1. Introduction
The International Roughness Index (IRI) is a globally recognized standard for measuring pavement smoothness and ride quality [
1]. Developed by the World Bank in the 1980s, the IRI quantifies the longitudinal profile of a road surface by calculating the vertical displacement of a vehicle’s suspension system over a standardized distance [
2]. Typically expressed in meters per kilometer (m/km) or inches per mile (in/mi), the IRI provides a numerical value that reflects the roughness of a pavement. Lower IRI values indicate smoother roads, while higher values denote rougher surfaces [
3]. This metric is crucial for understanding and comparing the performance of different pavement sections, making it an essential tool for engineers and road authorities worldwide [
4].
The IRI plays a pivotal role in pavement management by serving as a key indicator of pavement condition. Regular measurement of the IRI helps in monitoring the deterioration of road surfaces, enabling timely maintenance and rehabilitation interventions [
5]. By identifying areas with high roughness, road agencies can prioritize repairs, thereby extending the lifespan of pavements and optimizing the use of maintenance budgets. Additionally, maintaining low IRI values is critical for enhancing the safety and comfort of road users [
6]. Smoother roads reduce vehicle wear and tear, lower fuel consumption, and minimize the risk of accidents caused by poor road conditions. Furthermore, the IRI is often used in performance-based contracts and funding allocation, making it a vital metric for achieving sustainable and cost-effective pavement management practices [
7].
The UAE’s harsh environmental conditions present significant challenges for maintaining flexible pavements. Extreme air temperatures, which can exceed 50 °C (122 °F) in the summer, cause stiffness degradation of the asphalt concrete (AC) layers associated with thermal expansion and contraction in pavement materials, leading to cracking and rutting [
8]. Additionally, the region experiences frequent sandstorms that deposit fine particles on road surfaces, increasing abrasion and wear. These sandstorms also reduce visibility and pose hazards for drivers, further complicating maintenance efforts [
9]. Heavy traffic, especially from commercial vehicles, exacerbates the stress on pavements, accelerating deterioration. The combination of these factors creates a challenging environment for preserving pavement smoothness and achieving low IRI values [
10]. Flexible pavements in the UAE face numerous issues that demand constant attention. Frequent maintenance is necessary due to the rapid wear and tear from environmental and traffic-related stresses [
11]. Premature deterioration, such as cracking, rutting, raveling, and potholes, is common, necessitating regular inspections and repairs. These issues not only increase maintenance costs but also disrupt traffic flow and pose safety risks. Additionally, the accumulation of sand on road surfaces can reduce traction and increase the likelihood of skidding accidents [
12]. These local issues increase the degradation of surface smoothness, thereby increasing the necessity for more frequent IRI measurements. This typically results in higher costs and potential traffic disruptions. To address these challenges more efficiently, the development of cost-effective IRI predictive models tailored to local conditions presents a promising alternative [
13].
Machine learning (ML) is a subset of artificial intelligence (AI) that focuses on developing algorithms and statistical models that enable computers to learn from and make predictions or decisions based on data [
14,
15,
16,
17]. In pavement engineering, ML offers significant potential benefits by enhancing the ability to analyze vast amounts of data and identify patterns that might not be apparent through traditional methods. By leveraging ML, engineers can develop more accurate models for predicting pavement conditions, leading to improved decision-making and resource allocation [
18]. ML can handle complex, non-linear relationships within data, making it particularly effective in predicting various pavement performance indicators such as the IRI, pavement distress, and deterioration rates [
19].
Machine learning has been increasingly applied in pavement management with promising results [
20,
21]. For example, ML algorithms have been used to predict pavement distress, such as cracking, rutting, and potholes, based on historical data and environmental factors [
22]. These predictive models help road agencies anticipate and address issues before they become severe, thereby extending the life of pavement assets [
23]. Additionally, ML has been employed to optimize maintenance schedules by identifying the most critical sections of roadways that require immediate attention, ensuring efficient use of maintenance budgets [
24]. Furthermore, ML techniques have been utilized in improving pavement design by analyzing data from previous projects to refine material selection, structural design, and construction practices. Overall, the integration of ML in pavement engineering facilitates more proactive and cost-effective pavement management strategies, leading to enhanced road safety and performance [
25].
