
Machine Learning Algorithms for Urban Land Use Planning: A Review



Abstract
:1. Introduction
2. Theoretical Perspective
2.1. Machine Learning Based Algorithms
2.2. Urban Land Use Models
- -
- States: each cell can take an integer value that corresponds to the current state of that cell. There is a finite set of states.
- -
- Neighborhood: is a collection of cells that interact with the current one. To perform simulations on a satellite image we normally take the eight surrounding pixels as neighborhood.
- -
- Transition function (f): takes as input arguments the cell and neighborhood values and returns the new state of the current cell.
“The program involves as a series of nested loops: the outer control loop repeatedly executes each growth “history”, retaining cumulative statistical data, while the inner loop executes the growth rules for a single iteration, assumed to be a “-year-.” The rules apply to one cell at a time and the whole grid is updated as the iterations complete”.
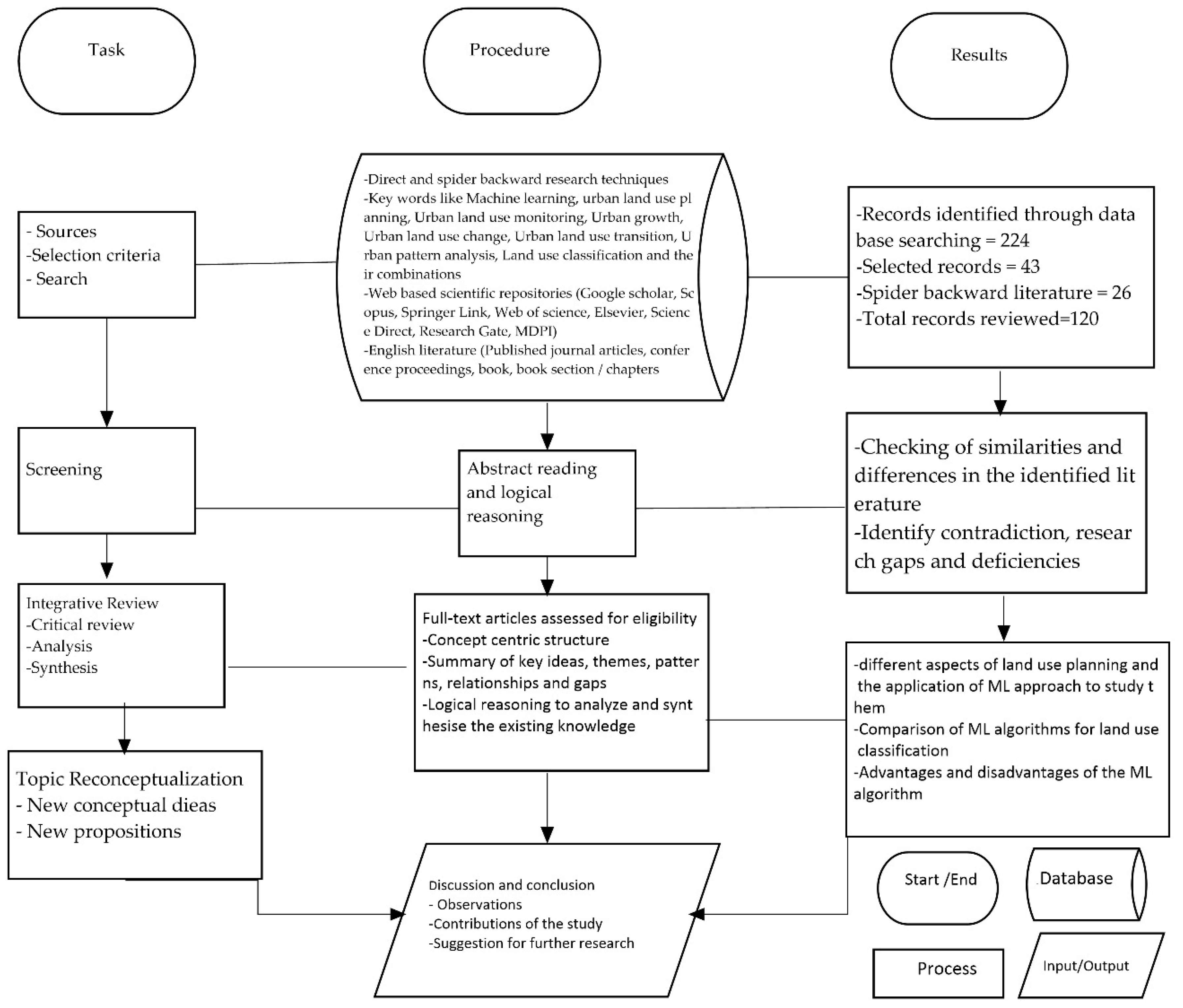
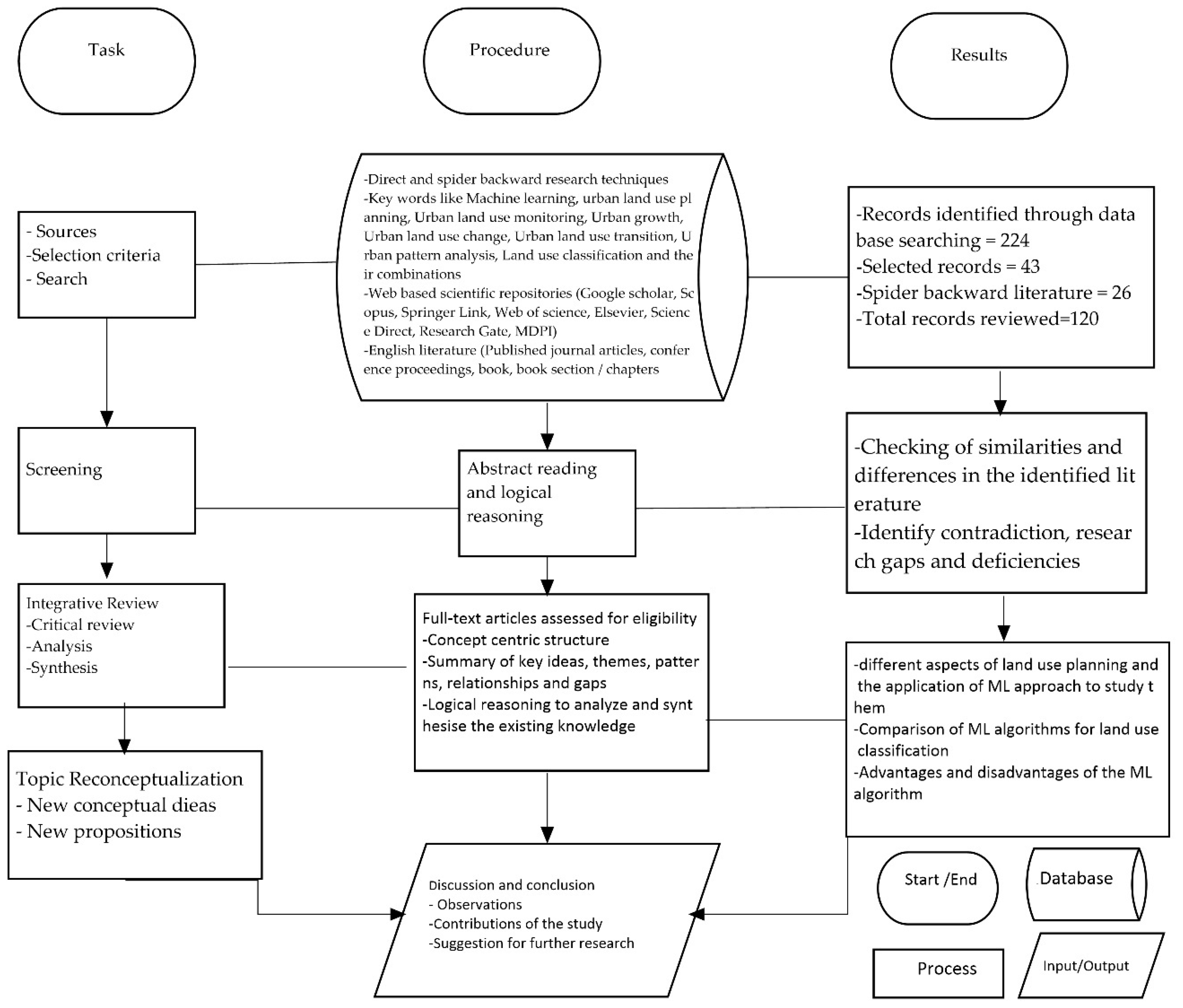
3. Materials and Methods
