1. Introduction
Our perception of the world is formed in the first phase of our growth, in our childhood, by means of experiences primarily done within the family and then within the surrounding community [
1]. Nevertheless, this paradigm of knowing the world does not end in this early stage; it continues along all our life, putting us in front of different and always-changing challenges which make us aware of objects and events and conscious about relations and behaviors. One of the major issue in the field of cognition (and experience-making), is that we not always are able to re-create the vivid sequence of events just lived in our mind. That happens because, in some cases, we do not have enough comparable experience to refer to, thus aligning what we have just listened or viewed with our previous background. We somehow miss the mental cognitive paradigms to understand, and then explain, what just experienced. This usually happens when we face something new or far from our daily life, that is not easy to comprehend for our mind and, therefore, difficult to include into our matrix of life’s connections [
2,
3].
In this scenario, the role of digital technologies can be extremely important: they can accompany users in the process of meaning-making, with a pluralism of communication strategies and cognitive expedients, supporting users’ memorization and elaboration processes. The fruition of the past can be really enhanced and supported by digital technologies so to provide a reliable and tangible experience. The latter emerges indeed from the integration of various aspects that connote an individual: a person’s primitive senses, the ability of perceiving the world around him, the actions asked to be performed in a specific environment, the motivations that lead him to understand what to perform, and the cognition processes involved (influenced by feelings and relations). A meaningful experience arises “from the integration of perception, action, motivation, and cognition into an inseparable, meaningful whole. It is a story, emerging from the dialogue of a person with her or his world through action” [
4]. Only a meaningful experience can guarantee a concrete moment of understanding and because direct actions, feelings, and learning are strictly connected [
5,
6] in what can be called ‘experiential learning’ [
7].
In order to live such an intense experience, technologies need to be “invisible” for users [
8]: they do not have to perceive the digital application separated from the cultural good-neither to be a substitute of it. To pursue such an objective, we need to imply usual communicative and mental strategies like (digital) storytelling and dramatization. From a cognitive point of view, this is possible by working on users’ perception: the latter refers to a process of significance that our mind activates once in front of something that need to be absorbed, interiorized, and understood by a person. It can be either an immersive virtual scenario to be explored through head-mounted displays (HMD) or immersive projections. Nevertheless, perception means an awareness of something, whether it is a vision or a sensation [
9]. From a technical point of view, instead, this is not always easy to fulfill because of usability constraints, quality, and quantity of content delivery and exploration mechanisms (game-alike, free exploration, storytelling-driven, etc.). The typical features of storytelling and dramatization (like sounds, visual imagery and gestures) are indeed tied together by the use of digital technology, especially virtual reality (VR), but this task is difficult to accomplished because it always requires a balance between such aspects. Furthermore, interactivity plays a major role in the process of meaning-making and it is even more important if we operate within the cultural heritage field. We could finally answer to questions like “How easy it is to imagine how Rome would have been under the age of Augustus or what the Sforzesco Castle was like in Milan in Medieval period?”, “How would the columns of the Pantheon in Rome have looked in the past?”, or, more, “How would the Byzantine trulla of Athens have appeared in its period of maximum splendor?”. VR is surely a technique—but also a strategy—which helps answer such questions by introducing the possibility to feel deeply immersed in an altered world, sharing emotions and sensations.
The main contribution of this work is thus to present a novel game model (
μVR): it allows the crafting of immersive VR applications targeting re-contextualization activities which ask users to relocate virtual cultural objects in their former locations. The proposed model employs real-walking locomotion techniques combined with adaptive multi-scale approaches-where users will deal with their proportion in relationship with the surrounding 3D environment. We will first describe in
Section 2 related works in re-contextualization applications and space-related issues in immersive VR locomotion.
Section 3 will then present and formalize the
μVR model, introducing all components and actors involved including the definition of unsolved volumes, reachability, solvability, the
μ operator, and their motivations. In
Section 4, we will introduce a case study and related implementation of the model on modern game engines. In
Section 5, we will finally test and validate the model on real users. The Conclusion will close the contribution together with further developments on this research line.
3. μVR Model: A Formalization
The latest attempts push the research in the above mentioned direction: finding a way to minimize the motion sickness of users when exploring the 3D environment, while enhancing their sense of presence and augmenting their understanding of what they are experiencing. Given that the focus is on the quality of the virtual experience, the very first goal of the proposed μVR game model is to remove any kind of virtual locomotion technique (e.g., teleport) by instead exploiting the physical tracked area and real walking techniques combined with game state and world scale. The following section will define and formalize the μVR model and its components.
3.1. Item
We first introduce the item game actor I and its components, defined as
An item
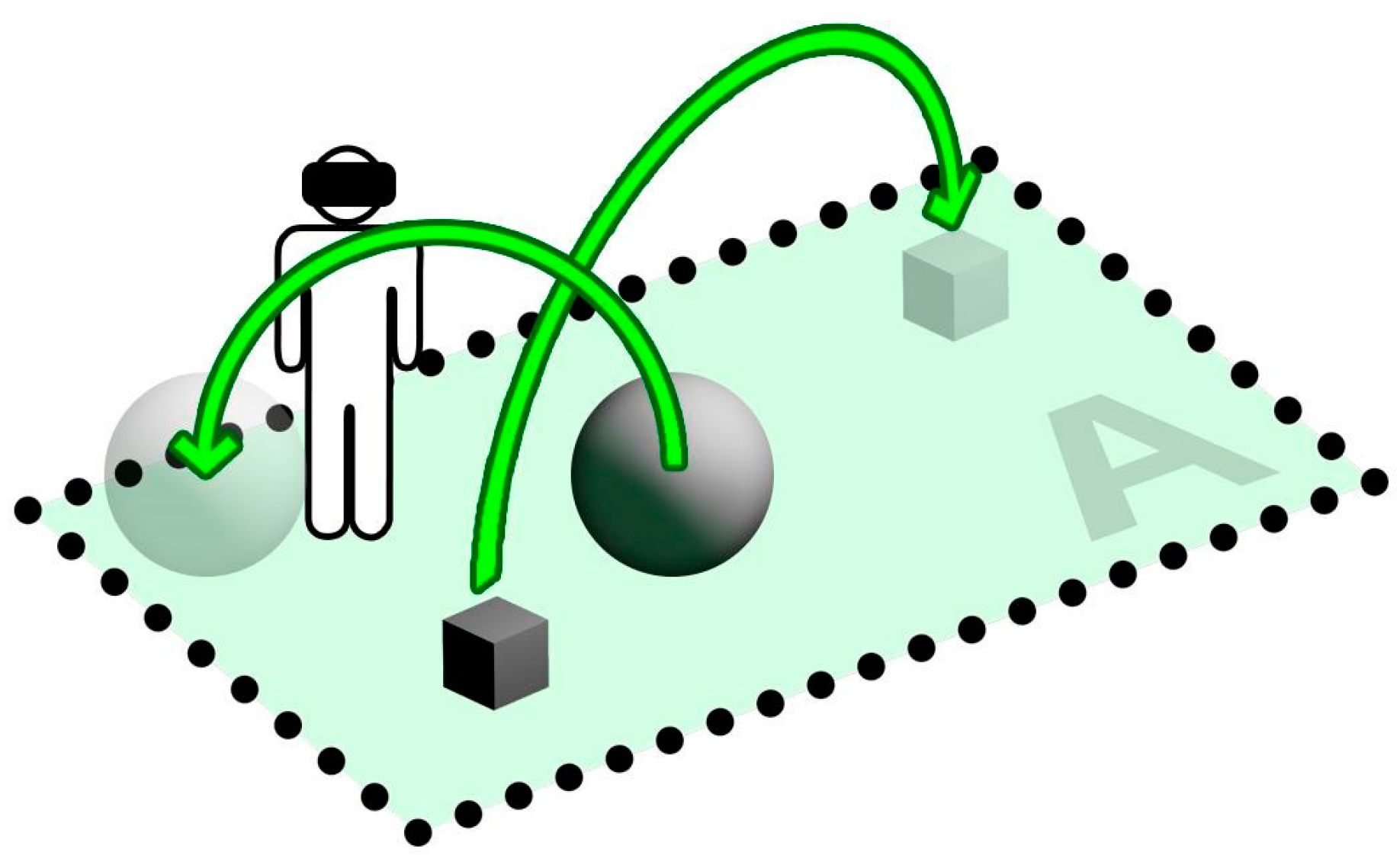
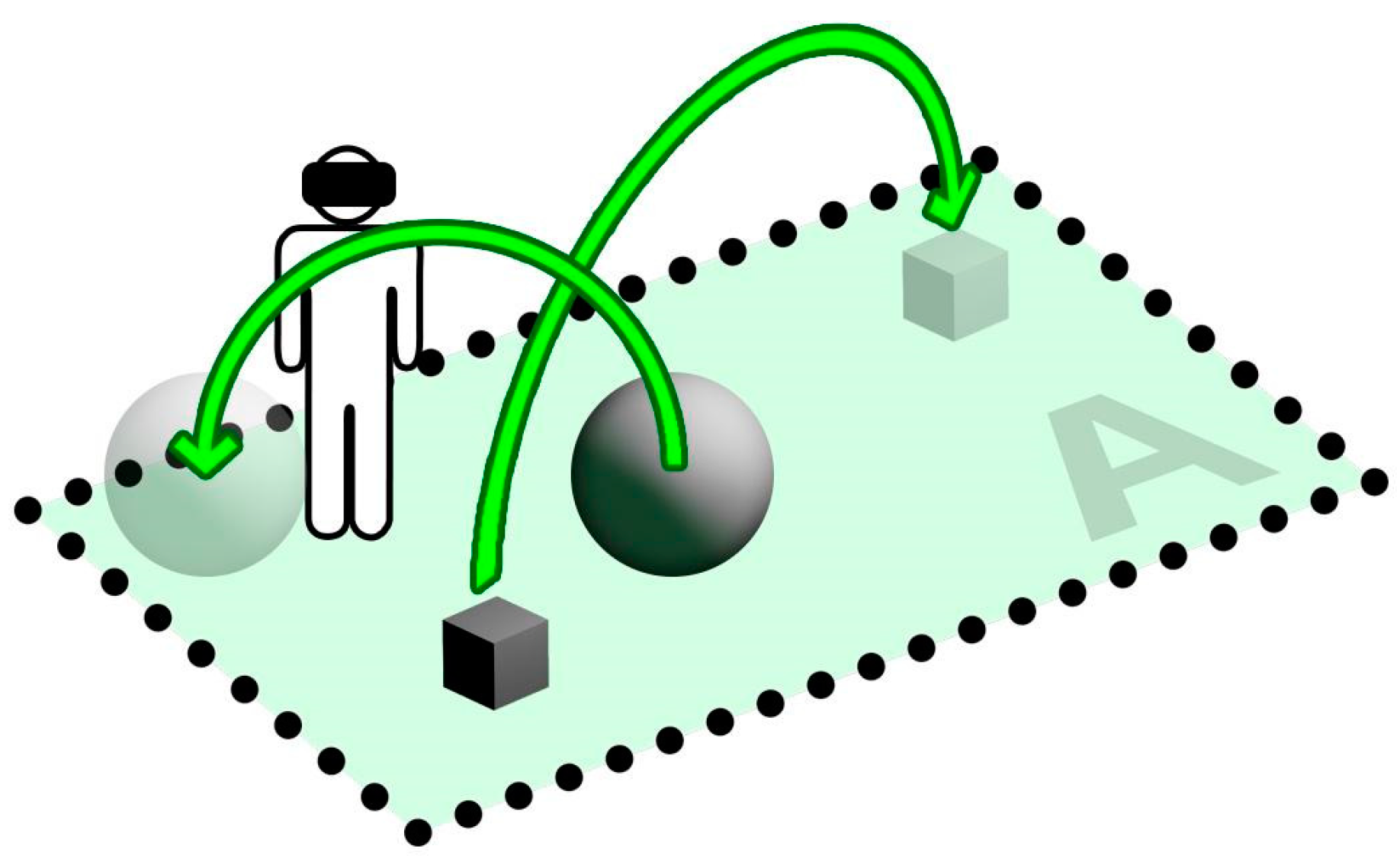
I in the model is a dynamic element: it has a 3D representation (a 3D model) in the virtual environment and it may change location and orientation during the session by means of user interaction (manipulation). An item can in fact be moved by performing a grab action through a 6-DOF controller or bare hands (e.g., using hand tracking sensors such as attached leap motion devices), thus modifying its current location and orientation within the virtual space (
Figure 6). In order to enhance the overall sense of presence, physics effects (such as gravity, collisions, etc.) are generally applied to such items during the session, in combination with haptic capabilities of VR controllers (e.g., rumble). The starting location and orientation of the item are represented by O (origin) while T represents the target location and orientation. Notice O and T are actually compound objects (standard 3D transforms), including location and orientation. Both O and T locations rely on the playable extents of the given virtual environment. The item state ◩ is binary (‘solved’ or ‘unsolved’) and it is initially marked as ‘unsolved’ (⬜). The game model allows to query a given item state on demand at any given time during the session. From a cultural heritage perspective, the ‘solved’ state corresponds to the item placed at its intended location (e.g., placing a roman column in its original spot in a temple).
