1. Introduction
The history of North America is in large parts driven by huge migration waves. After the arrival of the first Europeans, settlements, cities, and states were created and developed based on cultures, religions and national identities of their founders. Woodard [
1] describes in great detail how groups of early settlers formed several societies centered around various principles and beliefs. These groups developed the “dominant cultures” and shaped the basis for the “eleven American nations” that can still be found today and are responsible for the difficulties of making the United States a unified nation based on common concepts and values [
1,
2].
Three large immigration waves from mostly Europe to the North American continent can be identified between 1830 and 1924 [
1]. The first wave between 1830 and 1860 bringing mainly Irish, German and British people was followed by the second and even larger wave until 1890 where people from the afore-mentioned countries together with Scandinavians and Chinese arrived at the east coast. The third and largest wave brought people from mainly southern and eastern Europe such as Italy, Greece and Poland consisting to a large part of Catholics and Jews between 1890 and 1924. European immigrants arrived at the east coast and from there spread across North America leading to early settlements in the eastern states and only later to a migration to the western and southern parts. At the same time Spanish settlers arrived in the Mexican area and moved up north reaching the southern part of today’s US area, a region also described by the name “El Norte” in Woodard [
1].
European migrants included their own cultures, religions and languages when founding new settlements. Hence, place, street and city names reflected the countries of origin as well as the names, religion or culture of their founders [
3,
4].
Place names have been shown to clearly reflect migration patterns and historical population profiles. Naming and renaming of place names has various purposes [
5,
6]. As listed by Nash [
7], changing place names can be part of capitalist modernization [
8,
9], colonial settlement [
10], state formation [
11], national independence [
12] or official commemoration [
13]. This practices have mainly been used in colonial times by Europeans to claim the new territories and erase former cultures and collective identities of the indigenous population [
7] but also for identification purposes and as a means of forming and shaping settlements in the “new world” as their home [
3,
4].
Today, street names (odonyms) primarily serve as a means to uniquely determine locations of private houses, businesses and public spaces as well as to ensure basic supplies such as water and electricity. Street naming practices go back to medieval Europe where at first, street names solely fulfilled functional roles. Since then, most streets underwent numerous renaming events, reconstructions and changes during history. As mentioned in Badariotti [
14], five different epochs in Europe are mirrored within street naming practices:
During medieval times street names mainly fulfilled functional roles pointing out the usage of a certain space such as social, institutional or industrial/business zones (see also Algeo [
15]).
Commemorative street names became popular during the 17th and 18th century serving as glorifications of popular and mighty personalities such as the king.
During the time of the French revolution, the first large street renaming events occured where mainly names referring to religious terms were changed to terms popular in revolutionary thoughts, such as philosophers and non-religious values.
Napoleon’s era then reestablished old names and introduced street names referring to the Empire, victories, battles, officer’s names and other military terms.
Street names in the 19th and 20th centuries are mostly based on commemorative street names of well-known people, geographic terms for certain locations or local areas with specific themes such as plants’ or birds’ names.
However, until today, changes of regimes also lead to renaming of mainly commemorative street names [
13,
16,
17,
18,
19]. In recent history, streets were renamed extensively after World War I. In the US mainly German street names were removed [
20]. Also in Europe, naming of streets is considered to have political and historical impact, i.e., as shown in the case of West and East Germany [
21]. Renaming also occured within communities of mixed descent such as English and Hispanic cultures in New Mexico. Here, many street names changed from a Spanish to an English name [
15].
Based on the street naming epochs and today’s usage of themes among street names, phases of growth of a city and the construction of new suburbs can be traced back regarding street names [
14]. This also includes street names reminding of buildings or landmarks that have been located in a certain area, such as former schools, churches, rivers, or communities of people.
Exceptions to such street names can be seen in North America, where many streets are given a number depending on their location to a reference street. In Managua, the capital of Nicaragua, no street names are used at all. Instead, directions and reference points inside the city are used to describe locations [
14].
OpenStreetMap (OSM,
osm.org) is an online database providing geographic data and maps of cities, for routing, public transport, hiking or cycling. The data is freely available online and users can add and edit information, similar to Wikipedia (
wikipedia.org). In this contributiion, we analyse street names retrieved from OSM to investigate to what extent this type of easily accessible data can be harnessed to gain information into settlement and migration histories. We focus here on European settlements in North America and street name patterns in Europe, mainly because the corresponding data are most abundant and most easily interpretable to us. We then briefly investigate reflections of Africa’s colonial history.
Despite a large number of newly created streets due to fast growing cities and many renaming events, we observe that there are still easily detectable traces of very old and conserved street names in Europe and North America. Our results of street name comparison and resulting clusters of European origin in North America agree with results obtained by Han et al. [
22] and Woodard [
1]. We observe that the oldest and most conserved European clusters can be found in rural areas which are less prone to reconstruction and renaming of streets. The work by Woodard [
1] states the historical developments of the “11 American nations” that were formed by the first waves of immigration to North America. The results by Woodard [
1] are confirmed in the study by Han et al. [
22], which analyses reveil genetic diversity and ancestry of 770,000 genomes in the US. Similarly, French influences in northern and central Africa as well as Dutch influences in South Africa are consistent with the regions’ colonial history, even though the OSM street name data for the African continent are comparably sparse. Clearly, the analysis of street name data cannot replace a detailed historical analysis. Nevertheless, it serves to provide an easily accessible overview and is potentially useful as a means of generating hypotheses.
2. Materials and Methods
We consistently used street names downloaded and extracted in February 2020 (Europe and North America) and September 2020 (Africa) in the language that OSM defines as mainly spoken language in that area. No translations were applied. For further details on Materials and Methods see the
Supplementary Material.
2.1. Data Extraction and Curation
Geographic data has been downloaded from geofabrik (
download.geofabrik.de, February 2020, September 2020). The data were extracted and converted using osmium tool (
osmcode.org). Street names have been extracted filtering the data by the tag
highway, which defines the category of all types of streets in OSM. Streets are equipped with geographic coordinates which have been used for the analyses. Street entries in OSM are assigned a street type. In this analysis, we only include streets with types primary, secondary, tertiary, residential, pedestrian and unclassified. In this way, highways and motorways, which are typically named just by numbers, are excluded.
2.2. Extraction of Street Terms from Street Names
The extraction of street terms is done for each country separately and aims to split street names into specific and generic terms. Numbered streets are excluded from the analysis in order to be able to extract street names of European origin.
In many countries, street names are composed of two parts, a
specific term that makes the street name unique in a certain area and a
generic term, referring to the kind of street, such as
road, way or
boulevard [
14]. In numerous cases, a third term is added which denotes the direction or orientation of the street such as east and west or upper and lower.
