A Work Area Visualization by Multi-View Camera-Based Diminished Reality


Abstract
1. Introduction
- We present a multi-view-based work area visualization method that solves occlusion problems in hand-work scenarios.
- To achieve this, we propose to redesign an existing arbitrary viewpoint image generation method [8] as a core DR background rendering to recover views without undesirable objects (e.g., hands and tools).
- We conducted quantitative and qualitative experiments using real data to validate the performance of the proposed method.
2. Related Work
2.1. DR for Static Background
2.2. DR for Dynamic Background
3. Method
3.1. Overview
3.2. Multi-View Camera Calibration
3.3. Camera Blending Field with Penalty Points
3.4. Surface Extraction
3.5. Region of Interest Detection
3.6. View Synthesis
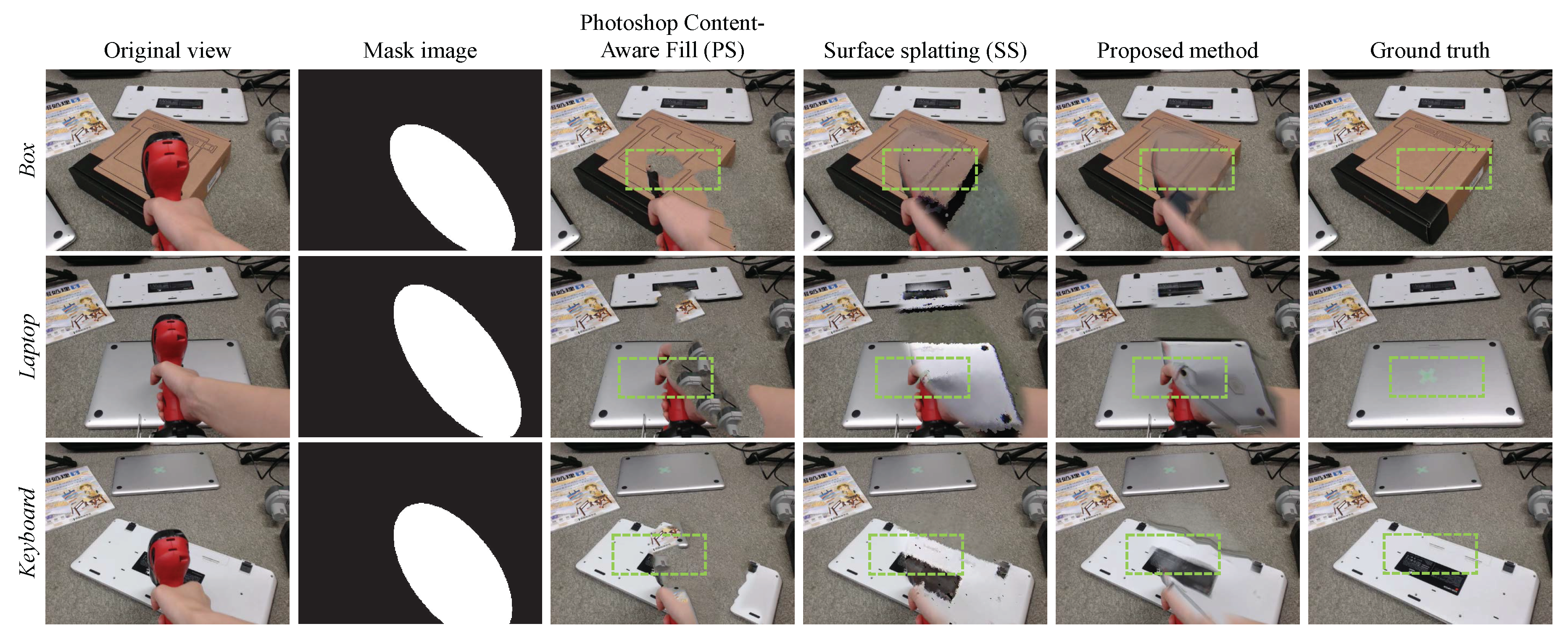
4. Experiments
4.1. Overview and Setup
4.2. Video Performance Evaluation
4.3. Similarity Measure
5. Discussion
5.1. Geometric Issues
5.2. Representation and Interface
6. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Azuma, R.T. A survey of augmented reality. Presence Teleoper. Virtual Environ. 1997, 6, 355–385. [Google Scholar] [CrossRef]
- Azuma, R.T. Recent advances in augmented reality. IEEE Comput. Graph. Appl. 2001, 21, 34–47. [Google Scholar] [CrossRef]
- Mori, S.; Ikeda, S.; Saito, H. A survey of diminished reality: Techniques for visually concealing, eliminating, and seeing through real objects. IPSJ Trans. Comput. Vision Appl. 2017, 9. [Google Scholar] [CrossRef]
- Cosco, F.; Garre, C.; Bruno, F.; Muzzupappa, M.; Otaduy, M.A. Visuo-haptic mixed reality with unobstructed tool-hand integration. IEEE Trans. Vis. Comput. Graph. 2013, 19, 159–172. [Google Scholar] [CrossRef] [PubMed]
- Buchmann, V.; Nilsen, T.; Billinghurst, M. Interaction with partially transparent hands and objects. In Proceedings of the Sixth Australasian User Interface Conference, Newcastle, Australia, 30 January–3 February 2005; Volume 40, pp. 17–20. [Google Scholar]
- Zokai, S.; Esteve, J.; Genc, Y.; Navab, N. Multiview paraperspective projection model for diminished reality. In Proceedings of the International Symposium on Mixed and Augmented Reality (ISMAR), Tokyo, Japan, 7–10 October 2003; pp. 217–226. [Google Scholar]
- Jarusirisawad, S.; Hosokawa, T.; Saito, H. Diminished reality using plane-sweep algorithm with weakly-calibrated cameras. Prog. Inform. 2010, 7, 11–20. [Google Scholar] [CrossRef]
- Buehler, C.; Bosse, M.; McMillan, L.; Gortler, S.; Cohen, M. Unstructured lumigraph rendering. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques (SIGGRAPH), Los Angeles, CA, USA, 31 July–4 August 2001; pp. 425–432. [Google Scholar]
- Kawai, N.; Sato, T.; Yokoya, N. Diminished reality based on image inpainting considering background geometry. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1236–1247. [Google Scholar] [CrossRef] [PubMed]