We define
d as standard 3D euclidean distance between item location and its target location, specifically
dstart is the initial distance (when the game begins) between O and T locations
When a user performs a grabbing or manipulation action on the item, the current distance
d to its target location clearly changes: if said
d is below a certain threshold (e.g.,: snap tolerance), the item state is marked as ‘solved’ (⬛). Furthermore, we define the item unsolved volume
V as the 3D bounding box defined by current and target locations: the initial unsolved volume
Vstart is obviously defined by O and T locations and the item bounds (
Figure 6, right). Note that
V can shrink (the item is closer to its target location) or even grow (item far away from its target). The latter can be limited at implementation level, for instance by capping growth to a maximum distance or within specific boundaries.
3.2. Global Unsolved Volume
Within the game model and a given virtual environment, we generally deal with a set of items𝕀, thus the set of all dynamic entities that can be rearranged by user intervention
Notice that at a given time during the game session, only a subset of 𝕀 is unsolved. For instance, with a set of five items we may have following state of 𝕀 at a given time
We thus define global unsolved volume𝕍 as the additive expansion of unsolved volumes
Vi for each single item in 𝕀
This mathematically means the size of 𝕍 will, in general, shrink during the game session—but never grow—due to decreasing number of unsolved items. At the beginning (initial game state) all the items are marked as ‘unsolved’: if the number of unsolved items equals 0 and other custom game conditions are met, the game ends (it is declared won).
3.3. Reachability and Solvability
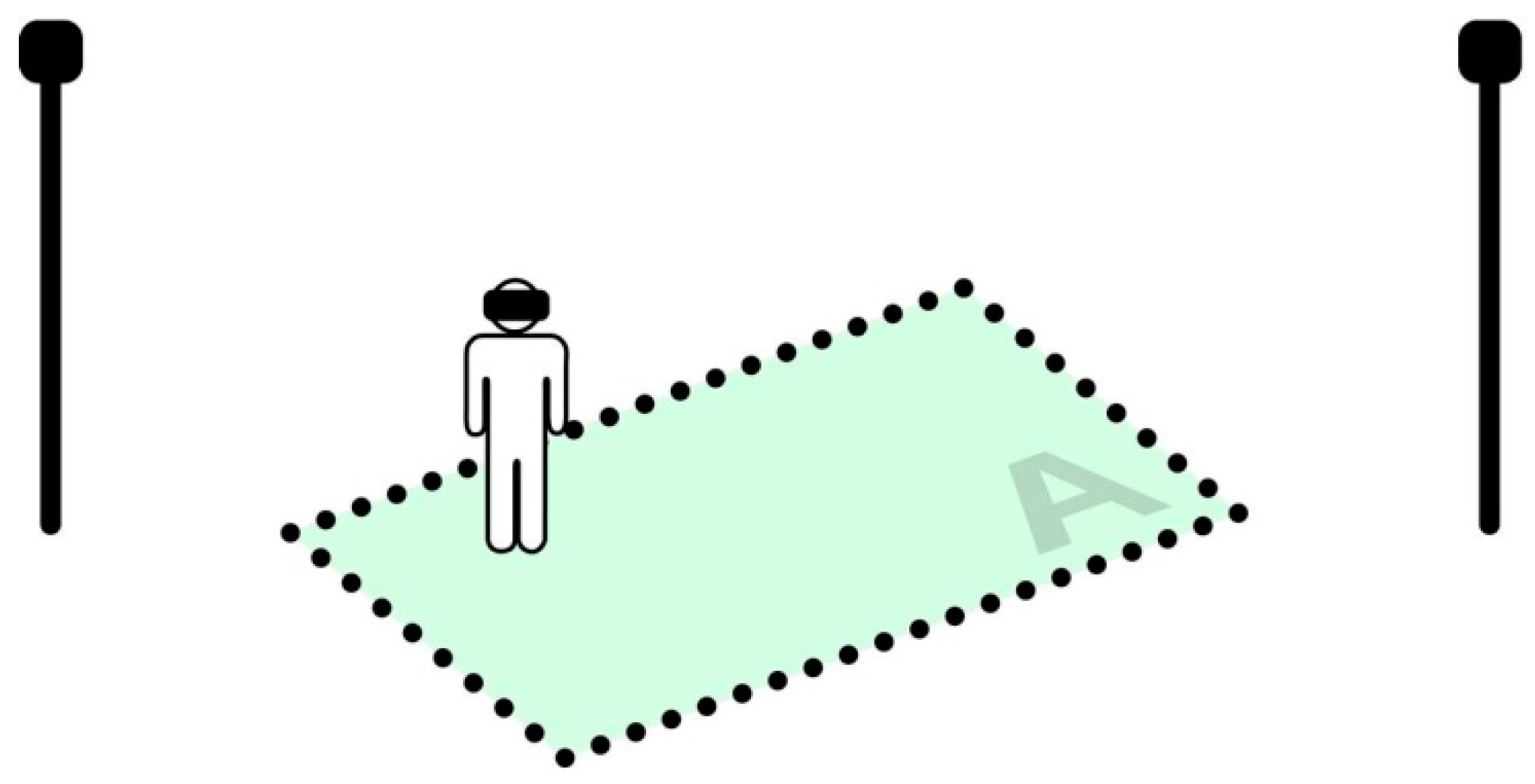
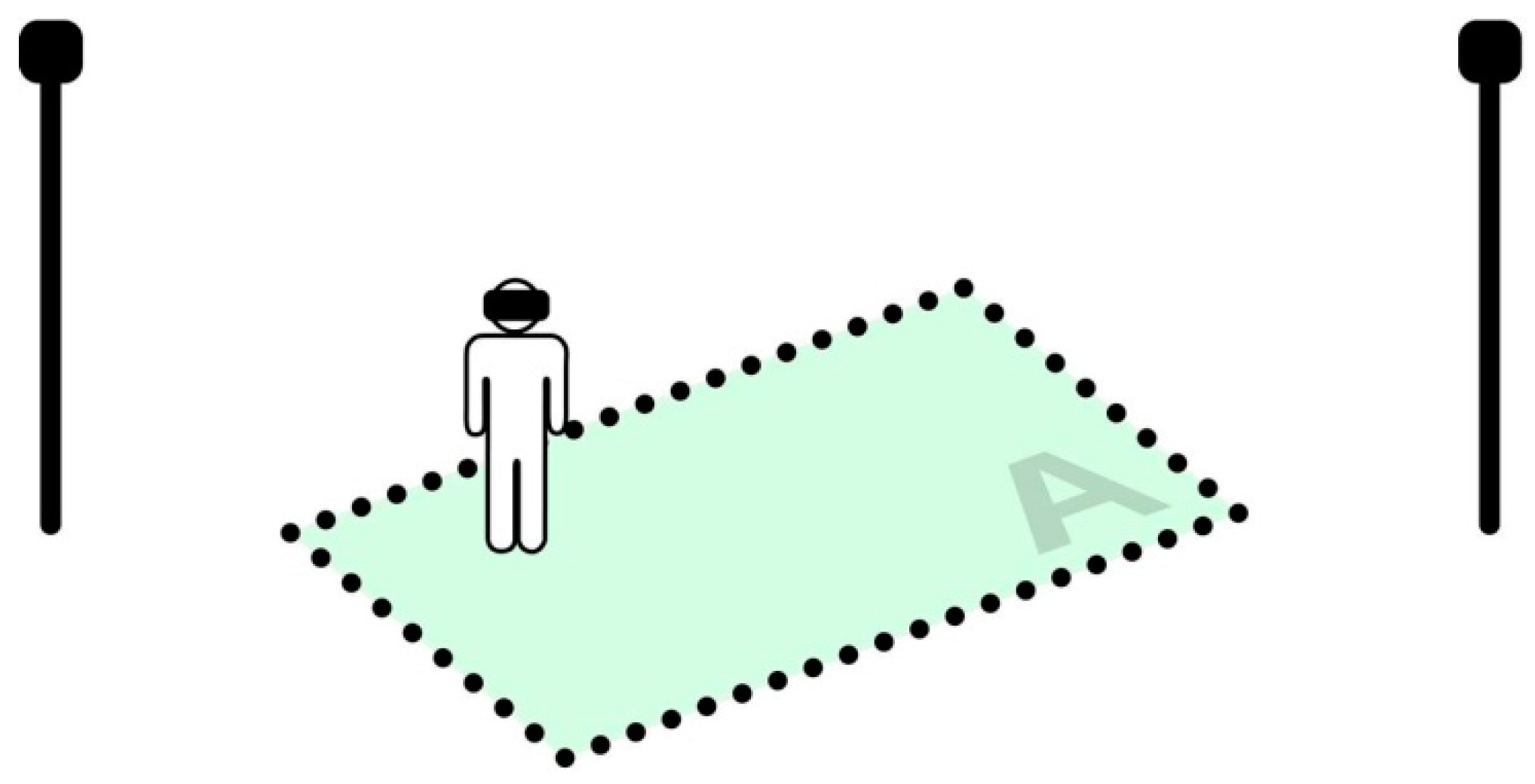
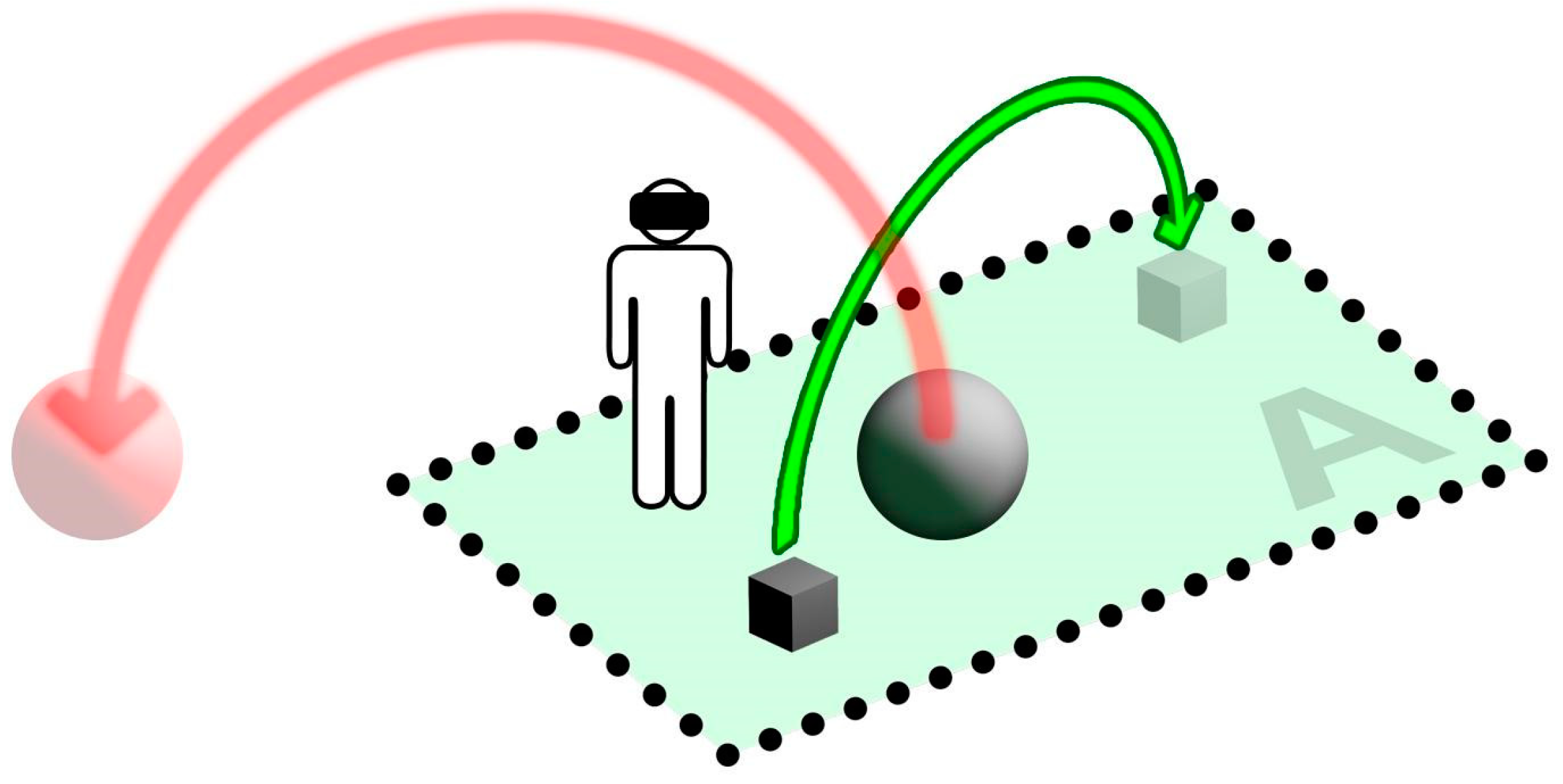
We define an item as ‘reachable’ if its current virtual location relies inside the physical (real) tracked area. This means the user is able to perform the grab action by performing a physical movement without any kind of virtual camera locomotion. We similarly define an item as ‘solvable’ if its target location relies inside the tracked area (
Figure 7 and
Figure 8). At this point, we have all the ingredients to define two crucial properties of
μVR model
At any given time, each unsolved item is always reachable;
Each unsolved item is solvable by user interaction.