3.1. Research Approach
3.2. Data Sources and Research Method
4. Results and Discussion
4.1. Machine Learning Models and Their Applications
4.1.1. Algorithms/Models to Study Urban Growth, Patterns and Land Use Change
4.1.2. Commonly Used Algorithms for Land Use Classification
4.1.3. Limitation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Samardžić, M.; Kovačević, M.; Bajat, B.; Dragićević, S. Machine learning techniques for modelling short term land-use change. ISPRS Int. J. Geo-Inf. 2017, 6, 387. [Google Scholar] [CrossRef] [Green Version]
- Cao, C.; Dragićević, S.; Li, S. Land-use change detection with convolutional neural network methods. Environments 2019, 6, 25. [Google Scholar] [CrossRef] [Green Version]
- Hagenauer, J.; Omrani, H.; Helbich, M. Assessing the performance of 38 machine learning models: The case of land consumption rates in Bavaria, Germany. Int. J. Geogr. Inf. Sci. 2019, 33, 1399–1419. [Google Scholar] [CrossRef] [Green Version]
- Amler, B.; Betke, D.; Eger, H.; Ehrich, C.; Kohler, A.; Kutter, A.; von Lossau, A.; Müller, U.; Seidemann, S.; Steurer, R. Land Use Planning Methods, Strategies and Tools; Deutsche Gesellschaft Für Technische Zusammenarbeit (GTZ) GmbH: Eschborn, Germany, 1999. [Google Scholar]
- Gidudu, A.; Hulley, G.; Marwala, T. Classification of images using Support Vector Machines. arXiv 2007, arXiv:0709.3967v1. [Google Scholar]
- Pal, M.; Mather, P.M. Support vector machines for classification in remote sensing. Int. J. Remote Sens. 2005, 26, 1007–1011. [Google Scholar] [CrossRef]
- Ruiz Hernandez, I.E.; Shi, W. A Random Forests classification method for urban land-use mapping integrating spatial metrics and texture analysis. Int. J. Remote Sens. 2018, 39, 1175–1198. [Google Scholar] [CrossRef]
- Duque, J.C.; Patino, J.E.; Betancourt, A. Exploring the potential of machine learning for automatic slum identification from VHR imagery. Remote Sens. 2017, 9, 895. [Google Scholar] [CrossRef] [Green Version]
- hd-pro, Applying Edge Detection to Feature Extraction and Pixel Integrity. (n.d.). Retrieved 13 April 2019. Available online: https://medium.com/hd-pro/applying-edge-detection-to-feature-extraction-and-pixel-integrity-2d39d9460842 (accessed on 16 January 2021).
