1. Introduction
Multimodal interfaces (MMIs) implement human-computer interaction paradigms that center around users’ natural behavior and communication capabilities [
1]. Such interfaces combine at least two modalities potentially operating simultaneously [
2]. During intentional interactions, the specification of parameters for required system actions can thus be distributed among adequate modalities in a synergistic fashion [
3]. For instance, using speech to specify an interaction and deictic gestures to specify operands and target locations (see
Figure 1). Potential benefits of such multimodal interfaces include increased expressiveness, flexibility, reliability, and efficiency [
4,
5,
6].
Natural (human) behavior or rather interpersonal communication is context dependent. Prior communication contents and especially the surrounding environment have to be taken into account when interpreting multimodal utterances. The benefits of MMIs thus become especially apparent if interactions are spatially and temporally grounded with an environment in which the user is (physically) situated [
10]. For example, it is easier to point at an object as part of a speech-gestural instruction than to provide similar information via a keyboard, because it uses the natural spatial referencing of interpersonal communication. Such situated human-computer interaction environments range from physical spaces to so called
virtual environments. Respective application areas range from smart homes [
11] and human-robot interaction [
12] to mixed reality [
8] and virtual reality [
7].
If MMIs are to be supported, input modalities have to be jointly analyzed at some point of processing to derive a conjoint meaning [
13,
14]. This analysis has been given different names, ranging from
combining [
15] to
multimodal integration [
16]. More widely the term
fusion is used, e.g.,
multimodal input fusion [
17] or the more recently used
multimodal fusion [
18,
19,
20]. Multimodal fusion is applied for a wide variety of scenarios. They range from analyzing intentionally performed communication based on speech and gesture [
7,
8,
12,
21,
22] to drawing conclusions on one’s intentions and feelings based on unintentional (social) signals [
23,
24,
25,
26], like eye movements and changes in body posture.
The concrete mechanism of applying fusion is denoted as
fusion method. There is a wide variety of methods used for multimodal fusion. They range from frame-based [
27,
28], over unification-based [
29,
30], symbolic-statistical [
31,
32,
33], and procedural methods [
15,
16,
34,
35] to machine learning approaches [
36,
37,
38]. An elaborated overview is given by [
14,
39]. Fusion methods can be categorized within a spectrum that extends from early fusion, comprising low-level data stream-oriented approaches, to late fusion, comprising high-level semantic inference-based approaches [
4,
40,
41].
Early fusion requires tightly synchronized input, like audio-visual speech recognition [
42]. Here, machine learning approaches exhibit great potential. It has been shown that deep learning approaches significantly out-perform traditional approaches in challenging tasks, such as computer vision, natural language processing, robotics, and information retrieval [
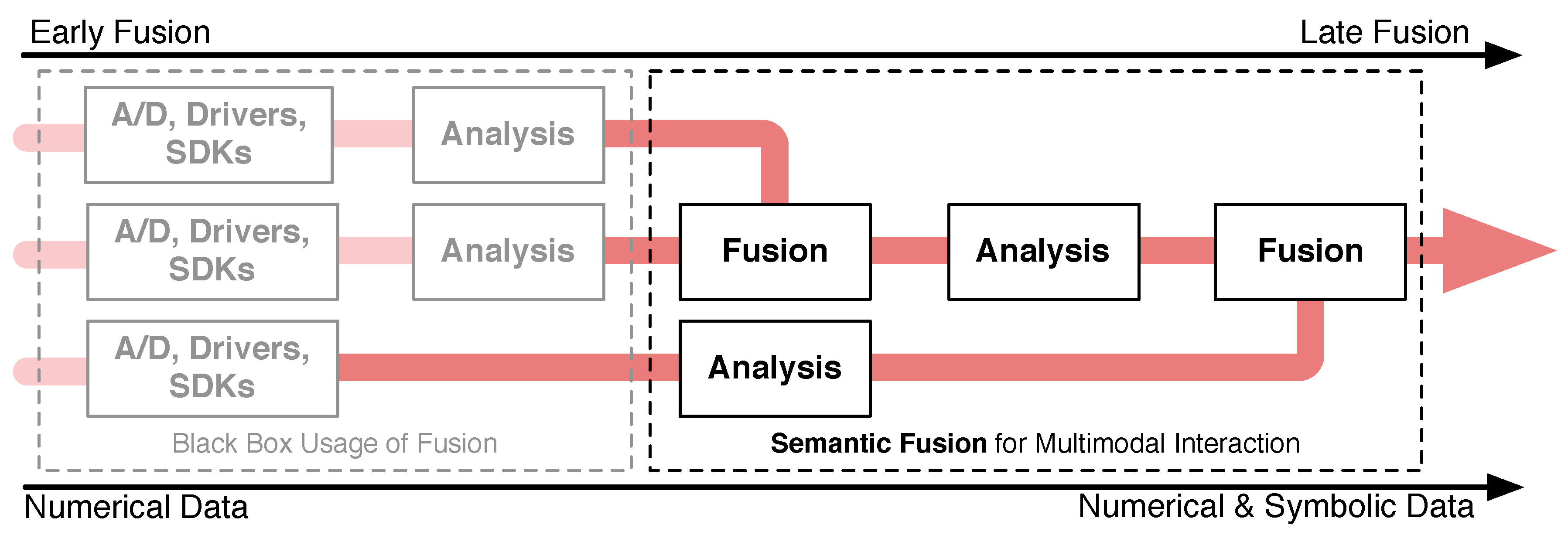
43]. When building multimodal systems, these approaches are predominantly used as a black box to interpret each modality individually, i.e., transforming raw data to features (see
Figure 2, left gray box).
For example, an infrared tracking system fuses gray scaled images and outputs positions and orientations of reflective markers. These numerical features can be fused with other features, e.g., angles obtained from a data glove, to provide symbolic features, like the type of performed gestures.
On the other end of this spectrum, a decision has to be made on what concrete system reactions are to be derived from intentional multimodal commands (see
Figure 2, right black box). This late fusion process leads to the explicit combination of primarily semantic features from multiple modalities. It is denoted as
semantic fusion [
44]. In contrast to early fusion, modalities at this level are typically loosely coupled with respect to their temporal occurrence, e.g., detected gestures and speech tokens.
Semantic fusion methods started to be influenced by machine learning as well. In human–robot interaction a suitably trained bayesian network has been successfully used as fusion method [
12]. Support vector machines have been used to combine gaze movement and brain activity to provide an interface for implicit selection in a graphical user interface [
45]. It has been demonstrated that a fusion method based on hidden Markov models (HMM) is more accurate than a classic frame-based fusion algorithm by adapting to the user [
33]. The
members to teams to committee technique [
31] increases the overall robustness of semantic fusion methods by offering a preprocessing step based on the empirical posterior distribution of co-occurring modality estimates.
However, machine learning is not without drawbacks. Respective approaches involve careful tuning of learning parameters and model hyperparameters [
46]. They also require the selection of relevant features and oftentimes large corpora for training [
47,
48]. Building these corpora and optimizing the algorithms requires a lot of effort and time. This, however, contradicts iterative prototyping and evaluation commonly applied in interface design to produce suitable interfaces [
49].
In contrast, descriptive fusion methods pose general-purpose approaches. In addition, they can be altered and adapted more easily without the need for time costly training and optimization procedures. This compatibility with typical interface development processes makes them the predominantly utilized approach for semantic fusion. Moreover, they are open for supplementation with machine learning, as shown by [
12,
31]. Descriptive fusion methods are thus also compatible with a possible future increase in machine learning approaches for multimodal fusion.
