4.1. Adaptive Dialogue Rules
Creating the character’s adaptive dialogue, which is tailored to different users, involved the use of data captured in three previous studies conducted from 2017 to 2018 that also used the Reducing Study Stress scenario with Sarah. The study design is shown in
Figure 2.
As illustrated in
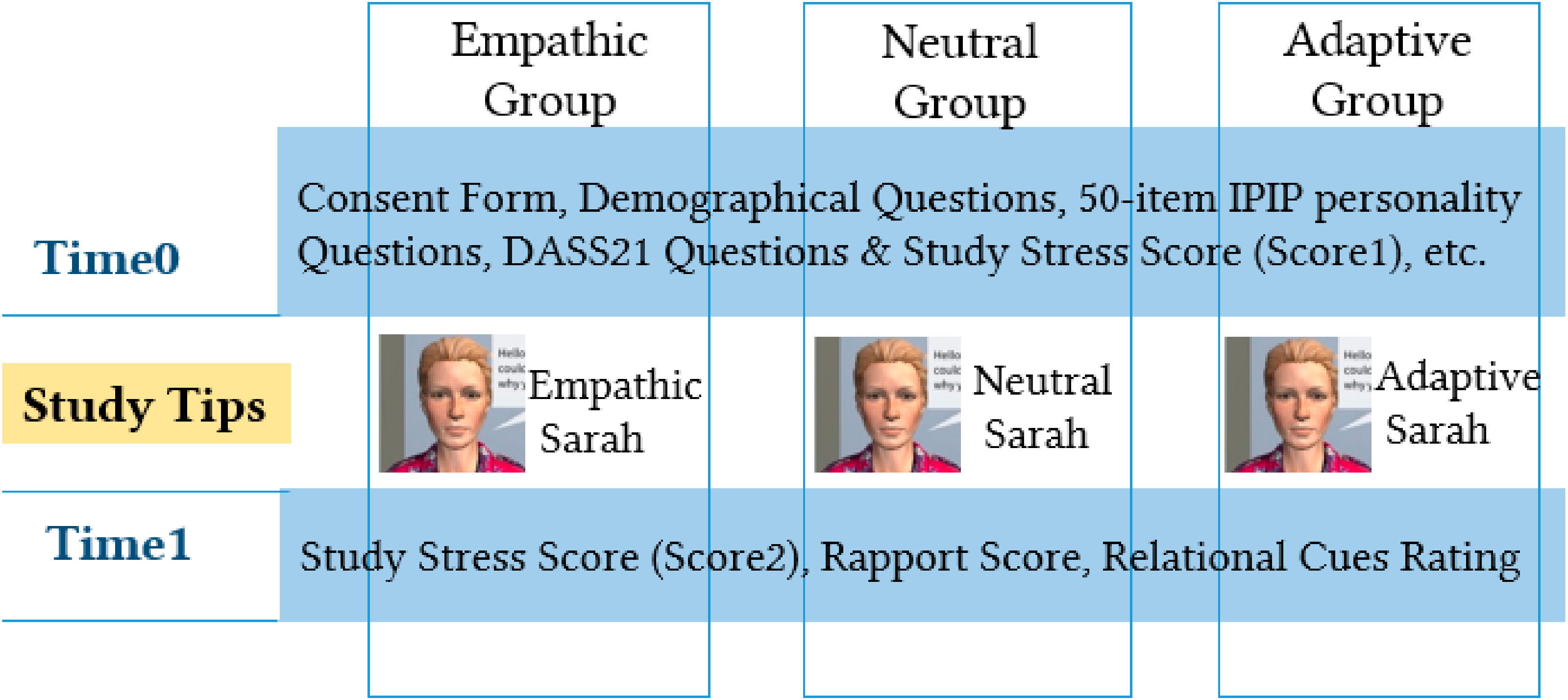
Figure 2, before interacting with the character, we collected demographic data including gender, age, cultural background, degree being studied, computer game activity, and attitude/aim towards study. Then, followed by IPIP (International Personality Item Pool), DASS21 (Depression Anxiety Stress Scores) questionnaires we also collected for other parameters such as their study stress score. The experiment consists of two groups to which participants were randomly assigned. Group A interacted with Empathic Sarah first, followed by Neutral Sarah. Group B did the reverse.
