
A Survey of Domain Knowledge Elicitation in Applied Machine Learning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
2.1. Understanding ML Practice
2.2. Knowledge Elicitation for Expert Decision Making
3. Materials and Methods
3.1. Scope
3.2. Sample Collection
3.3. Content Analysis
4. Elicitation Taxonomy
4.1. Elicitation Goal
4.2. Elicitation Target
4.3. Elicitation Process
4.4. Use of Elicited Knowledge
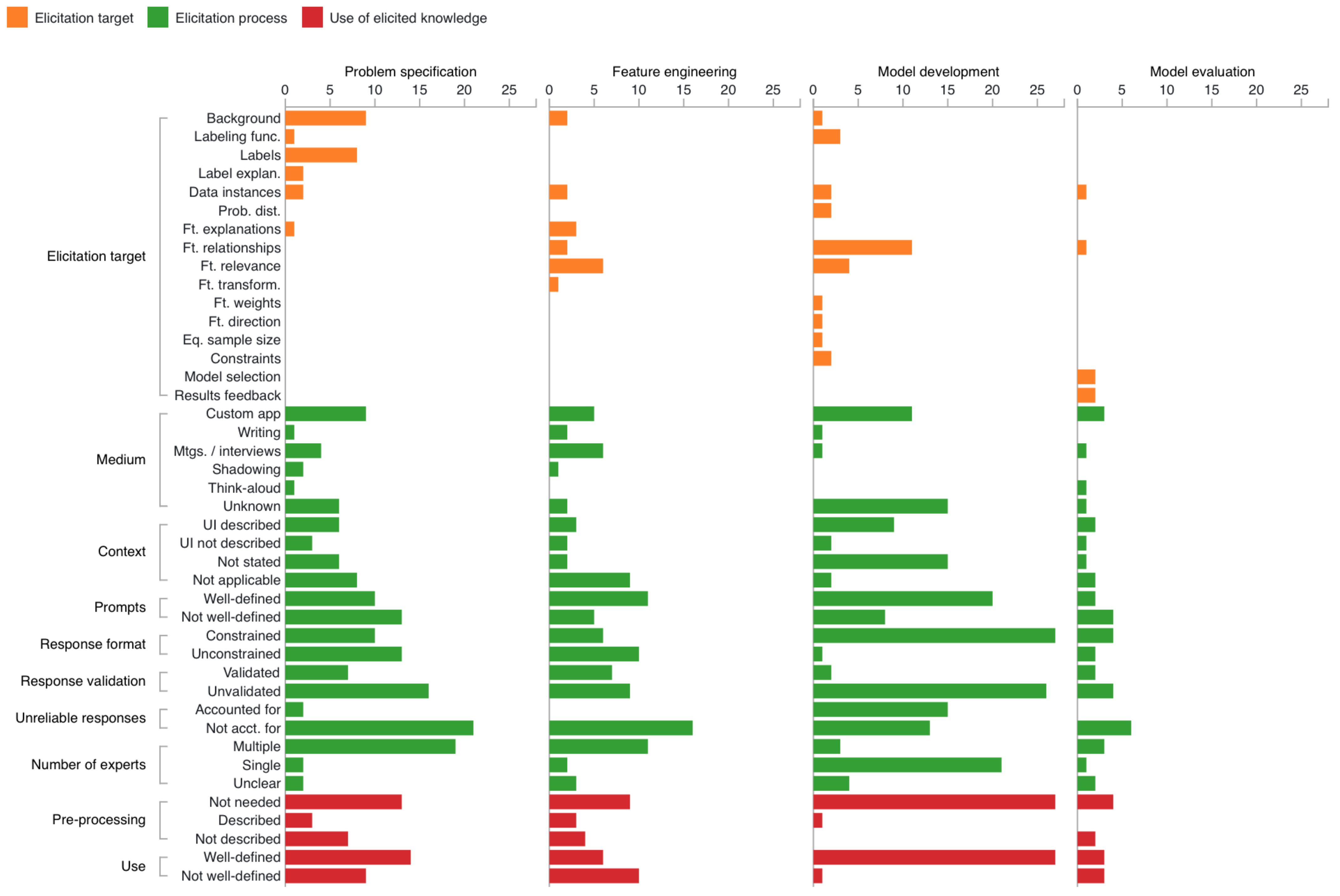
5. Results
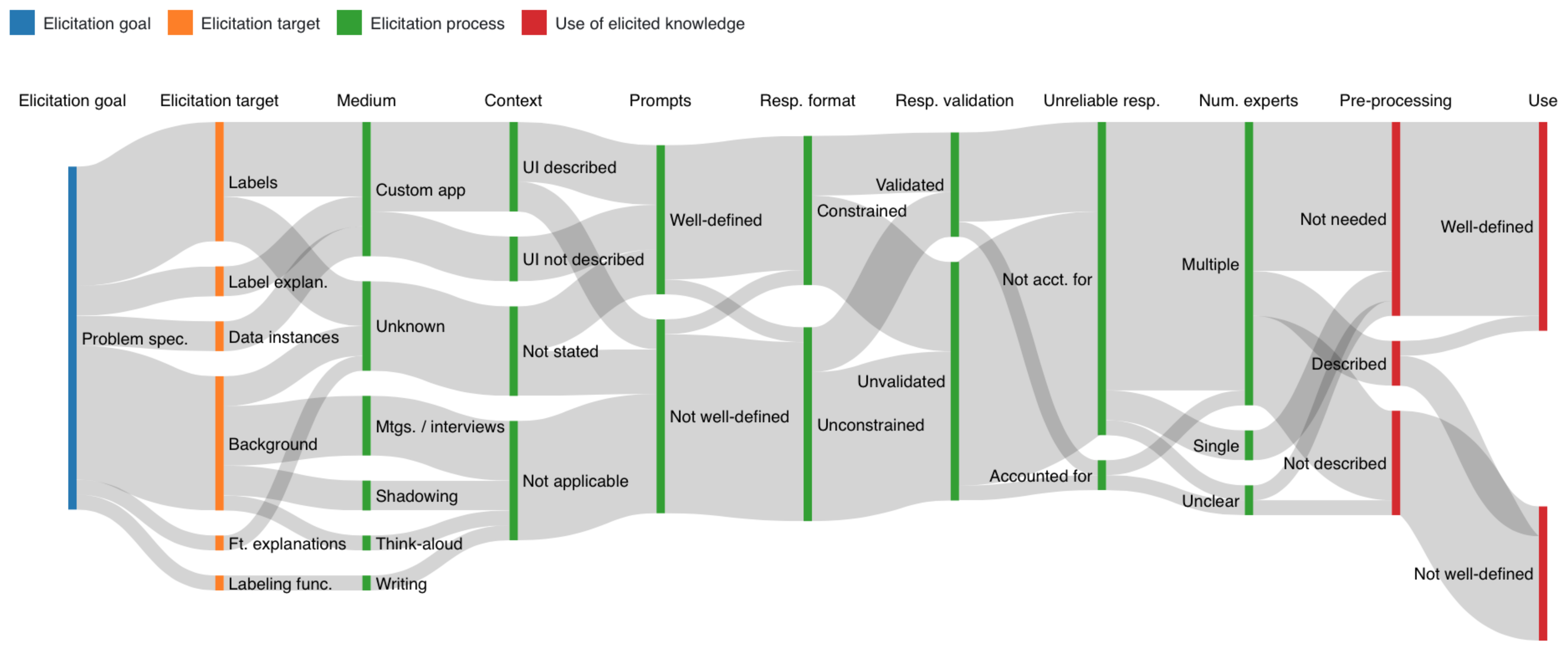
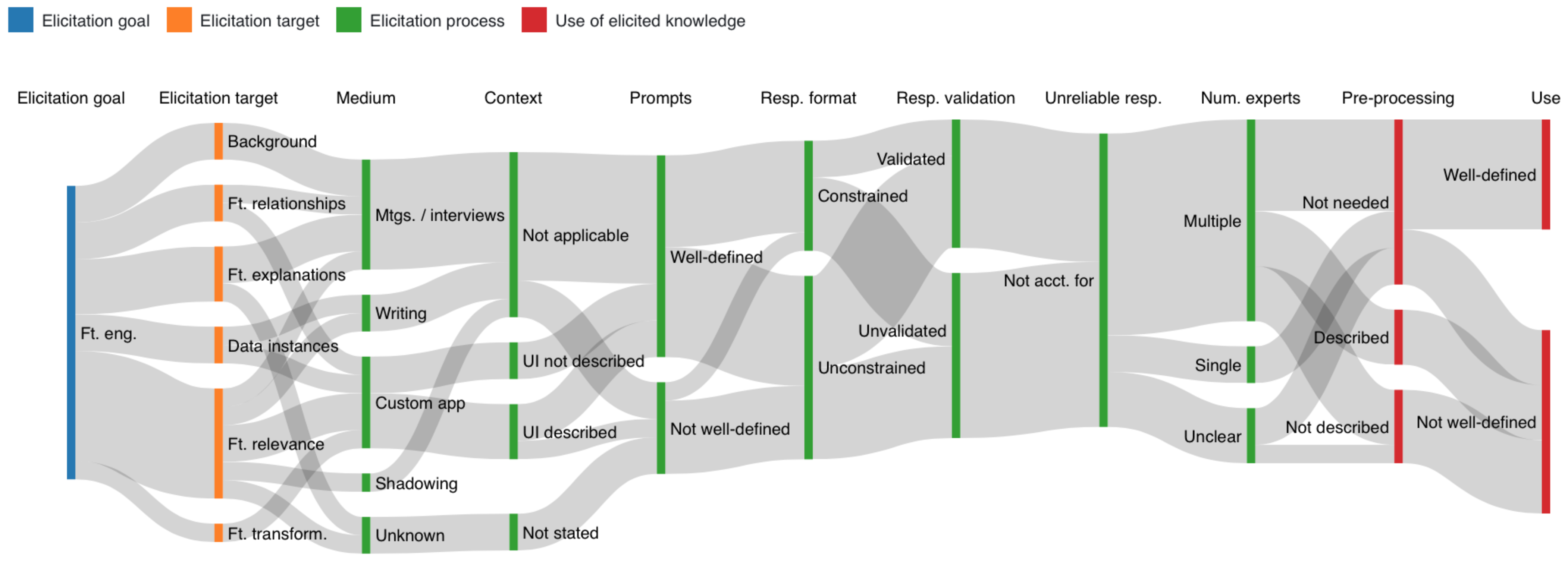
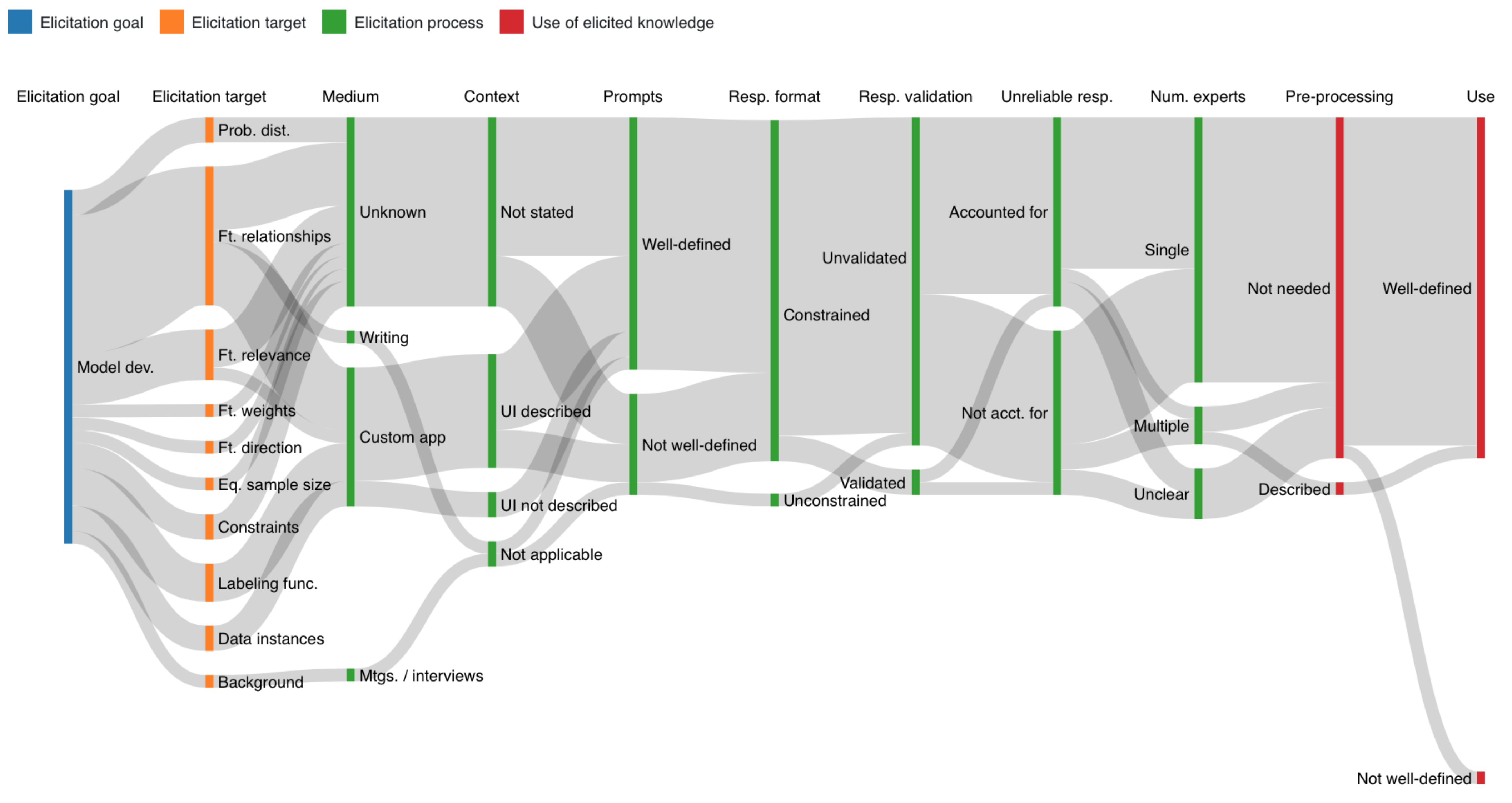
5.1. Characterizing Elicitation Paths
5.1.1. Problem Specification
5.1.2. Feature Engineering
5.1.3. Model Development
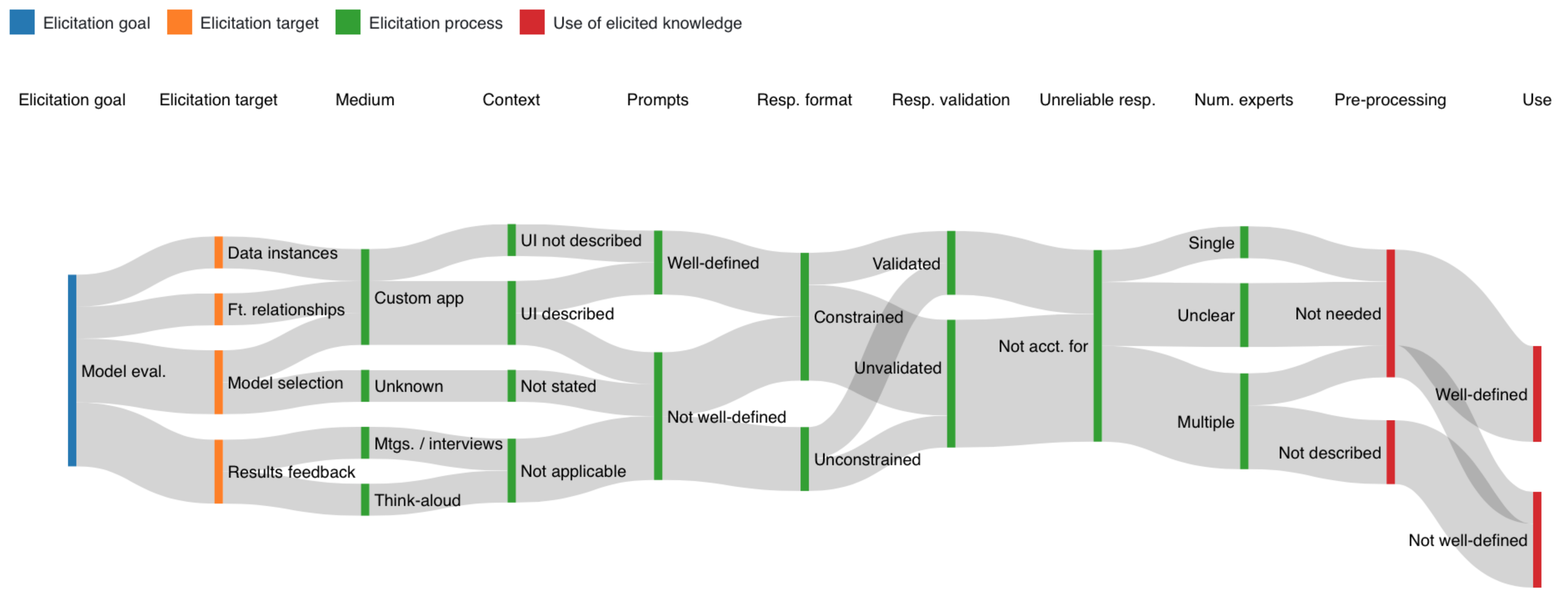
5.1.4. Model Evaluation
5.2. Gaps and Opportunities
5.2.1. Transparency and Traceability
5.2.2. Systematic Use of Elicited Knowledge
5.2.3. Motivating What Is Elicited
5.2.4. Establishing Context and Common Ground
5.2.5. Cognitive Bias
5.2.6. Validation of Elicited Information
6. Future Work and Limitations
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chi, M.T. Laboratory methods for assessing experts’ and novices’ knowledge. In The Cambridge Handbook of Expertise and Expert Performance; Cambridge University Press: Cambridge, UK, 2006; pp. 167–184. [Google Scholar]
- O’Hagan, A.; Buck, C.E.; Daneshkhah, A.; Eiser, J.R.; Garthwaite, P.H.; Jenkinson, D.J.; Oakley, J.E.; Rakow, T. Uncertain Judgements: Eliciting Experts’ Probabilities; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Cartwright, M.; Seals, A.; Salamon, J.; Williams, A.; Mikloska, S.; MacConnell, D.; Law, E.; Bello, J.P.; Nov, O. Seeing Sound: Investigating the Effects of Visualizations and Complexity on Crowdsourced Audio Annotations. Proc. ACM Hum.-Comput. Interact. 2017, 1, 1–21. [Google Scholar] [CrossRef]
- Cakmak, M.; Thomaz, A.L. Designing robot learners that ask good questions. In Proceedings of the 2012 7th ACM/IEEE International Conference on Human-Robot Interaction (HRI), Boston, MA, USA, 5–8 March 2012; pp. 17–24. [Google Scholar]