The two most prominent classes thereof are unification-based and procedural methods [
14]. Unification-based approaches, like [
30], are highly expressive and support many interface types. However, their computational complexity and their potential for mutual compensation amongst modalities render procedural methods the better choice [
34]. Traditional procedural methods, like the augmented transition network (ATN) [
50] and the finite-state transducer, are used but not designed for multimodal fusion. Because of their simple comprehensibility, they have been extended to meet more requirements of multimodal fusion. For instance, reference [
16] present a temporal Augmented Transition Network (tATN) that facilitates the consideration of temporal relations between input. However, there is currently no solution on how to fulfill two fundamental semantic fusion requirements (see
Table 1): Handling probabilistic and chronologically unsorted input [
14,
16].
1.1. Research Question
The problem addressed by this article is thus formulated as follows.
How can a procedural fusion method satisfy all fundamental requirements for performing semantic fusion, while maintaining the support of rapid MMI development processes?
1.2. Contribution
Targeting semantic fusion methods for natural and intentional multimodal interactions that are compliant with rapid development cycles, we identify seven fundamental requirements: Action derivation, continuous feedback, context-sensitivity, temporal relation support, access to the interaction context, as well as the support of chronologically unsorted and probabilistic input. Our main contribution, the Concurrent Cursor concept, provides a solution for fulfilling the latter two requirements with procedural methods. In addition, we showcase a reference implementation, the
Concurrent Augmented Transition Network (
cATN), that validates the concept’s feasibility in a series of proof of concept demonstrations as well as through a comparative performance benchmark. The
cATN fulfills all identified requirements and fills a lack amongst previous solutions. It supports the rapid prototyping of multimodal interfaces by means of five concrete traits: Its declarative nature, the recursiveness of the underlying transition network, the network abstraction constructs of its description language, the utilized semantic queries, and an abstraction layer for lexical information. Our reference implementation is available for the research community [
51].
1.3. Structure of the Paper
The remainder of this article is structured as follows.
Section 2 introduces an interaction use case and presents a requirement analysis for semantic fusion on the basis of a comprehensive review of associated contributions. Existing procedural fusion methods are evaluated with regard to the identified fundamental requirements.
Section 3 presents our results: The Concurrent Cursor concept, a reference implementation, as well as the comparative benchmark. Our validation activities by means of proof of concept demonstration are reported in
Section 4, followed by a discussion of results, implications, and limitations.
Section 5 concludes this article and points out promising future work.
3. Results
Our results are twofold. First, we present the Concurrent Cursor concept. It provides a solution for the two major shortcomings of procedural fusion methods: the analysis of probabilistic () and chronologically unsorted input (). These requirements presuppose that each input is annotated with a respective confidence and timestamp value. Our concept also provides a solution to effectively provide feedback () despite the challenging consequences of this kind of input. Second, we present a reference implementation, the Concurrent Augmented Transition Network (cATN). It takes four design decisions that are left open by the Concurrent Cursor concept: the choice of a procedural method, the choice of a description language, a measure for handling temporal relations between input, and an access scheme to the interaction context. Altogether, the cATN thus fulfills all identified requirements. Finally, we show how the cATN utilizes the Concurrent Cursor concept to perform semantic fusion using the example of the introduced use case and present a comparative benchmark.
3.1. Concurrent Cursors
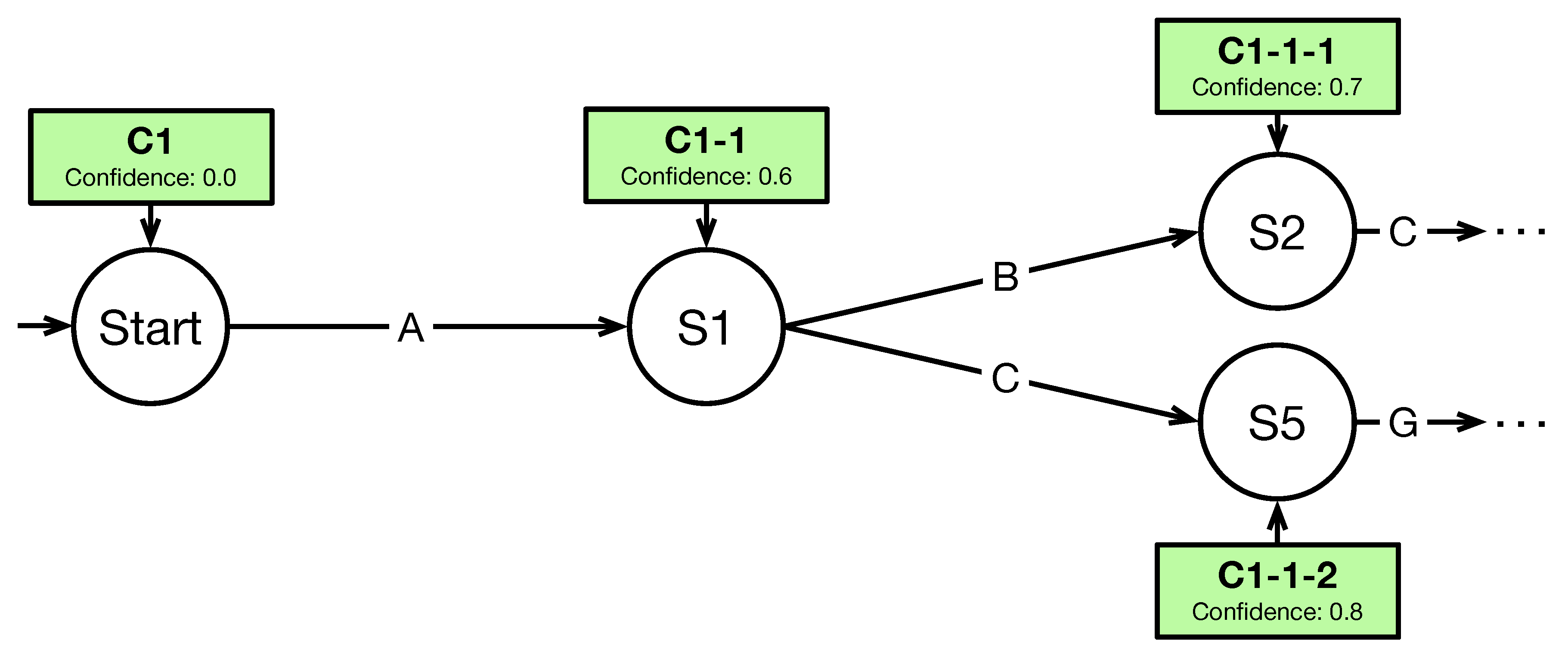
The Concurrent Cursor concept introduces so called
cursors. A cursor is a pointer indicating a currently active state in a procedural fusion method. For example,
in
Figure 5 represents a cursor pointing to the currently active start state
. Cursors do not move from one state to another, but spawn a child that is positioned on the target state. The original cursor remains on its current state. For instance, if a transition over
A is performed, the child
of cursor
is created. The child is positioned on state
while
remains on
. As a result, multiple states can be active at once and strands of cursors are created while processing input. A strand is interpreted as one viable path throughout the graph. All possible strands form a tree representing all possible parsings. Its leafs represent guesses of the fusion method. This way of copying cursors lays a foundation for interpreting hypotheses and different combinations of hypotheses, since multiple states can be active at the same time. In order to sort these n-best guesses by their confidence, every cursor has to store its own confidence. This value is based on the confidences of a cursor’s processed inputs. Different mathematical calculations can be used to calculate a cursor’s confidence, e.g., the median value of the processed inputs’ confidences. In summary, each cursor is copied to the target state when performing a transition and has its own confidence.
To illustrate the concept, consider the following example (see
Figure 5): Four states (
,
,
, and
) are active and two cursor strands have been formed:
represents the strand from
over
to
with a confidence of 0.7.
represents the strand from
over
to
with a confidence of 0.8. Both cursors are sorted by their confidence. As a result, the most confident recognition result would be the inputs processed by
.
