3.2. Comparative Analysis
A comprehensive comparative analysis was conducted to evaluate the performance of the EfficientDet-D3 model against other state-of-the-art object detection models, including YOLOv8 and Mask R-CNN (see
Figure 6). The comparison focused on key performance indicators such as detection accuracy, inference speed, and computational efficiency, which are crucial for real-time void detection applications in pavement infrastructure assessments. The evaluation metrics used for comparison included precision, recall, the F1-score, mean Average Precision (mAP) at different IoU thresholds, and inference time.
From the comparative analysis, it was observed that YOLOv8 achieved slightly higher precision than EfficientDet-D3; however, EfficientDet-D3 provided a balanced performance with better recall and F1-score, ensuring fewer missed detections. Mask R-CNN exhibited the highest precision and recall, making it a strong candidate for accuracy-focused applications. However, it suffered from a significantly higher inference time (120 ms), making it less suitable for real-time void detection tasks.
EfficientDet-D3 outperformed YOLOv8 and Mask R-CNN in terms of the trade-off between detection accuracy and inference speed. With an inference time of 68 ms, it proved to be an efficient choice for real-time applications where timely detection is crucial. Additionally, EfficientDet’s ability to scale with different resource constraints allows for flexible deployment in various operational environments.
The comparative analysis also highlighted the model’s robustness across different pavement conditions, as it maintained a high level of accuracy while processing GPR images with varying noise levels and surface textures. Furthermore, EfficientDet-D3’s compound scaling approach contributed to efficient memory usage and computational resource allocation, making it a viable choice for deployment in mobile and edge computing scenarios.