- Herling, J.; Broll, W. High-Quality Real-Time Video Inpaintingwith PixMix. IEEE Trans. Vis. Comput. Graph. 2014, 20, 866–879. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Wang, Y.; Guo, J.; Cheong, F.L.; Zhou, Z.S. Diminished reality using appearance and 3D geometry of Internet photo collections. In Proceedings of the International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, Australia, 1–4 October 2013; pp. 11–19. [Google Scholar]
- Barnum, P.; Sheikh, Y.; Datta, A.; Kanade, T. Dynamic seethroughs: Synthesizing hidden views of moving objects. In Proceedings of the International Symposium on Mixed and Augmented Reality (ISMAR), Orlando, FL, USA, 19–22 October 2009; pp. 111–114. [Google Scholar]
- Meerits, S.; Saito, H. Real-time diminished reality for dynamic scenes. In Proceedings of the International Workshop on Diminished Reality, Fukuoka, Japan, 29 September–3 October 2015; pp. 53–59. [Google Scholar]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR 2007), Nara, Japan, 13–16 November 2007; pp. 225–234. [Google Scholar]
- Kato, H.; Billinghurst, M. Marker tracking and hmd calibration for a video-based augmented reality conferencing system. In Proceedings of the IEEE and ACM International Workshop on Augmented Reality (IWAR), San Francisco, CA, USA, 20–21 October 1999; pp. 85–94. [Google Scholar]
- Lourakis, M.I.A.; Argyros, A.A. SBA: A software package for generic sparse bundle adjustment. Trans. Math. Softw. 2009, 36. [Google Scholar] [CrossRef]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An accurate O(n) solution to the PnP problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Zwicker, M.; Pfister, H.; Baar, J.V.; Gross, M. Surface splatting. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques (SIGGRAPH), Los Angeles, CA, USA, 31 July–4 August 2001; pp. 371–378. [Google Scholar]
- Handa, A.; Whelan, T.; McDonald, J.; Davison, A.J. A benchmark for RGB-D visual odometry, 3D reconstruction and SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–17 June 2014; pp. 1524–1531. [Google Scholar]
- Fitzgibbon, A.W.; Fisher, R.B. A buyer’s guide to conic fitting. In Proceedings of the British Machine Vision Conference (BMVC), Beimingham, UK, 11–14 September 1995; pp. 513–522. [Google Scholar]
- Debevec, P.; Borshukov, G.; Yu, Y. Efficient view-dependent image-based rendering with projective texture-mapping. In Proceedings of the Eurographics Rendering Workshop, Vienna, Austria, 29 June–1 July 1998; pp. 85–92. [Google Scholar]
- Davis, A.; Levoy, M.; Durand, F. Unstructured light fields. Comput. Graph. Forum 2012, 31, 305–314. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Proceess. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Levoy, M. Light fields and computational imaging. Computer 2006, 39, 46–55. [Google Scholar] [CrossRef]
- Butler, D.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Hodges, S.; Kim, D. Shake‘N’Sense: Reducing interference for overlapping structured light depth cameras. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Austin, TX, USA, 5–10 May 2012; pp. 1933–1936. [Google Scholar]
- Enomoto, A.; Saito, H. Diminished reality using multiple handheld cameras. In Proceedings of the Asian Conference on Computer Vision (ACCV), Tokyo, Japan, 18–22 November 2007; Volume 7, pp. 130–135. [Google Scholar]