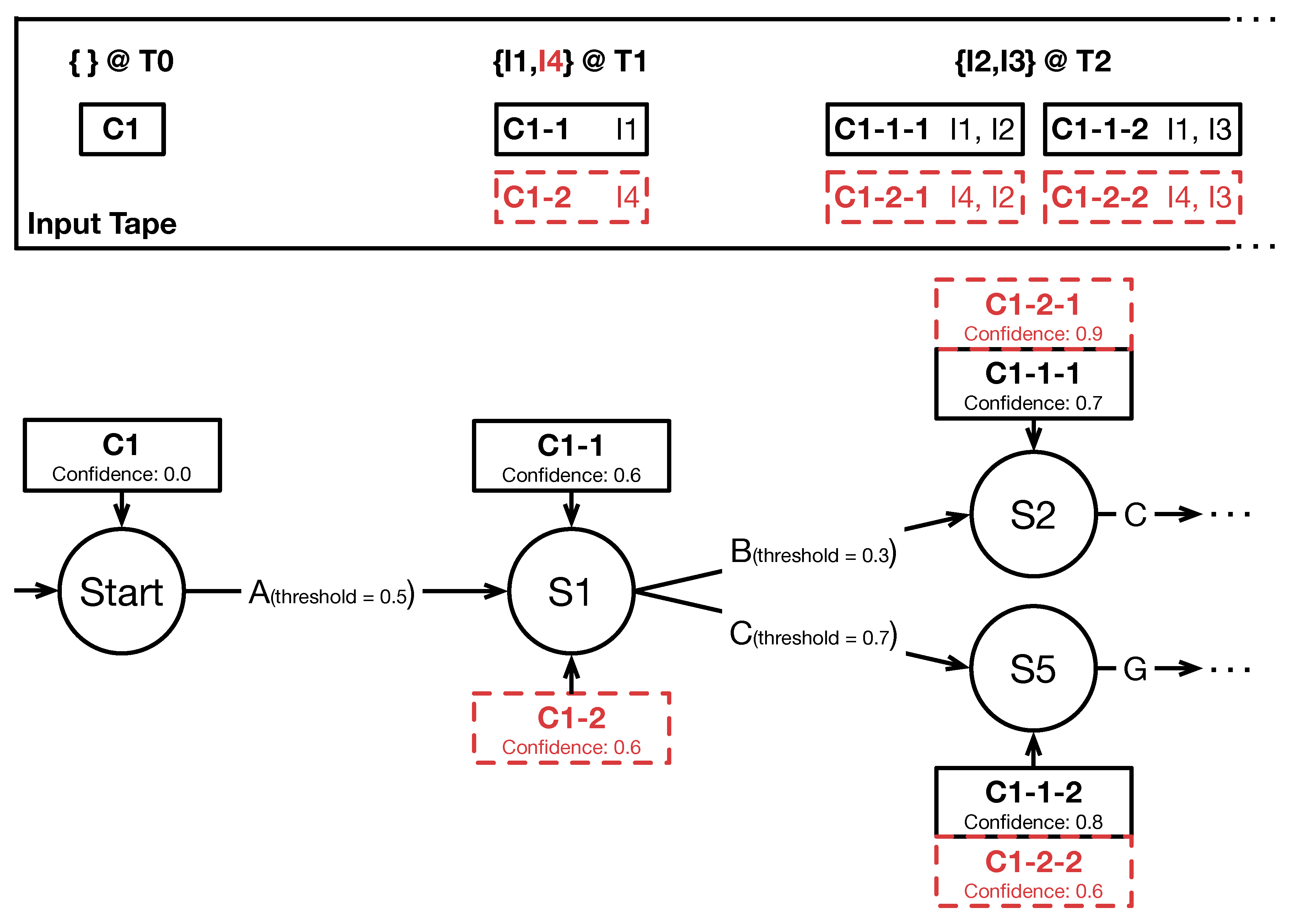
In the following we describe how the Concurrent Cursor concept allows to process chronologically unsorted input and consider temporally valid combinations of hypotheses. To this end, cursors use an extended two dimensional input tape. Recognizers usually provide timestamps indicating when a specific event took place. For example, when a user uttered a word or performed a gesture. Input is sorted on the tape depending on this timestamp instead of its arrival at the fusion method. In contrast to traditional one dimensional input tapes, which only store input sequentially, our input tape can store multiple inputs for one time cell in parallel to represent alternative hypotheses. Time cells represent a specified time interval that further discretize timestamps to cluster hypothesis.
Figure 6 depicts such an input tape. At time cell
no input has been received by the fusion method implementation while input
occurred at
. Two hypothesis
and
have been recognized at
and sorted into the tape. Cursors keep track of which inputs they already analyzed by pointing to respective time cells on the input tape. For example, in
Figure 6 cursor
points to state
and processed input
at time cell
. Cursor
points to
and processed
at
and
at
. If a new input
is sorted into the tape at
(see
Figure 6, red color) all cursors that already processed input at or later then
do not have to process
. For them it is not temporally valid to process input which, from their point of view, occurred in the past. The only eligible cursor to process
is
. If
passes transition
A’s conditions, a new child cursor
is created.
points to state
in the graph and to
at
on the tape. After processing this input the cursor has to check if newer input is available on the tape which could form another valid multimodal command. In the example of
Figure 6, two newer inputs are available for the newly created cursor
:
and
at
. If these inputs lead to new transitions, two new children are created from cursor
:
and
.
The described copying pattern of cursors in combination with the two dimensional input tape provides the means to process probabilistic and chronologically unsorted input ( & ). In addition, it reduces the computational complexity by reducing the number of triggered transitions for each new input by means of the described temporal validity check.
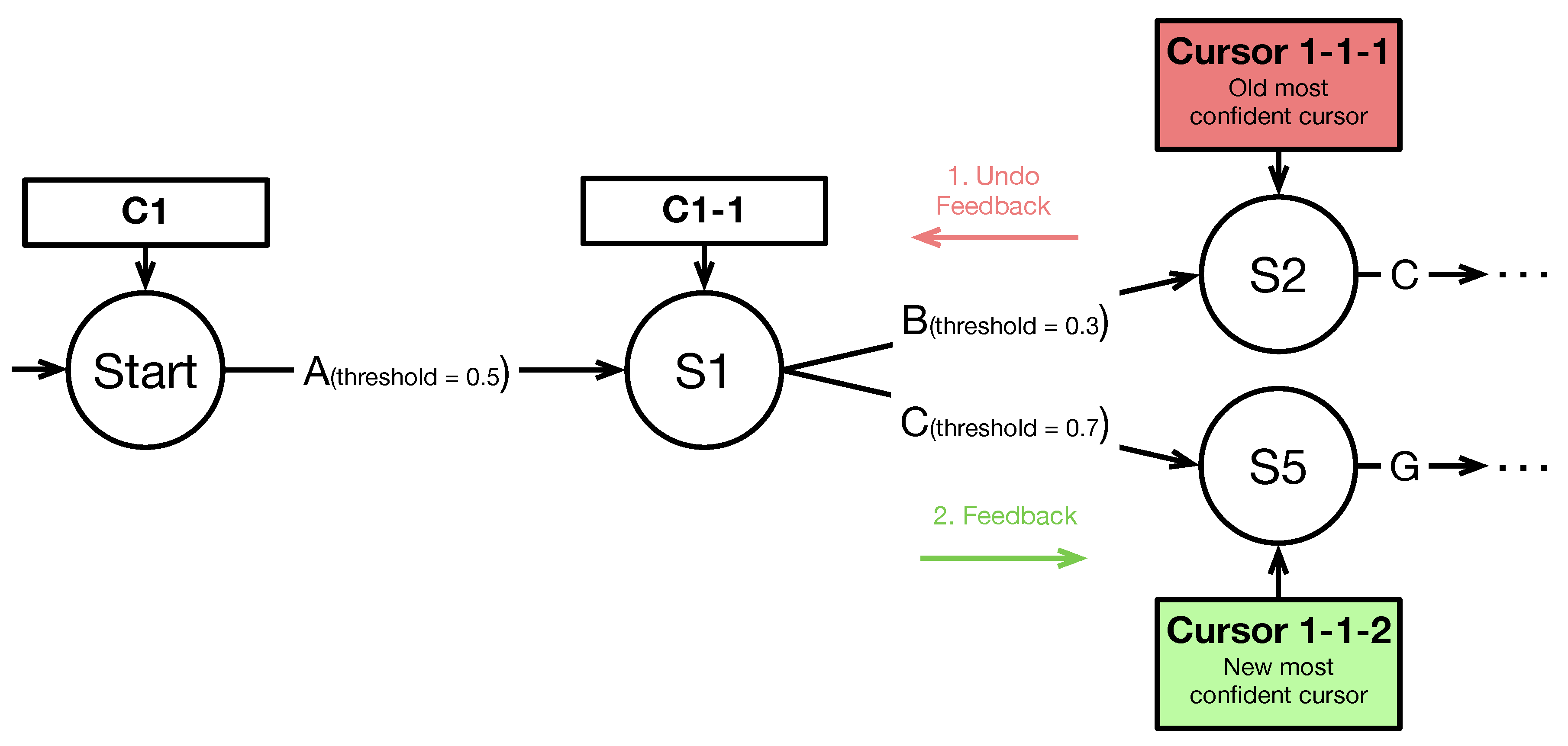
Providing proper feedback (
) is exacerbated since new hypotheses may cause the current best guess to change. To cope with this issue, the concept defines dedicated feedback functions for each arc (see
Figure 7, green arrow). The arc’s condition determines if a transition will be performed while the corresponding function is executed when it is performed. The feedback function will be executed after a transition has been performed. Besides the time of execution, feedback and function differ in one central aspect. Arcs might be traversed several times by different cursors resulting in multiple function calls. The user would receive a large number of feedback about every possible guess a fusion method is considering at the moment, if this function type is used for feedback. In contrast, feedback is only executed if the arc is traversed by the current most confident cursor, i.e., the cursor with the highest confidence. If the most confident cursor changes during processing previously executed feedback has to be revertible (
). Reverting feedback can not be automatically performed by the fusion method, since arbitrary functionality can be implemented in the feedback function. The developer has to specify dedicated undo feedback functions which negate the respective feedback (see
Figure 7, red arrow). All transitions made by the old most confident cursor have to be traced back until the first common parent between new and old most confident cursor. The feedback of these transitions has to be undone by executing the respective undo feedback functions. Upon reaching the first common parent, the feedback can be sequentially executed from the parent to the new most confident cursor.
