
An Enhanced Algorithm for Concurrent Recognition of Rail Tracks and Power Cables from Terrestrial and Airborne LiDAR Point Clouds


Abstract
:
1. Introduction
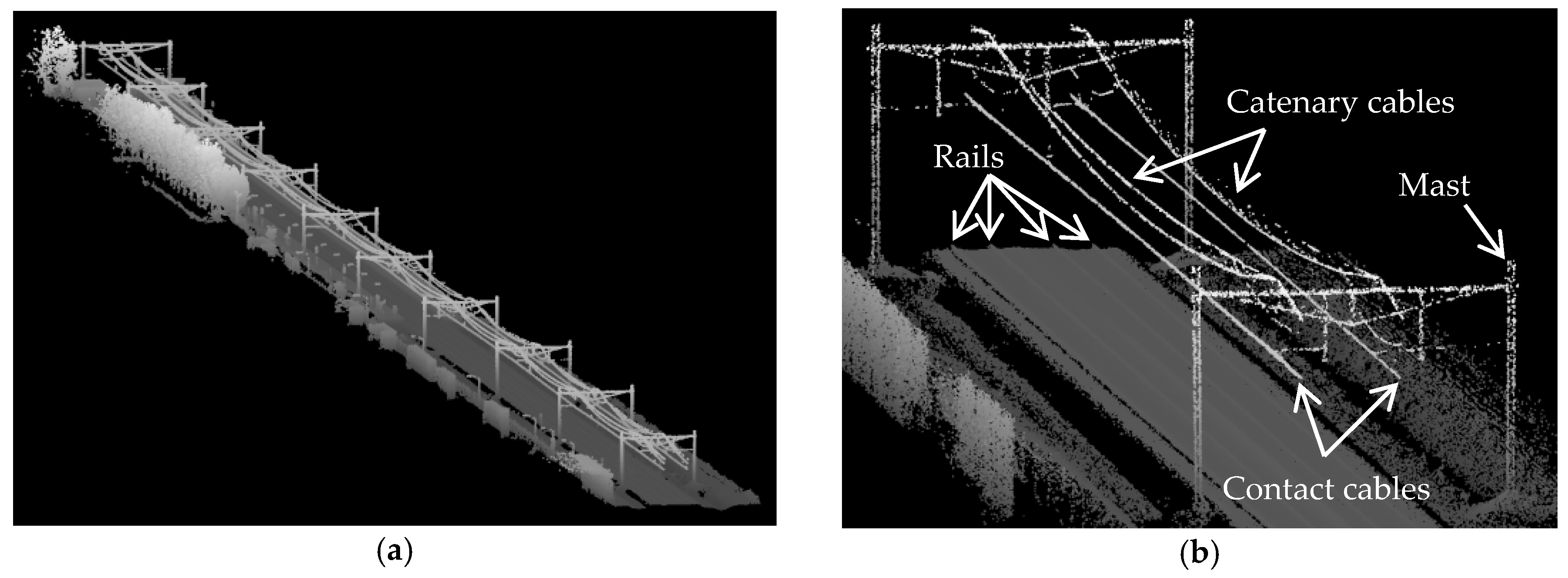
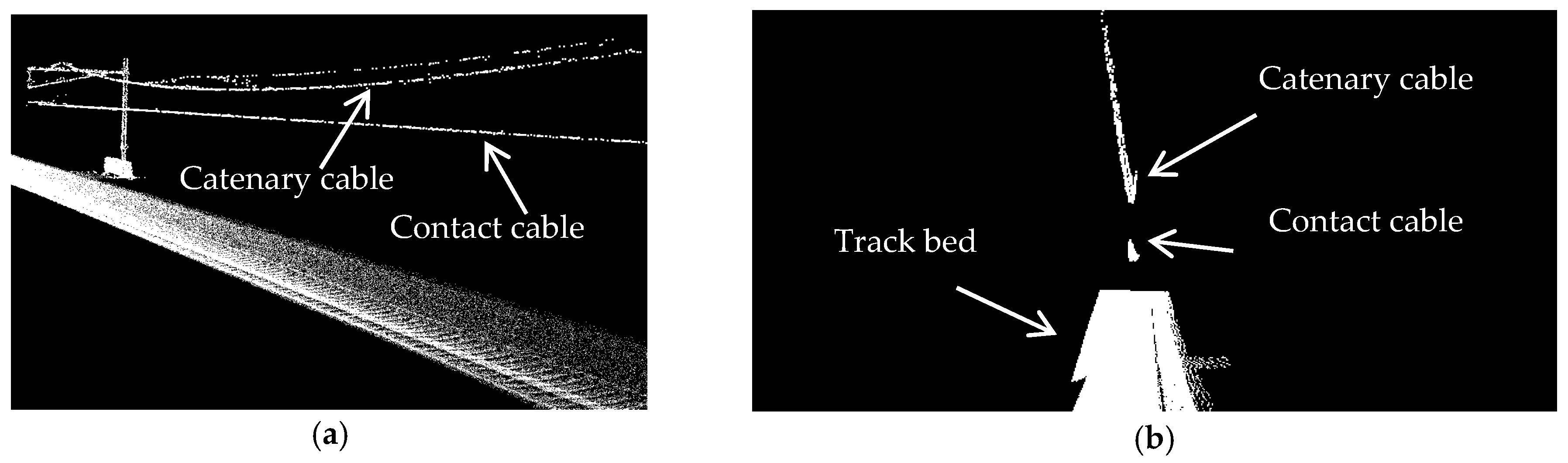
- Track bed is the surface beneath rail tracks and is topped with ballast, which holds rail tracks in line and on surface. The ballast consists of sized solid particles that are able to handle tamping and drain well [8]. Although track bed is not an essential component of railroad corridors, it indicates the areal extent of such environments.
- Rail tracks consist of two parallel steels with I-beam cross sectional profile. They come in pairs and provide a stable platform for trains in motion. Rails’ dimensions and gauge (the spatial offset between a pair of rails) follow a national or regional standard so that the railroad corridors of a country or a continent can be interconnected. The European standard gauge is 1.435 m and its rail height ranges from 0.142 m to 0.172 m [8].
- Masts are vertical poles that are located in regular spatial offset on track bed. They are either wooden or metal and hold the overhead cables in place.
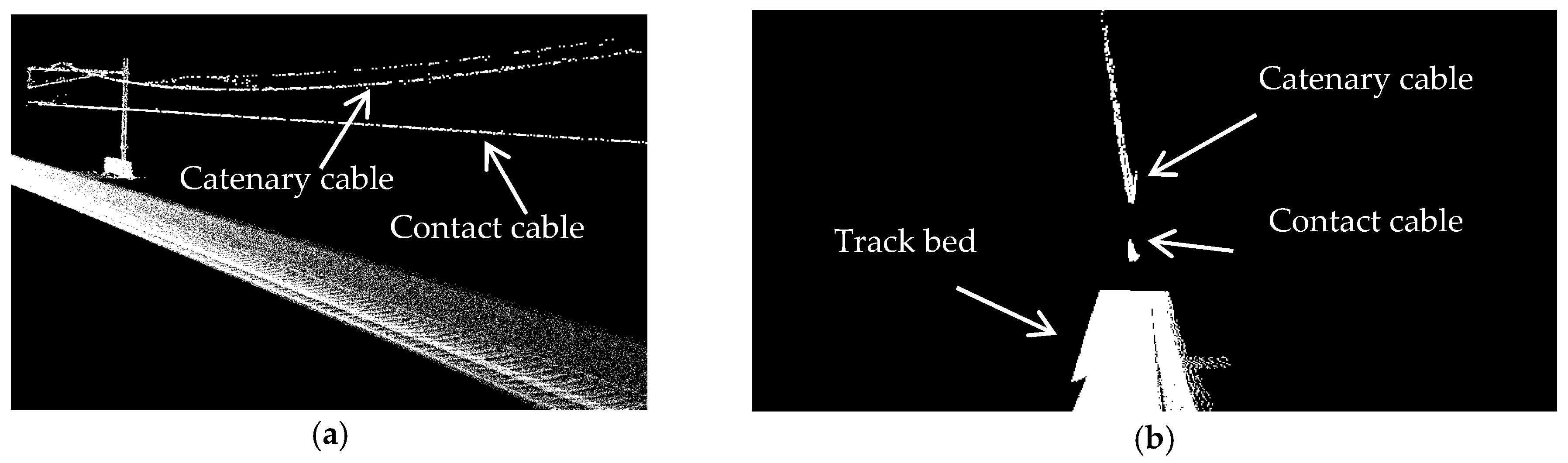
- Overhead cables comprise contact cables and catenary cables. Contact cables appear as linear-shaped objects that transmit power to trains. They lie in the lowest height among all overhead cables. Catenary cables are curvilinear-shaped objects that are located immediately above contact cables and keep the contact cables in place. Contact and catenary cables are interconnected by thin plastic tubes called droppers. Catenary cables are also connected to masts by metal tubes called cantilevers. The classification of droppers and cantilevers do not fit in the scope of this work though.