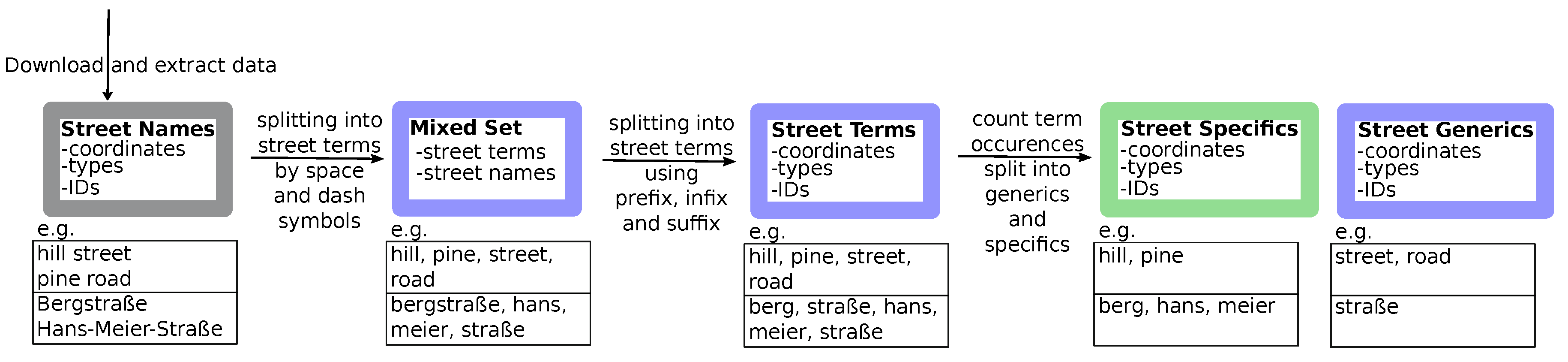
Splitting street names into single terms is done in a two-step process as depicted in the workflow in
Figure 1. Most of the street names in the data set are composed out of two or three terms concatenated by a space character (‘ ’). Even in countries where street terms are usually concatenated into one single word, we find street names separated by a space character or by a dash (‘-’). In order to extract and split street terms in street generics and specifics, street names are first split into terms by space and dash characters. This results in a mixed multi-set
of street terms
T and street names
N. Note that the same street name usually has many occurences in a country and thus, also in
M, however, each street is uniquely defined by its ID, i.e., we treat
M as multiset. This process is also described by an example in
Figure 1. Here, the analysis starts with two English street names (
hill street, pine road) and two German street names (
Bergstraße, Hans-Meier-Straße, English translation: hill street and Hans Meier street). In a first step, the street names are decomposed into terms by only splitting at space and dash symbols. This results in the mixed set of single terms such as
street and complete street names for entries such as
Bergstraße, which consists of just a single word.
In a second step, we now compare each entry
to all other entries