We collected 376 participants’ data. The empathic dialogues were created using 10 relational cues (RC) identified from the literature [
8]. For each relational cue
Table 1, there are multiple sentences uttered by the character in different situations. To evaluate the empathic dialogues, at the end of each empathic interaction (i.e., after the 1st session in group A, and 2nd session in group B), participants were asked if the sentences using the relational cues seemed helpful, empathic and/or stupid. We combined the RC values for positive responses, Helpful and/or Empathic (HE), by using ’Exclusive Or’ function to finally have two fields for each cue (i.e., RC_HE and RC_Stupid). More details of the study design can be found in our previous publications [
36].
To figure out when and how to adapt to the user, we generated the adaptive rules for our user model by using C5.0 classification modelling methods in IBM SPSS modeler version 18.0. Classification models use the value of input field/s to predict the value of output or target field/s. The modelling techniques in C5.0 includes machine learning, statistical methods, and rule induction. As well as generating a decision tree, C 5.0 also ranks the predictors based on their importance for the creation of the decision tree.
We created the C5.0 model for each 10 RC_HE, using three methods. In method 1, for each 10 RC, group A data was the training and group B data was the testing partitions to create the 10 models. Then, in method 2 we split the full dataset, including group A and group B, into 70% randomly assigned to the training and 30% to the testing data. We replicated method 2 to form method 3 by assigning 60% of the full dataset to the training and 40% to