Spatial Analytics Based on Confidential Data for Strategic Planning in Urban Health Departments



Abstract
:1. Introduction
2. Background
3. Data and Methods
3.1. Data Collection
3.2. Variables
3.3. Analysis
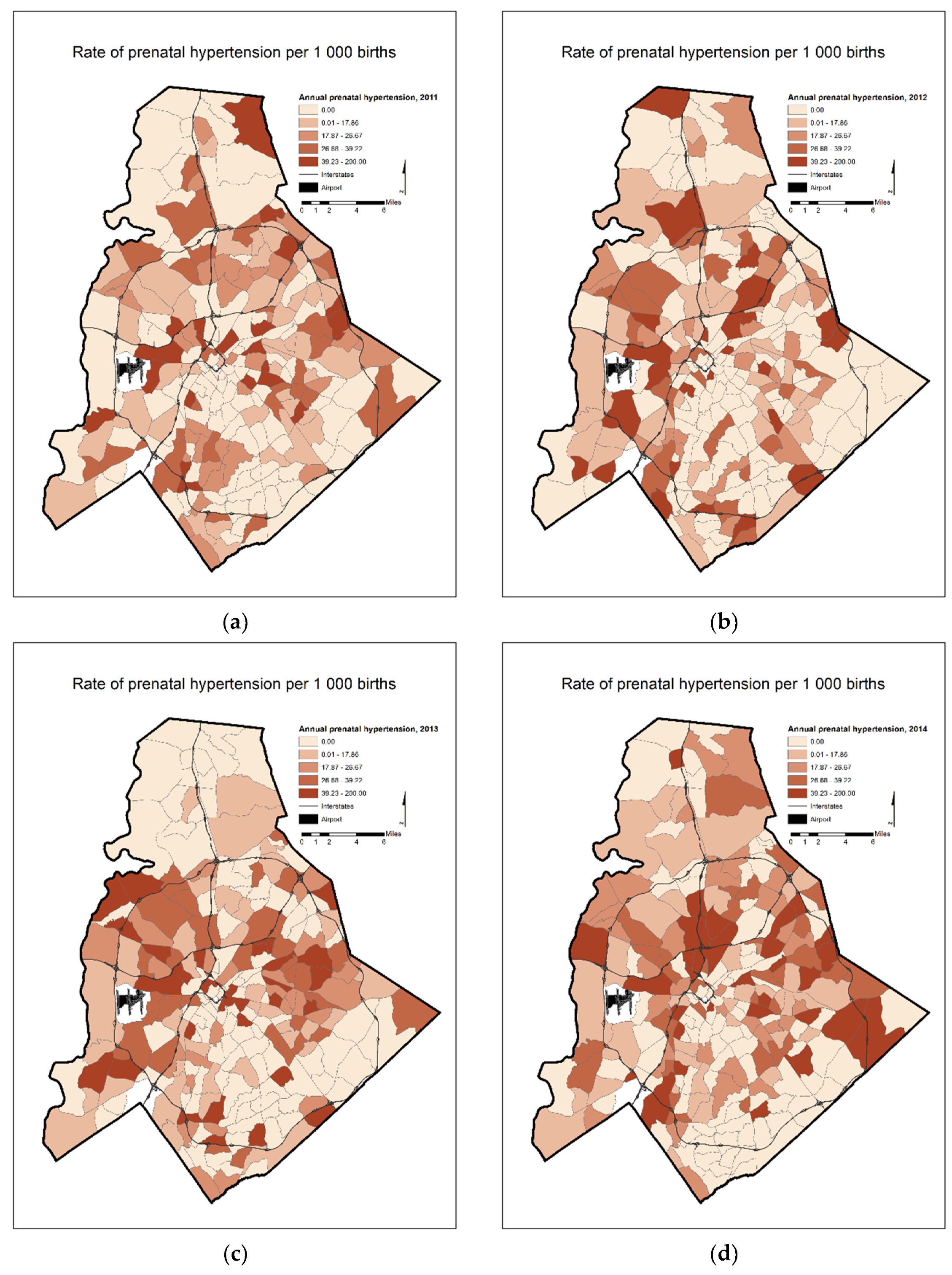
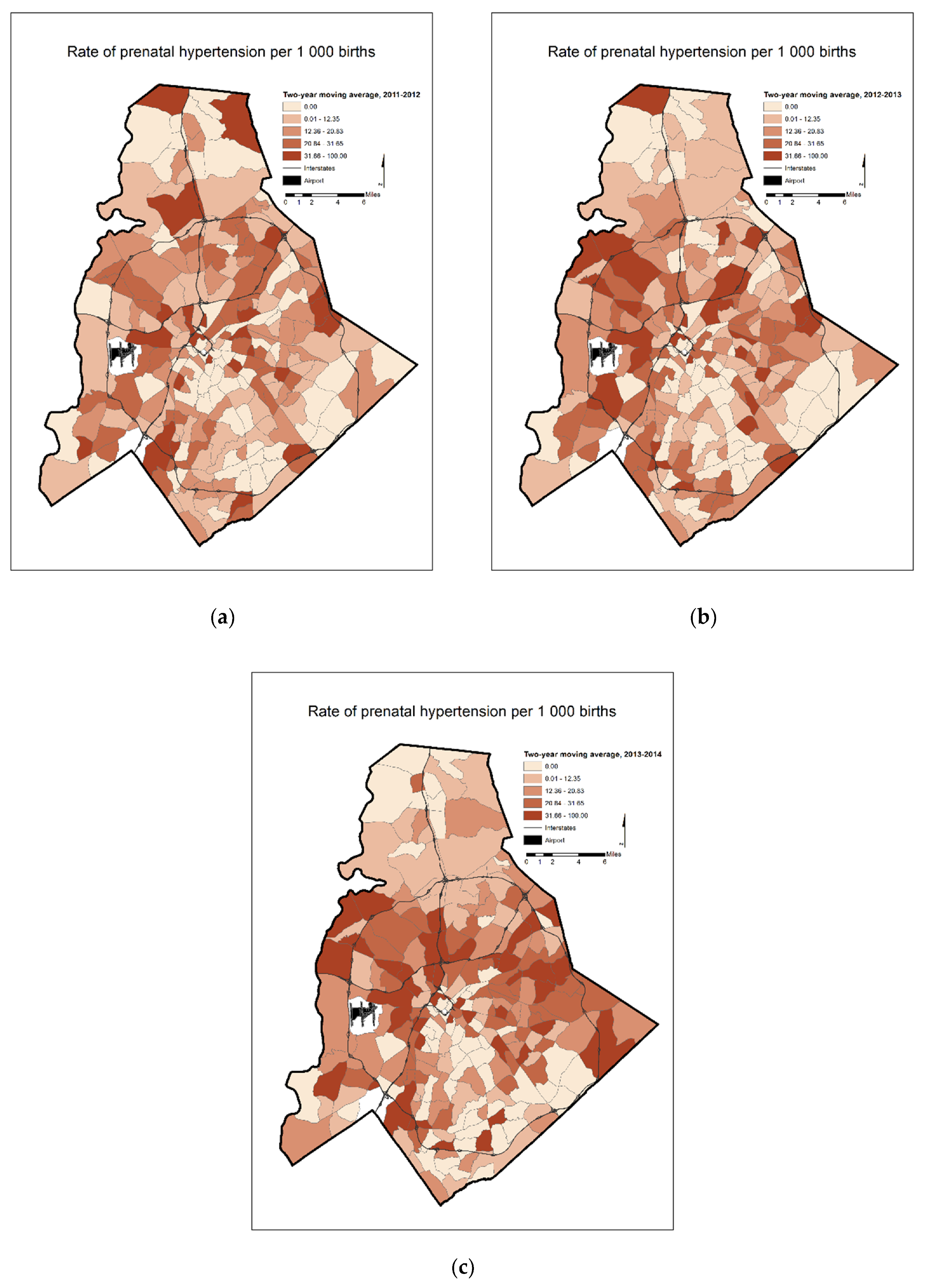
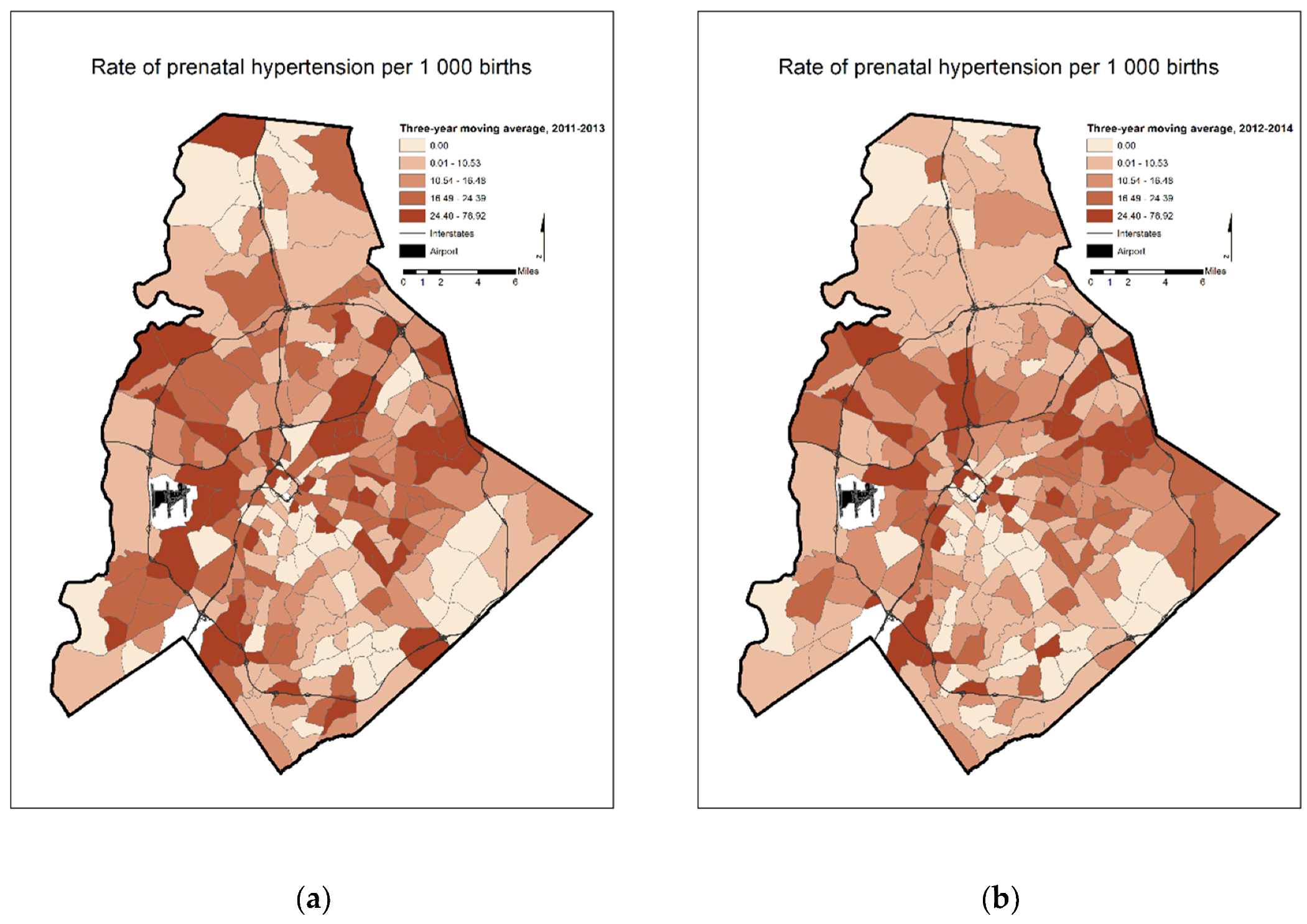
