Exploring Smart Agents for the Interaction with Multimodal Mediated Environments



Abstract
1. Introduction
2. Related Work
3. System Description
3.1. Mediated Atmospheres
- Color Temperature: Color temperature of the scene’s lighting configuration in Kelvin
- Brightness: Brightness of the scene’s lighting configuration, measured as the horizontal illumination on the desk in lux
- Primary Color: Dominant color of the scene’s video content
- Keywords: Keywords describing the scene’s video content
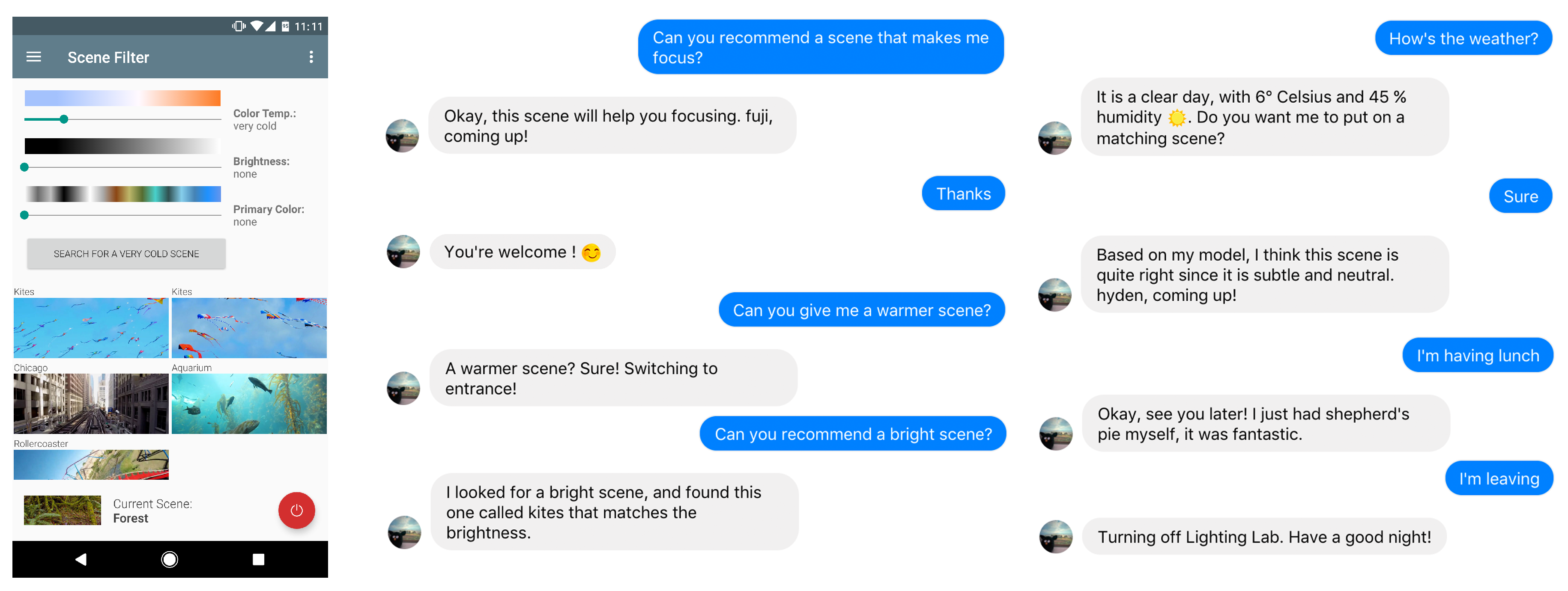
3.2. Smartphone Application
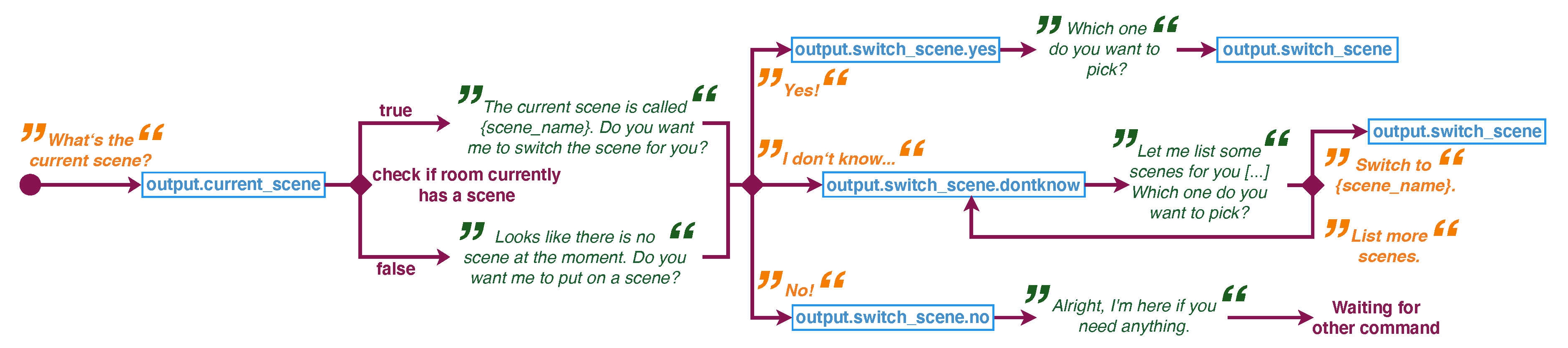
3.3. Smart Agents
3.3.1. Basic Voice Agent
3.3.2. Advanced Voice and Text Agent
- Weather: Recommending a scene according to the current weather was based on mapping real-time weather information (obtained from the Dark Sky API (https://darksky.net/dev)) to scene properties. We mapped the general weather situation to the scenes’ color temperature to approximate the current lighting situation outside. Additionally, because high levels of humidity were found to be a key factor for concentration loss and sleepiness [51], we counteracted this phenomenon by recommending scenes with higher brightness.
- Desired mental state: The advanced agents are aware of current occupant in the workspace, allowing them to recommend scenes to users based on their preferences, like scenes that helped them being more focused or more relaxed. To set these preferences users can create their own models using a website. The agent was then able to access these personal scene models.
4. Evaluation
4.1. Experiment Design
4.1.1. Agent Exploration
- Turn Mediated Atmospheres off because you’re about to get lunch, followed by Turn Mediated Atmospheres on after returning from lunch
- Find a scene that has warm color temperature
- Find an indoors scene
- Find a scene that helps you focus
- Find a scene that matches the current weather
4.1.2. Task Completion
- Find a city scene
- Find a scene that shows mountains
- Find a bright and blue scene
- Find a scene that is warm and shows a forest
- Find a scene that matches the current time of day
- Find a scene that helps you relax after a rough day
4.2. Procedure
4.3. Subjective Measures
4.3.1. Overall Usability
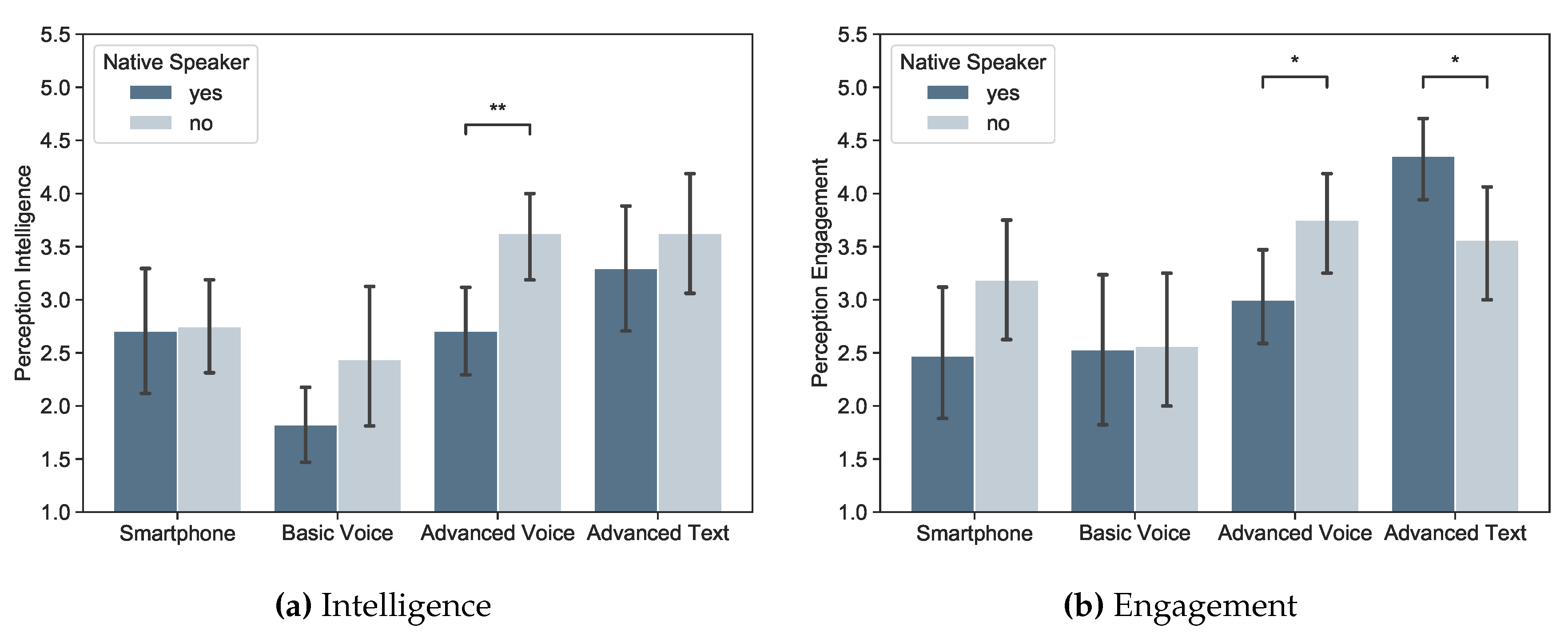
4.3.2. Intelligence and Engagement
4.3.3. Trust and Control
4.4. Objective Measures
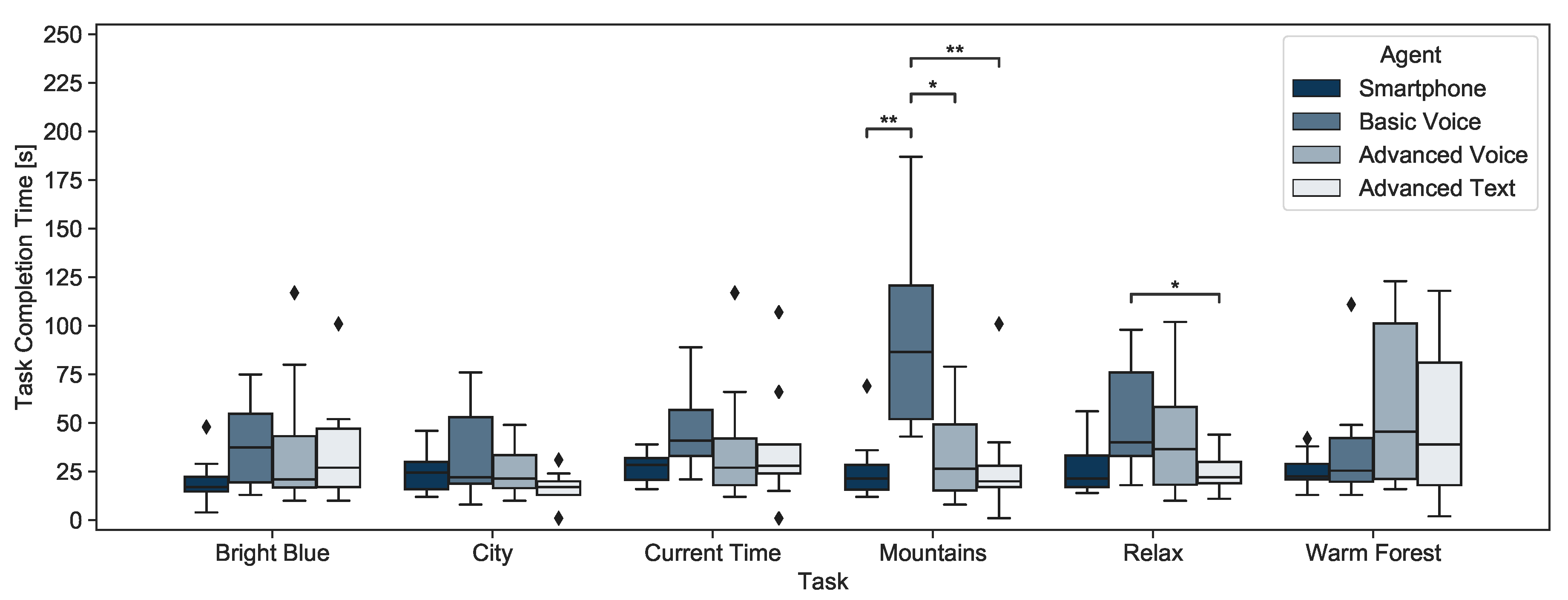
4.4.1. Task Completion Time
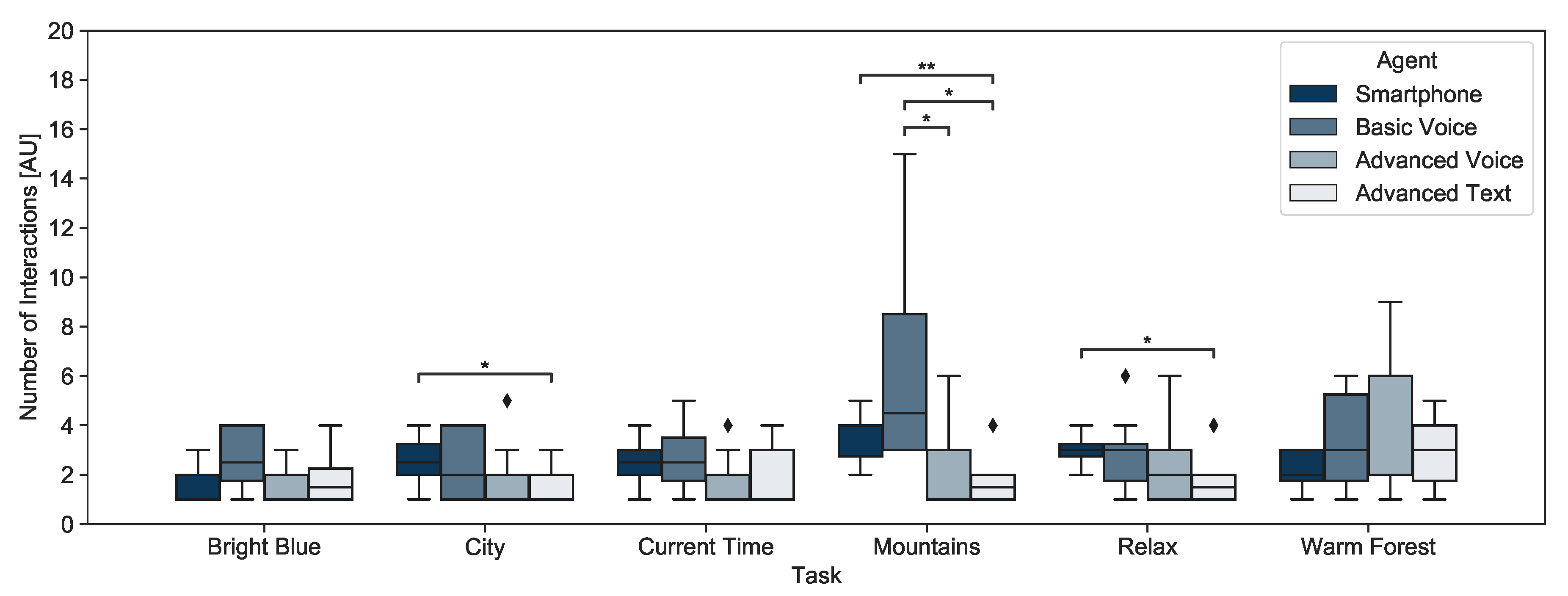
4.4.2. Number of Interactions
4.4.3. Recognition Rate
4.5. Statistics
5. Results
5.1. Subjective Measures
5.1.1. Overall Usability
5.1.2. Intelligence and Engagement
5.1.3. Trust and Control
5.2. Objective Measures
5.2.1. Task Completion Time
5.2.2. Number of Interactions
5.2.3. Recognition Rate
6. Discussion
6.1. Smartphone Application
6.2. Basic Voice Agent
6.3. Advanced Voice Agent
6.4. Advanced Text Agent
7. Conclusions and Outlook
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ANOVA | Analysis of variance |
| API | Application Programming Interface |
| AT | Advanced Text Agent |
| AV | Advanced Voice Agent |
| BV | Basic Voice Agent |
| M ± SD | Mean ± Standard Deviation |
| SP | Smartphone Application |
| SUS | System Usability Scale |
References
- Smith, A. U.S. Smartphone Use in 2015. Available online: http://www.pewinternet.org/2015/04/01/us-smartphone-use-in-2015 (accessed on 15 April 2020).
