


Biomaterials Research-Driven Design Visualized by AI Text-Prompt-Generated Images



Abstract
1. Introduction
2. AI Text-Prompt-Generated Images: The Models, the Operation, the In-Design Practice, and Authorship Debate
2.1. Text-to-Image AI Models and Architecture
2.2. Data Mining
2.3. AI Text-to-Image Model Comparison and Copyright Debate
3. Materials and Methods: The Role of AI Text-to-Image Models in Biomaterials Research-Driven Design Process
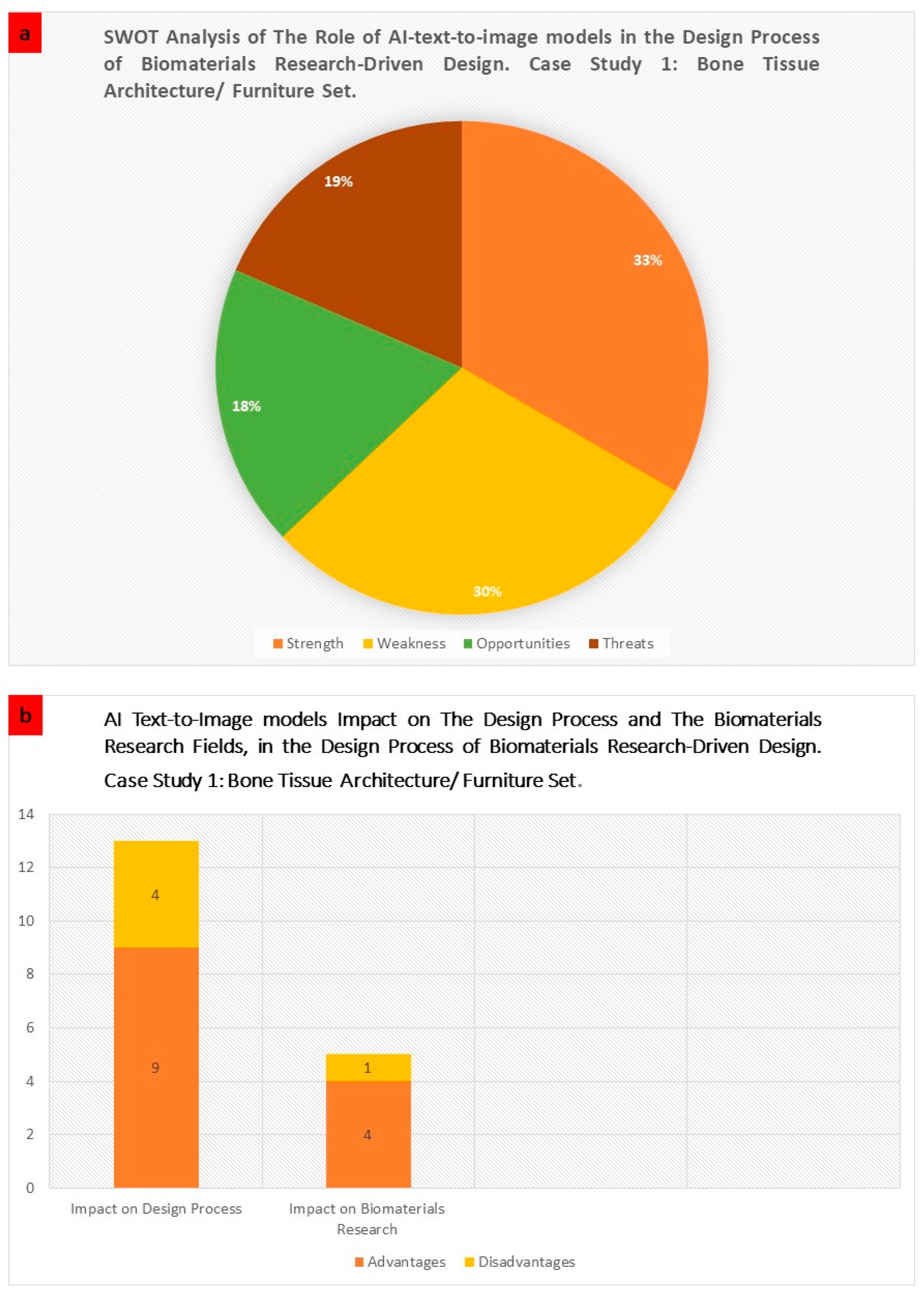
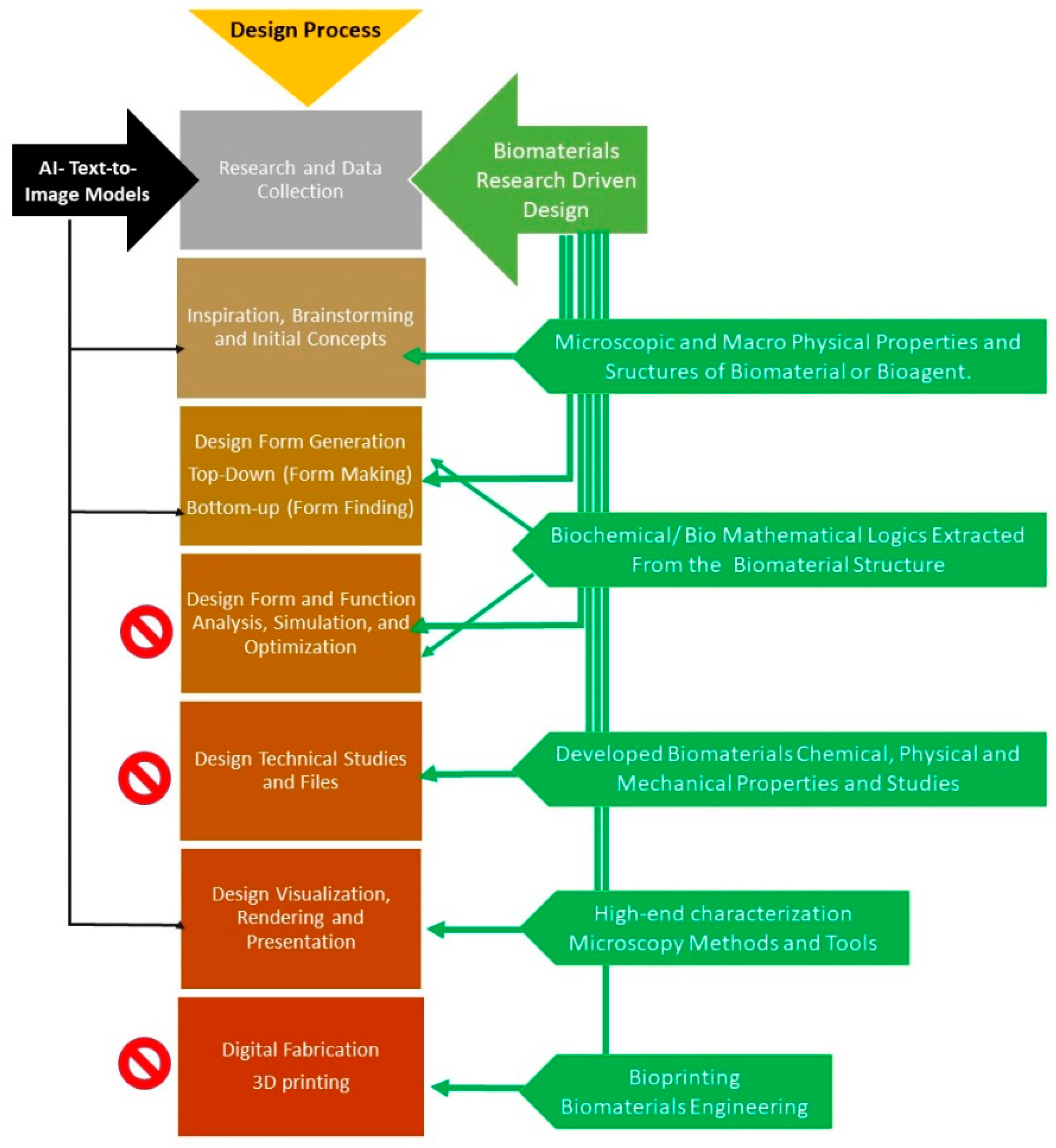
3.1. Case Study 1: The Bone Tissue Chair Set
3.2. Case Study 2: The Barcelona Pearl Cloud Furniture Set
4. Results: AI-Aided Design Criteria for Biomaterials Research-Driven Design Process
Conclusions and Authorship Decision
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, V.; Vermeulen, J.; Fitzmaurice, G.; Matejka, J. 3DALL-E: Integrating Text-to-Image AI in 3D Design Workflows. arXiv 2022, arXiv:2210.11603. [Google Scholar]
- Estevez, A.T.; Abdallah, Y.K. AI to Matter-Reality: Art, Architecture & Design; iBAG-UIC Barcelona: Barcelona, Spain, 2022; p. 260. [Google Scholar]
- Al-Kharusi, G.; Dunne, N.J.; Little, S.; Levingstone, T.J. The Role of Machine Learning and Design of Experiments in the Advancement of Biomaterial and Tissue Engineering Research. Bioengineering 2022, 9, 561. [Google Scholar] [CrossRef]