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Vali, A.; Comai, S.; Matteucci, M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Maithani, S. A neural network based urban growth model of an Indian city. J. Indian Soc. Remote Sens. 2009, 37, 363–376. [Google Scholar] [CrossRef]
- Tso, B.; Mather, P.M. Classification Methods for Remotely Sensed Data, 2nd ed.; CRC Press, LLC: Boca Raton, FL, USA, 2001; pp. 255–278. [Google Scholar] [CrossRef]
- Li, G.; Cai, Z.; Qian, Y. Identifying Urban Poverty Using High-Resolution. Satellite. Land 2021, 10, 648. [Google Scholar] [CrossRef]
- Nong, Y.; Du, Q. Urban growth pattern modeling using logistic regression. Geo-Spat. Inf. Sci. 2011, 14, 62–67. [Google Scholar] [CrossRef]
- Clarke, K.C. Cellular Automata and Agent-Based Models. In Handbook of Regional Science; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar] [CrossRef]
- Espínola, M.; Ayala, R.; Leguizamón, S.; Menenti, M. Classification of Satellite Images Using the Cellular Automata Approach. In The Open Knowlege Society; A Computer Science and Information Systems Manifesto: Berlin/Heidelberg, Germany, 2008; pp. 521–526. [Google Scholar]
- Berberoğlu, S.; Akin, A.; Clarke, K.C. Cellular automata modeling approaches to forecast urban growth for adana, Turkey: A comparative approach. Landsc. Urban Plan. 2016, 153, 11–27. [Google Scholar] [CrossRef]
- Hu, Z.; Lo, C.P. Modeling urban growth in Atlanta using logistic regression. Comput. Environ. Urban Syst. 2007, 31, 667–688. [Google Scholar] [CrossRef]
- National research council. Advancing Land Change Modeling; The National Academic Press: Washington, DC, USA, 2014; pp. 93–96. [Google Scholar] [CrossRef]
- Arsanjani, J.J.; Helbich, M.; Kainz, W.; Boloorani, A.D. Integration of logistic regression, Markov chain and cellular automata models to simulate urban expansion. Int. J. Appl. Earth Obs. Geoinf. 2012, 21, 265–275. [Google Scholar] [CrossRef]
- Gharaibeh, A.; Shaamala, A.; Obeidat, R.; Al-kofahi, S. Heliyon Improving land-use change modeling by integrating ANN with Cellular Automata-Markov Chain model. Heliyon 2020, 6, e05092. [Google Scholar] [CrossRef]
- Kamusoko, C.; Gamba, J. Simulating Urban Growth Using a Random Forest-Cellular Automata (RF-CA) Model. ISPRS Int. J. Geo-Inf. 2015, 4, 447–470. [Google Scholar] [CrossRef]
- Mustafa, A.; Cools, M.; Saadi, I.; Teller, J. Coupling agent-based, cellular automata and logistic regression into a hybrid urban expansion model (HUEM). Land Use Policy 2017, 69, 529–540. [Google Scholar] [CrossRef] [Green Version]
- Webster, J.; Watson, R.T. Analyzing the Past to Prepare for the Future: Writing a Literature Review. MIS Q. 2002, 26, xiii–xxiii. [Google Scholar]
- Torraco, R.J. Writing Integrative Literature Reviews: Guidelines and Examples. Hum. Resour. Dev. Rev. 2005, 4, 356–367. [Google Scholar] [CrossRef]
- Rodríguez, G.; Jesús, J.; Cuaresma, E.; Jose, M.; Risoto, M.; Valderrama, M.T. Generation of Test Cases from Functional Requirements. A Survey. May 2014. Available online: http://www.lsi.us.es/javierj/investigacion_ficheros/sv10.pdf (accessed on 27 July 2020).