2. Literature Review
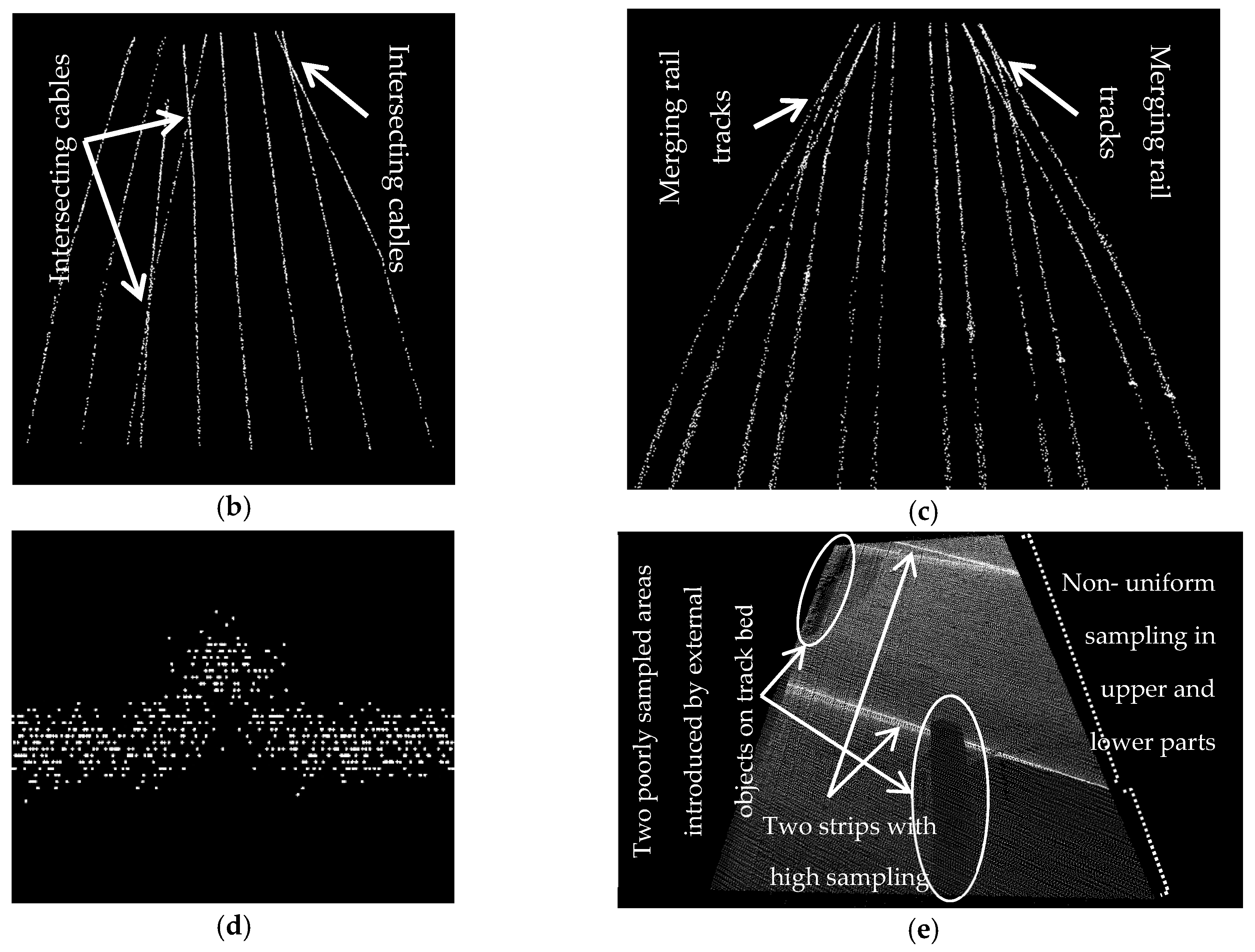
- Investigation of “only a small portion” of data to identify track bed in order to enhance the computational efficiency from 3 h in Arastounia [6] to less than 5 min in this study.
- Limiting the application of the coarse classification algorithm to a very small portion of the data, which makes the algorithm applicable to rail corridors with any slope angle.
- Modification of the rail seed point selection (by employing Eigen decomposition) in order to make it independent of the rails’ dimensions.
- Simultaneous recognition of the rail tracks and contact cables by a fully data-driven algorithm that takes advantage of the following two constraints. As a result, the false positives are successfully eliminated without imposing a notable computational burden. This decreased the computational time from approximately 5 h in Arastounia and Oude Elberink [7] to less than 30 min in this contribution.
- Rail tracks always appear as a pair of rails that are parallel and have an invariable spatial offset from one another.
- There is one contact cable above each rail track.
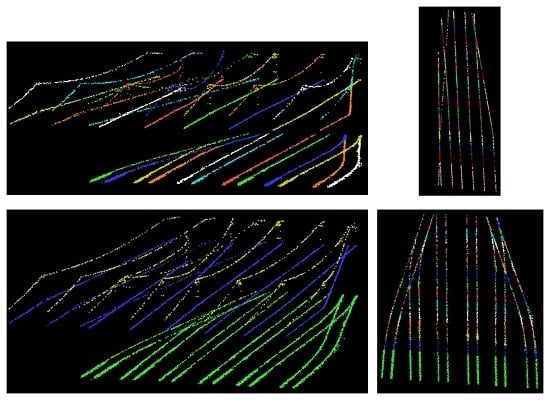
3. Datasets
3.1. Terrestrial LiDAR Point Cloud
3.2. Airborne LiDAR Point Cloud
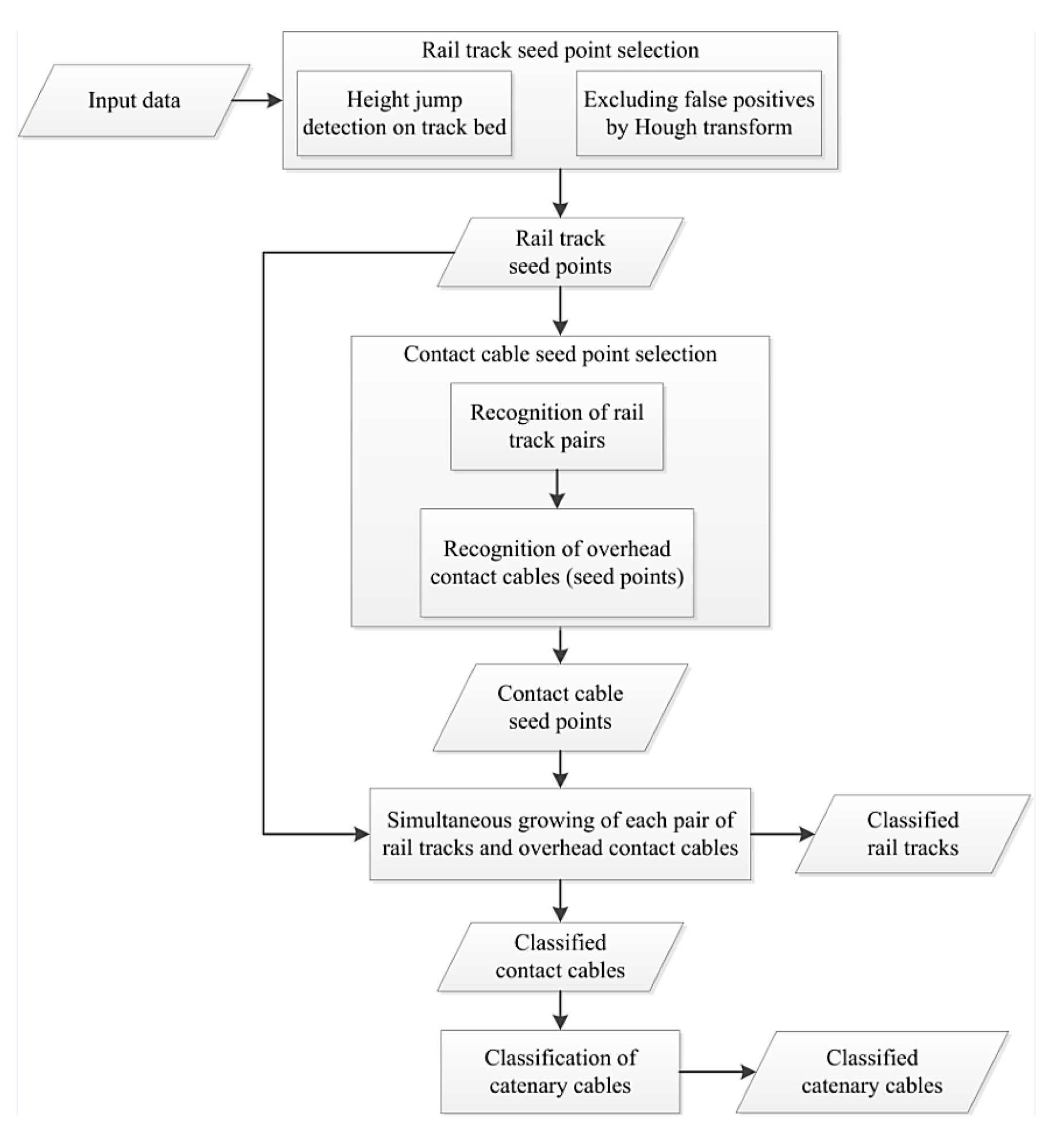
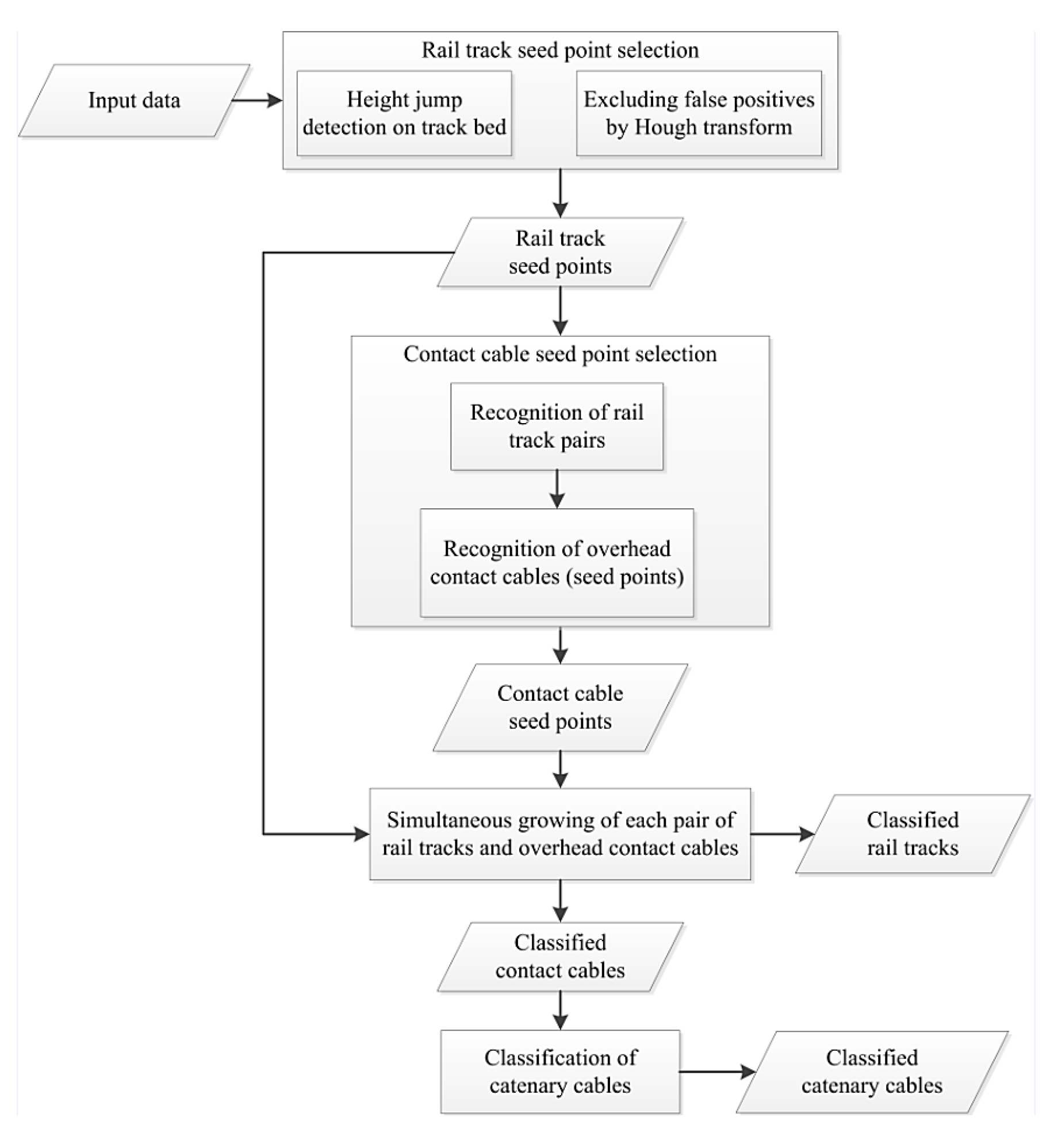
4. Methodology
4.1. Simultaneous Recognition of Rail Tracks and Contact Cables
4.1.1. Classification Based on Height
4.1.2. Rail Seed Point Selection
