Expressions Body Gestures | - | Subjects provided with situation or short scenarios for narrating an emotion eliciting situation. | 23 subjects (12 females and 11 males) | Video size of 9 Gb | 10 emotions: neutral, uncertainty, anger, surprise, fear, anxiety, happiness, disgust, boredom, sadness | [145] | Available. DB consists of subjects from different ethnicities, such as European, Middle Eastern, Latin American, Asian, and Australian | Posed, Induced |
| GEMEP-FERA 2011 [147,148] | Face, Speech | 2 pseudo-linguistic phoneme sequences. | Actors were guided by a professional director and uttered 2 pseudo-linguistic phoneme sequences or a sustained vowel `aaa’ | 10 professional actors (5 female and 5 male) | 7000 audio-video illustrations | 18 emotions (admiration, amusement, anger, tenderness, disgust, despair, pride, shame, anxiety, interest, irritation, joy, contempt, fear, pleasure–sensual, relief, surprise and sadness) | [16] | Not available publicly. Very subtle and not very common 18 emotional categories. | Posed, Induced |
| HUMAINE [149] | Face, Speech, Gestures | English, French, Hebrew | - | - | 50 video clips ranging from 5 s to 3 min | Emotional content at 2 levels: Global label, applied to whole clip, continuous annotation on one dimensional axis such as valence, activation, arousal, intensity or power. | [25] | Authors mentioned available, but the link is broken. Contains clips from TV chat shows and religious shows data annotated for audio visual only. | Posed, Natural |
| IEMOCAP [93] | Face, Speech, Head and Hand movement, DT, Word, Syllable and Phoneme level alignment | English | Subjects enacted in pairs on 3 selected emotional scripts in hypothetical scenarios with markers on their face, head and hands. | 10 professional actors (5 female and 5 male) | Approximately 12 h of data | 5 emotions in beginning (happiness, anger, sadness, frustration, neutral). Later (surprise, fear, disgust, excited) were added. | [13,19,33,131] | Available. Annotation done for utterances by at least 3 annotators annotated on valence, activation and dominance. | Spontaneous, Induced |
| LIRIS-ACCEDE [150,151] | Audio, Video | English, Italian, Spanish, French | - | - | 9800 high quality movie excerpts (duration 8–12 s) taken from 160 movies | Rankings for arousal and valence dimensions | [197] | Available. The DB was annotated by 1517 trusted annotators from 89 countries. | Spontaneous, Natural |
| RAVDESS [152] | Audio, Video | English | Two neutral statements were used (“Kids are talking by the door”, “Dogs are sitting by the door”) | 24 professional actors (12 females and 12 males). | 7356 recordings (total size: 24.8 GB) | 8 emotional categories: neutral, calm, angry, sad, fearful, surprise, disgust and happy; songs: neutral, sad, angry, calm, fearful and happy | [18,114,153,154] | Available. Each expression is produced at two levels of emotional intensity (normal, strong) | Posed, Induced |
| RML [155] | Face, Speech | English Mandarin Urdu Punjabi Persian Italian | 10 different sentences for each emotional class | 8 subjects | 720 visual clips of 5 s each. Total Size: 4.2 Gb | 6 emotions: (anger, disgust, fear, happiness, sadness and surprise) | [18,23,156] | Available. Participants were asked to recall any emotion related event in their lives to exhibit natural emotion | Spontaneous, Natural |
| SAL [149,157] | Face, Speech | English Hebrew Greek | Conversation between a machine and human. Machine had emotional traits | 20 subjects | 491 recordings total of approx. 10 h | Four emotions: happy, gloomy, angry and pragmatic | - | Available. Low intensity of recorded emotions. | Spontaneous, Induced |
| SAVEE [38,158] | Face, Speech | British English | Emotional video clips, texts and pictures were displayed for the participants (3 for each emotion) | 4 native English males | 480 recordings (120 for each subject) | Seven emotions: (anger, disgust, fear, happiness, sadness, surprise and neutral) | [19,24,156] | Available.Evaluated by 10 evaluators for accuracy | Spontaneous, Induced |
| SEED [159,160,161] | EEG | - | 15 Chinese films clips of 4 min | 15 subjects (8 females and 7 males) | 43.88 GB | 3 emotional states: neutral, happy and sad) | [160] | Available.Consists of EEG and Eye movement for 12 subjects and only EEG Data for 3 subjects. | Spontaneous, Induced |
| SEED-IV [162] | EEG and EM | - | 72 Video clips | 15 subjects (8 females and 7 males) | 6.88 GB | 4 emotional states: Happy, sad, fear, and neutral | [160] | Available. | Spontaneous, Induced |
| SEED-V [163] | EEG and EM | - | 15 movie clips | 16 subjects (10 females and 6 males) | 37.77 GB | 5 emotional states: happy, neutral, disgust, sad and fear | [160] | Available. | Spontaneous, Induced |
| SEED-VIG [164] | EEG and EOG | - | A 4-lane highway scene, a VR-based driving system | 23 subjects (12 females and 11 males) | 2.94 GB | Vigilance labels (ranging from 0 to 1) | [160] | Available. | Spontaneous, Induced |
| SEMAINE [165,198] | Face, Speech | English | Subjects talked to a SAL (sensitive artificial listener) | 150 subjects | 959 conversations of around 5 min duration of each clip. | 5 affective dimensions (arousal, expectation, intensity, power and valence) for 27 categories | - | Available. Participants from 8 different countries. | Spontaneous, Induced |
| The USC CreativeIT [166,167] | Speech, Body movements | English | Subjects in pairs did a conversation producing expressive affective behaviors. | 16 actors (8 females and 8 males) | 90 recordings of 3 min each | Annotated on Valence, activation and arousal on a scale 1–5 | [167] | Available. | Spontaneous, Induced |
| VAM [168] | Face, Speech | German | Extracted from German talk show “Vera am Mittag” | VAM-video 104, VAM-audio 47, VAM-faces 20 subjects | VAM-video 1421 utterances VAM-audio 1018 utterances VAM-faces 1872 images | Emotion marked on 3 continuous emotion parameters, i.e., valence (negative or positive), activation (calm or excited) and dominance (weak or strong). | - | Available. | Spontaneous, Natural |
| AFEW [169] | Face | - | - | 330 subjects | 957 video clips ranging from 300 ms to 5400 ms | Six emotions:angry, disgust, fear, happy, sad and surprise | [2,5,7,9,16,17,26] | Available. Referred to as wild because close to the real world. | Spontaneous, Natural |
| Berlin [170] | Speech | German | Simulated the emotion by speaking 10 sentences | 10 actors (5 females and 5 males) | 800 sentences | 6 emotions: anger, fear, happy, sad, disgust and boredom | [3,14,15,156] | Available. Each utterance was judged by 20 listeners. | Posed, Natural |
| CK/CK+ [146,175] | Face | - | Subjects were told to perform facial displays by the instructor | CK: 97 subjects, CK+: 123 subjects | CK: 486 excerpts CK+: 593 excerpts | 7 emotions: anger, contempt, disgust, happy, sad, surprise and neutral | [3,9,14,15,16,86,178,179] | Available.Another version of the Database is being planned for future release. | CK: Posed CK+: Posed and spontaneous, Natural |
| FER2013 [180,181] | Face | - | - | - | 35,887 images of size 48 × 48 | Seven emotions: anger, disgust, fear, happy, sad, surprise and neutral | [179] | Available. 3 variants of database: FER28, FER32 and FER32+EmotiW. | Spontaneous, Natural |
| JAFFE [182,183,184] | Face | - | Expressions were posed without any directives | 10 subjects | 217 images | 7 emotions: happy, sad, fear, anger, surprise, disgust and neutral | [179] | Available. 60 Japanese annotators labeled images. Size of image 240 × 292 | Posed, Natural |
| MMI [86] | Face | - | Each participant was asked to display all 31 AUs and a number of extra Action Descriptors. | Phase I: 19 (8 females and 11 males) PhaseII: 75 | Phase I:740 images 848 videos PhaseII: 2900 videos and high resolution images | 169 sequences are FACS coded. The DB comprise temporal pattern of expression: neutral-onset/apex/offset-neutral | [178] | Available. Frontal and dual view (frontal with profile view) | Posed, Natural |
| NTUA [167] | Speech | Chinese | Dyadic interaction between subjects designed by a professional director | 22 subjects | 204 recordings (approx. 3 min each) | Emotion labeled in arousal and valence dimension on a scale between (1,5) | [167] | Availability: unknown. Annotated by 42 annotators | Posed, Natural |
| SFEW [187] | Face | - | - | 95 subjects | 700 images | Seven emotions: angry, disgust, surprise, sad, happy, fear and neutral | [9] | Available. Subset of AFEW [169] | Spontaneous, Natural |
3. A Taxonomy for the Recognized Features in Modalities
|
|
4. The VIRI DB
4.1. Motivation
4.2. Process of DB Creation
4.2.1. Procedures and Participants
4.2.2. Devices
4.2.3. Viri DB Design
5. Future Research Directions
5.1. Artificial Emotional Intelligence (AEI)
5.2. Automatic Facial Expression Recognition (AFER) Refinement
- Unavailability of comprehensive DBs: The facial expression DBs are limited and are not all inclusive. There is a need to create such DBs containing natural expressions. Another aspect of an ideal DB missing in most of the current DB is the varied lighting conditions and the subject captured in an uncontrolled wild environment.
- Rotation invariance: One of the major drawbacks of the AFER is its inability to cope with head pose variations. This aspect of AFER needs attention to carry out impeccable emotion recognition. A way to resolve this could be using 3D facial data that capture depth information.
- Micro expressions: These are brief expressions that a person exhibits in high-stakes situations while expressing their feelings. Difficult to perceive by a novice person, an automatic recognition of these expressions might reveal the feelings that a person is trying to hide. An apposite demonstration of such an application of emotion recognition is shown in the award-winning television series “Lie to Me” [204] inspired by Dr. Ekman’s research.
- Intensity: The intensity of a facial expression may serve more value in analyzing behavior and may serve as a tool for differentiating a posed and spontaneous emotion. This arduous task of identifying the intensities of the observed emotion is still in its nascent stage and requires attention to perceive subtle emotional categories.
- Secondary emotional states: Most AFER are restrained to detecting only primary emotional states, such as happy and sad. Many secondary emotional states, such as frustration, pain, depression, etc., necessitate consideration.