and check if
m occurs as a proper prefix, infix or suffix of
or if
m and
are equal. If they are equal, the term is counted occuring as ’complete term’, thus it is part of a street name that could be split by a space or dash sign. A proper prefix, infix or suffix is here defined such that at least 2 letters of the original word
remain on both sides (infix) or as suffix or prefix, respectively. In the example in
Figure 1, the German street name
Bergstraße will be split into the prefix
Berg (hill) and the suffix
Straße (street) by comparing the complete term
Straße to the street name
Bergstraße to identify the proper prefix and suffix. For each
, the number of matchings as prefix, infix, suffix or complete term is counted as well as the total number and percentage of appearances in the data set in comparison to the total number of street terms (not street names!) in the data set. In this way, the composition of street names in a certain country is analysed and terms appearing in a much higher frequency than others are identified as street generics. More detailed information and examples can be found in the
supplemental data.
2.3. Calculating the Street Density in North America and Europe
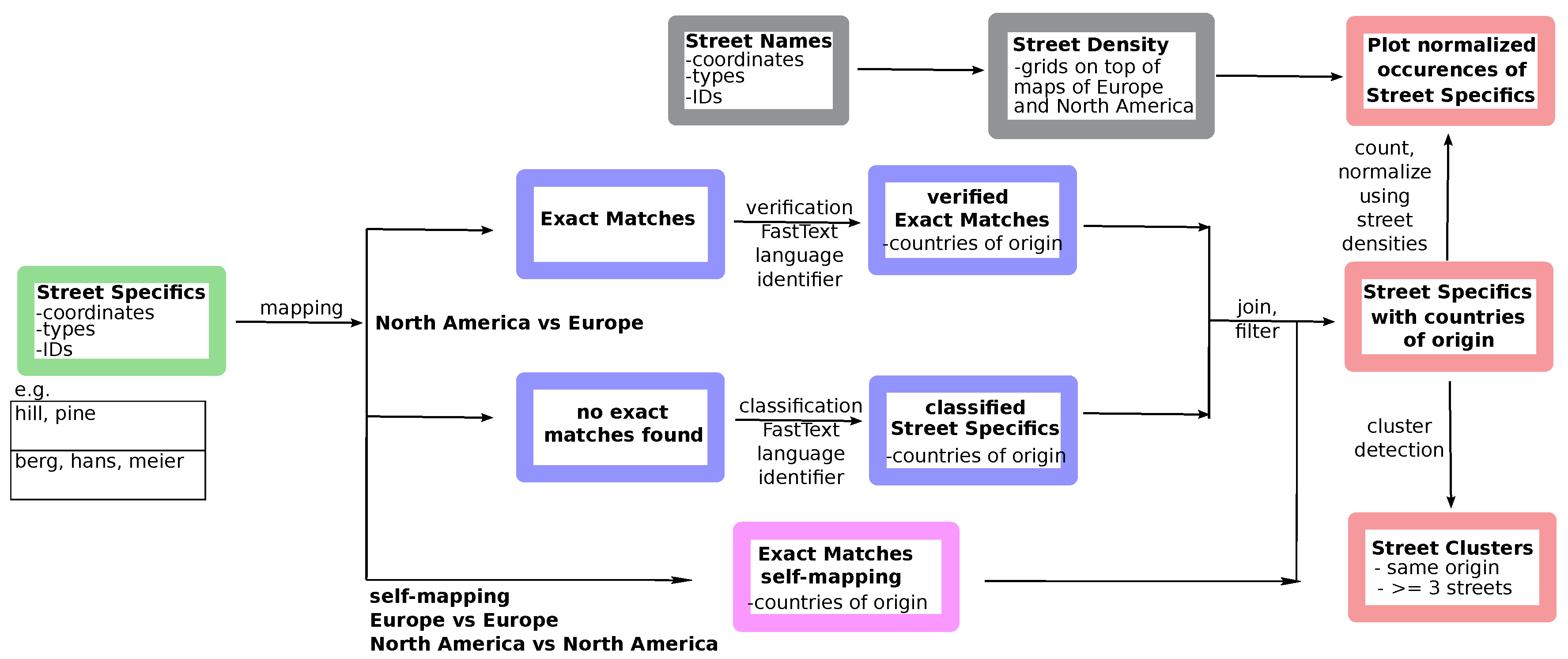
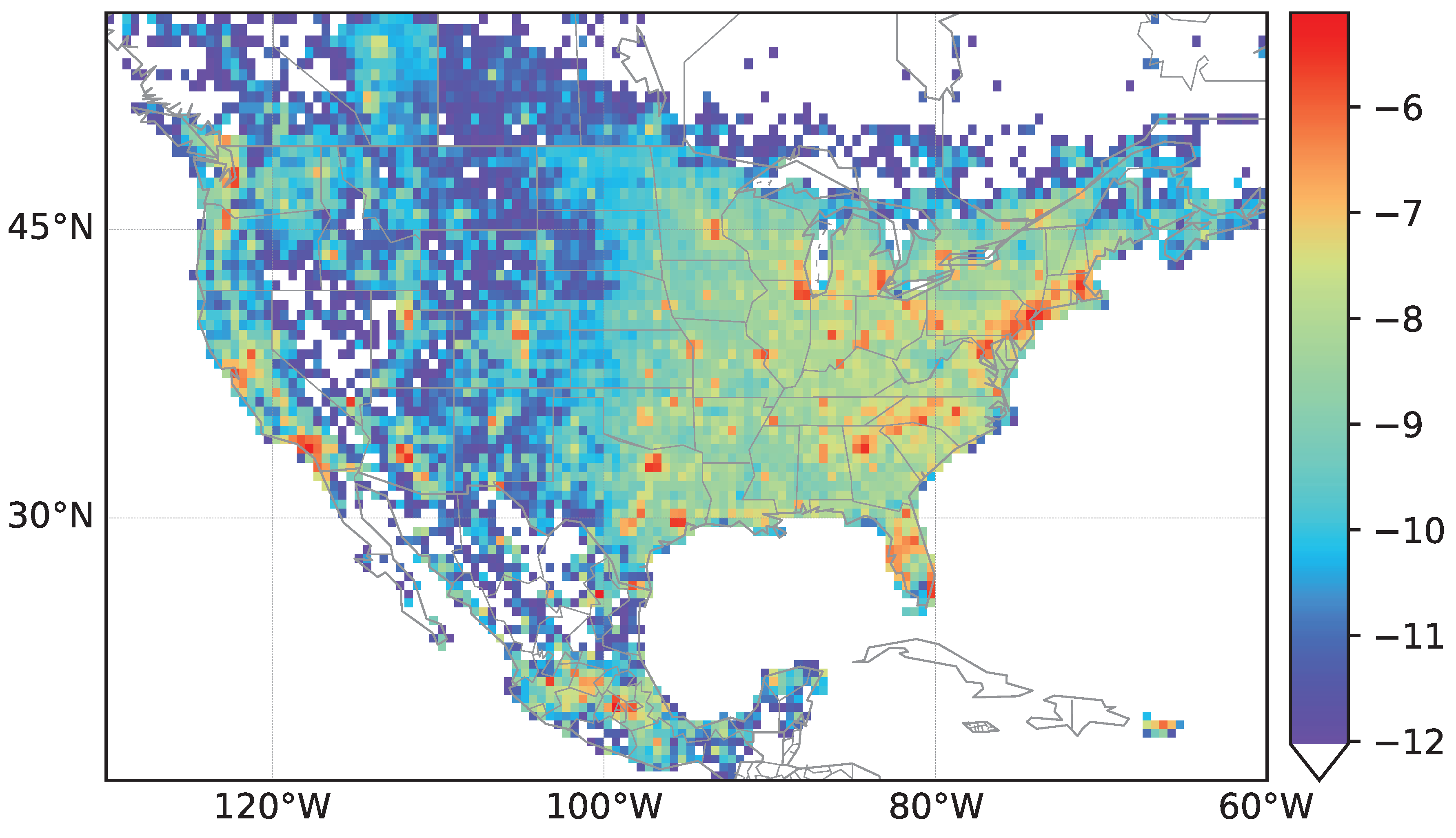
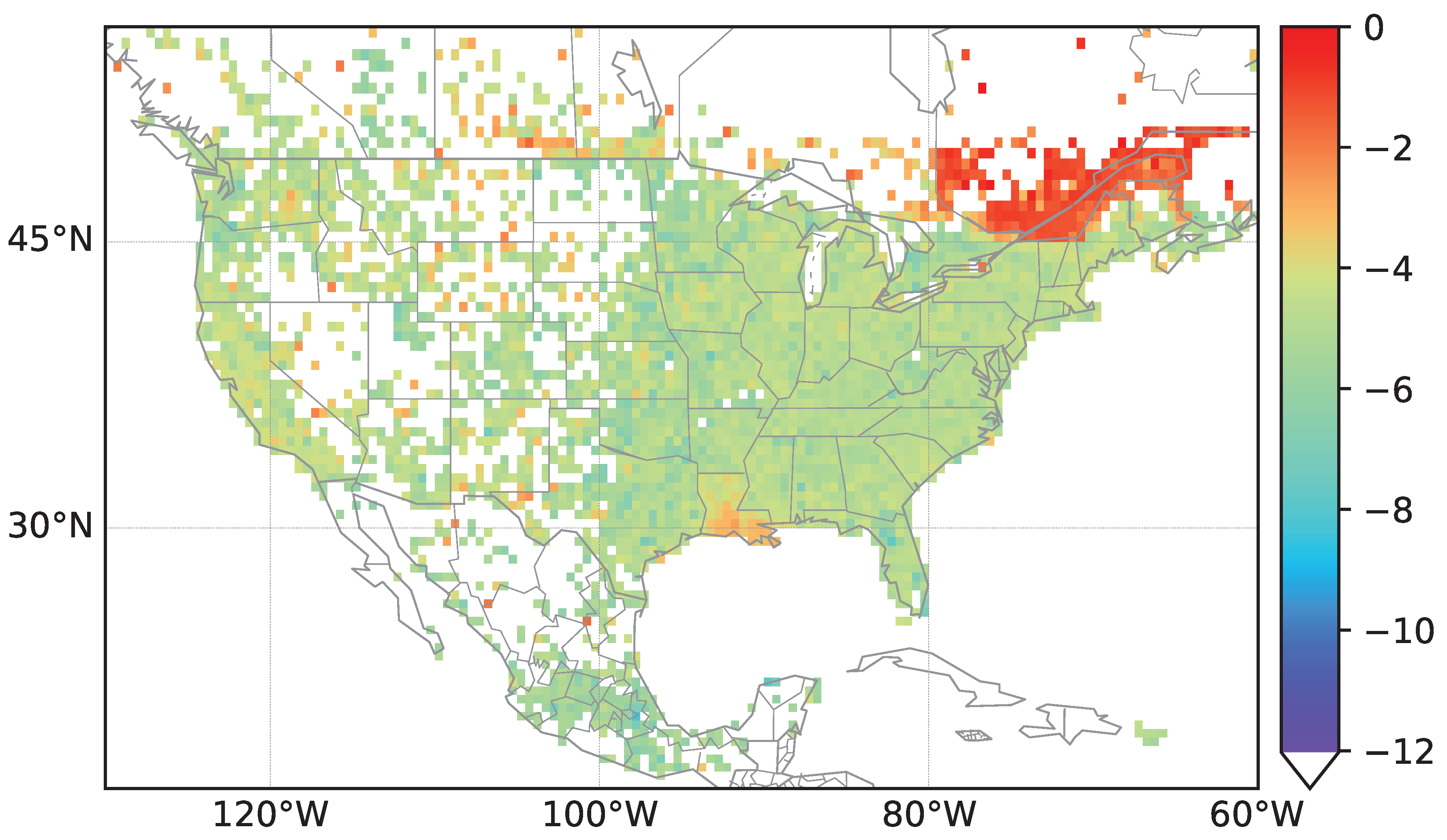
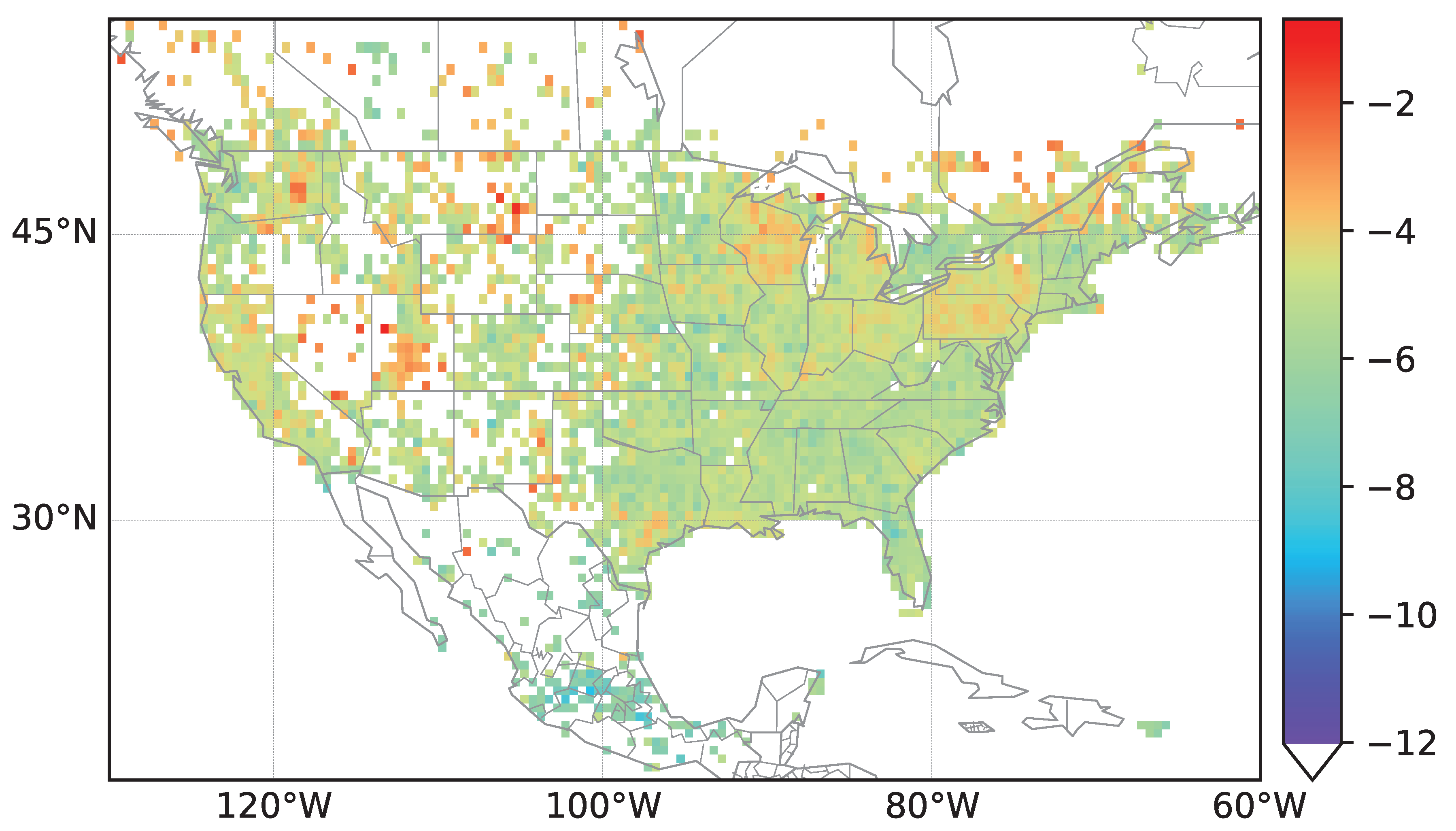
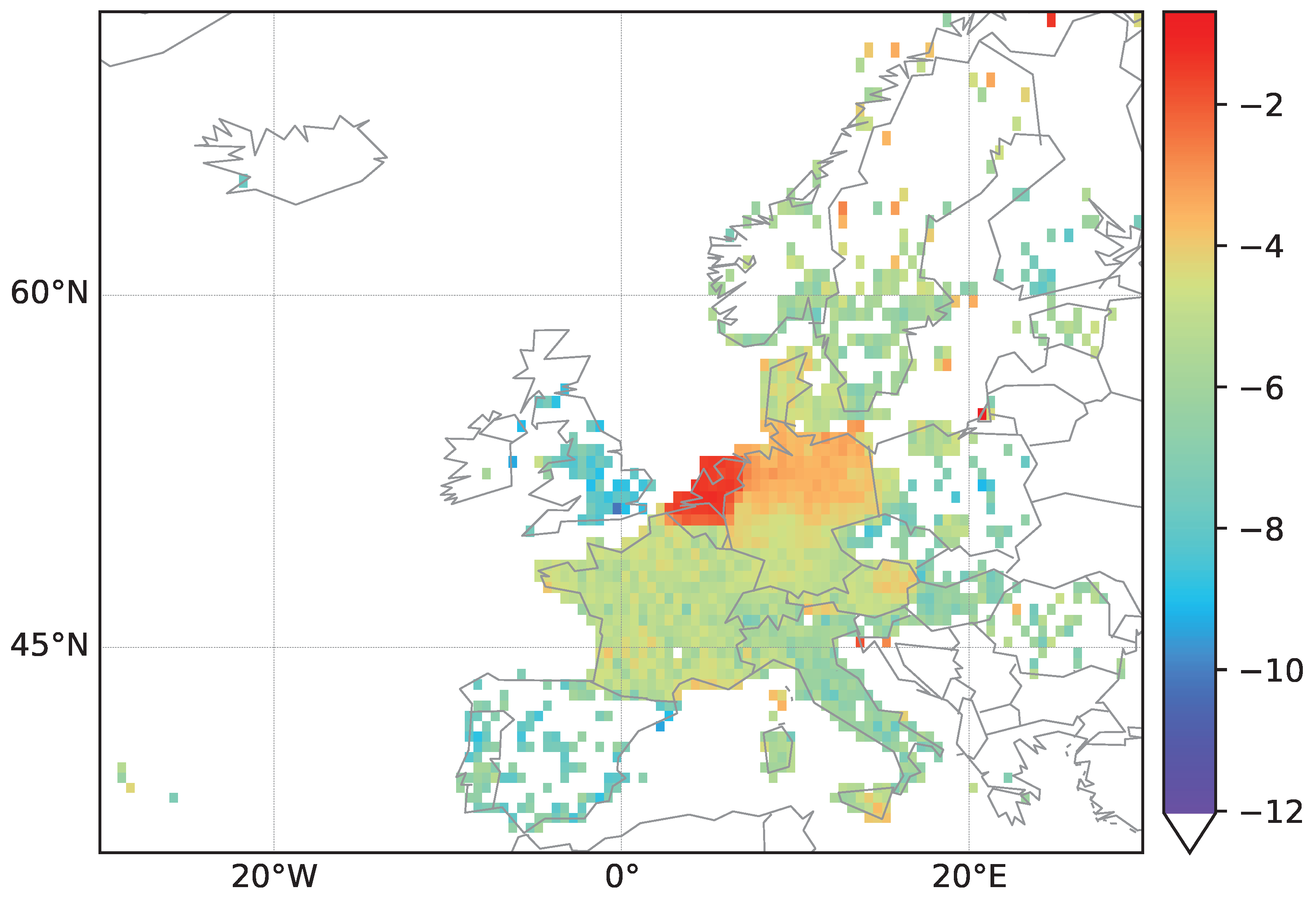