- O’Hagan, A. Expert Knowledge Elicitation: Subjective but Scientific. Am. Stat. 2019, 73, 69–81. [Google Scholar] [CrossRef]
- Yang, Q.; Suh, J.; Chen, N.C.; Ramos, G. Grounding Interactive Machine Learning Tool Design in How Non-Experts Actually Build Models. In Proceedings of the 2018 Designing Interactive Systems Conference, Hong Kong, China, 9–13 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 573–584. [Google Scholar] [CrossRef]
- Sundin, I.; Peltola, T.; Micallef, L.; Afrabandpey, H.; Soare, M.; Mamun Majumder, M.; Daee, P.; He, C.; Serim, B.; Havulinna, A.; et al. Improving genomics-based predictions for precision medicine through active elicitation of expert knowledge. Bioinformatics 2018, 34, i395–i403. [Google Scholar] [CrossRef] [PubMed]
- Madigan, D.; Gavrin, J.; Raftery, A.E. Eliciting prior information to enhance the predictive performance of bayesian graphical models. Commun. Stat.-Theory Methods 1995, 24, 2271–2292. [Google Scholar] [CrossRef]
- Ashdown, G.W.; Dimon, M.; Fan, M.; Terán, F.S.R.; Witmer, K.; Gaboriau, D.C.A.; Armstrong, Z.; Ando, D.M.; Baum, J. A machine learning approach to define antimalarial drug action from heterogeneous cell-based screens. Sci. Adv. 2020, 6, eaba9338. [Google Scholar] [CrossRef]
- Ustun, B.; Adler, L.A.; Rudin, C.; Faraone, S.V.; Spencer, T.J.; Berglund, P.; Gruber, M.J.; Kessler, R.C. The World Health Organization Adult Attention-Deficit/Hyperactivity Disorder Self-Report Screening Scale for DSM-5. JAMA Psychiatry 2017, 74, 520–526. [Google Scholar] [CrossRef]
- Sendak, M.; Elish, M.C.; Gao, M.; Futoma, J.; Ratliff, W.; Nichols, M.; Bedoya, A.; Balu, S.; O’Brien, C. “The Human Body is a Black Box”: Supporting Clinical Decision-Making with Deep Learning. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 99–109. [Google Scholar] [CrossRef]
- Bowles, K.H.; Potashnik, S.; Ratcliffe, S.J.; Rosenberg, M.; Shih, N.W.; Topaz, M.; Holmes, J.H.; Naylor, M.D. Conducting research using the electronic health record across multi-hospital systems: Semantic harmonization implications for administrators. J. Nurs. Adm. 2013, 43, 355–360. [Google Scholar] [CrossRef]
