
Creating a Novel Attention-Enhanced Framework for Video-Based Action Quality Assessment

 , ,
, ,  , , , and
, , , and
Abstract
1. Introduction
- Attention-Enhanced Feature Learning: To enhance the model’s capacity to concentrate on important details while eliminating extraneous features, we included an attention module. By giving distinct channels different weights, the module prioritizes features that significantly influence predicted scores, dynamically refining the model’s feature learning capacity.
- Uncertainty-Aware Feature Modeling: We applied a VAE to the extracted features, encoding latent variables as Gaussian distributions. The model captures uncertainty in the generated samples while learning the latent structure of the data through variational inference and reparameterization.
- Comprehensive Evaluation and Analysis: Numerous experiments were carried out using datasets that are accessible to the public, showing that our approach attains state-of-the-art results with respect to Spearman rank correlation. Additionally, ablation studies systematically assess the contributions of each model component, validating the effectiveness of our approach.
2. Related Work
2.1. Action Quality Assessment
2.2. Attention Mechanism
2.3. Uncertainty Learning
3. Approach
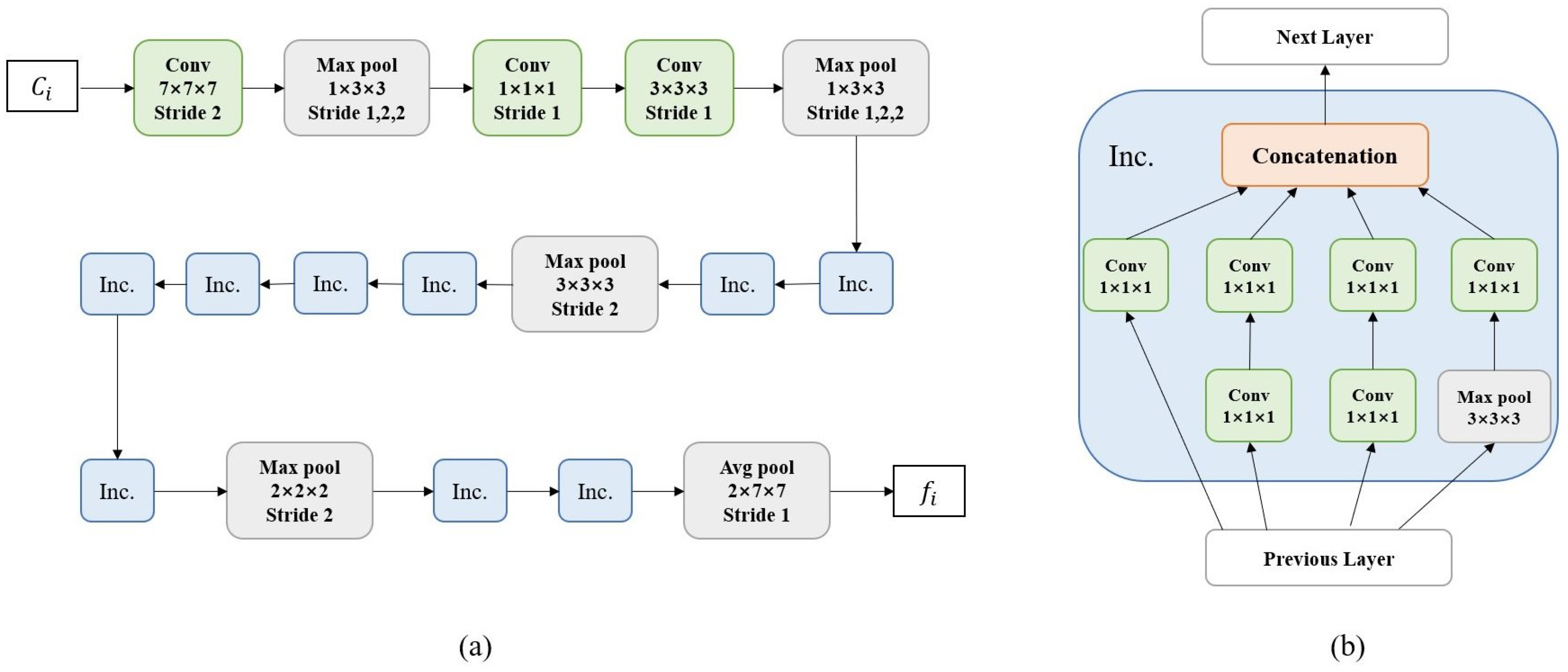
3.1. Feature Extraction
3.2. Attention Module
3.3. Score Distribution Regression
3.4. Loss Function
4. Experiment
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
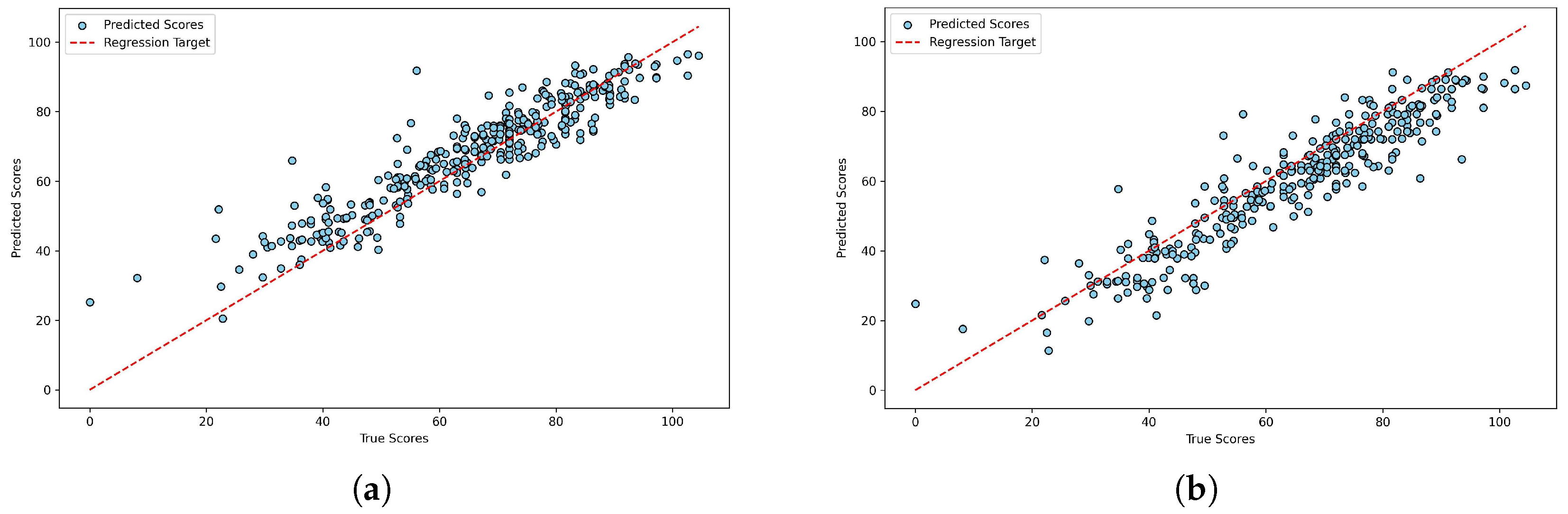
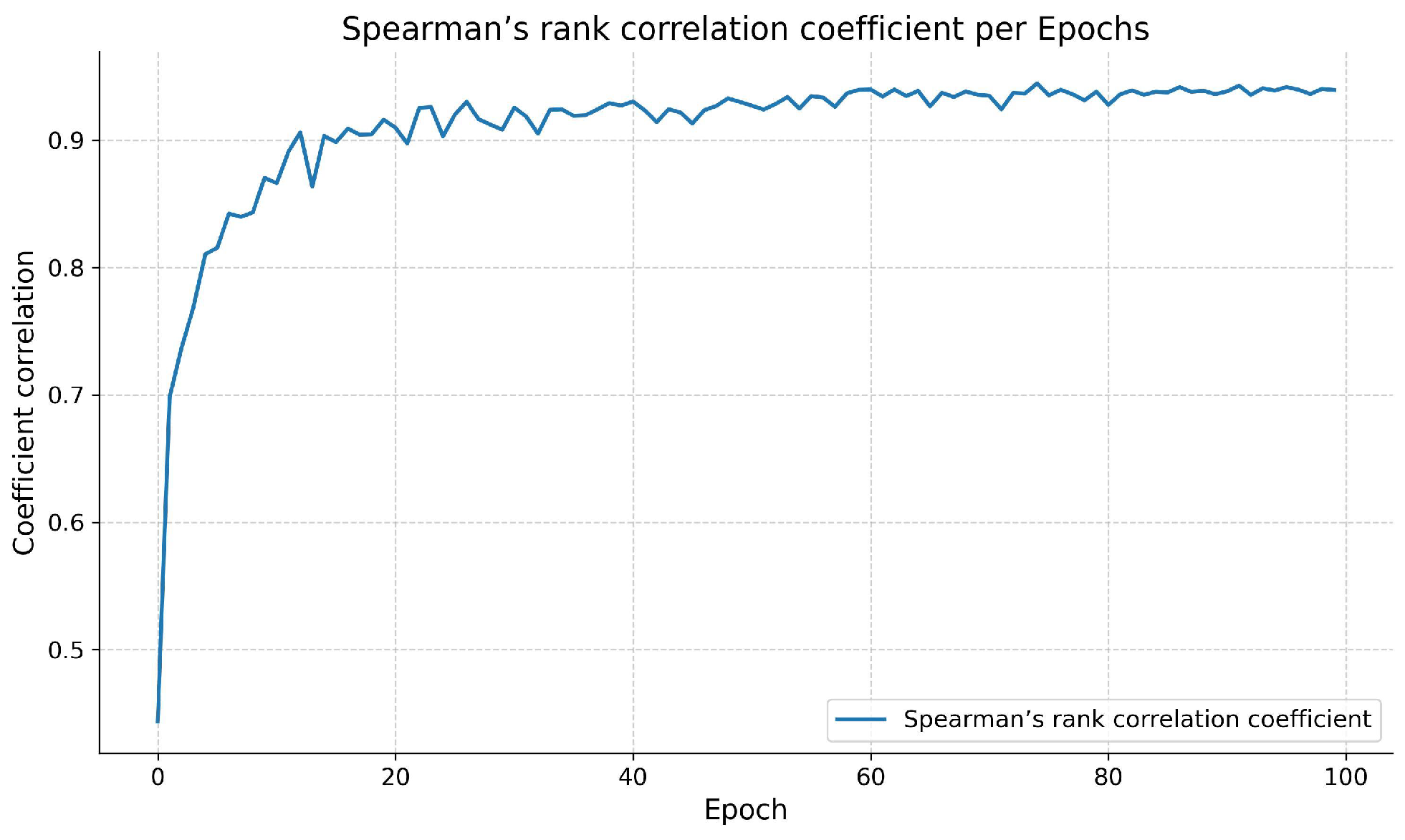
4.3. Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zeng, L.-A.; Zheng, W.-S. Multimodal Action Quality Assessment. IEEE Trans. Image Process. 2024, 33, 1600–1613. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.-J.; Zhang, H.-B.; Shi, Q.; Lei, Q.; Du, J.; Gao, S. Learning and fusing multiple hidden sub-stages for action quality assessment. Knowl.-Based Syst. 2021, 229, 107388. [Google Scholar] [CrossRef]