testing data. When the best model was identified for each RC, we used that model for adaptation of the speech. To measure the success of the three predictive models, we calculated the Lift value and accuracy for each outcome category and chose the best model for each RC.
For instance, for RC1, the model with 70% randomly assigned data for training dataset and 30% for testing dataset had the highest accuracy. The severity of pruning the C5.0 model was 85% for RC1 and no misclassification cost was required. For RC3, we used the model where group A was the training and group B was the testing partitions. Without misclassification cost, we were only able to identify one important predictor (stress), however, after including misclassification cost to 2, the number of predictors increased to four (i.e., stress, score1, extraversion, examsoon). Misclassification cost was used in RC3. For RC2, we used the model with 60% and 40% partitions for training and testing respectively and no misclassification cost was utilised.
In all models, each RC_HE is the target (outcome) and the 18 parameters from the user profile are the input (predictors). The predictors of the models are user profile information including age, gender, cultural group, degree being studied, computer game activity, grade being aimed to achieve, grade being expected to achieve, study attitude, any exam coming soon, DASS21 and IPIP results, and study stress score.
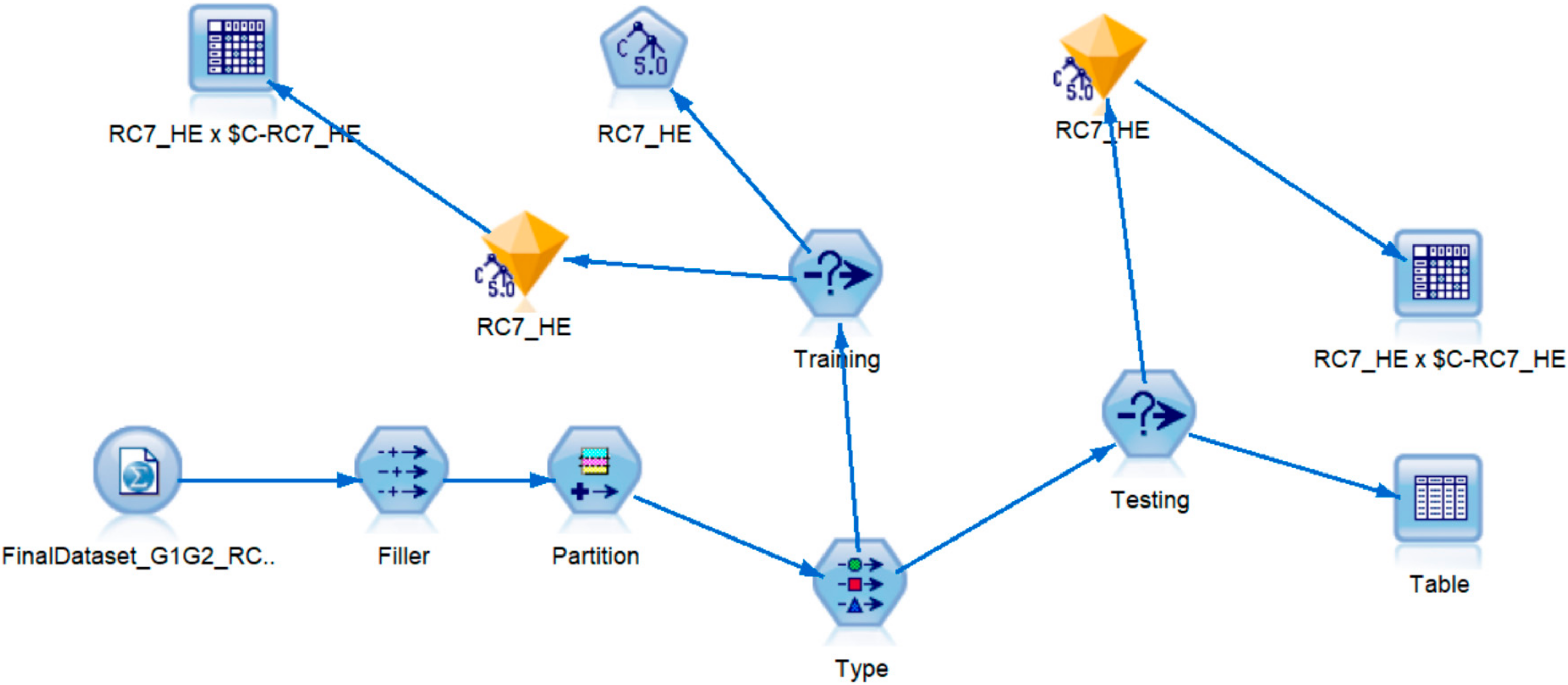
Figure 3 shows the training and testing C5.0 models for RC7_HE. Method 2 is used here when the full dataset is partitioned randomly into 70% for training and 30% for testing models. The accuracy of the training model is 78.5%. The lift values for the two outcomes are greater than one, so we can conclude that the accuracy of the model is better than randomly assigning the sentences.
