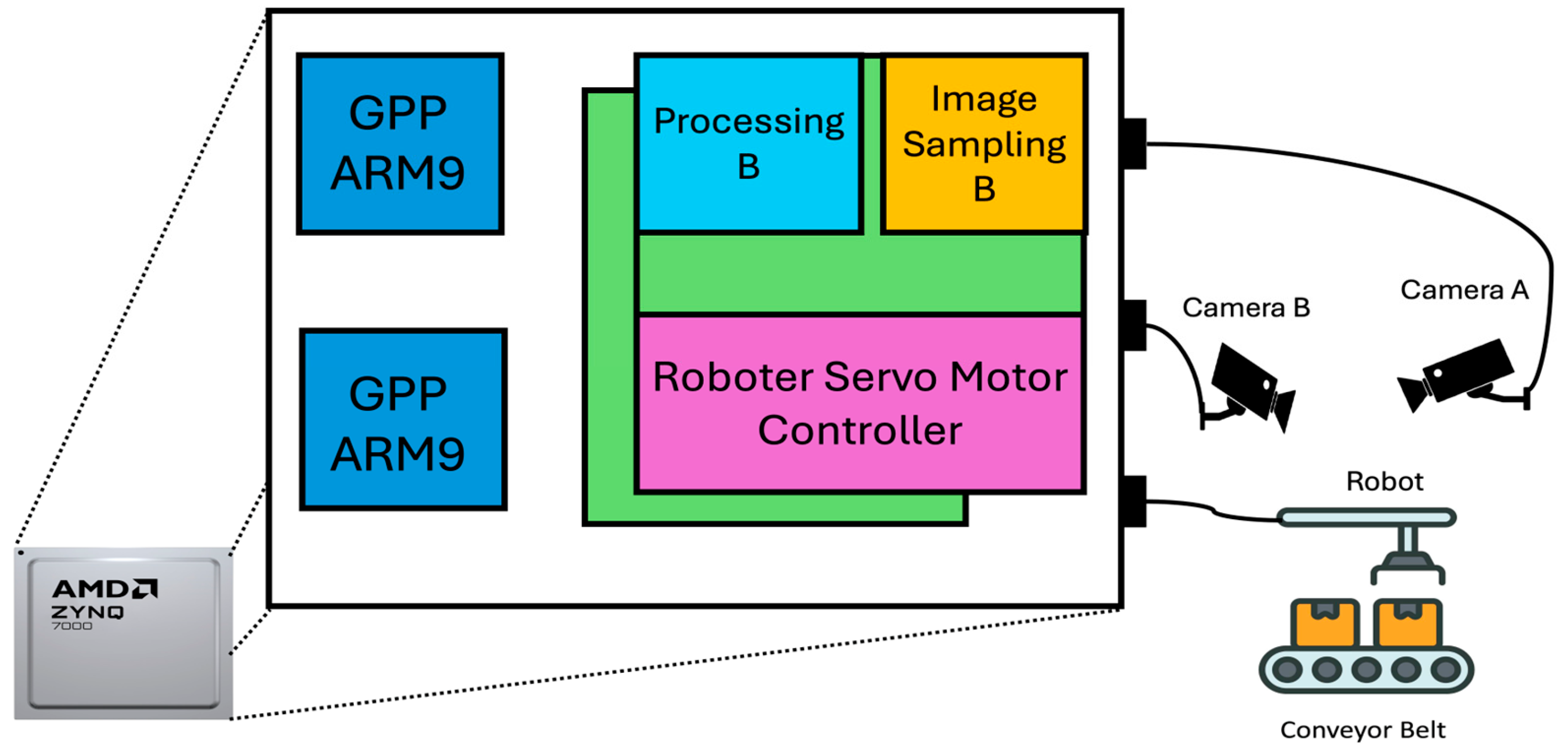
Before describing the proposed methodology, some assumptions are introduced, and an example of a FMS is given to clarify the different concepts used afterward.
3.2. Fault-Tolerant FMS Design
Given the harsh conditions of industrial environments, electromagnetic interference is very frequent, and the risk of faults arises in several ways, including sensor malfunctions, control systems failures, equipment damage, and actuator errors. Sensors can provide inaccurate readings or may fail entirely, while the controllers responsible for managing the manufacturing process can experience transient or permanent failures, thus affecting the overall operation. Moreover, the prolonged exposure of workcells to high levels of electromagnetic intrusions can damage the sensitive electronic components in the machinery. Accordingly, the design of a highly reliable FMS is proposed. The focus of this research will be on controller and/or SUP failures. Two levels of fault tolerance are introduced in the FMS: the workcell level and the system level.
At the workcell level, the fault model focuses on the faults that take place in the SRAM-based FPGA controller K, which include SEUs, SEFIs, and hard faults. SEUs in FPGAs are a significant concern, especially in harsh environments [
53]. SEUs occur when a charged particle hits the FPGA, causing a bit flip in the configuration memory or user data. This can result in potential malfunctions or incorrect circuit behavior. Moreover, it can corrupt the data stored in registers or memory blocks in the FPGA, affecting calculations and data processing. SEUs can be mitigated by employing redundant modules and dynamically reconfiguring the affected areas of the FPGA by Dynamic Function eXchange (DFX) to enhance fault tolerance [
54,
55]. DFX refers to a capability that enables the dynamic reconfiguration of some functional modules within the FPGA while other modules still run normally [
56]. It allows the FPGA to adapt to evolving requirements or operational conditions without the need to reconfigure the whole FPGA; as a result, the FPGA’s flexibility and efficiency are improved.
Unlike SEUs, which only affect individual bits, SEFIs induce a significant functional disruption, causing failure of the entire functionality of the FPGA because they occur in critical circuits involving Power-On-Reset (POR) circuitry, configuration port controllers (Joint Test Action Group (JTAG)), select-map communications ports, Internal Configuration Access Port (ICAP) controllers, reset nets and clock resources, as well as their associated control registers [
13]. The control registers are responsible for executing all commands required for programming, reading, and checking the status of a FPGA device. They include general control registers, Cyclic Redundancy Check (CRC) registers for readback, Frame Address Registers, and watchdog circuitry. Accordingly, they disrupt the ability to perform readback from the FPGA, cause configuration bits to be written to an inaccurate frame address or cause a reset of the entire FPGA. SEFI detection is challenging since the affected blocks are not directly controlled by the user; as a result, the detection process is performed by external observation of abnormal behavior from the device. The only possible operation to recover from SEFIs is to switch off the FPGA and reconfigure the entire FPGA from the golden configuration memory [
57].