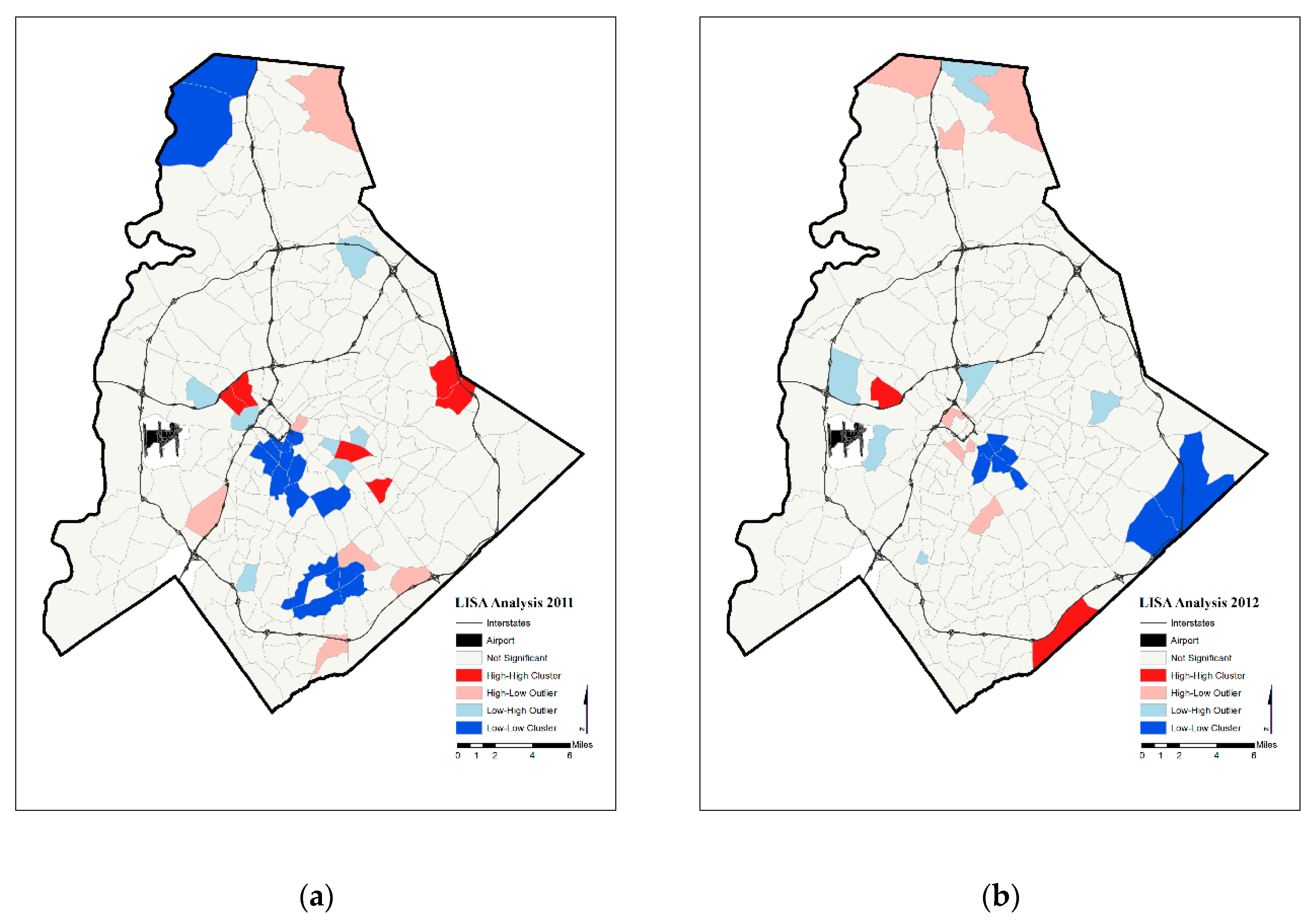
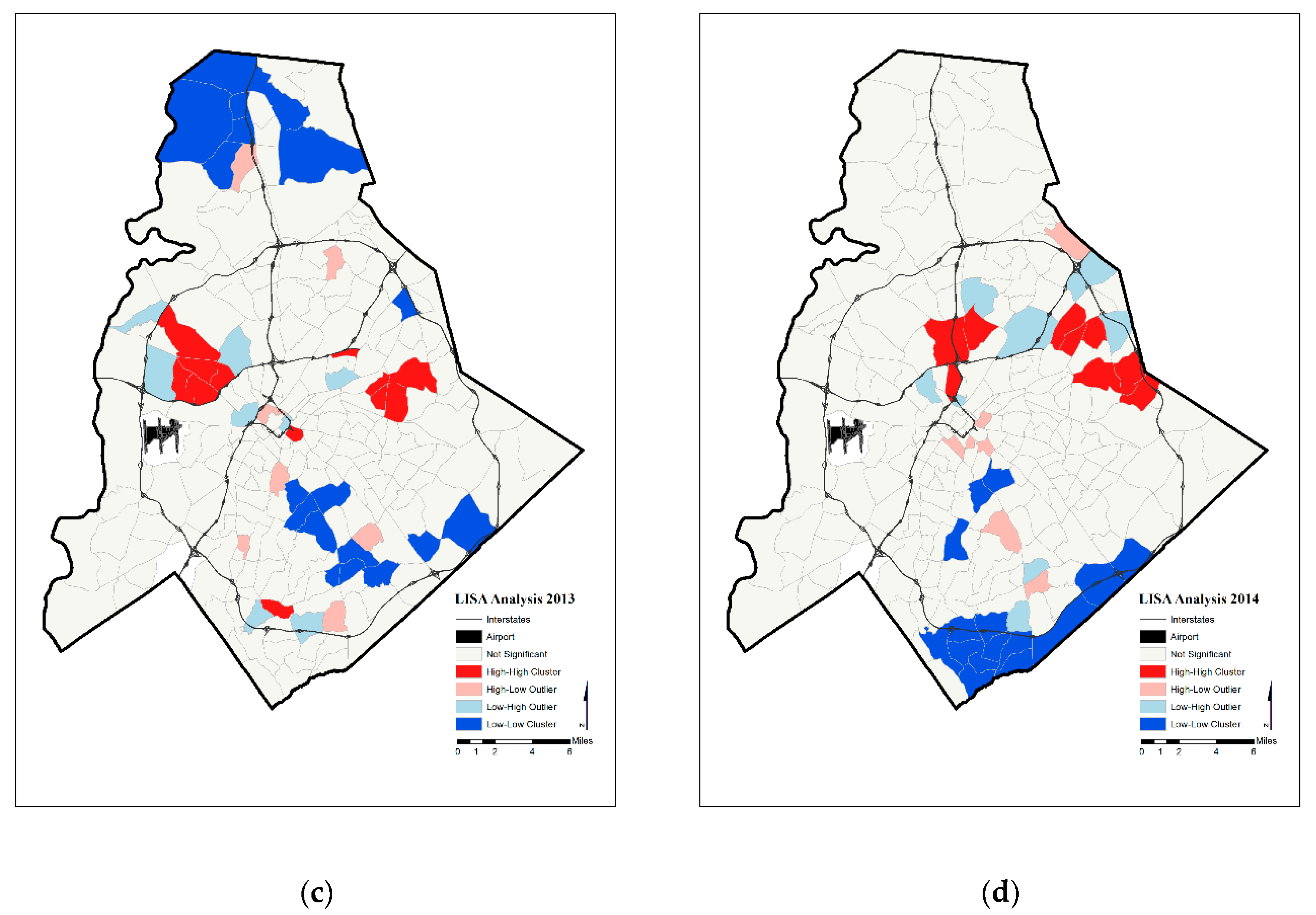
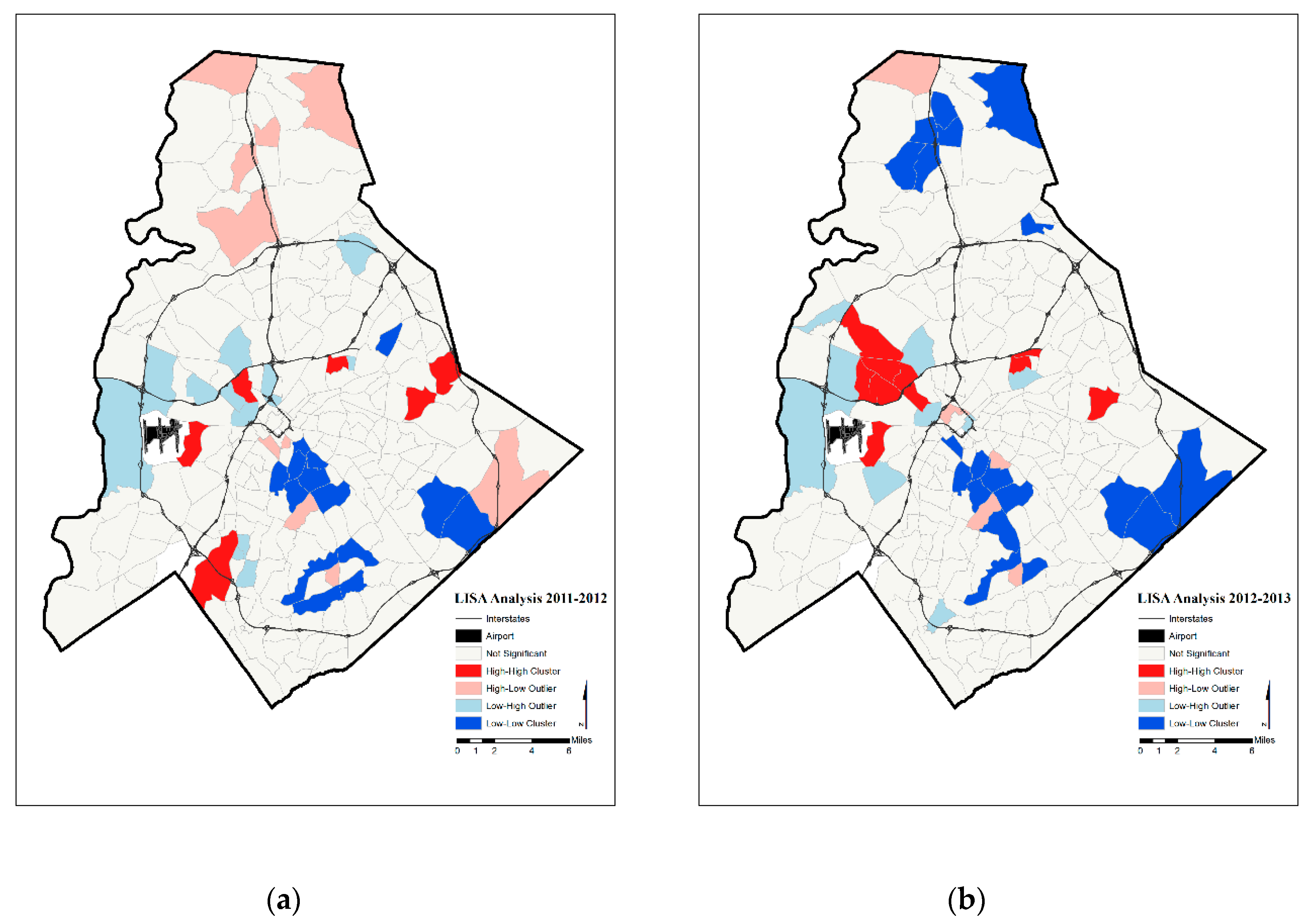
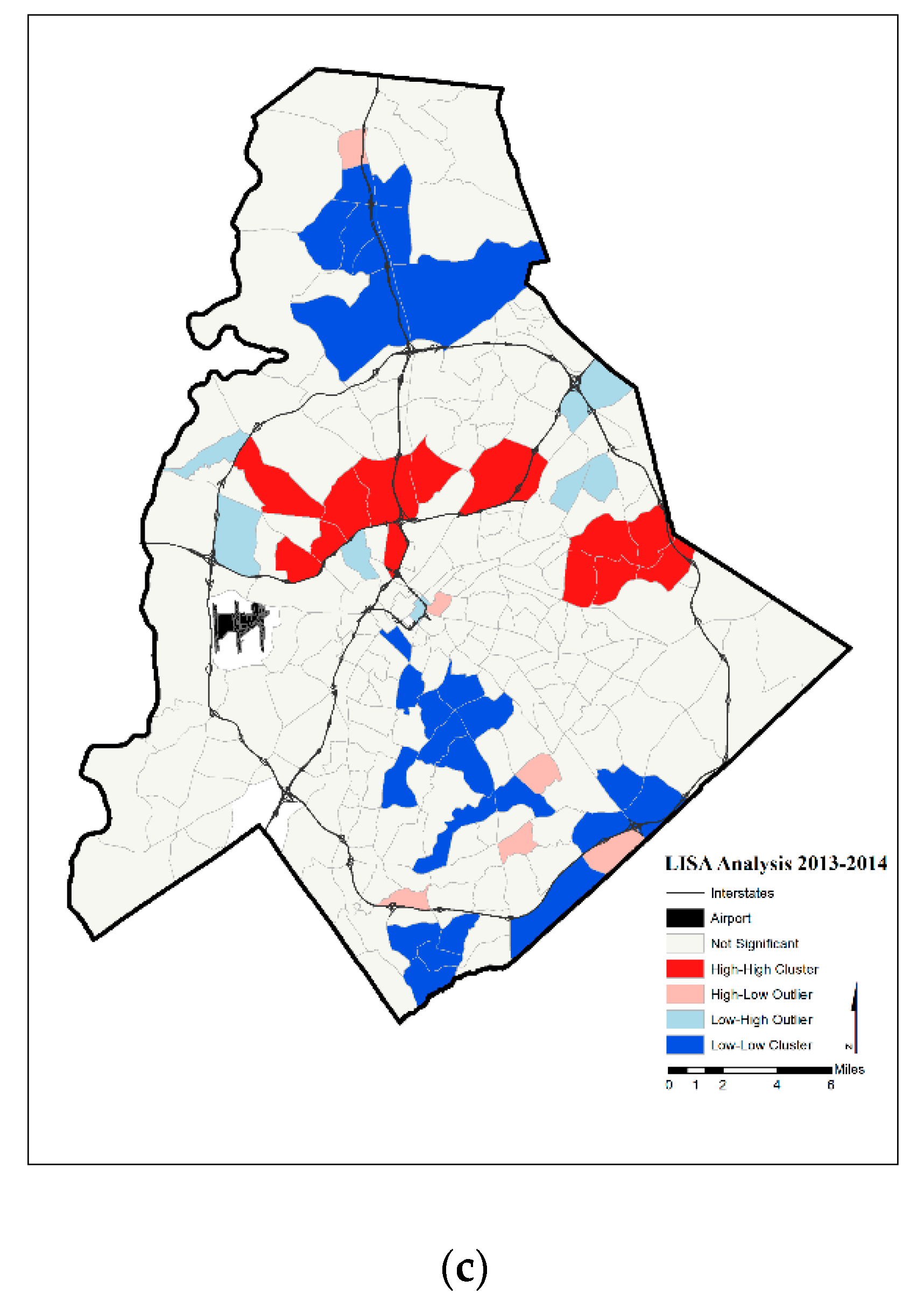
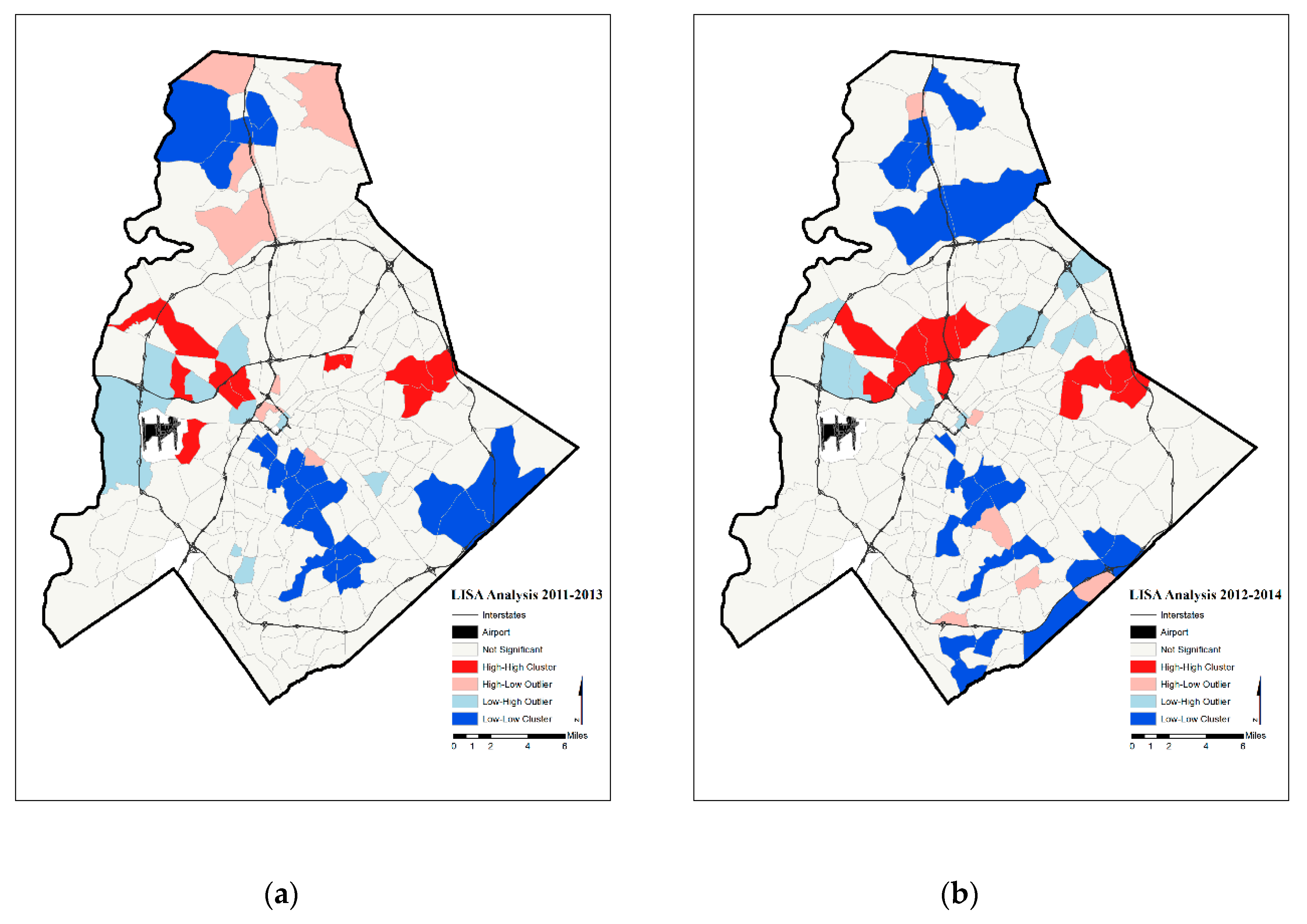
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Ethical Approval
References
- RESOLVE. The High Achieving Governmental Health Department in 2010 as the Community Chief Health StrateGISt; RESOLVE: Washington, DC, USA, 2014; Available online: http://www.resolv.org/site-healthleadershipforum/hd2020/ (accessed on 15 July 2015).