- Rickert, C.A.; Lieleg, O. Machine learning approaches for biomolecular, biophysical, and biomaterials research. Biophys. Rev. 2022, 3, 021306. [Google Scholar] [CrossRef]
- Agnese, J.; Herrera, J.; Tao, H.; Zhu, X. A survey and taxonomy of adversarial neural networks for text-to-image synthesis. WIREs Data Min. Knowl. Discov. 2020, 10, e1345. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Luc, P.; Couprie, C.; Chintala, S.; Verbeek, J. Semantic Segmentation Using Adversarial Networks. NASA ADS. Available online: https://ui.adsabs.harvard.edu/abs/2016arXiv161108408L (accessed on 1 November 2016).
- Zhang, H.; Shinomiya, Y.; Yoshida, S. 3D MRI Reconstruction Based on 2D Generative Adversarial Network Super-Resolution. Sensors 2021, 21, 2978. [Google Scholar] [CrossRef]
- Jian, Y.; Yang, Y.; Chen, Z.; Qing, X.; Zhao, Y.; He, L.; Chen, X.; Luo, W. PointMTL: Multi-Transform Learning for Effective 3D Point Cloud Representations. IEEE Access 2021, 9, 126241–126255. [Google Scholar] [CrossRef]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Tealab, A. Time series forecasting using artificial neural networks methodologies: A systematic review. Futur. Comput. Inform. J. 2018, 3, 334–340. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to Forget: Continual Prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020. [Google Scholar] [CrossRef]