Figure 8 depicts such a procedure. A new input has been processed by the fusion method implementation. It leads to a change of the most confident cursor from
to
. Their common parent is
. First, the undo feedback function of transition
B is triggered. Second, the transition
C’s feedback function is executed for cursor
.
In summary, the Concurrent Cursor concept provides effective means to analyze probabilistic and chronologically unsorted input and satisfies and . Cursors allow for multiple states to be active at the same time and contain their own confidence. This is essential for the fusion method to represent sorted n-best recognition results caused by analyzing multiple hypotheses and their combinations. Cursors keep a reference to their processed input on a two dimensional, chronologically sorted input tape. This enables cursors to properly parse new input in the correct order, independent of their time of arrival. Providing proper feedback is supported by the Concurrent Cursor concept, since the fusion methods best guess can be communicated to the application continuously and be reverted (), if the best guess changes.
3.2. Reference Implementation
Our reference implementation is called Concurrent Augmented Transition Network (cATN). In the following, we describe the implementation of the Concurrent Cursor concept and detail the four design decisions that are left open by the Concurrent Cursor concept: The choice of a procedural method, the choice of a description language, a measure for handling temporal relations between input, and an access scheme to the interaction context. Altogether, the cATN thus fulfills all identified requirements. Since the Concurrent Cursor concept is an extension to a procedural fusion method, we first elaborate this decision.
3.2.1. Design Decision: Augmented Transition Network
We chose to base the cATN on an augmented transition network which receives input by means of events. An ATN foresees data storage in form of state-specific registers. The cATN implements registers cursor-specific to comply with the Concurrent Cursor concept. That is, each cursor comprises its own set of registers. The content of a cursor’s register is copied to the register of its children. A cursor’s registers can thus be used to fulfill two essential requirements. On the one hand, they can store information about the syntactic structure of each particular guess, enabling the parsing of context-sensitive grammars (). On the other hand, they can store state and behavior references to permit semantic integration during fusion ().
A further benefit of basing on an ATN is its inherent recursiveness. Reoccurring recognition tasks, e.g., parsing a noun phrase, can be externalized into separate networks. These networks can be integrated into the main network of the ATN by means of dedicated subroutine calls. A concrete example of this functionality is provided in
Section 3.3. Dividing a large network into several small ones increases reusability and modifiability.
Besides normal and sub arcs, we implemented dedicated arcs for semantic integration called EpsilonArcs. An epsilon arc is not triggered with new input, but is automatically triggered if a cursor reaches its point of origin. While semantic integration can be performed in any arc, encapsulating this functionality in dedicated reusable arcs proofed to be easier to maintain.
3.2.2. Concurrent Cursor Implementation
Both cursors and the two dimensional input tape are implemented according to the Concurrent Cursor concept and utilized in the
cATN’s parser. The parser, as well as noteworthy optimizations, are described in the following.
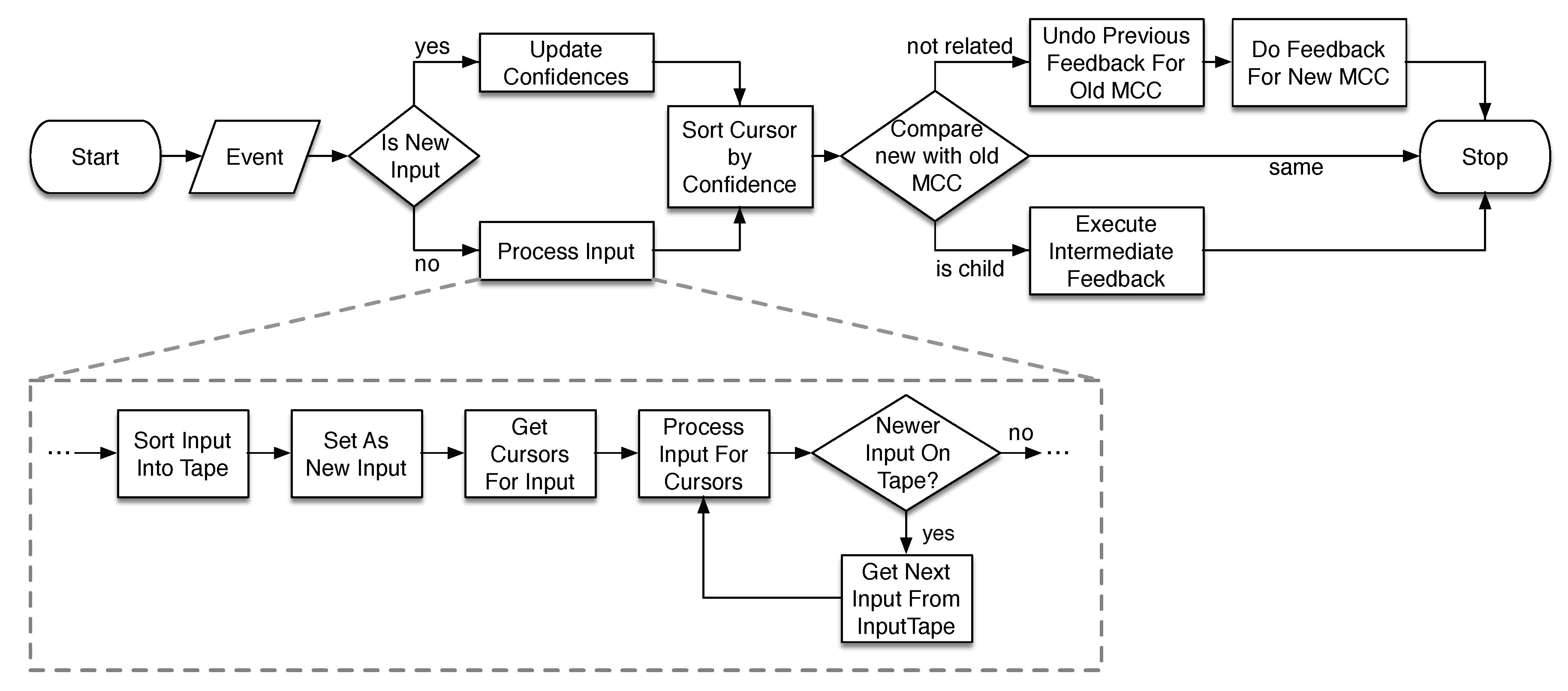
Figure 9 (top flow chart) depicts a flow chart illustrating the designed algorithm. One processing loop is triggered by an input event, which is first sorted in the input tape depending on its timestamp.