- Nagasko, E.; Waterman, B.; Reidhead, M.; Lian, M.; Gehlert, S. Measuring Subcounty Differences in Population Health Using Hospital and Census-Derived Data Sets: The Missouri ZIP Health Rankings Project. J. Public Health Manag. Pract. 2018, 4, 340–349. [Google Scholar] [CrossRef] [PubMed]
- Bemis, K.; Gray, S.; Patel, M.T.; Christiansen, D. Disproportionate emergency room use as an indicator of community health. Online J. Public Health Inf. 2016, 1, e9. [Google Scholar] [CrossRef]
- Lovett, D.A.; Poots, A.J.; Clements, J.T.C.; Green, S.A.; Samarasundera, E.; Bell, D. Using geographical information systems and cartograms as health services quality improvement tool. Spat. Spatio-Temporal Epidemiol. 2014, 10, 67–74. [Google Scholar] [CrossRef] [PubMed]
- Caprarelli, G.; Fletcher, S. A brief review of spatial analysis concepts and tools used for mapping, containment and risk modeling of infectious diseases and other illnesses. Parasitology 2014, 141, 581–601. [Google Scholar] [CrossRef] [PubMed]
- Berney, D.; Camponeschi, J.; Coon, M.; Creswell, P.D.; Schirmer, J.L.; Walsh, R. Using environmental public health tracking to identify community targets for public health actions in childhood lead poisoning in Wisconsin. J. Public Health Manag. Pract. 2015, 21, S80–S84. [Google Scholar] [CrossRef] [PubMed]
- Curtis, A.B.; Kothari, C.; Paul, R.; Connors, E. Using GIS and secondary data to target diabetes-related public health efforts. Public Health Rep. 2013, 128, 212–220. [Google Scholar] [CrossRef] [PubMed]
- Salinas, J.J.; Abdelbary, B.; Klass, K.; Tapia, B.; Sexton, K. Socioeconomic context and the food landscape in Texas: Results from hotspot analysis and border/non-border comparison of unhealthy food environments. Int. J. Environ. Res. Public Health 2014, 6, 5640–5650. [Google Scholar] [CrossRef] [PubMed]
- Brown, P.M.; Gonzales, M.; Dhaul, R.S. Cost of chronic disease in California: Estimates at the county level. J. Public Health Manag. Pract. 2015, 21, E10–E19. [Google Scholar] [CrossRef] [PubMed]
- Detres, M.; Lucio, R.; Vitucci, J. GIS as a community engagement tool: Developing a plan to reduce infant mortality risk factors. Matern. Child Health J. 2014, 18, 1049–1055. [Google Scholar] [CrossRef] [PubMed]
- Curtis, A.; Mills, J.; Agustin, L.; Cockburn, M. Confidentiality risks in fine scale aggregations of health data. Comput. Environ. Urban Syst. 2011, 1, 57–64. [Google Scholar] [CrossRef]
- Kanaroglou, P.; Delmelle, E.; Paez, A. Spatial Analysis in Health Geography; Routledge: New York, NY, USA, 2015. [Google Scholar]
- El Emnan, K.; Brown, A.; AbdelMalik, P. Evaluating predictors of geographic area population size cut-offs to manage re-identification risk. J. Am. Med. Inf. Assoc. 2009, 16, 256–266. [Google Scholar]
- Healy, M.A.; Gilliland, J.A. Quantifying the magnitude of environmental exposure misclassification when using imprecise address proxies in public health research. Spat. Spatio-Temporal Epidemiol. 2012, 3, 55–67. [Google Scholar] [CrossRef] [PubMed]
- Krefis, A.C.; Albrecht, M.; Kis, A.; Jagodzinski, A.; Augustin, M.; Augustin, J. Associations of Noise and Socioeconomic and -Demographic Status on Cardiovascular and Respiratory Diseases on Borough Level in a Large German City State. Urban Sci. 2017, 1, 27. [Google Scholar] [CrossRef]
- Waters, E.; Doyle, J. Evidence-based public health: Cochrane update. J. Public Health Med. 2003, 1, 72–75. [Google Scholar] [CrossRef]
- Boulos, M.N.K.; Curtis, A.; AbdelMalik, P. Musings on privacy issues in health research involving disaggregated geographic data about individuals. Int. J. Health Geogr. 2009, 8, 46. [Google Scholar] [CrossRef] [PubMed]
- Sherman, J.E.; Fetters, T.L. Confidentiality concerns with mapping survey data in reproductive health research. Stud. Fam. Plan. 2007, 4, 309–321. [Google Scholar] [CrossRef]
- Siffel, C.; Strickland, M.J.; Gardner, B.R.; Kirby, R.S.; Correa, A. Role of geographic information systems in birth defects surveillance and research. Birth Defects Res. A Clin. Mol. Teratol. 2006, 11, 825–833. [Google Scholar] [CrossRef] [PubMed]
- Matthews, S.A.; Moudon, A.V.; Daniel, M. Work group II: Using Geographic Information Systems for enhancing research relevant to policy on diet, physical activity, and weight. Am. J. Prev. Med. 2009, 4, S171–S176. [Google Scholar] [CrossRef]
- Smolders, R.; Casteleyn, L.; Joas, R.; Schoeters, G. Human biomonitoring and the INSPIRE directive: Spatial data as link for environment and health research. J. Toxicol. Environ. Health B Crit. Rev. 2008, 8, 646–659. [Google Scholar] [CrossRef]
- Foley, R. Assessing the applicability of GIS in a health and social care setting: Planning services for informal careers in East Sussex. Engl. Soc. Sci. Med. 2002, 1, 79–96. [Google Scholar] [CrossRef]
- McKenzie, G.; Janowicz, K.; Seidl, D. Geo-Privacy beyond Coordinates. In Geospatial Data in a Changing World: Selected Papers of the 19th AGILE Conference on Geographic Information Science; Sarjakoski, T., Santos, M., Sarjakoski, L., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 157–175. [Google Scholar]
- Centers for Disease Control and Prevention. HIPAA privacy rule and public health: Guidance from CDC and the US Department of Health and Human Services. MMWR Morb. Mortal. Wkly. Rep. 2003, 52, 1–20. [Google Scholar]
- Office of Clinical Research. Guidance Regarding Methods for De-identification of Protected Health Information in Accordance with the Health Insurance Portability and Accountability Act (HIPAA) Privacy Rule; United States Department of Health and Human Services: Washington, DC, USA, 2012. [Google Scholar]
- VanWey, L.K.; Rindfuss, R.R.; Gutmann, M.P.; Entwisle, B.; Balk, D.L. Confidentiality and spatially explicit data: Concerns and challenges. Proc. Natl. Acad. Sci. USA 2005, 102, 15337–15342. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- El Emam, K.; Jonker, E.; Arbuckle, L.; Malin, B. Correction: A systematic review of re-identification attacks on health data. PLoS ONE 2015, 4, e0126772. [Google Scholar] [CrossRef] [PubMed]
- Seidl, D.; Paulus, G.; Jankowski, P.; Regenfelder, M. Spatial obfuscation methods for privacy protection of household-level data. Appl. Geogr. 2015, 63, 253–263. [Google Scholar] [CrossRef]
- Acevedo-Garcia, D.; McArdle, N.; Hardy, E.F.; Crisan, U.I.; Romano, B.; Norris, D.; Baek, M.; Reece, J. The child opportunity index: Improving collaboration between community development and public health. Health Aff. 2014, 11, 1948–1957. [Google Scholar] [CrossRef] [PubMed]
- Boulos, M.N.K. Towards evidence-based, GIS-driven national spatial health information infrastructure and surveillance services in the United Kingdom. Int. J. Health Geogr. 2004, 1, 1–50. [Google Scholar] [CrossRef]
- Chun, Y.; Griffith, D.A. Spatial Statistics & Geostatistics; Sage: Los Angeles, CA, USA, 2013. [Google Scholar]
- Pfeiffer, D.; Robinson, T.P.; Stevenson, M.; Stevens, K.B.; Rogers, D.C.; Clements, A.C. Spatial Analysis in Epidemiology; Oxford University Press: New York, NY, USA, 2008. [Google Scholar]
- Stoto, M.A. Population Health in the Affordable Care Act Era; Academy Health: Washington, DC, USA, 2013; Available online: https://www.academyhealth.org/files/AH2013pophealth.pdf (accessed on 15 July 2015).