Traditional methods for predicting the IRI often rely on empirical models and linear regression techniques that can be limited in their accuracy and adaptability [
26]. These methods typically require simplified assumptions and may not fully capture the complex, non-linear relationships between various factors affecting pavement roughness. As a result, predictions may be less accurate and less responsive to changes in environmental or traffic conditions ML offers a more robust alternative by leveraging advanced algorithms capable of handling large datasets and uncovering intricate patterns within the data [
27]. ML models can continuously learn and improve over time, providing more precise and timely predictions. This data-driven approach enables better planning and optimization of maintenance activities, ultimately leading to more efficient resource allocation and improved pavement performance [
28]. ML models for IRI prediction can utilize a diverse range of data sources to enhance their accuracy and reliability [
29]. Historical IRI measurements are fundamental for training and validating the models, providing a baseline understanding of pavement performance over time. Traffic data, including vehicle types, volumes, and loadings, are crucial as they directly impact pavement wear and tear [
30]. Climatic conditions, such as temperature fluctuations, precipitation levels, and humidity, are also important as they influence the pavement’s structural integrity and surface characteristics. Additionally, data on material properties, including the type of asphalt or concrete used, layer thicknesses, and the presence of additives, can significantly affect the pavement’s response to external stresses. By integrating these diverse data types, ML models can provide comprehensive and nuanced predictions of the IRI, enabling more proactive and effective pavement management strategies [
31,
32].
This study aims to develop a predictive model for the International Roughness Index (IRI) of flexible pavements using advanced machine learning (ML) techniques, with a specific focus on addressing the unique environmental and traffic conditions in the UAE. While previous studies have predominantly relied on data from the Long-Term Pavement Performance (LTPP) database, they often generalize findings that may not be fully applicable to local contexts. To bridge this gap, our research combines data sourced from the Ministry of Energy and Infrastructure (MOEI) in the UAE with data from the LTPP. The MOEI data will provide region-specific insights, while the LTPP dataset will be used for broader comparisons and validation purposes due to its extensive and well-established global coverage. By leveraging ML techniques such as regression decision trees, support vector machines (SVMs), Gaussian process regression (GPR), ensemble trees, artificial neural networks (ANNs), and kernel-based approaches, this study aims to develop a robust, accurate model for predicting the IRI. The ultimate goal is to optimize pavement maintenance and management practices, improving the longevity and performance of road infrastructure in the UAE.
Table 1 highlights the historical efforts to predict the IRI for flexible pavements, revealing a significant research gap: most previous studies utilized data from the LTPP database. These studies, such as those employing linear regression, ANNs, and SVMs, demonstrated varying degrees of accuracy but often lacked applicability to specific regional conditions like those in the UAE.
This research contributes by developing three distinct predictive models for the IRI, each tailored to specific climatic conditions. The first model, using data from 233 sections in the LTPP database, captures global climatic diversity. The second model, based on 136 sections of the LTPP, focuses on warm climates. The third model leverages localized data from the MOEI, specifically targeting the UAE’s unique environmental and traffic conditions. This approach ensures the development of contextually relevant models, facilitating more effective pavement management locally and providing insights that could be applied worldwide.
3. Methodology
This research aims to develop predictive models for assessing asphalt pavement performance, specifically focusing on the IRI, across different climatic conditions. This study develops three predictive models: one using global climate data from the LTPP database, another using warm-climate data from the LTPP, and a third using localized data from the UAE’s federal highway network.
For the global and warm-climate models, data were sourced from the LTPP database, including parameters such as road section specifics, structural characteristics, traffic loading data, and IRI measurements. The global model includes 233 sections representing a wide range of climatic conditions, while the warm-climate model focuses on 136 sections from warmer regions. For the UAE model, data were sourced from the MOEI, covering major highways such as E55, E11, E88, E311, and E18, which serve the northern emirates including Fujairah, Ras Al Khaimah, Sharjah, Umm Al Quwain, and Ajman. These highways experience heavy traffic loads, making them more susceptible to deterioration compared to other road types in the UAE, thus necessitating precise and reliable IRI predictions to optimize maintenance and management efforts. Additional climatic data, such as temperature and humidity, were obtained from the UAE’s National Center of Meteorology.