- Ustuner, M.; Sanli, F.B.; Dixon, B. Application of Support Vector Machines for Landuse Classification Using High-Resolution RapidEye Images: A Sensitivity Analysis. Eur. J. Remote Sens. 2017, 48, 403–422. [Google Scholar] [CrossRef]
- Yuan, H.; Van Der Wiele, C.F.; Khorram, S. An automated artificial neural network system for land use/land cover classification from landsat TM imagery. Remote Sens. 2009, 1, 243–265. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Tomljenovic, I.; Lampoltshammer, T.J.; Blaschke, T.; Höfle, B. Ontology-based classification of building types detected from airborne laser scanning data. Remote Sens. 2014, 6, 1347–1366. [Google Scholar] [CrossRef] [Green Version]
- Niklas, U.; von Behren, S.; Soylu, T.; Kopp, J.; Chlond, B.; Vortisch, P. Spatial Factor—Using a Random Forest Classification Model to Measure an Internationally Comparable Urbanity Index. Urban Sci. 2020, 4, 36. [Google Scholar] [CrossRef]
- Flacke, J.; Retsios, B. Computers, Environment and Urban Systems Simulating informal settlement growth in Dar es Salaam, Tanzania: An agent-based housing model. Comput. Environ. Urban Syst. 2011, 35, 93–103. [Google Scholar] [CrossRef]
- Xie, C. Support Vector Machines for Land Use Change Modeling. UCGE Reports 20243. 2006. Available online: http://www.ucalgary.ca/engo_webdocs/BH/06.20243.ChenglinXie.pdf (accessed on 12 June 2020).
- Feng, Y.; Liu, Y.; Batty, M. Modeling urban growth with GIS based cellular automata and least squares SVM rules: A case study in Qingpu–Songjiang area of Shanghai, China. Stoch. Environ. Res. Risk Assess 2016, 30, 1387–1400. [Google Scholar] [CrossRef]
- Abdi, A.M. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data. GISci. Remote Sens. 2020, 57, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Batisani, N.; Yarnal, B. Urban expansion in Centre County, Pennsylvania: Spatial dynamics and landscape transformations. Appl. Geogr. 2009, 29, 235–249. [Google Scholar] [CrossRef]
- Albert, A.; Strano, E.; Kaur, J.; Gonzalez, M. Modeling urbanization patterns with generative adversarial networks. arXiv 2018, arXiv:1801.02710. [Google Scholar]
- Decraene, J.; Monterola, C.; Lee, G.K.K.; Hung, T.G.G.; Batty, M. The emergence of urban land use patterns driven by dispersion and aggregation mechanisms. PLoS ONE 2013, 8, e80309. [Google Scholar] [CrossRef]
- Change, L.; Sun, B.; Robinson, D.T. Comparisons of Statistical Approaches for Modelling Land-Use Change. Land 2018, 7, 144. [Google Scholar] [CrossRef] [Green Version]
- Samardžić-Petrović, M.; Dragićević, S.; Kovačević, M.; Bajat, B. Modeling Urban Land Use Changes Using Support Vector Machines. Trans. GIS 2016, 20, 718–734. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Jin, B.; Ye, P.; Zhang, X.; Song, W.; Li, S. Object-Oriented Method Combined with Deep Convolutional Neural Networks for Land-Use-Type Classification of Remote Sensing Images. J. Indian Soc. Remote Sens. 2019, 47, 951–965. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
| Indicators | Measurements | Data | Application |
|---|---|---|---|
| Urban expansion | Built-up density, settlement patterns, population distribution | EO based data, i.e., classified images, building footprints, urban heat islands | Classification and simulation (CA, spatial logistics regression, SVM, random forest, CNN) |
| Land restrictions | Land use/land cover change, built-up and non-built-up spaces, | Master plan, building by-laws, land use regulations | Classification, extraction of EO products like DEM, vegetation cover |
| Land allocations | Govt. policies, population growth, population distribution | Census data, socio-economic data | Spatial logistic regression, cellular automata |
| Zoning | Govt. policies and by-laws | Master plan, classified images | Planned development |
| Land use change | Settlement patterns, urban growth processes, (aggregated, compact, dispersed) population growth | Spatio-temporal EO based data | Spatial metrics, cellular automata, spatial logistic regression, agent-based modeling |
| Variables/Image Feature | Description | Examples | Description | Application in Land Use Planning |
|---|---|---|---|---|
| Spectral features | Provide information regarding the spectral response of objects, which differ for land coverage types, states of vegetation, soil composition, building materials [8] | NDVI (normalized difference vegetation index)—to measure/identify biomass | NDVI = (NIR−RED)/(NIR+RED) | Distinguishing built-up areas from non-built-up, green vegetation from barren land |