- Notation: : points identified as belonging to track bed in Section 4.1.1; : a sample point; : 3D spherical local neighborhood of a sample point; : covariance matrix of a sample point’s local neighborhood; : eigenvalues; : 90th height percentile of a query neighborhood; : a sample point’s height; : points lying higher than 90th height percentile within a query point’s neighborhood; : lines obtained from applying Hough transform; : a segment containing rail seed points.
- Input:
- for
- Find
- Construct
- Calculate eigenvalues of by applying PCA to
- if then
- Compute of
- for
- ○
- if then
- ○
- ○
- end if
- end for //loop on
- end if //condition on
- end for //loop on
- Calculate by applying 2D Hough transform to
- for
- if then
- end if //condition on
- end for //loop on .
4.1.3. Contact Cable Seed Point Selection
- Notation: : segments containing seed rail points obtained from Section 4.1.2; : points belonging to medium-height cluster obtained from Section 4.1.1; : number of (rail) pair segments; : a sample segment; : covariance matrix of points belonging to a sample segment; : eigenvector corresponding to the largest eigenvalue of points belonging to ith segment; : centroid of the ith segment; : the angle between two vectors; : planimetric distance between two points; : the rail pair segment; : the cable seed segment.
- Input: and
- Set
- for
- Construct and
- Calculate of by applying PCA to
- Calculate of by applying PCA to
- Calculate and
- if (() and ()) then
- ○
- Set
- ○
- ○
- ○
- for
- ○
- if () then
- ○
- ○
- end if
- ○
- end for //loop on
- end if
- end for //loop on and .
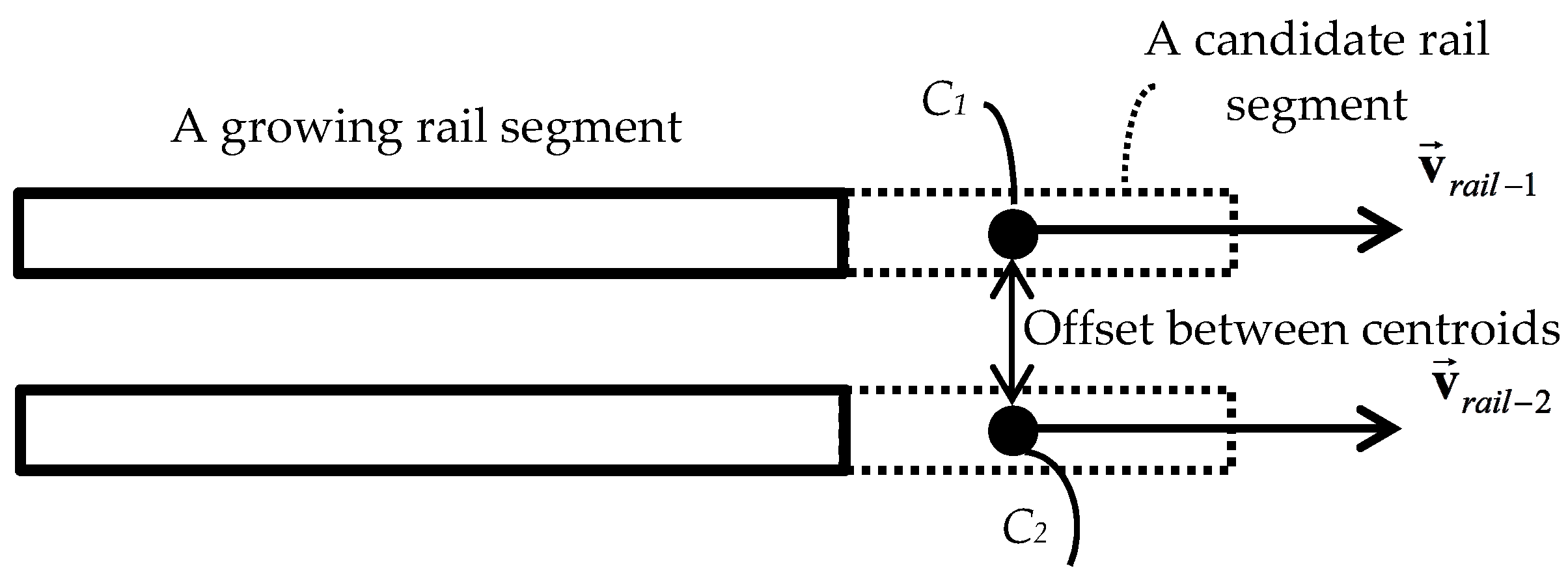
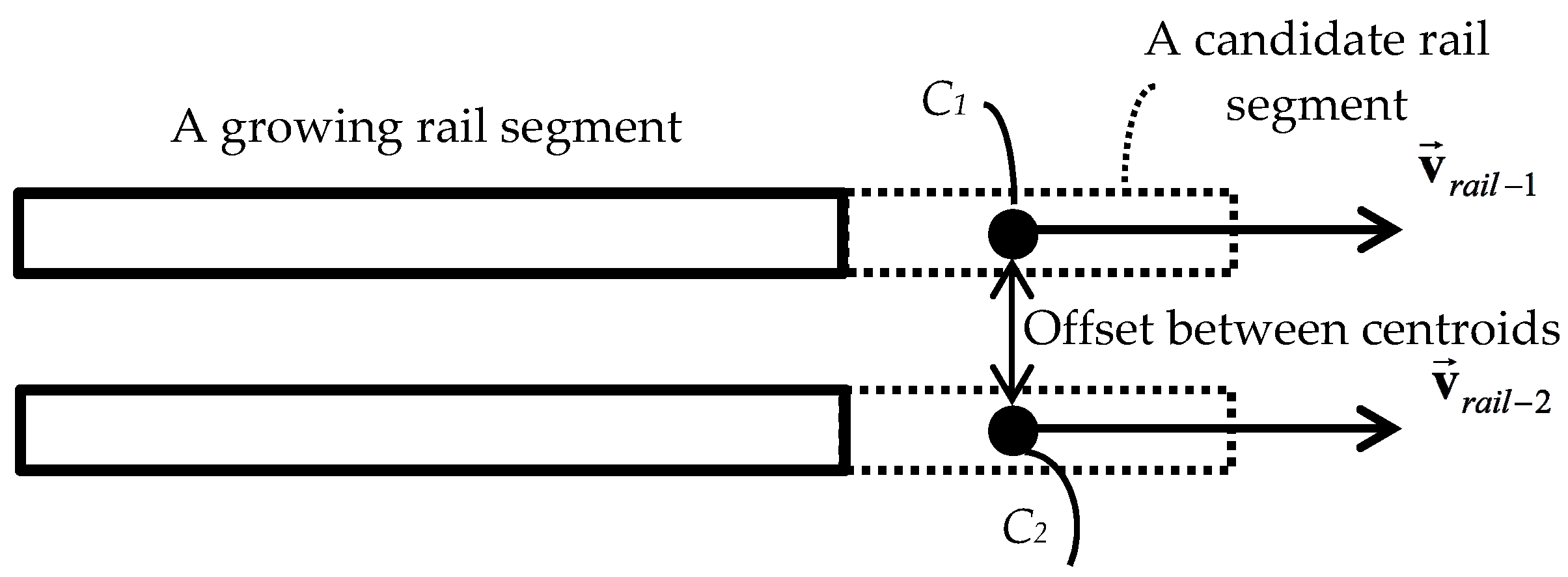
4.1.4. Region Growing
- The point’s height () is within 0.05 m (half rail height) of the rail segment’s average height (), as in Equation (6).