As depicted in
Figure 2, data for street densities are used in order to normalize counts of streets classified to having the same country of origin. We use a grid based on geographic coordinates and count street entries within each cell of the grid. Each cell
covers an area of
in longitude and latitude The grid is set in the region from
W to
W and
N to
N for North America,
W to
E and
N to
N for Europe and
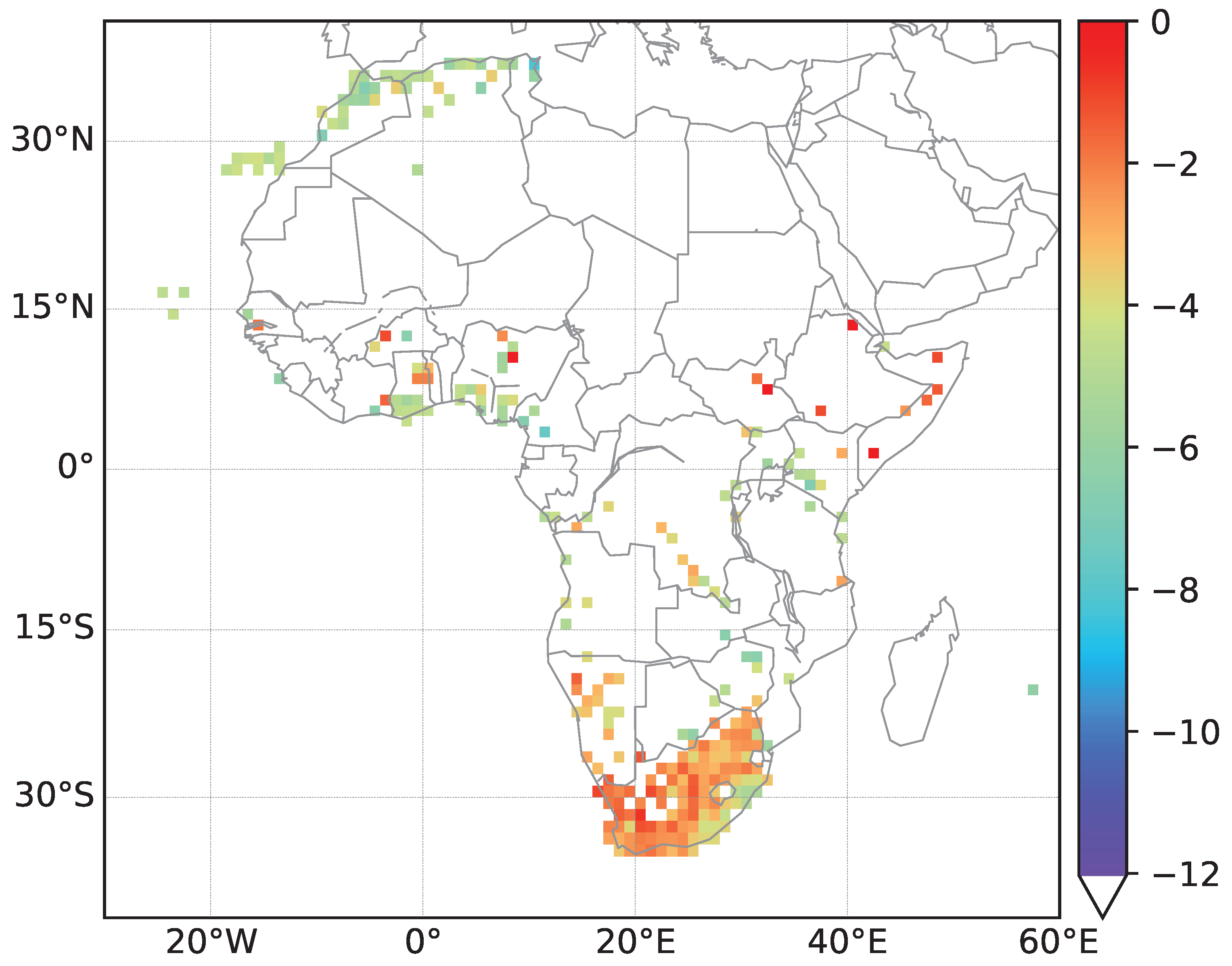
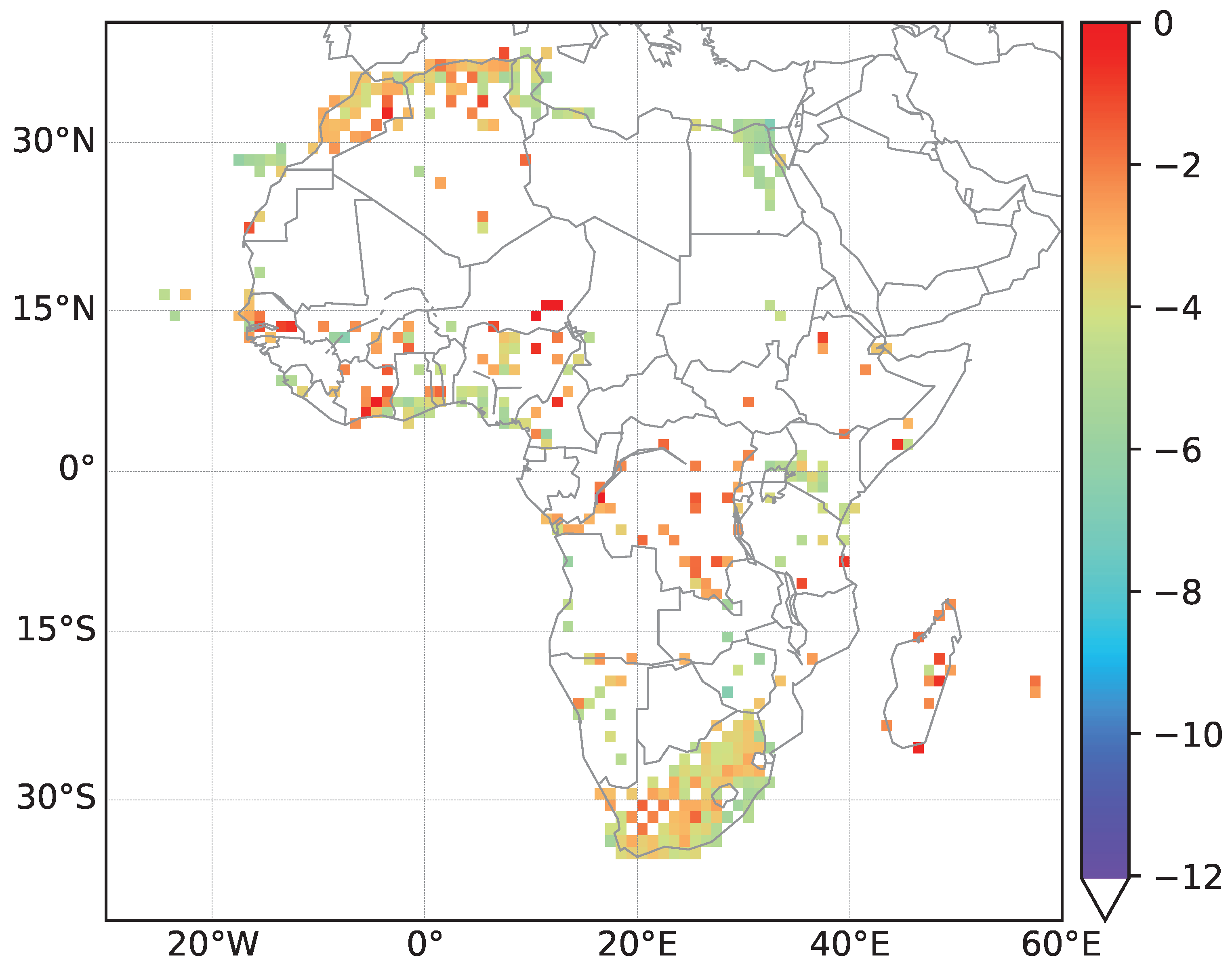
W to
E and
N to
S for Africa, respectively. For the Africa data a coarser grid with cells covering an area of
in longitude and latitude is used due to the sparsity of named streets in the OSM data set. For each cell in the grid we count the number of streets
intersecting the cell. Thus, for each street, we check in which grid of the cell it is located by looking at the street coordinates. As each street is described by several coordinates, we calculate a midpoint of the coordinates which is used when counting the streets. We compute
, where
is the total number of streets in the area of interest, i.e., the density values
for North America are shown in
Figure 3. Density plots for streets in Europe and Africa can be found in the
Supplementary Materials. Plots have been created using
Python matplotlib/basemap [
23].
2.4. Classification of Street Terms and Names