- Zhou, K.; Ma, Y.; Shum, H.P.H.; Liang, X. Hierarchical graph convolutional networks for action quality assessment. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7749–7763. [Google Scholar] [CrossRef]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Evaluating surgical skills from kinematic data using convolutional neural networks. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2018, Granada, Spain, 16–20 September 2018; pp. 214–221. [Google Scholar]
- Benmansour, M.; Malti, A.; Jannin, P. Deep neural network architecture for automated soft surgical skills evaluation using objective structured assessment of technical skills criteria. Int. J. Comput. Assist. Radiol. Surg. 2023, 18, 929–937. [Google Scholar] [CrossRef] [PubMed]
- Zia, A.; Sharma, Y.; Bettadapura, V.; Sarin, E.L.; Essa, I. Video and accelerometer-based motion analysis for automated surgical skills assessment. Int. J. Comput. Assist. Radiol. Surg. 2018, 13, 443–455. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the Kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Tang, Y.; Ni, Z.; Zhou, J.; Zhang, D.; Lu, J.; Wu, Y.; Zhou, J. Uncertainty-aware score distribution learning for action quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 9839–9848. [Google Scholar]
- Kingma, D.P. Auto-encoding variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Gordon, A.S. Automated video assessment of human performance. In Proceedings of the AI-ED, Washington, DC, USA, 16–19 August 1995; Volume 2, pp. 10–20. [Google Scholar]
- Ilg, W.; Mezger, J.; Giese, M. Estimation of skill levels in sports based on hierarchical spatio-temporal correspondences. In Pattern Recognition: 25th DAGM Symposium, Magdeburg, Germany, 10–12 September 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 523–531. [Google Scholar]
- Pirsiavash, H.; Vondrick, C.; Torralba, A. Assessing the quality of actions. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part VI; Springer: Berlin/Heidelberg, Germany, 2014; pp. 556–571. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Fu, Y.; Zhang, B.; Chen, Z.; Jiang, Y.-G.; Xue, X. Learning to score figure skating sport videos. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 4578–4590. [Google Scholar] [CrossRef]