The parser checks if the respective time cell already contains an input with equal value. That is, the confidence of a previously parsed input changed, e.g., the automated speech recognizer updated the confidence for having recognized “chair” at a certain timestamp. If this is the case, the confidence of all cursors that already processed this input is updated with the new input’s confidence. This step is optional but aids to optimize performance by not unnecessarily introducing new cursors to the cATN. It is based on the premise that later hypotheses are more reliable.
If the input is new, it is being processed. This may lead to the creation of multiple new cursors. If new cursors are created, the new most confident cursor will be calculated. Three different possibilities are considered. Firstly, the old most confident cursor remains the new most confident cursor, in which case no feedback has to be provided. Secondly, the new most confident cursor is a child of the old one. In this case, the feedback function of all arcs between the old most confident cursor’s state and the new one’s has to be executed. Thirdly, the new most confident cursor is not a child of the old one. In this case the previously provided feedback has to be undone by executing the dedicated undo-feedback functions and the new feedback has to be provided.
As an additional optimization, the cATN can be reset, e.g, after a successfully parsed command has been executed. A reset deletes all existing cursors and spawns a new cursor on the start state. The parser waits for the next input. On top of that we implemented an auto reset for the cATN. The auto reset is triggered if the cATN does not receive input in a configurable time frame. It avoids that the cATN’s parser gets stuck in an incomplete command.
Figure 9 (bottom) illustrates the
Process Input step in detail. The new input is sorted into the input tape. Next, all eligible cursor are identified. A cursor is deemed eligible if its position on the input tape precedes the new input. Additionally, we implemented a max time delta for how far in the past cursors can be eligible. This is an optimization and not part of the concept. However, it reduces the number of active cursors in practice which decreases processing time. It is based on the assumption that natural input occurs within a certain time interval to each other. Eligible cursors process the new input by checking the conditions of outgoing arcs from the states to which they are pointing to. If a condition is satisfied, the arc’s function is executed. Its feedback functions will be collected in the parser and maybe provided later depending on the new most confident cursor calculation step. A child of the cursor is created by cloning it. The child’s confidence is calculated and its pointers updated to the new state and position on the tape. Finally, the parser checks for newer input on the tape. If newer input exists it will be processed by the newly created children, if not the
Process Input step is finished.
3.2.3. Design Decision: The Programming Language Scala
The Scala programming language has been chosen as a description language for the cATN. Scala combines both object-oriented and functional paradigms. This fosters the definition of concise application programming interfaces (APIs), especially comprising callbacks, and is beneficial for addressing a large number of developers. In addition, Scala’s syntax is very flexible which greatly facilitates the use of a description languages. For example, Scala allows to omit the dot operator or the parentheses in certain cases. Listing 1 showcases our Scala based description language for defining the cATN’s transition graph. Line 1–3 define the transition graph’s composition. A dedicated start state is connected with arc A to the state (line 1). is connected with arc B to the end state (line 2). The end state is defined in line 3 while line 4 depicts the definition of the arc A. It’s condition isA, function doA and feedback feedbackA are Scala functions which can directly be passed to the description language. This description language fosters rapid prototyping and helps non-experts to effectively design multimodal interfaces.
Listing 1. Example of a concurrent Augmented Transition Network (cATN) defined with our description language. By omitting the dot operator and parentheses, the cATN can be defined in an easily readable manner. For example, the StartState method of the object create in line 1 accepts a string as parameter and yields an object with a method withArc.
1 create StartState “Start” withArc “A” toTargetState “S1”
2 create State “S1” withArc “B” toTargetState “End”
3 create EndState “End”
4 create Arc “A” withCondition isA andFunction doA provideFeedback feedbackA
5 create Arc “B” withCondition isB andFunction doB provideFeedback feedbackB
3.2.4. Design Decision: Network Abstraction Constructs
We include network abstraction constructs in the definition language to provide a convenient measure for handling temporal relations between input. An ATN’s conditions and registers already provide means to support this requirement, by storing timestamps in registers and checking them with conditions. However, the repeated definition of such constructs is cumbersome. Thus we utilize constructs in our description language to abstract this kind of reoccurring network configurations.
Split-Merge is an example of an network abstraction construct in our description language. It allows the definition of more complex temporal relations between input (
). Special
Split and
Merge states can be defined. A split state has to be connected to a merge state with at least two transitions in parallel. In order for a cursor to transition to the merge state, all transitions from split to merge have to be performed. These transitions have to satisfy an additional
Merge-Condition, e.g., a temporal condition. Listing 2 illustrates the description language for defining a split-merge. Both arcs
A and
B have to be traversed within the
maxTimeDelta(500L) condition. In other words, the
cATN has to receive appropriate input within 500 milliseconds next to each other. A dedicated
merge function can be freely implemented (line 4). The
merge function is automatically executed if both
A and
B are traversed in the
maxTimeDelta(500L) condition. This function can be used, for example, to clean the cursor’s registers or perform semantic integration. The temporal condition for the split-merge can be freely chosen. Allen’s interval algebra for representing relation between time intervals [
65] provides helpful guidelines for defining suitable conditions. The
cATN processes a split merge by mapping this high level definition to the low level functionality of the ATN.
Listing 2. An example code excerpt showcasing our network abstraction design decision Split-Merge. A dedicated split state Split is defined in line 1. Two arcs, A and B, connect Split with state Merge in line 2 and 3. Line 4 defines the dedicated merge state Merge with the on merge function merge.
1 create SplitState “Split” withCondition maxTimeDelta(500L)
2 andArc “A” toTargetState “Merge”
3 andArc “B” toTargetState “Merge”
4 create MergeState “Merge” withOnMergeFunction merge
Figure 10 illustrates this mapping. The left transition graph represents the in Listing 2 defined network. In a preprocessing step it is mapped to the transition graph on the right. Two new states
and
are automatically generated by the
cATN and placed between
Split and
Merge. All permutations of the two transitions
A and
B are thus represented. The time condition is added to the conditions of all arcs between
Split and
Merge. Similarly, a function is added to the respective arcs that automatically stores the inputs’ timestamps in the cursors’ registers. These timestamps can then be evaluated by the time condition to conclude a successful split-merge. Utilizing the network abstraction design decision the
Split-Merge construct provides a solution for defining more complex temporal relations between input (
).