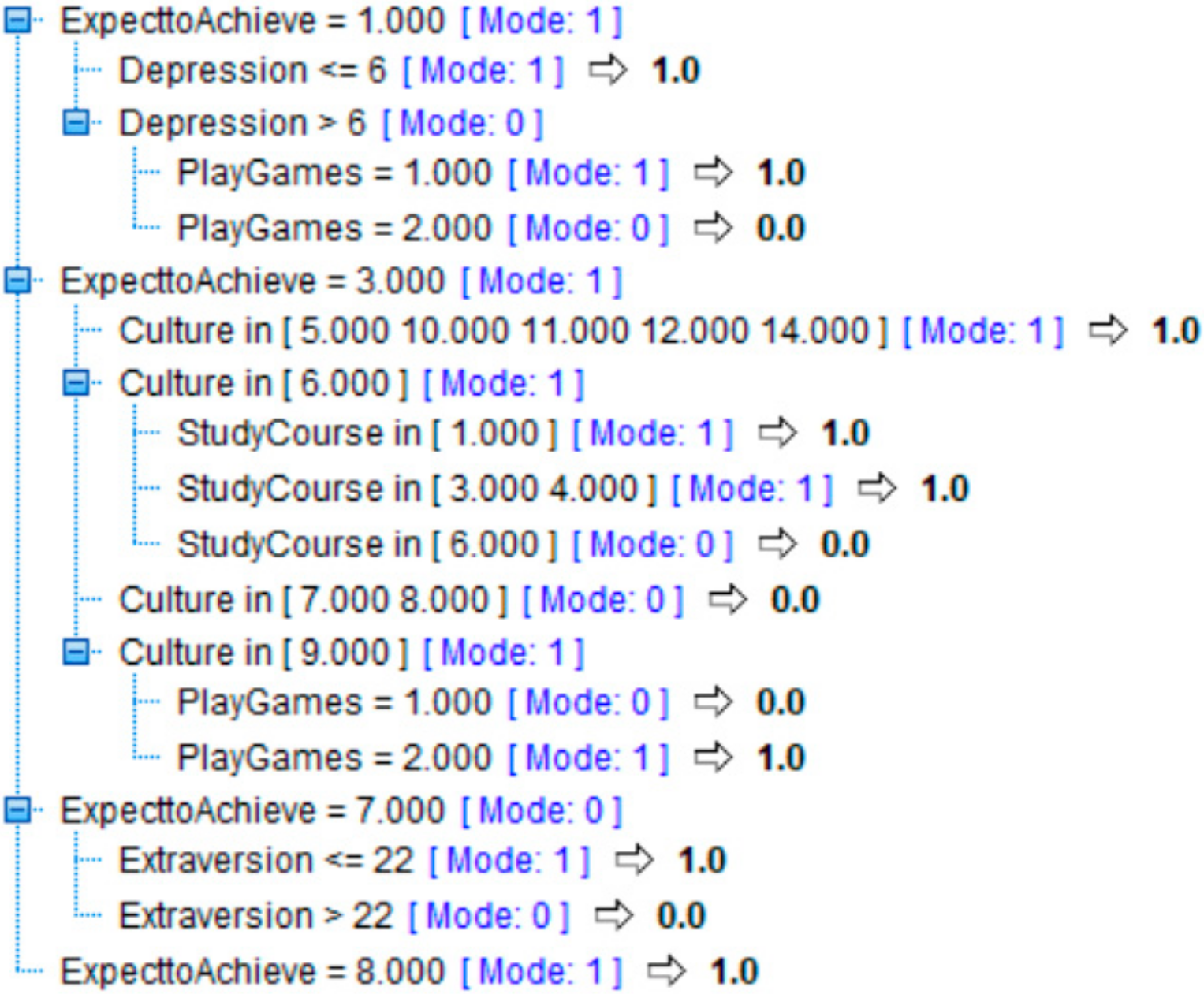
Figure 4 shows the rules for RC7_HE. To interpret the decision tree, after expanding all the branches, we can see that there are 13 leaves/rules and 7 predictors. If the target is 1 (rules predicted that RC7 is helpful/empathic to the user), then the user will receive all the sentences using RC7. If the outcome of the decision tree is 0 (rules did not predict that the cue was helpful/emphatic to the user), then the user will not receive the empathic sentences, instead they will receive the neutral versions of the sentences.
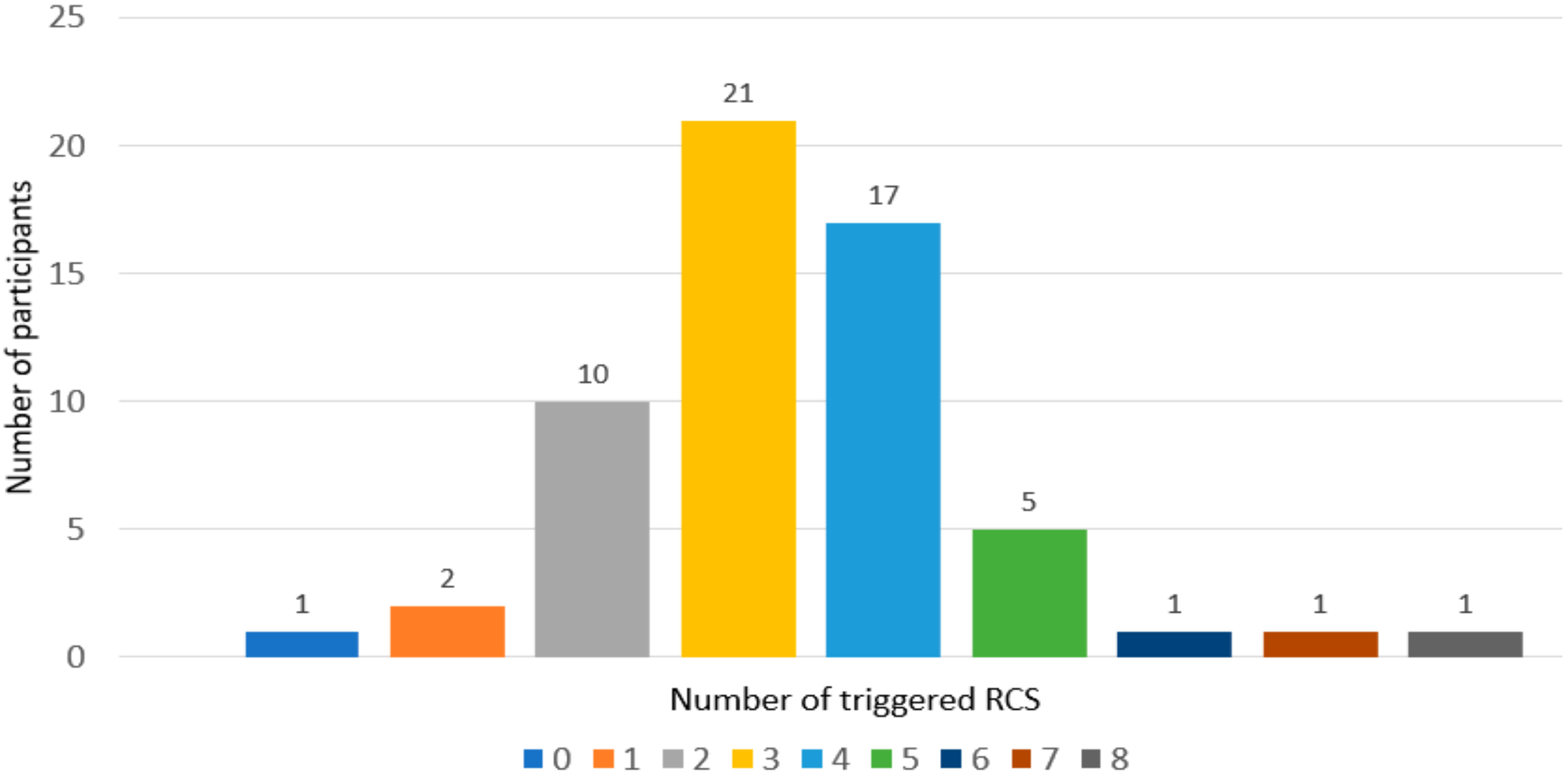
Based on the rules we generated, we provide three examples below based on three different types of adaptive dialogues for three different user groups. In the first one, RC2, RC3 and RC6 are triggered. In the second one, only RC10 is triggered and in the last one there is no RC triggered.
Adaptive Agent: Let’s talk about socializing, which is good for our mental health (RC2 & RC10). That’s why I’m here (RC2 & RC3). It helps reduce the symptoms of depression and anxiety. I’m supported by my friends and family (RC6). Do you feel supported in your life?
Adaptive Agent: Let’s talk about socializing, which is good for our mental health (RC2 & RC10) It helps reduce the symptoms of depression and anxiety. Do you feel supported in your life?
Adaptive Agent: Socializing is good for your mental health. It helps reduce the symptoms of depression and anxiety. Do you feel supported in your life?
4.2. Experimental Design for Evaluation