- Andrews, S.; Ellis, D.A.; Shaw, H.; Piwek, L. Beyond Self-Report: Tools to Compare Estimated and Real-World Smartphone Use. PLoS ONE 2015, 10, e0139004. [Google Scholar] [CrossRef] [PubMed]
- Google. Google Assistant, your Own Personal Google. Available online: https://assistant.google.com/ (accessed on 11 April 2020).
- Geller, T. Talking to machines. Commun. ACM 2012, 55, 14–16. [Google Scholar] [CrossRef]
- Brennan, S. Conversation as Direct Manipulation: An Iconoclastic View. In The Art of Human-Computer Interface Design; Laurel, B., Mountford, S.J., Eds.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1990. [Google Scholar]
- Mozer, M.C. An Intelligent Environment must be adaptive. IEEE Intell. Syst. 1999, 14, 11–13. [Google Scholar] [CrossRef]
- Kidd, C.D.; Orr, R.; Abowd, G.D.; Atkeson, C.G.; Essa, I.A.; MacIntyre, B.; Mynatt, E.; Starner, T.E.; Newstetter, W. The Aware Home: A Living Laboratory for Ubiquitous Computing Research. In Proceedings of the International Workshop on Cooperative Buildings, Pittsburgh, PA, USA, 1–2 October 1999; pp. 191–198. [Google Scholar]
- Zhao, N.; Azaria, A.; Paradiso, J.A. Mediated Atmospheres: A Multimodal Mediated Work Environment. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–23. [Google Scholar] [CrossRef]
- Gensler Research Institute. 2013 U.S. Workplace Survey Key Findings. Available online: https://www.gensler.com/research-insight/gensler-research-institute/the-2013-us-workplace-survey-1 (accessed on 25 April 2020).
- Maes, P. Agents that reduce work and information overload. Commun. ACM 1994, 37, 30–40. [Google Scholar] [CrossRef]
- Luger, E.; Sellen, A. Like Having a Really Bad PA: The Gulf between User Expectation and Experience of Conversational Agents. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 7 May 2016; pp. 5286–5297. [Google Scholar]
- Rossi, M.; Pandharipande, A.; Caicedo, D.; Schenato, L.; Cenedese, A. Personal lighting control with occupancy and daylight adaptation. Energy Build. 2015, 105, 263–272. [Google Scholar] [CrossRef]
- Chen, N.H.; Nawyn, J.; Thompson, M.; Gibbs, J.; Larson, K. Context-aware tunable office lighting application and user response. In SPIE Optical Engineering+ Applications; International Society for Optics and Photonics: Washington, DC, USA, 2013; p. 883507. [Google Scholar]
- Aldrich, M.; Zhao, N.; Paradiso, J. Energy efficient control of polychromatic solid state lighting using a sensor network. In SPIE Optical Engineering+ Applications; International Society for Optics and Photonics: Washington, DC, USA, 2010; p. 778408. [Google Scholar]
- Kalyanam, R.; Hoffmann, S. Visual and thermal comfort with electrochromic glass using an adaptive control strategy. In Proceedings of the 15th International Radiance Workshop (IRW), Padua, Italy, 30 August 2016. [Google Scholar]
- Feldmeier, M.; Paradiso, J.A. Personalized HVAC control system. In Proceedings of the 2010 Internet of Things (IOT), Tokyo, Japan, 29 November–1 December 2010; pp. 1–8. [Google Scholar]
- Kainulainen, A.; Turunen, M.; Hakulinen, J.; Salonen, E.P.; Prusi, P. A Speech-based and Auditory Ubiquitous Office Environment. In Proceedings of the 10th International Conference on Speech and Computer, Patras, Greece, 17–19 October 2005. [Google Scholar]
- Raskar, R.; Welch, G.; Cutts, M.; Lake, A.; Stesin, L.; Fuchs, H. The office of the future: A unified approach to image-based modeling and spatially immersive displays. In Proceedings of the 25th Annual Conference on Computer Graphics and Interactive Techniques, Anaheim, CA, USA, 21–25 July 1998; pp. 179–188. [Google Scholar]
- Tomitsch, M.; Grechenig, T.; Moere, A.V.; Renan, S. Information Sky: Exploring the Visualization of Information on Architectural Ceilings. In Proceedings of the 12th International Conference on Information Visualisation (IV ’08), London, UK, 8–11 July 2008; pp. 100–105. [Google Scholar]