- Li, Y.; Chai, X.; Chen, X. End-to-end learning for action quality assessment. In Proceedings of the Pacific Rim Conference on Multimedia, Hefei, China, 21–22 September 2018; pp. 125–134. [Google Scholar]
- Doughty, H.; Mayol-Cuevas, W.; Damen, D. The pros and cons: Rank-aware temporal attention for skill determination in long videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 7862–7871. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Wang, S.; Yang, D.; Zhai, P.; Chen, C.; Zhang, L. Tsa-net: Tube self-attention network for action quality assessment. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 4902–4910. [Google Scholar]
- Lei, Q.; Zhang, H.; Du, J. Temporal attention learning for action quality assessment in sports video. Signal Image Video Process. 2021, 15, 1575–1583. [Google Scholar] [CrossRef]
- Neal, R.M. Bayesian Learning for Neural Networks; Springer Science & Business Media: New York, NY, USA, 2012; Volume 118. [Google Scholar]
- Blei, D.M.; Kucukelbir, A.; McAuliffe, J.D. Variational inference: A review for statisticians. J. Am. Stat. Assoc. 2017, 112, 859–877. [Google Scholar] [CrossRef]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. In Proceedings of the 33nd International Conference on Machine Learning (ICML), New York, NY, USA, 19–24 June 2016; pp. 1050–1059. [Google Scholar]
- Ovadia, Y.; Fertig, E.; Ren, J.; Nado, Z.; Sculley, D.; Nowozin, S.; Dillon, J.; Lakshminarayanan, B.; Snoek, J. Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. Adv. Neural Inf. Process. Syst. 2019, 32, 13969–13980. [Google Scholar]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked convolutional auto-encoders for hierarchical feature extraction. In Proceedings of the International Conference on Artificial Neural Networks (ICANN), Espoo, Finland, 14–17 June 2011; pp. 52–59. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning (ICML), Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Zhou, C.; Huang, Y.; Ling, H. Uncertainty-driven action quality assessment. arXiv 2022, arXiv:2207.14513. [Google Scholar]