- The vector connecting the rail segment to the query point () makes a small angle with the rail segment’s orientation direction () as in Equation (7).
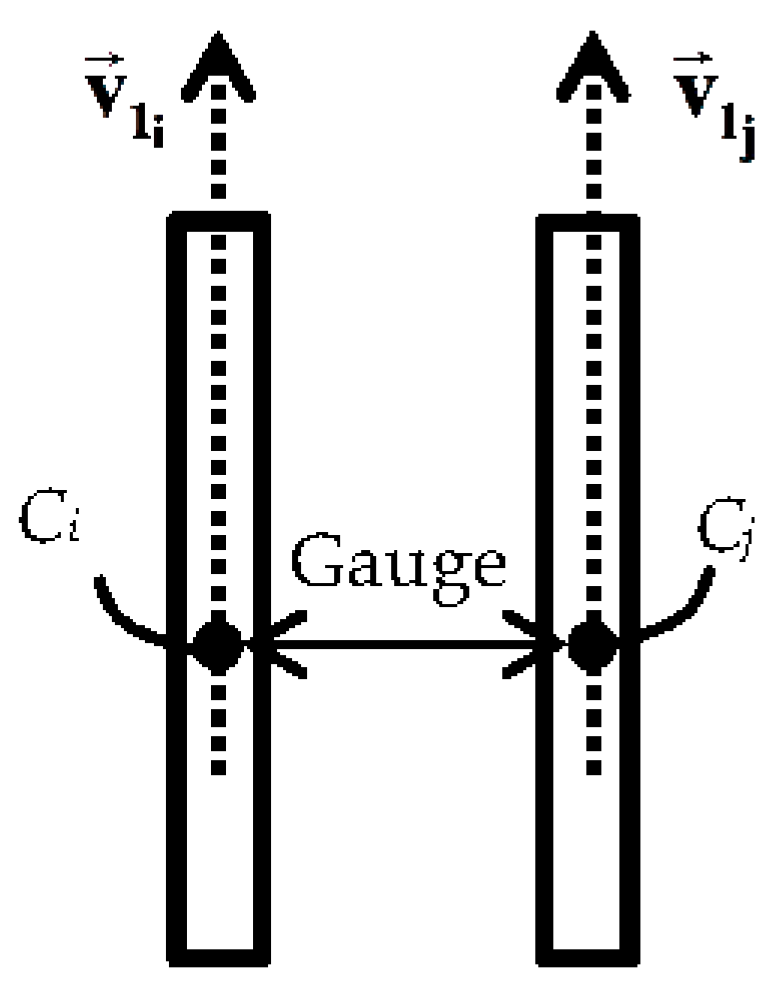
- Rail tracks always appear as two parallel rails that are located within a fixed spatial offset (gauge) from one another.
- There is one contact cable above each and every rail track.
- Notation: : a pair of growing rail segments obtained from Section 4.1.2; : two rail segments belonging to a growing rail pair; : average height of the ith growing rail segment; : principal distribution direction of the ith growing rail segment; : local neighborhood of the ith growing rail segment; : a sample point; : vector connecting a sample point to the growing rail segment; the ith candidate rail segment.
- Input:
- for
- Calculate and
- Compute and
- Find and
- for
- Calculate
- if (() and ()) then
- end if //condition on and
- end for //loop on
- for
- Calculate
- if (() and ()) then
- end if //condition on and
- end for //loop on
- end for //loop on and .
- Notation: : ith candidate rail segment belonging to a rail pair; : points belonging to cable seed segments obtained from Section 4.1.3; : principal distribution direction of the ith candidate rail segment; Ci: centroid of the ith candidate rail segment; : the angle between two vectors; : planimetric distance between two points; : average height of the growing contact cable above a rail pair; : principal distribution of the growing contact cable above a rail pair; : local neighborhood of the growing cable segment; : a sample point; : vector connecting a sample point to the growing contact cable segment; : points belonging to the growing rail segment; points belonging to the growing contact cable segment.
- Input: , , and
- Calculate and
- Calculate C1 and C2
- if (() and () ) then
- Calculate
- Compute
- Find
- for
- Calculate
- ○
- if (() and () ) then
- ○
- ○
- ○
- ○
- end if
- end for //loop on
- end if.
4.2. Classification of Catenary Cables
- Lie higher in elevation than a point belonging to the contact cables.
- Located within 0.2 m 2D spatial offset from either side of the same contact cable point.
- Notation: : points belonging to contact cables identified in Section 4.1.4; : points belonging to top-height cluster obtained from Section 4.1.1; : a sample point; : points belonging to contact cables that are within 0.2-m planimetric distance of a query point belonging to top-height cluster; : a sample point’s height; : segment containing points belonging to catenary cables.
- Input: and
- for
- Find
- for
- if then
- end if
- end for //loop on
- end for //loop on .