- Sequence Modeling with Neural Networks (Part 2): Attention Models. Indico Data. Available online: https://indicodata.ai/blog/sequence-modeling-neural-networks-part2-attention-models/ (accessed on 18 April 2016).
- Gu, S.; Chen, D.; Bao, J.; Wen, F.; Zhang, B.; Chen, D.; Yuan, L.; Guo, B. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10696–10706. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Deep Neural Networks for Acoustic Modeling in Speech Recognition–AI Research. 2015. Available online: http://airesearch.com/ai-research-papers/deep-neural-networks-for-acoustic-modeling-in-speech-recognition/ (accessed on 23 October 2015).
- Analyst, J.K. GPUs Continue to Dominate the AI Accelerator Market for Now. Information Week. 2019. Available online: https://www.informationweek.com/ai-or-machine-learning/gpus-continue-to-dominate-the-ai-accelerator-market-for-now (accessed on 27 November 2019).
- Chen, L.-P. Mehryar Mohri, Afshin Rostamizadeh, and Ameet Talwalkar: Foundations of machine learning, second edition. Stat. Pap. 2019, 60, 1793–1795. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; Mcgraw-Hill: New York, NY, USA, 1997. [Google Scholar]
- Alpaydin, E. Introduction to Machine Learning; The Mit Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Oxford Languages|The Home of Language Data. Available online: https://en.oxforddictionaries.com/definition/overfitting (accessed on 25 November 2022).