5.3. Contextual Emotion Recognition
5.4. Wireless Emotion Recognition
5.5. Biometric Surveillance and Monitoring
5.6. Automated Feedback
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AEI | Artificial Emotional Intelligence | kNN | k-Nearest Neighbor |
| AD | Accelerometer Data | LBP-TOP | Local Binary Pattern from Three Orthgonal Planes |
| AFER | Automatic Facial Expression Recognition | LIF | Local Invariant Feature |
| ALB | Available but Link Broken | LLD | Low Level Descriptors |
| ANN | Artificial Neural Network | LSTM | Long Short-Term Memory |
| AU | Action Units | MCC | Matthew Correlation Coefficient |
| B-hEOG | Bi-polar Horizontal Electrooculogram | MDR | Multi-Directional Regression |
| BOS | Blood Oxygen Saturation | MDR | Multi-Directional Regression |
| BP | Blood Pressure | MEG | Magnetoencephalogram |
| BS | Brain Signals | MER | Multimodal Emotion Recognition |
| B-tEMG | Bi-polar trapezius Electromyogram | MFCC | Mel-Frequency Cepstral Coefficients |
| BVP | Blood Volume Pressure | MKL | Multiple Kernel Learning |
| CCA | Canonical Correlation Analysis | ML | Machine Learning |
| CCC | Concordance Correlation Coefficient | MLP | Multi Layer Perceptron |
| CDBN | Convolutional Deep Belief Network | MSX | Multi Spectral Dynamic Imaging |
| CNN | Convolutional Neural Network | MuLOT | Multimodal Learning using Optimal Transport |
| DB | Database | NIR | Near Infrared |
| DBLSTM-RNN | Deep Bi-Directional LSTM-RNN | OF | Optical Flow |
| DBN | Deep Belief Network | PCA | Principal Component Analysis |
| DCNN | Deep Convolutional Neural Network | PG | Photoplethymogram |
| DeRL | De-Expression Residue Learning | PHOG | Pyramid Histograms of Oriented Gradients |
| DL | Deep Learning | PLP | Perceptual Linear Prediction |
| DRN | Deep Residual Networks | PPG | Plethysmography |
| DT | Dialogu Transcriptions | PPS | Psychophysiological signals |
| ECG | Electrocardiogram | PS | Physiological Signals |
| ECNN | Ensemble Convolutional Neural Network | RASTA | Relative Spectral Features |
| EDA | Electro Dermal Activity | RBM | Restricted Boltzmann Machines |
| EDA | Electro Dermal Activity | RBM | Restricted Boltzmann machines |
| EEG | Electroencephalogram | RNN | Recurrent Neural Network |
| ELM | Extreme Learning Machine | RP | Respiration Pattern |
| EM | Eye Movements | RR | Respiration Rate |
| EMA | Electromagnetic Articulography | RRR | Reduced Rank Regression |
| EMG | Electromyogram | RSM | Replicated Softmax Model |
| EOG | Electrooculography | SAL | Sensitive Artificial Listener |
| ERC | Emotion Recognition in Conversation | SCL | Skin Conductance Level |
| ESD | Emotional Shift Detection | SCR | Skin Conductance Response |
| FACS | Facial Action Cading System | SCSR | Skin Conductance Slow Response |
| FE | Facial Expressions | SCVCR | Skin Conductance Very Slow Response |
| GECNN | Graph-Embedded Convolutional Neural | SIFT | Scale-Invariant Feature Transform |
| Network | |||
| GSR | Galvanic Skin Response | SKRRR | Sparse Kernel Reduced Rank Regression |
| HCI | Human–Computer Interaction | SKT | Skin Temperature |
| HMI | Human–Machine Interaction | SVM | Support Vector Machines |
| HMM | Hidden Markov Models | VER | Voice-Based Emotion Recognition |
| HOG-TOP | Histogram of Oriented Gradients from | WLD | Weber Local Descriptor |
| Three Orthogonal Planes | |||
| HR | Heart Rate | WLD | Weber Local Descriptor |
| IR | Infrared | ZCR | Zero Crossing Rate |
References
- Bahreini, K.; Nadolski, R.; Westera, W. Data Fusion for Real-time Multimodal Emotion Recognition through Webcams and Microphones in E-Learning. Int. J. Hum.–Comput. Interact. 2016, 32, 415–430. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Li, L.; Zhou, G.; Wu, X.; He, J.; Yu, L.; Li, D.; Wei, Q. Combining multimodal features within a fusion network for emotion recognition in the wild. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 497–502. [Google Scholar]
- Xu, C.; Cao, T.; Feng, Z.; Dong, C. Multi-Modal Fusion Emotion Recognition Based on HMM and ANN. Contemp. Res.-Bus. Technol. Strategy 2012, 332, 541–550. [Google Scholar]
- Alonso-Martín, F.; Malfaz, M.; Sequeira, J.; Gorostiza, J.F.; Salichs, M.A. A multimodal emotion detection system during human–robot interaction. Sensors 2013, 13, 15549–15581. [Google Scholar] [CrossRef] [Green Version]
- Kahou, S.E.; Bouthillier, X.; Lamblin, P.; Gulcehre, C.; Michalski, V.; Konda, K.; Jean, S.; Froumenty, P.; Dauphin, Y.; Boulanger-Lewandowski, N.; et al. Emonets: Multimodal deep learning approaches for emotion recognition in video. J. Multimodal User Interfaces 2016, 10, 99–111. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Li, L.; Zuo, T.; Chen, Y.; Zhou, G.; Wu, X. Combining multimodal features with hierarchical classifier fusion for emotion recognition in the wild. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 481–486. [Google Scholar]
- Chen, J.; Chen, Z.; Chi, Z.; Fu, H. Emotion recognition in the wild with feature fusion and multiple kernel learning. In Proceedings of the 16th International Conference on Multimodal Interaction, Istanbul, Turkey, 12–16 November 2014; pp. 508–513. [Google Scholar]
- Tzirakis, P.; Trigeorgis, G.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. End-to-End Multimodal Emotion Recognition using Deep Neural Networks. arXiv 2017, arXiv:1704.08619. [Google Scholar] [CrossRef] [Green Version]
- Sun, B.; Li, L.; Wu, X.; Zuo, T.; Chen, Y.; Zhou, G.; He, J.; Zhu, X. Combining feature-level and decision-level fusion in a hierarchical classifier for emotion recognition in the wild. J. Multimodal User Interfaces 2016, 10, 125–137. [Google Scholar] [CrossRef]
- Torres, J.M.M.; Stepanov, E.A. Enhanced face/audio emotion recognition: Video and instance level classification using ConvNets and restricted Boltzmann Machines. In Proceedings of the International Conference on Web Intelligence, Leipzig, Germany, 23–26 August 2017; pp. 939–946. [Google Scholar]
- Dobrišek, S.; Gajšek, R.; Mihelič, F.; Pavešić, N.; Štruc, V. Towards efficient multi-modal emotion recognition. Int. J. Adv. Robot. Syst. 2013, 10, 53. [Google Scholar] [CrossRef] [Green Version]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Fusion of classifier predictions for audio-visual emotion recognition. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 61–66. [Google Scholar]
- Kim, Y.; Lee, H.; Provost, E.M. Deep learning for robust feature generation in audiovisual emotion recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 3687–3691. [Google Scholar]
- Hossain, M.S.; Muhammad, G. Audio-visual emotion recognition using multi-directional regression and Ridgelet transform. J. Multimodal User Interfaces 2016, 10, 325–333. [Google Scholar] [CrossRef]
- Hossain, M.S.; Muhammad, G.; Alhamid, M.F.; Song, B.; Al-Mutib, K. Audio-visual emotion recognition using big data towards 5G. Mob. Netw. Appl. 2016, 21, 753–763. [Google Scholar] [CrossRef]
- Chen, J.; Chen, Z.; Chi, Z.; Fu, H. Facial expression recognition in video with multiple feature fusion. IEEE Trans. Affect. Comput. 2016, 9, 38–50. [Google Scholar] [CrossRef]
- Yan, J.; Zheng, W.; Xu, Q.; Lu, G.; Li, H.; Wang, B. Sparse Kernel Reduced-Rank Regression for Bimodal Emotion Recognition From Facial Expression and Speech. IEEE Trans. Multimed. 2016, 18, 1319–1329. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W. Multimodal Deep Convolutional Neural Network for Audio-Visual Emotion Recognition. In Proceedings of the 2016 ACM on International Conference on Multimedia Retrieval, New York, NY, USA, 6–9 June 2016; pp. 281–284. [Google Scholar]
- Kim, Y. Exploring sources of variation in human behavioral data: Towards automatic audio-visual emotion recognition. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 748–753. [Google Scholar]
- Pei, E.; Yang, L.; Jiang, D.; Sahli, H. Multimodal dimensional affect recognition using deep bidirectional long short-term memory recurrent neural networks. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 208–214. [Google Scholar]
- Nguyen, D.; Nguyen, K.; Sridharan, S.; Ghasemi, A.; Dean, D.; Fookes, C. Deep spatio-temporal features for multimodal emotion recognition. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017; pp. 1215–1223. [Google Scholar]
- Fu, J.; Mao, Q.; Tu, J.; Zhan, Y. Multimodal shared features learning for emotion recognition by enhanced sparse local discriminative canonical correlation analysis. Multimed. Syst. 2017, 25, 451–461. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W.; Tian, Q. Learning Affective Features with a Hybrid Deep Model for Audio-Visual Emotion Recognition. IEEE Trans. Circuits Syst. Video Technol. 2017, 28, 3030–3043. [Google Scholar] [CrossRef]
- Cid, F.; Manso, L.J.; Núnez, P. A Novel Multimodal Emotion Recognition Approach for Affective Human Robot Interaction. In Proceedings of the Workshop on Multimodal and Semantics for Robotics Systems, Hamburg, Germany, 1 October 2015; pp. 1–9. [Google Scholar]
- Haq, S.; Jan, T.; Jehangir, A.; Asif, M.; Ali, A.; Ahmad, N. Bimodal Human Emotion Classification in the Speaker-dependent Scenario. Pak. Acad. Sci. 2015, 52, 27–38. [Google Scholar]
- Gideon, J.; Zhang, B.; Aldeneh, Z.; Kim, Y.; Khorram, S.; Le, D.; Provost, E.M. Wild wild emotion: A multimodal ensemble approach. In Proceedings of the 18th ACM International Conference on Multimodal Interaction, Tokyo, Japan, 12–16 November 2016; pp. 501–505. [Google Scholar]
- Noroozi, F.; Marjanovic, M.; Njegus, A.; Escalera, S.; Anbarjafari, G. Audio-visual emotion recognition in video clips. IEEE Trans. Affect. Comput. 2017, 10, 60–75. [Google Scholar] [CrossRef]
- Wagner, J.; Andre, E.; Lingenfelser, F.; Kim, J. Exploring fusion methods for multimodal emotion recognition with missing data. IEEE Trans. Affect. Comput. 2011, 2, 206–218. [Google Scholar] [CrossRef]
- Ghayoumi, M.; Bansal, A.K. Multimodal architecture for emotion in robots using deep learning. In Proceedings of the Future Technologies Conference (FTC), San Francisco, CA, USA, 6–7 December 2016; pp. 901–907. [Google Scholar]
- Kessous, L.; Castellano, G.; Caridakis, G. Multimodal emotion recognition in speech-based interaction using facial expression, body gesture and acoustic analysis. J. Multimodal User Interfaces 2010, 3, 33–48. [Google Scholar] [CrossRef] [Green Version]
- Yoshitomi, Y.; Kim, S.I.; Kawano, T.; Kilazoe, T. Effect of sensor fusion for recognition of emotional states using voice, face image and thermal image of face. In Proceedings of the Proceedings 9th IEEE International Workshop on Robot and Human Interactive Communication. IEEE RO-MAN 2000 (Cat. No.00TH8499), Osaka, Japan, 27–29 September 2000; pp. 178–183. [Google Scholar]
- Kitazoe, T.; Kim, S.I.; Yoshitomi, Y.; Ikeda, T. Recognition of emotional states using voice, face image and thermal image of face. In Proceedings of the Sixth International Conference on Spoken Language Processing, Beijing, China, 16–20 October 2000. [Google Scholar]
- Shah, M.; Chakrabarti, C.; Spanias, A. A multi-modal approach to emotion recognition using undirected topic models. In Proceedings of the 2014 IEEE International Symposium on Circuits and Systems (ISCAS), Melbourne, Australia, 1–5 June 2014; pp. 754–757. [Google Scholar]
- Verma, G.K.; Tiwary, U.S. Multimodal fusion framework: A multiresolution approach for emotion classification and recognition from physiological signals. NeuroImage 2014, 102, 162–172. [Google Scholar] [CrossRef]
- Keren, G.; Kirschstein, T.; Marchi, E.; Ringeval, F.; Schuller, B. End-to-end learning for dimensional emotion recognition from physiological signals. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; pp. 985–990. [Google Scholar]