Hard faults cause permanent failures within the FPGA fabric because they affect the silicon itself. They include Time-Dependent Dielectric Breakdown (TDDB), the hot-carrier effect, and electromigration [
58]. TDDB is the phenomenon that occurs when the FPGA is subjected to high electric fields, which results in the breakdown of the insulating dielectric material in the FPGA over time. This may lead to the eventual failure of the affected Configurable Logic Blocks (CLBs) of the FPGA, causing operational errors or complete device malfunction, while the hot-carrier effect occurs when charge carriers (electrons or holes) gain high kinetic energy, which is also due to high electric fields within the semiconductor device, which leads to transistor aging, threshold voltage shifts, and increased leakage currents that degrade the FPGA’s performance and reliability. Electromigration takes place when metal atoms in conductive paths migrate as a result of high current densities, causing material degradation and eventual open or short circuits. Consequently, this may lead to FPGA interconnect failures.
Addressing these reliability concerns is very critical in the FPGA design, requiring careful consideration and mitigation techniques to ensure the durability and reliability of the FPGA-based controllers. In this research, the redundancy approach, which will be applied to the FPGA-based controller in the workcell, is Duplication With Comparison (DWC) [
14,
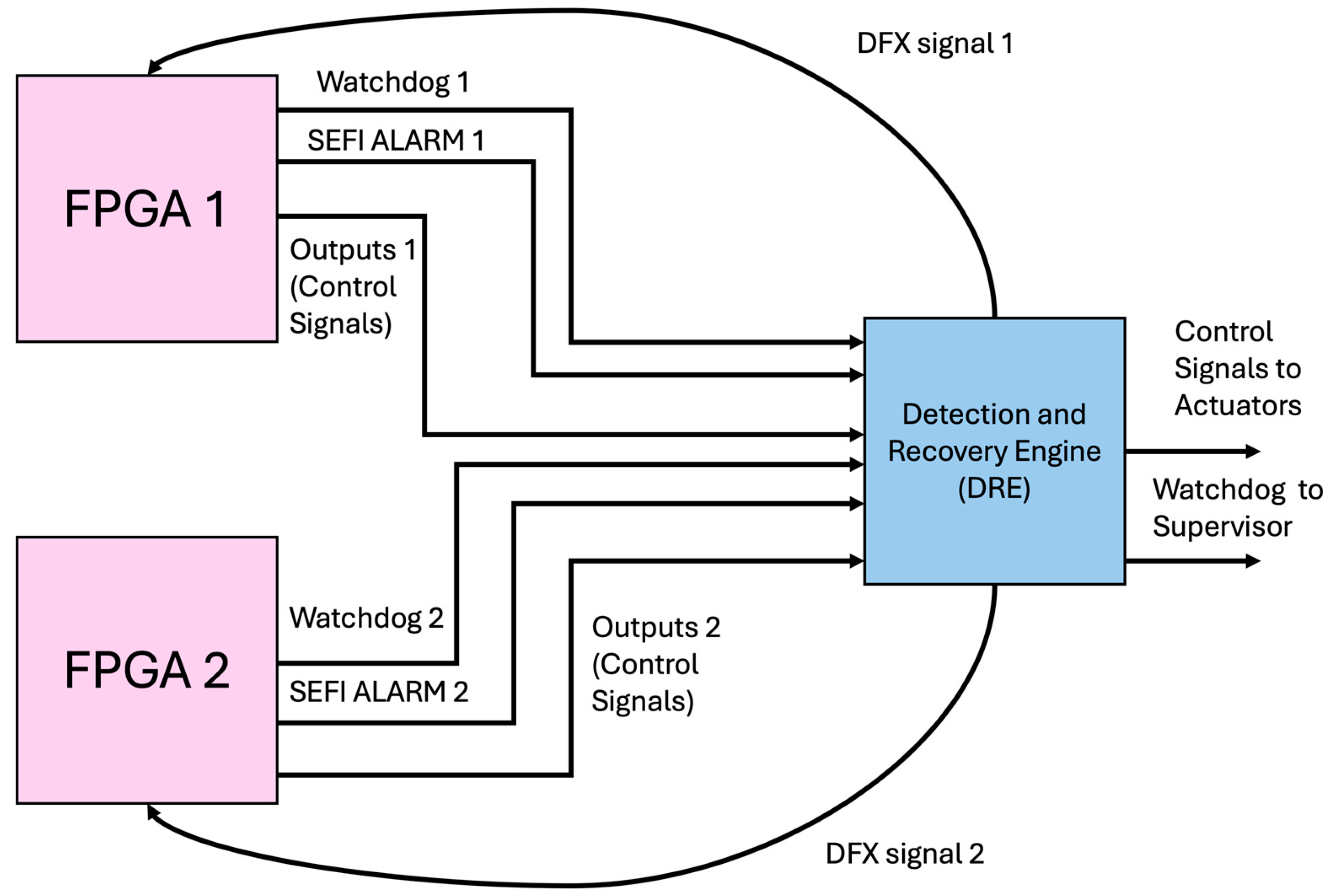
59]. The proposed fault-tolerant design is composed of two identical FPGA-based controllers (FPGA1 and FPGA2) and a Detection and Recovery Engine (DRE) block, as shown in
Figure 3. DFX signal 1 and DFX signal 2 represent the signals through which the recovery instructions are sent to FPGA1 and FPGA2.