The previous rules present an important constraint: such properties hold only if all items’ unsolved volumes (the global unsolved volume 𝕍) are contained inside the physical tracked area—i.e., each item is reachable and solvable by the user. Due to our initial assumptions on virtual locomotion, this scenario vastly restricts the model to spatially small-sized 3D scenes (e.g., a virtual table with a few items to rearrange). This is the main motivation for the μ operator that is introduced in the following section.
3.4. The μ Operator
The μ operator performs a liquid and adaptive miniaturization of the user each time an item is solved—i.e., when the user correctly placed a given item onto its target location and thus made a game progression. The basic behavior of μ consists in computing a specific set of VR parameters depending on 𝕍 (global unsolved volume). The algorithm computes a world scale factor (s) that satisfies the property of current 𝕍 entirely fitting inside the current physical tracked area A. Thus, on each ‘item solved’ event, the virtual world scale s and base VR position b (the virtual location of physical tracked area center) are recomputed.
Such transformation of virtual world scale and base position can, for each progression, fully exploit the physical tracked area in order to interact and manipulate items, without employing virtual locomotion techniques. For instance, s = 10 means the user is 10 times bigger compared to the virtual environment, thus objects are perceived 1/10th of their original size. There is more involved from a spatial perspective: the game progression offers a unique way to perceive the same virtual environment at different scale levels (reference frames) on each iteration, whenever an item is solved. Here the user’s perception is at the same time augmented and proportioned to one’s current reference frame: user can do ‘more’ in terms of accessibility compared to normal daily actions, but are always bound to a well-known cognitive structure. The influence of users’ bodies on perception has been originally introduced by Gibson [
42], who stressed that individuals do not perceive the environment, but rather they perceive the relationship between their body and the environment. Following this assumption, our user scale determines the range of potential actions we can perform within the environment, and thereby, defines the interactive value of the items of which our (virtual) environment is composed [
43]. Therefore, the
μVR model takes advantage of such cognitive paradigm to allow users to perform specific tasks.
3.5. μ-Progression
A game progression in the μVR model (μ-Progression) can be represented as sequence of game states, each tightly bound to a specific 𝕍
For each step (game state) in the chain, each transition (→) results in a decreased number of unsolved items. Furthermore, since at each stage multiple items are available at user reach, different paths are possible from 𝕍start to 𝕍end.