- Yin, Z.; Zhao, M.; Wang, Y.; Yang, J.; Zhang, J. Recognition of emotions using multimodal physiological signals and an ensemble deep learning model. Comput. Methods Programs Biomed. 2017, 140, 93–110. [Google Scholar] [CrossRef]
- Dai, Y.; Wang, X.; Zhang, P.; Zhang, W. Wearable Biosensor Network Enabled Multimodal Daily-life Emotion Recognition Employing Reputation-driven Imbalanced Fuzzy Classification. Measurement 2017, 109, 408–424. [Google Scholar] [CrossRef]
- Kortelainen, J.; Tiinanen, S.; Huang, X.; Li, X.; Laukka, S.; Pietikäinen, M.; Seppänen, T. Multimodal emotion recognition by combining physiological signals and facial expressions: A preliminary study. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 5238–5241. [Google Scholar]
- Hess, U.; Thibault, P. Darwin and emotion expression. Am. Psychol. 2009, 64, 120. [Google Scholar] [CrossRef]
- Laird, J.D.; Lacasse, K. Bodily influences on emotional feelings: Accumulating evidence and extensions of William James’s theory of emotion. Emot. Rev. 2014, 6, 27–34. [Google Scholar] [CrossRef]
- Corneanu, C.A.; Simón, M.O.; Cohn, J.F.; Guerrero, S.E. Survey on rgb, 3d, thermal, and multimodal approaches for facial expression recognition: History, trends, and affect-related applications. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1548–1568. [Google Scholar] [CrossRef] [Green Version]
- Ekman, P. Strong evidence for universals in facial expressions: A reply to Russell’s mistaken critique. Psychol. Bull. 1994, 115, 268–287. [Google Scholar] [CrossRef]
- Ekman, P.; Friesen, W.V.; Hager, J. Investigator’s Guide to the Facial Action Coding System; Consulting Psychologists Press: Palo Alto, CA, USA, 1978. [Google Scholar]
- Mase, K. Recognition of facial expression from optical flow. IEICE Trans. Inf. Syst. 1991, 74, 3474–3483. [Google Scholar]
- Lanitis, A.; Taylor, C.J.; Cootes, T.F. A unified approach to coding and interpreting face images. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 368–373. [Google Scholar]
- Black, M.J.; Yacoob, Y. Tracking and recognizing rigid and non-rigid facial motions using local parametric models of image motion. In Proceedings of the IEEE International Conference on Computer Vision, Cambridge, MA, USA, 20–23 June 1995; pp. 374–381. [Google Scholar]
- Rosenblum, M.; Yacoob, Y.; Davis, L.S. Human expression recognition from motion using a radial basis function network architecture. IEEE Trans. Neural Netw. 1996, 7, 1121–1138. [Google Scholar] [CrossRef]
- Essa, I.A.; Pentland, A.P. Coding, analysis, interpretation, and recognition of facial expressions. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 757–763. [Google Scholar] [CrossRef] [Green Version]
- Yacoob, Y.; Davis, L.S. Recognizing human facial expressions from long image sequences using optical flow. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 636–642. [Google Scholar] [CrossRef]
- Lang, P.J.; Bradley, M.M.; Cuthbert, B.N. International affective picture system (IAPS): Technical manual and affective ratings. NIMH Cent. Study Emot. Atten. 1997, 1, 39–58. [Google Scholar]
- Santamaria-Granados, L.; Munoz-Organero, M.; Ramirez-Gonzalez, G.; Abdulhay, E.; Arunkumar, N. Using deep convolutional neural network for emotion detection on a physiological signals dataset (AMIGOS). IEEE Access 2018, 7, 57–67. [Google Scholar] [CrossRef]
- Sourina, O.; Liu, Y. A fractal-based algorithm of emotion recognition from EEG using arousal-valence model. In Proceedings of the International Conference on Bio-Inspired Systems and Signal Processing, Rome, Italy, 26–29 January 2011; Volume 2, pp. 209–214. [Google Scholar]
- Liu, Y.; Sourina, O.; Nguyen, M.K. Real-time EEG-Based emotion recognition and its applications. In Transactions on Computational Science XII; Springer: Berlin/Heidelberg, Germany, 2011; pp. 256–277. [Google Scholar]
- Alhagry, S.; Fahmy, A.A.; El-Khoribi, R.A. Emotion recognition based on EEG using LSTM recurrent neural network. Emotion 2017, 8, 355–358. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Q.; Chen, X.; Zhan, Q.; Yang, T.; Xia, S. Respiration-based emotion recognition with deep learning. Comput. Ind. 2017, 92, 84–90. [Google Scholar] [CrossRef]
- Aleksic, P.S.; Katsaggelos, A.K. Automatic facial expression recognition using facial animation parameters and multistream HMMs. IEEE Trans. Inf. Forensics Secur. 2006, 1, 3–11. [Google Scholar] [CrossRef]
- Tian, Y.I.; Kanade, T.; Cohn, J.F. Recognizing action units for facial expression analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 97–115. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Matsugu, M.; Mori, K.; Mitari, Y.; Kaneda, Y. Subject independent facial expression recognition with robust face detection using a convolutional neural network. Neural Netw. 2003, 16, 555–559. [Google Scholar] [CrossRef]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D facial expression database for facial behavior research. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 211–216. Available online: https://dl.acm.org/doi/abs/10.5555/1126250.1126340 (accessed on 14 June 2022).
- Mandal, T.; Majumdar, A.; Wu, Q.J. Face recognition by curvelet based feature extraction. In Proceedings of the International Conference Image Analysis and Recognition, Montreal, QC, Canada, 22–24 August 2007; pp. 806–817. [Google Scholar]
- Li, C.; Soares, A. Automatic facial expression recognition using 3D faces. Int. J. Eng. Res. Innov. 2011, 3, 30–34. [Google Scholar]
- Jain, D.K.; Shamsolmoali, P.; Sehdev, P. Extended deep neural network for facial emotion recognition. Pattern Recognit. Lett. 2019, 120, 69–74. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, M.; Su, W.; Wu, M.; She, J.; Hirota, K. Softmax regression based deep sparse autoencoder network for facial emotion recognition in human-robot interaction. Inf. Sci. 2018, 428, 49–61. [Google Scholar] [CrossRef]
- Bazrafkan, S.; Nedelcu, T.; Filipczuk, P.; Corcoran, P. Deep learning for facial expression recognition: A step closer to a smartphone that knows your moods. In Proceedings of the 2017 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 8–11 January 2017; pp. 217–220. [Google Scholar]
- Zhang, T.; Zheng, W.; Cui, Z.; Zong, Y.; Yan, J.; Yan, K. A deep neural network-driven feature learning method for multi-view facial expression recognition. IEEE Trans. Multimed. 2016, 18, 2528–2536. [Google Scholar] [CrossRef]
- Sebe, N.; Cohen, I.; Gevers, T.; Huang, T.S. Multimodal approaches for emotion recognition: A survey. In Proceedings of the SPIE Internet Imaging VI, San Jose, CA, USA, 16–20 January 2005; Volume 5670, pp. 56–67. [Google Scholar]
- Busso, C.; Mariooryad, S.; Metallinou, A.; Narayanan, S. Iterative feature normalization scheme for automatic emotion detection from speech. IEEE Trans. Affect. Comput. 2013, 4, 386–397. [Google Scholar] [CrossRef]
- Mao, Q.; Dong, M.; Huang, Z.; Zhan, Y. Learning salient features for speech emotion recognition using convolutional neural networks. IEEE Trans. Multimed. 2014, 16, 2203–2213. [Google Scholar] [CrossRef]
- Gangeh, M.J.; Fewzee, P.; Ghodsi, A.; Kamel, M.S.; Karray, F. Multiview supervised dictionary learning in speech emotion recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1056–1068. [Google Scholar] [CrossRef]
- Wang, K.; An, N.; Li, B.N.; Zhang, Y.; Li, L. Speech emotion recognition using Fourier parameters. IEEE Trans. Affect. Comput. 2015, 6, 69–75. [Google Scholar] [CrossRef]
- Fayek, H.M.; Lech, M.; Cavedon, L. Towards real-time speech emotion recognition using deep neural networks. In Proceedings of the 2015 9th International Conference on Signal Processing and Communication Systems (ICSPCS), Cairns, Australia, 14–16 December 2015; pp. 1–5. [Google Scholar]
- Satt, A.; Rozenberg, S.; Hoory, R. Efficient Emotion Recognition from Speech Using Deep Learning on Spectrograms. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 1089–1093. [Google Scholar]
- Trigeorgis, G.; Ringeval, F.; Brueckner, R.; Marchi, E.; Nicolaou, M.A.; Schuller, B.; Zafeiriou, S. Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5200–5204. [Google Scholar]
- Rozgić, V.; Vitaladevuni, S.N.; Prasad, R. Robust EEG emotion classification using segment level decision fusion. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 1286–1290. [Google Scholar]
- Lakens, D. Using a smartphone to measure heart rate changes during relived happiness and anger. IEEE Trans. Affect. Comput. 2013, 4, 238–241. [Google Scholar] [CrossRef]
- Hernandez, J.; McDuff, D.; Fletcher, R.; Picard, R.W. Inside-out: Reflecting on your inner state. In Proceedings of the 2013 IEEE International Conference on Pervasive Computing and Communications Workshops (PERCOM Workshops), San Diego, CA, USA, 18–22 March 2013; pp. 324–327. [Google Scholar]
- Fridlund, A.; Izard, C.E. Electromyographic studies of facial expressions of emotions and patterns of emotions. In Social Psychophysiology: A Sourcebook; Guilford Press: New York, NY, USA, 1983; pp. 243–286. [Google Scholar]
- Lin, W.; Li, C.; Sun, S. Deep convolutional neural network for emotion recognition using EEG and peripheral physiological signal. In Proceedings of the International Conference on Image and Graphics, Shanghai, China, 13–15 September 2017; pp. 385–394. [Google Scholar]
- Paleari, M.; Chellali, R.; Huet, B. Features for multimodal emotion recognition: An extensive study. In Proceedings of the 2010 IEEE Conference on Cybernetics and Intelligent Systems, Singapore, 28–30 June 2010; pp. 90–95. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- De Silva, L.C.; Ng, P.C. Bimodal emotion recognition. In Proceedings of the Proceedings Fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat. No. PR00580), Grenoble, France, 26–30 March 2000; pp. 332–335. [Google Scholar]
- Chen, L.S.; Huang, T.S. Emotional expressions in audiovisual human computer interaction. In Proceedings of the 2000 IEEE International Conference on Multimedia and Expo, ICME2000, Latest Advances in the Fast Changing World of Multimedia (Cat. No. 00TH8532), New York, NY, USA, 30 July–2 August 2000; Volume 1, pp. 423–426. [Google Scholar]
- Caridakis, G.; Castellano, G.; Kessous, L.; Raouzaiou, A.; Malatesta, L.; Asteriadis, S.; Karpouzis, K. Multimodal emotion recognition from expressive faces, body gestures and speech. In IFIP International Conference on Artificial Intelligence Applications and Innovations; Springer: Boston, MA, USA, 2007; pp. 375–388. [Google Scholar]
- Tang, K.; Tie, Y.; Yang, T.; Guan, L. Multimodal emotion recognition (MER) system. In Proceedings of the 2014 IEEE 27th Canadian Conference on Electrical and Computer Engineering (CCECE), Toronto, ON, Canada, 4–7 May 2014; pp. 1–6. [Google Scholar]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2012, 3, 42–55. [Google Scholar] [CrossRef] [Green Version]
- Ranganathan, H.; Chakraborty, S.; Panchanathan, S. Multimodal emotion recognition using deep learning architectures. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Lee, H.; Grosse, R.; Ranganath, R.; Ng, A.Y. Convolutional deep belief networks for scalable unsupervised learning of hierarchical representations. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 609–616. [Google Scholar]
- Poria, S.; Chaturvedi, I.; Cambria, E.; Hussain, A. Convolutional MKL based multimodal emotion recognition and sentiment analysis. In Proceedings of the 2016 IEEE 16th International Conference on Data Mining (ICDM), Barcelona, Spain, 12–15 December 2016; pp. 439–448. [Google Scholar]
- Dataset 02: IRIS Thermal/Visible Face Database 2016. Available online: http://vcipl-okstate.org/pbvs/bench/ (accessed on 14 June 2022).