The aim of this study is to compare the results of user interactions with three different types of virtual advisors: neutral, empathic and adaptive. The adaptive virtual advisor used a scenario designed by the authors called “Reducing Study Stress” where Sarah talks to the user and provides study tips using neutral, empathic or tailored dialogue. The tailored dialogue was generated by adaptive dialogue rules described in
Section 4.1.
As shown in
Figure 5, participants in Empathic, Neutral and Adaptive groups interacted with empathic, neutral and adaptive Sarah, respectively. Data for Empathic and Neutral groups were collected from our previous study as depicted in
Figure 2. Since in the previous study each participant in group A and group B interacted with both Empathic and Neutral characters in the different orders in two consequent sessions, we only extracted the first session of each group, to form Empathic and Neutral groups for the current study as shown in
Figure 5. However, Adaptive group includes both adaptive sessions. For Adaptive group, we use the stress score and rapport obtained after the second session.
From these previous studies, we found that students significantly reduced their study stress levels through discussion with the virtual adviser but they did not necessarily establish more rapport with the empathic character and/or find them more helpful in terms of stress reduction, as compared to the neutral advisor. This led us to explore whether an adaptive agent would make a difference. Thus, we collected further data after implementing the Adaptive Engine and creating an adaptive Sarah, as described in the next section. These studies were approved by the Macquarie University’s Human Research Ethics Committee (approval reference number 5201700595).