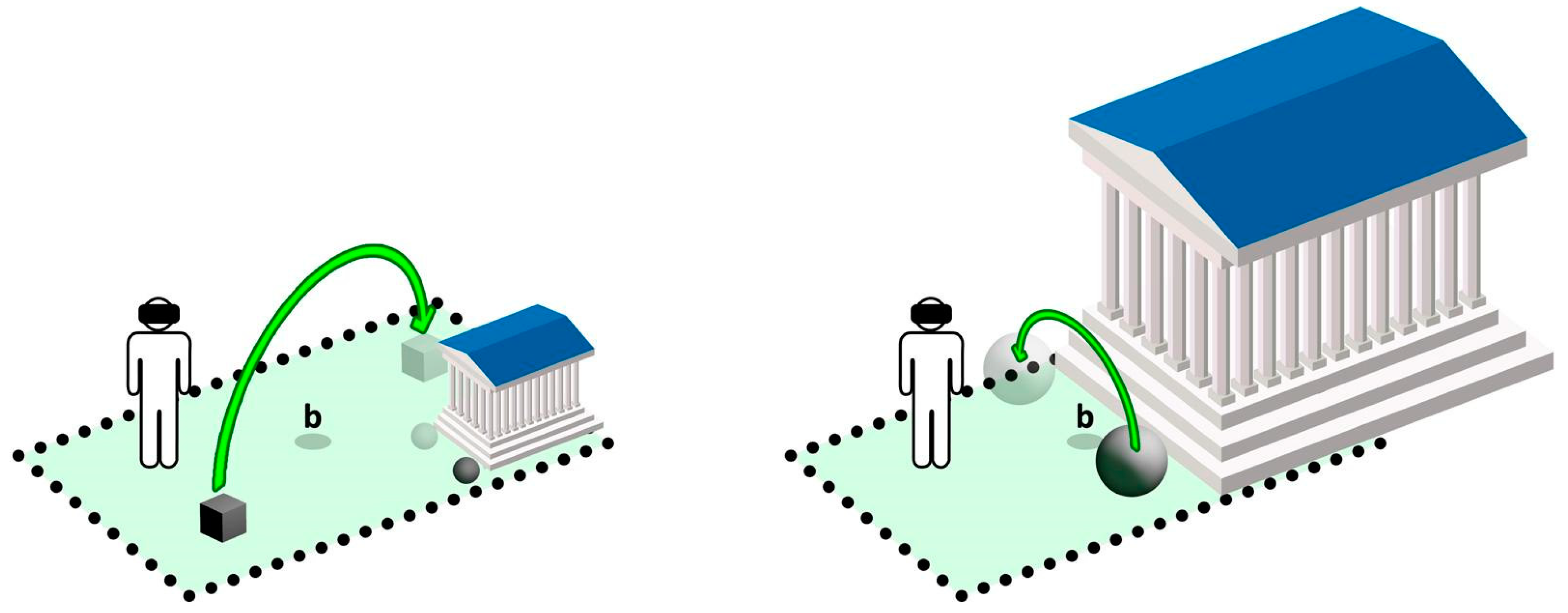
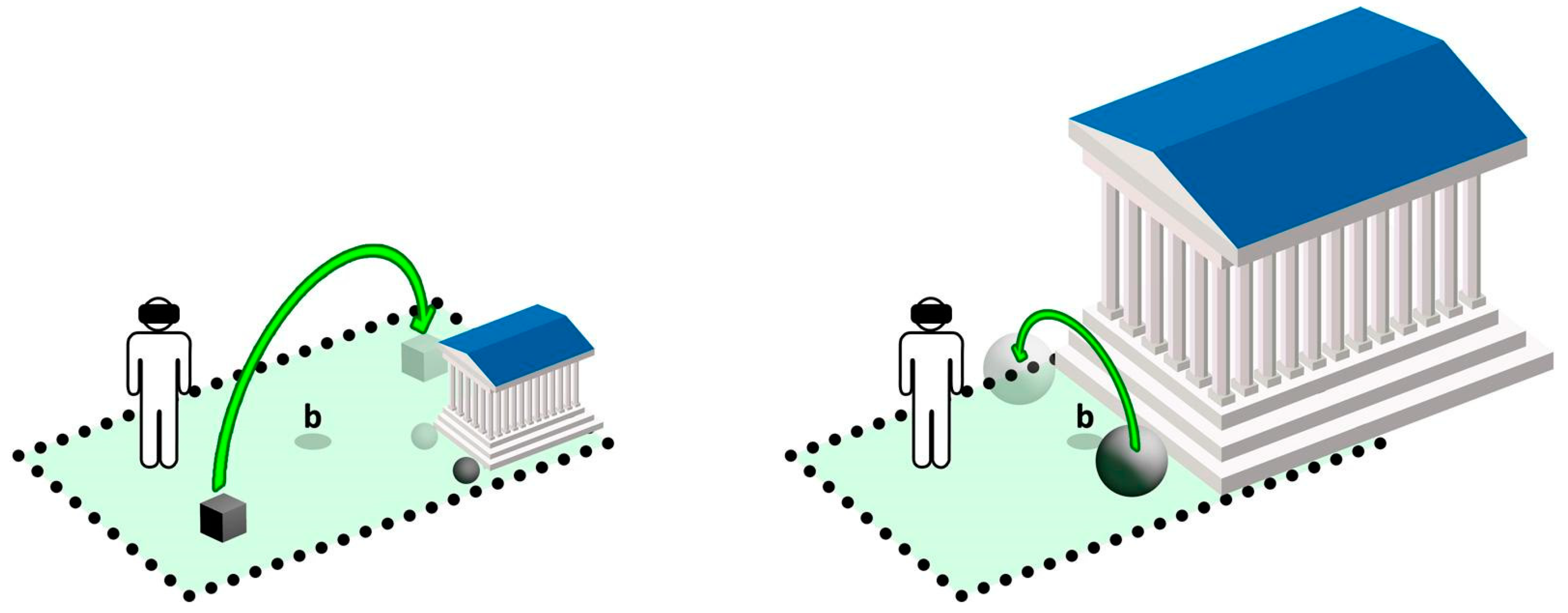
In
Figure 9, a sample transition to a new state is shown: the user (left scheme) first solves the cube item, a transition lead to the right scheme, where user can solve the sphere item. Notice how the scale factor of virtual environment (including items) and virtual origin
b are changed according to the size of tracked area, reachability and solvability of active game items. At each stage, the user is ‘descending’ (shrinking) or expanding towards the correct world scale, by solving items through real walking techniques inside the tracked area. Furthermore, it is important to notice that different progression routes are possible: for instance the user in 𝕍
a can also solve the sphere item first and then solve the cube. Due to presented multi-scale mechanics, at each step (performed by a
μ computation) we guarantee a decreased scale factor (s) after each transition, such that
Until all items are solved, and world scale is set to 1, thus restoring and ‘rewarding’ the user with the correct scale level of the virtual environment.
4. μVR Model Application: A Case Study
4.1. The 3D Reconstruction Environment
The case study adopted to test and validate the
μVR model is the tridimensional reconstruction of the Forum of Augustus. It was built by the Emperor Augustus between the end of the first century B.C. and the beginning of the first century A.D. (probably the construction begun after the 30 B.C. and was inaugurated in 2 B.C. when it was still unfinished.) and it is the first of the Imperial forums of Rome. It was a monumental complex which hosted the majestic temple of Mars Ultor (the Avenger) framed by two porticos supported by corinthian colonnade which could have served as the courts of justice, and behind this colonnade there were four semi-circular exedrae (two for each side of the forum) probably used for educational activities (
Ginnasi). The back wall of the porticoes and of the exedrae were articulated with columns framing a series of rectangular niches adorned with a rich variety of different statues. At the end of the northern portico, there was the Hall of Colossus, a decorated chamber which hosted the colossal statue, of approximately 11 m tall, representing the Genius Augusti (the protective deity of Augustus) [
44]. Nowadays, the remain of the Forum are still visible and well preserved in the archaeological area of the Imperial Fora (
Figure 10a,b) and all the findings discovered during the excavation performed during the last century (statues, architectural elements and decoration) are shown in the nearby museum of the Trajan’s Markets-Imperial Fora Museum.
Such archaeological context was reconstructed by the CNR ITABC in 2015 in occasion of the “Keys to Rome” international exhibition organized by the European consortium V-MusT, the largest European Network of Excellence on Virtual Museums (v-must.net). It focused on the museum collections belonging to the Roman Culture and mainly to the Augustan age (
Figure 11a,b).
The virtual reconstruction of the Forum was the result of a long and accurate work of digitization, related to museum’s objects, and 3D modeling of the hypothetical historical environment. The models created for Admotum are currently under revision both from an historical and a technical point of view. The former is aimed at updating the model according to recent archaeological discoveries; the latter is instead addressed to adapt the digital assets for modern game engines. However, the steps for creating historical assets based on sources (historical, archaeological, architectural, and so on) is based on a scientific workflow adopted and developed within this laboratory [
45,
46,
47]. Reconstructing ancient architectures is always a challenge and an huge amount of data from different scientific domain need to be surveyed and blended together in order to achieve reliable reconstructive hypothesis which will be then translated into a 3D models. In our case, first, several typology of archaeological data, such as previous reconstructive hypotheses, drawings, pictures, bibliographic resources, excavation data, were analyzed to design the building re-enactment. Afterwards the reconstructive hypotheses proposed, were discussed and refined with the support of experts from the Imperial Fora Museum of Rome and from the Superintendence of Rome. When not supported by historical sources or archaeological evidences, reconstructions were supported by formal rules, construction techniques, and roman modules or based on comparisons with other coeval imperial buildings.
Just after this, preparatory studies we started to draw up the 3D reconstructive models. The modeling was performed using computer graphic software; it allowed modelers to design 3D geometries with the support plans, sections, and profiles derived from technical drawings. On the other hand, some preserved architectural elements, such as the capitals of the Temple of Mars and the caryatid statues were designed using a virtual anastilosis approach. In other words, we first surveyed the fragments with scanning techniques and then, after integrating the missing parts in computer graphic, we relocated them in their original position. Once the drafted 3D model of the Forum was verified with the expert, the 3D models were optimized and improved using a ‘game-oriented’ approach (controlled number of polygons, atlas textures, physically-based rendering (PBR), materials, etc.); it was particularly useful for the real time output, allowing better performance for different game engines.