After the extraction of street terms, we now have a data set of street terms with total number and percentage of appearance for each European country and North American state. As depicted in
Figure 2, we only use the set of street specifics obtained after data extraction and preparation as described above and in
Figure 1. To classify North American street terms by their country of origin, we count exact matches of North American street specifics with European street specifics. Thus, for each North American street term, we obtain a list of putative European countries of origin. Approximately 2/3 of the street terms in North America can be assigned to a European correspondent by an exact match. In order to verify assigned countries of origin and classify terms that have not yet been classified, we apply the
FastText language identifier [
24,
25] that has been trained on Wikipedia data. For each street term, we extract the three most probable languages and corresponding countries, i.e., if the language is German, possible countries are Germany, Austria and Switzerland.
For most of the street terms, it was possible to correctly verify the country of origin using the language identification tool. The results agreed to more than 80% with the results obtained by matching street terms of American countries to street terms in Europe. Difficulties occured for very similar languages and countries with the same official language. Of course, also classifications based on street term matching might not always reflect the term’s language of origin. However, our aim is to detect clusters of North American street names based on European street names. The highest amount of misclassified street terms can be seen when the street term (specific) is a person’s or a city’s name, i.e.,
Lindbergh,
Lionel,
Christie,
Frazer,
Mozart,
Dessau,
Marionville,
Amalfi. Here, matching of the street terms results in different origins than using the language identifier tool. For only a few terms, no language identification is possible. These terms are excluded from further analyses. For further details we refer to the
supplemental data.
Final assignments of European countries to North American street terms are based on the intersection of street term matchings and results of the language identifier. If the intersection is empty, we remain with the street term matching. If the intersection contains more than one country, we keep all assignments in the intersection. North American street terms that could not be matched to European street terms are only classified by the language classifier. We see that in total, street generics are less accurately identified by the language identifier as the sets contain more abbreviations, e.g., ‘dr’ for drive. However, only street specifics are included in the cluster detections.