- Zou, D.; Tan, P. Coslam: Collaborative visual slam in dynamic environments. Trans. Pattern Anal. Mach. Intell. 2013, 35, 354–366. [Google Scholar] [CrossRef] [PubMed]
- Sandor, C.; Cunningham, A.; Dey, A.; Mattila, V.V. An augmented reality X-ray system based on visual saliency. In Proceedings of the International Symposium on Mixed and Augmented Reality (ISMAR), Seoul, Korea, 13–16 October 2010; pp. 27–36. [Google Scholar]
- Santos, M.; Souza, I.; Yamamoto, G.; Taketomi, T.; Sandor, C.; Kato, H. Exploring legibility of augmented reality X-ray. Multimed. Tools Appl. 2015, 75, 9563–9585. [Google Scholar] [CrossRef]
- Kameda, Y.; Takemasa, T.; Ohta, Y. Outdoor see-through vision utilizing surveillance cameras. In Proceedings of the International Symposium on Mixed and Augmented Reality (ISMAR), Arlington, VA, USA, 2–5 November 2004; pp. 151–160. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Background | Object of Interest | User Pose | Multi-View | Depth Search | View-Dependent Properties |
|---|---|---|---|---|---|---|
| Zokai et al. [6] | Static | Static | Pre-calibrated | Yes | Required | No |
| Herling et al. [10] | Static | Static | 6DoF (Homography) | No | Not required | No |
| Kawai et al. [9] | Static | Static | 6DoF (SLAM [14]) | No | Not required | No |
| Li et al. [11] | Static | Dynamic | 6DoF (Homography) | Yes | Not required | Image switching |
| Cosco et al. [4] | Static | Dynamic | 6DoF (AR Marker [15]) | Yes | Not required | ULR-based [8] |
| Jarusirisawad et al. [7] | Dynamic | Dynamic | 6DoF (Virtual Camera) | Yes | Required | No |
| Barnum et al. [12] | Dynamic | Static | 6DoF (Homography) | No | Not required | No |
| Meerits and Saito [13] | Dynamic | Dynamic | 6DoF (AR Marker [15]) | No | Not required | No |
| Proposed | Dynamic | Dynamic | Pre-calibrated | Yes | Not required | ULR-based [8] |
| NCC | PSNR | SSIM | |
|---|---|---|---|
| Photoshop Content-Aware Fill (PS) | 0.972 ± 0.014 | 18.40 ± 2.35 | 0.773 ± 0.049 |
| Surface splatting (SS) | 0.973 ± 0.013 | 18.44 ± 1.79 | 0.784 ± 0.043 |
| Proposed method | 0.980 ± 0.010 | 19.73 ± 2.03 | 0.801 ± 0.039 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mori, S.; Maezawa, M.; Saito, H. A Work Area Visualization by Multi-View Camera-Based Diminished Reality. Multimodal Technol. Interact. 2017, 1, 18. https://doi.org/10.3390/mti1030018
Mori S, Maezawa M, Saito H. A Work Area Visualization by Multi-View Camera-Based Diminished Reality. Multimodal Technologies and Interaction. 2017; 1(3):18. https://doi.org/10.3390/mti1030018
Chicago/Turabian StyleMori, Shohei, Momoko Maezawa, and Hideo Saito. 2017. "A Work Area Visualization by Multi-View Camera-Based Diminished Reality" Multimodal Technologies and Interaction 1, no. 3: 18. https://doi.org/10.3390/mti1030018
APA StyleMori, S., Maezawa, M., & Saito, H. (2017). A Work Area Visualization by Multi-View Camera-Based Diminished Reality. Multimodal Technologies and Interaction, 1(3), 18. https://doi.org/10.3390/mti1030018