- Dataset 01: NIST Thermal/Visible Face Database 2012. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwjRhJn--LP4AhVFCd4KHYiOAhgQFnoECAYQAQ&url=https%3A%2F%2Fwww.nist.gov%2Fdocument%2Fklare-nistdatasets2015pdf&usg=AOvVaw0O-vRUczPwxCTSp2_SWWe7 (accessed on 14 June 2022).
- Wang, S.; Liu, Z.; Lv, S.; Lv, Y.; Wu, G.; Peng, P.; Chen, F.; Wang, X. A natural visible and infrared facial expression database for expression recognition and emotion inference. IEEE Trans. Multimed. 2010, 12, 682–691. [Google Scholar] [CrossRef]
- Nguyen, H.; Kotani, K.; Chen, F.; Le, B. A thermal facial emotion database and its analysis. In Proceedings of the Pacific-Rim Symposium on Image and Video Technology, Guanajuato, México, 28 October–1 November 2013; pp. 397–408. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335. [Google Scholar] [CrossRef]
- Correa, J.A.M.; Abadi, M.K.; Sebe, N.; Patras, I. Amigos: A dataset for affect, personality and mood research on individuals and groups. IEEE Trans. Affect. Comput. 2018, 12, 479–493. [Google Scholar] [CrossRef] [Green Version]
- EMOTIV | Brain Data Measuring Hardware and Software Solutions. Available online: https://www.emotiv.com/ (accessed on 18 May 2020).
- SHIMMER | Wearable Sensor Technology | Wireless IMU | ECG | EMG | GSR. Available online: http://www.shimmersensing.com/ (accessed on 18 May 2020).
- Subramanian, R.; Wache, J.; Abadi, M.K.; Vieriu, R.L.; Winkler, S.; Sebe, N. ASCERTAIN: Emotion and personality recognition using commercial sensors. IEEE Trans. Affect. Comput. 2016, 9, 147–160. [Google Scholar] [CrossRef]
- Caridakis, G.; Wagner, J.; Raouzaiou, A.; Curto, Z.; Andre, E.; Karpouzis, K. A multimodal corpus for gesture expressivity analysis. In Proceedings of the Multimodal Corpora: Advances in Capturing, Coding and Analyzing Multimodality, LREC, Valetta, Malta, 18 May 2010. [Google Scholar]
- Caridakis, G.; Wagner, J.; Raouzaiou, A.; Lingenfelser, F.; Karpouzis, K.; Andre, E. A cross-cultural, multimodal, affective corpus for gesture expressivity analysis. J. Multimodal User Interfaces 2013, 7, 121–134. [Google Scholar] [CrossRef]
- Markova, V.; Ganchev, T.; Kalinkov, K. CLAS: A Database for Cognitive Load, Affect and Stress Recognition. In Proceedings of the 2019 International Conference on Biomedical Innovations and Applications (BIA), Varna, Bulgaria, 8–9 November 2019; pp. 1–4. [Google Scholar]
- SHIMMER3 ECG Unit| Wearable ECG Sensor | Wireless ECG Sensor | Electrocardiogram. Available online: https://www.shimmersensing.com/products/shimmer3-ecg-sensor (accessed on 19 May 2020).
- Shimmer3 GSR+ Sensor. Available online: http://www.shimmersensing.com/shimmer3-gsr-sensor/ (accessed on 19 May 2020).
- Zadeh, A.B.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2236–2246. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2012, 3, 18–31. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.K.; Subramanian, R.; Kia, S.M.; Avesani, P.; Patras, I.; Sebe, N. DECAF: MEG-based multimodal database for decoding affective physiological responses. IEEE Trans. Affect. Comput. 2015, 6, 209–222. [Google Scholar] [CrossRef]
- O’Reilly, H.; Pigat, D.; Fridenson, S.; Berggren, S.; Tal, S.; Golan, O.; Bölte, S.; Baron-Cohen, S.; Lundqvist, D. The EU-emotion stimulus set: A validation study. Behav. Res. Methods 2016, 48, 567–576. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, J.; Wang, C.; Wang, K.; Yin, C.; Zhao, C.; Xu, T.; Zhang, X.; Huang, Z.; Liu, M.; Yang, T. HEU Emotion: A large-scale database for multimodal emotion recognition in the wild. Neural Comput. Appl. 2021, 33, 8669–8685. [Google Scholar] [CrossRef]
- Huang, X.; Kortelainen, J.; Zhao, G.; Li, X.; Moilanen, A.; Seppänen, T.; Pietikäinen, M. Multi-modal emotion analysis from facial expressions and electroencephalogram. Comput. Vis. Image Underst. 2016, 147, 114–124. [Google Scholar] [CrossRef]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. Meld: A multimodal multi-party dataset for emotion recognition in conversations. arXiv 2018, arXiv:1810.02508. [Google Scholar]
- Chen, S.Y.; Hsu, C.C.; Kuo, C.C.; Ku, L.W. Emotionlines: An emotion corpus of multi-party conversations. arXiv 2018, arXiv:1802.08379. [Google Scholar]
- Tu, G.; Wen, J.; Liu, C.; Jiang, D.; Cambria, E. Context-and sentiment-aware networks for emotion recognition in conversation. IEEE Trans. Artif. Intell. 2022. [Google Scholar] [CrossRef]
- Zhang, Z.; Girard, J.M.; Wu, Y.; Zhang, X.; Liu, P.; Ciftci, U.; Canavan, S.; Reale, M.; Horowitz, A.; Yang, H.; et al. Multimodal spontaneous emotion corpus for human behavior analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3438–3446. [Google Scholar]
- Yang, H.; Ciftci, U.; Yin, L. Facial expression recognition by de-expression residue learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2168–2177. [Google Scholar]
- Jannat, R.; Tynes, I.; Lime, L.L.; Adorno, J.; Canavan, S. Ubiquitous emotion recognition using audio and video data. In Proceedings of the 2018 ACM International Joint Conference and 2018 International Symposium on Pervasive and Ubiquitous Computing and Wearable Computers, Singapore, 8–12 October 2018; pp. 956–959. [Google Scholar]
- Song, T.; Zheng, W.; Lu, C.; Zong, Y.; Zhang, X.; Cui, Z. MPED: A multi-modal physiological emotion database for discrete emotion recognition. IEEE Access 2019, 7, 12177–12191. [Google Scholar] [CrossRef]
- Song, T.; Zheng, W.; Liu, S.; Zong, Y.; Cui, Z.; Li, Y. Graph-Embedded Convolutional Neural Network for Image-based EEG Emotion Recognition. IEEE Trans. Emerg. Top. Comput. 2021. [Google Scholar] [CrossRef]
- Castro, S.; Hazarika, D.; Pérez-Rosas, V.; Zimmermann, R.; Mihalcea, R.; Poria, S. Towards multimodal sarcasm detection (an _obviously_ perfect paper). arXiv 2019, arXiv:1906.01815. [Google Scholar]
- Sarcasm | Psychology Today. Available online: https://www.psychologytoday.com/us/blog/stronger-the-broken-places/201907/sarcasm (accessed on 17 May 2020).
- Zhang, Y.; Tiwari, P.; Rong, L.; Chen, R.; AlNajem, N.A.; Hossain, M.S. Affective Interaction: Attentive Representation Learning for Multi-Modal Sentiment Classification. In ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM); ACM: New York, NY, USA, 2021. [Google Scholar]
- Pramanick, S.; Roy, A.; Patel, V.M. Multimodal Learning using Optimal Transport for Sarcasm and Humor Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikola, HI, USA, 5–7 January 2022; pp. 3930–3940. [Google Scholar]
- Chou, H.C.; Lin, W.C.; Chang, L.C.; Li, C.C.; Ma, H.P.; Lee, C.C. NNIME: The NTHU-NTUA Chinese interactive multimodal emotion corpus. In Proceedings of the 2017 Seventh International Conference on Affective Computing and Intelligent Interaction (ACII), San Antonio, TX, USA, 23–26 October 2017; pp. 292–298. [Google Scholar]
- Hsu, J.H.; Su, M.H.; Wu, C.H.; Chen, Y.H. Speech emotion recognition considering nonverbal vocalization in affective conversations. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1675–1686. [Google Scholar] [CrossRef]
- Perepelkina, O.; Kazimirova, E.; Konstantinova, M. RAMAS: Russian multimodal corpus of dyadic interaction for affective computing. In Proceedings of the International Conference on Speech and Computer, Leipzig, Germany, 18–22 September 2018; pp. 501–510. [Google Scholar]
- Sloetjes, H.; Wittenburg, P. Annotation by category-ELAN and ISO DCR. In Proceedings of the 6th international Conference on Language Resources and Evaluation (LREC 2008), Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Verkholyak, O.; Dvoynikova, A.; Karpov, A. A Bimodal Approach for Speech Emotion Recognition using Audio and Text. J. Internet Serv. Inf. Secur. 2021, 11, 80–96. [Google Scholar]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Mencattini, A.; Ringeval, F.; Schuller, B.; Martinelli, E.; Di Natale, C. Continuous monitoring of emotions by a multimodal cooperative sensor system. Procedia Eng. 2015, 120, 556–559. [Google Scholar] [CrossRef] [Green Version]
- Ganchev, T.; Markova, V.; Lefterov, I.; Kalinin, Y. Overall Design of the SLADE Data Acquisition System. In Proceedings of the International Conference on Intelligent Information Technologies for Industry, Sirius, Russia, 30 September–4 October 2017; pp. 56–65. [Google Scholar]
- Valstar, M.; Schuller, B.; Smith, K.; Eyben, F.; Jiang, B.; Bilakhia, S.; Schnieder, S.; Cowie, R.; Pantic, M. AVEC 2013: The continuous audio/visual emotion and depression recognition challenge. In Proceedings of the 3rd ACM International Workshop on Audio/Visual Emotion Challenge, Barcelona, Spain, 21 October 2013; pp. 3–10. [Google Scholar]
- Valstar, M.; Schuller, B.; Smith, K.; Almaev, T.; Eyben, F.; Krajewski, J.; Cowie, R.; Pantic, M. Avec 2014: 3d dimensional affect and depression recognition challenge. In Proceedings of the 4th International Workshop on Audio/Visual Emotion Challenge, Orlando, FL, USA, 7 November 2014; pp. 3–10. [Google Scholar]
- Tian, L.; Moore, J.; Lai, C. Recognizing emotions in spoken dialogue with hierarchically fused acoustic and lexical features. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 565–572. [Google Scholar]
- Zhalehpour, S.; Onder, O.; Akhtar, Z.; Erdem, C.E. BAUM-1: A Spontaneous Audio-Visual Face Database of Affective and Mental States. IEEE Trans. Affect. Comput. 2017, 8, 300–313. [Google Scholar] [CrossRef]
- Zhang, L.; Walter, S.; Ma, X.; Werner, P.; Al-Hamadi, A.; Traue, H.C.; Gruss, S. “BioVid Emo DB”: A multimodal database for emotion analyses validated by subjective ratings. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–6. [Google Scholar]
- Prabha, R.; Anandan, P.; Sivarajeswari, S.; Saravanakumar, C.; Babu, D.V. Design of an Automated Recurrent Neural Network for Emotional Intelligence Using Deep Neural Networks. In Proceedings of the 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 January 2022; pp. 1061–1067. [Google Scholar]
- Li, Y.; Tao, J.; Chao, L.; Bao, W.; Liu, Y. CHEAVD: A Chinese natural emotional audio–visual database. J. Ambient. Intell. Humaniz. Comput. 2017, 8, 913–924. [Google Scholar] [CrossRef]
- Li, Y.; Tao, J.; Schuller, B.; Shan, S.; Jiang, D.; Jia, J. Mec 2017: Multimodal emotion recognition challenge. In Proceedings of the 2018 First Asian Conference on Affective Computing and Intelligent Interaction (ACII Asia), Beijing, China, 20–22 May 2018; pp. 1–5. [Google Scholar]
- Wang, C.; Ren, Y.; Zhang, N.; Cui, F.; Luo, S. Speech emotion recognition based on multi-feature and multi-lingual fusion. Multimed. Tools Appl. 2022, 81, 4897–4907. [Google Scholar] [CrossRef]
- Liang, J.; Chen, S.; Zhao, J.; Jin, Q.; Liu, H.; Lu, L. Cross-culture multimodal emotion recognition with adversarial learning. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 4000–4004. [Google Scholar]
- Katsigiannis, S.; Ramzan, N. DREAMER: A database for emotion recognition through EEG and ECG signals from wireless low-cost off-the-shelf devices. IEEE J. Biomed. Health Inform. 2017, 22, 98–107. [Google Scholar] [CrossRef] [Green Version]
- Badcock, N.A.; Mousikou, P.; Mahajan, Y.; De Lissa, P.; Thie, J.; McArthur, G. Validation of the Emotiv EPOC® EEG gaming system for measuring research quality auditory ERPs. PeerJ 2013, 1, e38. [Google Scholar] [CrossRef] [Green Version]
- Ekanayake, H. P300 and Emotiv EPOC: Does Emotiv EPOC Capture Real EEG? 2010. Available online: http://neurofeedback.visaduma.info/emotivresearch.htm (accessed on 6 June 2022).