The methodology, detailed in
Figure 1, encompasses several stages from initial data acquisition to the final model validation, ensuring a comprehensive approach to developing and validating the predictive IRI models for each climatic scenario.
Table 2 shows the inputs and outputs for the three predictive models developed in this study. The models utilize various data attributes categorized into structure, traffic, climate, and performance parameters. These inputs are essential for predicting the IRI across different climatic conditions.
Before applying the machine learning models, several data preprocessing steps were undertaken to ensure the datasets from both the LTPP and UAE were clean, consistent, and suitable for analysis. As the selected variables from both datasets had complete observations, there were no missing values, eliminating the need for imputation. However, we addressed potential data issues by identifying and removing outliers in continuous variables such as pavement age, IRI, and AADTT using the interquartile range (IQR) method. This was essential to prevent skewed predictions caused by extreme values. Since some machine learning models, such as SVMs and ANNs, are sensitive to the scale of input features, all numerical data (e.g., pavement thickness, traffic load, and climate variables) were normalized using min–max scaling to ensure that all features were within a range of 0 to 1, which also improved model convergence during training. Categorical variables, such as climate zone and layer type, were transformed into numerical data using one-hot encoding, ensuring that the machine learning algorithms could process these non-numeric variables effectively without introducing unintended ordinal relationships. Instead of splitting the data into training and testing sets, we applied 10-fold cross-validation to assess the performance and generalizability of the models. This method provided a robust approach by ensuring that each part of the data was used for both training and validation, reducing the risk of overfitting. Finally, while the UAE dataset had some underrepresented road sections or conditions, we applied data balancing techniques, such as oversampling of minority classes and undersampling of majority classes, to avoid bias in the models and improve their predictive accuracy. These preprocessing steps were crucial for ensuring that the machine learning models could reliably predict pavement roughness under different climatic conditions.
3.1. Statistical Analysis
Statistical analysis is a crucial step in understanding the underlying relationships between the various variables in our dataset and the IRI. This study employs descriptive statistics to summarize the main characteristics of the dataset, including measures such as mean, standard deviation, and skewness. These statistics provide insights into the distribution and central tendencies of the input variables (e.g., pavement age, layer thickness, AADTT, temperature, precipitation) and the output variable (IRI).
Furthermore, a correlation analysis is conducted to identify the strength and direction of linear relationships between the input variables and the IRI. A correlation matrix is developed to visualize these relationships, with particular attention given to variables that exhibit strong positive or negative correlations with the IRI. This step helps in the initial selection of variables that are likely to have a significant impact on pavement roughness, thus guiding the subsequent machine learning model development.
3.2. Feature Importance
Feature importance analysis is an essential component of this study, as it helps identify the most significant variables influencing the IRI and provides insights into the impact of each variable across different datasets. Unlike cases with high-dimensional data, we chose not to remove less important features because our dataset consisted of only 10 input variables, a manageable number that did not require reduction. Instead, the focus was on understanding how each variable contributed to the prediction of the IRI across different climatic conditions. To assess feature importance, we employed a random forest model, known for its robustness in ranking variables based on their predictive power. The random forest algorithm, trained using 95 decision trees (a number optimized for accuracy and efficiency), allowed us to evaluate the relative influence of factors such as structural attributes (e.g., layer thicknesses), traffic data (AADTT), and climatic conditions (e.g., temperature and precipitation) on the IRI. This analysis helped us interpret the results by highlighting the most influential features, which provided valuable insights into the behavior of the models without requiring feature reduction.
The feature importance was calculated using the “Out-of-Bag Permuted Predictor Delta Error” method, integrated within the random forest model. This method assesses the increase in the prediction error of the model when the values of a specific feature are randomly permuted while all other features remain unchanged. A larger increase in error indicates that the feature is more important for the model’s predictions.
The resulting feature importance scores were then sorted in descending order to rank the variables according to their influence on the IRI. The following steps were taken to display and interpret the feature importance:
Sorting and Displaying Importance: The calculated importance scores were sorted, and the corresponding variables were ranked from most to least important. This sorting allowed for a clear identification of the key factors that drive pavement roughness.
Visualization: A bar plot was generated to visually represent the importance of each feature. The plot displayed the sorted feature importance scores, with the x-axis representing the feature names and the y-axis showing the importance scores. The features were labeled and rotated for clarity, and the plot was titled “Random Forest Feature Importance” to reflect its content.