The DRE block is responsible for SEU, SEFI, and hard fault detection. Then, if any fault is detected, it sends the appropriate recovery instructions to the faulty FPGA and delivers the control signals and the watchdog signal of the working controller to the actuators and the SUP, respectively. Each FPGA-based controller generates a watchdog signal and sends it to the DRE block along with the control signals (including the control action that should be sent to the actuators) and the SEFI alarm signal (indicating whether a SEFI event has occurred or not). For SEFI fault detection, the SEFI alarm signal is monitored by the DRE. If a SEFI exists, the DRE block orders the faulty FPGA to perform full reconfiguration of the FPGA. For SEUs and hard faults detection, the DRE block monitors the watchdog signals coming from the FPGA-based controllers and compares their control signals to check if they have identical values or not. If the control signals are not identical, this means that there is a SEU or a hard fault in one of the controllers. The faulty controller is identified by checking both watchdog signals. In this case, the DRE block orders the faulty controller to perform DFX and transmit the control signals from the active controller to the actuators. After completion of the DFX action, if the controller is still identified by the DRE as a faulty block, this means that a hard fault exists, and the system will continue working with the active controller only. If the active controller fails, the whole workcell will fail. However, if the faulty controller resumes operation, the system will function normally until the occurrence of another fault, upon which the same process will be repeated.
To test the robustness of the proposed architecture, the reliability of the fault-tolerant FPGA-based controller architecture is calculated using Stochastic Petri Nets (SPNs), and then it is compared to the reliability of the FPGA-based controller without applying any fault tolerance.
SPNs are widely used in the modeling and analysis of complex systems. SPNs permit the mathematical analysis of system functionality along with system reliability. They are composed of Place/Transition nets in which the place (
p) represents the state of the system (denoted as
p1,
p2, …,
pn) while the transitions (
t) refer to the changes that happen in the system (denoted as
t1,
t2, …,
tn) where these changes (firing events) occur after a random time. The distribution used for the interarrival time of the failures is usually the exponential distribution [
14]. The exponential distribution is memoryless and is well-suited to describe the failure/firing events. Its hazard rate (or failure rate) is constant.
When a transition fires, a change in the state of the associated elements takes place. The tokens are the dots inside places that represent a specific configuration of the net. Once the network experiences a transition, the tokens move across the model from one place to another [
60]. Markings (m) denoted as (m
1, m
2, …, m
m) represent the number of tokens in each place, while the firing rate (λ) is the rate of the exponential distribution associated with each transition. The SPN includes the following key components (
P,
T,
F,
K,
W,
M, and λ) [
61], which are described with the required conditions as follows:
- (1)
P = {p1, p2, …, pn} is a limited set of places;
- (2)
T = {t1, t2, …, tn} is a limited set of transitions;
- (3)
P ∪ T ≠ ∅ (means that the net is not empty);
- (4)
P ∩ T ≠ ∅ (means that both are dual);
- (5)
F ⊆ ((P × T) ∪ (T × P)) (means that the flow relationship is only between the elements of sets P and T);
- (6)
dom (F) = {x|∃y: (x, y) ∈ F} (represents the set of the first element of the order couple contained in F);
- (7)
cod (F) = {x|∃y: (y, x) ∈ F} (represents the set of the second element of the order couple contained in F);
- (8)
dom (F) ∪ cod (F) = P ∪ T (means that there are no isolated elements);
- (9)
N is a natural number, while N+ is a positive natural number;
- (10)
K: P → N+ ∪ {∞} (represents the capacity function of the place);
- (11)
W: F → N+ (represents the weight function of the directed arc);
- (12)
M: P → N (represents the initial marking which should satisfy ∀p ∈ P: M(p) ≤ K(p));
- (13)
λ = {λ1, λ2, …, λn} (represents the set of transition firing rates).
Each transition follows an exponential distribution function with parameter λ
i [
62]:
where
λi is the average firing rate (
λi > 0) and x is a variable (
x ≥ 0). Moreover, the probability that two transitions will fire simultaneously is zero, and the reachable state graph of the SPN is isomorphic to a homogeneous Markov chain (MC), allowing it to be solved using Markov stochastic processes.
A Petri Nets model N can be represented as an incidence matrix [
N] → ℤ, which is an integer matrix composed of |
T| × |
P| and indexed by
T and
P [
63,
64]. It describes the Petri Nets in mathematical form as follows:
The incidence matrix can be divided into the input matrix and output matrix:
Output matrix:
where
=
−
. Each negative element in
or non-zero element in
denotes one arc directed from place to transition.
The reliability of the system
R(
t) is the probability that the system remains in the operational state over time, which means that it can be calculated from the SPN as the probability that place
F (representing the failure state) is empty at time
t, where empty place indicates that it has no tokens. Let the number of places of the SPN be X. Let
(
t) be the probability of being in place
i at time
t. Using the Chapman–Kolmogorov equations [
14], the transient probability of being in any of the
i places can be evaluated.
P is the matrix, including the probabilities of each place
i while
T is the Transition Rate Matrix.
where
where
is the rate of transition from place
i to
jLet
(0) = 1, and all other places have an initial probability of zero. By substituting T and P in Equation (5),
(
t) for each place i can be computed, and system reliability
R(
t) at time t can be obtained using Equation (6).
where
is the probability of being in the place in which the whole system fails.