In summary, while YOLOv8 and Mask R-CNN provide competitive accuracy, EfficientDet-D3 offers a superior balance between detection accuracy and processing efficiency, making it the preferred model for real-time pavement void detection applications. Future work will focus on further optimizing inference speed and improving detection capabilities under extreme environmental conditions.
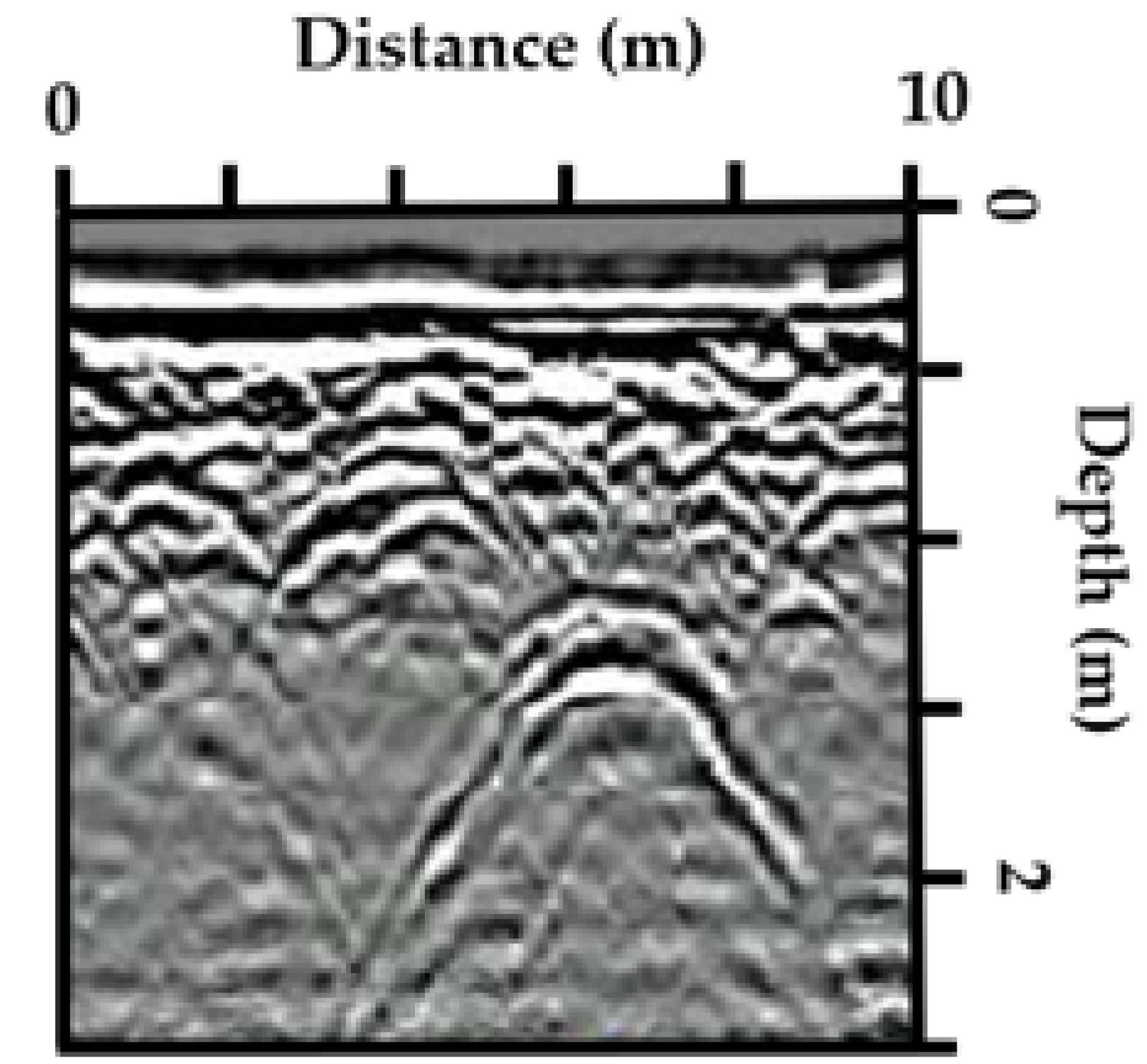
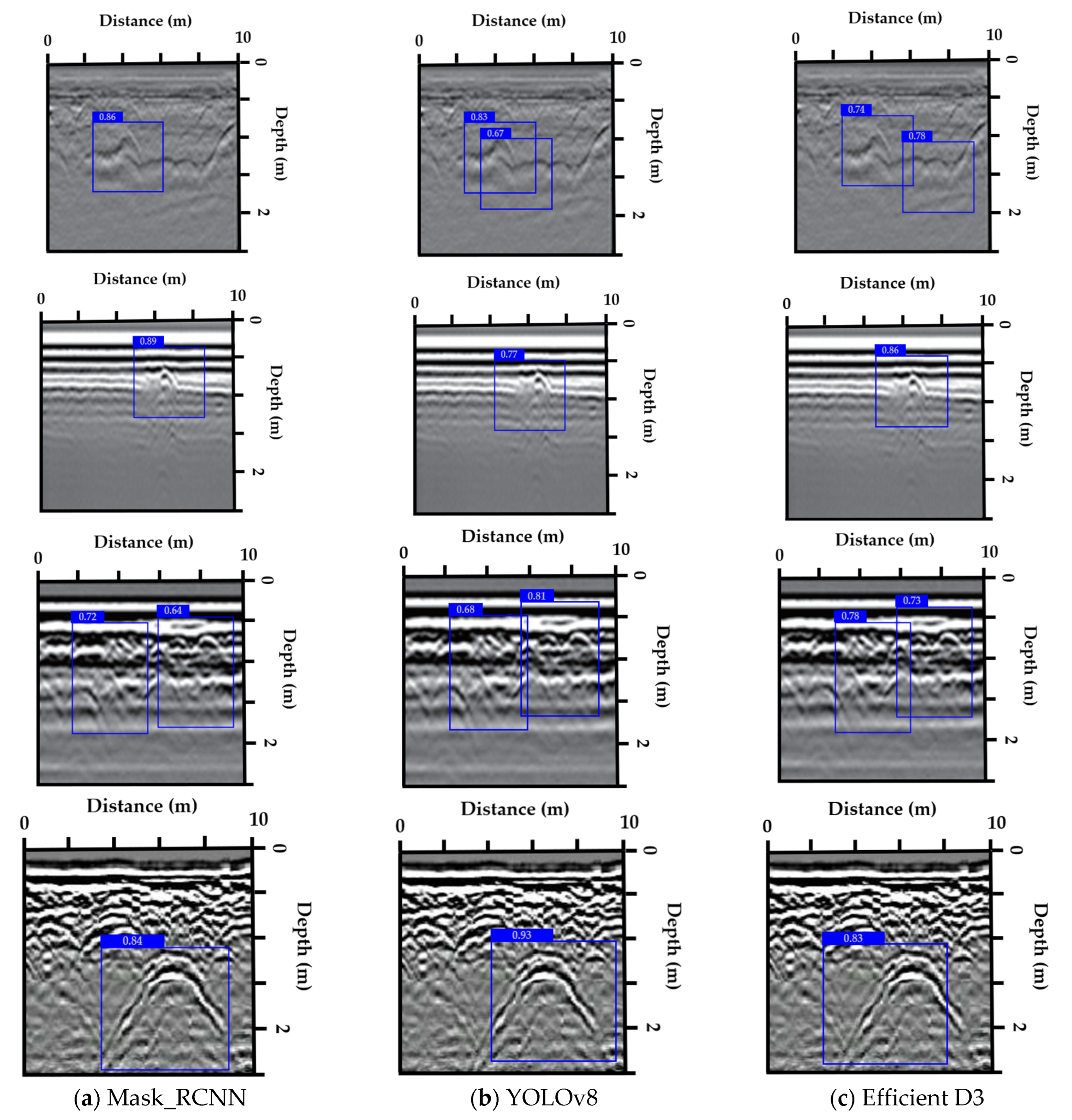
Figure 7 presents a comparison of void detection performance using three different models—Mask_RCNN, YOLOv8, and Efficient D3—on GPR images captured by a GPR device. Each image shows the results of the void detection, with blue bounding boxes highlighting the detected voids and the corresponding confidence scores in the upper left corner of each box. The images in the first row show the performance of the Mask_RCNN model (a), followed by YOLOv8 in the second row (b), and Efficient D3 in the third row (c). The confidence scores are listed alongside each bounding box, demonstrating how each model performs in terms of detecting voids at different distances and depths within the radar image. The results confirm that these models are effective tools for analyzing GPR images and detecting voids at varying depths and distances.
In this research, in order to improve the accuracy and robustness of void detection in GPR images, we implemented a two-step approach: confidence thresholding and post-processing. These methods worked together to filter out false positives, which were a common issue due to the noisy nature of GPR data. The use of these techniques allowed us to retain only high-confidence detections, ensuring that the final results reflected real void features more accurately.
Confidence thresholding was implemented to remove low-confidence detections from the results, focusing on retaining only the most reliable predictions made by the CNN models. In this step, we set a threshold value for the detection confidence score, and any detection below this threshold was discarded. For example, in