The feature importance analysis revealed that certain variables had a significantly higher impact on the IRI than others. For instance, variables related to traffic load, such as AADTT, were among the most influential factors. Structural features, particularly the thickness of pavement layers, also showed a strong correlation with the IRI, highlighting the importance of proper pavement design in maintaining road smoothness. Climatic conditions like temperature and precipitation, while still important, had a more variable impact depending on the specific climatic scenario being modeled.
This analysis not only informed the selection of input variables for subsequent machine learning models but also provided insights into the relative significance of different factors affecting pavement roughness. These insights can be used to prioritize areas for further research and guide practical decisions in pavement management and maintenance.
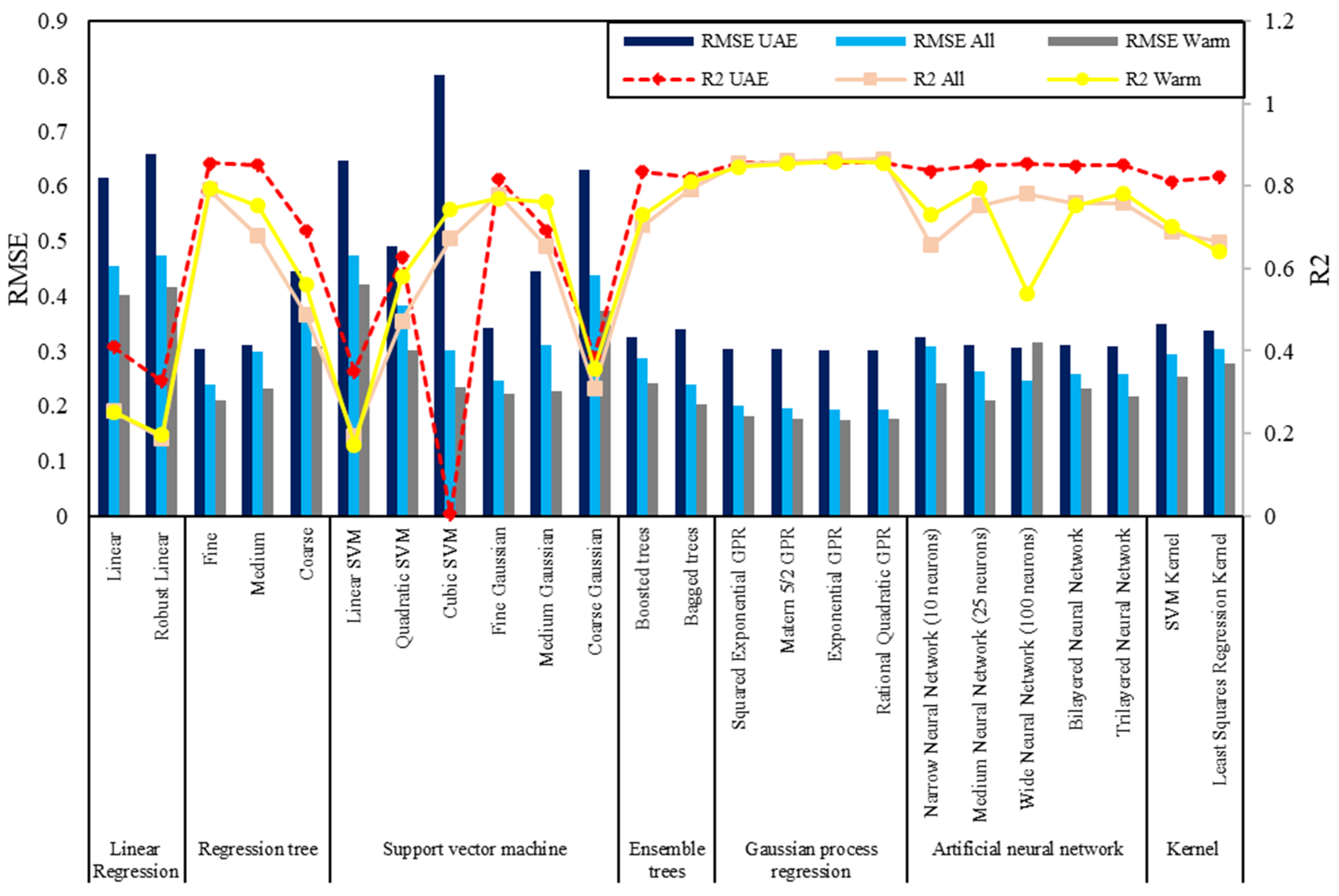
3.3. Machine Learning Models
This study employs a range of machine learning models to predict the IRI under varying climatic conditions. The models include regression decision trees, SVMs, ensemble trees, GPR, and ANNs. Each model is selected based on its ability to handle the non-linear relationships and high-dimensional data inherent in pavement performance prediction.