4.2. Pilot Test
Regarding the pilot test implemented through Unreal Engine 4 (
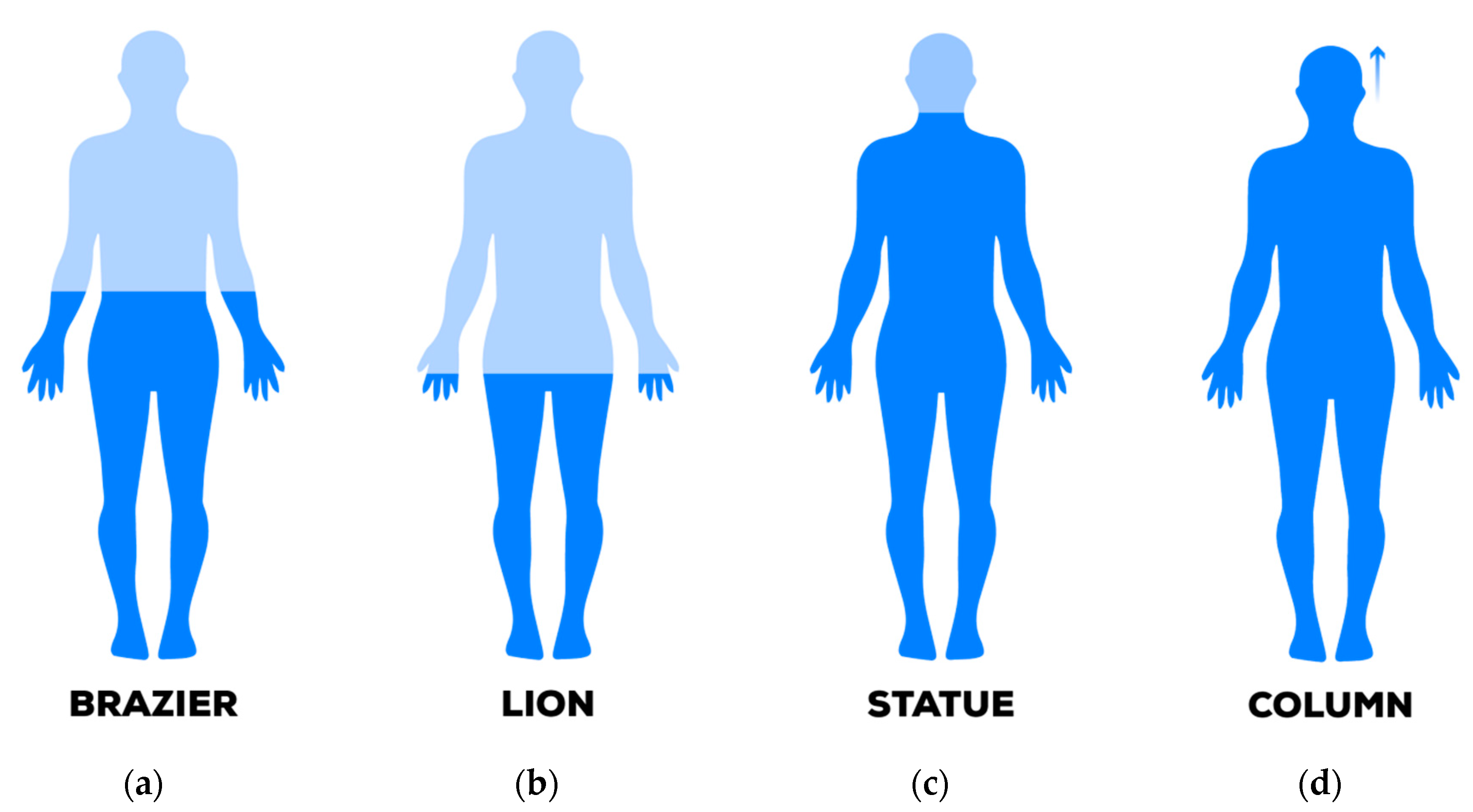
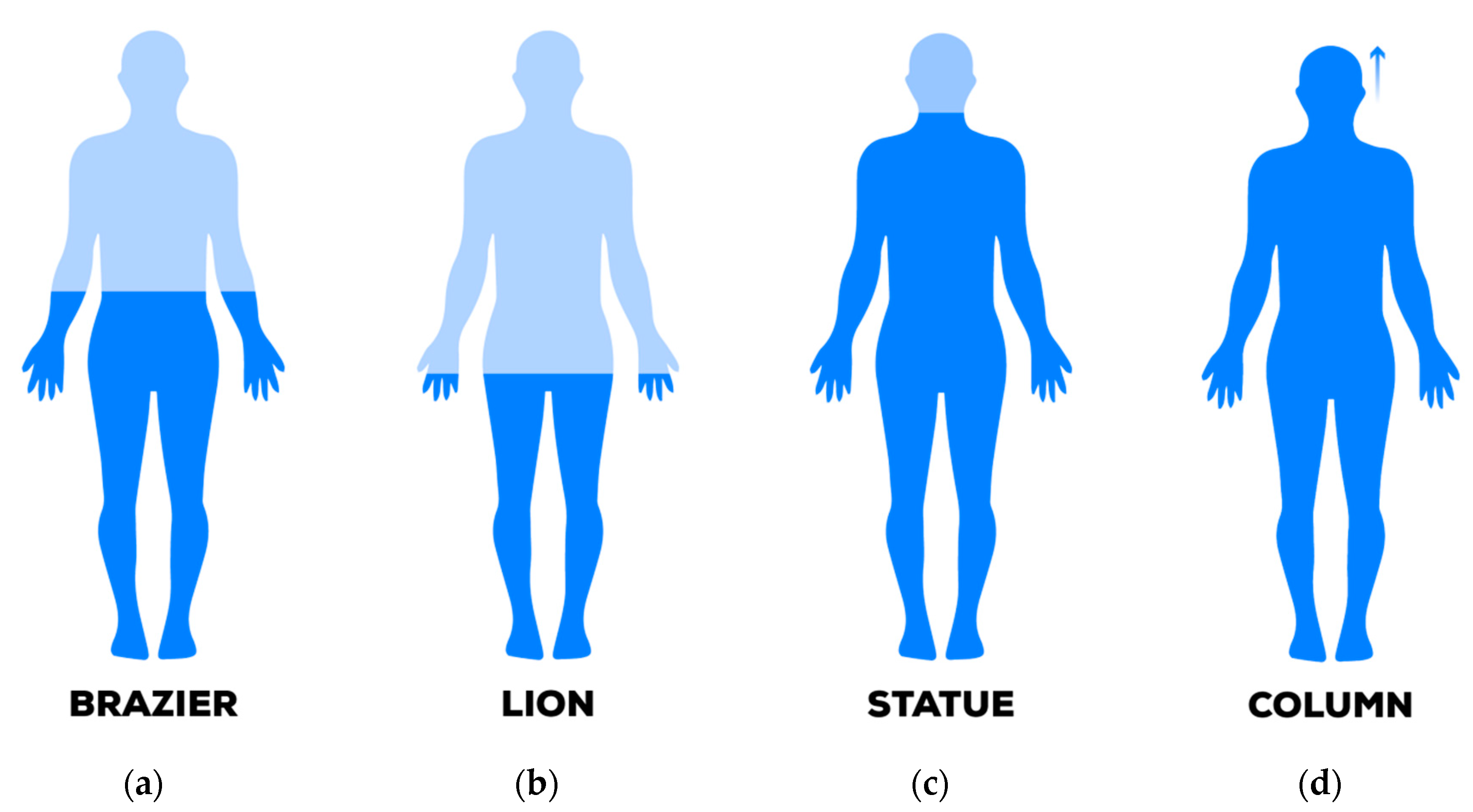
https://www.unrealengine.com), we selected and arranged a scene with n.4 game items (
Figure 12). They had different scales: specifically a column, a statue, a brazier and a lion, employing both visual and audio cues during the experience.
From a visual perspective, each item had a light animated string (a sort of ‘Ariadne thread’) to provide a subtle and continuous hint for current item target location. Due to stereoscopic perception, such a hint can offer valuable support during the immersive fruition on where the item has to be placed in order to solve it. Furthermore, each item’s starting location had a compass indicator providing an additional cue at the very beginning (
Figure 13a).
For audio cues, we used both spatialized sounds on unsolved items and a light background track with a dynamic pitch, depending on current world scale. The track playback was in fact initially slowed down and gradually restored on each game state progression, until game completion (audio pitch fully restored).
Since the pilot test employs physics, we took special care of collision geometries for items and static environment also to enhance the ‘physical’ aspect of the experience during manipulation tasks. Due to different scale levels, gravity plays also a major role during manipulation tasks, since it impacts physics behavior (e.g., items fall slowly and react differently at larger s values) thus providing additional cue on current world scale.