The reliability of the FPGA-based controller without applying the fault-tolerant technique is calculated using the SPN displayed in
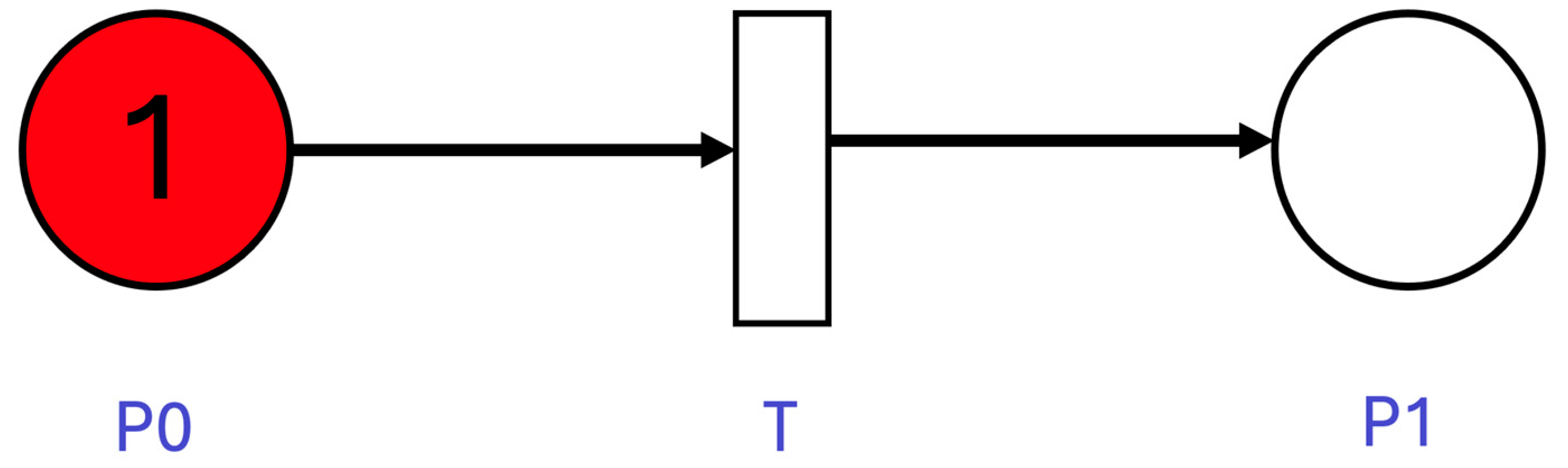
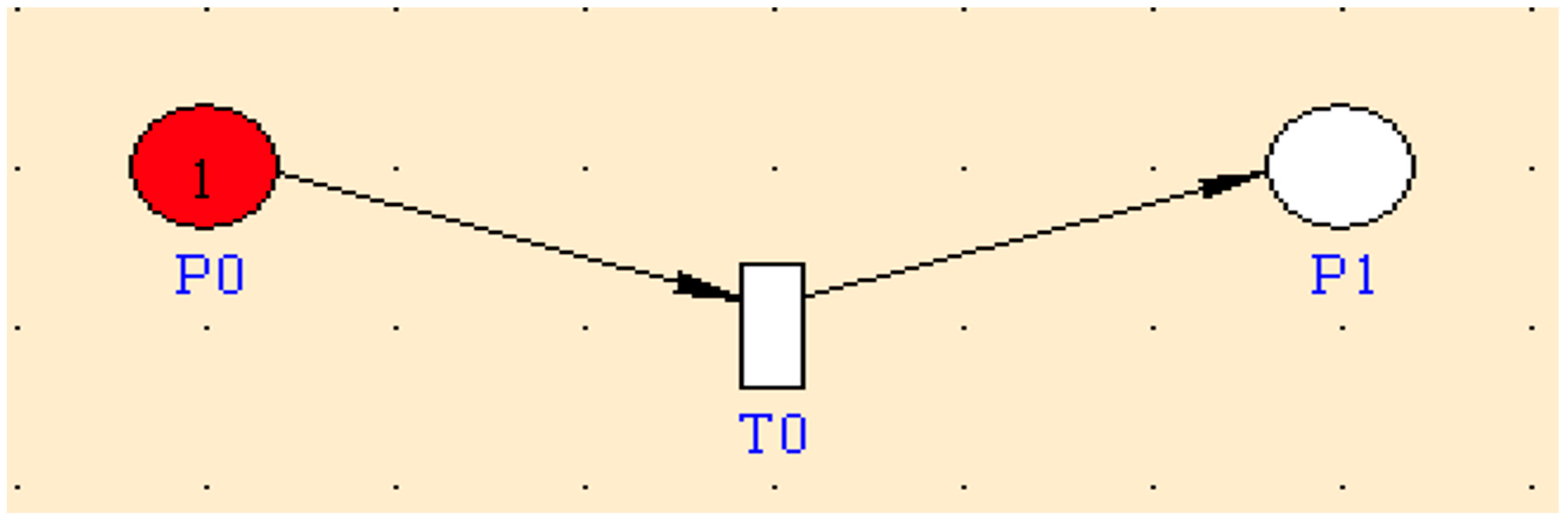
Figure 4.
Place P0 represents the fault-free state of the controller in which it works appropriately, and it contains 1 token, which shows that the system is initially in this place. If the controller is hit by a SEU, hard fault, or SEFI, with a rate of (SEU + HARD + SEFI), the token will move to place P1, which represents the failure of the controller through transition T0. The SEU is the SEU failure rate of the FPGA-based controller, which is calculated based on the SEU failure rate per bit and the size of the bit file of the controller. While HARD is the hard fault rate of the FPGA-based controller and SEFI is the SEFI rate of the controller. The reliability of the system is calculated as the probability that place P1 (representing the failure state) is empty at time t. The incidence matrix of the model is shown in the following equation:
The reliability of the FPGA-based controller without applying the fault-tolerant technique
(
t) is calculated as follows:
The proposed fault-tolerant FPGA-based controller can be described using nine places (states) and eighteen transitions in the SPN, which are described in
Table 2 and
Table 3. Assume that M1 and M2 are the two identical FPGA-based controllers, and the failure rates of the SEU, hard faults, and SEFI of M1 are SEU_M1, HARD_M1, and SEFI_M1, respectively. For M2, the failure rates for the SEU, hard faults, and SEFI are represented by SEU_M2, HARD_M2, and SEFI_M2. The model is based on the occurrence of a single fault at any given time.