- Johanson, B.; Fox, A.; Winograd, T. The Interactive Workspaces project: Experiences with ubiquitous computing rooms. IEEE Pervasive Comput. 2002, 1, 67–74. [Google Scholar] [CrossRef]
- Pejsa, T.; Kantor, J.; Benko, H.; Ofek, E.; Wilson, A. Room2Room: Enabling life-size telepresence in a projected augmented reality environment. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative Work & Social Computing, San Francisco, CA, USA, 27 February–2 March 2016; pp. 1716–1725. [Google Scholar]
- Schnädelbach, H.; Glover, K.; Irune, A.A. ExoBuilding: Breathing Life into Architecture. In Proceedings of the 6th Nordic Conference on Human-Computer Interaction: Extending Boundaries, Reykjavik, Iceland, 16–20 October 2010; pp. 442–451. [Google Scholar]
- Ishii, H.; Wisneski, C.; Brave, S.; Dahley, A.; Gorbet, M.; Ullmer, B.; Yarin, P. ambientROOM: Integrating Ambient Media with Architectural Space. In Proceedings of the CHI 98 Conference Summary on Human Factors in Computing Systems, Los Angeles, CA, USA, 18–23 April 1998; pp. 173–174. [Google Scholar]
- Mozer, M.C. The neural network house: An environment that adapts to its inhabitants. In Proceedings of the AAAI Spring Symposium on Intelligent Environments, Palo Alto, CA, USA, 23–25 March 1998; Volume 58. [Google Scholar]
- Mozer, M.C.; Dodier, R.; Miller, D.; Anderson, M.; Anderson, J.; Bertini, D.; Bronder, M.; Colagrosso, M.; Cruickshank, R.; Daugherty, B.; et al. The adaptive house. In Proceedings of the IEE Seminar on Intelligent Building Environments, Colchester, UK, 28 June 2005; Volume 11059. [Google Scholar]
- Mennicken, S.; Vermeulen, J.; Huang, E.M. From today’s augmented houses to tomorrow’s smart homes: New directions for home automation research. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; pp. 105–115. [Google Scholar]
- Cook, D.J.; Youngblood, M.; Heierman, E.O.; Gopalratnam, K.; Rao, S.; Litvin, A.; Khawaja, F. MavHome: An Agent-Based Smart Home. In Proceedings of the First IEEE International Conference on Pervasive Computing and Communications, Fort Worth, TX, USA, 23–26 March 2003; pp. 521–524. [Google Scholar]
- Abras, S.; Ploix, S.; Pesty, S.; Jacomino, M. A Multi-agent Home Automation System for Power Management. In Informatics in Control Automation and Robotics; Springer: Berlin, Germany, 2008; pp. 59–68. [Google Scholar]
- Alan, A.T.; Costanza, E.; Ramchurn, S.D.; Fischer, J.; Rodden, T.; Jennings, N.R. Tariff Agent: Interacting with a Future Smart Energy System at Home. ACM Trans. Comput. Hum. Interact. (TOCHI) 2016, 23, 25. [Google Scholar] [CrossRef]
- Danninger, M.; Stiefelhagen, R. A context-aware virtual secretary in a smart office environment. In Proceedings of the 16th ACM International Conference on Multimedia, Vancouver, BC, USA, 27–31 October 2008; pp. 529–538. [Google Scholar]
- Bagci, F.; Petzold, J.; Trumler, W.; Ungerer, T. Ubiquitous mobile agent system in a P2P-network. In Proceedings of the Fifth Annual Conference on Ubiquitous Computing, Seattle, WA, USA, 12 October 2003; pp. 12–15. [Google Scholar]
- Hossain, M.A.; Shirehjini, A.A.N.; Alghamdi, A.S.; El Saddik, A. Adaptive interaction support in ambient-aware environments based on quality of context information. Multimed. Tools Appl. 2013, 67, 409–432. [Google Scholar] [CrossRef]
- Straßmann, C.; von der Pütten, A.R.; Yaghoubzadeh, R.; Kaminski, R.; Krämer, N. The Effect of an Intelligent Virtual Agent’s Nonverbal Behavior with Regard to Dominance and Cooperativity. In Proceedings of the International Conference on Intelligent Virtual Agents, Los Angeles, CA, USA, 20–23 September 2016; pp. 15–28. [Google Scholar]
- Mennicken, S.; Zihler, O.; Juldaschewa, F.; Molnar, V.; Aggeler, D.; Huang, E.M. It’s like living with a friendly stranger: Perceptions of personality traits in a smart home. In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 120–131. [Google Scholar]