4.3. Materials and Method
Sarah provides study tips to reduce study stress. The contents of the dialogues were the same as the previous study and derived from the campus wellbeing of our university and included work, study and life balance, exercise and healthy eating, overcome exam stress and socialising tips. For empathic Sarah’s dialogue, we modified neutral Sarah’s dialogue to include Bickmore’s 10 empathic (relational) cues to create Empathic Sarah’s dialogue. The cues with related examples are shown in
Table 1.
Adaptive Sarah’s default dialogue is neutral. Based on her knowledge about the user on the fly, her dialogue will become adaptive. FatiMA uses a Hybrid approach to create the dialogue. In the hybrid state machine, each state is identified by a meaning, style, utterance and next state. The values in meaning and style help us to link the dialogue with other parts of the architecture. For each neutral sentence in the dialogue, there is an empathic version. The empathic and neutral sentences are distinguished by the value in style. For instance, if the value in style is RC2, it means that the sentence includes the second empathic cue. The process of identifying which cues were suitable for which user is presented in the next section.
The Unity3D game engine and FAtiMA Toolkit were used to implement Sarah (
Figure 6), the virtual adaptive advisor. Sarah uses lip-synching. She did not have any non-verbal behaviours except a smile. FAtiMA toolkit allowed us to import a dialogue file and use TextToSpeech feature to automatically generate Sarah’s synthesized voice, which is also selected based on users’ selection of answer options.
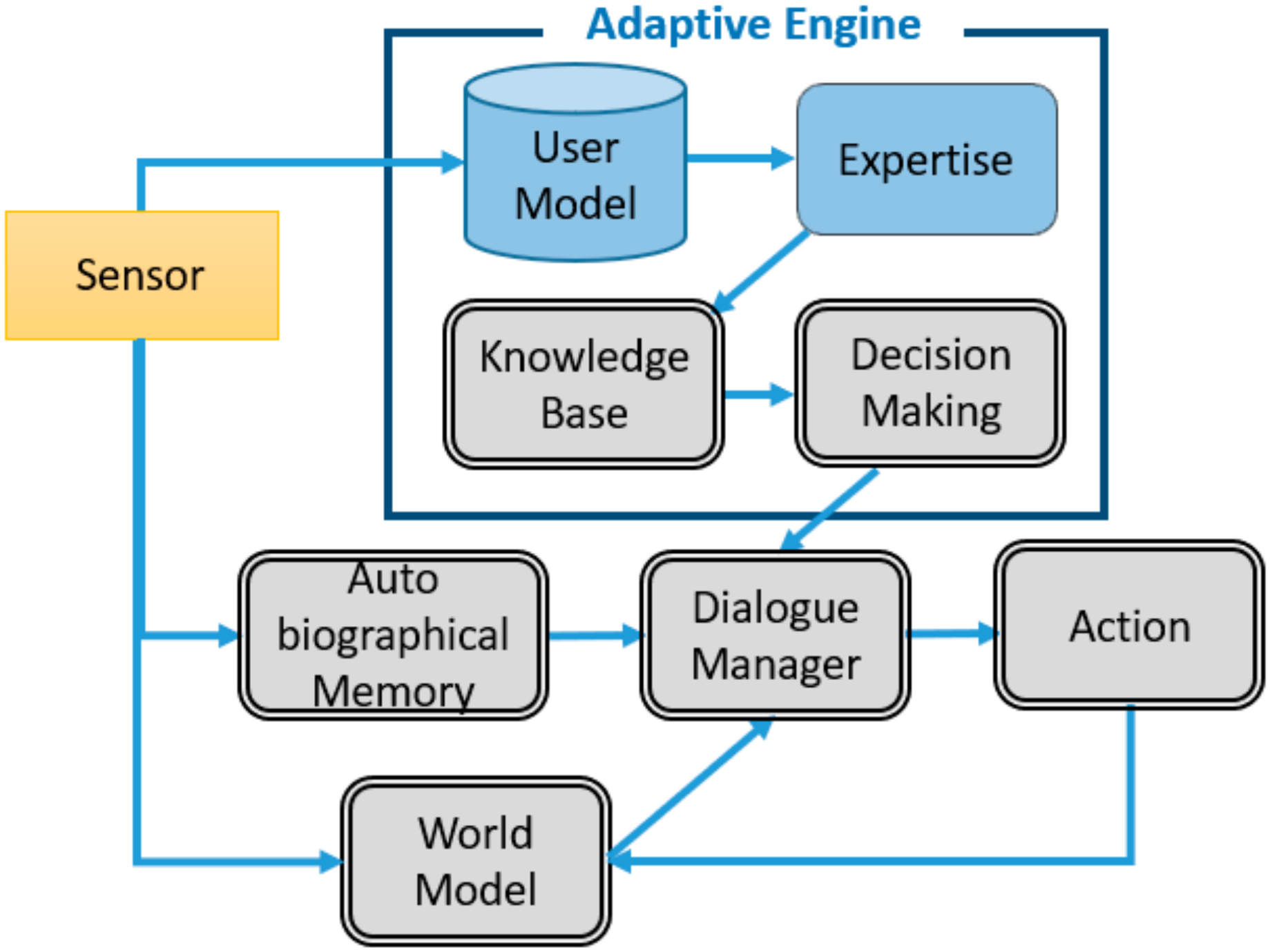
To implement the Adaptive Engine in FAtiMA, we specified Sarah as the role-playing character and used the simulator to test the dialogues. The Adaptive Engine was able to access the user model of each individual user from a repository of stored user profiles. Individual user profiles were populated by asking the user to complete a Qualtrics survey before the interaction. The user profile consists of 18 factors that cover the user’s demographics, personality, emotional state, and study goals and attitude. The adaptive rules are implemented in the knowledge base to provide the best adaptive responses to the user based on these 18 parameters.
4.4. Procedure and Data Collection
To create the individual user model for each participant, we collected demographic data including gender, age, cultural background, degree being studied, computer game activity, attitude and goal towards study and study stress score. The reasoning of Sarah is also influenced by the personality and psychological emotional state of the user. Thus, to model the personality of the user, we used International Personality Item Pool (IPIP), which is called the Big Five personality factor [