The incidence matrix of the model is presented in the following equation:
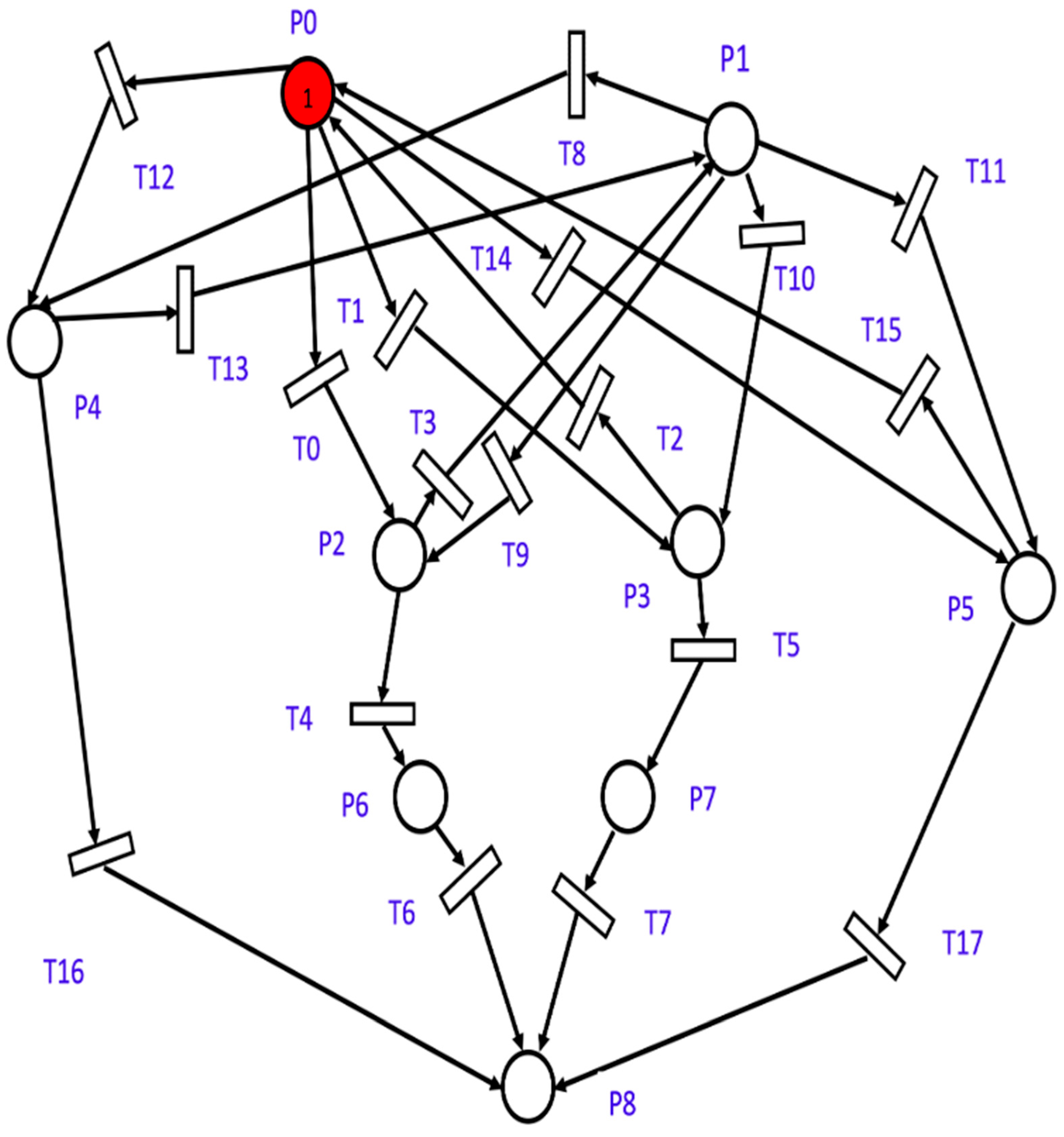
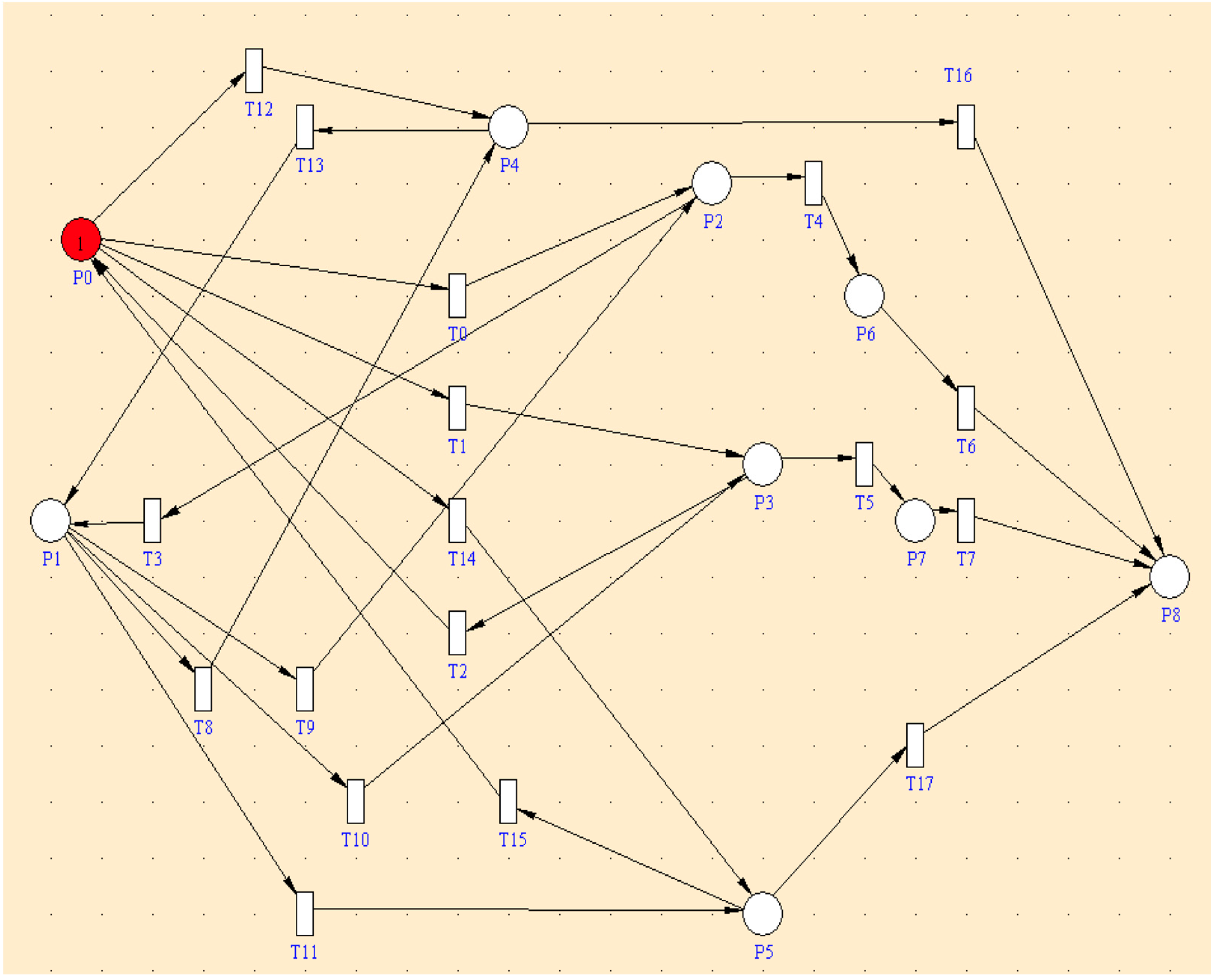
Initially, the system resides in place P0, marked by one token, as shown in
Figure 5. When a transition occurs in the network, the token transfers from one place to another within the model. If M1 becomes faulty due to a SEU or a hard fault, the system moves to place P2 through transition T0 with the rate of SEU_M1 + HARD_M1. In this place, the DRE block orders M1 to perform DFX and transmits the control signals from M2 to the actuators. Following the completion of the DFX, if the controller becomes online, the system will transfer to place P1 through transition T3 with a rate of Z * U, where Z is the conditional probability that the fault is a SEU. The relative frequency of a SEU versus hard failures is a crucial factor in the calculation of Z. Furthermore, assume that the time taken to reconfigure the controller (BIT file over the network) is exponentially distributed with an expected value of 1/U. Consequently, the repair rate is given by U. In the case that the DRE still identifies the controller as a faulty block, it signifies the existence of a hard fault, and the system will proceed to function with M2. This means that the system will move to place P6 through transition T4 with the rate of (1 − Z) * U. If M2 becomes defective, the whole system will fail, and this indicates that the system will move to place P8 via transition T6 at a rate of SEU_M2 + HARD_M2 + SEFI_M2.