- Turing, A.M. Computing machinery and intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Weizenbaum, J. ELIZA—A Computer Program For the Study of Natural Language Communication Between Man And Machine. Commun. ACM 1966, 9, 36–45. [Google Scholar] [CrossRef]
- D’Haro, L.F.; Kim, S.; Yeo, K.H.; Jiang, R.; Niculescu, A.I.; Banchs, R.E.; Li, H. CLARA: A Multifunctional Virtual Agent for Conference Support and Touristic Information. In Natural Language Dialog Systems and Intelligent Assistants; Springer: Berlin, Germany, 2015; pp. 233–239. [Google Scholar]
- Gnewuch, U.; Morana, S.; Maedche, A. Towards Designing Cooperative and Social Conversational Agents for Customer Service. In Proceedings of the Thirty Eigth International Conference on Information Systems, Seoul, Korea, 10–13 December 2017; pp. 1–13. [Google Scholar]
- Ferrara, E.; Varol, O.; Davis, C.; Menczer, F.; Flammini, A. The rise of social bots. Commun. ACM 2016, 59, 96–104. [Google Scholar] [CrossRef]
- Laranjo, L.; Dunn, A.G.; Tong, H.L.; Kocaballi, A.B.; Chen, J.; Bashir, R.; Surian, D.; Gallego, B.; Magrabi, F.; Lau, A.Y.; et al. Conversational agents in healthcare: A systematic review. J. Am. Med. Inform. Assoc. 2018, 25, 1248–1258. [Google Scholar] [CrossRef]
- Montenegro, J.L.Z.; da Costa, C.A.; da Rosa Righi, R. Survey of conversational agents in health. Expert Syst. Appl. 2019, 129, 56–67. [Google Scholar] [CrossRef]
- Provoost, S.; Lau, H.M.; Ruwaard, J.; Riper, H. Embodied conversational agents in clinical psychology: A scoping review. J. Med. Internet Res. 2017, 19. [Google Scholar] [CrossRef] [PubMed]
- Chu, Z.; Gianvecchio, S.; Wang, H.; Jajodia, S. Who is tweeting on Twitter: Human, bot, or cyborg? In Proceedings of the 26th Annual Computer Security Applications Conference, Austin, TX, USA, 6–10 December 2010; pp. 21–30. [Google Scholar]
- Subrahmanian, V.; Azaria, A.; Durst, S.; Kagan, V.; Galstyan, A.; Lerman, K.; Zhu, L.; Ferrara, E.; Flammini, A.; Menczer, F. The DARPA Twitter bot challenge. Computer 2016, 49, 38–46. [Google Scholar] [CrossRef]
- Schaffer, S.; Schleicher, R.; Möller, S. Modeling input modality choice in mobile graphical and speech interfaces. Int. J. Hum. Comput. Stud. 2015, 75, 21–34. [Google Scholar] [CrossRef]
- Weiß, B.; Möller, S.; Schulz, M. Modality Preferences of Different User Groups. In Proceedings of the Fifth International Conference on Advances in Computer-Human Interactions (ACHI 2012), Valencia, Spain, 30 January–4 February 2012. [Google Scholar]
- Silva, S.; Almeida, N.; Pereira, C.; Martins, A.I.; Rosa, A.F.; Oliveira e Silva, M.; Teixeira, A. Design and Development of Multimodal Applications: A Vision on Key Issues and Methods. In Universal Access in Human-Computer Interaction, Proceedings of the Today’s Technologies: 9th International Conference, UAHCI 2015, Los Angeles, CA, USA, 2–7 August 2015; Springer International Publishing: Cham, Switzerland, 2015. [Google Scholar]
- Kühnel, C.; Westermann, T.; Weiß, B.; Möller, S. Evaluating Multimodal Systems: A Comparison of Established Questionnaires and Interaction Parameters. In Proceedings of the 6th Nordic Conference on Human-Computer Interaction (NordiCHI 2010), Reykjavik, Iceland, 16–20 October 2010; pp. 286–294. [Google Scholar]
- Pyae, A.; Scifleet, P. Investigating the Role of User’s English Language Proficiency in Using a Voice User Interface: A Case of Google Home Smart Speaker. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–6. [Google Scholar]
- Sivasubramanian, S. Amazon dynamoDB: A seamlessly scalable non-relational database service. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; pp. 729–730. [Google Scholar]
- Howarth, E.; Hoffman, M.S. A multidimensional approach to the relationship between mood and weather. Br. J. Psychol. 1984, 75, 15–23. [Google Scholar] [CrossRef]
- Luminous, S. The Circadian Rhythm and Color Temperature. Available online: https://sigmaluminous.com/the-circadian-rhythm-and-color-temperature (accessed on 15 April 2020).