The chosen items arrangement for the experiment and their bounds (
Figure 13b) produce an initial unsolved volume 𝕍 and a computed scale s = 74.4. This means at the very initial stage of the game progression, the column item—for instance—was about 20 cm tall.
6. Results
Based upon the feedback collected on 27 testers, results were really interesting and presented specific issues not supposed by the developed pilot test.
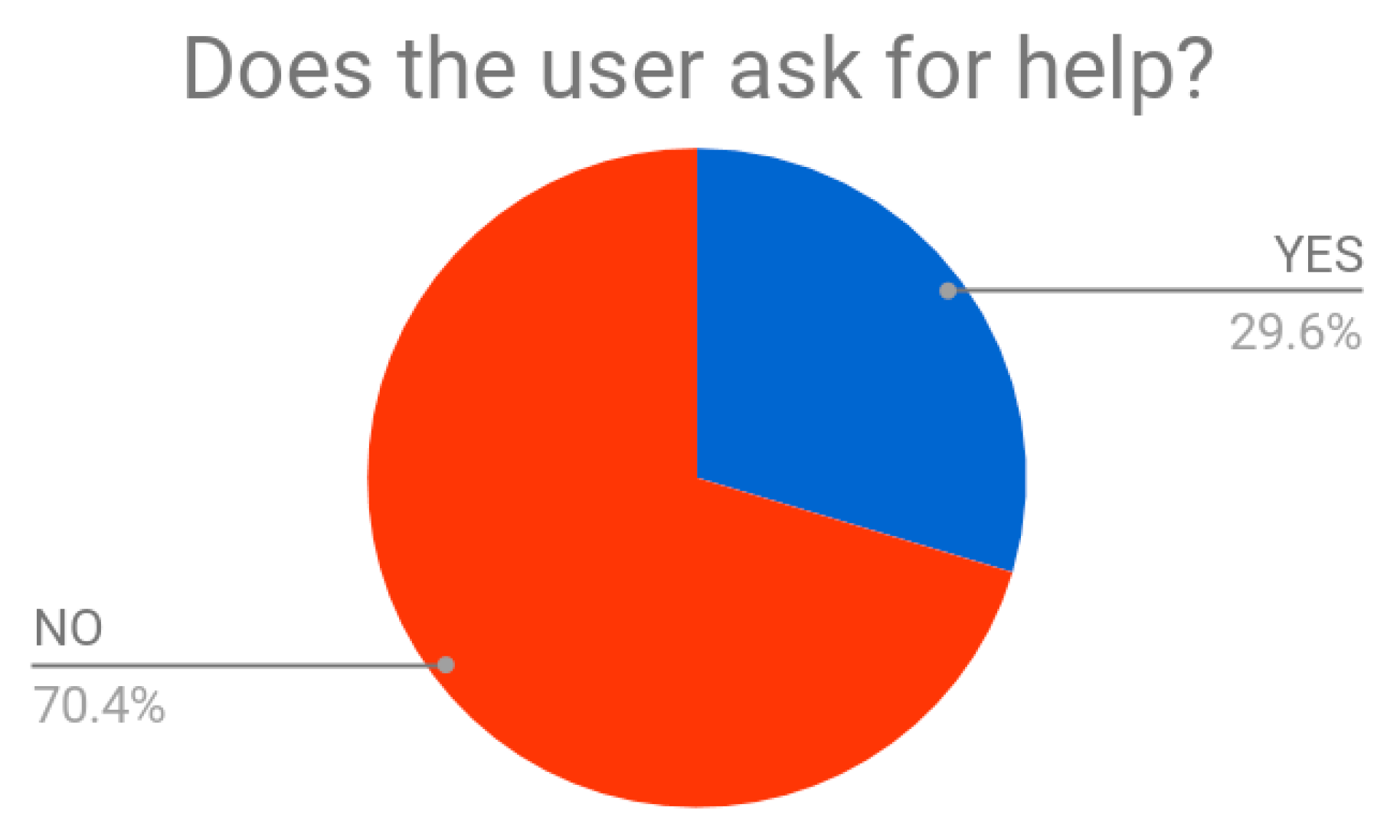
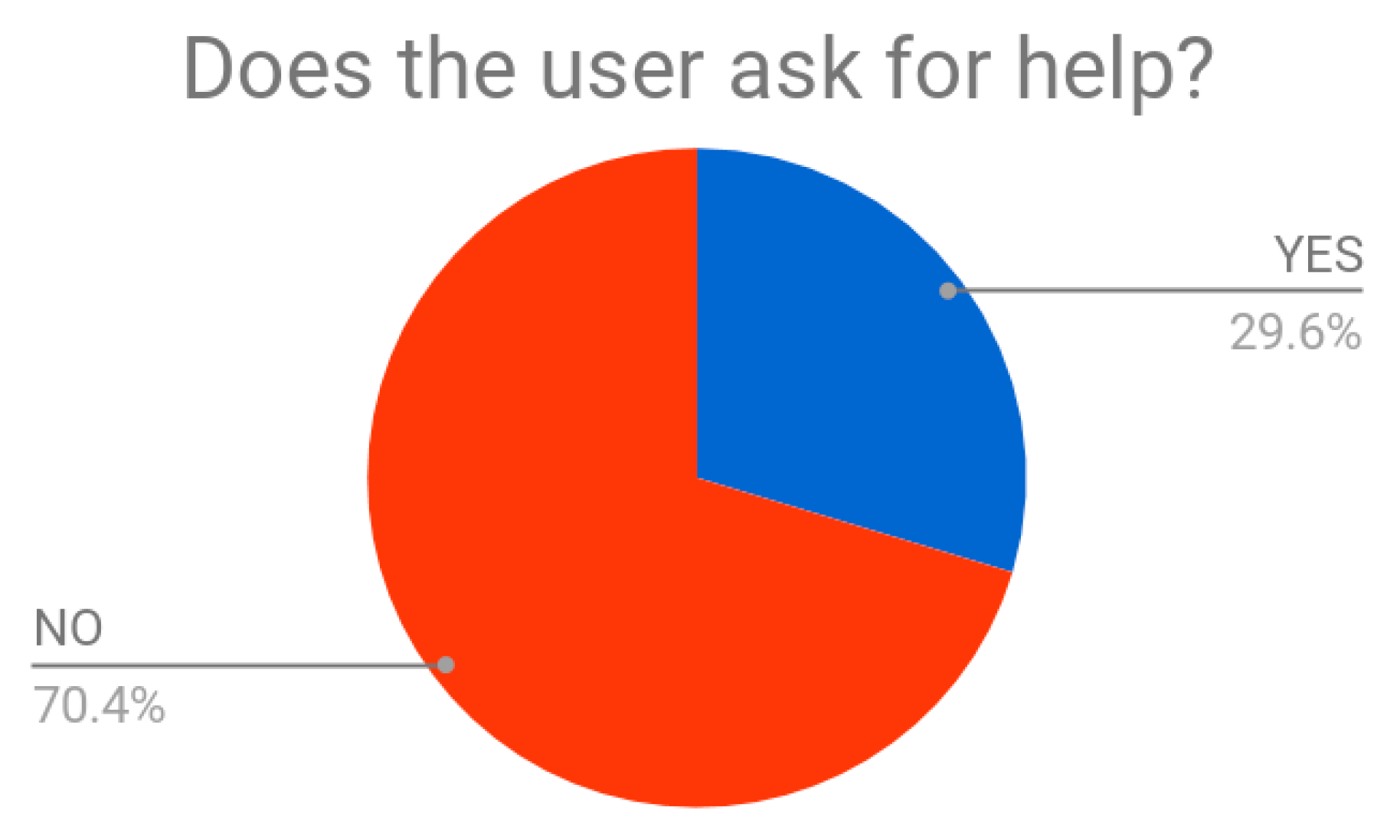
The target group resulted to be mostly composed by female of about 16 years old. The average time needed to experience the test scene was of about 1.35 min. Almost all the testers successfully accomplished the task with no aid from external personnel. Just 30% of them were helped during the experience (
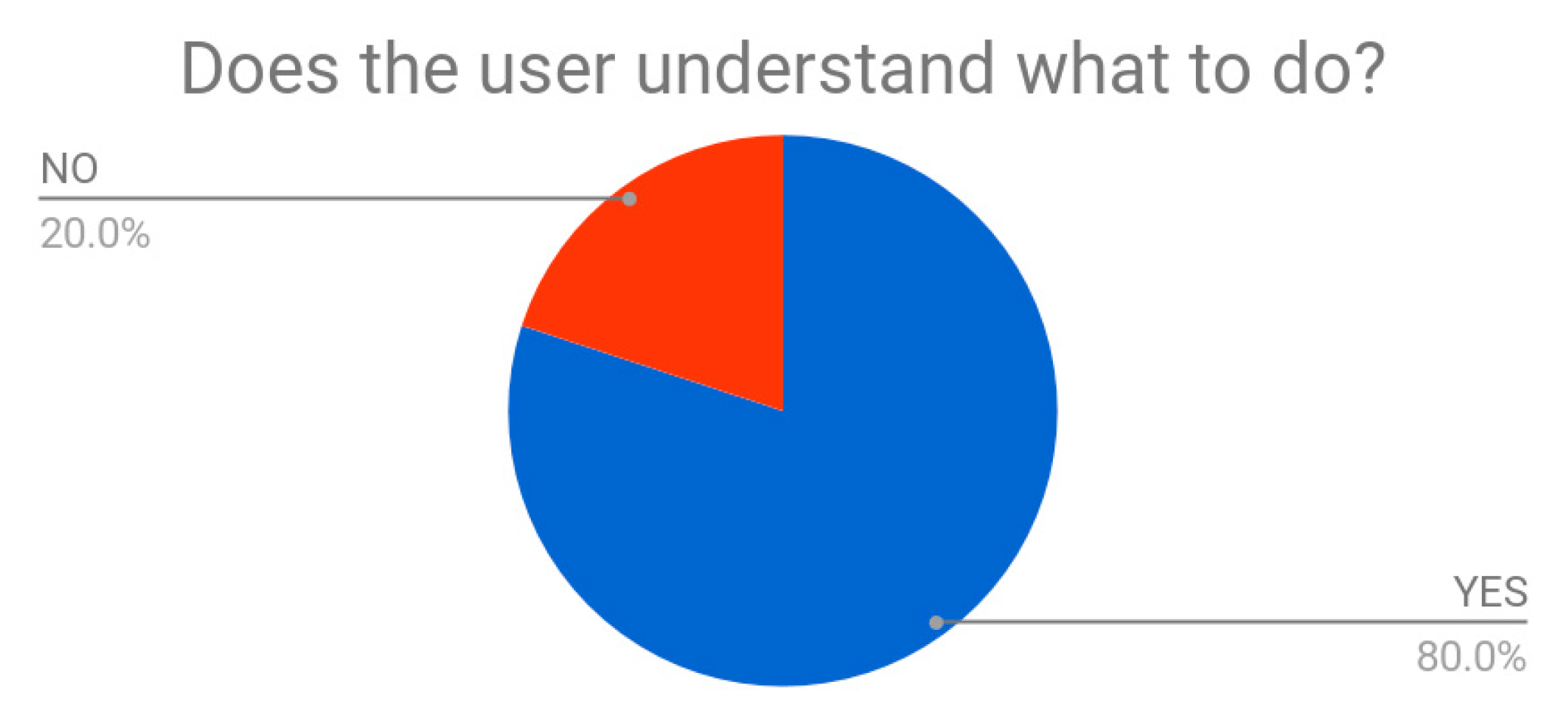
Figure 16), after specific request, especially in conditions of not clear visibility when they had the HMD on (students without glasses, large HMD respect to the student’s head…). Eighty percent of them quickly understood what to do in the VR (
Figure 17); this datum was also confirmed by direct responses of students who said at 100% they were able to ‘see’ how to solve the test. The contextualization process was easily activated in the testers’ mind through simple visual expedients: forms, colors, materials, and shapes; correct positioning was also got by means of logic, proportion attempts, correspondences, and recall.