If a SEFI is detected in M1, the DRE block instructs the faulty FPGA M1 to initiate a full reconfiguration process, and the system will continue working with M2; accordingly, the system will move from place P0 to place P4 through transition T12 with a rate of SEFI_M1. If M1 becomes online, the system will move to place P1 through T13 via rate USEFI_M1, which is the repair rate of M1 due to the SEFI fault. If any other fault exists, the entire system will fail, which means that the system will move to place P8 through transition T16 with a rate of SEU_M1 + HARD_M1 + SEFI_M1 + SEU_M2 + HARD_M2 + SEFI_M2.
Similarly, if the system is in place P0 and M2 becomes faulty due to a SEU or hard fault, the system transitions to place P3 through transition T1 at the rate of SEU_M2 + HARD_M2. In this state, the DRE orders M2 to perform DFX while M1 transmits control signals. If M2 becomes online after DFX, the system transitions to place P0 through transition T2 at the rate of Z * U. If M2 remains faulty, indicating a hard fault, the system moves to place P7 through transition T5 at the rate of (1 − Z) * U.
In the event that M1 becomes defective, the entire system will fail, leading to a transition to place P8 via transition T7 at a rate of SEU_M1 + HARD_M1 + SEFI_M1. If SEFI is detected in M2, the DRE commands a full reconfiguration, and the system moves to place P5 through transition T14 at the rate of SEFI_M2. If M2 becomes online, the system transitions to place P0 via T15 at the repair rate USEFI_M2. When any other fault leading to system failure occurs, the transfer to place P8 through transition T17 at the rate of SEU_M1 + HARD_M1 + SEFI_M1 + SEU_M2 + HARD_M2 + SEFI_M2 takes place. When the system is in P1 and M2 is hit by a SEU or a hard fault, the system transitions to place P3 through transition T10 at the rate of SEU_M2 + HARD_M2. Conversely, if M1 is struck by a SEU or a hard fault, the system transitions to place P2 through transition T9 at the rate of SEU_M1 + HARD_M1.