Taken together, the final assignments of North American street specifics to their European country of origin reveils that many street names can possibly be mapped to several countries of origin. In order to avoid too generic street names, we only take into account street names that have been assigned to at most four European countries of origin. This number especially accounts for European countries sharing the same language such as Germany, Austria and Switzerland being German-speaking countries and Belgium, Luxembourg and Netherlands having German minorities.
We not only calculate mappings of European street specifics to North American street names but also create self-mappings, thus mappings of European street specifics to European street names and analogously for North America. These mappings are only based on exact matches of street specifics but omit the verification and classification step using the language classifier (see also
Figure 2).
In an additional step, we downloaded street name data for the African continent (September 2020). Their analysis is conducted analogously to the analysis of North American street names. However, much less data is available and thus, we obtain a smaller amount of information. Still, the former colonial powers can in most cases be identified based on street names with European origins.
2.5. Construction of Street Clusters Based on European Origin
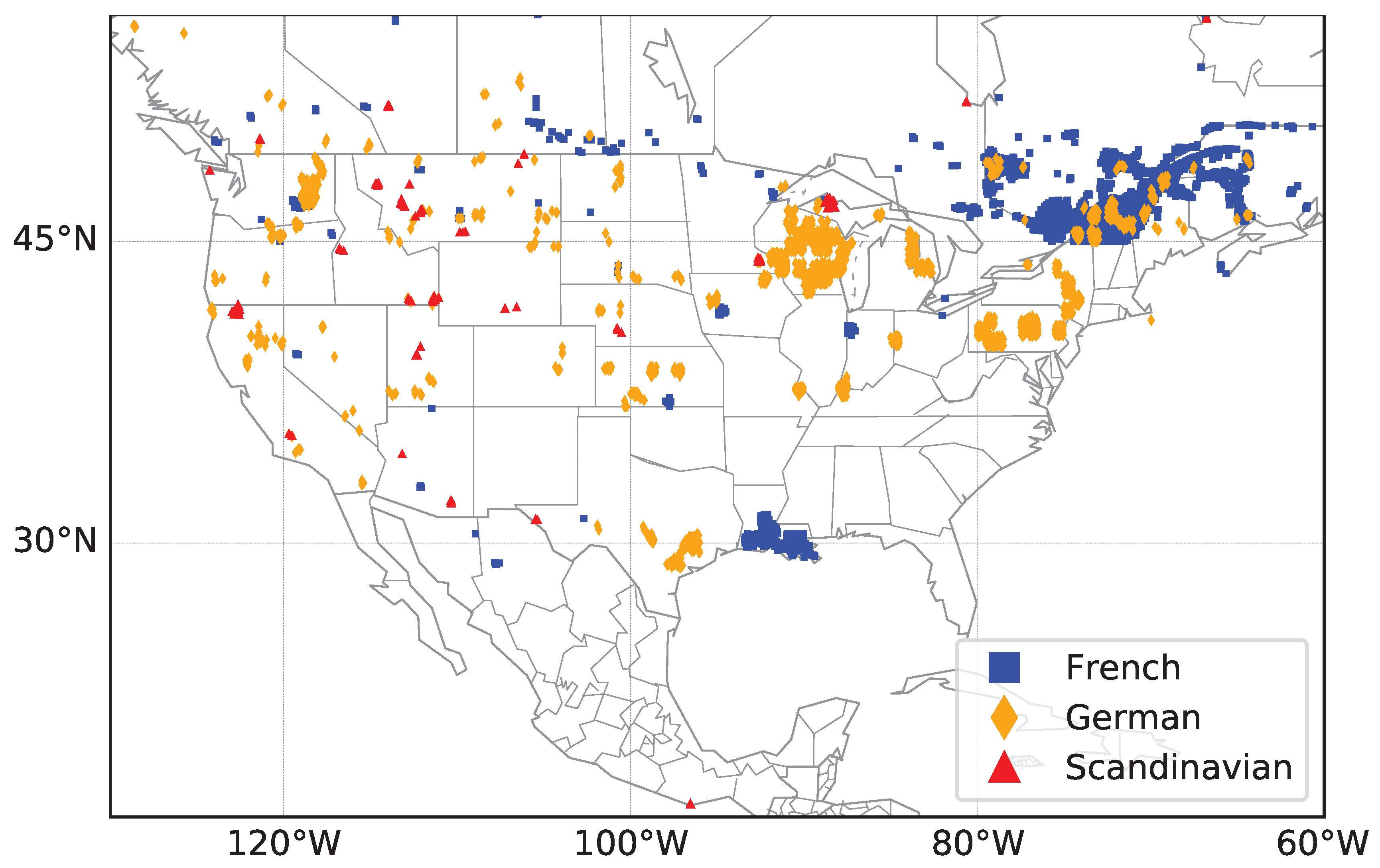
Dense regions of streets named by the same European origin are used to detect clusters of streets. Each cluster has to contain at least three streets with the same European origin. Only regions with a log density value of larger than −4 are taken into account. In this way, no distance threshold between the streets has to be defined as distances might be much larger in rural areas than in cities.
2.6. Code Availability
All scripts used to analyse the data sets and lists of data sources are freely available and can be found in the corresponding github repository, see
www.github.com/bsarah/osm-streetnames.