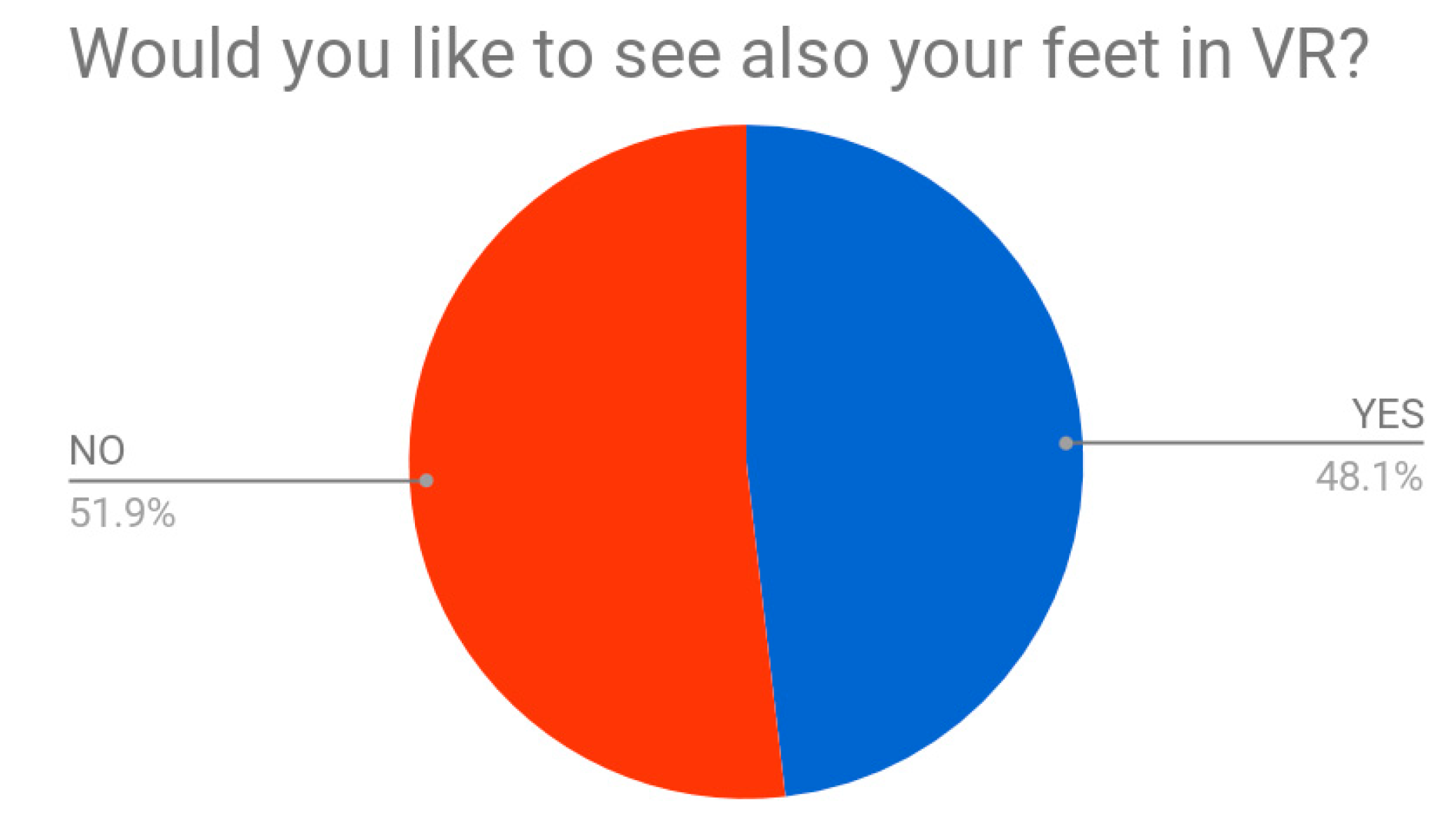
First impressions once they wore the HMD were interesting: exclamations like “I’m a giant”, “I’m very tall”, “I’m afraid of breaking something” reported a common feeling of preponderance of testers respect to the whole 3D environment. Here, the perception of the body is highly felt as hulking and oversized with respect to the surrounding architecture. Students seemed to move very softly in order to not accidentally ‘break’ anything in the virtual environment—like they were afraid of it. This datum is also confirmed by the fact that operator noticed that almost 86% of students just executed the task without really having fun. Developers supposed that testers might play with the items and the environment; instead, their behavior seemed really affected by dimensions: this does not mean that dimensions badly affected the tester’s behavior, but it surely had a weight in the overall experience. On this aspect, 48% students also affirmed that they would have liked to see their feet in the VR in order to have specific indication of where they were walking (
Figure 18). In our test, feet were not visible. This is interesting if we think about body’s correspondence in the 3D virtual environment: in the case of the hands’ gesture, indeed, the extent of the hands in the virtual world are useful for the tester to see and understand what to pick up, how to handle an item, and where to place it; so the same should work for feet, in order to understand in which direction the tester is moving, how fast or slow, and what he/she is stepping on. Such implementation is thus suggestable.
About the handling of the items in the VR, the 96% of testers said to have had a good feeling. Nevertheless, the operator, after the experience, noticed them performing the handling gestures again and the idea was that they felt the need to handle the items in a very delicate manner—as they seemed so tiny and easily breakable. This datum can be confirmed by the quotations they gave to each single item they collected in the VR (
Figure 19a–d). Students were asked to make an estimation about how such items would have been big or small in real life, with respect to a person. Answers were really curious and unpredictable: the average estimation of the brazier’s dimension was considered around half of a person (while in reality it is 150 cm high); the lion head, instead, was considered smaller than half of a person (while in reality it is 70 cm); the statue was estimated to be shorter than a person, about 150–160 cm (while in reality is 400 cm high); finally, the column was considered taller than a person, but that measure was far from the reality (500 cm high). These estimations surely do not match with real life architecture but gives a glimpse of how distances and proportions in VR change according to one’s body perception.
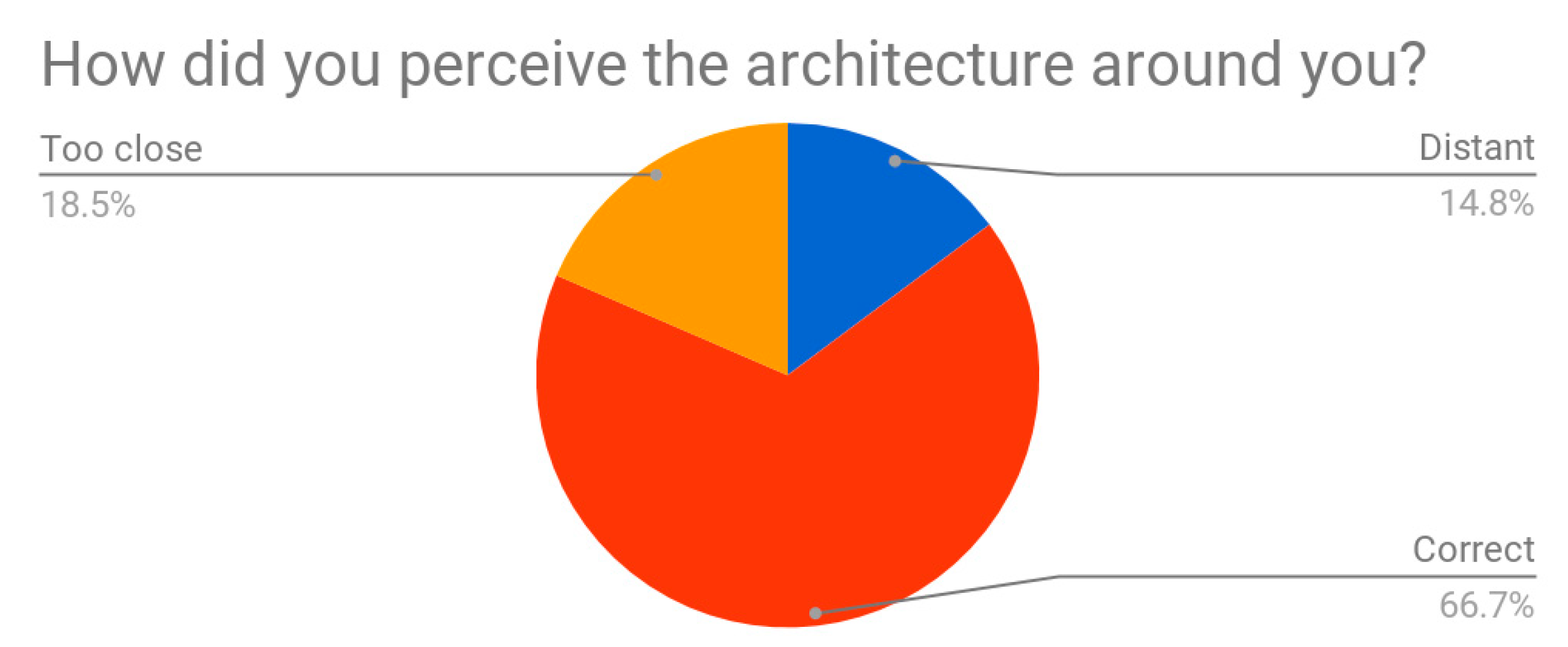
About visual imagery of VR and the proportions felt by testers, they affirmed to have perceived the architecture (the environmental space) as quite good (67%), even if 19% of them perceived it as too close and another 15% as too far. This is surely related to the virtual dimensions of testers inside the VR while they were performing the task (
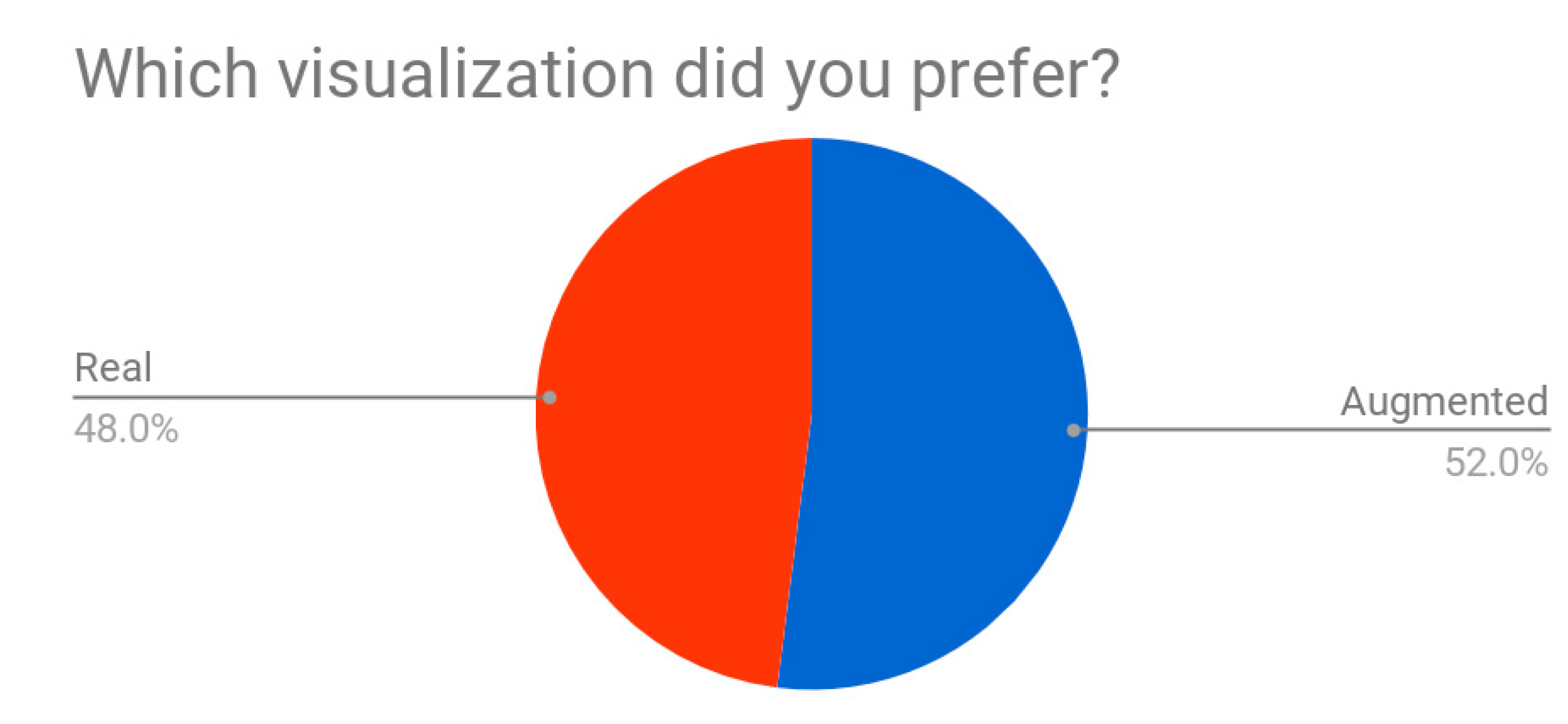
Figure 20): unlikely the balance between the virtual space and the virtual body changes in accordance with each item’s dimensions, the feeling of overimposition for certain testers remained high, finally giving them the impression of being “out of scale”. In general, testers preferred when they were giant (52%), even if a great percentage of them affirmed to love to be in the VR as in real life, with their current height (48%) (
Figure 21). Again, this datum gives us reason to think that testers generally feel more comfortable with their usual proportion paradigm instead of altered dimensions. Nevertheless, such aspects need to be further investigated.