- Yu, X.; Rao, Y.; Zhao, W.; Lu, J.; Zhou, J. Group-aware contrastive regression for action quality assessment. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021; pp. 7919–7928. [Google Scholar]
- Parmar, P.; Morris, B. Action quality assessment across multiple actions. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 1468–1476. [Google Scholar]
- Parmar, P.; Morris, B.T. What and how well you performed? A multitask learning approach to action quality assessment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 304–313. [Google Scholar]
- Gao, Y.; Vedula, S.S.; Reiley, C.E.; Ahmidi, N.; Varadarajan, B.; Lin, H.C.; Tao, L.; Zappella, L.; Yuh, D.D.; Chen, C.C.G.; et al. JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS): A surgical activity dataset for human motion modeling. In Proceedings of the MICCAI Workshop: M2CAI, Boston, MA, USA, 14 September 2014; Volume 3, pp. 3–10. [Google Scholar]
- Pan, J.H.; Gao, J.; Zheng, W.S. Action assessment by joint relation graphs. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6331–6340. [Google Scholar]
- Jain, H.; Harit, G.; Sharma, A. Action quality assessment using Siamese network-based deep metric learning. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 2260–2273. [Google Scholar] [CrossRef]
- Zhang, B.; Chen, J.; Xu, Y.; Zhang, H.; Yang, X.; Geng, X. Auto-encoding score distribution regression for action quality assessment. Neural Comput. Appl. 2024, 36, 929–942. [Google Scholar] [CrossRef]
- Parmar, P.; Morris, B.T. Learning to score Olympic events. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 20–28. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DD | Methods | Sp. Corr. |
|---|---|---|
| w/o | C3D-SVR [36] | 0.7716 |
| C3D-LSTM [36] | 0.8489 | |
| MSCADC-STL [31] | 0.8472 | |
