
A Record Linkage-Based Data Deduplication Framework with DataCleaner Extension

 ,
,  ,
,  ,
,  and
and 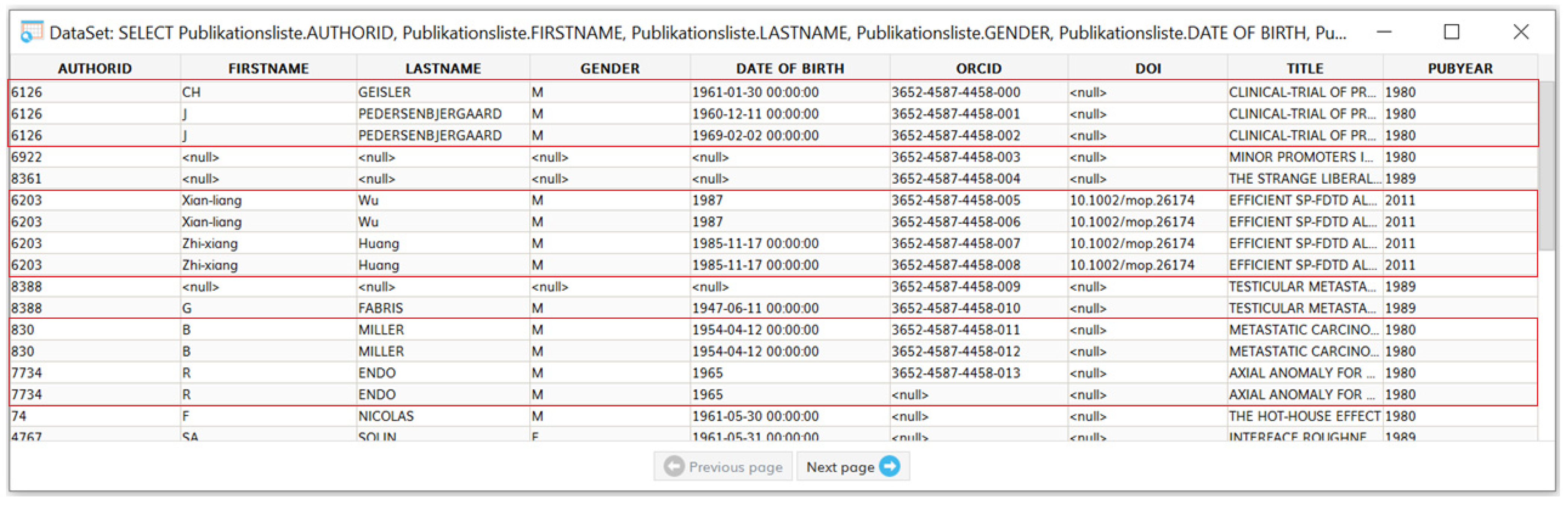{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Problem Relevance and Classification
3. Materials and Methods
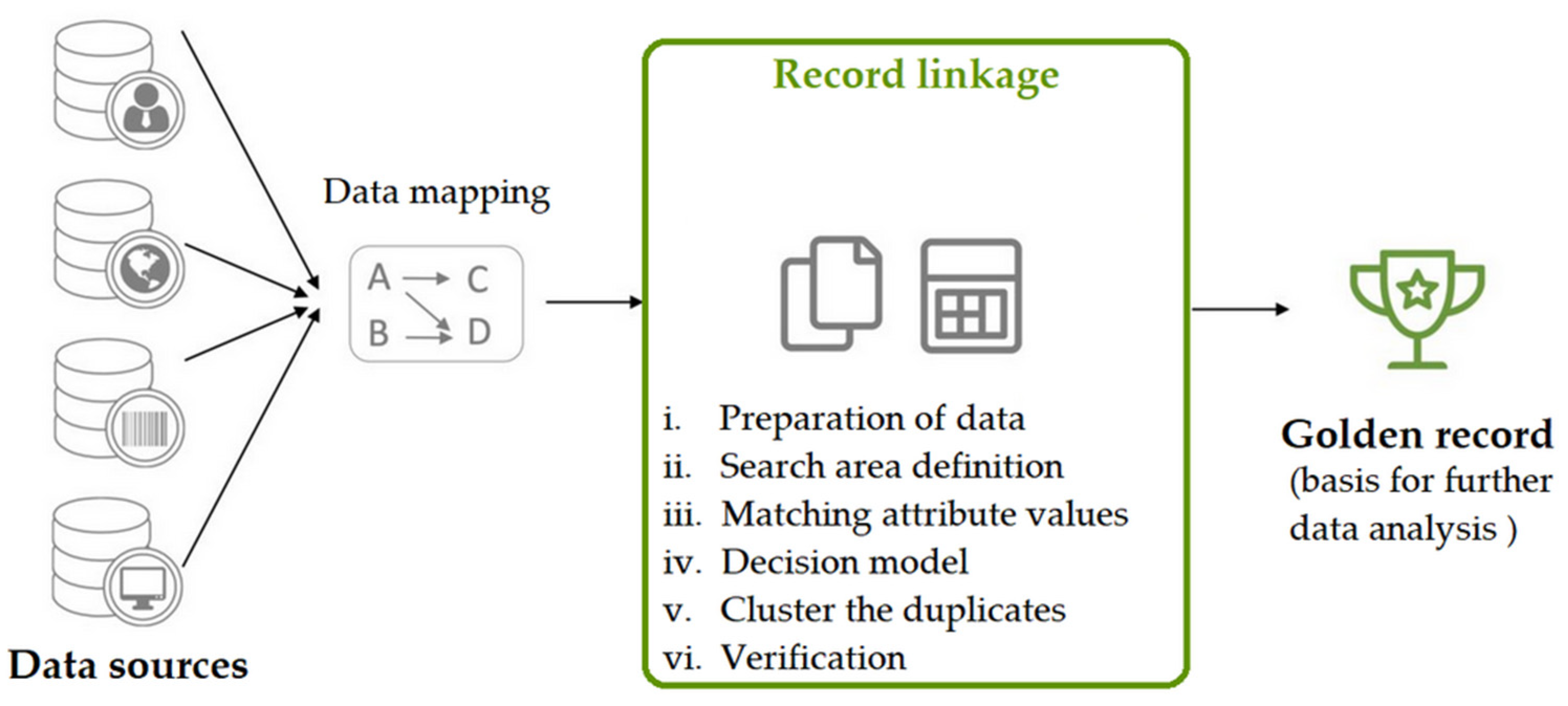
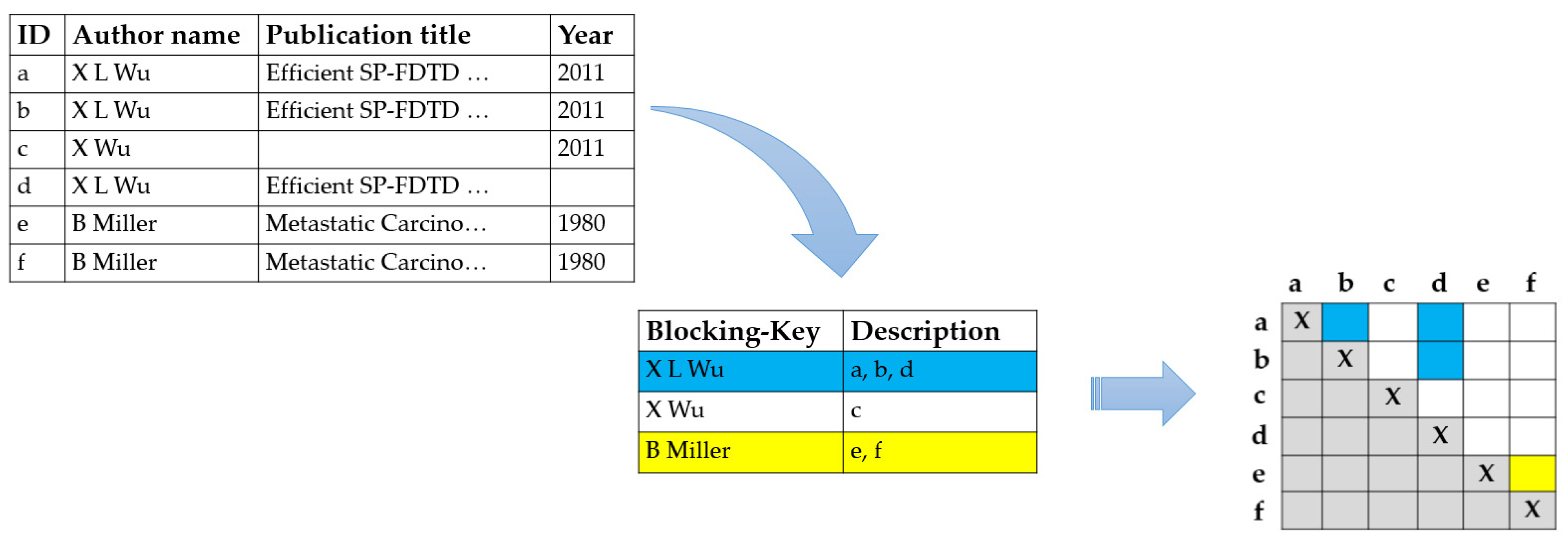
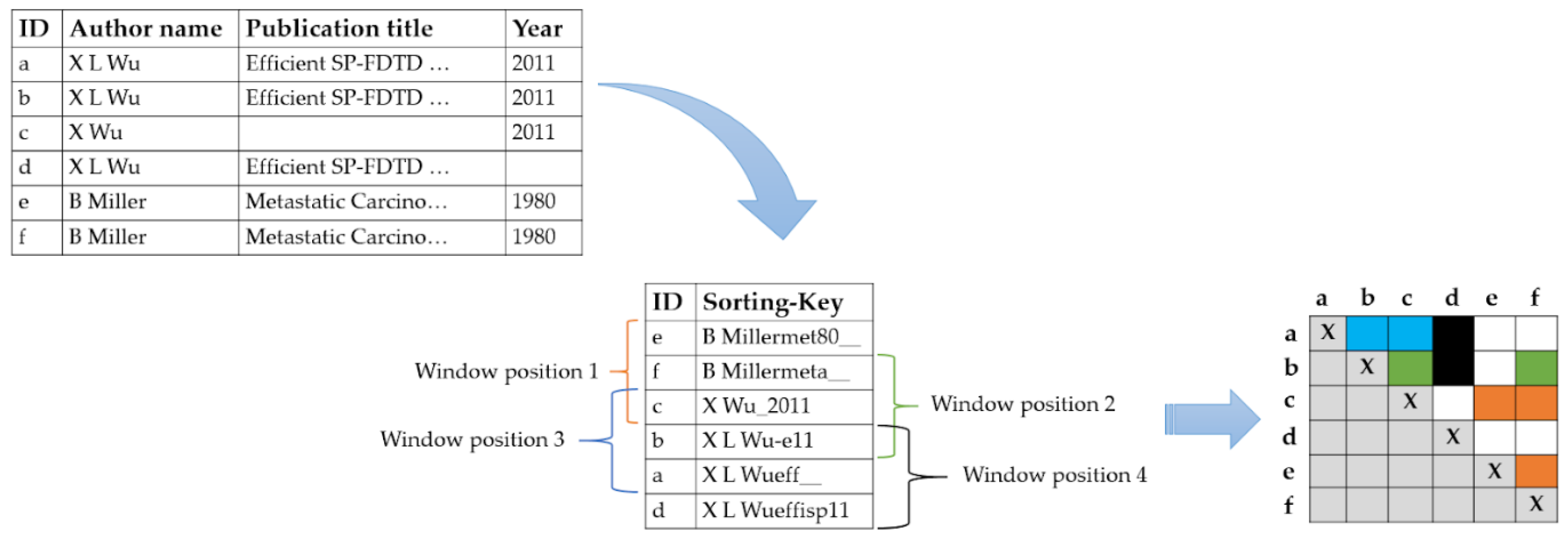
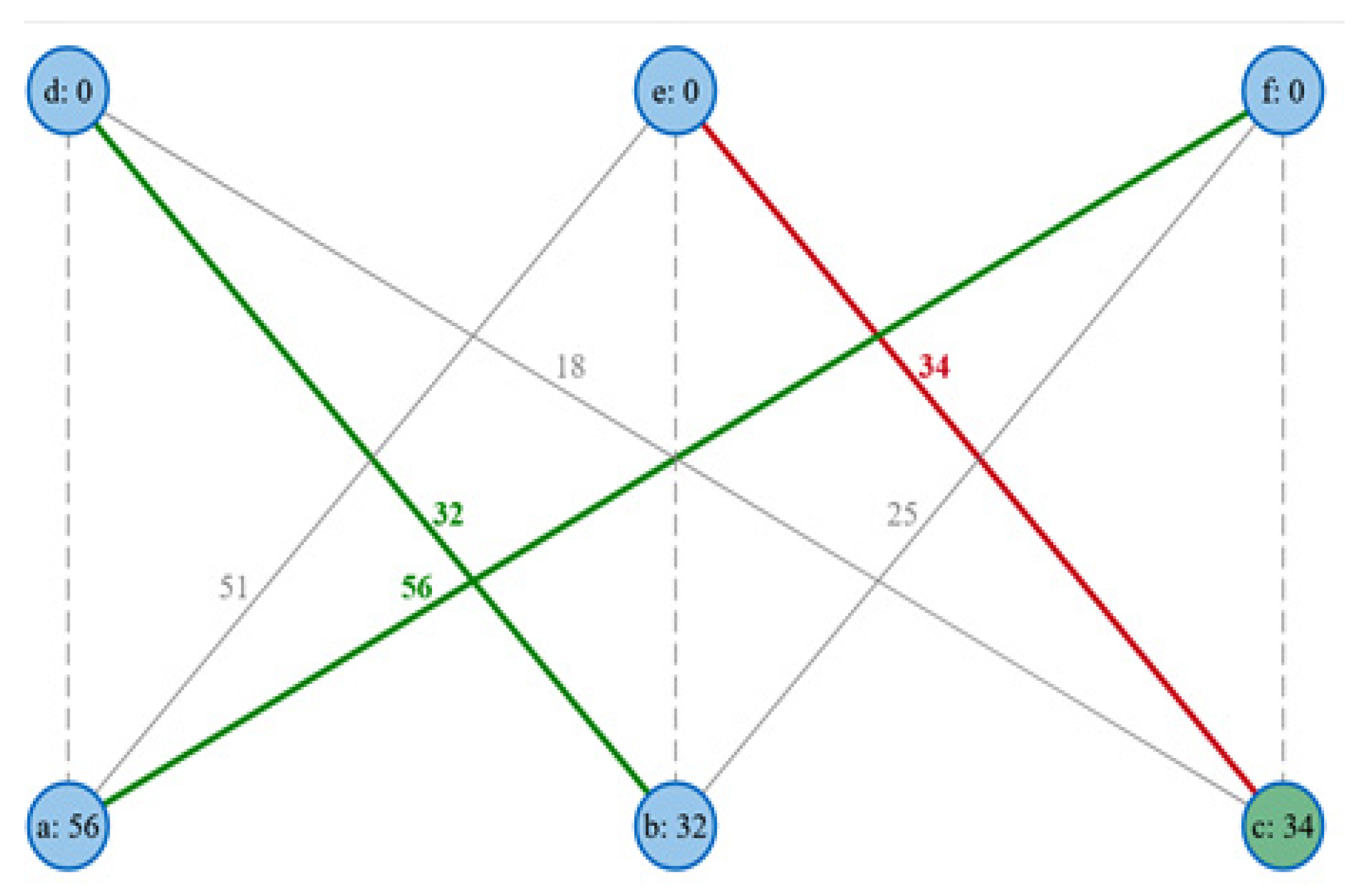
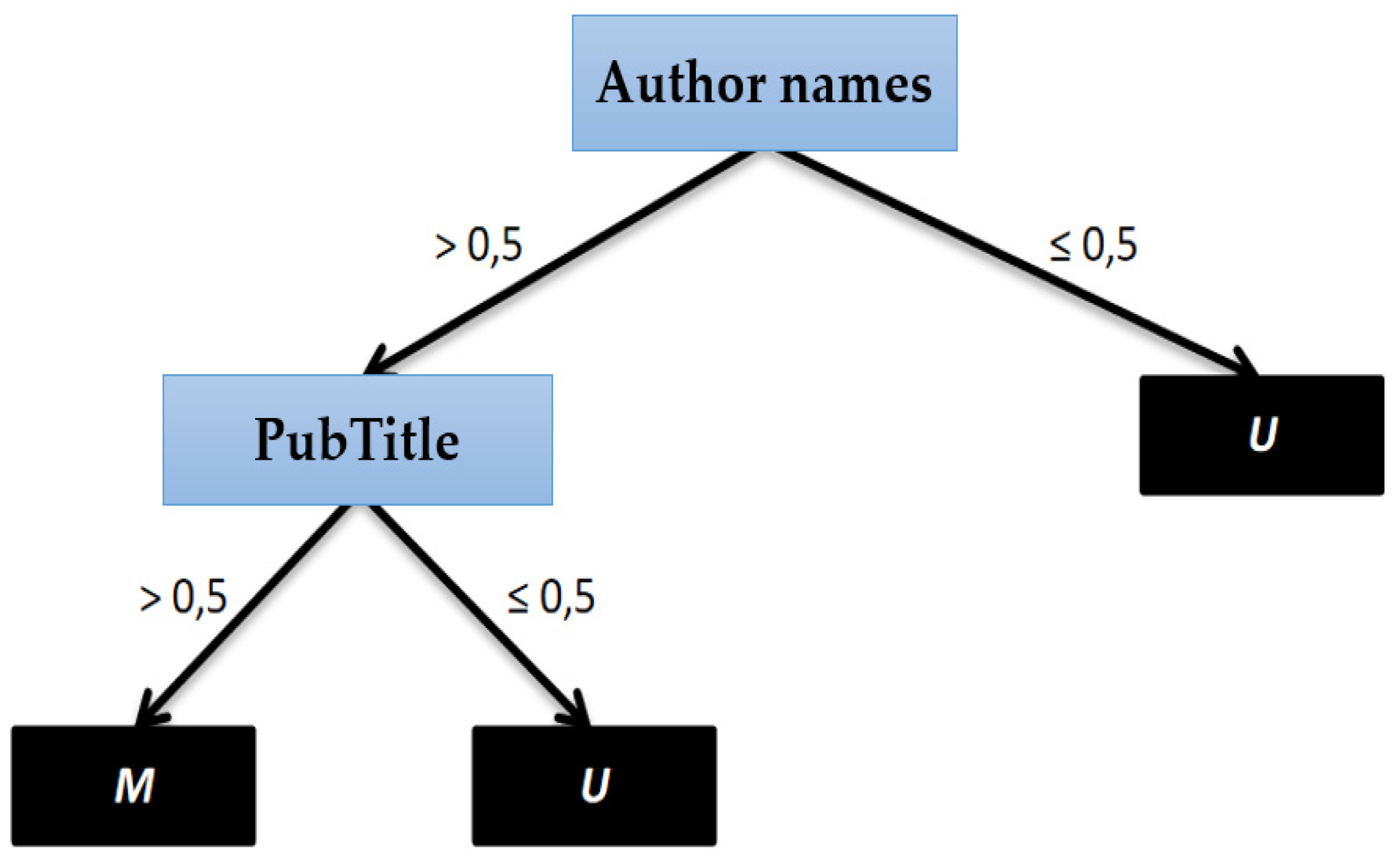
Record Linkage Framework
b = (b1, b2,…, bi),
P: if Ty ≤ R ≤ Tz
U: if R < Tz
| Duplicates | Not a Duplicate | |
| match | true-match | false-match |
| non-match | false-non-match | true-non-match |
4. Results
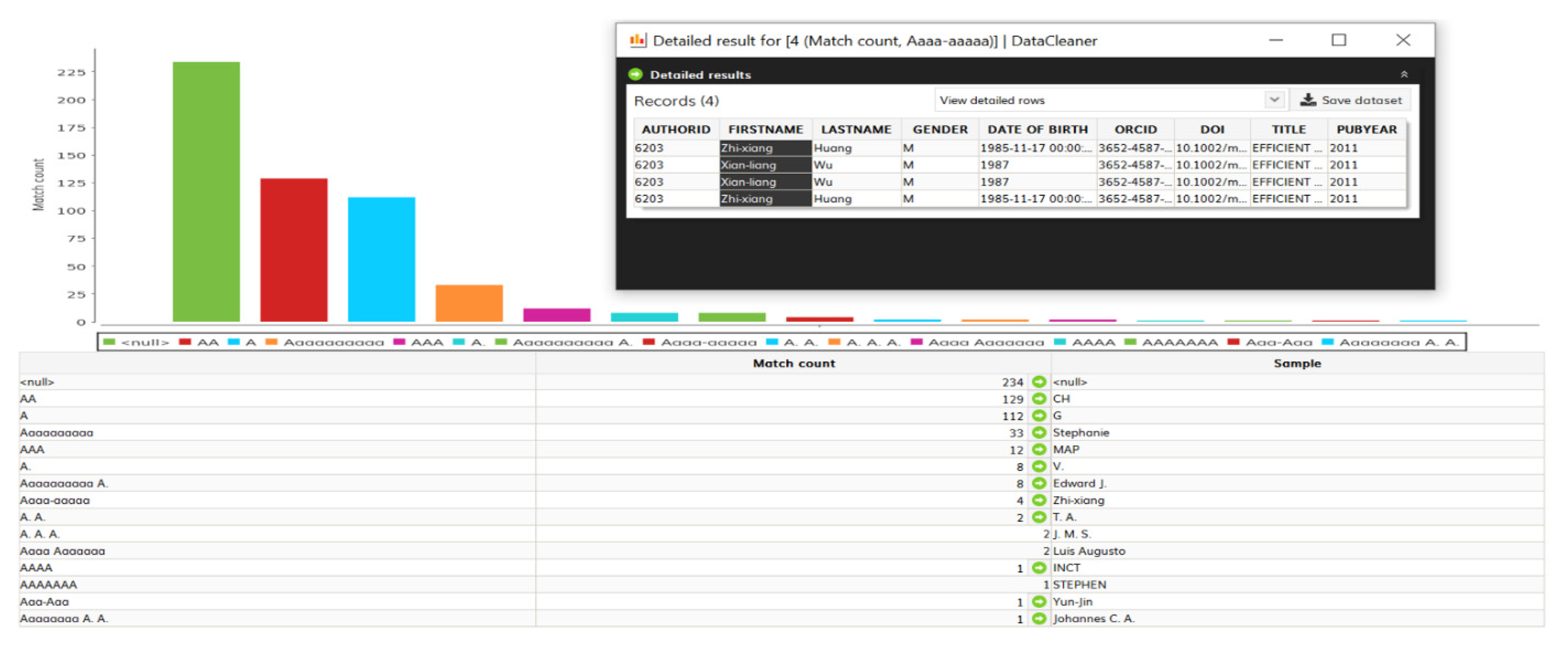
Deduplicate DataCleaner Extension