37], and to measure psychological emotional state of the user we used DASS21 questionnaire [
38]. The IPIP questionnaire consists of 50 questions, each with 10 items measuring one of the five personality traits. The big five factors include Openness to experience (O), Conscientiousness (C), Extraversion (E), Agreeableness (A) and Neuroticism (N), hence also known as the OCEAN model. Each trait is a dimension with two poles: Openness vs Closed; Conscientiousness vs Disorganized; Extraversion vs Introversion; Agreeableness vs Disagreeableness and Neuroticism vs Emotional Stability. A higher score on the 5-point likert scale indicates greater openness, conscientiousness, extraversion, agreeableness, and emotional stability. Thus, for increased comprehension and easier comparison between the five personality dimensions, we label and refer to the Neuroticism dimension as Emotional Stability. The DASS21 questionnaire measures depression, anxiety and stress level of the user. All these data form the 18 factors in the user model.
To measure the sense of rapport built between the user and the character, after each interaction participants were asked to answer 20 rapport questions. The questions used a 5-point Likert-type scale from “strongly disagree” (1) to “strongly agree” (5), derived from five studies [
25,
39,
40,
41,
42]. For each response to a rapport question, the negatively worded questions were reverse coded. Participants could also choose the option “not applicable”.
To determine if the adaptive behaviour and study tips were useful, Sarah asked the user twice (at the beginning and the end of the interaction) to ’think about your emotional feeling towards your study on a scale of 0 to 10. Zero means “extremely good and relaxed” and 10 means “extremely bad and stressed”’. To evaluate the dialogue provided by adaptive Sarah, we presented 20 empathic sentences (i.e., two for each relational cue) and asked the participants to specify if they found it empathic, helpful and/or stupid. They could select more than one option (i.e., relational cue rating questionnaire, depicted in
Figure 5). Participants were able to download Sarah through the Qualtrics survey and any interaction with Sarah through the keyboard and mouse was captured into a separate MySQL database.
The normality assumptions of the variables for the statistical analysis were checked by using Kolmogorov–Smirnov test of normality. For variables that were significantly different than normal distribution, we used non-parametric tests such as Kruskal–Wallis and Wilcoxon Signed-Ranks tests. To test the relationship between the categorical variables, chi-square test was conducted. We chose 0.05 for significance level.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}