3.2.5. Design Decision: Semantics-based State- and Behavior-Management Techniques
We utilize semantics-based state- and behavior-management techniques [
10,
20] to realize our access scheme to the interaction context. Entities are used as state representing objects containing a set of numerical and symbolic properties that are semantically grounded and can dynamically change during simulation. The chair in the running use case, for example, would be represented as such a
semantic entity [
20,
56], containing grounded properties like type, color, position, and orientation. The user and its position in the virtual environment or environmental information, such as the surrounding light level, can be represented with semantic entities as well. Most importantly however, these techniques incorporate a concept to semantically describe behavior as complement to the application state representation. State and behavior queries can be performed by means of semantic descriptions called
semantic queries. They support the resolution of references to (virtual) objects by permitting to query the application state for entities by a logical combination of desired present and past properties and property values. After “
… [deictic gesture] that green chair …” has been analyzed an entity could be queried for that is a chair, has a color property that equals
green, and is located within a certain area. Such a query would yield the above described semantic entity representing the chair in the virtual environment. This entity can also be altered by the
cATN during input analysis if required. Semantic queries likewise foster semantic integration. Since the goal of many multimodal user interactions is to trigger a certain action the application can perform, semantic-level fusion has to match uttered multimodal commands to available actions. Behavior queries support in exactly this task and yield so called
grounded actions that consist of a set of preconditions, a set of parameters, and a set of effects. A semantic validation can be performed using the action’s meta data by checking if the information contained in the multimodal utterance fulfills the action’s preconditions and covers the action’s parameters. In the use case, the analysis of the utterance “
Put …” could query a respective grounded action
collocate that takes an object as well as a destination (parameters) and requires the object to be moveable (preconditions).
We propose to integrate this semantics-based state- and behavior-management into procedural fusion as follows: Registers are realized as semantically grounded property sets just like semantic entities. Thus transition-conditions and -functions can exploit introspection. Semantic entities, grounded actions, as well as semantic queries complement the means for the implementation of transition. They are highly beneficial for resolving references to (virtual) objects and for realizing semantic integration. Transition functions can map input to semantic entities, grounded actions, and semantic queries to store them in their register.
Listing 3. An example code excerpt for an arc’s function which performs semantic integration after the user uttered the word “chair” with a preceding deictic gesture. A semantic query is used for identifying and subsequent accessing entities in the application state. In this example, the query returns an entity, if one exists, which possess a Semantics property with value Chair and intersects with the user’s pointing Ray at a specified time. Grounded properties are highlighted in blue.
1 def resolveNP(input: Event, register: SValSet) {
2 val ray = register.get(Ray).value
3 val timestamp = register.get(Timestamp).value
4 val word = input.get(Token).value // “chair”
5 val noun = Lexicon.nouns(word)
6 val pointedAtChair = HasProperty(Semantics(noun.assocEntity)) and
7 PointedAt(ray) at timestamp
8 val entity = Get the pointedAtChair
9 if(entity.isDefined) register.put(entity)
10 }
Listing 3 depicts an arc’s function which resolves a noun phrase accompanied with a deictic gesture using a semantic query. The goal of this function is to find the semantic entity
Chair. Both the direction
ray of the pointing gesture and the
timestamp at which the user performed the gesture can be retrieved from the register (line 2–3). The uttered word
"chair" is retrieved from the event that triggered the transition (
input) (line 4). We use a
Lexicon [
66] to map the word
"chair" to a respective
noun which is associated with a type of entity (line 5). This data is used to parameterize the query (line 7–8) which is then executed (line 9). The timestamp is of particular importance for identifying the respective entity in a dynamically changing environment. The
PointedAt(ray) at timestamp part of the query performs a lookup in the application state history to check if the ray intersected an entity at
timestamp. If the query yields a result, the entity is stored in the register (line 10) and can later be used to invoke a resolved action.
The semantics-based state- and behavior-management design decision allows multimodal systems to use entities and actions without requiring explicit references (). This decouples in terms of data sinks and sources as well as of utilization of application and system functionality. It facilitates the reuse of fusion method configurations in other contexts or applications, as long as the required application state and behavior representation elements exist. Thus an universal multimodal interface, comprised of basic commands like creation, collocation, and deletion, could be rapidly added to any application that is realized with an interactive system supporting this design decision.
3.3. Use Case Implementation
In this section, we present a concrete
cATN configuration capable of recognizing the example interaction introduced in
Section 2.1: “
Put [deictic gesture] that green chair near [deictic gesture] this table.”
Figure 11 illustrates the respective
cATN’s transition graphs. To represent parts of speech we use the Penn Treebank POS tagset [
67]. The primary transition graph (see
Figure 11, top transition graph) recognizes a verb (VB), a noun-phrase (NP), a preposition (IN), and another noun-phrase (NP) in a sequential order. A transition of the final arc
CMD implies that the command has been successfully recognized and executes the respective action. The
arc is a sub arc which points to the secondary transition graph (see
Figure 11, bottom transition graph). In order for a cursor to traverse from
to
or
to
, it has to traverse through the entire secondary graph first. A noun phrase starts with a split-merge consisting of a demonstrative (
) and a deictic gesture (
). The merge is followed by a noun (
) and finally a dedicated arc for semantic integration (
).
provides feedback by visually highlighting the resolved entity. Additionally the arc
allows for an optional number (0-n) of adjectives.
Listing 4 showcases the description language code to define the introduced
cATN configuration. Line 1–6 define the upper graph in
Figure 11, while line 8–15 define the lower graph. The Arc
VB is created in line 17–18. Since the description language is internal, Scala functions can be directly passed to it.
VB’s condition
isPartOfSpeech[Verb] firstly verifies whether the input is an input from the speech recognizer. Secondly, it checks if the recognized token is of a certain part of speech, i.e., a verb. The arcs function
saveAs[Verb] stores the verb in the cursor’s register for future reference. Arcs for recognizing the remaining speech tokens, i.e.,
VB,
IN,
DT,
ADJ, and
NN are all defined similarly. Line 21. illustrates how the
dG arc for parsing a pointing gesture is defined. Its condition
isGesture[Pointing] verifies whether the input is a pointing gesture. The
saveAs[Pointing] function stores the pointing ray semantically annotated in the cursors register.
If a cursor reaches S6 in the NP graph (line 14), a noun phrase accompanied with a gesture has been successfully recognized. Relevant information is stored in the cursor’s registers and can be retrieved from it in the resolveNP epsilon arc. Its condition entityExists (line 24) checks if an entity described by the parsed noun-phrase and accompanying deictic gesture exists using semantic queries. If such an entity exists in the application state, the arc’s function resolveNP (line 25) stores a reference to the entity in the cursor’s register. Finally, the resolveNP arc’s feedback function (line 26) highlights the entity if the cursor currently is the most confident one. An additional undo feedback is defined in case the most confident cursor changes during fusion and the wrong entity has been highlighted (line 27). The CMD arc (line 29) is implemented as an epsilon arc as well. It does not need a condition or function. If a cursor reaches state S4 (line 5) a command has been successfully recognized and all necessary information is stored in the cursor’s registers. It retrieves the appropriate action, i.e., colocate from the application’s behavior by means of a semantic query. The action is parameterized with the content of the cursor’s register, i.e., the semantic entity Chair and Table, and is executed.
This generalized approach to multimodal interface design leads to easy extensibility. Simply adding more determiner, adjectives, nouns and verbs to the lexicon is sufficient to recognize a multitude of commands, e.g., “Move [deictic gesture] that big vase to [deictic gesture] this counter.” or “Place [deictic gesture] that small yellow thing under [deictic gesture] that table.”.
Listing 4. A description language excerpt for creating the
cATN depicted in
Figure 11.