- Hawkins, D.M. The Problem of Overfitting. J. Chem. Inf. Comput. Sci. 2003, 44, 1–12. [Google Scholar] [CrossRef]
- Tetko, I.V.; Livingstone, D.J.; Luik, A.I. Neural network studies. 1. Comparison of overfitting and overtraining. J. Chem. Inf. Comput. Sci. 1995, 35, 826–833. [Google Scholar] [CrossRef]
- Diffuse The Rest—A Hugging Face Space by Huggingface-Projects. Available online: https://huggingface.co/spaces/huggingface-projects/diffuse-the-rest (accessed on 22 December 2022).
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. Machine Vision & Learning Group. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. Available online: https://ommer-lab.com/research/latent-diffusion-models/ (accessed on 22 December 2022).
- Vincent, J. Anyone Can Use This AI Art Generator—That’s the Risk. The Verge. Available online: https://www.theverge.com/2022/9/15/23340673/ai-image-generation-stable-diffusion-explained-ethics-copyright-data (accessed on 15 September 2022).
- Alammar, J. The Illustrated Stable Diffusion. 2022. Available online: https://jalammar.github.io/illustrated-stable-diffusion/ (accessed on 25 November 2022).
- Stable Diffusion. GitHub. Available online: https://github.com/CompVis/stable-diffusion (accessed on 30 September 2022).
- Baio, A. Exploring 12 Million of the 2.3 Billion Images Used to Train Stable Diffusion’s Image Generator. Available online: https://waxy.org/2022/08/exploring-12-million-of-the-images-used-to-train-stable-diffusions-image-generator/ (accessed on 30 August 2022).
- Ivanovs, A. Stable Diffusion: Tutorials, Resources, and Tools. Stack Diary. 2022. Available online: https://stackdiary.com/stable-diffusion-resources/ (accessed on 25 November 2022).
- Johnson, K. OpenAI Debuts DALL-E for Generating Images from Text. VentureBeat. 2021. Available online: https://venturebeat.com/business/openai-debuts-dall-e-for-generating-images-from-text/ (accessed on 5 January 2021).
- Inside Midjourney, The Generative Art AI That Rivals DALL-E. Available online: https://www.vice.com/en/article/wxn5wn/inside-midjourney-the-generative-art-ai-that-rivals-dall-e (accessed on 5 December 2022).
- Stable Diffusion with Diffusers. Available online: https://huggingface.co/blog/stable_diffusion (accessed on 25 November 2022).
- Smith, R. NVIDIA Quietly Launches GeForce RTX 3080 12GB: More VRAM, More Power, More Money. Available online: https://www.anandtech.com/show/17204/nvidia-quietly-launches-geforce-rtx-3080-12gb-more-vram-more-power-more-money (accessed on 22 December 2022).
- Meng, C.; Song, Y.; Song, J.; Wu, J.; Zhu, J.Y.; Ermon, S. Sdedit: Image synthesis and editing with stochastic differential equations. arXiv 2021, arXiv:2108.01073. [Google Scholar]
- Claburn, T. Holz, Founder of AI Art Service Midjourney, on Future Images. Available online: https://www.theregister.com/2022/08/01/david_holz_midjourney/ (accessed on 22 December 2022).
- Midjourney v4 Greatly Improves the Award-Winning Image Creation AI. (n.d.). TechSpot. Available online: https://www.techspot.com/news/96619-midjourney-v4-greatly-improves-award-winning-image-creation.html (accessed on 5 December 2022).
- Cai, K. Startup Behind AI Image Generator Stable Diffusion Is in Talks to Raise at a Valuation Up to $1 Billion. Forbes. 2022. Available online: https://www.forbes.com/sites/kenrickcai/2022/09/07/stability-ai-funding-round-1-billion-valuation-stable-diffusion-text-to-image/ (accessed on 25 November 2022).
- Heikkilä, M. This Artist Is Dominating AI-Generated Art. And He’s Not Happy about it. MIT Technology Review. Available online: https://www.technologyreview.com/2022/09/16/1059598/this-artist-is-dominating-ai-generated-art-and-hes-not-happy-about-it/ (accessed on 16 September 2022).