- Burns, A.; Greene, B.R.; McGrath, M.J.; O’Shea, T.J.; Kuris, B.; Ayer, S.M.; Stroiescu, F.; Cionca, V. SHIMMER™–A wireless sensor platform for noninvasive biomedical research. IEEE Sens. J. 2010, 10, 1527–1534. [Google Scholar] [CrossRef]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The enterface’05 audio-visual emotion database. In Proceedings of the 22nd International Conference on Data Engineering Workshops, Washington, DC, USA, 3–7 April 2006; p. 8. [Google Scholar]
- Gunes, H.; Piccardi, M. A bimodal face and body gesture database for automatic analysis of human nonverbal affective behavior. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–26 August 2006; Volume 1, pp. 1148–1153. [Google Scholar]
- Karatay, B.; Bestepe, D.; Sailunaz, K.; Ozyer, T.; Alhajj, R. A Multi-Modal Emotion Recognition System Based on CNN-Transformer Deep Learning Technique. In Proceedings of the 2022 7th International Conference on Data Science and Machine Learning Applications (CDMA), Riyadh, Saudi Arabia, 1–3 March 2022; pp. 145–150. [Google Scholar]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Valstar, M.F.; Jiang, B.; Mehu, M.; Pantic, M.; Scherer, K. The first facial expression recognition and analysis challenge. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition and Workshops (FG 2011), Santa Barbara, CA, USA, 21–23 March 2011; pp. 921–926. [Google Scholar]
- Bänziger, T.; Scherer, K.R. Introducing the geneva multimodal emotion portrayal (gemep) corpus. Bluepr. Affect. Comput. Sourceb. 2010, 2010, 271–294. [Google Scholar]
- Douglas-Cowie, E.; Cowie, R.; Sneddon, I.; Cox, C.; Lowry, O.; Mcrorie, M.; Martin, J.C.; Devillers, L.; Abrilian, S.; Batliner, A.; et al. The HUMAINE database: Addressing the collection and annotation of naturalistic and induced emotional data. Affect. Comput. Intell. Interact. 2007, 4738, 488–500. [Google Scholar]
- Baveye, Y.; Bettinelli, J.N.; Dellandréa, E.; Chen, L.; Chamaret, C. A large video database for computational models of induced emotion. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, Geneva, Switzerland, 2–5 September 2013; pp. 13–18. [Google Scholar]
- Baveye, Y.; Dellandrea, E.; Chamaret, C.; Chen, L. Liris-accede: A video database for affective content analysis. IEEE Trans. Affect. Comput. 2015, 6, 43–55. [Google Scholar] [CrossRef] [Green Version]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [Green Version]
- Iqbal, A.; Barua, K. A Real-time Emotion Recognition from Speech using Gradient Boosting. In Proceedings of the 2019 International Conference on Electrical, Computer and Communication Engineering (ECCE), Cox’sBazar, Bangladesh, 7–9 February 2019; pp. 1–5. [Google Scholar]
- Haque, A.; Guo, M.; Verma, P.; Fei-Fei, L. Audio-linguistic embeddings for spoken sentences. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 7355–7359. [Google Scholar]
- Wang, Y.; Guan, L. Recognizing human emotional state from audiovisual signals. IEEE Trans. Multimed. 2008, 10, 936–946. [Google Scholar] [CrossRef]
- Gievska, S.; Koroveshovski, K.; Tagasovska, N. Bimodal feature-based fusion for real-time emotion recognition in a mobile context. In Proceedings of the 2015 International Conference on Affective Computing and Intelligent Interaction (ACII), Xi’an, China, 21–24 September 2015; pp. 401–407. [Google Scholar]
- Gunes, H.; Pantic, M. Dimensional emotion prediction from spontaneous head gestures for interaction with sensitive artificial listeners. In Proceedings of the Intelligent Virtual Agents, Philadelphia, PA, USA, 20–22 September 2010; pp. 371–377. [Google Scholar]
- Haq, S.; Jackson, P.J. Multimodal emotion recognition. In Machine Audition: Principles, Algorithms and Systems; IGI Global: Hershey, PA, USA, 2010; pp. 398–423. [Google Scholar]
- Zheng, W.L.; Lu, B.L. Investigating critical frequency bands and channels for EEG-based emotion recognition with deep neural networks. IEEE Trans. Auton. Ment. Dev. 2015, 7, 162–175. [Google Scholar] [CrossRef]
- Liu, W.; Qiu, J.L.; Zheng, W.L.; Lu, B.L. Multimodal Emotion Recognition Using Deep Canonical Correlation Analysis. arXiv 2019, arXiv:1908.05349. [Google Scholar]
- Duan, R.N.; Zhu, J.Y.; Lu, B.L. Differential entropy feature for EEG-based emotion classification. In Proceedings of the 2013 6th International IEEE/EMBS Conference on Neural Engineering (NER), San Diego, CA, USA, 6–8 November 2013; pp. 81–84. [Google Scholar]
- Zheng, W.L.; Liu, W.; Lu, Y.; Lu, B.L.; Cichocki, A. Emotionmeter: A multimodal framework for recognizing human emotions. IEEE Trans. Cybern. 2018, 49, 1110–1122. [Google Scholar] [CrossRef]
- Li, T.H.; Liu, W.; Zheng, W.L.; Lu, B.L. Classification of five emotions from EEG and eye movement signals: Discrimination ability and stability over time. In Proceedings of the 2019 9th International IEEE/EMBS Conference on Neural Engineering (NER), San Francisco, CA, USA, 20–23 March 2019; pp. 607–610. [Google Scholar]
- Zheng, W.L.; Lu, B.L. A multimodal approach to estimating vigilance using EEG and forehead EOG. J. Neural Eng. 2017, 14, 026017. [Google Scholar] [CrossRef] [Green Version]
- McKeown, G.; Valstar, M.; Cowie, R.; Pantic, M.; Schroder, M. The semaine database: Annotated multimodal records of emotionally colored conversations between a person and a limited agent. IEEE Trans. Affect. Comput. 2012, 3, 5–17. [Google Scholar] [CrossRef] [Green Version]
- Metallinou, A.; Yang, Z.; Lee, C.c.; Busso, C.; Carnicke, S.; Narayanan, S. The USC CreativeIT database of multimodal dyadic interactions: From speech and full body motion capture to continuous emotional annotations. Lang. Resour. Eval. 2016, 50, 497–521. [Google Scholar] [CrossRef]
- Chang, C.M.; Lee, C.C. Fusion of multiple emotion perspectives: Improving affect recognition through integrating cross-lingual emotion information. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5820–5824. [Google Scholar]
- Grimm, M.; Kroschel, K.; Narayanan, S. The Vera am Mittag German audio-visual emotional speech database. In Proceedings of the 2008 IEEE International Conference on Multimedia and Expo, Hannover, Germany, 23–26 June 2008; pp. 865–868. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Collecting large, richly annotated facial-expression databases from movies. IEEE Multimed. 2012, 19, 34–41. [Google Scholar] [CrossRef] [Green Version]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of german emotional speech. In Proceedings of the Interspeech, Lisbon, Portugal, 4–8 September 2005; Volume 5, pp. 1517–1520. [Google Scholar]
- Staroniewicz, P.; Majewski, W. Polish emotional speech database–recording and preliminary validation. In Cross-Modal Analysis of Speech, Gestures, Gaze and Facial Expressions; Springer: Berlin/Heidelberg, Germany, 2009; pp. 42–49. [Google Scholar]
- Lee, S.; Yildirim, S.; Kazemzadeh, A.; Narayanan, S. An articulatory study of emotional speech production. In Proceedings of the Interspeech, Lisbon, Portugal, 4–8 September 2005; pp. 497–500. [Google Scholar]
- Strapparava, C.; Mihalcea, R. Semeval-2007 task 14: Affective text. In Proceedings of the 4th International Workshop on Semantic Evaluations. Association for Computational Linguistics, Prague, Czech Republic, 23–24 June 2007; pp. 70–74. [Google Scholar]
- Wallbott, H.G.; Scherer, K.R. How universal and specific is emotional experience? Evidence from 27 countries on five continents. Soc. Sci. Inf. 1986, 25, 763–795. [Google Scholar] [CrossRef]
- Kanade, T.; Cohn, J.F.; Tian, Y. Comprehensive database for facial expression analysis. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition, Grenoble, France, 26–30 March 2000; pp. 46–53. [Google Scholar]
- Ekman, P.; Friesen, W.V. Facial Action Coding System. 1977. Available online: https://psycnet.apa.org/doiLanding?doi=10.1037%2Ft27734-000 (accessed on 14 June 2022).
- Ekman, P.; Friesen, W.V.; Hager, J.C. FACS Investigator’s Guide. 2002, 96 Chapter 4 pp 29. Available online: https://www.scirp.org/%28S%28i43dyn45teexjx455qlt3d2q%29%29/reference/ReferencesPapers.aspx?ReferenceID=1850657 (accessed on 14 June 2022).