| SAVI (soil adjusted vegetation index) | SAVI = 1.5 × (NIR-R)/(NIR+R+0.5) | Differentiate between vegetation and built-up | ||
| BAI (built-up area index) | BAI = (B-NIR)/(B+NIR) | Built-up areas index has good performance in detecting asphalt and concrete surfaces | ||
| NDWI (normalized difference water index) | NDWI = (G-NIR)/(G+NIR) | Enhances water features and helps in distinguishing water features from other ground objects | ||
| Texture features | Characterize the spatial distribution of intensity values of an image and data on contrast, uniformity, rugosity, etc. [8] | GLCM (grey level co-occurrence matrix)—specifically relevant when measuring, qualifying | GLCM is a tabulation of how often different combinations of pixel brightness values (grey levels) occur in an image | Measuring spatial patterns which are repetitive on the image like crop land and built-up |
| Structural features | Help in identifying the spatial arrangement of elements in terms of the randomness or regularity of their distribution [8] | Edge detection filter specifically relevant when measuring, qualifying | Edge detection is a technique used to find the boundaries of features in an image. This uses an algorithm that searches for discontinuities in pixel brightness in an image that is converted to grayscale. (“Applying Edge Detection To Feature Extraction And Pixel Integrity,” n.d [9]) | For shape recognition, edge enhancement |
| Keywords | Description | Related/Alternative Keywords |
|---|---|---|
| Land use planning | Spatial arrangement of land between competing and conflicting uses | Urban planning, land allocation, urban design |
| Urban growth modeling | Statistical model that involves economics, demography, geography, sociology to explore the mechanisms of increase in urban areas | Urban agglomeration, built-up density |
| Machine learning | Type of knowledge engineering | ML algorithm, neural network, SVM, random forest |
| Urban land use change | Conversion of type of use of a piece of land by humans | Land use conversion, land use transition, land use transformation |
| Urban land use classification | Grouping of land into different categories based on their use | Zoning, urban land management |
| Urban land use patterns | Layout or arrangement of uses of land | Urban form, framework, urban structure, arrangement, urban fabric |
| Urban expansion | General increase in the land area or the population size of an urban area | Sprawl, urbanization, urban development |
| Artificial intelligence | Algorithm developed to perform tasks by learning or identifying patterns | Machine learning, deep learning, neural network, pattern recognition |
| Urban built-up area extraction | Extraction of building footprints and other manmade features | Classification, aggregation, conurbation, urban spread |
| Urban land use monitoring | To detect changes in land use over a period of time | Land development, land regulation, land management |
| Machine Learning Algorithms | Advantage/Useful When/Appropriate for Applications Related to |
|---|---|
| Support vector machines (SVMs) | - Once the hyperplane is found SVMs tend to generalize well - Once the boundary of hyperplane is established most training data is redundant - Powerful algorithm for land use pattern recognition - Capability of contextual feature extraction |
| Markov random field (MRF) | MRF combines both pixel information and region information |
| Convolutional neural network (CNN) | Local spatial coherence in input image makes CCN suited for feature extraction |
| Random forest (RF) | - Can deal with large number of features - It incorporates spectral bands and other feature selection layers like soil index, water index, NDVI - It incorporates texture features for classification which include metrics like entropy, variance, morphology, line feature, etc. - It avoids overfitting |
| Machine Learning Models | Advantages | Disadvantages | Particularly Useful for Applications of |
|---|---|---|---|
| Spatial logistic regression | -Can incorporate socio-economic and demographic factors -Logistic regression allows multi-scale calibration due to less demand of computation resource | -Lack of temporal dynamics -Does not consider location preferences, policies | Urban growth, land use change, land allocation |