5. Discussion and Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Benson, P.R. Identifying and Resolving Duplicates in Master Dats. White Paper ISO 8000. 2021. Available online: https://eccma.org/what-is-iso-8000/ (accessed on 19 January 2022).
- Naumann, F.; Herschel, M. An Introduction to Duplicate Detection. Synth. Lect. Data Manag. 2010, 2, 1–87. [Google Scholar] [CrossRef]
- Periasamy, J.; Latha, B. Efficient hash function–based duplication detection algorithm for data Deduplication deduction and reduction. Concurr. Comput. Pract. Exp. 2019, 33, e5213. [Google Scholar] [CrossRef]
- Nikiforova, A. Definition and Evaluation of Data Quality: User-Oriented Data Object-Driven Approach to Data Quality Assessment. Balt. J. Mod. Comput. 2020, 8, 391–432. [Google Scholar] [CrossRef]
- Hoy, M.B. The “Internet of Things”: What It Is and What It Means for Libraries. Med. Ref. Serv. Q. 2015, 34, 353–358. [Google Scholar] [CrossRef] [PubMed]
- Miorandi, D.; Sicari, S.; De Pellegrini, F.; Chlamtac, I. Internet of things: Vision, applications and research challenges. Ad Hoc Networks 2012, 10, 1497–1516. [Google Scholar] [CrossRef]
- Balaji, M.; Roy, S.K. Value co-creation with Internet of things technology in the retail industry. J. Mark. Manag. 2016, 33, 7–31. [Google Scholar] [CrossRef]
- Bail, R.d.F.; Kovaleski, J.L.; da Silva, V.L.; Pagani, R.N.; Chiroli, D.M.D.G. Internet of things in disaster management: Technologies and uses. Environ. Hazards 2021, 20, 493–513. [Google Scholar] [CrossRef]
- Pawar, A.; Kolte, A.; Sangvikar, B. Techno-managerial implications towards communication in internet of things for smart cities. Int. J. Pervasive Comput. Commun. 2021, 17, 237–256. [Google Scholar] [CrossRef]
- Samih, H. Smart cities and internet of things. J. Inf. Tehcnol. Case Appl. Res. 2019, 21, 3–12. [Google Scholar] [CrossRef]