- Bowles, K.H.; Ratcliffe, S.; Potashnik, S.; Topaz, M.; Holmes, J.; Shih, N.W.; Naylor, M.D. Using Electronic Case Summaries to Elicit Multi-Disciplinary Expert Knowledge about Referrals to Post-Acute Care. Appl. Clin. Inform. 2016, 7, 368–379. [Google Scholar] [CrossRef]
- Heckerman, D.; Geiger, D.; Chickering, D.M. Learning Bayesian Networks: The Combination of Knowledge and Statistical Data. Mach. Learn. 1995, 20, 197–243. [Google Scholar] [CrossRef]
- Cai, C.J.; Reif, E.; Hegde, N.; Hipp, J.; Kim, B.; Smilkov, D.; Wattenberg, M.; Viegas, F.; Corrado, G.S.; Stumpe, M.C.; et al. Human-Centered Tools for Coping with Imperfect Algorithms During Medical Decision-Making. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–14. [Google Scholar]
- Lee, M.H.; Siewiorek, D.P.; Smailagic, A.; Bernardino, A.; Bermúdez i Badia, S. Interactive Hybrid Approach to Combine Machine and Human Intelligence for Personalized Rehabilitation Assessment. In Proceedings of the ACM Conference on Health, Inference, and Learning, Toronto, ON, Canada, 2–4 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 160–169. [Google Scholar] [CrossRef]
- Seymoens, T.; Ongenae, F.; Jacobs, A.; Verstichel, S.; Ackaert, A. A Methodology to Involve Domain Experts and Machine Learning Techniques in the Design of Human-Centered Algorithms. In Human Work Interaction Design. Designing Engaging Automation; Barricelli, B.R., Roto, V., Clemmensen, T., Campos, P., Lopes, A., Gonçalves, F., Abdelnour-Nocera, J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 200–214. [Google Scholar]
- Schaekermann, M.; Hammel, N.; Terry, M.; Ali, T.K.; Liu, Y.; Basham, B.; Campana, B.; Chen, W.; Ji, X.; Krause, J.; et al. Remote Tool-Based Adjudication for Grading Diabetic Retinopathy. Transl. Vis. Sci. Technol. 2019, 8, 40. [Google Scholar] [CrossRef]
- Masegosa, A.R.; Moral, S. An interactive approach for Bayesian network learning using domain/expert knowledge. Int. J. Approx. Reason. 2013, 54, 1168–1181. [Google Scholar] [CrossRef]
- Cano, A.; Masegosa, A.R.; Moral, S. A Method for Integrating Expert Knowledge When Learning Bayesian Networks From Data. IEEE Trans. Syst. Man Cybern. Part B 2011, 41, 1382–1394. [Google Scholar] [CrossRef]