Figure 7b, detections with a confidence score below 0.5 were excluded, ensuring that only voids with high certainty were retained. This process significantly reduced false positives, particularly in cases where environmental factors, like electrical interference or weak signal reflection, caused the model to identify incorrect features as voids. By adjusting the threshold, we could fine-tune the model’s performance, balancing the retention of valid detections with the minimization of false positives. For instance, in a test dataset, we observed that increasing the threshold to 0.7 resulted in the exclusion of over 10% of detections, which were incorrectly identified as voids, without losing any critical true void locations.
Post-processing, particularly morphological operations, was applied to clean up the detections by removing false positives and refining bounding box accuracy. In our dataset, after the initial detection, many false detections were scattered or fragmented due to noise and artifacts. To address this, we applied dilation followed by erosion operations to smooth the detected boundaries and eliminate small, non-representative regions. For example, in
Figure 7, the detection of a void feature that appeared as several disconnected parts was corrected through dilation, connecting those parts into a continuous region, followed by erosion to remove small irrelevant detections at the boundaries. Additionally, opening and closing operations were used to remove isolated small detections caused by noise. For instance, an isolated detection that was identified as a void was eliminated using the opening operation, as it was smaller than the typical void size expected. Meanwhile, closing was useful in correcting minor gaps within the detected voids, ensuring the final shape more closely matched real-world cavity structures. These morphological operations proved highly effective in reducing noise, refining detection accuracy, and ultimately ensuring the integrity of the detected voids.