- Ranganathan, H.; Chakraborty, S.; Panchanathan, S. Transfer of multimodal emotion features in deep belief networks. In Proceedings of the 2016 50th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 6–9 November 2016; pp. 449–453. [Google Scholar]
- Wen, G.; Hou, Z.; Li, H.; Li, D.; Jiang, L.; Xun, E. Ensemble of Deep Neural Networks with Probability-Based Fusion for Facial Expression Recognition. Cogn. Comput. 2017, 9, 597–610. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Erhan, D.; Carrier, P.L.; Courville, A.; Mirza, M.; Hamner, B.; Cukierski, W.; Tang, Y.; Thaler, D.; Lee, D.H.; et al. Challenges in representation learning: A report on three machine learning contests. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; pp. 117–124. [Google Scholar]
- Ng, H.W.; Nguyen, V.D.; Vonikakis, V.; Winkler, S. Deep learning for emotion recognition on small datasets using transfer learning. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 443–449. [Google Scholar]
- Dailey, M.N.; Joyce, C.; Lyons, M.J.; Kamachi, M.; Ishi, H.; Gyoba, J.; Cottrell, G.W. Evidence and a computational explanation of cultural differences in facial expression recognition. Emotion 2010, 10, 874. [Google Scholar] [CrossRef] [Green Version]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with gabor wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Lyons, M.J.; Budynek, J.; Akamatsu, S. Automatic classification of single facial images. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 1357–1362. [Google Scholar] [CrossRef] [Green Version]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-based database for facial expression analysis. In Proceedings of the 2005 IEEE International Conference on Multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005; p. 5. [Google Scholar]
- Valstar, M.; Pantic, M. Induced disgust, happiness and surprise: An addition to the mmi facial expression database. In Proceedings of the 3rd Intern. Workshop on EMOTION (satellite of LREC): Corpora for Research on Emotion and Affect, Valletta, Malta, 23 May 2010; p. 65. [Google Scholar]
- Dhall, A.; Goecke, R.; Lucey, S.; Gedeon, T. Static Facial Expressions In The Wild: Data and Experiment Protocol. Available online: http://citeseerx.ist.psu.edu/viewdoc/versions?doi=10.1.1.671.1708 (accessed on 4 June 2022).
- Yin, G.; Sun, S.; Yu, D.; Li, D.; Zhang, K. A Multimodal Framework for Large-Scale Emotion Recognition by Fusing Music and Electrodermal Activity Signals. ACM Trans. Multimed. Comput. Commun. Appl. (Tomm) 2022, 18, 1–23. [Google Scholar] [CrossRef]
- Udovičić, G.; Ðerek, J.; Russo, M.; Sikora, M. Wearable emotion recognition system based on GSR and PPG signals. In Proceedings of the 2nd International Workshop on Multimedia for Personal Health and Health Care, Mountain View, CA, USA, 23 October 2017; pp. 53–59. [Google Scholar]
- Radhika, K.; Oruganti, V.R.M. Deep Multimodal Fusion for Subject-Independent Stress Detection. In Proceedings of the 2021 11th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 28–29 January 2021; pp. 105–109. [Google Scholar]
- Mittal, T.; Bhattacharya, U.; Chandra, R.; Bera, A.; Manocha, D. M3er: Multiplicative multimodal emotion recognition using facial, textual, and speech cues. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1359–1367. [Google Scholar]
- Pham, M.; Do, H.M.; Su, Z.; Bishop, A.; Sheng, W. Negative emotion management using a smart shirt and a robot assistant. IEEE Robot. Autom. Lett. 2021, 6, 4040–4047. [Google Scholar] [CrossRef]
- Sun, B.; Cao, S.; Li, L.; He, J.; Yu, L. Exploring multimodal visual features for continuous affect recognition. In Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge, Amsterdam, The Netherlands, 16 October 2016; pp. 83–88. [Google Scholar]
- Erdem, C.E.; Turan, C.; Aydin, Z. BAUM-2: A multilingual audio-visual affective face database. Multimed. Tools Appl. 2015, 74, 7429–7459. [Google Scholar] [CrossRef]
- Dar, M.N.; Akram, M.U.; Khawaja, S.G.; Pujari, A.N. CNN and LSTM-based emotion charting using physiological signals. Sensors 2020, 20, 4551. [Google Scholar] [CrossRef]
- Siddharth, S.; Jung, T.P.; Sejnowski, T.J. Utilizing deep learning towards multi-modal bio-sensing and vision-based affective computing. IEEE Trans. Affect. Comput. 2019, 13, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.; Wang, H.; Tang, P. Unified Multi-Stage Fusion Network for Affective Video Content Analysis. Available at SSRN 4080629. Available online: https://ssrn.com/abstract=4080629 (accessed on 14 June 2022).
- McKeown, G.; Valstar, M.F.; Cowie, R.; Pantic, M. The SEMAINE corpus of emotionally coloured character interactions. In Proceedings of the 2010 IEEE International Conference on Multimedia and Expo (ICME), Singapore, 19–23 July 2010; pp. 1079–1084. [Google Scholar]
- Siddiqui, M.F.H.; Javaid, A.Y. A Multimodal Facial Emotion Recognition Framework through the Fusion of Speech with Visible and Infrared Images. Multimodal Technol. Interact. 2020, 4, 46. [Google Scholar] [CrossRef]
- Andrew Ng: Why AI Is the New Electricity | The Dish. Available online: https://news.stanford.edu/thedish/2017/03/14/andrew-ng-why-ai-is-the-new-electricity/ (accessed on 3 May 2018).
- Emotional Intelligence is the Future of Artificial Intelligence: Fjord | ZDNet. Available online: http://www.zdnet.com/article/emotional-intelligence-is-the-future-of-artificial-intelligence-fjord/ (accessed on 3 May 2018).
- Synced | Emotional Intelligence is the Future of Artificial Intelligence. Available online: https://syncedreview.com/2017/03/14/emotional-intelligence-is-the-future-of-artificial-intelligence/ (accessed on 3 May 2018).
- Olszewska, J.I. Automated Face Recognition: Challenges and Solutions. In Pattern Recognition-Analysis and Applications; InTech: London, UK, 2016. [Google Scholar]
- Lie to Me | Paul Ekman Group. Available online: https://www.paulekman.com/lie-to-me/ (accessed on 3 June 2018).
- Arellano, D.; Varona, J.; Perales, F.J. Emotional Context? Or Contextual Emotions? In Handbook of Research on Synthesizing Human Emotion in Intelligent Systems and Robotics; IGI Global: Hershey, PA, USA, 2015; pp. 366–385. [Google Scholar]
- Bullington, J. ’Affective’computing and emotion recognition systems: The future of biometric surveillance? In Proceedings of the 2nd Annual Conference on Information Security Curriculum Development, Kennesaw, GA, USA, 23–24 September 2005; pp. 95–99. [Google Scholar]
- Disney Is Using Facial Recognition to Predict How You’ll React to Movies. Available online: https://mashable.com/2017/07/27/disney-facial-recognition-prediction-movies/#aoVIBBcxxmqI (accessed on 3 June 2018).
- Xie, Z.; Guan, L. Multimodal information fusion of audiovisual emotion recognition using novel information theoretic tools. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013; pp. 1–6. [Google Scholar]
- Wu, C.H.; Lin, J.C.; Wei, W.L. Survey on audiovisual emotion recognition: Databases, features, and data fusion strategies. APSIPA Trans. Signal Inf. Process. 2014, 3, e12. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Guan, L.; Venetsanopoulos, A.N. Kernel cross-modal factor analysis for information fusion with application to bimodal emotion recognition. IEEE Trans. Multimed. 2012, 14, 597–607. [Google Scholar] [CrossRef]
- Mehmood, R.M.; Lee, H.J. A novel feature extraction method based on late positive potential for emotion recognition in human brain signal patterns. Comput. Electr. Eng. 2016, 53, 444–457. [Google Scholar] [CrossRef]
- Pramerdorfer, C.; Kampel, M. Facial Expression Recognition using Convolutional Neural Networks: State of the Art. arXiv 2016, arXiv:1612.02903. [Google Scholar]
- Lang, P.; Bradley, M.M. The International Affective Picture System (IAPS) in the study of emotion and attention. Handb. Emot. Elicitation Assess. 2007, 29, 70–73. [Google Scholar]
- Kim, B.K.; Dong, S.Y.; Roh, J.; Kim, G.; Lee, S.Y. Fusing Aligned and Non-Aligned Face Information for Automatic Affect Recognition in the Wild: A Deep Learning Approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 48–57. [Google Scholar]
- Goshvarpour, A.; Abbasi, A.; Goshvarpour, A. Fusion of heart rate variability and pulse rate variability for emotion recognition using lagged poincare plots. Australas. Phys. Eng. Sci. Med. 2017, 40, 617–629. [Google Scholar] [CrossRef]
- Ghayoumi, M.; Thafar, M.; Bansal, A.K. Towards Formal Multimodal Analysis of Emotions for Affective Computing. In Proceedings of the DMS, Salerno, Italy, 25–26 November 2016; pp. 48–54. [Google Scholar]
- Gao, Y.; Hendricks, L.A.; Kuchenbecker, K.J.; Darrell, T. Deep learning for tactile understanding from visual and haptic data. In Proceedings of the Robotics and Automation (ICRA), 2016 IEEE International Conference on IEEE, Stockholm, Sweden, 16–20 May 2016; pp. 536–543. [Google Scholar]
- Dasdemir, Y.; Yildirim, E.; Yildirim, S. Emotion Analysis using Different Stimuli with EEG Signals in Emotional Space. Nat. Eng. Sci. 2017, 2, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Callejas-Cuervo, M.; Martínez-Tejada, L.; Botero-Fagua, J. Architecture of an emotion recognition and video games system to identify personality traits. In VII Latin American Congress on Biomedical Engineering CLAIB 2016, Bucaramanga, Santander, Colombia, October 26th–28th, 2016; Springer: Singapore, 2017; pp. 42–45. [Google Scholar]
- Ringeval, F.; Eyben, F.; Kroupi, E.; Yuce, A.; Thiran, J.P.; Ebrahimi, T.; Lalanne, D.; Schuller, B. Prediction of asynchronous dimensional emotion ratings from audiovisual and physiological data. Pattern Recognit. Lett. 2015, 66, 22–30. [Google Scholar] [CrossRef]
- Metallinou, A.; Wollmer, M.; Katsamanis, A.; Eyben, F.; Schuller, B.; Narayanan, S. Context-sensitive learning for enhanced audiovisual emotion classification. IEEE Trans. Affect. Comput. 2012, 3, 184–198. [Google Scholar] [CrossRef]