- Richardson, M.; Domingos, P. Learning with Knowledge from Multiple Experts. In Proceedings of the Twentieth International Conference on Machine Learning, Washington, DC, USA, 21–24 August 2003; pp. 624–631. [Google Scholar]
- Langseth, H.; Nielsen, T.D. Fusion of Domain Knowledge with Data for Structural Learning in Object Oriented Domains. J. Mach. Learn. Res. 2003, 4, 339–368. [Google Scholar]
- Afrabandpey, H.; Peltola, T.; Kaski, S. Human-in-the-loop Active Covariance Learning for Improving Prediction in Small Data Sets. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, Macao, China, 10–16 August 2019; pp. 1959–1966. [Google Scholar] [CrossRef]
- El-Assady, M.; Sperrle, F.; Deussen, O.; Keim, D.; Collins, C. Visual Analytics for Topic Model Optimization based on User-Steerable Speculative Execution. IEEE Trans. Vis. Comput. Graph. 2019, 25, 374–384. [Google Scholar] [CrossRef]
- El-Assady, M.; Kehlbeck, R.; Collins, C.; Keim, D.; Deussen, O. Semantic Concept Spaces: Guided Topic Model Refinement using Word-Embedding Projections. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1001–1011. [Google Scholar] [CrossRef]
- Daee, P.; Peltola, T.; Soare, M.; Kaski, S. Knowledge elicitation via sequential probabilistic inference for high-dimensional prediction. Mach. Learn. 2017, 106, 1599–1620. [Google Scholar] [CrossRef]
- Hu, R.; Granderson, J.; Auslander, D.; Agogino, A. Design of machine learning models with domain experts for automated sensor selection for energy fault detection. Appl. Energy 2019, 235, 117–128. [Google Scholar] [CrossRef]
- Webb, G.I. Integrating machine learning with knowledge acquisition through direct interaction with domain experts. Knowl.-Based Syst. 1996, 9, 253–266. [Google Scholar] [CrossRef]
- Camarinha-Matos, L.M.; Martinelli, F.J. Application of Machine Learning in Water Distribution Networks Assisted by Domain Experts. J. Intell. Robot. Syst. 1999, 26, 325–352. [Google Scholar] [CrossRef]
- Ratner, A.; Bach, S.H.; Ehrenberg, H.; Fries, J.; Wu, S.; Ré, C. Snorkel: Rapid Training Data Creation with Weak Supervision. Proc. VLDB Endow. 2017, 11, 269–282. [Google Scholar] [CrossRef]