3.2.1. Training and Validation Loss Analysis of Object Detection Models
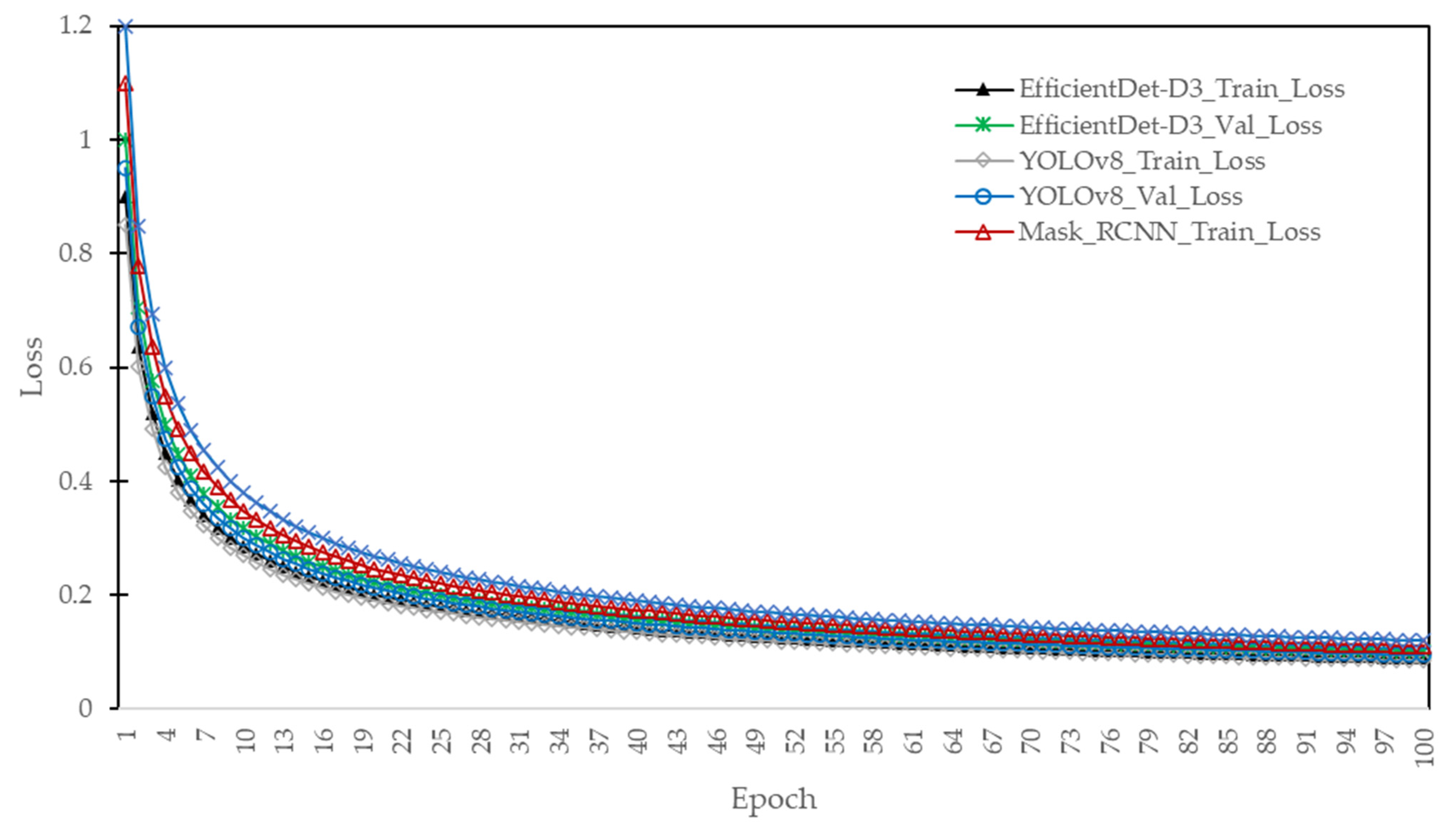
The training and validation loss results for the EfficientDet-D3, YOLOv8, and Mask R-CNN models across 100 epochs provide valuable insights into the learning behavior and convergence of each model (see
Figure 8). Initially, all three models exhibit higher loss values, with EfficientDet-D3 starting at a training loss of 0.90 and a validation loss of 1.00, YOLOv8 at 0.85 and 0.95, and Mask R-CNN at 1.10 and 1.20, respectively. As the training progresses, a consistent downward trend is observed in the loss values for all models, indicating effective learning of the underlying data patterns. By epoch 10, EfficientDet-D3 reaches a training loss of 0.2846 and a validation loss of 0.3162, while YOLOv8 achieves slightly lower loss values of 0.2688 and 0.3004, showcasing its faster learning ability in the initial stages. Mask R-CNN, however, maintains higher loss values at this stage, reflecting its more complex model architecture that requires longer training time for convergence.