1. Regression Decision Trees: These models are used for their simplicity and interpretability. They work by recursively partitioning the dataset into subsets based on the values of input variables, resulting in a tree-like model of decisions. Different configurations, such as fine, medium, and coarse trees, are tested to optimize performance.
2. Support Vector Machines (SVMs): SVM models are employed due to their effectiveness in high-dimensional spaces and their ability to handle both linear and non-linear relationships. Various kernel functions, including linear, quadratic, cubic, and Gaussian, are used to capture the complex patterns in the data.
3. Ensemble Trees: Ensemble methods, such as Boosted trees and Bagged trees, combine the predictions of multiple decision trees to improve accuracy. Boosted trees sequentially adjust the model to correct errors from previous iterations, while Bagged trees reduce variance by averaging predictions from multiple independent trees.
4. Gaussian Process Regression (GPR): GPR is chosen for its probabilistic approach, providing not only predictions but also uncertainty estimates. Different kernel functions, including squared exponential, Matern, and rational quadratic, are explored to capture the underlying data distributions.
5. Artificial Neural Networks (ANNs): ANN models are included for their ability to learn complex, non-linear patterns from large datasets. Various network architectures, including narrow, medium, wide, bilayered, and trilayered networks, are tested to identify the optimal configuration for IRI prediction.
To evaluate the performance of the machine learning models, several key metrics are employed, including Root Mean Square Error (RMSE), R-squared (), Mean Squared Error (MSE), and Mean Absolute Error (MAE). These metrics provide a comprehensive assessment of model accuracy and robustness.
RMSE is a standard way to measure the error of a model in predicting quantitative data. It is the square root of the average of the squared differences between predicted and observed values.
where
is the actual value.
is the predicted value.
N is the number of observations.
R-squared is a statistical measure that represents the proportion of the variance for the dependent variable that is explained by the independent variables in the model. It provides an indication of the goodness of fit.
where
is the mean of the actual value.
MSE is the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value.
MSE is useful for comparing different models, as a lower MSE indicates a better fit.
MAE measures the average magnitude of the errors in a set of predictions, without considering their direction. It is the average of the absolute differences between predicted and actual values.
MAE is easier to interpret than RMSE because it gives a clear view of the average error.
The machine learning models used in this study were carefully tuned using specific hyperparameters to optimize their performance, based on the regression learner application in MATLAB 2022a.
Table 3 summarizes the hyperparameter settings for each model. The selection of these hyperparameters was guided by MATLAB’s built-in optimization features, which streamline model configuration and ensure a systematic approach to improving performance.
For instance, in SVM models, various kernel functions (linear, quadratic, cubic, Gaussian) were tested to capture different patterns in the data, as MATLAB’s regression learner provides an efficient way to experiment with these kernels. The hyperparameters for SVM models, such as kernel scale and box constraint, were chosen based on automatic tuning by MATLAB, which optimizes them to minimize the prediction error. Similarly, GPR models were tested with different kernel functions (e.g., squared exponential, Matern 5/2, rational quadratic) to find the best fit for the data’s underlying variability, with MATLAB automatically adjusting signal standard deviation and kernel scale for optimal performance.
For ensemble trees, hyperparameters like the number of learners and learning rates in Boosted trees were selected through MATLAB’s cross-validation and grid search process, ensuring the models are neither overfitted nor underfitted. The regression trees (fine, medium, coarse) and artificial neural networks (narrow, medium, wide) were similarly configured using MATLAB’s recommended settings for leaf size, layer size, and iteration limits based on model accuracy and computational efficiency.