1 create StartState “Start” withArc “VB” toTargetState “S1”
2 create State “S1” withSubArc “NP” toTargetState “S2”
3 create State “S2” withArc “IN” toTargetState “S3”
4 create State “S3” withSubArc “NP” toTargetState “S4”
5 create State “S4” withEpsilonArc “CMD” toTargetState “End”
6 create EndState “End”
7
8 create SplitState “NP” withCondition maxTimeDelta(500L)
9 andArc “DT” toTargetState “S5”
10 andArc “dG” toTargetState “S5”
11 create MergeState “S5” withOnMergeFunction merge
12 withArc “NN” toTargetState “S6”
13 andArc “ADJ” toTargetState “S5”
14 create State “S6” withEpsilonArc “resolveNP” toTargetState “EndNP”
15 create EndState “EndNP”
16
17 create Arc “VB” withCondition isPartOfSpeech[Verb]
18 andFunction saveAs[Verb]
19 /*…*/
20
21 create Arc “dG” withCondition isGesture[Pointing]
22 andFunction saveAs[Pointing]
23
24 create Arc “resolveNP” withCondition entityExists
25 andFunction resolveNP
26 provideFeedback highlight
27 withUndoFeedback unhighlight
28
29 create ARC “CMD” withFeeedback executeCommand
3.4. Benchmark
The Concurrent Cursor concept provides an extension to procedural semantic fusion methods. It fulfills the two fundamental requirements handling probabilistic () and chronologically unsorted input (). The concept introduces concurrent cursors and a two dimensional input tape that could introduce a performance overhead. This section presents a fundamental comparative benchmark that provides basic insights into the impact of the Concurrent Cursor concept on the performance of ATNs and thus into the practicability of our contribution.
3.4.1. Concept
The benchmark measures and compares the mean processing time of both the cATN and a state of the art ATN-based approach implemented without the Concurrent Cursor concept (generic ATN) on a fabricated dataset D. D consists of two different types of inputs A and B, e.g., speech tokens and recognized gestures. The benchmark generates n guesses for each input, e.g., , as two guesses for A, to consider probabilistic input (). Timestamp is assigned to inputs of type A and to B, with . Additionally, a randomly generated confidence is assigned to each input.
The benchmark samples the mean processing time of the cATN and generic ATN for . For , for example, the following input dataset is constructed: . The input dataset is randomized before it is passed to the fusion methods, to simulate chronologically unsorted input (). The cATN natively supports this kind of input. The generic ATN approach is required to chronologically sort the passed list again before processing.
Figure 12 illustrates the networks that the benchmark uses for parsing
D. The main difference between the
cATN and the
generic ATN approach is that the
cATN can process all
using one configuration due to the Concurrent Cursor concept. A single
generic ATN, however, conceptually provides only one active state and is thus incapable of considering chronologically plausible combinations of guesses. To be nevertheless able to consider probabilistic input, a set of artificially constructed networks is generated:
.
Each network (cATN and generic ATN) consists of three states and two arcs. The arcs’ conditions are setup to accept the guesses, while the arcs’ function store the value, timestamp, and confidence of each input in their registers. In the case of the cATN, this information about all parsed inputs are thus available in registers that belong to cursors on the end state. To mimic this behavior with the generic ATN, the generic ATN ’s arc functions have to retrieve value, timestamp, and confidence from the previous state’s register and add them to the current state’s register.
The benchmark has been performed on a Windows 10 workstation with an Intel Core I7-8700k @ 3700GHz processor, 16GB DDR3 ram, and an Nvidia Geforce GTX 1080Ti graphics card. Both fusion methods have been implemented with the programming language Scala v. 2.11.8 and ran in the Java Virtual Machine(JVM) v. 1.8.0_181. For each 50,000 warm up cycles have been run before a total of 10,000 measurement cycles. The warm up cycles reduce the impact of the JVM’s runtime optimizations on the measurement cycles.
3.4.2. Results
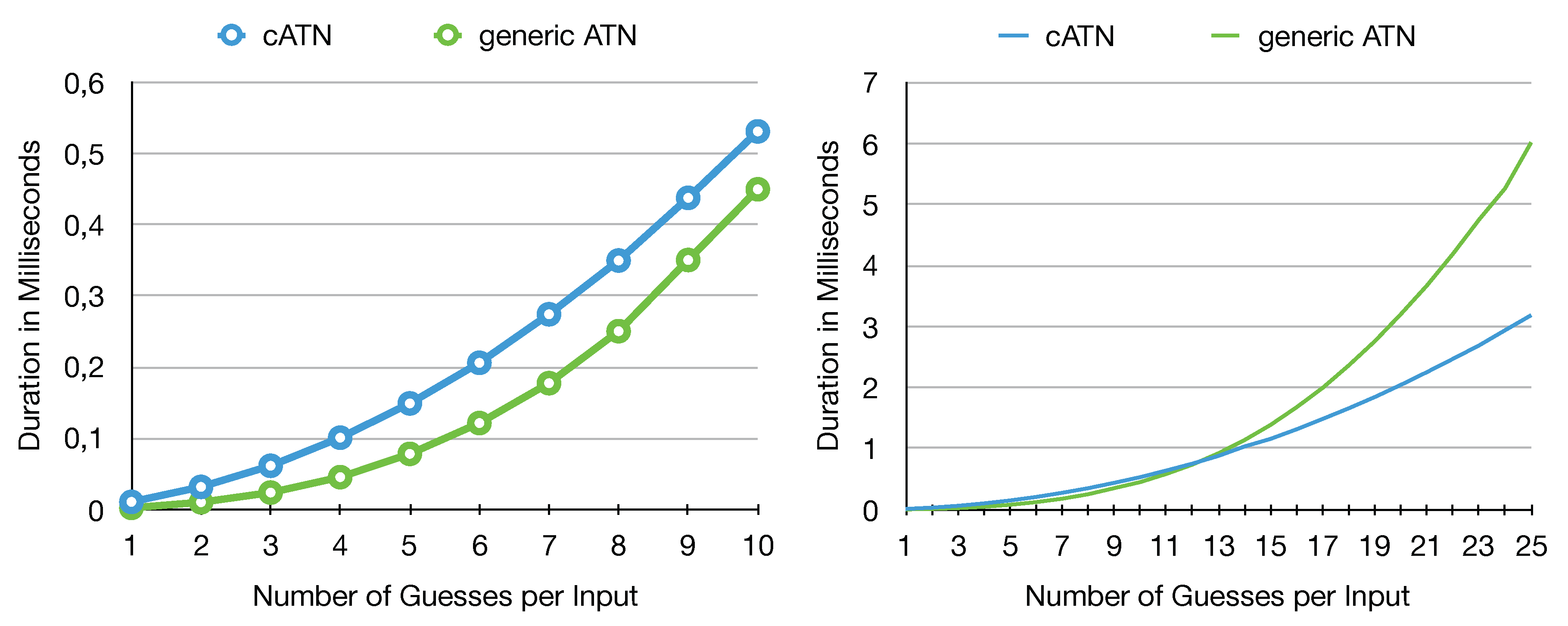
The obtained results are presented in
Figure 13. They show that the
cATN is comparable in performance to state of the art ATN-based approaches until
, with a peek difference at
of 0.099 milliseconds. For high numbers of
n the
cATN outperforms its comparison partner. At
the
cATN is in average 2.830 milliseconds faster than the ATN.
These results are in line with our expectations. The Concurrent Cursor concept introduces a small performance overhead, which can be observed for . Eligible cursors have to be identified before they can process the input and children of cursors have to be created, while the generic ATN can directly process all inputs. However, as n increases this overhead is negligible in comparison to the number of arcs tested and transitions made by the generic ATN. Before any input has been processed there are active states for the generic ATN approach, since there are constantly networks. In the cATN there is only one active cursor. After has been processed, there are still active states for the generic ATN approach. In the cATN there are cursors, since one cursor remains at the start state, n cursors represent with at , and at all combinations of with are considered. In total, both fusion approaches exhibit a quadratic growth of active states (). However, in terms of processing time the generic ATN tests more arcs and makes more transitions per input. Each input triggers a test for all active states right from the beginning. The cATN only processes input for eligible cursors. The number of such cursors starts with one and increases depending on the randomization of inputs.
In conclusion, the presented benchmark results support the fundamental practicability of our contribution. To make measurements comparable the generic ATN approach sorts chronologically unsorted input before the actual processing, artificially constructs a set of single ATNs, and copies register contents to the end state. The benchmark showcases that the generic ATN approach can not handle chronologically unsorted dynamically, since it has to wait until all guesses are provided. Further, the processing of probabilistic input is merely possible due to the artificial construction of networks, which impacts the clarity and conciseness of network definitions in realistic use cases.