- Vest, J.R.; Issel, L.M. Factors related to public health data sharing between local and state health departments. Health Serv. Res. 2014, 1, 373–391. [Google Scholar] [CrossRef]
- Meltzer, D.O.; Chung, J.W. The population value of quality indicator reporting: A framework for prioritizing health care performance measures. Health Aff. 2014, 33, 132–139. [Google Scholar] [CrossRef]
- Lyseen, A.K.; Nohr, C.; Sorensen, E.M.; Gudes, O.; Geraghty, E.M.; Shaw, N.T.; Bivona-Tellez, C.; IMIA Health GIS Working Group. A review and framework for categorizing current research and development in health related geographical information systems (GIS) studies. Yearb. Med. Inform. 2014, 1, 110–124. [Google Scholar]
- Geographic Research, Inc. Census 2012 Data; Geographic Research, Inc.: New York, NY, USA, 2015. [Google Scholar]
- Brondolo, E.; Love, E.E.; Pencile, M.; Schoenthaler, A.; Ogedegbe, G. Racism and hypertension: A review of the empirical evidence and implications for clinical practices. Am. J. Hypertens. 2011, 24, 518–529. [Google Scholar] [CrossRef]
- Committee on Practice-Obstetics. Gestational hypertension and preeclampsia. ACOG Practice Bulletin No. 202. American College of Obstetricians and Gynecologists. Obstet. Gynecol. 2019, 133, e1–e25. [Google Scholar] [CrossRef] [PubMed]
- Grady, S.C.; Ramirez, I.J. Mediating medical risk factors in the residential segregation and low birthweight relationship by race in New York City. Health Place 2008, 14, 661–677. [Google Scholar] [CrossRef] [PubMed]
- Hauspurg, A.; Parry, S.; Mercer, B.M.; Grobman, W.; Hatfield, T.; Silver, R.M.; Parker, C.B.; Haas, D.M.; Iams, J.D.; Saade, G.R.; et al. Blood pressure trajectory and category and risk of hypertensive disorders of pregnancy in nulliparous women. Am. J. Obstet. Gynecol. 2019, in press. [Google Scholar] [CrossRef] [PubMed]
- Olson-Chen, C.; Seligman, N.S. Hypertensive Emergencies in Pregnancy. Crit. Care Clin. 2016, 32, 29–41. [Google Scholar] [CrossRef] [PubMed]
- Gillon, T.E.; Pels, A.; von Dadelszen, P.; Magee, L.A. Hypertensive disorders of pregnancy: A systematic review of International clinical practice guidelines. PLoS ONE 2014, 9, e113715. [Google Scholar] [CrossRef] [PubMed]
- Nelson, E.J.; Shacham, E.; Boutwell, B.B.; Rosenfeld, R.; Schootman, M.; Vaughn, M.; Lewis, R. Childhood lead exposure and sexually transmitted infections: New evidence. Environ. Res. 2015, 143, 131–137. [Google Scholar] [CrossRef] [PubMed]
- Edwards, S.E.; Strauss, B.; Miranda, M.L. Geocoding large population-level administrative datasets at highly resolved spatial scales. Trans. GIS 2014, 4, 586–603. [Google Scholar] [CrossRef] [PubMed]
- Toledo, L.; Codeco, C.T.; Bertoni, N. Putting respondent-driven sampling on the map: Insights from Rio de Janeiro, Brazil. J. Acquir. Immune Defic. Syndr. 2011, 57, S136–S143. [Google Scholar] [CrossRef]
- Anselin, L. Local indicators of spatial association—LISA. Geogr. Anal. 1995, 2, 93–115. [Google Scholar] [CrossRef]
- Xia, J.; Cai, S.; Zhang, H.; Lin, W.; Fan, Y.; Qiu, J.; Sun, L.; Chang, B.; Nie, S. Spatial, temporal, and spatiotemporal analysis of malaria in Hubei Province, China from 2004–2011. Malar. J. 2015, 14, 1–10. [Google Scholar] [CrossRef]
- Abbas, T.; Younus, M.; Muhammad, S.A. Spatial cluster analysis of human cases of Crimean Congo hemorrhagic fever reported in Pakistan. Infect. Dis. Poverty 2015, 4, 9. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Yin, F.; Zhang, T.; Yang, C.; Zhang, X.; Feng, Z.; Li, X. Spatial analysis on human brucellosis incidence in mainland China: 2004–2010. BMJ Open 2014, 4, e004470. [Google Scholar] [CrossRef] [PubMed]
- Zhu, B.; Fu, Y.; Liu, J.; Mao, Y. Notifiable sexually transmitted infections in China: Epidemiologic trends and spatial changing patterns. Sustainability 2017, 9, 1784. [Google Scholar] [CrossRef]
- Zhu, B.; Liu, J.; Fu, Y.; Zhang, B.; Mao, Y. Spatio-temporal epidemiology of viral hepatitis in China (2003–2015): Implications for prevention and control policies. Int. J. Environ. Res. Public Health 2018, 15, 661. [Google Scholar] [CrossRef]
- Anselin, L.; Syabri, I.; Kho, Y. GeoDa: An Introduction to Spatial Data Analysis. Geogr. Anal. 2006, 38, 5–22. [Google Scholar] [CrossRef]
- Getis, A.; Ord, J.K. The analysis of spatial association by use of distance statistics. Geogr. Anal. 1992, 3, 189–206. [Google Scholar] [CrossRef]
- Anselin, L. The Moran scatterplot as an ESDA tool to assess local instability in spatial association. In Spatial Analytical Perspectives on GIS in Environmental and Socio-Economic Sciences; Fischer, M., Scholten, H., Unwin, D., Eds.; Taylor and Francis: London, UK, 1997; pp. 111–215. [Google Scholar]
- Bailey, T.C.; Gatrell, A.C. Interactive Spatial Data Analysis; Wiley: Hoboken, NJ, USA, 1995. [Google Scholar]
- Charlotte/Mecklenburg Quality of Life Explorer. 2019. Available online: https://mcmap.org/qol/#15/ (accessed on 15 July 2019).