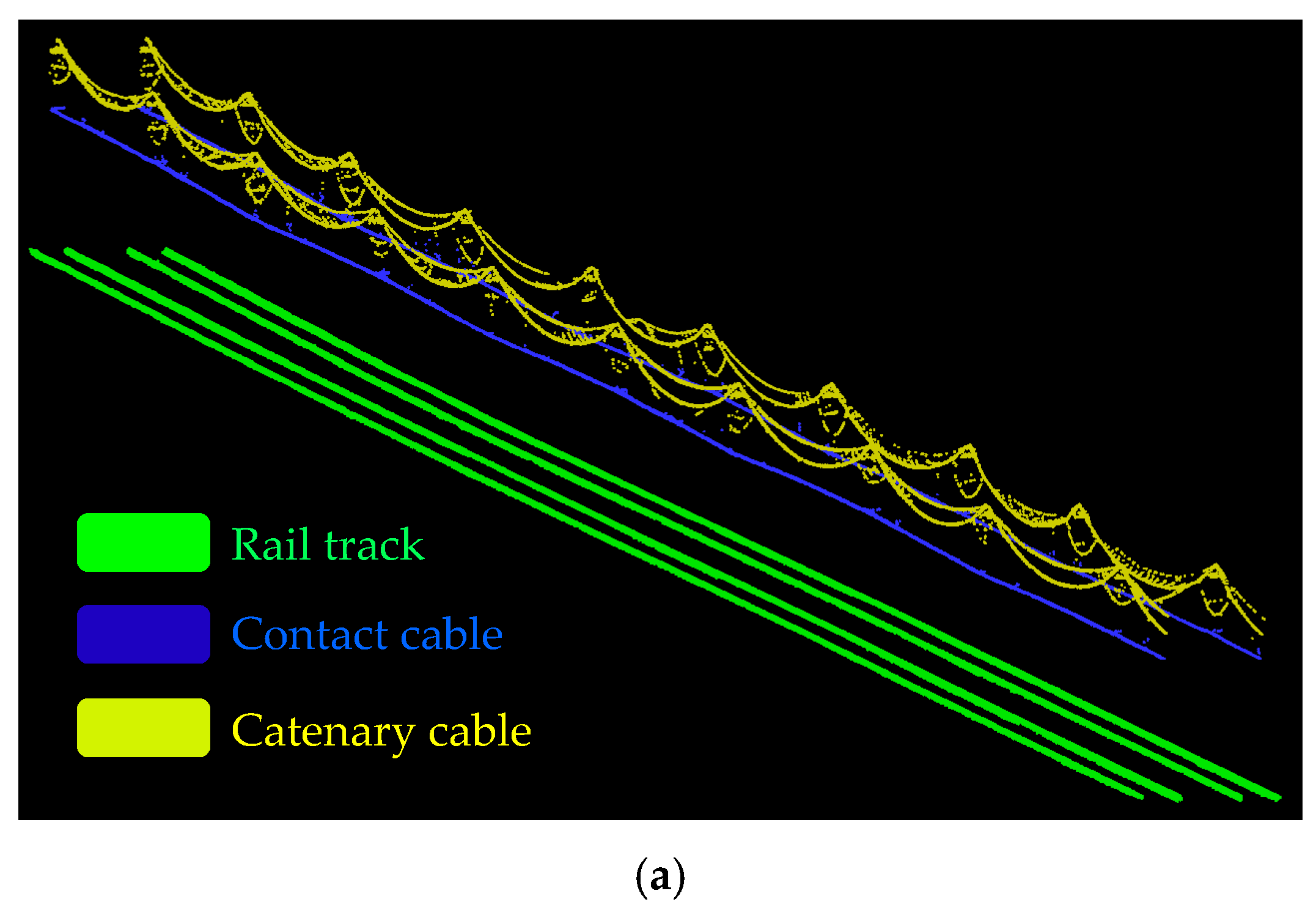
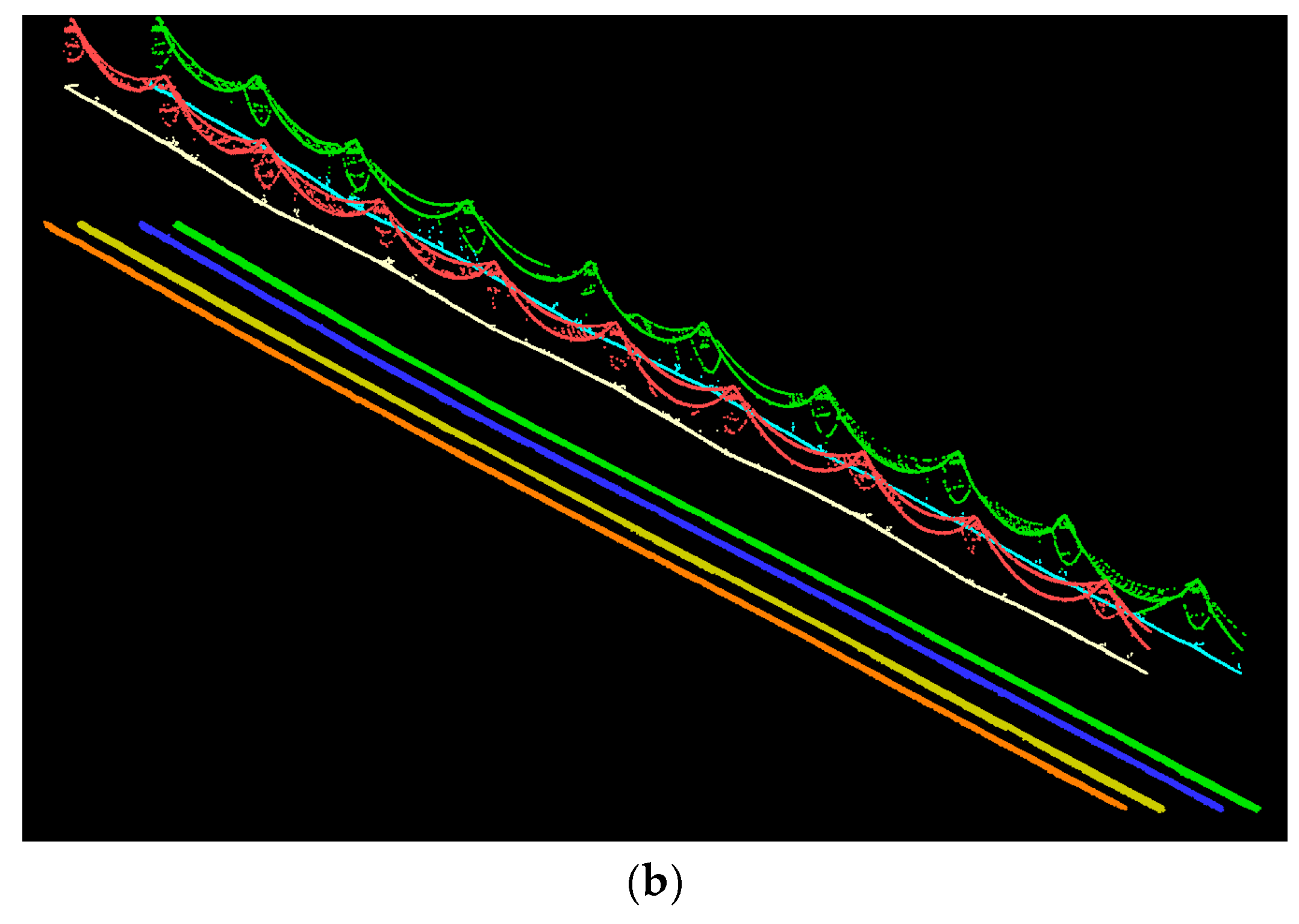
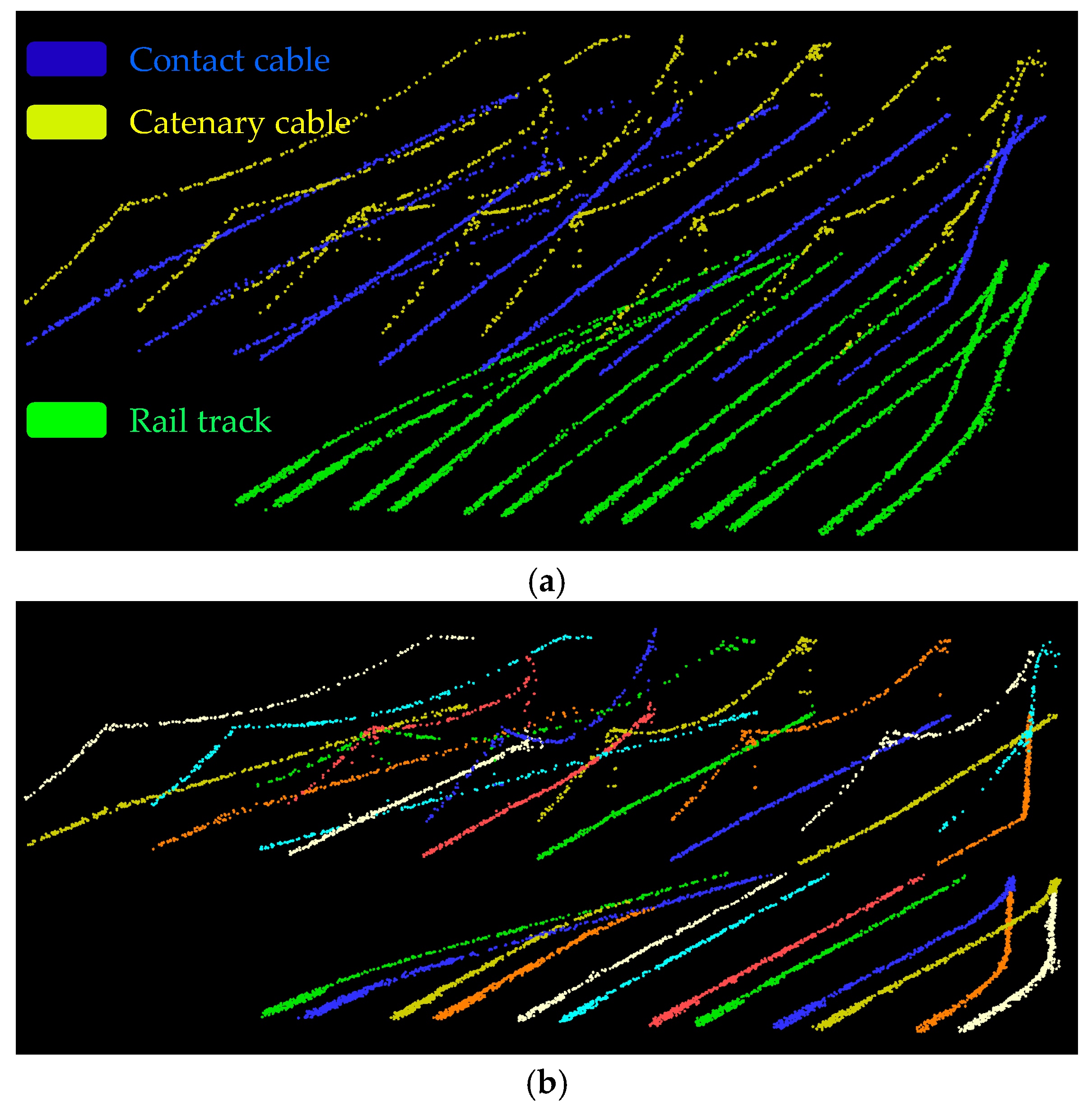
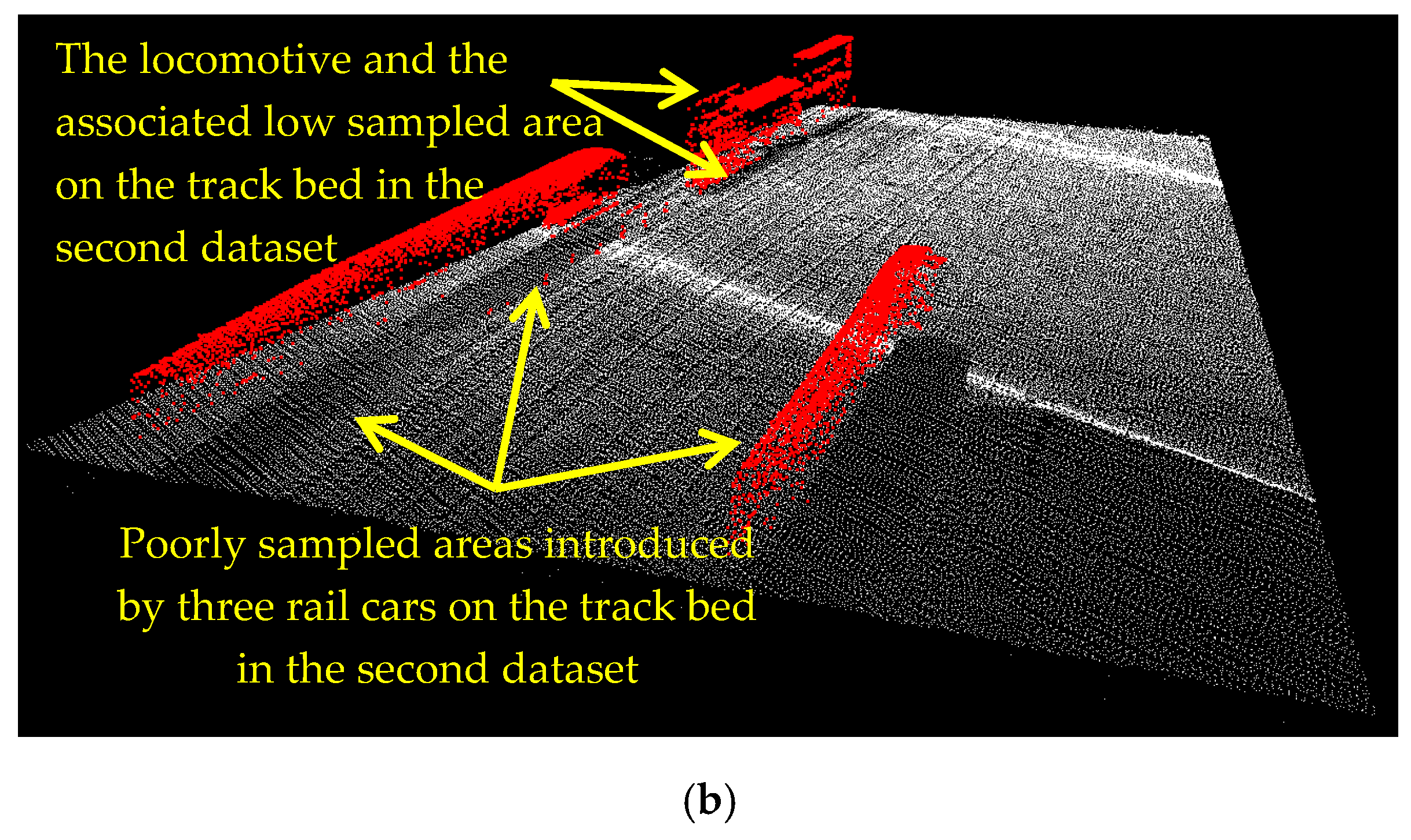
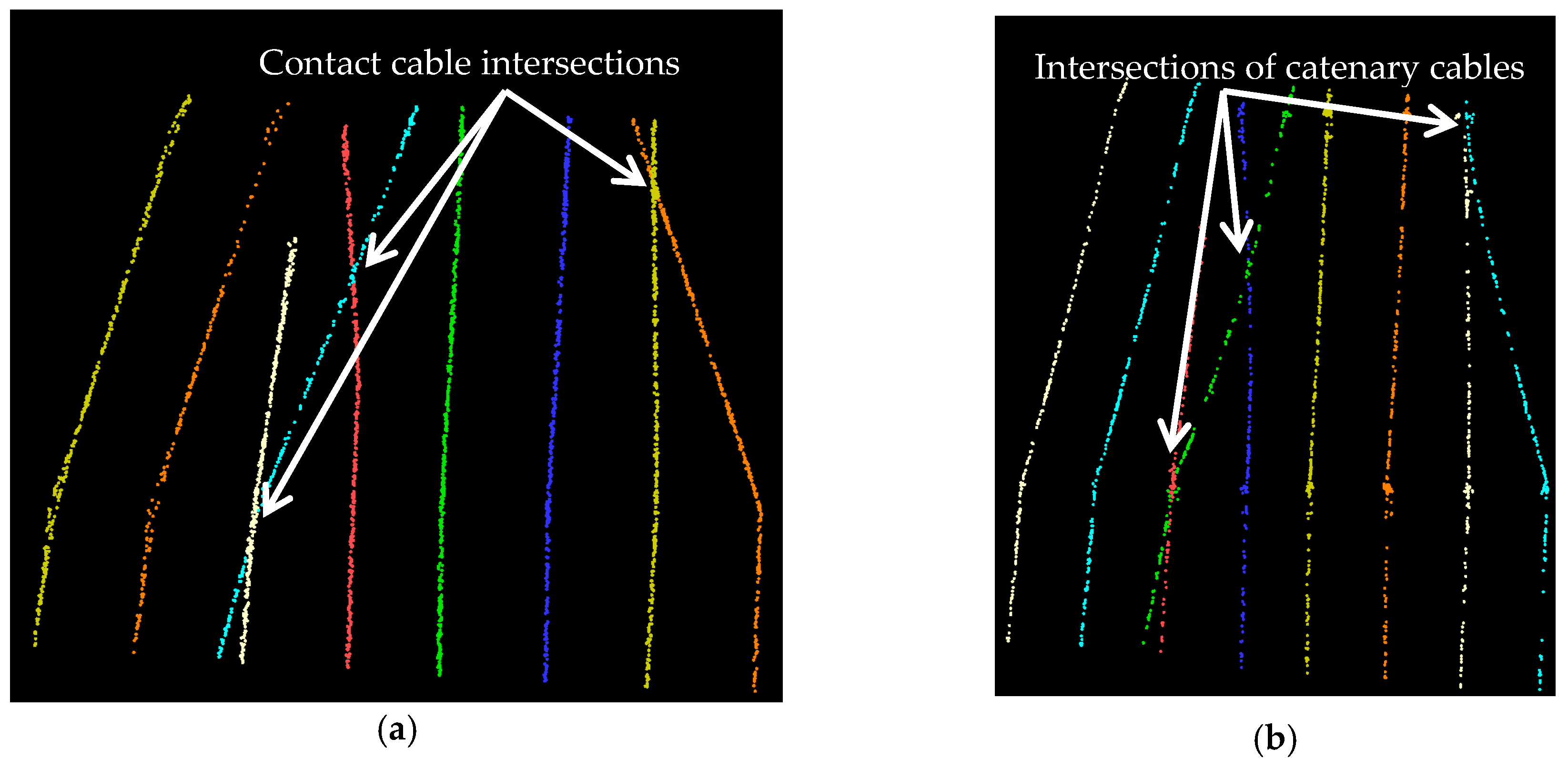
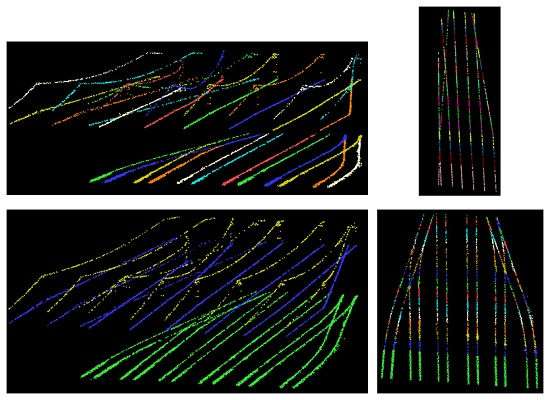