- Ustun, B.; Rudin, C. Learning Optimized Risk Scores. J. Mach. Learn. Res. 2019, 20, 1–75. [Google Scholar]
- Amershi, S.; Lee, B.; Kapoor, A.; Mahajan, R.; Christian, B. CueT: Human-Guided Fast and Accurate Network Alarm Triage. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 157–166. [Google Scholar]
- Altendorf, E.E.; Restificar, A.C.; Dietterich, T.G. Learning from Sparse Data by Exploiting Monotonicity Constraints. In Proceedings of the Twenty-First Conference on Uncertainty in Artificial Intelligence, Edinburgh, Scotland, 26–29 July 2005; AUAI Press: Arlington, Virginia, USA, 2005; pp. 18–26. [Google Scholar]
- Holstein, K.; Wortman Vaughan, J.; Daumé, H., III; Dudik, M.; Wallach, H. Improving fairness in machine learning systems: What do industry practitioners need? In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–16. [Google Scholar]
- Kaur, H.; Nori, H.; Jenkins, S.; Caruana, R.; Wallach, H.; Wortman Vaughan, J. Interpreting Interpretability: Understanding Data Scientists’ Use of Interpretability Tools for Machine Learning. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–14. [Google Scholar]
- Law, P.M.; Malik, S.; Du, F.; Sinha, M. Designing Tools for Semi-Automated Detection of Machine Learning Biases: An Interview Study. arXiv 2020, arXiv:2003.07680. [Google Scholar]
- Mao, Y.; Wang, D.; Muller, M.; Varshney, K.R.; Baldini, I.; Dugan, C.; Mojsilović, A. How Data ScientistsWork Together with Domain Experts in Scientific Collaborations: To Find the Right Answer or to Ask the Right Question? Proc. ACM Hum.-Comput. Interact. 2019, 3, 1–23. [Google Scholar] [CrossRef]
- Hong, S.R.; Hullman, J.; Bertini, E. Human Factors in Model Interpretability: Industry Practices, Challenges, and Needs. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–26. [Google Scholar] [CrossRef]
- Cai, C.J.; Winter, S.; Steiner, D.; Wilcox, L.; Terry, M. “Hello AI”: Uncovering the Onboarding Needs of Medical Practitioners for Human-AI Collaborative Decision-Making. Proc. ACM Hum.-Comput. Interact. 2019, 3, 1–24. [Google Scholar] [CrossRef]