- Kaupins, G.; Stephens, J. Development of Internet of Things-Related Monitoring Policies. J. Inf. Priv. Secur. 2018, 13, 282–295. [Google Scholar] [CrossRef]
- Ziegler, P.; Dittrich, K.R. Data Integration-Problems, Approaches, and Perspectives. Conceptual Modelling in Information Systems Engineering; Krogstie, J., Opdahl, A.L., Brinkkemper, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar] [CrossRef]
- Christen, P. A Survey of Indexing Techniques for Scalable Record Linkage and Deduplication. IEEE Trans. Knowl. Data Eng. 2011, 24, 1537–1555. [Google Scholar] [CrossRef]
- Leitão, L.; Calado, P.; Herschel, M. Efficient and Effective Duplicate Detection in Hierarchical Data. IEEE Trans. Knowl. Data Eng. 2012, 25, 1028–1041. [Google Scholar] [CrossRef]
- Daniel, C.; Serre, P.; Orlova, N.; Bréant, S.; Paris, N.; Griffon, N. Initializing a hospital-wide data quality program. The AP-HP experience. Comput. Methods Programs Biomed. 2018, 181, 104804. [Google Scholar] [CrossRef] [PubMed]
- Elmagarmid, A.K.; Ipeirotis, P.; Verykios, V. Duplicate Record Detection: A Survey. IEEE Trans. Knowl. Data Eng. 2006, 19, 1–16. [Google Scholar] [CrossRef]
- Chen, Q.; Britto, R.; Erill, I.; Jeffery, C.J.; Liberzon, A.; Magrane, M.; Onami, J.-I.; Robinson-Rechavi, M.; Sponarova, J.; Zobel, J.; et al. Quality Matters: Biocuration Experts on the Impact of Duplication and Other Data Quality Issues in Biological Databases. Genom. Proteom. Bioinform. 2020, 18, 91–103. [Google Scholar] [CrossRef] [PubMed]
- Kwon, Y.; Lemieux, M.; McTavish, J.; Wathen, N. Identifying and removing duplicate records from systematic review searches. J. Med. Libr. Assoc. 2015, 103, 184–188. [Google Scholar] [CrossRef]