4. Discussion
The Concurrent Cursor concept enables to process probabilistic (
) and chronologically unsorted input (
) typically provided to semantic-level fusion methods. At the same time it supports the provision of continuous and revertible feedback to inform the user about the current state of the semantic fusion and to provide insight in why a certain command has not been successfully recognized (
). Unification as used in
Quickset [
30] also meets
and
. However, the system has to wait for the user to finish the interaction before analyzing it. This restriction renders the fusion method unable to provide continuous feedback during interaction. Our reference implementation, the
cATN, builds upon four design decisions to jointly fulfill all identified fundamental requirements: An ATN, the Scala programming language, network abstraction constructs, and semantics-based state- and behavior-management techniques.
The cATN is set out to facilitate rapid prototyping of MMIs. Five characteristics concretely contribute to this trait. (1) The declarative nature of the cATN’s procedural approach avoids the time costly training required by machine-learning based approaches. (2) The recursiveness of the underlying transition network permits the reuse of substructures, like the dedicated subgraph for recognizing noun phrases shown in the use case implementation. (3) The network abstraction constructs of our description language complement this reuse by abstracting repeatedly required network configurations. Finally, the concrete state and behavior elements of the application are decoupled from (4) the semantic integration process, by means of semantic queries, and from (5) lexical information, i.e., from the tokens of the interface’s multimodal grammar, by means of the lexicon. Altogether, the options of reuse save time and thus foster rapid development cycles. Moreover, the achieved level of decoupling puts an “universal multimodal interface”, comprised of basic commands that can be readily added to any application, close at hand. Ultimately, it shows how a procedural fusion method can satisfy all fundamental requirements for performing semantic fusion, while maintaining the support of rapid MMI development processes and thus answers the research question.
This facilitation of development and the completeness of captured requirements has been validated by a series of proof of concept demonstrations. Their implementation guided the concept development process and provided a basis for assessment and improvements. In the following, the most relevant proof of concept demonstrations for our
cATN are briefly presented (see
Figure 14). They comprise various student projects, theses, as well as results of a master-level
Multimodal Interface course. It shows that non-experts can effectively implement MMIs even for non-trivial application areas like virtual and mixed reality. This is in line with the general benefits of procedural fusion methods identified in literature, i.e., simple comprehensibility and compatibility with typical interface development processes.
Figure 14 showcases a few of these applications and demonstrations. More details can be found on our project page [
51].
SiXton’s Curse [
9] is a semi immersive, multimodal adventure game in which a user has to defend a town from AI controlled virtual ghosts. For this purpose, the user has several spells at his disposal that can be cast by the combined use of speech and gestures. The demonstration by [
8] is a multimodal, mixed reality, real-time strategy game on a digital surface. Players can command their forces by speaking, touching, and gesturing. More recently, a cherry picking approach [
68] has been applied to allow the exploitation of the simulation and rendering capacities of game engines.
Space Tentacle [
7] and
Robot Museum [
69] have been developed with the
Unity 3D game engine.
Space Tentacle is a VR adventure game in which the user has to multimodally communicate with an artificial intelligence on a space ship to solve puzzles.
Robot Museum is a student project which explores multimodal communication with a virtual companion in a museums context.
Big Bang [
70] is a VR universe builder implemented with the
Unreal 4 game engine.
The general feasibility of the Concurrent Cursor concept and the cATN has further been validated through a comparative performance benchmark. The presented benchmark results support the fundamental practicability of our contribution. They show that the cATN is comparable in performance to state of the art ATN-based approaches. Apart from the raw performance comparison, the benchmark showcases that the comparison partner can not handle chronologically unsorted input dynamically. Further, the processing of probabilistic input is merely possible due to the artificial construction of an exponentially growing set of single ATN configurations (as a function of the number of n-best guesses). While this high number of networks makes the generic ATN approach impractical with respect to the definition of valid multimodal utterance, the concise description language of the cATN has been perceived to be usable during the development of the presented proof of concept demonstrations. For high numbers of n-best guesses the cATN outperforms its comparison partner. Thus, it may also prove effective in earlier stages of the input processing pipeline as well as in (future) use cases that consider a considerably higher number of modalities for fusion than just speech and gesture.
The main limitations of our contribution are twofold and indicate canonical future research. Firstly, an elaborated formal performance analysis that especially considers typical real-time constraints of RIS has not been conducted. Yet, the fundamental benchmark and the development of the presented proof of concept demonstrations indicate a principal suitability and revealed further insight. Conditions should check inputs in terms of their temporal, syntactical, and semantical validity early on, to avoid the creation of cursor strands for false guesses. In addition, it has proven to be advantages to model high frequency data sources as context, i.e., in the application state. They can thus be polled on demand instead of being pushed to the fusion method in large numbers, where they would substantially increase the number of active cursors. For instance, in case of the mixed reality board-game [
8], the detected positions of the users’ hands touching the interactive surface are represented as properties of a semantic entity
TouchInput. In response to an uttered demonstrative key word, i.e., “
that” or “
there”, a dedicated arc condition checks if touches occurred during the speech input by means of semantic queries and the application state history. Both of these best practices, representing high frequency data sources as context and defining restrictive arc conditions, led to proof of concept demonstrations with no noticeable performance impact regarding the flow of interaction. Secondly, the
cATN ’s description language and its network abstraction constructs are designed to facilitate development, however its effectiveness in this regard has solely been controlled by the application of an API peer review method [
20]. The usability of a system’s programming interface for developers, i.e., its API usability [
71] includes its learnability, the efficiency and correctness with which a developer can use it, its quality to prevent errors, its consistency, and its matching to the developers’ mental models. API usability is paramount for facilitating a rapid prototyping process (of MMIs). However, properly assessing or even comparing API usability is a delicate endeavor with a limited number of methods and no obvious choices [
72,
73]. Subjective methods are the primary choice for API usability assessment and comprise expert reviews based on guidelines and user studies, such as think-aloud usability evaluation, API peer reviews [
71,
74], or questionnaires based on programming tasks [
72,
73].
5. Conclusions
This article targets semantic fusion methods for natural, synergistic, and intentional multimodal interactions that are compliant with rapid development cycles. On the basis of a comprehensive review of associated contributions and with the help of an interaction use case, we identify seven fundamental requirements: Action derivation, continuous feedback, context-sensitivity, temporal relation support, access to the interaction context, as well as the support of chronologically unsorted and probabilistic input. The Concurrent Cursors concept provides a solution for fulfilling the latter two requirements and is proposed as the main contribution of this paper. The feasibility of the Concurrent Cursors concept is validated by our reference implementation the
cATN in a series of proof of concept demonstrations as well as through a comparative performance benchmark. The
cATN bases on four design decisions: An ATN, the Scala programming language, network abstraction constructs, and semantics-based state- and behavior-management techniques. Altogether, the
cATN thus fulfills all identified requirements and—to our best knowledge—fills a lack amongst previous solutions. The
cATN supports rapid prototyping of MMIs by means of five concrete traits: its declarative nature, the recursiveness of the underlying transition network, the network abstraction constructs of its description language, the utilized semantic queries, and the utilized lexicon. Our reference implementation is used in various student projects as well as master-level courses and shows that non-experts can effectively implement MMIs for non-trivial application areas like virtual and mixed reality. The
cATN is available for researchers [
51].
In our ongoing research we plan to further formally analyze the performance of the proposed concept under realistic conditions with respect to typical real-time constraints of interactive systems. Moreover, we intend to evaluate the API usability of the cATN ’s description language and its network abstraction constructs. Finally, we aim to research the practical limitations of a universal multimodal interface that is theoretically supported by the abstraction layers utilized in the cATN.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}