- Ericsson, K.; Hoffman, R.; Kozbelt, A.; Williams, A. (Eds.) The Cambridge Handbook of Expertise and Expert Performance, 2nd ed.; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar] [CrossRef]
- Chi, M.T.; Feltovich, P.J.; Glaser, R. Categorization and representation of physics problems by experts and novices. Cogn. Sci. 1981, 5, 121–152. [Google Scholar] [CrossRef]
- Chi, M.T.; Glaser, R.; Rees, E. Expertise in Problem Solving: Advances in the Psychology of Human Intelligence; Erlbaum: Hillsdale, NJ, USA, 1982; pp. 1–75. [Google Scholar]
- Garthwaite, P.H.; Kadane, J.B.; O’Hagan, A. Statistical methods for eliciting probability distributions. J. Am. Stat. Assoc. 2005, 100, 680–701. [Google Scholar] [CrossRef]
- Goldstein, D.G.; Rothschild, D. Lay understanding of probability distributions. Judgm. Decis. Mak. 2014, 9, 1–14. [Google Scholar]
- Wagner, W.P.; Najdawi, M.K.; Chung, Q. Selection of knowledge acquisition techniques based upon the problem domain characteristics of production and operations management expert systems. Expert Syst. 2001, 18, 76–87. [Google Scholar] [CrossRef]
- Wagner, W.P. Trends in expert system development: A longitudinal content analysis of over thirty years of expert system case studies. Expert Syst. Appl. 2017, 76, 85–96. [Google Scholar] [CrossRef]
- Rahman, P.; Nandi, A.; Hebert, C. Amplifying Domain Expertise in Clinical Data Pipelines. JMIR Med. Inform. 2020, 8, e19612. [Google Scholar] [CrossRef] [PubMed]
- Amershi, S.; Cakmak, M.; Knox, W.B.; Kulesza, T. Power to the people: The role of humans in interactive machine learning. AI Mag. 2014, 35, 105–120. [Google Scholar] [CrossRef]
- Cakmak, M.; Chao, C.; Thomaz, A.L. Designing interactions for robot active learners. IEEE Trans. Auton. Ment. Dev. 2010, 2, 108–118. [Google Scholar] [CrossRef]
- Thomaz, A.L.; Breazeal, C. Teachable robots: Understanding human teaching behavior to build more effective robot learners. Artif. Intell. 2008, 172, 716–737. [Google Scholar] [CrossRef]
- Rosenthal, S.L.; Dey, A.K. Towards maximizing the accuracy of human-labeled sensor data. In Proceedings of the 15th International Conference on Intelligent User Interfaces, Hong Kong, China, 7–10 February 2010; pp. 259–268. [Google Scholar]