4. Discussion
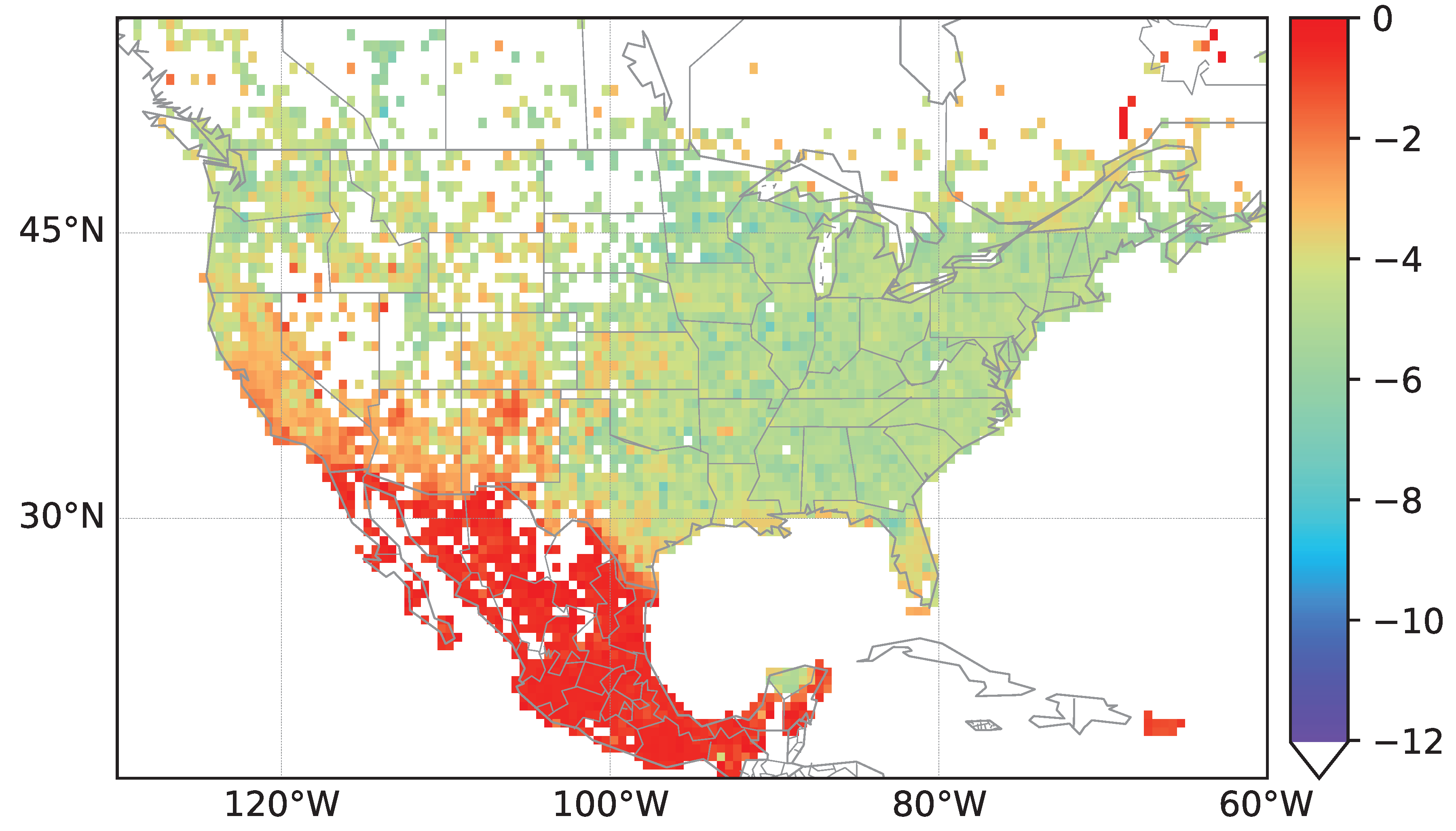
We have shown in this contribution that it is possible to detect former European settlements in North America based solely on the comparison of street names. Here, mainly the street specifics are encountered for the comparison. The results confirm Spanish and French speaking areas in North America such as Mexico and Quebec. However, Spanish street names can also be found in the southwestern states of the US and Florida which are known to have been settled by Spanish-speaking immigrants. A similar case exists for regions with a large portion of French street names. In addition to Quebec, Saskatchewan in Canada and Louisiana in the US show high amounts of French street names which confirms the immigration of settlers of French origin. As described by Woodard [
1], German-speaking immigrants as well as Scandinavians moved into the areas south of the Great Lakes which is confirmed by the high density of German street names in these regions.
The analysis of dense regions also reveils smaller clusters of streets of European origin. The central and western states of the US and Canada show a high amount of small European street clusters which indicate European settlements. Most of these clusters are located within rural areas as they are less prone to undergo reconstructions and renaming of streets. We again see German, Austrian and Scandinavian clusters not only in the vicinity of the Great Lakes but also in the central and western US states.
As a first step, our aim was primarily to show that the available data indeed contain a detectable signal. Our approach therefore was purely data driven, i.e., we did not use any knowledge based curation of street names and instead relied on statistical (co)occurences along. The simple statistical approach taken here can certainly be improved in future work, in particular regarding the assignment of the country or region of origin of a street name. While Spanish, French or German origins are different enough to yield clearly distinguishable signals, the resolution is insufficient to clearly distinguish e.g., Spanish and Portugese, or Austrian and German influence since each pair of countries shares too many street specifics. This observation suggests, in particular, in a next step to develop statistics to detect street specifics that are characteristic for geographically limited regions of origin.
Several methodological issues arise in this kind of quantitative analysis. Most importantly, extensive preprocessing is required to prepare good origin-specific collections of street name specifics. Starting from European data, street names in countries with a single dominating language provide a good starting point but are not specific enough. In particular language similarities as well as very frequently used geographic terms or surnames tend to generate spurious matches. Using the street specifics that appear in many different regions as a negative filter seems to work well, at least on the Europe-centric datasets used here. The development of training methods that are also applicable when the initial sets cannot not defined in an obvious manner by the border of countries or lower-level adminstrative entities within them remains as an interesting topic for future research.
In our initial analysis we have focussed on the most obvious signals reflecting settlement and migration history related to the ethnicity of migrant and minority populations. In particular in Africa, the patterns reflect colonial history. However, street name data can also reflect subsequent political changes such tendencies to eradicate colonial names after independence. Active renaming is in particular a likely explanation in former colonies that show no signal for street specifics matching the former colonial power. Such effects are difficult to detect with our current methodology. Since they involve a change in street naming conventions, temporally stratified data could be used. The most convenient data would be street name data for different points in time, which would allow a direct measurement of renaming rates and language/concept transitions. Since OSM exists only since 2004 and data were comparably sparse initially, a direct analysis of renaming is at least at present limited to very recent history. As a proxy, one could also associate streets in rapidly growing communities with the time at which they appeared on maps, even if past names are difficult to access.
5. Conclusions
In summary, we have shown that a statistical analysis of odonyms allows conclusions about regional settlement histories, despite renamings of streets, reconstructions and expansions of settlements, and a change in predominant language. The results agree with the historical context of European settlement as described in Woodard [
1]. Also the results of previous studies in North America [
5,
6,
22] are relected at least in part in our results.
We demonstrated that freely accessible and easily evaluated sources such as street name data can be used as additional information to review and confirm historical events such as settlements and migration profiles. However, this is only possible for countries or regions that homogenously have used one official language for a significant amount of time. Countries with a large number of different languages make comparison and mapping more complicated and languages cannot be distinguished readily based on geographic data alone. Despite the results obtained here, there are limitations to odonyms as the sole data source. Most naturally, they could be combined with additional socio-economic data such as census data.
For th technical point of view, the approach presented here is not limited to OSM data. However, as we use osmium tool to parse OSM files, the software accompanying this contribution will need to be adapted to use specific parsers for other data sources such as the Google Earth project. The use of proprietory data sources in addition may encounter legal constraints.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}