| MSCADC-MTL [31] | 0.8612 | |
| C3D-AVG-STL [31] | 0.8960 | |
| C3D-AVG-MTL [31] | 0.9044 | |
| USDL [10] | 0.9066 | |
| MUSDL [10] | 0.9158 | |
| I3D + MLP [29] | 0.9196 | |
| Ours | 0.9269 | |
| w/o | USDL [10] | 0.9231 |
| MUSDL [10] | 0.9273 | |
| I3D + MLP [29] | 0.9381 | |
| Ours | 0.9478 |
| Methods | S | NP | KT | Avg. Corr. |
|---|---|---|---|---|
| ST-GCN [33] | 0.31 | 0.39 | 0.58 | 0.43 |
| TSN [36] | 0.34 | 0.23 | 0.72 | 0.46 |
| JRG [33] | 0.36 | 0.54 | 0.75 | 0.57 |
| USDL [10] | 0.64 | 0.63 | 0.61 | 0.63 |
| MUSDL [10] | 0.71 | 0.69 | 0.71 | 0.70 |
| I3D + MLP [29] | 0.61 | 0.68 | 0.66 | 0.65 |
| Ours | 0.79 | 0.75 | 0.79 | 0.78 |
| Attention Module | Score Regression | Sp. Corr. |
|---|---|---|
| No Attention Module | Direct regression of scores | 0.9381 |
| No Attention Module | Score Distribution Regression | 0.9423 |
| With Attention Module | Direct regression of scores | 0.9441 |
| With Attention Module | Score Distribution Regression | 0.9478 |
| Method | Inference Time (ms) |
|---|---|
| No Attention Module | 1.42 |
| With Attention Module | 1.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, W.; Li, W.; Hu, H.; Song, Z.; Zeng, Z.; Sun, J.; Song, Y. Creating a Novel Attention-Enhanced Framework for Video-Based Action Quality Assessment. Sci 2025, 7, 54. https://doi.org/10.3390/sci7020054
Gong W, Li W, Hu H, Song Z, Zeng Z, Sun J, Song Y. Creating a Novel Attention-Enhanced Framework for Video-Based Action Quality Assessment. Sci. 2025; 7(2):54. https://doi.org/10.3390/sci7020054
Chicago/Turabian StyleGong, Wenhui, Wei Li, Huosheng Hu, Zhijun Song, Zhiqiang Zeng, Jinhua Sun, and Yuping Song. 2025. "Creating a Novel Attention-Enhanced Framework for Video-Based Action Quality Assessment" Sci 7, no. 2: 54. https://doi.org/10.3390/sci7020054
APA StyleGong, W., Li, W., Hu, H., Song, Z., Zeng, Z., Sun, J., & Song, Y. (2025). Creating a Novel Attention-Enhanced Framework for Video-Based Action Quality Assessment. Sci, 7(2), 54. https://doi.org/10.3390/sci7020054