In all cases, hyperparameters were tuned using a combination of empirical testing, prior studies, and MATLAB’s internal optimization functions, ensuring robust and reliable model performance while minimizing the potential for overfitting. These choices were specifically made to align with the strengths of MATLAB 2022a’s regression learner application, which provides a structured and powerful environment for optimizing machine learning models.
After training the models, their performance was evaluated using the performance measures (RMSE, R2, MSE, and MAE). Cross-validation techniques were employed to ensure the models were generalizable and performed well on unseen data. The models with the lowest error rates and highest R2 values were selected as the best-performing models for each climatic scenario.
5. Sensitivity Analysis
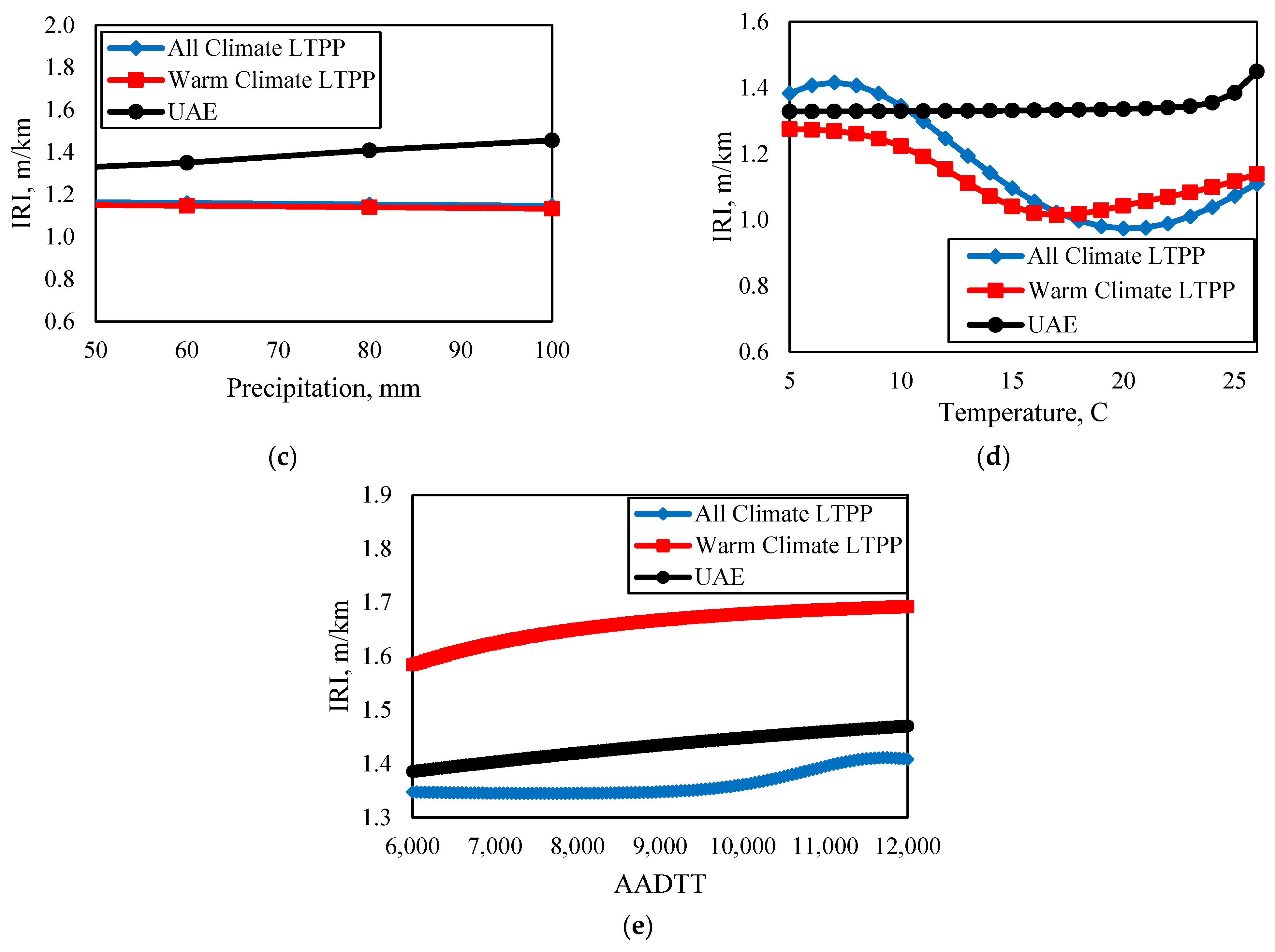
Figure 7 presents the sensitivity analysis results for the most influential variables affecting pavement performance: (a) age, (b) total thickness, (c) precipitation, (d) temperature, and (e) AADTT. In these analyses, each variable was evaluated while keeping all other variables fixed at their mean values to isolate the effect of each individual factor on the IRI. It is worth noting that the range for all independent variables was set to avoid extrapolations with the three dataset scenarios.