- Daee, P.; Peltola, T.; Vehtari, A.; Kaski, S. User modelling for avoiding overfitting in interactive knowledge elicitation for prediction. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; pp. 305–310. [Google Scholar]
- Budd, S.; Robinson, E.C.; Kainz, B. A survey on active learning and human-in-the-loop deep learning for medical image analysis. Med. Image Anal. 2021, 71, 102062. [Google Scholar] [CrossRef]
- Wu, X.; Xiao, L.; Sun, Y.; Zhang, J.; Ma, T.; He, L. A Survey of Human-in-the-loop for Machine Learning. arXiv 2021, arXiv:2108.00941. [Google Scholar]
- Lasecki, W.S.; Rzeszotarski, J.M.; Marcus, A.; Bigham, J.P. The Effects of Sequence and Delay on Crowd Work. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 1375–1378. [Google Scholar] [CrossRef]
- Attenberg, J.; Ipeirotis, P.G.; Provost, F.J. Beat the Machine: Challenging Workers to Find the Unknown Unknowns. In Proceedings of the Twenty-Fifth Conference on Artificial Intelligence (AAAI-11), San Francisco, CA, USA, 7–8 August 2011; Volume WS-11-11. [Google Scholar]
- Lofland, J.; Lofland, L.H. Analyzing Social Settings; Wadsworth Pub. Co.: Belmont, CA, USA, 1971. [Google Scholar]
- Clark, H.H.; Schreuder, R.; Buttrick, S. Common ground at the understanding of demonstrative reference. J. Verbal Learn. Verbal Behav. 1983, 22, 245–258. [Google Scholar] [CrossRef]
- O’Hagan, A. Probabilistic Uncertainty Specification: Overview, Elaboration Techniques and Their Application to a Mechanistic Model of Carbon Flux. Environ. Model. Softw. 2012, 36, 35–48. [Google Scholar] [CrossRef]
- O’Hagan, A.; Oakley, J.E. SHELF: The Sheffield Elicitation Framework (Version 4); University of Sheffield: Sheffield, UK, 2019. [Google Scholar]
- Gosling, J.P. SHELF: The Sheffield Elicitation Framework. In Elicitation: The Science and Art of Structuring Judgement; Dias, L.C., Morton, A., Quigley, J., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 61–93. [Google Scholar] [CrossRef]
- Cooke, R.M. Experts in Uncertainty: Opinion and Subjective Probability in Science; Oxford University Press: Oxford, UK, 1991; p. xii-321. [Google Scholar]