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.; Ghasemipour, S.K.S.; Ayan, B.K.; Mahdavi, S.S.; Lopes, R.G.; et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. arXiv 2022, arXiv:2205.11487. [Google Scholar]
- Robertson, A. How DeviantArt Is Navigating the AI Art Minefield. The Verge. Available online: https://www.theverge.com/2022/11/15/23449036/deviantart-ai-art-dreamup-training-data-controversy (accessed on 15 November 2022).
- DeviantArt’s AI Image Generator Aims to Give More Power to Artists. Popular Science, 12 November 2022. Available online: https://www.popsci.com/technology/deviantart-ai-generator-dreamup/ (accessed on 12 November 2022).
- Frolov, S.; Hinz, T.; Raue, F.; Hees, J.; Dengel, A. Adversarial text-to-image synthesis: A review. Neural Netw. 2021, 144, 187–209. [Google Scholar] [CrossRef]
- Harnad, S. The Annotation Game: On Turing (1950) on Computing, Machinery, and Intelligence (PUBLISHED VERSION BOWDLERIZED). In Parsing the Turing Test: Philosophical and Methodological Issues in the Quest for the Thinking Computer; Springer: Berlin/Heidelberg, Germany, 2008; pp. 23–66. ISBN 13: 978-1-4020-6708-2, e-ISBN-13: 978-1-4020-6710-5. [Google Scholar]
- Dazed. AI Is Reshaping Creativity, and Maybe That’s a Good Thing. 2022. Available online: https://www.dazeddigital.com/art-photography/article/56770/1/cyborg-art-ai-text-to-image-art-reshaping-creativity-maybe-thats-not-a-bad-thing (accessed on 18 August 2022).
- Estevez, A.T. Biodigital Architecture: FELIXprinters and iBAG-UIC to Test Living Biomaterials for Sustainable Architecture. 3DPrint.com|the Voice of 3D Printing/Additive Manufacturing. Available online: https://3dprint.com/276251/biodigital-architecture-felixprinters-and-ibag-uic-to-test-living-biomaterials-for-sustainable-architecture/ (accessed on 3 December 2020).
- Wittig, N.K.; Østergaard, M.; Palle, J.; Christensen, T.E.K.; Langdahl, B.L.; Rejnmark, L.; Hauge, E.-M.; Brüel, A.; Thomsen, J.S.; Birkedal, H. Opportunities for biomineralization research using multiscale computed X-ray tomography as exemplified by bone imaging. J. Struct. Biol. 2021, 214, 107822. [Google Scholar] [CrossRef]
- Buss, D.J.; Kröger, R.; McKee, M.D.; Reznikov, N. Hierarchical organization of bone in three dimensions: A twist of twists. J. Struct. Biol. X 2022, 6, 100057. [Google Scholar] [CrossRef]
- Jia, Z.; Deng, Z.; Li, L. Biomineralized Materials as Model Systems for Structural Composites: 3D Architecture. Adv. Mater. 2022, 34, 2106259. [Google Scholar] [CrossRef]
- Tang, T.; Landis, W.; Raguin, E.; Werner, P.; Bertinetti, L.; Dean, M.; Wagermaier, W.; Fratzl, P. A 3D Network of Nanochannels for Possible Ion and Molecule Transit in Mineralizing Bone and Cartilage. Adv. NanoBiomed Res. 2022, 2, 2100162. [Google Scholar] [CrossRef]
- 5th International Scientific Conference on Biomaterials and Nanomaterials|Edinburgh-UK|Mar 2022|STATNANO. 2022. Available online: https://statnano.com/event/3016/5th-International-scientific-conference-on-Biomaterials-and-Nanomaterials#ixzz7lN63BGDb (accessed on 25 November 2022).
- BioMat|Biomaterials World Forum|Continuum Forums. 2022. Available online: https://www.continuumforums.com/biomaterials-world-forum/ (accessed on 25 November 2022).
- Dg, D. Process of Formation of Pearl in Molluscs. Bioscience. Available online: https://www.bioscience.com.pk/topics/zoology/item/870-process-of-formation-of-pearl-in-molluscs (accessed on 22 December 2022).