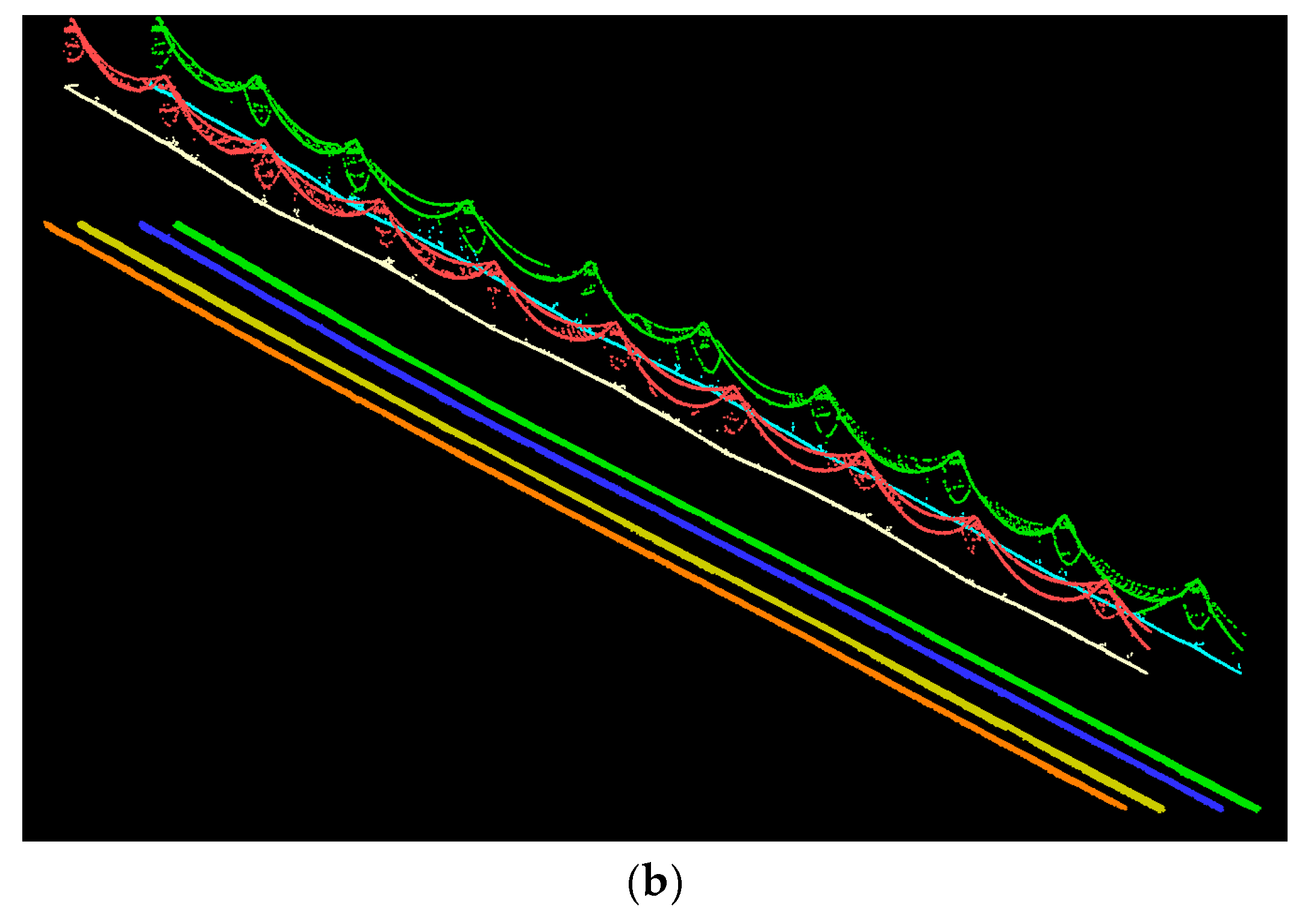
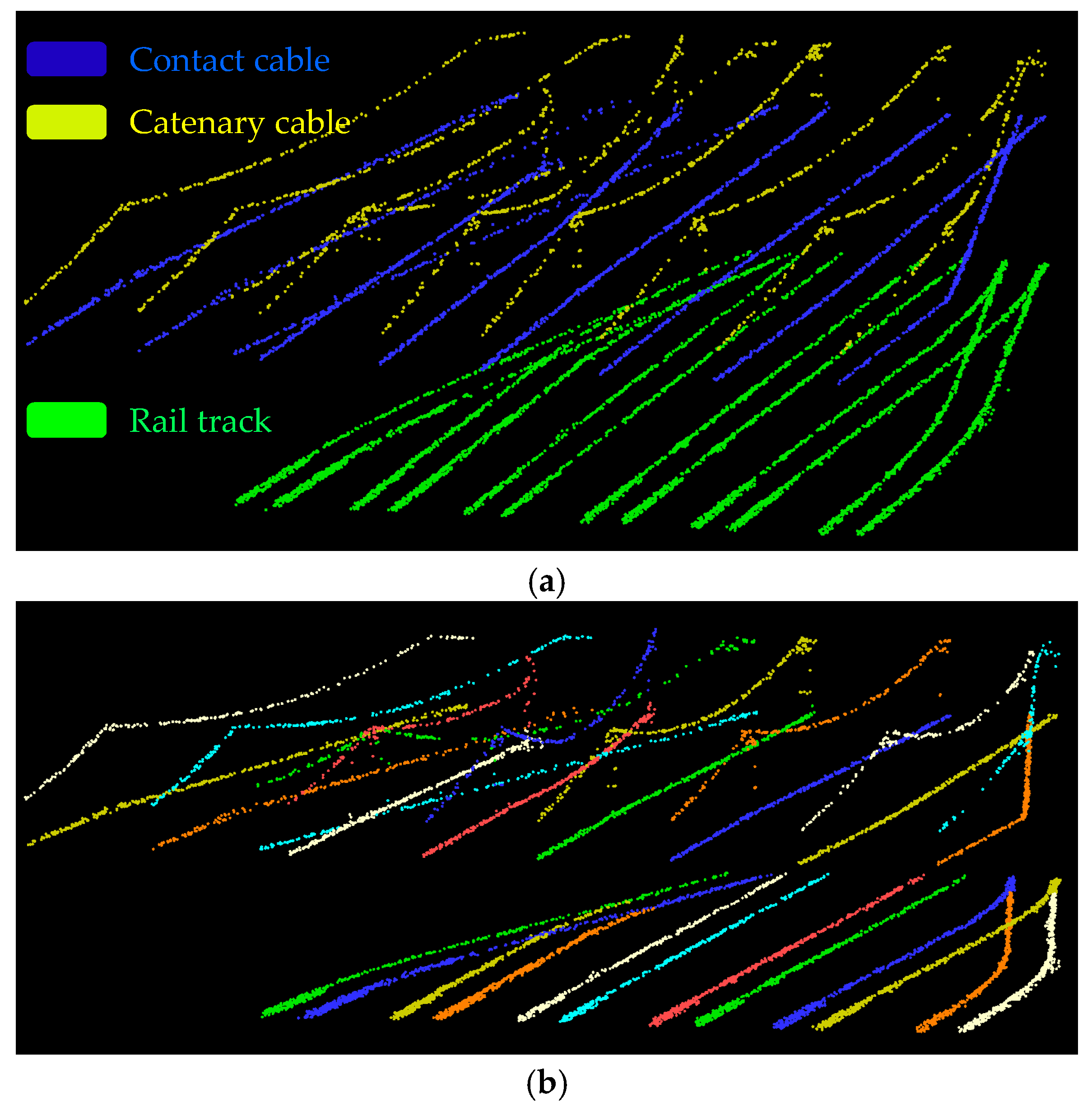
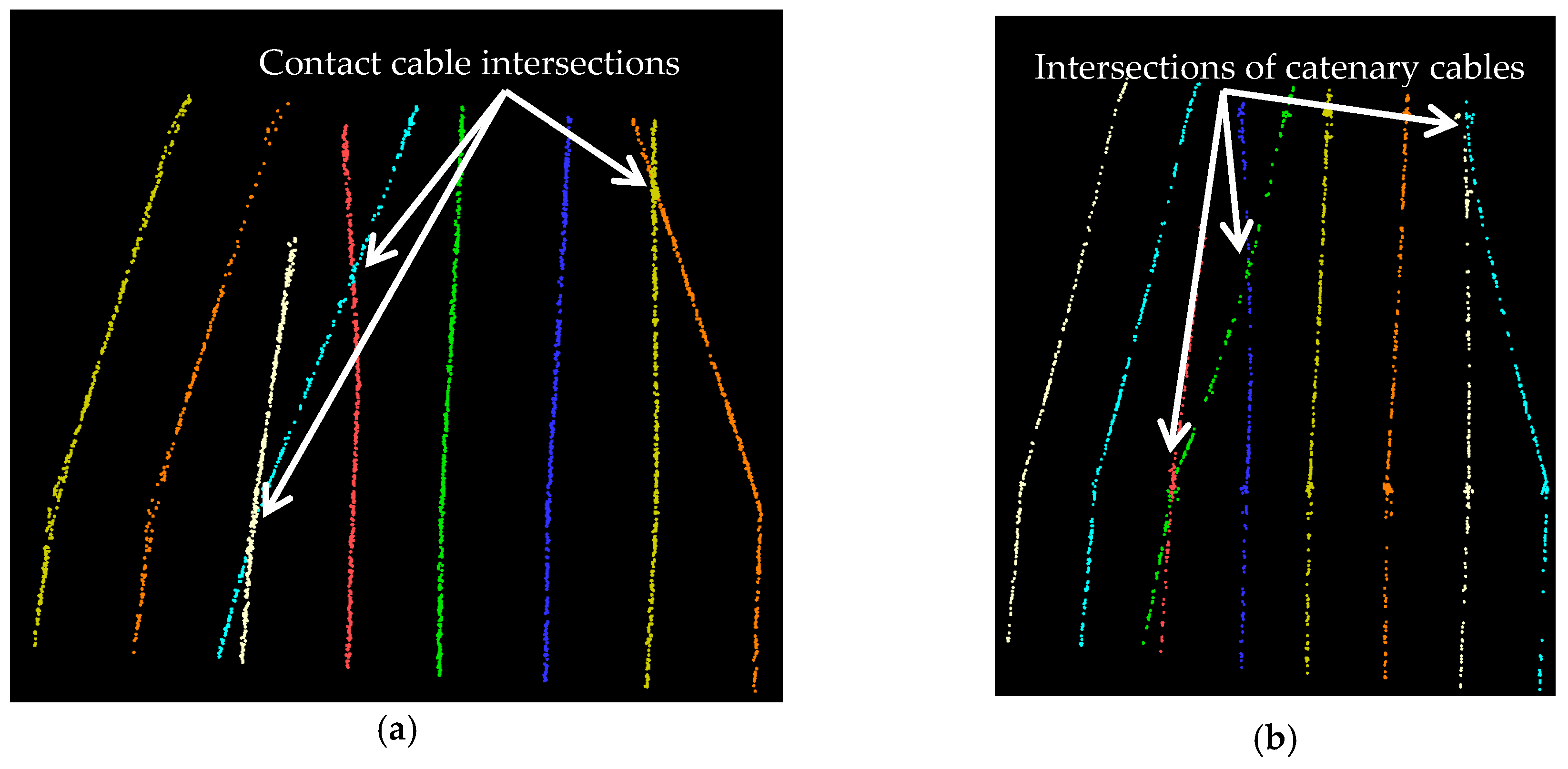
5. Results and Discussion
6. Conclusions
Acknowledgments
Conflicts of Interest
References
- Arastounia, M. Automated as-built model generation of subway tunnels from mobile LiDAR data. Sensors 2016, 16, 1486. [Google Scholar] [CrossRef] [PubMed]
- American Public Transportation Association. Available online: http://www.apta.com/resources/statistics/Documents/FactBook/2014-APTA-Fact-Book.pdf (accessed on 16 May 2015).