- Haq, S.; Jackson, P.J.; Edge, J. Speaker-dependent audio-visual emotion recognition. In Proceedings of the AVSP, Norwich, UK, 10–13 September 2009; pp. 53–58. [Google Scholar]
- Haq, S.; Jackson, P.J.; Edge, J. Audio-visual feature selection and reduction for emotion classification. In Proceedings of the International Conference on Auditory-Visual Speech Processing (AVSP’08), Moreton Island, Australia, 26–29 September 2008; pp. 185–190. [Google Scholar]
- Grimm, M.; Kroschel, K.; Mower, E.; Narayanan, S. Primitives-based evaluation and estimation of emotions in speech. Speech Commun. 2007, 49, 787–800. [Google Scholar] [CrossRef] [Green Version]
- Pringle, H. Brand Immortality: How Brands Can Live Long and Prosper; Kogan Page Publishers: London, UK, 2008. [Google Scholar]
- Kołakowska, A.; Landowska, A.; Szwoch, M.; Szwoch, W.; Wrobel, M.R. Emotion recognition and its applications. In Human-Computer Systems Interaction: Backgrounds and Applications 3; Springer: Berlin/Heidelberg, Germany, 2014; pp. 51–62. [Google Scholar]
- Li, G.; Wang, Y. Research on leamer’s emotion recognition for intelligent education system. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018; pp. 754–758. [Google Scholar]
- Majumdar, J.; Dhakal, P.; Rijal, N.S.; Aryal, A.M.; Mishra, N.K. Implementation of Hybrid Model of Particle Filter and Kalman Filter based Real-Time Tracking for handling Occlusion on Beagleboard-xM. Int. J. Comput. Appl. 2014, 95, 8887. [Google Scholar] [CrossRef]
- Majumdar, J.; Aryal, A.M.; Rijal, N.S.; Dhakal, P.; Mishra, N.K. Implementation of Real Time Local Search Particle Filter Based Tracking Algorithms on BeagleBoard-xM. Int. J. Comput. Sci. Issues (IJCSI) 2014, 11, 28. [Google Scholar]
- Smith, J.R.; Joshi, D.; Huet, B.; Hsu, W.; Cota, J. Harnessing ai for augmenting creativity: Application to movie trailer creation. In Proceedings of the 25th ACM international conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 1799–1808. [Google Scholar]
- Mehta, D.; Siddiqui, M.F.H.; Javaid, A.Y. Recognition of emotion intensities using machine learning algorithms: A comparative study. Sensors 2019, 19, 1897. [Google Scholar] [CrossRef] [Green Version]
- Jaiswal, S.; Virmani, S.; Sethi, V.; De, K.; Roy, P.P. An intelligent recommendation system using gaze and emotion detection. Multimed. Tools Appl. 2019, 78, 14231–14250. [Google Scholar] [CrossRef]
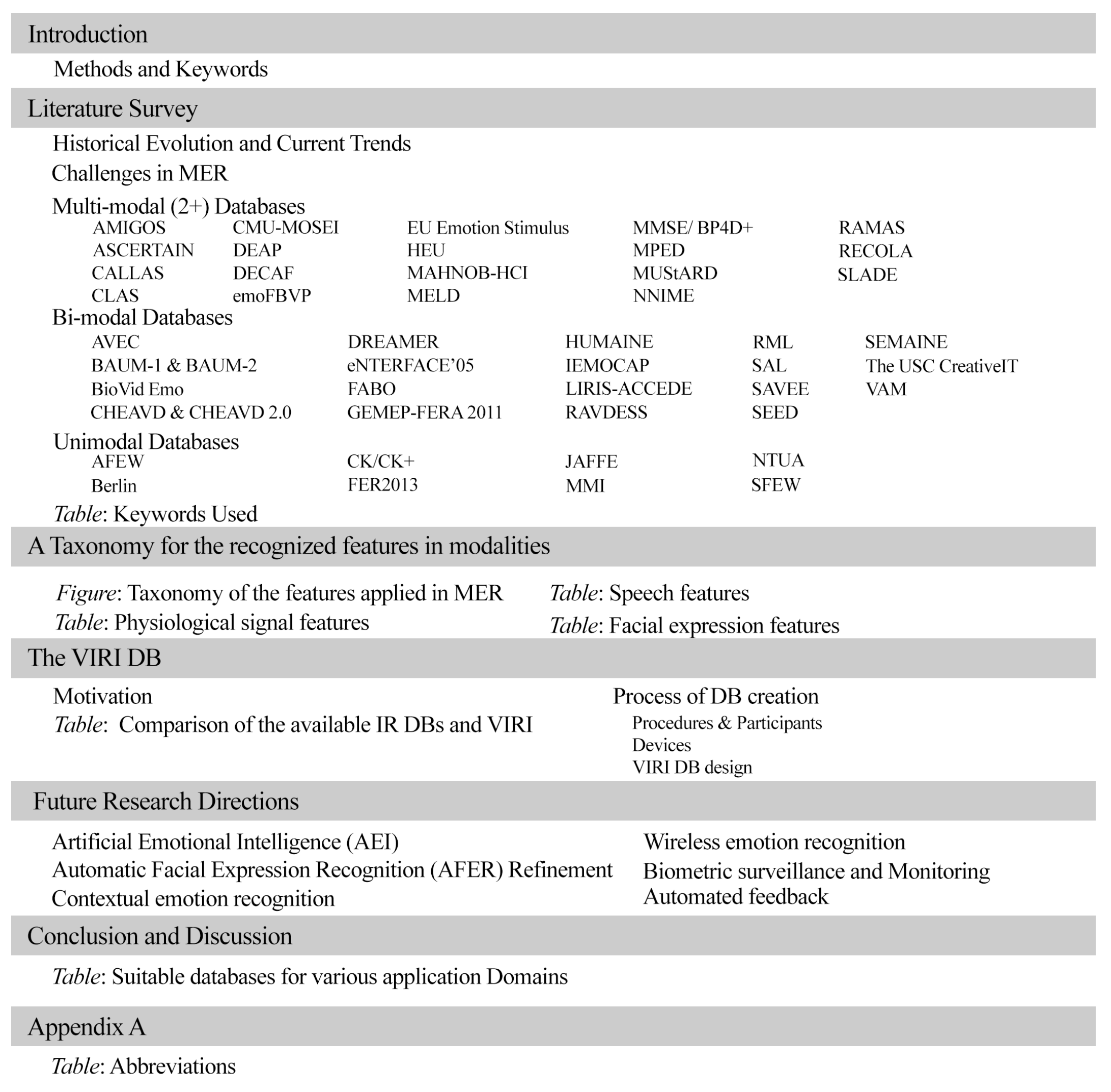




| Primary Keywords | |
|---|---|
| Core concept | Keywords |
| Emotion Recognition | Human computer interaction, human machine interaction, human robot interaction, expressions, expressive, wild, real-time, e-learning, contextual, biometric surveillance, marketing, monitoring, automatic feedback, medicine, intensity, elicitation method, geometric based, FACS coded, AU, continuous, discrete, emonets, sensors, stimuli. |
| ML | DL, classifiers, ensemble, WEKA classifiers, Naïve Bayes, ANN, CNN, RNN, HMM, DBN, CDBN, DCNN, supervised, unsupervised, wavelet, multiresolution, features, SVM, MLP, kNN, MCC, relational auto-encoders, transfer learning, pre-trained, ResNet, LSTM, RBM, pattern recognition, RF, regression. |
| DBs | Multimodal, bi-modal, unimodal, corpus, dataset, participants, categories, spontaneous, acted, posed, induced, natural, background, wild, languages, excitation, valence, activation, dominance, arousal, annotated, expectation, power, crowd sourced. |
| Modalities | Voice, speech, face, gesture, video, audio, body gesture, physiological signals, visible images, IR/thermal images, EEG, GSR, BVP, RP, SKT, EMG, EOG, aligned faces, non-aligned faces, visual features, acoustic features, physical interaction data, visual interaction data, HR, SCL, SCR, EDA, ECG, respiration frequency, pulse, language, acoustic features, lexical features, linguistic cues, acoustic cues, contextual social sciences. |
| Secondary Keywords | |
| fusion, feature level, decision level, hybrid fusion, late fusion, early fusion, hierarchical classifier fusion, multiple kernel learning, HOG-TOP, Support Vector Regression, ELM, MDR, WLD, HDFS, social robots, probability, n-fold cross validation | |
| Pitch | S01 | Entropy | S36 | RASTA based on PLP | S71 |
| Signal | S02 | Slope | S37 | f0 mean value | S72 |
| Energy | S03 | Psychoacoustic Sharpness | S38 | 25% and 75% quantiles | S73 |
| MFCC | S04 | Harmonicity | S39 | difference between f0 max and min | S74 |
| Spectral | S05 | Spectral Variance | S40 | difference of quartiles | S75 |
| Voice quality | S06 | Skewness | S41 | unvoiced and voiced segments duration ratio | S76 |
| Mean | S07 | Kurtosis | S42 | avg duration of voiced segments | S77 |
| Median | S08 | F0 (SHS & Viterbi smoothing) | S43 | intensity mean | S78 |
| Max | S09 | Prob. of voicing | S44 | energy range | S79 |
| Min | S10 | log. HNR | S45 | avg pause length | S80 |
| Variance | S11 | Jitter (local &) | S46 | speaking rate | S81 |
| Lower/upper quartile | S12 | Shimmer (local) | S47 | min and max of Mel freq | S82 |
| Absolute/quartile | S13 | 27 Mel Freq Band coef (MFB) | S48 | mean and std dev of I and II Gaussian of MFCC | S83 |
| Harmonics-to-noise ratio | S14 | Pitch mean | S49 | min and max of Mel freq first order difference | S84 |
| Mel-freq filter banks | S15 | Pitch median | S50 | mean and std dev of Mel freq I order difference | S85 |
| MFCC Derivative | S16 | pitch std dev | S51 | mean and std dev of total log energy; mean | S86 |
| MFCC Autocorrelation | S17 | std dev of duration of voiced segments | S52 | std dev | S87 |
| Formants (Formants up to 5500 Hz) | S18 | pitch range | S53 | voiced speech duration | S88 |
| Time freq | S19 | pitch variation rate | S54 | unvoiced speech duration | S89 |
| MSpectrum flux | S20 | rising/falling ratio | S55 | sentence duration | S90 |
| Spectral centroid | S21 | rising pitch slope max | S56 | average voiced phone duration | S91 |
| Delta spectrum magnitude | S22 | falling pitch slope map | S57 | average unvoiced phone duration | S92 |
| Band energy ratio | S23 | rising pitch slope mean | S58 | voiced-to-unvoiced speech duration ratio | S93 |
| Zero crossing rate (Avg, Std dev) | S24 | falling pitch slope mean | S59 | avg voiced-to-unvoiced speech duration ratio | S94 |
| Silence ratio (Prop of silence in a time window) | S25 | pitch rising range max | S60 | speech rate (phone/s) | S95 |
| pitch max | S26 | pitch falling range max | S61 | voiced-speech-to-sentence duration ratio | S96 |
| Sum of auditory spectrum (loudness) | S27 | pitch rising range mean | S62 | unvoiced-speech-to-sentence duration ratio | S97 |
| Sum of RASTA-filtered auditory spectrum | S28 | pitch falling range mean | S63 | 32 energy and spectral related LLD × 42 func | S98 |
| RMS Energy | S29 | overall pitch slope mean | S64 | 6 voicing related LLD × 32 func | S99 |
| Zero-Crossing Rate | S30 | overall pitch slope std dev | S65 | 32 delta coef of energy/spectral LLD × 19 func | S100 |
| RASTA-filt. aud. spect. bds. 1–26 (0–8 kHz) | S31 | overall pitch slope median | S66 | 6 delta coef of voicing related LLD × 19 func | S101 |
| Spectral energy 250–650 Hz, 1 k–4 kHz, | S32 | energy mean | S67 | avg duration of unvoiced segments | S102 |
| Spectral Roll-O Pt. 0.25, 0.5, 0.75, 0.9 | S33 | energy std dev | S68 | std dev of duration of voiced segments | S103 |
| Spectral Flux | S34 | energy max | S69 | ||
| Centroid | S35 | 10 voiced/unvoiced durational features | S70 |
| A (HL-inner eye corners, L-inner and outer eyebrow) | F01 | Lip pucker | F22 | SPTS | F43 |
| VD (outer eyebrows, L bw inner corners of eyes) | F02 | Lips part | F23 | CAPP | F44 |
| D (outer eyes’ corner, their upper eyelids) | F03 | D(lower lip and mouth corners) | F24 | PHOG | F45 |
| D (inner eyes’ corner, their upper eyelid) | F04 | D (between mouth corners) | F25 | LBP-TOP | F46 |
| D (outer eyes’ corner, their lower eyelids) | F05 | vertical D (upper and the lower lip) | F26 | opening of mouth | F47 |
| D (inner eyes’ corner, their lower eyelids) | F06 | Bounding box of face | F27 | facial expression | F48 |
| V D (upper eyelids, the lower eyelids) | F07 | position of eyes | F28 | Mean | F49 |
| D (upper lip, mouth corners) | F08 | position of mouth | F29 | Energy | F50 |
| 15 facial AU | F09 | position of nose | F30 | Std dev | F51 |
| head-pose in 3D | F10 | Jaw drop | F31 | Min | F52 |
| mean and std dev (optical flow in head region) | F11 | Local Binary Patterns (LBP) | F32 | Max | F53 |
| Gabor wavelet features | F12 | 240 VF (2D MC as mean and std dev of adjusted MC) | F33 | Range | F54 |
| Inner brow raiser | F13 | Local Phase Quantization (LPQ) | F34 | position min/max | F55 |
| Outer brow raiser | F14 | Patterns of oriented edge magnitudes (POEM) | F35 | number crossings/peaks | F56 |
| Brow lowerer | F15 | LPQ-45 | F36 | length | F57 |
| Cheek raiser | F16 | PHOG-46 | F37 | Geometric | F58 |
| Lid tightener | F17 | PHOG-45-PCA | F38 | 2D global head motion estimation | F59 |
| Upper lip raiser | F18 | LPQ-all | F39 | A measure | F60 |
| Lip corner puller | F19 | LPQ-all-PCA | F40 | two-rectangle features | F61 |
| Lip corner depressor | F20 | PHOG-all | F41 | three-rectangle features | F62 |
| Chin raiser | F21 | PHOG-all-PCA | F42 | four-rectangle features | F63 |
| AU 1–2, 4–12, 14–18, 20, 22–28, 38–41, 42–46 | F64 |
| avg skin resistance | P01 | E ratio bw the freq bands [0.04–0.15] Hz, [0.15–0.5] Hz | P14 | median peak to peak time | P27 |
| avg of D | P02 | SP in bands ([0.1–0.2] Hz, [0.2–0.3] Hz, [0.3–0.4] Hz) | P15 | avg | P28 |
| avg decrease rate in decay time | P03 | low freq [0.01–0.08] Hz | P16 | avg of D | P29 |
| prop of -ve samples in the D vs. all samples | P04 | medium freq [0.08–0.15] Hz | P17 | Band SP in ([0–0.1] Hz, [0.1–0.2] Hz) | P30 |
| no. of local minima in the GSR signal | P05 | high freq [0.15–0.5] Hz | P18 | EMG | P31 |