- Rowe, G.; Wright, G. The Delphi technique as a forecasting tool: Issues and analysis. Int. J. Forecast. 1999, 15, 353–375. [Google Scholar] [CrossRef]
- Hullman, J.; Kay, M.; Kim, Y.S.; Shrestha, S. Imagining replications: Graphical prediction & discrete visualizations improve recall & estimation of effect uncertainty. IEEE Trans. Vis. Comput. Graph. 2017, 24, 446–456. [Google Scholar]
- Cheng, P.W. From covariation to causation: A causal power theory. Psychol. Rev. 1997, 104, 367. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Tenenbaum, J.B. Structure and strength in causal induction. Cogn. Psychol. 2005, 51, 334–384. [Google Scholar] [CrossRef]
- Griffiths, T.L.; Tenenbaum, J.B. Theory-based causal induction. Psychol. Rev. 2009, 116, 661. [Google Scholar] [CrossRef]
- Hullman, J.; Gelman, A. Designing for Interactive Exploratory Data Analysis Requires Theories of Graphical Inference. Harvard Data Science Review 2021. [Google Scholar] [CrossRef]
- Kim, Y.S.; Walls, L.A.; Krafft, P.; Hullman, J. A bayesian cognition approach to improve data visualization. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–14. [Google Scholar]
- Bostock, M.; Ogievetsky, V.; Heer, J. D3 Data-Driven Documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kerrigan, D.; Hullman, J.; Bertini, E. A Survey of Domain Knowledge Elicitation in Applied Machine Learning. Multimodal Technol. Interact. 2021, 5, 73. https://doi.org/10.3390/mti5120073
Kerrigan D, Hullman J, Bertini E. A Survey of Domain Knowledge Elicitation in Applied Machine Learning. Multimodal Technologies and Interaction. 2021; 5(12):73. https://doi.org/10.3390/mti5120073
Chicago/Turabian StyleKerrigan, Daniel, Jessica Hullman, and Enrico Bertini. 2021. "A Survey of Domain Knowledge Elicitation in Applied Machine Learning" Multimodal Technologies and Interaction 5, no. 12: 73. https://doi.org/10.3390/mti5120073
APA StyleKerrigan, D., Hullman, J., & Bertini, E. (2021). A Survey of Domain Knowledge Elicitation in Applied Machine Learning. Multimodal Technologies and Interaction, 5(12), 73. https://doi.org/10.3390/mti5120073