Upon detection of a SEFI in M1, the system transitions to place P4 through transition T8 at the rate of SEFI_M1. On the other hand, if a SEFI is detected in M2, the system moves to place P5 through transition T11 at the rate of SEFI_M2. Then, the model proceeds as previously described.
The reliability of the proposed fault-tolerant FPGA-based controller is calculated as the probability that place P8 (representing the failure state) is empty at time t. The SPN of the proposed fault-tolerant FPGA-based controller is composed of 9 places. Let
(
t) be the probability of being in place
i (where
i ∈ {P0, P1, P2, P3, P4, P5, P6, P7, P8}) at time
t. Using the Chapman–Kolmogorov equations [
14] and assuming
(0) = 1 while
(0) =
(0) =
(0) =
(0) =
(0) =
(0) =
(0) =
(0) = 0, the transient probability of residing in any of the i places can be evaluated as follows:
where
The reliability of the proposed fault-tolerant FPGA-based controller technique
(
t) is calculated as follows:
The role of fault tolerance at the system level becomes obvious when the fault-tolerant FPGA-based controller fails. Under normal conditions, the SUP continuously receives a watchdog signal from the workcell’s controller. However, when the controller becomes faulty, the SUP replaces it. Consequently, all the sensor and actuator signals that were initially sent to the faulty controller are rerouted directly to the SUP. The evaluation of network performance is based on end-to-end delays. The system is modeled and simulated using the Riverbed Network Modeler [
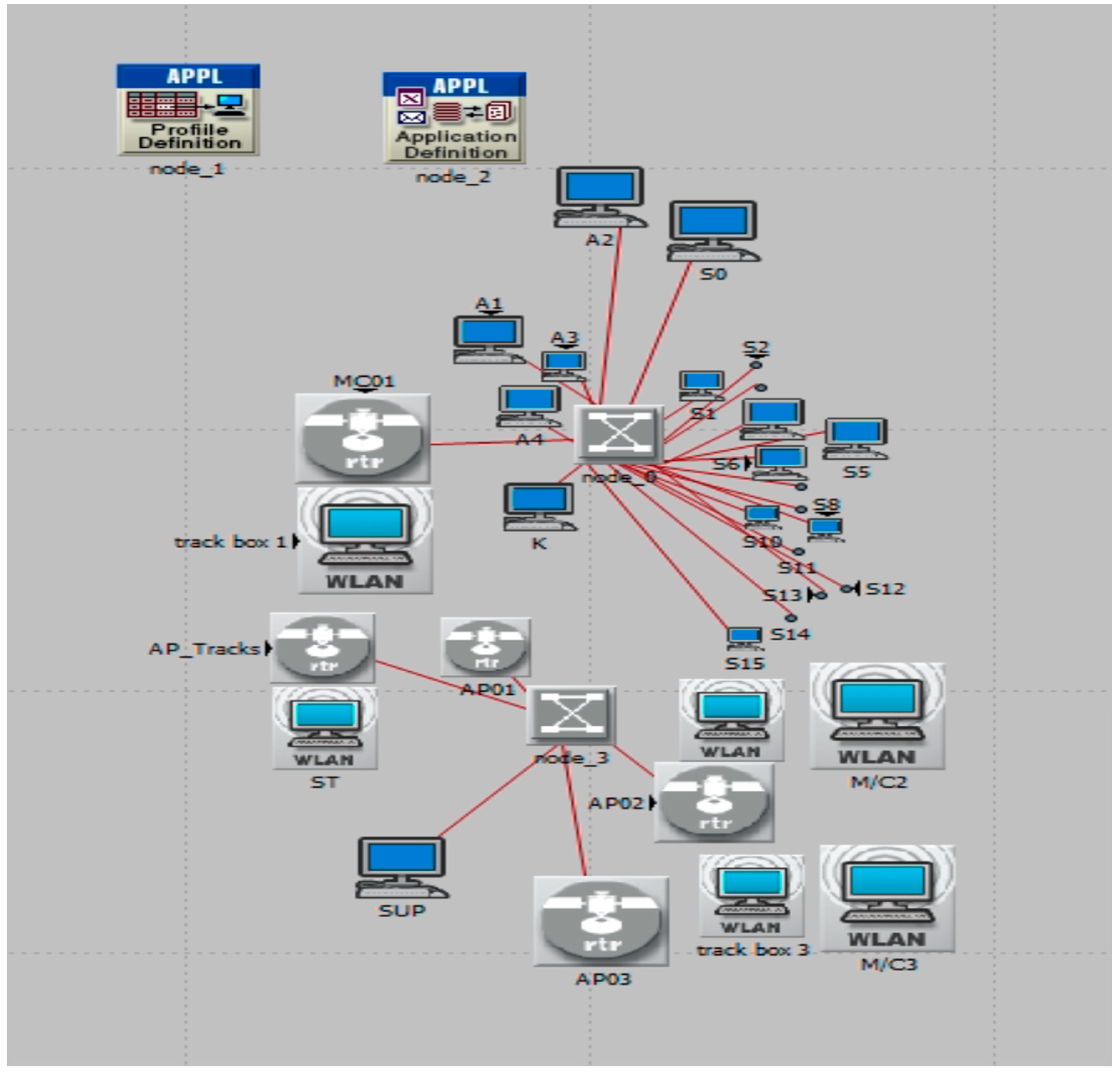
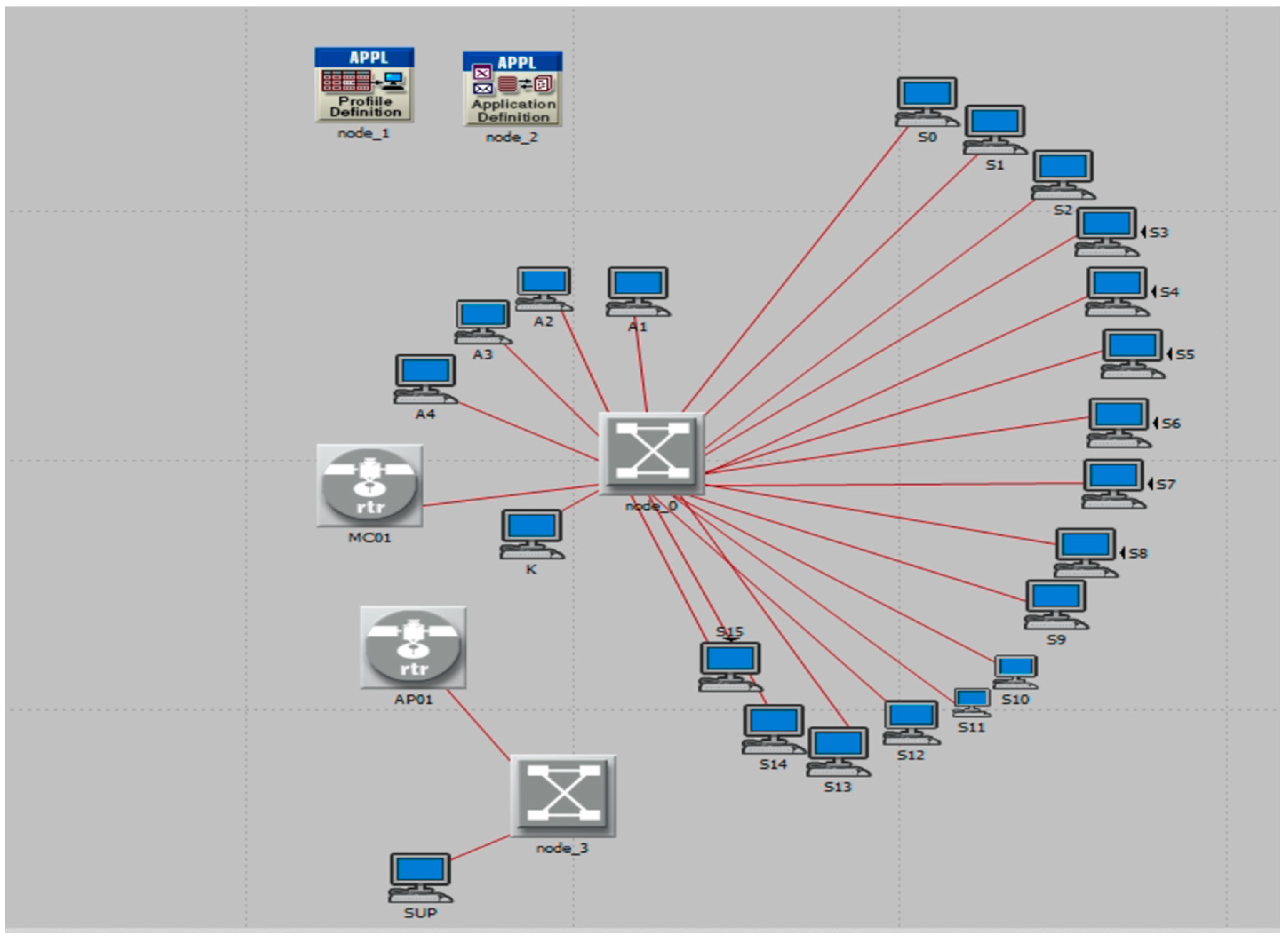
16] in both fault-free and fault-tolerant scenarios. Studying normal conditions is crucial to ensure that the system operates correctly in the absence of faults.