As training continues, EfficientDet-D3 demonstrates stable and consistent improvements, with its loss values gradually decreasing to 0.1273 for training and 0.1414 for validation at epoch 50. Similarly, YOLOv8 shows a steady decline to 0.1202 and 0.1344, indicating strong generalization capabilities. Mask R-CNN, although initially slower in convergence, progressively improves, reaching 0.1556 for training and 0.1697 for validation at epoch 50. By the end of training at epoch 100, EfficientDet-D3 achieves the lowest final loss values of 0.090 and 0.100, demonstrating its robust optimization strategy and efficient feature extraction capabilities. YOLOv8 follows closely with values of 0.085 and 0.095, confirming its effectiveness in achieving rapid convergence. Mask R-CNN, while slightly behind in terms of overall loss reduction, achieves a respectable final loss of 0.110 and 0.120, highlighting its ability to capture intricate spatial relationships despite a higher computational cost.
Overall, the results highlight that YOLOv8 exhibits faster convergence and a slightly better initial loss reduction compared to EfficientDet-D3, but the latter achieves comparable final loss values with superior stability. Mask R-CNN, while slower in convergence, proves to be effective for applications requiring high spatial accuracy. These findings emphasize the trade-offs between computational efficiency and accuracy, with EfficientDet-D3 providing an optimal balance suitable for real-time pavement void detection applications.
3.2.2. Hyperparameter Tuning Results (Validation Loss)
The results of hyperparameter tuning for the three models, focusing on the validation loss achieved after tuning the learning rate, batch size, and optimizer selection, are presented in
Table 9. EfficientDet-D3 achieved the lowest validation loss of 0.095, indicating its effectiveness in learning relevant features from GPR images while minimizing overfitting. YOLOv8 followed with a validation loss of 0.102, while Mask R-CNN had the highest loss of 0.110. The lower validation loss for EfficientDet-D3 suggests that its compound scaling mechanism optimizes resource utilization and improves feature extraction efficiency. These results validate the decision to employ adaptive learning rate scheduling and early stopping criteria to ensure optimal model convergence without excessive training time.
3.2.3. Model Inference Speed Comparison
The final figure compares the inference speed of the three models, measured in frames per second (fps), to evaluate their suitability for real-time applications, as shown in
Table 10. YOLOv8 achieved the fastest inference speed at 20 fps, making it the best choice for applications requiring rapid detection and analysis. EfficientDet-D3 followed with an inference speed of 15 fps, offering a reasonable trade-off between speed and accuracy. Mask R-CNN, while the most accurate model, had the slowest inference speed at just 8 fps, making it less suitable for time-sensitive applications. These findings underscore the importance of considering inference speed when deploying void detection models in operational environments, such as real-time pavement monitoring systems.
3.2.4. Comparison of YOLO Models and EfficientDet-D3 for Pavement Void Detection
This section broadens the comparison by incorporating EfficientDet-D3, along with several predecessors from the YOLO series, to provide a more comprehensive evaluation. The comparison now includes multiple YOLO variants, namely YOLOv8 [
19], YOLOv5 [
36], YOLOv4 [
19], YOLOv4-CSP [
37], and YOLOv3 [
21], to better assess their accuracy and inference times. Additionally, Mask R-CNN is included in this evaluation, which allows for a more thorough analysis of the trade-offs between accuracy and inference speed, helping to identify the most suitable model for real-time pavement void detection.