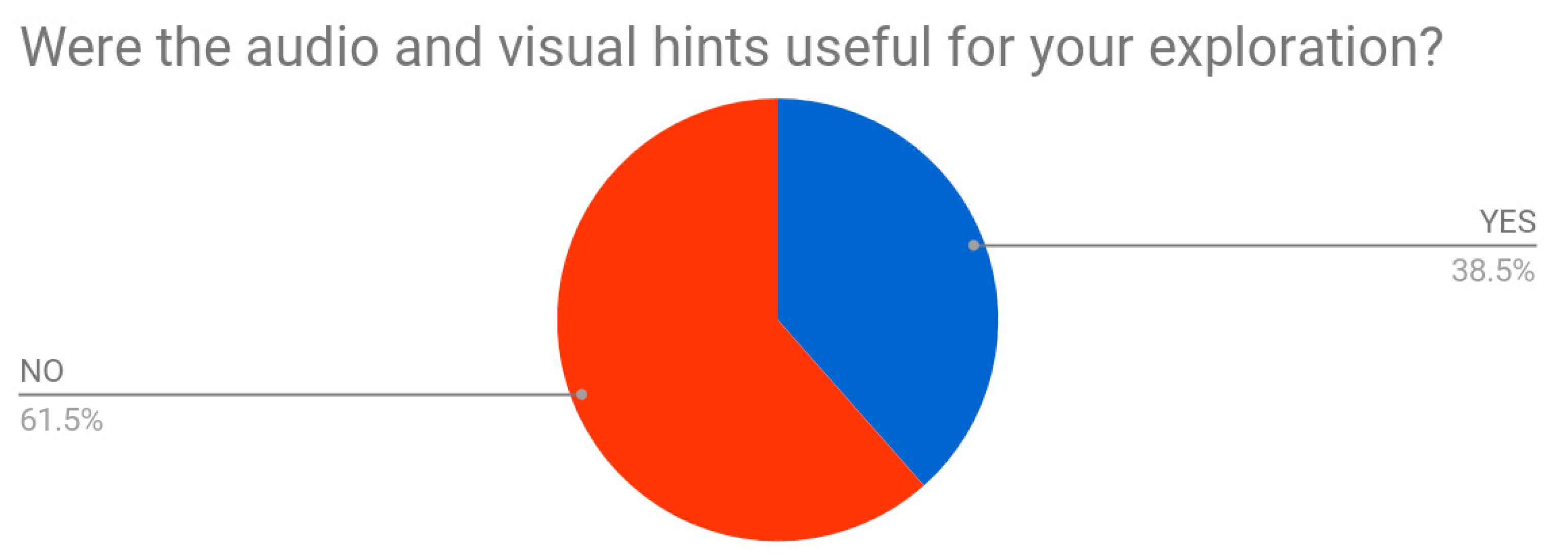
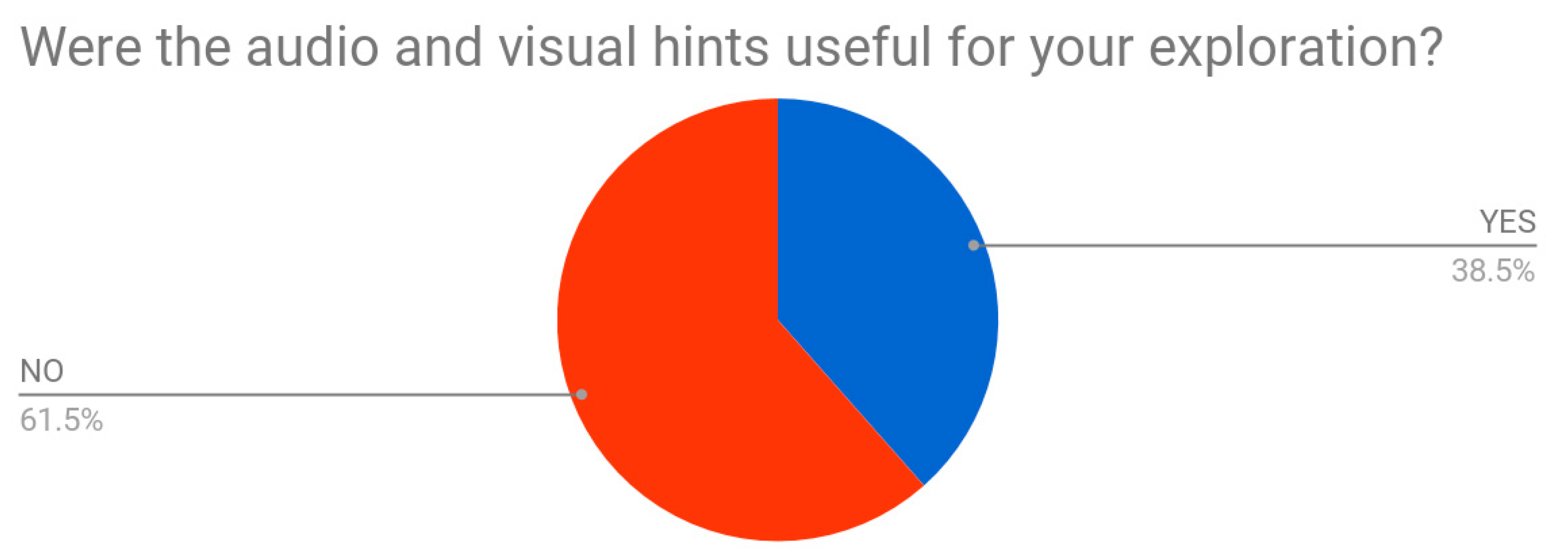
Regarding visual and audio cues—hints which should have helped testers in the resolution of the given task inside the VR—almost 62% of them affirmed to not have used them (
Figure 22). None of them noticed the compass indicator placed below each item indicating the direction to follow to correctly place it; all testers did put each item in the right position by simply using the reasoning and comparing forms, dimensions, and colors to their background notions. Speaking out loud, they proved to follow a logical mental pathway to place the item in the right location: throughout the observation of the surrounding environment, making comparisons with other similar objects, estimating dimensions and proportions, or simply drawing on everyday life experience.
In general, the majority of testers confirmed to the great usability of HMD and the deep sense of presence in the VR. They felt included into another separated environment, minimally influenced by other students or operators. Once they had taken off the device, they felt an ‘estranged’ sensation, like being snatched out of their present (as they directly mentioned); some of them had headache, others felt vertigo, but generally speaking 63% of testers affirmed to do not have problems with HMD. Almost 70% of them never used such kind of device before, although they knew of them.
All the students expressed the desire to test the scene again. Once they finished the experience, all the testers started chatting together to confront their feelings and perceptions. The operator had the impression of them being really enthusiastic and happy about the experience.
7. Conclusions and Future Works
The pilot test proposed here attempted to verify our main research question: how can we overcome the motion sickness in VR environment, which is the cause of the users’ low tolerance of the game-like mechanism? The solution we proposed through the μVR model took into account (a) the scale perception of each individual of the virtual environment as well as (b) the common paradigm of physical movements into real life experience. From a formal point of view, the pilot test did prove the robustness of the model by allowing reachability and solvability for each item, for each game state (reference frame) thus exploiting the full potential of the real-walking technique inside the physical tracked area to perform manipulation tasks, validating our assumptions. Due to the mathematical correlation between physical tracked area A and the game-driven unsolved volume 𝕍 of proposed model, a full hardware scalability of μVR is guaranteed. The μ operator and its progression mechanics in fact completely abstract from hardware equipment. The model adapts to different walkable space dimensions and it will suit all future advancements regarding HMD refresh rates, tracking technology and size (i.e.,: larger physical areas). This will allow us to craft immersive, multi-scale re-contextualization applications through such a flexible game model.
The obtained results also fueled several improvements and future directions for the
μVR model. Within game scenarios dealing with great differences in terms of items size and with special arrangements, few items could be really small. That does with respect to the scale of current game state, especially at the initial stages of the experience. For instance, the pilot test showed the lion item was almost never picked up on 𝕍
start, as the primary item (
Table 1), but just after few transitions. In the same scenario, if we deal with both urban and human scale recontextualization (e.g.,: an entire temple and a brazier), smaller items in a given 𝕍 may be inaccessible to manipulation tasks due to the world scale computed by the
μ operator. This is the main reason why a filtering operator could be introduced (
μ-Filtering) and investigated in order to perform a scale-based item selection within the current 𝕍, thus enabling items for user manipulation when they satisfy the filter.
The current model allows the unordered resolution of items (e.g., user can solve first A and then B or vice versa), so users can easily choose which virtual object to solve first, without influencing his gameplay. Rather, the gameplay arranges itself according to user’s selection. For this reason, another interesting direction is the investigation of items’ dependencies: specific items may depend on other items in terms of resolution. For instance, item A can be solved only if item B has already been solved (e.g., a temple roof and a statue on top of that roof). Future research may also investigate application of
μVR model to MCVEs [
38], thus enabling multi-user collaborative item solving in the same virtual environment. This may open very interesting game scenarios and derived modes where users perceive each other at different scales and cooperate to solve (re-contextualize) all the items. Such a direction could be implemented both in co-located or remote collaborative interaction models within computer supported cooperative work (CSCW). Given the stimulating feedback of this pilot with high school students, for the future we will plan other evaluations, taking into account different target group and an updated version of the promising
μVR model.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}