In
Figure 7a, the impact of pavement age on the IRI is shown across all datasets. The analysis indicates that older pavements tend to have higher roughness levels. This trend is most pronounced in the all-climate LTPP dataset, suggesting that aging effects are more significant in diverse climatic conditions. The warm-climate LTPP and UAE datasets also show an increase in the IRI with age, but the increase is more severe with the UAE dataset, which may reflect the adverse impact of harsh climate conditions associated with heavy truck traffic.
Figure 7b examines the influence of total pavement thickness on the IRI. An increase in total thickness generally results in an increase in the IRI across all datasets, to a certain total thickness level, after which any further increases in the total thickness results in a positive improvement in the surface roughness by decreasing the IRI. This peak point could be considered as the critical total pavement thickness, whereas increases in this total thickness will start to have a positive impact on the pavement roughness. This can be interpreted where a thicker pavement experiences less fatigue cracking and structural rutting, yet it could experience more rutting coming from the surface layer. The balance between these different distresses can define the critical total pavement thickness. For both the LTPP all-climate dataset and the warm-climate LTPP dataset, the critical total pavement thickness values are found relatively similar (800 mm and 700 mm, respectively). The UAE dataset shows a critical total pavement thickness of 450 mm, which is relatively lower than both LTPP datasets. This outcome reflects different pavement engineering practices and consequent relative impacts of the design factors on the IRI in the UAE compared to the LTPP dataset located mainly in the USA.
In
Figure 7c, the relationship between precipitation and the IRI is analyzed considering the UAE precipitation range to avoid extrapolation since it is relatively low compared to the LTPP dataset. For both the all-climate LTPP and warm-climate LTPP datasets, the impact of higher precipitation levels on the IRI seems very minimal, acknowledging that the investigated precipitation range has a very low value compared to extreme precipitation levels across the USA. Interestingly, the UAE dataset demonstrates more sensitivity to precipitation, indicating that local pavements are expected to get worse as rainfall increases.
Figure 7d illustrates the relationship between temperature and the IRI for different datasets. At lower temperatures, there appears to be minimal impact of temperature on IRI values for all datasets. In the all-climate and warm-climate LTTP datasets, temperature increases from 10 to 20 °C seem to slightly decrease IRI values, potentially due to reduced thermal and fatigue cracking in more moderate conditions without significant concerns about rutting. However, as temperatures rise above 20 °C, the IRI begins to increase, likely due to a worse rutting performance under higher temperatures. The UAE dataset exhibits a somewhat different trend, with temperature showing no impact on the IRI until around 23 °C, beyond which further temperature increases result in a noticeable rise in the IRI. This could be attributed to the unique climate and pavement conditions in the UAE, where higher temperatures exacerbate pavement roughness.
Finally,
Figure 7e illustrates the effect of AADTT on the IRI across different datasets. As expected, increased truck traffic correlates with higher IRI values in all datasets, highlighting the adverse impact of traffic loading on pavement deterioration. Notably, the warm-climate LTPP dataset shows the steepest rise in the IRI with increasing AADTT, suggesting that pavements in consistently warm climates are more susceptible to damage from heavy truck traffic. The UAE dataset also shows a noticeable increase in the IRI with AADTT, although the slope is less steep than in the warm-climate LTPP dataset, indicating that while heavy traffic does contribute to pavement roughness in the UAE, the effect is somewhat mitigated compared to other regions. The all-climate LTPP dataset exhibits the most gradual increase in the IRI with AADTT, suggesting that in more varied climatic conditions, the impact of heavy truck traffic on pavement deterioration is less severe, potentially due to less adverse effect on moderate climate regions, which are part of the all-climate LTPP dataset.



 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}