- Duffy, J.F.; Czeisler, C.A. Effect of light on human circadian physiology. Sleep Med. Clin. 2009, 4, 165–177. [Google Scholar] [CrossRef]
- Brooke, J. SUS—A quick and dirty usability scale. Usability Eval. Ind. 1996, 189, 4–7. [Google Scholar]
- Hone, K.S.; Graham, R. Towards a tool for the subjective assessment of speech system interfaces (SASSI). Nat. Lang. Eng. 2000, 6, 287–303. [Google Scholar] [CrossRef]
- Mennicken, S.; Brillman, R.; Thom, J.; Cramer, H. Challenges and Methods in Design of Domain-Specific Voice Assistants. In 2018 AAAI Spring Symposium Series; Association for the Advancement of Artificial Intelligence: Park, CA, USA, 2018; pp. 431–435. [Google Scholar]
- Zuckerberg, M. Building Jarvis. Available online: https://www.facebook.com/notes/mark-zuckerberg/building-jarvis/10154361492931634 (accessed on 10 April 2020).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Agent | ||||
|---|---|---|---|---|
| Feature/Action | Smart-Phone | Basic Voice | Advanced Voice | Advanced Text |
| Turn on/off | x | x | x | x |
| List scenes | x | x | x | x |
| Current scene | x | x | x | x |
| Switch scene based on: | ||||
| – | x | x | x |
| x | – | x | x |
| – | – | x | x |
| – | – | x | x |
| Context-awareness (information about occupant andprevious interactions) | – | – | x | x |
| Recommend scene based on: | ||||
| – | – | x | x |
| – | – | x | x |
| – | – | x | x |
| SA | BV | AV | AT | |
|---|---|---|---|---|
| Native Speaker | ||||
| Non-native Speaker |
| Bright & Blue | City | Current Time | Mountains | Relaxing | Warm Forest | ||
|---|---|---|---|---|---|---|---|
| Task Completion Time (in %) | SA | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| BV | 190.2 | 143.7 | 171.5 | 353.9 | 193.5 | 147.5 | |
| AV | 189.6 | 105.6 | 142.5 | 129.0 | 164.0 | 234.3 | |
| AT | 177.2 | 67.2 | 134.7 | 106.9 | 92.6 | 190.0 | |
| Number ofInteractions (in %) | SA | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 |
| BV | 150.0 | 90.5 | 110.0 | 182.1 | 95.8 | 158.8 | |
| AV | 95.2 | 76.2 | 75.6 | 63.5 | 81.5 | 183.0 | |
| AT | 107.1 | 57.1 | 75.0 | 50.0 | 58.3 | 135.3 |
| Strengths | Weaknesses | |
|---|---|---|
| Smartphone Application |
|
|
| BasicVoice Agent |
|
|
| Advanced Voice Agent |
|
|
| Advanced Text Agent |
|
|
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Richer, R.; Zhao, N.; Eskofier, B.M.; Paradiso, J.A. Exploring Smart Agents for the Interaction with Multimodal Mediated Environments. Multimodal Technol. Interact. 2020, 4, 27. https://doi.org/10.3390/mti4020027
Richer R, Zhao N, Eskofier BM, Paradiso JA. Exploring Smart Agents for the Interaction with Multimodal Mediated Environments. Multimodal Technologies and Interaction. 2020; 4(2):27. https://doi.org/10.3390/mti4020027
Chicago/Turabian StyleRicher, Robert, Nan Zhao, Bjoern M. Eskofier, and Joseph A. Paradiso. 2020. "Exploring Smart Agents for the Interaction with Multimodal Mediated Environments" Multimodal Technologies and Interaction 4, no. 2: 27. https://doi.org/10.3390/mti4020027
APA StyleRicher, R., Zhao, N., Eskofier, B. M., & Paradiso, J. A. (2020). Exploring Smart Agents for the Interaction with Multimodal Mediated Environments. Multimodal Technologies and Interaction, 4(2), 27. https://doi.org/10.3390/mti4020027