| Cellular automata | -Phenomena of sprawl can be efficiently simulated in CA models -CA models produce outputs according to the transition rules | -High demand of computation power -Capability to handle temporal dynamics | Land use change, land allocation |
| Agent based modeling | - It incorporates human behavior - Bottom up approach | -Variability in the results because of randomization of agents at initialization for combination of parameter settings -Hard to calibrate | Urban growth and land use change |
| Author and Year | Study Area | Data Used | Method | Performance |
|---|---|---|---|---|
| 1.Urban growth pattern modeling using logistic regression [15] | Jiayu County, Hubei Province, China | Vector data, map of the county, topographic map, DEM and data on population, agriculture, industrial from secondary data sources | Logistic regression modeling | Less demand of computation resources, vector-feature-based spatial analysis has higher accuracy, procedure is most effective when group membership is a truly categorical variable |
| 2. Support vector machines for land use change modeling [33] | Calgary, Southern Alberta, USA | Chronological land use data Landsat TM and ETM, demographic data, and transportation data (major roads and LRT lines), elevation data, community map, city amenity map, community service center map, and shopping center distribution map | Support vector machine (SVM) | Improved SVMs can greatly improve the accuracy and reliability of land use change modeling especially when the underlying data distribution is unknown and the dataset is significantly unbalanced |
| 3. Modelling urban growth with GIS based cellular automata and least squares SVM rules [34] | Qingpu–Songjiang area of Shanghai, China | Landsat images covering the study area acquired on 18 July 1992 and 24 March 2008 were used, topographic map at a scale of 1:50,000 as the reference data for georectification | MachCA model which is cellular automata (CA) with nonlinear transition rules based on least squares support vector machines (LS-SVM) | LS-SVM method is relatively complex in its theory and implementation. Therefore, it requires an understanding of the mechanisms of urban dynamics as well as mastery over the requisite mathematical and computer knowledge for its application |
| 4. Land cover and land use classification performance of machine learning algorithms in a boreal landscape using Sentinel-2 data [35] | Uppsala in South-Central Sweden | Sentinal-2 multi temporal images was used covering an area of 10 × 12 km mixed-use landscape | SVM, RF, extreme gradient boosting (Xgboost), and deep learning (DL) | The results show that the highest overall accuracy was produced by support vector machines closely followed by extreme gradient boosting, RF and finally deep learning |
| Urban expansion in Centre County, Pennsylvania: spatial dynamics and landscape transformations [36] | Centre County, Pennsylvania | Landsat TM images of the county for 1993 and 2000 | Cross-tabulation; logistic regression; CLUE-S regional modeling framework | Although the model is able to simulate urban land use location at the county level, it is less able to simulate these locations at the sub-county level due to non-availability of data at the appropriate scale |
| Modeling urbanization patterns with generative adversarial networks [37] | Global training samples of 30,000 cities (urban footprints) | Global training samples of 30,000 cities (urban footprints) https://github.com/adrianalbert/citygan (accessed on 4 April 2021). | Generative adversarial networks (GANs) | GAN model is able to generate realistic urban patterns that capture the great diversity of urban forms across the globe |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chaturvedi, V.; de Vries, W.T. Machine Learning Algorithms for Urban Land Use Planning: A Review. Urban Sci. 2021, 5, 68. https://doi.org/10.3390/urbansci5030068
Chaturvedi V, de Vries WT. Machine Learning Algorithms for Urban Land Use Planning: A Review. Urban Science. 2021; 5(3):68. https://doi.org/10.3390/urbansci5030068
Chicago/Turabian StyleChaturvedi, Vineet, and Walter T. de Vries. 2021. "Machine Learning Algorithms for Urban Land Use Planning: A Review" Urban Science 5, no. 3: 68. https://doi.org/10.3390/urbansci5030068
APA StyleChaturvedi, V., & de Vries, W. T. (2021). Machine Learning Algorithms for Urban Land Use Planning: A Review. Urban Science, 5(3), 68. https://doi.org/10.3390/urbansci5030068