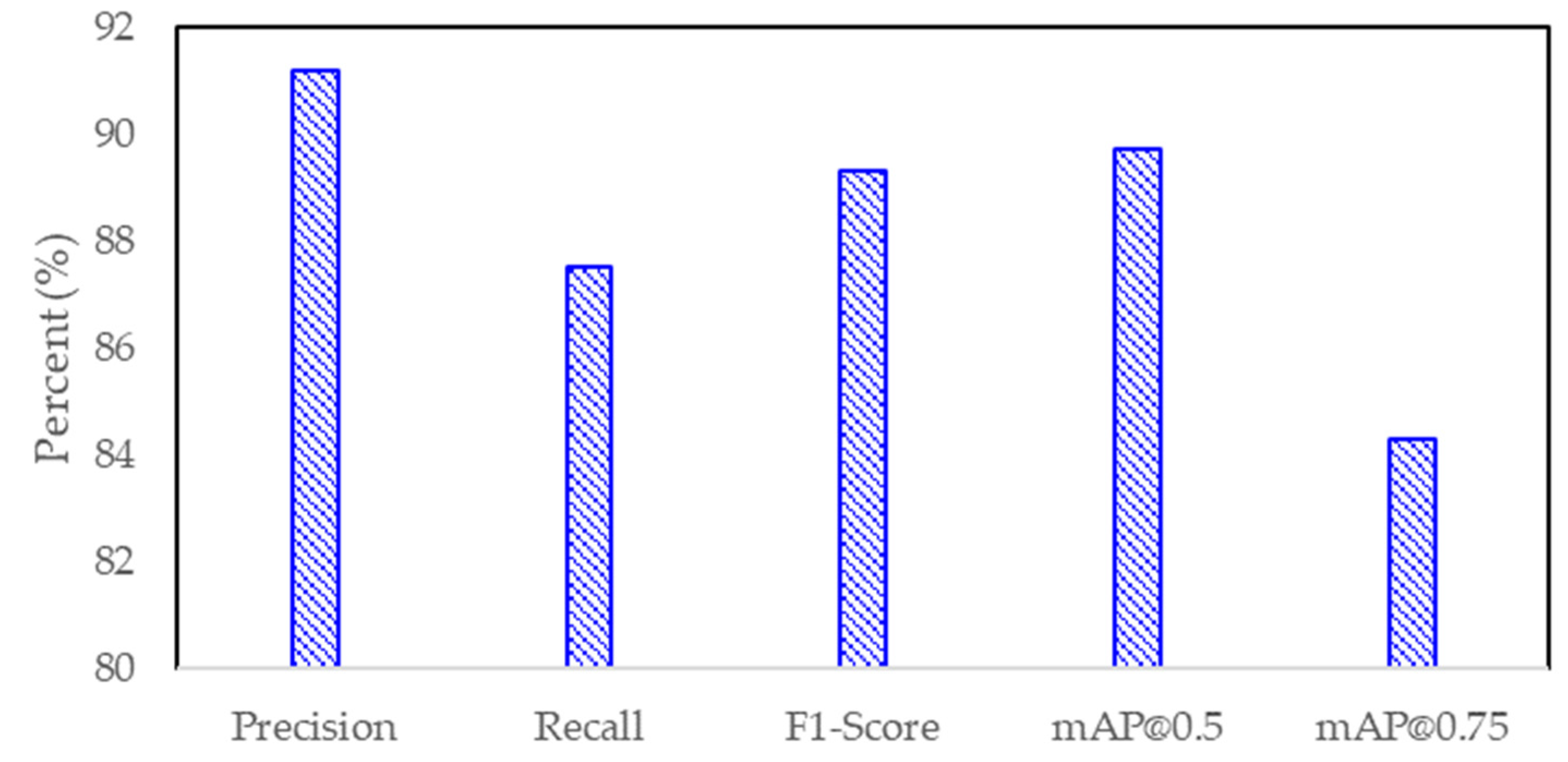
As shown in the
Figure 9, YOLOv8 consistently outperforms its YOLO predecessors in both precision and recall, achieving an impressive precision of 91.2%, a recall of 87.5%, and an F1-score of 89.3%, with a manageable inference time of 68 ms. This superior performance is particularly notable when compared to YOLOv4 (precision: 88.6% and recall: 85.2%) and YOLOv5 (precision: 89.3% and recall 86.0%), which, while still competitive, lag behind YOLOv8 in terms of detection accuracy. In contrast, older versions like YOLOv3 (precision: 87.5% and recall: 84.3%) show both lower accuracy and significantly slower inference times (150 ms), making them less suitable for real-time applications in pavement void detection.