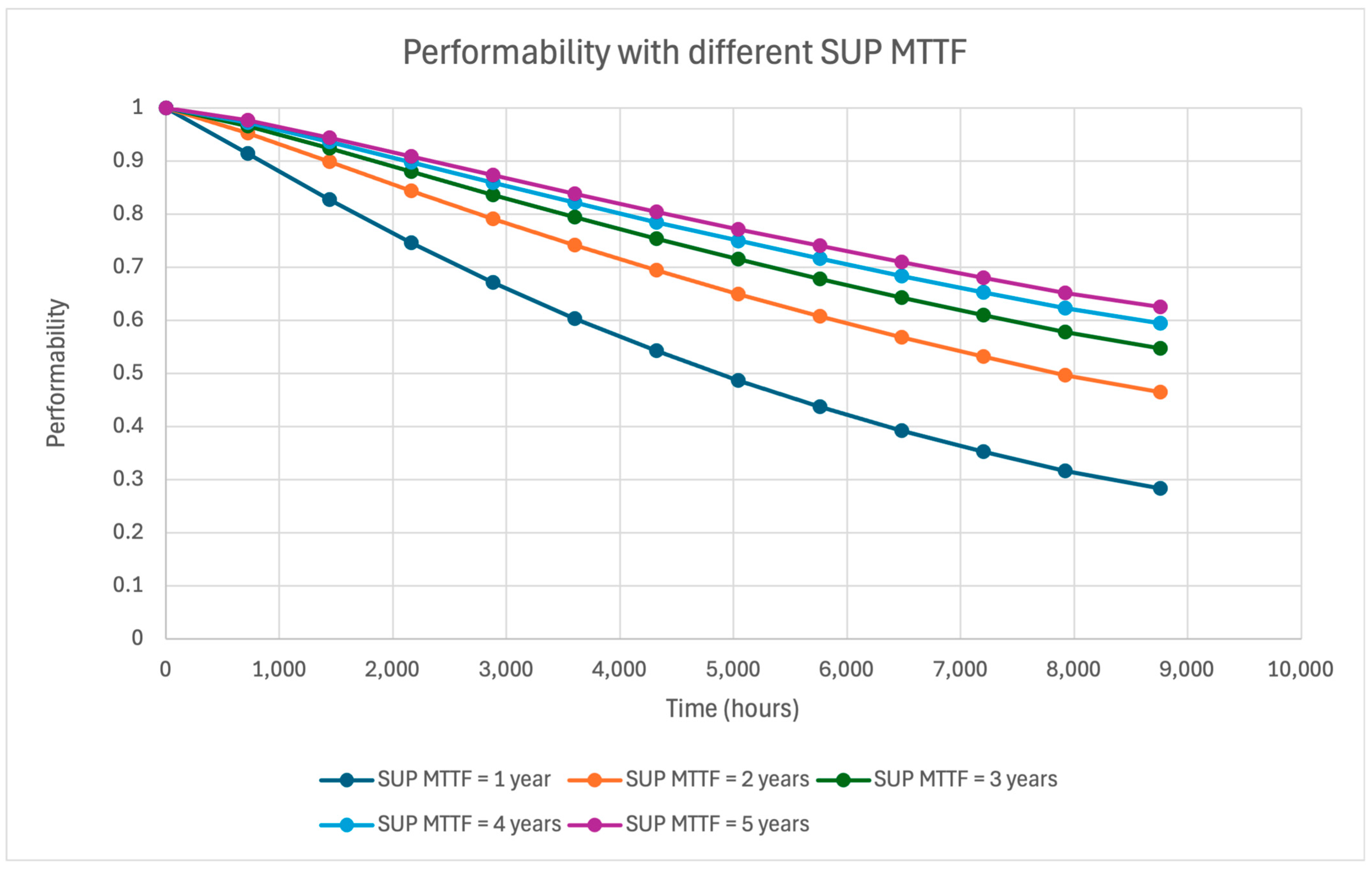
If the system is tested and shows increased delays due to network congestion, the solution is to reduce the workcell’s speed, bringing the network delay back within acceptable limits. To ensure that the system meets performance expectations despite reduced speeds resulting from a workcell failure, a performability analysis is conducted. Given that the analysis is time-dependent, the transient probabilities of the system being in each state over time will be considered, and the Transient Performability (TP) will be subsequently calculated.
TP is a metric used to assess a system’s performance during a temporary period of operation or transition, particularly when it is exposed to varying conditions or failures. It examines the system’s capability to maintain its operational performance or functionality during non-steady-state conditions, such as failure existence. The
TP(
t) is obtained as follows [
65]:
where ψ is the set of states of the system model,
(
t) is the probability of residing in state i at time t, and
Rewi is the reward/penalty of each state
i. The metric used as the penalty is the operational speed of the workcells in state
i. The calculation of TP begins with identifying the system’s operational and failure states and then determining the probability of the system being in each state at a given time
t. Subsequently, a penalty will be associated with each state to reflect the system’s performance in that state. The penalty (operational speed of the workcells) is determined based on the simulations conducted for each state using Riverbed Network Modeler (Riverbed Network Modeler; Riverbed Technology, Inc.: San Francisco, CA, USA) [
16]. Then, the performability is determined by summing the products of each state’s penalty and the probability that the system will be in that state at a given time. TP can be derived from the system’s reliability in operational states, as reliability functions provide the probability of the system being in an operational state. Therefore,
(
t), which is the probability of the system being in state
i at time
t, can be calculated based on the product of the reliability of the workcells in state
i at that time
t. In the following section, a case study is presented to rigorously evaluate and validate the proposed methodology. This analysis aims to assess the methodology’s applicability and effectiveness in a real-world context.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}