- Winkler, W.E. Matching and record linkage. WIREs Comput. Stat. 2014, 6, 313–325. [Google Scholar] [CrossRef]
- Baxter, R.; Christen, P.; Churches, T. A Comparison of Fast Blocking Methods for Record Linkage. In Proceedings of the Workshop on Data Cleaning, Record Linkage and Object Consolidation at the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24–27 August 2003. [Google Scholar]
- Weis, M.; Naumann, F.; Jehle, U.; Lufter, J.; Schuster, H. Industry-scale duplicate detection. Proc. VLDB Endow. 2008, 1, 1253–1264. [Google Scholar] [CrossRef]
- Newcombe, H.B.; Kennedy, J.M.; Axford, S.J.; James, A.P. Automatic Linkage of Vital Records. Science 1959, 130, 954–959. [Google Scholar] [CrossRef]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Conrad, J.G.; Guo, X.S.; Schriber, C.P. Online Duplicate Document Detection: Signature Reliability in a Dynamic Retrieval Environment. In Proceedings of the twelfth international conference on Information and knowledge management (CIKM ‘03), Association for Computing Machinery, New York, NY, USA, 3–8 November 2003; pp. 443–452. [Google Scholar] [CrossRef]
- Burdick, D.; Hernández, M.A.; Ho, C.T.; Koutrika, G.; Krishnamurthy, R.; Popa, L.; Stanoi, I.; Vaithyanathan, S.; Das, S.R. Extracting, Linking and Integrating Data from Public Sources: A Financial Case Study. IEEE Data Eng. Bull. 2011, 34, 60–67. [Google Scholar] [CrossRef]
- Khtira, A. Detecting Feature Duplication in a CRM Product Line. J. Softw. 2020, 15, 30–44. [Google Scholar] [CrossRef][Green Version]
- TechTarget, WhatIs.Com. Available online: https://whatis.techtarget.com/definition/golden-record (accessed on 20 September 2021).