| avg rising time of the GSR signal | P06 | ECG (64) | P19 | eye blinking rate | P32 |
| 10 SP in the [0–2.4] Hz bands | P07 | band E ratio log(E(0.05–0.25 Hz))-log(E(0.25–5 Hz)) | P20 | E of the signal | P33 |
| ZCR of SCSR [0–0.2] Hz | P08 | avg respiration signal | P21 | mean and variance of the signal | P34 |
| ZCR of SCVSR [0–0.08] Hz | P09 | mean of the respiration signal | P22 | 10 SP in the bands from 0 to 2.4 Hz | P35 |
| SCSR | P10 | std deviation | P23 | avg peak to peak time | P36 |
| SCVSR mean of peaks magnitude | P11 | range or greatest breath | P24 | Heart Rate Variability (HRV) | P37 |
| avg and std deviation of HR | P12 | breathing rhythm (spectral centroid) | P25 | inter beat intervals | P38 |
| breathing rate | P13 | inter beat intervals | P26 |
| IR DB | # Participants | Emotions | WB | S/P | Available |
|---|---|---|---|---|---|
| IRIS | 30 (28 M, 2 F) | S, L, A | No | P | Yes |
| NIST | 600 | SM, F, S | No | P | No |
| NVIE | 215 (157 M, 58 F) | H, SA, S, FE, A, D, N | No | S, P | Yes |
| KTFE | 26 (16 M, 10 F) | H, SA, S, FE, A, D, N | No | S | Yes |
| VIRI | 110 (70 M, 40 F) | H, SA, S, A, N | Yes | S | Yes |
| Applicatio;n Domain | Databases and Modalities | Remarks | |||||
|---|---|---|---|---|---|---|---|
| Marketing | CALLAS | According to [225], the advertising campaign focused on emotional content performs twice better than those with rational content. Furthermore, studies have also shown that people who are unable to feel emotion find extremely difficult to make a decision. Therefore, if you can evoke an emotional response in your target audience by studying their facial expressions, voice signals, and body/hand gestures, then there is a high chance that your prospective customer will buy from you. For instance, Nike’s “Just do it” fires inner-athlete in everyone and make consumers buy sports goods from them. Similar to Nike, companies such as GE, Cisco, Nike, IBM, AutoDesk, Qualcomm, Facebook, Google, etc., all evoke emotions in their marketing. Therefore, it is suggested to study and analyze databases containing modalities, such as the face, speech, and hand/body gestures, for marketing applications. | |||||
| EU Emotion Stimulus | |||||||
| IEMOCAP | |||||||
| HUMAINE | |||||||
| Medicine | MAHNOB-HCI | The study of the patient’s facial expression, speech tone, body movements, and physiological signals such as ECG, EEG, HR, etc., together can help doctors and nurses discern how the patient is feeling. This can also be useful in the treatment/healing process even if the patient is not physically present. One example of emotion recognition implemented in the field of medicine would be the psychiatrist evaluating the patient’s underlying medical conditions by studying their voice and facial expression via smartphones and tablets. | |||||
| emoFBVP | |||||||
| DEAP | |||||||
| RECOLA | |||||||
| Education and Research | MAHNOB-HCI | According to [226,227] the study of emotional states helps in the learning process as they give information about learner’s emotion by studying different modalities such as facial expression, speech tone, body/hand/eye movements, and physiological signals such as ECG, EEG, HR, etc. For example, the study of frustration in students related to educational software help improvise the software product. Similarly, the study of boredom in students during their interaction with resources can help ameliorate the study material. Finally, an emotional study on learners also helps in knowing their stereotypes, which further help in adapting the learning paths. | |||||
| emoFBVP | |||||||
| RECOLA | |||||||
| Autonomous Driving Vehicles | MAHNOB-HCI | In the 21st century, with a lot of automotive manufacturers competing to build autonomous driving vehicles, the study of the emotional state of a passenger inside the vehicle during the testing phase would help them build more customer-friendly vehicles. It would also help for future improvements in their vehicle design. For such purpose, the study of facial expression, speech signals, body gestures, and physiological parameters of a passenger inside the car is considered crucial. Moreover, IR databases can also be used for this purpose because it would help know the emotional states during low light conditions or during night time. Furthermore, some of them could also be used in wild conditions such as VIRI. | |||||
| emoFBVP | |||||||
| RECOLA | |||||||
| NIST | |||||||
| IRIS | |||||||
| NVIE | |||||||
| VIRI | |||||||
| KTFE | |||||||
| HCI/ Robotics | MAHNOB-HCI | Two most common medium for interaction between human and computer/robot are speech and image. This is achieved through the use of a camera and microphone [228,229]. Therefore, we believe that the study of facial expression, speech signals, eye gaze, and hand/body gestures help in training robots/computer for better interaction with humans. | |||||
| CALLAS | |||||||
| EU Emotion Stimulus | |||||||
| HUMAINE | |||||||
| IEMOCAP | |||||||
| Aid for Disabled | CALLAS | Different devices are used to provide aid to a disabled person to make their life easy. It is advised that facial expression, sound signals, and body gestures are important to consider for building aid devices for the disabled because it will help them know the emotional state of the person whom they are talking to and help then react based on that. Furthermore, IR databases can also be used for this application because they are capable of detecting blood flow on the facial regions, even if there is no facial expression on the face. This helps caretakers know very slight or even concealed emotions on the patient with a disability and help them accordingly. | |||||
| EU Emotion Stimulus | |||||||
| HUMAINE | |||||||
| IEMOCAP | |||||||
| NIST | |||||||
| IRIS | |||||||
| NVIE | |||||||
| VIRI | |||||||
| KTFE | |||||||
| Entertainment | eNTERFACE’05 | People often show their emotions either through face or speech when they watch a movie, sports, news, etc. Therefore, the study of speech signals and facial expressions helps the entertainment industry/ event planner know what people like and dislike, and based on this automatic feedback, they can improvise. Similarly, the study of emotion recognition also helps in movie trailer creation [230]. Additionally, this technique can also be used in gaming. Exergames frameworks and other interactive games have used emotion recognition technology to provide more immense gaming experience [231]. | |||||
| RML | |||||||
| GEMEPFERA 2011 | |||||||
| SAVEE | |||||||
| AVEC | |||||||
| BAUM-1 | |||||||
| BAUM-2 | |||||||
| VAM | |||||||
| SEMAINE | |||||||
| SAL | |||||||
| NTUA | |||||||
| Berlin | |||||||
| The USC CreativeIT | |||||||
| Recommender System | MMI | The recommender system predicts the preference of the user for any particular product and recommends the best possible option. It makes a recommendation based on the study of facial expressions of people from the previously used/watched contents. For example, during online shopping, change in facial expression for different products can be observed through a camera on laptops, smartphones, and tablets, and the product with positive facial expression can be boosted, while the importance can be reduced for the one with negative facial expression [232]. Apart from the aforementioned field, some of the fields that have successfully applied recommendation system are health care (e.g., emHealth), hospitals, multimedia, web-search, and e-commerce [231]. | |||||
| JAFFE | |||||||
| CK/CK+ | |||||||
| AFEW | |||||||
| FER2013 | |||||||
| SFEW | |||||||
| Automatic Surveillance | MMI | It is believed that the study of facial features and expression are critical for building of an automatic surveillance system because it helps track the movement of people, identify people at borders, spot criminals, and provide security. Apart from this, databases containing different modalities, such as face, speech, and gestures, can also be studied for automatic surveillance applications at places such as grocery stores, as it can help analyze the age, gender, mood, and behavior of people, which further helps in targeted marketing and product placement. Further, those modalities can also be used in automatic surveillance as seen in movies and videos. Besides the aforementioned databases, IR databases can be a good resource for automatic surveillance during night time. | |||||
| JAFFE | |||||||
| CK/CK+ | |||||||
| AFEW | |||||||
| FER2013 | |||||||
| SFEW | |||||||
| CALLAS Expressivity Corpus | |||||||
| EU Emotion Stimulus | |||||||
| IEMOCAP | |||||||
| HUMAINE | |||||||
| NIST | |||||||
| IRIS | |||||||
| VIRI | |||||||
| NVIE | |||||||
| The KTFE | |||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siddiqui, M.F.H.; Dhakal, P.; Yang, X.; Javaid, A.Y. A Survey on Databases for Multimodal Emotion Recognition and an Introduction to the VIRI (Visible and InfraRed Image) Database. Multimodal Technol. Interact. 2022, 6, 47. https://doi.org/10.3390/mti6060047
Siddiqui MFH, Dhakal P, Yang X, Javaid AY. A Survey on Databases for Multimodal Emotion Recognition and an Introduction to the VIRI (Visible and InfraRed Image) Database. Multimodal Technologies and Interaction. 2022; 6(6):47. https://doi.org/10.3390/mti6060047
Chicago/Turabian StyleSiddiqui, Mohammad Faridul Haque, Parashar Dhakal, Xiaoli Yang, and Ahmad Y. Javaid. 2022. "A Survey on Databases for Multimodal Emotion Recognition and an Introduction to the VIRI (Visible and InfraRed Image) Database" Multimodal Technologies and Interaction 6, no. 6: 47. https://doi.org/10.3390/mti6060047
APA StyleSiddiqui, M. F. H., Dhakal, P., Yang, X., & Javaid, A. Y. (2022). A Survey on Databases for Multimodal Emotion Recognition and an Introduction to the VIRI (Visible and InfraRed Image) Database. Multimodal Technologies and Interaction, 6(6), 47. https://doi.org/10.3390/mti6060047