- USA Federal Railroad Administration. Available online: http://safetydata.fra.dot.gov/OfficeofSafety/publicsite/Query/AccidentByRegionStateCounty.aspx (accessed on 11 January 2015).
- Petrie, G. Mobile mapping systems: An introduction to the technology. GeoInformatics 2010, 13, 32–43. [Google Scholar]
- Kutterer, H. Mobile Mapping. In Airborne and Terrestrial Laser Scanning, 1st ed.; Vosselman, G., Maas, H.-G., Eds.; Whittles Publishing: Caithness, UK, 2010; pp. 293–295. [Google Scholar]
- Arastounia, M. Automated recognition of railroad infrastructure in rural areas from LiDAR data. Remote Sens. 2015, 7, 14916–14938. [Google Scholar] [CrossRef]
- Arastounia, M.; Oude Elberink, S. Application of template matching for improving classification of urban railroad point clouds. Sensors 2016, 16, 2112. [Google Scholar] [CrossRef] [PubMed]
- Bianculli, A.J. Track: Introduction. In Trains and Technology; University of Delaware: Newark, DE, USA, 2003; pp. 60–95. [Google Scholar]
- Stefanik, K.V.; Gassaway, J.C.; Kochersberger, K.; Abbott, A. UAV-based stereo vision for rapid aerial terrain mapping. GISci. Remote Sens. 2013, 48, 24–49. [Google Scholar] [CrossRef]
- Jochem, A.; Hofle, B.; Rutzinger, M.; Pfeifer, N. Automatic roof plane detection and analysis in airborne Lidar point clouds for solar potential assessment. Sensors 2009, 9, 5241–5262. [Google Scholar] [CrossRef] [PubMed]
- Wu, B.; Yu, B.; Wu, Q.; Yao, S.; Zhao, F.; Mao, W.; Wu, J. A graph-based approach for 3D building model reconstruction from airborne LiDAR point clouds. Remote Sens. 2017, 9, 92. [Google Scholar] [CrossRef]
- Yu, Y.; Li, J.; Guan, H.; Wang, C. Automated extraction of urban road facilities using mobile laser scanning data. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2167–2181. [Google Scholar] [CrossRef]
- Hullo, J.F.; Thibault, G.; Boucheny, C.; Dory, F.; Mas, A. Multi-sensor as-Built models of complex industrial architectures. Remote Sens. 2015, 7, 16339–16362. [Google Scholar] [CrossRef]
- Fang, F.; Im, J.; Lee, J.; Kim, K. An improved tree crown delineation method based on live crown ratios from airborne LiDAR data. GISci. Remote Sens. 2016, 53, 402–419. [Google Scholar] [CrossRef]
- Morgan, D. Using mobile LiDAR to survey railway infrastructure. In Proceedings of the Innovative Technologies of Efficient Geospatial Management of Earth Resources, Lake Baikal, Listvyanka, Russia, 23–30 July 2009. [Google Scholar]
- Leslar, M.; Perry, G.; McNease, K. Using mobile LiDAR to survey a railway line for asset inventory. In Proceedings of the ASPRS 2010 Annual Conference, San Diego, CA, USA, 26–30 April 2010. [Google Scholar]
- Soni, A.; Robson, S.; Gleeson, B. Extracting rail track geometry from static terrestrial laser scans for monitoring purposes. In Proceedings of the ISPRS Technical Commission V Symposium, Riva del Garda, Italy, 23–25 June 2014. [Google Scholar]
- Beger, R.; Gedrange, C.; Hecht, R.; Neubert, M. Data fusion of extremely high resolution aerial imagery and LiDAR data for automated railroad center line construction. ISPRS J. Photogramm. Remote Sens. 2011, 66, 40–51. [Google Scholar] [CrossRef]
- Neubert, M.; Hecht, R.; Gedrange, C.; Trommler, M.; Herold, H.; Kruger, T.; Brimmer, F. Extraction of rail road objects from very high resolution helicopter-borne LiDAR and ortho-image data. In Proceedings of the Geographic-Object-Based Image Analysis (GEOBIA) 2008, Calgary, AB, Canada, 5–8 August 2008. [Google Scholar]
- Sawadisavi, S.; Edwards, J.R.; Resendiz, E.; Hart, J.; Barkan, C.P.L.; Ahuja, N. Machine-vision inspection of railroad track. In Proceedings of the American Railway Engineering and Maintenance-of-Way Association (AREMA) 2008 Annual Conference, Salt Lake City, UT, USA, 21–24 September 2008. [Google Scholar]
- Zhu, L.; Hyyppa, J. The use of airborne and mobile laser scanning for modelling railway environments in 3D. Remote Sens. 2014, 6, 3075–3100. [Google Scholar] [CrossRef]
- Fugro Geo-Services LTD. Available online: http://www.fugro.ca/services/aerial-survey/flimap/flimap400/ (accessed on 21 May 2016).
- Jolliffe, I.T. The Singular Value Decomposition. In Principal Component Analysis, 2nd ed.; Springer Series in Statistics: New York, NY, USA, 2002; pp. 44–47. [Google Scholar]
- Hough, P.V.C. Method and Means for Recognizing Complex Patterns. U.S. Patent 3069654, 18 December 1962. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specifications | Values |
|---|---|
| Laser pulse rate | 150,000 pulses per second |
| Laser eye safety | FDA certified class 1 laser (eye safe at the capture) |
| Nominal point density | >40 points per m2 at 150 m altitude and 75 km/h |
| Range accuracy | 0.01 m |
| Total system accuracy | 0.08 m horizontal and 0.05 m vertical at 1 sigma |
| Laser swath angle | Average 60 degrees (depends of the flying height) |
| Objects | Point Sampling | |
|---|---|---|
| Terrestrial LiDAR Point Cloud | Airborne LiDAR Point Cloud | |
| Track bed (points/m2) | 570 | 82 |
| Contact cable (points/m) | 17 | 4 |
| Catenary cable (points/m) | 9 | 2.5 |
| Objects | Terrestrial Point Cloud | Airborne Point Cloud | ||
|---|---|---|---|---|
| Precision | Accuracy | Precision | Accuracy | |
| Rail tracks | 97.6 | 95.3 | 93.1 | 92.1 |
| Contact cables | 99.4 | 99.1 | 95.9 | 96.4 |
| Catenary cables | 95.3 | 98.2 | 96.8 | 97.2 |
| Average | 97.4 | 97.5 | 95.3 | 95.2 |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arastounia, M. An Enhanced Algorithm for Concurrent Recognition of Rail Tracks and Power Cables from Terrestrial and Airborne LiDAR Point Clouds. Infrastructures 2017, 2, 8. https://doi.org/10.3390/infrastructures2020008
Arastounia M. An Enhanced Algorithm for Concurrent Recognition of Rail Tracks and Power Cables from Terrestrial and Airborne LiDAR Point Clouds. Infrastructures. 2017; 2(2):8. https://doi.org/10.3390/infrastructures2020008
Chicago/Turabian StyleArastounia, Mostafa. 2017. "An Enhanced Algorithm for Concurrent Recognition of Rail Tracks and Power Cables from Terrestrial and Airborne LiDAR Point Clouds" Infrastructures 2, no. 2: 8. https://doi.org/10.3390/infrastructures2020008
APA StyleArastounia, M. (2017). An Enhanced Algorithm for Concurrent Recognition of Rail Tracks and Power Cables from Terrestrial and Airborne LiDAR Point Clouds. Infrastructures, 2(2), 8. https://doi.org/10.3390/infrastructures2020008