- Charlotte/Mecklenburg Quality of Life Explorer. 2019. Available online: https://mcmap.org/qol/#/p1/ https://mcmap.org/qol/#14/ (accessed on 15 July 2019).
- Mecklenburg County Health Department. Mecklenburg County Community Health Assessment. 2018. Available online: https://www.mecknc.gov/HealthDepartment/HealthStatistics/Pages/Community-Health-Assessment.aspx (accessed on 13 July 2019).
- Gregorio, D.I.; Dechello, L.M.; Samociuk, H.; Kulldorff, M. Lumping or splitting: Seeking the preferred areal unit for health geography studies. Int. J. Health Geogr. 2005, 4, 6. [Google Scholar] [CrossRef]
- Beale, L.; Abellan, J.J.; Hodgson, S.; Jarup, L. Methodologic issues and approaches to spatial epidemiology. Environ. Health Perspect. 2008, 116, 1105–1110. [Google Scholar] [CrossRef]
- Elliott, P.; Wartenberg, D. Spatial epidemiology: Current approaches and future challenges. Environ. Health Perspect. 2004, 9, 998–1006. [Google Scholar] [CrossRef]
- Shah, G.H. A Guide to Designating Geographic Areas for Small Area Analysis in Public Health: Using Utah’s Example; NAHDO-CDC Cooperative Agreement Project; NAHDO-CDC Cooperative: Salt Lake City, UT, USA, 2005. [Google Scholar]
- Jung, P.H.; Thill, J.-C.; Issel, M. Spatial Autocorrelation and Data Uncertainty in the American Community Survey: A Critique. Int. J. Georgr. Inf. Sci. 2019, 6, 1155–1175. [Google Scholar] [CrossRef]
- Jung, P.H.; Thill, J.-C.; Issel, M. Spatial Autocorrelation Statistics of Areal Prevalence Rates under High Uncertainty in Denominator Data. Geogr. Anal. 2018, in press. [Google Scholar] [CrossRef]
- Major, E.; Delmelle, E.; Delmelle, E. SNAPScapes: Using geodemographic segmentation to classify the food access landscape. Urban Sci. 2018, 2, 71. [Google Scholar] [CrossRef]
- Gatrell, A.C.; Bailey, T.C.; Diggle, P.J.; Rowlingson, B.S. Spatial point pattern analysis and its application in geographical epidemiology. Trans. Inst. Br. Geogr. 1996, 21, 256–274. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| High Rates in Focal Census Tract | Low Rates in Focal Census Tract | |
|---|---|---|
| High Average Rates in Surrounding Census Tracts | “Hot spots” | Spatial outlier |
| Low Average Rates in Surrounding Census Tracts | Spatial outlier | “Cold spots” |
| Year(s) | Moran’s I Statistic |
|---|---|
| 2011 | 0.067 |
| 2012 | 0.071 |
| 2013 | 0.095 |
| 2014 | 0.068 |
| 2011–2012 | 0.037 |
| 2012–2013 | 0.067 |
| 2013–2014 | 0.010 |
| 2011–2013 | 0.106 |
| 2012–2014 | 0.108 |
| Year | Significant Tracts | Hot Spot | Cold Spot | |
|---|---|---|---|---|
| Annual Prenatal Hypertension Rates | 2011 | 36 | 6 | 17 |
| 2012 | 23 | 2 | 8 | |
| 2013 | 45 | 12 | 18 | |
| 2014 | 41 | 9 | 17 | |
| Two-Year Moving Average Prenatal Hypertension Rates | 2011–2012 | 43 | 6 | 14 |
| 2012–2013 | 43 | 10 | 19 | |
| 2013–2014 | 52 | 13 | 26 | |
| Three-Year Moving Average Prenatal Hypertension Rates | 2011–2013 | 50 | 12 | 22 |
| 2012–2014 | 49 | 11 | 22 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yonto, D.; Issel, L.M.; Thill, J.-C. Spatial Analytics Based on Confidential Data for Strategic Planning in Urban Health Departments. Urban Sci. 2019, 3, 75. https://doi.org/10.3390/urbansci3030075
Yonto D, Issel LM, Thill J-C. Spatial Analytics Based on Confidential Data for Strategic Planning in Urban Health Departments. Urban Science. 2019; 3(3):75. https://doi.org/10.3390/urbansci3030075
Chicago/Turabian StyleYonto, Daniel, L. Michele Issel, and Jean-Claude Thill. 2019. "Spatial Analytics Based on Confidential Data for Strategic Planning in Urban Health Departments" Urban Science 3, no. 3: 75. https://doi.org/10.3390/urbansci3030075
APA StyleYonto, D., Issel, L. M., & Thill, J.-C. (2019). Spatial Analytics Based on Confidential Data for Strategic Planning in Urban Health Departments. Urban Science, 3(3), 75. https://doi.org/10.3390/urbansci3030075