- Pérez-Huerta, A.; Cuif, J.-P.; Dauphin, Y.; Cusack, M. Crystallography of calcite in pearls. Eur. J. Miner. 2014, 26, 507–516. [Google Scholar] [CrossRef]
- Eberle, O.; Buttner, J.; Krautli, F.; Muller, K.-R.; Valleriani, M.; Montavon, G. Building and Interpreting Deep Similarity Models. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 1149–1161. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, Z.; Liu, B.; Yang, Z.; Liu, Y. ModelDiff: Testing-based DNN similarity comparison for model reuse detection. In Proceedings of the 30th ACM SIGSOFT International Symposium on Software Testing and Analysis, New York, NY, USA, 11–17 July 2021; pp. 139–151. [Google Scholar]
- Liu, Z.; Sun, L.; Zhang, Q. High Similarity Image Recognition and Classification Algorithm Based on Convolutional Neural Network. Comput. Intell. Neurosci. 2022, 2022, 2836486. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Alidoost, F.; Arefi, H.; Tombari, F. 2D Image-To-3D Model: Knowledge-Based 3D Building Reconstruction (3DBR) Using Single Aerial Images and Convolutional Neural Networks (CNNs). Remote Sens. 2019, 11, 2219. [Google Scholar] [CrossRef]
- Han, X.-F.; Laga, H.; Bennamoun, M. Image-Based 3D Object Reconstruction: State-of-the-Art and Trends in the Deep Learning Era. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1578–1604. [Google Scholar]
- Xu, C.; Yang, S.; Galanti, T.; Wu, B.; Yue, X.; Zhai, B.; Zhan, W.; Vajda, P.; Keutzer, K.; Tomizuka, M. Image2Point: 3D Point-Cloud Understanding with 2D Image Pretrained Models. arXiv 2021, arXiv:2106.04180. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SWOT Analysis of the AI-Text-to-Image Models Role in the Biomaterials Research Driven Design Case 1: Bone Tissue Architecture/Furniture Set. | |||
|---|---|---|---|
| Evaluation | Analysis | Role in Design Process | Role in Biomaterials Research |
| Strength Points |
|
|
|
| Weakness Points |
|
|
|
| Opportunities |
|
|
|
| Threats |
| ||
| SWOT Analysis of the AI-Text-to-Image Models Role in the Biomaterials Research Driven Design Case 2: Pearls Cloud Furniture Set. | |||
|---|---|---|---|
| Evaluation | Analysis | Role in Design Process | Role in Biomaterials Research |
| Strength Points |
|
|
|
| Weakness Points |
|
|
|
| Opportunities |
|
|
|
| Threats |
|
| |
| Criterion | Description | Phase of Design Process |
|---|---|---|
| Form Finding (Bottom-Up) Vs. Form Making (Top-Down) |
|
|
| Material Morphology from Nano to Meso/Macro |
|
|
| Auxiliary Model for Automatic Referencing Generator (Training Data and AI-Generated New Knowledge) |
|
|
| Translate 2D Images to 3D Models |
|
|
| Integration of Materials Research-Driven Design |
|
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdallah, Y.K.; Estévez, A.T. Biomaterials Research-Driven Design Visualized by AI Text-Prompt-Generated Images. Designs 2023, 7, 48. https://doi.org/10.3390/designs7020048
Abdallah YK, Estévez AT. Biomaterials Research-Driven Design Visualized by AI Text-Prompt-Generated Images. Designs. 2023; 7(2):48. https://doi.org/10.3390/designs7020048
Chicago/Turabian StyleAbdallah, Yomna K., and Alberto T. Estévez. 2023. "Biomaterials Research-Driven Design Visualized by AI Text-Prompt-Generated Images" Designs 7, no. 2: 48. https://doi.org/10.3390/designs7020048
APA StyleAbdallah, Y. K., & Estévez, A. T. (2023). Biomaterials Research-Driven Design Visualized by AI Text-Prompt-Generated Images. Designs, 7(2), 48. https://doi.org/10.3390/designs7020048