- Steorts, R.C.; Ventura, S.L.; Sadinle, M.; Fienberg, S.E. A Comparison of Blocking Methods for Record Linkage. In International Conference on Privacy in Statistical Databases; PSD 2014 Lecture Notes in Computer Science; Domingo-Ferrer, J., Ed.; Springer: Cham, Switzerland, 2014; Volume 8744, pp. 253–268. [Google Scholar] [CrossRef]
- Yan, S.; Lee, D.; Kan, M.Y.; Giles, L.C. Adaptive Sorted Neighborhood Methods for Efficient Record Linkage. In Proceedings of the 7th ACM/IEEE-CS joint conference on Digital libraries (JCDL ‘07). Association for Computing Machinery, New York, NY, USA, 18–23 June 2007; pp. 185–194. [Google Scholar] [CrossRef]
- Christophides, V.; Efthymiou, V.; Palpanas, T.; Papadakis, G.; Stefanidis, K. An Overview of End-to-End Entity Resolution for Big Data. ACM Comput. Surv. 2021, 53, 1–42. [Google Scholar] [CrossRef]
- Panse, F.; Van Keulen, M.; De Keijzer, A.; Ritter, N. Duplicate detection in probabilistic data. In Proceedings of the IEEE 26th International Conference on Data Engineering Workshops (ICDEW2010), Long Beach, CA, USA, 1–6 March 2010; pp. 179–182. [Google Scholar] [CrossRef]
- Fellegi, P.; Sunter, A.B. A theory for record linkage. J. Am. Stat. Assoc. 1969, 64, 1183–1210. [Google Scholar] [CrossRef]
- Batini, C.; Scannapieco, M. Data Quality: Concepts, Methodologies and Techniques; Springer: New York, NY, USA, 2006. [Google Scholar] [CrossRef]
- Manning, C.D.; Raghavan, P.; Schütze, H. Introduction to Information Retrieval; Cambridge University Press: New York, NY, USA, 2008. [Google Scholar] [CrossRef]
- Krasikov, P.; Obrecht, T.; Legner, C.; Eurich, M. Open Data in the Enterprise Context: Assessing Open Corporate Data’s Readiness for Use. In International Conference on Data Management Technologies and Applications; Springer: Cham, Switzerland, 2020; pp. 80–100. [Google Scholar] [CrossRef]
- Nikiforova, A.; Kozmina, N. Stakeholder-centred Identification of Data Quality Issues: Knowledge that Can Save Your Business. In Proceedings of the 2021 Second International Conference on Intelligent Data Science Technologies and Applications (IDSTA), Tartu, Estonia, 15–17 November 2021; pp. 66–73. [Google Scholar] [CrossRef]
- Premtoon, V.; Koppel, J.; Solar-Lezama, A. Semantic code search via equational reasoning. In Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI 2020), Association for Computing Machinery, New York, NY, USA, 15–20 June 2020; pp. 1066–1082. [Google Scholar] [CrossRef]
- Karkouch, A.; Mousannif, H.; Al Moatassime, H.; Noel, T. Data quality in internet of things: A state-of-the-art survey. J. Netw. Comput. Appl. 2016, 73, 57–81. [Google Scholar] [CrossRef]
- Vetrò, A.; Torchiano, M.; Mecati, M. A data quality approach to the identification of discrimination risk in automated decision making systems. Gov. Inf. Q. 2021, 38, 101619. [Google Scholar] [CrossRef]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azeroual, O.; Jha, M.; Nikiforova, A.; Sha, K.; Alsmirat, M.; Jha, S. A Record Linkage-Based Data Deduplication Framework with DataCleaner Extension. Multimodal Technol. Interact. 2022, 6, 27. https://doi.org/10.3390/mti6040027
Azeroual O, Jha M, Nikiforova A, Sha K, Alsmirat M, Jha S. A Record Linkage-Based Data Deduplication Framework with DataCleaner Extension. Multimodal Technologies and Interaction. 2022; 6(4):27. https://doi.org/10.3390/mti6040027
Chicago/Turabian StyleAzeroual, Otmane, Meena Jha, Anastasija Nikiforova, Kewei Sha, Mohammad Alsmirat, and Sanjay Jha. 2022. "A Record Linkage-Based Data Deduplication Framework with DataCleaner Extension" Multimodal Technologies and Interaction 6, no. 4: 27. https://doi.org/10.3390/mti6040027
APA StyleAzeroual, O., Jha, M., Nikiforova, A., Sha, K., Alsmirat, M., & Jha, S. (2022). A Record Linkage-Based Data Deduplication Framework with DataCleaner Extension. Multimodal Technologies and Interaction, 6(4), 27. https://doi.org/10.3390/mti6040027