EfficientDet-D3 slightly outperforms YOLOv8 in terms of precision (93.1% vs. 92.5%) and the F1-score (90.7% vs. 89.3%) but comes with a longer inference time of 68 ms, making it a slightly less optimal choice when inference speed is a critical factor for real-time applications. On the other hand, Mask R-CNN (precision: 92.8%, recall: 86.9%, and F1-score: 89.8%) shows good precision but suffers from a much slower inference time (120 ms), which makes it less suitable for real-time detection.
This comparison demonstrates that while earlier YOLO models made significant contributions to object detection, YOLOv8 stands out as one of the most well-rounded models for pavement void detection, offering an optimal balance between high detection accuracy and fast inference speed. Additionally, EfficientDet-D3 provides slight improvements in precision and the F1-score but comes with a slightly longer inference time. Despite this, YOLOv8 remains a strong contender, making it an excellent candidate for deployment in real-time pavement management systems, where both timely detection and efficient resource allocation are critical.
3.4. Practical Application of EfficientDet-D3 in PMS
The integration of EfficientDet-D3 into PMS can greatly enhance pavement maintenance by automating void detection and enabling proactive decision-making. By processing real-time GPR data, the model identifies voids beneath pavement surfaces, prioritizing areas that require urgent attention based on void size and severity. This reduces manual inspections and allows for optimized repair scheduling, ultimately lowering maintenance costs and extending pavement lifespan. Continuous updates ensure that the PMS remains current with the latest condition assessments, making it an invaluable tool for long-term infrastructure management.
In a practical example, EfficientDet-D3 was successfully applied to historical GPR dataset images from pavements in Seoul. These datasets, which had not been recently inspected, were found in the library and demonstrated the model’s ability to detect cavities effectively. The model identified voids beneath the surface, confirming its capability to handle older GPR data and further showcasing its potential for integration into real-world pavement management systems, even with non-recent data.
Figure 13 shows examples that highlight the successful application of EfficientDet-D3 in detecting cavities in pavements using historical GPR dataset images. These datasets, sourced from pavements in Seoul, were not part of recent inspections but were found in the library. The model effectively detected voids within these older images, demonstrating its capability to work with historical GPR data and further showcasing its potential for real-world pavement management applications.
3.5. Challenges and Limitations
Despite the promising results achieved in void detection using the EfficientDet-D3 model, several challenges and limitations were encountered during the study, which impacted the overall performance and reliability of the system. These challenges primarily stem from the inherent complexities of GPR imaging and the diverse conditions under which the data were collected. One of the primary challenges faced was the variability in GPR image quality due to environmental conditions.
Factors such as the temperature, moisture content, and soil composition significantly affected the quality of GPR scans, leading to inconsistencies in the acquired data. Moisture infiltration, in particular, introduced noise and signal attenuation, making it difficult to distinguish between actual voids and artifacts caused by environmental factors. As a result, preprocessing techniques such as noise filtering and normalization were critical in mitigating these issues but could not entirely eliminate them.
Another significant challenge was the difficulty in differentiating small voids from natural material variations. Pavement structures are composed of heterogeneous materials, including aggregates, asphalt, and concrete layers, which exhibit different electromagnetic properties. These variations often produced reflections and artifacts in the GPR images that closely resembled voids, leading to false positive detections. Small voids, in particular, were harder to identify accurately, requiring the model to have highly sensitive feature extraction capabilities. To address this, additional feature engineering techniques and enhanced training data augmentation were explored to improve the model’s ability to discern subtle differences.
Furthermore, this study highlighted the requirement for larger, more diverse datasets to improve generalization. The available dataset, while comprehensive, was limited in terms of geographical diversity and pavement types. The inclusion of data from different climatic regions, pavement materials, and varying traffic loads would enhance the model’s ability to better generalize unseen scenarios. Collecting and annotating such extensive datasets, however, is resource-intensive and time-consuming. Future research should focus on expanding the dataset and incorporating synthetic data generation techniques to simulate a broader range of real-world conditions.
In summary, while the EfficientDet-D3 model demonstrated a strong performance in void detection, addressing these challenges through improved data acquisition methods, advanced signal processing techniques, and more robust model architectures will be crucial for enhancing the reliability and applicability of the system in practical scenarios. Overcoming these limitations will ensure the development of a more comprehensive and scalable solution for pavement void detection using GPR imaging.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}